BAB II
LANDASAN
TEORI
2.1. Data Warehouse
2.1.1. Konsep Data Warehouse
Dalam dunia komputer data warehouse adalah sebuah database untuk menyimpan data history yang sangat besar. Berdasarkan definisi (Inmon, 2005, pp. 29), Data Warehouse (DWH) adalah subject-oriented, integrated, time-variant dan non-volatile dari kumpulan data untuk membantu proses pengambilan keputusan oleh manajemen. Berikut ini adalah penjelasan secara detil dari definisi DWH (Connolly & Begg, 2009, pp. 1197):
• Subject-oriented artinya DWH haruslah diorganisasikan berdasarkan subjek yang besar yang ada dalam suatu lingkungan enterprise (seperti data pelanggan, produk dan sales) bukan berdasarkan aplikasi besar yang digunakan (seperti invoice pelanggan, kontrol stok, dan sales produk). Hal ini menggambarkan bahwa menyimpan data decision-support lebih tepat daripada data application-oriented
• Integrated karena menggabungkan beberapa data yang berasal dari sumber berbeda dari sebuah sistem enterprise. Sering kali data sumber tersebut terdapat inkonsistensi dikarenakan perbedaan format data. Sehingga integrasi sumber data – data tersebut haruslah menjadi konsisten untuk menampilkan tampilan data yang seragam kepada pengguna.
• Time-variant karena data di dalam DWH hanya akurat dan valid pada beberapa waktu tertentu atau selama beberapa interval waktu. Data – data tersebut merupakan serangkain daripada snapshot.
• Non-volatile karena data tidak diperbarui secara realtime melainkan direfresh secara periodik dari sistem operasional. Data baru selalu ditambahkan sebagai suplemen untuk database bukan mengganti data yang sudah ada. Database selalu menyimpan data baru ini dan secara bertahap mengintegrasikan dengan data yang sebelumnya.
2.1.2. OLTP dan DWH
Secara umum sistem basis data dalam suatu perusahaan bisa dibedakan menjadi dua tipe yaitu Online Transaction Processing (OLTP) dan Online Analytical Processing (OLAP). Sistem OLTP didesain untuk memproses transaksi data dari suatu aplikasi koporat, sehingga di dalamnya ada banyak sekali proses manipulasi data. Data transaksi tersebut akan digunakan oleh DWH sebagai sumber data yang kemudian diolah untuk digunakan dalam aktivitas analisa. Alat bantu analisa inilah yang biasa disebut OLAP.
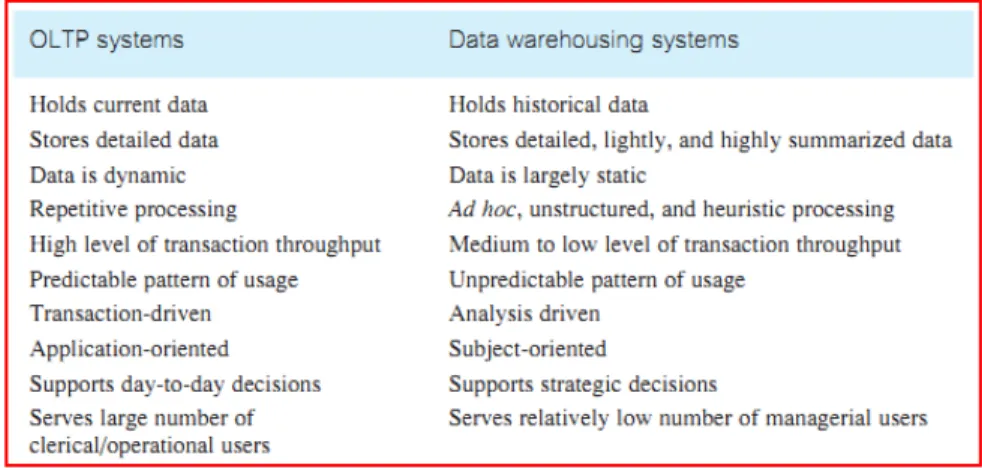
Ada perbedaan yang mendasar antara sistem OLTP dan sistem DWH. Tabel di bawah memberikan perbandingan dari masing – masing karakteristik sistem tersebut. Perbedaan utama adalah OLTP merupakan sistem untuk transaksi sehingga di dalamnya perubahan data sangat dinamis, sedangkan DWH merupakan data histori yang digunakan untuk analisa sehingga data di dalamnya bersifat statis.
Tabel 2.1. Perbedaan OLTP dan DWH (Connolly & Begg, 2009, pp. 1153)
Meskipun berbeda hubungan antara keduanya sangat erat di mana OLTP tidak bisa digunakan analisa dikarenakan datanya yang sangat majemuk. Oleh karena itu ada proses aggregasi atau yang biasa disebut ETL di dalam DWH untuk mempermudah proses analisa dari pengguna.
2.1.3. Arsitektur DWH
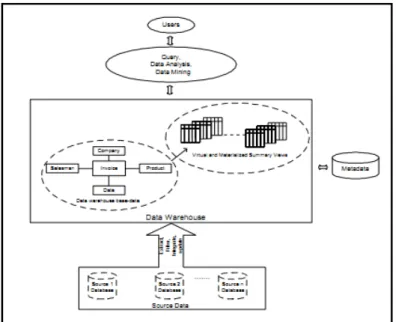
Arsitektur dari DWH secara garis besar dibagi menjadi empat elemen / komponen utama yaitu operational source system, data staging area, data presentation area dan data access tools (Kimball & Ross, 2002, pp. 7). Berikut adalah gambar arsitektur komponen – komponen dalam DWH.
Gambar 2.1. Arsitektur Data Warehouse (Kimball & Ross, 2002, pp. 7)
Operational Source System (OSS) merupakan sistem yang menyimpan semua data transaksi dari suatu aplikasi bisnis. Sehingga dibutuhkan kemampuan proses yang bagus dan ketersedian sistem yang handal. Data – data transaksi tersebut diolah (extract) kedalam data staging.
Data Staging Area (DSA) di dalamnya terdapat proses yang sering dikenal sebagai extract-transformation-load (ETL). Selain proses tersebut diperlukan juga media penyimpanan sementara ketika data tersebut diolah dan sebelum diload ke dalam komponen selanjutnya.
Data Presentation Area (DSP) merupakan tempat di mana data telah di aggregasi melalui proses ETL dan sudah siap untuk di query dalam proses analisa. Model data yang digunakan dalam DSP ini berbeda dengan model data pada OSS, di mana model yang digunakan adalah dimensional model bukan third-normal-form (3NF). Dalam dimensional model terdapat 2 tipe tabel yaitu fact dan dimension yang digabungkan dalam suatu data mart berdasarkan proses bisnis yang ada.
Komponen terakhir dalam arsitektur DWH adalah Data Access Tools (DAT). Alat bantu ini digunakan untuk mempermudah melakukan query dan analisa data dari DWH. Banyak tersedia aplikasi baik komersial maupun gratis untuk DAT.
2.1.4. Star Schema (SS)
Star Schema (SS) adalah salah satu implementasi desain logikal dari model multidimensional. Tujuan utama dari SS adalah untuk membuat skema menjadi lebih simpel sehingga akan mempercepat proses query yang di dalamnya biasanya terdapat banyak perintah join. SS terdiri dari sebuah atau beberapa tabel fact yang berkorelasi dengan beberapa tabel dimensi. Berikut definisi dari tabel fact dan dimensi :
• Tabel fact berisi informasi data utama yang digunakan dalam proses analisa, di dalamnya juga terdapat data kunci yang berkorelasi dengan tabel dimensi. Data pada tabel fact haruslah numerik sehingga dengan mudah untuk diaggregasi
• Tabel dimensi merupakan tabel yang berisi data deskriptif yang digunakan sebagai kriteria dalam query.
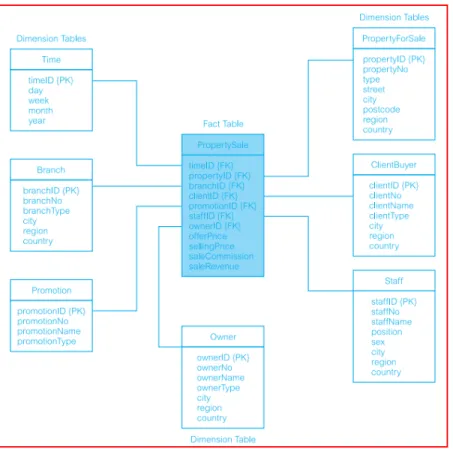
SS mempunyai keuntungan mempercepat proses query karena tabel dimensi telah di denormalized sehingga mengurangi waktu yang dibutuhkan untuk proses join. Berikut contoh gambar SS dalam sebuah data mart (Connolly & Begg, 2009, pp. 1228) :
Gambar 2.2. Contoh Skema Star (Connolly & Begg, 2009, pp. 1228)
2.1.5. Optimisasi DWH
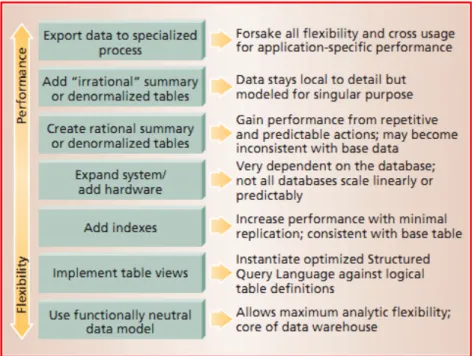
Untuk melakukan optimisasi DWH terdapat tujuh langkah utama agar peforma dari query menjadi lebih cepat (Armstrong, 2001). Berikut diagram dan penjelasan dari langkah – langkah tersebut :
Gambar 2.3. Tujuh Langkah optimasi DWH (Armstrong, 2001)
1. Mengimplementasi tabel view untuk mengoptimasi teknik join dari beberapa tabel ketika melakukan akses query. Selain itu tabel view bisa digunakan ketika desain tabel utama menggunakan tipe partitioning. 2. Menambahkan index pada kolom – kolom yang sering dipakai dalam
query terutama sebagai kondisi dalam where-clause. Penambahan index akan mengurangi akses ke dalam tabel secara keseluruhan (full table scan)
3. Mengupgrade sistem baik secara hardware dan software. Namun sangat sulit untuk memperkirakan rasio peningkatan karena adanya ketergantungan dari spesifikasi software dan hardware itu sendiri.
4. De-normalisasi tabel akan menyebabkan tabel mempunyai data yang duplikat namun mengurangi proses join antara beberapa tabel. Hal inilah yang diharapkan untuk mempercepat proses query.
5. Export data hanya jika diperlukan untuk memproses data ke dalam sistem eksternal yang memiliki performansi lebih bagus daripada sistem sebelumnya.
Namun ada kelemahan ketika optimisasi DWH dilakukan secara intensif, di mana fleksibilitas dari DWH tersebut akan semakin berkurang.
2.2. Aplikasi
Data
Warehouse System (DWS)
Sistem prepaid atau charging system adalah solusi charging untuk operator seluler. Dengan sistem ini, operator jaringan dapat melakukan charge terhadap event yang realtime atau sesi dalam jaringan mobil. Sesi atau event tersebut seperti voice calls, Short Message Serivice (SMS) atau General Packet Radio Service (GPRS).
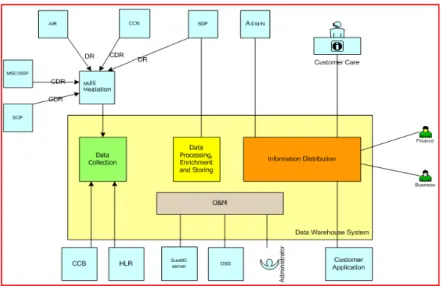
Data Warehouse System (DWS) adalah solusi DWH untuk sistem prepaid untuk jaringan mobil di mana menyediakan report business-critical di dalam organisasi bisnis pelanggan. DWS digunakan untuk mengumpulkan dan menampilkan informasi seperti status pelanggan serta informasi penggunaan.
Dalam arsitekur aplikasi DWS dapat dibagi menjadi empat sistem komponen utama :
1. Data Collection
2. Data Processing, Enrichment dan Storing 3. Information Distribution
4. Operation dan Maintenance Data Collection
DWS digunakan oleh operator selular untuk meningkatkan akses terhadap sistem prepaid dari beberapa sumber. Data tersebut dikirim ke DWS menggunakan File Transfer Protocol (FTP). Data tentang penggunaan atau usage dan informasi pelanggan didapatkan melalui Call Data Records (CDRs) dan Data Records (DR) dari beberapa Network Elements (NEs). Data – data CDRs dan DRs tersebut dikirim ke DWS melalui sistem mediation. Data informasi pelannggan secara optional juga dapat diterima secara langsung dari Home Location Register (HLR) dan Customer Care and Billing System (CCB).
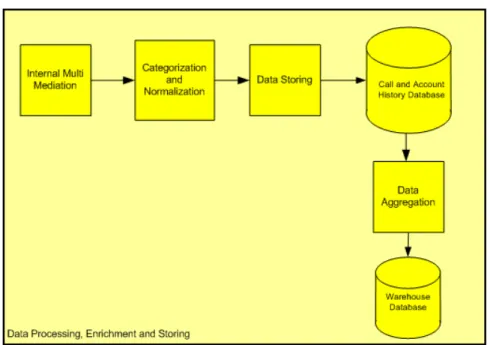
Data Processing, Enrichment and Storing
DWS melakukan integrasi, korelasi dan pemrosesan data dari beberapa sistem dan menyimpannya dalam sebuah database Call and Account History. Kemudian data selanjutnya diaggregasi dan disimpan dalam database Warehouse. Setelah data tersebut diolah oleh DWS, maka data tersebut akan berubah menjadi informasi yang dapat digunakan operator mobil untuk beberapa keperluan.
Gambar 2.6. Alur Data Processing (IT Charging & Billing Dept, 2009)
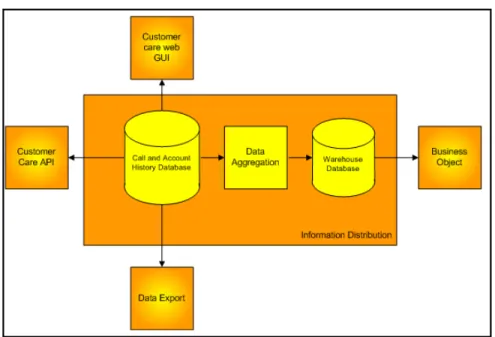
Information Distribution
Dalam proses ini, informasi akan didistribusikan kepada pengguna dalam beberapa cara. Secara distribusinya dapat dikategorisasikan menjadi empat area yaitu :
1. Report Customer Care melalui web
2. Report Customer Care melalui implementasi Application Programming Interface (API)
3. Report Business Object (BO) untuk keperluan keuangan, audit dan Ad-hoc query.
4. Export data dalam ASCII ke sistem external lain
Gambar 2.7. Distribusi Informasi (IT Charging & Billing Dept, 2009)
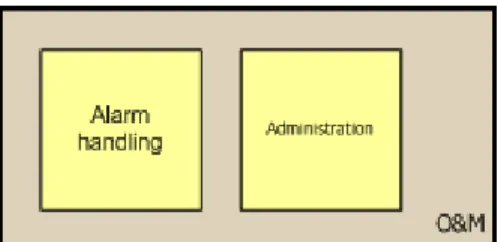
Operation and Maintenance
OAM adalah aktivitas – aktivitas internal yang harus dilakukan agar DWS terjaga fungsionalitasnya. Modul ini digunakan oleh tim monitoring untuk melihat apakah sistem aplikasi DWS berjalan normal atau tidak. Selain itu juga modul ini adalah satu pintu untuk user adminstrator dalam melakukan konfigurasi atau melakukan aktivitas operation and maintenance. Di dalamnya terdapat juga modul komunikasi dengan sistem alarm eksternal sehingga aplikasi DWS dapat terintegrasi dengan sistem lain dalam melakukan aktivitas monitoring
Gambar 2.8. Modul OAM (IT Charging & Billing Dept, 2009)
2.3. Business Intelligence (BI)
Secara definisi banyak sekali arti daripada BI, namun secara inti definisinya adalah segala aktivitas, alat bantu atau proses untuk mendapatkan informasi yang terbaik untuk membantu proses pengambilan keputusan yang mempunyai ciri timely, accurate, high-value dan actionable information (Scheps, 2008, pp. 11). Berikut ini adalah penjelasan tentang ciri – ciri dari BI :
• Timely artinya setiap proses untuk mengolah dan menghasil data
informasi kepada pengguna harus mempunyai interval waktu yang kecil atau cepat sehingga hasil output tersebut masih bisa relevan, berguna dan bermanfaat bagi pengambil keputusan
• Accurate artinya BI harus menghasilkan informasi data yang mendekati kondisi nyata. Tanpa akurasi maka pengetahuan yang ada dalam BI akan menjadi buruk dan tidak berguna.
• High-value artinya selain memberikan informasi yang akurat, BI harus bisa menghasilkan informasi yang bisa memberikan impak kepada organisasi atau perusahaan pengguna.
• Actionable mengharuskan BI selain menghasil informasi yang akurat, BI harus memberikan arahan untuk mengambil beberapa aksi berdasarkan hasil analisa.
Komponen – komponen utama dari BI adalah DWH dan OLAP (Ranjan, 2009). Selain dua komponen utama tersebut, data mining juga termasuk dalam komponen tersebut (Connolly & Begg, 2009, pp. 1279). DWH telah dijelaskan pada bagian sebelumnya akan memberikan informasi data yang dibutuhkan oleh BI untuk melakukan proses pengolahan dan analisa lebih lanjut. Namun dalam implementasinya kebutuhan DWH tidak mutlak untuk solusi BI, ada juga BI langsung memperoleh data dari sumber data operasional dan diolah secara real time (Serapiclia, 2010).
2.3.1. OLAP
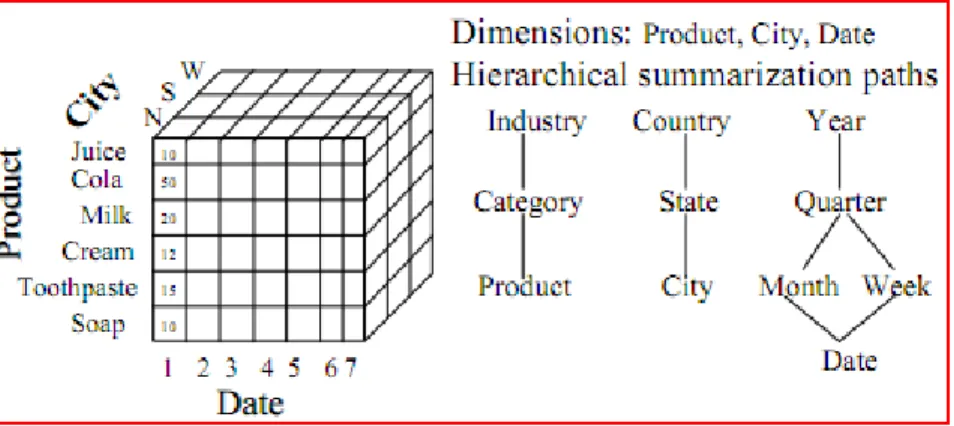
OLAP adalah teknologi atau alat bantu dalam melakukan analisis data pada solusi BI. Sebuah cube dibangun untuk menyediakan multi-dimensional dan multi-level view yang memungkinkan untuk melakukan analisis pada data dengan beberapa perspektif dan beberapa granularities (Chen et al, 2008). Di dalam OLAP terdapat beberapa operasi – operasi dalam proses analisa query yaitu :
• Rollup , melakukan konsolidasi data dengan cara meningkatkan level
aggregasi pada multidimensional data.
• Drill-down adalah kebalikan dari rollup dengan menurunkan level
aggregasi ke level yang memberikan informasi lebih detil.
Desain logik dari multi-dimensional model biasa diimplementasikan berupa bentuk cube yang biasa disebut OLAP cube yang memiliki operasi – operasi standard OLAP.
Gambar 2.9. OLAP Cube (Chen et al, 2008)
Secara umum OLAP dapat dikategorisasikan menjadi tiga jenis :
• Multidimensional OLAP (MOLAP) merepresentasikan data dalam bentuk
model multidimensional. Data dari sumber diload kedalam MOLAP server yang kemudian digunakan pengguna untuk melakukan query
• Relational OLAP (ROLAP) mepresentasikan data dalam bentuk model
relasional. Query dari pengguna langsung diolah oleh ROLAP server yang diterjemahkan menjadi SQL dan hasilnya akan dikembalikan lagi.
• Hybrid OLAP (HOLAP) merupakan penggabungan antara ROLAP dan
MOLAP.
Selain tiga jenis di atas ada juga kategori Desktop OLAP (DOLAP) yang menggunakan aplikasi desktop, Real-Time OLAP (RTOLAP) serta Web-based OLAP (WOLAP). Untuk melakukan optimisasi pada OLAP dapat dilakukan
dengan melakukan optimisasi di dalam DWH sebagai sumber data dalam melakukan proses analisa.
2.3.2. Data Mining
Data mining adalah proses ekstraksi informasi yang valid, tidak diketahui sebelumnya, komprehensif dan dapat ditindak lanjuti dari sebuah database besar yang digunakan untuk melakukan pengambilan keputusan bisnis yang sangat krusial. Karena data mining ini tidak digunakan dalam penulisan tesis, maka tidak akan dibahas secara lebih detail.
2.4. Database
Tuning
Pengertian daripada database tuning sangatlah beragam tergantung jenis aktivitas atau prosesnya namun pada dasarnya semuanya memiliki tujuan yang sama yaitu untuk memastikan sistem database berjalan pada performansi yang mendekati optimal. Database tuning adalah sebuah proses atau aktivitas dalam mencari atau memprediksi masalah performansi database kemudian mencoba mencari akar permasalahannya dan pada akhirnya menyelesaikan masalah tersebut (Wiese, 2009). Database tuning dilakukan oleh DBA dalam aktivitas operasional untuk menjaga performansi database tetap bagus karena adanya variasi workload di dalam database seperti query dan update transaksi data yang secara signifikan mempengaruhi performansi database (Su Chen et al, 2010). Dalam melakukan database tuning semua parameter database harus dikonfigurasi berdasarkan query workload, skema relasional dan kemampuan DBA agar performansi sistem database tetap berjalan dengan bagus (Debnath et al, 2008).
Ada tiga faktor yang dapat digunakan untuk mengukur efisiensi (Connolly & Begg, 2009, pp 532) :
1. Transaction throughput.
Yaitu berapa banyak transaksi yang dapat diproses dalam jangka waktu yang diberikan. Pada beberapa sistem seperti reservasi penerbangan, nilai
throughput yang besar merupakan hal yang kritis terhadap kesuksesan
keseluruhan sistem. Semakin banyak transaksi yang diproses dalam suatu waktu, maka semakin tinggi nilai throughput-nya.
2. Response time.
Yaitu waktu yang digunakan untuk menyelesaikan satu transaksi. Dari titik pandang seorang pemakai, semakin singkat response time-nya semakin baik. Bagaimanapun, ada beberapa faktor yang mempengaruhi response time yang tidak bisa dikontrol oleh perancang seperti pada saat sistem loading. Response time dapat diminimalisasi dengan cara:
1. Mengurangi waktu selisih dan waktu tunggu (contention and wait times), terutama waktu tunggu disk I/O.
2. Mengurangi jumlah waktu yang diperlukan sumber daya. 3. Menggunakan komponen yang lebih cepat.
3. Penyimpanan disk.
Yaitu jumlah media penyimpanan yang dibutuhkan pada suatu disk. Semakin minim penggunaan media penyimpanan, maka akan semakin efisien.
2.5. Materialized View (MV)
View adalah hasil dinamis dari satu atau lebih operasi relasional yang terjadi pada basis – basis relasi atau biasa disebut dengan tabel yang menghasilkan relasi yang baru (Connolly et al, 2009, pp 84). Sehingga sebuah view adalah sebuah relasi virtual yang tidak perlu ada dalam sebuah database namun dapat dihasilkan berdasarkan permintaan pengguna pada saat itu juga. Berikut adalah tiga tujuan dari pembetukan sebuah view adalah :
1. Meningkatkan mekanisne keamanan dengan cara menyembunyikan beberapa bagian penting dari sebuah database kepada pengguna. Sehingga pengguna tidak perlu tahu akan bagaimana proses data tersebut dihasilkan
2. Menyederhakan query – query yang membutuhkan operasi yang komplek seperti multi join dari beberapa tabel atau relasi basis
3. Untuk melakukan denormalisasi dari sebuah skema database sehingga diharapkan lebih mendekati kondisi nyata.
Berikut ini contoh dari sebuah view yang melakukan penyederhaan dari operasi query yang cukup komplek :
Sehingga menjadi lebih sederhana seperti berikut :
Contoh 2.2. Query dari sebuah View
Materialized View (MV) merupakan sebuah view yang materialisasikan artinya secara fisik MV itu ada dalam sebuah database layaknya obyek tabel dengan cara menyimpan hasil relasi kedalam database. Secara definisi MV adalah struktur fisik yang melakukan perhitungan awal untuk menghasilkan data sehingga akan meningkatkan waktu akses data (Ashadevi et al, 2010). Oleh karena itu akan ada konsenkuensi bahwa akses database akan menjadi lebih cepat ketika mengakses MV dibandingkan dengan cara akses melalui view. MV menghilangkan proses untuk melakukan komputasi ulang terhadap sebuah query seperti yang terjadi pada view. Berikut ini adalah dua keuntungan diterapkannya MV :
1. Mempercepat akses data karena data telah dikomputasi diawal dan hasilnya disimpan secara permanent
2. Untuk membantu proses replika dari sebuah database ke database lain. Keterkaitan antara MV dengan DWH adalah menyediakan sebuah view permanen dari multi-join dari beberapa basis tabel sehingga mengurangi waktu pemrosesan. Berikut ini adalah bagian MV dalam sebuah arsitektur DWH (Chan et al, 1999) :
Gambar 2.10. MV dalam arsitektur DWH (Chan et al, 1999)
Berikut ini adalah contoh dari MV yang diambil dari sebuah buku referensi (Gupta & Mumick, 1999, pp 4-5). Sebuah retailer memiliki beberapa toko yang tersebar dalam beberapa region di negara USA. Setiap toko menjual banyak barang dan berelaborasi dengan database relasional / data warehouse untuk melakukan analisis, marketing dan promosi. Berikut ini adalah contoh beberapa tabel beserta kardinalitasnya.
Contoh 2.3. Info tabel dan kardinalitas (Gupta & Mumick, 1999)
Tabel pos merepresentasikan transaksi pada Point of Sales (POS) dengan satu baris record setiap barang terjual dalam transaksi yang ada. Record tersebut memiliki informasi ID dari barang yang terjual, ID dari toko yang menjual, tanggal transaksi, jumlah barang yang terjual, dan harga jualnya. Tabel stores
menyimpan informasi lokasi setiap toko dengan memberi nama ID, kota dan region secara geografis. Tabel item menggambarkan setiap item barang seperti ID, nama produk, kategori produk dan harga per unitnya. Jika divisi business development ingin mengetahui total pendapatan setiap kategori item barang pada setiap toko. Di lain hal, mereka juga ingin memonitor total penjualan setiap region. Maka dua query berikut dapat merepresentasikan kebutuhan tersebut :
Contoh 2.4. Query Set (Gupta & Mumick, 1999)
Kedua query tersebut membutuhkan operasi join terhadap tabel pos dengan tabel lain kemudian melakukan proses aggregasi. Karena tabel pos memiliki data yang besar yaitu 1000.000.000 record maka akan sangat mahal untuk melakukan proses aggreasi. Sebagai alternatif adalah melakukan aggregasi secara parsial pada tabel pos seperti berikut.
Contoh 2.5. Definisi sebuah View (Gupta & Mumick, 1999)
Dari view diatas akan dihasilkan record yang lebih sedikit dibandingkan dengan tabel pos. Jika diasumsikan setiap toko menjual sekitar ½ dari item barang, maka kita akan mendapatkan (100 * 50000) / 2 record di dalam view total_sales di mana lebih kecil 40 kali dibanding dengan table pos. View di atas akan digunakan untuk menjawab kebutuhan dua query sebelumnya :
Contoh 2.6. Query set menggunakan View baru (Gupta & Mumick, 1999)
Selain mencegah operasi join dengan tabel yang 40 kali lebih besar, operasi join akan lebih efisien jika terdapat index pada storeID dan itemID di dalam view total_sales.
2.5.1. MV Cost Model
Cost model adalah estimasi biaya media penyimpanan, maintenance dan
query processing dapat dihitung berdasarkan biaya yang diperlukan untuk
mengakses disk dalam ukuran blok (B) yang biasanya dalam satuan byte (CB (Vi) = S(Vi)) . Berikut ini adalah perhitungan cost model dalam pemilihan MV (Kardee & Thakare, 2010; Chan et al, 1999) :
1. Biaya query processing untuk melakukan selection, aggregation dan joining. Di sini diasumsikan tidak ada index atau hash key digunakan. Biaya query processing untuk melakukan joining dari n tabel dimensi dengan view Vi adalah :
Cj(Vd1, Vd2,…, Vdn , Vi) = (S(Vd1) + S(Vd1) *S(Vi)) + (S(Vd2) + S(Vd2) *S(Vi)) +…..+ (S(Vdn) + S(Vdn)* S(Vi))
Untuk memproses sebuah query qi, maka view juga membutuhkan untuk melakukan joining dengan tabel dimensi lainya sehingga biaya query adalah Cq(qi):
Cq(Vi) = CB (Vi) + Cj(Vd1, Vd2,…, Vdn , Vi) =
S(Vi) + (S(Vd1) + S(Vd1) *S(Vi)) + (S(Vd2) + S(Vd2) *S(Vi)) + …. + (S(Vdn) + S(Vdn) *S(Vi))
Sehingga total biaya query processing (Cqr)untuk r query adalah :
Rumus 2.1. Biaya Query Processing
2. Biaya maintenance MV. Di sini diasumsikan setiap ada perubahan pada base table maka diperlukan operasi join untuk melakukan update terhadap MV. Perhitungan ulang akan membutuhkan selection dan aggregation dari view induknya Vai yang kemudian di joining dengan tabel dimensi. Sehingga total biaya maintenance adalah :
Cm(Vi) = CB (Vai) + Cj(Vd1, Vd2,…, Vdn , Vai) =
S(Vi) + (S(Vd1) + S(Vd1) *S(Vai)) + (S(Vd2) + S(Vd2) *S(Vai)) + ….+ (S(Vdn) + S(Vdn) *S(Vai))
Sehingga jika terdapat sejumlah j MV, total biaya maintenance (Cm) adalah :
Rumus 2.2. Biaya Maintenance MV
3. Biaya penyimpanan / storage dalam unit blok. Asumsi S(Vi) adalah jumlah blok yang dibutuhkan untuk menyimpan data.
Rumus 2.3. Biaya penyimpanan
2.5.2. Proses Seleksi MV
MV memainkan peran sentral di dalam DWH di mana peningkatan akan performa respon query akan menjadi lebih cepat. Oleh karena itu para komunitas penelitian database memberikan atensi tentang bagaimana cara melakukan seleksi dan memaintain MV. Masalah utama yang terjadi adalah bagaimana memilih MV yang tepat dengan memperhitungkan ukuran disk dan waktu maintenance untuk menghasilkan biaya query processing yang paling minimal. Ada lima parameter yang selalu diperhitungkan dalam melakukan seleksi MV (Thakur & Gosain, 2011) :
1. Frekuensi dari penggunaan query oleh pengguna 2. Frekuensi dari update base-relation
3. Biaya query processing 4. Biaya maintenance view
5. Kebutuhan ukuran penyimpanan disk
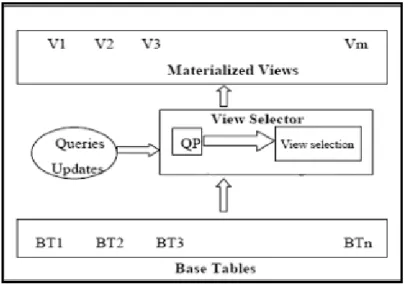
Secara umum desain arsitektur dari seleksi MV adalah pada gambar sebagai berikut (Karde & Thakare, 2010).
Gambar 2.11. Proses Seleksi MV (Karde & Thakare, 2010)
Di dalam nya terdapat tabel basis sebagai basis relasi dari sebuah MV. Berdasarkan pola dan frekuensi eksekusi sebuah query maka akan mempengaruhi hasil MV. Semakin sering sebuah query dieksekusi maka akan memiliki bobot lebih tinggi dibandingkan query yang jarang digunakan. Setelah mendapatkan kandidat MV yang akan terpilih maka sebuah perhitungan cost model terhadap biaya query processing sampai biaya maintenance MV dilakukan. Selain itu diperhitungkan juga kapasitas disk yang dibutuhkan oleh MV. Sehingga pada akhirnya didapatkan MV yang memenuhi kriteria biaya query processing dan biaya maintenance MV yang minimal namun memberikan peningkatan performa dari sebuah query.
Beberapa fitur – fitur dari database seperti query plan, statistic dan query
optimization digunakan untuk membantu menyediakan parameter – parameter
Gambar 2.12. Arsitektur seleksi MV (Agrawal et al, 2000)
Dalam proses pemilihan MV ada beberapa algoritma dan framework yang dapat digunakan. Secara umum apa yang dilakukan oleh algoritma dan framework yang ada adalah melakukan perhitungan cost model dari kandidat – kandidat MV untuk dipilih yang memiliki total cost yang lebih kecil dari threshold yang diinginkan. Salah satu yang cukup terkenal adalah pendekatan menggunakan algoritma greedy. Di mulai dari penelitian (Gupta & Mumick, 1999) yang menggunakan algoritma greedy untuk menghitung biaya maintenance yang minimal dari beberapa kandidat MV. Kemudian dikembangkan lagi dengan memperhitungkan biaya kapasitas penyimpanan atau storage constraint (Gupta & Mumick, 2005). Terdapat juga sebuah framework yang digunakan untuk melakukan seleksi MV dinamakan Optimized View Selection Problem (OVSP)
dalam sebuah penelitian (Ashadevi et al, 2010). Di mana dalam framework ini terdapat perhitungan pembobotan dari parameter frekuensi query dan kapasitas penyimpanan yang digabungkan dengan total biaya maintanance MV dan biaya query processing. Framework ini merupakan pengembangan dan optimisasi dari framework - framework sebelumnya yaitu Optimized Cost Effective approach for View Selection Problem - OCEMS (Ashadevi & Balasubramanian, 2009) dan Cost
Effective approach for View Selection Problem - CEMS (Ashadevi &
Balasubramanian, 2008). Untuk lebih detail tentang perbandingan antara framework dan algoritma yang ada saat ini dapat merujuk ke sebuah survei penelitian (Karde, 2010). Pada tesis ini nantinya akan merujuk kepada framework OVSP karena memperhitungkan semua metrik biaya dalam proses seleksi MV (Thakur & Gosain, 2011).
2.5.3. Framework OVSP
Seperti yang telah dibahas sub bab sebelumnya bahwa framework Optimized View Selection Problem (OVSP) merupakan hasil pengembangan dari framework – framework sebelumnya yaitu Cost Effective approach for Materialized view Selection (CEMS) and Optimized CEMS (OCEMS). Berikut akan dibahas mengenai prosedur – prosedur yang terdapat didalam framework OVSP.
Tujuan dari framework OVSP adalah melakukan seleksi untuk mendapatkan MV yang tepat (Mv) dengan memperhitungkan jumlah query (Q), ketersediaan storage (S) dan waktu maintenance (MT). Sehingga nantinya akan diperoleh kandidat MV yang mempunyai total biaya query processing dan
maintenance paling minimal. Berikut ini adalah prosedur yang digunakan dalam framework ini.
Gambar 2.13. Proses Framework OVSP 1. Maintenance dari MV yang sudah ada
Dari MV yang sudah ada, maka secara periodik prosedur ini akan melakukan pembobotan untuk mencari MV yang jarang diakses dan membutuhkan ukuran penyimpanan paling besar. Sehingga nantinya akan dibuang untuk diganti dengan MV yang lebih optimal.
Algoritma 2.1. MV Maintenance (Ashadevi et al, 2010)
2. Seleksi query berdasarkan bobot
Pada prosedur ini akan dikoleksi workload dari sebuah DWH untuk mendapatkan query – query yang digunakan untuk menghasilkan report. Sehingga dari query tersebut bisa dihitung bobot berdasarkan tinggi atau tidaknya frekuensi akses dan besarnya kapasitas yang dibutuhkan. Output yang dihasilkan oleh prosedur ini adalah kumpulan query yang memenuhi kriteria sering diakses dan rendah kapasitas
3. Ekstraksi conditional clause dari query – query
Dari vektor query yang dihasilkan, masing – masing query diekstrak jenis – jenis conditional clause (CC) untuk kemudian dihitung berdasarkan tingkat kemunculan. Parameter inilah yang nantinya akan digunakan untuk melakukan pembobotan query pada prosedur selanjutnya. Adapun contoh representasi format CC yang dihasilkan adalah sebagai berikut :
Gambar 2.14. Representasi format CC (Ashadevi et al, 2010)
Algoritma 2.3. CC Extractor (Ashadevi et al, 2010)
4. Seleksi kandidat MV
Proses ini melakukan seleksi kandidat MV berdasarkan bobot dari tingginya frekuensi akses query dengan conditional clause serta kapasitas storage yang dibutuhkan. Berikut ini adalah detilnya :
Algoritma 2.4. Kandidat MV (Ashadevi et al, 2010)
5. Hitung biaya query processing dari kandidat MV
Setelah mendapatkan kandidat MV dari prosedur 5, maka selanjutnya akan dihitung biaya query processing dengan rumus dibawah ini dengan asumsi frekuensi akses dari query (Freq) dan biaya akses query menggunakan view V adalah Ca(V).
Rumus 2.5. Biaya Query Processing (Ashadevi et al, 2010)
6. Hitung biaya maintenance dari kandidat MV
Biaya maintenance dari kandidat MV dihitung dari seberapa sering tabel basis melakukan update.
Algoritma 2.5. Biaya MV Maintanance (Ashadevi et al, 2010)
7. Pemilihan MV
Proses terakhir dari pemilihan MV adalah menjumlahkan dari hasil biaya query processing dan maintenance dari tiap – tiap kandidat MV dan diurutkan secara ascending. Kandidat MV yang diurutan atas layak untuk diimplementasi ke dalam DWH.
2.6. Partitioning
Partitioning sangat diperlukan dalam mengelola data di dalam DWH
karena membantu untuk membagi jumlah data yang sangat besar. Secara definisi partitioning adalah metode untuk membagi database logikal menjadi bagian – bagian yang lebih kecil dalam hal ini adalah dimensi dalam suatu tabel yaitu baris dan kolom (Connolly & Begg, 2009, pp. 555). Secara umum ada dua kategori teknik partitioning dalam database yaitu :
• Horizontal partition membagi tuple/baris dari sebuah tabel menjadi beberapa bagian yang lebih kecil berdasarkan suatu kriteria. Contoh membagi tabel berdasarkan waktu / tanggal dengan kriteria per bulan. • Vertical partition membagi attribute/kolom dari sebuah tabel menjadi
bagian yang lebih kecil berdasarkan suatu kriteria
Baik horizontal maupun vertical partition memberikan impak peningkatan performansi pada query maupun update data (Agrawal et al, 2004). Berikut ini adalah gambar ilustrasi dari perbedaan antara horizontal dan vertical partition :
Gambar 2.15. Teknik partitioning (Connolly & Begg, 2009, pp. 555)
Berdasarkan kriteria, partitioning dapat dibagi menjadi empat tipe utama : • Range memiliki kriteria nilai antara daripada satu atau beberapa atribute • List memiliki kriteria berdasarkan nilai yang telah terdefinisi
• Hash merupakan melakukan mapping berdasarkan algoritma hash • Composite merupakan gabungan dari beberapa tipe di atas
Gambar 2.16. Jenis – jenis tipe partitioning (Morales, 2007, pp 2-6)
Dilihat dari sisi keuntungan dan kerugian, metode partitioning ini lebih memberikan efek ke performansi dan managability untuk DWH. Berikut detail keuntungan dari partitioning :
• Meningkatkan performansi karena dengan jumlah data yang dilimitasi menjadi kecil akan mempercepat proses baca.
• Meningkatkan availability jika partitioning terdapat di media penyimpanan yang berbeda
• Meningkatkan waktu recovery karena data dibagi – bagi menjadi bagian lebih kecil
Adapun kerugian pada teknik partitioning :
• Kompleksitas akan meningkat jika perlu mengakses dari beberapa partisi yang berbeda
• Adanya duplikasi primary key pada vertical partitioning
2.7. Indexing
Karena persyaratan utama dari BI adalah respon yang cepat maka teknik index dapat digunakan untuk meningkatkan performa dari query. Index adalah sebuah struktur dalam sebuah database yang menyediakan akses yang sangat cepat terhadap record – record dalam tabel berdasarkan nilai dari satu atau beberapa kolom (Connolly & Begg, 2009, pp. 242). Di dalam indexing terdapat beberapa teknik yang penggunaannya tergantung daripada keragaman isi datanya (data cardinality).
Pemilihan indexing yang tepat untuk sebuah database sangat menentukan apakah performanya akan meningkat atau semakin menurun. Ada dua hal utama yang perlu di analisa sebelum menentukan jenis index yang akan digunakan (Vanichayobon & Gruenwald, 2004) :
1. Menganalisa karakteristik data pada suatu kolom sebuah tabel. Bagaimana tingkat kardinalitinya , bagaimana keragaman data dan juga tipe data itu sendiri akan sangat menentukan index mana yang akan dipakai
2. Menganalisa dari sintak – sintak query yang digunakan. Kolom apa saja yang sering dipakai, melakukan join tabel seberapa sering, dan bagaimana proses grouping akan menentukan teknik index yang dipakai.
Dalam sistem DWH ada beberapa teknik indexing yang masing – masing berbeda karakter dan manfaatnya. Berikut ini adalah teknik – teknik indexing yang umum digunakan dalam database (Vanichayobon & Gruenwald, 2004).
• B-Tree index : organisasi index yang membentuk struktur pohon dengan ada satu root dengan beberapa daun dibawahnya. Tiap – tiap daun memiliki key yang saling berkorelasi dengan parent ataupun child-nya.
Juga tiap – tiap daun akan berkorelasi dengan row_id di mana data asli disimpan dalam database. Index ini cukup bagus untuk data dengan kardinalitas tinggi.
• Bitmap index : organisasi index yang melalukan mapping dari row_id dari data asli menjadi sebuah bit – bit untuk mengurangi ruang penyimpanan. Index tipe ini cukup bagus ketika dipakai dengan data yang memiliki kardinalitas sangat rendah.
• Join index : organisasi index yang menggabungkan kolom – kolom yang diperlukan dalam beberapa tabel. Index ini sangat bagus digunakan dalam suatu query yang telah diketahui sebelumnya karena proses aggregasi dilakukan di awal.
• Projection index : organisasi index yang melakukan salinan dari sebuah kolom dari data asli. Jika sebuah query hanya membutuhkan sedikit kolom maka jenis index ini cukup bagus untuk digunakan.
Berdasarkan teknik – teknik index yang telah disebutkan di atas, hanya B-Tree index kurang cocok dipakai untuk solusi BI karena tidak support untuk ad-hoc query dan membutuhkan banyak operasi Input/Output (I/O) untuk query yang besar (Vanichayobon & Gruenwald, 2004).
2.8. Database
Oracle
Database Oracle adalah Object-Relational Database Management System (ORDBMS) yang diciptakan oleh Oracle Corp. Dalam bagian ini akan dibahas mengenai landasan teori baik berupa konsep dan fitur daripada database Oracle yang akan digunakan dalam penelitian.
2.8.1.Query Processing
Bedasarkan definisinya query processing adalah aktivitas – aktivitas yang meliputi parsing, validating, optimizing dan executing dari sebuah query (Connolly & Begg, 2009, pp 631). Tujuan dari query processing adalah untuk mengubah sebuah query yang ditulis dengan bahasa tingkat tinggi seperti Structured Query Language (SQL) kedalam strategi eksekusi yang benar dan effisien yang diekspresikan dengan bahasa tingkat rendah (implementasi dari aljabar relasional) kemudian untuk digunakan dalam mendapatkan data.
Di dalam sebuah query processing terdapat proses query optimization yaitu aktivitas untuk memilih strategi eksekusi yang paling efisien untuk melakukan proses sebuah query (Connolly & Begg, 2009, pp 632). Di mana akan terdapat banyak hasil dari transformasi sebuah SQL yang sama, sehingga dalam query optimization memilih salah satu yang memiliki penggunaan resource yang paling minimal. Semua query optimization sangat tergantung sekali dengan statistik database yang akan dibahas pada sub bab 2.7.4, untuk melakukan evaluasi terhadap beberapa opsi yang ada. Tingkat keakuratan dan keterbaruan dari sebuah statistik database memberikan impak yang besar dalam melakukan pemilihan strategi eksekusi yang paling efisien.
Berikut ini adalah ilustrasi dari strategi proses dari sebuah query yang diambil dari sebuah buku (Connolly & Begg, 2009, pp 633). Sebuah query digunakan untuk mendapatkan semua manajer yang bekerja di cabang London. Maka representasi query tersebut akan sebagai berikut :
Contoh 2.7. Query dalam SQL (Connolly & Begg, 2009, pp 633)
Dari perintah SQL diatas akan menghasilkan tiga aljabar relasional yang berekivalensi, yaitu :
Untuk contoh ini diasumsikan terdapat 1000 record dalam table Staff, 50 record dalam tabel Branch, 50 record manajer (satu setiap branch) dan 5 record untuk cabang London. Diasumsikan juga tidak terdapat index dan setiap record dianggap diakses dalam satu blok meskipun pada kondisi nyata setiap blok terdiri atas beberapa record. Hasil perhitungannya adalah sebagai berikut :
• Query pertama : (1000 + 50) + 2 * (1000 * 50) = 101 050 akses ke disk • Query kedua : 2 * 1000 + (1000 + 50) = 3050 akses ke disk
• Query ketiga : 1000 + 2 * 50 + 5 + (50 + 5) = 1160 akses ke disk
Dengan jelas bahwa pilihan query ketiga adalah pilihan terbaik dalam hal ini. Sehingga dapat disimpulkan bahwa cartession product dan join mempunyai biaya yang lebih besar daripada selection.
2.8.2.Oracle Query Processing
Di dalam database Oracle query processing biasa disebut juga query optimization karena prosesnya terdiri dari tiga komponen utama, yaitu :
1. Query Transformator. Oracle akan melakukan transformasi dari
sebuah query untuk menghasilkan beberapa kandidat plan.
2. Estimator. Oracle akan melakukan estimasi biaya dari beberapa plan berdasarkan statistik yang ada di dalam data dictionary untuk distribusi data dan karakteristik storage dari tabel – tabel, index – index dan partisi – partisi yang diakses.
3. Plan Generator. Oracle melakukan perbandingan dari beberapa biaya plan yang ada dan memilih salah satu yang memiliki total biaya paling minimal.
Komponen – komponen tersebut di atas dapat digambarkan sebagai berikut :
Aktivitas transformasi query yang terdapat dalam komponen query transformer salah satunya adalah query rewrite dengan MV yang akan dibahas lebih detil dalam sub bab 2.7.5. Sebuah MV seperti halnya sebuah query di mana hasilnya dimaterialkan dan disimpan dalam sebuah tabel. Ketika sebuah query dari pengguna sesuai dengan query yang diasosiasikan dalam sebuah MV, maka query tersebut ditulis ulang (query rewrite) oleh Oracle untuk mengakses MV. Teknik ini akan meningkatkan performa eksekusi dari sebuah query, karena hampir semua hasil query telah dihitung di awal. Sebuah query akan diarahkan ke MV jika hanya total biaya lebih kecil dibanding biaya dari query tersebut.
2.8.3. Oracle Query Plan
Untuk melakukan eksekusi sebuah query , Oracle melakukan beberapa langkah. Setiap langkah tersebut diantaranya mengambil record – record yang terdapat dalam sebuah database atau menyiapkan data tersebut untuk diolah oleh proses selanjutnya. Kombinasi dari beberapa langkah tersebut yang digunakan Oracle untuk melakukan eksekusi sebuah query dinamakan execution plan atau query plan. Di dalam execution plan bisa saja terdapat bagaimana cara melakukan akses data atau path access dan bagaimana melakukan proses join dari beberapa tabel.
Oracle menyediakan sebuah alat bantu untuk melihat bagaimana execution plan dari sebuah query. Alat ini dinamakan EXPLAIN PLAN, di mana ada empat cara untuk menggunakannya :
1. Menggunakan script UTLXPLAN.SQL untuk membuat tabel keluaran yang disebut PLAN_TABLE dalam sebuah skema
2. Menggunakan perintah klausa EXPLAIN PLAN FOR diawal sebuah query.
3. Menggunakan script atau package yang disediakan oleh Oracle untuk membaca hasil dari perintah EXPLAIN PLAN FOR.
4. Urutan dari eksekusi di dalam EXPLAIN PLAN adalah dimulai dari baris yang paling menjorok ke kanan. Langkah selanjutnya adalah baris diatasnya atau baris induknya. Jika ada dua baris urutan menjoroknya sama maka dipilih baris yang paling atas.
Berikut ini adalah contoh dari penggunaan EXPLAIN PLAN, bagaimana hasilnya dan bagaimana cara membaca prosesnya. Sebuah query ingin mendapatkan informasi pegawai dengan ID < 103.
Contoh 2.8. EXPLAIN PLAN sebuah Query (Chan, 2008, pp 13-12)
Dari perintah di atas akan dihasilkan keluaran dari EXPLAIN PLAN sebagai berikut :
Gambar 2.18. Hasil keluaran EXPLAIN PLAN (Chan, 2008, pp 13-12)
Setiap baris pada hasil keluaran EXPLAIN PLAN merepresentasikan satu langkah dalam execution plan. Baris dengan tanda asterisk (bintang) menandakan informasi predicate. Berikut ini adalah penjelasan dari masing – masing langkah :
• Langkah 3 membaca semua record dari tabel employees
• Langkah 5 mencari job_id di dalam sebuah index job_id_pk dan mengasosiasikan rowids dengan record di dalam tabel jobs. Hasil recordnya akan digunakan pada langkah 4.
• Langkah 7 mencari departement_id di dalam sebuah index dept_id_pk dan mengasosiasikan rowids dengan record di dalam tabel departements. Hasil recordnya akan digunakan pada langkah 6.
• Langkah 2 melakukan operasi nested loop pada job_id di tabel jobs dan tabel employees berdasarkan hasil dari langkah 3 dan 4. Setelah itu melakukan operasi join pada setiap record hasil langkah 3 dengan record hasil langkah 4.
• Langkah 1 melakukan operasi nested loop berdasarkan hasil dari langkah 2 dan 6. Setelah itu melakukan operasi join pada setiap record hasil langkah 2 dengan record hasil langkah 6.
2.8.4. Oracle Statistics
Oracle statistics atau optimizer statistics adalah koleksi data yang menjelaskan informasi lebih detil tentang database dan obyek – obyek yang terdapat di dalamnya (Chan, 2008, pp 14-1). Statistik ini digunakan oleh query optimizer untuk memilih execution plan terbaik untuk setiap query yang dieksekusi. Optimizer statistics yang nantinya disimpan dalam sebuah dictionary, terdiri dari :
• Table statistics terdiri dari jumlah record, jumlah blok dan rata – rata panjang record.
• Column statistics terdiri dari jumlah nilai unik dalam kolom (NDV), jumlah nilai null, dan distribusi data (histrogram).
• Index statistics terdiri dari jumlah blok daun, level dan faktor clustering
• System statistics terdiri dari performansi dan utilitas dari I/O serta CPU Secara default Oracle melakukan proses koleksi statistik secara otomatis berdasarkan jadwal yang terlah ditentukan. Optimizer statisitcs secara otomatis dijalankan menggunakan job GATHER_STATS_JOB. Tugas ini melakukan pengumpulan statistik semua obyek – obyek yang missing dan stale. Meskipun begitu job ini bisa diaktifkan dan dinon-aktifkan secara manual sebagai berikut :
Oracle juga menyediakan utilitas jika menginginkan untuk secara manual melakukan proses statistik. Utilitas tersebut adalah package DBMS_STATS, yang bisa digunakan untuk merubah, menampilkan, export, import, dan mendelete statistik. DBMS_STATS mampu mengumpulkan statistik pada tabel dan index serta kolom – kolom dan partisi dari sebuah tabel. Berikut adalah tabel dari prosedur – prosedur yang terdapat dalam DBMS_STATS package :
Tabel 2.2. DBMS_STATS package (Chan, 2008, pp 14-5)
Berikut adalah contoh dari prosedur GATHER_TABLE_STATS, untuk lebih detil terdapat pada buku (Chan, 2008, pp 14-5).
2.8.5. Oracle MV dan Query Rewrite
Seperti yang telah dibahas sebelumnya bahwa MV melakukan perhitungan diawal fungsi – fungsi seperti SUM, MAX, AVG dll, untuk mempercepat respon sebuah query. Oracle menyediakan fitur MV dengan menggunakan perintah MATERIALIZED VIEW. Pada contoh 2.9. diilustrasikan pembuatan MV yang dinanamakan cost_mv yang melakukan perhitungan SUM dari cost terhadap time dan prod_name. Ketika sebuah MV didefinisikan ada beberapa aturan yang harus diikuti seperti dalam SELECTlist harus terdapat semua kolom dalam GROUP BY dan kolom GROUP BY harus merupakan kolom sederhana. Selain itu expression yang diaggregasi tidak mengandung subquery atau fungsi nested aggregate (Hobbs, 2005, pp 9).
Contoh 2.9. Definisi MV (Hobbs, 2005, pp 9)
Selain itu, Oracle juga menyediakan DBMS_MVIEW package yang digunakan untuk memelihara MV. Berikut ini adalah daftar prosedur yang terdapat didalamnya. Dengan DBMS_MVIEW package kita dapat memahami kemampuan dari MV dan kandidat MV termasuk kemampuan untuk rewrite. Melakukan refresh terhadap data MV juga dapat dilakukan dengan package ini.
Table 2.3. DBMS_MVIEW package (Raphaely, 2007, pp 61-5)
Salah satu keuntungan lain menggunakan MV adalah mengakomodasi kemampuan query rewrite. Query Rewrite adalah fitur Oracle bagian dari teknik query optimization yang melakukan transformasi sebuah query untuk dapat dieksekusi secara cepat dengan cara mengambil data dari MV. Proses tersebut dilakukan secara transparan terhadap pengguna, sehingga tidak perlu mengubah perintah SQL di level aplikasi. Meskipun komposisi dari query tidak selalu sama dengan definisi MV, selama masih berelasi dan menghasilkan biaya yang lebih rendah maka database secara otomatis akan dapat menggunakan MV tersebut. Gambar di bawah memberikan ilustrasi bagaimana proses query rewrite terjadi.
Gambar 2.19. Proses Query Rewrite (Lane, 2005, pp 18-3)
Ada beberapa tipe dari query rewrite yang disupport dalam database Oracle yang ditampilkan dalam tabel 2.3.
Berikut ini adalah contoh 2.10. sebuah MV dan relasinya dengan tipe – tipe query rewrite :
Contoh 2.10. Definsi MV dan Query Rewrite (Hobbs, 2005, pp 17)
• Exact Match
Pada tipe ini definisi query dan MV benar – benar sama persis baik itu klausa dari FROM, WHERE dan GROUP BY. Misalkan terdapat query seperti dibawah ini maka MV all_cust_sales_mv akan dipakai oleh query rewrite.
Contoh 2.11. Exact Match (Hobbs, 2005, pp 17)
• Join Back
Kasus ini terjadi jika sebuah query memiliki referensi terhadap kolom yang tidak terdapat dalam MV, tapi masih bisa dilakukan operasi join antara MV dengan tabel dimensi yang ada. Jika query seperti contoh dibawah, maka
query rewrite akan menggunakan MV all_cust_sale_mv dan menjoinkan
Contoh 2.12. Join Back (Hobbs, 2005, pp 17)
• Rollup dan Aggregate Rollup
Ketika sebuah query meminta aggregasi dengan level lebih tinggi daripada yang terdapat pada definisi MV, maka query rewrite akan menggunakan MV tersebut dan melakukan aggregasi ke level yang lebih tinggi. Misal jika query di bawah dieksekusi maka query rewrite akan melakukan re-aggregasi MV all_cust_sales_mv dan roll-up ke level state.
Contoh 2.13. Rollup (Hobbs, 2005, pp 17)
• Data Subsets
Dalam sebuah MV terdapat sebuah subset data, maka jika terdapat query dengan klausa IN dan BETWEEN maka query rewrite akan menggunakan MV tersebut.
• Multiple MV
Kadangkala untuk sebuah query memerlukan data dari beberapa MV, maka Oracle juga menyediakan tipe query rewrite jenis ini.
2.8.6.Oracle Audit
Auditing adalah aktivitas monitoring dan merecord terhadap aksi – aksi daripada pengguna database (Jeloka, 2011, pp 8-1). Oracle memperbolehkan option dari audit lebih terfokus atau secara general, misal berdasarkan sukses atau tidaknya sebuah eksekusi pada setiap sesi pengguna atau aktivitas semua pengguna. Berikut ini adalah tipe – tipe audit yang disupport oleh Oracle 10g.
Tabel 2.4. Tipe – tipe Audit (Jeloka, 2011, pp 8-2)
Pada penelitian ini akan lebih banyak menggunakan schema object auditing yang berfungsi untuk menghitung frekuensi akses daripada sebuah MV. Audit terhadap obyek skema dapat berupa semua perintah SELECT atau DML yang diperbolehkan dalam sebuah skema. Sebuah contoh query di bawah akan menggenerate dua record audit yaitu satu untuk view employees_departement dan satu lagi untuk tabel employees.
Mulai Oracle versi 10g, maka audit terhadap MV sudah disupport untuk perintah – perintah SELECT dan DML. Berikut ini adalah tabel fitur audit yang baru diimplementasi di Oracle 10g.
Tabel 2.5. Fitur baru auditing di Oracle 10g (Jeloka, 2011, pp 8-9)
2.9. Constructive
Cost
Model
Constructive Cost Model (COCOMO) adalah algoritma permodelan biaya untuk menghitung estimasi biaya yang akan dikeluarkan dalam membangun sebuah aplikasi. Model ini dikembangkan oleh Barry W. Boem dengan memperhitungkan jumlah kode baris (Boehm, 1997). Meskipun ini kurang begitu akurat karena membutuhkan perkiraan jumlah baris di awal, namun dalam penelitian ini akan dijadikan sebagai acuan sederhana dalam menghitung estimasi biaya pengembangan prototipe. Karena di dalam prototipe peneliti sudah bisa melakukan estimasi jumlah kode baris dari aplikasi.
Dalam COCOMO, terdapat tiga jenis model yaitu :
1. Model basic COCOMO yaitu melakukan perhitungan estimasi biaya pengembangan aplikasi berdasarkan jumlah kode baris
2. Model intermediate COCOMO yaitu menambahkan parameter penilaian secara subyektif terhadap produk, hardware, tim dan juga atribut proyek
3. Model detailed COCOMO yaitu menggabungkan parameter – parameter dalam model intermediate dengan parameter penilaian pada setiap langkah proses pengembangan aplikasi.
Karena aplikasi prototipe yang dikembangkan dapat dikategorisasikan proyek kecil, maka model basic COCOMO akan digunakan. Pada model basic ini terdapat tiga kelas untuk kategori proyek pengembangan aplikasi.
1. Model organic dikategorisasikan sebagai proyek sederhana dan relatif kecil di mana terdapat anggota tim yang cukup berpengalaman dengan aturan proyek yang tidak terlalu ketat
2. Model semi-detached merupakan kategori proyek menengah dalam segi hal ukuran dan kompleksitasnya di mana jumlah tim yang relatif cukup besar dengan pengalaman yang berbeda – beda bekerja sama dengan aturan yang tidak begitu ketat
3. Model embedded merupakan kombinasi dari kedua model sebelumnya dengan aturan proyek yang sangat ketat.
Tabel 2.6. Model Basic COCOMO
Sehingga model perhitungan COCOMO adalah sebagai berikut :
• Effort Applied (E) = ab(SLOC)bb
• Development Time (D) = cb(Effort Applied)db • People required (P) = E / D
dimana :
E adalah usaha yang diaplikasikan dalam person-month D adalah waktu pengembangan dalam bulan kronologis
SLOC adalah jumlah baris penyampaian kode yang diperkirakan untuk proyek tsb Koefisien ab dan cb dan eksponen bb dan db ada pada tabel 2.6
COCOMO II adalah versi perbaikan dari versi sebelumnya dengan memperhitungkan proses reuse dalam pengembangan perangkat lunak. Hal ini didorong karena saat ini banyak pengembangan menggunakan
Comercial-Off-The-Self (COTS) dan pemrograman 4GL (4 Generation Language) untuk
mempercepat proses development. Dalam model ini terdapat tiga sub model yang menjelasan tingkat kedetilan dalam proses pengembangan :
Melakukan estimasi usaha berdasarkan object-points dan menghitung dengan formula sederhana sebagai berikut :
Di mana :
PM : usaha dalam person-months NOP : jumlah object-points
PROD : produktivitas dari developer 2. Early Design level
Perhitungan estimasi usaha berdasarkan function-points yang kemudian dirubah menjadi total jumlah baris kode (LOC). Ditambah dengan perhitungan 7 cost drivers.
3. Post-architecture level
Menghitung estimasi usaha berdasarkan function-points atau jumlah baris kode yang dikombinasikan dengan 17 cost drivers.
Untuk formula Early Design level dan Post-architecture level adalah sebagai berikut :
Di mana :
Effort : usaha dalam person-months
A : konstanta berdasarkan tingkat kesulitan project atau kondisi organisasi Size : berupa jumlah kode baris atau functional-points
B : Diturunkan secara empiris dari projek – projek sebelumnya M : cost drivers
2.10. Cost Benefit Analysis
Cost Benefit Analysis (CBA) adalah suatu proses yang membandingkan antara biaya yang dikeluarkan dengan manfaat atau keuntungan yang diterima dari sebuah investasi (Remenyi et al, 2007, pp 308). Atau dengan kata lain analisis yang dilakukan untuk mengetahui nilai besaran dari keuntungan dan kerugiain dalam menilai kelayakan sebuah proyek atau solusi. Di dalam CBA nilai besaran manfaat dan biaya merupakan sebuah pasangan yang tidak terpisahkan.
Dalam evaluasi sebuah proyek atau solusi bisa saja persepsinya berbeda dengan pengertian dalam analisis keuangan secara umum. Baik dalam klasifikasi biaya dan manfaat, keduanya masing – masing mempunyai dua jenis yaitu tangible dan intangible. Biaya tangible adalah biaya nyata yang nilainya dengan mudah dapat dihitung, sedangkan biaya intangible adalah biaya yang tidak bisa secara langsung dihitung besarannya. Berikut contoh klasifikasi pada biaya dalam hubungannya dengan proyek TI :
1. Biaya tangible : biaya untuk software, hardware, gaji developer dan alat – alat komputer
2. Biaya intangible : biaya ketika aplikasi mati, perubahan struktur organisasi dan biaya pendukung operasional.
Begitu juga dengan arti pada manfaat atau benefit, di mana manfaat tangible adalah manfaat yang dapat diukur besaran nilainya, sedangkan manfaat intangible adalah sebaliknya artinya tidak dapat dihitung secara langsung besaran
nilainya. Berikut contoh klasifikasi pada manfaat dalam hubungannya dengan proyek TI :
1. Manfaat tangible : performansi sistem meningkat, kapasitas media penyimpanan lebih hemat dan efisiensi biaya hardware dan software
2. Manfaat intangible : ketersedian laporan lebih cepat, jam kerja lebih efisien, dan waktu operasional lebih efektif
Dalam kaitannya dengan CBA terhadap performansi dan biaya sebuah arsitektur TI, di mana satuan yang digunakan berbeda – beda maka perbandingan tersebut dipisah antara perbandingan biaya dan perbandingan manfaat seperti dalam sebuah referensi (Kondo et al, 2009). Dalam penelitian ini, untuk mengukur manfaat yang didapatkan baik yang tangible maupun intangible digunakan analisis gap (gap analysis) antara dua buah obyek. Gap Analysis (GA) adalah sebuah alat bantu untuk mengukur atau melakukan evaluasi terhadap kondisi sekarang dengan kondisi yang akan dicapai. Sehingga nilai besaran manfaat dapat diperbandingkan antara sebelum dan sesudah adanya perbaikan dari sistem. Pada akhirnya akan membantu untuk memperkuat kelayakan sebuah proyek atau solusi.