Skripsi
Diajukan Untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Sains
Program Studi Ilmu Komputer
Oleh :
Andreas Wahyu Utama NIM : 033124038
PROGRAM STUDI ILMU KOMPUTER FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
Skripsi
Diajukan Untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Sains
Program Studi Ilmu Komputer
Oleh :
Andreas Wahyu Utama NIM : 033124038
PROGRAM STUDI ILMU KOMPUTER JURUSAN MATEMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
2008
THESIS
Presented As Partial Fulfillment Of The Requirements To Obtain The Sarjana Sains Degree In Computer Sciences
By :
Andreas Wahyu Utama NIM : 033124038
STUDY PROGRAM OF COMPUTER SCIENCES DEPARTMENT OF MATHEMATICS FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY YOGYAKARTA
2008
tidak memuat karya/bagian karya orang lain, kecuali yang telah disebutkan dalam kutipan dan daftar pustaka, sebagaimana layaknya karya ilmiah.
Yogyakarta, 9 Oktober 2008 Penulis
Andreas Wahyu Utama
Namun sebuah misteri untuk dijalani.
(M. Scott Peck)
Hanya orang-orang dengan tekad yang kuat yang
mampu membuka tirai kehebatan.
(Comte de Mirabeau)
Saya memang seorang yang melangkah dengan lambat,
Tetapi saya tidak akan pernah berjalan mundur ke belakang.
(Abraham Lincoln)
Ide-ide lebih kuat daripada senapan.
Kami tidak akan membiarkan musuh kami memiliki senapan,
Mengapa kami harus membiarkan mereka memiliki ide-ide?
(Joseph Stalin)
Skripsi ini aku persembahkan untuk kedua orang tuaku Bapak (alm) H. Sumarlan dan ibu E.M. Wartinem
memerlukan penyimpanan data yang besar. Data buku yang besar diakses oleh dua aplikasi yaitu perpustakaan Mrican dan Paingan yang lokasinya terpisah jarak yang jauh. Hal ini dapat mempengaruhi kinerja komputer server dalam pengelolaan basis data. Untuk itu diperlukan penyimpanan basis data buku di beberapa lokasi menggunakan sistem basis data terdistribusi. Sistem basis data terdistribusi merupakan cara untuk mendistribusikan basis data yang berelasi secara logis pada beberapa lokasi secara terpisah dengan menggunakan jaringan komputer.
Implementasi sistem basis data terdistribusi pada perpustakaan dengan metode telaah fragmentasi ini menggunakan 2 strategi yaitu: fragmentasi horizontal dan fragmentasi vertikal. Fragmentasi horizontal memecah tabel berdasarkan record sedangkan fragmentasi vertikal memecah tabel berdasarkan kolom. Berdasarkan penelitian, implementasi sistem basis data pada perpustakaan menggunakan strategi fragmentasi horizontal lebih cocok digunakan untuk basis data buku dan dapat meminimalkan total biaya.
amount of storage. It is accessed by two application that are Mrican and Paingan library which spread out in some separate locations. This condition influences the server performance in processing the database. Therefore, book database should be stored in several storages at some different locations by implementing distributed database system. The distributed database system is a way to distribute logically related database in some different locations, using computer network.
The implementation of distributed database system at library with study method fragmentation uses two strategies that are: horizontal fragmentation and vertical fragmentation. Horizontal Fragmentation breaks the table based on the records while vertical Fragmentation break the table based on the columns. According to research, this implementation of distributed database system at library uses horizontal fragmentation because this strategy is more compatible for the books database and can minimize the total cost.
Yang bertanda tangan di bawah ini, saya mahasiswa Universitas Sanata Dharma : Nama : Andreas Wahyu Utama
Nomor Mahasiswa : 033124038
Demi pengembangan ilmu pengetahuan, saya memberikan kapada Perpustakaan Universitas Sanata Dharma Karya ilmiah saya yang berjudul :
IMPLEMENTASI SISTEM BASIS DATA TERDISTRIBUSI PADA UNIVERSITAS SANATA DHARMA YOGYAKARTA
Beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikan kepada Perpustakaan Universitas Sanata Dharma hak untuk menyimpan, mengalihkan, dalam bentuk media lain, mengelolanya dalam bentuk pangkalan data, mendistribusikan secara terbatas, dan mempublikasikannya di internet atau media lain untuk kepentingan akademis tanpa perlu meminta ijin dari saya maupun membarikan royalti kepada saya selama tetap mencantumkan nama saya sebagai penulis.
Demikian pernyataan ini saya buat dengan sebenarnya. Dibuat di Yogyakarta
Pada tanggal : 9 Oktober 2008 Yang menyatakan
(Andreas Wahyu Utama)
berkat kemampuan dan pengetahuan kepada saya sehingga penyusunan skripsi dapat terselesaikan. Skripsi ini disusun sebagai salah satu syarat untuk memperoleh gelar Sarjana Sains di Fakultas Sains dan Teknologi. Penulis menyadari masih banyak kekurangan dan kesalahan dalam karya tulis ini dan semoga kekurangan dan kesalahan tersebut tidak mengurangi kemanfaatannya. Dalam rangka perbaikan karya tulis ini penulis menerima kritik dan saran yang dapat dikirim melalui :
e-mail : [email protected] atau melalui Nomor HP : 085647395146 (Andre).
Yogyakarta, Oktober 2008
Penulis
proses penyusunan yang tidak sebentar. Namun berkat dukungan dari banyak pihak, akhirnya skripsi ini dapat terselesaikan. Terima kasih atas semua pihak yang telah membantu penyusunan skripsi ini, secara khusus Kepada :
1. Romo Greg Heliarko selaku dekan FST atas kesempatan yang masih diberikan kepada kami.
2. Ibu P.H. Prima Rosa, S.Si., M.Sc. selaku Kaprodi Ilmu Komputer FST.
3. Ibu A. Rita Widiarti, S.Si., M.Kom. selaku dosen pembimbing atas saran, bimbingan, dan waktu yang diberikan.
4. Seluruh dosen Fakultas Sains Dan Teknologi yang telah membagi pengalaman, pengetahuan, dan membantu selama kuliah, sampai pada saat hari H pendadaran.
5. Staff sekretariat FST atas bantuannya selama ini.
6. Seluruh staff perpustakaan USD terutama untuk Romo Frans Susilo atas ijinnya, sehingga penulis dapat melakukan penelitian di perpustakaan USD. 7. Bapak Supriyanto selaku administrator perpustakaan USD atas waktu yang
diberikan kepada penulis untuk melakukan wawancara.
8. Bapak Drs. M. Tarmanta sekeluarga atas dukungan, doa, motivasi yang diberikan kepada penulis.
10.Pak Tomo dan Bu Muncar yang selalu menanyakan “Kapan Kamu Lulus?”. 11.Teman-teman Kos 132 A paingan : Kenthus (atas motivasinya), Paijho (suwun
komputer + kamarnya), Simbah (atas nasehat-nasehatnya), Yoo (atas bantuan dan motivasinya).
12.Rina, Iin, Toto, Lia atas bantuan, bimbingan, dan semangat yang telah diberikan kepada penulis.
13.Bang Teguh untuk saran-saran yang diberikan, pinjaman laptop, dan kamarnya selama sebulan ini thank’s a lot bro..
14.Seluruh teman-teman IKOM angkatan 2003 terima kasih atas semua kebersamaan yang telah kita lalui selama ini. (Tetap Kompak)
15.Semua pihak yang tidak bisa disebutkan satu persatu, terima kasih atas semuanya.
Segala sesuatu tidak ada yang sempurna, demikian juga dengan skripsi ini. Kritik dan saran menjadi harapan penulis agar skripsi ini menjadi labih baik. Semoga skripsi ini dapat berguna bagi adik-adik sejurusan dan yang utama, semoga skripsi ini barguna bagi ilmu pengetahuan.
Yogyakarta, Oktober 2008
Penulis
HALAMAN JUDUL………... i
HALAMAN PERSETUJUAN PEMBIMBING ……….……… iii
HALAMAN PENGESAHAN……….……… iv
HALAMAN KEASLIAN KARYA ………....……… v
HALAMAN PERSEMBAHAN ………...….. vi
ABSTRAK ………..…… vii
ABSTRACT ………..….. viii
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS ... ix
2.2 Arsitektur Sistem Basis Data Terdistribusi ……….. …… 10
2.2.1 Model Arsitektur untuk Sistem Basis Data Terdisribusi ... ... 10
2.2.2 Arsitektur Sistem Manajemen Basis Data Terdistribusi …………. ……. 12
2.3 Desain Sistem Basis Data Terdistribusi ……… …… 15
2.3.1 Fragmentasi ………. …… 16
2.3.2 Alokasi ………. …… 47
2.4 QUERY-PROCESSOR TERDISTRIBUSI ……… 48
2.4.1 Definisi Query-Processor Terdistribusi ... 48
2.4.2 Peran Utama Query-Processor Terdistribusi ... 48
2.4.3 Contoh Kasus Query-Processor Terdistribusi 1... 50
2.4.4 Contoh Kasus Query-Processor Terdistribusi 2 ... 51
2.4.5 Optimasi Kueri ... 53
BAB III ANALISA DAN PERANCANGAN SISTEM ... 55
3.1 Analisis Masalah ... 55
3.2 Analisis Kelayakan ... 56
3.3 Analisis Kebutuhan ... 58
3.3.1 Kebutuhan Perpustakaan Paingan ... 58
3.3.2 Kebutuhan Perpustakaan Mrican ... 59
3.4 Gambaran Umum Sistem ... 60
3.5 Perancangan Proses ... 61
3.5.1.3. DAD Level 0 untuk Perpustakaan Paingan ………. 63
3.5.2 Kamus Data ... 64
3.6 Perancangan Basis Data ... 66
3.6.1 Entity Relational Diagram (ERD) ……… 66
3.6.2 Relasi Antar Tabel ... 69
3.6.3 Mapping ... 69
3.6.4 Normalisasi Relasi ... 70
3.6.5 Tabel Awal ... 70
3.7 Perancangan SBDT Perpustakaan Universitas Sanata Dharma ... 70
3.7.1 Primary Horizontal Fragmentation dari Tabel BUKU ... 70
3.7.2 Derived Horizontal Fragmentation Dari Tabel KLASIFIKASI ……….. 76
3.7.3. Fragmentasi Vertikal... 78
3.7.3 Perhitungan Total Biaya ...……….……….……... 102
3.8 Perancangan User Interface ……….……… ……. 108
3.8.1. Form Utama Perpustakaan Mrican ... 108
3.8.2. Form Penelusuran Buku Perpustakaan Mrican ……… 108
3.8.3. Form Utama Perpustakaan Paingan ... 110
3.8.4. Form Penelusuran Buku Perpustakaan Paingan ... 110
BAB IV IMPLEMENTASI ... 111
4.1 Implementasi Komputer Server ... 111
4.2.1 Implementasi Komputer Klien Perpustakaan Mrican ... 115
4.2.2 Implementasi Komputer Klien Perpustakaan Paingan ... 122
BAB V PENUTUP ... 128
5.1 Kesimpulan ... 128
5.2 Saran ... 129
DAFTAR PUSTAKA ... 130
Gambar 2.2. Referensi Arsitektur Client-Server ………. 13
Gambar 2.7. Lokasi Pemisahan ke-1 ……… 29
Gambar 2.8. Lokasi Pemisahan ke-2 ……… 29
Gambar 2.9. Lokasi Pemisahan ke-3 ……… 30
Gambar 2.10. Ekspresi Relasi Antar Tabel Menggunakan Link (Li) ………... 33
Gambar 2.11. Ekspresi dari Relasi Tabel Owner dan Tabel Member Menggunakan Link (Li) ………... 42
Gambar 2.12. Diagram Pemetaan ……… 49
Gambar 2.13. Lokasi Fragmen-fragmen ASG dan EMP ………. 51
Gambar 3.1. Blok Diagram Sistem Basis Data Terdistribusi Perpustakaan ……… 60
Gambar 3.2. Diagram Konteks ……… 61
Gambar 3.3. DAD Level 0 untuk Perpustakaan Mrican ………. 62
Gambar 3.4. DAD Level 0 untuk Perpustakaan Paingan ……… 63
Gambar 3.31. Matriks Cluster M21 ... 93
Gambar 3.39. Form Utama Perpustakaan Mrican ... 108
Gambar 3.40. Form Penelusuran Buku Perpustakaan Mrican ………. 109
Gambar 3.41. Form Utama Perpustakaan Paingan ... 110
Gambar 3.42. Form Penelusuran Buku Perpustakaan Paingan ... 110
Gambar 4.1. Koneksi ke MySQL Server ………. 113
Gambar 4.2. Membuat Basis Data Baru ……….. 113
Gambar 4.3. Membuat Tabel Baru ……….. 114
Gambar 4.5. Form Utama Perpustakaan Mrican ………. 116
Gambar 4.6. Form Penelusuran Data Buku Perpustakaan Mrican ……….. 117
Gambar 4.7. Form Tentang Program ………... 118
Gambar 4.8. Form Petunjuk Pemakaian Program ………... 118
Gambar 4.9. Form Profil Pembuat ………... 119
dengan Klasifikasi Manajemen ……… 120
Gambar 4.12. Form Penelusuran Data Buku yang Menampilkan Data Buku dengan Klasifikasi Ekonomi ……… 120
Gambar 4.13. Form Penelusuran Data Buku yang Menampilkan Data Buku dengan Klasifikasi Sejarah ………... 121
Gambar 4.14. Form Penelusuran Data Buku yang Menampilkan Data Buku dengan Klasifikasi Bahasa ………... 121
Gambar 4.15. Form Utama Perpustakaan Paingan ……….. 122
Gambar 4.16. Form Penelusuran Data Buku Perpustakaan Paingan ………... 123
Gambar 4.17. Form Tentang Program ………. 123
Gambar 4.18. Form Profil Pembuat ………. 124
Gambar 4.19. Form Petunjuk Penggunaan Program ……… 124
Gambar 4.20. Form Penelusuran Data Buku yang Menampilkan Data Buku dengan Klasifikasi Komputer ………... 125
Gambar 4.21. Form Penelusuran Data Buku yang Menampilkan Data Buku dengan Klasifikasi Psikologi ……… 125
Gambar 4.22. Form Penelusuran Data Buku yang Menampilkan Data Buku dengan Klasifikasi Matematika ……… 126
Gambar 4.23. Form Penelusuran Data Buku yang Menampilkan Data Buku dengan Klasifikasi Fisika ………. 126
dengan Klasifikasi Teknik ……… 127
Tabel 2.2. Tabel PAY ……….. 38 Tabel 2.3a. Tabel PAY1 ……….. 39 Tabel 2.3b. Tabel PAY2 ……….. 39 Tabel 2.4. Tabel Hasil Fragmentasi Horizontal Primer (PHF) ……… 40 Tabel 2.5. Tabel Hasil Derived Horizontal Fragmentation (DHF) ………. 43 Tabel 2.6. Tabel Derived Fragment ASG berdasar PHF PROJ ……….. 45 Tabel 2.7. Tabel Fragmen ASG berdasar Derived Fragmen EMP ………. 46 Tabel 2.8. Tabel Total Biaya dari Strategi A ……….. 52 Tabel 2.9. Tabel Total Biaya dari Strategi B ……….. 53 Tabel 2.10. Tabel Kompleksitas Operasi Aljabar Relasional ………. 54 Tabel 3.1. Tabel Spesifikasi Proses Pada Perpustakaan Mrican ………. 62 Tabel 3.2. Tabel Spesifikasi Proses Pada Perpustakaan Paingan ………... 63 Tabel 3.3. Tabel Awal (Tabel BUKU) ……… 70 Tabel 3.4. Tabel Klasifikasi Buku (Dewey, 2003) ...……….... 72 Tabel 3.5. Tabel BUKU1 ……… 75 Tabel 3.6. Tabel BUKU2 ……… 75 Tabel 3.7. Tabel KLASIFIKASI1 ………... 77 Tabel 3.8. Tabel KLASIFIKASI2 ………... 77 Tabel 3.9. Tabel Rumus untuk Menghitung Angka Bond ... 84 Tabel 3.9. Tabel Total Biaya dari Strategi A pada SBDT Perpustakaan …………. 107 Tabel 3.10. Tabel Total Biaya dari Strategi B pada SBDT Perpustakaan ………... 107
BAB I PENDAHULUAN
1.1 LATAR BELAKANG
Dewasa ini penggunaan basis data semakin bertambah. Hal ini dapat mempengaruhi kinerja komputer server dalam pengelolaan basis data. Permasalahan tersebut makin bertambah jika aplikasi komputer klien membutuhkan akses data yang semakin besar dan data diakses oleh banyak komputer klien yang tersebar di beberapa lokasi.
Dalam sebuah perpustakaan, pengelolaan data buku memiliki peranan yang sangat penting karena dengan pengelolaan data yang baik dapat meningkatkan efektifitas kinerja dan layanan dari suatu perpustakaan, basis data semakin bertambah seiring berjalanya waktu. Hal ini dapat mempengaruhi kinerja komputer server dalam pengelolaan basis data. Permasalahan tersebut makin bertambah jika aplikasi komputer klien membutuhkan akses data yang semakin besar dan data diakses oleh banyak komputer klien yang tersebar di beberapa lokasi.
Dalam sebuah perpustakaan, pengelolaan data buku memiliki peranan yang sangat penting karena dengan pengelolaan data yang baik dapat meningkatkan efektifitas kinerja dan layanan dari suatu perpustakaan.
Seiring dengan berjalannya waktu, penyimpanan data pada perpustakaan semakin besar dan memerlukan proses yang sangat kompleks bahkan pada beberapa perpustakaan mengunakan sistem jaringan untuk
pengelolaan basis data perpustakaan karena lokasi yang terpisah. Tingginya pengaksesan dari masing-masing lokasi mempengaruhi layanan dan kinerja dari perpustakaan karena hanya memiliki satu server.
Pada perpustakaan USD yang lokasinya terpisah, layanan pada suatu lokasi tidak selalu menggunakan seluruh data yang ada. Data yang dibutuhkan oleh perpustakaan Mrican dan Paingan tidaklah sama. Dengan menggunakan satu server, akses database menjadi lambat karena pada saat perpustakaan Mrican atau Paingan mengakses basis data, data-data yang seharusnya tidak perlu diakses oleh salah satu lokasi akan diakses secara bersamaan. Salah satu alternatif penyelesaian masalah untuk pengaksesan data yang lambat adalah implementasi Sistem Basis Data Terdistribusi (SBDT). SBDT merupakan cara untuk mendistribusian basis data yang ber-relasi secara logis pada beberapa lokasi secara terpisah dengan menggunakan jaringan komputer.
Sedangkan alokasi adalah peletakan tiap-tiap fragmen pada suatu lokasi dengan distribusi paling optimal.
Pendistribusian basis data diatur sedemikian rupa agar tidak menimbulkan masalah baru, seperti meningkatnya biaya pengiriman data dan overhead yaitu pemunculan pesan kegagalan karena keterbatasan waktu pencarian yang disebabkan pendistribusian basis data tidak optimal.
Banyak sebab mengapa melakukan pendistribusian basis data, misalnya dalam kasus data perpustakaan. Perpustakaan Paingan tidak menginginkan mengakses seluruh data perpustakaan Mrican secara lengkap dan juga sebaliknya. Oleh karena itu, perpustakaan Mrican atau Paingan hanya perlu mengelola sebagian data yang dibutuhkan saja untuk mengoptimalkan pengaksesan basis data. Untuk itu dilakukan suatu basis data perpustakaan yang terdistribusi dengan menggunakan metode fragmentasi di setiap perpustakaan supaya ketersediaan data dapat meningkatkan kinerja dan layanan di perpustakaan. Dalam hal ini pengunaan metode pendistribusiannya dilakukan berdasarkan kebutuhan dari masing-masing perpustakaan.
1.2 RUMUSAN MASALAH
1.3 BATASAN MASALAH
1. Sistem ini hanya membahas tentang fragmentasi pada Perpustakaan Universitas Sanata Dharma saja.
2. Sistem ini hanya bisa digunakan oleh Perpustakaan Mrican dan Paingan saja.
3. Karya tulis ini tidak membahas tentang jaringan komputer secara detail. 4. Simulasi menggunakan 2 komputer, dimana komputer berfungsi sebagai
komputer server sekaligus komputer klien.
5. Basis data perpustakaan dianggap statis tidak ada manipulasi data, manipulasi data dianggap dilakukan oleh server lain.
6. Karya tulis ini tidak membahas transaksi peminjaman maupun pengembalian buku secara detail
7. Tools yang digunakan :
a. Sistem operasi menggunakan Windows XP Service pack 2 b. Pengelolaan basis data menggunakan MySql server
c. Bahasa pemrograman menggunakan Microsofts Visual Basic .Net 2005
1.4 TUJUAN PENELITIAN
1.5 METODOLOGI
Metode pengembangan perangkat lunak menggunakan metode Waterfall (Pressman,1992). Metode tersebut terdiri dari :
1. Tahap Perencanaan
Merupakan tahap untuk menentukan kebutuhan sistem yang diperlukan untuk membuat sebuah SBDT.
2. Tahap Analisis
Dalam tahapan ini penulis langsung berhubungan dengan pemakai sistem. Pengumpulan kebutuhan ini dilakukan dengan cara wawancara, observasi, dan pengumpulan dokumen-dokumen terkait.
a. Wawancara
Metode ini dilakukan dengan cara komunikasi langsung dengan pengguna sistem untuk memperoleh informasi yang berkaitan dengan pengembangan sistem.
b. Observasi
Metode ini dilakukan dengan pengamatan langsung ke objek system yang digunakan selama ini.
c. Mengumpulkan dokumen-dokumen
3. Tahap Perancangan / Desain
Membuat desain atau rancangan basis data terdistribusi agar pelaksanaan pembuatan SBDT menjadi lebih mudah. Hal yang nantinya akan dirancang berupa :
a. Perancangan Proses (DAD)
b. Perancangan Basis Data (Diagram ER) c. Perancangan Sistem
4. Tahap Implementasi
Tahapan ini penulis menuangkan semua proses yang dirancang ke dalam pembuatan program.
5. Tahap Pengujian / Testing
Dalam tahapan ini sistem yang telah selesai dibangun, diuji aplikasinya apakah sudah sesuai dengan rancangan-rancangan sebelumnya yang diterapkan. Mengadakan pengujian terhadap program atau sistem basis data terdistribusi yang telah selesai dibuat apakah sudah layak atau belum.
1.6 SISTEMATIKA PENULISAN
BAB I Pendahuluan
Bab ini berisi tentang latar belakang, rumusan masalah, batasan masalah, tujuan penelitian, manfaat penelitian, metodologi, dan sistematika penulisan.
BAB II Dasar Teori
Bab ini berisi tentang teori-teori yang berhubungan dengan pembuatan Tugas Akhir ini, dimana teori-teori ini sebagai landasan atau dasar dalam penulisan.
BAB III Analisis dan Perancangan Sistem
Bab ini berisi tentang analisa atas permasalahan yang dihadapi dan desain yang akan digunakan dalam membangun sistem.
BAB IV Implementasi
Dalam bab ini penulis menuangkan hasil analisa dan perancangan ke dalam program.
BAB V Kesimpulan dan Saran
2.1 DEFINISI SISTEM BASIS DATA TERDISTRIBUSI
Basis Data Terdistribusi (BDT) adalah sekumpulan basis data yang
saling terhubung secara logis dan secara fisik terdistribusi pada berbagai
tempat melalui jaringan komputer [McFadden,1994]. Sistem Basis Data
Terdistribusi (SBDT) menggunakan software yang mengelola Basis Data
Terdistribusi dan menyediakan mekanisme agar distribusi tersebut
transparan di hadapan user. Sistem Basis Data Terdistriusi dihubungkan oleh
sebuah jaringan komputer untuk memungkinkan antar lokasi dapat saling
berbagi data dan informasi yang diambil dari data pada satu basis data.
Sistem basis data terdistribusi terdiri dari himpunan basis data yang
datanya disimpan dalam beberapa komputer, di mana masing-masing dapat
mengakses dan mengeksekusi transaksi data dari sebuah lokasi atau beberapa
lokasi. Lokasi-lokasi tersebut harus dapat saling bekerja sama, berbagi data
dan informasi, sehingga seorang pemakai dapat mengakses data dari lokasi di
mana saja seolah-olah semua datanya disimpan pada lokasi pemakai tersebut.
Gambaran SDBT menurut (Ozsu,1999) secara sederhana dapat
dilihat pada gambar 2.1 . Masing-masing lokasi yang berbeda memiliki media
penyimpanan sendiri dan untuk berkomunikasi, dari masing-masing tersebut
terhubung dengan jaringan.
Gambar 2.1. Lingkungan Sistem Basis Data Terdistribusi
Pendistribusian basis data dimaksudkan untuk meningkatkan kinerja
sistem dengan cara membagi beban secara seimbang pada komputer-komputer
yang digunakan dan mampu menjaga ketersediaan data dengan adanya
duplikasi basis data pada beberapa komputer.
Beberapa ciri yang mendasari SBDT adalah :
2.1.1 Data disimpan pada sejumlah tempat. Setiap tempat secara logik terdiri
dari processor tunggal
2.1.2 Processor pada tempat yang berbeda tersebut dihubungkan dengan
jaringan komputer
2.1.3 SBDT bukan sekumpulan file yang berada pada berbagai tempat tetapi
2.1.4 Setiap tempat mempunyai kemampuan untuk secara mandiri memproses
permintaan user yang membutuhkan akses ke data di tempat tersebut,
dan juga mampu untuk memproses data yang tersimpan di tempat lain.
2.2 ARSITEKTUR SISTEM BASIS DATA TERDISTRIBUSI
Definisi arsitektur adalah struktur dari sistem. Arsitektur yang
didefinisikan dalam sistem basis data terdistribusi adalah komponen dari
struktur, Fungsi setiap komponen dalam struktur, hubungan dan interaksi antar
komponen dalam struktur.
2.2.1 Model-model Arsitektur untuk Sistem Manajemen Basis Data Terdisribusi
Dilihat dari sisi basis data, banyak basis data yang diletakkan
bersama-sama dan digunakan oleh banyak Sistem Manajemen Basis Data
(SMBD) maka digunakan klasifikasi yang memandang sistem dari tiga
hal yaitu : otonomi sistem lokal, distribusi, dan heterogenitas.
a. Otonomi, merujuk pada kontrol distribusi.
Mengindikasikan tingkat individual sistem manajemen basis data
dapat beroperasi, misal kemampuan komponen sistem untuk dapat
bertukar informasi, melakukan transaksi, dan kemampuan
memodifikasi komponen yang lain.
a.1 Integrasi ketat
Image tunggal dari keseluruhan basis data tersedia untuk
semua user yang ingin berbagi informasi yang terdapat
pada banyak basis data. User hanya melihat data secara logical
tersimpan pada satu basis data pada satu tempat.
a.2 Semi otonom
Sistem basis data terdistribusi dapat beroperasi secara
independen tetapi akan bekerja secara bersama untuk
membuat lokal dapat dipakai bersama-sama.
a.3 Isolasi
Satu sistem memiliki satu sistem basis data terdistribusi dan
tidak dapat berkomunikasi dengan sistem basis data
terdistribusi yang lain.
b. Distribusi, merupakan kebalikan dari otonomi, distribusi
merujuk pada data. Dua alternatif yang ditawarkan :
b.1 Distribusi client/server
Berkonsentrasi pada tugas server dan client. Server
berkewajiban mengatur data, sedangkan client memusatkan
perhatian pada penyediaan lingkungan aplikasi termasuk
di dalamnya user interface.
b.2 Distribusi peer-to-peer (full distribusi).
Tidak ada perbedaan antara mesin client dan mesin server.
terdistribusi utuh dan dapat berkomunikasi dengan mesin
yang lain untuk mengeksekusi.
c. Heterogenitas
Heterogen bisa terjadi pada hardware atau pada sebagian
protokol jaringan atau perbedaan pengelola data. Terjadi karena
adanya berbagai form dalam sisterm distribusi, juga
mengakibatkan berbagai variasi manajemen data.
2.2.2 Arsitektur Sistem Manajemen Basis Data Terdistribusi
Tiga pendekatan alternatif yang digunakan untuk memisahkan
fungsionalitas melalui proses yang berkaitan dengan SMDB yang
berbeda, arsitektur SMDB terdistribusi menjadi tiga macam yaitu :
Client Server Sistem, Middleware Sistem, dan Collaborating Sistem.
1. Sistem berbasis client-server memiliki satu atau lebih klien proses
dan satu atau lebih server proses. Klien proses dapat mengirimkan
sebuah kueri ke beberapa server proses. Klien bertanggung
jawab terhadap layanan antar muka dan server bertanggung
jawab untuk mengatur data dan mengeksekusi transaksi
(Ramakhrisnan, R. dan Gehrke, J. 2003), secara sederhana arsitektur
Gambar 2.2. Referensi Arsitektur Client-Server
Arsitektur berbasis client-server sangat populer karena beberapa
alasan :
a. Sederhana dalam implementasi karena adanya pemisahan fungsi
dan pemusatan server.
b. Mesin server yang mahal menjadi tidak mubazir karena
klien mesin yang murah dapat mengoptimalkan kerja server.
c. User lebih familiar menjalankan antar muka grafis pada
mesin klien, daripada pada mesin server.
Yang masih perlu dipelajari adalah menyimpan sementara (cache)
pada sisi klien untuk mengurangi kepadatan jalur jaringan,
meskipun harus tetap memperhatikan status data.
2. Collaborating System
Arsitektur client-server tidak dapat mengirimkan sebuah
kueri tunggal untuk dikerjakan oleh beberapa server, hal ini
disebabkan klien proses harus dapat memecah sebuah kueri
lokasi dan kemudian menggabungkan potongan jawaban ke
subkueri yang lain. Hal ini mengakibatkan klien proses
mengerjakan pekerjaan yang sangat kompleks sehingga tidak
dapat dibedakan dengan server proses.
Kesulitan di atas diatasi dengan collaborating server
system yang memungkinkan untuk memiliki beberapa server
basis data dan setiap server proses dapat menjalankan transaksi
menggunakan data lokal kemudian secara bersama-sama
mengeksekusi transaksi yang melibatkan banyak server.
Ketika sebuah server menerima kueri yang membutuhkan
akses ke data pada lain server, maka server akan membangkitkan
subkueri yang sesuai untuk dieksekusi oleh server yang lain dan
kemudian mengambil hasil kueri tersebut untuk digunakan
sebagai data agar dapat menghasilkan hasil akhir yang diminta
kueri awal. Yang harus diperhatikan adalah proses pemecahan
kueri menjadi sub kueri harus mempertimbangkan biaya
komunikasi jaringan.
3. Middleware System
Arsitektur middleware memungkinkan kueri tunggal untuk
dikerjakan oleh banyak server, tetapi tidak perlu semua server basis
Ide ini muncul karena hanya ada satu server basis data yang
dapat mengatur kueri dan transaksi pada banyak server, tetapi server
yang lain hanya dapat menangani kueri lokal dan transaksi lokal.
Pada arsitektur ini ada server khusus yang memiliki software untuk
mengkoordinasikan eksekusi kueri dan transaksi untuk beberapa
server basis data lainnya. Software ini disebut middleware. Pada sisi
middleware akan dapat melakukan eksekusi join dan operator relasi
lain yang diperoleh dari server lain, tetapi server ini tidak mengatur
data sendiri.
2.3 DESAIN SISTEM BASIS DATA TERDISTRIBUSI
Dalam perencanaan dan pembuatan sistem basis data terdistribusi
terdapat tiga cara yaitu replikasi, fragmentasi, dan alokasi. Meskipun proses
yang digunakan oleh ketiga cara ini untuk mendistribusikan data berbeda,
tetapi tujuannya sama yaitu :
1. Referensi lokalitas
2. Meningkatkan kehandalan dan ketersediaan data
3. Meningkatkan unjuk kerja
4. Keseimbangan kapasitas penyimpanan dan biaya
5. Biaya Komunikasi Minimal
Perbedaannya terletak pada proses pendistribusiannya. Replikasi merupakan
penduplikasian atau pengkopian basis data di dua atau labih lokasi server
sudah terpecah menjadi beberapa bagian dimana masing-masing basis data
yang tersimpan di tempat yang berbeda-beda [H.F. Korth dan Silberscatz.
Ambraham, 1986]. Ada dua strategi dasar fragmentasi yaitu fragmentasi
vertikal dan fragmentasi horizontal yang secara lengkap akan dibahasi pada
sub bab berikutnya. Sedangkan alokasi adalah penempatan fragmen data di
suatu tempat.
2.3.1 Fragmentasi
Salah satu cara untuk mendistribusikan basis data adalah
dengan metode fragmentasi. Pada sistem basis data terdistribusi relasi
diletakkan pada beberapa lokasi basis data server. Alasan yang
menyebabkan data dalam suatu tabel dibagi menjadi fragmen data
untuk didistribusikan adalah :
a. Penggunaan. Dalam realitas, data yang sering digunakan
bukanlah data dalam seluruh tabel, tetapi hanyalah sebagian
data atau sering disebut view.
b. Efisiensi. Data disimpan di lokasi yang paling dekat dengan
pengguna yang sering mengakses. Sehingga data yang tidak
sering dibutuhkan oleh lokasi tertentu tidak disimpan di lokasi
yang bersangkutan.
c. Paralel. Karena data yang didistribusikan berupa fragmen data,
maka transaksi yang berupa kueri tunggal dapat dipecah
sehingga transaksi dapat dilakukan secara bersamaan
(concurrent).
d. Keamanan. Data yang tidak dibutuhkan oleh aplikasi lokal
tidak akan disimpan dalam lokasi tersebut, sehingga user yang
tidak memiliki hak untuk mengakses tidak akan bisa
mengakses data yang lain.
Fragmen data akan mendukung beberapa hal seperti diatas, tetapi
penggunaan fragmen data juga memiliki beberapa kelemahan, yaitu :
a. Menurunnya unjuk kerja. View yang melibatkan lebih dari satu
fragmen data pada lokasi yang berbeda akan mengalami
penurunan unjuk kerja.
b. Integritas. Pengendalian integritas lebih sulit jika atribut yang
berperan dalam dependensi didistribusikan ke beberapa lokasi.
Fragmentasi tidak dapat dilakukan secara sembarangan. Untuk
memastikan bahwa tidak terdapat perubahan data dalam basis data
selama menjalani proses fragmentasi.
Proses fragmentasi harus memenuhi 3 aturan berikut ini:
a. Completeness
i. Jika sebuah relasi R dibagi menjadi fragmen-fragmen R1 , R2
, ..., Rn maka fragmentasi dikatakan komplit jika dan hanya
jika setiap item data yang dapat ditemukan dalam R dapat
ii. Aturan ini diperlukan untuk memastikan bahwa tidak ada data
yang hilang selama proses fragmentasi.
b. Reconstruction
i. Jika sebuah relasi R dibagi menjadi fragmen-fragmen R1 , R2
, ..., Rn maka fragmentasi dikatakan rekonstruksi jika dan
hanya jika R dapat dibentuk dari fragmen-fragmen Ri.
ii. Dengan kata lain, bahwa dimungkinkan untuk membentuk
sebuah relasi R yang terbentuk dari fragmen-fragmen yang ada.
iii. Aturan ini diperlukan untuk memastikan bahwa
ketergantungan secara fungsi (functional dependencies)
terpenuhi.
c. Disjointness
i. Jika sebuah relasi R dibagi menjadi fragmen-fragmen R1 , R2
,..., Rn dan data item di berada di dalam fragmen Rj maka
fragmentasi dikatakan disjoint jika dan hanya jika data item di
tidak berada di dalam fragmen lain Rk dimana k ≠ j.
ii. Dengan kata lain, jika suatu item data sudah muncul dalam
sebuah fragmen, maka item data tersebut tidak boleh muncul
lagi di fragmen yang lain.
iii. Fragmentasi secara vertikal adalah perkecualian dalam aturan
ini, karena atribut-atribut dari primary key harus diulang untuk
dapat melakukan rekonstruksi. Aturan ini diperlukan untuk
1. Fragmentasi Vertikal
Fragmentasi vertikal dari table R adalah proses untuk
mendapatkan fragmen R1, R2,…, Rn sedemikian rupa sehingga
setiap fragmen memuat himpunan bagian dari atribut-atribut R dan
kunci primer. (Ozsu, 1999).
Tujuan utama dari fragmentasi vertikal adalah membagi
sebuah tabel ke dalam tabel-tabel yang lebih kecil sedemikian rupa
sehingga aplikasi user hanya berjalan pada satu tabel. Dengan
demikian meminimalkan waktu eksekusi aplikasi yang berjalan
dalam fragmen-fragmen tersebut. (Ozsu,1999).
Fragmentasi ini lebih sulit daripada fragmentasi horizontal,
karena lebih banyak alternatif hasil yang dapat dibuat dari
fragmentasi vertikal ini. Jika sebuah relasi memiliki m atribut
bukan kunci primer, maka fragmen yang mungkin adalah B(m),
dalam urutan kebenaran dari Bell Number. Untuk nilai yang
besarnya m, maka B(m) ≈ mm. ; sebagai contoh, untuk m = 100,
B(m) ≈115,000, untuk m = 15, B(m) ≈ 109, untuk m = 30, B(m) ≈
1023. (Ozsu, 1999).
Terdapat dua pendekatan untuk memperoleh penyelesaian
terbaik dari fragmentasi vertikal yaitu :
a. Pendekatan Kelompok (Grouping)
Dimulai dengan menempatkan setiap atribut ke dalam sebuah
dengan beberapa fragmen sampai kriteria yang diinginkan
terpenuhi.
b. Pendekatan Pemecahan (Splitting)
Dimulai dengan sebuah tabel dan memutuskan manfaat dari
pembagian yang berlandaskan pada jalannya aplikasi yang
mengakses atribut-atribut.
Kebutuhan informasi dalam fragmentasi vertikal adalah
informasi yang berhubungan dengan aplikasi.
a. Attribute Affinities adalah ukuran yang mengindikasikan
bagaimana relasi antar atribut.
b. Attribute Usage Value apabila diberikan himpunan kueri Q =
{q1, q2, …, qq} yang akan dijalankan pada tabel R[A1, A2, …,
An], maka attribute usage value (use) adalah :
Use(qi,Aj) = {1 jika atribut Aj diakses oleh kueri qi
0 jika sebaliknya}
Dalam skripsi ini hanya akan dibahas mengenai fragmentasi
yang menggunakan pendekatan pemecahan (splitting).
1.2 Tahap-Tahap Proses Fragmentasi Vertikal
Sebagai gambaran untuk kemudahan dan kejelasan dalam
tahap-tahap fragmentasi vertikal akan diberikan contoh kasus. Bila
Tabel 2.1. Tabel PROJ
Dari tabel tersebut akan dilakukan fragmentasi vertikal.
Misalkan terdapat kueri yang dijalankan terhadap tabel PROJ
adalah sebagai berikut :
q1 : SELECT Budget FROM PROJ WHERE Pno = Value
q2 : SELECT Pname,Budget FROM PROJ
q3 : SELECT Pname FROM PROJ WHERE Loc = Value
q4 : SELECT SUM(Budget) FROM PROJ WHERE Loc = Value
Tahap 1 : Menentukan bagaimana akses kueri (q1) pada
setiap atribut (Aj)
Dalam tahap ini akan dibuat matriks use(qi,Aj), matriks tersebut
sering disebut Muse, pada baris ke q1 dari kolom A1, isikan
angka1 atau 0 :
a. 1 : jika kueri q1 mengakses atribut A1
b. 0 : jika kueri q1 tidak mengakses atribut A1
Dari empat kueri yang dijalankan pada table PROJ akan didapat
Muse sebagai berikut : andaikan A1= Pno, A2= Pname, A3=
Muse
Tahap 2 : Menentukan frekuensi akses query qi pada setiap
lokasi Lk.
Tahap ini akan dibuat sebuah matrik baru yang menggambarkan
berapakali setiap lokasi mengakses kueri-kueri yang ada, matrik
ini sering disebut Macc. Dalam kasus ini diandaikan terdapat
tiga lokasi yang mengakses, setiap kueri (acci(qi)) di setiap
lokasinya adalah sebagai berikut :
L1 L2 L3
q1 15 20 10
q2 5 0 0
q3 25 25 25
q4 3 0 0
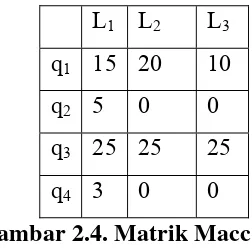
Gambar 2.4. Matrik Macc
Tahap 3 : Menentukan seberapa dekat hubungan antar atribut
Matrik Affinitas atau sering disebut Maff ini didapat dari Muse
dari relasi R(A1,A2,…,An) dengan sekumpulan aplikasi Q =
adalah ukuran frekuensi aplikasi terakses yang telah dijabarkan
dan dimodifikasi untuk mencantumkan frekuensi di lokasi
berbeda.
Hasil dari penghitungan adalah matrik n x n, setiap
elemen dimana setiap ukuran dijabarkan ke atas. Kita
menyebutnya matrik attribute affinity (Maff). Dalam tahap ini
berlaku juga sifat simetris, (Ai,Aj) = (Aj,Ai).
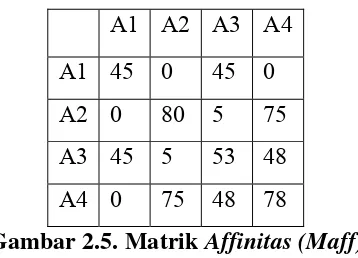
Gambar 2.5. Matrik Affinitas (Maff)
Dari persamaan di atas dicari ukuran persamaan antara
atribut A1 dan A3 sebagai berikut :
Tugas yang paling mendasar dalam mendesain perhitungan
fragmentasi vertikal adalah menemukan beberapa sarana
pengelompokan atribut dari sebuah hubungan berdasar pada
atribut affinity nilai dalam AA. Bond Energy Algorithm (BEA)
untuk mendapatkan matrik pengelompokan (Mcluster)
melakukan tiga langkah :
a. Initialization. Meletakkan dan memperbaiki salah satu kolom
dari AA secara adak ke dalam CA. kolom 1 dipilih dalam
algoritma.
b. Iteration. Ambil tiap n yang tersisa dari kolom n-i, dimana i
adalah jumlah kolom-kolom yang telah diletakkan di CA dan
meletakkan CA ke dalam partisi i+1 yang tersisa dalam
matrik CA. Pilih peletakan yang memberikan nilai yang
paling besar kepada penghitungan persamaan global
tergambar di atas. Lanjutkan langkah ini sampai tidak ada
lagi kolom tersisa untuk ditempati.
c. Row Ordering. Sekali pengaturan kolom ditentukan
penempatan dari baris harus juga diubah sehingga posisi
relatif mereka cocok dengan posisi relatif kolom.
cont digunakan untuk mendefinisikan kontribusi dari
atribut untuk penempatan setiap atributnya. Didefinisikan
dengan rumus :
cont(Ai,Ak,Aj) = 2bond(Ai,Ak)+2bond(Ak,Aj)-2bond(Ai,Aj)
Berdasar langkah initialization, kita mengkopi kolom1
dan 2 matrik AA ke matrik CA dan memulai dengan kolom 3
(contoh : atribut A3). Ada tiga tempat alternatif dimana
kolom 3 dapat ditempatkan : di kiri kolom 1, menghasilkan
urutan (3-1-2) di antara kolom 1 dan 2 menghasilkan (1-3-2) dan
di sebelah kanan kolom 2 menghasilkan (1-2-3). Untuk
menghitung kontribusi dari susunan terakhir kita harus
menghitung cont(A2,A3,A4) dari pada cont(A1,A2,A3). Lebih jauh
lagi dalam konteks ini A4 mengacu pada indeks posisi dalam
matrik CA yang kosong (gbr) tidak pada kolom atribut A4 dari
matrik AA.
Perhitungan kontribusi dari susunan (0-3-1) adalah
sebagai berikut :
cont(A0,A3,A1) = 2bond(A0,A3)+2bond(A3,A1
)-2bond(A0,A1)
dimana kita ketahui nilai bond :
bond(A0,A3) = bond(A0,A1) = 0
bond(A3,A1) = ((45*45)+(5*0)+(53*45)+(3*0)) = 4410
cont(A0,A3,A1) = ((2*0)+(2*4410)-(2*0)) = 8820
Perhitungan kontribusi dari susunan (1-3-2) :
cont(A1,A3,A2) = 2bond(A1,A3)+2bond(A3,A2)-2bond(A1,A2)
Kontribusi dari susunan (1-3-2) adalah yang
terbesar, kita memilih untuk meletakkan A3 di sebelah kanan A1
(Gambar 2.6b.). Selanjutnya menyisipkan kolom 4.
Kontribusi susunan (0-4-1) adalah sebagai berikut :
cont(A0,A4,A1) = 2bond(A0,A4)+2bond(A1,A4)-2bond(A1,A0)
Perhitungan kontribusi susunan (1-4-3) adalah sebagai berikut :
cont(A1,A4,A3) = 2bond(A1,A4)+2bond(A3,A4)-2bond(A1,A3)
dimana kita ketahui nilai bond :
bond(A3,A4) = ((45*0)+(75*5)+(3*53)+(78*3)) = 768
bond(A1,A3) = bond(A3,A1) = 4410
dapat diperoleh nilai cont :
cont(A1,A4,A3) = ((2*135)+(2*768)-(2*4410)) = -7014
Perhitungan dari susunan (3-4-2) adalah sebagai berikut :
cont(A3,A4,A2) = 2bond(A3,A4)+2bond(A2,A4)-2bond(A2,A3)
dimana kita ketahui nilai bond :
bond(A3,A4) = ((45*0)+(75*5)+(3*53)+(78*3)) = 768
bond(A2,A4) = ((0*0)+(75*80)+(3*5)+(78*75)) = 11865
bond(A2,A3) = bond(A3,A2) = 890
dapat diperoleh nilai cont :
cont(A3,A4,A2) = ((2*768)+(2*11865)-(2*890)) = 23486
Perhitungan kontribusi dari susunan (2-4-5) adalah sebagai
berikut
cont(A2,A4,A5) = 2bond(A2,A4)+2bond(A5,A4)-2bond(A2,A5)
dimana kita ketahui nilai bond :
bond(A2,A4) = bond(A4,A2) = 11865
bond(A5,A4) = 0
bond(A2,A5) = 0
dapat diperoleh nilai cont :
cont(A2,A4,A5) = ((2*0)+(2*11865)-(2*0)) = 23730
Dari perhitungan kontribusi di atas (2-4-5) memberikan nilai
susunan yang sama seperti kolom dan hasilnya dapat dilihat
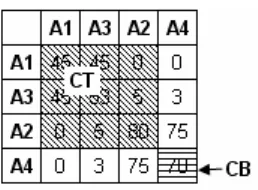
Tahap 5 : Menentukan Pemisahan Tabel dengan Mengacu pada Matrik Cluster
Tujuan dari aktifitas pemisahan adalah untuk menemukan
pasangan atribut yang diakses atau pada sebagian besar
pasangan aplikasi tertentu. Adapun langkah-langkah yang
a. Mencari Himpunan Atribut yang Diakses oleh aplikasi qi.
AQ(qi) = {Aj|use (qi,Aj) =1}
Dari contoh matrik use di atas akan dihasilkan atribut untuk
setiap aplikasi qi sebagai berikut :
q1= {A1,A3}, q2= {A2,A3}, q3= {A2,A4}, q4= {A3,A4}
b. Mencari Jumlah total frekuensi akses untuk setiap aplikasi qi
pada semua lokasi. Dari matrik acc akan didapat total acc
sebagai berikut :
q1 = 45, q2 = 5, q3 = 75, q4= 3
c. Mencari nilai terbesar partisi dengan menggunakan
algoritma partisi. Matrik cluster akan dibagi menjadi 4
dengan 3 macam cara yaitu :
Gambar 2.7. Lokasi pemisahan ke-1
Gambar 2.9. Lokasi pemisahan ke-3 Kemudian mencari TQ, BQ, dan OQ yaitu :
TQ : Aplikasi qi dimana himpunan atribut yang diakses oleh
apliaksi qi merupakan himpunan bagian dari TA.
TQ = {qi|AQ(qi) ⊆ TA}
BQ : Aplikasi qi dimana himpunan atribut yang diakses oleh
apliaksi qi merupakan himpunan bagian dari BA.
BQ = {qi|AQ(qi) ⊆ BA}
OQ : Aplikasi qi selain TQ dan BQ
OQ = Q - {TQ ∪ BQ}
Dari 3 lokasi pemisahan di atas (gambar 2.7; 2.8; 2.9 ) akan
didapat TQ, BQ, dan OQ sebagai berikut :
Untuk lokasi pemisahan ke-1 :
TQ : {q1,q2}; BQ : 0 ; OQ : {q3,q4}
Untuk lokasi pemisahan ke-2 :
TQ : {q1}; BQ : {q3} ; OQ : {q2,q4}
Untuk lokasi pemisahan ke-3 :
d. Hitung jumlah akses total atribut setiap aplikasi dengan
mencari : CTQ, CBQ, dan COQ. CTQ adalah jumlah akses
total untuk aplikasi qi dari himpunan TQ, CBQ adalah
jumlah akses total untuk aplikasi qi dari himpunan BQ, dan
COQ adalah jumlah akses total untuk aplikasi qi dari
himpunan OQ. Dimana :
Dari 3 lokasi pemisahan diatas didapat CTQ, CBQ, dan COQ
sebagai berikut :
Untuk lokasi pemisahan ke-1 :
CTQ = 45+5 = 50; CBQ = 0; COQ = 128-50 = 78
Untuk lokasi pemisahan ke-2 :
CTQ = 45; CBQ = 75; COQ = 128-120 = 8
Untuk lokasi pemisahan ke-3 :
CTQ = 0; CBQ = 5+75+3 = 83; COQ = 128-83 = 50
e. Untuk setiap matrik pemisahan diatas cari nilai matrik
Z = CTQ * CBQ – COQ2
Kemudian nilai z yang terbesar akan menjadi dasar
penentuan atribut untuk pembagian matrik secara vertikal.
Dari kasus diatas didapat nilai z sebagai berikut :
i. Untuk lokasi pemisahan ke-1 : 50 * 0 – (78)2 = -6084
ii. Untuk lokasi pemisahan ke-2 : 45 * 75 – (8)2 = 3311
iii. Untuk lokasi pemisahan ke-3 : 0 * 83 – (50)2 = -2500
Karena lokasi pemisahan ke-2 menghasilkan nilai z yang
terbesar maka fragmentasi yang terbentuk adalah :
PROJ1 = {A1,A3}, dan PROJ2 = {A1,A2,A4}.
Setelah didapat fragmen-fragmen data, langkah berikutnya
adalah menguji kebenaran fragmentasi, yaitu apakah
memenuhi syarat completeness, reconstruction, dan disjoint.
a. Completeness
Hasil fragmentasi diatas sudah memenuhi syarat
completeness, karena tidak ada data yang hilang selama
proses fragmentasi.
b. Recontruction
Syarat reconstruction sudah dipenuhi, karena dari hasil
fragmen-fragmen data di atas dapat dibentuk kembali sebuah
c. Disjoint
Langkah pemecahan tabel di atas sudah memenuhi syarat
disjoint, karena tidak ada atribut yang berada pada dua
fragmen, kecuali kunci primer.
2. Fragmentasi Horizontal
Dua syarat informasi untuk fragmentasi horizontal, yaitu:
a. Database information
Database information terdiri dari dua macam informasi yaitu
relasi dan kardinalitas. Untuk lebih jelasnya dapat dilihat pada
gambar 2.10.
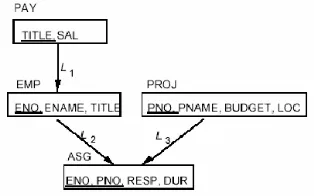
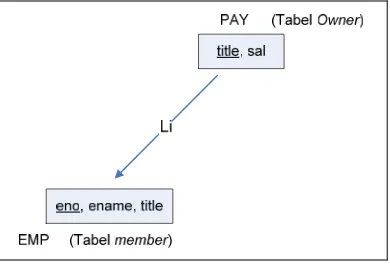
Gambar 2.10. Ekspresi Relasi Antar Tabel Menggunakan Link (Li)
Dengan memberikan link L1 pada gambar, fungsi owner dan
member bernilai :
Owner (L1) = PAY
b. Application information
Informasi kualitatif yang paling mendasar dari sebuah aplikasi
adalah predicate yang digunakan dalam kueri. Dari predikat
dapat dibentuk :
i. Simple Predicates
Untuk relasi R[A1,A2,A3,…,An], maka simple predicate P,
adalah Pj : Ai θ Value. Dimana Ai adalah atribut, θ∈{<, >,
≤, ≥, =, ≠} adalah operasi pembanding, dan Value adalah
nilai domain. Untuk relasi R didefinisikan Pr =
{P1,P2,P3,…,Pm} (Ozsu, 1999).
Contoh :
p1 : Pname = “ Maintenance”
p2 : Budget ≤ 200000
Maka domain dari atribut Pname adalah “Maintenance”,
dan domain dari atribut Budget adalah 200000.
ii. Minterm Predicates
Kombinasi atau kumpulan dari simple predicates akan
membentuk minterm predicates. Diberikan R dan Pr =
{P1,P2,P3,…,Pm}, didefinisikan M= {m1,m2,m3,...,mn}
sebagai :
M = {mij|mij = P*ik}, l ≤ k ≤ m , l ≤ j ≤ z
Pik∈Pri
Contoh :
m1 : PNAME="Maintenance" ^ BUDGET ≤ 200000
m2 : NOT(PNAME="Maintenance") ^ BUDGET ≤
200000
m3 : PNAME= "Maintenance" ^ NOT(BUDGET ≤
200000)
m4 : NOT(PNAME="Maintenance") ^ NOT(BUDGET ≤
200000)
Dalam hal ini, m1 dan m4 adalah contradictory dengan
implikasi l dan dapat di eliminasi dari M [Otzu, 1999].
Informasi kuantitatif dari aplikasi adalah :
i. Selektivitas Minterm (Minterm selectivity)
Jumlah tuple dari relasi yang akan diakses oleh user
berdasarkan minterm predicate.
Contoh : dari minterm pada contoh diatas maka sel(m2 ) =
0, sedangkan sel(m2 ) = 2.
ii. Frekuensi Akses (Access frequency)
Frekuensi aplikasi mengakses mengakses data. Jika Q =
{q1,q2,q3,…,qz} adalah himpunan kueri user, maka Acc(qi)
2.A Primary Horizontal Fragmentation (PHF)
1. PHF adalah sebuah fragmentasi dari tabel R yang
difragmen menjadi tabel-tabel {R1,R2,, Rw} menurut kueri Fj,
dimana kueri Fj adalah minterm predicates (mi) (Ozsu, 1999).
2. Algoritma PHF :
Input : Sebuah table R, dan himpunan simple predicates
Pr
Output : Himpunan fragmen R = {R1,R2,…,Rw} yang
memenuhi aturan fragmentasi.
Syarat : Pr harus complete, dan Pr harus minimal.
3. Aturan pada himpunan simple predicates
a) complete
Sebuah himpunan simple predicates Pr dikatakan
complete jika dan hanya jika setiap dua tuple pada
fragmen yang sama mempunyai probabilitas yang
sama untuk diakses oleh setiap transaksi.
Contoh :
Asumsikan bahwa relasi PROJ [PNO, PNAME,
BUDGET, LOC] diakses oleh dua aplikasi :
a. Aplikasi 1 : temukan budget dari setiap project
pada masing-masing lokasi
b. Aplikasi 2 : temukan project dengan budget <
Jika berdasar aplikasi 1 maka didapat :
Pr={LOC=”Montreal”,LOC=”New York”, LOC=
”Paris”}
Tetapi tidak complete untuk aplikasi 2.
Maka Pr dimodifikasi menjadi :
Pr={LOC=”Montreal”,LOC=”New York”, LOC=
”Paris”, BUDGET ≤ 200000, BUDGET >
200000}
Yang memenuhi sifat complete.
b) Minimal
Sebuah simple predicates dikatakan minimal jika
dan hanya jika terdapat paling sedikit ada satu
transaksi yang mengakses akan menghasilkan akses
pada fragmen-fragmen yang berbeda.
Sebagai contoh, jika terdapat dua buah fragmen
yang berbeda fi dan fj maka paling sedikit terdapat
sebuah aplikasi yang dapat mengakses dua fragmen
yang berbeda tersebut.
Contoh :
Pr = {LOC=”Montreal”, LOC=”New York”,
LOC=”Paris”, BUDGET ≤ 200000, BUDGET >
200000}
Namun, jika kita tambahkan simple predikat berikut
ke Pr :
PNAME =”Instrumentation”
maka Pr menjadi tidak minimal.
Contoh Primary Horizontal Fragmentation (PHF)
Sebagai gambaran untuk kemudahan dan kejelasan dalam
tahap-tahap fragmentasi horizontal primer (PHF) akan
diberikan contoh kasus. Bila terdapat tabel PAY dan PROJ
sebagai berikut :
Fragmentasi dari relasi PAY :
Relasi PAY adalah sebagai berikut :
Tabel 2.2. Tabel PAY
Aplikasi akan meminta :
a. Melihat info gaji.
b. Daftar pegawai berada pada dua aplikasi yang berjalan
di dua lokasi
Simple predicates :
p1 : SAL ≤ 30000
p2 : SAL > 30000
Minterm predicates :
m1 : (SAL ≤ 30000)
m2 : NOT(SAL ≤ 30000) = (SAL > 30000)
hasil fragmentasi :
Tabel 2.3(a). Tabel PAY1 Tabel 2.3(b). Tabel PAY2
Fragmentasi dari relasi PROJ
Aplikasi akan meminta :
a. Cari nama dan budget project yang berada pada tiga
lokasi (1)
b. Akses informasi project untuk budget pada satu lokasi
≤ 200000 dan yang lain > 200000 (2)
m1 : (LOC = “Montreal”) ^ (BUDGET ≤ 200000)
m2 : (LOC = “Montreal”) ^ (BUDGET > 200000)
m3 : (LOC = “New York”) ^ (BUDGET ≤ 200000)
m4 : (LOC = “New York”) ^ (BUDGET > 200000)
m5 : (LOC = “Paris”) ^ (BUDGET ≤ 200000)
m6 : (LOC = “Paris”) ^ (BUDGET > 200000)
Hasil Fragmentasi
Tabel 2.4. Tabel Hasil Fragmentasi Horizontal Primer
(PHF)
PROJ1
PROJ2
PROJ3
PROJ4
Uji kebenaran PHF
a. Completeness
Karena Pr' complete dan minimal, maka selection
b. Reconstruction
Jika relasi R dibuat menjadi fragmen FR = {R1,R2,…,Rr}
maka R = ∪∀Ri∈FRRi adalah reconstruction.
c. Disjointness
Minterm predicates untuk setiap fragmen adalah mutually
exclusive.
2.B Derived Horizontal Fragmentation (DHF)
Derived Horizontal Fragmentation dari tabel R
didefinisikan sebagai :
Dengan R adalah tabel member, Si = σ Fi(S),dimana Fi
merupakan formula yang berdasarkan pada Primary
Horizontal Fragmentation Si mana yang didefinisikan, serta w
adalah jumlah maksimun fragmentasi yang akan didefinisikan
pada R.
Derived Horizontal Fragmentation didefinisikan pada link
relasi tabel member menurut pilihan operasi yang spesifik dari
tabel owner [Otzu, 1999]. Ada dua poin yang perlu diingat.
Pertama, link diantara relasi owner dan member terdefinisi
sebagai equi-join. Poin yang kedua menjadi sangat penting
ketika akan dilakukan partisi dari dari sebuah relasi member
juga jika diinginkan hasil fragmentasi yang didefinisikan
hanya pada attribut relasi tabel member. Link yang dimaksud
adalah primary key pada tabel owner kemudian juga menjadi
foreign key pada tabel member. Berikut adalah gambar relasi
tebel owner dan tabel member menurut :
Gambar 2.11 Ekspresi dari relasi tabel owner dan tabel member menggunakan link (Li)
Algoritma DHF :
Input : Tabel member R, fragmen PHF S
={S1,S2,…,Sw} dan atribut penghubung tabel
member R dan tabel owner S.
Output : Himpunan fragmen R ={R1,R2,…,Rw} yang
memenuhi aturan fragmentasi.
Syarat :
a. Pr harus complete
b. Pr harus minimal
Dari contoh fragmen horisontal primer, kita telah mendapatkan
gambar 2.11., kita memiliki tabel owner PAY dan tabel
member EMP.
Contoh 1 Derived Horizontal Fragmentation
Aplikasi : Diasumsikan bahwa user ingin mengelompokkan
data pegawai berdasar gaji yang diterima.
Simple predicates table PAY
p1 : SAL ≤30000
p2 : SAL > 30000
PHF tabel PAY
PAY1 = σSAL ≤ 30000 (PAY)
PAY2 = σSAL > 30000 (PAY)
Derived Fragment table PAY
Hasilnya adalah :
Tabel 2.5. Tabel Hasil Derived Horizontal Fragmentation (DHF)
EMP2
Contoh 2 Derived Horizontal Fragmentation
Aplikasi :
a. Menemukan data pegawai yang bekerja di suatu lokasi.
b. Menampilkan data pegawai yang mengakses proyek
pada lokasi dimana data pegawai di fragmen.
PHF tabel PROJ
PROJ1 :σ(LOC=“Montreal”) ^ (BUDGET ≤ 200000)
PROJ
PROJ3 :σ (LOC=“New York”) ^ (BUDGET ≤ 200000)
PROJ
PROJ4 :σ (LOC=“New York“) ^ (BUDGET > 200000)
PROJ
PROJ6 :σ (LOC =“Paris”) ^ (BUDGET > 200000) PROJ
Derived Fragment table ASG berdasar PHF PROJ
Hasilnya adalah :
Tabel 2.6. Tabel Derived Fragment ASG berdasar PHF
PROJ
ASG1
ASG2
ASG3
ASG4
Derived fragmen tabel ASG berdasar derived fragmen
Hasilnya adalah :
Tabel 2.7. Tabel derived fragmen ASG berdasar derived fragmen EMP
ASG1
ASG2
Uji kebenaran PHF
a. Completeness
Karena Pr' complete dan minimal, maka selection
predicates adalah komplit.
b. Reconstruction
Jika relasi R dibuat menjadi fragmen FR = {R1 ,R2 ,…,Rr}
maka R = ∪∀Ri∈FRRi adalah reconstruction.
c. Disjointness
Minterm predicates untuk setiap fragmen adalah mutually
Aturan Pemilihan Derived Fragmentasi
Terkadang sebuah tabel memiliki lebih dari satu tabel
owner (seperti ASG memiliki table owner EMP dan PROJ),
sehingga akan mendapatkan dua derived fragment.
Jika terdapat lebih dari satu derived fragment maka dapat
dipilih salah satu dengan menggunakan kriteria :
a. Fragmentasi akan menghasilkan sifat join yang lebih
baik.
b. Fragmentasi digunakan pada lebih banyak aplikasi.
2. Alokasi
Alokasi dalam sistem terdistribusi dapat diartikan dengan
peletakan tiap-tiap fragmen pada suatu lokasi dengan distribusi
yang optimal (Ozsu, 1999). Ketika kita sudah memfragmen data,
masih ada yang perlu dipertimbangkan, yaitu alokasi fragmen data
tersebut. Dalam menentukan alokasi, Fragmen(F), lokasi data(S),
dan aplikasi(Q) yang ingin ditentukan adalah distribusi paling
optimal fragmen F pada lokasi S.
Ukuran optimal yang digunakan adalah :
a. Biaya Paling Minimal
Yang dimaksud biaya disini adalah biaya penyimpanan
biaya meng-update fragmen pada semua lokasi penyimpanan,
dan biaya komunikasi data.
b. Unjuk Kerja
Meminimalkan waktu respond dan memaksimalkan keluaran
dari sistem.
2.4 QUERY-PROCESSOR TERDISTRIBUSI 2.4.1 Definisi Query-Processor Terdistribusi
Query-processor adalah modul dari sistem manajemen basis data
tredistribusi yang dipakai untuk melayani kueri data (Ozsu,1999).
Query-processor dipakai supaya pengguna tidak perlu memakai bahasa
prosedural (aljabar) yang rumit. Dalam hal ini dipakai bahasa
non-prosedural (kalkulus) seperti SQL (Ozsu,1999). Bahasa non-non-prosedural
akan menyembunyikan detail low-level dari organisasi fisik data. Sehingga
kueri yang kompleks dapat dilakukan dalam bentuk ekspresi bahasa yang
ringkas dan sederhana. Query-processor juga melakukan optimasi kueri.
2.4.2 Peran Utama Query-Processor Terdistribusi
Peran utama dari query-processor terdistribusi adalah melakukan
pemetaan (mapping) dari kueri high-level (relasi kalkulus dalam sebuah
basis data terdistribusi) menjadi sederetan operasi basis data lokal
Berikut adalah gambar diagram pemetaan untuk memperjelas definisi di
atas.
Gambar 2.12. Diagram Pemetaan Fungsi-fungsi dari pemetaan (mapping) :
a. Kueri kalkulus harus disusun balik menjadi sederetan operasi relasional
yang disebut kueri aljabar.
b. Data yang diakses oleh kueri harus dilokalisasi sehingga operasi
terhadap relasi dilakukan pada data lokal atau fragmen data.
c. Kueri aljabar terhadap fragmen-fragmen harusdiperluas dengan operasi
komunikasi dan dioptimisasi untuk meminimalkan fungsi biaya. Fungsi
biaya menyangkut sumber daya komputasi seperti disk I/O, CPU, dan
jaringan komunikasi.
Dengan kata lain, peran utama dari query-processor relasional
adalah melakukan transformasi kueri high-level (relasi kalkulus) menjadi
kueri low-level (relasi aljabar) yang ekuivalen. Kueri low-level akan
Dua hal penting dalam transformasi :
1. Ketepatan (correctness). Yaitu, kueri low-level memiliki semantik
yang sama dengan kueri aslinya.
2. Efisiensi (strategi eksekusi yang efisien). Sebuah kueri kalkulus
relasional dapat ditransformasikan ke dalam beberapa bentuk kueri
aljabar yang ekuivalen dan benar. Memilih salah satu kueri aljabar
yang paling efisien akan tergantung pada pemilihan strategi eksekusi
yang meminimalkan sumber daya komputasi.
2.4.3 Contoh Kasus Query-Processor Terdistribusi 1 Kueri :
”Cari nama-nama pegawai yang menjabat manajer proyek”
Ekspresi kueri kalkulus relasional, memakai sintaks SQL : SELECT ENAME
FROM EMP, ASG
WHERE EMP.ENO = ASG.ENO
AND RESP = "Manager"
Dua macam kueri aljabar relasional yang ekuivalen, hasil transformasi dari
kueri di atas :
Dalam sistem terdistribusi, aljabar relasional masih belum cukup untuk
mengeksekusi kueri. Diperlukan operasi pertukaran data antar lokasi agar
2.4.4 Contoh Kasus Contoh Kasus Query-Processor Terdistribusi 2
Contoh ini menggambarkan begitu pentingnya pemilihan dan
komunikasi antar lokasi bagi sebuah kueri aljabar relasional terhadap basis
data yang sudah terfragmen.
Kueri dari contoh 1 :
Diasumsikan relasi antara EMP dan ASG terfragmentasi horisontal
sebagai berikut :
Fragmen-fragmen ASG1, ASG2, EMP1, dan EMP2 disimpan pada
lokasi-lokasi 1,2,3,dan 4 dan hasilnya diharapkan berada pada lokasi-lokasi 5.
Gambar 2.13. Lokasi Fragmen-fragmen ASG dan EMP
Strategi B : Memusatkan semua data pada result-site sebelum memproses kueri.
Konsumsi sumber daya dengan model simple-cost (Ozsu, 1999) Asumsi :
• Tuple-acces : tupacc adalah 1 unit (Ozsu, 1999)
• Tuple-transfer : tuptrans adalah 10 unit (Ozsu, 1999)
• Relasi EMP mempunyai 400 tuple
• Relasi ASG mempunyai 1000 tuple
• Ada 20 manajer dalam relasi ASG
• Data terdistribusi secara uniform pada semua lokasi
• Relasi ASG secara lokal terikat pada atribut RESP. Terdapat akses
langsung ke tuple-tuple ASG yang berdasarkan nilai atribut RESP.
• Relasi EMP secara lokal terikat pada atribut ENO. Terdapat akses
langsung ke tuple-tuple EMP yang berdasarkan nilai atribut ENO.
Tabel 2.8. Tabel total biaya dari strategi A
Tabel 2.9. Tabel total biaya dari strategi B
1. Tra nsfe r EMP ke lo ka si 5 p e rlu 400*tup tra ns 4000 2. tra nsfe r ASG ke lo ka si 5 p e rlu 1000*tup tra ns 10000 3. Pro d uc e EMP d e ng a n jo in ASG d a n EMP p e rlu
(10+10)*tup a c c *2 1000
4. jo in EMP d a n ASG p e rlu 400*20*tup a c c 8000
To ta l Bia ya 23000
Dalam strategi B kita menganggap bahwa metode akses ke relasi EMP dan
ASG yang berdasarkan kepada atribut RESP dan ENO telah hilang karena
transfer data, ini merupakan asumsi yang biasa dalam praktek.
Strategi A lebih baik dengan faktor 50. Dengan demikian merupakan
strategi yang lebih baik untuk distribusi data di antara lokasi-lokasi.
2.4.5 Optimasi Kueri
Tujuan dari optimasi kueri adalah meminimalkan :
Biaya I/O+biaya CPU + biaya komunikasi
Karena untuk memproses kueri membutuhkan aljabar relasional, maka
kompleksitas operasi aljabar relasional akan mempengaruhi waktu
Tabel 2.10. Tabel kompleksitas operasi aljabar relasional
Beberapa sifat dari pemroses kueri akan digunakan sebagai dasar untuk
optimisasi yaitu :
1. Tipe Optimisasi
2. Waktu Optimisasi
3. Statistik
4. Keputusan Lokasi
5. Topologi Jaringan
6. Fragmen Replikasi
7. Penggunaan Semijoin
Permasalahan yang akan dibahas pada bab ini adalah mengenai analisis
sistem dan pembahasan perancangan sistem yang akan dibuat. Tahap analisis
merupakan tahap menganalisa kebutuhan sistem dan kebutuhan software yang digunakan sistem untuk kemudian didokumentasikan dan di review bersama
kostumer apakah telah sesuai dengan kebutuhan atau belum sesuai.
3.1 ANALISIS MASALAH
Dalam sebuah perpustakaan, pengelolaan data buku memiliki peranan
yang sangat penting karena dengan pengelolaan data yang baik dapat
meningkatkan efektifitas kinerja dan layanan dari suatu perpustakaan.
Seiring dengan berjalannya waktu, penyimpanan data pada perpustakaan
semakin besar dan memerlukan proses yang sangat kompleks bahkan pada
beberapa perpustakaan mengunakan sistem jaringan untuk pengelolaan basis
data perpustakaan karena lokasi yang terpisah. Tingginya pengaksesan dari
masing-masing lokasi mempengaruhi layanan dan kinerja dari perpustakaan
karena hanya memiliki satu server.
Pada perpustakaan USD yang lokasinya terpisah, layanan pada suatu
lokasi tidak selalu menggunakan seluruh data yang ada. Data yang dibutuhkan
oleh perpustakaan Mrican dan Paingan tidaklah sama. Dengan menggunakan
satu server, akses basis data menjadi lambat karena pada saat perpustakaan Mrican atau Paingan mengakses basis data, data-data yang seharusnya tidak
perlu diakses oleh salah satu lokasi akan diakses secara bersamaan. Salah satu
alternatif penyelesaian masalah untuk pengaksesan data yang lambat pada saat
proses penelusuran buku dilakukan adalah implementasi Sistem Basis Data
Terdistribusi (SBDT). Sistem basis data terdistribusi merupakan cara untuk
mendistribusikan basis data yang ber-relasi secara logis pada beberapa lokasi
secara terpisah dengan menggunakan jaringan komputer.
Sistem basis data terdistribusi pada perpustakaan Universitas Sanata
Dharma ini akan diterapkan menggunakan metode fragmentasi horizontal.
Fragmentasi horizontal cocok diterapkan pada sistem ini karena basis data
perpustakaan mempunyai jumlah record yang banyak dan mempunyai kueri
yang sering digunakan berdasarkan record tertentu.
3.2 ANALISIS KELAYAKAN
Sistem Basis data Terdistribusi pada Pepustakaan layak untuk
di-implementasikan karena :
1. Efisien
Sistem ini hanya menyimpan data yang paling sering digunakan sehingga
proses akses ke basis data dapat dilakukan lebih cepat karena data yang
tidak sering dipakai pada lokasi perpustakaan tertentu tidak disimpan
(tidak adanya penumpukan data ).
2. Kehandalan
Sistem ini menempatkan fragmen - fragmen data yang diperlukan oleh