Concurrent Processing of Increments in
Online Integration of Semi-structured Data
Handoko
∗, Janusz R. Getta
†School of Computer Science and Software Engineering University of Wollongong, Australia
Email:∗[email protected], †[email protected]
Abstract—An online integration system enables incremental computation shortly after an increment data arrived at the central site. Processing increments serially ensures all data containers are in their updated states for computation of the next increment data. In general, a data container may show up as several arguments in a data integration expression. Serial processing of increments at this data container failed to show its best performance due to expensive IO costs for materialization updates.
This paper proposes an online integration system with dy-namic scheduling to enable concurrent processing of increments of data. The online integration system allows a series of transfor-mation of a data integration expression into a single increment expression upon the increments of multiple data containers, and generates a data integration plan. The dynamic scheduling system employs a monitoring system and a priority scheduling which is able to dynamically change the data integration plans according to the increment data behavior.
Keywords—Data integration, dynamic scheduling, distributed database, semi-structured data.
I. INTRODUCTION
Data integration systems are generally equips with a me-diator at the central site and wrappers at the remote sites. A mediator has a role to provide general view of data, receives a user query, send sub-queries to the wrappers, and then integrate the sub-query results to produce a final answer to user. Meanwhile, the wrappers map the general view into the data sources. Integration processing at the central site can create a bad performance because the central site does not have enough information about remote site’s behavior [1].
Online integration is a process of continuous consolidation of data transmitted over a network with data already available at a central site of a multi-database system. The intermediate results of online integration provide a user with the most up-to-date results of a query being processed by the system. Online integration applies online processing where a smallest unit of increment data is instantly processed without having entire set of data available. Then, the result ofincrementalprocessing of data is combined with the current state of processing to obtain a new state of processing. Online integration systems take user requests and transform them into global query expressions. After decomposition of global query expressions,data integra-tion expressionsare generated, where results from remote sites become their arguments. A number of increment expressions are derived from data integration expressions such that every argument is assigned to an increment expression. Then,online integration plansare produced, and processing increment data
is performed through evaluation of selected online integration plan. In a sequence of increment data, executing all steps of integration plan is unnecessary and creating high IO cost for materialization updates.
This paper mainly addresses the poor performance of integration system due to unpredictable data arrival rate and serialization of increments. At operator level, we propose an online integration system which shortly computes every increment data received at a central site. The system con-siders concurrent processing of increments at multiple data containers. In order to support this technique, we propose an algebraic system for semi-structured data which are consistent with the basic operators of relational data model. The algebra has enough properties to provide a mechanism to generate an increment expression of a data container from a data integra-tion expression. Atscheduling level, we propose a monitoring system of data arrival and materialization management such that minimum materialization updates is obtained.
The structure of this paper is as follows: section 2 covers the previous work. Then, we describe online integration system architecture in section 3. In section 4, we discuss online integration plan scheduling, and section 5 concludes the paper.
II. PREVIOUSWORK
Data integration systems for semi-structured data require data model and algebra that allow for efficient processing of semi-structured structures. XML algebra proposed in [2] is a tree-based algebra generalizing the relational algebra.
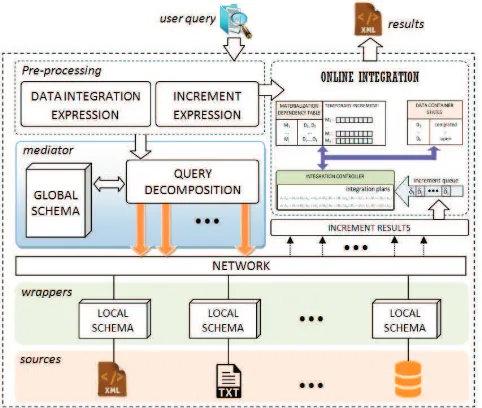
Fig. 1. Online integration system architecture
Query scrambling is a popular technique in dynamic scheduling strategy. Its basic strategy is to modify the query plan whenever unexpected delay occurs at any data sources. Getta [11] proposed combination of query scrambling and reduction technique for integration system. Bouganim [1] proposed a technique which includes delay in the execution strategy by monitoring arrival rate and available memory.
III. ONLINEINTEGRATIONSYSTEMARCHITECTURE
We consider an online integration system which contains a mediator and a number of wrappers (see Fig. 1). In the first step of query processing, amediatortransforms a query expressed in a high level query language like XQuery into XQuery Core [12]. Then, X-Query Core is translated into a global query expression and optimized using the standard techniques of syntax-based optimization, e.g. moving filtering before binary operations.
Definition 1: Let {x1, ..., xn} be a set of pointers to the data containers with XML documents located at remote sites. Aglobal query expressione(x1, ..., xn)is an expression built from the operations offiltering(σ),join(⊲⊳),antijoin(∼) and union (∪), and the pointers to remote data containers.
A. Data Integration Expression
After it is constructed, aglobal query expressionis decom-posed into a number of sub-expressions such that an optimal solution can be obtained by employing remote sites to do part of computations, and the central site combines the result to produce a final result.
Definition 2: Query decomposition is as a process, that transforms aglobal query expressione(x1, . . . , xn)into an ex-pressionf(q1, . . . , qk)where for alli= 1, . . . , k,qi=ei(xi1, . . . ,xij),{xi1, . . . ,xij} ⊆ {x1, . . . ,xn}, andxi1, . . . ,xij point
to the same remote site. Results of processing off(q1, . . . , qk) are identical with the results of processing of e(x1, . . . , xn).
Definition 3: Letf(q1, ..., qk)be a result of decomposition of e(x1, . . . , xn). Let Di be a result of processing qi at a
Fig. 2. (a) A decomposition strategy to balance central and remote site processing (b) A data integration expression (c) Increment expression for increment dataδ1
remote site for i = 1, . . . , k. A data integration expression f(D1, ..., Dk) is an expression obtained from f(q1, . . . , qk) by a systematic replacement of the symbols q1, . . . , qk with the data containerD1, . . . , Dk being the results of processing q1, . . . , qk at the remote sites.
For example, lete(x1, . . . , x4)be a global query expression where x1 is located at a remote site S1, and {x2, . . . , x4} are at a remote site S2. Fig. 2 (a) shows a decomposition strategy to balance processing between central and remote sites. Decomposition strategy for remote site S2 is such that nodes with label 1 is processed at the central site and a sub-expression rooted at node 2 is sent to a remote site for processing [12]. The central site collects all data received from remote sites in data containers (D) for integration. Figure 2(b) shows a syntax tree of a data integration expression e.
B. Increment Expression
In the next step, a data integration expression is trans-formed into a form which allows us to compute it step by step as an increment of a data container arrives at the central site. Letδij be an increment of a data containerDi, then a data
container is formed asDi=δi1∪δi2∪. . .∪δin. In this work
a data integration operation is presented by a unionoperation, while in some other models it may have different properties or operations. A data increment (δ) is also considered as a complete XML document.
Definition 4: Let Di be a data container, δi be an incre-ment data of Di, and Ma =ha(D1, . . . , Dk) : a= 1, . . . , j be a set of intermediate materializations.Increment expression gi(δi, M1, . . . , Mj)is an expression to compute an increment data against intermediate materializations by the operations of join, antijoinandunion.gihas a form of left/right deep expres-sion such thatgi=gij(. . .(gi2(gi1(δi, M1), M2), . . .), Mj). In a special case Ma can be an identity function,Ma=Da.
Theorem 1: Any data integration expression f(D1, . . . , Di∪δi, . . . , Dk) can be always transformed into one of equivalent expressions:
f(D1, . . . , Di, . . . , Dk)∪gi(δi, M1, . . . , Mj) (1) f(D1, . . . , Di, . . . , Dk)∼gi(δi, M1, . . . , Mj) (2)
C. Online integration plans
The next step is to prepare an online integration plan for every increment expression generated at the earlier stage.
Definition 5: Let Di be a data container, gi( δi, M1, . . . , Mj) is an increment expression of Di in a form of gij(. . .(gi2(gi1(δi, M1), M2). . .), Mj), and di is a plan to compute increment of Di. pj : j = 1, . . . , m is a sequence of steps where in each step a simple expression is evaluated and the results of evaluation are stored in a temporary variable or materialization. Each pj is associated withgij, a data container update, or a materialization update.
Online integration plan of Di is defined as di : p1;. . .;pm wherepj :j= 1, . . . , m is evaluated to accomplish increment operation by passing result from one step to the next step.
Transformation of an increment expression gi into an online integration plan di is performed in the following steps: (1) we add a stepp1to update a data containerDi. (2) we map every sub-expressiongij :j= 2, . . . , minto a steppj from the
inner-most to the outer most sub-expression; (3) we append a steppm+1to update a final materialization (Me) with the last result of the increment computation; (4) we identify affected intermediate materializations which are result computation of expressions ha(D1, . . . , Dk), where Di ∈ {D1, . . . , Dk}. Then, we perform the same procedure of increment processing for all ha identified without updating data container and intermediate materializations.
D. Concurrent increment data
We consider a user query ”Give me all books which one of their author is not a reviewer of any other book” is received at the central site. The user query can be translated into an XQuery scripts below:
for $b in doc("MyBooks.xml")//books/book let $r := doc("MyBooks.xml")//reviewer where not(exists($b//author[. = $r])) return $b
Definition 6: LetDi be a data container,Di is acommon data containerif it shows up as arguments in a data integration expression more than once,e(D1, ..., Di, ..., Di, ..., Dk).
Let xi be a pointer to book documents at a remote site. Then, the user query above can be translated into a global query expression: e(x1) = x1 ∼ (σA1=A2(ρA1,a12(x1) ⊲⊳ ρa21,A2(x1))). Ifrename(ρ) operation is ignored, we are able to transform it into a data integration expression f(D1) = D1 ∼a1=a2 (σ(D1 ⊲⊳a1=a2 D1)), where a1 is an author attribute of D1, and a2 is a reviewer attribute of D1. In this case a data integration expression contains acommon data container (D1).
A data integration expression with a common data con-tainer Di can be transformed into increment expressions in two different approaches:
Serialization of increments. Every instance of Di is consid-ered as a unique data container. It allows us to assign these data containers (Di)s to Dij, Di2, ..., Din wheren is the number of occurrence of data container Di in the data integration expression. Then, we generatennumber increment expressions and online integration plans for processing an increment ofDi; Concurrent processing of increments. We transform the data
integration expression for all instances of Di into a single increment expression by considering an instances of Di at a time. Then, we generate an online integration plan.
For an example, consider a data integration expression in Fig. 2(c) where D1, D2, and D3 are same data containers. Replacing the data containers withD1 will create a data inte-gration expressionf(D1) = (D1 ∼a1=a2 (D1 ⊲⊳a1=a2 D1)). LetD1be a data container,δ1is an increment of data container D1 and all operation conditions are removed from algebra operation to reduce space. Then, in serialization approach, increment expression forf(D1)can be obtained as follows:
1) we assign a unique data container for every occurrence of D1 to get a data integration expressionf(D1) =D11∼
(D12⊲⊳ D13);
2) the next step, we transform the data integration expression into increment expression for every data container, and produce: δ11 : f(D11, D12, D13)∪(δ11 ∼ M1), where M1 = D12 ⊲⊳ D13; δ12 : f(D11, D12, D13) ∼ (δ12 ⊲⊳ D13); andδ13:f(D11, D12, D13)∼(D12⊲⊳ δ13).
In the next step, an online integration plan will be generated for every increment expression.
d1 1:D1 1= (D1 1∪δ1 1);δA= (δ1 1∼M1);Me= (Me∪δA).
d1 2:D1 2= (D1 2∪δ1 2);δB= (δ1 2⊲⊳ D1 3);Me= (Me∼δB);
M1= (M1∪δB).
d1 3:D1 3= (D1 3∪δ1 3);δC= (D1 2⊲⊳ δ1 3);Me= (Me∼δC);
M1= (M1∪δC).
Since these integrated plans are actually processing of a single increment (δi), we encapsulate the plans in a transaction to ensure its atomicity. The processing produces correct results only if all of generated integration plans are executed in the order they are generated, in this exampled1, d2, d3. Processing increment of a common data container in this approach re-quires anupdateoperation for every instance of data container D1, because D11, D12, D13 are considered as unique data containers. It also requires a materialization update for every instance of data container.
To minimize processing of materialization updates, we move data container and materialization updates to be executed at the end of transaction in the following steps:
1) substitution of Di1, Di2, . . . , Din symbols with Di and δi1, δi2, . . . , δin withδi;
2) we introduce a temporary updated data container D′ i =
(Di∪δi);
3) the number of increment result to be updated to a mate-rialization is minimized in several steps:
a) collect and combine (union) increment results from the same increment expression form (see expression 1 and 2 in Theorem 1). LetδM f, δM s be results from increment expression in the form of expression 1 and 2 respectively.
b) compute the increment results δM r =δM f ∼δM s to minimize the number of document to be processed. 4) we compute (M ∼δM s), and then (M ∪δM r) or (M ∪
δM f) if δM r is empty.
At the end of this process, we obtain a single integration plan d1 : D1′ = (D1∪δ1);δA = (δ1 ∼ M1);δB = (δ1 ⊲⊳ D1);δC = (D1′ ⊲⊳ δ1);δM s = (δB ∪δC);δM r = (δA ∼ δM s);D1 = (D1′);Me = (Me ∼δM s);{Me = (Me∪δM r) or Me= (Me∪δA)};M1= (M1∪δM s).
In the concurrent processing of increments approach, we generate a single increment expression by transformation of each data container and its corresponding increment at a time. Let Dh and Di be common data containers, and δh, δi be their increments respectively. An increment expres-sion is obtained by transformation of the data integration expression for one of the increment followed by the other increment regardless the order of increment to be processed. According to Theorem 1, transformation of a data integra-tion expression f(D1, ..., Dh ∪ δh, ..., Dk) produces either an expression:f(D1, ..., Dh, ..., Dk)∪gh(δh, M1, . . . , Mj), or f(D1, ..., Dh, ..., Dk)∼gh(δh, M1, . . . , Mj).
Since intermediate materializationsMaare computation results of ha(D1, . . . , Dk) : a= 1, . . . , j, then gh(δh, M1, . . . , Mj) can be transform into gh(D1, . . . , δh, Di, . . . , Dk). An in-crement expression for δi is produced by transforma-tion of both expressions f(D1, ..., Dh, Di ∪ δi, ..., Dk) and gh(D1, ..., δh, Di∪δi, ..., Dk).
Transformation of f(D1, ..., Dh, Di∪δi, ..., Dk)produces: f(D1, ..., Dh, Di, ..., Dk)∪gi(δi, M1′, . . . , Mj′), or
f(D1, ..., Dh, Di, ..., Dk)∼gi(δi, M1′, . . . , Mj′).
Transformation of gh(D1, ..., δh, Di∪δi, ..., Dk)produces: gh(δh, M1, . . . , Mj)∪ghi(δh, δi, M1′′, . . . , Mj′′), or gh(δh, M1, . . . , Mj)∼ghi(δh, δi, M1′′, . . . , Mj′′)
Therefore, an increment expression can be produced in one of expressions in Theorem 2.
Theorem 2: Let δh, δi be concurrent increment of data container Dh, Di. Any data integration expression f(D1, . . . , Dh∪δh, Di∪δi, . . . , Dk)can be always transformed into one of equivalent expressions:
f(D1, . . . , Dh, Di, . . . , Dk)∪gh∪gi∪ghi (3) f(D1, . . . , Dh, Di, . . . , Dk)∪gh∪gi∼ghi (4) f(D1, . . . , Dh, Di, . . . , Dk)∪gh∼gi∪ghi (5) f(D1, . . . , Dh, Di, . . . , Dk)∪gh∼gi∼ghi (6) f(D1, . . . , Dh, Di, . . . , Dk)∼gh∪gi∪ghi (7) f(D1, . . . , Dh, Di, . . . , Dk)∼gh∪gi∼ghi (8) f(D1, . . . , Dh, Di, . . . , Dk)∼gh∼gi∪ghi (9) f(D1, . . . , Dh, Di, . . . , Dk)∼gh∼gi ∼ghi (10)
where gh = gh(δh, M1, . . . , Mj), gi = gi(δi, M1′, . . . , Mj′) andghi =ghi(δh, δi, M′′
1, . . . , Mj′′)
For example, an increment expression of a data integration expression f(D1) = (D1 ∼ (D1 ⊲⊳ D1)) is obtained as follows: First, we replace the secondD1withD1′ and the third D1 with D1′′ such that it forms a data integration expression f(D1) = (D1∼(D′1⊲⊳ D′′1)).
Then, we transform the data integration expression for an increment of D1 in the following steps:
=(D1∪δ1)∼(D′1⊲⊳ D′′1)
=(D1∼(D′1⊲⊳ D′′1))∪(δ1∼(D1′ ⊲⊳ D1′′))
Next, we transform the data integration expression regarding to an increment ofD′
1 as follows:
=(D1∼((D′1∪δ1′)⊲⊳ D′′1))∪(δ1∼((D′1∪δ1′)⊲⊳ D′′1))
=. . .
=(D1∼(D1′ ⊲⊳ D1′′))∪(δ1 ∼(D′1⊲⊳ D′′1))∼(δ1′ ⊲⊳ D′′1)
During transformation process, the expression can be simpli-fied to f(D1, D′1, D′′1)∪g1(δ1, M1)∼g′1(δ′1, M1′).
Last, we transform an increment of D′′
1 as follows:
=[(D1∼(D′1⊲⊳(D1′′∪δ1′′)))∼(δ1′ ⊲⊳(D′′1∪δ′′1))]
∪[(δ1∼(D1′ ⊲⊳(D1′′∪δ1′′)))∼(δ1′ ⊲⊳(D′′1∪δ′′1))]
=. . .
=(D1∼(D1′ ⊲⊳ D′′1))∪(δ1∼(D′1⊲⊳ D′′1))∼(D1′ ⊲⊳ δ′′1))∼
(δ′
1⊲⊳ D1′′)∼(δ1′ ⊲⊳ δ′′1)
Then, substitution of D′
1, D′′1 by D1 andδ1′, δ1′′ by δ1 allows us to get an increment expression:(D1∼(D1⊲⊳ D1))∪(δ1∼ M1)∼(D1⊲⊳ δ1))∼(δ1⊲⊳ D1)∼(δ1⊲⊳ δ1).
Based on the increment expression generated earlier, we generate an online integration plan: d1 : δA = (δ1 ∼ M1);δB = (D1 ⊲⊳ δ1);δC = (δ1 ⊲⊳ D1);δD = (δ1 ⊲⊳ δ1);δE = (δB ∪ δC);δM s = (δE ∪ δD);δM r = (δA ∼ δM s);D1 = (D1∪δ1);Me = (Me ∼ δM s);{Me = (Me∪ δM r)or Me= (Me∪δA)};M1= (M1∪δM s).
The serialization approach requires a common data con-tainerto be exists in two states (i.e. before and after updated) within increment computation. Therefore, an additional vari-able is needed to save the new data container state temporary. The data container will be really updated after all increment computation executed. This approach is consistent with the algebra proposed in [2] where the operators compute increment against a data container or a materialization.
Meanwhile, the concurrent approach allows computation without new state of common data container and allows computation an increment (δh) against another increment (δi). This technique will reduce a data container update process, and replace it with an additional computation between arguments with small amount of data.
Both of approaches are feasible to be applied for concurrent processing of multiple increments at different data containers in a data integration expression.
IV. SCHEDULING OF ONLINE INTEGRATION PLAN
At the compilation process, a mediator prepares a set of online integration plan in which every data container (Di) is assigned to an integration plan. Every integration plan includes processing to compute increment against data container or materialization, to update a data container, and to update intermediate and final materializations.
a collection of plans for every data container. An increment queue manages increments received from remote sites, and prepares the next increment to be processed. Amaterialization dependency table is used to determine which intermediate materializations need to be updated if an increment data occurs. It contains information about which materializations are affected by an increment data, and determines which data containers use the materializations in their integration plan.
Temporary increment listskeep a number of results which later on need to be combined to a corresponding tion. When integration controller defers process of materializa-tion update, computamaterializa-tion results will be kept in a temporary increment list associated to each of materialization, and will be combined to the corresponding materialization whenever needed. Adata container state tableis used to determine data container states. Together with materialization dependency table, the system is able to identify which materialization updates can be excluded from the operation for a completed data container.
We consider that an increment expression can be union-ed (first form) or antijoin-ed (second form) with a previous materialization (see expression 1 and 2 in Theorem 1). In-crement data which has inIn-crement expression in the second form might potentially reduce the computation results. On the other hand, increment expression in the first form will likely increase the number of result documents. Therefore, by giving a higher priority in processing increment expression in the second form may potentially reduce the result documents and yields increasing of system performance.
We also consider the sequence of increment data to be processed at the central site. Let δi and δj be a sequence of increment data, where δi arrives at the central site before δj. This sequence of increments might have three possible conditions as follows:
1) Both increments (δi and δj) occur at a single data con-tainer. For further discussion, it is named as type 1. 2) Both increments occur at different data containers
(Di, Dj), and they form an expression of an intermediate materializationha(Di, Dj). It is referred as type 2. 3) Both increments occur at different data containers
(Di, Dj), and computation of increment dataδj requires an updated materialization which involves data container Di. It is referred as type 3.
We propose a dynamic scheduling system based on a sliding windowmodel. Increment data in asliding windoware labeled and sorted by their priority in two phases. The purpose of the first phase is to obtain a sequence of increment data in a sorted priority, while the second phase intends to find two increments which can be computed in a concurrent processing.
The first phaseis performed in the following steps:
1) we get sequence of increment data from asliding window; 2) we consider data containers which have increment expres-sion in second form. All increment data from these data containers are scheduled at the first rows, and the most often increment data will be set with higher priorities; 3) if such increment data in step 2 does not exists, we select
increment at data container that appears most often among other data containers in the current sliding window;
4) the next increment data is determined by the current increment data chosen. Increment data which satisfies type 1 will be selected, followed by increment data in type 2, and the rest of increment data will have the least priority. Step 3 is repeated until all increment data in the current sliding window are scheduled.
The second phase is done at the execution time. An increment of acommon data container automatically triggers a concurrent processing. While for a non common data con-tainer, concurrent processing is obtained by finding a single nearest increment in type 2 from the sorted increment data. The condition for concurrent processing is defined in some reasons: (1) they share the same intermediate materialization to compute with; (2) they share the same intermediate mate-rialization to update; (3) the transformation process is simple. Therefore, concurrent processing allows us to compute two increments faster, and reduce materialization updates.
For example, let a sequence of increment δ11 ← δ12 ← δ21 ← δ31 ← δ41 ← δ51 arrive at the central site in an integration expression as in Figure 2 (b). Suppose, all increment data fit the size of asliding window. Priority labeling and sorting will perform in the following steps:
1) δ51is the first increment data to process as its increment expression is in the second form;
2) since there is no other increment data at D5 (no more increment satisfies Type 1), we choose the next increment data in Type 2. Since data container D5 andD4 forms an expression of materialization M3,δ41 is taken as the next increment to be scheduled;
3) the remaining increment data does not satisfy type 1 and 2. Therefore we consider increment from D1 because it appears most often among others. δ11is scheduled; 4) it is followed by δ12 because it occurs at the same data
container with the previous increment (type 1).
5) increment data δ21 follows δ12 because they form an expression for intermediate materialization M1 (type 2). 6) δ31 be the last increment data to be scheduled.
At the end of thefirst phase, we get a sequence of increment dataδ51←δ41←δ11←δ12←δ21←δ31 in the queue. The second phase of dynamic scheduling results to a modified schedule as: (δ51, δ41)←(δ11, δ21)←δ12←δ31.
Dynamic scheduling proposed in this paper minimizes materialization updates which are IO cost expensive by early termination of plan, orprocrastination of plan.Early termina-tion of plan eliminates unneeded computations when the rest steps in a plan have no impact for the rest of computation. As an example in Figure 2 (c), when an increment δ1 occurs at data container D1 and computation(δ1⊲⊳ D2)has no results, then the rest steps of the current plan will be terminated. In the case that data container D2 is empty, dynamic scheduling performs early termination without execution of(δ1⊲⊳ D2).
For example, online integration for a sequence of increment data described earlier is performed by dynamic scheduling system in the following steps:
1) δ51andδ41are computed in concurrent processing; com-putation results (δ41∼δ51) are sent to materialization list. D4 and D5 updates are unnecessary because they have been completed. Integration monitoring system detects that M2 is empty, then early terminationis performed; 2) δ11andδ21are computed in parallel; computation results
(δ11∪δ21) are sent to materialization list, data container D1andD2are updated, and process is terminated because D3 is empty.
3) δ12: computation results (δ11∪D21) are sent to materi-alization list, data container D1 is updated and process terminated becauseD3is empty. Because the next incre-ment is δ31,M1 andM3 are updated.
4) δ31: all prepared plan are executed except materialization update, as D4 andD5 are complete andM2 will never been used anymore.
5) Final result is ready to released as D4 andD5 are com-pleted, then the next increment at D1, D2, and D3 will not update final materialization (Me) and intermediate materializationM2.
In the example above we get two concurrent processing, two data container updates are ignored, three integration plans can be early terminated, two materialization updates are deferred, and a materialization update is terminated. We also notice that a final materialization (Me) is never updated because integration results are directly passed through the user.
At the ending stage of online data integration, we might consider on the permanent termination of all increment data. Permanent terminationis a process to cancel all running plan, and stop the current online integration process. It is employed to eliminate unnecessary execution if any new increment will cause no impact to the final result. For example, let D4 and D5 in Figure 2 (c) are completed and computation result of (D4 ∼ D5) returns nothing. Then, any increment at data container D1, D2, andD3 will always result nothing. In this case, the system allows termination of the rest step of current plan, cancel the remaining increment data.
After sending for processing, an increment data will be re-moved from the currentsliding window. Then,sliding window slides and collects a new increment data, and sorting process is repeated with new increment data in a newsliding window. In a significant delay between arrivals of increment data, dynamic scheduling performance might fall to the static scheduling if all steps in an integration plan are executed before a new increment arrives. In this paper we assume that delay between arrivals of increment data is relatively small.
V. CONCLUSIONS ANDFUTUREWORK
Concurrent processing of increments proposed in this paper optimizes the online integration of semi-structured data by removing unnecessary computation before and in the running phase. At preparation phase, the system prepares an increment expression and an integration plan for parallel computation of data containers. In running phase, increments arrived in an online integration system is assigned to a prepared integration plan which is a sequence of simple expression evaluation over
increment data and materialization. At the initial state, ending state, and consecutive increments, some steps in a prepared plan are unnecessary. The system is able to stop the plan when no increment results to pass to the next operation, and to update materialization if needed.
The system is able to process increments of data in parallel mode with less computation and materialization update, which yields lower CPU and IO costs to get a better performance.
VI. ACKNOWLEDGMENTS
This work is supported by Directorate General of Higher Education (Dikti), Indonesian Ministry of National Education.
REFERENCES
[1] L. Bouganim, F. Fabret, C. Mohan, and P. Valduriez, “Dynamic query scheduling in data integration systems,” in Data Engineering, 2000. Proceedings. 16th International Conference on, 2000, pp. 425–434. [2] Handoko and J. R. Getta, “An XML algebra for online processing of
XML documents,” in The 15th International Conference on Information Integration and Web-based Applications & Services, IIWAS ’13, Vienna - December 2-4, 2013.
[3] R. Salem, O. Boussa¨ıd, and J. Darmont, “Active XML-based Web data integration,” Information Systems Frontiers, vol. 15, no. 3, 2013, pp. 371–398. [Online]. Available: http://dx.doi.org/10.1007/s10796-012-9405-6
[4] X.-Q. Yan and Y. Liu, “XQuery optimization in heterogeneous data integration system,” in Management and Service Science, 2009. MASS ’09. International Conference on, Sept 2009, pp. 1–6.
[5] W. Viyanon, S. Madria, and S. Bhowmick, “XML data integration based on content and structure similarity using keys,” in On the Move to Meaningful Internet Systems: OTM 2008, ser. Lecture Notes in Computer Science. Springer Berlin Heidelberg, 2008, vol. 5331, pp. 484–493. [Online]. Available: http://dx.doi.org/10.1007/978-3-540-88871-0 35
[6] W. May, “Logic-based XML data integration: a semi-materializing approach,” Journal of Applied Logic, vol. 3, no. 2, 2005, pp. 271 – 307. [Online]. Available: http://www.sciencedirect.com/science/article/pii/S1570868304000618 [7] A. Poggi and S. Abiteboul, “XML data integration with identification,”
in Database Programming Languages, ser. Lecture Notes in Computer Science. Springer Berlin Heidelberg, 2005, vol. 3774, pp. 106–121. [Online]. Available: http://dx.doi.org/10.1007/11601524 7
[8] M. EL-Sayed, L. Wang, L. Ding, and E. A. Rundensteiner, “An algebraic approach for incremental maintenance of materialized XQuery views,” in Proceedings of the 4th International Workshop on Web Information and Data Management, ser. WIDM ’02. New York, NY, USA: ACM, 2002, pp. 88–91. [Online]. Available: http://doi.acm.org.ezproxy.uow.edu.au/10.1145/584931.584950 [9] L. Fegaras, “Incremental maintenance of materialized XML views,”
in Database and Expert Systems Applications, ser. Lecture Notes in Computer Science, A. Hameurlain, S. Liddle, K.-D. Schewe, and X. Zhou, Eds. Springer Berlin Heidelberg, 2011, vol. 6861, pp. 17–32. [Online]. Available: http://dx.doi.org/10.1007/978-3-642-23091-2 2 [10] A. Bonifati, M. Goodfellow, I. Manolescu, and D. Sileo, “Algebraic
incremental maintenance of XML views,” ACM Trans. Database Syst., vol. 38, no. 3, Sep 2013, pp. 14:1–14:45. [Online]. Available: http://doi.acm.org.ezproxy.uow.edu.au/10.1145/2508020.2508021 [11] J. Getta, “Query scrambling in distributed multidatabase systems,” in
Database and Expert Systems Applications, 2000. Proceedings. 11th International Workshop on, 2000, pp. 647–652.