PENGEMBANGAN APLIKASI TRANSLATOR SUNDA-INDONESIA-INGGRIS MENGGUNAKAN CAPTURE CAMERA PADA SMARTPHONE ANDROID
Maulana Wahid Abdurrahman [email protected]
Teknik Informatika, UIN Syarif Hidayatullah Jakarta
Abstrak
Pemerintah Jawa Barat berusaha mengfungsikan bahasa Sunda secara maksimal dengan menetapkan beberapa kebijakan sebagai bagian dari perencanaan pengembangan bahasa Sunda. Dengan menggunakan kamera pada smartphone, penulis berusaha mengembangkan aplikasi penerjemahan teks bahasa Sunda menggunakan kamera agar memudahkan masyarakat mempelajari bahasa Sunda secara interaktif. Pengembangan aplikasi ini library Tesseract sebagai engine OCR. Hasil pengujian membuktikan bahwa aplikasi ini dapat digunakan dengan tingkat keberhasilan 70 %.
Kata Kunci : Translator, Sunda, Indonesia, Inggris, Capture Camera, Tesseract, Android
Pendahuluan
Bahasa sunda merupakan salah satu bahasa daerah di Indonesia yang memiliki jumlah penutur terbesar kedua di Indonesia setelah bahasa Jawa (65 Juta). Terdapat 23 juta penutur bahasa sunda yang berada di seluruh Indonesia, terutama yang mendiami Propinsi Jawa Barat dan Banten. Tak heran bila bahasa Sunda memiliki posisi yang sangat penting dalam konteks keindonesiaan (Kuswara, 2011:2). Bahkan, bahasa Sunda diakui UNESCO sebagai bahasa indung Internasional (Ahmadheryawan.com, 20/09/2012).
Beberapa penelitian skripsi dan tesis dari Universitas Pendidikan Indonesia menunjukan perlunya sebuah upaya dari berbagai kalangan untuk membantu melestarikan bahasa sunda. Sebagai contoh, Cindy Nurwulan misalnya mengembangkan Computer Assisted Instuction agar
dapat meningkatkan pelajar bahasa sunda di kelas V (Nurwulan, 2011). Selanjutnya, Eli Martini berusaha mengembangkan model peningkatan penguasaan kosakata bahasa Sunda anak melalui penggunaan media Flash Card (Martini, 2009). Iis Aisyah berusaha meningkatkan penguasaan kosakata bahasa Sunda pada anak menggunakan melalui metode bercerita dengan menggunakan media gambar (Aisyah, 2011). Contoh-contoh penelitian tersebut menunjukan bahwa upaya mengembangkan kemampuan bahasa Sunda terus dilakukan oleh kalangan akademik. Beberapa diantara mereka seperti (Martini, 2009) dan (Aisyah,2011) merekomendasikan metode ataupun teknologi baru untuk membantu meningkatkan kemampuan kosakata bahasa Sunda bagi para siswa.
Color Image
Otsu Thresholding
Connected Component
Labeling
Line Finding Algorithm
Baseline Fitting Algorithm
Fixed Pitch Detection
UTF 8 Text Non Fixed Pitch Spacing Delimiting
Adaptive Classifier mengembangkan Aplikasi Translator
Sunda Indonesia Inggris menggunakan Capture Camera Pada Smartphone Android.
Landasan Teori
Optical Character Recognition
Optical Character Recognition
merupakan konversi elektronik ataupun mekanik dari gambar yang berupa tulisan tangan maupun teks menjadi teks digital sehingga dapat digunakan secara elektronik untuk berbagai keperluan.
Optical character recognition ini merupakan bagian dari konsep pattern recognition (Pandya, 1995).
Tesseract
Google Tesseract merupakan engine optical character recognition yang awalnya dikembangkan oleh Hewlet Packard pada tahun 1985 hingga 1995. Pada tahun 1995 Tesseract merupakan salah satu yang terbaik pada test akurasi engine UNVL. Saat ini Tesseract dikembangkan oleh google dan dikembangkan sebagai proyek open source. Dengan demikian, Tesseract dapat dikembangkan dengan bebas oleh siapapun. Tesseract dianggap sebagai
engine OCR open source terbaik saat ini (Smith, 2007 :1).
Alur kerja tesseract ocr engine
tesebut sebagai berikut (Bhaskar, 2011 :
1):
1. Color Image
Color Image atau citra warna merupakan citra digital yang menyimpan nilai warna pada setiap piksel. Setiap piksel pada citra diisi oleh nilai bit yang merupakan representasi dari nilai warna. Informasi nilai warna pada citra direpresentasikan dengan array dua dimensi dalam bentuk raster map atau bitmap (Putra, 2010 : 41).
2. Otsu Thresholding
Otsu Thresholding
merupakan pengambangan citra agar menjadi citra biner dengan mengambil nilai ambang
masing-masing bagian dari citra dapat memiliki nilai ambang yang berbeda.
3. Connected Component Labelling
Connected Component Labelling adalah proses untuk mendeteksi component-component karakter yang saling terhubung. Pada proses ini Tesseract melakukan pencarian sepanjang citra kemudian mengidentifikasi piksel latar depan, dan menandai mereka sebagai blob atau karakter potensial.
4. Line Finding Algorithm
Line Finding Algorithm
merupakan algoritma untuk mencari baris pada teks. Pada Tesseract, algoritma line finding
dirancang supaya halaman miring dapat dikenali tanpa harus di
deskew (proses untuk mengubah halaman yang miring menjadi tegak lurus) sehingga tidak menurunkan kualitas gambar. Kunci bagian proses ini adalah
blob filtering dan line construction
(Smith, 2007 : 2).
5. Baseline Fitting Algorithm
Setelah baris teks telah ditemukan, garis pangkal (baseline) dicocokan secara lebih tepat menggunakan quadratic spline. Quadratic spline
merupakan metode untuk menghasilkan titik pada sebuah rentang data yang telah diketahui sebelumnya. Quadratic spline
menggunakan polinomial dengan degree rendah sehingga mampu membentuk garis dengan halus (Smith, 2007 : 2).
6. Fixed Pitch Detection
Tahap selanjutnya tesseract memperkirakan lebar karakter yang dideteksi. Tahap ini mendeteksi karakter yang memiliki lebar tetap. Bila karakter berhasil dideteksi, selanjutnya tesseract
melakukan chopping
(pemotongan) karakter sehingga karakter pada teks menjadi terpotong-potong. Potongan ini yang selanjutnya akan diklasifikasikan (Smith, 2007 : 2). Contoh gambar karakter yang telah di potong.
Fixed Pitch Detection Pada Tesseract
7. Non Fixed Pitch Detection
Bila teks yang digunakan tidak memiliki lebar garis tepi tetap, Tesseract akan melakukan algoritma non fixed pitch detection
dengan cara mengukur batasan kesenjangan antara base line
dengan mean line (garis tengah). Ruang pada citra yang mendekati
nilai threshold akan
dikalsifikasikan dengan fuzzy
sehingga akan ditentukan sebagai bagian fitur yang akan dikenali ataupun tidak (Smith, 2007 : 2). Contoh gambar non fixed pitch :
Contoh Non Fixed Pitch
8. Adaptive Classifier
yang telah diolah pada proses sebelumnya dengan menggunakan algoritma klasifikasi (classifier)
adaptive classifier.
Alur Program
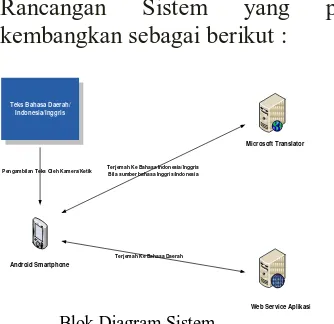
Rancangan Sistem yang penulis
kembangkan sebagai berikut :
Teks Bahasa Daerah/ Indonesia/Inggris
Microsoft Translator
Android Smartphone
Web Service Aplikasi Terjemah Ke Bahasa Indonesia/Inggris
Bila sumber bahasa Inggris/Indonesia
Terjemah Ke Bahasa Daerah Pengambilan Teks Oleh Kamera/Ketik
Blok Diagram Sistem
Penjelasan blok diagram sistem sebagai berikut :
1. Pengguna aplikasi melakukan penangkapan gambar teks dengan menggunakan kamera pada smartphone Android.
2. Gambar yang ditangkap kemudian di kenali oleh sistem yang selanjutnya akan diterjemahkan dalam bentuk teks unicode. Teks dalam bentuk unicode ini kemudian akan ditampilkan pada layar dan selanjutnya diterjemahkan sesuai bahasa yang dituju.
3. Bila bahasa asal merupakan bahasa Inggris sedangkan bahasa tujuan merupakan bahasa Indonesia, maupun sebaliknya, maka aplikasi akan menggunakan library Microsoft Translator untuk mengakses database Microsoft Translator yang ada pada Server Microsoft untuk menerjemahkan teks bahasa sumber menuju bahasa tujuan agar didapatkan hasil terjemahan yang diinginkan.
4. Bila bahasa asal atau bahasa tujuan adalah bahasa daerah, maka teks yang dihasilkan akan diterjemahkan menggunakan web service aplikasi.
Web service aplikasi sendiri merupakan layanan web yang meberikan layanan penerjemahan teks bahasa daerah. Pada server web tersebut, penulis mengembangkan database kamus bahasa daerah.
Proses pengenalan pola yang dilakukan oleh aplikasi ini sebagai berikut :
Proses Pengenalan Dan Penerjemahan.
Pengujian
Hasil dari total pengujian yang dilakukan ialah :
Jumlah Gambar
Sukses Gagal
71 50 (70 %)
21 (30
Gambar
Tangkap Gambar CameraPreview.java
Simpan Gambar Sd/iterator/test.jpg
Pengenalan Pola Tulisan startOCR();
Panggil Microsoft Translator/ Ambil JSON dari Iterator Web
Service
Tampilkan Hasil Panggil Tesseract OCR Engine
%)
Kesimpulan dari pengujian yang telah dilakukan :
1. Aplikasi ini dapat digunakan karena memiliki tingkat keberhasilan hingga 70 %.
2. Kegagalan pengenalan pola disebabkan karena :
a) Jenis Font b)Pencahayaan
c) Ukuran Gambar Warna Font
3. Background Font Kegagalan penerjemahan diakibatkan karena : a)Kegagalan pengenalan pola tulisan
b)Data yang belum tersedia
c)Akses koneksi internet yang tidak
memadai
Kesimpulan
Dari pembahasan yang sudah diuraikan, dapat disimpulkan bahwa :
1. Aplikasi penerjemahan teks bahasa Sunda menggunakan kamera dapat digunakan dengan tingkat keberhasilan hingga 70 %.
2. Aplikasi ini dapat menerjemahkan teks ke dalam tiga bahasa, yakni Sunda, Indonesia, dan Inggris.
3. Tidak semua kata dapat terbaca. Hal ini dipengaruhi oleh jenis font, pencahayaan, kemiringan, kejelasan tulisan, warna tulisan, warna latar belakang, dan ukuran piksel.
4. Penerjemahan dipengaruhi oleh koneksi internet dan ketersediaan data di database server.
Saran
Sistem yang dibangun masih memiliki beberapa kekurangan, oleh karena itu perlu adanya pengembangan agar sistem menjadi lebih baik.
1. Pengenalan pola bisa lebih ditingkatkan kembali.
2. Perlu ditambahkan fitur autofocus dan zoom.
3. Diharapkan data kamus dikembangkan ke dalam bahasa daerah lainnya, seperti Jawa, Madura, Minang, dan lain-lain.
Daftar Pustaka
Aisah, Iis. 2011. Meningkatkan Penguasaan Kosakata Bahasa Sunda Anak Taman Kanak-kanak melalui Metode Bercerita dengan Menggunakan Media Gambar. Bandung : Universitas Pendidikan Indonesia.
Bhaskar, Sonia. et al. 2011.
Implementing Optical
Character Recognition on the Android Operating System for Business Cards. USA : Stanford University.