TESIS – KI142502
PREDIKSI RELIABILITAS PERANGKAT LUNAK
MENGGUNAKAN SUPPORT VECTOR REGRESSION
DAN MODEL MINING
VIKA FITRATUNNANY INSANITTAQWA 5114201044
DOSEN PEMBIMBING
Dr. Ir. Siti Rochimah, MT.
PROGRAM MAGISTER
BIDANG KEAHLIAN REKAYASA PERANGKAT LUNAK JURUSAN TEKNIK INFORMATIKA
FAKULTAS TEKNOLOGI INFORMASI
INSTITUT TEKNOLOGI SEPULUH NOPEMBER SURABAYA
ii
iv
v
Prediksi Reliabilitas Perangkat Lunak Menggunakan Support Vector
Regression dan Model Mining
Nama Mahasiswa : Vika Fitratunnany Insanittaqwa
NRP : 5114 201 044
Pembimbing : Dr. Ir. Siti Rochimah, MT.
ABSTRAK
Reliabilitas perangkat lunak didefinisikan sebagai probabilitas operasi perangkat lunak yang bebas dari kegagalan (failure) dalam sebuah periode waktu tertentu. Pemodelan reliabilitas perangkat lunak ini dapat dilakukan salah satunya dengan memanfaatkan data kegagalan perangkat lunak untuk melakukan prediksi kegagalan di masa datang. Salah satu arsitektur yang dipakai dalam pemodelan ini pada umumnya adalah dengan menggunakan beberapa data terakhir untuk melakukan prediksi. Padahal, kegagalan perangkat lunak dapat saja dipengaruhi oleh data yang terdahulu seperti yang telah dibuktikan pada satu penelitian, yang menggunakan teknik model mining untuk memilih data masukan terdahulu tersebut. Pada penelitian ini, diusulkan penggunaan Binary Particle Swarm Optimization (BPSO) sebagai metode model mining untuk melakukan prediksi reliabilitas perangkat lunak dengan menggunakan Support Vector Regression (SVR). Data yang dipakai atau tidak dipakai masing-masing disimbolkan dengan angka “1” atau “0” dan metode ini diujicobakan pada 6 data dari proyek perangkat lunak yang nyata, yaitu data FC1, FC2, FC3, TBF1, TBF2, dan TBF3. Keakuratan model yang diusulkan dibandingkan dengan prediksi yang tidak menggunakan model mining dengan mengukur nilai Mean Squared Error (MSE) dan Average Relative Prediction Error (AE). Metode SVR-BPSO yang diusulkan terbukti dapat menghasilkan prediksi yang lebih akurat, terutama untuk data FC1, FC2, dan FC3 yang bersifat stabil. Sifat data TBF yang berbeda dengan data FC menunjukkan bahwa data ini tidak cocok digunakan sebagai bahan uji coba metode yang diusulkan karena time-between-failure pada data tidak bergantung pada urutan kegagalan tertentu, seperti yang terlihat pada data TBF1, TBF2, dan TBF3. Pemilihan parameter SVR juga mempengaruhi keakuratan prediksi, dimana hal ini dapat diperbaiki pada penelitian selanjutnya. Secara umum, metode yang diusulkan telah dapat menghasilkan prediksi reliabilitas perangkat lunak dengan baik dan penggunaan model mining terbukti dapat memberikan manfaat yang nyata dalam bidang prediksi reliabilitas perangkat lunak.
vi
vii
Software Reliability Prediction based on Support Vector Regression and
Model Mining
Student Name : Vika Fitratunnany Insanittaqwa
NRP : 5114 201 044
Supervisor : Dr. Ir. Siti Rochimah, MT.
ABSTRACT
Software reliability is defined as the pobability of failure-free software operation in certain period of time. The modelling of software reliability can be done in one way by using software failure data to predict the future failures. One architecture in this modelling is done generally by using the last few consecutive data to predict the future value, where actually the failure of a software can be dependent also to earlier data as showed in one research about the use of model mining to determine which data to use as prediction. In this research, we propose the use of Binary Particle Swarm Optimization (BPSO) as a model mining method to predict the reliability of software by using Support Vector Regression (SVR) as predictor. To determine which data to use in model mining, the data is symbolized with one “1” or “0” in the structure of BPSO particle. The proposed method is tested with 6 real data from real project, which are called FC1, FC2, FC3, TBF1, TBF2, and TBF3. The accuracy of the proposed model is compared with a predictor without model mining by computing the Mean Squared Error (MSE) and Average Relative Prediction Error (AE). The proposed SVR-BPSO method is proved to be able to predict more accurately, especially in FC1, FC2, and FC3 data which are more stable in nature. The use of TBF data sets proved to be inappropriate as it yields poor prediction results in TBF1, TBF2, and TBF3 data, which may have rooted from the differing nature with FC data. The method to choose SVR parameters can also affect the accuracy of prediction, which opens room for improvement in future research. In general, the proposed method is able to predict the reliability of a software and the use of model mining is important in effort to produce more accurate prediction in software failure data.
viii
ix
KATA PENGANTAR
Puji syukur penulis panjatkan kehadirat Allah SWT karena atas rahmat dan hidayah-Nya penulis dapat menyelesaikan menyelesaikan Tesis ini yang berjudul “Prediksi Reliabilitas Perangkat Lunak Menggunakan Support Vector Regression dan Model Mining”.
Tesis ini juga tidak akan terselesaikan tanpa bantuan dari berbagai pihak. Ucapan terima kasih dan penghormatan yang sebesar-besarnya penulis sampaikan kepada:
1. Allah SWT atas segala rahmat dan hidayah-Nya.
2. Kedua orang tua penulis atas doa, dukungan, dan kasih sayang yang tak terhingga. 3. Kedua adik kandung penulis yang selalu dapat memberikan tawa dan semangat. 4. Ibu Dr. Ir. Siti Rochimah, MT. selaku dosen pembimbing yang telah memberikan
bimbingan, arahan, dan motivasi untuk membantu pengerjaan Tesis ini.
5. Bapak Daniel Oranova, S.Kom, MSc. PD.Eng., Ibu Nurul Fajrin Ariyani, S.Kom, M.Sc, dan Ibu Adhatus Sholichah, S.Kom, M.Sc selaku dosen penguji yang telah memberikan saran, arahan, dan koreksi dalam pengerjaan Tesis ini.
6. Bapak dan Ibu dosen Jurusan Teknik Informatika ITS yang telah banyak memberikan ilmu dan bimbingan yang tak ternilai harganya.
7. Seluruh staf dan karyawan Teknik Informatika ITS yang telah banyak memberikan kelancaran administrasi akademik.
8. Rekan-rekan Pascasarjana Teknik Informatika ITS terutama angkatan 2014 atas segala dorongan semangat dan kebersamaan semasa perkuliahan.
9. Pihak-pihak lain yang tidak sempat penulis sebutkan pada lembaran ini.
Penulis berharap Tesis ini dapat memberikan manfaat untuk kedepannya, namun penulis sadar bahwa Tesis ini masih jauh dari sempurna. Penulis mohon maaf sebesar-besarnya apabila terjadi kekurangan pada Tesis ini. Semoga kritik dan saran yang membangun dapat digunakan untuk perbaikan di masa yang akan datang.
Surabaya, Juli 2017
x
[Halaman ini sengaja dikosongkan]
xi
BAB II KAJIAN PUSTAKA DAN DASAR TEORI ... 7
2.1. Prediksi Reliabilitas Perangkat Lunak ...7
2.2. ASRM dan DDSRM ...8
2.3. SISO dan MDISO ...10
2.4. Support Vector Regression ...12
2.5. Binary Particle Swarm Optimization ...16
2.6. LIBSVM...18
2.7. Penelitian Terkait ...18
BAB III METODOLOGI PENELITIAN ... 25
3.1. Studi Literatur ...25
3.2. Perancangan dan Implementasi ...26
3.2.1. Data Kegagalan Perangkat Lunak ... 26
3.2.2. Inisialisasi Parameter BPSO ... 29
3.2.3. Penempatan Posisi Partikel Awal ... 30
3.2.4. Inisialisasi Parameter SVR dan Proses Training SVR ... 31
3.2.5. Evaluasi Peforma ... 32
3.2.6. Kondisi Berhenti ... 32
xii
3.2.8. Pembaruan Kecepatan dan Posisi Partikel ... 33
3.3. Analisis Pengujian...33
3.3.1. Inisialisasi Parameter BPSO ... 34
3.3.2. Parameter Pengujian ... 35
BAB IV UJI COBA DAN EVALUASI... 37
4.1. Evaluasi Hasil Pengujian ...37
4.1.1. Evaluasi Hasil Pengujian pada data FC1 ... 37
4.1.2. Evaluasi Hasil Pengujian pada data FC2 ... 39
4.1.3. Evaluasi Hasil Pengujian pada data FC3 ... 40
4.1.4. Evaluasi Hasil Pengujian pada data TBF1 ... 41
4.1.5. Evaluasi Hasil Pengujian pada data TBF2 ... 42
4.1.6. Evaluasi Hasil Pengujian pada data TBF3 ... 43
4.2. Analisa Hasil Pengujian ...44
4.2.1. Hasil prediksi FC1 ... 45
4.2.2. Hasil prediksi FC2 dan FC3 ... 45
4.2.3. Hasil prediksi TBF1 dan TBF3 ... 46
4.2.4. Hasil prediksi TBF2 ... 47
BAB V PENUTUP... 49
5.1. Kesimpulan ...49
5.2. Saran ...50
DAFTAR PUSTAKA ... 51
LAMPIRAN... 59
xiii
DAFTAR GAMBAR
Gambar 2.1. Penggambaran pada SVR linear (Schölkopf & Smola, 2002) ... 14
Gambar 3.1. Tahapan metodologi penelitian ... 25
Gambar 3.2. Diagram alir proses training SVR dengan model mining pada penelitian ... 26
Gambar 3.3. Struktur sebuah partikel pada BPSO ... 30
Gambar 3.4. Interpretasi posisi pada sebuah partikel BPSO ... 31
Gambar 3.5. Fungsi pemilihan parameter SVR pada Matlab ... 32
Gambar 3.6. Diagram alir skenario pengujian ... 34
Gambar 4.1. Hasil prediksi SVR-BPSO dan SVR untuk Data FC1 ... 38
Gambar 4.2. Hasil prediksi SVR-BPSO dan SVR untuk Data FC2 ... 39
Gambar 4.3. Hasil prediksi SVR-BPSO dan SVR untuk Data FC3 ... 40
Gambar 4.4. Hasil prediksi SVR-BPSO dan SVR untuk Data TBF1 ... 42
Gambar 4.5. Hasil prediksi SVR-BPSO dan SVR untuk Data TBF2 ... 43
xiv
xv
DAFTAR TABEL
Tabel 2.1. Rangkuman Penelitian Terdahulu dengan ANN ... 19
Tabel 2.2. Rangkuman Penelitian Terdahulu dengan SVR ... 23
Tabel 3.1. Data asli FC1 dan data setelah scaling ... 28
Tabel 3.2. Hasil percobaan data FC1 dengan jumlah partikel yang berbeda ... 30
xvi
1
BAB I
PENDAHULUAN
1.1. Latar Belakang
Komputer telah menjadi bagian penting pada aktifitas keseharian manusia. Salah satu komponen komputer adalah perangkat lunak, dimana perangkat lunak ini harus dapat menjalankan fungsinya tanpa terjadi kesalahan ataupun kegagalan. Untuk memastikan hal ini, proses pengujian perangkat lunak perlu dilakukan. Dalam proses ini, kesalahan (fault) ataupun kegagalan (failure) perangkat lunak harus ditemukan agar dapat dilakukan perbaikan. Hal ini bertujuan agar perangkat lunak yang diberikan pada pengguna adalah perangkat lunak yang memiliki tingkat reliabilitas yang tinggi.
Reliabilitas perangkat lunak didefinisikan sebagai probabilitas operasi perangkat lunak yang bebas dari kegagalan dalam sebuah periode waktu yang ditentukan pada lingkungan tertentu (American Institute of Aeronautics and Astronautics, 1993). Pada siklus hidup perangkat lunak, pengukuran reliabilitas perangkat lunak memiliki beberapa manfaat. Salah satu contohnya adalah pada tahap pengujian, dimana pengukuran reliabilitas perangkat lunak dapat digunakan sebagai acuan pengembang untuk memperkirakan seberapa besar sumber daya yang diperlukan untuk melakukan pengujian yang optimal. Dalam dunia penelitian, pemodelan reliabilitas perangkat lunak adalah topik yang aktif dan diminati karena pentingnya peranan pengukuran reliabilitas tersebut.
2
satunya adalah tidak adanya sebuah model universal yang dapat diterapkan pada semua situasi (Goel, 1985). Hal ini disebabkan karena pemodelan SRGM yang didasarkan pada beberapa asumsi yang bergantung pada jenis sistem tertentu.
Untuk mengatasi kelemahan ini, pendekatan DDSRM mulai banyak ditelusuri karena pendekatan ini hanya mengandalkan data kesalahan atau kegagalan perangkat lunak tanpa disertai asumsi yang terlalu ketat. Terdapat banyak metode yang diusulkan, misalnya Bayesian networks, model Autoregressive Integrated Moving Average (ARIMA) untuk time series, dan lain-lain. Diantara metode-metode tersebut, metode Machine Learning, seperti Artificial Neural Network (ANN) dan Support Vector Machine (SVM), merupakan metode yang populer dan banyak dikembangkan dalam penelitian. Penerapan ANN untuk melakukan prediksi reliabilitas perangkat lunak menuai banyak perhatian semenjak dilakukan pertama kali pada tahun 1991 (Karunanithi dkk., 1991) dan telah banyak pengembangan yang dilakukan untuk mendapatkan hasil prediksi yang lebih baik. Namun, metode ini dinilai memiliki beberapa kelemahan, diantaranya adalah sulitnya mendapatkan hasil yang stabil dan ancaman terjadinya over-fitting. Untuk mengatasi hal ini, SVM untuk regresi atau Support Vector Regression (SVR) mulai diterapkan dan mulai mendapatkan perhatian pada tahun 2005 sebagai metode yang dinilai lebih baik daripada ANN (Tian & Noore, 2005c). Beberapa teknik optimasi juga telah diusulkan untuk memperbaiki hasil prediksi SVR, diantaranya Simulated Annealing (SA) (Pai & Hong, 2006), Genetic Algorithm (GA) (Ho & Hsieh, 2009), metode hibrida GA-SA (Jin, 2011), Particle Swarm Optimization (PSO) (Qin, 2011), dan Improved Estimation of Distribution Algorithm (Jin & Jin, 2014).
3
memodelkan hubungan diantara data kegagalan perangkat lunak, dimana data masukan yang digunakan umumnya berupa data lagged time series (𝑥𝑡−1,𝑥𝑡−2,…,𝑥𝑡−𝑧) dengan menggunakan z data sebagai masukan. Hal ini menyebabkan MDISO dianggap memiliki nilai yang lebih daripada model SISO biasa karena pada kenyataannya, reliabilitas perangkat lunak dipengaruhi oleh kondisi perangkat lunak di waktu yang lalu.
Jumlah masukan pada arsitektur MDISO dapat ditentukan dengan proses
“trial-and-error” atau dari pengalaman sebelumnya. Pada awalnya, penelitian MDISO menggunakan asumsi bahwa kegagalan perangkat lunak hanya bergantung pada data kegagalan yang paling akhir saja. Namun, kemudian ditemukan bahwa kegagalan perangkat lunak dapat juga dipengaruhi oleh data yang terdahulu karena korelasi pada model time series dapat terjadi lebih rumit. Hal ini dibuktikan dengan penelitian dengan menggunakan metode model mining untuk menentukan data yang dipakai untuk melakukan prediksi (Yang dkk., 2010), dimana pada penelitian tersebut terbukti bahwa metode model mining dapat digunakan untuk mencari hubungan time lags yang terdahulu untuk mendapatkan hasil prediksi yang lebih akurat daripada data masukan yang mengambil data paling akhir saja.
Meskipun hal ini dinilai sebagai temuan yang baru, tidak banyak penelitian yang dilakukan untuk mengembangkan temuan ini lebih jauh. Padahal, terdapat kesempatan untuk menyelidiki apakah metode lain dapat diterapkan untuk melakukan model mining pada data kegagalan perangkat lunak. Binary Particle Swarm Optimization (BPSO) adalah algoritma pengembangan PSO yang dikhususkan untuk masalah diskrit. PSO itu sendiri adalah algoritma pencarian yang optimal dalam ruang solusi yang bersifat heuristik, dimana proses pencarian tersebut terinspirasi dari kumpulan partikel yang bergerak dengan arah masing-masing. Pada proposal ini, diusulkan sebuah penelitian mengenai prediksi reliabilitas perangkat lunak dengan menggunakan SVR dengan model mining yang dilakukan dengan algoritma BPSO. Metode BPSO dipilih karena kemampuannya dalam mencari solusi diskrit yang dapat diterapkan pada masalah model mining, dimana data yang dipakai atau tidak dipakai masing-masing dapat
4
dimaksudkan untuk menemukan time lags terbaik yang dipakai untuk prediksi reliabilitas perangkat lunak.
Pada akhir penelitian ini, hasil yang ditemukan diharapkan dapat menunjukkan bahwa BPSO dapat digunakan sebagai metode model mining untuk melakukan prediksi reliabilitas perangkat lunak dengan menggunakan SVR. Penggunaan BPSO sebagai metode model mining juga diharapkan mampu menghasilkan hasil prediksi yang lebih akurat daripada prediksi yang dilakukan hanya dengan SVR saja.
1.2. Perumusan Masalah
Rumusan masalah pada penelitian ini adalah sebagai berikut:
1. Bagaimana BPSO dapat digunakan sebagai metode model mining pada data kegagalan perangkat lunak?
2. Berapa nilai keakuratan prediksi reliabilitas perangkat lunak dengan menggunakan SVR dan BPSO sebagai model mining?
3. Apakah penerapan BPSO sebagai model mining dapat menghasilkan nilai prediksi yang lebih akurat daripada prediksi yang dilakukan tanpa menggunakan model mining?
1.3. Tujuan
Penelitian ini bertujuan untuk menyelidiki apakah BPSO dapat digunakan dalam proses model mining dalam prediksi reliabilitas perangkat lunak dan bagaimana cara menerapkan metode tersebut. Selain itu, penelitian ini juga bertujuan untuk menyelidiki apakah model mining dengan menggunakan BPSO menghasilkan prediksi yang lebih akurat daripada prediksi tanpa menggunakan model mining.
1.4. Manfaat
5
pengujian perangkat lunak ataupun pada tahap operasi perangkat lunak. Bagi para akademisi, penelitian ini dapat memberikan manfaat berupa temuan baru dalam bidang DDSRM dengan arsitektur MDISO yang menggunakan model mining untuk mendapatkan data masukan.
1.5. Kontribusi Penelitian
Penelitian ini memberikan kontribusi dalam bidang prediksi reliabilitas perangkat lunak dengan pendekatan DDSRM dengan arsitektur MDISO dengan model mining. Lebih khusus lagi, penelitian ini memberikan kontribusi dengan penerapan algoritma BPSO sebagai metode baru dalam melakukan model mining dalam prediksi reliabilitas perangkat lunak dengan menggunakan SVR.
1.6. Batasan Masalah
Batasan masalah pada penelitian ini adalah sebagai berikut.
1. Arsitektur model reliabilitas perangkat lunak yang digunakan pada penelitian ini menggunakan MDISO dengan jumlah maksimal sliding window (jumlah data masukan) yang ditentukan sebelumnya. Penelitian mengenai pencarian jumlah sliding window yang optimal tidak akan diselidiki pada penelitian ini.
6
7
BAB II
KAJIAN PUSTAKA DAN DASAR TEORI
2.1. Prediksi Reliabilitas Perangkat Lunak
Menurut American National Standard Institute (ANSI), definisi reliabilitas perangkat lunak adalah probabilitas operasi perangkat lunak yang bebas dari kegagalan (failure) dalam sebuah periode waktu yang ditentukan pada lingkungan tertentu (American Institute of Aeronautics and Astronautics, 1993). Karena dewasa ini perangkat lunak yang ada memiliki ukuran dan kompleksitas yang tinggi, muncul kebutuhan bagi pengembang perangkat lunak untuk dapat memprediksikan reliabilitas perangkat lunak. Manfaat dari prediksi ini antara lain adalah untuk menentukan apakah program telah siap dipasarkan pada konsumen dan berapa lama pengujian yang dibutuhkan. Prediksi ini juga berguna untuk menaksir jumlah kegagalan yang mungkin terjadi di lingkungan pengguna setelah program dijalankan. Selain itu, prediksi ini dapat membantu menentukan jumlah bantuan yang dibutuhkan untuk memperbaiki defect setelah perangkat lunak dipasarkan (Wood, 1996).
8
pada pendekatan ini lebih banyak menggunakan teknik soft computing dengan regresi atau analisis time series.
2.2. ASRM dan DDSRM
Kegagalan dalam perangkat lunak dapat terjadi pada proses eksekusinya, baik itu dalam tahap pengujian maupun dalam tahap operasi. Pada tahap pengujian, terdapat waktu yang dibutuhkan untuk mendeteksi dan menghilangkan defect yang menyebabkan kegagalan dan reliabilitas perangkat lunak memiliki trend yang tumbuh sepanjang waktu (growth) (Cai dkk., 2001). Oleh karena itu, pemodelan reliabilitas secara analitis menghasilkan sebuah model yang bernama Software Reliability Growth Model (SRGM). Hal ini juga berkaitan dengan reliabilitas perangkat lunak yang tumbuh hingga waktu release (Karunanithi dkk., 1992c). Dalam literatur, banyak sekali ditemukan penelitian mengenai SRGM sejak diperkenalkan pertama kali pada 1972, dimana terdapat lebih dari 100 model yang telah diusulkan hingga saat ini (Lyu, 2007). Model ini dapat diklasifikasikan
menjadi dua kelompok, yaitu model “time between failures” dan “failure count”.
Asumsi-asumsi yang dipakai dalam pemodelan bermacam-macam. Namun, asumsi yang paling penting adalah sebagai berikut (Amin dkk., 2013).
1. Waktu antara kegagalan yang independen.
2. Perbaikan yang seketika saat kesalahanterdeteksi.
3. Perbaikan kesalahantanpa menghasilkan kesalahanyang baru.
Meskipun SRGM telah menyediakan cara untuk menilai, menaksir dan memprediksikan reliabilitas perangkat lunak, pendekatan ini memiliki beberapa kelemahan. Tidak ada sebuah model yang dapat diterapkan secara efektif pada sistem yang berbeda (Goel, 1985). Hal ini dapat diatasi dengan menggunakan beberapa model sekaligus untuk mendapatkan hasil prediksi yang lebih baik. Namun, proses ini memakan banyak waktu dan membutuhkan tenaga ahli untuk menentukan model yang tepat untuk lingkungan tertentu.
9
ASRM adalah penggunaan non-parametric statistics (Robinson & Dietrich, 1987) (Barghout & Abdel-Ghaly, 1998) dan Bayesian Networks (Bai dkk., 2005) (Wiper dkk., 2012). Namun, metode-metode tersebut tidak dapat menjawab masalah tentang applicability. Terdapat pula prediksi dengan menggunakan analisa time series, terutama dengan menggunakan model ARIMA. Namun, metode ini masih berada pada tahap awal dan masih memiliki beberapa batasan (Amin dkk., 2013), salah satunya adalah ARIMA membutuhkan asumsi tersendiri pada data yang digunakan untuk membangun model yang benar.
Metode lainnya yang populer adalah dengan menggunakan teknik machine learning, seperti ANN dan SVM, untuk menjawab masalah applicability SRGM. Definisi permasalahan yang dipakai pada awalnya adalah sebagai berikut: jika terdapat data waktu eksekusi kumulatif (𝑥1,𝑥2,⋯,𝑥𝑘) ∈ 𝑋𝑘(𝑡), data fault yang
diamati pada waktu tersebut (𝑦1,𝑦2,⋯,𝑦𝑘)∈ 𝑌𝑘(𝑡) hingga saat ini (waktu t), dan ∆ adalah waktu eksekusi kumulatif dari 𝑥𝑘+1 hingga 𝑥𝑘+, maka prediksikan jumlah fault kumulatif 𝑦𝑘+(𝑡+∆) pada waktu mendatang 𝑘+,𝑥𝑘+(𝑡+∆).
Definisi ini kemudian berkembang sepanjang perkembangan penelitian dengan penggunaan data masukan dan keluaran yang berbeda. Dalam hal jangkauan prediksi, batasan prediksi h harus ditentukan untuk menentukan seberapa jauh prediksi dilakukan. Untuk h = 1, prediksinya dinamakan “next-step-prediction”
(atau “short-term prediction”). Untuk =𝑛(≥ 2), prediksinya dinamakan “ n-step-ahead prediction” (atau “long-term prediction”) (Karunanithi dkk., 1992c). Dalam literatur lain, selain dua macam prediksi tersebut (yang disebut juga
“variable-term prediction”), terdapat pula “end-point prediction” yang hanya memprediksikan kapan sistem menjadi stabil (Sitte, 1999).
Penerapan ANN untuk melakukan prediksi reliabilitas perangkat lunak menuai banyak perhatian semenjak dilakukan pertama kali pada tahun 1991 (Karunanithi dkk., 1991), dimana ditemukan bahwa Feed Forward ANN dapat melakukan prediksi lebih akurat dan memiliki tingkat applicability yang lebih baik daripada SRGM. Penelitian ini kemudian dilanjutkan dengan tiga penelitian
lanjutan yang menunjukkan bahwa Jordan’s NN dan Elman’s NN juga dapat
10
untuk melakukan prediksi reliabilitas (Adnan & Yaacob, 1994). Metode NN juga telah dibandingkan dengan metode parametric recalibration dan ditemukan bahwa NN lebih unggul (Sitte, 1999). Non-parametric NN kemudian dibandingkan dengan metode regresi pada penelitian selanjutnya (Aljahdali dkk., 2001). Recurrent NN dibuktikan memiliki akurasi lebih baik daripada Feed Forward NN (Ho dkk., 2003). Beberapa teknik optimasi juga telah diusulkan untuk hasil prediksi yang lebih baik, yaitu Pseudoinverse Learning Algorithm (Guo & Lyu, 2004), GA (Tian & Noore, 2005) (Tian & Noore, 2005b), Fuzzy Min-Max Algorithm (Zemouri & Zerhouni, 2012), dan Imperialist Competitive Algorithm (Noekhah dkk., 2013). Beberapa model ensemble juga telah diusulkan dengan mengkombinasikan beberapa NN untuk mendapatkan hasil yang lebih akurat (Kiran & Ravi, 2008) (Zheng, 2009) (Li dkk., 2013). Meskipun ANN dinilai dapat melakukan pemodelan non-linear dengan mempelajari hubungan yang kompleks antara masukan dan keluaran tanpa harus memiliki pengetahuan tentang kondisi sistem, metode ini dinilai memiliki beberapa kelemahan. Misalnya, metode ini sulit mendapatkan hasil yang stabil dan memiliki ancaman terjadinya over-fitting.
Untuk mengatasi hal ini, SVM untuk regresi atau SVR mulai diterapkan dan mulai mendapatkan perhatian pada tahun 2005 (Tian & Noore, 2005c). Beberapa teknik optimasi juga telah diusulkan untuk memperbaiki hasil prediksi SVR, diantaranya Simulated Annealing (SA) (Pai & Hong, 2006), Genetic Algorithm (GA) (Ho & Hsieh, 2009), metode hibrida GA-SA (Jin, 2011), Particle Swarm Optimization (PSO) (Qin, 2011), dan Improved Estimation of Distribution Algorithm (Jin & Jin, 2014).
2.3. SISO dan MDISO
11
hubungan waktu eksekusi kumulatif sebagai masukan dan jumlah akumulasi kegagalan perangkat lunak sebagai keluaran. MDISO, di lain pihak, mencoba memodelkan hubungan diantara data kegagalan perangkat lunak, dimana data masukan yang digunakan umumnya berupa data lagged time series. Hal ini menyebabkan MDISO dianggap memiliki nilai yang lebih daripada model SISO biasa karena pada kenyataannya, reliabilitas perangkat lunak dipengaruhi oleh kondisi perangkat lunak tersebut di waktu yang lalu. Sehingga, data masukan pengukuran reliabilitas perangkat lunak juga harus mempertimbangkan data kegagalan di waktu yang lalu.
Pada awalnya, penelitian dengan arsitektur MDISO mendefinisikan bahwa kegagalan 𝑥𝑖 memiliki korelasi dengan beberapa kegagalan z yang paling akhir, yaitu (𝑥𝑖−1,𝑥𝑖−2,…,𝑥𝑖−𝑧), dimana z adalah dimensi vektor masukan (jumlah node
masukan pada ANN atau SVM) yang terkadang disebut juga sebagai ukuran
“sliding window”, “fixed-length of moving window”, atau “order of
autoregressive terms”. Penelitian terdahulu menggunakan beberapa nilai z dengan
proses “trial-and-error” atau dari pengalaman sebelumnya yang berbeda-beda. Dua penelitian (Hu dkk., 2006) (Ho & Hsieh, 2009) menggunakan nilai z sebanyak 3. Tiga penelitian (Aljahdali dkk., 2001) (Benaddy dkk., 2011) (Lo, 2010) menggunakan nilai z sebanyak 4. Sitte (Sitte, 1999) menggunakan beberapa nilai z, yaitu 2, 4, 8, dan 16. Cai, dkk. (Cai dkk., 2001) menggunakan nilai 10, 20, 30, 40, dan 50. Li, dkk. (Li dkk., 2013) menggunakan nilai 2, 3, 4, dan 5. Yang dan Li (Yang & Li, 2007) menggunakan nilai 3, 4, dan 17. Jin dan Jin (Jin & Jin, 2014) menggunakan nilai 3 dan 4. Penelitian lain mencari jumlah z yang terbaik dengan algoritma yang berbeda-beda (Tian & Noore, 2005) (Tian & Noore, 2005b).
12
Hal ini kemudian dibuktikan dengan penelitian lainnya bahwa kegagalan dapat memiliki korelasi dengan data yang terdahulu. Penelitian Yang dkk (Yang dkk., 2010) menunjukkan bahwa masukan pada MDISO belum tentu harus menggunakan time lags yang paling akhir. Data time lags yang digunakan pada model MDISO juga dapat diambil dari data terdahulu. Penentuan time lags terbaik yang dapat digunakan dalam proses prediksi dapat dilakukan dengan proses yang disebut model mining. Penemuan tersebut juga menunjukkan bahwa model mining dapat menghasilkan prediksi yang lebih akurat daripada data masukan paling akhir saja. Berdasarkan hasil penelitian ini, sebuah kegagalan𝑦𝑖, misalnya, dapat berkorelasi dengan 𝑥𝑖−8, 𝑥𝑖−6, dan 𝑥𝑖−2. Sehingga, pemodelan MDISO yang lebih
umum dapat dituliskan seperti Persamaan (1).
𝑦𝑖 = 𝐹(𝑥𝑖−𝑚1,𝑥𝑖−𝑚2,…,𝑥𝑖−𝑚𝑝) (1) Pada Persamaan (1), 𝑦𝑖 adalah sebuah observasi proses kegagalan perangkat lunak; (𝑥𝑖−𝑚1,𝑥𝑖−𝑚2,…,𝑥𝑖−𝑚𝑝) adalah time lag yang diambil pada time series; dan 𝐹(∙) adalah model time series. Untuk melakukan sebuah prediksi, perlu ditentukan pula time lag yang akan digunakan pada 𝐹(∙) untuk menentukan nilai p dan m. Dengan model ini, time lag yang digunakan pada prediksi belum tentu berasal dari data yang terakhir dan dapat berasal dari data yang terdahulu. Nilai z dan time lags yang terbaik dalam sebuah model dapat ditentukan dengan bantuan teknik kecerdasan komputasional.
2.4. Support Vector Regression
SVM pertama kali diusulkan berdasarkan teori pembelajaran statistika (Vapnik, 1995). Teknik ini memiliki prinsip untuk meminimalkan resiko structural untuk meminimalkan batas atas error pada generalisasi daripada meminimalkan error proses training seperti ANN. Dengan prinsip ini, SVM dapat mencapai struktur jaringan yang optimal dan memiliki generalisasi yang lebih baik daripada ANN. SVM pada awalnya dikembangkan untuk menyelesaikan
13
menunjukkan peforma yang sangat baikdalam memecahkan masalah regresi (Vapnik dkk., 1997).
SVR dapat menyelesaikan masalah prediksi linear atau non-linear dengan memetakan data masukan x ke high-dimensional feature space F dan menyelesaikannya dengan regresi linear pada feature space. Jika terdapat sebuah set data 𝐺 = {(𝑥𝑖,𝑑𝑖)}𝑖𝑛, dimana 𝑥𝑖 adalah vector masukan, 𝑑𝑖 adalah vector keluaran (target), dan n adalah jumlah total pola data, SVR bertujuan untuk mengidentifikasi fungsi regresi untuk secara akurat memprediksi keluaran. Fungsi regresi linear pada feature space ditunjukkan pada Persamaan (2).
𝑓 𝑥 =𝜔𝜙 𝑥 +𝑏 (2)
Pada Persamaan (2), 𝜔 dan 𝑏 adalah koefisien, dan 𝜙 𝑥 adalah fungsi pemetaan feature space. Tujuan ummnya adalah untuk menemukan fungsi dengan
tingkat “flatness” tertinggi. Nilai dari koefisien 𝜔 dan 𝑏 dapat ditentukan dengan meinimalkan fungsi resiko regularisasi seperti pada Persamaan (3).
𝑅 = 1
Pada Persamaan (3), C adalah konstanta regularisasi yang menunjukkan trade-off antara kompleksitas struktur model 1
2 𝜔
2 dan error empiris 1
14
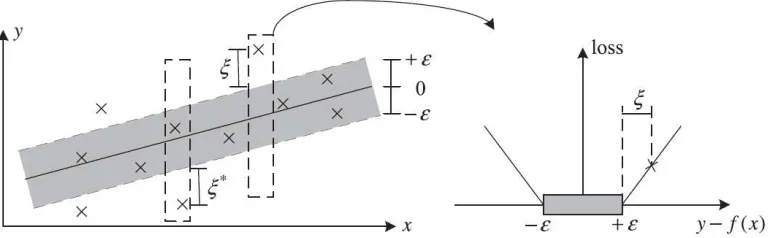
Gambar 2.1. Penggambaran pada SVR linear (Schölkopf & Smola, 2002)
Pada Gambar 2.1, terdapat dua variabel “slack” 𝜉 dan 𝜉∗ yang menggambarkan deviasi positif dan negatif. Variabel ini memiliki posisi non-zero di luar area [-]. Trade-off antara kompleksitas model (flatness) dan titik-titik yang berada di luar tabung (variabel slack) ditentukan dengan meminimalkan Persamaan (4).
𝑦𝑖 − 𝑓(𝑥𝑖) − 𝜀= 𝜉𝜉∗ if if 𝑓 𝑥𝑦𝑖 − 𝑓 𝑥𝑖 >𝜀,
𝑖 − 𝑦𝑖 >𝜀. (4)
Dengan demikian, fungsi resiko regularisasi dapat ditulis sebagai Persamaan (5).
15 Persamaan Kernel Gaussian dapat ditulisan seperti Persamaan (8).
𝐾 𝑥𝑖,𝑥𝑗 = exp −
(𝑥𝑖−𝑥𝑗)2
2𝜎2 (8)
Untuk membangun model SVR yang efisien, beberapa parameter perlu dispesifikasikan. Beberapa parameter tersebut adalah sebagai berikut.
1) Fungsi kernel
2) Parameter regularisasi C 3) Bandwidth fungsi kernel (2)
4) Ukuran tabung fungsi -insensitive loss
Pemilihan nilai parameter yang tidak tepat akan berujung pada “over
-fitting” atau “under-fitting”. Umumnya, peneliti masih menggunakan prosedur standar dengan trial-and-error, membangun dengan parameter yang berbeda, lalu mengujinya dengan validasi untuk mendapatkan parameter yang optimal. Salah satu cara yang mudah namun efektif untuk menentukan nilai parameter SVR
16
Dalam penggunaan teknik SVR, proses “scaling” dan normalisasi juga dapat dilakukan pada data. Proses ini dinilai dapat mengurangi waktu konvergensi training (Liu dkk., 1995) dan mempermudah perbandingan banyak data dengan jangkauan nilai yang berbeda-beda (Sitte, 1999). Dalam literatur, terdapat beberapa cara untuk melakukan scaling atau normalisasi pada data. Salah satu cara yang paling banyak digunakan adalah dengan melakukan scaling secara absolut, yaitu dengan merubah nilai pada data dengan jangkauan [0.0,1.0] dengan persamaan tertentu. Selain cara absolut, terdapat pula scaling yang merubah nilai pada data menjadi nilai baru dengan jangkauan [0.1, 0.9] dengan Persamaan (9) sebenarnya, 𝑖𝑚𝑎𝑥 adalah nilai paling besar pada data, dan 𝑖𝑚𝑖𝑛 adalah nilai paling kecil pada data. Scaling dengan jangkauan ini dinilai dapat menghasilkan prediksi lebih baik daripada hasil yang didapatkan dari scaling secara absolut (Karunanithi dkk., 1992c).
2.5. Binary Particle Swarm Optimization
BPSO adalah pengembangan dari algoritma Particle Swarm Optimization (PSO). PSO pertama kali diperkenalkan oleh Kennedy dan Eberhart sebagai sebuah algoritma optimasi yang terinspirasi dari perilaku kumpulan organisme
atau “swarm” (Kennedy & Eberhart, 1995). Pada algoritma PSO, “swarm” sering digambarkan sebagai kumpulan partikel yang masing-masing memiliki atribut berupa posisi dan kecepatan yang digunakan untuk mencari solusi yang paling optimal secara iteratif. Posisi partikel merepresentasikan solusi dan kecepatan partikel menggambarkan seberapa cepat partikel bergerak pada ruang solusi. Pada akhir algoritma, partikel dengan posisi terbaik akan diambil sebagai solusi permasalahan.
17
kemudian akan dievaluasi dengan fungsi fitness tertentu, dimana posisi yang terbaik akan direkam dan disajikan sebagai solusi akhir.
Ruang solusi algoritma PSO dapat diasumsikan sebagai ruang dengan dimensional d. Partikel ke-i dapat direpresentasikan dengan vektor posisi 𝑃𝑖 = (𝑝𝑖1,𝑝𝑖2,…,𝑝𝑖𝑑) dan kecepatannya dengan 𝑉𝑖 = (𝑣𝑖1,𝑣𝑖2,…,𝑣𝑖𝑑). Tiap kali
partikel bergerak, posisi terbaik yang pernah dikunjungi oleh partikel tersebut disimpan pada vektor 𝑃𝑖𝑏𝑒𝑠𝑡 = (𝑝𝑖1,𝑝𝑖2,…,𝑝𝑖𝑑) yang disebut juga “personal best”.
Posisi terbaik dari semua partikel juga disimpan pada sebuah vektor 𝑃𝑔𝑏𝑒𝑠𝑡 = (𝑝𝑔1,𝑝𝑔2,…,𝑝𝑔𝑑) yang disebut juga “global best”. Kecepatan dan posisi partikel
akan selalu diperbarui hingga kondisi berhenti tercapai.
BPSO adalah sebuah algoritma yang dikembangkan dari PSO untuk mengatasi masalah diskrit (Kennedy & Eberhart, 1997). Partikel dapat
menentukan masalah “ya” atau “tidak”, “benar” atau “salah”, “1” atau “0”, dan
sebagainya. Perbedaan BPSO dengan PSO terletak pada definisi kecepatannya, dimana kecepatan partikel pada BPSO didefinisikan sebagai probabilitas
berubahnya nilai “1” atau “0”. Dengan demikian, kecepatan harus dibatasi dengan
jangkauan [0,1] dan pemetaan harus dilakukan pada nilai kontinu agar muat pada jangkauan tersebut. Normalisasi dapat diimplementasikan dengan fungsi sigmoid pada Persamaan (10).
𝑣𝑖𝑗′ 𝑡 =𝑠𝑖𝑔 𝑣𝑖𝑗(𝑡) = 1
1 +𝑒−𝑣𝑖𝑗(𝑡) (10)
Kecepatan dapat diperbaruhi dengan Persamaan (11).
𝑣𝑖 𝑡+ 1 = 𝑤𝑣𝑖 𝑡 +𝑐1𝜑1(𝑝𝑖 − 𝑥𝑖 𝑡 ) +𝑐2𝜑2(𝑝𝑔− 𝑥𝑖 𝑡 ) (11)
Pada Persamaan (11), 𝑐1 dan 𝑐2 adalah konstanta positif, 𝜑1 dan 𝜑2 adalah
dua variabel acak dengan distribusi uniform antara 0 dan 1, 𝑤 adalah inersia weight yang menunjukkan efek vektor kecepatan yang lama pada vektor yang baru. Terdapat batas atas 𝑉𝑚𝑎𝑥 untuk kecepatan partikel untuk mencegah partikel bergerak terlalu cepat. Nilai ini biasanya diinisialisasi sebagai fungsi jangkauan masalah. Misalnya, jika jangkauan untuk semua 𝑥𝑖𝑗 adalah [-50,50], maka 𝑉𝑚𝑎𝑥 adalah proporsional dengan 50.
18
𝑥𝑖𝑗(𝑡+ 1) = 0, 1, 𝑖𝑓𝑟𝑖𝑗 < 𝑠𝑖𝑔(𝑣𝑜𝑡𝑒𝑟𝑤𝑖𝑠𝑒𝑖𝑗(𝑡+ 1)) (12)
Pada Persamaan (12), 𝑟𝑖𝑗 adalah angka acak uniform dengan jangkauan [0,1].
2.6. LIBSVM
LIBSVM adalah pustaka untuk implementasi SVM yang telah dikembangkan sejak tahun 2000 (Chang & Lin, 2011). Tujuan pengembangan LIBSVM adalah untuk membantu praktisi untuk mengaplikasikan SVM secara mudah. Penggunaan LIBSVM pada umumnya membutuhkan dua langkah.
Pertama, “training” pada data dapat dilakukan untuk menghasilkan sebuah model yang dapat melakukan klasifikasi atau regresi. Kedua, menggunakan model tersebut untuk memprediksikan data uji dalam proses “testing”. LIBSVM memiliki beberapa modul yang dapat digunakan untuk berbagai aplikasi SVR, diantaranya adalah C-Support Vector Classification (C-SVC), v-SVC, estimasi distribusi (one-class SVM), -SVR, dan v-SVR.
C-SVC merupakan implementasi dari SVM untuk masalah klasifikasi. Hal ini berbeda dengan v-SVC yang memiliki parameter v, yaitu sebuah parameter baru yang diperkenalkan pada tahun 2000 (Schölkopf dkk., 2000). One-class SVM adalah implementasi dari algoritma yang diusulkan tentang distribusi dalam masalah high-dimension (Schölkopf dkk., 2001). -SVR dan v-SVR digunakan untuk masalah regresi, dimana v-SVR menggunakan parameter v untuk mengontrol jumlah support vector.
2.7. Penelitian Terkait
19
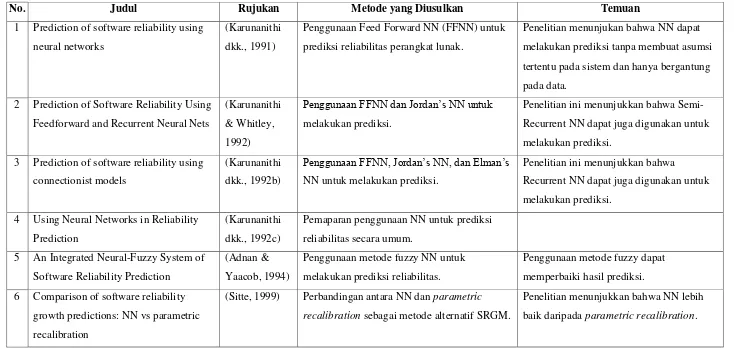
Tabel 2.1. Rangkuman Penelitian Terdahulu dengan ANN
No. Judul Rujukan Metode yang Diusulkan Temuan
1 Prediction of software reliability using
neural networks
(Karunanithi
dkk., 1991)
Penggunaan Feed Forward NN (FFNN) untuk
prediksi reliabilitas perangkat lunak.
Penelitian menunjukan bahwa NN dapat
melakukan prediksi tanpa membuat asumsi
tertentu pada sistem dan hanya bergantung
pada data.
2 Prediction of Software Reliability Using
Feedforward and Recurrent Neural Nets
(Karunanithi
& Whitley,
1992)
Penggunaan FFNN dan Jordan’s NN untuk
melakukan prediksi.
Penelitian ini menunjukkan bahwa
Semi-Recurrent NN dapat juga digunakan untuk
melakukan prediksi.
3 Prediction of software reliability using
connectionist models
(Karunanithi
dkk., 1992b)
Penggunaan FFNN, Jordan’s NN, dan Elman’s
NN untuk melakukan prediksi.
Penelitian ini menunjukkan bahwa
Recurrent NN dapat juga digunakan untuk
melakukan prediksi.
4 Using Neural Networks in Reliability
Prediction
(Karunanithi
dkk., 1992c)
Pemaparan penggunaan NN untuk prediksi
reliabilitas secara umum.
5 An Integrated Neural-Fuzzy System of
Software Reliability Prediction
(Adnan &
Yaacob, 1994)
Penggunaan metode fuzzy NN untuk
melakukan prediksi reliabilitas.
Penggunaan metode fuzzy dapat
memperbaiki hasil prediksi.
6 Comparison of software reliability
growth predictions: NN vs parametric
recalibration
(Sitte, 1999) Perbandingan antara NN dan parametric
recalibration sebagai metode alternatif SRGM.
Penelitian menunjukkan bahwa NN lebih
20
No. Judul Rujukan Metode yang Diusulkan Temuan
7 Prediction of Software Reliability: A
Comparison between Regression and
NN Non-parametric models
(Aljahdali
dkk., 2001)
Perbandingan antara Non-Parametric NN dan
teknik regresi.
Penelitian menunjukkan bahwa
Non-Parametric NN lebih baik daripada
parametric recalibration.
8 On the neural network approach in
software reliability modeling
(Cai dkk.,
2001)
Pemaparan penggunaan FFNN untuk prediksi
reliabilitas secara umum.
9 A study of connectionist models for
software reliability prediction
(Ho dkk.,
2003)
Penggunaan Elman’s NN yang dimodifikasi untuk melakukan prediksi.
10 A pseudoinverse learning algorithm for
feedforward neural networks with
11 Evolutionary neural network modeling
for software cumulative failure time
prediction
(Tian &
Noore, 2005)
Penggunaan GA untuk mengoptimalisasi
jumlah neuron masukan dan jumlah layer
tersembunyi pada NN.
12 On-line prediction of software reliability
using an evolutionary connectionist
model
(Tian &
Noore, 2005b)
Penggunaan GA untuk mengoptimalisasi
jumlah neuron masukan dan jumlah layer
tersembunyi pada NN. Prediksi dilakukan
secara online.
Prediksi dapat dilakukan secara online,
dimana model dapat beradaptasi jika
21
No. Judul Rujukan Metode yang Diusulkan Temuan
13 Early Software Reliability Prediction
with Extended ANN Model
(Hu dkk.,
2006)
Penggunaan data failure perangkat lunak pada
proyek terdahulu untuk memprediksikan
terjadinya failure pada awal waktu
pengembangan.
Data terdahulu dapat dimanfaatkan
untuk melakukan prediksi proyek baru
yang belum memiliki banyak data
failure yang cukup.
14 Neural Network-Based Approaches for
Software Reliability Estimation using
Dynamic Weighted Combinational
Models
(Su & Huang,
2007)
Analisa NN dari sudut pandang matematis dan
penurunan ekspresi matematis dari SRGM untuk
diterapkan pada NN.
Penelitian menggunakan analisa
matematis untuk menurunkan model
yang dapat secara akurat
memprediksikan reliabilitas.
15 Software Reliability Prediction by Soft
Computing Techniques
(Kiran & Ravi,
2008)
Penggunaan model ensemble (penggabungan
beberapa model NN) dengan Back Propragation
NN.
Penggunaan model ensemble dapat
menghasilkan prediksi yang lebih akurat
daripada satu model NN saja.
16 Software Reliability Prediction Based on
Discrete Wavelet Transform and Neural
Network
(Jin dkk.,
2009)
Penggunaan Wavelet Transform dan NN untuk
melakukan prediksi reliabilitas.
17 Predicting software reliability with
neural network ensembles
(Zheng, 2009) Penggunaan model ensemble (penggabungan
beberapa model NN) untuk melakukan prediksi
reliabilitas.
18 Prediction of Software Reliability Using
Feed Forward Neural Networks
(Singh &
Kumar, 2010)
Penggunaan FFNN untuk prediksi reliabilitas
22
No. Judul Rujukan Metode yang Diusulkan Temuan
19 Study of Software Reliability Prediction
Based on GR Neural Network
(Wu & Yang,
2011)
Penggunaan General Regression NN untuk
prediksi reliabilitas perangkat lunak.
Penelitian ini menunjukkan bahwa
General Regression NN dapat juga
digunakan untuk melakukan prediksi.
20 Evolutionary prediction for cumulative
failure modeling: A comparative study
(Benaddy
dkk., 2011)
Penggunaan Real-coded GA untuk mengestimasi
model NN dan auto-regresi yang terbaik.
21 Software Reliability Prediction using
Neural Network with Encoded Input
(Bisi & Goyal,
2012)
Penggunaan skema encoding yang berbeda, yaitu
NN with Exponential Encoding (NNE) dan NN
with Logarithmic Encoding (NNL) untuk
melakukan prediksi.
22 Autonomous and adaptive procedure for
cumulative failure prediction
(Zemouri &
Zerhouni,
2012)
Penggunaan algoritma Fuzzy Min-Max untuk
mengoptimalkan model NN secara online.
Prediksi dapat dilakukan secara online,
dimana model dapat beradaptasi jika
terdapat data baru yang masuk.
23 Neural Network Ensemble Based on
K-means Clustering Individual Selection
and Application for Software Reliability
Prediction
(Li dkk., 2013) Penggunaan K-Means untuk memilih beberapa
model NN yang digunakan secara ensemble untuk
prediksi realiabilitas perangkat lunak.
Penelitian memperkenalkan cara untuk
memilih ensemble dengan metode
klasterisasi.
24 Software Reliability Prediction Model
Based On Ica Algorithm and Mlp Neural
Network
(Noekhah
dkk., 2013)
Penggunaan ICA sebagai algoritma optimasi
untuk Multilayer Perceptron NN untuk melakukan
23
No. Judul Rujukan Metode yang Diusulkan Temuan
25 Robust feedforward and recurrent neural
network based dynamic weighted
combination models for software
reliability prediction
(Roy dkk.,
2014)
Penggabungan beberapa SRGM tradisional dari
pembelajaran FFNN dan pemanfaatan Real-coded
GA untuk optimasi model NN.
Tabel 2.2. Rangkuman Penelitian Terdahulu dengan SVR
No. Judul Rujukan Metode yang Digunakan Temuan
1 Dynamic Software Reliability
Prediction: An Approach Based On
Support Vector Machines
(Tian &
Noore, 2005c)
Penggunaan SVR untuk melakukan prediksi
reliabilitas secara online.
Prediksi dapat dilakukan secara online,
dimana model dapat beradaptasi jika
terdapat data baru yang masuk.
2 Prediction of Software Reliability by
Support Vector Regression
(Wang &
Chen, 2005)
Penggunaan SVR untuk melakukan prediksi
reliabilitas.
3 Software reliability forecasting by
support vector machines with simulated
annealing algorithms
(Pai & Hong,
2006)
Penggunaan SA untuk melakukan optimasi
parameter SVR.
4 A Study on Software Reliability
Prediction Based on Support Vector
Machines
(Yang & Li,
2007)
Penelitian ini menggunakan SVR untuk
menyelidiki data yang lebih baik digunakan untuk
prediksi realibilitas.
Penelitian ini menemukan bahwa data
failure kumulatif lebih baik digunakan
24
No. Judul Rujukan Metode yang Digunakan Temuan
5 Prediction of software reliability by
support vector regression with genetic
algorithms
(Ho & Hsieh,
2009)
Real-value GA digunakan sebagai algoritma
optimasi parameter SVR.
6 Early Software Reliability Prediction
Based on Support Vector Machines with
Genetic Algorithms
(Lo, 2010) GA digunakan sebagai algoritma optimasi
parameter SVR untuk prediksi reliabilitas di awal
masa pengembangan.
7 A generic data-driven software
reliability model with model mining
technique
(Yang dkk.,
2010)
GA digunakan sebagai algoritma model mining,
dimana time lags yang digunakan untuk
melakukan prediksi belum tentu data yang
terakhir. Selain itu, GA digunakan untuk optimasi
parameter SVR.
Penelitian ini menunjukkan bahwa
model mining dapat digunakan untuk
mengetahui hubungan internal data dan
memperbaiki hasil prediksi.
8 Software reliability prediction based on
support vector regression using a hybrid
genetic algorithm and simulated
annealing algorithm
(Jin, 2011) GA dan SA diintegrasi untuk optimasi parameter
e-SVR.
9 Software reliability prediction model
based on support vector regression with
improved estimation of distribution
algorithms
(Jin & Jin,
2014)
Estimation of Distribution Algorithm (EDA)
digunakan untuk memperbaiki populasi dan
25
BAB III
METODOLOGI PENELITIAN
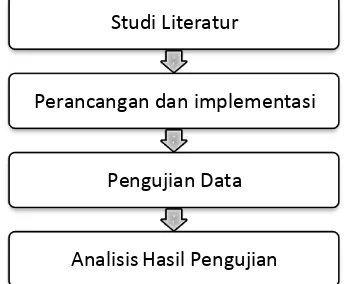
Bab ini memaparkan tentang metodologi penelitian yang digunakan pada penelitian ini, yang terdiri dari (1) studi literatur, (2) perancangan metode yang diusulkan dan implementasi kode, (3) pengujian data, dan (4) analisis hasil pengujian. Tahapan metodologi penelitian ini dapat dilihat pada Gambar 3.1.
Gambar 3.1. Tahapan metodologi penelitian
Penjelasan dari tahapan metode penelitian pada Gambar 3.1 akan dijelaskan secara rinci sebagai berikut.
3.1.Studi Literatur
Studi literatur adalah proses pengkajian artikel penelitian terdahulu yang berhubungan dengan topik penelitian ini. Referensi yang digunakan adalah referensi yang berkaitan dengan prediksi reliabilitas perangkat lunak, khususnya bagi pendekatan yang menggunakan teknik DDSRM dengan arsitektur MDISO. Selain itu, literatur yang berkaitan dengan metode yang diusulkan juga dipelajari, antara lain metode SVR dan metode BPSO. Studi literatur tambahan juga akan dilakukan untuk membantu mendesain langkah kerja penelitian, terutama mengenai data kesalahan atau kegagalan perangkat lunak dan kakas bantu yang dapat digunakan pada penelitian.
Studi Literatur
Perancangan dan implementasi
Pengujian Data
26 3.2.Perancangan dan Implementasi
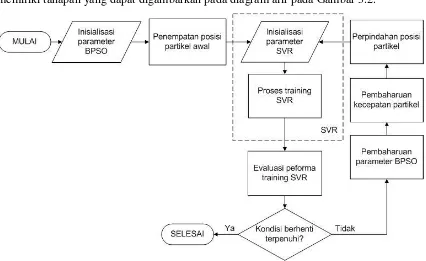
Dalam penelitian ini, akan diimplementasikan sebuah sistem yang dapat melakukan prediksi reliabilitas perangkat lunak dengan menggunakan SVR dan model mining dengan BPSO (metode SVR-BPSO). Implementasi metode ini akan dilakukan pada lingkungan pemrograman Matlab 7.0 dengan memanfaatkan tools LibSVM untuk menjalankan beberapa perintah yang berkaitan dengan SVR. Sistem yang akan dibangun memerlukan proses training dan testing untuk menguji keakuratan metode yang diusulkan. Proses training pada penelitian ini memiliki tahapan yang dapat digambarkan pada diagram alir pada Gambar 3.2.
Gambar 3.2. Diagram alir proses training SVR-BPSO pada penelitian
Dibutuhkan data kegagalan perangkat lunak untuk menjalankan tahapan yang digambarkan pada Gambar 3.2. Penjelasan secara lebih rinci tentang data dan metode ini akan dijelaskan pada subbab berikut.
3.2.1. Data Kegagalan Perangkat Lunak
27 kegagalan dengan catatan waktu antar kegagalan dalam satuan menit. FC1 adalah data dari sistem tracking bug pada laman web Xfce (Tamura & Yamada, 2005). FC2 adalah data dari sebuah produk jaringan wireless (Jeske dkk., 2005). FC3 adalah data dari sistem TROPICO R-1500, sebuah sistem Electronic Switching dari Brazil (Kanoun dkk., 1991). Masing-masing data dapat dilihat pada Lampiran.
Selain menggunakan dua macam data yang berbeda, data yang dipakai pada penelitian ini memiliki catatan kegagalan yang bervariasi. TBF1, TBF2, dan TBF3 memiliki jumlah data time-between-failure untuk 86, 207, dan 397 kegagalan. Sedangkan FC1, FC2, dan FC3 memiliki data jumlah total kegagalan dalam 21, 51, dan 81 minggu waktu eksekusi kumulatif perangkat lunak. Dengan adanya dua kelompok data dan jumlah kegagalan yang bervariasi, diharapkan metode yang diusulkan pada penelitian ini dapat diuji dengan baik.
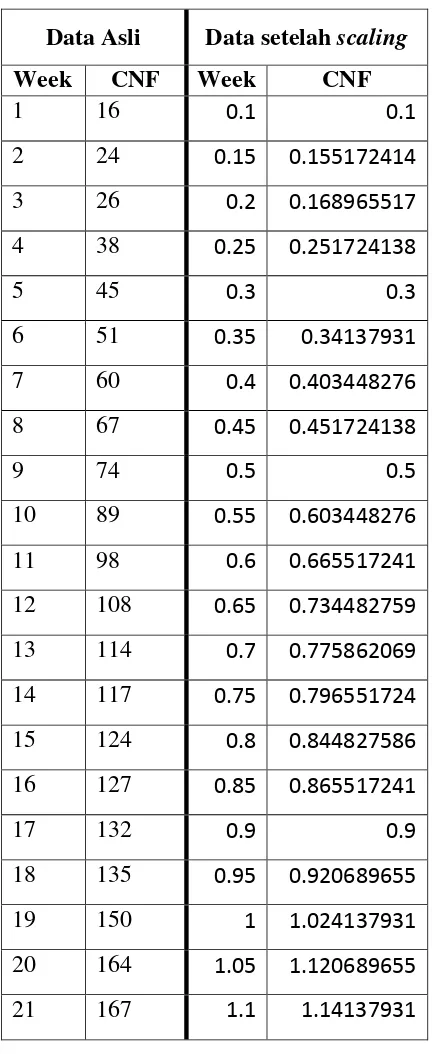
Dalam penelitian ini, data akan digunakan untuk proses training dan testing model yang diusulkan. Sebanyak 80% data secara terurut akan digunakan sebagai data training, sedangkan 20% data terakhir akan digunakan sebagai data testing. Dalam proses training, data akan diolah terlebih dahulu dengan proses scaling dengan jangkauan nilai [0.1, 0.9] untuk meminimalkan dampak scaling secara absolut. Persamaan yang digunakan untuk proses ini ditunjukkan pada Persamaan (9). Tabel 3.1 menunjukkan data asli FC1 dan data FC1 setelah proses scaling.
Pada Tabel 3.1, terlihat data asli FC1 pada bagian kiri dan data FC1 setelah scaling pada bagian kanan. Kolom “Week” menunjukkan waktu eksekusi
perangkat lunak dalam satuan minggu dan kolom “CNF” menunjukkan jumlah
28
pertama hingga minggu ke-17 karena memenuhi 80% porsi data untuk data setelah scaling.
Tabel 3.1. Data asli FC1 dan data setelah scaling Data Asli Data setelah scaling
Week CNF Week CNF
29
Persamaan (9), dapat diketahui bahwa nilai 𝑖𝑚𝑎𝑥 dan 𝑖𝑚𝑖𝑛 untuk kolom Week pada data training masing-masing adalah bernilai 1 dan 17, sedangkan nilai 𝑖𝑚𝑎𝑥 dan 𝑖𝑚𝑖𝑛 untuk kolom CNF masing-masing adalah 16 dan 132. Nilai 𝑖𝑚𝑎𝑥 dan 𝑖𝑚𝑖𝑛 ini kemudian juga dipakai untuk menghitung proses scaling data minggu
ke-18 hingga ke-21. Dengan kata lain, nilai 𝑖𝑚𝑎𝑥 dan 𝑖𝑚𝑖𝑛 yang digunakan adalah nilai pada data training, sehingga hasil scaling data testing pada Tabel 3.1 memiliki nilai yang lebih besar dari jangkauan [0.1, 0.9].
3.2.2. Inisialisasi Parameter BPSO
Terdapat beberapa parameter algoritma BPSO perlu diinisialisasi, yaitu 𝑐1, 𝑐2, Vmax, dan 𝑤. Parameter 𝑐1 dan 𝑐2 diinisialisasi dengan nilai 2.0 berdasarkan
aplikasi PSO yang dipakai pada banyak aplikasi (Eberhart & Shi, 2001). Vmax diinisialisasi pada ±4.0 berdasarkan ukuran yang direkomendasikan untuk masalah BPSO (Kennedy dkk., 2001). Parameter w diinisialisasi sebesar 0.8 berdasarkan anjuran dari penelitian lain untuk nilai Vmax ≥ 3 (Shi & Eberhart, 1998). Kondisi berhenti algoritma BPSO pada penelitian ini adalah ketika kondisi konvergen tercapai dengan selisih threshold sebesar 5 × 10-6.
Jumlah partikel merupakan salah satu parameter lainnya yang perlu diinisialisasi. Dalam algoritma PSO secara umum, tidak ada aturan khusus untuk menentukan jumlah tersebut. Dalam penelitian ini, dilakukan beberapa percobaan awal dengan menjalankan metode yang diusulkan pada data FC1 dengan jumlah partikel yang berbeda untuk mencari jumlah partikel yang ideal dengan batasan waktu penelitian. Hasil waktu eksekusi dan jumlah iterasi yang diperlukan untuk mencapai konvergensi yang didapatkan dari percobaan awal tersebut dapat terlihat pada Tabel 3.2.
30
waktu yang tersedia. Pada penelitian ini, jumlah partikel ditentukan sebanyak 5 karena percobaan awal pada Tabel 3.2 mengindikasikan bahwa iterasi yang diperlukan untuk mencapai konvergen lebih sedikit daripada jumlah partikel yang lainnya.
Tabel 3.2. Hasil percobaan data FC1 dengan jumlah partikel yang berbeda No. Jumlah
Selain itu, setiap partikel memiliki komponen sliding window maksimal sejumlah z. Pada penelitian ini, z ditetapkan dengan nilai 8 yang menandakan bahwa terjadinya kegagalan perangkat lunak 𝑦𝑖 dipengaruhi oleh 8 kegagalan perangkat lunak yang terjadi sebelumnya. Oleh karena itu, struktur sebuah partikel pada penelitian ini dapat digambarkan pada Gambar 3.3.
𝑝𝑖1 𝑝𝑖2 𝑝𝑖3 𝑝𝑖4 𝑝𝑖5 𝑝𝑖6 𝑝𝑖7 𝑝𝑖8
Gambar 3.3. Struktur sebuah partikel pada BPSO
Pada Gambar 3.3., terlihat bahwa sebuah partikel P terdiri dari 8 sub-partikel 𝑝𝑖 yang merepresentasikan batas ukuran sliding window yang digunakan. Sub-partikel 𝑝𝑖 dapat bernilai nol (“0”) atau satu (“1”).
3.2.3. Penempatan Posisi Partikel Awal
Posisi pada BPSO direpresentasikan dengan string biner yang bernilai nol
31
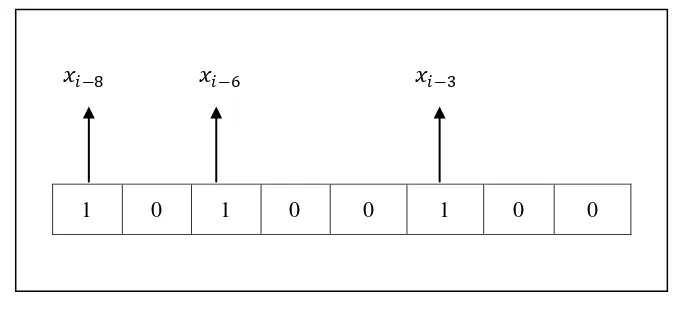
dengan nilai biner “10100100” menunjukkan bahwa data 𝑥𝑖−3, 𝑥𝑖−6 dan 𝑥𝑖−8 akan
digunakan sebagai masukan seperti yang ditunjukkan pada Gambar 3.4.
Gambar 3.4. Interpretasi posisi pada sebuah partikel BPSO
Untuk memulai metode SVR-BPSO, partikel perlu memiliki posisi awal dan kecepatan awal. Posisi dari masing-masing sub-partikel akan diinisialisasi secara acak, sehingga masing-masing partikel akan memiliki kombinasi nilai nol (“0”)
atau satu (“1”) yang berbeda-beda pada tiap kali metode SVR-BPSO dijalankan. Kecepatan juga perlu diinisialisasi secara acak untuk tiap subpartikel, dimana nilai kecepatan berada pada jangkauan desimal antara -4.0 hingga 4.0.
3.2.4. Inisialisasi Parameter SVR dan Proses Training SVR
Data yang dipakai pada proses training dipilih berdasarkan posisi partikel. Misalnya, partikel pertama pada percobaan awal dengan posisi “10100100” menunjukkan bahwa data 𝑥𝑖−3, 𝑥𝑖−6 dan 𝑥𝑖−8 digunakan sebagai masukan untuk memprediksikan nilai 𝑦𝑖, sedangkan data 𝑥𝑖−1, 𝑥𝑖−2, 𝑥𝑖−4, 𝑥𝑖−5, dan 𝑥𝑖−7 tidak digunakan sebagai masukan. Sehingga, pemilihan data perlu dilakukan berdasarkan posisi partikel tertentu.
Setelah dilakukan pemilihan masukan, proses training dapat dilakukan dengan aturan sebagai berikut: 1) kernel yang akan digunakan adalah kernel Gaussian karena fungsi kernel ini dinilai mampu menghasilkan prediksi yang lebih baik daripada fungsi kernel lainnya (Jin & Jin, 2014); 2) parameter C, , dan ditentukan dengan metode 5-fold cross-validation seperti yang telah dilakukan pada penelitian terdahulu (Ho & Hsieh, 2009). Pemilihan ketiga parameter ini dapat diimplementasikan dengan fungsi Matlab seperti pada Gambar 3.5. Dengan
𝑥𝑖−8 𝑥𝑖−6 𝑥𝑖−3
32
menggunakan fungsi ini, parameter yang terbaik dapat didapatkan setelah beberapa iterasi.
Gambar 3.5. Fungsi pemilihan parameter SVR pada Matlab 3.2.5. Evaluasi Peforma
Evaluasi peforma yang dimaksud adalah perhitungan nilai keakuratan hasil training. Perhitungan yang diambil adalah nilai Mean Squared Error (MSE) yang dapat dilihat pada Persamaan (13).
𝑀𝑆𝐸𝑡𝑟𝑎𝑖𝑛𝑖𝑛𝑔 = (observasi sebenarnya). MSE digunakan untuk mengukur besarnya rata-rata nilai kuadrat kesalahan prediksi. Sehingga, nilai MSE yang kecil menunjukkan prediksi yang semakin akurat.
3.2.6. Kondisi Berhenti
33
digunakan pada proses training. Jika kondisi konvergen belum tercapai, maka algoritma akan dilanjutkan ke langkah berikutnya.
3.2.7. Pembaruan Parameter BPSO
Terdapat beberapa parameter BPSO akan diperbarui pada tahap ini, yaitu Ppbest dan Pgbest. Ppbest dan Pgbest berisi salinan posisi partikel terbaik secara
personal dan global. Dengan demikian, Ppbest dan Pgbest memiliki struktur yang sama dengan partikel BPSO.
Tiap partikel memiliki Ppbest masing-masing yang akan diperbarui jika peforma partikel yang terbaru lebih baik daripada peforma Ppbest yang disimpan. Hal ini berbeda dengan Pgbest yang mencerminkan peforma partikel yang terbaik diantara partikel lainnya. Nilai Pgbest akan diperbarui jika ada catatan Ppbest yang lebih baik daripada Pgbest.
3.2.8. Pembaruan Kecepatan dan Posisi Partikel
Kecepatan dan posisi partikel kemudian juga akan diperbarui dengan beberapa langkah berikut. Kecepatan baru partikel dihitung dengan Persamaan (11). Variabel 𝜑1 dan 𝜑2 pada persamaan tersebut dihasilkan dengan membuat bilangan acak. Nilai sigmoid dari kecepatan baru tersebut lalu dihitung dengan Persamaan (10). Setelah itu, dihasilkan bilangan acak 𝑟𝑖𝑗 untuk semua partikel. Posisi baru partikel kemudian dapat ditentukan dengan Persamaan (12). Kecepatan baru dan posisi baru yang didapatkan digunakan untuk iterasi berikutnya.
Pada iterasi berikutnya, proses training berulang lagi dengan kombinasi masukan yang berbeda. Setelah kondisi berhenti tercapai, partikel yang tercatat pada Pgbest akan diambil sebagai solusi terbaik.
3.3.Analisis Pengujian
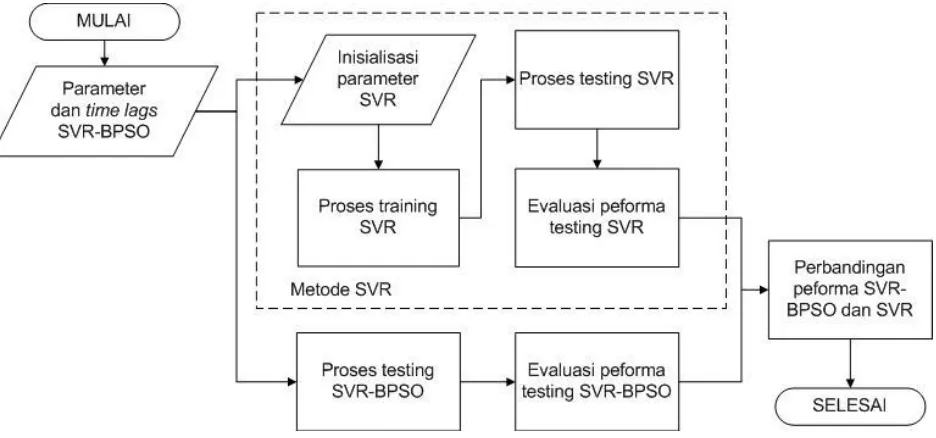
34 3.3.1. Inisialisasi Parameter BPSO
Pengujian dilakukan dengan membandingkan hasil yang didapatkan pada metode yang diusulkan (metode SVR-BPSO) dengan metode tanpa model mining (Metode SVR). Metode SVR memiliki alur yang sedikit berbeda dengan metode SVR-BPSO, dimana masukan yang digunakan diambil dengan jumlah tertentu tanpa dilakukan pemilihan dengan algoritma BPSO. Nilai peforma keduanya akan dibandingkan untuk mengetahui keakuratan metode yang diusulkan. Diagram alir skenario pengujian dapat dilihat pada Gambar 3.6.
Gambar 3.6. Diagram alir skenario pengujian
35 3.3.2. Parameter Pengujian
Nilai peforma yang digunakan untuk menilai keakuratan hasil testing kedua metode adalah nilai MSE yang dapat dihitung dengan Persamaan (14) dan Average Relative Prediction Error (AE) yang dapat dihitung dengan Persamaan (15).
Pada Persamaan (14), 𝑦 𝑖 adalah prediksi atau keluaran yang didapatkan dari model dan 𝑦𝑖 adalah data sebenarnya. Nilai MSE yang kecil menandakan kesalahan prediksi pada data testing yang lebih kecil pula.
36
37
BAB IV
UJI COBA DAN EVALUASI
Bab ini membahas evaluasi hasil pengujian metode yang diusulkan. Pembahasan pertama adalah tentang hasil prediksi yang didapat dari keenam data uji beserta penjelasan perbandingan nilai MSE dan AE. Pembahasan kedua adalah tentang analisa hasil pengujian.
4.1. Evaluasi Hasil Pengujian
Subbab ini membahas tentang hasil pengujian dan evaluasi dari hasil prediksi yang didapatkan dari metode SVR-BPSO dan metode SVR pada enam data uji. Perbandingan nilai MSE dan AE dilakukan untuk mengukur tingkat akurasi metode yang diusulkan.
4.1.1. Evaluasi Hasil Pengujian pada data FC1
Pada penelitian ini, metode SVR-BPSO diujicobakan sebanyak 5 kali untuk tiap data. Hal ini dilakukan karena metode SVR-BPSO dapat menghasilkan keluaran yang berbeda pada tiap uji coba yang disebabkan oleh penempatan posisi dan kecepatan partikel yang bersifat acak. Selain itu, penentuan jumlah percobaan ini juga didasarkan pada jangka waktu penelitian yang terbatas. Pada tiap percobaan, nilai MSE dan AE metode SVR-BPSO akan dibandingkan dengan metode SVR (tanpa menggunakan model mining) untuk dapat mengetahui nilai keakuratan prediksi metode yang diusulkan. Hasil masing-masing percobaan secara detail dapat dilihat pada bagian Lampiran, sedangkan hasil rata-rata prediksi untuk data FC1 dapat dilihat pada Gambar 4.1.
38
dapat dibandingkan, dimana masing-masing metode memiliki keakuratan prediksi yang lebih baik pada minggu-minggu tertentu. Misalnya, pada minggu ke-18 dan ke-21, metode SVR-BPSO dapat memprediksikan jumlah kegagalan dengan lebih baik daripada metode SVR. Sedangkan, pada minggu ke-19 dan ke-20, metode SVR-BPSO menghasilkan prediksi yang kurang akurat daripada metode SVR.
Gambar 4.1. Hasil prediksi SVR-BPSO dan SVR untuk Data FC1
Keakuratan prediksi ini dapat dihitung dengan lebih rinci dengan mencari nilai MSE dan AE kedua metode. Dari rata hasil percobaan, nilai MSE rata-rata yang didapatkan untuk metode SVR-BPSO adalah 0.00095, sedangkan nilai MSE rata-rata untuk metode SVR adalah 0.002. Dari nilai MSE ini, metode SVR-BPSO memiliki keakuratan yang lebih baik daripada metode SVR.
39
metode SVR-BPSO memiliki keakuratan yang lebih baik setelah hasil prediksi dinormalisasi seperti skala aslinya.
4.1.2. Evaluasi Hasil Pengujian pada data FC2
Setelah dilakukan percobaan sebanyak 5 kali, didapatkan hasil prediksi untuk metode SVR-BPSO dan SVR untuk data FC2. Hasil rata-rata prediksi untuk data FC2 dapat dilihat pada Gambar 4.2.
Gambar 4.2. Hasil prediksi SVR-BPSO dan SVR untuk Data FC2
40
Setelah dilakukan perhitungan, nilai MSE rata-rata yang didapatkan untuk metode SVR-BPSO adalah 0.00077, sedangkan nilai MSE rata-rata untuk metode SVR adalah 0.0072. Dari nilai MSE ini, metode SVR-BPSO memiliki keakuratan yang lebih baik daripada metode SVR.
Hasil prediksi yang didapatkan ini kemudian dinormalisasi kembali dengan skala yang sesuai dengan data asli FC2. Dari nilai normalisasi ini, dapat dihitung keakuratan AE. Metode SVR-BPSO memiliki nilai AE sebesar 2.92% dan metode SVR memiliki nilai AE sebesar 8.30%. Dari kedua nilai AE ini, terlihat bahwa metode SVR-BPSO memiliki keakuratan yang lebih baik setelah hasil prediksi dinormalisasi seperti skala aslinya.
4.1.3. Evaluasi Hasil Pengujian pada data FC3
Setelah dilakukan percobaan sebanyak 5 kali, didapatkan hasil prediksi untuk metode SVR-BPSO dan SVR untuk data FC3. Hasil rata-rata prediksi untuk data FC3 dapat dilihat pada Gambar 4.3.
41
Dari Gambar 4.3, terlihat bahwa proses testing dilakukan pada 16 data berdasarkan titik-titik pemetaan pada grafik, yaitu kegagalan pada minggu ke-66 hingga minggu ke-81. Selain itu, terlihat bahwa metode SVR-BPSO dan SVR memiliki kemampuan prediksi yang berbeda untuk data FC3. Metode SVR-BPSO cenderung dapat mengikuti trend data yang naik, sedangkan metode SVR tidak dapat mengikuti trend tersebut. Nilai MSE rata-rata yang didapatkan untuk metode SVR-BPSO adalah 0.00037, sedangkan nilai MSE rata-rata untuk metode SVR adalah 0.0034. Dari nilai MSE ini, metode SVR-BPSO memiliki keakuratan yang lebih baik daripada metode SVR.
Hasil prediksi yang didapatkan ini kemudian dinormalisasi kembali dengan skala yang sesuai dengan data asli FC3. Dari nilai normalisasi ini, dapat dihitung keakuratan AE. Metode SVR-BPSO memiliki nilai AE sebesar 1.88% dan metode SVR memiliki nilai AE sebesar 4.34%. Dari kedua nilai AE ini, terlihat bahwa metode SVR-BPSO memiliki keakuratan yang lebih baik setelah hasil prediksi dinormalisasi seperti skala aslinya.
4.1.4. Evaluasi Hasil Pengujian pada data TBF1
Setelah dilakukan percobaan sebanyak 5 kali, didapatkan hasil prediksi untuk metode SVR-BPSO dan SVR untuk data TBF1. Hasil rata-rata prediksi untuk data TBF1 dapat dilihat pada Gambar 4.4.
Dari Gambar 4.4, terlihat bahwa metode SVR-BPSO dan SVR tidak dapat mendeteksi fluktuasi data dengan baik. Nilai MSE rata-rata yang didapatkan untuk metode SVR-BPSO adalah 0.083, sedangkan nilai MSE rata-rata untuk metode SVR adalah 0.083. Dari nilai MSE ini, metode SVR-BPSO memiliki keakuratan yang lebih baik daripada metode SVR.