BAB 3
METODOLOGI PENELITIAN
Bab ini menjelaskan tahapan-tahapan yang dilakukan dalam penelitian, mulai dari dataset yang digunakan dalam melatih dan menguji LVQ, arsitektur jaringan pada
LVQ dengan menggunakan Entropy sebagai penentuan vektor bobot awalnya, dan contoh dari perhitungan penelitian.
3.1. Tahapan Penelitian
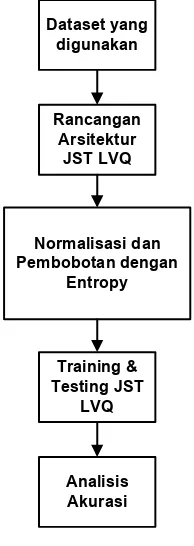
Tahapan penelitian ditunjukkan pada Gambar 3.1 di bawah ini :
Gambar 3.1 Tahapan Penelitian
3.2. Dataset yang Digunakan
Pada penelitian ini digunakan dataset (kumpulan data) yang berasal dari UCI Machine Learning Repository yaitu dataset breast cancer. Dataset ini terdiri dari 699 jumlah
Dataset yang digunakan
Rancangan Arsitektur
JST LVQ
Normalisasi dan Pembobotan dengan
Entropy
Training & Testing JST
LVQ
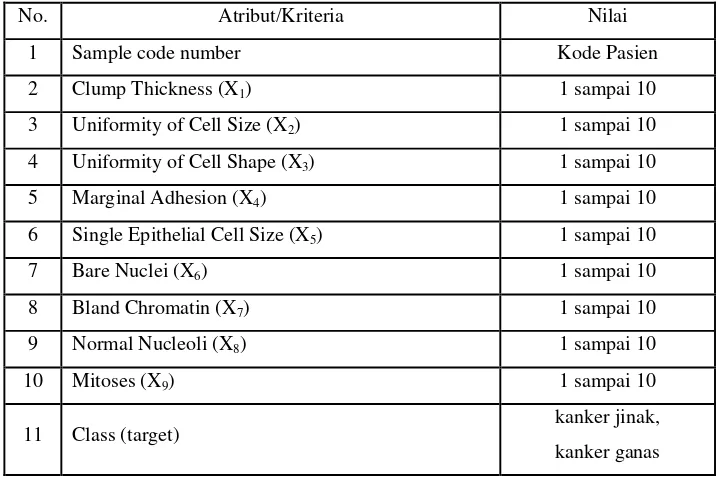
data pasien, dengan klasifikasi 458 (65,5%) pasien kanker jinak dan 241 (34,5%) pasien kanker ganas. Pada dataset tersebut terdapat satu atribut sebagai kode pasien, 9 kriteria/atribut yang masing-masing atribut memiliki skala data dari 1-10 dan satu atribut lagi sebagai output dari kesembilan kriteria sebelumnya yaitu klasfikasi sebagai tumor jinak atau ganas. Namun dataset ini memiliki nilai yang hilang (missing value) beberapa atribut dan akan diganti dengan metode median yaitu dengan mencari nilai tengah, metode ini adalah metode yang paling baik untuk kasus dataset tersebut (Nurul et al, 2012). Adapun atribut/kriteria dan nilai dari dataset breast cancer dapat dilihat pada Tabel 3.1
Tabel 3.1 Atribut Data
No. Atribut/Kriteria Nilai
1 Sample code number Kode Pasien
2 Clump Thickness (X1) 1 sampai 10
3 Uniformity of Cell Size (X2) 1 sampai 10 4 Uniformity of Cell Shape (X3) 1 sampai 10
5 Marginal Adhesion (X4) 1 sampai 10
6 Single Epithelial Cell Size (X5) 1 sampai 10
7 Bare Nuclei (X6) 1 sampai 10
8 Bland Chromatin (X7) 1 sampai 10
9 Normal Nucleoli (X8) 1 sampai 10
10 Mitoses (X9) 1 sampai 10
11 Class (target) kanker jinak,
kanker ganas
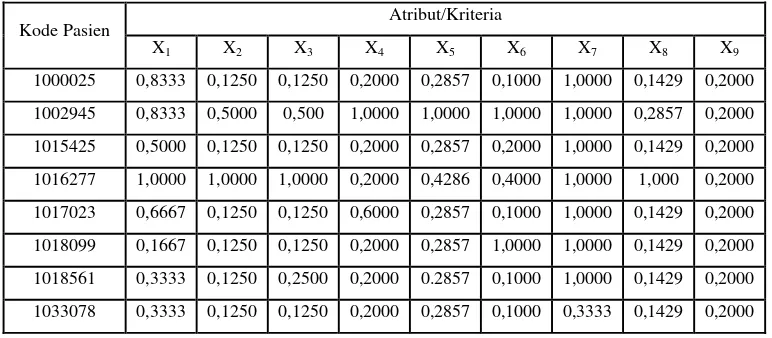
Dataset pasien dipisah sesuai target kelas untuk masuk ke dalam proses perhitungan Entropy untuk menentukan vektor bobot terbaik yang dijadikan perwakilan setiap kelasnya. Adapun contoh dataset breast cancer ditunjukkan pada Tabel 3.2 , Tabel 3.3 dan Tabel 3.4.
Tabel 3.2 Dataset Kelas Kanker Jinak
No. Kode Pasien Atribut/Kriteria
X1 X2 X3 X4 X5 X6 X7 X8 X9
1 1000025 5 1 1 1 2 1 3 1 1
2 1002945 5 4 4 5 7 10 3 2 1
3 1015425 3 1 1 1 2 2 3 1 1
Tabel 3.3 Dataset Kelas Kanker Jinak (lanjutan)
No. Kode Pasien Atribut/Kriteria
X1 X2 X3 X4 X5 X6 X7 X8 X9
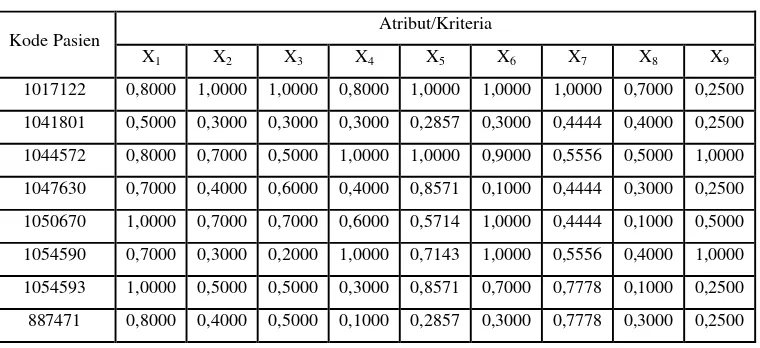
Tabel 3.4 Dataset Kelas Kanker Ganas
No. Kode Pasien Atribut/Kriteria
X1 X2 X3 X4 X5 X6 X7 X8 X9
3.3. Perancangan Arsitektur JST LVQ
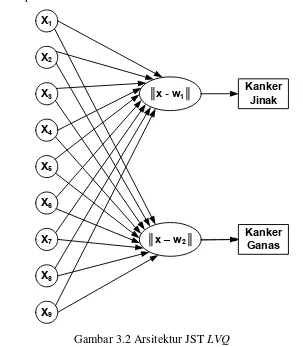
Arsitektur JST LVQ yang dibangun (lihat Gambar 3.2) memiliki satu lapisan input dan satu lapisan output dengan parameter sebagai berikut.
1. Jumlah Node pada Lapisan Input (Input Layer)
yaitu atribut ke-2 sampai ke-10, karena kesembilan atribut tersebut merupakan kriteria-kriteria yang dapat menentukan output dari klasifikasi. Sedangkan atribut ke-1 hanya sebagai inisial kode dari setiap pasien.
2. Jumlah Node pada Lapisan Output (Output Layer)
Lapisan output pada LVQ merupakan lapisan untuk memproses data input yang kemudian mencari jarak antara data input dan bobot awal secara kompetitif yang kemudian dijadikan sebagai output untuk menentukan pada kelas mana data input tersebut berada. Jumlah node pada lapisan output terdiri dari 2 node karena didapat dari target dataset yang dihasilkan memiliki 2 kelas yang berbeda yaitu kanker jinak dan kanker ganas. Untuk arsitektur JST pada penelitian ini ditunjukkan pada Gambar 3.2.
Gambar 3.2 Arsitektur JST LVQ
Selanjutnya dalam penentuan parameter-parameter pada JST yaitu nilai laju pembelajaran (learning rate), penururan tingkat pembelajaran (decrease rate), dan maksimum iterasi (epoch). Untuk learning rate (α), jika nilai terlalu besar, amak algoritma akan menjadi tidak stabil, sebaliknya jika terlalu besar makan proses nya akan terlalu lama, oleh karena itu nilai learning rate haruslah 0 < α < 1 (Safwandi,
X2
X3
X5
X4
X7
X6
║x - w1║
║x – w2║
Kanker Jinak
Kanker Ganas X1
X8
2016). Pada penelitian tesis ini, penentuan konstanta learning rate mengacu pada penelitian sebelumnya, dimana penelitian tersebut menggunakan dataset yang sama pada penilitian tesis ini. Peneliti sebelumnya mendapatkan parameter yang memiliki hasil terbaik dalam klasifikasi breast cancer menggunakan JST LVQ standar, yaitu 0,1 untuk learning rate dan 0,3 untuk penurunan tingkat pembelarajan (Nurdiyanto, 2015).
3.4. Penentuan Bobot Awal menggunakan Metode Entropy
Pada proses penentuan vektor bobot awal dengan metode Entropy dilakukan dengan dua cara yaitu :
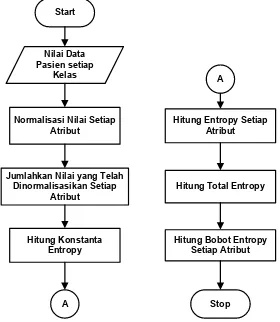
1. Penentunan vektor bobot awal langsung dihasilkan dari perhitungan menggunakan Entropy dari dataset pasien dalam setiap kelasnya. Alur dalam penentuan bobot awal dengan cara pertama dapat dilihat pada Gambar.3.3.
Gambar 3.3 Penentuan Bobot Awal Cara Pertama
Berikut contoh perhitungan penentuan bobot awal menggunakan Entropy cara pertama dengan dataset pasien kanker jinak yang ditampilkan pada Tabel 3.5.
Start
Nilai Data Pasien setiap
Kelas
Normalisasi Nilai Setiap Atribut
Jumlahkan Nilai yang Telah Dinormalisasikan Setiap
Atribut
Hitung Konstanta Entropy
Hitung Entropy Setiap Atribut
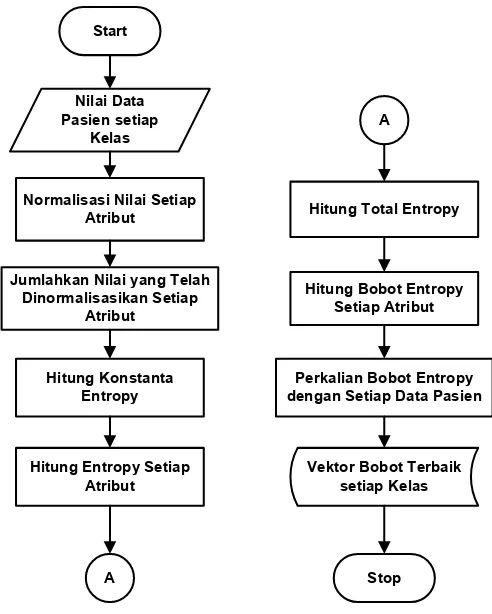
Hitung Total Entropy
Hitung Bobot Entropy Setiap Atribut
Stop A
Tabel 3.5 Contoh Dataset Entropy Cara Pertama
No. Kode Pasien Atribut/Kriteria
X1 X2 X3 X4 X5 X6 X7 X8 X9
a. Normalisasi Nilai Setiap Atribut Xi
Hasil normalisasi dari Tabel 3.5 dapat dilihat pada Tabel 3.6. Tabel 3.6 Contoh Normalisasi Entropy Cara Pertama
Kode Pasien
Dengan :
∑ , maka :
c. Perhitungan Bobot Entropy untuk setiap kriteria ke-i
̅ [ ] ̅
maka didapatkan :
̅ ̅̅̅ ̅̅̅ ̅̅̅ ̅̅̅ ̅̅̅ ̅̅̅ ̅̅̅ ̅̅̅
d. Dataset pasien breast cancer memiliki nilai range dari 1 hingga 10 maka bobot Entropy dikalikan 10, maka vektor bobot yang dihasilkan dapat dilihat pada Tabel 3.7
Tabel 3.7 Contoh Vektor Bobot Entropy Cara Pertama
Atribut X1 X2 X3 X4 X5 X6 X7 X8 X9
Bobot 0,4986 1,7396 1,5499 1,0347 0,5592 1,8347 0,1531 1,5355 1,0947
Gambar 3.4 Penentuan Bobot Awal Cara Kedua
Berikut contoh perhitungan penentuan bobot awal menggunakan Entropy cara pertama dengan beberapa dataset pasien kanker ganas yang dilihat pada Tabel 3.8.
Tabel 3.8 Contoh Dataset Entropy Cara Kedua
No. Kode Pasien Atribut/Kriteria
X1 X2 X3 X4 X5 X6 X7 X8 X9
a. Normalisasi Nilai Setiap Atribut Xi
Tabel 3.9 Contoh Normalisasi Entropy Cara Kedua
b. Perhitungan Entropy untuk setiap kriteria ke-i
c. Perhitungan Bobot Entropy untuk setiap kriteria ke-i
̅ [ ] ̅
maka didapatkan :
̅̅̅ ̅̅̅ ̅̅̅ ̅̅̅ ̅̅̅ ̅
d. Bobot Entropy dikalikan dengan nilai dari setiap data pasien dan diranking sehingga menghasilkan pasien yang memiliki nilai tertinggi, maka vektor bobot yang dihasilkan dapat dilihat pada Tabel 3.10.
Tabel 3.10 Contoh Vektor Bobot Entropy Cara Kedua
Atribut X1 X2 X3 X4 X5 X6 X7 X8 X9
Bobot 8 10 10 8 7 10 9 7 1
Penentuan vektor bobot menggunakan Entropy dan pemilihan data pasien sebagai vektor bobot tersebut diharapkan dapat menghasilkan proses pembelajaran dan tingkat akurasi dapat lebih baik dibandingkan LVQ standar.
3.5. Training JST LVQ
Setelah menentukan arsitektur dan penentuan vektor bobot awal pada JST LVQ maka langkah selanjutnya adalah melakukan proses training dan testing dataset. Training
dataset bertujuan untuk pembelajaran dari setiap masukkan data pasien agar jaringan mengenali pola masukkan sehingga dapat mengklasifikasikan data pasien sesuai kelasnya. LVQ akan mengenali pola masukkan berdasarkan pada pendekatan jarak antara dua vektor yaitu vektor dari unit masukkan dengan vektor bobot. Karena dalam penelitian ini mengharapkan tingkat pembelajran dan tingkat akurasi yang cepat makan data yang digunakan pada saat traning akan bervariasi. Hal itu dilakukan untuk mengetahui cara penentuan vektor bobot awal yang mana akan menghasilkan proses pembelajaran data yang cepat. Dalam penenlitian ini data yang digunakan untuk proses traning adalah sebanyak 697 dan 2 data pasien pertama pada kelas yang berbeda digunakan sebagai vektor bobot pada LVQ standar.
Dalam traninig JST LVQ membutuhkan sejumlah data training. Data training
pembelajaran ataupun pengelanan pola dataset. Pada penelitian ini jumlah data pasien yang akan dilatih bervariasi, yaitu 20, 50, 100, dan 350 data dari 697 dataset pasien. Dataset training tersebut juga akan dijadikan sebagai data masukan dari proses perhitungan algoritma JST LVQ. Untuk menentukan data pasien mana yang akan menjadi data training, maka digunakan metode statistik yaitu standar deviasi. Standar deviasi sendiri memiliki kemampuan dalam mencari tingkat keberagaman yang baik pada suatu sekumpulan dataset.
√ ∑ ∑
(3.1)
dimana,
s = standar deviasi n = ukuran sampel
Penentuan jumlah data training sebanyak 20 dilakukan dengan membagi 697 dataset ke dalam 20 data pasien sehingga menghasilkan 35 dataset. Kemudian 35 dataset tersetbut yakan dihitungan masing-masing standar deviasinya dan dibandingkan nilai standar deviasi. Dataset yang menghasilkan standar deviasi tertinggi akan dijadikan perwakilan sebagai data traninng (data masukan). Begitu juga untuk mencari jumlah data training 50, 100 dan 350. Untuk jumlah data training
sebanyak 50 maka ada 14 dataset yang akan dihitung dan dibandingkan nilai standar deviasinya. Pada jumlah data training sebanyak 100 maka ada 7 dataset yang akan dihitung dan dibandingkan nillai standar deviasinya. Begitu juga untuk jumlah data
training 350 maka ada 2 dataset yang akan dihitung dan dibandingkan standar deviasinya. Penentuan jumlah data training tersebut diharapkan menghasilkan data
training yang memiliki tingkat keberagaman yang tinggi sehingga dapat mewakili keseluruhan dataset. Flowchart training JST LVQ dapat dilihat pada Gambar 3.5.
Begitu juga untuk jumlah iterasi, pada penelitian ini memilki jumlah data yang beravariatif yakni sebanayak 5, 10, dan 20 iterasi. Setiap vektor bobot akhir yang dihasilkan dalam setiap proses pembelajaran data, akan digunakan dalam setiap proses
training pada data selanjutnya hingga akhir iterasi.
Gambar 3.5 Flowchart Training JST LVQ Start
Data Input (X), Target, dan Parameter (MaxEpoch, α)
Penetuan Vektor Bobot Awal dengan Entropy
Epoch = Epoch + 1
Baca Xi
Hitung Jarak ║Xi - Wj║
Temukan Jarak Terpendek Xi
Sesuai Target ?
Wj’ = Wj + α (Xi – Wj) Wj’ = Wj - α (Xi – Wj) Tidak Ya
Mengurangi nilai α = α - Deca atau α = α * Deca
Ya
Bobot Akhir
Ya
Stop Epoch = 0
Xi = n Tidak
3.6. Testing JST LVQ
Setelah dilakukan pelatatihan terhadap semua data maka akan diperolah vektor bobot akhir (w). Bobot tersebut selanjutnya akan digunakan untuk melakukan proses simulasi atau testing data. Data untuk proses testing terdiri dari sisa data pada setiap jumlah data training. Untuk jumlah data training sebanyak 20 maka jumlah data
testing sebanyak 677 data. Untuk jumlah data training sebanyak 50 maka jumlah data
testing sebanyak 647 data. Untuk jumlah data training sebanyak 100 maka jumlah data testing sebanyak 597 data. Kemudian untuk jumlah data training sebanyak 350 maka jumlah data testing sebanyak 347. Flowchat testing JST LVQ pada penelitian ini dapat dilihat pada Gambar 3.6.
Gambar 3.6 Flowchart Testing JST
Start
Data Input Testing (Xi), Target, dan Vektor Bobot
Akhir (Wj)
Hitung Jarak Xi-Wj
Temukan Jarak Terpendek
Jumlah Kelas yang Dikenali dan Tidak
Dikenali
Stop Baca Xi
Sesuai Target
Kelas Sesuai
Target Sesuai TargetKelas Tidak Tidak Ya
Xi = n Input? Tidak
3.7. Perhitungan Nilai Akurasi
Pada evaluasi penelitian ini, untuk mengentahui seberapa tingkat akurasi pengklasifikasian pasien breast cancer akan dilakukan dengan cara membandingkan dengan LVQ standar. Dalam menentukan vektor bobot awalnya diambil dari data pasien pertama dan kedua sesuai kelasnya tanpa menormalisasikan data, serta learning rate yaitu 0,1 dan penururan tingkat pembelajaran yaitu 0,3. Kemudian untuk parameter pengujian nilai dalam penelitian ini akan digunakan parameter seperti pada Tabel 3.11.
Tabel 3.11 Parameter Pengujian Nilai
Parameter Pengujian Nilai
Jumlah Iterasi 5,10,20
Jumlah Data Training 20, 50, 100, 350
Proses perhitungan dalam penelitian ini dimulai dari pembagian dataset pasien ke dalam dua kelas yaitu 457 data pasien kanker jinak sebanyak dan 240 data kanker ganas. Kedua kelas dataset tersebut selanjutnya diproses menggunakan metode
Entropy untuk menentukan vektor bobot awal pada masing-masing kelas. Pada proses metode Entropy, dimulai dengan menormalisasikan keseluruhan dataset pada setiap kelas. Kemudian masuk ke dalam proses perhitungan Entropy untuk setiap atirbut/kriteria.
Proses Perhitungan Entropy pada Kelas Kanker Jinak
o Perhitungan Entropy untuk setiap kriteria ke-i
Dengan :
∑ , maka :
o Perhitungan Bobot Entropy untuk setiap kriteria ke-i
̅ [ ] ̅
Proses Perhitungan Entropy pada Kelas Kanker Ganas
o Perhitungan Bobot Entropy untuk setiap kriteria ke-i
̅ [ ] ̅
maka didapatkan :
̅ ̅̅̅ ̅̅̅ ̅̅̅ ̅̅̅ ̅̅̅ ̅̅̅ ̅̅̅ ̅
Perhitungan Penentuan Vektor Bobot Awal dengan Entropy
o Perhitungan Cara Pertama
Nilai Bobot Entropy dikalikan dengan 10 pada setiap atributnya karena nilai pada setiap dataset breast cancer memiliki range nilai antara 1 sampai 10. Maka vektor bobot awal yang dihasilkan ditunjukkan pada Tabel 3.12.
Tabel 3.12 Contoh Perhitungan Vektor Bobot Cara Pertama
Kelas W1 W2 W3 W4 W5 W6 W7 W8 W9
JINAK 1,2920 1,1585 1,2977 1,3003 0,5335 1,6575 0,9206 1,4248 0,4151
GANAS 0,4990 0,7371 0,6389 1,4459 0,8266 0,8327 0,6031 1,4767 2,9501
o Perhitungan Cara Kedua
Bobot Entropy dikalikan dengan nilai dari setiap data pasien dan diranking sehingga menghasilkan pasien yang memiliki nilai tertinggi. Maka vektor bobot yang dihasilkan ditunjukkan pada Tabel 3.13.
Tabel 3.13 Contoh Perhitungan Vektor Bobot Cara Kedua
Kelas W1 W2 W3 W4 W5 W6 W7 W8 W9
JINAK 1 1 1 1 1 1 1 1 1
Penentuan Dataset Training menggunakan Standar Deviasi
Dalam contoh ini, jumlah data training yang digunakan sebanyak 20 data dari 697 data pasien dan 2 data pasien pada kelas berbeda digunakan sebagai vektor bobot awal untuk LVQ biasa. Untuk menentukan data pasien mana yang akan dijadikan data training maka dilakukan dengan cara perhitungan statistik yaitu perhitungan standar deviasi. Dengan standar deviasi akan didapatkan data yang mempunyai keberagaman yang lebih baik. Maka 697 akan dibagi dengan 20 sehingga menghasilkan 35 dataset . Kemudian 35 dataset tersebut dihitung standar deviasinya dan nilainya dibandingkan. Dataset yang memiliki nilai standar deviasi
yang tertinggi akan dijadikan dataset dalam proses training. Maka dataset yang dihasilkan dapat dilihat pada Tabel 3.13.
Tabel 3.13 Data Training 20 Pasien dari Hasil Standar Deviasi
No. Kode
Perhitungan Proses Training pada JST LVQ
10 iterasi(epoch). 20 dataset yang telah ditentukan pada proses sebelumnya akan digunakan sebagai inputan pada proses training.
o Training pada Entropy Cara Pertama
Iterasi ke-1
Data inputan ke-1 : (1,1,1,1,2,1,3,1,1) Jarak pada :
Bobot Ke-1 =√
= 3,1993
Bobot Ke-2 =√
= 4,3788
Jarak terkecil didapat pada Bobot Ke-1 dan target data 1 = 2, maka data ke-1 sesuai dengan target.
Bobot ke-1 baru adalah
W(baru) = W(lama) + α (X – W(lama)) = (1,4628 ; 1,1427 : 1,2679 : 1,2703 ; 0,6802 ; 1,6918 ; 1,1285 ; 1.3823 ; 0.4736)
Data inputan ke-2 : (5,1,1,1,2,1,3,1,1) Jarak pada :
Bobot Ke-1 =√
= 12,6115
Bobot Ke-2 =√
= 13,8691
Jarak terkecil didapat pada Bobot Ke-1 dan target data 1 = 2, maka data ke-1 sesuai dengan target.
Bobot ke-1 baru adalah
W(baru) = W(lama) + α (X – W(lama)) = (1,9165; 1,8284: 1,9411: 1,2433; 0, 9121; 1,9226; 1,3157; 1.9441; 0.5262)
Bobot ke-1 baru : (2,6852 ; 0,9497 ; 0,9648 ; 0,9664 ; 1,7996 ; 1,6832 ; 2,4115 ; 0,8536 ; 1,2657)
Bobot ke-2 baru : (6,9302 ; 4,5274 ; 4,4022 ; 6,2760 ; 4,8983 ; 6,4282 ; 4,7865 ; 4,2461 ; 2,4632)
o Training pada Entropy Cara Kedua
Proses training dilakukan dengan cara yang sama pada Entropy Cara Pertama. Dihitung hingga data ke-20 dan epoch ke-10. Sehingga menghasilkan bobot ke-1 dan bobot ke-2 yang baru, yaitu :
Bobot ke-1 baru : (2,2369; 0,6734; 0,4669; 0,6685; 1,4827; 1, 9035; 2,2541; 0,5663; 1,3718)
Bobot ke-2 baru : (8,3314 ; 6,8984 ; 6,3763 ; 8,5513 ; 6,9803 ; 9,8767 ; 6,7225 ; 6,2892 ; 4,2076)
o Training pada LVQ Biasa
Proses training dilakukan dengan cara yang sama pada Entropy Cara Pertama. Dihitung hingga data ke-20 dan epoch ke-10. Sehingga menghasilkan bobot ke-1 dan bobot ke-2 yang baru, yaitu :
Bobot ke-1 baru : (2,3430 ; 0,5943 ; 0,3868 ; 0, 6675 ; 1,4976 ; 1,8332 ; 2,3076 ; 0,4978 ; 1,3734)
Bobot ke-2 baru : (8,2117 ; 5,4951 ; 4,9668 ; 7,7992 ; 6,6472 ; 10,1771 ; 5,6753 ; 5,3569 ; 2,2533)
Perhitungan Proses Testing
Proses testing dilakukan dengan sisa jumlah datapasien yang belum diolah yaitu 697 – 20 = 677 data pasien. Proses testing akan mencari berapa banyak data pasien yang sesuai dengan kelasnya.
o Testing pada Entrpopy Cara Pertama Data testing ke-1 : (5,4,4,5,7,10,3,2,1) Jarak pada :
Bobot Ke-1 =√
Bobot Ke-2 =√
= 11,2074
Jarak terkecil didapat pada Bobot Ke-1 dan target data 1 = 2, maka data ke-1 sesuai dengan target.
Proses tersebut dilakukan hingga data ke-677, sehingga diperoleh jumlah data yang sesuai pada kelasnya ada sebanyak 658 data dan yang tidak sesuai sebanyak 17 data pasien. Maka diperoleh tingkat akurasi pada Entropy cara Pertama sebesar 660/677 = 97,48 %.
o Testing pada Entropy Cara Kedua
Proses testing dilakukan dengan cara yang sama juga dengan cara Entropy
Pertama. Sehingga meghasilkan jumlah data yang sesuai dengan kelasnya sebanyak 643 data dan yang tidak sesuai sebanyak 34 data pasien. Maka diperoleh tingkat akurasi pada Entropy cara Kedua sebesar 643/677 = 94,97 %.
o Testing pada LVQ Standar
Proses testing dilakukan dengan cara yang sama juga dengan cara Entropy
BAB 4
HASIL DAN PEMBAHASAN
4.1. Pendahuluan
Pada bab ini menjelaskan bagaimana hasil penelitian dan pembahasan dari kinerja metode Entropy untuk menentukan vektor bobot awal pada LVQ terhadap tingkat akurasi yang dihasilkan. Vektor bobot awal yang dihasilkan oleh metode Entropy
diharapkan mendapatkan tingkat akurasi yang lebih baik pada proses klasifikasi jika dibandingkan dengan cara LVQ standar.
Penelitian dilakukan dengan menggunakan daataset pasien breast cancer yang didapat UCI Machine Learning Repository yang disumbang oleh Rumah Sakit University of Wisconsin Madison. Dataset yang digunakan sebanyak 699 data pasien
yang terdiri dua kelas yaitu 458 data pasien kanker jinak dan 241 pasien kanker ganas. Kemudian dataset tersebut dilakukan proses training LVQ untuk mengenali data agar dapat diuji pada proses testing. Dalam proses pengujian ini, penelitian ini diimplementasikan menggunakan aplikasi Matlab 6.1 pada sistem operasi Windows 7.
4.2.Vektor bobot Awal yang Dihasilkan
Penentuan vektor bobot awal pada penelitian ini dilakukan dengan tiga cara yaitu hasil perhitungan bobot dengan metode Entropy, data pasien terbaik dari perhitungan metode Entropy dan vektor bobot yang diiambil dari data pasien pertama pada setiap kelasnya.
4.2.1. Perhitungan Bobot dengan Metode Entropy (Entropy Cara Pertama)
Penentuan vektor bobot awal dilakukan dengan menggunakan metode Entropy dari dataset yang telah terbagi atas dua kelas yang berbeda, yaitu data pasien kanker jinak
Tabel 4.1 Vektor Bobot dengan Entropy Cara Pertama
Kelas W1 W2 W3 W4 W5 W6 W7 W8 W9
JINAK 1,2920 1,1585 1,2977 1,3003 0,5335 1,6575 0,9206 1,4248 0,4151
GANAS 0,4990 0,7371 0,6389 1,4459 0,8266 0,8327 0,6031 1,4767 2,9501
4.2.2. Data Pasien Terbaik dari Perhitungan Entropy (Entropy Cara Kedua)
Penentuan vektor bobot awal dilakukan dengan perhitungan hasil metode Entropy
dikali dengan dataset pada setiap kelasnya sehingga didapatkan data pasien mana yang memiliki nilai terbaik yang akan digunakan sebagai vektor bobot awal. Dari hasil perhitungan diperoleh data dengan nomor pasien 1158247 untuk kelas kanker jinak dan nomor pasien 877291 untuk kelas kanker ganas. Maka vektor bobot awal yang
dihasilkan dapat dilihat pada Tabel 4.2.
Tabel 4.2 Vektor Bobot dengan Entropy Cara Kedua
Kelas W1 W2 W3 W4 W5 W6 W7 W8 W9
JINAK 1 1 1 1 1 1 1 1 1
GANAS 6 10 10 10 10 10 8 10 10
4.2.3. LVQ standar
Penentuan vektor bobot awal pada LVQ standar dilakukan dengan mengambil data pertama dalam dataset pada setiap kelasnya. Maka dari dataset, pasien yang memiliki nilai pertama adalah nomor pasien 1000025 untuk kelas kanker jinak dan nomor pasien 1017122 untuk kelas kanker ganas. Maka vektor bobot awal yang dihasilkan dapat dilihat pada Tabel 4.3.
Tabel 4.3 Vektor Bobot dengan LVQ standar
Kelas W1 W2 W3 W4 W5 W6 W7 W8 W9
JINAK 5 1 1 1 2 1 3 1 1
4.3. Hasil Penelitian
Dalam melakukan pengujian pada penelitian ini dilakukan sebanyak 12 kali pengujian terhadap tiga vektor yang telah dihasilkan. Ketiga vektor masuk ke dalam proses
trainingLVQ sehingga menghasilkan bobot yang akan digunakan sebagai pada proses
testing. Proses training dilakukan terhadap parameter varian jumlah data training dan jumlah iterasi. Untuk menentukan data pasien mana yang akan dijadikan data training
maka dilakukan dengan cara perhitungan statistik yaitu perhitungan standar deviasi. Dengan standar deviasi akan didapatkan data training yang mempunyai keberagaman yang lebih baik. Pada proses testing akan dilakukan dengan menggunakan sisa data pada setiap proses training sehingga menghasilkan berapa persentase tingkat akurasi dalam pengklasifikasian breast cancer. Dan hasil dari proses testing, akan dilakukan perbandingan sejauh mana tingkat akurasi yang dihasilkan.
Untuk jumlah data training sebanyak 20 maka jumlah data testing sebanyak 677 data. Untuk jumlah data training sebanyak 50 maka jumlah data testing sebanyak 647 data. Untuk jumlah data training sebanyak 100 maka jumlah data testing
sebanyak 597 data. Kemudian untuk jumlah data training sebanyak 350 maka jumlah data testing sebanyak 347. Pada setiap masing-masing jumlah data traininng akan dilakukan iterasi sebanyak 20, 50, 100, dan 350 sehingga total pengujian pada penelitian ini sebanyak 12 jumlah pengujian.
Adapun hasil pengujian dilakukan dengan menggunakan parameter pada tabel terhadap pengklasifikasian pasien breast cancer ditampilkan pada Tabel 4.4 dan Tabel 4.5.
Tabel 4.4 Hasil Pengujian
No DT I
Bobot Entropy 1 Bobot Entropy 2 Bobot LVQ Standar
S TS P S TS P S TS P
1 20 5 660 17 97,48 643 34 94,97 652 25 96,30
2 20 10 658 19 97,19 643 34 94,97 650 27 96,01
3 20 20 658 19 97,19 643 34 94,97 650 27 96,01
4 50 5 614 33 94,89 613 34 94,74 613 34 94,74
5 50 10 611 36 94,43 611 36 94,43 611 36 94,43
6 50 20 611 36 94,43 611 36 94,43 611 36 94,43
Tabel 4.5 Hasil Pengujian (lanjutan)
No DT I
Bobot Entropy 1 Bobot Entropy 2 Bobot LVQ standar
S TS P S TS P S TS P
8 100 10 572 25 95,81 572 25 95,81 572 25 95,81
9 100 20 572 25 95,81 572 25 95,81 572 25 95,81
10 350 5 343 4 98,56 343 4 98,56 343 4 98,56
11 350 10 343 4 98,56 343 4 98,56 343 4 98,56
12 350 20 343 4 98,56 343 4 98,56 343 4 98,56
Tingkat Akurasi 96,59 95,99 96,28
Keterangan Tabel :
DT = Jumlah Data Training I = Jumlah Iterasi
S = Jumlah pasien yang SESUAI dengan kelasnya TS = Jumlah pasien yang TIDAK sesuai dengan kelasnya. P = Presentase Tingkat Akurasi Pengklasifikasian (%)
Dari tabel dan grafik di atas bisa dilihat bahwa vektor bobot awal diperoleh dari cara Entropy pertama memiliki tingkat akurasi yang lebih baik dalam mengklasifikasi jika dibandingkan cara yang lain yakni sebesar 96,59 %. Penentuan vektor bobot awal dengan cara pertama juga menghasilkan tingkat pembelajaran yang cepat dalam mengenali dataset. Hal itu dilbuktikan dari hasil pengujian pada jumlah data training sejumlah 20 dan jumlah iterasi sebanyak 5 iterasi, yakni sebesar 97,48 % , lebih baik dari cara penentuan bobot awal yang lainnya. Namun apabila semakin besar jumlah data training dan jumlah iterasinya maka ketiga cara penentuan vektor bobot awal tersebut memiliki tingkat akurasi yang sama baiknya.
4.4. Pembahasan
training yang sedikit yaitu hanya 20 data walaupun dengan jumlah iterasi sebanyak 5. Namun dengan iterasi yang lebih banyak lagi yaitu sebanyak 20 iterasi, proses pemebelajaran semakin baik pula. Sehingga vektor bobot awal tersebut juga menghasilkan tingkat akurasi yang lebih baik jika dibandkingkan dengan vektor bobot awal yang dihasilkan metode Entropy cara kedua dan vektor bobot awal yang dihasilkan dengan mengambil data pasien pertama dari setiap kelas. Hal ini disebabkan oleh sifat dari perhitungan metode Entropy yang mampu menyelidiki tingkat keserasian dalam sekumpulan data dan mampu beradaptasi dengan sekumpulan data beratribut jamak yang memiliki variasi nilai yang berbeda antara satu data pasien dengan data pasien lainnya. Sehingga vektor bobot awal yang didapat mampu mempelajari dan mewakili data pasien dari setiap kelas jinak ataupun ganas dengan cepat. Oleh karena itu, vektor bobot awal sangatlah mempengaruhi dari proses pembelajaran data dan tingkat akurasi yang didapat.
Selain itu dalam hasil penelitian ini juga diperoleh bahwa semakin besar jumlah data training yang dilakukan maka tingkat akurasi yang didapat semakin baik pula. Hal ini dibuktikan pada ketiga cara penentuan vektor bobot awal tersebut yang memiliki tingkat akurasi yang sama baiknya yaitu sebesar 98,56 % dengan jumlah data training sebesar 350. Hal ini disebabkan oleh proses pembelajaran yang dilakukan semakin banyak sehingga menghasilkan vektor bobot yang baik pula untuk mengenali kelas pada proses testing. Namun secara keseluruhan pengujian, vektor bobot awal yang dihasilkan dengan metode Entropy cara pertama memiliki tingkat keberhasilan dalam pengklasifikasian data pasien breast cancer dibandkingkan dengan cara yang lainnya. Maka dapat disimpulkan bahwa vektor bobot awal sangatlah mempengaruhi dari proses pembelajaran data dan tingkat akurasi yang didapat. Kemudian penentuan vektor bobot awal pada JST LVQ dengan menggunakan metode
BAB 5
KESIMPULAN DAN SARAN
5.1. Kesimpulan
Kesimpulan dari hasil penelitian yang telah dilakukan yaitu :
1. Metode Entropy dalam penentuan vektor bobot awal pada Jaringan Syaraf Tiruan Learning Vector Quantization membantu kinerja proses pembelajaran
Learning Vector Quantization dan menghasilkan tingkat akurasi yang lebih baik dalam proses klasifikasi.
2. Dengan jumlah data training lebih sedikit, vektor bobot awal yang dihasilkan metode Entropy mampu mempelajari data dengan baik dan menghasilkan tingkat akurasi lebih tinggi, hal ini disebabkan sifat metode Entropy mampu menyelidiki keserasian dari sekumpulan dataset sehingga menghasilkan vektor bobot yang dapat mewakili setiap dataset pada setiap kelas.
5.2. Saran
Adapun saran yang diberikan oleh penulis yaitu :
1. Untuk hasil yang lebih akurat lagi dapat menggunakan metode penentuan bobot selain metode Entropy ataupun mengkombinasikan JST LVQ dengan metode lainnya.