commit to user
PEMANFAATAN METODE K-MEANS
CLUSTERING
DALAM
PENENTUAN PENERIMA BEASISWA
SKRIPSI
Diajukan untuk memenuhi sebagian persyaratan mendapatkan gelar Strata Satu
Jurusan Informatika
Disusun Oleh:
NOOR FITRIANA HASTUTI
NIM. M0508059
JURUSAN INFORMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SEBELAS MARET
SURAKARTA
commit to user
PEMANFAATAN METODE K-MEANS
CLUSTERING
DALAM
PENENTUAN PENERIMA BEASISWA
SKRIPSI
Diajukan untuk memenuhi sebagian persyaratan mendapatkan gelar Strata Satu
Jurusan Informatika
Disusun Oleh:
NOOR FITRIANA HASTUTI
NIM. M0508059
JURUSAN INFORMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SEBELAS MARET
SURAKARTA
commit to user
SKRIPSI
PEMANFAATAN METODE K-MEANS
CLUSTERING
DALAM
PENENTUAN PENERIMA BEASISWA
Disusun Oleh:
Noor Fitriana Hastuti
NIM. M0508059
Skripsi ini telah disetujui untuk dipertahankan di hadapan Dewan Penguji
pada tanggal: 22 Januari 2013
commit to user
SKRIPSI
PEMANFAATAN METODE K-MEANS CLUSTERING
DALAM PENENTUAN PENERIMA BEASISWA
Disusun Oleh:
NOOR FITRIANA HASTUTI
NIM. M0508059
telah dipertahankan di hadapan Dewan Penguji
pada tanggal: 28 Januari 2013
Susunan Dewan Penguji
commit to user
MOTTO.
commit to user
PERSEMBAHANDipersembahkan untuk:
Ayah dan Ibu tercinta yang tanpa henti
memberikan doa, nasehat, dukungan, dan
commit to user
PEMANFAATAN METODE K-MEANS CLUSTERING DALAM
PENENTUAN PENERIMA BEASISWA
NOOR FITRIANA HASTUTI
Jurusan Informatika. Fakultas MIPA. Universitas Sebelas Maret.
ABSTRAK
Pengelompokkan data mahasiswa berdasarkan kriteria Indeks Prestasi Kumulatif (IPK), penghasilan total orang tua, dan jumlah tanggungan keluarga dapat membantu dalam proses penerimaan beasiswa. Metode yang bisa digunakan untuk pengelompokkan data mahasiswa ini adalah K-Means Clustering. Metode K-Means Clustering berusaha mengelompokkan data yang ada ke dalam beberapa kelompok, dimana data dalam satu kelompok mempunyai karakteristik yang sama. Data mahasiswa dikelompokkan menjadi tiga cluster yaitu menerima, dipertimbangkan, dan tidak berhak menerima beasiswa. Kemudian setiap cluster
diklasifikasikan berdasarkan kriteria mana yang lebih diprioritaskan. Cluster
dengan nilai terbesar pada centroid akhir merupakan cluster yang direkomendasikan menerima beasiswa, sedangkan cluster dengan nilai terkecil pada centroid akhir merupakan cluster yang tidak berhak menerima beasiswa. Pengujian sistem dilakukan sebanyak 40 kali percobaan terhadap 48 data mahasiswa untuk mendapatkan presisi hasil implementasi metode K-Means
Clustering. Nilai presisi dihitung dengan Error Presisi, dengan membandingkan data hasil clustering dari 40 percobaan. Hasil perhitungan Error Presisi pada hasil klasifikasi berdasarkan IPK adalah 0,118 dan berdasarkan penghasilan orang tua adalah 0,076. Nilai Error Presisi yang rendah menunjukkan bahwa nilai presisinya tinggi. Nilai presisi tinggi menunjukkan ketetapan data pada setiap percobaan dengan menggunakan tiga cluster juga tinggi.
commit to user
USE OF K-MEANS CLUSTERING METHOD FOR DETERMINATION OF SCHOLARSHIP RECIPIENTS
NOOR FITRIANA HASTUTI
Department of Informatics. Mathematic and Natural Science Faculty. Sebelas Maret University
ABSTRACT
Student data clustering based on the criteria of grade point average (GPA), parent s total income, and the number of family dependents can assist in the process of receiving a scholarship. Method that can be used for data classification of these students are K-Means Clustering. K-Means Clustering Method attempt to group the data into several groups, where data in one group have the same characteristics. The student data are grouped into three clusters, which received, considered, and is not eligible to receive the scholarship. Then each cluster is classified based on which criteria is prioritized. Cluster with the greatest value on the last centroid, is the recommended cluster receive scholarships, while the cluster with the smallest value on the last centroid is a cluster that is not eligible to receive the scholarship. Testing the system carried 40 times experimental with 48 students data to obtain the precision of the implementation of K-Means clustering results of method. Precision values computed by Precision Error, by comparing the clustering result data from 40 experiment. Precision Error calculation results on the classification results based on GPA is 0.118 and based on parent
is 0.076. Low Error Precision value indicates that the precision value of it is high. High precision value indicates determination of data on each experiment using three clusters are also high.
commit to user
KATA PENGANTARPuji syukur kehadirat Allah SWT karena dengan ridho dan rahmat-Nya,
penulis dapat menyelesaikan Tugas Pemanfaatan Metode
K-Means Clustering dalam Penentuan Penerima Beasiswa Banyak kesulitan dan
hambatan yang Penulis temui dalam penyusunan laporan ini. Namun berkat
bantuan dan bimbingan dari berbagai pihak, Penulis dapat menyelesaikannya.
Penulis mengucapkan terima kasih kepada berbagai pihak yang telah
memberikan bimbingan, dukungan dan saran dalam pembuatan laporan ini,
terutama kepada:
kesabaran memberikan bimbingan dan pengarahan selama proses penyusunan
skripsi ini.
4. Ibu Esti Suryani, S.Si., M.Kom. selaku Dosen Pembimbing II yang penuh
kesabaran memberikan bimbingan dan pengarahan selama proses penyusunan
skripsi ini.
5. Ayah dan Ibu tercinta untuk setiap kasih sayang, nasehat, dan dukungan
moral maupun material yang tak mungkin terbalas.
6. Teman-teman semua terutama mahasiswa Informatika FMIPA UNS dan Eska
Sebayu Rian Putra yang selalu memberikan bantuan, dukungan, dan motivasi
kepada Penulis.
Semoga skripsi ini dapat bermanfaat bagi pihak yang berkepentingan.
Surakarta, 15 Januari 2013
commit to user
BAB 3 METODOLOGI PENELITIAN... 20
3.1 Pengumpulan Data ... 20
3.1.1 Tempat dan Waktu Penelitian ... 20
3.1.2 Metode Pengumpulan Data ... 20
3.2 Pemodelan Data ... 21
3.3 Proses Clustering ... 22
3.4 Klasifikasi Hasil Clustering ... 23
3.5 Implementasi Sistem ... 23
3.6 Pengujian Clustering ... 24
BAB 4 PEMBAHASAN ... 25
4.1 Pemodelan Data ... 25
4.2 Proses Clustering ... 25
4.3 Klasifikasi Hasil Clustering ... 30
4.4 Implementasi Sistem ... 31
4.4.1 Gambaran Umum Sistem ... 32
4.4.2 Perancangan Basis Data ... 33
4.5 Pengujian Clustering ... 34
BAB 5 PENUTUP ... 35
5.1 Kesimpulan ... 35
5.2 Saran ... 35
commit to user
DAFTAR TABELHalaman
Tabel 2.1 Daftar objek yang akan diolah dalam clustering ... 12
Tabel 2.2 Hasil clustering ... 14
Tabel 3.1 Pengategorian PO ... 22
Tabel 4.1 Hasil perhitungan jarak awal pada iterasi-1 ... 27
Tabel 4.2 Hasil cluster iterasi-1 ... 28
Tabel 4.3 Hasil dua centroid akhir ... 29
Tabel 4.4 Hasil klasifikasi ... 30
Tabel 4.5 Hasil klasifikasi mahasiswa ... 31
Tabel 4.6 Tb_mahasiswa ... 33
Tabel 4.7 Tb_cmsd ... 33
Tabel 4.8 Tb_dokumentasi ... 33
commit to user
DAFTAR GAMBARHalaman
Gambar 2.1 Diagram alir algoritma k-means ... 11
Gambar 2.2 Ilustrasi algoritma k-means ... 11
Gambar 2.3 Partitional coeficient (PC) ... 14
Gambar 2.4 Classification entropy (CE) ... 14
Gambar 2.5 Partition index (SC) ... 15
Gambar 2.6 Separation index (S) ... 15
Gambar 2.7 Xie and beni index (XB) ... 15
Gambar 2.8 Dunn index (DI) ... 15
Gambar 3.1 Alur rancangan penelitian ... 20
commit to user
DAFTAR LAMPIRANHalaman
Lampiran A ... 38
Lampiran B ... 39
Lampiran C ... 40
Lampiran D ... 41
Lampiran E ... 42
commit to user
BAB 1PENDAHULUAN
1.1Latar Belakang
Beasiswa adalah pemberian berupa bantuan keuangan yang diberikan
kepada perorangan yang bertujuan untuk digunakan demi keberlangsungan
pendidikan yang ditempuh (Putranto, 2011). Pemberian beasiswa merupakan
program kerja yang ada di setiap universitas atau perguruan tinggi. Program
beasiswa diadakan untuk meringankan beban mahasiswa dalam menempuh masa
studi kuliah khususnya dalam masalah biaya. Pemberian beasiswa kepada
mahasiswa dilakukan secara selektif sesuai dengan jenis beasiswa yang diadakan.
Universitas Sebelas Maret menyediakan beberapa program beasiswa, sebagai
contoh yaitu beasiswa Peningkatan Prestasi Akademik (PPA), Beasiswa Bantuan
Belajar Mahasiswa (BBM), beasiswa astra, dan lain sebagainya. Indeks Prestasi
Kumulatif (IPK), jumlah tanggungan keluarga, dan penghasilan total orang tua
(penghasilan ayah ditambah penghasilan ibu) menjadi kriteria dalam proses
rekruitmen beasiswa.
Proses seleksi penerimaan beasiswa secara manual yaitu dengan
menginputkan satu persatu data mahasiswa ke dalam file spreadsheet kemudian
melakukan sorting data mahasiswa seringkali menimbulkan beberapa
permasalahan, antara lain membutuhkan waktu yang lama dan ketelitian yang
tinggi. Selain itu, transparansi serta ketidakjelasan metodologi yang digunakan
dalam proses komputasi penerimaan beasiswa juga menjadi salah satu
permasalahan, sehingga dibutuhkan suatu sistem yang dapat membantu dalam
proses pengambilan keputusan siapa saja mahasiswa yang direkomendasikan
menerima beasiswa berdasarkan kriteria-kriteria yang telah ditentukan secara
cepat dan tepat sasaran.
Salah satu metode yang dapat digunakan untuk menyelesaikan
permasalahan tersebut adalah metode K-Means Clustering. K-Means Clustering
merupakan salah satu metode data clustering non hirarki yang berusaha
commit to user
Metode ini mempartisi data ke dalam cluster/kelompok sehingga data yang
memiliki karakteristik sama dikelompokkan ke dalam satu cluster yang sama
(Agusta, 2007).
Pada penelitian sebelumnya, Nanjaya (2005) melakukan pembahasan
mengenai penggunaan metode K-Means pada suatu clustering data non-numerik
(categorical) untuk studi kasus biro jodoh. Dari penelitian tersebut didapatkan
bahwa clustering dapat dilakukan pada atribut-atribut kategorikal yang
ditransformasikan terlebih dahulu ke dalam bentuk numerik.
Penelitian lainnya mengenai perbandingan performa antara algoritma
K-Means Clustering dengan algoritma Fuzzy C-Means Clustering oleh Santhanam
dan Velmurugan (2010). Dalam penelitian ini, kedua algoritma tersebut
diimplementasikan dan dianalisis kinerjanya berdasarkan pada kualitas hasil
clustering dan waktu eksekusi. Kedua algoritma menghasilkan hasil clustering
yang hampir sama, namun algoritma K-Means Clustering memiliki waktu
komputasi yang lebih unggul, dengan kata lain kinerja dari algoritma K-Means
lebih baik dibandingkan dengan Fuzzy C-Means.
Berdasarkan penelitian tersebut, sistem pendukung keputusan
penerimaan beasiswa yang akan diimplementasikan dibangun dengan
menggunakan metode K-Means Clustering. Dengan penerapan sistem pendukung
keputusan dengan metode K-Means Clustering ini diharapkan dapat membantu
dalam proses pengambilan keputusan siapa saja mahasiswa yang
direkomendasikan menerima beasiswa berdasarkan kriteria-kriteria yang telah
ditentukan secara cepat dan tepat sasaran.
1.2Rumusan Masalah
Berdasarkan latar belakang yang telah dijelaskan sebelumnya, rumusan
masalah yang akan diselesaikan adalah bagaimana mengelompokkan data
mahasiswa untuk mendukung keputusan penentuan penerima beasiswa dengan
commit to user
3
1.3Batasan Masalah
Batasan masalah dalam tugas akhir ini adalah:
1. Kriteria yang digunakan dalam clustering antara lain Indeks Prestasi
Kumulatif (IPK), jumlah tanggungan keluarga, dan penghasilan total orang
tua (penghasilan ayah ditambah dengan penghasilan ibu).
2. Sistem bersifat general (tidak mengacu pada satu jenis beasiswa) dan hanya
melakukan clustering data mahasiswa berdasarkan kriteria-kriteria yang
telah disebutkan pada poin pertama, sedangkan keputusan penerima
beasiswa tergantung pada salah satu kriteria yang lebih diprioritaskan pada
beasiswa tersebut, yaitu salah satu dari prioritas kriteria IPK dan prioritas
kriteria penghasilan total orang tua dibagi dengan jumlah tanggungan
keluarga.
3. Jumlah cluster yang akan digunakan pada kasus ini adalah tiga (3)
berdasarkan perhitungan validasi cluster optimal, yaitu mahasiswa yang
direkomendasikan menerima beasiswa, dipertimbangkan menerima
beasiswa, dan tidak menerima beasiswa.
4. Quota penerima beasiswa dan pendanaan tidak termasuk dalam
pengklasteran.
1.4Tujuan Penelitian
Tujuan penelitian yang ingin dicapai dalam tugas akhir ini adalah
mengelompokkan data mahasiswa untuk mendukung keputusan penetuan
penerima beasiswa dengan metode K-Means Clustering.
1.5Manfaat Penelitian
Manfaat penelitian dalam tugas akhir ini adalah pendukung keputusan
yang dihasilkan diharapkan mampu membantu untuk membuat keputusan dalam
commit to user
1.6Sistematika Penulisan
Agar mudah dipahami, laporan ini dibuat dalam suatu sistematika
penulisan yang dapat dijadikan acuan mengenai keterkaitan antar bab yang ada
dalam laporan, dengan uraian sebagai berikut :
BAB 1 : PENDAHULUAN
Bab Pendahuluan memuat tentang latar belakang masalah, perumusan
masalah, tujuan dan manfaat penelitian, metodologi penelitian dan sistematika
penyusunan laporan.
BAB 2 : LANDASAN TEORI
Bab Landasan Teori memuat penjelasan tentang dasar teori yang
digunakan untuk dasar pembahasan dari penelitian.
BAB 3 : METODE PENELITIAN
Bab Metodologi Penelitian berisi tentang metode atau langkah langkah
dalam pemecahan masalah.
BAB 4 : PEMBAHASAN
Bab Pembahasan memuat pembahasan permasalahan yang telah
dirumuskan dengan menggunakan landasan teori yang mendukung. Teori tersebut
harus mengacu pada pustaka yang digunakan. Pembahasan dilakukan pada
metode penyelesaian permasalahan.
BAB 5 : PENUTUP
Bab Penutup berisi kesimpulan dan saran. Kesimpulan berisi rumusan
jawaban terhadap pertanyaan (perumusan masalah) dan hasil pembahasan dari
penelitian yang telah dilakukan. Saran merupakan sesuatu yang belum ditempuh
commit to user
BAB 2TINJAUAN PUSTAKA
2.1 Dasar Teori
2.1.1 Sistem Pendukung Keputusan (SPK)
Sistem Pendukung Keputusan (SPK) pertama kali didefinisikan oleh
Scott-Morton pada tahun 1970 sebagai sistem berbasis komputer yang interaktif, yang
membantu pengambil keputusan memanfaatkan data dan model untuk
menyelesaikan masalah tidak terstruktur. Sistem pendukung keputusan diharapkan
dapat mendukung para pengambil keputusan manajerial dalam situasi semi
terstruktur dan tidak terstruktur. Sistem pendukung keputusan dimaksudkan untuk
menjadi alat bantu bagi para pengambil keputusan untuk memperluas kapabilitas
mereka, namun tidak untuk menggantikan penilaian mereka (Turban et al, 2011).
Menurut Turban et al (2011), sistem pendukung keputusan terdiri dari
empat subsistem, yaitu:
1. Subsistem Manajemen Data
Subsistem manajemen data mencakup suatu database yang berisi data yang
relevan untuk situasi dan dikelola oleh perangkat lunak yang disebut Database
Management System (DBMS). Manajemen data dapat diinterkoneksikan dengan
data warehouse perusahaan, suatu repositori untuk data perusahaan yang relevan
untuk pengambilan keputusan. Biasanya data dimasukkan dan diakses melalui
database Web Server.
2. Subsistem Manajemen Model
Subsistem manajemen model merupakan suatu paket perangkat lunak yang
mencakup model keuangan, statistik, ilmu manajemen, atau model kuantitatif
lainnya yang memberikan kemampuan analitik dan manajemen perangkat lunak
yang sesuai. Perangkat lunak ini sering disebut Model Base Management System
(MBMS).
3. Subsistem Antarmuka Pengguna
Pengguna berkomunikasi dan memerintahkan SPK melalui subsistem
commit to user
menegaskan bahwa beberapa kontribusi yang unik dari SPK berasal dari interaksi
yang intensif antara komputer dan pengambil keputusan. Web Browser
menyediakan struktur antarmuka Graphical User Interface (GUI) yang familier
dan konsisten. Istilah antarmuka pengguna mencakup semua aspek komunikasi
antara pengguna dengan sistem.
4. Subsistem Manajemen Berbasis Pengetahuan
Subsistem manajemen berbasis pengetahuan dapat mendukung subsistem lain
atau berlaku sebagai komponen yang berdiri sendiri. Subsistem manajemen
berbasis pengetahuan dapat saling berhubungan dengan repositori pengetahuan
organisasi yang disebut organization knowledge base.
Proses pengambilan keputusan dilakukan dengan menggunakan beberapa
tahapan. Menurut Turban et al (2011), tahapan dalam pengambilan keputusan
antara lain:
1. Intelligence
Tahap ini merupakan proses penelusuran dan pendeteksian dari lingkup
problematika serta proses pengenalan masalah. Data masukkan diperoleh,
diproses, dan diuji dalam rangka mengindentifikasikan masalah.
2. Design
Tahap ini merupakan proses menemukan, mengembangkan, dan menganalisis
alternatif tindakan yang bisa dilakukan. Tahap ini meliputi proses untuk mengerti
masalah, menurunkan solusi, menguji kelayakan solusi.
3. Choice
Tahap ini merupakan proses pemilihan di antara berbagai alternatif tindakan
yang mungkin dijalankan. Tahap ini dimulai dengan mencari solusi dengan
menggunakan model, melakukan analisis sensitivitas, menyeleksi alternatif yang
terbaik, melakukan aksi atau rencana untuk mengimplementasikan, dan
merancang sistem pengendalian.
4. Implementation
Fase implementasi meliputi pembuatan suatu solusi yang direkomendasikan.
sensitivitas-commit to user
7
analisis masalah. Fase ini mengadaptasikan materi yang dipilih untuk diterapkan
pada situasi pemilihan (penyelesaian masalah).
2.1.2 Clustering
Clustering adalah mengelompokkan item data ke dalam sejumlah kecil
grup sedemikian sehingga masing-masing grup mempunyai sesuatu persamaan
yang esensial (Andayani, 2007).
Ada beberapa pendekatan yang digunakan dalam mengembangkan metode
clustering. Dua pendekatan utama adalah clustering dengan pendekatan partisi
dan clustering dengan pendekatan hirarki. Clustering dengan pendekatan partisi
atau sering disebut dengan partition-based clustering mengelompokkan data
dengan memilah-milah data yang dianalisa ke dalam cluster-cluster yang ada.
Clustering dengan pendekatan hirarki atau sering disebut dengan hierarchical
clustering mengelompokkan data dengan membuat suatu hirarki berupa kurva
yang menggambarkan pengelompokan cluster dimana data yang mirip akan
ditempatkan pada hirarki yang berdekatan dan yang tidak pada hirarki yang
berjauhan.
Menurut Andayani (2007), Algoritma clustering dibagi ke dalam
beberapa kelompok besar, antara lain:
1. Partitioning algorithms: algoritma dalam kelompok ini membentuk
bermacam partisi dan kemudian mengevaluasinya dengan berdasarkan
beberapa kriteria.
2. Hierarchy algorithms: pembentukan dekomposisi hirarki dari sekumpulan
data menggunakan beberapa kriteria.
3. Density based: pembentukan cluster berdasarkan pada koneksi dan fungsi
densitas.
4. Grid based: pembentukan cluster berdasarkan pada struktur multiple level
granularity.
5. Model based: sebuah model dianggap sebagai hipotesa untuk
masing masing cluster dan model yang baik dipilih diantara model
commit to user
2.1.3 K-Means Clustering
Metode K-Means pertama kali diperkenalkan oleh MacQueen JB pada
tahun 1976. Metode ini adalah salah satu metode non hierarchi yang umum
digunakan. Metode ini termasuk dalam teknik penyekatan (partition) yang
membagi atau memisahkan objek ke k daerah bagian yang terpisah. Pada
K-Means, setiap objek harus masuk dalam kelompok tertentu, tetapi dalam satu
tahapan proses tertentu, objek yang sudah masuk dalam satu kelompok, pada satu
tahapan berikutnya objek akan berpindah ke kelompok lain.
Hasil cluster dengan dengan metode K-Means sangat bergantung pada
nilai pusat kelompok awal yang diberikan. Pemberian nilai awal yang berbeda
bisa menghasilkan kelompok yang berbeda. Ada beberapa cara memberi nilai
awal misalnya dengan mengambil sampel awal dari objek, lalu mencari nilai
pusatnya, memberi nilai awal secara random, menentukan nilai awalnya atau
menggunakan hasil dari kelompok hierarki dengan jumlah kelompok yang sesuai
(Santosa 2007).
K-Means adalah suatu metode penganalisaan data atau metode Data
Mining yang melakukan proses pemodelan tanpa supervisi (unsupervised) dan
merupakan salah satu metode yang melakukan pengelompokan data dengan
sistem partisi. Metode K-Means berusaha mengelompokkan data yang ada ke
dalam beberapa kelompok, dimana data dalam satu kelompok mempunyai
karakteristik yang sama satu sama lainnya dan mempunyai karakteristik yang
berbeda dengan data yang ada di dalam kelompok yang lain. Dengan kata lain,
metode ini berusaha untuk meminimalkan variasi antar data yang ada di dalam
suatu cluster dan memaksimalkan variasi dengan data yang ada di cluster lainnya
(Agusta, 2011).
Menurut Nuningsih (2010), algoritma K-Means memerlukan 3 komponen,
yaitu:
1. Jumlah Cluster K
K-Means merupakan bagian dari metode non-hirarki sehingga dalam
metode ini jumlah k harus ditentukan terlebih dahulu. Jumlah cluster k dapat
commit to user
9
tidak terdapat aturan khusus dalam menentukan jumlah cluster k, terkadang
jumlah cluster yang diiinginkan tergantung pada subyektif seseorang.
2. Cluster Awal
Cluster awal yang dipilih berkaitan dengan penentuan pusat cluster awal
(centroid awal). Dalam hal ini, terdapat beberapa pendapat dalam memilih cluster
awal untuk metode K-Means sebagai berikut:
a. Berdasarkan Hartigan (1975), pemilihan cluster awal dapat ditentukan
berdasarkan interval dari jumlah setiap observasi
b. Berdasarkan Rencher (2002), pemilihan cluster awal dapat ditentukan
melalui pendekatan salah satu metode hirarki.
c. Berdasarkan Teknomo (2007), pemilihan cluster awal dapat secara
acak dari semua observasi.
Oleh karena adanya pemilihan cluster awal yang berbeda ini maka
kemungkinan besar solusi cluster yang dihasilkan akan berbeda pula.
3. Ukuran Jarak
Metode k-means dimulai dengan pembentukan prototipe cluster di awal
kemudian secara iteratif prototipe cluster ini diperbaiki hingga konvergen (tidak
terjadi perubahan yang signifikan pada prototipe cluster). Perubahan ini diukur
dengan ukuran jarak Euclidean. Ukuran jarak ini digunakan untuk menempatkan
observasi ke dalam cluster berdasarkan centroid terdekat.
Menurut Sarwono (2011), Algoritma K-Means adalah sebagai berikut:
1. Menentukan k sebagai jumlah cluster yang ingin dibentuk.
2. Membangkitkan nilai random untuk pusat cluster awal (centroid)
sebanyak k
3. Menghitung jarak setiap data input terhadap masing-masing centroid
menggunakan rumus jarak Eucledian (Eucledian Distance) hingga
ditemukan jarak yang paling dekat dari setiap data dengan centroid.
Berikut adalah persamaan Eucledian Distance:
commit to user
dimana:xi : data kriteria
µj : centroid pada cluster ke-j
4. Mengklasifikasikan setiap data berdasarkan kedekatannya dengan centroid
(jarak terkecil).
5. Memperbaharui nilai centroid. Nilai centroid baru diperoleh dari rata-rata
cluster yang bersangkutan dengan menggunakan rumus:
... (2)
dimana:
µj (t+1) : centroid baru pada iterasi ke (t+1),
Nsj : banyak data pada cluster Sj
6. Melakukan perulangan dari langkah 2 hingga 5 hingga anggota tiap cluster
tidak ada yang berubah.
7. Jika langkah 6 telah terpenuhi, maka nilai pusat cluster (µj) pada iterasi
terakhir akan digunakan sebagai parameter untuk menentukan klasifikasi
data. Ilustrasi dari perubahan cluster/kelompok data ditunjukkan pada
commit to user
11
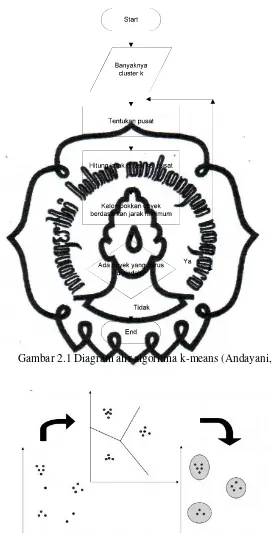
Gambar 2.1 Diagram alir algoritma k-means (Andayani, 2007)
commit to user
Berikut ini adalah ilustrasi penggunaan metode K means untuk
menentukan cluster dari 4 buah objek dengan 2 atribut, seperti ditunjukkan dalam
Tabel 2.1. Clustering akan dilakukan untuk membentuk 2 cluster jenis obat
berdasarkan atributnya (Andayani, 2007). Langkah langkah metode K means
adalah sebagai berikut :
a) Pengesetan nilai awal titik tengah. Misalkan obat A dan Obat B masing-masing
menjadi titik tengah (centroid) dari cluster yang akan dibentuk. Tentukan
koordinat kedua centroid tersebut, yaitu c1=(1,1) dan c2=(2,1).
Tabel 2.1 Daftar objek yang akan diolah dalam clustering
Objek Atribut1(x): indeks berat Atribut2(y): pH
Obat A 1 1
menunjukkan objek sedangkan baris pertama menunjukkan jarak ke centroid
pertama, baris kedua menunjukkan jarak ke centroid kedua.
Iterasi-0
1) Matriks jarak setelah iterasi ke-0 adalah sebagai berikut:
D =
A B C D
2) Clustering objek: Memasukkan setiap objek ke dalam cluster (grup)
berdasarkan jarak minimumnya. Jadi obat A dimasukkan ke grup 1, dan
obat B, C, dan D dimasukkan ke grup 2. Keanggotaan objek ke dalam grup
dinyatakan dengan matrik, elemen dari matriks bernilai 1 jika sebuah
commit to user
13
G =
A B C D
Iterasi-1
1) Menentukan centroid: Berdasarkan anggota masing-masing grup,
selanjutnya ditentukan centroid baru. Grup 1 hanya berisi 1 objek,
sehingga centroidnya tetap c1=(1,1). Grup 2 mempunyai 3 anggota,
sehingga centroidnya ditentukan berdasarkan rata-rata koordinat ketiga
anggota tersebut: c2= =
2) Menghitung jarak objek ke centroid: selanjutnya, jarak antara centroid
baru dengan seluruh objek dalam grup dihitung kembali sehingga
diperoleh matriks jarak sebagai berikut:
D =
A B C D
3) Clustering objek: menentukan keanggotaan grup berdasarkan jaraknya.
Berdasarkan matriks jarak baru, maka obat B harus dipindah ke grup 1.
G1 =
A B C D
Iterasi-2
1) Menetukan centroid: menentukan centroid baru berdasarkan keanggotaan
grup yang baru. Grup 1 dan 2 masing-masing mempunyai 2 anggota,
sehingga centroidnya menjadi
c1= = dan c2= =
2) Menghitung jarak objek ke centroid: diperoleh matriks jarak sebagai
berikut:
D =
commit to user
3) Clustering objek: mengelompokkan tiap-tiap objek berdasarkan jarak
minimumnya, diperoleh:
G2 =
A B C D
Hasil pengelompokkan pada iterasi terakhir dibandingkan dengan hasil
sebelumnya, diperoleh G2=G1. Hasil ini menunjukkan bahwa tidak ada lagi
objek yang berpindah grup, dan metode telah stabil. Hasil akhir clustering
ditunjukkan dalam Tabel 2.2.
Tabel 2.2 Hasil clustering
Objek Atribut1(x): indeks berat Atribut2(y): pH Grup Hasil
Obat A 1 1 1
Obat B 2 1 1
Obat C 4 3 2
Obat D 5 4 2
2.1.3. 1 Jumlah Cluster Optimal
Jumlah cluster optimal ditentukan dengan validitas indeks cluster melalui
perbandingan nilai indeks pada berbagai validity measure. Perhitungan nilai
indeks dengan berbagai validity measure dilakukan dengan parameter yang telah
-3
Gambar 2.3 Partition coeficient (PC)
commit to user
15
Gambar 2.5 Partition index (SC)
Gambar 2.6 Separation index (S)
Gambar 2.7 Xie and beni index (XB)
Gambar 2.8 Dunn index (DI)
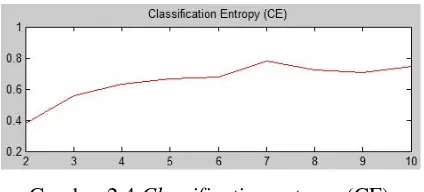
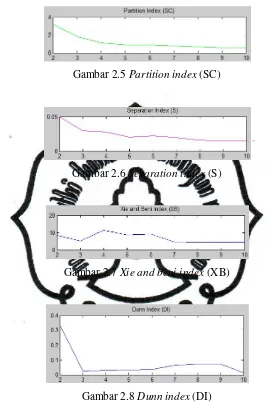
Hasil perhitungan validitas indeks menggunakan PC menunjukkan bahwa
indeks semakin menurun seiring pertambahan jumlah cluster. Indeks mengalami
penurunan signifikan pada c (jumlah cluster opimal) = 3 (Gambar 2.3). Hasil
perhitungan validitas indeks menggunakan CE menunjukkan bahwa indeks
semakin meningkat seiring pertambahan jumlah cluster dan mengalami perubahan
signifikan pada c = 3 (Gambar 2.4). Hasil perhitungan validitas indeks
menggunakan SC dan S menunjukkan bahwa indeks relatif semakin menurun
seiring pertambahan jumlah cluster (Gambar 2.5 dan Gambar 2.6). Sedangkan
commit to user
mencapai nilai minimum pada c = 3 (Gambar 2.7). Sedangkan nilai
mengalami perubahan signifikan dan mencapai nilai minimum pada lembah
pertama pada c = 3 (Gambar 2.8). Berdasarkan hasil perbandingan index dengan
berbagai validity measure yang telah dilakukan, jumlah cluster optimal berada
pada c = 3.
2.1.4 Beasiswa
Beasiswa adalah pemberian berupa bantuan keuangan yang diberikan
kepada perorangan yang bertujuan untuk digunakan demi keberlangsungan
pendidikan yang ditempuh (Putranto, 2011).
Pemberian beasiswa merupakan program kerja yang ada di setiap
universitas atau perguruan tinggi. Program beasiswa diadakan untuk meringankan
beban mahasiswa dalam menempuh masa studi kuliah khususnya dalam masalah
biaya. Pemberian beasiswa kepada mahasiswa dilakukan secara selektif sesuai
dengan jenis beasiswa yang diadakan.
Adapun jenis beasiswa yang diselenggarakan antara lain Beasiswa
Peningkatan Prestasi Akademik (PPA), Beasiswa Bantuan Belajar Mahasiswa
(BBM), Beasiswa yang diberikan pihak swasta, seperti beasiswa djarum, astra,
dan sebagainya.
Tujuan diselenggarakan beasiswa antara lain (Dikti, 2011):
1. Meningkatkan akses dan pemerataan kesempatan belajar di perguruan
tinggi bagi rakyat Indonesia.
2. Mengurangi jumlah mahasiswa yang putus kuliah, karena tidak mampu
membiayai pendidikan.
3. Meningkatkan prestasi dan motivasi mahasiswa, baik pada bidang
akademik/kurikuler, ko-kurikuler, maupun ekstrakurikuler.
Sasaran mahasiswa penerima beasiswa antara lain (Dikti, 2011):
1. Mahasiswa berprestasi (baik pada bidang akademik/kurikuler, ko-kurikuler
maupun ekstra kurikuler).
2. Mahasiswa dengan prestasi minimal yang orang tua/wali-nya tidak mampu
commit to user
17
Adapun urutan prioritas kriteria yang digunakan untuk penetapan
mahasiswa penerima beasiswa adalah tidak sama untuk setiap jenis beasiswa.
Sebagai contoh urutan prioritas kriteria penerima beasiswa PPA dan BBM adalah
berbeda .
Penentukan mahasiswa penerima beasiswa PPA sesuai dengan urutan
prioritas sebagai berikut (Dikti, 2011):
1. Mahasiswa yang mempunyai IPK paling tinggi.
2. Mahasiswa yang mempunyai SKS paling banyak (jumlah semester paling
sedikit)
3. Mahasiswa yang memiliki prestasi di kegiatan ko/ekstra kurikuler
(olahraga, teknologi, seni/budaya tingkat internasional/dunia,
regional/Asia/Asean dan nasional).
4. Mahasiswa yang (orang tuanya) paling tidak mampu.
Sedangkan penentukan mahasiswa penerima beasiswa BBM sesuai dengan
urutan prioritas sebagai berikut (Dikti, 2011):
1. Mahasiswa yang (orang tuanya) paling tidak mampu.
2. Mahasiswa yang memiliki prestasi di kegiatan ko/ekstra kurikuler
(olahraga, teknologi, seni/budaya tingkat internasional/dunia,
regional/Asia/Asean dan nasional).
3. Mahasiswa yang mempunyai IPK paling tinggi.
4. Mahasiswa yang mempunyai SKS paling banyak (jumlah semester paling
sedikit).
2.2 Penelitian Terkait
1. Aplikasi K-Means untuk Pengelompokkan Mahasiswa Berdasarkan
Nilai Body Mass Index (BMI) dan Ukuran Kerangka (Kusumadewi,
2008)
Penelitian tersebut membahas tentang penerapan metode K-Means
Clustering untuk mengelompokkan mahasiswa berdasarkan kriteria Body
Mass Index (BMI) dan ukuran kerangka. Kriteria tersebut didasarkan pada
commit to user
terlebih dahulu. Data kondisi fisik yang digunakan adalah tinggi badan,
berat badan dan lingkar lengan bawah. Diasumsikan data yang diambil
adalah data mahasiswa putra. Setelah data tersebut diperoleh kemudian
dilakukan perhitungan untuk mencari status gizi dan ukuran rangka dari
masing-masing data yang ada.
Setelah mendapatkan status gizi dan nilai rangka dari masing-masing
data maka langkah selanjutnya adalah melakukan proses klasifikasi data
menggunakan metode klasifikasi K-Means.
Kesimpulan dari hasil penelitian adalah bahwa algoritma klasifikasi
K-Means dapat digunakan untuk mengelompokkan mahasiswa berdasarkan
status gizi dan ukuran kerangka. Diperoleh 3 kelompok berdasarkan BMI
dan ukuran kerangka, yaitu BMI normal dan kerangka besar, BMI obesitas
sedang dan kerangka sedang, BMI obesitas berat dan kerangka kecil.
2. Clustering Data Non-numerik dengan Pendekatan Algoritma
K-Means dan Hamming Distance Studi Kasus Biro Jodoh (Nanjaya,
2005)
Penelitian tersebut membahas tentang penerapan algoritma k-means
pada suatu clustering data non-numerik (categorical), dengan dibantu
Hamming Distance sebagai alat untuk mengukur jarak dari masing-masing
atribut kategorikalnya. Metodologi yang digunakan dalam penelitian ini
meliputi beberapa tahapan. Modifikasi yang dilakukan adalah proses
modifikasi data dari non-numerik menjadi numerik. Dari penelitian tersebut
didapatkan bahwa clustering dapat dilakukan pada atribut-atribut
kategorikal yang ditransformasikan terlebih dahulu ke dalam bentuk
numerik. Selain itu, kesamaan (similarity) dan karakterisktik dari
masing-masing keanggotaan bisa diketahui.
3. Performance Evaluation of K-Means and Fuzzy C-Means Clustering
Algorithms for Statistical Distributions of Input Data Points(Santhanam,
2010)
Penelitian tersebut membahas tentang perbandingan performa antara
commit to user
19
Clustering. Kedua algoritma tersebut diimplementasikan dan dianalisis
kinerjanya berdasarkan pada kualitas hasil clustering. Perilaku kedua
algoritma tergantung pada jumlah titik data serta pada jumlah cluster. Input
data poin dihasilkan oleh dua cara, yaitu dengan menggunakan distribusi
normal dan lain dengan menerapkan distribusi seragam dengan Box-Muller
formula. Kinerja algoritma dianalisis selama eksekusi yang berbeda dari
program pada titik input data. Waktu eksekusi untuk masing-masing
algoritma juga dianalisis dan hasilnya dibandingkan. Hasil penelitian
menunjukkan bahwa kinerja dari algoritma K-Means lebih baik
dibandingkan dengan Fuzzy C-Means untuk distribusi normal dan seragam.
FCM menghasilkan hasil yang dekat dengan K-Means clustering, namun
membutuhkan waktu komputasi lebih lama dari K-means. Jadi untuk data
poin yang dihasilkan dengan menggunakan distribusi statistik, algoritma
K-Means tampaknya lebih unggul daripada Fuzzy C-K-Means.
2.3 Rencana Penelitian
Proses seleksi penerimaan beasiswa secara manual yaitu dengan
menginputkan satu persatu data mahasiswa ke dalam file excel kemudian
melakukan sorting data mahasiswa menimbulkan beberapa permasalahan, antara
lain membutuhkan waktu yang lama dan ketelitian yang tinggi.
Salah satu cara untuk membantu dalam proses seleksi penerimaan
beasiswa adalah dengan cara mengelompokkan mahasiswa berdasarkan
kriteria-kriteria yang telah ditentukan, antara lain IPK, jumlah tanggungan keluarga, dan
penghasilan total orang tua. Pengelompokan dilakukan dengan menerapkan
algoritma K-Means Clustering. Pengelompokan ini akan menunjukkan siapa saja
yang akan masuk ke dalam masing-masing kelompok.
Jumlah cluster yang digunakan pada kasus ini adalah tiga (3) berdasarkan
perhitungan validasi cluster optimal, yaitu mahasiswa yang direkomendasikan
menerima beasiswa, dipertimbangkan menerima beasiswa, dan tidak menerima
commit to user
BAB 3METODOLOGI PENELITIAN
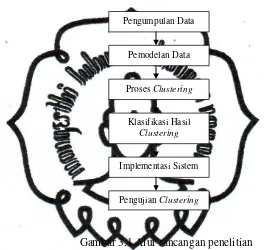
Penelitian ini akan dilaksanakan berdasarkan rancangan penelitian seperti
yang ditunjukkan pada Gambar 3.1
Gambar 3.1 Alur rancangan penelitian
3.1 Pengumpulan Data
3.1.1 Tempat dan Waktu Penelitian
Penelitian ini dilakukan di Fakultas Matematika dan Ilmu Pengetahuan
Alam Universitas Sebelas Maret Surakarta (FMIPA UNS). Data yang digunakan
adalah data mahasiswa Informatika FMIPA UNS, pendaftar beasiswa PPA dan
BBM tahun 2012.
3.1.2 Metode Pengumpulan Data
Pengumpulan data digunakan untuk mengumpulkan data-data dan
informasi-informasi yang diperlukan dalam pembuatan sistem pendukung
keputusan. Pengumpulan data pada penelitian ini menggunakan metode
pengumpulan data study literature dan telaah dokumen. Pengumpulan Data
Pemodelan Data
Proses Clustering
Klasifikasi Hasil
Clustering
Implementasi Sistem
commit to user
21
a. Study Literature
Study literature dilakukan dengan cara mencari bahan materi yang
berhubungan dengan permasalahan, perancangan, metode K-Means
Clustering, sistem pendukung keputusan dan beasiswa, guna
mempermudah proses implementasi sistem. Pencarian materi dilakukan
melalui pencarian di buku panduan dan internet.
b. Telaah Dokumen
Telaah dokumen adalah pengumpulan data dengan cara
mengumpulkan dan mempelajari dokumen-dokumen yang didapatkan
dari pihak Jurusan Informatika FMIPA UNS. Dari metode pengumpulan
data ini diperoleh 48 data mahasiswa.
3.2 Pemodelan Data
Proses clustering menggunakan data kriteria IPK dan PO (penghasilan
total orang tua dibagi jumlah tanggungan keluarga). Oleh karena data IPK dan
data PO memiliki perbedaan nilai yang cukup jauh, maka kriteria PO di
kategorikan. Proses pengategorian adalah sebagai berikut:
1. Hitung mean (nilai rata-rata) dari seluruh data PO dengan rumus:
... (3)
Dengan:
: mean
: hasil penjumlahan nilai PO
n : jumlah data mahasiswa
2. Hitung standart deviasi dari seluruh data PO dengan rumus:
S= ... (4)
Dengan:
S : standart deviasi
x : nilai individu data PO mahasiswa
: nilai rata-rata/mean
commit to user
3. Membuat kategori PO:Tabel 3.1 Pengategorian PO
Kategori Kualifikasi Kodifikasi
Kategori 4 S 4
Kategori 3 S < PO < 3
Kategori 2 2
Kategori 1 PO 1
3.2 Proses Clustering
Tahap ini akan diterapkan metode K-Means untuk mengelompokkan
data. Hasil pengelompokkan ini kemudian akan digunakan untuk pertimbangan
menentukan mahasiswa yang berhak menerima beasiswa. Adapun algorima
K-Means Clustering pada penerimaan beasiswa adalah sebagai berikut:
1. Jumlah cluster yang dibentuk sebagai nilai k adalah tiga (k = 3).
2. Membangkitkan nilai random untuk pusat cluster awal (centroid)
sebanyak 3 dari data yang telah diinputkan. Centroid kriteria 1 adalah IPK
dan centroid kriteria 2 adalah PO.
3. Menghitung jarak setiap data mahasiswa yang telah diinputkan terhadap
masing-masing centroid menggunakan rumus jarak Eucledian Distance
hingga ditemukan jarak paling dekat dari setiap data dengan centroid.
Berikut adalah persamaan Eucledian Distance:
d(xi , j) = ... (5)
dimana:
xi : data mahasiswa
µj : centroid pada cluster ke-j
xia : IPK mahasiswa
xib : penghasilan total orang tua dibagi jumlah tanggungan keluarga
µja : nilai kriteria 1 dari centroidcluster ke-j adalah nilai random data IPK
commit to user
23
4. Mengklasifikasikan setiap data mahasiswa berdasarkan kedekatannya
dengan centroid (jarak terkecil).
5. Memperbaharui nilai centroid. Nilai centroid baru diperoleh dari rata-rata
cluster yang bersangkutan dengan menggunakan rumus:
... (6)
dimana:
µj (t+1) : centroid baru pada iterasi ke (t+1),
Nsj : banyak data mahasiswa pada cluster Sj
6. Melakukan perulangan dari langkah 2 hingga 5 hingga anggota tiap cluster
tidak ada yang berubah.
7. Jika langkah 6 telah terpenuhi, maka nilai pusat cluster (µj) pada iterasi
terakhir akan digunakan sebagai parameter untuk menentukan klasifikasi
data mahasiswa.
3.4 Klasifikasi Hasil Clustering
Setelah proses clustering, tahap selanjutnya adalah proses klasifikasi. Di
sini akan ditentukan cluster mana yang lebih berhak untuk menerima beasiswa.
3.5 Implementasi Sistem
Tahap implementasi ini dimulai dengan analisis dan perancangan sistem
yang akan dibuat. Selanjutnya tahap implementasi sistem dengan tujuan
menghasilkan prototype program yang sesuai dengan hasil perancangan yang
telah ditentukan sebelumnya, yaitu penulisan kode program (coding)
menggunakan lingkungan bahasa pemrograman PHP. Data yang digunakan akan
disimpan dalam database. Debugging dilakukan untuk menguji aplikasi serta
commit to user
3.6 Pengujian Clustering
Pengujian dilakukan untuk mengetahui keakuratan yang dihasilkan dalam
penerapan metode K-Means Clustering sebagai model untuk menentukan
penerima beasiswa. Pengujian dilakukan terhadap presisi hasil cluster dengan data
testing yang digunakan.
Presisi adalah ukuran yang menunjukkan derajat kesesuaian antara hasil
uji individual yang diukur melalui penyebaran hasil individual dari rata-rata
secara berulang pada sampel-sampel yang diambil. Presisi dapat dihitung dengan:
... (7)
Dengan
ei : hasil data cluster yang berbeda
n : jumlah percobaan/testing
Percobaan/testing dilakukan sebanyak 40 kali. Nilai Error Presisi
tergantung pada ketetapan data pada cluster untuk setiap percobaan. Kemudian
commit to user
BAB 4PEMBAHASAN
4.1 Pemodelan Data
Sejumlah 48 data mahasiswa kemudian dikategorikan dengan terlebih
dahulu menghitung mean dan standart deviasi PO (penghasilan total orang tua
dibagi jumlah tanggungan keluarga). Berikut adalah hasil perhitungannya:
Mean PO : 672870,141
Standart Deviasi PO : 484555,170
Pengategorian data PO berdasarkan Tabel 3.1 adalah sebagai berikut:
Kategori 4 : PO 188314,971
Kategori 3 : 188314,971 < PO < 672870,141
Kategori 2 : 672870,141 PO < 1157425,311
Kategori 1 : PO 1157425,311
4.2 Proses Clustering
Proses clustering dengan menggunakan metode K-Means akan dilakukan
terhadap 48 sampel data mahasiswa. Hasil clustering akan diperoleh kelompok
data mahasiswa yang akan digunakan untuk proses klasifikasi penentuan cluster
(kelompok data) yang direkomendasikan menerima beasiswa. Adapun
langkah-langkah proses clustering adalah sebagai berikut:
1. Mula-mula sistem akan mengambil pusat cluster (centroid) awal. Pusat
cluster (centroid) awal yang digunakan untuk memulai proses clustering
dengan metode K-Means diperoleh dengan pembangkitan secara random dari
data yang telah diinputkan. Karena pusat cluster (centroid) awal dibangkitkan
secara random, maka hasil centroid awal berubah setiap kali melakukan
percobaan proses clustering. Hal ini akan menyebabkan setiap dilakukan
proses clustering anggota cluster yang dihasilkan juga akan berbeda. Selain
itu, ada kemungkinan centroid awal yang dihasilkan pusat jauh berbeda
dengan cluster yang terbaik, sehingga kemungkinan akan terjadi proses iterasi
commit to user
contoh satu percobaan. Dari hasil pengambilan secara random, diperoleh
centroid untuk masing-masing cluster. Centroid kriteria 1 adalah IPK dan
centroid kriteria 2 adalah PO:
C1 = (3.45, 1)
C2 = (3.39, 2)
C3 = (3.88, 3)
2. Kemudian akan dihitung jarak dari setiap data yang ada terhadap setiap pusat
cluster awal. Jarak inilah yang akan menjadi penentu termasuk ke dalam
cluster mana data tersebut. Misalkan untuk menghitung jarak data mahasiswa
pertama (IPK 2,87; PO kategori 3) dan dengan pusat cluster pertama adalah :
d11 = = 2,084001
Jarak data mahasiswa pertama dengan pusat cluster kedua:
d12 = = 1,169767
Jarak data mahasiswa pertama dengan pusat cluster ketiga:
d13 = = 0,599219
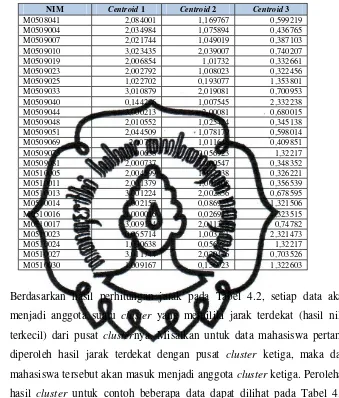
Hasil perhitungan jarak awal pada iterasi-1 untuk contoh 25 data dapat dilihat
commit to user
27
Tabel 4.1 Hasil perhitungan jarak awal pada iterasi-1
NIM Centroid 1 Centroid 2 Centroid 3
M0508041 2,084001 1,169767 0,599219
M0509004 2,034984 1,075894 0,436765
M0509007 2,021744 1,049019 0,387103
M0509010 3,023435 2,039007 0,740207
M0509019 2,006854 1,01732 0,332661
M0509023 2,002792 1,008023 0,322456
M0509025 1,022702 0,193077 1,353801
M0509033 3,010879 2,019081 0,700953
M0509040 0,144286 1,007545 2,332238
M0509044 3,000213 2,00081 0,680015
M0509048 2,010552 1,025424 0,345138
M0509051 2,044509 1,078179 0,598014
M0509069 2,00758 1,011648 0,409851
M0509073 1,000638 0,056923 1,32217
M0509081 2,000737 1,000547 0,348352
M0510005 2,004599 1,012238 0,326221
M0510011 2,001379 1,001408 0,356539
M0510013 3,001224 2,002856 0,678595
M0510014 1,002157 0,086923 1,321506
M0510016 1,000016 0,026923 1,323515
M0510017 3,009134 2,011318 0,74782
M0510023 0,065714 1,003771 2,321473
M0510024 1,000638 0,056923 1,32217
M0510027 3,011744 2,020476 0,703526
M0510030 1,009167 0,156923 1,322603
3. Berdasarkan hasil perhitungan jarak pada Tabel 4.2, setiap data akan
menjadi anggota suatu cluster yang memiliki jarak terdekat (hasil nilai
terkecil) dari pusat clusternya. Misalkan untuk data mahasiswa pertama
diperoleh hasil jarak terdekat dengan pusat cluster ketiga, maka data
mahasiswa tersebut akan masuk menjadi anggota cluster ketiga. Perolehan
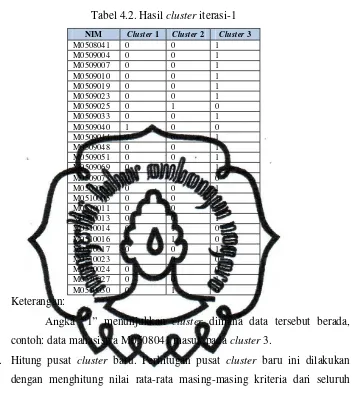
hasil cluster untuk contoh beberapa data dapat dilihat pada Tabel 4.2.
commit to user
Tabel 4.2. Hasil cluster iterasi-1
NIM Cluster 1 Cluster 2 Cluster 3
contoh: data mahasiswa M0508041 masuk pada cluster 3.
4. Hitung pusat cluster baru. Perhitugan pusat cluster baru ini dilakukan
dengan menghitung nilai rata-rata masing-masing kriteria dari seluruh
anggota yang menjadi anggota masing-masing cluster (dapat dilihat pada
Tabel 4.4). Misalkan untuk cluster pertama, ada 7 data. Sehingga pusat
cluster baru:
C11 =
C12 =
Untuk cluster kedua ada 13 data, sehingga pusat cluster baru:
C21 =
commit to user
29
Untuk cluster ketiga ada 28 data, sehingga pusat cluster baru:
C31 =
C32 = 3,321
5. Proses 2 sampai 4 akan terus berulang hingga posisi data sudah tidak
mengalami perubahan dan nilai pusat cluster sama. Dalam percobaan kali
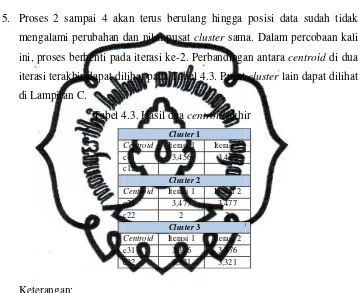
ini, proses berhenti pada iterasi ke-2. Perbandingan antara centroid di dua
iterasi terakhir dapat dilihat pada Tabel 4.3. Pusat cluster lain dapat dilihat
di Lampiran C.
Tabel 4.3. Hasil dua centroid akhir
Keterangan:
Centroid Iterasi 1 Iterasi 2
c11 3,456 3,456
c12 1 1
Cluster 2
Centroid Iterasi 1 Iterasi 2
c21 3,477 3,477
c22 2 2
Cluster 3
Centroid Iterasi 1 Iterasi 2
c31 3,376 3,376
commit to user
4.3 Klasifikasi Hasil Clustering
Proses klasifikasi memerlukan adanya suatu aturan untuk menentukan
kelompok (cluster) mana yang berhak untuk menerima beasiswa. Dalam
penelitian ini, sistem akan mengelompokkan mahasiswa menjadi tiga (3) cluster
yaitu:
1. Cluster yang direkomendasikan menerima beasiswa
2. Cluster yang dipertimbangkan menerima beasiswa
3. Cluster yang tidak menerima beasiswa
Kemudian setiap cluster dibagi berdasarkan kriteria mana yang lebih
diprioritaskan (berdasarkan IPK atau PO(penghasilan orang tua dibagi jumlah
tanggungan keluarga)).
Iterasi pada percobaan ini berhenti pada iterasi ke-2. Hasil akhir clustering
yang diperoleh adalah:
1) Cluster pertama memiliki pusat cluster (3,456; 1)
2) Cluster kedua memiliki pusat cluster (3,477; 2)
3) Cluster ketiga memiliki pusat cluster (3,376; 3,321)
Hasil klasifikasi clustering dapat dilihat pada Tabel 4.4.
Tabel 4.4 Hasil klasifikasi
Hasil klasifikasi mahasiswa berdasarkan Tabel 4.6 untuk 25 data dapat
dilihat pada Tabel 4.5. Data selengkapnya dapat dilihat pada Lampiran D. Prioritas IPK
Menerima Dipertimbangkan Tidak Berhak
Cluster 2 Cluster 1 Cluster 3
3,477 3,456 3,376
Prioritas PO
Menerima Dipertimbangkan Tidak Berhak
Cluster 3 Cluster 2 Cluster 1
commit to user
31
Tabel 4.5 Hasil klasifikasi mahasiswa
NIM IPK PO Cluster Prioritas IPK Prioritas PO
Sistem penentuan penerima beasiswa ini akan mengelompokkan data
dengan kecenderungan cluster yang sama ke dalam satu cluster. Cluster center
yang dihasilkan oleh proses clustering digunakan sebagai variabel penentu
klasifikasi. Sistem ini tidak memberi keleluasaan bagi pengguna untuk
menentukan jumlah cluster dan penambahan kriteria yang digunakan dalam
proses clustering. Dalam kasus ini, jumlah cluster yang digunakan adalah tiga (3),
yaitu cluster yang direkomendasikan menerima beaiswa, dipertimbangkan
commit to user
didasarkan pada perhitungan validasi cluster optimal. Sedangkan kriteria pokok
yang digunakan dalam proses clustering adalah dua (2) kriteria yaitu IPK dan PO.
Penentuan cluster mana yang direkomendasikan menerima beasiswa didasarkan
pada kriteria mana yang lebih diprioritaskan, dan keputusan mahasiswa penerima
beasiswa sepenuhnya berada ditangan pengambil keputusan. Implementasi sistem
menggunakan metode metode K-Means Clustering menghasilkan prototype
sistem yang dapat dilihat pada Lampiran E.
4.4.1 Gambaran Umum Sistem
Sistem penentuan penerima beasiswa merupakan sistem berbasis web yang
diharapkan dapat membantu mendukung keputusan untuk menetukan siapa saja
mahasiswa yang berhak untuk menerima beasiswa. Dalam sistem ini data
mahasiswa akan diolah menjadi beberapa kelompok data dengan metode K-means
Clustering. Dari kelompok-kelompok tersebut kemudian diklasifikan menjadi
kelompok yang direkomendasikan menerima, dipertimbangkan menerima, dan
tidak menerima beasiswa. Selama ini, penentuan penerima beasiswa dilakukan
dengan cara manual dan seringkali menimbulkan beberapa permasalahan, antara
lain membutuhkan waktu yang lama dan ketelitian yang tinggi karena data
mahasiswa akan dibandingkan dengan kriteria beasiswa satu persatu.
Sistem penentuan penerima beasiswa ini dibangun dengan basis data
MySql. Sebelum diolah dengan metode K-means Clustering, data input disimpan
ke sebuah database. Kemudian data akan diolah oleh sistem dan hasilnya akan
disimpan ke dalam database dan ditampilkan pada user interface. Gambaran
umum sistem dapat dilihat pada Gambar 4.1.
Gambar 4.1 Gambaran Umum Sistem
commit to user
33
4.4.2 Perancangan Basis Data
Basis data yang digunakan dalam sistem ini dimodelkan dalam relational
database model. Database Management Sistem yang digunakan adalah MySQL
5.5.20. Data data yang digunakan dalam proses clustering penentuan penerima
beasiswa disimpan dalam database, yang terdiri dari tabel tb_mahasiswa,
tb_cmsd, tb_dokumentasi, dan tb_login.
Adapun penjelasan mengenai tabel-tabel pada database adalah sebagai
berikut:
1. Tabel tb_mahasiswa
Tabel 4.6 Tb_mahasiswa
Field Type Keterangan
Nim Varchar(10) Not Null, Primary Key
Ipk Float Not Null
Jml_tk Int(1) Not Null
Gaji_total Int(10) Not Null
Po Varchar(10) Not Null
Por Int(1) Not Null
2. Tabel tb_cmsd
Tabel 4.7 Tb_cmsd
Field Type Keterangan
Id Int(1) Not Null
Field Type Keterangan
Nim Varchar(9) Not Null, Primary Key
Ipk Float Not Null
Gaji Int(1) Not Null
Cluster Int(1) Not Null
Stat_ipk Varchar(10) Not Null
commit to user
4. Tabel tb_loginTabel 4.9 Tb_login
Field Type Keterangan
Username Varchar(10) Not Null
Password Varchar(10) Not Null
4.5 Pengujian Clustering
Pengujian dilakukan untuk mengetahui keakuratan yang dihasilkan dalam
penerapan metode K-Means Clustering sebagai model untuk menentukan
penerima beasiswa. Pengujian dilakukan pada 48 data mahasiswa dengan
pengukuran presisi pada 40 kali percobaan. Data mahasiswa yang digunakan sama
tetapi dengan centroid awal berbeda akibat pembangkitan secara random. Dari 40
percobaan tersebut, diperoleh nilai minimum, maksimum, rata-rata, standart
deviasi, dan Error Presisi. Perhitungan Errror Presisi dihitung dari hasil
klasifikasi berdasarkan IPK dan berdasarkan PO.
Hasil perhitungan Errror Presisi berdasarkan klasifikasi IPK adalah
sebagai berikut:
Hasil perhitungan Errror Presisi berdasarkan klasifikasi PO adalah sebagai
berikut:
nilai Error Presisi pada hasil klasifikasi berdasarkan penghasilan orang tua adalah
0,076. Nilai Error Presisi rendah, sehingga menunjukkan bahwa nilai presisinya
tinggi. Nilai presisi yang tinggi menunjukkan ketetapan data pada setiap
percobaan dengan menggunakan 3 cluster juga tinggi. Untuk detail hasil
commit to user
BAB VPENUTUP
5.1 Kesimpulan
Kesimpulan yang dapat diambil berdasarkan hasil pembahasan adalah:
1. Algortima K-Means Clustering dapat digunakan untuk mengelompokkan data
mahasiswa sebagai pendukung keputusan penentuan penerimaan beasiswa.
2. Data mahasiswa dikelompokkan menjadi tiga cluster (menerima,
dipertimbangkan, dan tidak berhak menerima beasiswa). Kemudian setiap
cluster diklasifikasikan berdasarkan kriteria mana yang lebih diprioritaskan
yaitu salah satu dari kriteria IPK dan penghasilan orang tua. Cluster dengan
nilai terbesar pada centroid akhir merupakan cluster yang direkomendasikan
menerima beasiswa, sedangkan cluster dengan nilai terkecil merupakan
cluster yang tidak berhak menerima beasiswa.
3. Pengujian clustering dilakukan sebanyak 40 kali percobaan untuk
mendapatkan nilai presisi hasil implementasi metode K-Means. Nilai Error
Presisi pada hasil klasifikasi berdasarkan ipk adalah 0,118 dan nilai Error
Presisi pada hasil klasifikasi berdasarkan penghasilan orang tua adalah 0,076.
Nilai Error Presisi yang rendah menunjukkan bahwa nilai presisinya tinggi.
Nilai presisi yang tinggi menunjukkan ketetapan data pada setiap percobaan
dengan menggunakan 3 cluster juga tinggi. Namun demikian, clustering data
mahasiswa berdasarkan klasifikasi IPK memiliki hasil yang tidak bagus
(dapat dilihat pada Lampiran D, IPK tinggi seharusnya lebih berpeluang
untuk menerima beasiswa), sehingga tidak dapat dipakai untuk mendukung
keputusan penerimaan beasiswa dengan prioritas kriteria IPK.
5.2 Saran
Saran yang dapat digunakan untuk pengembangan penelitian selanjutnya
yaitu melakukan clustering dengan menambahkan kriteria lain dari Dikti yang
tidak digunakan pada penelitian ini seperti jumlah sks dan prestasi ko/ekstra