Identifikasi DNA dengan Rantai Markov Orde Satu dan
Probabilistic Neural Network
Toto Haryanto
1)Habib Rijzaani
2)Muhammad Luthfi Fajar
3)1)
Laboratorium Komputasi Terapan, Departemen Ilmu Komputer FMIPA IPB
Jl. Meranti Wing 20 Level 5 Kampus IPB Dramaga, 16680
email : [email protected] 2)
BB-Biogen, Badan Litbang Pertanian, Kementerian Pertanian
Jl. Tentara Pelajar 3 No.3A Bogor 16111
email : [email protected] 3)
Laboratorium Komputasi Terapan, Departemen Ilmu Komputer FMIPA IPB
Jl. Meranti Wing 20 Level 5 Kampus IPB Dramaga, 16680
email : [email protected]
ABSTRACT
Genetic differences among organisms causing much research in system identification deoxyribonucleic acid or DNA. In the DNA identification system , there are two main parts, feature extraction methods and classification methods. In this research, feature extraction method used was first order Markov chain while classification methods combined with Probabilistic Neural Network (PNN). DNA sequence is derived from the genus Burkholderia, Clostridium, and Streptococcus with various length of base pairs (bp) from 100 bp, 200 bp, 400 bp, 800 bp, and 1000 bp were obtained from the National Center For Biotechnology Information (NCBI). Result of identification are sensitive and specific to length of base pair (bp). The high value of sensitvity and spesificity due to the number of classes that use relatively little.
Key words
DNA sequence, markov chain, probabilistic neural network, , sensitivity, specificity
1. Pendahuluan
DNA (Deoxyribo Nucleid Acid) merupakan polimer, atau lebih tepatnya suatu himpunan dari dua polimer yang bersifat double helix. Setiap monomer yang membentuk polimer ini merupakan nukleotida yang terdiri atas gula, fosfat, dan basa nitrogen. Gula dan fosfat dari seluruh nukleotida sama, tetapi setiap nukleotida dapat dibedakan melalui peninjauan komponen basanya. Komponen basa nitrogen dibedakan menjadi empat tipe yang dimasukkan ke dalam dua kategori, Kategori purine terdiri atas
Adenine (A) dan Guanine (G) yang memiliki dua cincin aromatis dan kategori pirimidine terdiri atas Cytosine (C) dan Thymine (T) yang memiliki satu cincin aromatis [1]. DNA pada setiap organisme akan berbeda satu sama lain. Adanya perbedaan genetik di antara organisme inilah yang menyebabkan banyaknya penelitian dalam sistem identifikasi DNA. Bioinformatika merupakan disiplin ilmu yang pada awalnya muncul karena kebutuhan untuk memperkenalkan urutan dari sebuah data besar yang dihasilkan oleh teknologi baru biologi molekuler seperti sekuensing DNA dalam skala besar, pengukuran konsentrasi RNA dalam beberapa array ekspresi gen, dan teknik profiling baru di proteomik. Dengan demikian, bioinformatika mengintegrasikan sejumlah ilmu tradisional kuantitatif seperti matematika, statistika, dan ilmu komputer dengan ilmu biologi seperti genetika, genomik, proteomik dan evolusi molekuler [2]. Dimulai dari bioinformatika inilah dikenal istilah metagenome. Metagenome adalah konten genetik dari suatu komunitas biologis. Istilah ini biasa diterapkan pada komunitas mikroba yang dianggap sebagai satu entitas sehingga diperlakukan dan dipelajari sebagai satu meta-organism dengan genom tunggal [3]. Metagenome ini dapat berupa sekuens DNA.
Dalam mengenali sekuens DNA dari suatu organisme tertentu, dibutuhkan metode ekstraksi ciri dan metode klasifikasi. Kedua metode ini merupakan bagian penting dari proses gene mapping. Dalam menentukan hubungan kekerabatan antara organisme yang satu dengan yang lainnya, penciri yang dapat digunakan adalah DNA, RNA dan urutan protein, struktur protein, profil ekspresi gen, jalur biokimia, dan jenis-jenis enzim [4].
Salah satu metode ekstraksi ciri yang digunakan untuk melakukan klasifikasi sekuens DNA adalah metode
Rantai Markov. Penelitian menggunakan Rantai Markov telah dilakukan oleh Ryabko dan Usotskaya [5]. Dalam penelitiannya Ryabko dan Usotskaya menjelaskan bahwa pemodelan sekuens DNA menggunakan Rantai Markov dengan orde satu dan orde dua. Model tersebut kemudian digunakan untuk memprediksi memori atau konektivitas dari suatu teks genetik dan memecahkan masalah berbasis DNA yang berkaitan dengan sistem filogenetik dari berbagai kelompok organisme. Adapun Simons et al [6]. melakukan pemodelan Rantai Markov untuk data nukleotida eukariot. Dalam penelitiannya Simons et al. memfokuskan kepada kesamaan karakteristik intra-species dan reversibilitas beserta komplementari dari dua untai kromosom.
Penelitian menggunakan metode klasifikasi Probabilistic Neural Network (PNN) juga telah dilakukan oleh Wu et al. (2005) [7]. Wu et al. melakukan penelitian menggunakan metode ekstraksi ciri hamming distance dan edit distance dan metode klasifikasi Probabilistic Neural Network (PNN). Dalam penelitian Wu et al. diperoleh nilai Sensitivity terbaik pada panjang sekuens 200 base pair (bp) sebesar 0,83 dan pada panjang sekuens 300 bp sebesar 0,93. Keduanya dilakukan terhadap 12 target kelas dan banyak sekuens pada setiap kelasnya sebesar 30.
Berdasarkan latar belakang tersebut, pada penelitian ini penulis akan melakukan identifikasi terhadap sekuens DNA bakteri dari genus Burkholderia, Clostridium, dan Streptococcus menggunakan ekstraksi ciri Rantai Markov orde satu dengan Probabilistic Neural Network sebagai classifier.
2. Ekstraksi Ciri Rantai Markov
Rantai Markov adalah suatu model stokastik yang diperkenalkan oleh matematikawan Rusia bernama A. A. Markov pada awal abad ke-20. Dengan menggunakan proses Markov maka dimungkinkan untuk memodelkan fenomena stokastik dalam dunia nyata yang berkembang menurut waktu. Masalah dasar dari metode stokastik dengan proses Markov adalah menentukan deskripsi state yang sesuai, sehingga proses stokastik yang berpaduan akan benar-benar memiliki apa yang akan disebut sifat Markov (Markovian property), yaitu pengetahuan terhadap state ini adalah cukup untuk memprediksi perilaku stokastik yang akan datang [8].
Suatu Rantai Markov dikatakan diskret (Discrete Time Markov Chain) jika ruang dari proses Markov tersebut adalah himpunan terbatas (finite) atau tercacah (countable), dengan himpunan indeks adalah . Jika nilai suatu state pada periode tertentu hanya bergantung pada satu periode sebelumnya, maka rantai tersebut disebut Rantai Markov Orde Satu (First Order Markov Chain) dan jika nilai suatu state pada periode
tertentu bergantung pada periode sebelumnya, maka rantai tersebut disebut Rantai Markov Orde m (m Order Markov Chain). Rantai Markov Orde Satu secara matematika dirumuskan sebagai berikut:
{ }
Adapun Rantai Markov Orde secara matematika dirumuskan sebagai berikut:
{ } Peluang bahwa berada pada state jika berada pada state disebut sebagai peluang transisi satu langkah (one step transition probability). Secara matematis dapat terlihat pada rumus di bawah ini:
{
}
Jika peluang ini bebas dari indeksnya, maka peluang ini disebut proses Markov dengan peluang transisi stasioner. Sehingga peluang transisi tersebut dirumuskan sebagai berikut:
Peluang transisi ini disusun dalam bentuk matriks, yang disebut peluang matriks transisi P, yang setiap unsurnya adalah yaitu { } . Matriks tersebut terdapat di bawah ini:
[
]
Dalam penelitian ini, matriks peluang transisi dibentuk dari peluang-peluang munculnya komponen basa tertentu setelah sebelumnya merupakan komponen basa tertentu. Matriks transisi Rantai Markov Orde Satu dibentuk dari peluang-peluang munculnya komponen basa tertentu setelah sebelumnya merupakan tepat satu komponen basa tertentu. Dengan demikian matriks transisi Rantai Markov Orde Satu terdiri atas , yaitu peluang munculnya komponen basa A setelah sebelumnya merupakan komponen basa A, , , , dan seterusnya, sehingga pada matriks transisi Rantai Markov Orde Satu terdapat 16 elemen matriks [9].
Matriks transisi tersebut kemudian menjadi penciri dari setiap sekuens DNA yang mewakili genus tertentu.
3. Probabilistic Neural Network
Probabilistic Neural Network (PNN) merupakan Jaringan Saraf Tiruan (JST) yang menggunakan teorema probabilitas klasik seperti pengklasifikasian Bayes dan penduga kepekatan Parzen. Proses yang dilakukan oleh PNN dapat berlangsung lebih cepat bila dibandingkan dengan JST Back Propagation. Hal ini disebabkan PNN hanya membutuhkan satu kali iterasi pelatihan bila dibandingkan dengan JST Back Propagation yang membutuhkan beberapa kali iterasi pelatihan [10].
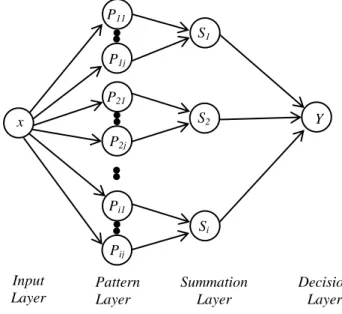
Struktur PNN terdiri atas empat lapisan, seperti yang terlihat pada Gambar 2, yaitu lapisan masukan, lapisan pola, lapisan penjumlahan, dan lapisan keputusan. Lapisan masukan merupakan sekuens DNA yang terdiri atas nilai ciri yang akan diklasifikasikan pada n kelas. Struktur PNN ditunjukkan pada Gambar 1.
Gambar 1 Struktur PNN Dengan
x : Instance sekuens (vektor hasil ekstraksi ciri) Pij : data ke –j kelas ke-i
Si : hasil penjumlahan kelas ke-i
Y : Peluang tersbesar
Proses-proses yang terjadi setelah input layer adalah : 1. Lapisan Masukan
Layer ini merupakan layer ciri atau atribut hasil proses ekstraksi ciri dengan menggunakan rantai markov. Layer ini merupakan vektor dengan panjang 16. 2. Lapisan Pola
Pattern layer menggunakan satu node untuk setiap data pelatihan yang digunakan. Setiap node pola merupakan selisih dari vektor masukan yang akan diklasifikasikan dengan vektor bobot , yaitu
, kemudian dibagi dengan faktor bias σ dan selanjutnya dimasukkan ke dalam fungsi radial basis, yaitu
. Dengan demikian, persamaan yang digunakan pada pattern layer adalah :
( ( ) ( )
)
3. Lapisan Penjumlahan
Lapisan Penjumlahan menerima masukan dari setiap node lapisan pola yang terkait dengan kelas yang ada. Persamaan yang digunakan pada lapisan ini adalah:
∑ ( ( ) ( ) ) 4. Lapisan Keputusan
Lapisan Keputusan Menentukan kelas dari input yang diberikan. Input akan masuk ke kelas jika nilai peluang masuk ke { } paling besar dibandingkan peluang terhadap kelas lainnya.
4. Hasil dan Percobaan Identifikasi Sekuens
DNA
Proses Identifikasi DNA dilakukan melalui beberapa tahap mulai dari pengambilan data, praproses, pembagian data latih dan data uji, proses ekstraksi ciri DNA, proses identifikasi DNA serta analisis hasil identifikasi. 4.1 Pengambilan Data
Data Data yang digunakan dalam penelitian ini merupakan data metagenome yang diunduh dari situs National Center For Biotechnology Information (NCBI) dengan alamat web http://www.ncbi.nlm.nih.gov/. Setelah mendapatkan data dari NCBI, data tersebut kita proses dalam perangkat lunakMetaSim (ver. 0.9.1). Keluaran dari perangkat lunak ini adalah fail berupa FASTA yang berisi sekuens DNA. Sekuens DNA terdiri atas A, C, G, dan T yang merupakan komponen basa dari nukleotida. Pada penelitian ini, data metagenome yang akan digunakan terdiri atas tiga genus, yaitu Burkholderia, Clostridium, dan Streptococcus dengan panjang sekuens 100 bp, 200 bp, 400 bp, 800 bp, dan 1000 bp. Ketiga genus ini digunakan karena memiliki keberagaman species paling besar dari data yang diperoleh dari NCBI. Deskipsi data yang digunakan dapat dilihat seperti pada Tabel 1. Input Layer Pattern Layer Summation Layer Decision Layer x P11 P1j P21 P2j Pi1 Pij S1 S2 Si Y
Tabel 1 Tiga genus data sekuens DNA dengan panjang sekuens 100 bp, 200 bp, 400 bp, 800 bp, dan 1000 bp
Genus Jumlah Sekuens DNA
Burkholderia 1000 sekuens
Clostridium 1000 sekuens
Streptococcus 1000 sekuens 4.2 Praproses
Pada tahap praproses dilakukan pemisahan antara data informasi dengan sekuens DNA-nya. Sekuens DNA yang telah dipisahkan kemudian akan digunakan sebagai penciri dari sebuah organisme. Contoh data yang terdapat dalam fail FASTA:
>r1.1|SOURCES={GI=115350056,fw,24251462425 246}|ERRORS={}|SOURCE_1="Burkholderia ambifaria AMMD chromosome chromosome 1"(cc1f7490881b379f77fffd84822b0921a35eb86 5)ACTTCCGCCTCCCGGATCACGAGCGGCGGCGACAGCAGCA TCCGATCACCGGTCGCGCGCATGATCAGGTTGCCGTTGAAAC AGAAGTCGCGGCAGATCG
Sekuens DNA yang digunakan:
ACTTCCGCCTCCCGGATCACGAGCGGCGGCGACAGCAGCATC CGATCACCGGTCGCGCGCATGATCAGGTTGCCGTTGAAACAG AAGTCGCGGCAGATCG
4.3 Pembagian data latih dan data uji
Penelitian ini menggunakan metode k-fold cross validation untuk membagi data latih dan data uji. Dalam metode ini dilakukan perulangan sebanyak kali. Setiap kali perulangan, salah satu subset akan dijadikan data uji dan subset lainnya dijadikan sebagai data latih. Pada perulangan ke-i, subset digunakan sebagai data pengujian dan subset lainnya digunakan sebagai data pelatihan, dan seterusnya [11]. Penelitian ini menggukan 5 sebagai nilai k. Dengan demikian, untuk setiap genus berjumlah 1000, akan terdapat 800 data uji dan 200 data latih. Skema pembagian data latih dan data uji dapat dilihat pada Tabel 2.
Tabel 2 Proses pada metode 5-fold cross validation Perulangan ke- Data Uji Data Latih
1
2
3
4
5
4.4 Ekstraksi ciri dengan Rantai Markov
Ekstraksi ciri yang digunakan adalah Rantai Markov dengan orde satu dan orde dua. Pada orde satu, untuk setiap genus dan panjang sekuens yang digunakan, diperoleh matriks dengan dimensi 4 x 4. Matriks ini kemudian dibuat menjadi matriks berdimensi 1 x 16 untuk memudahkan penghitungan. Pada orde dua, untuk setiap genus dan panjang sekuens yang digunakan, diperoleh matriks dengan dimensi 16 x 4. Matriks ini kemudian dibuat menjadi matriks berdimensi 1 x 64 untuk memudahkan penghitungan.
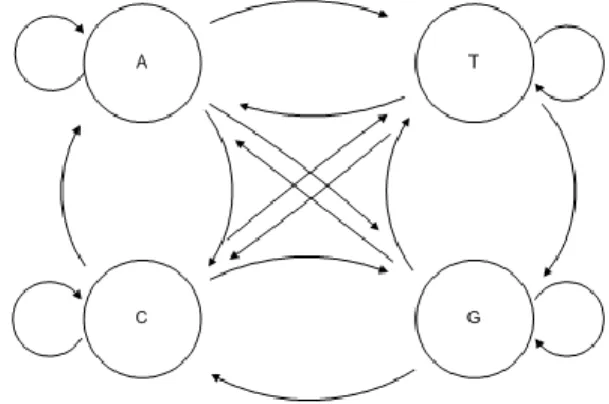
Setiap basa nitrogen A, C, G atau T dapat dipresentasikan sebagai suatu state seperti ditunjukkan pada Gambar 2.
Gambar 2 Diagram State Transisi
Dalam suatu sekuens akan dihitung seluruh peluang nilai transisi sehingga akan memiliki matrik transisi yang menyatakan peluang suatu basa tertentu jika sebelumnya muncul basa tertentu pula dengan ilustrasi.
Apabila diberikan sebuah sekuens:
TAGGTTTAGGTAGAACTTTTCAAAATATCCGACTTTTT AAAAATATGACTGTTTTAGACAATGTACTAGTAGGACT CAGTAATCATCACTTATCACATCC
maka matriks transisi Rantai Markov Orde Satu yang dihasilkan dari sekuens tersebut adalah sebagai berikut:
4.5 Identifikasi sekuens DNA
Matrik transisi hasil ekstraksi fitur tersebut kemudian akan disimpan dalam suatu basis data dan menjadi penciri
dari setiap fragmen. Ciri tersebut kemudian akan menjadi vektor ciri untuk masuk ke dalam proses identifikasi menggunakan Probabilistik Neural Network.
Hasil pengujian kemudian dilakukan dengan membuat matrik konfusi untuk setiap genus seperti dilihat pada tabel 3.
Tabel 3 Matrik Konfusi
Terdeteksi sebagai
sequence DNA genus A
Terdeteksi sebagai bukan sequence genus A Sequence DNA uji genus A tp fn Bukan sequence DNA uji genus A fp tn dengan
tp : true positive (jumlah sequence DNA uji genus A yang tepat teridentifikasi sebagai sequence DNA genus A) tn : true negative (jumlah bukan sequence DNA uji genus
A yang tepat teridentifikasi sebagai bukan sequence DNA genus A)
fp : false positive (jumlah bukan sequence DNA uji genus A yang teridentifikasi sebagai sequence DNA genus A) fn : false negative (jumlah sequence DNA uji genus A yang teridentifikasi sebagai bukan sequence DNA genus A) Sensitivity mengukur proporsi positif yang diidentifikasi dengan benar, sedangkan specificity mengukur proporsi negatif yang diidentifikasi dengan benar.
Persamaan dari nilai sensitivity adalah:
Adapun persamaan dari nilai specificity adalah:
4.6 Perbandingan nilai sensitivity setiap genus
Nilai sensitivity setiap genus akan dihitung untuk menujukkan bagaimana kinerja Probabilistic Neural Network dalam melakukan identifikasi setiap genus. Tabel 4 menunjukkan perbandingan nilai sensitivity untuk setiap genus.
Pada Tabel 4 terlihat bahwa nilai sensitivity genus Burkholderia memiliki nilai yang paling tinggi dibandingkan dengan dua genus lainnya. Berdasar Tabel 4 juga dapat dilihat bahwa untuk ketiga jenis genus, penggunaan jumlah pasang basa yang lebih banyak memiliki kecenderungan meningkatkan nilai sensitivity. Dengan kata lain, identifikasi DNA ini sensitif terhadap
panjang basa yang digunakan pada saat dilakukan proses ekstraksi ciri.
Tabel 4. Perbandingan nilai sensitivity tiga genus Panjang
sekuens Streptococcus Burkholderia Clostridium
100 bp 0.952 0.97 0.44 200 bp 0.938 0.979 0.594 400 bp 0.95 0.98 0.699 800 bp 0.961 0.984 0.75 1000 bp 0.968 0.992 0.772
Berdasar Tabel 4, terlihat bahwa penggunaan pasang basa yang paling banyak, dalam hal ini 1000bp memberikan kontribusi terhadap meningkatnya nilai sensivity. Hal ini disebabkan informasi genetik yang dapat diekstrak lebih banyak meskipun memiliki waktu komputasi yang makin meningkat. Tingginya nilai sensitivity ini disebabkan jumlah kelas yang digunakan masih sangat sedikit selain bahwa ketiganya merupakan genus yang memang relatif berbeda.
Di sisi lain, berdasar Tabel 4 juga diketahui bahwa nilai sensitivity masih rendah untuk genus Clostridium terutama pada pemilihan 100 pasang basa atau 100(bp). Hal ini menunjukkan bahwa sedikitnya genus Clostridium yang teridentifikasi sebagai dirinya sendiri dan cenderung banyak teridentifikasi ke kelas lain.
4.7 Perbandingan nilai specificity setiap genus
Nilai specificity juga dilakukan untuk setiap genus untuk mengetahui apakah terdapat genus lain yang yang teridentfikasi sebagai kelas tersebut. Perbandingan nilai specificity untuk setiap genus dapat dilihat pada Tabel 5.
Tabel 5. Perbandingan nilai specificity tiga genus Panjang
sekuens Streptococcus Burkholderia Clostridium
100 bp 0.7075 0.994 0.979
200 bp 0.787 0.999 0.969
400 bp 0.839 1 0.975
800 bp 0.867 1 0.980
1000 bp 0.882 1 0.984
Secara rata-rata nilai specificity terbesar terdapat pada genus Burkholderia yaitu 0.998. Semakin besar nilai ini menunjukkan bahwa semakin sedikit genus selain Burkholderia yang teridentifikasi sebagai genus Burkholderia. Bahkan untuk nilai specificity 1 menunjukkan bahwa tidak ada satu pun genus selain Burkolderia yang diidentifikasi sebagai genus Burkholderia. Ini berarti bahwa pola sekuens dari genus
Streptococcus dan Clostridium sangat berbeda bila dibandingkan dengan Bulkhoderia.
Nilai specificity juga cenderung mengalami kenaikan seiring dengan bertambahnya jumlah pasang basa yang digunakan dalam pengujian. Penggunaan Panjang pasang basa yang makin banyak akan mampu memberikan informasi saat proses ekstraksi ciri sehingga nilai specificity yang dihasilkan semakin besar.
5. Kesimpulan
Berdasarkan penelitian yang telah dilakukan dapat disimpulkan bahwa konsep rantai markov orde satu dapat digunakan untuk melakukan ekstraksi ciri untuk melakukan identifikasi dengan metode PNN sebagai classifier. Hasil Identifikasi DNA sensitif terhadap panjang pasang basa yang digunakan. Nilai sensitivity dan specificity relatif tinggi disebabkan jumlah kelas yang digunakan masih sedikit. Oleh karena itu, untuk penelitian selanjutnya melakukan penambahan jumlah kelas yang akan digunakan. Selain itu, penggunaan rantai markov orde 2 dan penambahan jumlah coverage fragmen untuk panjang basa tertentu dapat dilakukan untuk menjamin bahwa sekuens organisme terwakili secara genomik.
REFERENSI
[1] Peyrard M. 2004. Nonlinear dynamics and statistical
physics of DNA. Nonlinearity 17 (2004) R1-R40.
[2] Polanski A, Kimmel M. 2007. Bioinformatics. Berlin: Springer.
[3] Gargaud M et al. 2011. Encyclopedia of Astrobiology, Volume 1 A-F. Berlin: Springer.
[4] Wang J, Zaki M, Toivonen H, Shasha D. 2005. Data Mining
in Bioinformatics. London: Springer.
[5] Ryabko B, Usotskaya N. 2008. DNA-sequence analysis using Markov chain models. IEEE. 119-123.
[6] Simons G,Yao Y-C, Morton G. 2004. Global Markov Model for eukaryote nucleotide data. Journal of Statistical
Planning and Inference 130 (2005) 251-275.
[7] Wu X, Lu F, Wang B, Cheng J. 2005. Analysis of DNA nequence pattern using probabilistic neural network model.
J RES PRACT INF TECH. 37(4)353-363.
[8] Mangku IW. 2005. Dasar-dasar Pemodelan Stokastik. Departemen Matematika Fakultas MIPA, IPB, Bogor. [9] Robin S, Rodolphe F, Schbath S. 2005. DNA , Words, and
Models. Cambridge: Cambridge University Press.
[10] Spetch DF. 1990. Probabilistic neural network. Neural
Network. 3(1) 109-118.
[11] Hastie T, Tibshirani R, Friedman J. 2011. The Elemets of Statistical Learning: Data Mining, Inference, and Prediction. New York: Springer.
Toto Haryanto, memperoleh gelar Sarjana Komputer (S.Kom)
dan Magister Sains (M.Si) dari Institut Pertanian Bogor, Indonesia pada tahun 2006 dan 2011. Minat riset penulis pada bidang Bioinformatika dan Sistem Pakar. Saat ini sebagai Staf Pengajar dan Peneliti di Departemen Ilmu Komputer Institut Pertanian Bogor (IPB).
Habib Rijzaani, menyelesaikan pendidikan S1 (B.Sc) bidang
Bioteknologi pada tahun 1997 di University of Queensland, Australia. Pendidikan Magister Sains (M.Si) diselesaikan di Institut Teknologi Bandung (ITB) pada tahun 2000. Saat ini sebagai peneliti di Balai Besar Litbang Bioteknologi dan Sumber Daya Genetik Pertanian, Bogor.
Muhammad Luthfi Fajar, Saat ini sebagai mahasiswa tingkat
IV Program Sarjana di Departemen Ilmu Komputer Institut Pertanian Bogor (IPB).