ANALISIS SENTIMEN PADA PRODUK LAYANAN TRANSPORTASI ONLINE MENGGUNAKAN METODE K-NEAREST NEIGHBOR
SENTIMENT ANALYSIS ON ONLINE TRANSPORTATION SERVICE USING K-NEAREST NEIGHBOR METHOD
Savira Rohwinasakti1, Budhi Irawan, S.Si., M.T.2 Casi Setianingsih, S.T., M.T..3
1,2,3Prodi S1 Teknik Komputer, Fakultas Teknik Elektro, Universitas Telkom 1 [email protected], 2[email protected],
Abstrak
Pada tahun 2018 pengguna rata-rata harian layanan transportasi online 8 juta/hari di wilayah Asia Tenggara, dan negara Indonesia merupakan negara terbesar dibanding dengan negara Asia Tenggara lainnya [2]. Para pelanggan menyampaikan tanggapan mengenai layanan yang diberikan kedua penyedia jasa transportasi online melalui berbagai media, salah satunya melalui kolom komentar Instagram. Tanggapan yang diajukan pun beragam sehingga mengandung sentimen yang mengekspresikan perasaan terhadap layanan tertentu. Oleh karena itu untuk menentukan respon pelanggan terhadap layanan yang diberikan, tingkat kepuasan, serta dapat membantu pelanggan memilih layanan yang terbaik, maka dibuat sistem analisis sentimen dengan metode K-Nearest Neighbor. Hasil dari penelitian tugas akhir yang dilakukan dalam mengklasifikasikan komentar positif dan negatif pada produk layanan transportasi online mendapatkan akurasi terbaik 94.4%, Ini menyimpulkan bahwa dari hasil evaluasi algoritma yang digunakan bekerja dengan baik untuk menganalisis sentimen.
Kata kunci: Analisis sentimen, K-nearest neighbor, Pembelajaran mesin, Text Mining Abstract
In 2018 the average daily user of online transportation services is up to 8 million users/day in the Southeast Asian region, and Indonesia is the largest country in using the services compared to other Southeast Asian countries [2]. The customers submit their responses to the services provided by both online transportation service providers through various media, one of them is through the Instagram comments section. The responses submitted were also varied, so that they also contained sentiments that expressed their feelings about certain services. Therefore, to determine customers' responses to the services provided, the level of satisfaction, and to help customers choose the best services, a sentiment analysis system was made using the K-Nearest Neighbor method. Result from this study show that the proposed system is able to classify user opinion with 94.4% Accuracy. This concludes that from evaluation results, the proposed algorithm performs well to automatically analyze sentiment.
Keywords: K-Nearest Neighbor, Machine Learning, Sentiment Analysis, Text Mining
1. Pendahuluan
Perkembangan teknologi di Indonesia tergolong cepat. Dikutip dari hasil survei Asosiasi Penyelenggara Jasa Internet Indonesia (APJI) dan Polling Indonesia jumlah pengguna internet di Indonesia pada 2018 bertambah 27,91 juta (10,12%) dari tahun sebelumnya yaitu 2017 menjadi 171,18 juta jiwa [1]. Salah satu penggunaan internet yang diminati oleh masyarakat adalah penggunaan transportasi online. Pada tahun 2018 pengguna rata-rata harian layanan transportasi online mencapai 8 juta/hari di wilayah Asia Tenggara, dan negara Indonesia merupakan yang terbesar dibanding dengan negara lainnya [2].
Kemudahan akses dalam menggunakan transportasi online membuat popularitas transportasi online semakin meningkat. Para pelanggan menyampaikan tanggapan mengenai layanan yang diberikan kedua penyedia jasa transportasi online melalui berbagai media, salah satunya melalui kolom komentar Instagram akun resmi dari layanan transportasi online. Pendapat yang diajukan pun beragam sehingga komentar pelanggan tersebut mengandung sentimen yang mengekspresikan perasaan terhadap layanan tertentu. Salah satu contoh permasalahan yang sempat terjadi adalah kenaikan tarif transportasi online pasca uji coba di 5 kota pada 1 Mei 2019. Hal tersebut menghasilkan berbagai macam opini baik opini yang bernilai positif maupun negatif [3].
Oleh karena itu, dibuatlah sistem analisis sentimen untuk menentukan respon pelanggan terhadap layanan yang diberikan dan tingkat kepuasannya agar pelanggan dapat mengetahui serta memilih penyedia transportasi online yang lebih baik dalam memberikan layanan untuk pelanggan. Analisis sentimen ini dilakukan dengan menggunakan metode klasifikasi K-Nearest Neighbor (KNN). Dilatarbelakangi masalah di atas maka dilakukan penelitian dengan topik “Analisis sentimen pada produk layanan transportasi online menggunakan metode K-Nearest Neighbor”.
2. Dasar Teori 2.1 Instagram
Instagram merupakan platform media sosial dengan jumlah pengguna terbanyak ketiga di dunia dengan pengguna aktif sebanyak 55 juta pengguna menurut hasil survei pada tahun 2018[4]. Instagram digunakan untuk mengunggah foto maupun video pengguna untuk dibagikan kepada pengguna lainnya. Fitur lainnya yang dimiliki Instagram yakni fitur komentar. Fitur tersebut tersedia di setiap foto atau video yang telah dibagikan.
2 Pengguna dapat saling berinteraksi satu sama lain menggunakan fitur tersebut. Tak jarang hal ini digunakan oleh pengguna untuk menyampaikan opini tentang suatu layanan dari perusahaan penyedia jasa.
2.2 Preprocessing
Preprocessing adalah suatu proses pengubahan bentuk data yang belum terstruktur menjadi data yang terstruktur. Tahapan ini merupakan tahapan awal dalam proses text mining. Dalam penelitian ini terdapat 4 tahapan, yaitu Case Folding,Tokenizing, Filtering / Stopword Removal, Stemming [5].
2.3 Analisis Sentimen
Analisis sentimen merupakan pengkategorian pendapat atau opini pada suatu hal atau persoalan yang diungkapkan berdasarkan teks agar dapat ditarik kesimpulan juga menentukan reaksi selanjutnya [6]. Analisis sentimen atau bisa juga disebut dengan opinion mining biasanya digunakan untuk menganalisis opini dari suatu dokumen atau kalimat yang mempunyai nilai emosi untuk diproses oleh suatu algoritma baik menggunakan algoritma klasifikasi maupun klustering. Tugas dari analisis sentimen ini adalah memproses pendapat atau opini tersebut untuk digolongkan dalam kategori kalimat yang bersifat positif dan negatif. Pada penelitian ini analisis sentimen yang dilakukan adalah analisis terhadap komentar yang muncul di kolom komentar Instagram. Data tersebut akan dikumpulkan lalu dilatih untuk dapat memahami pola dari komentar pengguna yang nantinya dapat memprediksi nilai respon dari pengguna tersebut masuk ke dalam komentar bernilai positif atau pun negatif. Nilai tersebut juga dapat digunakan untuk memprediksi berapa banyak komentar positif ataupun negatif terhadap kedua penyedia layanan transportasi online.
2.4 Pembobotan Kata TF-IDF
Term Frequency Inverse-Document Frequency (TF-IDF) adalah salah satu metode algoritma yang digunakan untuk menganalisis hubungan antara suatu kata (term) dengan sekumpulan dokumen. Term Frequency merupakan proses untuk menghitung kemunculan dari suatu kata (term) dalam sebuah dokumen. Inverse Document Frequency merupakan proses untuk menghitung seberapa penting perhitungan dari term yang didistribusikan secara luas pada dokumen yang bersangkutan[7]. Berikut persamaan TF-IDF pada persamaan 1 [8].
𝑤𝑡,𝑑= 𝑡𝑓𝑡,𝑑× 𝑖𝑑𝑓𝑡 (1)
Keterangan:
tf : jumlah term dalam dokumen
idf : jumlah term pada seluruh dokumen yang ada pada data t : term (istilah)
d : dokumen (keseluruhan data yang dimiliki)
Dengan tf adalah jumlah suatu term yang terdapat dalam suatu dokumen. Untuk melihat nilai idf dapat dilihat pada persamaan 2
𝑖𝑑𝑓𝑡 = 𝑙𝑛 𝑁+1
𝑑𝑓𝑡+1+ 1 (2) Keterangan:
𝑖𝑑𝑓𝑡 : jumlah term pada seluruh dokumen yang ada pada data 𝑑𝑓𝑡 : jumlah dokumen yang didalamnya terdapat term t N : jumlah seluruh dokumen yang digunakan dalam data.
N merupakan total jumlah dokumen yang dianalisis, K adalah jumlah dokumen dimana kata t ditemukan. Setelah diperoleh nilai TF-IDF, maka dilakukan normalisasi agar selisih antar bobot TF-IDF lebih dekat. Karena jika tidak dilakukan normalisasi akan mempengaruhi akurasi yang akan diperoleh. Persamaan untuk normalisasi yaitu:
𝑉𝑛𝑜𝑟𝑚 = 𝑣
√𝑣12+𝑣22+⋯+𝑣𝑛2 (3) Dengan v merupakan bobot TF-IDF yang akan dinormalisasikan.
2.5 K-Nearest Neighbor(KNN)
K-Nearest Neighbor (KNN) adalah salah satu metode sederhana pada algoritma machine learning. Tujuan algoritma ini adalah untuk mengklasifikasikan objek ke dalam salah satu kelas yang telah ditetapkan dari kelompok sampel yang telah dibuat oleh machine learning. KNN didasarkan pada menemukan objek yang paling mirip (dokumen) dari kelompok sampel antara jarak Euclidean[10]. Metode ini mudah untuk
digunakan dan cukup efisien untuk melakukan klasifikasi dokumen tekstual[9]. Tahapan dalam KNN dengan perhitungan jarak Euclidean adalah sebagai berikut:
1. Menentukan kemiripan antara dokumen uji setiap dokumen latih yang telah diberikan label dan dilakukan pembobotan menggunakan ekstraksi ciri TF-IDF.
2. Berdasarkan hasil pengurutan jarak antara data uji dan data latih, maka selanjutnya akan dilakukan proses perhitungan menggunakan persamaan Euclidean Distance untuk menentukan jarak antara dua
titik pada data latih dan data uji. Persamaan Euclidean distance yang digunakan dapat dilihat pada persamaan 4. 𝑑 = √∑𝑥 (𝑋𝑖 − 𝑌𝑖)2 𝑖=0 (4) Keterangan: d = jarak Euclidean X = data 1 Y = data 2 i = data ke- i n = jumlah data
3. Rumus Euclidean digunakan untuk menentukan jarak antara dua titik pada data latih dan data uji. 4. Perhitungan tiap dokumen pada data latih dan data uji didapatkan dari perhitungan ekstraksi ciri tiap
kata yang telah dinormalisasi.
5. Ketika jarak antara data uji dan data latih telah didapatkan selanjutnya menentukan parameter K yang akan digunakan untuk menentukan jumlah tetangga acuan (jumlah tetangga paling dekat yang akan dijadikan acuan).
6. Mengurutkan data pada tahap no 3 tadi dengan cara ascending kemudian tentukan tetangga yang terdekat berdasarkan jarak minimum ke-K.
Berdasarkan hasil pengurutan diambil sejumlah nilai K data yang memiliki jarak terkecil. Maka didapatkan hasil berupa output data yang merupakan kelas positif dan negatif.
3. Perancangan
3.1 Gambaran Umum Sistem
Gambar 1 Gambaran umum sistem.
Gambar 3.1 merupakan perancangan sistem analisis sentimen pada produk transportasi online. Pertama data akan diambil dari kolom komentar produk transportasi online di Instagram dengan menggunakan Instagram scrapper dan format keluaran yang akan dihasilkan oleh Instagram scrapper adalah JSON (Java Script Object Notation). Selanjutnya data di convert dari JSON ke CSV untuk proses pembersihan kalimat pada data. Setelah proses pembersihan kalimat, data akan dilakukan pemberian bobot nilai oleh sistem. Setelah proses pemberian bobot nilai, data masuk ke proses klasifikasi, proses ini mengetahui kualitas layanan dari produk layanan pada transportasi online, dan hasil akan divisualisasikan melalui user interface berbasis web.
3.2 Data Retrieval
Dataset yang digunakan adalah dataset berbahasa Indonesia yang diambil dari 6 akun Instagram official yang terdiri dari 3 akun BRG dan 3 akun KJG. Akun tersebut merupakan akun layanan dari jasa transportasi, antar makanan, dan pembayaran online. Dataset yang diambil yaitu 600 komentar per-akun dengan keterangan 300 komentar berlabel negatif dan 300 lainnya berlabel positif. Maka total dataset yang diambil adalah 3600 komentar, dengan rincian komentar yang diambil dari akun Instagram BRG sebanyak 1800 dan untuk akun Instagram KJG sebanyak 1800. Berikut contoh dari komentar yang telah diambil menggunakan instgram scrapper:
4
Tabel 1 Contoh beberapa komentar dari produk transportasi online.
No Komentar
1 Pelayanan TERBAIK dan ramah semua abangnya 2 Susah bgt dapet.
3 Fitur2nya sekarang sangat lengkap,mempermudah siapa saja yang menggunakannya sukses selalu
4 Selalu inovatif, kreatif dan terbaik 5 Suka banget pelayanan ok banget ramah 6 Tarifnya ampun.... Bonus kalah ama sebelah ...
7 Smg makin maju karena membantu perekonomian masyarakat indonesia 8 Pengemudi pada belagu!!!!
9 Maps nya sering ngaco ya? Masa diarahin ke jalan tikus? Emangnya mobil Mr Bean? 10 Ah mahal ongkir nya padahal deket
11 Cepat dan praktis terimakasih atas oelayannya 12 Mahal tukang tipu
3.3 Preprocessing Teks
Tahapan ini adalah tahapan yang digunakan untuk membersihkan data dan menghilangkan karakter-karakter yang mengganggu. Gangguan tersebut dapat menyebabkan pembobotan tidak berjalan sempurna. Ketika pembobotan tidak berjalan sempurna maka data akan sulit untuk diklasifikasikan. Pada penelitian ini terdapat 4 tahap dalam text pre-processing yaitu:
1. Case Folding
Tahap ini adalah proses untuk mengubah semua kata masukan menjadi karakter kecil. 2. Tokenizing
Pada proses ini dilakukan pemecahan kalimat berdasarkan spasi menjadi berberapa kata terpisah. 3. Filtering
Proses pengambilan kata penting pada sebuah kalimat, jika mengandung kata-kata yang sering keluar dan dianggap tidak penting, seperti waktu, penghubung, dan lain sebagainya makan akan dihapuskan. 4. Stemming
Stemming suatu proses yang dilakukan setelah proses filtering dan tokenizing. Tujuan proses stemming adalah mengubah bentuk kata pada data kembali ke bentuk awalnya untuk mencegah ambiguitas yang terdeteksi oleh sistemnya.
Ilustrasi dari preprocessing dapat dilihat pada Tabel 2 dibawah ini. Tabel 2 Tahapan preprocessing.
Preprocesing Data
Data asli Pelayanan TERBAIK dan ramah semua abangnya
Case Folding pelayanan terbaik dan ramah semua abangnya
Tokenization ‘pelayanan’ ‘terbaik’ ‘dan’ ‘ramah’ ‘semua’ ‘abangnya’ Filtering/ Stopword
Removal
‘pelayanan’ ‘terbaik’ ‘ramah’ ‘abangnya’
Stemming layanan baik ramah abang
3.4 Ekstraksi Ciri TF-IDF
Data yang telah melalui preprocesing selanjutnya akan dilakukan pembobotan pada kata didalam dataset. Pembobotan akan dilakukan menggunakan ekstraksi ciri TFIDF. Proses pembobotan dilakukan dengan memberikan bobot hubungan suatu kata (term) terhadap dokumen data komentar. Berikut diagram alir pada proses pembobotan TFIDF.
Gambar 2 Diagram alir pembobotan TFIDF.
Gambar 3.2 merupakan diagram alir dari proses pembobotan menggunakan ekstraksi ciri TFIDF. Setelah proses preprocessing dilakukan, hasil dari data tersebut akan melalui tahap selanjutnya, yaitu proses untuk penghitungan bobot setiap kalimat pada dokumen data komentar. Berikut contoh kalimat komentar yang sudah dibersihkan pada tahapan preprocessing dapat dilihat pada Tabel 3.
Tabel 3 Contoh data yang telah di preprocessing dan memiliki label
Dokumen Komentar Kelas
D1 Selalu terbaik inovatif kreatif terbaik 1
D2 Mahal ongkir padahal deket 0
D3 Suka pelayanan terbaik ramah 1
D4 Pengemudi belagu 0
D5 terbaik ramah abangnya ?
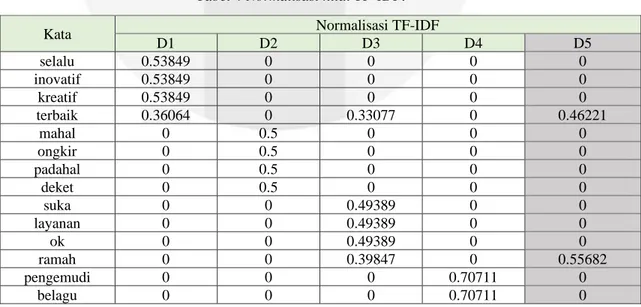
Pada Tabel 3 terdapat 2 komentar dengan 2 label positif yaitu pada D1 dan D3 sedangkan pada dokumen D2 dan D4 komentar bernilai negatif. Sedangkan D5 merupakan contoh data yang akan diuji dengan 4 dokumen lainnya. Penerapan proses pembobotan TF-IDF diawali dengan melihat tingkat kemunculan kata pada sebuah dokumen, sebagai contoh salah satu dokumen di atas memiliki kata “kreatif”. Kata tersebut hanya muncul satu kali maka diketahui TF=1 dan terdapat hanya pada dokumen pertama yaitu D1. Kata tersebut tidak muncul pada dokumen lainnya baik dokumen kedua, ketiga maupun keempat, maka diketahui DF=1. Implementasi ekstraksi ciri TF-IDF dengan normalisasi menggunakan persamaan 1,2 dan 3 dapat dilihat pada Tabel 4.
Tabel 4 Normalisasi nilai TF-IDF.
Kata Normalisasi TF-IDF
D1 D2 D3 D4 D5 selalu 0.53849 0 0 0 0 inovatif 0.53849 0 0 0 0 kreatif 0.53849 0 0 0 0 terbaik 0.36064 0 0.33077 0 0.46221 mahal 0 0.5 0 0 0 ongkir 0 0.5 0 0 0 padahal 0 0.5 0 0 0 deket 0 0.5 0 0 0 suka 0 0 0.49389 0 0 layanan 0 0 0.49389 0 0 ok 0 0 0.49389 0 0 ramah 0 0 0.39847 0 0.55682 pengemudi 0 0 0 0.70711 0 belagu 0 0 0 0.70711 0
6 3.5 Klasifikasi menggunakan K-Nearest Neighbor
Data yang diproses pada tahap ini merupakan data yang telah melalui proses preprocessing dan telah melalui tahapan pembobotan dengan menggunakan TF-IDF. Cara kerja klasifikasi menggunakan metode K Nearest Neighbor adalah mengelompokkan sesuatu ke dalam kelas yang paling sesuai berdasarkan data latih yang jaraknya paling dekat dengan objek tersebut. Proses ini memiliki beberapa tahapan sebagai berikut.
Gambar 3 Diagram alir klasifikasi KNN.
Gambar 3.8 di atas merupakan diagram alir sebuah metode klasifikasi terhadap sekumpulan data uji berdasarkan pembelajaran data latih yang sudah terklasifikasikan sebelumnya dengan memiliki dua kelas, yaitu kelas positif dan negatif. Setelah mendapatkan bobot dari TFIDF lalu akan dilakukan perhitungan Euclidean antara dokumen D1,D2,D3,D4 dengan dokumen D5. Hasil perhitungan tersebut lalu dipakai untuk mengurutkan kedekatan antara dokukem tersebut. Urutan kedekatan dokumen dapat dilihat pada Tabel 5 dibawah ini.
Tabel 5 Urutan hasil Euclidean distance. Urutan hasil kedekatan dokumem
1 2 3 4
D3(+) D1(+) D2(-) D4(-)
Berdasarkan Tabel 3.11 dapat dilihat jarak antar dokumen training dengan dokumen uji dengan menggunakan nilai K yang telah ditentukan sebagai berikut:
• Jika K=1, D5 mendekati D3 maka hasil klasifikasi adalah positif. • Jika K=3, D5 mendekati D3 dan D1 maka hasil klasifikasi adalah positif.
4. Implementasi dan pengujian sistem 4.1 Pengujian partisi data
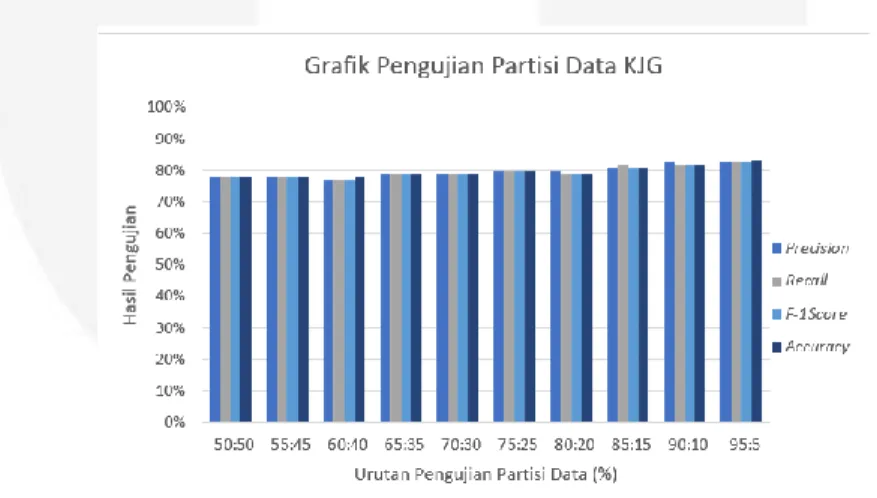
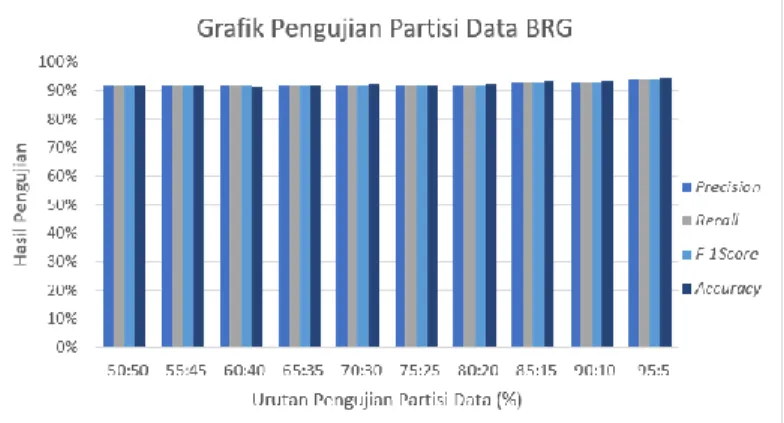
Pengujian partisi ini dilakukan untuk mengukur kinerja dari algoritma K Nearest Neighbor yang digunakan untuk melakukan klasifikasi data sesuai dengan kelas yang telah ditentukan yaitu kelas positif dan negatif. Hasil klasifikasi akan divisualisasikan dalam bentuk tabel confusion matrix dan untuk pengukuran performansi dari sistem akan dilakukan perhitungan dengan menghitung accuracy, precision, recall dan f1-score. Berikut data pengujian partisi yang telah dilakukan dan nilai confusion matrix yang dihasilkan ditampilkan pada Tabel 6 dan Tabel 7.
Tabel 6 Pengujian partisi layanan KJG dengan ekstraksi ciri TF-IDF. Pengujian
Ke- Data Latih(%) Data Uji(%) Precision(%) Recall(%) F1-Score(%) Accuracy(%)
1 50 50 77 77 77 76.76
2 55 45 77 77 77 77.16
Pengujian
Ke- Data Latih(%) Data Uji(%) Precision(%) Recall(%) F1-Score(%) Accuracy(%)
3 60 40 78 78 78 77.64 4 65 35 77 77 77 76.82 5 70 30 80 79 79 79.44 6 75 25 79 79 79 79.11 7 80 20 81 81 81 80.55 8 85 15 80 80 80 79.63 9 90 10 77 77 77 77.22 10 95 5 83 83 83 83.3
Tabel 7 Pengujian partisi layanan BRG dengan ekstraksi ciri TF-IDF. Pengujian
Ke- Data Latih(%) Data Uji(%) Precision (%) Recall(%) F1-Score(%) Accuracy(%)
1 50 50 92 92 92 92 2 55 45 92 92 92 91.73 3 60 40 92 92 92 91.53 4 65 35 92 92 92 91.9 5 70 30 92 92 92 92.2 6 75 25 92 92 92 91.78 7 80 20 92 92 92 92.2 8 85 15 93 93 93 93.3 9 90 10 93 93 93 93.3 10 95 5 94 94 94 94.4
Dari tabel hasil pengujian partisi data di atas, dapat dilihat grafik perbandingannya antara dataset KJG dengan BRG pada Gambar 4 dan Gambar 5.
8 Gambar 4 Grafik pengujian partisi pada data BRG.
Gambar 3 dan Gambar 4 menunjukan bahwa hasil dari pengujian partisi dengan pembagian data latih 95% dan data uji 5% dari produk layana KJG dan BRG merupakan pembagian partisi paling baik dengan nilai akurasi 94.4% pada dataset grab dan 83.3% pada dataset KJG. Pengujian ini membuktikan bahwa akurasi dari pengujian menggunakan dataset BRG dan dataset JKG memiliki akurasi yang lebih tinggi hal ini disebabkan oleh data latih dari BRG memiliki dataset dengan kalimat ambigu lebih sedikit sehingga pada saat pengujian akurasi yang didapatkan lebih tinggi.
4.2 Pengujian nilai K
Pengujian ini bertujuan untuk mendapatkan akurasi terbaik pada sistem dan pengaruh dari nilai K terhadap akurasi yang didapatkan. Berikut ini hasil pengujian nilai K dengan partisi data sebesar 95% data latih dan 5% data uji menggunakan data layanan BRG.
Gambar 5 Hasil pengujian nilai K.
Pada Gambar 5 dapat dilihat hasil pengujian nilai K dengan partisi data sebesar 95% data latih dan 5% data uji. Dari pengujian tersebut dapat diketahui nilai K terbaik, yaitu K=9 dengan akurasi sebesar 94.44%, precision, recall dan F1-score sebesar 94%.
5. Kesimpulan dan Saran 5.1 Kesimpulan
Berdasarkan dari hasil pengujian yang telah dilakukan pada tugas akhir ini, maka dapat disimpulkan sebagai berikut:
1. Sistem sentiment analysis layanan transportasi online menggunakan metode K-nearest Neighbor berhasil mengklasifikasikan komentar Instagram berupa komentar positif dan komentar negatif.
2. Hasil performansi yang dihasilkan oleh metode klasifikasi KNN dengan ekstraksi ciri TF-IDF mendapatkan akurasi tertinggi sebesar 94.4% dengan partisi terbaik dengan pembagian 95% data latih dan 5% data uji, dan nilai K terbaik yaitu k=9 kemudian proses pengujian kinerja sistem didapatkan nilai precision, recall, f1- score sebesar 94%.
Berdasarkan hasil dari pengujian yang telah dilakukan pada tugas akhir ini, maka ada hal yang dapat penulis sarankan untuk penelitian selanjutnya sebagai berikut:
1. Penambahan metode clustering pada hasil klasifikasi agar dapat mengetahui topik yang dibahas pada masing-masing label.
10 Daftar Pustaka
[1] V. B. Kusnandar, “Pengguna Internet di Indonesia 2018 Bertambah 28 Juta” [online]. Available: https://databoks.katadata.co.id/datapublish/2019/05/16 /pengguna-internet-di-indonesia-2018-bertambah-28-juta [Accessed: 05-Des-2019].
[2] Temasek, “Pangsa Pasar Layanan Transportasi Online Indonesia Terbesar di ASEAN”[online].Available : https://databoks.katadata.co.id/datapublish/ 2018/11/29/pangsa-pasar-layanan-transportasi-online-indonesia-terbesar-di-asean. [Accessed: 10-Nov-2019].
[3] Fira Nursyabani , “Tarif Baru Mahal, Warganet Ancam Berhenti Pakai Ojol”.[Online]. Available: https://www.ayobandung.com/read/2019/05/ 03/51339/tarif-baru-mahal-warganet-ancam-berhenti-pakai-ojol. [Accessed: 10-Nov-2019].
[4] Databoks “Berapa Pengguna Instagram dari Indonesia?” [online]. Available: https://databoks.katadata.co.id/datapublish/2018/02/09/berapa-pengguna-instagram-dari-indonesia. [Accessed: 8-April-2029].
[5] Rosid, M. A., Fitrani, A. S., Astutik, I. R. I., Mulloh, N. I., & Gozali, H. A. (2020). ‘Improving Text Preprocessing For Student Complaint Document Classification Using Sastrawi.” IOP Conference Series: Materials Science and Engineering, 874, 012017. doi:10.1088/1757-899x/874/1/012017
[6] Pawar, T., Kalra, P., & Mehrotra, D. (2018). “Analysis of Sentiments for Sports data using RapidMiner,” 2018 Second International Conference on Green Computing and Internet of Things (ICGCIoT). doi: 10.1109/icgciot.2018. 8752989 [7] A. Mishra and S. Vishwakarma, “Analysis of TF-IDF Model and its Variant for Document Retrieval,” Proc. - 2015
Int. Conf. Comput. Intell. Commun. Networks, CICN 2015, pp. 772–776, 2016.
[8] Matthew J. Lavin,” Analyzing Documents with TF-IDF” [online] Available: https://programminghistorian.org/en/lessons/analyzingdocuments-with-TF-IDF#fn:7. [Accessed: 25-Jun-2020]. [9] Wibawa, D. W., Nasrun, M., & Setianingsih, C. (2018). “Sentiment Analysis on User Satisfaction Level of Cellular
Data Service Using the K-Nearest Neighbor (K-NN) Algorithm,” 2018 International Conference on Control, Electronics, Renewable Energy and Communications (ICCEREC). doi: 10.1109/iccerec. 2018.8711992.
[10] K. Khamar, “Short Text Classification Using kNN Based on Distance 53 Function,” vol. 2, no. 4, pp. 1916–1919, 2013.