!
SAMPUL
!!
!
PROCEEDING!
SEMINAR NASIONAL
TEKNOLOGI INFORMASI DAN
APLIKASINYA 2013
“Aplikasi Teknologi Informasi dalam
Menunjang Pelestarian Budaya Nasional dan
Pengembangan Sektor Pariwisata”
Bali, 20 September 2013
Diselenggarakan Oleh :
Program Studi Teknik Informatika
Jurusan Ilmu Komputer
Universitas Udayana
!
DAFTAR ISI
Kata Pengantar
Daftar Isi
Penerapan
Analytical Network Process Dalam
Purchasing
Motor Second
(Studi Kasus : Sumber Baru Motor, Yogyakarta)
Agus Aan Jiwa Permana ...
1
Transformasi Model Warna Yuv Dan Fuzzy Support Vector Machine
Untuk Klasifikasi Citra Satelit
Ahmad Afif Supianto, Sutrisno ...
13
Passage Retrieval In Question Answering System
I Wayan Supriana, I Wayan Santiyasa, Cokorda Rai Adi Pramartha ...
23
Sentiment Analysis Dokumen E-Complaint Kampus Menggunakan
Additive Selected Kernel SVM
Imam Cholissodin, Budi Darma S ...
29
Segmentasi Data Citra Satelit Berdasarkan Homogenitas Spektral
Menggunakan Model Markov Random Field
Murinto, Agus Harjoko, Sri Hartati ...
53
Penerapan Algoritma Boyer More Dan Levenshtein Distance Dalam
Koreksi Penulisan Kata Berbahasa Indonesia
Yulison Herry Chrisnanto, Erna Dhini Nurhasanah, Agus Komarudin ...
61
Artificial Stigmergy
Semut Dalam Penanganan Masalah Optimasi
Pencarian Jalur Terpendek Ekspedisi Barang
Ketut Bayu Yogha Bintoro, Ni G. A. P. Harry Saptarini ...
73
Pengembangan Sistem Informasi Akuntansi BMT Berbasis Web (studi
kasus BMT AZZAM)
Tedy Setiadi, Risfi Syarif ...
81
Pengaturan Penempatan Buku Di Perpustakaan Menggunakan Metode
Association Rule Analysis Dan Vertical Format Algorithm
Ni Wayan Mirah Pratiwi Negari, Agus Muliantara, Ngurah Agus Sanjaya
ER ... ...
93
Pengamanan Data Citra Digital Menggunakan Metode Vigenere Cipher
Hamdani , Anindita Septiarini, Irmadani Apriningrum ...
103
Teknik Pengamanan dari Serangan Spammers
!
Femur Length Detection And Measurement Using Cascade Adaboost And
Morphology Operators
Zaki Imaduddin, I Putu Satwika, Robeth Rahmatullah, Wisnu Jatmiko ...
119
Sistem Pendukung Pemilihan Keputusan Penentuan Kelayakan Penerima
Jaminan Kesehatan Masyarakat Menggunakan Multiple Attribut Decision
Making (MADM) Dan Metode Simple Additive Weighting (SAW)
Gunawan Abdillah, Agus Komarudin, Agun Abdul Gani ...
127
Pseudo Random Number Generator Untuk Kode Acak Pin Pada Sistem
Informasi PMDK Online
Made Putra Wira Dharma, Agus Muliantara ...
135
SMS Gateway Untuk Peningkatan Pelayanan Kepada Customer (Studi
Kasus : PT Bhakti Jaya Mobil Indonesia)
Ni G. A. P. Harry Saptarini, Zulfahmi Alif Abdi ...
145
Optimasi Sistem Distribusi Dua Tingkat Dengan Algoritma Genetika
Adaptif
Putu Indah Ciptayani, Zulfahmi Indra ...
159
Pengaruh Nguyen Widrow Dan Momentum Pada Kinerja Jaringan Syaraf
Tiruan Backpropagation
I Gusti Agung Ari Bawarta, I Made Widiartha ...
167
Peramalan Hujan Harian Menggunakan Algoritma Backpropagation
Ida Bagus Gede Bayu Priyanta, Elsyantri Nana Suhendra,
I Gede Santi
Astawa ... ...
175
Pengenalan Pola Daun Dengan Menggunakan Metode
Radial Basis
Function Dengan K-Means Clustering Untuk Penentuan Jenis Tanaman
Ni Putu Tessa Intaran, Agus Muliantara ...
181
Prototype Sistem Penunjuk Arah dan Pelacakan Bagi Penyandang Tuna
Netra berbasis RFID (Radio Frequency Identification)
I Made Widhi Wirawan ...
189
Aplikasi Mobile Menampilkan Data Property Perusahaan Property
Menggunakan Sistem Operasi Android
Cok. Istri Oka Diah Anggaraeni ...
201
Implementasi Fuzzy dalam Proses Pengereman Secara Otomatis
Menggunakan Metode Mamdani
Proceeding Seminar Nasional Teknologi Informasi & Aplikasinya
2013%
!PENGATURAN PENEMPATAN BUKU DI PERPUSTAKAAN
MENGGUNAKAN METODE ASSOCIATION RULE ANALYSIS DAN
VERTICAL FORMAT ALGORITHM
Ni Wayan Mirah Pratiwi Negari
1, Agus Muliantara
2,
Ngurah Agus Sanjaya ER
31 Jurusan Ilmu Komputer, Fakultas MIPA Universitas Udayana
Jl. Kampus UNUD Bukit Jimbaran, Badung, Bali
2 Jurusan Ilmu Komputer, Fakultas MIPA Universitas Udayana
Jl. Kampus UNUD Bukit Jimbaran, Badung, Bali
3 Jurusan Ilmu Komputer, Fakultas MIPA Universitas Udayana
Jl. Kampus UNUD Bukit Jimbaran, Badung, Bali
Email : [email protected], [email protected]2,![email protected]3
ABSTRAK
Berdasarkan pengklasifikasian decimal dewey (DDC) yang terdapat di perpustakaan, pengaturan penempatan buku sangat penting dilakukan agar antar kategori buku mempunyai hubungan keterkaitan dalam penempatannya. Untuk mendapatkan pengaturan penempatan buku yang sesuai dengan prediksi kemunculan setiap buku dilakukan dengan mencari hubungan keterkaitan antar buku melalui data transaksi peminjaman buku dengan menggunakan metode Association Rule Analysis dan menggunakan Vertical Format Algorithm untuk mengurangi kandidat dari aturan asosiasi yang telah dihasilkan.
Pengaturan penempatan buku ini sangat penting dilakukan karena diharapkan dapat membantu dalam pencarian informasi dan ilmu pengetahuan secara cepat dan efisien. Oleh karena itu dalam pengujian penelitian ini dilakukan perbandingan tingkat efisiensi dari segi waktu terhadap model pengaturan penempatan buku menggunakan metode Association Rule Analysis dengan pengaturan penempatan buku yang telah berlaku sebelumnya di perpustakaan.
Berdasarkan hasil pengujian, diperoleh bahwa pengaturan penempatan buku dengan menggunakan metode Association Rule Analysis lebih efisien dibandingkan dengan pengaturan penempatan buku yang telah berlaku sebelumnya di perpustakaan. Hal ini dibuktikan dengan rata – rata waktu tempuh yang dimiliki pengaturan penempatan buku dengan menggunakan metode Association Rule Analysis lebih singkat dibandingkan dengan pengaturan penempatan buku di perpustakaan.
Kata Kunci: Pengaturan penempatan buku, Association Rule Analysis, Vertical Format Algorithm, Support, Confidence
1
PENDAHULUANPerpustakaan merupakan salah satu pusat informasi, sumber ilmu pengetahuan, penelitian dan rekreasi. Namun fungsi perpustakaan tersebut hingga kini belum optimal karena memiliki beberapa kendala. Hal ini disebabkan faktor pengaturan penempatan setiap kategori buku dengan kategori buku lainnya terbilang acak. Dalam bidang kepustakawanan, sebuah perpustakaan umum paling tidak memiliki kategori buku sejumlah sepuluh kategori utama yang didasarkan pada pengelompokan kepustakawanan yang dinamakan pengklasifikasian decimal dewey (DDC). Mengacu dari pengklasifikasian ini, sebuah permasalahan muncul yaitu bagaimana aturan penempatan buku yang tepat terhadap pola prediksi kemunculan dari suatu kategori buku dengan kategori buku yang lain sesuai dengan data transaksi peminjaman buku. Dengan kata lain, penempatan setiap kategori buku dengan kategori buku yang lainnya harus memiliki suatu hubungan atau relasi yang saling berkaitan. Pengaturan penempatan buku ini sangat penting dilakukan karena diharapkan dapat membantu dalam pencarian informasi dan ilmu pengetahuan secara cepat dan efisien.
Dalam permasalahan pengaturan penempatan buku, perlu adanya pengurangan kandidat untuk menemukan aturan asosiasi. Berdasarkan penelitian sebelumnya oleh Wirdasari (Wirdasari, 2011), tentang penempatan buku di perpustakaan, dikemukakan bahwa untuk mendapatkan penyusunan buku yang sesuai dengan prediksi kemunculan setiap buku dilakukan dengan mencari hubungan keterkaitan antar buku melalui data transaksi peminjaman buku dengan menggunakan metode Association Rule Analysis dan menggunakan algoritma Apriori untuk mengurangi kandidat dari aturan asosiasi yang telah dihasilkan. Walaupun algoritma
Proceeding Seminar Nasional Teknologi Informasi & Aplikasinya
2013%
!Apriori sangat mudah untuk dipahami dan dimplementasikan, akan tetapi algoritma Apriori juga memiliki kekurangan yaitu, untuk melakukan pencarian frequent itemset (data yang sering muncul), algoritma Apriori harus melakukan akses ke basis data berulang kali untuk setiap kombinasi item. Hal tersebut menyebabkan banyaknya waktu yang dibutuhkan untuk melakukan scanning database (Erwin, 2009).
Selain dari kekurangan tersebut, algoritma Apriori juga merupakan algoritma lama yang sudah lazim digunakan untuk beberapa penelitian. Maka dibutuhkan suatu algoritma baru yang dapat mengatasi kekurangan dari algoritma Apriori. Vertical Format Algorithm merupakan algoritma baru yang mencari frequent itemset dengan format vertikal. Algoritma ini dipilih karena berdasarkan penelitian sebelumnya oleh Kurniawan (Kurniawan, 2011), menunjukkan bahwa performa Vertical Format Algorithm jauh lebih cepat dibandingkan algoritma Apriori. Hal ini disebabkan karena algoritma ini hanya melakukan satu kali scanning database untuk mendapatkan frequent 1-itemset dan untuk selanjutnya tidak perlu dilakukan scan terhadap database lagi.
Sehingga dari penelitian ini diharapkan dapat menemukan aturan penempatan buku di perpustakaan yang paling optimal. Keoptimalan dari aturan (rule) yang dihasilkan diukur berdasarkan nilai support dan confidence yang memenuhi syarat minimum untuk support (minimum support) dan syarat minimum untuk confidence (minimum confidence), dimana nilai minimum support dan minimum confidence harus ditetapkan sebelumnya.
Oleh karena inilah, penulis mengangkat judul penelitian Tugas Akhir, yaitu “Pengaturan Penempatan Buku di Perpustakaan Menggunakan Metode Association Rule Analysis dan Vertical Format Algorithm”. Adapun permasalahan yang harus diselesaikan dalam penelitian adalah bagaimana cara menentukan aturan penempatan buku dari proses Association Rule Analysis? Tujuan dari penelitian ini adalah mencari pengaturan penempatan buku yang efisien dengan metode Association Rule Analysis dan menentukan aturan penempatan buku dari proses Association Rule Analysis.
2
TINJAUAN PUSTAKA 2.1 Association Rule AnalysisAssociation Rule Analysis merupakan suatu metode untuk menemukan relasi antar dataset. Relasi ini dapat direpresentasikan dengan aturan asosiasi yang akan memprediksi kemunculan setiap item terhadap kemunculan item yang lain dalam suatu transaksi. (Tan P.N, 2006:327)
2.2 Itemset dan Support Count
Itemset adalah kumpulan dari satu atau lebih item. Jika suatu itemset terdiri dari k item maka dapat dikatakan sebagai k itemset. Sebagai contoh {Beer,Diapers,Milk} dikatakan sebagai 3-itemset. Set kosong pada itemset tidak berarti tidak ada item pada itemset.
Support count (σ) adalah frekuensi kemunculan setiap itemset. Jika suatu transaksi terdiri dari itemset X, maka secara matematis, support count σ(X), untuk suatu itemset X dapat dinyatakan sebagai :
( )
X ={
ti X⊆ti,ti∈T}
σ
Dimana :
σ(X) = support count atau frekuensi kemunculan itemset X X = itemset atau kumpulan dari beberapa item
ti = transaksi yang mengandung itemset X
T = semua transaksi
= jumlah elemen dalam satu set (Tan P.N, 2006:329)
2.3 Support dan Confidence
Suatu aturan asosiasi adalah ekspresi maksud dari X ! Y. Support adalah prosentase dari transaksi pada setiap item yang mengandung X dan Y. Confidence adalah prosentase yang menunjukkan seberapa sering item Y muncul di X. Secara matematis support dan confidence dapat dinyatakan sebagai :
Proceeding Seminar Nasional Teknologi Informasi & Aplikasinya
2013%
!(
)
N Y X Y X s Support, ( ""→ )=σ ∪(
)
( )
X Y X Y X c Confidence σ σ ∪ = #→ # ) ( , Dimana := frekuensi kemunculan dari itemX gabungan itemY dalam seluruh transaksi.
= frekuensi kemunculan dari item yang mengandung X dalam seluruh transaksi.
N = jumlah seluruh transaksi (Tan P.N, 2006:330)
2.4 Penemuan Aturan Asosiasi
Association Rule Analysis didefinisikan sebagai suatu proses untuk menemukan semua
aturan asosiasi yang memenuhi syarat minimum support (minsup) dan syarat minimum
confidence (minconf) (Pramudiono, 2007). Selanjutnya, terdapat dua strategi dalam menemukan
aturan asosiasi :
1. Frequent itemset generation, dimana tujuannya untuk menemukan semua itemset yang
memenuhi ambang minsup. Itemset ini disebut juga frequent itemset.
2. Rule generation, dimana tujuannya untuk mengekstraksi semua aturan high-confidence dari
frequent itemset pada langkah sebelumnya. Aturan ini disebut strong rules (Tan P.N, 2006).
2.5 Vertical Format Algorithm
Vertical Format Algorithm adalah sebuah algoritma baru yang diciptakan oleh Yi-ming
Gou dan Zhi-jun Wan dari Universitas Teknik Liaoning, Huludao, China dengan mencari
frequent itemset dengan format vertikal. Algoritma ini melakukan scanning database hanya satu
kali untuk mendapatkan frequent 1-itemset dan untuk langkah selanjutnya tidak perlu dilakukan scan terhadap database lagi.
Keuntungan dari algoritma ini adalah dapat menentukan itemset non-frequent sebelum generate itemset kandidat sehingga dapat menghemat waktu. Setiap id transaksi pada k-itemset membawa informasi yang lengkap yang dapat mengkalkulasi tingkat support, sehingga tidak perlu lagi melakukan scan database untuk mencari tingkat support dari (k+1) itemsets (Kurniawan, 2011).
2.6. Cara Kerja Vertical Format Algorithm
Pada awalnya dilakukan scanning database untuk mendapatkan frequent 1-itemset. Kemudian merubah format horizontal menjadi format vertikal pada frequent 1-itemset tersebut. Langkah selanjutnya adalah dengan melakukan “operasi AND” untuk setiap elemen dari
frequent itemset tersebut dan simpan hasilnya. Jika hasilnya melebihi minimum support, maka
kita mendapatkan kandidat set untuk Ck+1 dan dilakukan “operasi AND” berikutnya dan dilakukan secara berulang – ulang sampai mendapatkan situasi seperti berikut ini :
• Hanya tersisa satu frequent itemset dan tidak mungkin dapat digunakan “operasi AND” lagi. • Seluruh hasil dari “operasi AND” kurang dari minimum support.
2.7 Rule Generation
Proses Rule Generation yaitu mengekstraksi setiap aturan yang memenuhi minimum
confidence dari frequent itemset yang dihasilkan. Sebagai contoh dihasilkan frequent itemset
yaitu {I1, I2, I5}. Dari frequent itemset tersebut dapat dihasilkan kombinasi aturan asosiasi. Kombinasi aturan asosiasi tersebut yaitu :
{I1, I2} ! {I5} {I1, I5} ! {I2} {I2, I5} ! {I1} {I1} ! {I2, I5} {I2} ! {I1, I5} {I5} ! {I1, I2}
Masing – masing dari kombinasi aturan tersebut dihitung tingkat confidencenya sehingga akan dapat diketahui aturan yang memenuhi minimum confidence. Sehingga dari
Proceeding Seminar Nasional Teknologi Informasi & Aplikasinya
2013%
!aturan yang memenuhi minimum confidence merupakan output akhir dari proses Association Rule Analysis. (Jiawei Han and Micheline Kamber, 2006)
2.8 Decimal Dewey Classification (DDC)
Sistem klasifikasi DDC diberi nama desimal karena sistem tersebut mengatur semua pengetahuan sebagaimana tertuang dalam bahan perpustakaan menjadi sepuluh kelas utama yang diberi nomor 000 sampai 900. Desimal sama dengan persepuluh artinya setiap bilangan dibagi menjadi sepuluh lalu selanjutnya di bagi sepuluh lagi. Misalnya kelas 400 di bagi menjadi 400, 410, 420, 430, 440, 450, 460, 470, 480, 490 kelas 490 dibagi lagi menjadi 490, 491, 492, 493, 494, 495, 496, 497, 498, 499, kelas 491 dibagi menjadi 491.1 – 491.7, lalu dibagi lagi, demikian seterusnya.
Adapun susunan singkatan 10 kelas utama DDC (first summarry atau ringkasan pertama) sebagai berikut:
000 Computer science, information & general works 100 Philosopy & psychology
200 Religion 300 Social sciences 400 Language 500 Science 600 Technology 700 Arts & recreation 800 Literature
900 History & geography
3
METODELOGI PENELITIAN 3.1 Pengumpulan DataData set yang diambil yaitu berdasarkan data transaksi peminjaman buku di perpustakaan Universitas Udayana. Data set yang digunakan sebanyak 100 data transaksi peminjaman buku, diambil dari data transaksi pada bulan Januari – April 2013.
3.2 Analisis Sistem
Adapun kebutuhan sistem yang diperlukan dalam permasalahan pengaturan penempatan buku yaitu :
1. Proses penemuan Frequent Itemset dengan menggunakan Vertical Format Algorithm. 2. Proses penemuan Association Rule dari frequent itemset dengan membentuk aturan asosiasi
yang memenuhi minimum confidence. 3.3 Perancangan Sistem
3.3.1 Flowchart Sistem
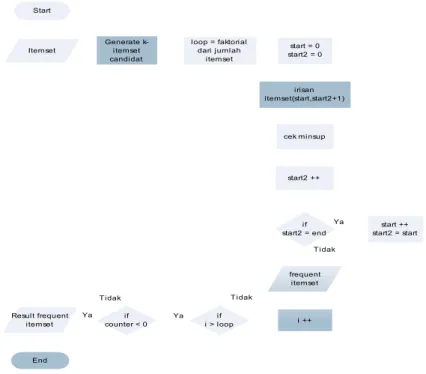
Dalam sistem yang akan dibangun terdapat dua proses dalam mencari aturan asosiasi. Pada Gambar 3.1 merupakan flowchart yang menggambarkan langkah-langkah yang dilakukan selama proses penemuan frequent itemset dengan Vertical Format Algorithm. Pada proses ini dilakukan AND operation untuk setiap elemen frequent itemset. Selanjutnya dari hasil AND operation tersebut dilakukan pengecekan terhadap minimum support. Hasil yang memenuhi dijadikan kandidat itemset selanjutnya.
Proceeding Seminar Nasional Teknologi Informasi & Aplikasinya
2013%
! Start Itemset Generate k-itemset candidat loop = faktorial dari jumlah itemset start = 0 start2 = 0 irisan itemset(start,start2+1) cek minsup start2 ++ if start2 = end start ++ start2 = start frequent itemset i ++ if i > loop if counter < 0 Result frequent itemset End Tidak Ya Tidak Ya Tidak YaGambar 1. Flowchart proses Frequent Itemset Generation
Pada gambar 3.2 merupakan flowchart dari proses penemuan aturan asosiasi. Dimana
pada proses ini mengekstraksi semua kombinasi aturan asosiasi dari masing – masing frequent
itemset. Start maksimal frequent itemset Generate kombinasi i = 0 counter = jumlah solusi itemset counter_kombinasi = jumlah kombinasi ke i j = 0 hitung confidence if confidence > minconf list conf j ++ if j < counter_kombinasi i ++ if i < counter cetak list conf End Ya Tidak Ya Tidak Tidak Ya
Gambar 2. Flowchart proses Rule Generation
3.3.2 Diagram Konteks Sistem
Pengguna 0 Sistem Pengaturan Penempatan Buku data transaksi peminjaman buku
aturan asosiasi penempatan buku minimum support minimum confidence
Proceeding Seminar Nasional Teknologi Informasi & Aplikasinya
2013%
!Dari gambar 3.3 dapat dijelaskan bahwa sistem pengaturan penempatan buku mendapatkan input data transaksi peminjaman buku dari pengguna sistem. Selanjutnya sistem akan memberikan output kepada pengguna berupa aturan asosiasi yang dapat dijadikan aturan dalam penempatan buku.
3.3.3 Data Flow Diagram Sistem
DFD level 0 ini menjelaskan bagian – bagian atau sub proses dari diagram konteks di atas. DFD level 0 ini memiliki dua proses, antara lain : proses penemuan frequent itemset dan proses penemuan association rule.
Pengguna 1.0 Proses Penemuan Frequent Itemset 2.0 Proses Penemuan Association Rule tb_dt_frequent itemset data transaksi peminjaman buku
aturan asosiasi penempatan buku data frequent itemset
data frequent itemset tb_dt_transaksi peminjaman buku
minimum confidence minimum support
Gambar 4. Data Flow Diagram level 0
4
HASIL DAN PEMBAHASAN4.1 Implementasi Sistem
Implementasi dari sistem ini mencakup lingkungan perangkat keras dan perangkat lunak. Dalam implementasinya, sistem pengaturan penempatan buku dengan metode Association Rule Analysis ini diimplementasikan pada bahasa pemrograman web PHP. Adapun spesifikasi untuk perangkat keras adalah sebagai berikut :
1. Processor Intel Pentium Dual Core T4200 2,00 Ghz
2. RAM 2 GB
3. Hardisk 250 GB
4. Perangkat output berupa monitor 14’ 5. Perangkat input berupa keyboard dan mouse
Sedangkan untuk spesifikasi dari perangkat lunak adalah sebagai berikut : 1. Database Management System (DBMS) MySQL
2. Web Server Apache ( XAMPP 1.7.3 )
3. Web Browser Mozilla Firefox
4. Sistem Operasi Windows 7
4.2 Hasil Pengujian
Pengujian ini dilakukan dengan menentukan batas minsup dan minconf terlebih dahulu. Batasan tersebut dapat diatur oleh pengguna. Sehingga pengujian dilakukan dengan beberapa kali percobaan dengan nilai minsup 5% dan nilai minconf 50%, 60%, 70%, 80%.
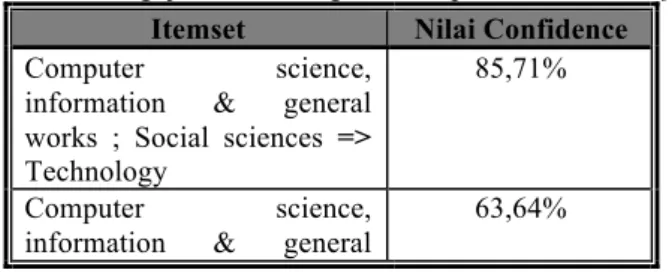
a. Pengujian dengan minsup 5% dan minconf 50%
Tabel 1. Hasil Pengujian Data dengan Minsup 5% dan Minconf 50%
Itemset Nilai Confidence
Computer science, information & general works ; Social sciences => Technology
85,71%
Computer science, information & general
Proceeding Seminar Nasional Teknologi Informasi & Aplikasinya
2013%
!works ; Language => Technology
Computer science,
information & general works ; Science => Technology
55,56%
Social sciences ; Language => Technology
70% Social sciences ; Science =>
Technology
54,55% Social sciences ; Literature
=> Technology
66,67% Science ; Literature =>
Technology
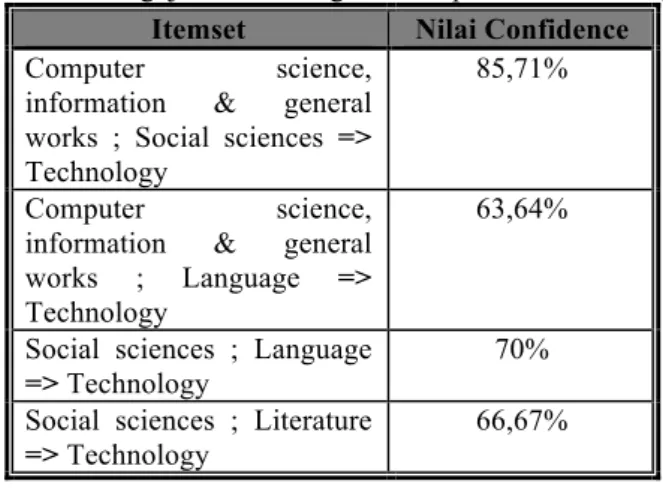
55,56% b. Pengujian dengan minsup 5% dan minconf 60%
Tabel 2. Hasil Pengujian Data dengan Minsup 5% dan Minconf 60%
Itemset Nilai Confidence
Computer science,
information & general works ; Social sciences => Technology
85,71%
Computer science,
information & general works ; Language => Technology
63,64%
Social sciences ; Language => Technology
70% Social sciences ; Literature
=> Technology
66,67% c. Pengujian dengan minsup 5% dan minconf 70%
Tabel 3. Hasil Pengujian Data dengan Minsup 5% dan Minconf 70%
Itemset Nilai Confidence
Computer science,
information & general works ; Social sciences => Technology
85,71%
Social sciences ; Language => Technology
70% d. Pengujian dengan minsup 5% dan minconf 80%
Tabel 4. Hasil Pengujian Data dengan Minsup 5% dan Minconf 80%
Itemset Nilai Confidence
Computer science,
information & general works ; Social sciences => Technology
85,71%
Dari hasil pengujian tersebut menunjukan bahwa itemset yang dihasilkan merupakan aturan asosiasi yang telah memenuhi batas minsup dan minconf yang telah ditentukan. Nilai
minsup dan minconf mempengaruhi jumlah aturan asosiasi yang dihasilkan. Hal tersebut dapat
dilihat dari kesimpulan berikut :
• Minsup 5% dan Minconf 50% = 7 aturan asosiasi
• Minsup 5% dan Minconf 60% = 4 aturan asosiasi
• Minsup 5% dan Minconf 70% = 2 aturan asosiasi
Proceeding Seminar Nasional Teknologi Informasi & Aplikasinya
2013%
!
Dari masing – masing kombinasi nilai minsup dan minconf yang menghasilkan aturan asosiasi dapat dibentuk sebuah model pengaturan penempatan buku yang dapat dijadikan bahan rekomendasi bagi perpustakaan.
4.3 Analisis Hasil Pengujian
Analisis hasil pengujian ini terdiri dari perbandingan model pengaturan penempatan buku dari aturan asosiasi yang dihasilkan dengan pengaturan penempatan buku yang telah ada sebelumnya di perpustakaan. Dari hasil pengujian sebelumnya yang dilakukan dengan 4 macam kombinasi nilai minsup dan minconf maka dapat dibentuk 4 model pengaturan penempatan buku. Sedangkan di perpustakaan sudah terdapat 1 pengaturan penempatan buku yang telah ada sebelumnya. Sehingga terdapat 5 macam pengaturan penempatan buku yang akan dibandingkan untuk mencari pengaturan penempatan buku yang lebih efisien dari segi waktu.
Kategori buku yang berdekatan letaknya dianggap memiliki waktu tempuh sebanyak t satuan waktu. Hal ini bertujuan untuk mempermudah menghitung waktu tempuh dari setiap kategori buku ke kategori buku yang lain. Untuk mengetahui pengaturan penempatan buku yang lebih efisien dari segi waktu dilakukan penghitungan waktu tempuh dari sampel data uji transaksi peminjaman buku.
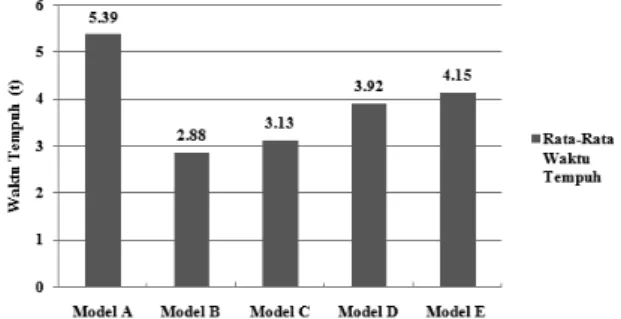
Dari hasil pengujian terhadap kelima macam pengaturan penempatan buku maka dapat diperoleh bahwa pengaturan penempatan buku menggunakan metode Association Rule Analysis dengan minsup 5% dan minconf 50% lebih baik karena memiliki rata – rata waktu tempuh yang lebih singkat yaitu 2,88t satuan waktu. Data hasil penelitian ini dapat dilihat sesuai dengan visualisasi pada gambar grafik 4.8 yang merupakan hasil rata-rata waktu tempuh dari masing – masing pengaturan penempatan buku dengan menggunakan sampel data transaksi yang sama. Dimana Model A merupakan pengaturan penempatan buku yang telah berlaku di perpustakaan, Model B merupakan pengaturan penempatan buku dengan minsup 5% dan minconf 50%, Model C adalah pengaturan penempatan buku dengan minsup 5% dan minconf 60%, Model D yaitu pengaturan penempatan buku dengan minsup 5% dan minconf 70% dan Model E yaitu pengaturan penempatan buku dengan minsup 5% dan minconf 80%.
Gambar 5. Grafik Perbandingan Rata – Rata Waktu Tempuh Masing – Masing Pengaturan Buku
5
KESIMPULAN1. Berdasarkan hasil pengujian, keempat model pengaturan penempatan buku dengan menggunakan metode Association Rule Analysis lebih efisien dari segi waktu dibandingkan dengan pengaturan penempatan buku yang telah berlaku sebelumnya di perpustakaan. Hal ini dibuktikan dengan rata – rata waktu tempuh yang dimiliki keempat pengaturan penempatan buku dengan menggunakan metode Association Rule Analysis lebih singkat dibandingkan dengan pengaturan penempatan buku di perpustakaan yaitu memiliki rata – rata waktu tempuh 5,39t satuan waktu.
2. Berdasarkan hasil pengujian, kombinasi nilai minimum support dan minimum confidence yang paling baik dalam melakukan pengaturan penempatan buku yaitu nilai minimum support 5% dan minimum confidence 50%. Hal ini disebabkan karena pengaturan penempatan buku menggunakan nilai minimum support 5% dan minimum confidence 50% memiliki rata – rata waktu tempuh paling singkat yaitu 2,88t satuan waktu.
3. Berdasarkan hasil pengujian dengan beberapa kombinasi minimum support dan minimum confidence terlihat bahwa kategori buku Computer science, information & general works
Proceeding Seminar Nasional Teknologi Informasi & Aplikasinya
2013%
!dan Social science serta Technology memiliki hubungan keterkaitan yang tinggi karena prediksi kemunculan rule yang memuat kategori buku tersebut sangat tinggi dibandingkan rule lainnya.
6
DAFTAR PUSTAKA[1] Dewey, Melvil. 2003. Decimal Classification and Relatif Index, 22th ed.Vol.1-Vol.4. Dublin, Ohio : OCLC Online Computer Library Center, Inc.
[2] Erwin. 2009. “Analisis Market Basket Dengan Algoritma Apriori dan FP-Growth”. Jurnal Fakultas Ilmu Komputer Universitas Sriwijaya
[3] Jiawei Han and Micheline Kamber. 2006. Data Mining – Concepts and Techniques. Morgan Kaufmann, 2 edition
[4] Kurniawan Soekamto, Daniel. 2011. “Implementasi Data Mining Dengan Metode Association Rule Untuk Mengetahui Pola Belanja Pelanggan (Studi Kasus PT. Vision Interprima Pictures)”. Thesis Program Pasca Sarjana Ilmu Komputer Universitas Bina Nusantara Jakarta
[5] Raorane A.A., Kulkarni R.V., Jitkar B.D., 2012. “Association Rule – Extracting Knowlegde Using Market Basket Analysis”. Research Journal of Recent Sciences
[6] Santosa, Budi. 2007. Data Mining Teknik Pemanfaatan Data untuk Keperluan Bisnis. Yogyakarta: Graha Ilmu
[7] Subrata, Gatot. 2009. “Klasifikasi Bahan Pustaka”. Jurnal Pustakawan Perpustakaan UM
[8] Tan P.N., Steinbach M., Kumar V., 2006. Introduction to Data Mining. Pearson Education
[9] Wandi, Nugroho. 2012. “Pengembangan Sistem Rekomendasi Penelusuran Buku dengan Penggalian Association Rule Menggunakan Algoritma Apriori (Studi Kasus Badan Perpustakaan dan Kearsipan Propinsi Jawa Timur)”. Jurnal Teknik ITS
[10] Winata, Andrey. 2010. “Pencarian Association Rule Terhadap Data Penjualan Barang Sebuah Butik”. Skripsi Fakultas Ilmu Komputer Universitas Pembangunan Nasional “Veteran” Jakarta
[11] Wirdasari, Dian dan Ahmad Calam. 2011. “Penerapan Data Mining untuk Mengolah Data Penempatan Buku di Perpustakaan SMK TI PAB 7 Lubuk Pakam dengan Metode Association Rule”. Jurnal Saintikom Universitas Sumatera Utara