Statistika Nonparametrik
Asumsi2 Parametrik
Observasinya harus independen
Observasinya harus diambil dari populasi
normal, kecuali ukuran sampel cukup besar
Semua populasi variansinya harus sama
Asumsi2 Nonparametrik
Observasi2 nya independen
Variablenya merupakan variabel yang
Ukuran/Skala Data
Ada 4 (empat) macam, yaitu:
1. Skala Nominal (Classificatory) Gender, latar belakang etnik
2. Skala Ordinal (Ranking)
Kekerasan batu, kecantikan, pangkat militer 3. Skala Interval
Celsius atau Fahrenheit 4. Skala Ratio
Metode Nonparametrik
Ada paling sedikit satu uji nonparametrik
yang ekivalen dgn suatu uji parametrik
Uji2 tersebut dapat di kelompokkan
dalam beberapa kategori, yaitu:
1. Uji beda antar kelompok (sampel independen)
Jika berhadapan dengan suatu
populasi dichotomous (hasilnya
digolongkan sebagai sukses atau
gagal: biasa juga dikenal sebagai
populasi dua hasil), maka objek
yang dapat dijadikan perhatian
Inferensi Statistika Untuk
Parameter Distribusi Binomial
Untuk melakukan inferensi statistika
untuk p, maka diambil sampel
random berukuran-n dari populasi
tersebut dan diketahui bahwa
distribusi sampling jumlah sukses
(dalam sampel random berukuran-n)
berdistribusi Binomial dengan
Jika X ~ Bin (n , p), maka
dengan mean X = np variansi
X = np( 1 - p), dan X adalah
jumlah sukses.
( ) ( ) n x(1 )n x, 0, 1, 2, .... f x P X x p p x n x Jelas
bahwa
menggunakan
teorema
limit
pusat
dapat
dibuktikan bahwa untuk n yang
cukup besar
atau
~
(
.
(1
))
X
N np np
p
x p sehingga inferensi statistika untuk p
dapat dilakukan berdasarkan
distribusi normal. Suatu hal yang
sering dilakukan agar hasil yang
diperoleh menjadi lebih tepat adalah
menggunakan faktor koreksi
berhubung distribusi binomial adalah
distribusi variabel random diskrit
Faktor koreksi yang digunakan adalah + ditambah untuk batas atas dari X dan -ditambahkan untuk batas bawah.
Jika n tidak cukup besar, maka pendekatan normal tidak dapat dilakukan, sehingga inferensi statistika untuk p adalah harus didasarkan pada distribusi binomial, yaitu dengan cara berikut:
Karena X ~ Bin (n , p), dari
dapat diperoleh interval konfidensi (1 -α) 100% untuk p adalah
1.1. Estimasi Interval
( L u ) (1 )100%
P X X X
dengan
p
L,
p
udapat
diperoleh dari suatu tabel,
misalnya tabel C6 dalam
buku
"Statistics
:
A
Biomedical
Introduction"
Untuk menguji H0 = p = p0, daerah X ~ Bin (n , p0), maka
untuk menguji Ha = p ≠ p0, daerah
kritisnya adalah X > xu atau X < XL dengan Xu ditentukan dari dan XL ditentukan dari atau sebaliknya
untuk Ha = p > p0, daerah kritisnya adalan
X < X dengan X ditentukan dari P(X < X ) ≤
Catatan:
1. Untuk n , p tertentu Xu atau XL dapat
dicari dengan tabel distribusi Binomial.
2. Inferensi Statistika untuk experimen
Bernoulli atau Binomial atau populasi dichotomous dapat pula dilakukan dengan pendekatan ke distribusi normal.
Karena X ~ Bin (n , p) dengan X =
jumlah sukses dalam sampel,
maka X adalah variabel random
diskrit. Kriteria untuk menentukan
apakah berlaku pendekatan normal
adalah 0,1 < p < 0,9 (rule of
thumb), maka distribusi
tidak
Contoh 6.1 : Dari tabel di bawah ini ujilah apakah merokok mempengaruhi waktu hidup ? Hidup dalam 6 th Hidup Jumlah Yang tidak merokok 117 950 1067 perokok 54 348 402 Jumlah 171 1298 1469
Jika X1 ~ Bin (n1 , p1) dan X2 ~ Bin(n2 , p2), maka untuk menguji Ho = p1 = p2 = p digunakan statistik
1.3. Inferensi Statistika
Untuk Beda Proporsi
1 2 1 2
X
X
P
n
n
A Ā Jumlah Sampel I X1 n1 - X1 n Sampel II X2 n2 - X2 n2 Jumlah X1 + X2 n1 + n2 - X1 - X2 n1 + n2
Berikut ini adalah suatu cara lain untuk melakukan inferensi statistika untuk membandingkan dua proporsi. Cara yang sangat populer ini adalah:
Sukses Gagal
Sampel I p1 1 - p1
dengan X1 ~ Bin (n1 , p1) dan X2 ~ Bin (n2 , p2) saling independen, maka Ho benar berakibat p1 = p2 = p, sehingga X1 + X2 ~ Bin (n1 + n2 , p) dan
1 2 1 1 1 1 1 2 n n x k x P X x X X k n n Jika X berdistribusi Binomial ditulis : X ~ Bin (n , p), maka
dengan x = 0, 1, 2, ... n dan o < p < 1.
Jika X ~ Bin (nx , px) dan Y ~ Bin (ny , py) dengan X dan Y saling independen, maka
( ) n x (1 )n x P X x p p x
Jika dua populasi dependen, maka penyajian tabel keadaan berikut
adalah tidak benar, karena yang
Sembuh tidak
Obat A 18 82 100
Dengan demikian penyajian tabel yang benar adalah sebagai berikut
Sembuh tidak
Sakit 9 1 10
tidak 9 81 90
Dengan mudah dapat dilihat bahwa PA dan PB tidak independen.
AB
n
n
AB
Dari tabel di atas dapat diperoleh dengan mudah bahwa
Dengan demikian untuk menguji Ho = pA = pB adalah sama/ekivalen dengan menguji
dan
A AB AB B AB AB
P p p p p p
Jika dan tertentu maka
Untuk dan besar, biasanya 25, maka atau AB
n
n
AB 1 1 ( , ) 2 AB AB AB n B n n ABn
n
AB (0 , 1) AB AB AB AB n n N n n 2 2 1 AB AB AB AB n n n n Perhatikan tabel berikut
Jika x + y, nx dan ny diketahui, maka yang lain juga diketahui dan
I X nX - X nX II Y nY - Y nY X + Y nX + nY - X - Y nX + nY n n k k
Untuk menguji Ho = px = py = p, maka X ~ Bin(nx , px) dan Y ~ Bin (ny , py) saling independen mengakibatkan X - Y ~ Bin (nx + ny , p) jika Ho benar. Dengan demikian berlaku
~ (0,1) x x y n x k n n N Uji hipotesis di atas dapat juga digunakan untuk menguji homogenitas atau independensi. Jika digunakan tabel berikut
Sukses O11 O12 n1.
Gagal O21 O22 n2.
maka statistik yang digunakan untuk menguji homogenitas adalah
sedangkan yang digunakan untuk menguji independensi adalah
2
x
2
Setelah kita mempelajari bagaimana
cara menguji Ho bahwa tidak ada
beda antara mean dua populasi,
suatu hal yang dapat difikirkan
sebagai
kelanjutannya
adalah
bagaimana cara menguji H
bahwa
II. INFERENSI STATISTIKA UNTUK MEMBANDINGKAN k (> 2) POPULASI
Suatu cara yang dapat difikirkan untuk menyelesaikan hal tersebut adalah menguji Ho dari semua pasangan 2 secara terpisah masing-masing menggunakan uji distribusi normal atau uji distribusi t.
Andaikan ada 5 populasi yang akan diuji beda meannya, maka banyak semua
Jika dipilih tingkat signifikansi α = 5% untuk setiap uji hipotesis, maka kemungkinan gagal menolak Ho bahwa tidak ada aturan multiplikatif kemungkinan, jika dianggap masing-masing uji hipotesis independen satu dengan yang lain, maka kemungkinan gagal menolak Ho dalam kesepuluh uji hipotesis adalah (95%)10 = 59,87%.
Ini
berakibat
kemungkinan
menolak paling sedikit satu Ho
adalah 1 - 59,87% = 40,13%,
yang
adalah
terlalu
besar.
Tentunya hal ini tidak akan disukai,
sehingga
perlu
dicari
jalan
keluarnya,
yaitu
menggunakan
Model ini sering juga disebut Rancangan Random Lengkap atau Model Analisis Satu Faktor.
Data dari populasi-populasi yang diteliti dapat disajikan dengan cara sebagai berikut:
2.1. Model Analisis variansi
satu arah
Treatment (= Perlakuan)
1 2 3 ... k
x11 x12 x13 x1k
xn11 xn22 xn33 ... Xnkk Total T.1 T.2 T.3 T.k T..
-xij = Observasi ke-i dari atau dalam populasi ke j. i = 1, 2, ..., ni dan j = 1, 2, ....k, ( k > 2). = mean perlakuan ke - j. = mean dari , , . j x
x
1x
x2 xkModel Analisis variansi satu faktor ini adalah suatu teknik statistik untuk mempelajari hubungan antara suatu vairabel dependen dengan satu variabel independen (dalam hal ini biasa disebut faktor).
Model ini dapat dibedakan menurut 2 macam, yaitu model efek tetap dan model efek random.
Beda antar kelompok independen
Dua sampel – membandingkan mean beberapa variabel yang menjadi perhatian Parametrik Nonparametrik Uji-t untuk sampel independenUji runs Wald-Wolfowitz
Uji U Mann-Whitney
Kolmogorov-Uji U Mann-Whitney
Padanan nonparametrik untuk uji t dua sampel Ukuran sebenarnya diganti dengan/oleh ranknya Data dapat di rank dari nilai tertinggi ke
terendah atau dari terendah ke tertinggi
Statistik U Mann-Whitney
Contoh Soal Uji U Mann-Whitney
Hipotesis null dua sisi bahwa tidak adabeda tinggi mahasiswa putra dan putri
Ho: Tinggi mahasiswa putra dan putri
sama
HA: Tinggi mahasiswa putra dan putri
Tinggi mhs putra (cm) Tinggi mhs putri (cm) Rank tinggi mhs putra Rank tinggi mhs putri 193 175 1 7 188 173 2 8 185 168 3 10 183 165 4 11 180 163 5 12 178 6 170 9 n1 = 7 n2 = 5 R1 = 30 R2 = 48 U = n1n2 + n1(n1+1) – R1 2 U=(7)(5) + (7)(8) – 30 2 U = 35 + 28 – 30 U = 33 U’ = n1n2 – U U’ = (7)(5) – 33 U’ = 2
Beda antar kelompok independen
Kelompok lebih dari satu Parametrik Nonparametrik Analisis variansi (ANOVA/ MANOVA) Analisis rank Kruskal-Wallis Uji MedianBeda antar kelompok dependen
Membanding dua
variabel diukur dalam sampel yang sama
Parametrik Nonparametrik
Uji-t untuk sampel
dependen Uji Tanda Uji Data
Berpasangan Wilcoxon
Hubungan Antar Variabel
Kedua variabel kategorik Parametrik Nonparametrik Koefisien Korelasi Pearson r Spearman R Kendall Tau Gamma Koefisien Chi Kuadrat Koefisien PhiTabel Statistik Uji
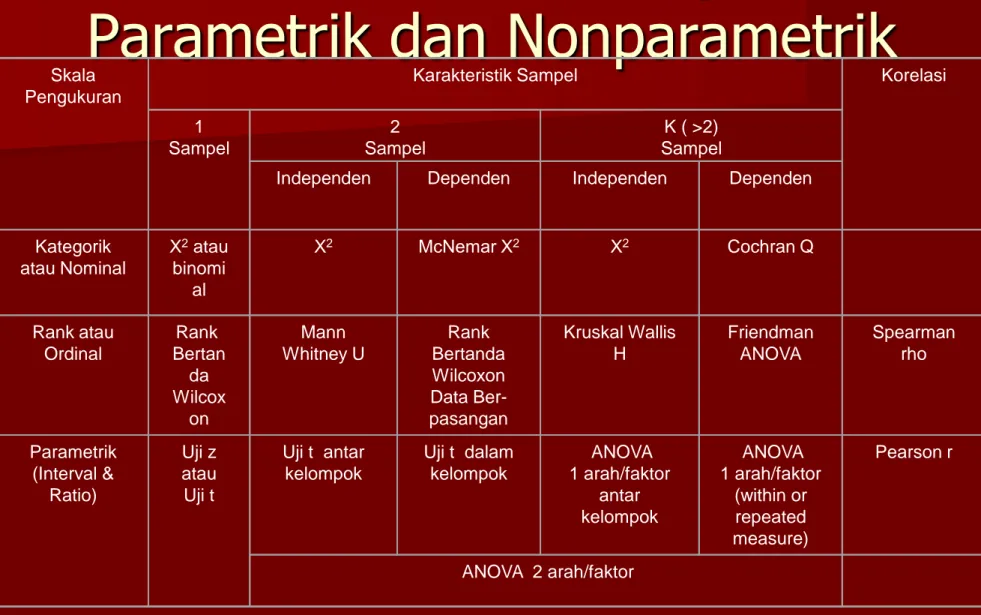
Parametrik dan Nonparametrik
Skala Pengukuran
Karakteristik Sampel Korelasi 1 Sampel 2 Sampel K ( >2) Sampel
Independen Dependen Independen Dependen Kategorik atau Nominal Χ2atau binomi al Χ2 McNemar Χ2 Χ2 Cochran Q Rank atau Ordinal Rank Bertan da Wilcox on Mann Whitney U Rank Bertanda Wilcoxon Data Ber-pasangan Kruskal Wallis H Friendman ANOVA Spearman rho Parametrik (Interval & Ratio) Uji z atau Uji t Uji t antar kelompok Uji t dalam kelompok ANOVA 1 arah/faktor antar ANOVA 1 arah/faktor (within or Pearson r
Keuntungan Uji Nonparametrik
Probability statements obtained from most
nonparametric statistics are exact
probabilities, regardless of the shape of
the population distribution from which the random sample was drawn
If sample sizes as small as N=6 are used,
Keuntungan Uji Nonparametrik
Treat samples made up of observations from
several different populations.
Can treat data which are inherently in ranks as
well as data whose seemingly numerical scores have the strength in ranks
They are available to treat data which are
Kritik untuk Metode Nonparametrik
Losing precision/wasteful of data Kuasa rendah
False sense of security
Tidak banyak
software
pendukung Hanya menguji distribusi saja Tidak dapat digunakan untuk interaksi
Kuasa suatu Uji
Kuasa statistik – probability of rejecting
the null hypothesis when it is in fact false and should be rejected
– Power of parametric tests – calculated from formula, tables, and graphs based on their underlying distribution
![Keputusan Menteri Kesehatan Republik Indonesia Nomor 1099/MENKES/SK/VII/2004 tentang Penerima dana program kompensasi pengurangan subsidi bahan bakar minyak bidang kesehatan (PKPS-BBM BIDKES) - [PERATURAN]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==)