Perbandingan unjuk kerja database clustering versus database konvensional
Bebas
110
0
0
Teks penuh
(2) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. Performance Comparison Of MySQL Cluster and MySQL Conventional THESIS Presented as Partial Fulfillment of the Requirements To Obtain The Sarjana Komputer Degree in Informatics Engineering. By: Florencia Paramitha Hapsari Hendra Sutanto 105314075. INFORMATICS ENGINEERING STUDY PROGRAM DEPARTMENT OF INFORMATICS ENGINEERING FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY YOGYAKARTA 2015. ii.
(3) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. HALAMAN PERSETUJUAN TUGAS AKHIR Perbandingan Unjuk Kerja MySQL Cluster Versus MySQL Konvensional Oleh : Florencia Paramitha Hapsari Hendra Sutanto 105314075 Telah disetujui oleh :. Pembimbing,. Henricus Agung Hernawan, S.T., M. Kom. Tanggal : ________________. iii.
(4) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. SKRIPSI Perbandingan Unjuk Kerja MySQL Cluster Versus MySQL Konvensional Dipersiapkan dan ditulis oleh : Florencia Paramitha Hapsari Hendra Sutanto NIM : 105314075 Telah dipertahankan di depan panitia penguji pada tanggal 15 Januari 2015 dan dinyatakan memenuhi syarat Susunan Panitia Penguji Nama Lengkap. Tanda Tangan. Ketua. Puspaningtyas Sanjoyo Adi S.T., M. T.. ………………. Sekretaris. Stephanus Yudianto Asmoro S.T., M.Kom.. ………………. Anggota. Henricus Agung Hernawan S. T., M. Kom.. ………………. Yogyakarta, ………………….. Fakultas Sains dan Teknologi Universitas Sanata Dharma Dekan,. Paulina Heruningsih Prima Rosa S.Si., M.Sc. iv.
(5) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. HALAMAN MOTTO. 1Korintus 2:9 Tetapi seperti ada tertulis:"Apa yang tidak pernah dilihat oleh mata, dan tidak pernah didengar oleh telinga, dan yang tidak pernah timbul di dalam hati manusia: semua yang disediakan Allah untuk mereka yang mengasihi Dia." Flipi 4:13 Segala perkara dapat kutanggung di dalam Dia yang memberi kekuatan kepadaku.. v.
(6) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. HALAMAN PERSEMBAHAN. Karya ini saya persembahkan kepada :. Tuhan Yesus, yang sudah memberi saya kesempatan dan kemampuan untuk menyelesaikan kuliah. Keluarga tercinta, mami, papi, dan adik-adik ku. Terimakasih atas dukungan dan doanya. Kekasih tercinta, Abiya Wyanto. Terimakasih untuk kerja keras dan doanya dalam membantu pembuatan skripsi ini. Teman-teman Teknik Informatika 2010 yang tidak dapat disebut satu per satu. Terimakasih untuk semua dukungan dan semangatnya. Jemaat GPIA Keluarga Kristus yang tidak dapat disebut satu per satu. Terimakasih untuk semua dukungan dan doanya.. vi.
(7) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. PERNYATAAN KEASLIAN KARYA Saya menyatakan dengan sesungguhnya bahwa di dalam skripsi yang saya tulis ini tidak memuat karya atau bagian karya orang lain, kecuali yang telah disebutkan dalam kutipan dan daftar pustaka, sebagaimana layaknya karya ilmiah. Yogyakarta, 15 Januari 2015. Penulis. Florencia Paramitha Hapsari Hendra Sutanto. vii.
(8) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS Yang bertanda tangan di bawah ini, saya mahasiswa Universitas Sanata Dharma: Nama : Florencia Paramitha Hapsari Hendra Sutanto NIM : 105314075 Demi pengembangan ilmu pengetahuan, saya memberikan kepada Perpustakaan Universitas Sanata Dharma karya ilmiah yang berjudul: PERBANDINGAN UNJUK KERJA MYSQL CLUSTER VERSUS MYSQL KONVENSIONAL Beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikan kepada perpustakaan Universitas Sanata Dharma hak untuk menyimpan, mengalihkan dalam bentuk media lain, mengelolanya dalam bentuk pangkalan data mendistribusikan secara terbatas, dan mempublikasikannya di Internet atau media lain untuk kepentingan akademis tanpa perlu meminta ijin dari saya maupun memberikan royalti kepada saya selama tetap mencamtumkan nama saya sebagai penulis. Demikian pernyataan ini saya buat dengan sebenarnya. Dibuat di Yogyakarta, Pada tanggal: 15 Januari 2015. Yang menyatakan,. (Florencia Paramitha Hapsari Hendra Sutanto) viii.
(9) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. ABSTRAK MySQL Cluster diciptakan untuk mengatasi masalah database yang sering diakses oleh banyak orang. Database yang besar dalam pelayanannya tidak menggunakan server database tunggal, tetapi dilayani oleh sekelompok server database, beberapa buah server database dihubungkan menjadi satu. Cara kerja MySQL Cluster ini adalah dengan memisahkan fungsi storage dan fungsi pengolahan query. Untuk mengetahui perbandingan cara kerja MySQL Cluster dengan MySQL konvensional maka perlu dilakukan pengujian. Parameter yang digunakan dalam pengujian adalah banyaknya jenis klien yang dapat mengakses serta kecepatan eksekusi query yang diperlukan. Pengujian menggunakan program mysqlslap yang sudah terinstal pada komputer klien. Dari. pengujian. tersebut. dapat. ditarik. kesimpulan. bahwa. peningkatan kecepatan query insert, update, dan delete serta jumlah klien yang dapat mengakses pada MySQL Cluster, berbanding lurus dengan banyaknya Daemon Node yang digunakan.. Kata Kunci: Database, MySQL, clustering, InnoDB, NDBCluster. ix.
(10) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. ABSTRACT MySQL Cluster was created to overcome problems that arise when a database is frequently accessed by many people. A large database is not served by a single server, but by a group of servers. MySQL Cluster separates the functions of storage and query processing to different servers. To determine how MySQL Cluster compares with conventional MySQL it is necessary to analyse their performance. The parameters used in testing are number of clients that can access the database simultaneously and query execution time. Testing is done using mysqlslap that is installed on the client computer. From these tests it can be concluded that the increase in the speed of insert, update, and delete queries as well as the number of clients that can access the MySQL Cluster simultaneously are directly proportional to the number of Node Daemons used.. Keywords: Database, MySQL, clustering, InnoDB, NDBCluster. x.
(11) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. KATA PENGANTAR Puji dan syukur penulis panjatkan kepada Tuhan Yang Maha Esa, sehingga penulis dapat menyelesaikan tugas akhir sebagai salah satu mata kuliah wajib dan merupakan syarat akademik pada jurusan Teknik Informatika Universitas Sanata Dharma Yogyakarta. Pada kesempatan ini, penulis ingin mengucapkan terima kasih kepada pihak-pihak yang telah membantu penulis baik selama penelitian maupun saat pengerjaan skripsi ini. Ucapan terima kasih penulis sampaikan di antaranya kepada : 1.. Tuhan Yesus Kristus, sebagai penuntun langkah hidup penulis yang selalu memberikan penulis hikmat dan kekuatan dalam menjalani kehidupan.. 2.. Orang tua, Hendra Sutanto dan Christine Ratna Dewi atas dukungan doa, moral, spiritual dan finansial dalam penyusunan skripsi.. 3.. Contessa Prastica Puteri dan Marlon Adhitama Sutanto, adik-adik penulis yang selalu memberikan semangat kepada penulis.. 4.. Abiya Wyanto. Yang selalu mendukung penulis dalam mengerjakan skripsi dari awal sampai akhir, baik melalui doa maupun dalam pengambilan data serta menganalisisnya.. 5.. Bapak Henricus Agung Hernawan S. T., M. Kom., sebagai Dosen Pembimbing Tugas Akhir. Yang selalu memberikan masukan dan membantu penulis ketika mengalami kesulitan.. xi.
(12) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. 6.. Bp. Pdt. Henky N.S, M.Th, selaku Gembala penulis. Yang tidak pernah berhenti mendoakan dan menuntun penulis.. 7.. Ibu Sri Hartati Wijono, S. T., selaku Dosen Pembimbing Akademik.. 8.. Ibu Ridowati Gunawan, S. T., selaku Kepala Program Studi Tkenik Informatika.. 9.. Ibu P.H. Prima Rosa, S.T., selaku Dekan Fakultas Sains dan Teknologi.. 10. Seluruh teman-teman Teknik Informatika 2010. 11. Seluruh teman-teman Pejuang Skripsi, terutama Mas Yoshi, Windy, Yoyo, Angga, Kejut, Krisma, Topel, Hohok, Mbak Nisa dan yang lain yang telah berjuang membuka Lab Jarkom Utara. 12. Tiara, Eka, Queen, dan teman-teman lain yang selalu berbagi canda tawa dengan penulis. 13. Mas Danang dan Mas Darno, yang sudah bersedia melayani peminjaman alat. 14. Semua pihak yang tidak dapat disebutkan satu per satu yang telah membantu penulis dalam pengerjaan skripsi ini. Akhirnya penulis berharap semoga skripsi ini dapat berguna bagi pembaca. Penulis,. Florencia Paramitha Hapsari H.S. xii.
(13) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. DAFTAR ISI HALAMAN PERSETUJUAN ................................................................ iii HALAMAN MOTTO ............................................................................... v HALAMAN PERSEMBAHAN .............................................................. vi PERNYATAAN KEASLIAN KARYA ................................................. vii LEMBAR PERNYATAAN PERSETUJUAN ..................................... viii ABSTRAK ................................................................................................ ix ABSTRACT ............................................................................................... x KATA PENGANTAR .............................................................................. xi DAFTAR ISI........................................................................................... xiii BAB I .......................................................................................................... 1 1.1.. Latar Belakang ........................................................................ 1. 1.2.. Rumusan Masalah ................................................................... 3. 1.3.. Tujuan Penelitian .................................................................... 3. 1.4.. Batasan Masalah ...................................................................... 3. 1.5.. Metodologi Penelitian .............................................................. 4. 1.5.1. Studi literatur ....................................................................... 4 1.5.2. Implementasi sistem ............................................................. 4 1.5.3. Metode Pengukuran dan pengumpulan data .................... 5 1.5.4. Metode Analisis Data ........................................................... 5 xiii.
(14) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. 1.6.. Sistematika Penulisan.............................................................. 6. BAB II ........................................................................................................ 8 2.1.. Database.................................................................................... 8. 2.1.1. Pengertian Database ............................................................ 8 2.1.2. Program Aplikasi Database ............................................... 11 2.2.. SQL ......................................................................................... 12. 2.2.1. Pengertian SQL .................................................................. 12 2.2.2. Komponen SQL .................................................................. 13 2.3.. MySQL ................................................................................... 14. 2.3.1. Pengertian MySQL ............................................................... 14 2.3.2. Macam-Macam Storage Engine MySQL ............................ 15 2.4.. Clustering ............................................................................... 20. 2.4.1. Pengertian Clustering ........................................................ 20 2.4.2. MySQL Cluster .................................................................. 23 2.5.. Mysqlslap ................................................................................ 28. BAB III ..................................................................................................... 30 3.1.. Spesifikasi Perangkat Lunak dan Perangkat Keras .......... 30. 3.1.1.. Perangkat Keras (Hardware)............................................ 30. 3.1.2.. Switch Ethernet (Mikrotik Router Board RB951GS) .... 31. 3.1.3.. Kabel Ethernet ................................................................... 32. xiv.
(15) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. 3.2.. Diagram Alir Desain Pengujian ........................................... 33. 3.3. Rencana Kerja ....................................................................... 35. 3.4 Desain Sistem Jaringan ................................................................ 36 BAB IV ..................................................................................................... 43 4.1.. Pembangunan Infrastuktur .................................................. 43. 4.2.. Data Penelitian ....................................................................... 43. 4.2.1.. Analisa Skenario 2 dan 4 .................................................. 44. 4.2.2.. Query Select ....................................................................... 45. 4.2.3.. Query Insert ....................................................................... 50. 4.2.4. Query Update...................................................................... 55 4.2.5. Query Delete ....................................................................... 59 BAB V ...................................................................................................... 64 5. 1.. Kesimpulan............................................................................. 64. 5. 2.. Saran ....................................................................................... 64. DAFTAR PUSTAKA .............................................................................. 66 LAMPIRAN ............................................................................................. 68. xv.
(16) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. BAB I PENDAHULUAN 1.1.. Latar Belakang Teknologi informasi saat ini memiliki peranan penting dalam berbagai aspek kehidupan, mulai dari bidang pendidikan, bisnis, politik hingga perekonomian. Hal ini disebabkan oleh karena teknologi informasi dapat memenuhi kebutuhan masyarakat akan informasi. Dengan perkembangan teknologi informasi, kita dapat mencari dan mengolah informasi dengan mudah, cepat dan akurat, serta dengan biaya yang lebih murah. Namun dalam mewujudkan hal tersebut diperlukan sebuah sistem agar dapat berjalan dengan baik. Database adalah kumpulan data yang secara logis terkait satu sama lain dan digunakan bersama oleh banyak pemakai, serta dirancang untuk memenuhi kebutuhan informasi banyak pemakai dalam suatu organisasi. Berbagai macam aplikasi database dituntut untuk mampu melayani banyak akses data, hal ini sangat wajar karena database server memang dirancang untuk dapat melayani berbagai macam jenis akses data. Seiring dengan berkembangnya berbagai macam aplikasi database, baik dalam segi fungsi, ukuran, maupun kompleksitas, hal tersebut secara langsung akan berdampak pada server database sebagai penyedia layanan terhadap akses database, konsekuensinya adalah beban database bertambah berat. 1.
(17) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. dan mengakibatkan kinerja dari server tidak optimal. Selain itu, ketika sebuah database diakses oleh banyak orang dalam waktu bersamaan sering menyebabkan server database menjadi down, sehingga membuat banyak orang kesulitan untuk mengakses data. [5] Teknologi clustering diciptakan untuk mengatasi masalah database yang sering diakses oleh banyak orang.[5] Banyak sekali manfaat yang diperoleh dari teknologi cluster salah satunya adalah untuk meningkatkan kinerja sistem. Analoginya, database yang besar dalam pelayanannya tidak menggunakan server database tunggal, tetapi dilayani oleh sekelompok server database, beberapa buah server database dihubungkan menjadi satu, sehingga beban yang dimiliki server akan berkurang karena bebannya sudah dibagi-bagi menjadi beberapa komputer. MySQL saat ini sedang mengembangkan teknik clustering dan dalam teknologinya terdapat replikasi database yang mampu mengatasi failure sistem database itu sendiri. Melalui tugas akhir ini, penulis tertarik untuk merancang database server secara cluster dan menguji kinerja teknik clustering menggunakan MySQL Cluster, sehingga dapat dilihat sejauh apa teknik clustering ini berjalan cukup baik dibandingkan tanpa menggunakan teknik clustering.. 2.
(18) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. 1.2.. Rumusan Masalah Dengan melihat latar belakang masalah tersebut maka masalah yang akan diselesaikan adalah: Seberapa jauh peningkatan kinerja terkait dengan banyaknya koneksi yang dapat terhubung dengan MySQL Cluster jika dibandingkan dengan MySQL konvensional?. 1.3.. Tujuan Penelitian Tujuan penelitian pada tugas akhir ini adalah : 1. Memberi pemaparan mengenai perbandingan peningkatan kinerja terkait dengan banyaknya koneksi yang dapat terhubung dengan MySQL Cluster jika dibandingkan dengan MySQL konvensional. 2. Untuk menambah penelitian dan studi ilmiah. tentang cara. perancangan dan pembangunan database berbasis clustering.. 1.4.. Batasan Masalah Untuk menghindari pembahasan yang terlalu luas maka penulis akan membatasi dalam penulisan ini hal-hal berikut: 1. Penelitian menggunakan 4 buah komputer fisik untuk MySQL Cluster yaitu, 1 komputer untuk komputer management node, 2 komputer untuk daemon node, dan 1 komputer untuk data node. Spesifikasi ke-empat komputer adalah sama.. 3.
(19) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. 2. Sistem operasi yang digunakan adalah CentOS-6.5-x86_64. 3. Penelitian menggunakan software mysqlslap untuk menguji kinerja MySQL Cluster yang diinstal pada 2 buah komputer fisik yang digunakan sebagai klien. 4. MySQL Cluster yang digunakan adalah versi 7.0. 5. Parameter yang diukur adalah beban CPU, memory, kecepatan eksekusi query, network traffic dan jumlah klien. 6. Parameter yang diubah adalah jumlah klien dan jenis query. 7. Penelitian dilakukan pada jaringan intranet dan tidak menguji keamanan dari database clustering.. 1.5.. Metodologi Penelitian Metodologi yang digunakan dalam pelaksanaan tugas akhir dan penelitian adalah sebagai berikut:. 1.5.1. Studi literatur Mengumpulkan referensi literatur tentang clustering database, MySQL Cluster, mysqlslap dan command CentOS dengan mengumpulkan jurnal-jurnal, buku-buku, dan referensi lainnya yang dapat mendukung topik ini. 1.5.2. Implementasi sistem Implementasi dilakukan dengan menguji sebuah server MySQL dengan jumlah klien awal 25 dan terus ditambah hingga server tidak dapat. 4.
(20) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. merespon, kemudian menguji server mysql cluster dengan menggunakan 1 komputer sebagai management node, 1 komputer sebagai daemon node, dan 1 komputer sebagai data node, kemudian menguji server MySQL cluster menggunakan 1 komputer sebagai management node, 2 komputer sebagai daemon node dan 1 komputer sebagai Data node. Hasil dari masing-masing skenario akan dibandingkan. 1.5.3. Metode Pengukuran dan pengumpulan data Data yang diambil dalam penelitian ini adalah berupa hasil beban CPU, memory, kecepatan eksekusi query, network traffic dan jumlah klien pada MySQL Cluster maupun MySQL konvensional. Metode pengumpulan data yang digunakan dalam penelitian ini adalah: a. Metode observasi Kegiatan observasi dalam penelitian dilakukan untuk mengamati kinerja database pada teknik clustering maupun teknik konvensional, yang diamati langsung di tempat penilitian. b. Metode dokumentasi. Dokumentasi yang dimaksud dalam penelitian ini adalah gambar atau foto tentang penelitian, perangkat dan software serta data-data yang yang didapat saat penelitian. 1.5.4. Metode Analisis Data Dalam metode ini, penulis menganalisis dan menyimpulkan hasil penelitian yang telah didapat. Hal itu dilakukan dengan melakukan 5.
(21) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. perbandingan terhadap data dari beberapa kali pengukuran dan dicari penyebab jika terjadi perbedaan terhadap data tersebut. 1.6.. Sistematika Penulisan A. BAB I: PENDAHULUAN Bab ini berisi latar belakang penulisan tugas akhir, rumusan masalah, batasan masalah, tujuan penelitian, metodologi penelitian dan sistematika penulisan. B. BAB II: LANDASAN TEORI Bab ini menjelaskan tentang teori-teori yang digunakan dan menjadi dasar penelitian, serta berkaitan dengan judul atau rumusan masalah tugas akhir. C. BAB III: PERENCANAAN PENELITIAN Bab ini menjelaskan tentang spesifikasi alat dan spesifikasi teknis skenario pengujian yang akan dilakukan dan perencanaan pengujian. D. BAB IV: IMPLEMENTASI DAN ANALISIS Bab ini berisi setting yang digunakan pada saat implementasi, pelaksanaan pengujian dan hasil pengujian, serta analisis data hasil pengujian. E. BAB V: KESIMPULAN DAN SARAN. 6.
(22) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. Bab ini berisi kesimpulan dan saran berdasarkan hasil analisa pengujian yang telah dilaksanakan.. 7.
(23) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. BAB II DASAR TEORI 2.1.. Database. 2.1.1. Pengertian Database Sejarah penelitian database selama 30 tahun terakhir merupakan salah satu produktivitas yang luar biasa yang telah menyebabkan database menjadi perkembangan yang paling penting di bidang software engineering. Database saat ini menjadi kerangka dasar system informasi, dan secara fundamental telah mengubah cara banyak organisasi beroperasi. Selama beberapa tahun terakhir, teknologi ini secara khusus telah menghasilkan sistem yang lebih kuat dan lebih intuitif untuk digunakan. Data merupakan fakta mengenai suatu objek seperti manusia, benda, peristiwa, konsep, keadaan dan sebagainya yang dapat dicatat dan mempunyai arti secara implisit. Data dapat dinyatakan dalam bentuk angka, karakter atau simbol, sehingga bila data dikumpulkan dan saling berhubungan maka dikenal dengan istilah database. Database menurut Connoly adalah kumpulan data yang secara logis terkait satu sama lain dan digunakan bersama oleh banyak pemakai, serta dirancang untuk memenuhi kebutuhan informasi banyak pemakai dalam suatu organisasi. Artinya database merupakan penyimpanan data yang tunggal dan besar. 8.
(24) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. yang dapat digunakan secara simultan oleh banyak bagian departemen dan user. Di dalam database semua item diintegrasikan dengan jumlah duplikasi data yang minimum. Database tidak lagi dimiliki oleh suatu departemen, melainkan resource perusahaan yang dapat dibagi. Database tidak hanya mengandung data operasional organisasi, tetapi juga deskripsi dari data tersebut. Untuk itu, sebuah dataabse juga mendefinisikan integrasi record dari database itu sendiri (self-describing of integrated record). Deskripsi dari data dikenal sebagai sistem catalog (data dictionary-meta data). Deskripsi ini menciptakan kebebasan dari program aplikasi (program data independence). Pendekatan dengan sistem database, dimana definisi dari data adalah dipisahkan dari program aplikasi. Pemakai atau user dalam melihat sebuah objek hanya pada definisi eksternal dan tidak mengetahui bagaimana objek didefinisikan dan objek bisa berfungsi. Pendekatan ini dikenal sebagai abstraksi data (data abstraction), di mana perubahan definisi internal dari sebuah objek tanpa mempengaruhi pemakai (user) atau tidak mempengaruhi definisi eksternal. Dalam arti lainnya, pendekatan database memisahkan struktur dari pada data dari program aplikasi dan menyimpannya ke dalam database. Jika ada penambahan struktur data atau perubahan struktur data yang ada maka tidak akan mempengaruhi program aplikasi, sehingga tidak perlu bergantung langsung dengan apa yang telah dirubah. Sedangkan menurut George Tsu-der Chou database merupakan kumpulan informasi. 9.
(25) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. bermanfaat yang diorganisasikan ke dalam aturan yang khusus. Informasi ini adalah data yang telah diorganisasikan ke dalam bentuk yang sesuai dengan kebutuhan seseorang. Menurut Encyclopedia of Computer Science and Engineer, para ilmuwan di bidang informasi menerima definisi standar informasi yaitu data yang digunakan dalam pengambilan keputusan. Menurut Ramez Elmasri mendefinisikan database lebih dibatasi pada arti implisit yang khusus, yaitu:[6] a. Database merupakan penyajian suatu aspek dari dunia nyata (real world). b. Database merupakan kumpulan data dari berbagai sumber yang secara logika mempunyai arti implisit. Sehingga data yang terkumpul secara acak dan tanpa mempunyai arti, tidak dapat disebut basis data. c. Database perlu dirancang, dibangun dan data dikumpulkan untuk suatu tujuan. Database dapat digunakan oleh beberapa user dan beberapa aplikasi yang sesuai dengan kepentingan user. Dari beberapa definisi-definisi tersebut, dapat dikatakan bahwa database merupakan data yang dikumpulkan dari berabagai sumber yang dirancang dan dibuat agar mudah digunakan oleh user untuk berbagai keperluan.. 10.
(26) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. Berikut ini kegunaan basis data dalam mengatasi masalah penyusunan data : a. Redudansi dan inkosistensi data. b. Multiple user. c. Kesulitan pengaksesan data. d. Security (keamanan). e. Kebebasan data. Pada umumnya data dalam database bersifat integrated dan shared. Integrated artinya adalah dataabse merupakan gabungan dari beberapa file data yang saling berbeda satu dengan yang lainnya dengan membatasi pengulangan baik keseluruhan file atau sebagian. Shared maksudnya adalah data individual dalam database dapat digunakan secara bersamasamaan antara beberapa pengguna yang berbeda.. 2.1.2. Program Aplikasi Database Program Aplikasi Database adalah sebuah program computer yang berinteraksi dengan database dengan mengeluarkan permintaan yang sesuai (pada umumnya sebuah perintah SQL) ke database. User berinteraksi dengan database melalui berbagai macam program aplikasi yang digunakan untuk membuat dan memelihara database dan menghasilkan informasi. Program tersebut dan berupa aplikasi batch konvensional ata pada umumnya sekarang aplikasi online. Program. 11.
(27) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. aplikasi tersebut dapat ditulis dalam sebuah bahasa programming atau dalam higher-level fourth-generation language. 2.2.. SQL. 2.2.1. Pengertian SQL Idealnya, sebuah bahasa database harus memungkinkan user untuk: . Membuat database dan struktur relasi.. . Melaksanakan tugas database manajemen seperti, insert, update, dan menghapus data dari relasi.. . Melaksanakan query yang simple dan complex.. SQL adalah suatu bahasa komputer yang mengikuti standard ANSI (American National Standard Institute), yaitu sebuah bahasa standard yang digunakan untuk mengakses dan melakukan manipulasi suatu sistem database. Statemen dalam SQL dapat digunakan untuk mengakses data atau meng-update data pada suatu database. SQL utamanya berfungsi dalam suatu relational database seperti misalnya Oracle, SQL Server, DB2, Informix, Sybase, MS Acces, MySQL, Firebird dan masih banyak lagi yang lainnya. Dengan adanya berbagai perusahaan/vendor yang membuat berbagai produk SQL maka efeknya adalah timbul berbagai macam perbedaan dalam bahasa SQL yang dikembanglan oleh tiap-tiap. 12.
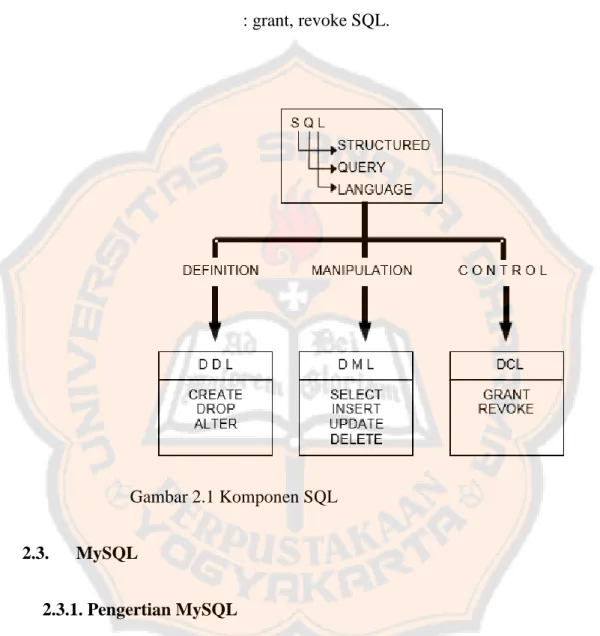
(28) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. perusahaan tersebut. Contohnya saja, bahasa SQL yang dimiliki oleh Microsoft (yang bernama T-SQL) akan berbeda dengan bahasa SQL yang dikembangkan oleh Oracle (yang bernama PL/SQL). Namun demikian semua vendor diwajibkan untuk mendukung bahasa standard yang ditentukan oleh ANSI, misalnya semua pengembang bahasa SQL wajib dalam mengimplementasikan kata kunci atau statemen standard SQL seperti SELECT, UPDATE, DELETE, INSERT, WHERE dan lain sebagainya. Perbedaan bahasa SQL yang dikembangkan oleh setiap vendor itu dinamakan extension atau juga disebut dengan dialek. 2.2.2. Komponen SQL Komponen-Komponen SQL adalah sebagai berikut: a. Data Definition Language (DDL) : Digunakan untuk mendefinisikan data dengan menggunakan perintah : create, drop, alter. b. Data Manipulation Language (DML) : Digunakan untuk memanipulasi data dengan menggunakan perintah : select, insert, update, delete. Data Manipulation Language merupakan bagian terpadu bahasa SQL. Perintah- perintahnya dapat dibuat secara interaktif atau ditempelkan pada sebuah program aplikasi. Pemakai hanya perlu menentukan 'APA' yang ia inginkan, DBMS menentukan 'BAGAIMANA' cara mendapatkannya. 13.
(29) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. c. Data Control Language (DCL) : Digunakan untuk mengontrol hak para pemakai data dengan perintah : grant, revoke SQL.. Gambar 2.1 Komponen SQL 2.3.. MySQL. 2.3.1. Pengertian MySQL MySQL adalah perangkat lunak system manajemen basis data yang digunakan untuk menyimpan dan mengolah data.. 14.
(30) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. 2.3.2. Macam-Macam Storage Engine MySQL 2.3.2.1.. MyISAM Storage Engine secara bawaan sudah ada dalam Mysql, jadi secara. default Mysql akan menggunakan storage engine ini. MyISAM menangani tabel yang non-transactional. Tipe tabel ini menyediakan penyimpanan dan retrieval berkecepatan tinggi, dan juga kemampuan pencarian fulltext. MyISAM didukung di semua konfigurasi MySQL. Kelebihan . Lebih cepat daripada InnoDB pada keseluruhan, baik penyimpanan data ataupun konsumsi memory RAM sebagai akibat dari strukturnya yang sederhana sehingga jauh lebih sedikit konsumsi sumber daya server.. . Sederhana untuk perancangan sehingga memudahkan bagi pemula.. . Lebih cepat pada proses pembacaan, sangat dianjurkan jika table sering terjadi proses pembacaan.. . Kapasitas yang tertampung bisa lebih besar dibanding engine InnoDB. Sekitar 256TB, sedangkan InnoDB daya tampungnya 64TB.. Kekurangan. 15.
(31) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. . Tidak mendukung integritas data, sehingga untuk proses integritas data dilakukan secara program bukan di databasenya.. . Tidak mendukung transaksi seperti commit, rollback ataupun crash recovery.. . Lebih lambat dibanding InnoDB jika proses yang sering terjadi adalah insert atau update.. 2.3.2.2.. InnoDB Storage engine ini sering dikenal karena mempunyai fitur. transaksi, seperti commit, rollback dan crash recovery layaknya oracle. Disamping itu juga mempunyai fitur tabel relasi dan integritas – foreignkey. InnoDB termasuk dalam semua distribusi biner MySQL 5.1. Dalam distribusi sumber, kita dapat mengatur pemakaian salah satu engine dengan melakukan konfigurasi MySQL. Kelebihan . Mendukung integritas data secara penuh dengan adanya foreign key.. . Mendukung transaksi seperti commit, rollback ataupun crash recovery.. . Lebih cepat dalam proses menulis intensif (insert, update) tabel.. 16.
(32) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. Kekurangan . Mengkonsumsi sumber daya sistem lebih besar baik dalam penyimpanan maupun memory RAM.. . Karena InnoDB mementingkan integritas, maka proses. perancangan. tentu. membutuhkan usaha yang lebih besar. . Tidak mendukung pengindeksan teks penuh.. . Untuk query update dan delete maksimum antrian koneksi hanya 200, selebihnya akan mengalami deadlock. [4]. 2.3.2.3.. Merge Storage engine ini mengijinkan koleksi dari tabel MyISAM yang. serupa untuk dihandle sebagai tabel tunggal. Seperti MyISAM, storage engine Merge menghandle nontransactional table dan juga termasuk dalam defaultnya MySQL. Storage engine ini memungkinkan DBA MySQL atau pengembang untuk secara logis mengelompokkan serangkaian tabel MyISAM yang identik dan referensi mereka sebagai satu obyek. Proses ini baik untuk lingkungan VLDB seperti data warehouse. 2.3.2.4.. Memory Storage engine ini menyimpan semua data dalam RAM untuk. akses yang sangat cepat dalam lingkungan yang memerlukan pencarian referensi yang cepat dan data seperti lainnya. Storage engine Memory. 17.
(33) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. menyediakan tabel memory di dalam (in-memory) dan menghandle nontransactional tabel. Storage engine ini sebelumnya dikenal dengan nama Heap engine. 2.3.2.5.. Archive Storage engine ini menyediakan solusi untuk menyimpan dan. mengambil sejarah informasi dalam jumlah yang besar, arsip, atau informasi audit keamanan. Storage engine Archive digunakan untuk menyimpan sejumlah data yang besar tanpa mengindex dengan footprint yang sangat kecil. 2.3.2.6.. Federated Storage engine Federated hanya bekerja dengan MySQL dan. menggunakan MySQL C Client API pada saat ini. Storage engine ini menyimpan data di database yang jauh. Query tabel Federated lokal secara otomatis menarik data dari remote tabel. Tidak ada data yang disimpan pada tabel lokal. Storage engine Federated menawarkan kemampuan untuk menghubungkan server terpisah MySQL untuk membuat satu database logis dari banyak server fisik. Hal ini sangat baik untuk lingkungan terdistribusi atau data mart. 2.3.2.7.. NDBCLUSTER Storage engine ini digunakan oleh cluster MySQL untuk. mengimplementasikan tabel yang dibagi melalui banyak komputer. Jenis ini tersedia di distribusi biner MySQL-Max 5.1. Storage engine. 18.
(34) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. NDBCLUSTER sangat cocok untuk aplikasi yang membutuhkan uptime dan ketersediaan (availability) dengan tingkat tinggi. Kekurangan dari NDBCLUSTER ini adalah banyaknya scan data hanya 500 klien.[1] 2.3.2.8.. CSV Storage engine ini menyimpan data dalam file text menggunakan. format nilai pemisah koma. Kita dapat menggunakan storage engine CSV untuk proses pertukaran data antara perangkat lunak dan aplikasi yang dapat mengimpor dan mengekspor ke dalam format CSV. 2.3.2.9.. Example Storage engine ini tidak melakukan apapun. Kita dapat membuat. tabel dengan storage engine Example, tapi tidak ada data yang dapat disimpan atau diretrieval pada storage engine ini. Kegunaan storage engine example adalah menyajikan contoh dalam source code MySQL yang mengilustrasikan bagaimana memulai penulisan engine penyimpanan yang baru. Ini merupakan minat utama untuk para developer. 2.3.2.10.. Blackhole. Storage engine ini menerima tetapi tidak menyimpan data dan retrievals selalu mengembalikan set kosong. Fungsi tersebut dapat digunakan dalam desain database terdistribusi di mana data secara otomatis direplikasi, tetapi tidak disimpan secara lokal. Storage engine. 19.
(35) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. Blackhole bertindak sebagai “lubang hitam” yang menerima data tetapi membuang dan tidak menyimpannya. 2.4.. Clustering. 2.4.1. Pengertian Clustering Clustering adalah sekelompok server atau resource lain yang terhubung melalui perangkat keras, jaringan, dan perangkat lunak untuk berperilaku seolah-olah semuanya itu merupakan sebuah sistem. Secara sederhana, clustering adalah sekumpulan server yang terhubung namun seolah-olah hanya ada satu server saja. Pada awalnya, clustering secara ekslusif identik dengan kebutuhan untuk menyediakan skalabilitas untuk perusahaan yang. Faktanya, pada tahun. 1997,. dilakukan. clustering. sekelompok. RE/6000s. untuk. menyediakan kebutuhan skalabilitas untuk kejuaraan cater yang terkenal “Deep Blue” yang mengadu otak elektronik melawan kepandaian Gary Kasparov, seorang jenius catur dari Russia. Database clustering adalah kumpulan dari beberapa server yang berdiri sendiri yang kemudian bekerjasama sebagai suatu sistem tunggal.[3] Saat ini aplikasi database semakin berkembang, baik dalam hal kegunaan, ukuran, maupun kompleksitas. Hal ini secara langsung berdampak pada server database sebagai penyedia layanan terhadap akses database, konsekuensi dari semua itu adalah beban database server akan semakin. 20.
(36) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. bertambah berat dan mengakibatkan kurang optimalnya kinerja dari server tersebut. Oleh karena itu diperlukan perancangan yang tepat dan handal dalam membangun database server. Database pada masa sekarang ini dituntut agar dapat berjalan dengan cepat, mempunyai kehandalan dan keseterdiaan yang tinggi, dengan clustering database yang disimpan dapat terbagi ke beberapa mesin dan pada saat aplikasi berjalan, semua mesin yang menyimpan data tersebut dianggap sebagai satu kesatuan. Metode clustering seperti ini sangat baik untuk load-balancing dan penanganan system failure karena kemampuan tiap mesin akan digunakan dan jika ada salah satu mesin yang mengalami failure maka sistem tidak akan langsung terganggu karena mesin lain akan tetap berfungsi. Kemampuan clustering memungkinkan sebuah database tetap hidup dalam waktu yang lama. Berikut adalah contoh arsitektur dari database cluster itu sendiri. a. Shared Disk Clusters Arsitektur shared disk clusters menggunakan server-server independent dan berbagi sebuah sistem penyimpanan tunggal. Setiap server mempunyai prosesor dan memori sendiri, tetapi berbagi disk resources. Implementasi utama dari shared-disk clustering adalah bukan untuk scalability. Shared-disk clustering ini diimplementasikan untuk availability dan menambah node cadangan sebagai failover node.. 21.
(37) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. Gambar 2.2. Shared Disk Clusters b. Shared Nothing Cluster Dalam arsitetur shared nothing cluster, tiap server dalam cluster menangani prosesor, memori, storage, record locks dan transaksi yang terpisah dan melakukan koordinasi dengan server lain melalui jaringan dengan menggunakan high speed, low-latency interconnect technology. Dalam proses permintaan data suatu node harus mengirimkan pesan ke node yang lain yang memiliki data yang diakses. Hal ini juga dilakukan saat koordinasi data yang dilakukan pada node yang lain seperti insert, select, update dan delete. Berbeda dengan shared disk, shared nothing didisain untuk high availability dan scalability.. 22.
(38) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. Gambar 2.3. Shared Nothing 2.4.2. MySQL Cluster MySQL adalah sebuah database open source terbukti dari kemudahan dalam penggunaan, arsitektur database yang lebih cepat dan handal. Keuntungan utama dari MySQL database berasal dari cirinya pada pengurangan TCO database. (Gupta, 2004) [2] MySQL Cluster merupakan sebuah tipe database yang dapat beroperasi dalam ukuran data yang besar. MySQL Cluster adalah sebuah teknologi baru untuk memungkinkan clustering di dalam memory database dalam sebuah sistem share-nothing. Arsitektur share-nothing mengijinkan sistem dapat bekerja dengan hardware yang sangat murah, dan tidak membutuhkan perangkat keras dan lunak dengan spesifikasi khusus. Arsitektur tersebut juga handal karena masing-masing komponen mempunyai memory dan disk tersendiri.. 23.
(39) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. MySQL Cluster menggabungkan MySQL Server biasa dengan sebuah mesin penyimpanan in-memory tercluster yang dinamakan NDB. NDB berarti bagian dari suatu rangkaian yang dikhususkan sebagai mesin penyimpanan, sedangkan MySQL Cluster diartikan sebagai kombinasi atau gabungan dari MySQL dan mesin penyimpanan yang baru tersebut. Sebuah MySQL Cluster terdiri dari sekumpulan komputer, masingmasing menjalankan sejumlah proses mencakup beberapa MySQL server, node-node penyimpanan untuk cluster NDB, server-server manajemen dan program-program pengakses data yang khusus. Semua program-program tersebut bekerja bersama-sama untuk membentuk MySQL Cluster. Ketika data disimpan di dalam mesin penyimpan media NDB cluster, tabel-tabel disimpan didalam node-node penyimpanan pada NDB Cluster. Tabel-tabel seperti itu dapat diakses secara langsung dari semua MySQL server yang lain di dalam cluster tersebut. Data yang disimpan di dalam node-node penyimpanan pada MySQL Cluster dapat di mirror (dicerminkan), cluster tersebut dapat menangani kegagalan dari node-node penyimpanan individual dengan tidak ada dampak lain dari sejumlah transaksi dihentikan karena kegagalan proses transaksi. Di dalam konfigurasi mysql cluster itu sendiri terdapat tiga node cluster, ketiga node cluster itu adalah: [5]. 24.
(40) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. a. Management node (ndb_mgmd process) : Peran node ini untuk mengelola node lain dalam Cluster MySQL, melakukan fungsifungsi seperti menyediakan konfigurasi data, menjalankan dan menghentikan node, menjalankan backup, dan lain sebagainya. Karena node ini mengelola konfigurasi node lain, node jenis ini harus dimulai terlebih dahulu, sebelum node lain. Sebuah node MGM dimulai dengan perintah ndb_mgmd. b. Data node (ndbd process) : Node ini digunakan untuk menyimpan data. c. SQL node (mysqld process): Node ini digunakan untuk mengakses data. Dalam kasus MySQL Cluster, sebuah SQL node adalah MySQL biasa yang menggunakan NDBCLUSTER sebagai mesin penyimpanan Ketiga node tersebut dapat dilihat di gambar berikut:[5]. 25.
(41) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. Gambar 2.3. Node dalam MySQL Cluster Pengaturan node yang akan dilakukan itu sendiri berdasarkan dari adanya ketersedian data, dan apa hardware yang diperlukan untuk memenuhi kebutuhan sistem anda. Ketika kita telah memutuskan bahwa MySQL Cluster dapat memenuhi keinginan kita, kita perlu menentukan berapa banyak mesin yang dibutuhkan untuk memenuhi kebutuhan dari sistem yang akan kita rancang dan memberikan jumlah yang tepat untuk redundansi. Berikut adalah contoh dari beberapa pengaturan node. a. Simple Arrangement b. Robust Arrangement c. Minimalist Arrangement MySQL Cluster merupakan sebuah database yang menggunakan arsitektur shared-nothing dan antarmuka SQL yang telah umum digunakan. Sistem database ini terdiri dari beberapa node yang dapat didistribusikan ke beberapa perangkat keras dan ke beberapa wilayah/zona yang berbeda sekaligus untuk tetap menjaga ketersediaan data meskipun jaringan ataupun salah satu node sedang mengalami kegagalan (failure).. 26.
(42) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. Gambar 2.5. Arsitektur MySQL Cluster Arsitektur MySQL sangat berbeda dibadingkan dengan database server lainnya, dan hal ini berguna untuk banyak tujuan lainnya. MySQL tidak sempurna, tapi cukup fleksibel untuk bekerja dengan baik dalam berbagai macam lingkungan, seperti aplikasi web. Pada waktu yang sama, MySQL. dapat. menggerakkan. aplikasi. embedded,. gudang. data,. mengindeks konten, dan mengirim perangkat lunak, transaksi online, dan masih banyak lagi. 8] MySQL Cluster diimplementasikan sebagai sebuah multi-master database yang aktif yang memastikan update ada pada setiap node dan dengan segera tersedia pada seluruh cluster. Tabel otomatis dibagikan dengan komoditas data node yang rendah, memungkinkan database untuk read and write-instansive workloads, diakses melalui SQL dan NoSQL APIs.. 27.
(43) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. 2.5.. Mysqlslap Mysqlslap adalah program diagnostic yang dirancang untuk mensimulasikan beban klien dan melaporkan waktunya setiap tahap. Program. ini. bekerja. seolah-olah. beberapa. klien. mengakses. server. Mysqlslap tersedia di MySQL 5.1.4. Perintah mysqlslap seperti ini:. shell> mysqlslap [ options ]. Beberapa pilihan seperti --create atau --query memungkinkan kita untuk menentukan string yang berisi pernyataan SQL atau file yang berisi pernyataan. Jika Anda menentukan sebuah file, secara default file tersebut harus berisi satu pernyataan per baris. (Artinya, pembatasan pernyataan secara implisit adalah baris baru.) Gunakan --delimiter untuk menentukan pembatas yang berbeda, yang memungkinkan Anda untuk menentukan pernyataan yang menyertakan beberapa baris atau tempat beberapa pernyataan pada satu baris. Anda tidak dapat menyertakan komentar dalam file; mysqlslap tidak memahami hal tersebut. Mysqlslap berjalan dalam tiga tahap: 1. Membuat skema, tabel, dan secara opsional program disimpan atau data yang akan digunakan untuk ujian. Tahap ini menggunakan koneksi klien tunggal.. 28.
(44) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. 2. Jalankan tes beban. Tahap ini dapat menggunakan banyak koneksi klien. 3. Bersihkan (lepaskan, drop table bila ditentukan). Tahap ini menggunakan koneksi klien tunggal.. 29.
(45) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. BAB III RANCANGAN PENELITIAN 3.1.. Spesifikasi Perangkat Lunak dan Perangkat Keras Pada pengujian MySQL Cluster akan dilakukan beberapa skenario untuk mengetahui unjuk kerja MySQL Cluster dan MySQL konvensional. Pengujian dilakukan dengan menggunakan perangkat sebagai berikut:. 3.1.1. Perangkat Keras (Hardware) Hardware ini digunakan sebagai infrastruktur untuk membangun MySQL Cluster. Infrastruktur yang digunakan untuk membangun MySQL Cluster pada tiap node dan klien adalah sama. Spesifikasi hardware yang disediakan akan ditunjukkan pada Tabel 3.1: Platform. Desktop PC. Processor. Intel® Pentium® CPU G630 @ 2.70GHz (2 CPUs),~2.7GHz. Memory. 2GB DDR2. Total Hard Drive Capacity. 80 GB. Hard Drive Interface. Serial ATA. Hard Drive RPM. 7200. Optical Drive. DVD-Super Multi Drive. Graphics. Intel. ®. Graphics. 30. Sandybridge. Desktop.
(46) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. NIC. TP-Link. TG-3468. 10/100/1000. Mbps 32-bit PCIe Gigabit Network Adaptor. Tabel 3.1 Spesifikasi Perangkat Keras (Hardware). 3.1.2. Switch Ethernet (Mikrotik Router Board RB951GS) Router ini akan dikonfigurasi menjadi bridge sehingga fungsi router. akan berubah menjadi fungsi switch yang digunakan sebagai. infrastruktur jaringan pada MySQL Cluster. Spesifikasi router yang disediakan akan ditunjukkan pada Tabel 3.2:. Product Code. RB951Gs. Port 10/100/1000 Ethernet Port 5 port PoE Support. Yes. Power Jack. 9-28V DC. Dimensions. 113x139x28mm. Operating System. Mikrotik SwOS. CPU. None. 31.
(47) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. Max Power Consumption. 6W. Tabel 3.2 Spesifikasi Perangkat Keras (Switch). Gambar 3.1 Mikrotik Router Board RB951Gs. 3.1.3. Kabel Ethernet Dalam pembangunan database MySQL Cluster, Ethernet kabel yang digunakan adalah kabel straight kategori 5e. Kabel Ethernet kategori 5e merupakan kabel Ethernet seri 5 yang telah ditingkatkan atau disempurnakan (5 Enhanced), dikembangkan untuk transmisi secara bersamaan dua arah.. 32.
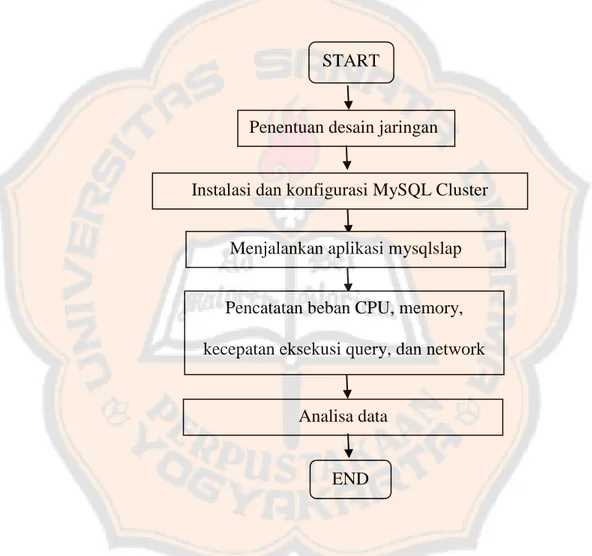
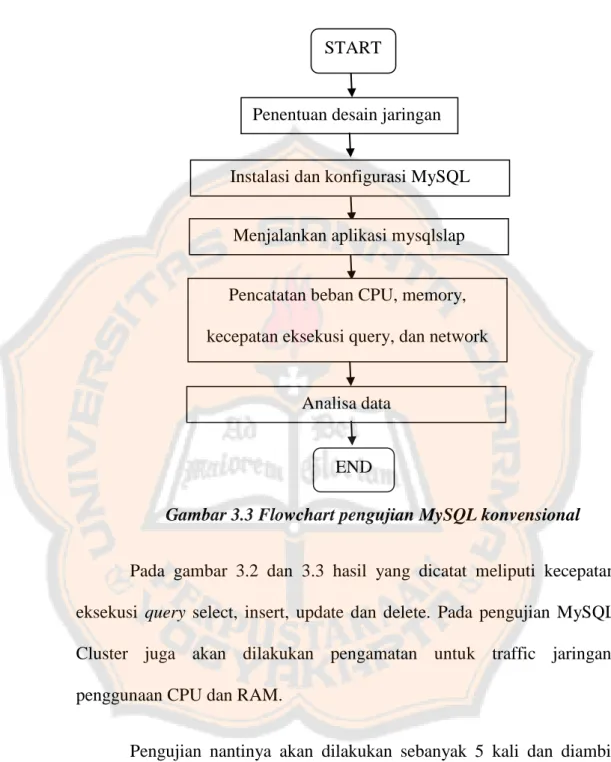
(48) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. 3.2.. Diagram Alir Desain Pengujian Pada pengujian MySQL Cluster ini dibutuhkan suatu perencanaan yang tepat agar hasil yang didapat sesuai dengan yang diharapkan. Gambar 3.2 menunjukkan flowchart atau diagram alir pengujian.. START. Penentuan desain jaringan. Instalasi dan konfigurasi MySQL Cluster Menjalankan aplikasi mysqlslap Pencatatan beban CPU, memory,. kecepatan eksekusi query, dan network. Analisa data. END. Gambar 3.2 Flowchart pengujian MySQL Cluster. Pada pengujian MySQL konvensional juga dibutuhkan suatu perencanaan yang tepat agar hasil yang didapat sesuai dengan yang diharapkan. Gambar 3.3 menunjukkan flowchart atau diagram alir pengujian. 33.
(49) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. START. Penentuan desain jaringan. Instalasi dan konfigurasi MySQL. Menjalankan aplikasi mysqlslap Pencatatan beban CPU, memory, kecepatan eksekusi query, dan network. Analisa data. END Gambar 3.3 Flowchart pengujian MySQL konvensional Pada gambar 3.2 dan 3.3 hasil yang dicatat meliputi kecepatan eksekusi query select, insert, update dan delete. Pada pengujian MySQL Cluster juga akan dilakukan pengamatan untuk traffic jaringan, penggunaan CPU dan RAM. Pengujian nantinya akan dilakukan sebanyak 5 kali dan diambil rata-ratanya. Jumlah klien yang akan digunakan untuk menguji akan diawali dengan 25 klien dan ditambah 25 klien seterusnya, hingga server tidak dapat mengirimkan respon lagi. Hasil pengujian pada MySQL Cluster akan dibandingkan dengan MySQL konvensional.. 34.
(50) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. 3.3. Rencana Kerja Rencana kerja yang akan digunakan dalam proses pengukuran adalah. sebagai berikut: 1. Memastikan topologi sistem yang diukur. 2. Menentukan database yang akan digunakan yaitu sakila. 3. Menentukan engine database yang akan digunakan yaitu: innodb dan ndbcluster. 4. Menentukan macam-macam query yang akan digunakan. Query yang akan digunakan: -. select * From customer. -. insert into customer (store_id, first_name, last_name, email, address_id, active) values ('1', 'a', 'b', 'A@b', '1', '1'). -. update customer set store_id=2, first_name='c', last_name='d' where first_name!='c' limit 1;. -. delete from customer where first_name='a' limit 1;. 5. Menentukan jumlah klien yang akan menjalankan query Jumlah klien yang akan digunakan mulai dari 25 klien dan ditambah 25 seterusnya hingga server tidak lagi merespon. 6. Menjalankan mysqlslap yang telah diinstal di komputer klien untuk menguji kinerja mysql cluster.. 35.
(51) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. 7. Melihat output yang dihasilkan dari alat ukur yaitu kecepatan mengeksekusi query dan banyaknya klien yang dapat terkoneksi serta pencatatan beban CPU, memory, dan netwok traffic yang akan dipantau melalui system monitoring yang telah ada pada CentOS. 3.4 Desain Sistem Jaringan Terdapat beberapa asumsi sebelum melakukan pengukuran unjuk kerja MySQL Cluster. Asumsi tersebut adalah: a. Komputer yang digunakan untuk client hanya satu sampai dua buah yang dapat mensimulasikan beberapa client menggunakan software mysqlslap. b. Setiap klien akan mengeksekusi satu kueri. c. Nilai parameter yang dipakai untuk masing-masing pengujian diubah menurut jenis query dan jumlah client yang mengirimkan query. d. Query yang digunakan adalah select, insert, update, dan delete. e. Pada skenario pertama akan dilakukan pengujian untuk MySQL konvensional dengan database sakila dan engine database innodb, skenario kedua akan dilakukan pengujian untuk MySQL cluster dengan satu node untuk data dan satu node untuk SQL daemon dengan database sakila dan engine. 36.
(52) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. database innodb, sedangkan pada skenario ketiga akan dilakukan pengujian. untuk. MySQL cluster. dengan. menambah satu node untuk SQL daemon, sehingga node utnuk SQL daemon akan berjumlah sebayak dua buah dengan database sakila dan engine database innodb, sedangkan. pada. scenario. keempat. akan. dilakukan. pengujian untuk MySQL cluster dengan menambah satu node untuk SQL daemon, sehingga node utnuk SQL daemon akan berjumlah sebayak dua buah dengan database sakila dan engine database ndbcluster. Pada pengujian ini akan dibangun infrastruktur dari MySQL konvensional terlebih dahulu yang kemudian akan diuji dan hasilnya akan dibandingkan dengan kinerja MySQL Cluster. Adapun desain sistem jaringan yang akan dipakai terbagi menjadi beberapa skenario. 3.4.1. Skenario 1. Gambar 3.4 Pengujian MySQL Server Gambar 3.4 ini menunjukkan akan dilakukan percobaan pada MySQL Server untuk mengetahui beban CPU, memory, kecepatan eksekusi query dan network traffic, serta banyaknya klien yang dapat 37.
(53) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. terkoneksi menurut jenis query. PC client akan mensimulasikan beberapa client menggunakan software mysqlslap. Pengujian akan berhenti ketika server sudah tidak dapat lagi merespon pada jumlah klien tertentu. Pada skenario ini, database yang digunakan adalah sakila, dan engine database yang akan digunakan adalah innodb.. 3.4.2. Skenario 2. Gambar 3.5 Pengujian MySQL Server Clustering Gambar 3.5 ini menunjukkan akan dilakukan percobaan pada MySQL Server clustering dengan data node, SQL node, dan Management Node masing-masing berjumlah satu untuk mengetahui beban CPU, memory, kecepatan eksekusi query dan network traffic, serta banyaknya klien yang dapat terkoneksi menurut jenis query. PC client akan. 38.
(54) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. mensimulasikan beberapa client menggunakan software mysqlslap. Pengujian akan berhenti ketika server sudah tidak dapat lagi merespon pada jumlah klien tertentu. Pada skenario ini, database yang digunakan adalah sakila, dan engine database yang akan digunakan adalah innodb. 3.4.3. Skenario 3. Gambar 3.6 Pengujian MySQL Server Clustering Gambar 3.6 ini menunjukkan akan dilakukan percobaan pada MySQL Server clustering dengan data node, SQL node, dan Management Node masing-masing berjumlah satu untuk mengetahui beban CPU, memory, kecepatan eksekusi query dan network traffic, serta banyaknya klien yang dapat terkoneksi menurut jenis query. PC client akan mensimulasikan beberapa client menggunakan software mysqlslap. Pengujian akan berhenti ketika server sudah tidak dapat lagi merespon. 39.
(55) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. pada jumlah klien tertentu. Pada skenario ini, database yang digunakan adalah sakila, dan engine database yang akan digunakan adalah ndbcluster. 3.4.4. Skenario 4. Gambar 3.7 Pengujian MySQL Server Clustering 2 Gambar 3.7 ini menunjukkan akan dilakukan percobaan pada MySQL Server clustering dengan SQL node berjumlah dua buah, data node, dan Management Node masing-masing berjumlah untuk mengetahui beban CPU, memory, kecepatan eksekusi query dan network traffic, serta banyaknya klien yang dapat terkoneksi menurut jenis query. PC client akan mensimulasikan beberapa client menggunakan software mysqlslap. Pengujian akan berhenti ketika server sudah tidak dapat lagi merespon. 40.
(56) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. pada jumlah klien tertentu. Pada skenario ini, database yang digunakan adalah sakila, dan engine database yang akan digunakan adalah innodb. 3.4.5. Skenario 5. Gambar 3.8 Pengujian MySQL Server Clustering 2 Gambar 3.8 ini menunjukkan akan dilakukan percobaan pada MySQL Server clustering dengan SQL node berjumlah dua buah, data node, dan Management Node masing-masing berjumlah untuk mengetahui beban CPU, memory, kecepatan eksekusi query dan network traffic, serta banyaknya klien yang dapat terkoneksi menurut jenis query. PC client akan mensimulasikan beberapa client menggunakan software mysqlslap. Pengujian akan berhenti ketika server sudah tidak dapat lagi merespon. 41.
(57) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. pada jumlah klien tertentu. Pada skenario ini, database yang digunakan adalah sakila, dan engine database yang akan digunakan adalah ndbcluster.. 42.
(58) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. BAB IV IMPLEMENTASI DAN ANALISA 4.1.. Pembangunan Infrastuktur Langkah pertama yang harus dilakukan sebelum melakukan pengukuran adalah membangun MySQL konvensional dan MySQL Cluster. Untuk itu perlu dilakukan instalasi dan konfigurasi pada beberapa komputer fisik yang akan digunakan sebagai MySQL konvensional dan MySQL Cluster. Pada komputer yang akan dijadikan klien hanya diperlukan menginstal MySQL server agar dapat menggunakan software mysqlslap yang merupakan bawaan dari MySQL Server. Adapun langkah-langkah intalasi dan konfigurasi telah ditulis dalam lampiran.. 4.2.. Data Penelitian Hasil pengujian yang diamati adalah data kecepatan eksekusi query, jumlah klien maksimal yang dapat mengakses, penggunaan CPU, penggunaan ram, dan network traffic pada database konvensional dan database clustering ketika mengeksekusi query select, insert, update, dan delete. Adapun syntax query yang digunakan sudah ditulis pada bab 3. Hasil pengukuran yang didapat dari database clustering (scenario 3 dan 5) akan dibandingkan dengan hasil pengukuran yang didapat dari database konvensional (scenario 1). Hasil pengukuran pada tiap query adalah sebagai berikut:. 43.
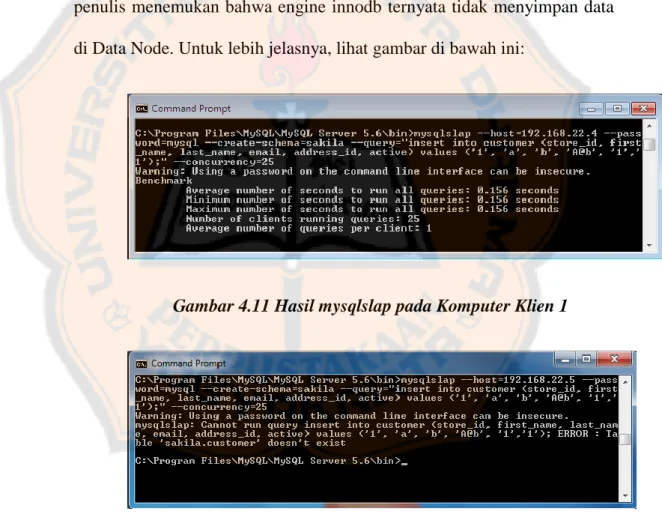
(59) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. 4.2.1. Analisa Skenario 2 dan 4 Pada skenario 2 dan 4, penulis memisahkan analisa ini dan tidak dibandingkan dengan skenario 1, 3 dan 5 karena hasilnya tidak dapat dibandingkan dengan skenario lainnya. Skenario ini menggunakan engine innodb namun topologi yang digunakan adalah topologi cluster (penjelasan lebih lanjut telah dibahas pada bab sebelumnya). Namun penulis menemukan bahwa engine innodb ternyata tidak menyimpan data di Data Node. Untuk lebih jelasnya, lihat gambar di bawah ini:. Gambar 4.11 Hasil mysqlslap pada Komputer Klien 1. Gambar 4.12 Hasil mysqlslap pada Komputer Klien 2 Pada klien 1 yang terkoneksi dengan Daemon Node satu, mysqlslap menghasilkan output kecepatan query 0.156 dan berhasil, sedangkan pada klien 2 yang terkoneksi dengan Daemon Node dua 44.
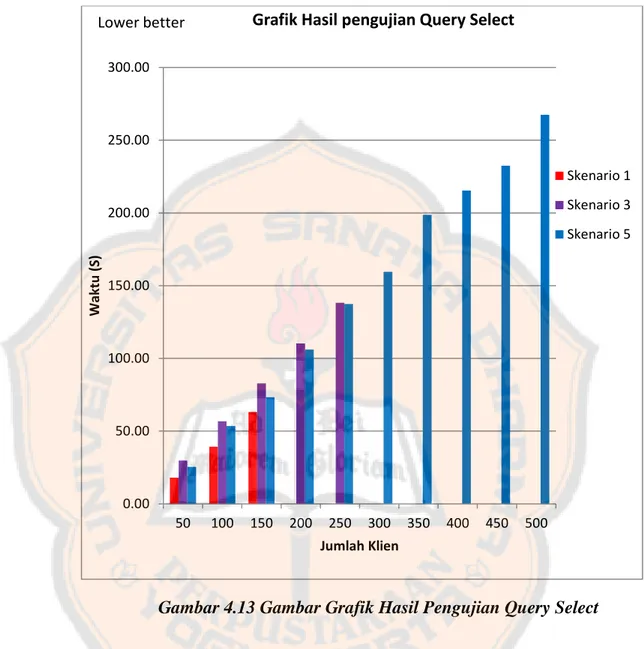
(60) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. menghasilkan output yang menyatakan bahwa table sakila.customer tidak ada. Hal ini membuktikan bahwa engine innodb hanya menyimpan data secara lokal di Daemon Node, karena itu database hanya terbaca oleh satu Daemon Node saja dan tidak terdeteksi pada Daemon Node yang lain. Maka, ketika Daemon Node hanya satu buah, innoDB masih bisa berjalan meskipun fungsi clusteringnya tidak terpakai. 4.2.2. Query Select Pengujian ini akan mengukur kecepatan eksekusi query select dan maksimum klien yang dapat mengakses database. Setiap pengujian akan dilakukan lima kali, hasil yang ditampilkan adalah rata-rata dari lima kali pengujian yang telah dilakukan. Data dari hasil pengujian database akan digambarkan sebagai grafik, sehingga penulis lebih mudah untuk menjelaskan perbandingan kecepatan eksekusi query antara satu skenario dengan skenario yang lain serta perbandingan banyaknya klien yang dapat terkoneksi.. 45.
(61) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. Grafik Hasil pengujian Query Select. Lower better 300.00. 250.00 Skenario 1 Skenario 3. 200.00 Waktu (S). Skenario 5 150.00. 100.00. 50.00. 0.00 50. 100. 150. 200. 250. 300. 350. 400. 450. 500. Jumlah Klien. Gambar 4.13 Gambar Grafik Hasil Pengujian Query Select Pada grafik di atas dapat dilihat bahwa clustering dapat menangani lebih banyak klien, namun hal ini membuat kecepatan eksekusi query menjadi lebih lambat dibandingkan MySQL konvensional. Namun, kecepatan query menjadi sedikit lebih cepat ketika Daemon Node ditambah.. 46.
(62) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. Penggunaan Network Receiving pada Query Select (MiB/s) 30.00. Receiving. 25.00 20.00. Skenario 1. 15.00. Skenario 3. 10.00. Skenario 5. 5.00 0.00 50. 100. 150. 200. 250 300 350 Jumlah Klien. 400. 450. 500. Gambar 4.14 Gambar Grafik Penggunaan Network Receiving pada Query Select Penggunaan Network Sending pada Query Select (MiB/s) 40 35. Sending. 30 25. Skenario 1. 20. Skenario 3. 15. Skenario 5. 10 5 0 50. 100. 150. 200. 250 300 350 Jumlah Klien. 400. 450. 500. Gambar 4.15 Gambar Grafik Penggunaan Network Sending pada Query Select Pada grafik di atas dapat dilihat bahwa clustering menjadi lebih lambat karena mengambil data dari computer Data Node, dapat dilihat dari gambar 4.16 yang menunjukkan skenario 3 dan 5 memiliki trafik jaringan. 47.
(63) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. penerimaan jauh lebih tinggi dibandingkan skenario 1 yang tidak menggunakan engine cluster. Penggunaan CPU pada Query Select. Lower better 250. CPU. 200 Skenario 1. 150. Skenario 3. 100. Skenario 5 50 0 50. 100. 150. 200. 250 300 350 Jumlah Klien. 400. 450. 500. Gambar 4.16 Gambar Grafik Penggunaan CPU pada Query Select Penggunaan CPU pada mysql konvensional (skenario 1) cenderung menggunakan seluruh CPU yang ada sehingga mengakibatkan klien yang mengakses terbatas hanya sampai 150 karena CPU sudah habis. Namun pada engine ndbcluster dapat mengendalikan penggunaan CPU sehingga lebih banyak klien yang dapat mengakses, tetapi hanya terbatas sampai 500. klien. saja. yang. disebabkan. karena. nilai. MaxNoOfConcurrentScans hanya terbatas sampai 500.. 48. maksimum. dari.
(64) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. Penggunaan RAM pada Query Select. RAM. Lower better 9 8 7 6 5 4 3 2 1 0. Skenario 1 Skenario 3 Skenario 5. 50. 100. 150. 200. 250 300 350 Jumlah Klien. 400. 450. 500. Gambar 4.17 Gambar Grafik Penggunaan RAM pada Query Select Pada skenario 1 hanya menggunakan ram yang lebih sedikit namun mengalami kenaikan seiring dengan bertambahnya klien. Pada skenario 3 dan 5 menggunakan ram lebih banyak dibandingkan mysql konvensional. Pada skenario 3 dan 5, penggunaa CPU dan ram pada data node cenderung stabil, namun penggunaan network berubah-ubah sesuai dengan besarnya data. Di bawah ini adalah contoh salah satu hasil capture computer data node.. 49.
(65) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. Gambar 4.18 Gambar Contoh Capture Aktivitas Komputer Data Node. 4.2.3. Query Insert Pengujian ini akan mengukur kecepatan eksekusi query insert dan maksimum klien yang dapat mengakses database. Setiap pengujian akan dilakukan lima kali, hasil yang ditampilkan adalah rata-rata dari lima kali pengujian yang telah dilakukan. Data dari hasil pengujian database akan digambarkan sebagai grafik, sehingga penulis lebih mudah untuk menjelaskan perbandingan kecepatan eksekusi query antara satu skenario dengan skenario yang lain serta perbandingan banyaknya klien yang dapat terkoneksi.. 50.
(66) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. Lower better. Grafik Hasil Pengujian Query Insert. 12. Query Time. 10 8. Skenario 1. 6. Skenario 3. 4. Skenario 5. 2 0 50. 100 150 200 250 300 350 400 450 500 550 600 Jumlah Klien. Gambar 4.19 Gambar Grafik Hasil Pengujian Query Insert Pada grafik di atas dapat dilihat bahwa clustering dapat menangani lebih banyak klien serta memerlukan waktu eksekusi query yang lebih cepat dibandingkan MySQL konvensional. Namun dalam 5 kali pengujian, tidak semua pengujian 100% berhasil, pada skenario 1 hanya sampai 300 klien yang berhasil 100%, skenario 3 hanya 250 dan skenario 5 memiliki 500 klien yang berhasil 100%. Ketika hampir mendekati batas limit keberhasilan pengujian maupun setelah melewati batas limit, dari grafik di atas dapat dilihat bahwa kenaikan waktu eksekusi tidak stabil. Hal ini terjadi karena server sudah tidak mampu lagi mengolah data sebanyak klien tersebut.. 51.
(67) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. Penggunaan Network Receiving pada Query Insert (KiB/s) 300. Receiving. 250 200 Skenario 1 150. Skenario 3 Skenario 5. 100 50 0 50. 100 150 200 250 300 350 400 450 500 550 600 Jumlah Klien. Gambar 4.20 Gambar Grafik Penggunaan Network Receiving pada Query Insert Penggunaan Network Sending pada Query Insert (KiB/s) 300 250. Sending. 200 Skenario 1 150. Skenario 3 Skenario 5. 100 50 0 50. 100 150 200 250 300 350 400 450 500 550 600 Jumlah Klien. Gambar 4.21 Gambar Grafik Penggunaan Network Sending pada Query Insert. 52.
(68) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. Lower better. Penggunaan CPU pada Query Insert. 35 30. CPU. 25 Skenario 1. 20. Skenario 3. 15. Skenario 5. 10 5 0 50. 100 150 200 250 300 350 400 450 500 550 600 Jumlah Klien. Gambar 4.22 Gambar Grafik Penggunaan CPU pada Query Insert. Lower better. Penggunaan RAM pada Query Insert. 14 12. RAM. 10 8. Skenario 1 Skenario 3. 6. Skenario 5 4 2 0 50. 100 150 200 250 300 350 400 450 500 550 600 Jumlah Klien. Gambar 4.23 Gambar Grafik Penggunaan RAM pada Query Insert. 53.
(69) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. Pada grafik di atas dapat terlihat bahwa makin banyak query atau klien maka makin tinggi penggunaan ram maupun CPU. Namun dari grafik Gambar 4.20-23, tidak terdapat masalah karena keterbatasan alat. Ketika hampir mendekati batas limit maupun setelah melewati batas limit keberhasilan pengujian, dari grafik di atas dapat dilihat bahwa grafik tidak stabil. Hal ini terjadi karena server sudah tidak mampu lagi mengolah data sebanyak klien tersebut. Pada skenario 3 dan 5, penggunaa CPU dan ram pada data node cenderung stabil, namun penggunaan network berubah-ubah sesuai dengan besarnya data. Di bawah ini adalah contoh salah satu hasil capture computer data node.. Gambar 4.24 Gambar Contoh Capture Aktivitas Komputer Data Node. 54.
(70) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. 4.2.4. Query Update Pengujian ini akan mengukur kecepatan eksekusi query update dan maksimum klien yang dapat mengakses database. Setiap pengujian akan dilakukan lima kali, hasil yang ditampilkan adalah rata-rata dari lima kali pengujian yang telah dilakukan. Data dari hasil pengujian database akan digambarkan sebagai grafik, sehingga penulis lebih mudah untuk menjelaskan perbandingan kecepatan eksekusi query antara satu skenario dengan skenario yang lain serta perbandingan banyaknya klien yang dapat terkoneksi.. Lower better. Grafik Hasil Pengujian Query Update. 14. Query Time. 12 10 Skenario 1. 8 6. Skenario 3. 4. Skenario 5. 2 0 50. 100 150 200 250 300 350 400 450 500 550 600 Jumlah Klien. Gambar 4.25 Gambar Grafik Hasil Pengujian Query Update Pada grafik di atas dapat dilihat bahwa clustering dapat menangani lebih banyak klien serta memerlukan waktu eksekusi query yang lebih cepat dibandingkan MySQL konvensional. Pada skenario 1, maksimal banyaknya klien hanya 200 tidak bisa lebih. Hal ini dikarenakan batasan. 55.
(71) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. dari innodb, yaitu membatasi antrian sebanyak 200, jika lebih dari 200 maka akan terjadi deadlock. Namun dalam 5 kali pengujian, tidak semua pengujian 100% berhasil, skenario 3 hanya 250 dan skenario 5 memiliki 500 klien yang berhasil 100%. Ketika hampir mendekati batas limit keberhasilan pengujian maupun setelah melewati batas limit, dari grafik di atas dapat dilihat bahwa kenaikan waktu eksekusi tidak stabil. Hal ini terjadi karena server sudah tidak mampu lagi mengolah data sebanyak klien tersebut. Penggunaan Network Receiving pada Query Update (KiB/s) 350 300 Receiving. 250 200. Skenario 1. 150. Skenario 3 Skenario 5. 100 50 0 50. 100 150 200 250 300 350 400 450 500 550 600 Jumlah Klien. Gambar 4.26 Gambar Grafik Penggunaan Network Receiving pada Query Update. 56.
(72) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. Sending. Penggunaan Network Sending pada Query Update (KiB/s) 180 160 140 120 100 80 60 40 20 0. Skenario 1 Skenario 3 Skenario 5. 50. 100 150 200 250 300 350 400 450 500 550 600 Jumlah Klien. Gambar 4.27 Gambar Grafik Penggunaan Network Sending pada Query Update. Lower better. Penggunaan CPU pada Query Update. 25 20 15 CPU. Skenario 1 Skenario 3. 10. Skenario 5. 5 0 50. 100 150 200 250 300 350 400 450 500 550 600 Jumlah Klien. Gambar 4.28 Gambar Grafik Penggunaan CPU pada Query Update. 57.
(73) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. Penggunaan RAM pada Query Update. Lower better 12 10. RAM. 8. Skenario 1. 6. Skenario 3. 4. Skenario 5. 2 0 50. 100 150 200 250 300 350 400 450 500 550 600 Jumlah Klien. Gambar 4.29 Gambar Grafik Penggunaan RAM pada Query Update Pada grafik di atas dapat terlihat bahwa makin banyak query atau klien maka makin tinggi penggunaan ram maupun CPU. Namun dari grafik Gambar 4.24-27, tidak terdapat masalah karena keterbatasan alat. Ketika hampir mendekati batas limit maupun setelah melewati batas limit keberhasilan pengujian, dari grafik di atas dapat dilihat bahwa grafik tidak stabil. Hal ini terjadi karena server sudah tidak mampu lagi mengolah data sebanyak klien tersebut. Pada skenario 3 dan 5, penggunaa CPU dan ram pada data node cenderung stabil, namun penggunaan network berubah-ubah sesuai dengan besarnya data. Di bawah ini adalah contoh salah satu hasil capture computer data node.. 58.
(74) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. Gambar 4.30 Gambar Contoh Capture Aktivitas Komputer Data Node 4.2.5. Query Delete Pengujian ini akan mengukur kecepatan eksekusi query delete dan maksimum klien yang dapat mengakses database. Setiap pengujian akan dilakukan lima kali, hasil yang ditampilkan adalah rata-rata dari lima kali pengujian yang telah dilakukan. Data dari hasil pengujian database akan digambarkan sebagai grafik, sehingga penulis lebih mudah untuk menjelaskan perbandingan kecepatan eksekusi query antara satu skenario dengan skenario yang lain serta perbandingan banyaknya klien yang dapat terkoneksi.. 59.
(75) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. Lower better. Grafik Hasil Pengujian Query Delete. 8 7. Query Time. 6 5. Skenario 1. 4. Skenario 3. 3. Skenario 5. 2 1 0 50. 100 150 200 250 300 350 400 450 500 550 Jumlah Klien. Gambar 4.31 Gambar Grafik Hasil Pengujian Query Delete Pada grafik di atas dapat dilihat bahwa clustering dapat menangani lebih banyak klien serta memerlukan waktu eksekusi query yang lebih cepat dibandingkan MySQL konvensional. Pada skenario 1, maksimal banyaknya klien hanya 200 tidak bisa lebih. Hal ini dikarenakan batasan dari innodb, yaitu membatasi antrian sebanyak 200, jika lebih dari 200 aka akan terjadi deadlock. Namun dalam 5 kali pengujian, tidak semua pengujian 100% berhasil, skenario 3 hanya 225 dan skenario 5 memiliki 500 klien yang berhasil 100%. Ketika hampir mendekati batas limit maupun setelah melewati batas limit keberhasilan pengujian, dari grafik di atas dapat dilihat bahwa grafik tidak stabil. Hal ini terjadi karena server sudah tidak mampu lagi mengolah data sebanyak klien tersebut.. 60.
(76) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. 1400. Penggunaan Network Receiving pada Query Delete (KiB/s). 1200 Receiving. 1000 800. Skenario 1. 600. Skenario 3 Skenario 5. 400 200 0 50. 100 150 200 250 300 350 400 450 500 550 Jumlah Klien. Gambar 4.32 Gambar Grafik Penggunaan Network Receiving pada Query Delete. Penggunaan Network Sending pada Query Delete (KiB/s). 250. Sending. 200 150. Skenario 1 Skenario 3. 100. Skenario 5. 50 0 50. 100 150 200 250 300 350 400 450 500 550 Jumlah Klien. Gambar 4.33 Gambar Grafik Penggunaan Network Sending pada Query Delete. 61.
(77) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. Lower better. Penggunaan CPU pada Query Delete. 30 25. CPU. 20 Skenario 1 15. Skenario 3. 10. Skenario 5. 5 0 50. 100 150 200 250 300 350 400 450 500 550 Jumlah Klien. Gambar 4.34 Gambar Grafik Penggunaan CPU pada Query Delete. Lower better. Penggunaan RAM pada Query Delete. 12 10. RAM. 8. Skenario 1. 6. Skenario 3. 4. Skenario 5. 2 0 50. 100 150 200 250 300 350 400 450 500 550 Jumlah Klien. Gambar 4.35 Gambar Grafik Penggunaan RAM pada Query Delete Pada grafik di atas dapat terlihat bahwa makin banyak query atau klien maka makin tinggi penggunaan ram maupun CPU. Namun dari. 62.
(78) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. grafik Gambar 4.32-35, tidak terdapat masalah karena keterbatasan alat. Ketika hampir mendekati batas limit maupun setelah melewati batas limit keberhasilan pengujian, dari grafik di atas dapat dilihat bahwa grafik tidak stabil. Hal ini terjadi karena server sudah tidak mampu lagi mengolah data sebanyak klien tersebut. Pada skenario 3 dan 5, penggunaa CPU dan ram pada data node cenderung stabil, namun penggunaan network berubah-ubah sesuai dengan besarnya data. Di bawah ini adalah contoh salah satu hasil capture computer data node.. Gambar 4.36 Gambar Contoh Capture Aktivitas Komputer Data Node. 63.
(79) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. BAB V PENUTUP 5. 1.. Kesimpulan Dari pengujian dan analisa yang telah dilakukan, kesimpulan yang dapat ditarik adalah: a. Pada MySQL konvensional, proses penyimpanan data dan. pemrosesan query terjadi dalam satu komputer dan hanya dilakukan oleh satu komputer. Hal ini mengakibatkan semakin sedikitnya klien yang dapat mengakses. Untuk query select, banyaknya klien yang dapat mengakses dipengaruhi oleh kapasitas CPU. b. Engine. innoDB kurang tepat digunakan pada lingkungan. clustering. Karena fungsi clustering menjadi tidak berjalan. c. MySQL cluster dapat meningkatkan kemampuan eksekusi query. yang lebih cepat dalam penggunaan query insert, update, delete, serta penambahan daemon node dapat menambah banyaknya klien yang dapat mengakses database server tersebut. 5. 2.. Saran Terdapat beberapa saran dari penulis agar peneliti selanjutnya dapat memperhatikan hal-hal di bawah ini, guna perbaikan ke arah yang lebih baik. Adapun saran tersebut adalah:. 64.
(80) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. 1. Perlu diteliti lebih lanjut jika data node yang ditambah. Hal ini diperlukan agar kecepatan query select meningkat. 2. Perlu diteliti lebih lanjut dampak kemampuan komputasi server terhadap performa database, apakah mampu menangani lebih banyak client atau query secara bersamaan secara lebih cepat.. 65.
(81) PLAGIAT PLAGIATMERUPAKAN MERUPAKANTINDAKAN TINDAKANTIDAK TIDAKTERPUJI TERPUJI. DAFTAR PUSTAKA [1]. Defining. MySQL. Cluster. Data. Nodes:. [http://dev.mysql.com/doc/refman/5.1/en/mysql-cluster-ndbddefinition.html] (diakses tanggal 12 Oktober 2014) [2]. Gupta,Rakhi.. 2004.. MySQL. Database. Replication. and. Failover. Clustering. TATA Consultancy Services Limited. [3]. Hodges, R. 2007. Database High Availability and Scalability, CTO Continuent, Inc. <URL: http://www.pgday.it/files/scalability.pdf> (Diakses pada tanggal 19 Agustus 2014). [4]. InnoDB Lock Modes,: [http://dev.mysql.com/doc/refman/5.0/en/innodblock-modes.html] (diakses tanggal 10 Oktober 2014). [5]. MySQL. Cluster. Core. Concepts,. Available:. [http://dev.mysql.com/doc/mysql-cluster-excerpt/5.1/en/mysql-clusterbasics.html] (diakses tanggal 1 Juni 2013) [6]. Prabowo, Aditya, dkk. 2010. Perancangan MySQL Cluster Untuk Mengatasi Kegagalan Sistem Basis Data Pada Sisi Server.. [7]. Ramez Elmasri & Shamkant B Navathe. 2000. Database System.. [8]. Schwartz, Baron, dkk. 2008. High Performance MySQL. 2nd. O’Reilly Media, Inc.. [9]. Syafyar, Faisal. 2011. Membangun Perangkat Monitoring Performa dan Notifikasi Fault Dengan Cacti.. 66.
Gambar


+7



Garis besar
Dokumen terkait
Penelitian ini dilakukan dengan cara pengujian secara langsung terhadap produk SP 04 Haemonetics dimana produk tersebut adalah produk hasil produksi mesin injection molding
Tesis berjudul "Anal isis Ekonomi Makro Domestik dan Asing sebagai Deteminan Indeks Harga Saham Gabungan di Pasar Modal Indonesia" yang ditulis dan
Hubungan keeratan dalam kategori kuat antara peran fasilitator dengan tingkat keberdayaan peternak ini dikarenakan penyuluh telah cukup berperan dalam membantu menyediakan fasilitas
Vi hade en förhoppning på att detta även skulle kunna leda till minskade behandlingar mot ledinflammationer i de olika besättningarna, men här har vi för lite försöksresultat och
Melaksanakan urusan penataan standart pela#anan minimum s#stem dan prosedur kerja Melaksanakan urusan penataan standart pela#anan minimum s#stem dan prosedur kerja di lin$kun$an
Penelitian ini bertujuan untuk mengetahui pengaruh konsentrasi kitosan – kolagen, melihat karakterisasi optimum dari membran selulosa bakteri coating kitosan – kolagen
Eksploitasi Gili Trawangan sebagai tempat pariwisata menjadi penyebab utama terancam punahnya burung gosong kaki-oranye, jika masih ingin melihat keberadaan burung tersebut
Penelitian ini bertujuan untuk mengetahui karakteristik arang aktif sabut siwalan sebagai adsorben, pengaruh pH dan waktu interaksi terhadap kemampuan adsorpsi Pb(II), model adsorpsi
