BAB 2
TINJAUAN PUSTAKA & LANDASAN TEORI
2.1 Tinjauan Pustaka
Sudoku dalam bahasa inggris bermakna Number Place yang mengartikan aturan game Sudoku itu sendiri berkaitan dengan letak atau posisi angka yang ditulis.
Menurut Ankur Pal (2017) terdapat dua hal yang dipengaruhi oleh posisi angka, yaitu Single Step Complexity dan Single Step Dependency. Complexity bermakna tingkat kerumitan dari langkah tunggal dengan langkah lainnya dan Dependency bermakna tingkat kebebasan dari sebuah langkah dengan angka disekitarnya.
Semakin tinggi nilai tingkat kerumitan dan kebebasan dari sebuah langkah, maka semakin sulit pula Sudoku tersebut untuk diselesaikan.
Setiap permainan Sudoku bersifat unik, baik itu pada kondisi awal ataupun kondisi akhir nya. Namun permainan Sudoku bisa jadi terdapat kemiripan satu sama lain, yaitu pada nilai complexity dan dependency nya, sehingga beberapa Sudoku yang memiliki kemiripan dapat dikelompokkan menjadi kelompok yang sama, sebab Asroni (2015) mengatakan bahwa clustering adalah proses membagi data yang tidak berlabel menjadi beberapa kelompok data yang memiliki kemiripan. Proses pengelompokkan data terbagi menjadi dua cara, yaitu hierarchial clustering yang membentuk pohon berjenjang dan partitional clustering bersifat membagi data ke dalam kelompok yang tidak saling overlap sehingga setiap data berada tepat di satu kelompok.
Pengelompokkan data dengan metode k-means harus mempertimbangkan nilai k yang tepat. Salah satu cara atau metode yang digunakan untuk menentukan nilai k pada beberapa kelompok data adalah Metode Sillhoutte Coeficient. Nitya Sai (2017) menyatakan bahwa Metode Sillhoutte Coefficient merupakan suatu medote yang dapat memberikan informasi berupa kualitas hasil cluster dengan menghitung jarak rata-rata objek dengan semua objek pada K-Means Clustering dengan inisiasi nilai antara -1 sampai 1, sehingga hasil cluster yang lebih baik akan diperoleh dari data set tertentu. Oleh karena itu k-means menjadi metode clustering yang tepat untuk
mengelompokkan data permainan Sudoku berdasarkan dengan tingkat kesulitan permainan dengan nilai k pada K-Means Clustering.
2.2 Landasan Teori
2.2.1 Sudoku
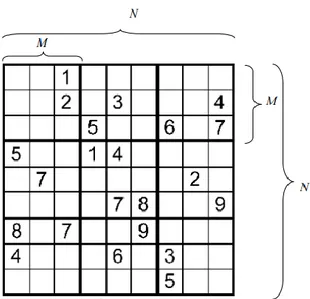
Sudoku adalah sebuah permainan teka-teki berdasarkan logika dengan kombinasi penempatan angka. Dalam permainan Sudoku, terdapat beberapa kotak yang sudah terisi angka dan pemain diminta untuk mengisi kotak kosong yang tersisa berukuran N*N dengan angka dari 1 hingga N itu sendiri. Aturan permainan pada tiap baris yang sejajar dan pada tiap kolom yang sejajar harus memiliki angka yang unik atau tidak boleh memiliki angka yang sama. N memiliki M x M kotak yang dimana nilai dari M adalah akar dari N. Persamaan tersebut dapat ditulis sebagai berikut
𝑀 = √𝑁
Pada kotak M x M juga memiliki aturan yang sama dengan kotak N x N.
Gambar 2.1 N X N sudoku dengan M sebagai jaring kecil dari akar N
Cara membangkitkan permainan Sudoku yaitu mengisikan angka-angka tetap pada kotak N x N dengan mengikut aturan angka harus unik sehingga dapat menghasilkan beberapa solusi. Jika pada proses pembangkitan permainan
Sudoku tidak mengikuti aturan awal, maka dapat dipastikan bahwa Sudoku tersebut tidak memiliki solusi sama sekali.
2.2.2 K-Means
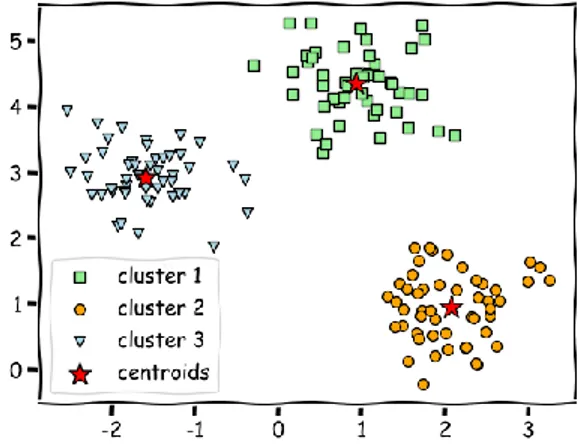
K-Means Clustering adalah suatu metode penganalisaan data atau metode Data Mining yang melakukan proses pemodelan tanpa supervise dan merupakan salah satu metode yang melakukan pengelompokan data dengan sistem partisi. Metode k-means clustering berusaha mengelompokkan data yang ada ke dalam beberapa kelompok dengan centroid sebagai titik pusat, dimana data dalam satu kelompok mempunyai karakteristik yang sama satu sama lainnya dan mempunyai karakteristik yang berbeda dengan data yang ada di dalam kelompok yang lain.
Gambar 2.2 Contoh data yang dikelompokkan berdasarkan K-Means
Dengan kata lain, metode k-means clustering bertujuan untuk meminimalisasikan objective function yang diset dalam proses clustering dengan cara meminimalkan variasi jarak antar data yang ada di dalam suatu cluster dan memaksimalkan variasi dengan data yang ada di cluster lainnya.
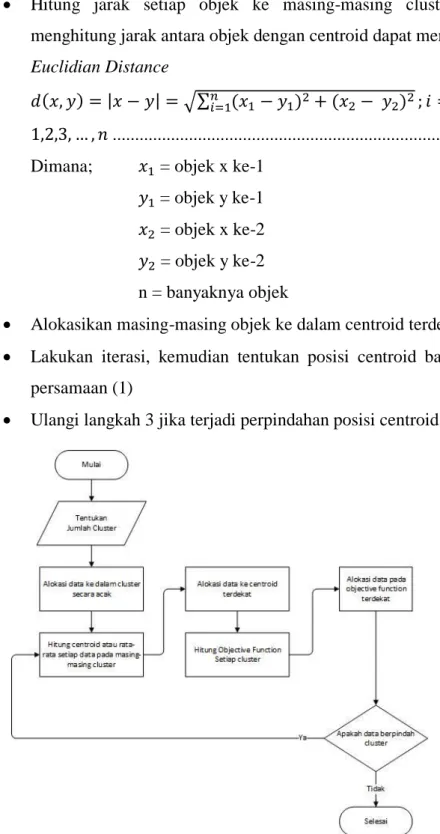
Clustering menggunakan metode k-means secara umum dapat dilakukan dengan algoritma dasar sebagai berikut
Tentukan k sebagai jumlah cluster yang akan dibentuk
Tentukan k centroid(titik pusat cluster) awal secara acak 𝑐 = ∑𝑛𝑖=1𝑥𝑖
𝑛 ; 𝑖 = 1,2,3, … , 𝑛 ... (1)
Dimana; c = centroid pada cluster xi = objek ke-i
n = banyaknya objek/jumlah objek yang menjadi anggota cluster
Hitung jarak setiap objek ke masing-masing cluster. Untuk menghitung jarak antara objek dengan centroid dapat menggunakan Euclidian Distance
𝑑(𝑥, 𝑦) = |𝑥 − 𝑦| = √∑𝑛𝑖=1(𝑥1− 𝑦1)2+ (𝑥2− 𝑦2)2; 𝑖 = 1,2,3, … , 𝑛 ... (2) Dimana; 𝑥1 = objek x ke-1
𝑦1 = objek y ke-1 𝑥2 = objek x ke-2 𝑦2 = objek y ke-2 n = banyaknya objek
Alokasikan masing-masing objek ke dalam centroid terdekat
Lakukan iterasi, kemudian tentukan posisi centroid baru dengan persamaan (1)
Ulangi langkah 3 jika terjadi perpindahan posisi centroid
Gambar 2.3 Flowchart k-means
2.2.3 Sillhoutte Coefficient
Metode silhouette coefficient merupakan gabungan dari dua metode yaitu metode cohesion yang berfungsi untuk mengukur seberapa dekat relasi antara objek dalam sebuah cluster, dan metode separation yang berfungsi untuk mengukur seberapa jauh sebuah cluster terpisah dengan cluster lain [8]. Tahapan perhitungan silhouette coefficient adalah sebagai berikut
Hitung rata-rata jarak objek dengan semua objek lain yang berada di dalam satu cluster dengan persamaan
𝑎𝑖 = 1
𝑚−1∑𝑚𝑟=1𝑑(𝑥𝑖, 𝑥𝑟) ... (3) Dimana; i = index data
ai = rata-rata jarak index ke-i terhadap semua data pada satu cluster
j = jumlah data dalam satu cluster
d(xi, xr) = jarak data ke-i dengan data ke-r pada satu cluster
Hitung rata-rata jarak objek dengan semua objek lain yang berada pada cluster lain, kemudian ambil nilai paling minimum dengan persamaan
𝑏𝑖𝑗 = 1
𝑚𝑛∑𝑚𝑛=1𝑛 𝑑(𝑥𝑖𝑗, 𝑥𝑛𝑟) ... (4) Dimana; 𝑏𝑖𝑗 = rata-rata jarak data ke-i terhadap semua data
yang tidak dalam satu cluster dengan data ke-i 𝑚𝑛 = jumlah data dalam cluster ke-n
𝑑(𝑥𝑖𝑗, 𝑥𝑟𝑛) = jarak data ke-i dengan data ke-j dalam satu cluster n
Hitung nilai silhouette coefficient dengan persamaan 𝑠𝑖 = 𝑏𝑖−𝑎𝑖
max (𝑎𝑖,𝑏𝑖) ... (5) Dimana; 𝑠𝑖 = Silhouette Index data ke-I dalam satu cluster Nilai hasil silhouette coefficient terletak pada kisaran nilai -1 hingga 1.
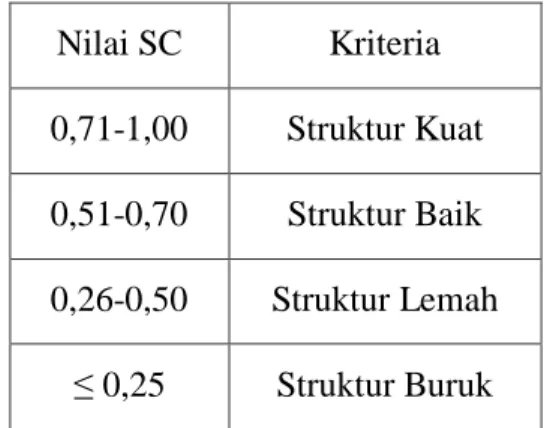
Kriteria penilaian hasil clustering berdasarkan nilai dari silhouette
coefficient menurut Kauffman dan Roesseeuw pada penelitian Dewi dan Pramita dilampirkan pada tabel dibawah ini
Tabel 2.1 Kriteria Pengukuran Silhouette Coefficient
Nilai SC Kriteria 0,71-1,00 Struktur Kuat 0,51-0,70 Struktur Baik 0,26-0,50 Struktur Lemah
≤ 0,25 Struktur Buruk
2.2.4 Algoritma Backtracking
Algoritma Backtracking merupakan algoritma yang berbasiskan pada algoritma DFS(Depth First Search) untuk mencari solusi persoalan lebih mangkus. Jika dilihat lebih teliti, algoritma Backtracking ini sebenarnya merupakan modifikasi algoritma Bruteforce. Modifikasi ini menyebabkan algoritma Backtracking dapat secara sistematis mencari solusi persoalan tanpa harus memeriksa seluruh kemungkian solusi yang ada. Hanya pencarian yang mengarah ke solusi saja yang dipertimbangkan oleh algoritma ini, sedangkan pencarian yang tidak mengarah ke sebuah solusi tidak dilanjutkan. Hal ini menyebabkan waktu komputasi algoritma Backtracking jauh lebih baik. Algoritma Backtracking membentuk sebuah pohon ruang status selama prosesnya. Struktur pohon inilah, yang juga merupakan sebuah graf tak berarah,yang ditraversal. Simpul-simpul pada pohon ruang status yang tidak mengarah ke solusi maka akan dimatikan, sedangkan simpul-simpul pohon ruang status yang masih mengarah ke solusi akan terus berkembang. Pematian simpul pohon ruang status yang tidak mengarah kepada solusi ini disebut dengan istilah prunning.
Algoritma backtracking dapat digunakan untuk mencari solusi atau menentukan masalah. Dalam kasus permainan Sudoku, algoritma
backtracking lebih banyak digunakan untuk pencarian solusi. Berikut adalah gambaran atau langkah-langkah pencarian solusi dengan algoritma backtracking
Solusi dicari dengan membentuk lintasan dari akar ke daun.
Simpul yang sudah dilahirkan dinamakan simpul hidup dan simpul hidup yang diperluas dinamakan simpul-E (Expand node)
Jika lintasan yang diperoleh dari perluasan simpul-E tidak mengarah ke solusi, maka simpul itu akan menjadi simpul mati dimana simpul itu tidak akan diperluas lagi
Jika posisi terakhir berada di simpul mati, maka pencarian dilakukan dengan membangkitkan child node yang lain dan jika tidak ada child node maka dilakukan backtracking ke parent node
Pencarian dihentikan jika telah ditemukan solusi atau tidak ada simpul hidup yang diperlukan
Gambar 2.4 Contoh Algoritma Backtracking