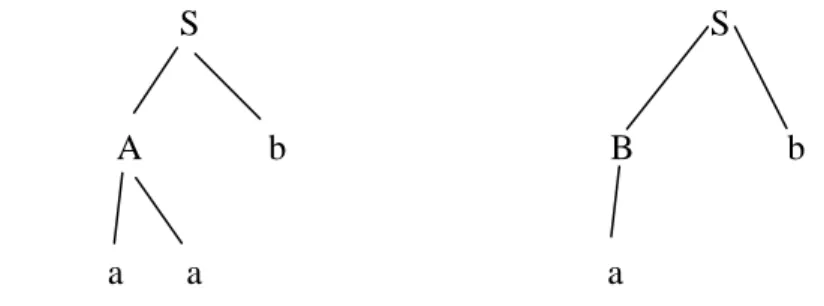1
T
T
E
E
O
O
R
R
I
I
B
B
A
A
H
H
A
A
S
S
A
A
D
D
A
A
N
N
O
O
T
T
O
O
M
M
A
A
T
T
A
A
Amir Hamzah
AKPRIND PRESS
2009
i
T
T
E
E
O
O
R
R
I
I
B
B
A
A
H
H
A
A
S
S
A
A
D
D
A
A
N
N
O
O
T
T
O
O
M
M
A
A
T
T
A
A
Amir Hamzah
JURUSAN TEKNIK INFORMATIKA
FAKULTAS TEKNOLOGI INDUSTRI
INSTITUT SAINS DAN TEKNOLOGI AKPRIND
YOGYAKARTA
ii
Kata Pengantar
Puji syukur dipanjatkan kehadirat Allah Subhanallah Wa Ta’ala, karena hanya atas petunjuk dan redhaNya akhirnya diktat ini dapat terselesaikan. Diktat ringkas ini mungkin masih sangat sedikit dapat membantu dalam penyampaian Teori Bahasa dan Otomata kepada mahasiswa. Akan tetapi mengingat terbatasnya buku yang ada di perpustakaan dan masih sedikitnya buku-buku berbahasa indonesia tentang Teori Bahasa dan Otomata, diharapkan diktat ini dapat membantu mempermudah menerima materi kuliah.
Diktat ini mendukung proses pembelajaran mata kuliah Teori Bahasa dan Otomata, yang disampaikan dalam 3 sks. Diktat memuat tujuan instruksional setiap bab pembahasan dan memuat uraian-uraian yang dibuat sesingkat mungkin dengan beberapa contoh penyelesaian masalah dan beberapa soal latihan sebagai evaluasi pembelajaran. Tentu saja diperlukan buku-buku tambahan bagi mahasiswa untuk dapat menguasai materi-materi lebih mendalam.
Akhirnya mudah-mudahan tulisan singkat ini dapat membantu para mahasiswa. Kritik dan koreksi kami ucapkan terima kasih.
Yogyakarta, Oktober 2009 Penulis
iii
DAFTAR ISI
BAB I KONSEP DASAR OTOMATA DAN BAHASA FORMAL ………… 1
1.1 Tujuan Instruksional ……….. 1
1.2 Pengertian Otomata dan Bahasa Formal ……… 1
1.3 Hubungan Otomata dengan Bahasa Formal ……….. 2
1.4 Bahasa Natural dan Bahasa Formal ……….. 2
1.5 Analogi Bahasa Natural dan Bahasa Formal ………... 3
1.6 Elemen Bahasa Formal ………. 6
1.7 Latihan ……….. 7
BAB II KELAS-KELAS BAHASA DAN MESIN PENGENALNYA 8 2.1 Tujuan Instruksional ………. 8
2.2 Tata Bahasa dan Bahasa ……… 8
2.3 Hierarchi Tata Bahasa ……….. 12
2.4 Mesin Pengenal Bahasa ……….. 16
2.5 Latihan ……….. 17
BAB III EKSPRESI REGULAR DAN KELAS BAHASA REGULAR …… 18
3.1 Tujuan Instruksional ………... 18
3.2 Ekspresi Regular ……….. 18
3.3 Tata-Bahasa Regular ………. 21
3.4 Pengenal Bahasa Regular ………. 22
3.5 Latihan ………. 23
BAB IV FINITE STATE MACHINE (FSM) DAN FINITE STATE AUTOMATA (FSA) 24 4.1 Tujuan Instruksional ………. 24
4.2 Finite State Machine (Mesin keadaan terbatas) ……….. 24
4.3 Finite State Automata (FSA) ……… 26
4.4 FSA Sebagai Pengenal String ……….. 28
4.5 Deterministik dan Non Deterministik FSA ……….. 29
4.6 Konversi dari NFA ke DFA ……… 30
4.7 FSA Sebagai Pengenal Bahasa Regular ………. 33
4.8 Latihan ……… 37
BAB V TATA BAHASA BEBAS KONTEKS (CONTEXT FREE GRAMMAR ) 5.1 Tujuan Instruksional ……… 38
5.2 Batasan Tata Bahasa Bebas Konteks ……….. 38
5.3 Masalah Ambiguity Dalam CFG……… 39
5.4 Penyederhanaan Tata Bahasa Bebas Konteks ……… 42
5.4.1 Membuang aturan produksi yang tidak berguna ………….. 43
iv
5.4.3 Menghilangkan produksi epsilon ( ) ………. 46
5.5 Latihan ……...……… 49
BAB VI BENTUK NORMAL CHOMSKY DAN NORMAL GREIBACH UNTUK TATA BAHASA BEBAS KONTEKS 6.1 Tujuan Instruksional ……… 50
6.2 Bentuk Tata Bahasa Bebas Konteks Tidak Normal ……… 50
6.3 Bentuk Normal Chomsky (CNF) ……… 51
6.4 Bentuk Normal Greibach (Greibach Normal Form=GNF) … 54 6.5 Latihan ………. 57
BAB VII PUSH DOWN AUTOMATA (PDA) ……… 58
7.1 Tujuan Instruksional ……… 58
7.2 Pengertian Push Down Automata (PDA) ……… 58
7.3 PDA Sebagai Pengenal Bahasa ……… 59
7.4 Deskripsi Sesaat (Instantoneus Discription) Gerakan PDA 61 7.5 Latihan ………. 66
BAB VIII MESIN TURING ……….……… 67
8.1 Tujuan Instruksional ……… 67
8.2 Keterbatasan FSA dan PDA ……… 67
8.3 Definisi Mesin Turing ………...……… 67
8.4 Deskripsi Sesaat untuk gerakan Mesin Turing ……… 70
8.5 Mesin Turing sebagai Pengenal Bahasa ……… 71
8.5 Loop yang Terus Menerus pada Mesin Turing ……….. 73
8.6 Latihan ……… 75
DAFTAR PUSTAKA ………...……….……… 76
BAB I. Konsep Dasar Otomata & Bahasa Formal
1
1
BAB I
KONSEP DASAR OTOMATA DAN BAHASA FORMAL
1.3 Tujuan instruksional
Pada bab ini akan diuraiakan pengertian dan definisi dari otomata, bahasa, bahasa formal dan bahasa natural. Hubungan dan analogi antara bahasa natural yang umumnya telah lebih dahulu diketahui dengan konsep bahasa formal yang lebih akhir dijumpai akan disajikan sebagai cara pemahaman yang lebih mudah. Diharapkan setelah mempelajari bab ini mahasiswa akan memahami konsep, urgensi dan penerapan teori bahasa dalam kajian bidang informatika umumnya dan khususnya dalam topik bahasa-bahasa pemrograman komputer.
1.4 Pengertian Otomata dan Bahasa Formal
Kata otomata merupakan bentuk jamak dari automaton. Kata ini berasal dari bahasa Yunani automatos yang berarti self-acting. Dalam Kamus American
-Heritage kata ini diartikan sebagai : ( 1) a robot
(2) one that behaves in automatic or mechanical fashion
Istilah ini sudah dikenal sejak abad 17 yang terkait dengan misalnya : jam mekanik,
mechanical-duck karya de Vaucanson (1738), mesin tenun otomatis (1745).
Dalam matematika istilah otomata terkait dengan teori mesin abstrak yang antara lain dapat didefinisikan secara sederhana sebagai : "Automata adalah mesin sekuensial otomatis yang menerima input dan mengeluarkan output yang keduanya dalam bentuk diskreet". Beberapa sistem yang dapat dibuat model otomatanya antara lain :
- mesin jaja
- mesin penukar uang - model transmisi data - kunci kombinasi
- parser
2
Sifat-sifat Otomata :
1. Kelakuan mesin otomata bergantung pada rangkaian input yang diterima mesin tersebut.
2. Setiap saat berada pada status tertentu, dan dapat pindah ke status baru karena perubahan input.
1.3 Hubungan Otomata dengan Bahasa Formal :
Hubungan otomata dengan bahasa formal dapat dilukiskan sebagai berikut : - Rangkaian input diskreet pada mesin otomata dapat dianggap sebagai bahasa
yang harus dikenali oleh otomata.
- Mesin otomata dapat pula digunakan untuk membangkitkan bahasa tertentu yang aturannya ditentukan oleh tatabahasa tertentu.
Dengan demikian dapat dilihat keterkaitan antara : mesin otomata, bahasa yang dibangkitkan atau dikenali oleh mesin dan tata bahasa yang membangkitkan sebuah bahasa.
1.4 Bahasa Natural dan Bahasa Formal :
Perlu disini dibatasi pengertian bahasa formal dengan bahasa sehari-hari. Bahasa manusia sehari-hari (misalnya bahasa inggris) umumnya dinamakan sebagai bahasa alami (natural language). Bahasa alami memiliki tata bahasa dan aturan yang lebih luas dan luwes. Bahasa yang lebih kaku dengan aturan-aturan yang lebih ketat (misalnya bahasa pemrograman komputer) dinamakan dengan bahasa formal (formal language). Sehingga dengan demikian bahasa formal dapat lebih mudah dipelajari dan dianalisis dari pada bahasa alami. Sebaliknya analisis dan pengembangan riset tentang bahasa alami dapat dimulai dengan mempergunakan bahasa formal sebagai langkah awalnya.
Ada dua hal penting yang terkait dengan bahasa formal, yaitu :
- Pembangkitan kalimat (generation) : Berkaitan dengan algoritma yang dapat menghasilkan semua kalimat dalam bahasa tertentu yang dikaji berdasarkan aturan yang dimiliki oleh bahasa tersebut. Aturan ini disebuat tata bahasa (grammar). Penerapan konsep ini terjadi pada bahasa-bahasa pemrograman visual seperti Visual Basic, Delphi, Visual C, Java Net Bean dan lain-lain yang
BAB I. Konsep Dasar Otomata & Bahasa Formal
3
3
mana programmer tidak menuliskan kode program tetapi kode tersebut dibangkitkan ketika sebuah aktivitas dilakukan, misalnya ketika progammer memasang Button pada sebuah Form maka nama variabel Button dan prosedur aktifitas Button akan dibangkitkan sehingga progammer tinggal mengisikan kode intinya saja.
- Pengenalan kalimat (recognition) : Pembuatan algoritma yang dapat mengetahui apakah suatu string s (kalimat) termasuk anggota himpunan bahasa L. Algoritma ini memeriksa keanggotaan s dalam bahasa L berdasarkan aturan yang banyaknya terhingga. Penerapan ini terjadi pada saat sebuah kode program sudah diparsing menjadi token-token dan proses kompilasi akan dilakukan maka langkah pertama adalah pemeriksaan apakah token-token sudah berada dalam sintak yang benar sesuai dengan aturan bahasa yang ada. Jika belum memenuhi aturan bahasa maka proses kompilasi akan dihentikan, biasanya dengan memberikan pesan “syntax error”.
1.5 Analogi Bahasa Natural dan Bahasa Formal :
Beberapa analogi bahasa formal dengan bahasa natural dapat digambarkan antara lain sebagai berikut :
1. He sleeps, adalah sebuah kalimat bahasa inggris yang benar 2. He runs quickly, adalah juga kalimat yang benar
3. The Big rabbit hopes neatly, juga benar.
Sebuah kalimat dikatakan benar apabila ia memenuhi grammar yang ada dalam suatu bahasa. Dalam bahasa inggris sebuah kalimat dikatakan benar jika memenuhi grammar berikut :
SENTENCE (S) = NOUN-PHRASE (NP) + VERB-PHRASE (VP)
NOUN-PHRASE dapat berupa : NOUN atau PRONOUN atau ARTICLE + NOUN atau ARTICLE+ADJECTIVE + NOUN.
VERB-PHRASE dapat berupa : VERB atau VERB + ADVERB.
Dengan notasi yang lebih singkat ditulis : S = NP + VP
4
VP dapat berupa : V atau ADV
Dengan demikian penurunan kalimat He sleeps dapat digambarkan :
SENTENCE
NOUN VERB
He Sleeps
Gambar 1.1 Proses penurunan kalimat dari grammar : N+V
Penurunan kalimat He runs quickly dapat digambarkan (dengan notasi yang lebih singkat):
S
NP VP
V ADV
He runs quickly
Gambar 1.2 Proses penurunan kalimat dari grammar : N+V+Adj
Dan penurunan kalimat ketiga adalah :
S
NP VP
Art ADJ N V ADV
The big rabbit runs neatly
BAB I. Konsep Dasar Otomata & Bahasa Formal
5
5
Selanjutnya Grammar bahasa inggris tersebut dapat dituliskan sebagai himpunan aturan-aturan produksi sebagai berikut :
S NP VP
NP Noun ; NP Pro ; NP Art ADJ Noun VP V ; VP V ADV
N rabbit Pro He
V runs ; V sleeps
ADV neatly ; ADV quickly
Suatu hasil yang secara grammar benar tetapi mungkin aneh dalam kenyataannya adalah kalimat : The large mathematician sleeps quickly. Hal ini cukup memberikan gambaran bahwa dalam bahasa natural ada hal-hal yang sulit dirumuskan secara eksak diluar grammar. Sebuah kalimat yang benar secara grammar belum tentu dalam realitasnya 'make sense'. Disinilah letak kesulitan analisis bahasa natural.
Analogi yang digunakan dalam bahasa formal yang diambil dari bahasa natural bahasa inggris diatas antara lain adalah : Ada sebuah simbol dalam abjad yang didefinisikan sebagai S, atau start simbol, yang berfungsi seperti SENTENCE. Dari simbol S inilah seluruh string dalam suatu bahasa dapat diturunkan. Selanjutnya aturan produksi dalam grammar dapat dianalogikan sebagai rumusan aturan tata bahasa tersebut. Aturan produksi dinamakan demikian karena aturan tersebut diciptakan untuk memproduksi suatu kalimat atau “string”
Dalam bahasa formal persoalannya banyak disederhanakan. Suatu aturan produksi dengan ketat harus diikuti untuk menurunkan string. Misalnya dimiliki aturan produksi :
S Ab ; S Bb A aa
B a
Maka dengan aturan tersebut dapat diturunkan suatu string : aab dan ab String aab dengan penurunan : S Ab aab
6
String ab dari jalur penurunan : S Bb ab
Proses penurunan string aab dan ab dapat digambarkan dalam diagram pohon sebagai berikut :
S S
A b B b
a a a
Gambar 1.4 Penurunan string aab dan ab
1.6 Elemen Bahasa Formal :
Beberapa istilah yang perlu dicatat berkaitan dengan bahasa formal adalah sebagai berikut :
Abjad (alphabet): Himpunan berhingga dari simbol-simbol yang dapat disusun untuk membentuk suatu kalimat. Dalam konteks teori bahasa: kalimat, string atau kata ketiganya digunakan merujuk kepada hal yang sama, yaitu rangkaian simbol-simbol yang dapat disusun dengan menggunakan simbol yang diambil dari himpunan abjad. Himpunan abjad biasa dinotasikan dengan simbol .
Bahasa (Language): Himpunan seluruh string yang dapat dibangkitkan dari sebuah tatabahasa (grammar) G. Bahasa yang dibangkitkan oleh tata bahasa G biasa dinotasikan dengan L(G) atau L saja. Himpunan ini dapat berhingga atau tak berhingga.
Aturan produksi (production rule : Adalah himpunan berhingga dari aturan-aturan penataan simbol dalam pembentukan sebuah string. Dengan aturan ini kita mem-produksi sebuah string , anggota suatu bahasa. Himpunan aturan produksi biasa disimbolkan sebagai P.
BAB I. Konsep Dasar Otomata & Bahasa Formal
7
7
1.7 Latihan
1. Jelaskan apa pengertian otomata dan berikanlah contoh-contoh otomata dalam kehidupan sehari-hari?
2. Jelaskan perbedaan prinsip bahasa natural dengan bahasa formal !
3. Apa yang dimaksud dengan penurunan string, dalam pengertian bahasa natural dan pengertian bahasa formal?
4. Dalam tata bahasa formal dikenal istilah Non terminal, apa analoginya istilah non terminal ini dalam bahasa natural?
5. Apa bedanya string dalam bahasa formal dengan kalimat dalam bahasa natural?
BAB II
KELAS-KELAS BAHASA DAN MESIN PENGENALNYA 2.1 Tujuan Instruksional
Setelah mempelajari bab ini diharapkan mahasiswa dapat memahami tentang definisi secara formal tentang tata bahasa, bahasa dan kelas-kelas bahasa dengan pendekatan teori himpunan. Mahasiswa juga akan memahami operasi-operasi dasar yang dapat dilakukan pada bahasa dan juga mengenali dan memahami kelas-kelas bahasa berdasarkan karakteristik tata bahasanya. Secara umum juga diharapkan memahami jenis-jenis otomata yang mengenali bahasa dari berbagai kelas bahasa tersebut.
2.2 Tata Bahasa dan Bahasa
Dalam bab I telah disinggung secara singkat tentang perbedaan bahasa natural dengan bahasa formal. Pada kajian selanjutnya yang dimaksud dengan bahasa dalam pembahasan tulisan ini adalah bahasa formal.
Telah dijelaskan bahwa bahasa tidak lebih dari himpunan, yang dapat berhingga atau tak hingga dari string-string yang diproduksi dengan aturan-aturan yang disebut dengan tata bahasa. Berikut ini didefinisikan secara lebih konkrit apa itu tata bahasa dan bahasa.
Definisi 1 : Tata bahasa (grammar) G didefinisikan sebagai tuple-4 G( , N , S, P)
Dimana :
: Himpunan berhingga dari simbol-simbol abjad / alphabet / vocabulary. Simbol-simbol elemen dan rangkaian simbol-simbol yang terdiri dari elemen dinamakan juga dengan simbol terminal. Simbol terminal dilambangkan dengan huruf kecil : a,b,c atau abjad 0,1,2.
N : Himpunan berhingga dari simbol-simbol yang disebut sebagai simbol Non Terminal, yaitu simbol-simbol yang dapat digantikan oleh simbol lain. Dalam bahasa natural simbol non terminal misalnya : S, NP , VP, ADJ dan lain-lain. Sedangkan dalam bahasa formal simbol non terminal dilambangkan dengan
BAB II. Kelas-kelas Bahasa dan Mesin Pengenalnya 9
abjad huruf besar, dan cukup SATU HURUF BESAR saja, misalnya : A, B, atau C.
S : Sebuah simbol yang dinamakan simbol awal (start symbol). Simbol S merupakan awal penurunan seluruh string anggota bahasa yang dibangkitkan oleh tata bahasa G tersebut.
P : Himpunan berhingga aturan-aturan produksi. Aturan produksi merupakan ekspresi yang dapat dituliskan sebagai , dengan dan masing-masing adalah string (rangkaian simbol-simbol) yang dapat terdiri dari simbol terminal dan atau simbol non terminal, misalnya : A Ba
Catatan : Penulisan grammar dibeberapa buku ditulis sebagai G ( V, T,S,P), dengan V adalah himpunan Vocabulary, atau himpunan seluruh simbol yang ada (baik simbol terminal maupun non terminal). Sehingga dalam hal ini V terdiri dari S (start simbol), N (Non terminal simbol) dan T (Terminal simbol), atau dapat di tulis : V = T N
Operasi-operasi string suatu tata bahasa Operasi Concatenation :
Pada prinsipnya teori bahasa akan selalu menggunakan sebuah operasi penggabungan (concatenation), karena pada hakekatnya string/kata/kalimat adalah penggabungan dari simbol-simbol. Kata adalah penggabungan huruf. Kalimat adalah penggabungan kata-kata. Tetapi sekali lagi perlu dicatat bahwa dalam bahasa formal, string, kata (word) atau kalimat (sentence) semuanya dianggap sama, yaitu :"rangkaian simbol-simbol", disebut sebagai STRING atau UNTAI.
Selanjutnya operasi penggabungan didefinisikan sebagai :
= + = string digandengkan (dirangkaikan) dengan string
adalah rangkaian simbo-simbol dan juga rangkaian simbol-simbol, yang sekali lagi dapat berupa simbol non terminal atau terminal.
Contoh2.1 :
= ABab = BBa
maka = ABabBBa
dan = BBaABab
Perlu diingat bahwa operasi penggabungan tidak bersifat komutatif , artinya
, kecuali jika = Panjang string :
Panjang string dimaksudkan sebagai banyaknya simbol dalam string . Panjang string dilambangkan sebagai || .
Contoh : = ABc maka || = 3 = abc maka || = 3
Panjang string tidak memperhatikan apakah simbol tersebut terminal atau non terminal, setiap simbol dihitung memiliki panjang satu .
Empty String (
) atau ( ) :Suatu string khusus yang panjangnya nol, atau string yang terdiri dari "tak satupun simbol" disebut sebagai string kosong (empty string) yang dilambangkan dengan (baca : epsilon) atau (baca: lambda).
String kosong memiliki sifat penggandengan sebagai :
=
= Penutup (Closure) :Jika dimiliki himpunan A, maka Cleene-closure dari A, dinotasikan dengan A* didefinsikan sebagai :
A* = A0 A1 A2 … A
Dengan notasi An (baca: A pangkat n) didefinisikan sebagai concatenation
(gandengan) : AAA …A sebanyak n kali, atau A di gandengkan dengan A sebanyak n kali.
Definisi lebih formal dapat ditulis secara rekursif sebagai: An = A An-1
An-1 = A An-2 An-2 = A An-3
BAB II. Kelas-kelas Bahasa dan Mesin Pengenalnya 11 … A = A A0 A0 = Contoh2.2 : Jika A = {0} maka A* = { , 0, 00, 000, 0000, …} Jika B = {0,1} maka B* = { , 0, 1, 00, 01, 10, 11, 000, 001, …} B* diperoleh dari : B*={ B0 B1 B2 …} Dimana : B0 = { } B1 = B = {0,1} B2 = BB = {0,1}{0,1} = {00, 01, 10, 11} B3 = BB2 = {0,1} {00, 01, 10, 11} = { 000,001, 010,011, 100,101,110,111} dst
Dengan demikian perlu dicermati secara hati-hati bahwa : {0,1}* tidak sama dengan {01}*, karena :
{0,1}* = { , 0, 1, 00, 01, 10, 11, 000, 001, …} sedangkan {01}* = { , 01, 0101, 010101, …}
Positive Closure :
Selain Cleene-Closure, atas himpunan A juga dapat didefinisikan suatu closure yang disebut sebagai positive-closure (A+), yang didefinisikan sebagai :
A+ = A1 A2 … A
Dengan demikian dapat ditulis pula bahwa : A* = A+
atau A+ = A* -
Bahasa yang dibangkitkan oleh grammar G.
Definisi 2 : Bahasa yang dibangkitkan oleh tata bahasa G adalah himpunan seluruh string yang dapat dibangkitkan oleh grammar G, dapat ditulis sebagai L(G):
Dengan simbol S * w
dibaca : seluruh rangkaian string w yang dapat diturunkan dari S dengan sembarang produksi dalam P dan sembarang penurunan. String w adalah hanya terdiri dari simbol-simbol terminal saja atau empty string.
Contoh 2.3:
Dimiliki suatu tata-bahasa G( , N , S, P) dengan :
={ a,b } N = { A, B} dan P ={ SAa ; SAB ; Aaa; Bb; B
}
tentukan bahasa yang dibangkitkan oleh grammar G di atas.
Jawab : Bahasa yang dibangkitkan adalah L(G) = { aaa, aab, aa}
aaa , aab dan aa masing-masing diperoleh dari pohon penurunan :
S S S A a A B A B aa aa b aa
Gambar 2.1 Penurunan string aaa, aab dan aa
Atau penulisan yang lebih singkat dari proses penurunan adalah : Untuk aaa : SAaaaa
aab diperoleh dari penurunan : SAB aaBaab aa diperoleh dari penurunan : SAB aaB aa
aa 2.3 Hierarchi Tata BahasaMenurut Noam Chomsky (1950), Tata-bahasa formal dapat dikelompokkan menjadi 4 tingkatan (hierarchi), biasa disebut hierarchi tata-bahasa menurut Chomsky. Pengelompokan tata-bahasa menurut Chomsky ini ditentukan oleh aturan produksi yang dimiliki oleh grammar, yaitu tata-bahasa Tipe-0, Tipe-1, Tipe-2 dan Tipe-3.
BAB II. Kelas-kelas Bahasa dan Mesin Pengenalnya 13
dengan masing-masing dan adalah string-string yang dapat terdiri dari simbol Non terminal atau pun simbol terminal, atau : , ( N)* maka masing-masing kelas tata-bahasa dibatasi sebagai berikut:
Tata-bahasa Tipe 0 (Non-restricted Grammar):
Tata-bahasa tipe-0, atau biasa disebut sebagai non-restricted grammar adalah tata-bahasa yang paling luas, juga biasa disebut PHRASE STRUCTURED GRAMMAR. Tata-bahasa Tipe-0 adalah tata-bahasa yang memiliki aturan produksi : dengan batasan :
: minimal terdiri dari 1 simbol Non terminal , atau {( N)* N ( N)*}
: tidak dibatasi, atau : {( N)* Contoh 2.4. :
Dimiliki grammar G( ,N ,S , P) dengan = { a, b } , N={ A, B , S} dan P = { SABa, ABB, B ab, ABab, BBBaa}. Perlihatkan bahwa string : abababa dan aaa adalah string-string yang diproduk oleh grammar tersebut.
Jawab :
Jika dicermati produksi yang ada , terlihat bahwa seluruh produksi yang ada memenuhi syarat grammar tipe-0, yaitu string kiri dalam aturan produksi minimal terdiri SATU non terminal.
Penurunan abababa , ditempuh dari proses penurunan :
S ABaBBBaababBaabababa
Penurunan string aaa ditempuh dengan penurunan berikut: S ABaBBBaaaa
Tata-bahasa Tipe 1 (Context Sensitive Grammar):
Tata-bahasa tipe-1, adalah tata-bahasa tipe-0 yang memiliki aturan produksi : dengan tambahan batasan :
yaitu panjang string lebih kecil atau sama dengan panjang string Contoh 2.5. :
Dimiliki grammar G( ,N ,S , P) dengan = { a, b } , N={ A, B , S} dan P = { SABa, ABB, B ab, ABAAA , Aaa , A
}
Apakah tatabahasa ini termasuk dalam tipe-1? Bandingkan dengan tatabahasaa contoh 2.4, apakah termasuk tipe -1? Tunjukkan bahwa string a termasuk anggota bahasa.
Jawab :
Grammar contoh 2.5 memenuhi tata bahasa tipe-0 dan tipe satu . Sedangkan tatabahasa pada contoh 2.4 hanya memenuhi tipe-0 dan tidak memenuhi tipe-1, karena ada aturan produksi : BBBaa pada contoh 2.4.
Penurunan string "a" ditempuh dengan :
SABa AAAa
a aTata-bahasa Tipe 2 (Context -Free Grammar):
Tata-bahasa tipe-2, adalah tata-bahasa tipe-1 yang memiliki aturan produksi : dengan tambahan batasan :
: HANYA terdiri dari 1 simbol Non terminal saja, atau N
: tidak dibatasi, atau : {( N)* Contoh 2.6.:
Tunjukkan bahwa contoh 2.5. adalah tidak termasuk pada grammar tipe 2.
Jawab:
Jika diperhatika aturan produksi pada contoh 2.5 :
BAB II. Kelas-kelas Bahasa dan Mesin Pengenalnya 15
Ada aturan : AB AAA ; yaitu aturan produksi dimana ruas kiri (AB) memiliki panjang lebih dari 1. Ini melanggar aturan untuk grammar tipe-2, dengan demikian tidak termasuk grammar tipe-2.
Tata-bahasa Tipe 3 ( Regular Grammar):
Tata-bahasa tipe-3, adalah tata-bahasa tipe-2 yang memiliki aturan produksi : dengan tambahan batasan :
: HANYA terdiri dari 1 simbol Non terminal saja, atau N
: dalam bentuk salah satu diantara : a, aB, atau
dimana a adalah simbol terminal dan B adalah simbol Non terminal.
Tata bahasa tipe-3 (regular) merupakan tata bahasa yang paling ketat (paling banyak aturan) dari hierarkhi tata bahasa yang ada. Secara diagram keempat tata bahasa dapat digambarkan sebagai berikut :
Gambar 2.2 Hierarkhi Tata Bahasa (Grammar) menurut Noam Chomsky
Contoh 2.7 :
Dimiliki grammar G( ,N ,S , P) dengan = { a, b } , N={ A, B , S} dan P = { SaA, AaA, A B, BbB, B
}. Tentukan bahasa yang
dibangkitkan oleh tata bahasa regular berikut. Jawab :
Penurunan : SaAa B a
a menghasilkan string : aPenurunan : SaAaaAaaaA … aaaa..aa Baaa..a
aaa..aa Hasilnya : aaaa..aa0 = Tipe-0 1 = Tipe-1 2 = Tipe-2 3 = Tipe-3
Penurunan : SaAaaAaaaA … aaaa..aa B
aaa..abBaaa..aab
Hasilnya : aaa..aab
Penurunan : SaAaaAaaaA … aaaa..aa B
aaa..abBaaa..aabbB
aaa..aabb…bBaaa..aabb…b
aaa..aabb…bHasilnya : aaa..aabbb..b
Bahasa yang dibangkitkan adalah "sederatan a dengan jumlah minimal SATU buah diikuti sederetan b dengan jumlah minimal NOL buah" atau dapat dituliskan sebagai:
L(G)={aa*b*}
Dimana
a*={a
0
a
1
a
2…
a
}
b*={b
0
b
1
b
2…
b
}
2.4 Mesin Pengenal Bahasa
Beberapa tingkatan tata bahasa melahirkan beberapa tingkatan bahasa. Tata bahasa regular membangkitkan bahasa regular, tata bahasa bebas konteks membangkitkan bahasa bebas konteks dan seterusnya. Mesin abstract yang merupakan pengenal dari berbagai tingkatan bahasa tersebut dimulai dari yang paling sederhana adalah :
1. Bahasa regular , mesin pengenalnya : Finite State Automata
2. Bahasa bebas konteks, mesin pengenalnya Push Down Automata
3. Bahasa konteks sensitive, mesin pengenalnya Linear Bounded Automata
4. Bahasa unsrestricted mesin pengenalnya adalah Mesin Turing
Pembahsan menganai mesin-mesin abstract pengenal suatu bahasa akan dibahas dalam bab-bab selanjutnya.
BAB II. Kelas-kelas Bahasa dan Mesin Pengenalnya 17
2.5 Latihan
1. Jika dimiliki suatu tata-bahasa G( , N , S, P) dengan ={ a,b } N = { A, B} dan P ={ SAa ; SAB ; Aaa; B bB; B
},
tentukan bahasa yang dibangkitkan oleh grammar G di atas.2. Dimiliki grammar G( ,N ,S , P) dengan = { a, b } , N={ A, B , S} dan P = {
SABa, ABB, B ab, ABab, BBBaa}. Perlihatkan bahwa string : aba
dan abababa adalah string-string yang diproduk oleh grammar tersebut.
3. Dimiliki grammar G( ,N ,S , P) dengan = { a, b } , N={ A, B , S} dan P = {
SABC, ABB, B Bab, B , Caa , A }. Termasuk tipe apakah tata bahasa tersebut? Apakah alasannya?
4. Dimiliki grammar G( ,N ,S , P) dengan = { a, , c } , N={ A, B ,C, S} dan P = { SABC, AaA, A B, BbB, BC, CcC, C
}. Tentukan bahasa
yang dibangkitkan oleh tata bahasa tersebut.5. Dimiliki grammar G( ,N ,S , P) dengan = { a, b, c } , N={ A, B , C, S} dan P = { SABC, AaA, A
, BbB, B,
CcC, C }. Tentukan bahasa
yang dibangkitkan oleh tata bahasa tersebut. Apakah perbedaan bahasa yang dibangkitkan dengan tata bahasa nomor 4? Jelaskan alasannya6. Tentukan tata bahasa yang mengenali bahasa-bahasa berikut ini : a) L = { (abc)n | n > 0 }
b) L = { (ab)n c| n > 0 } c) L = { an bmck | n,m,k > 0 }
7. Tentukan tata bahasa yang mengenali bahasa-bahasa berikut ini : a) L = { 1*0* }
b) L = { 10* } c) L = { 1*0 } d) L = (1,0)*
8. Tentukan tata bahasa yang mengenali bahasa-bahasa berikut ini : a) L = { a*aa, b*a }
b) L = { a*bbbb* } c) L = { abcd }
BAB III
EKSPRESI REGULAR DAN KELAS BAHASA REGULAR 3.1 Tujuan Instruksional
Setelah mempelajari bab ini diharapkan mahasiswa dapat memahami pengertian ekspresi regular, kaidah-kaidah ekspresi regular dan operasi-operasi yang dapat dikerjakan pada eksprfesi regular. Setelah pemahaman ekspresi regular dapat dikuasai selanjutnya dapat mengaitkan ekspresi regular dengan bahasa regular dan selanjutnya dengan tata bahasa regular. Diharapkan pula penguasaan hubungan timbal balik antara bahasa dan tata bahasa sedemikian sehingga jika dimiliki suatu bahasa akan dapat ditetapkan tata bahasanya dan sebaliknya jika dimiliki tata bahasa akan dapat ditetapkan bahasanya.
3.2 Ekspresi Regular
Sebelum memasuki bahasan tentang ekspresi regular dan bahasa regular, dapat dinyatakan suatu kenyataan berikut. Jika adalah suatu himpunan abjad (yang tentu saja jumlahnya terhingga), maka :
1. * = himpunan seluruh string yang dapat disusun dari abjad dalam (seperti yang telah disampaikan dalam bab II) adalah berjumlah TAK HINGGA (countably inifinite).
2. Kumpulan dari semua bahasa yang dapat dibangkitkan dari abjad dalam berjumlah tak terhitung (uncountably)
Selanjutnya ekspresi regular dapat didefinisikan secara rekursif dari definisi-definisi berikut :
Definisi Ekspresi Regular :
1. = {} = (himpunan kosong) adalah sebuah ekspresi regular 2. { } =string kosong adalah ekspresi regular
3. Untuk setiap a , maka a adalah ekspresi regular
4. Jika a dan b adalah ekspresi regular maka ab , ab dan a* adalah ekspresi regular.
BAB III. Ekspresi Regular dan Kelas Bahasa Regular 19
Selanjutnya untuk menghindari kebingungan perlu dibedakan dengan jelas antara yang melambangkan himpunan kosong, atau tidak punya anggota, sedangkan { } adalah himpunan yang memiliki satu anggota , yaitu string kosong. Notasi ab , ab dan a* adalah penyederhanaan notasi yang diperoleh dari notasi asli sebagai berikut : Jika dimiliki himpunan A,B sebagai himpunan berikut :
Ekspresi ab maksudnya : A={a} dan B={b}
AB = gabungan/union antara himpunan A dengan himpunan B = {a,b} Ini dinotasikan secara singkat sebagai : ab
Ekspresi ab maksudnya : A={a} dan B={b}
AB = CONCATENATION antara himpunan A dengan himpunan B = {ab} Ini dinotasikan secara singkat sebagai : ab
Ekspresi a* maksudnya : A={a}
A* = CLEENE closure dari himpunan A, seperti yang telah didefinisikan dalam bab II : A0 A1 A2 … A , yang menghasilkan suatu himpunan : {
,
a, aa, aaa, aaaa, ….}, dinotasikan sebagai a*Dari definisi tentang ekspresi regular selanjutnya dapat dituliskan beberapa akibat logis, berdasarkan aturan-aturan dalam teori himpunan, sebagai berikut :
Jika a,b,c adalah ekspresi regular dalam 1. ab = ba 2. a = a 3. aa = a 4. (ab) c = a(bc) 5. a = a = a 6. a = a = 7. (ab)c=a(bc) 14
8. a(bc)=abac = dan (ab)c = acbc
9. a* = a** = a*a* = (a)*=a*(a) = (a)a* = aa* 10.aa*= a*a
Contoh 3.1:
Ekspresikan dalam bentuk ekspresi reguler kalimat-kalimat berikut : 1. Sederatan NOL minimal nol buah
2. Sederatan NOL minimal satu buah
3. Sederetan NOL minimal satu buah diikuti sederetan SATU sebanyak satu buah atau lebih
4. Sederetan bit NOL dan SATU sembarang yang diawali dengan NOL dan diakhiri dengan SATU
5. Sederetan SATU dengan jumlah GENAP
6. Sederetan NOL dengan jumlah GENAP diikuti sederetan SATU dengan jumlah GANJIL
Jawab :
1. Ekspresinya : 0* 2. Ekspresinya : 00* 3. Ekspresinya : 00*11*
4. Ekspresinya : 0(0,1)*1 atau ditulis : 0(01)*1 5. Ekspresinya : 11(11)*
6. Ekspresinya : 00(00)*1(11)*
Contoh 3.2:
String apakah ekspresi-ekspresi regular berikut : 1. Ekspresi : (1,0)*
2. Ekspresi : (10)* 3. Ekspresi : (0,1)*1* 4. Ekspresi : (00)*(11)* 5. Ekspresi : (11)* (00)*
BAB III. Ekspresi Regular dan Kelas Bahasa Regular 21
Jawab :
1. Sederetan bit NOL dan SATU dengan jumlah sembarang dan susunan sembarang
2. Sederetan 10 berulang-ulang dengan jumlah ulangan nol atau lebih
3. Sederetan bit NOL dan SATU dengan jumlah sembarang urutan sembarang diikuti dengan deretan bit SATU dengan jumlah nol atau lebih
4. Deretan NOL kosong atau Genap diikuti deretan SATU kosong atau genap 5. String kosong atau berisi bit NOL genap atau bit SATU genap dengan posisi
sembarang
3.3 Tata-Bahasa Regular
Seperti telah dituliskan dalam bab sebelumnya, bahasa regular merupakan kelas bahasa yang dibangkitkan oleh tata bahasa regular. Tata bahasa ini memiliki aturan produksi dengan batasan :
: HANYA terdiri dari 1 simbol Non terminal saja, atau N
: dalam bentuk salah satu diantara : a, aB, atau
Contoh 3.3:
Tentukan bahasa yang dihasilkan oleh tata bahasa regular berikut : G(, N, S, P) ; dimana ={ a,b } N = { A, B} dan
P ={ SaS ; SaB ; SA ; Bb; BbB; B
; A
a}
Jawab :
Untuk menurunkan bahasa dari suatu grammar yang diketahui, maka seluruh kemungkinan penurunan yang dapat dilakukan oleh grammar tersebut harus dilakukan. String-string yang dihasilkan dihimpun membentuk suatu bahasa dari grammar tersebut. Untuk mempermudah pelacakan, tetapkan cacah aturan produksi yang ada , dalam grammar tersebut ada 7 aturan produksi, yaitu :
1. SaS ; 2. SaB ;
3. SA ; 4. Bb; 5. BbB; 6. B ; 7. Aa
Kemungkinan 1 : aturan (1,1,1,…)(2)(4) aa*ab Kemungkinan 2 : aturan (1,1,1,…)(2)(6) aa*a
Kemungkinan 3 : aturan (1,1,1,…)(2)(5,5,5,…)(4) aa*abb*b Kemungkinan 4 : aturan (1,1,1,…)(2)(5,5,5,…)(6) aa*abb* Kemungkinan 5 : aturan (1,1,1,…)(3)(7) aa*a
Setelah kemungkinan penurunan seluruhnya dievaluasi selanjutnya hasil evaluasi yang mungkin sama digabung :
- Kemungkinan 2 dengan kemungkinan 5 adalah sama
- Kemungkinan 1 adalah kemungkinan 2 digandeng dengan b - Kemungkinan 3 adalah kemungkinan 4 digandeng dengan b Dengan demikian bahasa yang dihasilkan adalah :
L(G) = { aa*a aa*ab aa*abb* aa*abb*b} = { aa*a aa*abb*)( b)
3.4 Pengenal Bahasa Regular
Pengenal pada bahasa regular adalah mesin abstrak yang disebut dengan otomata berhingga (Finite State Automata , biasa disingkat FSA). Secara mendetail akan di bahas pada bab selanjutnya.
BAB III. Ekspresi Regular dan Kelas Bahasa Regular 23
3.5 Latihan
1. Tuliskanlah notasi untuk ekspresi regular-ekspresi regular di bawah ini : a) Sederetan a dengan panjang minimal 1
b) Sederatan a dengan panjang minimal nol dan diakhiri dengan b c) a atau b dengan panjang minimal nol
d) Sederetan ab dengan panjang minimal nol
2. Bagaimanakah mengungkapkan kalimat untuk ekspresi regular berikut a) {a,b} b) {ab} c) {ab*} d) {a*b} e) {a*,b} f) {a,b*} g) {a*b*} h) {a*,b*}
3. Tentukan bahasa yang dihasilkan oleh tata bahasa regular berikut :
G(, N, S, P) ; dimana ={ a,b } N = { A, B} dan jika aturan produksi masing-masing bahasa adalah sebagai berikut :
a) P ={ SaS ; S
}
b) P ={ SaS ; S a}c) P ={ SaS ; SB ; BbB; Bb}
d) P ={ SaS ; S
; S
B ; BbB; B
} e) P ={ SaS ; SB ; BbB; B
}4. Tentukan bahasa yang dihasilkan oleh tata bahasa regular berikut :
G(, N, S, P) ; dimana ={ a,b,c } N = { A, B, C} dan jika aturan produksi masing-masing bahasa adalah sebagai berikut :
a) P ={ SaA ; AaA; AbB; BbB; BcC; CcC; C
}
b) P ={ SaA ; AaA; AbB; BbB; BcC; CcC; C
;
B } c) P ={ SaA ; AbB; BcC; CcC; C }
BAB IV
FINITE STATE MACHINE (FSM) DAN
FINITE STATE AUTOMATA (FSA)
Tujuan Instruksional
Setelah mempelajari bab ini mahasiswa diharapkan dapat memahami konsep
Finite State Machine (FSM) dan Finite State Automata (FSA) sebagai suatu konsep abstrak matematis yang menggambarkan perilaku suatu mesin logik yang menggambarkan cara kerja dari suatu mesin fisik, suatu program, algoritma atau konsepsi pemecahan masalah. Dalam konteks teori bahasa, mesin FSA dapat diterapkan untuk mengenali suatu string yang berasal dari bahasa regular yang dibangkitkan dari suatu grammar regular. Dengan demikian ada hubungan timbal balik antara bahasa regular dan FSA, yaitu jika dimiliki bahasa rtegular pasti dapat dikonstruksi suatu mesin FSA, dan sebaliknya jika dimiliki suatu FSA pasti dapat diturunkan suatu bahasa yang akan dikenali oleh mesin tersebut.
Finite State Machine (Mesin keadaan terbatas)
Finite State Machine adalah suatu mesin abstrak yang diwakili oleh sekumpulan keadaan, sekumpulan masukan, sekumpulan aturan transisi (perpindahan kedudukan mesin) dan (mungkin) sekumpulan keluaran.
Contoh dari mesin seperti ini adalah : - Mesin Jaja (Vending Machine) - Pintu otomatis
- Telepon Umum
Contoh 4.1. FSM Dengan Output : Mesin Jaja (Vending Machine) :
Misalkan dimiliki sebuah mesin jaja yang dapat mengeluarkan dua macam keluaran yaitu Juss Jeruk dan Juss Apel. Mesin ini memiliki kedudukan sebanyak 7 (misalkan dicatat sebagai : S0, S1, S2,…, S6). Mesin ini dapat menerima masukan uang pecahan yang dapat berupa 5-an, 10-an dan 25-an. Mesin ini selain dapat menerima masukan uang pecah juga disediakan dua tombol kuning (K) dan merah (M). Jika mesin dalam kedudukan S6, maka jika ditekan ditekan K akan keluar Juss
BAB IV. Finite State Machine(FSM) dan Finite State Automata (FSA) 25
Jeruk dan jika ditekan R akan keluar Juss Apel. Tabel transisi kedudukan dari mesin ini dapat disajikan seperti tabel 4.1.
Penggunaan tabel 4.1 sebagai fungsi transisi dari mesin Jaja dapat dipahami dalam beberapa contoh, misalnya :
- Pada saat awal mesin selalu dalam state S0
- Jika pada state S0 menerima masukan 5-an maka akan pindah ke-state S1 - Jika pada state S0 menerima masukan 10-an maka akan pindah ke-state S2 - Jika pada state S0 menerima masukan 25-an maka akan pindah ke-state S5 - Jika pada state S1 menerima masukan 5-an maka akan pindah ke-state S2 - Jika pada state S1 menerima masukan 25-an maka akan pindah ke-state S6 Output mesin jaja diperoleh jika mesin dalam state-S6, yaitu :
- Jika pada state S6 menerima masukan K maka akan pindah ke-state S0 dan menghasilkan OUTPUT JJ= yaitu keluar Juss Jeruk
- Jika pada state S6 menerima masukan R maka akan pindah ke-state S0 dan menghasilkan OUTPUT JA= yaitu keluar Juss Apel
Tabel 4.1. Fungsi Transisi Untuk Mesin Jaja Tabel transisi kedudukan mesin
State Next State Output
Input
5-an 10-an 25-an K M
Input
5-an 10-an 25-an K M S0 S1 S2 S3 S4 S5 S6 S1 S2 S5 S0 S0 S2 S3 S6 S1 S1 S3 S4 S6 S2 S2 S4 S5 S6 S3 S3 S5 S6 S6 S4 S4 S6 S6 S6 S5 S5 S6 S6 S6 S0 S0 n n n n n n n n n n n n 5 n n n n 10 n n n n 15 n n n 5 20 n n 5 10 25 JJ JA Keterangan : n = tidak ada keluaran
K=tombol Kuning ditekan M=tombol Merah ditekan
Mesin jaja tersebut hanya bisa menerima uang receh maksimum 30. Isi mesin adalah 30 ditunjukkan dengan keadaan S6. Pada kondisi S6 ini mesin berharap menerima masukan pencet tombol K atau R, bukan menerima masukan uang lagi. Ini nampak jika dalam state tertentu dimasukkan uang receh sehingga nilai uang dalam mesin jaja diatas 30 maka akan dikeluarkan kembaliannya. Misalnya :
- Jika pada state S6 menerima masukan 5-an maka akan TETAP pada state S6 dan menghasilkan OUTPUT (kembalian) 5-an
- Jika pada state S2 menerima masukan 25-an maka akan PINDAH menuju state S6 dan menghasilkan OUTPUT (kembalian) 5-an
Finite State Automata (FSA)
Finite State Machine dapat berupa suatu mesin yang tidak memiliki output.
Finite State Machine yang tidak mengeluarkan output ini dikenal sebagai FINITE STATE AUTOMATA (FSA). Pada FSA mesin mula-mula dalam state S0 dan menerima sederatan masukan yang dapat mengubahnya ke state-state berikutnya. Dalam FSA juga dikenal himpunan state-state tertentu yang disebut sabagai FINAL STATE. Perubahan dari satu state ke state berikutnya mengikuti sturan tertentu yang dirumuskan sebagai suatu FUNGSI transisi .
Secara formal FSA dapat didefinisikan sebagai TUPLE-5 : Kumpulan dari 5 himpunan, atau dinotasikan sebagai :
FSA adalah M = ( S, , , S0 dan F) Dimana :
S = himpunan terhingga dari state-state
= himpunan terhingga dari simbol-simbol masukan pada mesin
= fungsi transisi yang mengatur gerakan mesin S0=State AWAL
F = himpunan state-state FINAL
Perilaku Finite State Automata diekspresikan dalam bentuk tabel transisi atau dalam bentuk diagram transisi.
BAB IV. Finite State Machine(FSM) dan Finite State Automata (FSA) 27
Contoh 4.2
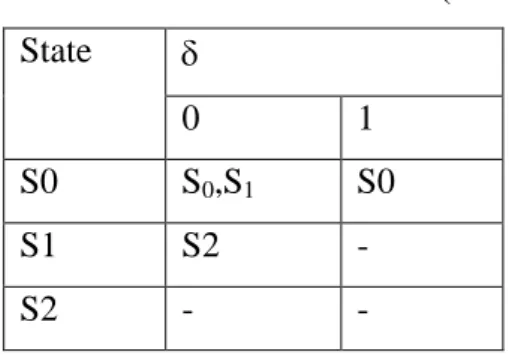
Buatlah diagram transisi dari FSA yang didefinisikan sebagai : M = ( S, , , S0 dan F) dimana :
S={S0 , S1 , S2 , S3 }
={ 0,1 } F={ S0 , S3 }
Dengan fungsi transisi ada pada tabel transisi adalah sebagi berikut: Tabel 4.2. Tabel transisi State Input 0 1 S0 S1 S2 S3 S0 S1 S0 S2 S0 S0 S2 S1
Jawab : Diagram transisi dari FSA tersebut dapat digambarkan sebagai :
Gambar 4.1. Diagram transisi
Cara kerja FSA :
- Mula-mula dalam state S0
- Jika dari S0 menerima 1 : akan ke State-S1
- Jika dari S0 menerima 11 : akan ke State-S1 lalu ke S2 - Jika dari S0 menerima 0 : akan tetap di State-S0
- Jika dari S0 menerima 10 : akan tetap kembali lagi State-S0
S0 0 0 0 0 0 0 0 0 0 0 0 0 S3 S2 S1 1,0 0 1 1 0 1 0 Start
- Jika dari S0 berturut-turut menerima masukan : 111, maka ia akan kembali ke-S0
4.4 FSA Sebagai Pengenal String
Mesin FSA tersebut jika menerima masukan sederetan simbol masukan dari simbol-simbol yang diijinkan maka akan menuju suatu state tertentu. Jika state akhir yang ditempuh setelah suatu FSA menerima sederetan simbol adalah state FINAL, maka deretan simbol (string) tersebut dikatakan DIKENALI oleh FSA, atau dengan kata lain FSA mengenali string tersebut.
Untuk FSA diatas string-string yang dikenali adalah antara lain : 0 00..0 atau 0* 10 010 010010 100* 110 111
Kumpulan seluruh string yang dikenali oleh FSA merupakan suatu BAHASA yang dikenali oleh FSA tersebut. Jika dimiliki FSA M maka bahasa yang dikenali oleh FSA di notasikan sebagai :
L(M) = { x | x semua string yang mengantar M dari S0 ke (Si F) } Untuk mesin FSA diatas :
L(M) = { 0* , 0*(10)0* , 0*(110,111)0* }
Contoh 4.3. : Tentukan bahasa L(M) yang dikenali oleh Mesin M berikut ini : 0 start S3 Gambar 4.2 S0 S1 0,1 1 0 S2 1
BAB IV. Finite State Machine(FSM) dan Finite State Automata (FSA) 29
Jawab : Dari diagram terlihat bahwa final-state adalah S3. Pergerakan state yang mengantar ke final-state adalah S0S1S2S3 yakni string : 011 atau string 111 yang dapat ditulis sebagai (0,1)11.
Pergerakan yang lain adalah dari S0 langsung ke S2 yaitu : S0S2S3 yang dilakukan melalui string : 01
Setelah berada pada final state masih ada pergerakan yang bersifat rekursif pada S3 yaitu apabila diberikan masukan 0,00,000,… atau : 0*. Dengan demikian jika seluruh string tersebut digabungkan akan menjadi : (0,1)110* 010*, sehingga bahasa yang dikenali adalah :
L(M)= { (0,1)110* 010* } = { ((0,1)11 01)0* }
4.5 Deterministik Dan Non Deterministik FSA
FSA dapat dikelompokkan menjadi Deterministik FSA (DFA) dan Non deterministik FSA (NFA) berdasarkan sifat fungsi transisinya.
DFA (Deterministik FSA):
Jika pada setiap state dari FSA tersebut apabila menerima input sebuah simbol maka HANYA ada SATU NEXT STATE yang mungkin dituju.
NFA (NON Deterministik FSA):
Jika FSA tersebut menerima input simbol maka minimal ada satu state yang akan berpindah ke LEBIH DARI SATU NEXT STATE yang mungkin dituju.
Contoh 4.4 :
Perhatikan gambar FSA a) (Gambar 4.3) dan FSA b) (Gambar 4.4) berikut. Ini adalah contoh-contoh DFA dan NFA
Tunjukkan gambar a) ini adalah NFA : 0,1 a). start Gambar 4.3. S0 S1 0,1 1 0 S2
Jawab : Dari S0 jika menerima masukan 0 dapat memilih ke salah satu NEXT state yaitu S1 atau S2.
Dari S1 jika menerima masukan 1 dapat ke S2 atau tetap di S1. Dengan demikian gambar diatas adalah NFA
Tunjukkan gambar b) berikut adalah DFA :
0 b).
start
Gambar 4.4.
Jawab : Pada setiap state , jika menerima masukan selalu HANYA satu NEXT state yang dituju. Dengan demikian gambar b) adalah DFA.
4.6 Konversi dari NFA ke DFA
Apabila dimiliki suatu FSA, misalnya M= ( S, , , S0 dan F) yang merupakan suatu NFA, maka selalu akan dapat dibuat FSA baru yang merupakan DFA yang akan mengenali string yang sama dengan NFA. Misalkan DFA baru tersebut adalah M*={ S*, *, * , S0* dan F* }
dimana :
* = ; S0* = S0
S* = himpunan state yang baru
* = fungsi transisi yang baru
F* = himpunan final state yang baru
DFA hasil konversi NFA berbeda dalam himpunan statenya, fungsi transisi dan final statenya. Himpunan state yang baru merupakan gabungan dari next-state yang lebih dari satu membentuk himpunan state sedangkan final state yang baru adalah gabungan next state-next state yang lama apabila ia mengandung satu atau lebih final state. Untuk proses konversi NFA ke DFA dapat dilakukan dengan membuat diagram pohon transisi.
S0 S1
1 1
0
BAB IV. Finite State Machine(FSM) dan Finite State Automata (FSA) 31
Contoh 4.4 : FSA berikut merupakan FSA pengenal bilangan kelipatan 4 yang merupakan suatu NFA. Carilah konversi NFA tersebut menjadi suatu DFA.
NFA: Pengenal string : (0,1)*00 (bilangan kelipatan 4 (biner)) 0,1 start Gambar 4.5. Jawab:
Jika diperhatikan FSA di atas , yang menyebabkan merupakan NFA adalah pada state S0 apabila menerima masukan 0 maka next-state nya tidak pasti, yaitu dapat tetap di S0 atau pindah ke S1. Apabila unsur ini dapat dieliminir maka konversi dapat dilakukan. Jika diamati diagram di atas NFA tersebut adalah :
M= ( S, , , S0 dan F) dengan : S ={S0,S1 S2 } = {0,1} F={S2} : ( S0,0) = {S0,S1} ( S0,1)=S0 ( S1,0)=S2
Selanjutnya dapat disusun diagram pohon transisi sebagai berikut :
({S0,S1,S2},0)= {S0,S1,S2} ({S0,S1}, 0 )={S0,S1,S2} (S0,0)={S0,S1} ({S0,S1,S2},1)= {S1} S0 ({ S0,S1}, 1 )={ S0} ( S0,1)={ S0}
Gambar 4.6 Proses konversi
S0 S1
0 0
Penjelasan :
Pohon transisi diperoleh dengan menggabungkan next-state yang mungkin lebih dari satu menjadi suatu himpunan-next state yang pada gilirannya ini dianggap sebagai suatu state baru. Misalnya apabila pada state S0 diberi masukan 0 maka ada dua next-state yang mungkin, yaitu S0 dan S1, ini dihimpun menjadi satu himpunan, yaitu {S0,S1}. Jika dilanjutkan apabila { S0,S1 } mendapat masukan 0 maka next-state nya menjadi himpunan dari : next-next-state jika S0 mendapat masukan 0 dan next-state jika S1 mendapat masukan 0, yakni menjadi {S0,S1,S2}. Demikian seterusnya apabila next-state next-state yang mungkin dihimpun sampai keseluruhan kemungkinan selesai dikonstruksi dalam suatu pohon penurunan.
Hasil akhir yang dapat diperoleh adalah : M*= ( S*, *, * , S0* dan F*)
Dengan :
S*={ {S0}, { S1}, {S0,S1} dan {S0,S1,S2} } F*={{S0,S1,S2} }
* = seperti terlihat dalam diagram pohon atau dapat dibandingkan sebagai berikut : Tabel 4.3. Untuk FSA semula (NFA)
State
0 1
S0 S0,S1 S0
S1 S2 -
S2 - -
Tabel 4.4. Dikonversi menjadi (lihat diagram pohon)
State *
0 1
{ S0} {S0,S1} S0
{S0,S1} {S0,S1,S2} S0 {S0,S1,S2} {S0,S1,S2} S0
BAB IV. Finite State Machine(FSM) dan Finite State Automata (FSA) 33
Dengan demikian diagram konversi nya adalah :
DFA: string yang dikenali adalah sama, yaitu : (1,0)*00 1
start
Gambar 4.7 Hasil konversi NFA ke DFA
4.6 FSA Sebagai Pengenal Bahasa Regular
FSA baik itu DFA maupun NFA merupakan pengenal terhadap kelas bahasa regular yang dapat dicirikan sebagai berikut :
Aturan bahasa regular memiliki aturan produksi :
: HANYA terdiri dari 1 simbol Non terminal saja, atau | | =1 : dalam bentuk salah satu diantara : a, aB, atau
Tiap aturan produksi yang mungkin dapat diwakili oleh gerakan dalam FSA sebagai berikut :
1. Ekspresi regular diwakili oleh gerakan :
2. Ekspresi regular diwakili oleh gerakan :
3. Ekspresi regular a, atau r Aturan produksi : A a di wakili oleh :
4. Aturan A aB di wakili oleh :
A Start a S1 S0 Start S0 Start A Start a B {S0,S1) S0 0 {S0,S1,S2} 0 0 1 0
5. Aturan A di wakili oleh :
6. Aturan produksi rekursif : A aA di wakili oleh :
a
Dengan demikian jika dimiliki suatu grammar regular G tertentu maka akan dapat ditemukan FSA yang mampu mengenali bahasa yang dibangkitkan oleh grammar tersebut. Demikian juga jika dimiliki suatu FSA maka akan dapat ditentukan tata bahasa regular yang membangkitkan bahasa yang dikenali FSA tersebut.
Contoh 4.5. : Tentukan tata bahasa yang mengenali bahasa yang dibangkitkan oleh FSA berikut : 0 start Gambar 4.8
Jawab : G(, N, S, P) ; dimana ={ 0 , 1 } N = { S, A, B} yakni dengan mengamati diagram dan menaganalogikan state-state sebagai non terminal, yaitu : S0 terkait dengan non terminal S, S1 terkait dengan non terminal A dan S2 terkait dengan nonterminal B. Jika diagram tersebut diuraikan setiap tahapnya akan berkait dengan aturan-aturan produksi P seperti uraian berikut : S0 S1 1 1 0 S2 A A
BAB IV. Finite State Machine(FSM) dan Finite State Automata (FSA) 35
Start analog dengan aturan S 1A
0
analog dengan aturan A 0A
analog dengan A 1B
start analog dengan S 0B
Analog dengan B
Dengan demikian ada 5 aturan produksi yang menjadi bagian dari tata bahasa yang membangkitkan bahasa yang sama dengan bahasa yang dikenali oleh FSA tersebut, yaitu :
P={ S1A, A 0A , A1B , S0B, B
}
Contoh 4.6 : Tentukan FSA yang mampu mengenali bahasa yang dibangkitkan oleh grammar berikut ini :
G(, N, S, P) ; dimana ={ 0 , 1 } N = { A, B} dan dengan P: S0A; A0A; A1B; B1B dan B
Jawab :
Jika aturan produksi tersebut di rinci menjadi : 1. S 0A 2. A 0A 3. A 1B S0 S1 1 S1 S1 1 S2 S0 0 S2 S2
4. B 1B 5. B
Penurunan string dapat menempuh aturan : 1,3, 5 yaitu : S 0A01B01 =01 Atau aturan : 1 diteruskan 2 (diulang tak terbatas), dilanjutkan 3, kemudian 4 (diulang tak tertentu) dan aturan 5 : yaitu :
S 0A 00A000A…0 ….0A0…01B0…011B0…0111B 0..01.. Sehingga bahasa yang dibangkitkan oleh grammar tersebut adalah :
L(G) = { 00*11* }
Adapun FSA yang mengenali bahasa tersebut adalah :
0
start
Gambar 4.8
Contoh 4.7 : Tentukan FSA yang mampu mengenali bahasa dan Tata bahasa nya untuk bahasa yang mewakili ekspresi bilangan real yang dapat ditulis sebagai : xxx.yyyy ; dimana {x,y | 0,1,2,3,4,5,6,7,8,9}
Jawab :
Untuk tata bahasa dapat dituliskan sebagai berikut
G(, N, S, P) ; dimana ={ 0 , 1 } N = { S, A} dengan aturan produksi : S 0S|1S|2S|3S|4S|5S|6S|7S|8S|9S|.A
A 0A|1A|2A|3A|4A|5A|6A|7A|8A|9A|ε FSA sebagai berikut :
0,1,2,3,4,5,6,7,8,9 0,1,2,3,4,5,6,7,8,9 start S0 S1 0 1 1 S2 S0 S1
.
BAB IV. Finite State Machine(FSM) dan Finite State Automata (FSA) 37
4.7 Latihan
1. Tentukan bahasa dan grammar yang dikenali oleh FSA berikut : 0 start
1
2. Tentukan bahasa dan grammar yang dapat dikenali oleh FSA berikut ini : 0
start
3. Tentukanlah FSA yang mampu mengenali bahasa berikut ini dan tentukan pula grammar yang membangkitkan bahasa tersebut.
a). 1*0* b). 10*11) c). (1*0*11) d). (10*11*)
4. Tentukan bahasa dan mesin pengenal bahasa dari suatu grammar dengan aturan produksi berikut ini :
S aA AaA | bB BbB | b
5. Tentukan bahasa dan mesin pengenal bahasa dari suatu grammar dengan aturan produksi berikut ini :
S aA AaA | bB BbB | b S0 S1 0 1 S2 S3 1 S0 1 S1 1 0 S3 S2 0,1
BAB V
TATA BAHASA BEBAS KONTEKS (CONTEXT FREE GRAMMAR )
5.1. Tujuan Instruksional
Setelah mempelajari bab ini diharapkan mahasiswa menguasai konsep tentang tata bahasa dalam kelas bebas konteks dan bahasa bebas konteks. Bentuk tat bahasa bebas konteks yang hanya mengikat simbol di sebelah kiri, yaitu panjangnya 1 non terminal, sedangkan di sebelah kanan tidak terikat menyebabkan tata bahasa ini bebas untuk ruas kanannya, sehingga terkadang memerlukan penyederhanaan. Penyederhanaan tata bahasa dari berbagai bentuk yang tidak efisien seperti adanya rekursif kiri dan pelebaran dan peninggian pohon penurunan string juga akan di bahas.
5.2. Batasan Tata Bahasa Bebas Konteks
Telah disinggung pada Bab II bahwa tata bahasa bebas context (Context Free Grammar, biasa disingkat dengan CFG memiliki batasan sebagai berikut :
Tata-bahasa Tipe 2 (Context -Free Grammar) G( ,N ,S , P) , adalah tata-bahasa tipe-1 yang memiliki aturan produksi : dengan tambahan batasan :
: HANYA terdiri dari 1 simbol Non terminal saja, atau N
: tidak dibatasi, atau : {( N)*
Sehingga dengan demikian perbedaan dengan bahasa regular adalah pada string sisi kanan tanda panah untuk bahasa regular harus satu terminal tunggal atau terminal tunggal diikuti non terminal sedang untuk bahasa bebas konteks tidak dibatasi : Contoh 5.1. :
Grammar dengan aturan : Sa|aA
AbB B
Adalah tata bahasa regular Contoh 5.2. :
BAB V. Tata Bahasa Bebas Konteks (Context Free Grammar) 39 Sa|aA AbB | AA B
Adalah tata bahasa bebas konteks karena ada aturan produksi : AAA
Contoh 5.3. :
Tentukan bahasa yang dibangkitkan oleh grammar pada contoh 5.2. Jawab :
1. Anggota bahasa yang pertama adalah a, jika digunakan aturan : Sa 2. Jika aturan SaA, kemudian AbB dan B diperoleh :
SaAabBabab
3. Jika aturan SaA, kemudian AAA , AbB dan B diperoleh : SaAaAAabBbBabbabb
Atau
SaAaAAabBAAabbBbBabbbabbb Kesimpulan : Bahasa yang dibangkitkan adalah :
L(G)={a,ab,abb,abbb,abbbb,…}
5.3. Masalah Ambiguity Dalam CFG
Sebuah tata bahasa bebas konteks dkatakan mendua arti (ambiguous) apabila dalam menurunkan string dapat ditempuh dua atau lebih pohon penurunan string. Perhatikan suatu CFG berikut ini :
SAB AaA|a BbB|b
Suatu string aabbb dapat diturunkan melalui proses penurunan : AABaABaaBaabBaabbBaabbb
Jika digambarkan dalam pohon penurunan diperoleh seperti gambar 5.1. Dapat dicatat bahwa penurunan yang mungkin dapat ditulis adalah :
AABAbBAbbBAbbbaAbbbaabbb atau AABaABaAbBaAbbBaabbBaabbb Dan masih banyak kemungkinan yang lain.
S A B a A b B a b B b Gambar 5.1
Akhirnya dapat dicatat bahwa untuk menghasilkan string aabbb ada banyak jalur penurunan, akan tetapi semua jalur penurunan itu akan memiliki pohon penurunan yang sama. CFG yang untuk penurunan suatu string hanya memiliki satu pohon penurunan yang sama disebut CFG yang tidak mengandung ambiguity.
Sekarang perhatikan CFG berikut ini : SSbS | ScS |a
Untuk menurunkan string abaca dapat dibuat penurunan : SSbSabSabScSabacSabaca
Atau dapat juga
SScSSbScSSbacSSbacaabaca
Jika jalur penurunan yang pertama dibuat pohon penurunan diperoleh :
S S b S a S c S b a a Gambar 5.2
BAB V. Tata Bahasa Bebas Konteks (Context Free Grammar)
41
Sedangkan untuk jalur penurunan yang kedua jika dibuat pohon penurunan : SScSSbScSSbacSabacSabaca
S S c S S b S a a a Gambar 5.3
Jika dicermati gambar 5.2 dan gambar 5.3 menghasilkan string yang sama yaitu :abaca, tetapi ternyata pohon penurunan yang dihasilkan adalah berbeda, untuk menurunkan string yang sama. Hal ini terjadi karena pada gambar 5.2 S disebelah kanan diturunkan rekursif baru ke terminal sedangkan pada gambar 5.3 S yang sebelah kiri yang diturunkan rekursif baru ke terminal. Grammar seperti ini dikatakan grammar yang memiliki sifat ambiguity.
Ambiguity dapat menjadi sebuah masalah untuk bahasa-bahasa tertentu jika artinya tergantung pada struktur, seperti halnya pada bahasa alami (natural language) atau bahasa pemrograman. Meskipun dalam bahasa natural ambiguity ini tidak menjadi masalah apabila konteksnya diketahui.
Sebagai contoh kalimat :
“Ali melihat seorang laki-laki dengan sebuah teropong”
dapat berarti bahwa “Ali menggunakan alat teropong untuk melihat seorang laki-laki” atau “Ali melihat seorang laki-laki dengan mata telanjang dan laki-laki yang dilihat Ali tersebut sedang memegang teropong”
Contoh lain kalimat :
“Silahkan makan sama kambing!!”
dapat berarti “Silahkan makan dengan lauk daging kambing” atau dapat pula “Silahkan makan bersama kambing yang juga sedang makan”. Jika konteksnya kita sedang berada di restoran dan mempersilahkan makan tentunya arti yang pertama
yang mungkin, tetapi bila kita sedang berada di padang gembala menggembalakan kambing bisa jadi arti yang kedua yang mungkin.
Dalam bahasa pemrograman BASIC dapat kita jumpai potongan statemen yang mendua arti, misalnya :
X=5 Dalam konteks :
IF X=5 THEN … berarti membandingkan isi variabel X apakah sama dengan 5 atau tidak, sedang dalam konteks :
LET X=5 berarti menugasi variabel X untuk menampung nilai data 5. Dalam beberapa hal jika suatu tata bahasa bebas konteks memiliki ambiguity , tata bahasa yang lain yang menghasilkan bahasa yang sama dapat dibuat, meskipun tidak selalu dapat dibuat. Misalnya tata bahasa berikut :
SA|B Aa Ba
Tata bahasa yang lain yang tidak mendua arti adalah : Sa
Jika suatu tata bahasa bebas konteks yang mendua arti tidak dapat dicari padanan tata bahasa lain yang tidak mendua arti maka tata bahasa tersebut disebut sebagai “Inherently ambiguous context free grammar”
5.4. Penyederhanaan Tata Bahasa Bebas Konteks
Kadangkala dijumpai dalam sebuah tata bahasa bebas konteks terdapat beberapa aturan produksi yang tidak berperan dalam penurunan string, atau aturan produksi yang terlalu panjang sehingga pada pohon penurunan berakibat percabangan terlalu lebar dan sulit dikendalikan. Perhatikan tata bahasa berikut :
SabcdefS | abcdef
akan melahirkan pohon penurun yang melebar kesebelah kanan.
Sedangkan tata bahasa berikut akan menghasilkan pohon yang tinggi dan sempit : SA
AB BC
BAB V. Tata Bahasa Bebas Konteks (Context Free Grammar)
43
CD Da|A
Jika dicermati grammar yang terakhir ini terlihat bahwa sebenarnya aturan produksi yang sangat panjang tersebut dapat disederhanakan menjadi hanya :
S a
dengan membuang SABCDA yang merupakan proses penurunan yang “melingkar” dan dapat ditiadakan tanpa mengurangi bahasa yang dihasilkan oleh tata bahasa tersebut.
Secara garis besar penyederhanaan tata bahasa bebas konteks dapat ditempuh dengan :
1. Membuang aturan produksi yang tidak berguna 2. Menghilangkan produksi unit
3. Menghilangkan produksi epsilon ( )
5.4.1. Membuang aturan produksi yang tidak berguna
Aturan produksi yang secara umum dapat ditulis P={} adalah sekumpulan aturan yang digunakan untuk pengubahan simbol S menjadi simbol terminal untuk menyusun suatu string anggota suatu bahasa. Dengan demikian setiap aturan produksi harus dapat terlibat dalam penyusunan suatu string terminal. Apabila aturan produksi ternyata dapat dibuktikan tidak berfungsi atau gagal dalam penurunan string menuju string terminal maka aturan produksi tersebut dapat dibuang dari himpunan aturan produksi P.
Perhatikan grammar bebas konteks dengan aturan produksi berikut : Contoh 5.4
G ={ SaSa | Aab | Baa | b Aab|
B Baa }
Bahasa yang dibangkitkan oleh grammar G tersebut dapat dilacak dari : Aturan penurunan : SaSaaaSaa aaaSaaa aa...aSa...a aa..aba..aa Atau penurunan : S... aa...aSa...a aa..aAaba..aa aa...aababa..aa