Abstrak—Pada tulisan ini dibuat sebuah aplikasi penghilangan duplikasi data SNMPTN berbasis web menggunakan kerangka kerja Vaadin. Duplikasi data disebabkan oleh kesalahan pengisian data nama atau nomor peserta oleh peserta pada saat hari ujian. Peserta mengisikan data nama yang berbeda dengan yang diisikan pada data pendaftaran. Sistem tentu akan menganggap dua data ini sebagai data yang berbeda. Sehingga terjadi duplikasi data pada sebuah nomor peserta. Ada juga peserta yang salah mengisikan nomor peserta sehingga satu nomor peserta diklaim oleh dua peserta, atau nomor peserta tidak valid. Duplikasi data diperiksa menggunakan algoritma pencocokan string. Algoritma yang digunakan adalah algoritma Levenshtein Distance, Longest Common Subsequence, dan Soundex. Algoritma tersebut akan menentukan status dari data yang terduplikasi. Data yang dianggap valid akan dicarikan padanannya. Berdasarkan hasil pengujian yang dilakukan tingkat keberhasilan penghilangan duplikasi data mencapai 99,6%. Sedangkan tingkat akurasi kebenaran pencarian padanan mencapai 99,4%.
Kata Kunci—algoritma pencocokan string, duplikasi data, Vaadin.
I. PENDAHULUAN
ELEKSI Nasional Masuk Perguruan Tinggi Negeri (SNMPTN) adalah salah satu bentuk ujian yang diselenggarakan oleh pemerintah. Dilaksanakan serentak dan terpadu di seluruh Indonesia untuk menyeleksi siswa-siswi Sekolah Menengah Atas (SMA) yang akan melanjutkan pendidikannya ke perguruan tinggi negeri di Indonesia. SNMPTN terdiri dari dua macam ujian yaitu ujian jalur undangan dan ujian jalur tertulis.
Pada ujian jalur tertulis, peserta mengisikan data pribadi serta jawabannya pada Lembar Jawaban Komputer (LJK). LJK ini kemudian dipindai dan datanya dimasukkan ke dalam basis data. Saat diperiksa, ternyata banyak didapati duplikasi data pada basis data. Duplikasi data disebabkan oleh kesalahan pengisian data nama atau nomor peserta oleh peserta pada saat hari ujian. Peserta mengisikan data nama yang berbeda dengan yang diisikan pada data pendaftaran. Sistem tentu akan menganggap dua data ini sebagai data yang berbeda. Sehingga terjadi duplikasi data pada sebuah nomor peserta. Ada juga peserta yang salah mengisikan nomor peserta sehingga satu nomor peserta diklaim oleh dua peserta, atau nomor peserta tidak valid. Jika ada duplikasi data, sistem akan menganggap data tersebut tidak sah. Akibatnya, peserta yang mampu
menjawab soal dengan baik pun bisa dinyatakan tidak lulus ujian hanya karena kesalahan pengisian data. Agar hal ini tidak terjadi, maka duplikasi data harus dihilangkan.
Saat ini, untuk pemeriksaan duplikasi data, ditunjuk orang tertentu untuk memeriksa data secara manual. Pemeriksaan secara manual tentunya membutuhkan waktu yang lama, dan tidak menjamin terbebas dari human error. Dalam artikel ini akan dibuat sistem yang mengimplementasikan algoritma pencocokan string untuk menghilangkan masalah duplikasi data tersebut. Sistem ini akan menggantikan pemeriksaan manual yang tidak efisien dan hasilnya kurang maksimal.
II. METODEDANPERANCANGANSISTEM A. Algoritma Levenshtein Distance
Levenshtein Distance adalah jumlah minimal operasi yang dibutuhkan untuk mengubah suatu string menjadi string yang lain. Dengan algoritma ini dapat diketahui tingkat perbedaan dua buah string dalam representasi angka. Operasi yang dilakukan ada 3 macam yaitu [1]:
1. Insertion
Insertion adalah penyisipan sebuah karakter ke dalam sebuah string tertentu.
2. Deletion
Deletion adalah penghapusan sebuah karakter dari sebuah string tertentu.
3. Substitution
Substitution adalah penggantian sebuah karakter dari sebuah string dengan karakter lain.
Pseudocode algoritma Levenshtein Distance ditunjukkan pada Gambar 1. function LevenshteinDistance(s1[1..m], s2[1..n]) levDist <- array (0..m, 0..n) for i ← 0 to m for j ← 0 to n if i = 0 levDist[i,j] ← j else if j = 0 levDist[i,j] ← i else
if (s1[i] = s2[j]) levDist[i,j] ← levDist [i-1,j-1]
else levDist[i,j] ← 1 + minimum (1,j-1], levDist[i-1,j],
levDist[i-1][j-1])
return levDist[i,j]
Gambar 1. Pseuducode algoritma Levenshtein Distance
Pembangunan Aplikasi Penghilangan Duplikasi Data
Seleksi Nasional Masuk Perguruan Tinggi Negeri
(SNMPTN) Menggunakan Algoritma Pencocokan String
Berbasis Kerangka Kerja Vaadin
Kukuh Indrayana, Dwi Sunaryono, dan Abdul Munif
Teknik Informatika, Fakultas Teknologi Informasi, Institut Teknologi Sepuluh Nopember (ITS)
Jl. Arief Rahman Hakim, Surabaya 60111
E-mail: [email protected]
B. Algoritma Longest Common Subsequence
Subsequence adalah sebuah rangkaian yang dapat diperoleh dari rangkaian lain dengan cara menghapus beberapa elemen tertentu tanpa mengubah urutan dari elemen lain yang tersisa [2]. Misalkan ada rangkaian X dan Y, rangkaian S dikatakan sebuah common subsequence dari X dan Y apabila S adalah subsequence dari keduanya. Longest Common Subsequence (LCS) adalah common subsequence terpanjang dari seluruh common subsequence. Algoritma untuk masalah LCS ini berdasarkan teorema berikut [3]:
Misal X = <x1,x2, .. , xm> dan Y = <y1,y2, .. , yn> adalah rangkaian dan Z = <z1,z2, .. , zk> adalah suatu LCS dari X dan Y.
1. Jika xm = yn, maka zk = xm = yn dan Zk-1 adalah suatu LCS dari Xm-1 dan Yn-1.
2. Jika xm≠ yn maka zk≠ xm mengimplikasikan bahwa Z adalah suatu LCS dari Xm-1 dan Y.
3. Jika xm≠ ym maka zk≠ yn mengimplikasikan bahwa Z adalah suatu LCS dari X dan Yn-1.
Misalkan lcs adalah matriks berukuran m x n dan lcs[i,j] adalah panjang LCS dari i karakter pertama rangkaian X dengan j karakter pertama rangkaian Y maka fungsi rekursif untuk mendapatkan panjang LCS adalah sebagai berikut:
lcs[i,j] = 0 jika i = 0 atau j = 0 = lcs [i-1,j-1] + 1 jika X[i] = Y[j]
= max ( lcs [i,j-1], lcs [i-1,j]) jika X[i] ≠ Y[j] Pseudocode untuk algoritma LCS ditunjukkan pada Gambar 2.
function LCS (x[1..m], y[1..n]) lcs ← array (0..m, 0..n) for i ← 0 to m for j ← 0 to n if i = 0 or j = 0 lcs[i,j] ← 0 else if x[i] = y[j] lcs[i,j] ← lcs[i-1,j-1] + 1 else
lcs[i,j] ← max (lcs[i,j-1], lcs[i-1,j])
return lcs[m,n]
Gambar 2. Pseudocode algoritma Longest Common Subsequence
C. Algoritma Soundex dan Normalisasi String
Algoritma Soundex pertama kali dipatenkan oleh Margaret O’Dell dan Robert C. Russell pada tahun 1918 [4]. Algoritma Soundex mengambil masukan berupa sebuah kata atau nama. Algoritma ini menghasilkan sebuah string yang mengidentifikasi apakah sepasang kata tersebut mirip secara fonetik. String ini disebut dengan kode fonetis.
Fonetik adalah ilmu yang menyelidiki bunyi bahasa tanpa melihat fungsi bunyi itu sebagai pembeda makna dalam suatu bahasa. Pencocokan string fonetik adalah suatu teknik pencocokan string yang membandingkan suatu string dengan string yang lain berdasarkan kode fonetis masing-masing [5]. Sebuah string yang berbeda namun mempunyai cara pengucapan yang sama, akan memiliki kode fonetis yang sama.
Aturan pemberian kode fonetis per huruf pada algoritma Soundex [6] dapat dilihat pada Tabel 1.
Tabel 1. Aturan pemberian kode fonetis pada algoritma Soundex
Huruf Kode Klasifikasi Fonetis
A,E,H,I,O,U,W,Y 0
Diperlakukan sebagai bunyi vokal
B,F,P,V 1 Labial dan labio-dental
C,G,J,K,Q,S,X,Z 2 Glottal
D,T 3 Dental-mute
L 4 Palatal fricative
M,N 5 Labio-nasal dan dental
R 6 Dental fricative
Langkah-langkah algoritma Soundex dalam menghasilkan kode fonetis dari sebuah string masukan adalah sebagai berikut [4]:
1. Ubah semua huruf menjadi huruf kapital, dan hilangkan tanda baca.
2. Pertahankan huruf pertama pada kata tersebut.
3. Ubah huruf lainnya menjadi kode fonetis berdasarkan table.
4. Hapus semua pasangan dari kode fonetis yang berurutan. 5. Hapus semua kode fonetis 0.
6. Tulis empat posisi karakter pertama yang mengikuti pola: <uppercase letter><digit><digit><digit>. Ini adalah kode fonetis sebagai keluaran. Jika kode fonetis tidak sampai empat karakter, maka ditambahkan digit 0 sampai menjadi empat karakter.
Algoritma Soundex dibuat berdasarkan pengucapan dalam bahasa Inggris. Untuk mendukung pencocokan string berdasarkan bahasa Indonesia, sekaligus melakukan optimasi terhadap algoritma tersebut, diperlukan suatu proses normalisasi. Salah satu cara untuk proses normalisasi adalah dengan menggunakan aturan translasi q-gram [7]. Aturan translasi q-gram dijelaskan pada Tabel 2.
Tabel 2. Aturan translasi q-gram
q-gram Awal Translasi KH,CH HH DJ JJ TJ CC CQ,CK KK PH FF DZ ZZ SJ SY SY SS BH,DH,GH,JH,SH,TH,ZH BB,DD,GG,JJ,SS,TT,ZZ V F KS XX OE UU IE II Y I
D. Perancangan Proses Pemeriksaan data
Pada proses ini sistem memeriksa data jawaban. Data yang memiliki data nomor dan nama peserta yang sesuai dengan
data pendaftaran akan diberikan status identik. Data yang memiliki data nomor peserta yang valid akan ditentukan statusnya pada subproses pemeriksaan data nama menggunakan algoritma pencocokan string. Rancangan alur subproses pemeriksaan data nama menggunakan algoritma pencocokan string ditunjukkan pada Gambar 3.
Pada subproses pemeriksaan data nama menggunakan algoritma pencocokan string, urutan algoritma yang digunakan adalah algoritma Levenshtein Distance, lalu algoritma LCS, dan terakhir adalah algoritma Soundex. Urutan ini didasarkan pada tingkat toleransi masing-masing algoritma. Algoritma Levenshtein Distance menoleransi 3 jenis kesalahan penulisan yaitu penyisipan, penghapusan, serta penggantian karakter. Algoritma LCS hanya menoleransi kesalahan penulisan berupa penyisipan dan penghapusan. Algoritma Soundex hanya menoleransi kesalahan berupa penggantian karakter.
Untuk menentukan status kevalidan data, perlu ditetapkan batasan-batasan pada hasil keluaran masing-masing algoritma pencocokan string. Untuk algoritma Levenshtein Distance, dua string masukan dinyatakan mirip apabila Levenshtein Distance keduanya kurang dari atau sama dengan 3. Batasan ini dipilih karena algoritma ini dapat menoleransi 3 jenis kesalahan penulisan yaitu penyisipan, penghapusan, dan penggantian karakter. Untuk algortima LCS dan Soundex, dua string masukan dinyatakan mirip apabila persentase kemiripannya lebih dari atau sama dengan 60%. Persentase kemiripan adalah perbandingan antara jumlah kata pada nama yang lebih pendek yang ada padanannya dengan jumlah kata pada nama yang panjang. Nilai 60% ditetapkan berdasarkan pengamatan pada data SNMPTN 2011. Data nama terdiri dari satu sampai lima kata. Untuk nama yang hanya terdiri dari satu atau dua kata, maka semua kata harus mirip dengan nama yang akan dibandingkan. Untuk nama yang terdiri dari tiga kata, maka dua dari tiga kata tersebut harus mirip dengan nama yang akan dibandingkan. Sedangkan untuk nama yang terdiri dari empat atau lima kata, minimal tiga kata harus mirip dengan nama yang akan dibandingkan.
Data nama peserta yang setelah diperiksa dianggap sama dengan data pendaftaran, maka diberikan status valid. Status temporary invalid diberikan pada data yang memiliki nomor peserta yang valid namun data nama peserta tidak lolos pemeriksaan algoritma. Status temporary invalid juga diberikan pada data yang nomor pesertanya tidak valid.
Data yang identik dan valid akan dimasukkan ke tabel padanan. Padanan adalah data pendaftaran yang ekuivalen dengan data jawaban berdasarkan kesamaan nomor atau kemiripan nama. Pengguna dapat memutuskan untuk menghapus data tersebut dari tabel padanan pada proses verifikasi hasil pemeriksaan. Rancangan alur proses pemeriksaan data digambarkan dengan diagram alir seperti yang ditunjukkan pada Gambar 4.
Mulai
Masukkan data nama dari data pendaftaran (s1)
Masukkan data nama dari data jawaban (s2) s1.equal(s2) Kedua data dianggap sama Ya Hitung levenshtein distance dari s1 dan s2 Tidak Levenshtein distance <= 3 Ya Tidak Hitung persentase
kemiripan dari s1 dan s2 menggunakan
algoritma LCS
Persentase >=
60% Ya
Tidak Ubah s1 dan s2 menjadi
kode fonetis menggunakan algoritma
soundex dan hitung persentase kemiripannya Ya Kedua data dianggap tidak sama Tidak Selesai Persentase >= 60%
Gambar 3. Diagram alir subproses pemeriksaan data nama menggunakan algoritma pencocokan string
Mulai Sistem mengambil data jawaban dari
basis data
Sistem mengambil data pendaftaran dari basis data
Sistem memeriksa nomor peserta
pada data jawaban
Nomor peserta valid
Beri status temporary invalid Sistem
mencocokkan data nama peserta
Nama peserta
identik Beri status identik
Periksa data nama dengan algoritma pencocokan string
Data nama dianggap valid
Beri status valid
Tidak Ya Ya Tidak Tidak Ya Selesai Masukkan data ke tabel padanan
Gambar 4. Diagram alir proses pemeriksaan data
E. Perancangan Proses Pemberian Sugesti
Pada proses ini sistem akan memberikan sugesti terhadap data hasil pemeriksaan yang statusnya temporary invalid. Sistem akan mencari nama peserta pada data pendaftaran yang identik dengan data jawaban. Jika ada, maka sistem akan memberikan status suggested pada data tersebut lalu membandingkan data tanggal lahir. Jika data tanggal lahir sama, maka sistem memberikan nilai prioritas 1. Jika tidak, sistem memberikan nilai prioritas 2.
Jika tidak ada nama yang identik, maka sistem akan mencari data pendaftaran yang dianggap mirip dengan data jawaban. Kemiripan ditentukan berdasarkan pemeriksaan menggunakan algoritma pencocokan string. Jika ada data nama pendaftaran yang mirip, maka sistem akan memberikan status suggested pada data tersebut lalu membandingkan data
tanggal lahir. Jika data tanggal lahir sama, maka sistem memberikan nilai prioritas 3. Jika tidak, sistem memberikan nilai prioritas 4.
Jika tetap tidak ada data nama pendaftaran yang dianggap mirip, sistem akan memasukkan data tanggal lahir sebagai kata baru pada data nama. Kemudian sistem akan kembali mencari data nama pendaftaran yang dianggap mirip. Jika ada, sistem akan memberikan status suggested dengan nilai prioritas 5. Apabila tidak ditemukan data yang dianggap mirip, maka sistem akan memberikan status invalid pada data jawaban.
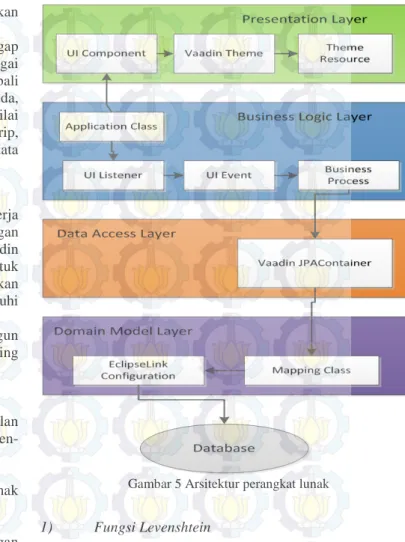
F. Perancangan Arsitektur Sistem
Sistem ini akan dibangun menggunakan kerangka kerja Vaadin. Vaadin adalah kerangka kerja untuk pengembangan aplikasi web AJAX untuk sisi server. Fokus dari Vaadin adalah kemudahan untuk digunakan, kemampuan untuk digunakan kembali (reusability), kemampuan untuk digunakan dalam jangka panjang (extensibility), serta mampu memenuhi kebutuhan dari aplikasi usaha berskala besar [8].
Dalam segi arsitektur, perangkat lunak yang akan dibangun memiliki 4 lapisan. Berikut penjelasan dari masing-masing lapisan yang diterapkan dalam aplikasi ini:
1. Presentation Layer
Lapisan presentasi bertanggung jawab dalam hal tampilan antarmuka aplikasi. Lapisan ini terdiri atas komponen-komponen antarmuka pengguna serta Vaadin theme. 2. Business Logic Layer
Lapisan ini merupakan bagian dari sistem perangkat lunak yang berhubungan dengan logika dari proses bisnis. 3. Data Access Layer
Lapisan ini bertanggung jawab dalam hal koneksi dengan basis data yang digunakan. Lapisan ini memiliki tugas yang berkaitan dengan membaca dan menulis pada basis data. Aplikasi ini menggunakan pustaka Vaadin JPAContainer untuk mengakses data baik dari antarmuka pengguna maupun proses bisnis.
4. Domain Model Layer
Domain model layer berisi implementasi kelas-kelas yang ditunjukkan pada diagram PDM pada subbab 3.2.2. Aplikasi ini menggunakan pustaka EclipseLink untuk menangani masalah object relational mapping antara kelas yang ada di dalam aplikasi dengan basis data relasional yang digunakan.
Hubungan antara lapisan-lapisan tersebut dapat dilihat pada Gambar 5.
III. IMPLEMENTASI A. Implementasi Algoritma Pencocokan String
Implementasi algoritma Levenshtein Distance, Longest Common Subsequence, dan Soundex mengacu pada penjelasan bagian II.A, II.B dan II.C tentang algoritma tersebut. Masing-masing algoritma tersebut diimplementasikan dalam sebuah fungsi.
Gambar 5 Arsitektur perangkat lunak
1) Fungsi Levenshtein
Fungsi Levenshtein merupakan implementasi dari algoritma Levenshtein Distance. Parameter fungsi ini adalah dua String yang akan dihitung Levenshtein Distance-nya. Tipe nilai kembalian dari fungsi ini adalah Integer. Implementasi fungsi ini dapat dilihat pada Gambar 6.
public int levenshtein(String a, String b) { for(i=0;i<=a.length();i++) { for(j=0;j<=b.length();j++) { if(i==0)ar[i][j]=j; else if(j==0)ar[i][j]=i; else { if(a.charAt(i-1)==b.charAt(j-1)) ar[i][j]=ar[i-1][j-1]; else
ar[i][j]=1 + Math.min( Math.min(ar[i][j-1],ar[i-1][j]) , ar[i-1][j-1]) }
} }
return ar[x][y]; }
Gambar 6. Kode sumber fungsi Levenshtein
2) Fungsi LCS
Fungsi LCS merupakan implementasi dari algoritma Longest Common Subsequence. Parameter fungsi ini adalah dua String yang akan diperiksa apakah salah satu String
merupakan LCS dari String yang lain. Tipe nilai kembalian dari fungsi ini adalah Boolean.
3) Fungsi Soundex
Fungsi Soundex meupakan implementasi dari algoritma Soundex. Parameter fungsi ini adalah sebuah String yang akan dicari kode fonetisnya. Tipe nilai kembalian dari fungsi ini adalah String.
IV. PENGUJIANDANEVALUASI
Pengujian dilakukan untuk menguji tingkat keberhasilan penghilangan duplikasi data. Masukan untuk pengujian ini adalah data dari SNMPTN tahun 2011. Tingkat keberhasilan didasarkan pada persentase keberhasilan sistem dalam menentukan status data terduplikasi berdasarkan pemeriksaan menggunakan algoritma pencocokan string. Skenario pengujian dapat dilihat pada Tabel 3.
Tabel 3. Skenario pengujian tingkat keberhasilan penghilangan duplikasi data Skenario Jumlah data pendaftaran Jumlah data jawaban Jumlah data jawaban identik Jumlah data jawaban terduplikasi Skenario 1 174.269 562.793 440.693 122.100
Persentase tingkat keberhasilan pada tahap pemeriksaan adalah perbandingan antara jumlah data terduplikasi yang dinyatakan valid dengan jumlah total data terduplikasi. Berdasarkan hasil pengujian, persentase tingkat keberhasilan pada tahap ini adalah 96,57%. Persentase tingkat keberhasilan pada tahap sugesti adalah perbandingan antara jumlah data terduplikasi berstatus suggested dengan jumlah total data terduplikasi. Berdasarkan hasil pengujian, tingkat keberhasilan pada tahap ini adalah 3,09%. Sehingga total persentase tingkat keberhasilan adalah 99,66%. Hasil pengujian ditunjukkan oleh Tabel 4.
Tabel 4. Hasil pengujian tingkat keberhasilan penghilangan duplikasi data Jumlah data Persentase dari jumlah data ans Persentase dari jumlah data ans terduplikasi Persentase dari jumlah data ans temporary invalid
Jumlah data ans 562793
Jumlah data ans identik
440693 78,30%
Jumlah data ans terduplikasi
122100 21,70%
Jumlah data ans valid
117914 20,95% 96,57% Jumlah data ans
temporary invalid
4186 0,74% 3,43%
Jumlah data ans
suggested
3773 0,67% 3,09% 90,14%
Jumlah data ans
invalid
413 0,07% 0,34% 9,86%
Pengujian juga dilakukan untuk mengukur tingkat akurasi kebenaran pencarian padanan. Tingkat akurasi kebenaran pencarian padanan diukur melalui pengamatan data pada saat proses validasi data Seleksi Bersama Masuk Perguruan Tinggi Negeri (SBMPTN) 2013.
Berdasarkan hasil pengamatan data, dijumpai rata-rata 3 kesalahan padanan setiap 5 batch. Setiap batch berisi rata-rata 100 data jawaban. Jadi, tingkat akurasi kebenaran pencarian padanan adalah 99,4%.
V. KESIMPULAN/RINGKASAN
Berdasarkan pengamatan selama proses perancangan
,
implementasi, dan pengujian perangkat lunak, dapat diambil kesimpulan sebagai berikut:
1. Aplikasi penghilangan duplikasi data berbasis web dapat dibangun menggunakan kerangka kerja Vaadin.
2. Algoritma pencocokan string Soundex, Levenshtein Distance, dan Longest Common Subsequence dapat diimplementasikan untuk proses penghilangan duplikasi data SNMPTN.
3. Implementasi algoritma pencocokan string pada proses penghilangan duplikasi data memiliki tingkat keberhasilan yang tinggi, yaitu 99,66%. Tingkat keberhasilan ini didapatkan berdasarkan hasil pengujian pada data SNMPTN tahun 2011.
4.
Pencarian padanan untuk setiap data jawaban menggunakan algoritma pencocokan string memiliki tingkat akurasi kebenaran yang tinggi, yaitu 99,4%. Tingkat akurasi kebenaran ini didapatkan berdasarkan hasil pengujian pada proses validasi data SBMPTN tahun 2013.DAFTARPUSTAKA
[1] Pinzon, Yoan. 2006. Algorithm for Approximate String Matching. Universidad Nacional de Colombia..
[2] Sala, Jared. 2000. Longest Common Subsequence. University of New Mexico.
[3] Cormen, Thomas H., Leiserson, Charles E., Rivest, Ronald L., Stein, Clifford. 1992. Introduction to Algorithm. Electrical Engineering and Computer Science, Massachusetts Institute of Technology.
[4] Creativyst, Inc. Understanding Classic Soundex Algorithms.
<URL:http://www.creativyst.com/Doc/Articles/SoundEx1/SoundEx1.ht m diakses pada September 2012>
[5] Purnamasari, Tryas Ayu dan Luthfi, Emha Taufiq. 2012. Membangun
Aplikasi Pencocokan String Berdasarkan Penulisan dan Kemiripan Pengucapan. Jurusan Teknik Informatika, STMIK AMIKOM
Yogyakarta.
[6] GenealogyInTime Magazine. Soundex Coding Rules.
<URL:http://www.genealogyintime.com/GenealogyResources/Articles/ what_is_soundex_and_how_does_soundex_work_page2.html diakses pada September 2012.>
[7] Karhendana, Arie, Wizanajani, Dicky, dan Yuliawan, Fajar. 2004.
Normalisasi String untuk Optimasi Phonetic String Matching dalam Bahasa Indonesia. Sekolah Teknik Elektro dan Informatika, Institut
Teknologi Bandung.