ANALISIS OPTIMISASI FORMULA DISTRIBUTED QUERY
DALAM BASIS DATA RELASIONAL
R. SUDRAJAT
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
BOGOR
2007
RINGKASAN
Proses join query dalam sistem basis data terdistribusi adalah salah satu masalah penting dan cukup rumit dan dapat melibatkan proses komputasi dan formula yang cukup kompleks. Penelitian dalam tesis ini ditujukan untuk menganalisis optimisasi query secara teoritis yang didukung oleh percobaan dalam basis data relasional dengan melibatkan ukuran data yang besar.
Analisis difokuskan pada join query dengan menggunakan Nested-Loops-Join, Block-Nested-Loops-Nested-Loops-Join, Sort-Merge-Join dan Hash-Join yang didasarkan pada analisis fungsi biaya. Dalam penelitian ini kasus data yang digunakan diambil dari Perusahaan Asuransi yang secara transaksional data tersimpan tersebar di beberapa cabang perusahaan.
Hasil dari analisis dan pecobaan menunjukkan bahwa metode Hash-Join dapat menyelesaikan join query dengan biaya terendah. Fragmentasi dan partisi dalam jumlah data yang besar diperlukan untuk menghasilkan join query yang lebih baik. Dengan demikian dalam melakukan proses transaksi dengan jumlah data yang besar (lebih dari satu juta record) fragmentasi dan optimisasi sangat diperlukan untuk mengurangi waktu proses. Proses komputasi secara paralel dengan menggunakan multi processors sangat diperlukan agar dapat meningkatkan unjuk kerja proses query dalam basis data terdistribusi.
ABSTRACT
Joined query is considered an expensive operation therefore specific optimization technique involving formulation, strategy and transformation is required. The purpose of this thesis is to perform optimization analysis of query, theroretically and experimentaly, on distributed relational databases comprising large size data tables.
The analysis is focused on join query using Nested-Loops-Join, Block-Nested-Loops-Join, Sort-Merge-Join and Hash-Join with respect to cost function analysis. The data case used in this research has been taken from an Insurance Company that maintains and operates transactional data stored distributively in several company branches.
The result of the analysis and experiment shows that Hash-Join provides the best (smalest) cost for join query. It is also shown that fragmentation and partition of large data contributes to the better performace of join query. Therefore, it is recommended that the transactional data comprising large data records (one million records or more) needs to be well partitioned to reducethe query execution time. Furthermore, the use of parallel computation using multiple processors are recommended to improve futher the performance of query processing on distributed databases.
ANALISIS OPTIMISASI FORMULA DISTRIBUTED QUERY
DALAM BASIS DATA RELASIONAL
R. SUDRAJAT
Tesis
Sebagai salah satu syarat untuk memperoleh gelar
Magister Sains pada
Program Studi Ilmu Komputer
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
BOGOR
2007
SURAT PERNYATAAN
Dengan ini menyatakan bahwa tesis saya yang berjudul : Analisis Optimisasi Formula Distributed Query dalam Basis Data Relasional adalah merupakan hasil karya saya sendiri dan belum pernah dipublikasikan. Sumber informasi berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam daftar pustaka di bagian akhir tesis ini.
Bogor, Juli 2007
Sudrajat, R. NRP: G651024024
JUDUL : Analisis Optimisasi Formula Distributed Query dalam Basis Data
Relasional
NAMA : R. SUDRAJAT
NRP : G651024024
Disetujui
Komisi Pembimbing
Prof. Dr. Ir. Kudang Boro Seminar M.Sc.
Ir. Fahren Bukhari, M.Sc.
Ketua
Anggota
Diketahui
Ketua Program Studi Ilmu Komputer
Dekan Sekolah Pascasarjana
Dr. Sugi Guritman
Prof. Dr. Ir. Khairil A. Notodiputro, MS.
@ Hak cipta milik Institut Pertanian Bogor, tahun 2007
Hak cipta dilindungi
Dilarang mengutip dan memperbanyak tanpa ijin tertulis dari
Institut Pertanian Bogor, sebagian atau seluruhnya dalam
bentuk apapun, baik cetak, fotokopi, microfilm, dan sebagainya
SURAT PERNYATAAN
Dengan ini menyatakan bahwa tesis saya yang berjudul : Analisis Optimisasi Formula Distributed Query dalam Basis Data Relasional adalah merupakan hasil karya saya sendiri dan belum pernah dipublikasikan. Sumber informasi berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam daftar pustaka di bagian akhir tesis ini.
Bogor, Juli 2007
Sudrajat, R. NRP: G651024024
PRAKATA
Puji Syukur ke Hadirat Allah SWT Yang Maha Pengasih dan Maha Penyayang atas Rahmat serta KaruniaNya, penulis diberi kemampuan dan kekuatan untuk dapat menyelesaikan tesis ini dengan judul: “ Analisis Optimisasi Formula Distributed Query dalam Basis Data Relasional “
Pada kesempatan ini penulis menyampaikan rasa hormat dan rasa terima kasih kepada Bapak Prof. Dr. Ir. Kudang Boro Seminar M.Sc. dan Bapak Ir. Fahren Bukhari, M.Sc yang telah meluangkan waktunya untuk membimbimg dan mengarahkan penulis hingga terselesaikannya tesis ini. Ucapan terima kasih juga penulis sampaikan kepada Bapak Drs. Edi Maryanto selaku Data Administrator Manager pada PT. Taspen yang telah memberikan penulis berupa data peserta Asuransi, dan terima kasih kepada Bapak Agus Muhtarom SSi. sebagai kepala Sistem Informasi FMIPA-UNPAD yang telah memberikan fasilitas penggunaan Lab.Penelitian Fakultas MIPA. Akhirnya penulis menyampaikan terima kasih pula untuk Istri tercinta dan putra-putri atas segala do’a dan dukungannya.
Semoga segala bantuan dan dorongan yang telah diberikan kepada penulis mendapatkan balasan dari Allah SWT, dan semoga karya ilmiah ini bermanfaat.
Bogor, Juli 2007
DAFTAR RIWAYAT HIDUP
Penulis dilahirkan di Sumedang Jawa Barat pada tanggal 12 Pebruari 1960 sebagai anak ke tiga dari pasangan R. Kusdinar dan Ibu Epon Suhaenah (Alm). Pendidikan Sarjana ditempuh di Jurusan Matematika FMIPA Universitas Padjadjaran Bandung , lulus tahun 1986. Kesempatan untuk melanjutkan program Pascasarjana pada program studi Ilmu Komputer FMIPA IPB, diperoleh pada tahun 2002.
Penulis bekerja sebagai tenaga pengajar di Universitas Padjadjaran Bandung sejak tahun 1987 di bidang algoritma pemrograman dan struktur data.
DAFTAR ISI
Halaman
DAFTAR TABEL ... xi
DAFTAR GAMBAR ... xii
DAFTAR LAMPIRAN...xiii
BAB I PENDAHULUAN ... 1
1.1. Latar Belakang ... 1
1.2. Formulasi Permasalahan ... 2
1.3. Tujuan Penelitian ... 2
1.4. Manfaat Penelitian ... 2
1.5. Ruang Lingkup ... 3
BAB II TINJAUAN PUSTAKA ... 4
2.1. Basis Data Terdistribusi ... 4
2.1.1. Sistem Basis Data Terdistribusi ... 4
2.1.2. Arsitektur Sistem Basis Data Terdistribusi ... 5
2.2. Konsep Aljabar Relasional …………... 7
2.2.1. Selection ……...………...……....………... 8
2.2.2. Projection …………...…...…….………... 9
2.2.3. Join …....……….………... 9
2.2.3.1 Cross Join …………... 11
2.2.3.2. Natural Join ………... 11
2.2.4. Operasi Himpunan …... ………..….……... 12
2.2.4.1.Union………...………... 12
2.2.4.2.Intersection………...………... 13
2.2.4.3. Difference ………...………... 13
2.3. Proses Query ……….………... 13
2.4. Optimisasi Query ……….………... 16
2.5. Prinsip Optimisasi Query ……….………... 16
2.6. Metoda Optimisasi Query ………..………... 17
2.6.1. Optimisasi Query Basis Formula ………... 18
2.6.2. Optimisasi Query Basis Biaya …...………... 18
2.6.3. Fungsi Biaya dari Statistik Basis Data ... 19
2.6.4. Optimizer DBMS MySQL ... 21
BAB III METODOLOGI DAN RANCANGAN PENELITIAN ... 22
3.1 Metodologi Penelitian ... 22
3.2 Sistematika Penelitian dan Pembahasan ... 23
Halaman
BAB IV HASIL DAN PEMBAHASAN ... 27
4.1 Formulasi Masalah dan Penentuan Tujuan ... 27
4.2 Formulasi Optimisasi Query ... 32
4.2.1. Analisis Selectivity Factor dari Karakteristik Basis Data ... 35
4.2.2. Analisis Optimisasi Secara Spesifik ... 36
4.2.3.1. Nested -Loops-Join ... 38
4.2.3.2. Block-Nested-Loops-Join ... 39
4.2.3.3. Sort-Merge-Join ... 42
4.2.3.4. Biaya Sort-Merge-Join ... 46
4.2.3.5. Hash-Join... 46
4.2.3. Analisis Signifikansi Optimisasi Query ... 50
4.2.4. Analisis Optimisasi Query Optimizer DBMS MySQL... 54
4.3 Percobaan ... 59
BAB V KESIMPULAN DAN SARAN ... 71
5.1. Kesimpulan.. ... 71
5.2. Saran ... 71
DAFTAR TABEL
Halaman
1. Fragmentasi Horizontal, Vertical dan Mixed Fragmentasi... 7
2. Segmen Tabel peserta S
1... 8
3. Segmen Tabel peserta S
2... 8
4. Segmen Tabel pmk_ke1 R
1... .8
5. Segmen Tabel pstpens B
1... 8
6. Hasil Join dari S1 dan R
1... 10
7. Tahapan Proses Penelitian ... 24
8. Tabel informasi data tabel relasi ... 29
9. Contoh Segmen tabel pst_ke1 ... 45
10. Contoh Segmen tabel pstaktif ... 45
11. Running time query tabel satu relasi tanpa join,
Q
1tanpa optimisasi, Q
2dengan optimisasi satu kriteria ... 62
12. Perbadingan join query tidak dioptimisasi dan dioptimisasi... 64
13. Running time query , Q
6mendahulukan operasi join sebelum seleksi ,
Q
7mendahulukan operasi seleksi sebelum operasi join ... 66
14. Perbandingan Running time fragmentasi setelah proses join query dan
fragmentasi sebelum proses join query... 67
DAFTAR GAMBAR
Halaman
1. Lingkungan Basis Data Terdistribusi... 5
2. Arsitektur Sistem Basis Data Terdistribusi... 6
3. Tahapan proses sebuah Query ... 14
4. Bagan alir proses penelitian ... 26
5. Diagram E-R keseluruhan tabel peserta ... 29
6. Diagram E-R tabel peserta spesialisasi menjadi tabel pst_ke1 dan pstaktif ... 30
7. Diagram E-R tabel pensiun spesialisasi menjadi pmk_ke1 dan pmk_fd1 ... 31
8. Rencana evaluasi query dari join tree ... 33
9. Rencana evaluasi Query mendahulukan operasi seleksi ... 34
10. Contoh perintah Join... 37
11. Algoritma Simple Nested Loops Join ... 38
12. Algoritma Block Nested Lopps Join ... 40
13. Penggunaan buffer Block Nested Lopps Join ... 41
14. Algoritma Sort Merge Join ... 44
15. Tahap Partisi Proyeksi Hash Based ... 47
16. Tahap Equality Join menggunakan Hash Join ... 49
17. Algoritma Hash Join ... 50
18. Running time query satu relasi tanpa join, Q
1tanpa optimisasi,
Q
2dengan optimisasi satu kriteria ... 63
19. Perbandingan join query tidak dioptimisasi dan dioptimisasi ... 65
20. Running time query, Q
6mendahulukan operasi join sebelum seleksi,
dan Q
2mendahulukan operasi seleksi sebelum operasi join. ... 66
21. Perbandingan Running time Q
8: fragmentasi setelah proses query dan
Q
9:fragmentasi sebelum proses query ... 68
22. Perbandingan Runtime client yang berbeda spesifikasi ... 69
DAFTAR LAMPIRAN
Halaman
1. Contoh kamus data tabel relasi pst_ke1 4 buah atribut 3.873.324 record... 75
2. Contoh kamus data tabel relasi pstaktif dengan 8 buah attribut
3.619.423 record ... 76
3. Contoh kamus data tabel relasi pmk_ke1 dengan 6 buah attribut
1.401.040 record... 77
4. Contoh kamus data tabel relasi pmk_fd1 dengan 13 buah attribut
1.261.239 record ... 78
5. Contoh kamus data tabel relasi pstpens dengan 11 buah attribut
1.264.037 record... 79
6. Contoh isi data dari tabel relasi pst_ke1 ... 80
7. Contoh isi data dari tabel relasi pstaktif... 81
8. Contoh isi data dari tabel relasi pmk_ke1 ... 82
9. Contoh isi data dari tabel relasi pmk_ke1 ... 83
PENDAHULUAN
1.1.Latar Belakang
Sebuah perusahaan yang cukup besar biasanya mempunyai banyak cabang, misalnya sebuah bisnis supermarket yang cukup besar memiliki ratusan cabang dan tersebar di beberapa kota besar, sistem stok barangnya setiap hari harus dihitung yang terdiri dari merek, produk, jenis dan transaksi berisi saldo penjualan harian dan saldo barang. Demikian juga perusahaan-perusahaan yang bergerak dibidang jasa, misalnya perusahaan asuransi jasa pensiun yang cukup besar mempunyai banyak cabang tersebar di beberapa kota, setiap minggu atau setiap bulan harus melaporkan hasil transaksi-transaksi dari semua cabang yang tersebar tersebut. Sedangkan dalam menggabungkan tabel-tabel transaksi yang terpisah-pisah menjadi satu tabel secara berkala, sistem harus memprosesnya melalui join query. Masalah akan timbul bilamana prosesnya sangat lambat dan tidak sesuai dengan yang diharapkan. Keterlambatan proses akan menghambat pembuatan laporan dan pengambilan keputusan. Operasi join query adalah merupakan operasi yang cukup mahal dan sangat membutuhkan teknik dan metode tertentu untuk dapat menghasilkan keluaran sesuai dengan yang diharapkan (Chen Li. 2003).
Proses join query dalam sistem basis data terdistribusi adalah salah satu masalah penting dan cukup rumit, prosesnya banyak menggunakan metode-metode optimisasi yang melibatkan formula-formula dan biaya-biaya query. Para ahli melakukan penelitian mencoba menggunakan teknik-teknik terdistribusi yang dilandasi oleh perkembangan lokal. Sistem harus melindungi users dari kompleksitas basis data, agar supaya proses query yang didistribusikan dapat mencapai hasil optimal dan mudah dikontrol (Richard 2000).
Para programmer melakukan proses optimisasi query dapat menggunakan fasilitas optimizer dari DBMS, karena dalam kasus tertentu dapat memberikan hasil sesuai dengan yang diharapkan, misalnya : Oracle 9i’s selalu menemukan yang ideal untuk mengeksekusi query, karena bahasa SQL Oracle melakukan query dari berbagai jalur secara cepat, dan menemukan baris (row) dengan cara full-table scan, via b-tree index , menggabungkan dua tabel dengan beberapa
teknik Sort / Merge, tetapi Oracle 9i’s sangat membutuhkan unjuk kerja CPU dan memory yang cukup memadai (Ken 2002).
Pada perkembangan penelitian terdapat sebuah tantangan lain, yaitu signifikansi mungkin akan tercapai bilamana komputasi dilakukan secara spesifik dan parsial disesuaikan dengan hardware dan software DBMS yang digunakan.
1.2.Formulasi Permasalahan
Pada dasarnya permasalahan dalam optimisasi query belum tentu layak di optimisasi, dan belum tentu signifikan optimisasi query akan dicapai bila tidak disesuaikan antara DBMS, hardware sumber, lokasi dan karakteristik dari statistik basis datanya. Untuk basis data yang cukup besar apakah signifikansi dapat tercapai apabila proses optimisasinya dilakukan secara spesifik dan parsial, serta bagaimana pengaruh nilai selectivity factor dari statistik basis data yang cukup besar terhadap proses optimisasi dalam operasi join query.
1.3.Tujuan Penelitian
Tujuan penelitian ini adalah menganalisis pengaruh optimisasi query dalam basis data terdistribusi secara spesifik dan parsial dilihat dari karakteristik basis datanya secara teoritis yang didukung secara empiris oleh percobaan. Menganalisis teknik formulasi relasi aljabar relasional untuk proses optimisasi query dan mencari signifikansi query berdasarkan biaya yang disetarakan dengan waktu berupa runtime hasil eksekusi query disesuaikan dengan DBMS, hardware dan karakteristik dari statistik basis data yang digunakan.
1.4. Manfaat Penelitian
Manfaat penelitian ini untuk memberi wawasan tentang analisis optimisasi query secara parsial disesuaikan dengan karakteristik statistik basis data, hardware dan software yang digunakan. Dan diharapkan dapat membantu users atau programmer dalam menganalisis dan menentukan formula-formula optimisasi query.
1.5. Ruang Lingkup
Ruang Lingkup dalam penelitian ini yaitu menguraikan proses optimisasi query menggunakan fasilitas DBMS Optimizer menggunakan algoritma Nested-Loops-Join, Block-Nested-Nested-Loops-Join, Sort-Merge-Join dan Hash-Join. Melakukan percobaan proses optimisasi query menggunakan tabel data peserta asuransi PT. Taspen, jumlah record terkecil 1,2 juta dan terbesar 3,8 juta, proses eksekusi dilakukan menggunakan software DBMS MYSQL pada jaringan komputer client-server FMIPA-UNPAD Jatinangor.
TINJAUAN PUSTAKA 2.1. Basis Data Terdistribusi
2.1.1. Sistem Basis Data Terdistribusi
Dalam pengelolaan basis data terdapat dua sistem basis data, yaitu Basis Data Terpusat ( Centralized ) dan Basis Data Terdistribusi ( Distributed ). Perbedaan utama antara sistem basis data terpusat dan terdistribusi adalah jika pada sistem basis data terpusat, data ditempatkan di satu lokasi saja dan semua lokasi lain dapat mengakses data di lokasi tersebut, sedangkan pada system basis data terdistribusi, data di tempatkan di banyak ( lebih dari satu ) lokasi, tetapi menerapkan suatu mekanisme tertentu untuk membuatnya menjadi satu kesatuan basis data, dan hal ini berbeda dengan system basis data terpisah (Isolated) yang mana dalam sistem basis data terpisah, basis data ditempatkan di banyak lokasi, tetapi tidak saling berhubungan sama sekali.
Menurut Özsu MT, Valduriez P. (1999) Basis Data Terdistribusi didefinisikan sebagai berikut :
Suatu Basis Data Terdistribusi ( DDBS ) adalah suatu koleksi beberapa basis data yang secara logika saling berhubungan dan terdistribusi dalam suatu jaringan komputer, sedangkan Sistem Basis Data Manajemen Terdistribusi ( D-DBMS ) adalah Perangkat Lunak yang mengatur Basis Data Terdistribusi (DDB) dan menyediakan suatu mekanisme akses yang membuat distribusi ini dapat diketahui oleh pemakai.
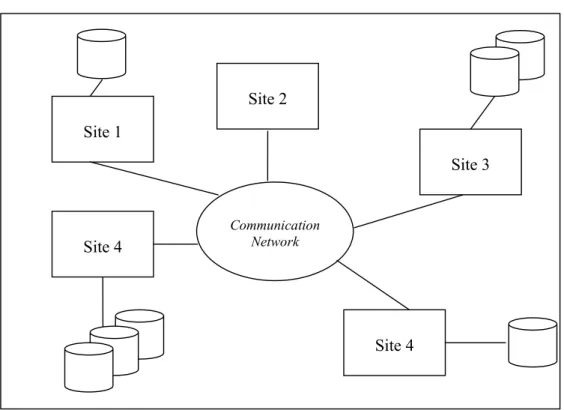
Jadi Sistem Basis Data Terdistribusi ( DDBS )= DDB+ D-DBMS Lokasi-lokasi penempatan basis data dapat terlihat dalam Gambar 1.
Gambar 1. Lingkungan Basis Data Terdistribusi ( Valduriez P. 1999) 2.1.2. Arsitektur Sistem Basis Data Terdistribusi
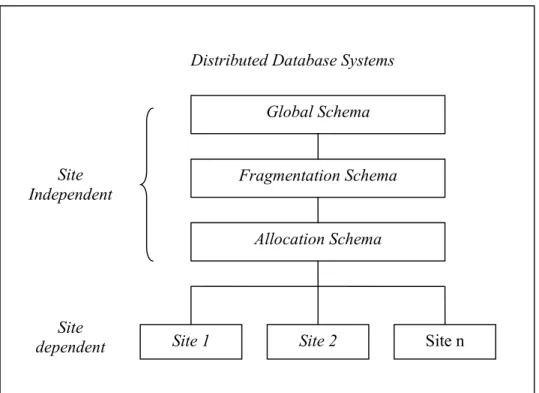
Dalam arsitektur basis data terdistribusi konsep basis data relasional lebih banyak digunakan, karena dalam operasionalnya dapat disesuaikan dengan sistem basis data terpusat, secara formal relasional basis data terdistribusi mencakup : Global Level, Fragmentation Level dan Allocation Level ( Kuijk 2000 )dan hal ini dapat terlihat dalam Gambar 2 berikut.
Site 2 Site 1 Site 4 Site 4 Site 3 Communication Network
Gambar 2 : Arsitektur Sistem Basis Data Terdistribusi (Kuijk 2000)
- Global Level : suatu skema basis data secara global yang menggambarkan basis data terdistribusi yang seolah-olah tidak seluruhnya terdistribusi. - Fragmentation level : suatu skema fragmentasi yang menggambarkan suatu
pemetaan antara relasi individu dengan fragmentasinya
- Allocation Level : suatu skema alokasi yang menggambarkan pemetaan antara fragmen individu dimana basis data disimpan
Dalam melakukan fragmentasi terdapat kriteria-kriteria yang harus dipenuhi, yaitu : Reconstruction Condition, Completeness Condition dan Disjointness Condition (Kuijk 2000)
Global Schema
Site 1
Fragmentation Schema
Allocation Schema
Site 2 Site n
Distributed Database Systems
Site Independent
Site dependent
Jika R adalah tabel relasi, Ai adalah atribut dari R, r adalah record dari R dan Fi
kondisi dari operasi seleksi, maka hasil fragmentasi dapat direkonstruksi terlihat dalam Tabel 1.
Tabel 1: Fragmentasi Horizontal, Vertical dan Mixed Fragmentasi (Kuijk 2000).
Type Partitioning Reconstruction
Horizontal r
( )
Ri =σ
Fi( )
r( )
R( )
Un( )
i r Ri R r i 1 = = Vertical r( )
R(
r( )
R)
i A i =π
n r(
Ri)
= ⋈πAi(
r(
R))
i = 1 Mixed r( )
R(
(r(R)))
i i F A i =π
σ
( )
U1( )
1 1 1 n i r Ri R r i = = ⋈…⋈ … Uk( )
n k i =1rRik2.2 Konsep Aljabar Relasional.
Relasi aljabar adalah bahasa prosedural, dan salah satu cara untuk membangun relasi satu atau lebih relasi berdasarkan konsep aljabar. Dalam basis data relasional relasi aljabar mempelajari bagaimana struktur properti dan kendala-kendala akan menjadi dasar dalam operasi basis data, formulasi query dipetakan pada relasi aljabar dan sejauh mana pendekatan teori set digunakan. Bahasa query memiliki sejumlah operasi yang memanfaatkan satu atau beberapa tabel/relasi basis data sebagai masukkan dan menghasilkan sebuah tabel/relasi basis data yang baru sebagai keluarannya. Operasi dasar dalam Aljabar Relasional antara lain mencakup : Select, Project, Cartesian-Product, Union, Set-Difference (Kuijk 2000).
Konsep optimisasi query dalam Aljabar Relasional yang banyak digunakan adalah operasi-operasi yang berhubungan dengan operasi join. Dalam tesis ini ditampilkan sejumlah contoh dengan menggunakan skema tabel relasi berikut :
peserta (notsp : integer, tgl_lhr : date, tmt_pst : date, gapok : integer) pensiun(nopen : integer, nama : string, tgl_kej : date)
Skema dari tabel-tabel relasi di atas ditunjukkan pada segmen Tabel 2, Tabel 3, Tabel 4 dan Tabel 5.
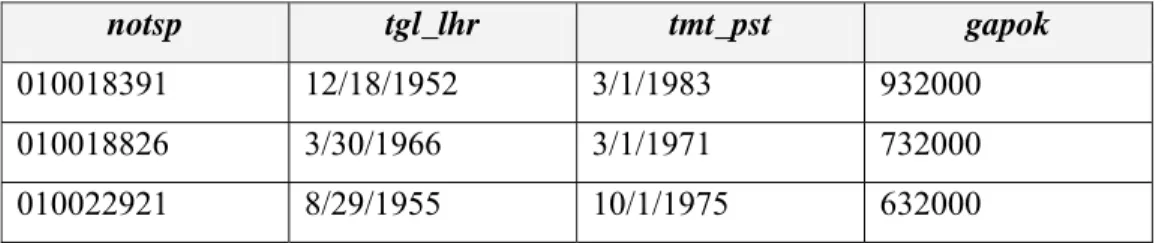
Tabel 2. : Segmen Tabel peserta S1
notsp tgl_lhr tmt_pst gapok
010013098 12/31/1955 1/1/1975 832000 010018391 12/18/1952 3/1/1973 932000
Tabel 3 : Segmen Tabel peserta S2
notsp tgl_lhr tmt_pst gapok
010018391 12/18/1952 3/1/1983 932000 010018826 3/30/1966 3/1/1971 732000 010022921 8/29/1955 10/1/1975 632000
Tabel 4 : Segmen Tabel pmk_ke1 R1
notsp Nopen tgl_kej
010013098 0000007700 12/31/1999 010022921 0000008880 12/23/1989 010018391 0000009990 13/21/1990
Tabel 5 : Segmen Tabel pensiun B1
nopen Nama tgl_kej
0000007700 Nangkuh 12/31/1999
0000008880 Abdul Hadi 12/23/1989
0000009990 Siddik 13/21/1990
2.2.1. Selection
Operasi Selection digunakan untuk memilih subset record-record dari tabel sebuah relasi yang memenuhi pilihan. Kondisi harus berupa formula yang proporsional. Tata cara penulisan yang digunakan pada operasi ini adalah :
p adalah <selection condition> berupa predikat pada atribut-atribut di R, dan R adalah tabel/relasi yang akan diakses oleh operasi selection. Jika merujuk Tabel 2 pada tabel peserta, perintah mengambil baris data (record) peserta yang tanggal lahirnya ’9/9/1969’, maka operasi ini dapat dituliskan
σ
tgl_lhr = ‘9/9/1969’(peserta)
2.2.2. Projection
Operasi Projection dilakukan untuk memilih atribut-atribut dari tabel/relasi. dan dapat mengambil atributsatu atau lebih.Tata cara penulisan pada operasi ini adalah :
Π<attribute list>(R)
Atribut list adalah daftar atribut yang akan ditampilkan yang ada di R. Misalkan pada Tabel 2 yaitu dalam tabel peserta akan ditampilkan notsp dan tgl_lhr, untuk semua baris data yang ada pada tabel tersebut, maka perintahnya adalah :
Π
notsp,tgl_lhr(peserta)Dapat pula menampilkan berupa hasil operasi/query. Misalkan akan ditampilkan notsp dan tgl_lhr dngan tmt_pst pada tanggal ’1/1/1975’ saja, maka operasi seleksi dan projeksi harus digunakan secara bersamaan, seperti berikut :
Π
notsp,tgl_lhr(
σ
tmt_pst= ’1/1/1975’(peserta))
2.2.3. Join.
Operasi Join adalah untuk menggabungkan lebih dari satu tabel/relasi. Operasi Join dilambangkan dengan “⋈” dan digunakan untuk mengkombinasikan hubungan record-record dari dua relasi kedalam record tunggal. Pada umumnya operasi PROJECT pada dua relasi R(A1,A2,…An) dan S(B1,B2,…Bm) ditunjukkan oleh :
Hasil dari Join adalah sebuah relasi Q dengan n + m atribut Q(A1,A2,…An, B1,B2,…Bm). Q mempunyai satu record untuk masing-masing kombinasi dari record, satu dari R dan satu dari S. Dalam join, hanya kombinasi-kombinasi dari record-record yang memenuhi kondisi join yang akan tampak pada hasil. Kondisi Join ditentukan oleh atribut-atribut dari relasi R dan S dan evaluasi untuk tiap kombinasi dari record-record
Bentuk dari kondisi Join secara umum adalah :
<condition> AND <condition> AND … AND <condition>
dimana tiap kondisi adalah bentuk dari Aiθ Bj. Ai adalah sebuah atribut dari R dan Bj adalah sebuah atribut dari S. Ai dan Bj mempunyai domain yang sama, dan θ (theta) adalah salah satu dari operator-operator pembanding {<, ≤, ≠, ≥, >,}. Operasi Join dengan sebuah kondisi join yang umum disebut dengan theta join. Contoh : (R ⋈c S) = σc (R x S)
Jadi,
⋈
ditentukan untuk menjadi sebuah cross product diikuti dengan satu selection, Jika diperhatikan c condition dapat merujuk ke atribut baik R maupun S. Referensi ke sebuah atribut dari sebuah relasi, misalnya R , dapat berdasarkan posisi (dari bentuk Ri) atau berdasarkan nama dan bentuk Rname, merujuk padaTabel 2 dan Tabel 4, maka hasil dari
S1
⋈
S1.notsp<R1.notspR1 ditunjukkan pada Tabel 6, notsp muncul baik dalam S1 maupun R1, maka atribut hasil dari cross productS1 x R1tidak diberi nama.Tabel 6 : Hasil Join S1 dan R1
notsp tgl_lhr tmt_pst gapok notsp nopen tgl_kej 010018391 12/31/1955 1/1/1975 832000 010022921 0000008880 12/23/1989 010018826 12/18/1952 3/1/1973 932000 010022921 0000008880 12/23/1989
2.2.3.1. Cross Join
Operasi Cross Join yang juga biasa disebut dengan Cross Product atau Cartesian Product dilambangkan dengan “ X “ yang juga merupakan sebuah kumpulan operasi biner. Contoh (R1 X S1) operasinya memungkinkan untuk menggabungkan data dari dua buah tabel atau hasil query yang berakibat semua record di R1 dipasangkan dengan semua record di S1 dan hasil operasi akan memuat semua atribut yang ada di R1 dan di S1dan operasi ini bersifat komutatif. Operasi Cross Join umumnya tidak berdiri sendiri, tetapi digunakan bersama operasi lainnya, seperti operasi seleksi dan proyeksi dengan berbagai bentuk sesuai kebutuhan, sebagaimana dapat dilihat dalam contoh berikut :
Akan diambil data dari penggabungan tabel S1 dan R1 untuk tmt_pst=‘1/11975’ dan tgl_kej = ‘12/23/1989’ operasinya dapat dituliskan sebagai berikut :
σ
tmt_pst= ’1/1/1975’
∧ tg_kej = ’ 2/23/1989’∧S1.notsp =R1.notsp ( S1 X R1) 2.2.3.2. Natural JoinSebuah query yang melibatkan operasi Cartesian Product umumnya menggunakan operasi seleksi untuk memberikan hasil query yang diinginkan. Contoh : cari dari semua peserta yang telah pensiun dan tampilkan nama dan tanggal kejadian, notsp diambil dari gabungan Tabel 4 (pmk_ke1) dan Tabel 5 (pensiun). Mula-mula akan menggunakan operasi Cartesian Product tabel pensiun yang menyimpan data nama dan nopen kemudian dari tabel pmk_ke1 yang menyimpan data notsp, kemudian menyeleksi yang sesuai dengan kriteria yang diminta yaitu no_tsp dari Tabel 4 yaitu tabel pmk_ke1 dan Tabel 5 yaitu tabel pensiun
Π
nama,notsp,tgl_kej(
σ
PMK.nopen=Pensiun.nopen(pmk_ke1 X pensiun))Bentuk di atas dapat disederhanakan dengan operasi natural join yang menggabungkan operasi cartesian product dan operasi seleksi dengan menggunakan simbol
⋈
, operasi natural join membentuk sebuah cartesian product dari kedua argumennya, lalu menetapkan sebuah seleksi untuk baris-baris data yang memiliki kesamaan nilai untuk atribut-atribut yang muncul di keduaargumennya dan akhirnya mengabaikan data-data duplikat dan perintahnya sebagai beikut :
Π
nama,notsp,tgl_kej(pmk_ke1 ⋈ pensiun))Secara formal, jika S1 memiliki himpunan atribut s dan R1 memiliki himpunan atribut r, maka dapat didefinisikan :
S1
⋈
R1 =Π
s r(σ
s1.a1=r1.a2 ∧ s1.a1=r1.a2∧...∧ s1.an=r1.an(
S1X R1)
Dimana s =domain atribut dari S1r =domain atribut dari R1 s r = { a1, a2, a3, …, an }
Jika tidak ada atribut yang sama di kedua ekspresi S1dan R1 atau s r =0, maka :
S1
⋈
R1 = S1X R12.2.4 Operasi Himpunan
Operasi Himpunan yang digunakan adalah Union, Intersection dan Difference.
2.2.4.1. Union (R S)
Operasi ini untuk menggabungkan data dari dua kelompok baris data (row) yang sejenis (memiliki hasil proyeksi yang sama)
Simbol dari operasi ini adalah : R S
Atribut notsp terdapat pada Tabel 5 (pensiun) dan Tabel 4 (pmk_ke1), sehingga notsp pada kedua tabel tersebut dapat diproyeksikan dengan operasi Union :
Π
tglkej (pensiun)Π
tglkej (pmk_ke1)Pada operasi UnionR Sterdapat dua syarat yang dipenuhi yaitu : 1) S dan R harus memiliki jumlah atribut yang sama.
2) Domain dari atribut ke i dari S dan atribut ke i dari R haruslah sama, dan harus berlaku untuk semua atribut di S dan R
2.2.4.2. Intersection (R S)
Operasi Intersection digunakan untuk menyatakan atau mendapatkan irisan (kesamaan anggota) dari dua buah kelompok data dari suatu tabel atau hasil query.
Tata penulisannya adalah (R S) yang ekivalen dengan penggunaan operasi dasar
Set-Difference S – ( S – R ). Contoh untuk mendapatkan notsp mana saja yang sama-sama dipunyai, baik dari Tabel 2 (peserta) maupun Tabel 4 (pmk_ke1), query tersebut dapat dipenuhi dengan operasi
Π
notsp (Peserta)Π
notsp (pmk_ke1)2.2.4.3. Difference (R - S)
Operasi difference merupakan pengurangan data di tabel/hasil proyeksi pertama R oleh data/hasil proyeksi yang kedua S
Simbolnya adalah : R – S
Ketentuannya sama dengan operasi Union yaitu harus mempunyai jumlah atribut yang sama baik di S maupun di R, contoh :
Π
tglkej (pensiun) –Π
tglkej (pmk_ke1)2.3. Proses Query
Dalam Database Manajemen System (DBMS) akses data dapat dilakukan dengan berbagai macam cara. Ada banyak plan (rencana) yang dapat diikuti oleh DBMS dalam memproses dan menghasilkan jawaban sebuah query. Semua rencana pada akhirnya akan menghasilkan jawaban (output) yang sama tetapi pasti mempunyai biaya yang berbeda-beda.
Kebanyakan aplikasi secara nyata adalah permintaan-permintaan secara langsung dari user yang memerlukan informasi tentang bentuk maupun isi dari basis data. Apabila permintaan user terbatas pada sekumpulan query-query standar, maka query-query tersebut dapat dioptimisasi secara manual oleh pemrograman. Tetapi bagaimanapun juga, sebuah sistem optimisasi query otomatis menjadi penting apabila query-query khusus dinyatakan dengan
menggunakan bahasa query yang digunakan secara umum seperti Structure Query Language (SQL).
Optimisasi query memberikan suatu pemecahan untuk menangani masalah dengan cara menggabungkan sejumlah besar teknik-teknik dan strategi, yang meliputi transformasi-transformasi logika dari query-query pada sistem file penyimpanan data. Setelah ditransformasikan, sebuah query dipetakan ke dalam sebuah langkah-langkah operasi untuk menghasilkan data-data yang diminta.
QueryLanguage (SQL)
Hasil Query
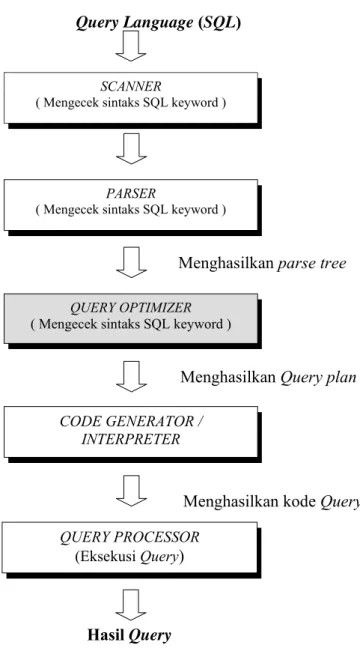
Gambar 3. Tahapan proses sebuah Query (Swamy 2001)
PARSER
( Mengecek sintaks SQL keyword )
CODE GENERATOR / INTERPRETER
QUERYPROCESSOR
(Eksekusi Query)
QUERYOPTIMIZER
( Mengecek sintaks SQL keyword )
SCANNER
( Mengecek sintaks SQL keyword )
Menghasilkan Queryplan
Menghasilkan kode Query Menghasilkan parse tree
Sebuah query yang diekspresikan dalam sebuah bahasa query tingkat tinggi seperti SQL mula-mula harus dibaca, diuraikan dan disahkan (scanning, parsing, validating). Query tersebut kemudian dibentuk menjadi sebuah struktur data yang biasa disebut dengan query tree.
Kemudian DBMS merencanakan sebuah strategi eksekusi untuk mendapatkan kembali hasil dari query dari file-file basis data. Tahapan-tahapan proses dari sebuah query didalam sebuah sistem basis data ditunjukkan pada Gambar 3 dan berikut penjelasan dari masing-masing tahapan :
Scanner melakukan identifikasi (pengenalan) perintah-perintah seperti SQL keywords, atribut, dan relation name. Proses ini disebut dengan scanning.
Query Parser mengecek validitas query dan kemudian
menterjemahkannya dalam bentuk internal yaitu ekspresi relasi aljabar atau parse tree proses ini disebut dengan parsing.
Query Optimizer memeriksa semua ekspresi-ekspresi aljabar yang sama untuk query yang diberikan dan memilih salah satu dari ekspresi tersebut yang terbaik yang memiliki perkiraan paling murah. Dengan kata lain, tugas dari query optimizer adalah menghasilkan sebuah rencana eksekusi dan proses ini disebut optimisasi query.
Code Generator atau Interpreter mentransformasikan rencana akses yang dihasilkan oleh optimizer ke dalam kode-kode. Setelah itu, kode-kode tersebut dikirimkan ke dalam query processor untuk dijalankan.
Query Processor melakukan eksekusi query untuk mendapatkan hasil query yang diinginkan.
Bagian yang diarsir pada Gambar 3 adalah optimizer yang sudah disediakan oleh DBMS. Tahapan proses query pada Gambar 3 tersebut adalah untuk memberikan gambaran yang jelas tentang bagaimana pada umumnya sebuah query diproses di dalam sebuah Data Base Manajemen Sistem .
2.4. Optimisasi Query
Optimisasi Query adalah suatu proses untuk menganalisis query untuk menentukan sumber-sumber apa saja yang digunakan oleh query tersebut dan apakah penggunaan dari sumber tersebut dapat dikurangi tanpa merubah keluaran. Atau dengan kata lain bahwa optimisasi query adalah sebuah prosedur untuk meningkatkan strategi evaluasi dari suatu query untuk membuat evaluasi tersebut menjadi lebih efektif (Richard 2000).
2.5. Prinsip Optimisasi Query
Prinsip Optimisasi Query terdapat dalam pemilihan strategi query, dan terletak pada penentuan strategi operasi Join. Bahasa query salah satu yang biasa digunakan, misalnya SQL, tetapi untuk beberapa kasus khusus, suatu query dapat mempunyai hubungan dengan pemetaan aljabar. Bentuk yang lebih sederhana sangat diperlukan dari pada bentuk-bentuk aljabar tersebut, dan diasumsikan bahwa operasi gabungan adalah salah satu operasi relasi aljabar ( Ken 2000).
Menurut Richard Vlach (2000), optimisasi query dalam basis data terdistribusi, ada dua aspek yang sangat penting, yaitu :
1. Tranmisi data dan kontrol data ke tempat tujuan sangat dipengaruhi oleh bentuk komunikasi, dan dapat memperlambat keseluruhan proses.
2. Pengolahan data secara paralel transmisi data dapat mempercepat respone
Optimisasi Query adalah proses untuk menunjukkan bahwa baik total biaya maupun total waktu suatu query diminimalkan. Total biaya diukur oleh penggunaan sumber daya sistem seperti CPU atau bentuk komunikasi data. Respone time optimizers yaitu untuk meminimalkan respone time dalam sebuah query bersama-sama secara paralel.
Menurut Özsu MT, Valduriez P. (1999 ) formulasi untuk meminimalkan biaya (cost function) adalah :
Total Cost = I/O cost + CPU cost + communication cost ... (2.1) Dimana I/O cost = unit disk I/O cost + no. of disk I/Os
CPU cost = unit instruction cost + no. of instruction Communicatin cost = message initiation + transmition
Formula (2.1) masing-masing bagiannya dapat mempunyai bobot yang berbeda tergantung dari terdistribusinya data, antara lain :
- Apabila proses query menggunakan Wide Area Networks (WAN), maka biaya komunikasi sangat dipengaruhi low bandwidth, low speed dan high protocol
overhead. Sedangkan algoritma-algoritma yang ada pada umumnya
mengabaikan komponen biaya.
- Apabila menggunakan Local Area Networks (LAN), biaya komunikasi dan pengiriman data tidak mempengaruhi, tetapi total biaya dari fungsi-fungsi yang digunakan harus dipertimbangkan.
2.6. Metoda Optimisasi Query
Biaya query sangat dipengaruhi oleh dua hal, yaitu proses secara lokal dan transmisi data antar lokasi, karena berkaitan dengan fungsi biaya. Proses perhitungan diperlukan untuk menghasilkan biaya query yang akurat secara parsial. Karakteristik relasi secara lokal harus diketahui dalam optimisasi waktu. Beberapa diantaranya adalah kardinalitas dari relasi secara lokal, banyaknya byte dalam nilai atribut, dan nilai selectivity factor yang terdapat dalam relasi diperlukan.
Optimisasi proses pengolahan data secara global dengan cara menggunakan metoda secara lokal, dalam pelaksanaannya adalah mengoperasikan atas kedua proses, yaitu memproses data lokal dan memproses data secara lokal yang datang dari lokasi lain.
Besar biaya untuk optimisasi lokal pada umumnya didasarkan pada banyaknya akses dari memori sekunder, ukuran buffers dan ukuran operand. Data yang akan dioperasikan secara lokal dan tambahan struktur data lokal seperti indek, hash tabel akan dapat mempercepat proses secara lokal.
Operasi join adalah operasi yang sangat mahal. Dan diketahui bahwa metoda operasi join secara lokal adalah : nested-loops, sort-merge dan hash join. Walaupun ada metoda optimisasi query global yang mempertimbangkan proses lokal, ongkos proses secara lokal pada umumnya dapat diabaikan jika dibandingkan dengan ongkos transmisi data. Selama transmisi data dioptimisasi, jelas asumsinya bahwa nilai waktu selama transmisi bergantung pada jumlah data yang dialirkan.
Perhitungkan respone time yang minimal, optimisasi global memanfaatkannya secara paralel dan mencoba untuk memperkecil transmisi pada alur yang ”paling buruk”. Operasi secara lokal yang membatasi relasi lokal harus dieksekusi secepat mungkin. Kemudian, utamakan pada optimisasi pada berbagai operasi join. Metoda optimisasi secara dinamis dapat memilah perencanaan ekseskusi query pada tahapan eksekusi. Pada awalnya rencana eksekusi didasarkan pada penilaian hasil secara parsial. Perubahan selama tahap eksekusi didasarkan pada ukuran secara parsial dan perubahan mengarahkan pada sisa query yang akan diproses. (Richard 2000)
2.6.1. Optimisasi Query Basis Formula
Optimisasi basis formula (Rule Based) biasa juga disebut heuristic optimization adalah optimisasi query dengan menggunakan aturan-aturan heuristic dan dijalankan pada rencana query secara logika yang terdiri dari urutan operasi-operasi relasional yang biasanya digambarkan sebagai query tree
2.6.2. Optimisasi Query Basis Biaya
Dalam optimisasi basis biaya dapat digunakan solution space dan cost function yaitu dengan total time atau total cost. Hal ini dapat mereduksi setiap biaya ( dalam setiap termin waktu ) semua komponen satu persatu kemudian melakukan proses optimisasi untuk setiap utilitas dari setiap sumber-sumber daya sehingga meningkatkan kinerja sistem.
Faktor-faktor yang terdapat dalam total cost yang ditunjukkan oleh persamaan (2.1) menghasilkan total cost factor dan tergantung dari arsitektur jaringan yang digunakan. Untuk penggunaan Wide Area Network dipengaruhi
oleh inisiasi pesan dan transmisi cost sangat tinggi, dan biaya pemrosesan secara lokal lambat (kecuali untuk mainframe dan mini komputer). Demikian juga rasio dari komunikasi ke I/O costs adalah = 20 : 1, tetapi untuk penggunaan Local Area Network komunikasi dan proses secara lokal biayanya lebih sedikit dengan rasio dari komunikasi ke I/O costs = 1 : 1,6 ( Valduriez P. 1999).
Dalam menghitung Respone time dapat mengerjakan hal-hal yang mungkin secara paralel sehingga dapat meningkatkan total time karena meningkatnya total aktifitas, dan berdasarkan rumus (2.1)
Respone time = CPU time + I/O time + communication time ... (2.2) Dimana CPU time = unit instruction time * no. of sequential instruction
I/O time = Unit I/O time * no.of sequential I/Os
Communication time = unit msg initiation time + no.of sequential msg + unit transmition time * no.of sequential bytes 2.6.3. Fungsi Biaya dari Statistik Basis data
Untuk melihat cost factor yang utama dalam statistik basis data menurut (Valduriez P. 1999), ukuran relasi dari basis data memiliki nilai selectivity factor untuk setiap relasi dalam setiap operasi, yaitu :
1. Operasi joins card(R
⋈
S) SF (R,S) = --- ... (2.3) card(R)*card(S) 2. Operasi Selection size(R) = card(R)*length ... (2.4) card(σ F (R)) = SF σ (F) *card(R) ... (2.5) dimana 1 S F σ(A = value) = --- ... (2.6) card(∏A (R))max(A) – value S F σ(A > value) = --- ... (2.7) max(A) – min(A) value – max(A) S F σ(A < value) = --- ... (2.8) max(A) – min(A) SF σ(p(A i ) ∧ p(A j )) = SF σ(p(A i )) *SF σ(p(A j ) ... (2.9) SF σ(p(A i )∨ (p(A j )) = SF σ(p(A i )) + SF σ(p(A j )) – (SF σ(p(A i )) *SF σ(p(A j))) ... (2.10) SF σ(A∈ value) = SF σ(A= value) * card(value) ... (2.11) 3. Projection
card(ΠA (R))=card(R) ... (2.12) 4. Cartesian Product
card(R × S) = card(R) .card(S) ... (2.13) 5. Union
Batas atas: card(R ∗S) = card(R) + card(S) ... (2.14) Batas Bawah: card(R ∗S) = max{card(R), card(S)} ... (2.15) 6. Set Difference
Batas atas: card(R–S) = card(R) ... (2.16) Batas bawah: 0 ... (2.17) 7. Join
Dalam kasus khusus: A adalah primary key dari R danB adalah foreign key dari S;
card(R
⋈
A=BS) = card(S) ... (2.18)Lebih umum:
2.6.4. Optimizer DBMS MySQL
MySQL melakukan optimisasi melalui fasilitas query optimizer. Query
optimizer secara rutin memeriksa dan melakukan transformasi semua ekspresi-ekspresi aljabar yang sama dan memilih salah satu dari ekspresi-ekspresi yang terbaik dan memiliki perkiraan paling murah dengan menggunakan fungsi optimize() dari optimizer MySQL dan secara rutin diaplikasikan pada semua tipe query ([email protected]. 1998-2007 MySQL AB ).
MySQL Optimizer melakukan proses optimisasi menggunakan 5 langkah, yaitu :
1. Menentukan tipe join.
Sistem menetapkan tabel yang akan dibaca dalam join, kemudian menetapkan primary index secara berurutan dalam equality relation dengan nilai indek tidak null, menetapkan jangkauan dari indek dan membaca seluruh tabel menurut indek secara berurutan.
2. Menentukan metode akses dan join
Metode akses dan join dilakukan dengan Query Execution Plan (QEP) dan mencari rencana yang terbaik dengan menggunakan prosedur find_best() dari MySQL Optimizer.
3. Menentukan rentang indek dari tipe join
Tipe join dalam tabel diberi rentang indek agar optimizer dengan mudah mengambil data dari tabel yang berada dalan rentang indek.
4. Menentukan indek dari tipe join
Tipe join dalam tabel diberi indek, agar optimizer dengan mudah mengambil data berdasarkan indek.
5. Menentukan indek dari tipe merge join
Indek merge join digunakan bilamana kondisi atribut join dalam tabel dapat dibentuk kedalam beberapa kondisi indek yang terdiri dari cond_1 OR cond_2 ... OR cond_N. Jika cond_1 OR cond_j , dan dapat digabung menjadi satu rentang yang sama, maka diberikan satu rentang indek, hal ini dilakukan untuk menghindari dan mengeliminasi duplikasi data.
METODOLOGI DAN RANCANGAN PENELITIAN
3.1. Metodologi Penelitian
Sejak tahun 1960 an penelitian-penelitian tentang basis data sudah dimulai dan dikembangkan sesuai kebutuhan, terutama dengan menggunakan metode kuantitatif, namun perkembangan software dan hardware terus-menerus berkembang ke arah otonomi komputasi sehingga metode penelitian-penelitian dikembangkan kepada metode kualitatif atau gabungan dari metode tersebut yang diarahkan kepada komputasi tersdistribusi.
Materi dan bahan penelitian dikumpulkan dari internet dan buku-buku teks pustaka. Informasi dari internet yang digunakan adalah jurnal atau paper penelitian-penelitian sejenis yang membahas permasalahan basis data terdistribusi atau permasalahan-permasalahan yang berhubungan dengan optimisasi query.
Sumber utama data penelitian yang akan diolah adalah tabel-tabel relasi dari peserta asuransi PT. Taspen berlandaskan pada jumlah record dengan jumlah data terkecil 1,2 juta record dan terbesar 3,8 juta record. Diasumsikan jumlah data cukup besar memenuhi syarat untuk diteliti, karena penelitian-penelitian yang banyak dilakukan masih dalam kapasitas puluhan ribu record. Penelitian tidak melihat bentuk dan isi tabel, sehingga update tabel kepada isi tabel yang mutakhir tidak dilakukan. Pada saat bersamaan, dikumpulkan berbagai informasi mengenai data yang dapat diakses oleh user dari tabel-tabel tersebut. Kemudian dianalisa proses penggunaan tabel-tabel tersebut yang terkait dengan proses optimisasi. Data-data dan informasi yang telah dikumpulkan kemudian dikompilasi untuk melakukan percobaan. Perintah-perintah query yang diuji coba adalah perintah-perintah query untuk melakukan join sesuai kebutuhan. Penelitian juga dilakukan untuk mencari solusi yang terbaik atau mencari signifikansi optimisasi query dengan sumber-sumber hardware dan software yang digunakan.
Penelitian fokus kepada karaktersitik basis data secara spesifik dengan jumlah record disesuaikan pada sumber hardware dan software yang digunakan dalam percobaan, dengan harapan dapat menghasilkan rancangan optimisasi query yang optimal.
3.2. Sistematika Penelitian dan Pembahasan
Pada dasarnya tesis ini membahas empat bagian yaitu :
Bagian pertama menggambarkan tentang perkembangan basis data terdistribusi, yang mungkin saat ini terdapat pada perusahaan-perusahaan besar dan mempunyai banyak cabang di beberapa tempat dan menjelaskan kemungkinan permasalahan yang akan timbul dalam proses transaksi-transaksi antar perusahaan yang melibatkan join query.
Bagian kedua mencoba memberikan gambaran tentang konsep basis data terdistribusi dengan segala sumber-sumbernya, membahas teori-teori aljabar relasional yang digunakan dalam analisis teori optimisasi query mencakup : Select, Project, Cartesian-Product, Union, Set-Difference.
Bagian ketiga menjelaskan langkah-langkah yang dilakukan dalam penelitian awal dan kajian teoritis, kemudian menjelaskan langkah-langkah penelitian dalam mengkaji perkembangan optimisasi query, berikutnya menjelaskan langkah-langkah menganalisis dengan implementasi menggunakan formula-formula untuk mengevaluasi optimisasi query.
Bagian keempat membahas tentang formulasi masalah dan penentuan tujuan, kemudian bagaimana menganalisis algoritma dari metode-metode Nested-Loops-Join, Block–Nested-Loops-Join, Sort-Merge-Join dan Hash Join yang merupakan fasilitas dari DBMS, berikutnya menjelaskan perhitungan biaya query dari algoritma tersebut secara teoritis yang didukung percobaan.
Bagian kelima membahas percobaan yang dilakukan dalam mengeksekusi perintah-perintah query, menggambarkan hasilnya berupa tabel-tabel yang diilustrasikan pada grafik-grafik hasil eksekusi dan dijadikan bahan kajian untuk menganalisis optimisasi query hasil implementasi.
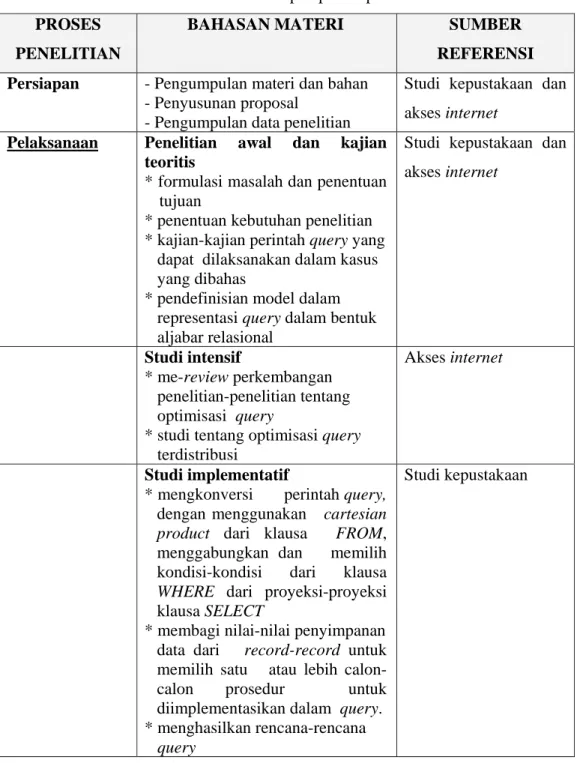
3.3. Tahapan Proses Penelitian
Tahapan penelitian untuk proses optimisasi query adalah urutan langkah yang harus dikerjakan dalam melakukan optimisasi sebuah proses query. Tahapan proses penelitian tersebut secara umum dijelaskan dalam Tabel 7.
Tabel 7 : Tahapan proses penelitian PROSES
PENELITIAN
BAHASAN MATERI SUMBER
REFERENSI Persiapan - Pengumpulan materi dan bahan
- Penyusunan proposal
- Pengumpulan data penelitian
Studi kepustakaan dan akses internet
Pelaksanaan Penelitian awal dan kajian teoritis
* formulasi masalah dan penentuan tujuan
* penentuan kebutuhan penelitian * kajian-kajian perintah query yang dapat dilaksanakan dalam kasus yang dibahas
* pendefinisian model dalam representasi query dalam bentuk aljabar relasional
Studi kepustakaan dan akses internet
Studi intensif
* me-review perkembangan penelitian-penelitian tentang optimisasi query
* studi tentang optimisasi query terdistribusi
Akses internet
Studi implementatif
* mengkonversi perintah query, dengan menggunakan cartesian product dari klausa FROM, menggabungkan dan memilih kondisi-kondisi dari klausa WHERE dari proyeksi-proyeksi klausa SELECT
* membagi nilai-nilai penyimpanan data dari record-record untuk memilih satu atau lebih calon-calon prosedur untuk diimplementasikan dalam query. * menghasilkan rencana-rencana query
PROSES PENELITIAN
BAHASAN MATERI SUMBER
REFERENSI Pelaksanaan * mencari signifikansi optimisasi
query berdasarkan biaya yang disetarakan dengan waktu runtime dilihat dari karakteristik basis data
Studi kepustakaan
Pengembangan formulasi otpimisasi
* penentuan optimisasi secara spesifik
* penentuan formulasi biaya * penentuan karakteristik statistik basis data yang dikaji
* penentuan signifikansi optimisasi query yang dilakukan
Studi kepustakaan
Pengujian dan evaluasi * analisis kajian signifikansi optimisasi query berdasarkan biaya, dilihat dari karakteristik basis data secara spesifik
Studi kepustakaan dan Percobaan
Penyelesaian - Penyusunan laporan - Dokumentasi
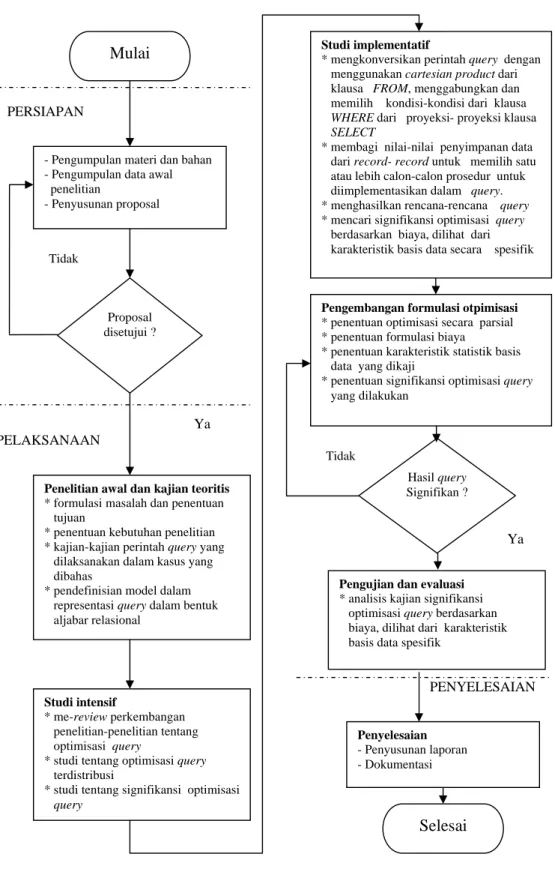
Tahapan-tahapan proses penelitian tersebut diuraikan pada bagan alir Gambar 4 berikut.
Gambar 4 : Bagan alir proses penelitian. Mulai
- Pengumpulan materi dan bahan - Pengumpulan data awal penelitian
- Penyusunan proposal
Penelitian awal dan kajian teoritis * formulasi masalah dan penentuan tujuan
* penentuan kebutuhan penelitian
* kajian-kajian perintah query yang
dilaksanakan dalam kasus yang dibahas
* pendefinisian model dalam
representasi query dalam bentuk
aljabar relasional
Studi intensif
* me-review perkembangan
penelitian-penelitian tentang
optimisasi query
* studi tentang optimisasi query
terdistribusi
* studi tentang signifikansi optimisasi query
Penyelesaian - Penyusunan laporan - Dokumentasi Pengujian dan evaluasi * analisis kajian signifikansi
optimisasi query berdasarkan
biaya, dilihat dari karakteristik basis data spesifik
Studi implementatif
* mengkonversikan perintah query dengan
menggunakan cartesian product dari
klausa FROM, menggabungkan dan
memilih kondisi-kondisi dari klausa WHERE dari proyeksi- proyeksi klausa SELECT
* membagi nilai-nilai penyimpanan data
dari record- record untuk memilih satu
atau lebih calon-calon prosedur untuk
diimplementasikan dalam query.
* menghasilkan rencana-rencana query
* mencari signifikansi optimisasi query
berdasarkan biaya, dilihat dari karakteristik basis data secara spesifik
Pengembangan formulasi otpimisasi * penentuan optimisasi secara parsial * penentuan formulasi biaya
* penentuan karakteristik statistik basis data yang dikaji
* penentuan signifikansi optimisasi query
yang dilakukan Proposal disetujui ? Hasil query Signifikan ? PERSIAPAN PELAKSANAAN Selesai Ya Tidak Tidak Ya PENYELESAIAN
HASIL DAN PEMBAHASAN 4.1. Formulasi Masalah dan Penentuan Tujuan.
Dalam bagian ini dibahas tentang formulasi masalah dan penentuan tujuan yang akan dicapai, diperlukan tahapan-tahapan analisis yang akan timbul selama proses optimisasi query dijalankan.
Aspek utama pemilihan strategi query untuk sistem basis data terdistribusi terletak dalam penentuan strategi operasi join. Strategi operasi join dapat menggunakan fasilitas optimizer yang terdapat dalam DBMS, antara lain : Metode Nested-Loops-Join, Block–Nested-Loops-Join, Sort-Merge-Join dan Hash Join. Tetapi tidak semua DBMS dapat melakukan strategi dengan metode-metode tersebut. Dalam penelitian ini penulis mencoba membahas secara spesifik optimisasi join query sesuai dengan karakteristik basis data dan spesifikasi komputer yang digunakan.
Untuk memformulasi masalah terdapat beberapa faktor yang harus dipertimbangkan dalam sistem terdistribusi, antara lain :
• Biaya / waktu untuk transmisi data dan biaya operasi join.
• Potensi peningkatan unjuk kerja karena adanya sejumlah simpul yang dapat melaksanakan query secara paralel.
• Karakteristik basis data.
Biaya / waktu transfer data dalam jaringan dan transfer data ke dan dari disk, sangat berbeda-beda tergantung pada tipe jaringan yang dipilih dan kecepatan akses dari disk yang digunakan. Sementara unjuk kerjanya akan sangat tergantung pada desain basis data terdistribusi yang kita terapkan serta strategi DBMS dalam melakukan transformasi setiap perintah query.
Ambil sebuah contoh perintah query sederhana, “ tampilkan semua baris data dalam tabel pst_ke1 “. Pemrosesan query tersebut menjadi tidak sederhana, jika tabel tersebut telah direplikasi atau difragmentasi atau sekaligus direplikasi dan difragmentasi. Jika tabel pst_ke1 tersebut ternyata telah direplikasi, maka dapat dengan mudah untuk memenuhi query tersebut dengan memilih salah satu simpul tempat tabel pst_ke1 berada, dan kemudian mengeksekusi query. Jika
tabel tersebut tidak difragmentasi, pemilihan simpul didasarkan pada simpul yang memberikan ongkos transmisi data paling rendah. Akan tetapi jika tabel pst_ke1 tersebut difragmentasi dan ditempatkan di berbagai simpul yang berbeda, maka harus melakukan operasi join atau union untuk merekontruksi isi seluruh tabel pst_ke1.
Penerapan operasi di atas disamping tergantung pada bentuk perintah query, tergantung pada jenis fragmentasi yang diterapkan pada tabel terlibat. Jika tabel pst_ke1 telah difragmentasi horizontal, perlu rekonstruksi dengan menggunakan operasi union, tetapi jika fragmentasi dilakukan vertikal , maka rekonstruksi operasi natural join yang harus digunakan. Dalam berbagai kasus dan berbagai keadaan banyak pilihan strategi dan metode yang harus dipetimbangkan, tetapi besar kemungkinan akan memperberat upaya optimisasi query yang kadang-kadang menjadi tidak praktis untuk diterapkan.
Percobaan dilakukan untuk menganalisis permasalahan menggunakan tabel peserta asuransi, dengan tabel hasil fragmentasi dari peserta didekomposisi (spesialisasi) menjadi tabel pst_ke1 dan tabel pstaktif, tabel peserta pensiun (pstpens) didekomposisi menjadi tabel pmk_ke1 dan tabel pmk_fd1. Tabel-tabel yang digunakan dalam percobaan hanya menggunakan 5 buah tabel yang terdiri dari tabel pstaktif, pst_ke1, pstpens, pmk_ke1 dan pmk_fd1. Hal ini dilakukan dengan pertimbangan efisiensi ruang penyimpanan. Untuk lebih jelasnya situasi tabel secara keseluruhan dapat dilihat pada kamus data di bawah ini dan Diagram E-R ditunjukkan pada Gambar 5.
Kamus data dari 5 buah tabel yang dianalisis antara lain : a. pst_ke1 ( no_tsp, tgl_lhr, tmt_pst, kd_bup)
b. pstaktif ( nippa, tgl_lhr, tmt_pst, sex, gaji_pokok, blth_gapok, suskel, pangkat)
c. pmk_ke1( no_tsp, tmt_pst, tglhr_ymk, tgl_kej, kd_kej,)
d. pmk_fd1 ( nippa, tmt_pst, kd_kej, tgl_klim, tgl_trans, pangkat, gaji_pokok, thp, suskel, nama_ymk, tglhr_ymk, rp_hak)
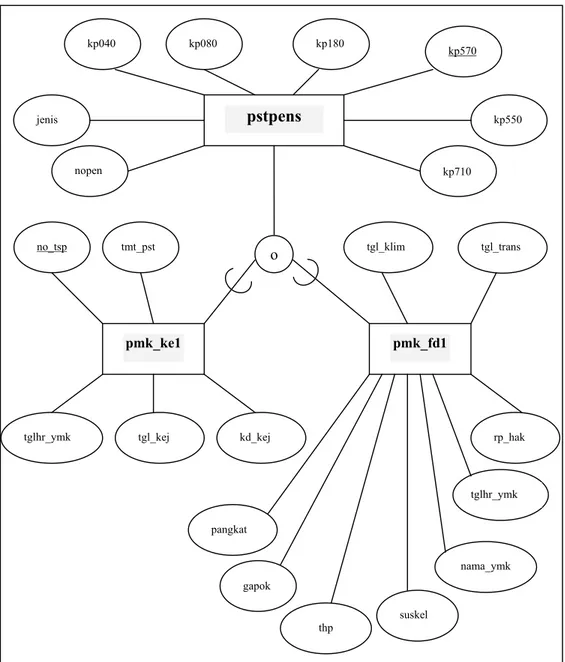
e. pstpens ( nopen, jenis, kp030, kp040, kp080, kp180, kp380, kp570, kp550, kp710).
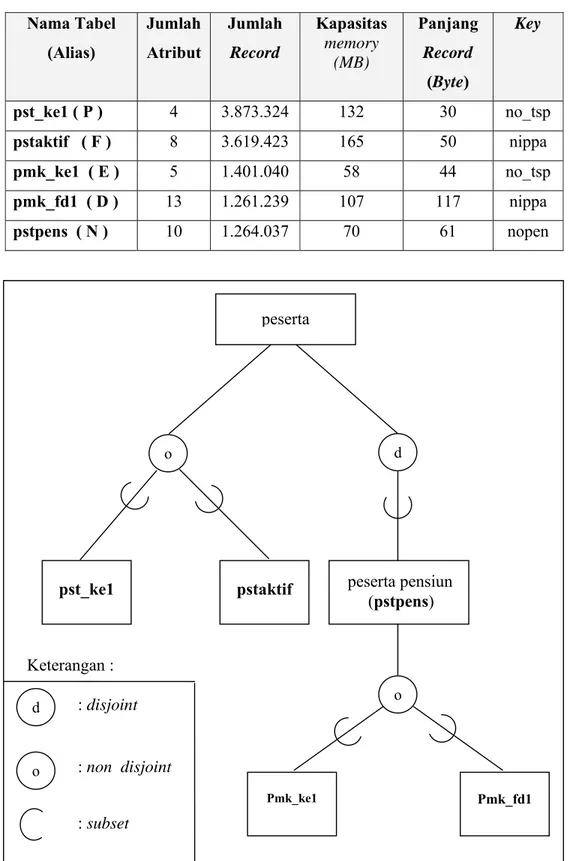
Tabel 8 : Tabel informasi data tabel relasi Nama Tabel (Alias) Jumlah Atribut Jumlah Record Kapasitas memory (MB) Panjang Record (Byte) Key pst_ke1( P) 4 3.873.324 132 30 no_tsp pstaktif ( F ) 8 3.619.423 165 50 nippa pmk_ke1 ( E ) 5 1.401.040 58 44 no_tsp pmk_fd1 ( D ) 13 1.261.239 107 117 nippa pstpens ( N ) 10 1.264.037 70 61 nopen
Gambar 5 : Diagram E-R dari keseluruhan tabel peserta peserta peserta pensiun (pstpens) pst_ke1 pstaktif Pmk_ke1 Pmk_fd1 o d o Keterangan : o d : disjoint : non disjoint : subset
Tanda ‘d’ dalam konektor lingkaran menunjukkan dekomposisi (spesialisasi) disjoint dan tidak terdapat relasi spesialisasi antar tabel, dan tanda ‘o’ menunjukkan non disjoint dan terdapat relasi spesialisasi antar tabel dan menunjukkan perbedaan tiap entitas, tanda ‘ С ‘ menunjukkan subset (Begg C. 1996). 5 buah tabel yang digunakan dalam percobaan lebih dijelaskan pada Diagram E-R Gambar 6 dan Gambar 7.
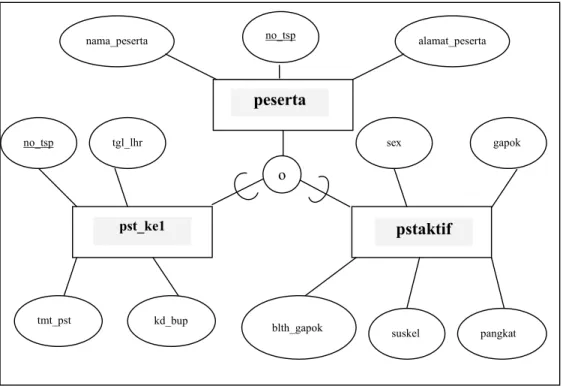
Gambar 6 : Diagram E-R tabel peserta spesialisasi menjadi tabel pst_ke1 dantabel pstaktif.
pstaktif pst_ke1 o no_tsp tgl_lhr kd_bup gapok blth_gapok suskel sex pangkat peserta nama_peserta alamat_peserta tmt_pst no_tsp
Gambar 7 : Diagram E-R tabelpensiun (pstpens) spesialisasi menjadi tabel pmk_ke1 dantabel pmk_fd1.
4.2. Formulasi Optimisasi pstpens pmk_fd1 pmk_ke1 o jenis kp040 kp080 kp180 kp570 kp550 kp710 no_tsp tmt_pst
tglhr_ymk tgl_kej kd_kej
gapok pangkat tgl_trans tgl_klim thp nama_ymk tglhr_ymk suskel nopen rp_hak
Pada bagian ini bagaimana proses query diformulasi, dianalisis dan dievaluasi. Data deskriptif atau metadata disimpan dalam tabel khusus yang disebut katalog sistem yang digunakan untuk menemukan cara terbaik dalam mengevaluasi query. Secara umum query tersusun dari beberapa operator, algoritma pada operator relasi dapat dikombinasikan dengan berbagai cara untuk mengevaluasi query. Setiap perintah query sebaiknya dievaluasi dengan melalui formulasi tree aljabar relasional. Keterangan pada masing-masing node menggambarkan metode akses untuk masing-masing tabel dan metode implementasi untuk tiap operator relasional.
Penulis mencoba mempertimbangkan contoh dengan menggunakan skema berikut :
a. pst_ke1 (no_tsp, tgl_lhr, tmt_pst, kd_bup)
b. pstaktif (nippa, tgl_lhr, tmt_pst, sex, gaji_pokok, blth_gapok, suskel, pangkat)
Tabel di atas masing-masing record dari pst_ke1 panjangnya 30 byte, dengan asumsi sebuah halaman yang akan masuk dalam buffer dapat menangani 100 record pst_ke1, maka dalam pst_ke1 terdapat 3.873.324 record akan mempunyai 38.730 halaman dalam buffer, demikian juga bahwa masing-masing record dari pstaktif panjangnya 50 byte, mempunyai 3.619.423 record, sebuah halaman dapat menangani 80 record pstaktif, sehingga mempunyai 45.242 halaman.
Perhatikan query SQL berikut ini :
SELECT F. tmt_pst
FROM pst_ke1 P, pstaktif F WHERE P.no_tsp = F.nippa
ANDP. kd_bup= ‘100’ ANDF. pangkat >= ‘3A’ Query di atas dapat dinyatakan dalam aljabar relasional seperti berikut :
Pernyataan di atas dapat dinyatakan dalam bentuk join tree pada Gambar 8. Sebagian pernyataan aljabar dapat menentukan bagaimana mengevaluasi query pertama, join dihitung secara alami dari pst_ke1 dan pstaktif, kemudian melakukan seleksi dan akhirnya memproyeksikan atribut tmt_pst. Untuk proses evaluasi harus dijelaskan implementasi untuk masing-masing operasi aljabar yang terlibat. Sebagai contoh dapat digunakan page-oriented dari nested-loop-join yang sederhana dengan pst_ke1 sebagai tabel pertama yang dibaca, dan mengaplikasikan seleksi dan proyeksi untuk masing-masing record pada hasil join, hasil dari join tersebut sebelum seleksi dan proyeksi tidak disimpan seluruhnya.
Π
tmt_pst (proyeksi)σ
kd_bup = ’100’∧ pangkat >=’3A’ (proses seleksi)⋈
no_tsp= nippa (proses join)
(baca file) pst_ke1 pstaktif
(baca file) Gambar 8 : Rencana evaluasi query dari join tree
Pada Gambar 8 ditunjukkan bahwa pst_ke1 adalah tabel pertama dibaca, terletak disebelah kiri dari join tree atau disebut tabel luar dari operator join.
Mendahulukan operasi seleksi sebelum operasi join
Untuk melakukan operasi Join secara heuristik sebaiknya tabel dibuat dengan ukuran sekecil mungkin, dan operasi seleksi dilakukan lebih awal. Sebagai contoh seleksi kd_bup =”100” hanya melibatkan atribut dari pst_ke1 dan dapat diaplikasikan pada pst_ke1 sebelum join. Sama halnya dengan seleksi pangkat >= ”3A” hanya melibatkan atribut dari pstaktif, dapat diaplikasikan pada pstaktif sebelum join.
Andaikan bahwa seleksi didahulukan dengan menggunakan scan file, hasil dari masing-masing seleksi ditulis ke tabel temporer pada disk, selanjutnya tabel temporer digabung menggunakan metode sort-merge-join seperti ditunjukkan pada Gambar 9. Hasil eksekusi menunjukkan perbedaan waktu yang cukup signifikan, untuk jumlah record masing-masing 10.000 record eksekusi medahulukan seleksi lebih cepat dari pada eksekusi mendahulukan join. Penurunan waktu eksekusi mencapai 37,45 %
Π
tmt_pst(proyeksi akhir)
⋈
(lakukan Sort-Merge-Join)
no_tsp = nippa
kd_bup = ”100” pangkat >=”3A”
(baca : tulis ke tabel temp T1) (baca : tulis ke tabel Temp T2)
(baca file) pst_ke1 pstaktif