ALGORITMA K-MEANS CLUSTERING DALAM
PENGOLAHAN CITRA DIGITAL LANDSAT
Nur Ridha Apriyanti1, Radityo Adi Nugroho2, Oni Soesanto3
1,2,3Prodi Ilmu Komputer FMIPA UNLAM Jl. A. Yani Km 36 Banjarbaru, Kalimantan selatan
Email : [email protected]
Abstract
Digital image processing can now be done with a variety of assistive software, one of which ArcGIS. At ArcGIS there are some features of image classification with multiple algorithms, but there is an algorithm that has not been used, this is K-Means algorithm. From the test results are obtained 12 land cover classes as follows pastures, airports, mining, open land, plantations, swamps, bushes, shrubs, settlements, plantations, dryland agriculture, and vegetated land. Results of field inspections showed 94.4% fit, and 5.6% did not correspond to actual field conditions.
Keywords : Digital Image Processing, K-Means Algorithm, Clustering.
Abstrak
Pengolahan citra digital saat ini bisa dilakukan dengan berbagai macam software bantu, salah satunya ArcGIS. Pada ArcGIS terdapat beberapa fitur klasifikasi citra dengan beberapa algoritma, namun ada satu algoritma yang belum digunakan yaitu algoritma K-Means. Dari hasil pengujian didapatkan 12 kelas penutupan lahan sebagai berikut padang rumput, bandara udara, pertambangan, lahan terbuka, hutan tanaman, rawa, semak, belukar, pemukiman, perkebunan, pertanian lahan kering, dan lahan bervegetasi. Hasil pengecekan lapangan menunjukkan 94,4% sesuai, dan 5,6% tidak sesuai dengan kondisi lapangan yang sebenarnya.
Kata kunci : Pengolahan Citra Digital, Algoritma K-Means, Clustering
1. PENDAHULUAN
Pengolahan citra digital merupakan salah satu cara pengolahan data secara digital. Pengolahan citra digital sering digunakan untuk menganalisis suatu citra satelit yang hasilnya dapat dibandingkan dengan kenampakan suatu wilayah yang sebenarnya secara langsung. Citra satelit merupakan gambar (image) yang diambil dari satelit mengenai kenampakan permukaan bumi melalui penginderaan jauh
Dari sekian banyak satelit pengindraan jauh menurut Rahmi[5] yang sering
digunakan untuk pemetaan penutupan lahan adalah jenis citra Landsat (Land
Satellite).
Menurut Apriyanti[2] Citra Landsat dapat digunakan dengan terlebih dahulu
melalui proses pengolahan citra digital, dengan cara klasifikasi citra. Klasifikasi citra terdapat 2 cara, yaitu klasifikasi terawasi (supervised) dan klasifikasi tak terawasi (unsupervised). Klasifikasi terawasi yaitu pengelompokkan pixel-pixel dalam citra yang sebelumnya dianalisis terlebih dahulu untuk menentukan beberapa daerah contoh kemudian nilai-nilai pixel dalam daerah contoh yang memiliki nilai yang
dari klasifikasi terawasi, yaitu nilai-nilai pixel dikelompokkan terlebih dahulu oleh komputer menjadi beberapa kelas.
Banyak sekali algoritma yang digunakan dalam klasifikasi citra. Algoritma yang bisa digunakan untuk menyelesaikan klasifikasi terawasi antara lain
Parallelepiped, Minimum Distance, Mahalanobis Distance, Maximum Likelihood, Naive Bayesian, K-Nearest Neighbor. Algortima yang bisa digunakan untuk
menyelesaikan klasifikasi tak terawasi antara lain Isodata, K-Means, Improved Split
and Merge Classification (ISMC), dan Clustering Adaptif (CA).
Dari semua algoritma klasifikasi tak terawasi, ada algoritma yang belum digunakan pada aplikasi ArcGIS 10.2 yaitu algoritma K-Means Clustering. Algoritma
ini digunakan karena mudah diterapkan, dan menurut Ediyanto[4] dalam
penelitiannya, algoritma K-Means cukup efektif diterapkan dalam proses pengklasifikasian karakteristik objek, dan tidak terpengaruh terhadap urutan objek
yang digunakan. Menurut Danoesoebroto[3], karakteristik K-Means yaitu, proses
klasterisasi sangat cepat, sangat sensitif pada pembangkitan centroids awal secara random, dan memungkinkan suatu klaster tidak mempunyai anggota.
Penelitian ini mencoba untuk menggunakan algoritma K-Means Clustering dalam pengolahan citra digital, yaitu mengklasifikasikan citra landsat. Kemudian hasil dari klasifikasi citra ini dapat digunakan untuk klasifikasi lahan dimana klasifikasi lahan itu sendiri merupakan pengelompokkan lahan berdasarkan kesamaan karakteristik tertentu. Hasil dari klasifikasi lahan ini dapat digunakan untuk pemetaan penggunaan lahan di suatu wilayah.
2. METODE PENELITIAN
Citra Landsat akan diubah menjadi matriks RGB yang masing-masing komponen warna memiliki nilai pixel masing-masing dengan format vektor (𝑅, 𝐺, 𝐵) kemudian dari nilai pixel tersebut diambil nilai pixel masing-masing R, G dan B. Nilai ini akan dijadikan sebagai atribut-atribut dalam perhitungan algoritma K-Means.
Menurut Akhiruddin[1], jika dua garis vector adalah saling berdekatan, warna akan
ditampilkan serupa, rata-rata dari dua garis vector, jika warna yang yang akan ditampilkan sangat berbeda, maka akan diambil jalan tengah dengan menghadirkan suatu warna secara kasar dari warna aslinya. Berikut untuk detilnya dari penjelasan di atas, bagaimana pilihan penampilan warna mempengaruhi hasil proses
clustering:
a. Langkah yang pertama adalah menetapkan data set dari algoritma yang akan
digunakan (KMeans), yaitu dengan melakukan pengambilan nilai acak dari k.
b. Kemudian, penampilan RGB dari tiap pixel diciptakan, dan menghasilkan
dataset dalam 3- vektor.
c. Algoritma K-Means diterapkan pada dataset, menetapkan klusterisasi pusat k.
Algoritma K-Means akan menghadirkan k warna untuk menggambarkan citra tersebut.
d. Tiap-Tiap piksel citra dikonversi dalam suatu garis vektor RGB, dan
ditampilkan menggunakan rata-rata dari kelompok warna yang dihasilkan. Algoritma K-Means mengelompokkan objek berdasarkan pada atribut ke dalam pembagi k. Diasumsikan bahwa format atribut objek itu adalah suatu garis
vektor ruang. Menurut Akhiruddin[1], tujuannya adalah untuk memperkecil total
𝑉 = ∑ ∑|𝑥𝑗 − 𝜇𝑖|2 𝑗∈𝑆𝑖
𝑘
𝑖=1
⋯ ⋯ ⋯ ⋯ ⋯ ⋯ (1)
di mana ada k cluster Si, i = 1, 2,….,k dan 𝜇𝑖 adalah pusat luasan atau titik dari semua
poin-poin. Menurut Akhiruddin[1] algoritma ini dimulai dengan penyekatan
masukan menunjuk ke dalam tetapan k secara acak. Kemudian mengkalkulasi rata-rata titik, atau pusat luasan, dari tiap set. Hal ini mengakibatkan suatu sekat baru dengan menghubungkan masing-masing dengan pusat luasan yang terdekat. Kemudian pusat luasan dihitung kembali untuk klaster yang baru, dan algoritma yang diulangi dua langkah sampai pemusatan, yang mana diperoleh ketika poin-poin tidak lagi berpindah klaster.
Menurut Widodo[7], algoritma K-Means secara umum dilakukan dengan
algoritma dasar sebagai berikut:
a. Data yang ada dipisahkan dalam kelompok-kelompok data (klaster) k dan
nilai-nilai data diacak ke dalam hasil-hasil kelompok data dalam kelompok data yang memiliki kesamaan jumlah dari nilai data.
b. Tiap nilai data dihitung menggunakan jarak Euclidean untuk tiap klaster.
c. Jika nilai data diwakili kelompok data tersendiri, biarkan, dan jika nilai data
tak terwakili oleh kelompok data, pindah ke dalam kelompok data yang telah terwakili.
d. Ulangi langkah hingga lengkap meliputi seluruh hasil nilai data dalam
perpindahan satu klaster ke klaster lainnya.
Menurut Syakry[6], data yang digunakan untuk diklaster diperoleh dengan
membandingkan jarak (distance), jarak digunakan untuk menentukan tingkat kesamaan (similarity degree) atau ketidaksamaan dua vektor fitur. Tingkat kesamaan berupa suatu nilai (score) dan berdasarkan skor tersebut dua vektor fitur akan dikatakan mirip atau tidak. Euclidean distance adalah metrika yang paling sering digunakan untuk menghitung kesamaan 2 vektor. Euclidean distance menghitung akar dari kuadrat perbedaan 2 vektor.
𝑑𝑦 = √∑ (𝑥𝑖𝑘− 𝑥𝑗𝑘)
2 𝑛
𝑘=1 ... (2)
Gambar 1. Pemetaan Warna RGB.
Sumber : Klasifikasi Citra Sidik Jari (Berminyak, Normal, Kering) Berdasarkan Nilai Pixel Menggunakan K-Means Klastering. 2013
Contoh dari algoritma K-Means menurut Danoesoebroto[3] yaitu:
a. Iterasi ke-1. Pusat – pusat gugusan ditetapkan secara acak. Piksel – piksel
akan ditempatkan ke pusat – pusat terdekat.
b. Iterasi ke-2. Setiap pusat – pusat gugusan berpindah/bergerak ke pusat
tengah rataan, semua pikselnya.
c. Iterasi ke-n. Semua pusat gugusan telah stabil.
Gambar 2. Perubahan kelompok piksel.
Sumber : Klasifikasi Citra/Lahan- Klasifikasi Terbimbing dan Tak Terbimbing.2010 3. HASIL DAN PEMBAHASAN
3.1 Hasil
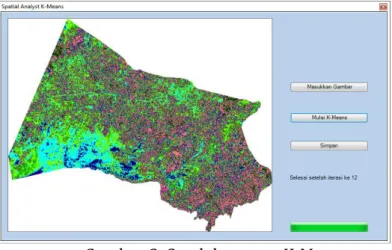
Form Spatial Analyst K-Means adalah form yang digunakan untuk menampilkan data raster yang akan diproses dan menampilkan hasil dari clustering. Terlebih dahulu user akan memasukkan format file gambar TIFF yang dipilih dari direktori, kemudian format file gambar TIFF akan ditampilkan di form Spatial
Analyst K-Means. Setelah itu user dapat menekan button proses agar proses
klasifikasi citra dengan algoritma K-Means dapat dilakukan. Selama proses
clustering user akan melihat progressbar berjalan, jika telah selesai akan message
dialog berisi pemberitahuan bahwa clustering telah selesai. Setelah proses selesai, gambar hasil dari clustering akan ditampilkan di form Spatial Analyst K-Means. Hasil dari clustering dapat disimpan ke dalam direktori sesuai pilihan user. Dan hasil dari
clustering juga akan ditampilkan pada ArcMap.
Adapun hasil dari pengolahan citra digital dengan K-Means adalah sebagai berikut:
Gambar 3. Setelah proses K-Means
Sumber : Pengolahan Citra Digital Landsat 8 dengan Algoritma K-Means Clustering (Studi Kasus : Banjarbaru, Kalimantan Selatan). 2015
3.2 Pembahasan
User akan menginputkan citra landsat 8 yang telah melalui proses composite
band dalam format file gambar TIFF dengan memilih data raster dari direktori yang
dimiliki oleh user, kemudian sistem akan berjalan ketika user menekan tombol proses. Dalam sistem, ada beberapa hal yang bisa dilakukan salah satunya mendapatkan data pixel gambar.
a. Ambil nilai pixel panjang (x)
b. Ambil nilai pixel tinggi/ lebar (y)
c. Untuk mengambil data masing-masing pixel, dilakukan iterasi / pengulangan
pembacaan data dari x=0 dan y=0 sampai dengan panjang dan lebar gambar input. Kemudian data pixel akan disimpan dalam bentuk matrik menggunakan tipe data array.
Ada berbagai unsur dalam suatu pixel yang dapat diambil atau diolah, seperti mendapatkan unsur warna RGB dan pengelompokkan nilai pixel. Untuk mendapatkan unsur warna gambar dengan ukuran 980x726 pixel akan dikonversi menjadi matrik [980, 726], setiap nilai dalam matrik mengandung nilai R, G, dan B, misal matrik [1,1] dengan nilai pixel (128, 128, 128), matrik [1,2] dengan nilai pixel (128, 128, 128), dan seterusnya hingga matrik [980, 726]. Kemudian dari nilai pixel yang terdapat pada matrik tersebut dibaca satu persatu untuk setiap nilai pixel Red, nilai pixel Green, dan nilai pixel Blue. Dari hasil tersebut dibentuk sebuah array yang memiliki nilai pixel Red, nilai pixel Green, dan nilai pixel Blue dengan jumlah data sebanyak 711.480 pixel untuk masing-masing model warna.
Pengelompokkan nilai pixel yang telah didapat dari proses sebelumnya akan dilakukan dengan algoritma K-Means, yang termasuk dalam klasifikasi tak terawasi (unsupervised). Adapun algoritma K-Means itu sendiri, yaitu sebagai berikut:
a. Menetapkan jumlah cluster (pengelompokkan atau kelas) yang akan
diklasifikasikan. Pada program ini peneliti telah menetapkan jumlah cluster yaitu 14.
b. Menetapkan secara acak nilai tengah (centroid) cluster.
Sumber data yang digunakan merupakan format file gambar TIFF, dengan ukuran 980 x 726 pixel, sehingga sebelum memasuki proses clustering sumber data akan diubah terlebih dahulu menjadi matriks pixel seperti gambar 4
dibawah ini dengan diambil ukuran 4x4 pixel:
Gambar 4. Matriks pada citra
Sumber : Pengolahan Citra Digital Landsat 8 dengan Algoritma K-Means Clustering (Studi Kasus : Banjarbaru, Kalimantan Selatan). 2015
Nilai yang dibaca oleh sistem yaitu nilai pixel RGB. Dari gambar 4 dapat dibuat tabel warna yaitu seperti tabel 1 di bawah ini:
Tabel 1. Nilai Pixel Warna
Data R Atribut Warna G B
1 62 62 62 2 76 76 76 3 80 80 80 4 81 81 81 5 64 64 64 6 65 65 65 7 64 64 64 8 62 62 62 9 67 67 67 10 66 66 66 11 60 60 60 12 57 57 57 13 67 67 67 14 75 75 75 15 72 72 72 16 66 66 66
Sumber : Pengolahan Citra Digital Landsat 8 dengan Algoritma K-Means Clustering (Studi Kasus : Banjarbaru, Kalimantan Selatan). 2015
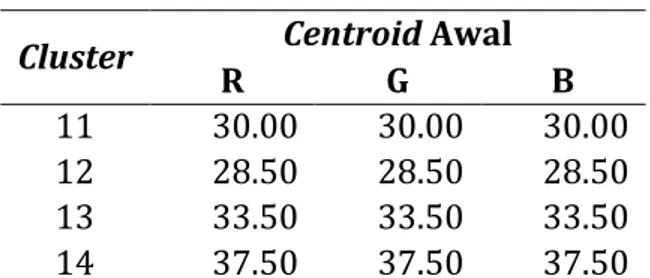
Untuk menentukan centroid awal digunakan cara yaitu diambil sebanyak 14 data dari tabel 1. Kemudian dari setiap nilai pixel data tersebut diambil nilai tengahnya. Contoh untuk data ke 1 atribut warna R, nilai pixel 62 maka
centroid awalnya yaitu 62 : 2 = 31. Langkah tersebut dilakukan untuk setiap
nilai R, G dan B hingga didapatkan 14 cluster sehingga didapatkan nilai
centroid awal seperti tabel 2 di bawah ini.
Tabel 2. Nilai Centroid Awal Cluster Warna
Cluster Centroid Awal
R G B 1 31.00 31.00 31.00 2 38.00 38.00 38.00 3 40.00 40.00 40.00 4 40.50 40.50 40.50 5 32.00 32.00 32.00 6 32.50 32.50 32.50 7 32.00 32.00 32.00 8 31.00 31.00 31.00 9 33.50 33.50 33.50 10 33.00 33.00 33.00
Cluster Centroid Awal R G B 11 30.00 30.00 30.00 12 28.50 28.50 28.50 13 33.50 33.50 33.50 14 37.50 37.50 37.50
Sumber : Pengolahan Citra Digital Landsat 8 dengan Algoritma K-Means Clustering (Studi Kasus : Banjarbaru, Kalimantan Selatan). 2015
c. Menghitung jarak Euclidean untuk tiap cluster.
Jarak untuk setiap data dihitung dengan persamaan di atas. Dengan penjelasan yaitu jarak untuk setiap anggota cluster dengan data yaitu dihitung dengan cara nilai pixel data 1 atribut warna R di kurangi dengan nilai centroid awal cluster 1 atribut warna R kemudian dipangkatkan dua, ditambah nilai
pixel data 1 atribut warna G di kurangi dengan nilai centroid awal cluster 1
atribut warna G kemudian dipangkatkan dua, nilai pixel data 1 atribut warna B di kurangi dengan nilai centroid awal cluster 1 atribut warna B kemudian dipangkatkan dua. Hasil penjumlahan tersebut diakarkan. Langkah tersebut dilakukan untuk semua data dari 1 hingga 16 untuk cluster 1 hingga cluster 3. Berikut contoh perhitungan untuk data 1 dengan cluster 1,
𝑑11= √(62 − 31)2+ (62 − 31)2+(62 − 31)2 = 53.69
data 1 dengan cluster 2,
𝑑12= √(62 − 38)2+ (62 − 38)2+(62 − 38)2 = 41.57
data 1 dengan cluster 3,
𝑑13= √(62 − 40)2+ (62 − 40)2+(62 − 40)2 = 38.11
Kemudian lakukan langkah yang sama untuk data ke 2 hingga ke 16. Tabel 3 berikut ini adalah hasil perhitungan jarak untuk setiap anggota cluster dari data ke 1 hingga ke 16.
Tabel 3. Jarak Tiap Cluster
Data Jarak C1 C2 C3 C4 C5 C6 C7 C8 C9 C10 C11 C12 C13 C14 1 53.69 41.57 38.11 37.24 51.96 51.10 51.96 53.69 49.36 50.23 55.43 58.02 49.36 42.44 2 77.94 65.82 62.35 61.49 76.21 75.34 76.21 77.94 73.61 74.48 79.67 82.27 73.61 66.68 3 84.87 72.75 69.28 68.42 83.14 82.27 83.14 84.87 80.54 81.41 86.60 89.20 80.54 73.61 4 86.60 74.48 71.01 70.15 84.87 84.00 84.87 86.60 82.27 83.14 88.33 90.93 82.27 75.34 5 57.16 45.03 41.57 40.70 55.43 54.56 55.43 57.16 52.83 53.69 58.89 61.49 52.83 45.90 6 58.89 46.77 43.30 42.44 57.16 56.29 57.16 58.89 54.56 55.43 60.62 63.22 54.56 47.63 7 57.16 45.03 41.57 40.70 55.43 54.56 55.43 57.16 52.83 53.69 58.89 61.49 52.83 45.90 8 53.69 41.57 38.11 37.24 51.96 51.10 51.96 53.69 49.36 50.23 55.43 58.02 49.36 42.44 9 62.35 50.23 46.77 45.90 60.62 59.76 60.62 62.35 58.02 58.89 64.09 66.68 58.02 51.10 10 60.62 48.50 45.03 44.17 58.89 58.02 58.89 60.62 56.29 57.16 62.35 64.95 56.29 49.36 11 50.23 38.11 34.64 33.77 48.50 47.63 48.50 50.23 45.90 46.77 51.96 54.56 45.90 38.97 12 45.03 32.91 29.44 28.58 43.30 42.44 43.30 45.03 40.70 41.57 46.77 49.36 40.70 33.77 13 62.35 50.23 46.77 45.90 60.62 59.76 60.62 62.35 58.02 58.89 64.09 66.68 58.02 51.10 14 76.21 64.09 60.62 59.76 74.48 73.61 74.48 76.21 71.88 72.75 77.94 80.54 71.88 64.95 15 71.01 58.89 55.43 54.56 69.28 68.42 69.28 71.01 66.68 67.55 72.75 75.34 66.68 59.76 16 60.62 48.50 45.03 44.17 58.89 58.02 58.89 60.62 56.29 57.16 62.35 64.95 56.29 49.36
Sumber : Pengolahan Citra Digital Landsat 8 dengan Algoritma K-Means Clustering (Studi Kasus : Banjarbaru, Kalimantan Selatan). 2015
d. Memindahkan data ke cluster yang memiliki sedikit jarak. Tabel 4. Posisi Data
Data Anggota Cluster
C1 C2 C3 C4 C5 C6 C7 C8 C9 C10 C11 C12 C13 C14 1 * 2 * 3 * 4 * 5 * 6 * 7 * 8 * 9 * 10 * 11 * 12 * 13 * 14 * 15 * 16 *
Sumber : Pengolahan Citra Digital Landsat 8 dengan Algoritma K-Means Clustering (Studi Kasus : Banjarbaru, Kalimantan Selatan). 2015
Berdasarkan hasil pengelompokkan pada tabel 4, posisi data terletak pada
cluster anggota cluster ke 4.
e. Menghitung centroid baru dari hasil cluster yang sekarang, karena data
kemungkinan berpindah. Dari tabel 4 dapat dilihat bahwa cluster yang memiliki anggota yaitu cluster ke 4 sedangkan cluster yang lain tidak memiliki anggota sehingga untuk menghitung centroid yang baru cara yang dilakukan adalah untuk cluster ke 1 hingga ke 14 kecuali cluster ke 4 centroid barunya bernilai sama dengan centroid awal. Sedangkan untuk cluster ke 4 nilai centroid barunya didapat dengan cara menghitung nilai pixel data ke 1 hingga data ke 16 untuk setiap nilai R, G dan B yaitu sebagai berikut:
CR4 =(62+76+80+81+64+65+64+62+67+66+60+57+67+75+72+66) 16 = 67.75 CG4= (62+76+80+81+64+65+64+62+67+66+60+57+67+75+72+66) 16 = 67.75 CB4= (62+76+80+81+64+65+64+62+67+66+60+57+67+75+72+66) 16 = 67.75
Berikut ini adalah tabel hasil perhitungan centroid yang baru: Tabel 5. Nilai Centroid Baru Cluster Warna
Cluster R Centroid Baru G B
1 31.00 31.00 31.00 2 38.00 38.00 38.00 3 40.00 40.00 40.00 4 67.75 67.75 67.75 5 32.00 32.00 32.00 6 32.50 32.50 32.50 7 32.00 32.00 32.00 8 31.00 31.00 31.00 9 33.50 33.50 33.50
Cluster R Centroid Baru G B 10 62.45 62.45 62.45 11 62.25 62.25 62.25 12 61.85 61.85 61.85 13 62.21 62.21 62.21 14 70.25 70.25 70.25
Sumber : Pengolahan Citra Digital Landsat 8 dengan Algoritma K-Means Clustering (Studi Kasus : Banjarbaru, Kalimantan Selatan). 2015
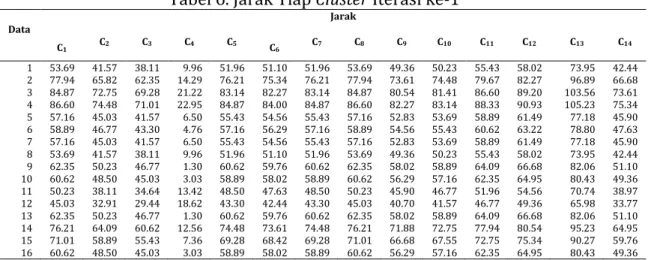
Kemudian dari centroid baru dilakukan kembali perhitungan jarak untuk setiap cluster. Seperti yang dilakukan pada langkah ke 3. Berikut adalah hasil perhitungan jarak yang baru yaitu:
Tabel 6. Jarak Tiap Cluster Iterasi ke-1
Data Jarak C1 C2 C3 C4 C5 C6 C7 C8 C9 C10 C11 C12 C13 C14 1 53.69 41.57 38.11 9.96 51.96 51.10 51.96 53.69 49.36 50.23 55.43 58.02 73.95 42.44 2 77.94 65.82 62.35 14.29 76.21 75.34 76.21 77.94 73.61 74.48 79.67 82.27 96.89 66.68 3 84.87 72.75 69.28 21.22 83.14 82.27 83.14 84.87 80.54 81.41 86.60 89.20 103.56 73.61 4 86.60 74.48 71.01 22.95 84.87 84.00 84.87 86.60 82.27 83.14 88.33 90.93 105.23 75.34 5 57.16 45.03 41.57 6.50 55.43 54.56 55.43 57.16 52.83 53.69 58.89 61.49 77.18 45.90 6 58.89 46.77 43.30 4.76 57.16 56.29 57.16 58.89 54.56 55.43 60.62 63.22 78.80 47.63 7 57.16 45.03 41.57 6.50 55.43 54.56 55.43 57.16 52.83 53.69 58.89 61.49 77.18 45.90 8 53.69 41.57 38.11 9.96 51.96 51.10 51.96 53.69 49.36 50.23 55.43 58.02 73.95 42.44 9 62.35 50.23 46.77 1.30 60.62 59.76 60.62 62.35 58.02 58.89 64.09 66.68 82.06 51.10 10 60.62 48.50 45.03 3.03 58.89 58.02 58.89 60.62 56.29 57.16 62.35 64.95 80.43 49.36 11 50.23 38.11 34.64 13.42 48.50 47.63 48.50 50.23 45.90 46.77 51.96 54.56 70.74 38.97 12 45.03 32.91 29.44 18.62 43.30 42.44 43.30 45.03 40.70 41.57 46.77 49.36 65.98 33.77 13 62.35 50.23 46.77 1.30 60.62 59.76 60.62 62.35 58.02 58.89 64.09 66.68 82.06 51.10 14 76.21 64.09 60.62 12.56 74.48 73.61 74.48 76.21 71.88 72.75 77.94 80.54 95.23 64.95 15 71.01 58.89 55.43 7.36 69.28 68.42 69.28 71.01 66.68 67.55 72.75 75.34 90.27 59.76 16 60.62 48.50 45.03 3.03 58.89 58.02 58.89 60.62 56.29 57.16 62.35 64.95 80.43 49.36
Sumber : Pengolahan Citra Digital Landsat 8 dengan Algoritma K-Means Clustering (Studi Kasus : Banjarbaru, Kalimantan Selatan). 2015
Kemudian pindahkan data ke cluster yang memiliki sedikit jarak. Sehingga diperoleh posisi data yang baru sebagai berikut:
Tabel 7. Posisi Data yang Baru
Data Anggota Cluster
C1 C2 C3 C4 C5 C6 C7 C8 C9 C10 C11 C12 C13 C14 1 * 2 * 3 * 4 * 5 * 6 * 7 * 8 * 9 * 10 * 11 * 12 * 13 * 14 * 15 * 16 *
Berdasarkan hasil pengelompokkan pada tabel 7, posisi data tetap seperti sebelumnya terlihat pada tabel 4.
f. Mengulangi langkah ke 3 hingga langkah ke 5 jika posisi data yang baru untuk
nilai centroid baru hasilnya berbeda. Jika posisi data yang baru untuk nilai
centroid baru hasilnya sama maka proses berhenti. Berdasarkan hasil
pengelompokkan pada tabel 7 posisi data yang baru sama dengan posisi data pada perhitungan sebelumnya seperti terlihat pada tabel 4. Sehingga proses iterasi dihentikan.
Hasil clustering kemudian diberi warna berbeda ditiap kelompoknya. Kemudian dari setiap warna tersebut dilakukan pengecekan lahan secara langsung. Berikut adalah hasil pengecekan keadaan sebenarnya di lapangan:
(a) (b)
Gambar 5. Hasil pengecekan lapangan (a) Pada peta hasil Clustering (b) Keadaan Lahan yang ditunjukkan peta
Sumber : Pengolahan Citra Digital Landsat 8 dengan Algoritma K-Means Clustering (Studi Kasus : Banjarbaru, Kalimantan Selatan). 2015
(a) (b)
Gambar 6. Hasil pengecekan lapangan (a) Pada peta hasil Clustering (b) Keadaan Lahan yang ditunjukkan peta (Bandara)
Sumber : Pengolahan Citra Digital Landsat 8 dengan Algoritma K-Means Clustering (Studi Kasus : Banjarbaru, Kalimantan Selatan). 2015
Tabel 8. Klasifikasi Penutupan Lahan
No Warna RGB Jenis Klasifikasi Lahan
1
(Biru Muda)
No Warna RGB Jenis Klasifikasi Lahan
2
(Biru Tua)
0, 0, 123 Bandara Udara Internasional, Pertambangan
3
(Biru Keunguan)
64, 0, 128 Lahan Terbuka / tanpa vegetasi
4
(Biru Elektrik)
0, 0, 160 Lahan Terbuka / tanpa vegetasi
5
(Biru)
0, 0, 255 Lahan Terbuka/tanpa vegetasi
6
(Merah Keunguan)
128, 0, 64 Hutan Tanaman, dan Pohon-pohon
7
(Merah Muda)
255, 128, 128
Rawa, vegetasi, semak dan belukar
8 (Jingga) 255, 128, 0 Vegetasi 9 (Hijau Kekuningan) 128, 255, 0 Pemukiman 10 (Hijau) 0, 200, 0 Vegetasi 11 (Hijau Gelap)
0, 64, 0 Perkebunan, Perkebunan Campuran, Hutan
Tanaman, Pertanian Lahan Kering. 12
(Cream)
255, 255, 128
Vegetasi
Sumber : Pengolahan Citra Digital Landsat 8 dengan Algoritma K-Means Clustering (Studi Kasus : Banjarbaru, Kalimantan Selatan). 2015
Peneliti melakukan pengecekan secara langsung ke lapangan sesuai warna yang ditunjukkan pada peta Banjarbaru. Untuk setiap warna diwakili oleh 3 lokasi. Jadi total lokasi yang diteliti yaitu 36 lokasi. Namun dari ke-36 lokasi tersebut ada 2 lokasi yang berbeda kondisi di lapangannya, yaitu warna merah muda tidak terdapat rawa seperti yang ditunjukkan pada peta hasil clustering. Dan biru muda di kecamatan Banjarbaru Utara tidak terdapat padang rumput seperti yang ditunjukkan pada peta hasil clustering. Jadi, berdasarkan hasil pengecekan lapangan yang didapatkan yaitu 94,4% sesuai, dan 5,6% tidak sesuai.
4. KESIMPULAN
Dari hasil penelitian dan pengamatan dari sistem yang telah dibuat, maka dapat diperoleh kesimpulan sebagai berikut:
a. Algoritma K-Means dapat digunakan dalam pengolahan citra digital, yaitu
sebagai algoritma untuk mengklasifikasikan citra sesuai nilai pixelnya.
b. Dengan algoritma K-Means wilayah Banjarbaru dibagi menjadi 12 kelas
dengan warna yang berbeda ditiap kelasnya untuk menandakan setiap penutupan lahan. 12 kelas pembagian wilayah Banjarbaru tersebut yaitu, padang rumput, bandara udara, pertambangan, lahan terbuka, hutan tanaman, rawa, semak, belukar, pemukiman, perkebunan, pertanian lahan kering, dan lahan bervegetasi.
c. Berdasarkan hasil pengecekan lapangan yaitu 94,4% sesuai, dan 5,6% tidak
DAFTAR PUSTAKA
[1] Apriyanti, Nur Ridha. 2015. Pengolahan Citra Digital Landsat 8 dengan
Algoritma K-Means Clustering (Studi Kasus: Banjarbaru, Kalimantan Selatan). Program S-1 Ilmu Komputer, Universitas Lambung Mangkurat:
Banjarbaru.
[2] Danoesoebroto, Ardityo. 2010. Klasifikasi Citra/Lahan- Klasifikasi Terbimbing
dan Tak Terbimbing. Institut Teknologi Bandung, Bandung.
[3] Ediyanto, dkk. 2013. Pengklasifikasian Karakteristik dengan Metode
K-Means Cluster Analysis. Buletin Ilmiah Mat. Stat. dan Terapannya
(Bimaster) vol 02, No.2, hal 133-136.
[4] Rahmi, Julia. 2009. Hubungan Kerapatan Tajuk dan Penggunaan Lahan
Berdasarkan Analisis Citra Satelit dan Sistem Informasi Geografis di Taman Nasional Gunung Leuser (Stidi Kasus: Kawasatn Hutan Resort Tangkahan, Cinta Raja, Sei Lepan dan Kawasan Ekosistem Leuser (KEL)).
Program Sarjana Departemen Kehutanan Fakultas Pertanian Universitas Sumatera Utara, Medan.
[5] Syakry, Sila Abdullah. 2013. Klasifikasi Citra Sidik Jari (Berminyak, Normal,
Kering) Berdasarkan Nilai Pixel Menggunakan K-Means Klastering. Politeknik
Negeri Lhokseumawe, Aceh.
[6] Widodo, Saptono; Hidayatno, Achmad; Isnanto, R Rizal. 2011. Segmentasi
Citra Menggunakan Teknik Pemetaan Warna (Color Mapping) dengan Bahasa Pemrograman Delphi. Program Sarjana Teknik Elektro Universitas