23
BAB IV
HASIL PENELITIAN DAN PEMBAHASAN
4.1. Pengujian Signifikansi Parameter a. Uji serentak parameter regresi logistik
Uji serentak adalah uji yang mempunyai fungsi dimana untuk mengetahui signifikansi parameter pada konstanta secara keseluruhan. Dibawah ini adalah tabel yang menggambarkan hasil dari uji serentak dengan Hipotesis :
∶ = = . . . = = 0 ∶ Paling tidak ada satu ≠ 0
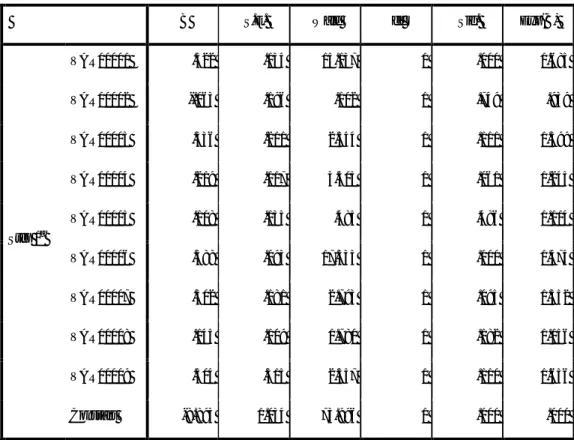
Tabel 4.1 uji omnibus koefisien model Omnibus Tests of Model Coefficients
Chi-square df Sig.
Step 1
Step 595.388 9 .000
Block 595.388 9 .000
Model 595.388 9 .000
Berdasarkan tabel 4.1 diperoleh nilai signifikansi model sebesar 0.000 karena nilai ini lebih kecil dari 5% maka tolak H0 sehingga disimpulkan bahwa
variabel bebas yang digunakan, secara bersama-sama berpengaruh terhadap jenis breast cancer terhadap variabel prediktornya atau ada salah satu variabel prediktor yang berpengaruh.
Pembentukan model pada uji serentak bisa dilihat pada tabel 4.1 Pada uji diharapakan H0 akan ditolak sehingga variabel yang sedang di uji masuk
kedalam model. Berdasarkan tabel 4.1 dapat dilihat variabel mana saja yang berpengaruh signifikan sehingga bisa dimasukkan ke model. Jika signifikan lebih kecil 5% maka H0 ditolak.
b. Uji parsial
Uji parsial ini berkebalikan dengan uji serentak, salah satu fungsi dari uji parsial adalah untuk mengetahui signifikansi parameter konstanta secara individu. Dimana dapat ditampilkan pada tabel dibawah ini dengan hipotesis
∶ = 0
∶ ≠ 0 ;j = 1,2,…,p
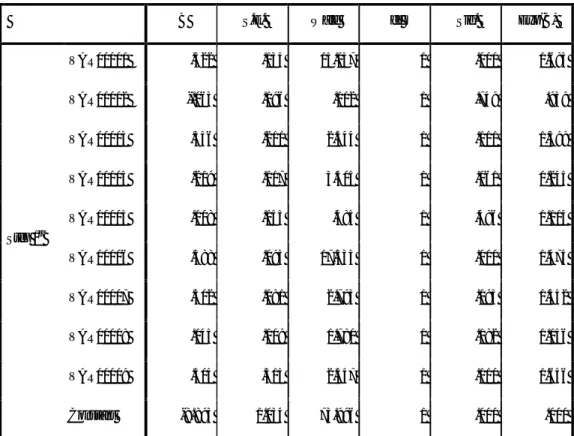
Tabel 4.2 Estimasi Parameter Variables in the Equation
B S.E. Wald df Sig. Exp(B)
Step 1a VAR00001 .522 .134 15.137 1 .000 1.685 VAR00002 -.063 .196 .102 1 .749 .939 VAR00003 .336 .211 2.544 1 .111 1.399 VAR00004 .219 .117 3.505 1 .061 1.245 VAR00005 .108 .155 .485 1 .486 1.114 VAR00006 .388 .093 17.333 1 .000 1.474 VAR00007 .302 .181 2.793 1 .095 1.352 VAR00008 .145 .109 1.780 1 .182 1.156 VAR00009 .504 .315 2.557 1 .110 1.656 Constant -8.893 1.034 73.996 1 .000 .000
a. Variable(s) entered on step 1: VAR00001, VAR00002, VAR00003, VAR00004, VAR00005,
Tabel 4.2 untuk uji parsial bisa dilihat pada nilai signifikansi mana yang nilainya lebih besar dari alfa. Nilai signifikansi yang sesuai model pada tabel 4.2 ada 2 yaitu pada VAR00001 dan VAR00006, dimana kedua variabel itu dijelaskan oleh jenis kanker antara lain untuk VAR00001 adalah Clump Thickness dan VAR00006 adalah
bare nuclei.
4.2 Uji kesesuaian model
Uji ini dilakukan untuk mengetahui apakah ada perbedaan antara hasil observasi dengan kemungkinan hasil prediksi model. Berdasarkan model regresi logistik diatas untuk selanjutnya pada uji kesesuaian model dapat dilihat pada tabel 4.3
Tabel 4.3 Uji hosmer dan lemeshow Hosmer and Lemeshow Test
Step Chi-square Df Sig.
1 9.429 8 .307
Tabel Hosmer and Lemeshow Test di atas juga dapat menguji kelayakan model serentak, hipotesis yang digunakan sebagai berikut:
H0 : Model sesuai (tidak ada perbedaan yang signifikan antara hasil pengamatan
dengan prediksi model)
H1 : Model tidak sesuai (ada perbedaan yang signifikan antara hasil pengamatan
dengan prediksi model) Tolak H0 jika nilai sig < 0,05
Nilai Chi-Square mendekati 9.429 dengan nilai signifikan sebesar 0.307 maka terima H0, sehingga dapat disimpulkan bahwa model yang dihasilkan pada regresi
bebas. Dengan kata lain tidak terdapat perbedaan yang signifikan antara hasil pengamatan dengan prediksi model karena terlihat dari tabel bahwa nilai sig = 0.307 yang berarti lebih dari 0,05 (terima H0). Dengan tingkat keyakinan 95 % dapat diyakini
bahwa model regresi logistik yang digunakan telah cukup mampu menjelaskan data/sesuai.
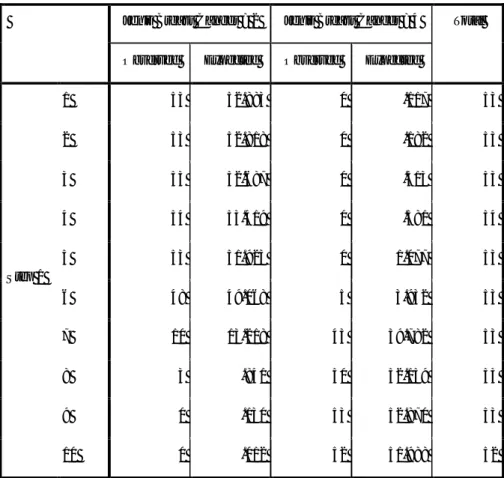
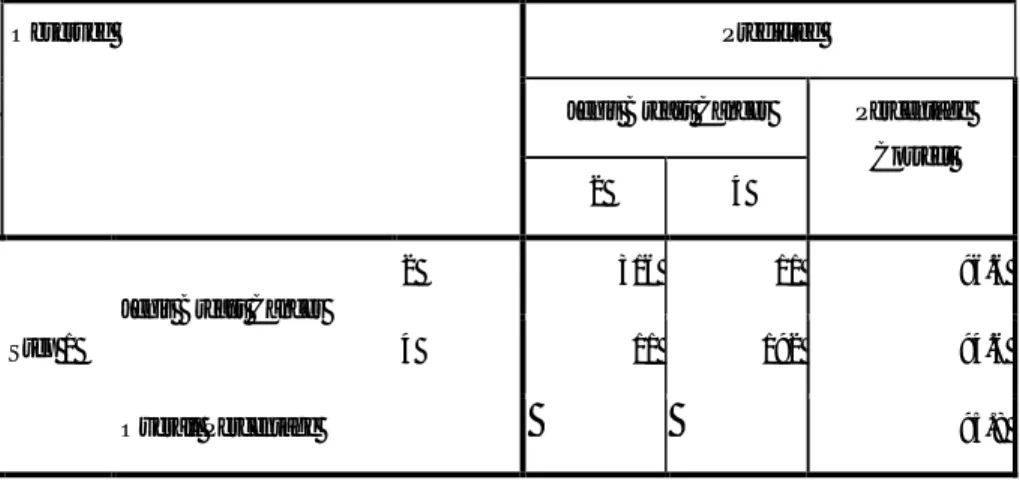
Tabel 4.4 Tabel kontingensi Uji hosmer dan Lemeshow Contingency Table for Hosmer and Lemeshow Test
Jenis Breast Cancer = 2 Jenis Breast Cancer = 4 Total
Observed Expected Observed Expected
Step 1 1 53 52.883 0 .117 53 2 53 52.818 0 .182 53 3 53 52.687 0 .313 53 4 54 53.419 0 .581 54 5 53 51.923 0 1.077 53 6 48 49.068 5 3.932 53 7 10 13.218 43 39.782 53 8 3 .841 50 52.159 53 9 0 .130 53 52.870 53 10 0 .012 52 51.988 52
Berdasarkan tabel 4.4 dapat dilihat frekuensi amatan dan harapan dari data, bahwa pada observasi 1 untuk kasus jenis breast cancer jinak berdasarkan pengamatan sejumlah 53 yang didiagnosa adalah 52 sehingga dapat disimpulkan bahwa selisih keduanya tidak terlalu jauh sehingga model bisa dikatakan sesuai. Sedangkan pada
observasi 1 untuk kasus jenis breast cancer ganas berdasarkan pengamatan sejumlah 0 yang didiagnosa adalah 0,1 sehingga dapat disimpulkan bahwa model tidak sesuai.
4.3 Interpretasi Koefisien Parameter a. Interpretasi odds ratio
Nilai odds ratio ini juga disediakan oleh tabel “variables in the equation”pada kolom Exp(B):
Tabel 4.5 Estimasi Parameter Variables in the Equation
B S.E. Wald df Sig. Exp(B)
Step 1a VAR00001 .522 .134 15.137 1 .000 1.685 VAR00002 -.063 .196 .102 1 .749 .939 VAR00003 .336 .211 2.544 1 .111 1.399 VAR00004 .219 .117 3.505 1 .061 1.245 VAR00005 .108 .155 .485 1 .486 1.114 VAR00006 .388 .093 17.333 1 .000 1.474 VAR00007 .302 .181 2.793 1 .095 1.352 VAR00008 .145 .109 1.780 1 .182 1.156 VAR00009 .504 .315 2.557 1 .110 1.656 Constant -8.893 1.034 73.996 1 .000 .000
a. Variable(s) entered on step 1: VAR00001, VAR00002, VAR00003, VAR00004, VAR00005,
VAR00006, VAR00007, VAR00008, VAR00009.
Berdasarkan hasil taberl 4.5 di atas kita dapat menginterpretasikan Odds ratio sebagai berikut:
1. Exp (B) pada observasi 1 artinya bahwa seseorang yang memiliki Clump
Thickness cenderung berisiko terkena breast cancer jinak sebesar 1.6 kali
dibandingkan yang terkena breast cancer ganas.
2. Exp (B) pada observasi 2 artinya bahwa seseorang yang memiliki Uniformity of
Cell size cenderung berisiko terkena breast cancer jinak sebesar 0.9 kali
dibandingkan yang terkena breast cancer ganas.
3. Exp (B) pada observasi 3 artinya bahwa seseorang yang memiliki Uniformity of
Cell shape cenderung berisiko terkena breast cancer jinak sebesar 1.3 kali
dibandingkan yang terkena breast cancer ganas.
4. Exp (B) pada observasi 4 artinya bahwa seseorang yang memiliki Marginal
Adhesion cenderung berisiko terkena breast cancer jinak sebesar 1.2 kali
dibandingkan yang terkena breast cancer ganas.
5. Exp (B) pada observasi 5 artinya bahwa seseorang yang memiliki Single
epithelial cell size cenderung berisiko terkena breast cancer ganas sebesar 1.1
kali dibandingkan yang terkena breast cancer jinak.
6. Exp (B) pada observasi 6 artinya bahwa seseorang yang memiliki bare nuclei cenderung berisiko terkena breast cancer jinak sebesar 1.4 kali dibandingkan yang terkena breast cancer ganas.
7. Exp (B) pada observasi 7 artinya bahwa seseorang yang memiliki Bland
Chromatin cenderung berisiko terkena breast cancer jinak sebesar 1.3 kali
dibandingkan yang terkena breast cancer ganas.
8. Exp (B) pada observasi 8 artinya bahwa seseorang yang memiliki Normal
nucleoli cenderung berisiko terkena breast cancer jinak sebesar 1.1 kali
9. Exp (B) pada observasi 9 artinya bahwa seseorang yang memiliki mitosis cenderung berisiko terkena breast cancer jinak sebesar 1.65 kali dibandingkan yang terkena breast cancer ganas.
Berdasarkan Tabel 4.5 dari variabel variabel respon untuk peluang besar yang terkena breast cancer adalah padaClump Thickness karena mempunyai nilai yang paling besar yaitu sebesar 1.685 dibanding dengan nilai dari variabel-variabel lain.
b. Model regresi logistik biner
Setelah dilakukan pengujian serentak, maka diperoleh model regresi logistik sebagai berikut:
g (x)= -8.893 + 0.522 x1 – 0.063x2 + 0.336x3 +0.219x4 +0.108x5 +0.388x6 +0.302x7 +
0.145x8+ 0. 504x9
dan model regresi logistiknya adalah:
( ) =
. . . .
1 + . . . .
Model dari regresi logistik diatas bisa disimpulkan bahwa peluang seseorang untuk terkena breast cancer jinak dipengaruhi oleh faktor Clump Thickness sebesar 0.522,
Uniformity of cell size sebesar -0.063, Uniformity of cell shape sebesar 0.336, Marginal Adhesion sebesar 0.219, Single Epithelial cell size sebesar 0.108, Bare nuclei
sebesar 0.388, Bland chromatin sebesar 0.302, Normal nucleoli sebesar 0.145, Mitosis sebesar 0.504.
c. Model summary
Tabel 4.6 Model summary
Model Summary
Step -2 Log likelihood Cox & Snell R Square
Nagelkerke R Square
1 110.066a .675 .917
a. Estimation terminated at iteration number 8 because parameter estimates changed by less than .001.
Cox & Snell R Square merupakan ukuran yang mencoba meniru ukuran R Square pada multiple regression yang didasarkan pada teknik estimasi likelihood dengan nilai maximum kurang dari 1 sehingga sulit untuk diinterpretasikan. Oleh karena itu, Nagelkerke R Square yang merupakan modifikasi dari cox & Snell di mana nilainya bervariasi dari 0-1, akan lebih mudah untuk diinterpretasikan sebagaimana interpretasi atas R Square pada multiple regression atau Pseudo R-Square dalam multinominal logistik regression.
Berdasarkan tabel model summary diatas menunjukkan nilai -2 log Likelihood sebesar 110.066 dimana nilai tersebut sangat besar. Selain itu dari nilai Nagelkerke R-Square sebesar 0.917 atau 91% maka variabilitas model penyakit breast cancer dapat dijelaskan oleh variabel bebas sebesar 91%, sedangkan sisanya akan dijelaskan oleh variabel lain.
4.4 Ketepatan Klasifikasi
Setelah dilakukan interpretasi koefisien, maka langkah selanjutnya menganalisis ketepatan klasifikasi model. Berikut ini hasil tabel klasifikasi:
Tabel 4.7 Tabel klasifikasi Classification Tablea
Observed Predicted
Jenis Breast Cancer Percentage
Correct
2 4
Step 1
Jenis Breast Cancer
2 316 11 96.6
4 11 192 94.6
Overall Percentage 95.8
a. The cut value is .500
Dari tabel ketepatan klasifikasi model diperoleh hasil responden jenis breats
cancer dengan kategori jinak dan diprediksi jinak ada 316 sedangkan yang berjenis
jinak tetapi diprediksi ganas ada 11. Responden yang berkategori ganas tetapi diprediksi jinak ada 11, sedangkan untuk responden yang mempunyai breast cancer ganas dan diprediksi ganas ada 192. Sehingga secara keseluruhan ketetapan klasifikasi model regresi logistik biner untuk kategori breats cancer jinak dan ganas sebesar 95.8%.
Penelitian yang sama pada kasus breast cancer yang dilakukan Darsyah (2013) dengan menggunkan Support Vector Machine (SVM) menghasilkan akurasi sebesar 99%. Dari hasil kedua metode SVM dan regresi logistik biner diketahui bahwa metode SVM memiliki tingkat akurasi lebih tinggi tetapi hasil yang diperoleh dari metode regresi logistik biner tidak berbeda jauh dari Support Vector Machine.