Seleksi Aturan Menggunakan Rough Set Theory
Untuk Diagnosis Gangguan Transformator Daya
Berbasis Dissolved Gas Analysis (DGA)
Hendra Marcos1, Noor Akhmad Setiawan2, Suharyanto3
Email: [email protected], [email protected], [email protected] Jurusan Teknik Elektro dan Teknik Informasi, Universitas Gadjah Mada
Abstrak - Tujuan dari penelitian ini adalah
mengembangkan metode seleksi aturan (rule) dari sejumlah
rule yang dihasilkan dari metode induksi rule menggunakan Rough Set Theory (RST). Aturan yang terseleksi digunakan
untuk diagnosis gangguan transformator daya dari dataset berbasis Dissolved Gas Analysis (DGA). Seleksi aturan berdasarkan batasan nilai accuracy dan coverage tertentu dilakukan pada tahap awal. Aturan yang terseleksi kemudian diekstrak menggunakan RST dengan konsep reduksi atribut, dimana aturan terseleksi disusun membentuk decision table baru. Dari percobaan yang telah dilakukan terhadap aturan (rule) yang terseleksi, metode yang diusulkan dapat memilih sejumlah kecil aturan yang berkualitas tinggi terhadap hasil klasifikasi dibandingkan dengan metode seleksi aturan sebelumnya.
Kata Kunci : Rough Set Theory, DGA, seleksi aturan
I. PENDAHULUAN
Transformator merupakan salah satu peralatan paling penting dari sistem tenaga listrik, yang berfungsi untuk mengkonversikan daya [1]. Namun transformator seringkali menjadi peralatan listrik yang kurang diperhatikan dan tidak diberikan perawatan yang memadai. Padahal perbaikan transformator yang rusak tidaklah mudah dan tidak dapat dikerjakan dalam waktu yang singkat. Transformator yang tidak bekerja sebagaimana mestinya akan menimbulkan dampak terganggunya suplai listrik ke konsumen.
Dissolved Gas Analysis (DGA) atau analisis gas terlarut
adalah salah satu cara yang paling mudah dan efektif untuk mendiagnosis gangguan permulaan pada transformator daya [2][3]. Dengan ditemukannya gangguan yang lebih awal pada transformator akan memudahkan pemeliharaan rutin, dan dapat memperpanjang usia transformator. Salah satu uji yang dilakukan untuk pengujian kandungan gas terlarut pada material minyak isolasi adalah dengan uji kromatografi. Dengan adanya uji kromatografi ini akan diperoleh kandungan gas yang terlarut dalam minyak transformator. Gas yang dapat diperoleh dari uji DGA adalah Oksigen (O2),
karbondioksida (CO2), karbonmonoksida (CO), hidrogen
(H2), etana (C2H6), metana (CH4), etilen (C2H4), dan asetilen
(C2H2). Gas yang dihasilkan diukur dalam satuan ppm (part per milion) [4]. Konsentrasi dari beberapa jenis gas yang
dihasilkan tergantung pada jenis gangguan yang terjadi. Tetapi dapat dikatakan pula bahwa setiap jenis gangguan akan menghasilkan gas, yang dikenal dengan key gases [5]. Untuk itu dibuat perbandingan 15 gas yang mewakili semua kemungkinan gas yang muncul berdasarkan pada penelitian sebelumnya.
Akan tetapi diagnosis gangguan transformator
berdasarkan DGA yang memetakan antara variabel kandungan gas dengan jenis kesalahan tidaklah linier dan sulit dimodelkan secara matematis. RST diperlukan dalam
proses ini untuk menangani masalah uncertainty,
imprecision, dan vagueness sehingga ditemukan pola
hubungan antara gas yang dikandung dengan jenis gangguan. Pola tersebut merupakan informasi yang diharapkan dapat digunakan untuk menggantikan pakar yang mahal dalam memetakan data kandungan gas terlarut lainnya di masa mendatang [6].
Beberapa penelitian sebelumnya telah menggunakan teknik machine learning untuk memudahkan diagnosis. Metode rough set menunjukkan hasil klasifikasi yang lebih bagus dari teknik lainnya [6][7]. Kemudian beberapa penelitian dengan menggabungkan metode juga telah dilakukan, diantaranya menggunakan RST dan fuzzy logic [8], RST dan ANN [9]. Dari penelitian tersebut masih terdapat kekurangan diantaranya masih sulitnya didapatkan pengetahuan yang intrinsik dan masih rendahnya nilai akurasi klasifikasi. Dengan metode DGA dan RST yang sudah dilakukan [6], didapatkan jumlah rule dari atribut perbandingan gas hasil reduksi yang masih berjumlah besar, kemudian dengan metode rule filtering menggunakan RST [11]. Dengan batasan support dan coverage didapatkan rule yang lebih sedikit. Pengujian terhadap data uji menunjukkan hasil akurasi yang masih rendah yaitu 81,5% [6].
Pada paper ini diusulkan metode klasifikasi menggunakan DGA dan rough set theory. Dengan konsep dataset gangguan dibuat binary classification. Metode seleksi rule (aturan) pada tahap awal diusulkan pada penelitian ini. Dengan batasan nilai support dan coverage terhadap sejumlah aturan yang masih berjumlah besar, didapatkan aturan yang lebih sedikit. Teknik RST kemudian digunakan untuk mereduksi sejumlah aturan agar didapatkan aturan yang lebih sedikit, sehingga hasil akurasi klasifikasi meningkat dari penelitian sebelumnya.
II. METODOLOGI A. DATASET GANGGUAN TRANSFORMATOR
Dataset Gangguan transformator daya diambil dari New IEC Publication 60 599 dan IEC TC 10 Databases [2]
yang mengadopsi data transformator dengan data Normal. Dengan total data 165 obyek, data ini digunakan untuk data latih dan data uji. Perbandingan data gas yang terlarut
kemudian dibuat menjadi 15 perbandingan gas yang mewakili dari seluruh kemungkinan rasio gas yang dapat diklasifikasikan menjadi 6 jenis gangguan.
B. Rough Set Theory (RST)
Rough set theory (RST) dikembangkan oleh Zdzislaw
Pawlak pada tahun 1980-an [12], RST ini sangat berguna untuk menemukan hubungan dalam data yang disebut pengetahuan. Hasil penemuan pengetahuan berupa rule (aturan) yang mudah dimengerti dan bermakna, yang dihasilkan dari ekstraksi pola data. Metode RST muncul sebagai salah satu metode matematika untuk mengelola ketidakpastian, ambiguitas dan ketidakjelasan dari hubungan data yang tidak lengkap dan sulit dimodelkan secara matematis.
Untuk S=(U,A) dan B ⊆ A, dimana a ∈ B, dengan :
INDs (B) = {(x, x') ∈ U x U | ∀a ∈ B, a(x) = a(x')} dapat
dikatakan bahwa a dapat diabaikan dalam B, dan :
INDs (B) = INDs (B – {a} jika sangat diperlukan a dapat
diabaikan.
Himpunan B dikatakan independen jika semua atributnya diperlukan. Setiap subset B' dari B disebut reduct dari B jika
B' adalah independen dan INDs (B’) = INDs (B).
Reduct dapat didefinisikan sebagai subset minimal dari
beberapa atribut yang memiliki hasil klasifikasi yang sama. Dengan kata lain, atribut yang bukan unsur reduct merupakan redundant dari klasifikasi. Reducts relatif didasarkan pada elemen obyek-obyek tertentu.
C. Rule Extraction dan Rule Selection
Ekstraksi rule (aturan) didasarkan pada nilai coverage dan
support dari masing-masing rule. Hal ini telah dilakukan
pada penelitian sebelumnya [11]. Misalnya untuk,
DS = (U, C ∪D)
Yang merupakan decision table dari ∀ x ∈ U, maka
c1(x),...,ck(x), d(x) dapat didefinisikan, dimana {c1,...,ck} = C
dan {d} = D. Decision rule didapatkan dari,
c1(x),...,c2(x) → d(x).
C merupakan reduct dari atribut kondisi yang merupakan perbandingan gas yang direduksi dari decision table.
Seleksi rule RST dilakukan karena rule yang ada terlalu banyak dan panjang. Untuk menyerderhanakan jumlah rule dapat dilakukan melalui metode RST. Jika R = {Rule1, Rule2,..., Rulej} merupakan subset rule yang didapatkan dari
Rough Set sebagai decision table yang baru, dimana rule
berlaku sebagai subset atribut. Nilai 1 dari atribut Rulea jika
obyek xb pada decision (d) mempunyai nilai yang sama
dengan decision table, dan bernilai 0 jika tidak bernilai sama. Nilai pada kolom (atribut) j+1 sama dengan nilai decision, dengan a = 1,...,j dan b = 1,...,i. Tabel keputusan baru dapat direduksi menggunakan konsep rough set. Reduct yang didapat dari hasil reduksi atribut merupakan rule yang memiliki nilai accuracy dan coverage besar. Untuk selanjutnya sejumlah rule hasil reduksi RST dapat diuji coba nilai accuracy dan coverage-nya menggunakan data uji kembali. Untuk lebih jelas decision table dari seleksi rule yang akan dilakukan menggunakan RST, dapat dilihat pada Tabel I.
TABELI
DECISION TABLE RULE SEBAGAI ATRIBUT
x∈U Rule1 Rule2 ... Rulej-1 Rulej D
x1 x2 . . . xi-1 xi 0 0 . . . 0 0 1 0 . . . 1 1 ... ... . . . ... ... 1 0 . . . 0 1 1 0 . . . 1 1 PD non-PD . . . PD PD D. Langkah-langkah Penelitian
Langkah-langkah pada penelitian ini dapat dilihat pada Gambar 1 dibawah ini.
GAMBAR 1.LANGKAH-LANGKAH PENELITIAN
Pertama dataset gangguan transformator daya sebagai
decision table dibuat menjadi binary, dimana untuk 6 jenis
klasifikasi menjadi 6 dataset. Data dinormalisasi dengan sebaran 0-10. Kemudian didiskretisasi dengan algoritme
boolean reasoning yang kemudian data terdiskretisasi
tersebut direduksi atributnya memakai exhaustive
calculation dengan piihan object related reduct yang
sekaligus menghasilkan rule. Untuk proses selanjutnya dilakukan ekstraksi dan seleksi rule menggunakan teknik RST.
III. HASIL DAN ANALISIS A. Data Preprocessing
Pada proses awal data set dibuat menjadi dua kelas yaitu kelas positif dan kelas negatif, untuk kelas positif merupakan jenis gangguan/normal dan kelas negatif adalah yang bukan terkena gangguan. Dapat dilihat pada Tabel II dengan perincian jumlah obyek masing-masing jenis gangguan.
TABELII DATA SET BINARY KELAS
Label Kelas Positif Jumlah Data Kelas Positif Label Kelas Negatif Jumlah Data Kelas Negatif PD 9 non-PD 156 D1 26 non-D1 139 D2 48 non-D2 117 T1&T2 15 non-T1&T2 150 T3 18 non-T3 147 Normal 49 Gangguan 116
Untuk atribut adalah 15 perbandingan gas yang mewakili kemungkinan dari perbandingan gas yang terlarut pada isolasi minyak transformator.
TABELIII
KODE PERBANDINGAN GAS TERLARUT
C1 C2H2/C2H4 C2 CH4/H2 C3 C2H4/C2H6 C4 C2H6/CH4 C5 CH4/C2H4 C6 C2H2/CH4 C7 C2H2/C2H6 C8 C2H6/H2 C9 C2H4/H2 C10 C2H2/H2 C11 CH4/Total Hydrocarbon C12 C2H4/Total Hydrocarbon C13 C2H6/Total Hydrocarbon C14 C2H2/Total Hydrocarbon C15 H2/Total Hydrocarbon +H2)
Dengan skala yang besar dari hasil 15 perbandingan gas, data dinormalisasi menggunakan persamaan (1), untuk kemudian dilakukan discretization menggunakan boolean
reasoning algorithm [13].
X 10 (1)
Dimana :
xmax dan xmin masing-masing adalah nilai maksimal dan
minimal dari data set untuk tiap-tiap atribut pada decision
table. Dan , masing-masing adalah nilai normalisasi dari
data yang dicari dari nilai x, dimana i bernilai 1 sampai 165. Sesuai dengan jumlah data set gangguan PD berjumlah 9 obyek dan non-PD berjumlah 156 obyek. Pada Tabel IV diperlihatkan data set hasil normalisasi dengan nilai yang mempunyai skala 0-10.
TABELIV
DECISION TABLE DATA HASIL NORMALISASI
No C1 C2 C3 . . . C13 C14 C15 Diag 1 0 0,0015 0 . . . 0,8726 0 9,4710 PD 2 0,5395 0,0010 0,0009 . . . 1,7627 0,0428 9,6915 PD 3 0 0,0023 0 . . . 0 0 9,1929 PD . . . . . 163 0,0135 0,0161 0,0077 . . . 6,3408 0,0369 3,4713 non-PD 164 0,2698 0,0302 0,0040 . . . 5,8171 0,3517 2,5199 non-PD 165 0,2698 0,0021 0,0040 . . . 5,8171 0,3517 8,4811 non-PD
Tabel V contoh hasil diskretisasi untuk kasus gangguan PD dan selain itu dibuat non-PD.
TABELV
HASIL DISKRETISASI DATA SET PD DAN NON-PD
Atribut Nilai Diskret
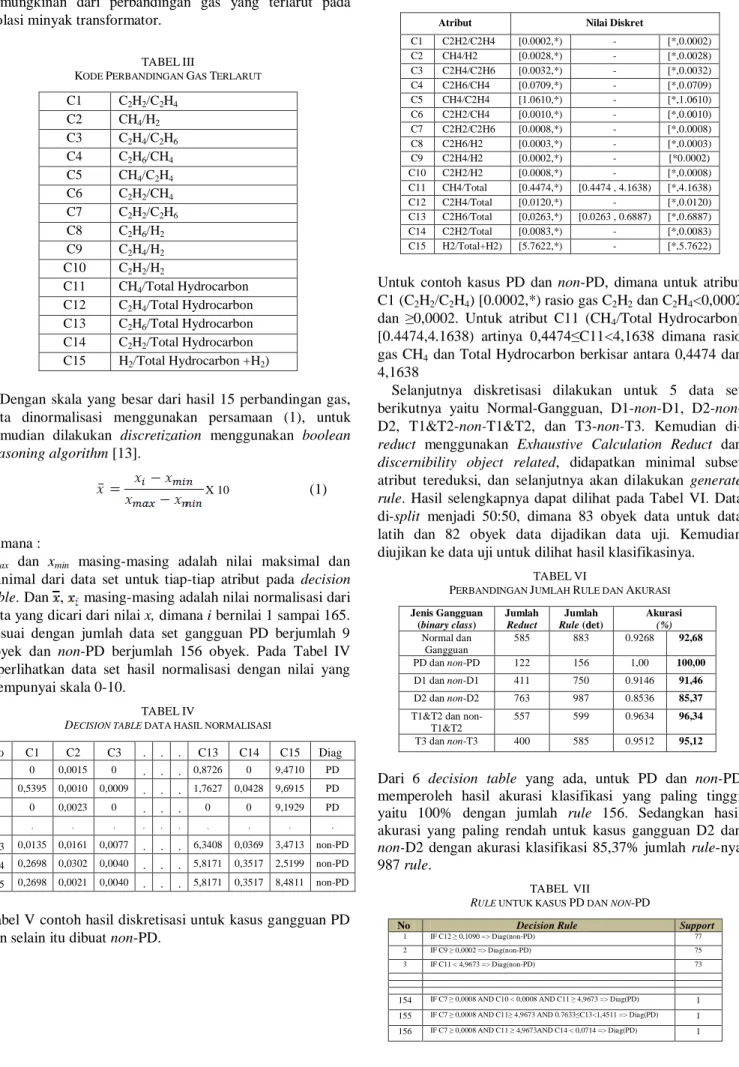
C1 C2H2/C2H4 [0.0002,*) - [*,0.0002) C2 CH4/H2 [0.0028,*) - [*,0.0028) C3 C2H4/C2H6 [0.0032,*) - [*,0.0032) C4 C2H6/CH4 [0.0709,*) - [*,0.0709) C5 CH4/C2H4 [1.0610,*) - [*,1.0610) C6 C2H2/CH4 [0.0010,*) - [*,0.0010) C7 C2H2/C2H6 [0.0008,*) - [*,0.0008) C8 C2H6/H2 [0.0003,*) - [*,0.0003) C9 C2H4/H2 [0.0002,*) - [*0.0002) C10 C2H2/H2 [0.0008,*) - [*,0.0008) C11 CH4/Total [0.4474,*) [0.4474 , 4.1638) [*,4.1638) C12 C2H4/Total [0.0120,*) - [*,0.0120) C13 C2H6/Total [0,0263,*) [0.0263 , 0.6887) [*,0.6887) C14 C2H2/Total [0.0083,*) - [*,0.0083) C15 H2/Total+H2) [5.7622,*) - [*,5.7622)
Untuk contoh kasus PD dan non-PD, dimana untuk atribut C1 (C2H2/C2H4) [0.0002,*) rasio gas C2H2 dan C2H4<0,0002
dan ≥0,0002. Untuk atribut C11 (CH4/Total Hydrocarbon)
[0.4474,4.1638) artinya 0,4474≤C11<4,1638 dimana rasio gas CH4 dan Total Hydrocarbon berkisar antara 0,4474 dan
4,1638
Selanjutnya diskretisasi dilakukan untuk 5 data set berikutnya yaitu Normal-Gangguan, D1-non-D1, D2-non-D2, T1&T2-non-T1&T2, dan T3-non-T3. Kemudian
di-reduct menggunakan Exhaustive Calculation Reduct dan discernibility object related, didapatkan minimal subset
atribut tereduksi, dan selanjutnya akan dilakukan generate
rule. Hasil selengkapnya dapat dilihat pada Tabel VI. Data
di-split menjadi 50:50, dimana 83 obyek data untuk data latih dan 82 obyek data dijadikan data uji. Kemudian diujikan ke data uji untuk dilihat hasil klasifikasinya.
TABELVI
PERBANDINGAN JUMLAH RULE DAN AKURASI
Jenis Gangguan (binary class) Jumlah Reduct Jumlah Rule (det) Akurasi (%) Normal dan Gangguan 585 883 0.9268 92,68 PD dan non-PD 122 156 1,00 100,00 D1 dan non-D1 411 750 0.9146 91,46 D2 dan non-D2 763 987 0.8536 85,37
T1&T2 dan non-T1&T2
557 599 0.9634 96,34
T3 dan non-T3 400 585 0.9512 95,12
Dari 6 decision table yang ada, untuk PD dan non-PD memperoleh hasil akurasi klasifikasi yang paling tinggi yaitu 100% dengan jumlah rule 156. Sedangkan hasil akurasi yang paling rendah untuk kasus gangguan D2 dan
non-D2 dengan akurasi klasifikasi 85,37% jumlah rule-nya
987 rule.
TABEL VII
RULE UNTUK KASUS PD DAN NON-PD
No Decision Rule Support
1 IF C12 ≥ 0,1090 => Diag(non-PD) 77 2 IF C9 ≥ 0,0002 => Diag(non-PD) 75 3 IF C11 < 4,9673 => Diag(non-PD) 73 . . . . . .
154 IF C7 ≥ 0,0008 AND C10 < 0,0008 AND C11 ≥ 4,9673 => Diag(PD) 1 155 IF C7 ≥ 0,0008 AND C11≥ 4,9673 AND 0.7633≤C13<1,4511 => Diag(PD) 1 156 IF C7 ≥ 0,0008 AND C11 ≥ 4,9673AND C14 < 0,0714 => Diag(PD) 1
B. Rule Extraction dan Rule Selection
Pada proses ini rule yang didapatkan kemudian diekstraksi menggunakan basic filtering, dimana parameter yang digunakan adalah berdasar nilai coverage dan support. Tabel VII dan VIII memperlihatkan rule hasil seleksi untuk satu kasus yaitu PD dan
non-PD. Selanjutnya akan dilakukan untuk 5 gangguan lainnya.
TABEL VIII
RULE TEREKSTRAKSI UNTUK KASUS PD DAN NON-PD
No Decision Rule Support
1 IF C12 ≥ 0,1090 => Diag(non-PD) 77 2 IF C9 ≥ 0,0002 => Diag(non-PD) 75 3 IF C11< 4,9673 => Diag(non-PD) 73 4 IF C10 ≥ 0,0008 => Diag(non-PD) 73 . . . . . . 14 IF C8 < 0,0003 AND C12 < 0,1090 => Diag(PD) 5 15 IF C12< 0,1090 AND C14< 0,0714 => Diag(PD) 5 16 IF C3 < 0,0033 AND C14 < 0,0714 => Diag(PD) 5
Tabel VII dan VIII memperlihatkan contoh untuk kasus gangguan PD dan non-PD dari 156 rule yang didapatkan dari RST dengan seleksi rule menggunakan pengurangan rule dengan nilai coverage dan support akhirnya didapatkan 16 rule terseleksi dengan nilai akurasi klasifikasi tetap 100%. Untuk selanjutnya dapat dilihat pada Tabel IX perbandingan dari jumlah rule dan nilai akurasinya dari sebelum dan sesudah seleksi rule.
TABELIX
PERBANDINGAN JUMLAH RULE DAN AKURASI
SEBELUM DAN SESUDAH SELEKSI
Jenis Gangguan (binary class) Jumlah Rule (det) Accuracy (%)
Rule Selection Method (Basic Filter process)
Jumlah Rule
Selection Accuracy
(%)
Normal dan 1. Coverage ≤ 0,2
Gangguan 883 92,68 2. Length ≥ 4 82 90,24 PD dan 1. Coverage ≤ 0,8 non-PD 156 100,00 2. Length ≤ 3 16 100,00 3. Coverage ≤ 0,935897 D1 dan 1. Coverage ≤ 0,3 non-D1 750 91,46 2. Length ≤ 4 45 95,12 3. Support ≤ 5 D2 dan 1. Coverage ≤ 0,30398 non-D2 987 85,37 2. Length ≤ 4 22 93,90
T1&T2 dan 1. Coverage ≤ 0,125
non-T1&T2 599 96,34 2. Length ≥ 5 74 96,34
3. Support ≤ 3
T3 dan 1. Support ≤ 9
non-T3 585 95,12 2. Length ≥ 6 47 95,12
3. Coverage ≤ 0,183099
Dengan teknik seleksi rule, kemudian dibuat decision table dari
rule yang sudah terekstraksi. Rule yang ada disusun menjadi
atribut dari tabel keputusan baru, dan 83 obyek dari data latih sebagai instance. Hasil seleksi rule dengan metode RST mendapatkan jumlah rule yang lebih sedikit, dapat dilihat pada Tabel X.
TABELX
RULE YANG SUDAH TERSELEKSI
Jenis Rule RuleNo.
Normal
IF C4 < 0.3333 AND C5 ≥ 0.0026 THEN Gangguan Rule 1
IF C4 < 0.3333 AND C10 ≥ 0.1030 AND C13 < 2.0841 THEN Gangguan Rule 5 IF 0.0001 ≤ C2 < 0.0142 AND C4 < 0.3333 THEN Gangguan Rule 10 IF C1 ≥ 0.4364 AND 0.0001 ≤ C2 < 0.0142 THEN Gangguan Rule 15 IF C1 < 0.4364 AND C3 ≥ 0.0633 AND C13 < 2.0841 THEN Gangguan Rule 30 IF C4 ≥ 0.3333 AND 1.8302 ≤ C11 < 4.5805 AND C12 ≥ 1.3678 THEN Normal Rule 41 IF C1 < 0.4364 AND C11 < 1.8302 AND C13 ≥ 2.0841 THEN Normal Rule 60 IF C5 < 0.0026 AND C10 0.0048 ≤ C10 < 0.1030 THEN Normal Rule 73
PD IF C6 < 0.0010 AND C9 < 0.0002 THEN PD Rule 6
D1
IF C1 < 0.8535 AND C15 < 4.1268 THEN non-D1 Rule 1
IF C4 ≥ 0.0595 AND C12 ≥ 2.2249 THEN non-D1 Rule 2
IF C7 < 0.0188 AND C14 < 3.5764 THEN non-D1 Rule 8
IF 0.0239 ≤ C10 < 0.2972 AND C12 ≥ 2.2249 THEN non-D1
Rule 37
D2
IF C7 < 0.0533)) AND C13 ≥ 0.4712 THEN non-D2 Rule 2
IF C5 < 0.0085 AND C6 < 0.1583 THEN non-D2 Rule 5
IF C12 < 2.2966 THEN non-D2 Rule 14
IF C6 ≥ 0.1583 AND C8 < 0.0005)) AND C12 ≥ 2.2966 THEN D2 Rule 18 D2 IF C7 ≥ 0.0533 AND C8 < 0.0005)) AND C9 ≥ 0.0013 AND C12 ≥ 2.2966 THEN D2 Rule 19 IF C5 ≥ 0.0085 AND C8 < 0.0005)) AND C10 < 0.3498))
AND C12 ≥ 2.2966 THEN D2 Rule 50 T1&T2
IF C5 < 0.0206 AND C11 < 3.6823 THEN non-T1&T2 Rule 2
IF C5 < 0.0206)) AND C10 ≥ 0.0526 THEN non-T1&T2 Rule 3
IF C3 ≥ 0.0760 AND C6 ≥ 0.0007 AND C9 ≥ 0.0003 THEN non-T1&T2 Rule 22 IF C2 < 0.0297 AND C3 < 0.0760 AND C5 < 0.0206 THEN non-T1&T2 Rule 42
IF C2 < 0.0297 AND C12 < 1.5578 THEN non-T1&T2 Rule 56
T3
IF C9 < 0.0042 AND C12 < 5.0052 THEN non-T3 Rule 1
IF C4 ≥ 0.1897 AND C12 < 5.0052 THEN non-T3 Rule 23
IF C2 < 0.0211 AND C11 < 2.0124 THEN non-T3 Rule 24
IF C1 < 0.0321 AND C9 < 0.0042 THEN non-T3 Rule 38
Selanjutnya dilakukan pengujian rule terseleksi kepada 82 obyek data ujiting, dengan hasil ditunjukkan pada Tabel XI.
TABELXI
AKURASI HASIL KLASIFIKASI RULE TERSELEKSI
No Jenis Gangguan
(binary class) Akurasi
1 Normal dan Gangguan 100%
2 PD dan non-PD 98,78%
3 D1 dan non-D1 92,68%
4 D2 dan non-D2 100%
5 T1&T2 dan non-T1&T2 100%
6 T3 dan non-T3 96,34%
Rata-rata 98%
Tabel XII menunjukkan hasil perbandingan akurasi antara beberapa metode konvensional, kecerdasan buatan dan metode yang diusulkan.
TABELXII
PERBANDINGAN AKURASI HASIL KLASIFIKASI
No Metode Akurasi 1 Segitiga Duval 48% 2 Rasio Roger 41% 3 IEC 58% 4 MLP 75% 5 RST 81,5% 6 Metode Usulan 98%
Metode konvensional menunjukkan hasil akurasi yang masih rendah yaitu dibawah 70%, metode kecerdasan buatan seperti MLP 75%, metode RST pada paper sebelumnya memberikan akurasi 81,5%.
IV. KESIMPULAN
Dari seleksi aturan (rule) menggunakan metode RST didapatkan jumlah aturan yang lebih sedikit dan mudah dipahami. Hasil akurasi yang bagus dari masing-masing
decision table ditunjukkan pada klasifikasi menggunakan
DGA dengan akurasi 98%, diharapkan dapat digunakan untuk memudahkan proses klasifikasi selanjutnya. Untuk selanjutnya rule berkualitas tinggi akan digunakan untuk memudahkan pengambilan keputusan dalam mendiagnosis gangguan transformator daya dengan membuat fuzzy
inference-nya.
REFERENSI
[1] W.H.Tang, Q.H.Wu,”Condition Monitoring and Assessment of Power Transformers Using Computational Intelligence” The University of Liverpool, Springer, 2011
[2] M. Duval, M. “Interpretation of Gas-In-Oil Analysis Using New IEC Publication 60599 and IEC TC 10 Databases”. Electrical Insulation Magazine, IEEE, Vol 17:2, pp. 31-41, 2001
[3] M. Duval, “Dissolved gas analysis: It can save your transformer,” IEEE Electrical Insulation Magazine, vol. 5, no. 6, pp. 22-27, 1989 [4] Dr. DiGiorgio,” Dissolved Gas Analysis Of Mineral Oil Insulating
Fluids”, Northern Technology & Ujiting, 2001
[5] R. R. Rogers, “IEEE and IEC codes to interpret incipient faults in transformers, using gas in oil analysis,” IEEE Trans. on Electrical Insulation, vol. 13, no. 5, pp. 349-354, 1978
[6] N.A.Setiawan,Sarjiya,Z.Ardhiaga,” Power Transformer Incipient Faults Diagnosis Using Dissolved Gas Analysis and Rough Set, IEEE International Conference, 2012
[7] Y.C. Huang, H.C. Sun, K.Y. Huang and Y.S. Liao, “Fault Diagnosis of Power Transformers Using Rough Set Theory”. Proceeiding of Fourth International Conference on Innovative Computing, Information, and Control, pp.1422-1426, 2009.
[8] X.Zheng“Intelligent Fault Diagnosis of Power Transformer based on Fuzzy logic and Rough Set Theory”. Proceeding, of the 7th, 2008 [9] X. Yu and H. Zang, “Transformer Fault Diagnosis Based on Rough
Sets Theory and Artificial Neural Networks”. International Conference on Condition Monitoring and Diagnosis. pp 1342 - 1345, 2008
[10] M.Zhou, T.Wang,”Fault Diagnosis of Power Transformer Based on Assosiation Rules Gained by Rough Set”, IEEE 2010
[11] N.A.Setiawan,P.A.Venkathachalam,and Ahmad Fadzil M.H,”Rule Selection for Coronary Artery Disease Diagnosis Based on Rough Set, International Journal of Recent Trends Engineering, 2009
[12] Z. Pawlak, "Rough Sets," International Journal of Computer and Information Sciences, vol. 11, pp. 341-355, 1982
[13] T. Agotnes, "Filtering large propositional rule sets while retaining classifier performance," in Department of Computer and Information Science: Norwegian Universtiy of Science and Technology, 1999, pp. 143