Named Entity Recognition for Indonesian Language
Gunawan
Electrical Engineering Department
Faculty of Industrial Technology
Sepuluh Nopember Institute of Technology
Kampus ITS Keputih, Sukolilo
Surabaya 60111, East Java, Indonesia
[email protected]
Dyan Indahrani
Computer Science Department
Sekolah Tinggi Teknik Surabaya
Ngagel Jaya Tengah 73-77
Surabaya 60284, East Java, Indonesia
[email protected]
Abstract
This paper describes Named Entity Recognition system built for Indonesian. The system will handle three categories of named entity: person, location, and organization using maximum entropy and decision tree. These methods are belonging to automated ap-proach so training data is needed in order the system can learn and produces a statistical model. Three fea-ture types are extracted by maximum entropy covers binary feature, lexical feature and dictionary feature. While in decision tree induction using ID3 algorithm, 36 attributes are needed to construct its tree. After training process is ended, every word-future probabil-ity which have been formed will be processed further by Viterbi Search. The experiment result with maxi-mum entropy gets 0.64 for its F-measure. While deci-sion tree’s F-measure is higher, it reaches 0.76.
1. Introduction
The effort to classify words in text into several catego-ries which is called Named Entity Recognition (NER) has been widely known since it was in the Seventh Message Understanding‟s (MUC-7) agenda. NER is a basic step to build more complex NLP applications. For example, 1) in machine translation system, knowing all named entities in the text first will lessen the ambiguity degree, or 2) in lexi-cal database construction such as WordNet (unfortunately until now Indonesia doesn‟t have one), named entities have to be included too.
In MUC-7, NER system which is built at least able to classify words into seven categories: person, location, or-ganization, time, date, percentage, and monetary value (plus „none of the above‟). The high rate of success in ap-plying NER into several languages –like Dutch [1], Swe-dish [2], German [3], Japan [4], Korean [5], Chinese [6][7], Bengali and Hindi [8]- challenge us to apply NER
in Indonesian. The system built is able to classify words into three categories: person, location, and organization.
Automated approach is chosen to build the system be-cause of its main advantages, 1) can be applied in new language (domain) and 2) no linguist is needed. Many dif-ferent methods have been used to build a NER system such as Conditional Random Field [9], Hidden Markov Model [8], Character Level Models [10], N-best Lists [6], AdaBoost [11]. In this paper maximum entropy and deci-sion tree are chosen.
In the following section, we describe our NER system in more detail. In Section 2 we describe some examples of Indonesian named entity found in training corpus. Section 3 gives a global overview of the system architecture. We report result of our NER system on a testing document in Section 4. The last section, we end with some conclusions and propose possible future works.
2. Examples
In training corpus, organization named entity usually starts with „PT‟ (abbreviation from „Perseroan Terbatas‟) and or ends with „Tbk.‟ (abbreviation from „Terbuka‟). While location named entity usually starts with „Jln.‟ (a b-breviation from „Jalan‟; „Street‟). Those common abbrevi-ations can be found in Kamus Besar Bahasa Indonesia [12] (Indonesian Dictionary). However there are also daily life abbreviations which cannot be found in Kamus Besar Ba-hasa Indonesia. For example, „Departemen Keuangan‟ („Department of Finance’) can be shortened as „Depkeu‟ just like „SBY‟ in person named entity example.
It needs more attention to distinguish every named enti-ty in Indonesian especially for its ambiguienti-ty. The use of capital can change the meaning of a word. From above, we know that „Depkeu‟ is an organization named entity. When we add „Gedung‟ (‘Building’) in front of it, then „Gedung Depkeu‟ (‘Depkeu Building’) should be a location named entity. But if „gedung‟ is added (the difference is on alph a-bet „G‟ and „g‟) so it becomes „gedung Depkeu‟ (‘Depkeu’s Building’), then just word „Depkeu‟ only that will be categorized as an organization named entity. „Ge-dung Depkeu‟ means a building named „Depkeu‟ while
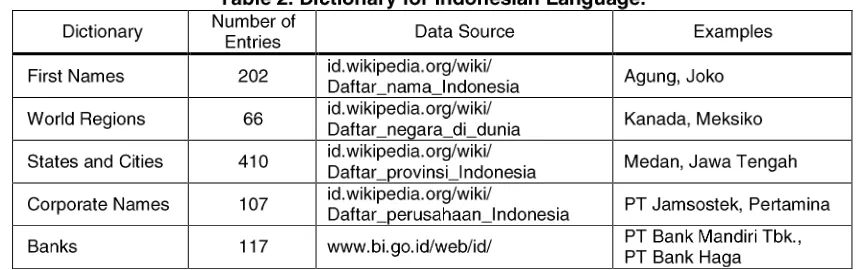
For training corpus, a document consists of 10,000 lines (130,837 words) from 1,614 detikFinance news articles from November until December 2007. For additional in-formation, detikFinance (www.detikfinance.com) is a sub category of Indonesian most popular online news, De-tik.com (www.deDe-tik.com). In training corpus, every line must contains at least one named entity and finally we get 4,428 person named entities, 8,085 location named entities and 10,550 organization named entities.
Globally, system is divided into four parts: preprocess-ing, trainpreprocess-ing, testing and post processing.
3.1. Preprocessing
The first task of this phase is giving a special sign tag for every named entity which is found in training corpus. The format for this sign tag is discussed further more in Section 3.3, Testing phase. Tagging process is done ma-nually by human. Next step is features extraction. Even though maximum entropy and decision tree are different in how the work, but they have similar goal. That makes the feature types to be extracted also not so different.
Types of feature that would be extracted in maximum entropy are:
Binary Feature
Every word must fulfill only one of these categories: 1) isAllCaps („WHO‟, „UK‟), 2) isInitialCaps („James‟, „Singapore‟), 3) isInternalCaps („McDonalds‟, „m i-dAir‟), 4) isUnCaps („understand‟, „they‟), and 5) is-Number (1, 500). An example of binary feature is shown below.
where a is possible classes and b is the word. The for-mula results 1 if the named entity class to be checked is person and the word being checked is all caps.
Lexical Feature
All words in range -2…+2 between token (token is a word in named entity) are checked for its existence in the vocabulary. The vocabulary consist every word in training corpus that has appearance frequencies ≥ 3. Our system gets 5,362 words in the list. An example of lexical feature is shown below.
where a is possible classes and b is the word. The for-mula results 1 if the named entity class to be checked is person and the word being checked is preceded with nary. An example of dictionary feature is shown below.
where a is possible classes and b is the word. The for-mula results 1 if the named entity class to be checked is person and the word being checked is in the dictionary.
So all maximum entropy‟s features only have two va l-ues. „True‟ (results 1) if meet the condition, „False‟ (results 0) is in contrast. The features in decision tree are similar with its attributes. Types of feature/attribute that would be extracted in decision tree are:
Orthography
Values for this attribute are: 1) isAllCaps, 2) isInitial-Caps, 3) isInternalisInitial-Caps, 4) isUnisInitial-Caps, and 5) isNumber. Orthography feature is same as binary feature in maxi-mum entropy.
Frequency of Token
Frequency of Word
Making frequency of word list is similar with making vocabulary in lexical feature in maximum entropy. It will return „True‟ value if a word is in list, return „False‟ for otherwise.
Appear As
This attribute aims check if a word in training corpus has been tagged with another future (has different value for its target attribute). Every word that has been tagged with two or more different futures in training corpus must have „True‟ value for this attribute.
Is In Dictionary
At a glance, this attribute is same as dictionary feature in maximum entropy because it uses the same entry. However there is one difference. In maximum entropy, all of the entries become one dictionary. While the de-cision tree is divide into three dictionaries: person dic-tionary, location dictionary and organization dictionary. Values for this attribute are „True‟ or „False‟ for each dictionary.
„Frequency of Token‟ and „Frequency of Word‟ are ex-ecuted for every word in range -2…+1 of the current word. That will produce 8 attributes (four of two types) have been extracted. While „Appear As‟ is executed for every word in range -2…+1 and for every future (minus other), and will produce another 24 attributes (four of six futures). Adding all with a „Orthography‟ and three „Is In Dictio-nary‟, last we have 36 attributes to be extracted in decision tree.
Simply, 1) binary feature is same as orthography attribute, 2) lexical feature is same as frequency of token attribute, frequency of word attribute and appear as attribute, and 3) dictionary feature is same as is in dictio-nary attribute. We use the same source during build the dictionary for maximum entropy and decision tree (see Table 2). Our person dictionary contains only first names of the people; location dictionary contains world regions, states and cities in Indonesia. Last, organization dictionary contains corporate and bank names.
3.2. Training
Features extraction in maximum entropy produces a features pool which each feature in it is belonging to one of feature types in Section 3.1. The number of features in features pool‟s system is 23,643 where 44 features are binary feature (0.18%), 23,515 features are lexical feature (99.46%) and 84 features are dictionary feature (0.36%). The core of maximum entropy‟s training phase is building a maximum entropy model which produces weight for every feature in the pool.
While training phase in decision tree is making the de-cision tree. Dede-cision tree which is produced by our system shows that all attributes have its own branch except „In Person Dictionary‟; it gives no contribution at all to the decision tree. There is a great difference on executing the training phase between these methods. Maximum Entropy takes time around 6 hours 48 minutes, decision tree only around 14 minutes.
3.2.1. Maximum Entropy. C.E. Shannon [13] said that entropy is a measure of uncertainty from a probability dis-tribution.
Adwait [14] in his thesis shows a good explanation about maximum entropy. If A denotes the collection of the possible classes so that A = {a1, a2, a3, …, an} and B
de-notes the collection of possible contexts so that B = {b1,
b2, b3, …, bn} , then a conditional entropy could be find
with:
where is observed probability of context b and is probability of class a given context b.
where is the collection of probability distribution from observation, is expected value according from model to the i-th feature, is empirical expected value from observation to the i-th and adalah number of features.
The calculation of have no direct dependency with observation, but rather found by doing this way:
where is the probability of class a given context b, is i-th feature, is the weight of i-th feature, is the number of features, is a normalization constant to
make sure that .
Feature is a constraint from class and context to the model. Feature takes form as a function, generally written by this format:
where cp (contextual predicates) is a function too that will return „True‟ or „False‟ value corresponding to the pres-ence or abspres-ence of some useful information in the context. Correcting distribution probability that maximizes en-tropy means trying to make model expectation as close as observation expectation.
The way to make the model expectation as close as ob-servation expectation is by finding the appropriate weight ( ). This weight is compute for every available feature by
using Generalized Iterative Scaling (GIS) algorithm that invented by J.N. Darroch and D. Ratcliff [15].
3.2.2. Decision Tree. In this paper, we use ID3 (Induction of Decision Tree) algorithm, by Ross Quinlan [16], as one kind of decision tree. Globally ID3 algorithm can be sum-marized as follows:
1. Taking all unused attributes and counting their entropy concerning test samples
2. Choosing attribute whose entropy is minimum 3. Creating a node containing that attribute
4. All three processes above are repeated until these con-ditions achieved: a) all values in target attribute are same, b) all attributes are used up, and c) no data left.
A little change is occurred in above algorithm to fulfill our NER system need. In ID3 algorithm, each leaf is forced to choose a value from target attribute, which is the most common value in data. While in NER case, each leaf formed by decision tree keeps all of the probability value of target attribute. This has to be done so the output of decision tree appropriates with the input of Viterbi Search. An example of decision tree that our system needed is shown in Figure 1.
3.3. Testing
With maximum entropy method, we calculate the prob-ability value for each word in testing corpus and each fu-ture available ( ). This calculation is based on weight of each feature produced after training phase. The futures given to words in this method are following And-rew Borthwick‟s [17] rule where every category has 4
‘Bapak’ ‘Ketua’ ‘Wibawa’ ‘DKI’
‘kata’ ‘di’ ‘Direktur’
Wn-2
Wn+1
Wn-1 Person : 0%
Location : 100% Organ : 0% Other : 0%
Person : 1% Location : 1% Organ : 54% Other : 44% Person : 61%
Location : 0% Organ : 5% Other : 34% Person : 5%
Location : 1% Organ : 72% Other : 22% Person : 89%
states. X is category and we abbreviate „PER‟ for person name, „LOC‟ for location, and „ORG‟ for organization.
X_UNIQUE: beginning and finishing of a one word named entity
X_START: beginning of a two or more words named entity
X_END: finishing of a two or more words named entity X_CONT: otherwise
That results 13 futures:
PER_UNIQUE, PER_START, PER _CONT, PER_END
LOC_UNIQUE, LOC_START, LOC_CONT, LOC_END
ORG_UNIQUE, ORG_START, ORG_CONT, ORG_END
OTHER
While decision tree method will trace the tree for every word until reaches the leaf. From that leaf we will find the probability of each future / value of target attribute. The values of target attribute are following the rule invented by William J. Black [18] in his paper, where every category only has 2 states:
B_X: beginning of a named entity I_X: finishing of a named entity
finally we have 9 values of target attribute: B_PER, I_PER
B_LOC, I_LOC B_ORG, I_ORG MISC
For example, 1) an organization named entity „PT Bank Mandiri Tbk.‟ 2) a person named entity „Ahmad‟ and 3) a not named entity „meja‟ (=„table‟). Values of target attribute given to every word as shown at Table 3.
3.4. Post Processing
Post processing is dominated by finding the appropriate futures sequence based on training output, the probability of every word to its futures. Suppose we have a sentence with three words inside it. Maximum Entropy will find
2,197 (133) possibility futures sequences and decision tree
will find 343 (73) futures sequences. How to choose the
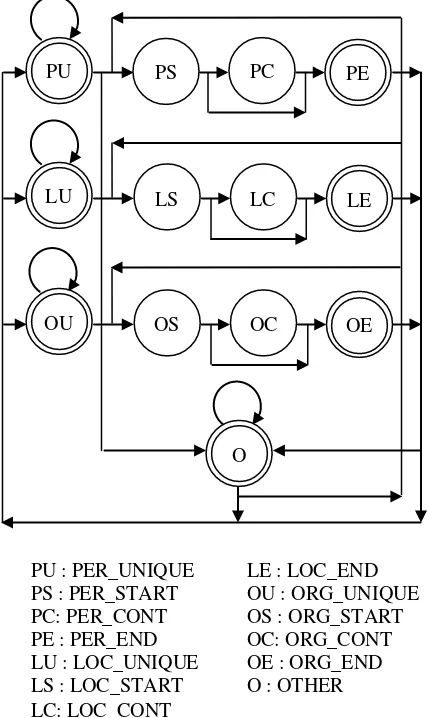
most possible sequence is the task of Viterbi Search. Viterbi Search, an algorithm which is invented by And-rew J. Viterbi [19] works like a state machine. It decides future of the next word by: 1) the probability of the next word to each future ( ) and 2) the probability of fu-tures sequence that has been built. Figure 2 shows allowed path for a futures sequence in maximum entropy while Figure 3 for decision tree.
In maximum entropy:
„X_UNIQUE‟ future can‟t be followed by another f u-ture that ended with „_CONT‟ or „_END‟ even for the same future
„X_START‟ future can be followed by „X_CONT‟ fu-ture or „X_END‟ future only
„X_CONT‟ future can be followed by „X_CONT‟ fu-ture or „X_END‟ fufu-ture only
PU PS PC PE
LU LS LC LE
OU OS OC OE
O
„X_END‟ future can‟t be followed by another future that ended with „_CONT‟ or „_END‟ even for the same future
„OTHER‟ future can be followed by „X_UNIQUE‟ or „X_START‟ future only
Simpler in decision tree:
„B_PER‟ and „I_PER‟ future can‟t be followed by „I_LOC‟ or „I_ORG‟ future
„B_LOC‟ and „I_LOC‟ future can‟t be followed by „I_PER‟ or „I_ORG‟ future
„B_ORG‟ and „I_ORG‟ future can‟t be followed by „I_PER‟ or „I_LOC‟ future
„MISC‟ future can‟t be followed by any „I_X‟ future
4. Evaluation
For experiment purpose, we have prepared a testing corpus from 199 detikFinance articles in December 2007. But, there will not be any same article in this document with training corpus, guaranteed. In this experiment, the
testing corpus contains 2,500 lines with 41,414 words of total. The testing corpus is not prepared to have minimal a named entity in every line. The tagging process in this testing corpus is also done manually.
In order to look for the methods‟ accuracy, the testing corpus has been tagged first and gives result: 625 person named entities, 881 location named entities and 1,301 or-ganization named entities. Then this tagged testing corpus is compared with the system result testing corpus and cal-culate the accuracy. This accuracy calculation using precision (PRE), recall (REC) and F-measure (F) with formula:
If the result from our system called „response‟ and the correct answer in the testing document called „key‟ then:
correct: response equals key incorrect: response not equal to key
missing: answer key tagged, response untagged spurious: response tagged, answer key untagged
For examples: correct
key: “Dia pergi ke <LOC> Jakarta </LOC>.” (He goes to <LOC> Jakarta <LOC>.)
response: “Dia pergi ke <LOCATION> Jakarta </LOCATION>.”
(He goes to <LOC> Jakarta <LOC>.) incorrect: response not equal to key
key: “Dia pergi ke <LOC> Jakarta </LOC>.” (He goes to <LOC> Jakarta <LOC>.)
response: “Dia pergi ke <PER> Jakarta </PER >.” (He goes to <PER> Jakarta <PER>.)
missing: answer key tagged, response untagged key: “Dia pergi ke <LOC> Jakarta </LOC>.” (He goes to <LOC> Jakarta <LOC>.) response: “Dia pergi ke Jakarta.” (He goes to Jakarta.)
spurious: response tagged, answer key untagged key: “Dia pergi ke rumahnya.”
(He goes to his house.)
response: “Dia pergi ke <LOC> rumahnya </LOC>.” (He goes to <LOC> his house </LOC>.)
It needs 1 hour 36 minutes to do the experiment using maximum entropy, while decision tree only needs 2 mi-nutes. The result of our experiment is shown at Table 4. Decision Tree gives more F-measure then maximum en-BP : B_PER BL : B_LOC
IP : I_PER IL : I_LOC BO : B_ORG M : MISC IO : I_ORG
BP IP
BO IO
BL IL
tropy because supported by its recall value. Decision Tree depends on named entities that have been appeared in training corpus. If a named entity in our training corpus comes back in the testing corpus, then this method gives a high probability that it will be tagged as same as in train-ing corpus. This phenomenon appeared because the first branch of our decision tree is „Frequency of Current To-ken‟. This attribute will check whether the current word is in system‟s frequency of token list.
Comparison Maximum Entropy Decision Tree
correct 1,585 1,600
incorrect 49 10
missing 734 758
spurious 951 199
PRE 0.6693412 0.6756757
REC 0.6131528 0.8844665
F 0.6400161 0.7661
In maximum entropy, many words are preceded by „X_UNIQUE‟ future but ended with „X_CONT‟ or „X_END‟ future whereas there is no allowed path from „X_UNIQUE‟ to „X_CONT‟ or „X_END‟. Second case is preceded by „X_START‟ future but not ended with „X_END‟ future. In Viterbi Search, both cases make a lower probability of future sequences that has been built because the transition probability between two states is zero.
5. Conclusion and Future Work
This paper describes a Named Entity Recognition for Indonesian using maximum entropy and decision tree. Indonesian is an easy to learn language because it has an orderly grammar structure similar with English as main international language. Therefore it‟s not so difficult to apply Named Entity Recognition in Indonesian.
From our system experiment result, lexical feature gives a big influence in recognizing named entities. It is proved by 1) the calculation of is more contributed from lexical feature than other features in maximum en-tropy and 2) all attribute -minus „orthography‟ and „is in dictionary‟ feature- branches are in top position of the de-cision tree. While binary feature or orthography attribute is important to recognize a named entity more precisely, like a previous example „Gedung‟ and „gedung‟.
For improving our ideas, we propose some ideas. Max-imum Entropy needs more feature types to be extracted so it can reach a better accuracy. Borthwick (1999) suggests 8 types of feature include binary, lexical and dictionary that are used in this paper to achieve F-measure greater than 90. If we pay more attention to the mechanism of the me-thods, there is a chance that these methods could also be implemented in another Natural Language Processing
tasks such as Sentence Boundary Detection, Part of Speech Tagging, Parsing, or Text Categorization, of course for Indonesian. Improvement can be done as well by choosing another method to implement NER for Indonesian such as Hidden Markov Model or Semantic Classification Tree as an unusually intensive tree algorithm.
6. References
[1] Fien De Meulder, Walter Daelemans and Véronique Hoste,
“A Named Entity Recognition System for Dutch”, In Proceed-ings CLIN 2001, Rodopi, 2002, pp. 77-88.
[2] Hercules Dalianis and Erik Åström, “SweNam-A Swedish Named Entity Recognizer : Its construction, training, and evalua-tion”, NADA-KStockholm, TH, Sweden, 2001.
[3] Marc Rössler, “Corpus-based Learning of Lexical Resources for German Named Entity Recognition”, Computational Linguis-tics, University Duisburg-Essen, Germany, 2004.
[4] Satoshi Sekine, Ralph Grishman and Hiroyuki Shinnou, “A Decision Tree Method for Finding and Classifying Names in Japanese Texts”, In Proceedings of The Sixth Workshop on Very Large Corpora, 1998.
[5] Yi-Gyu Hwang, Eui-Sok Chung and Soo-Jong Lim, “HMM based Korean Named Entity Recognition”, Speech/Language Technology Research Center, Electronics and Telecommunica-tions Research Institute, Korea, 2003.
[6] Lufeng Zhai, Pascale Fung, Richard, Schwartz, Marine Car-puat and Dekai Wu, “Using N-best Lists for Named Entity Rec-ognition for Chinese Speech”, Human Language Technology Center, University of Science and Technology, Hong Kong, 2004.
[7] Hua-Ping Zhang, Qun Liu, Hong-Kui Yu, Xue-Qi Cheng, and
Shuo Bai, “Chinese Named Entity Recognition using Role
Mod-el”, Computational Linguistics and Chinese Language
Processing, vol. 8, no.2, 2003.
[8] Asif Ekbal and Sivaji Bandyopaghyay, “A Hidden Markov Model Based Named Entity Recognition System: Bengali and Hindi as Case Studies”, Computer Science and Engineering De-partment, Jadavpur University, India, 2007.
[9] Burr Settles, “Biomedical Named Entity Recognition using Conditional Random Field and Rich Feature Sets”, In Proceed-ings of the COLING 2004 International Joint Workshop on Natu-ral Language Processing in Biomedicine and its Applications (NLPBA), 2004.
[10]Dan Klein, Joseph Smarr, Huy Nguyen and Christopher D.
Manning, “Named Entity Recognition with Character-Level Models”, In Proceedings Co-NLL 2003, Edmonton-Canada, 2003.
Departament de LLenguatges, i Sistemes Informàtics, Universitat Politècnica de Catalunya, Spain, 2002.
[12] Language Establishment and Development Center, Kamus Besar Bahasa Indonesia, Education and Culture Department, Indonesia, 1991.
[13] C.E. Shannon, “A Mathematical Theory of Communica-tion”,Bell Systems Technical Journal, vol. 27, 1948, p. 379-423, p. 623-656.
[14] Adwait Ratnaparkhi, “Maximum Entropy Models for Natu-ral Language Ambiguity Resolution”, Ph. D. thesis, Computer and Information Science Department, University of Pennsylva-nia, PennsylvaPennsylva-nia, 1998.
[15] J. N. Darroch and D. Ratcliff, “Generalized Iterative Scaling for Log Linear Models”,The Annals of Mathematical Statistics 43, 1972, pp. 1470-1480.
[16] J. Ross Quinlan, “Induction of Decision Trees”,Machine Learning I, The Netherlands, 1986, p. 81-106.
[17] Andrew Borthwick, “A Maximum Entropy Approach to Named Entity Recognition”, Ph. D. thesis, Computer Science Department, New York University, New York, 1999.
[18] William J. Black and Argyrios Vasilakopoulos, “Language Independent Named Entity Classification by modified Transfor-mation-based Learning and by Decision Tree Induction”, De-partment of Computation, UMIST, United Kingdom 2002.