1
PENDETEKSI KUALITAS BIJI KOPI MENGGUNAKAN
ALGORITMA NAÏVE BAYES
Rio Ardiarta M1,T. Sutojo,S.Si, M.Kom2 1Fakultas Ilmu Komputer,2Universitas Dian Nuswantoro
Jl. Nakula 1 No. 5-11, Jawa Tengah 50131 Telp : (024) 3517261 E-mail :[email protected], [email protected]2
Abstrak
Kopi adalah sejenis minuman yang berasal dari proses pengolahan dan ekstraksi biji tanaman kopi merupakan salah satu hasil komoditi perkebunan yang memiliki nilai ekonomis yang cukup tinggi di antara tanaman perkebunan lainnya dan berperan penting sebagai sumber devisa negara. Kata kopi sendiri berasal dari bahasa Arab Qahwah yang berarti kekuatan, mengalami perubahan menjadi Kahveh yang berasal dari bahasa Turki dan kemudian berubah lagi menjadi Koffie dalam bahasa Belanda. Koffie segera diserap ke dalam bahasa Indonesia menjadi kata Kopi. Keberhasilan agribisnis kopi membutuhkan dukungan semua pihak yang terkait dalam proses produksi kopi pengolahan dan pemasaran komoditas kopi. Teknologi budi daya dan pengolahan kopi meliputi pemilihan bahan tanam kopi unggul, pemeliharaan, pemangkasan tanaman dan pemberian penaung, pengendalian hama dan gulma, pemupukan yang seimbang, pemanenan, serta pengolahan kopi pasca panen. Berdasarkan pertimbangan diatas, maka perlu diadakan penelitian mengenai proses penyangraian biji kopi berkaitan dengan suhu dan lama waktu yang digunakan selama penyangraian. Berdasarkan hasil penelitian ditunjukan bahwa, klasifikasi mutu biji kopi (RWP 1 dan RWP 4) dengan menggunakan algoritma naive bayes berdasarkan tekstur pada citra dapat digunakan sebagai penentu kualitas biji kopi secara visual. Hasil penelitian menunjukan bahwa klasifikasi mutu biji kopi dengan menggunakan metode naive bayes berdasarkan tekstur pada citra memperoleh nilai akurasi sebesar 73,33%.
Kata Kunci: Biji Kopi, Naïve Bayes, Citra Fitur
Abstract
Coffee is a beverage that comes from processing and seed extraction plant coffee is one commodity plantations results that have a fairly high economic value among other plantation crops and plays an important role as a source of foreign exchange of the country. Own coffee words derived from Arabic Qahwah which means strength, changes become Kahveh which derives from the Turkey and then changed again into Koffie in Netherlands language. Koffie is immediately absorbed into the language of Indonesia became the word coffee. Coffee agribusiness success requires the support of all parties concerned in the process of coffee production processing and marketing of commodities. The technology of cultivation and processing of coffee include material selection of superior coffee planting, pruning, maintenance plant and the granting of the patron, weed and pest control, balanced fertilization, harvesting, post-harvest coffee processing as well. Based on the above considerations, it is necessary held research on the process of cooking beans related to temperature and the length of time used during cooking. Based on the results of the study indicated that, in the classification of the quality of the coffee beans (RWP RWP 1 and 4) with the naive bayes algorithm based on texture on the image can be used as a determinant of the quality of the coffee beans are visually. Research results show that the classification of the quality of the coffee beans with naive bayes algorithm based on texture on the image gain value accuracy of 73,33%.
2
1. PENDAHULUAN
Kopi merupakan salah satu hasil komoditi perkebunan yang memiliki nilai ekonomis yang cukup tinggi di antara tanaman perkebunan lainnya dan berperan penting sebagai sumber devisa negara. Kopi tidak hanya berperan penting sebagai sumber devisa melainkan juga merupakan sumber penghasilan bagi tidak kurang dari satu setengah juta jiwa petani kopi di Indonesia.
Keberhasilan agribisnis kopi membutuhkan dukungan semua pihak yang terkait dalam proses produksi kopi pengolahan dan pemasaran komoditas kopi. Upaya meningkatkan produktivitas dan mutu kopi terus dilakukan sehingga daya saing kopi di Indonesia dapat bersaing di pasar dunia.
Teknologi budi daya dan pengolahan kopi meliputi pemilihan bahan tanam kopi unggul, pemeliharaan, pemangkasan tanaman dan pemberian penaung, pengendalian hama dan gulma, pemupukan yang seimbang, pemanenan, serta pengolahan kopi pasca panen. Pengolahan kopi sangat berperan penting dalam menentukan kualitas dan cita rasa kopi.
Saat ini, peningkatan produksi kopi di Indonesia masih terhambat oleh rendahnya mutu biji kopi yang dihasilkan sehingga mempengaruhi pengembangan produksi akhir kopi. Hal ini disebabkan, karena penanganan pasca panen yang tidak tepat antara lain proses fermentasi, pencucian, sortasi, pengeringan, dan penyangraian. Selain itu spesifikasi alat/mesin yang digunakan juga dapat mempengaruhi setiap tahapan pengolahan biji kopi.
Oleh karena itu, untuk memperoleh biji kopi yang bermutu baik maka diperlukan penanganan pasca panen yang tepat dengan
melakukan setiap tahapan secara benar. Proses penyangraian merupakan salah satu tahapan yang penting, namun saat ini masih sedikit data tentang bagaimana proses penyangraian yang tepat untuk menghasilkan produk kopi berkualitas.
Berdasarkan pertimbangan diatas, maka perlu diadakan penelitian mengenai proses penyangraian biji kopi berkaitan dengan suhu dan lama waktu yang digunakan selama penyangraian.
Naive bayes berdasarkan
konsep ‘learning by analogy’. Data
learning dideskripsikan dengan atribut numerik n-dimensi. Tiap data
learning merepresentasikan sebuah
titik, yang ditandai dengan c, dalam ruang n-dimensi. Jika sebuah data
query yang labelnya tidak diketahui
diinputkan, maka Naive bayes akan mencari k buah data learning yang jaraknya paling dekat dengan data
query dalam ruang n-dimensi. Jarak
antara data query dengan data
learning dihitung dengan cara mengukur jarak antara titik yang merepresentasikan data query dengan semua titik yang merepresentasikan data learning dengan rumus
Euclidean Distance.
Pada fase training,
algoritma ini hanya melakukan penyimpanan vektor-vektor fitur dan klasifikasi data training sample. Pada fase klasifikasi, fitur – fitur yang sama dihitung untuk testing data (klasifikasinya belum diketahui). Jarak dari vektor yang baru ini terhadap seluruh vektor training
sample dihitung, dan sejumlah k buah
yang paling dekat diambil. Titik yang baru klasifikasinya diprediksikan termasuk pada klasifikasi terbanyak dari titik – titik tersebut.
Ketepatan algoritma Naive bayes ini sangat dipengaruhi oleh ada
3 atau tidaknya fitur-fitur yang tidak
relevan, atau jika bobot fitur tersebut tidak setara dengan relevansinya terhadap klasifikasi. Riset terhadap algoritma ini sebagian besar membahas bagaimana memilih dan memberi bobot terhadap fitur, agar performa klasifikasi menjadi lebih baik.
K buah data learning terdekat akan
melakukan voting untuk menentukan label mayoritas. Label data query akan ditentukan berdasarkan label mayoritas dan jika ada lebih dari satu label mayoritas maka label data query dapat dipilih secara acak di antara label-label mayoritas yang ada.
2. TINJAUAN PUSTAKA
2.1 Tinjauan Pustaka
Penelitian yang telah dilakukan oleh peneliti – peneliti terdahulu terkait dengan penelitian yang akan dilakukan oleh penulis yang selama ini diketahui, adalah :
Untuk mengatasi
permasalahan peningkatan keakuratan
dalam penentuan pengklasifikasian jenis tebu tersebut diperlukan sebuah penghitungan yang menerapkan
metode yang dapat
mengklasifikasikan varietas tebu produktif sesuai dengan atribut yang ada pada data Dinas Kehutanan dan Perkebunan Pati, atribut yang digunakan antara lain adalah jenis tebu, hasil produksi, umur panen, diameter batang daerah tanam, bobot batang, rendeman, serta macam got. Salah satu metode yang dapat diterapkan dalam permasalahan ini adalah Naïve BayesClassifier (NBC).
Penggunaan metode naïve bayes dalam penelitian ini salah satunya adalah adanya keterkaitan antara penggunaan metode naïve bayes dalam menanganipermasalahan penentuan tebu yang produktif. Metodenaïve bayes memberikan kemudahan dalam menghitung dan
menentukan
kemungkinan-kemungkinan jenis tebuproduktif
dengan menggunakan semua atribut yang ada sehingga dalam penentuan jenis tebu produktif atau tidak lebih akurat, sehingga dapat meningkatkan level produktivitas perkebunan tebu di Pati dan meminimalkan biaya produksi untuk membeli varietas tebu yang produktif saja serta dapat memberikan kemudahan bagiindustri tebu untuk meningkatkan pola pembudidayaan dan produksi tebu agar menghasilakan tebu-tebu yang berkualitas.
2.2 Landasan Teori
2.2.1 Biji Kopi
Kopi adalah sejenis minuman yang berasal dari proses pengolahan dan ekstraksi biji tanaman kopi. Kata kopi sendiri berasal dari bahasa Arab Qahwah yang berarti kekuatan, karena pada awalnya kopi digunakan sebagai makanan berenergi tinggi. Kata qahwah kembali mengalami perubahan menjadi Kahveh yang berasal dari bahasa Turki dan kemudian berubah lagi menjadi Koffie dalam bahasa Belanda. Penggunaan kata koffie segera diserap ke dalam bahasa Indonesia menjadi kata Kopi yang dikenal saat ini.
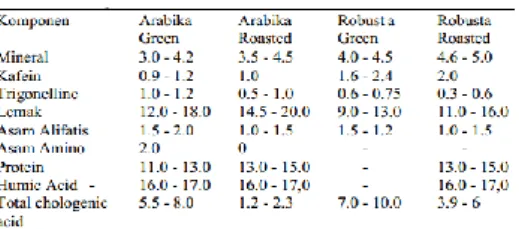
Tabel 2.1 Komposisi Biji Kopi Sebelum
dan sesudah disangrai
2.2.2 Sejarah Awal Ditemukannya Koi
Era penemuan biji kopi dimulai sekitar tahun 800 SM. Pada saat itu, banyak orang di Benua Afrika, terutama bangsa Etiopia, yang mengonsumsi biji kopi yang dicampurkan dengan lemak hewan dan anggur untuk memenuhi kebutuhan protein dan energi tubuh. Penemuan kopi sendiri terjadi secara tidak sengaja ketika seorang penggembala kambing mengamati
4 kawanan kambing gembalaannya
yang tetap terjaga bahkan setelah matahari terbenam setelah memakan sejenis beri-berian. Sang gembala pun melihat kambingnya selalu melompat-lompat setiap kali ia memakan biji-bijian dari suatu tanaman yang kelak dinamakan
kopi
2.2.3 Perkembangan Kopi di Arab
Dari Ethiophia, kopi kemudian dibawa ke Arab. Pada abad ke-11 bangsa Arab yang memiliki peradaban yang lebih maju daripada bangsa Afrika saat itu, tidak hanya memasak biji kopi, tetapi juga direbus untuk diambil sarinya. Pada saat itu kopi menjadi minuman utama di Negara-Negara Muslim. Kepopuleran kopi bisa jadi disebabkan oleh dua hal yaitu karena memberikan efek bugar kepada tubuh dan sebagai pengganti minuman khamar atau alkohol yang memang dilarang oleh Islam.
Kepopuleran kopi pun turut meningkat seiring dengan penyebaran agama Islam pada saat itu hingga mencapai daerah Afrika Utara, Mediterania, dan India. Kisah pengembaraan umat Muslim tidak terlepas dari kopi, kemanapun orang Muslim menyebarkan agamanya, kopi selalu dibawa. Sehingga pada abad ke-13 kopi sudah menyebar ke Afrika Utara, Negara-Negara Mediterania dan India. Pada abad ke-14 dan 15, budaya minum kopi sudah menyebar di Turki, Mesir, Syiria, Persia
.
2.2.4 Penyebaran Kopi ke Seluruh
Dunia
Eropa tidak mengenal kopi hingga abad ke-17 ketika orang-orang Itali untuk pertama kali berhasil membawa biji kopi ke Venezia (1615). Mereka mendapatkan pasokan biji kopi dari orang Turki. Kehadiran kopi di Itali segera tercium ke Negara Eropa lainnya. Hingga satu tahun
kemudian, Belanda menjadi Negara Eropa pertama yang berhasil membudidayakannya pada tahun 1616. Pada tahun 1650, untuk pertama kalinya Inggris memiliki kedai kopi di kota Oxford. 2 tahun kemudian Inggris sudah memiliki ratusan kedai kopi.
Kemudian pada tahun 1690, biji kopi dibawa ke Pulau Jawa untuk dikultivasi secara besar-besaran. Pada saat itu, Indonesia masih merupakan negara jajahan Kolonial Belanda. Di sini Belanda membuka perkebunan kopi di Pulau Jawa dan menjual hasilnya ke Eropa. Penanaman kopi oleh Belanda sukses besar dan Amsterdam menjadi pusat
perdagangan
kopi
se-Eropa
hingga abad ke-18.
2.2.5 Pengolahan Citra Digital
Pengolahan citra digital adalah sebuah disiplin ilmu yang mempelajari hal-hal yang berkaitan dengan perbaikan kualitas gambar,transformasi gambar, melakukan pemilihan ciri (feature
images) yang optimal untuk tujuan
analisis, melakukan proses informasi didalam citra, melakukan kompresi atau reduksi data untuk tujuan peniyimpanan data, transmisi data, dan waktu proses data.
Data atau informasi biasanya didapatkan pada suatu teks. Pada kenyataannya suatu citra dapat memberikan data atau informasi, pengolahan citra merupakan salah satu cara untuk mendapatkan data atau informasi yang di dapatkan pada suatu citra. Proses analisis data sering digunakan dalam pengambilan data pada suatu citra.
2.2.6 Citra Digital
Secara garis besar, pengolahan citra digital berlandaskan pada pemrosesan
5
gambar dua dimensi
menggunakan komputer. Citra digital adalah sebuah larik (array) yang berisikan atas nilai – nilai real maupun kompleks yang direpresentasikan dalam deretan
bit.
Suatu citra dapat diwakili oleh fungsi f(x,y) berukuran M baris dan N kolom, dimana nilai x dan y merupakan koordinat spasial. Nilai pada suatu irisan antara baris dan kolom (pada posisi x,y) disebut dengan picture
elements, image elements, atau
piksel. Namun, yang lebih sering digunakan pada citra digital adalah piksel.
2.2.7 Ekstraksi Fitur
Ekstraksi fitur merupakan suatu pengambilan ciri / feature dari suatu citra yang nantinya nilai yang didapatkan akan dianalisis untuk proses selanjutnya. Feature
extraction dilakukan dengan cara
menghitung jumlah titik atau piksel yang ditemui dalam setiap pengecekan, dimana pengecekan dilakukan dalam berbagai arah tracing pengecekan pada koordinat kartesian dari citra digital yang dianalisis, yaitu vertikal, horizontal, diagonal kanan, dan
diagonal kiri.
2.2.8 Mean
Pada Mean nilai intensitas setiap pixel diganti dengan rata – rata dari nilai intensitas pixel tersebut dengan pixel-pixel tetangganya. Filter ini biasanya disebut sebagai filter penghalus (smoothing filters). Filter ini biasa digunakan untuk mengaburkan (blurring) citra untuk mereduksi noise. Blurring biasanya digunakan untuk menghilangkan detail kecil dari suatu citra sebelum dilakukan ekstraksi objek dan untuk menghubungkan celah kecil yang memisahkan garis atau kurva dan juga bisa digunakan untuk mereduksi noise
2.2.9 Standtart Deviasi
Standard Deviasi adalah akar kuadrat dari total selisih dengan nilai rata-ratanya. Standard deviasi adalah salah satu teknik statistik yg digunakan untuk menjelaskan homogenitas kelompok. Standard deviasi disebut juga dengan atau simpangan baku. Standard deviasi merupakan variasi sebaran data. semakin kecil nilai sebarannya berarti variasi nilai data makin sama. Jika sebarannya bernilai 0, maka nilai semua datanya adalah sama. Semakin besar nilai sebarannya berarti data semakin bervariasi. Dengan menghitung nilai standar deviasi dari sebuah citra, akan didapat jumlah ukuran yang detail pada sub band.
2.2.10 Kurtois dan Skewness
Skewness dan kurtosis
merupakan rata- rata nilai piksel
(Px) dikurangi mean (μ)
kemudian dipangkatkan dengan
n pada masing-masing channel
RGB (Red, Green, Blue), HSI
(Hue, Saturation, Intensity) dan
HSV (Hue, Saturation, Value).
2.2.11 Pengertian Metode Klasifikasi
dan Algoritma Naïve Bayes
Klasifikasi dapat didefinisikan secara detail sebagai suatu pekerjaan yang melakukan pelatihan atau pembelajaran terhadap fungsi target f yang memetakan setiap vektor x ke dalam suatu dari sejumlah label y kelas yang tersedia. Pekerjaan tersebut akan menghasilkan suatu model yang kemudian disimpan sebagai memori.
Model yang sudah dibangun pada saat pelatihan kemudian dapat digunakan memprediksi label kelas dari data baru yang belum diketahui label kelasnya. Dalam pembangunan model selama proses pelatihan tersebut, dibutuhkan adanya suatu algoritma pelatihan
6 diantaranya: Decission Tree,
KNN, SVM, Naive Bayes dan sebagainya.
Naive Bayes Classifier
(NBC) disebut juga Bayesian
Classification merupakan metode pengklasifikasian statistik yang dapat digunakan
untuk memprediksi
probabilitas keanggotaan dari suatu class. Naive bayes classifier didasarkan pada teorema Bayes yang memiliki kemampuan klasifikasi serupa
Decision Tree dan Neural Network. Selain itu NBC juga
efisien, efektif dan handal menangani derau data seperti atribut yang tidak relevan.
Naive bayes classifier juga dapat menangani dataset yang besar baik dengan atribut variabel diskrit atau kontinyu
.
3. METODE PENELITIAN
3.1 Jenis Penelitian
Jenis penelitian yang dilaksanakan ini merupakan penelitian eksperimental, yaitu penelitian yang pengumpulan datanya melalui pengambilan citra biji kopi secara langsung dengan menggunakan
smartphone android. Data yang sudah
terkumpul selanjutnya dilakukan perhitungan nilai nilai mean, standar deviasi, kurtosis, dan skewness warna dari kopi tersebut dan kemudian dilakukan prediksi melalui klasifikasi NAIVE BAYES.
3.2 Instrumen Penelitian
Dalam penelitian ini, dibutuhkan beberapa komponen peralatan, yaitu:
3.2.1 Kebutuhan Software
Kebutuhan perangkat lunak merupakan faktor penting yang harus dipenuhi dalam penelitian ini, sehingga perangkat lunak tersebut sesuai dengan maksud dan tujuan peneliti. Adapun perangkat lunak yang dibutuhkan dalam penelitian ini adalah sebagai berikut :
a. Sistem Operasi
Sistem operasi yang digunakan dalam penelitian ini adalah Windows 7. b. MATLAB
Software ini digunakan untuk perhitungan nilai nilai mean, standar deviasi,
kurtosis, dan skewness
warna pada citra biji kopi yang nantinya akan implementasikan pada
mobile android.
c. Eclipse
Software ini digunakan untuk implementasi proses yang sudah dirancang
sehingga dapat
menghasilkan sebuah aplikasi pendeteksi biji kopi dan biji kopi jelek. d. Ms. Word
Software ini digunakan untuk
membuat laporan hasil penelitian.
3.2.2 Kebutuhan Hardware
Selain kebutuhan software, diperlukan pula hardware yang harus dipenuhi agar penelitian ini berjalan dengan lancar. Adapun hardware yang digunakan dalam penelitian ini adalah sebagai berikut:
a. Personal Computer atau laptop dengan spesifikasi :
Prosesor : Dual core Sistem Operasi : Windows 7 RAM : 2 GB
b. Smartphone android dengan spesifikasi :
Prosesor : Dual core Sistem Operasi : Android RAM : 512 MB Kamera : 3 Megapiksel Printer, digunakan untuk mencetak hasil penelitian ke dalam bentuk hardcopy
.
7
3.3 Pengupulan Data
Dalam usaha untuk
mendapatkan data –data yang benar sehingga tercapai maksud dan tujuan penyusunan Tugas Akhir ini, Penulis menggunakan metode pengumpulan data dari jenis data dengan cara sebagai berikut :
a. Data Primer
Data primer yaitu data yang diperoleh secara langsung dapat dilakukan melalui pengambilan citra secara langsung dari kamera smartphone android.
Data primer dapat berupa :
Data dari penelitian biji kopi.
Data dari warna biji kopi b. Data Sekunder
Data sekunder yaitu data yang diperoleh secara tidak langsung yang dapat berupa catatan –catatan, laporan –laporan tertulis, dokumen – dokumen dan makalah – makalah serta daftar pustaka.
Data Sekunder dapat berupa :
Literatur tentang perbedaan warna biji kopi.
3.4 Metode Yang Diusulkan
Secara umum deteksi biji kopi
dapat di gambarkan pada kerangka
pemikiran sebagai berikut :
Gambar 3.1 Kerangka Pemikiran Citra Digital
3.4.1 Fase Pelatihan
Fase pelatihan adalah tahapan pertama dalam pegenalan pola yang membangun pengetahuan sistem. Pada fase ini, sampel biji kopi ditangkap (capture) citranya melalui sensor kamera smartphone
android. Sampel biji kopi yang digunakan
terdiri dari beberapa sampel kualitas biji kopi untuk masing – masing kelas, kemudian dilakukan pemrosesan awal (preprocessing).
3.4.2 Fase Pengenalan
Fase pengenalan adalah tahapan kelas yang mengambil ciri objek untuk ditentukan kelas objeknya. Pada fase pengenalan, biji kopi yang akan di deteksi diambil atau capture citranya melalui sensor kamera smartphone android,
kemudian dilakukan pemrosesan awal (preprocessing) dan ekstraksi fitur seperti pada fase pelatihan (training).
3.4.3 Pengukuran Kinerja Klasifikasi
Sebuah system yang melakukan klasifikasi diharapkan melakukan klasifikasi pada set data dengan benar, tetapi tidak dapat di pungkiri bahwa kinerja suatu sistem tidak bisa 100% benar sehingga sebuah sistem klasifikasi juga harus diukur kinerjanya. Pada penelitian kali ini pengukuran klasifikasi dilakukan dengan matriks konfusi (confusion matrix).
4. HASIL PENELITIAN DAN
PEMBAHASAN
Bab ini membahas tentang implementasi dari langkah–langkah penelitian yang dilakukan beserta hasil eksperimen dan hasil analisis data yang telah dilakukan.
4.1 Citra Biji Kopi
Dalam melakukan
eksperimen ini diperlukan sejumlah 157 citra biji kopi yang digunanakan sebagai dataset. Dataset tersebut didapatkan dengan meminjam data atau bahan dari PTPN IX. Sebelum dilakukan
8 proses klasifikasi, proses
penyortiran citra sesuai jenis kualitas biji kopi terlebih dahulu. Hal tersebut dilakukan untuk memudahkan dalam pemilihan kualitas biji kopi permutu dan pengelompokan untuk data training dan memudahkan dalam melakukan pencocokan hasil data testing dari penggunaan metode yang diusulkan.
(a)
(b)
RWP 1
RWP 4
Gambar 4.1 Contoh Dataset Biji Kopi dari Jenisnya
4.2Pengolahan Awal Citra Biji Kopi
Tahap pengolahan awal data citra diperlukan untuk menyiapkan data yang valid sebelum diproses kedalam tahapan selanjutnya. Beberapa proses dilakukan sebelum citra biji kopi dapat diekstraksi fitur-fiturnya. Tahapan ini berlaku untuk data training maupun data testing. Langkah yang dilakukan dalam pengolahan awal citra yaitu : normalisasi dan color convertion. 4.2.1 Normalisasi Citra Biji Kopi
Citra biji kopi memiliki dimensi yang besar, sehingga perlu dilakukan normalisasi ke dalam ukuran tertentu untuk semua data. Hal ini bertujuan untuk menyamakan ukuran dan menyamakan perhitungan serta meminimalkan konsumsi memori. Ukuran yang ditentukan untuk penelitian ini adalah 128x128 piksel.
(a) (b)
Gambar 4.2 Citra Biji Kopi RWP Sebelum (a) dan Sesudah Normalisasi Ukuran (b).
4.2.2 Color Convertion Citra Biji Kopi Tahapan color convertion
berfungsi untuk mengubah citra biji kopi hasil normalisasi yang masih merupakan citra warna RGB ke dalam bentuk citra berskala keabuan atau grayscale.
(a) (b)
Gambar 4.3 Citra Biji Kopi RWP Sebelum (a) dan Sesudah Konversi
Grayscale (b).
4.3 Ekstraksi Fitur Citra Biji Kopi
Tahapan selanjutnya yang akan dilakukan setelah tahapan pengolahan awal citra adalah tahap ekstraksi fitur. Ekstraksi fitur citra biji kopi ini bertujuan untuk mendapatkan informasi mengenai fitur–fitur yang dibutuhkan dalam klasifikasi jenis mutu biji kopi. Fitur–fitur tersebut didapatkan dengan melakukan analisa dan perhitungan yang dilakukan pada gambar digital. Hasil dari tahap ekstraksi fitur inilah yang nantinya akan mempengaruhi hasil klasifikasi jenis mutu biji kopi.
4.3.1 Ekstraski Fittur Tekstur Citra Biji Kopi
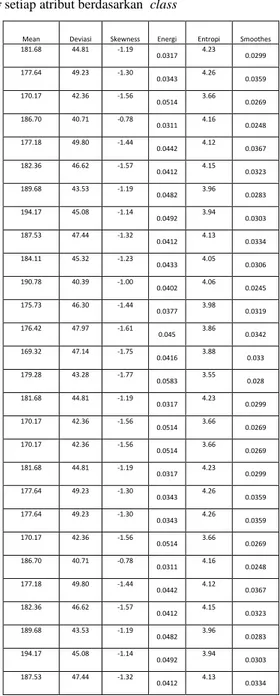
Ekstraksi fitur tekstur citra biji kopi bertujuan untuk mendapatkan ciri tekstur dari citra biji kopi. Metode ekstraksi fitur tekstur yang digunakan pada citra biji kopi tersebut menggunakan metode stastistical histogram. Adapun fitur yang didapatkan adalah intensitas, deviasi standar, skewness, energi, entropi, dan smoothness.
Tabel 4.1 Fitur Tekstur Berbassis Histogram Pada RWP 1
4.4 Klasifikasi Citra Biji Kopi
Proses pengujian model menggunakan Naive Bayes adalah fokus dari eksperimen klasifikasi mutu biji kopi. Tahapan–tahapan sebelum pengenalan dan pelatihan telah selesai
9 dilakukan, dimana hasilnya didapatkan
ekstraksi fitur biji kopi berupa ciri tekstur berdasarkan pada histogram. Selanjutnya hasil dari pengolahan data
testing akan dilakukan prosedur klasifikasi berdasarkan pada data
training yang telah dibuat.
Pada tahap pengujian 15 data citra biji kopi yang berbeda dengan data latih digunakan sebagai citra uji. Citra tersebut terdiri dari 5 data tiap jenis biji kopi. Dari hasil pengolahan tiap citra uji tersebut, selanjutnya dilakukan prosedur klasifikasi menggunakan perhitungan metode
naive bayes.
Tabel 4.5 Nilai RWP 1 mean μ dan standar deviasi
σ setiap atribut berdasarkan class
Mean Deviasi Skewness Energi Entropi Smoothes 181.68 44.81 -1.19 0.0317 4.23 0.0299 177.64 49.23 -1.30 0.0343 4.26 0.0359 170.17 42.36 -1.56 0.0514 3.66 0.0269 186.70 40.71 -0.78 0.0311 4.16 0.0248 177.18 49.80 -1.44 0.0442 4.12 0.0367 182.36 46.62 -1.57 0.0412 4.15 0.0323 189.68 43.53 -1.19 0.0482 3.96 0.0283 194.17 45.08 -1.14 0.0492 3.94 0.0303 187.53 47.44 -1.32 0.0412 4.13 0.0334 184.11 45.32 -1.23 0.0433 4.05 0.0306 190.78 40.39 -1.00 0.0402 4.06 0.0245 175.73 46.30 -1.44 0.0377 3.98 0.0319 176.42 47.97 -1.61 0.045 3.86 0.0342 169.32 47.14 -1.75 0.0416 3.88 0.033 179.28 43.28 -1.77 0.0583 3.55 0.028 181.68 44.81 -1.19 0.0317 4.23 0.0299 170.17 42.36 -1.56 0.0514 3.66 0.0269 170.17 42.36 -1.56 0.0514 3.66 0.0269 181.68 44.81 -1.19 0.0317 4.23 0.0299 177.64 49.23 -1.30 0.0343 4.26 0.0359 177.64 49.23 -1.30 0.0343 4.26 0.0359 170.17 42.36 -1.56 0.0514 3.66 0.0269 186.70 40.71 -0.78 0.0311 4.16 0.0248 177.18 49.80 -1.44 0.0442 4.12 0.0367 182.36 46.62 -1.57 0.0412 4.15 0.0323 189.68 43.53 -1.19 0.0482 3.96 0.0283 194.17 45.08 -1.14 0.0492 3.94 0.0303 187.53 47.44 -1.32 0.0412 4.13 0.0334 184.11 45.32 -1.23 0.0433 4.05 0.0306 190.78 40.39 -1.00 0.0402 4.06 0.0245 175.73 46.30 -1.44 0.0377 3.98 0.0319 176.42 47.97 -1.61 0.045 3.86 0.0342 169.32 47.14 -1.75 0.0416 3.88 0.033 179.28 43.28 -1.77 0.0583 3.55 0.028 181.68 44.81 -1.19 0.0317 4.23 0.0299 170.17 42.36 -1.56 0.0514 3.66 0.0269 170.17 42.36 -1.56 0.0514 3.66 0.0269 181.68 44.81 -1.19 0.0317 4.23 0.0299 177.64 49.23 -1.30 0.0343 4.26 0.0359 177.64 49.23 -1.30 0.0343 4.26 0.0359 170.17 42.36 -1.56 0.0514 3.66 0.0269 186.70 40.71 -0.78 0.0311 4.16 0.0248 177.18 49.80 -1.44 0.0442 4.12 0.0367 182.36 46.62 -1.57 0.0412 4.15 0.0323 189.68 43.53 -1.19 0.0482 3.96 0.0283 194.17 45.08 -1.14 0.0492 3.94 0.0303 187.53 47.44 -1.32 0.0412 4.13 0.0334 184.11 45.32 -1.23 0.0433 4.05 0.0306 190.78 40.39 -1.00 0.0402 4.06 0.0245 175.73 46.30 -1.44 0.0377 3.98 0.0319 176.42 47.97 -1.61 0.045 3.86 0.0342 169.32 47.14 -1.75 0.0416 3.88 0.033 179.28 43.28 -1.77 0.0583 3.55 0.028 181.68 44.81 -1.19 0.0317 4.23 0.0299 170.17 42.36 -1.56 0.0514 3.66 0.0269 170.17 42.36 -1.56 0.0514 3.66 0.0269 181.68 44.81 -1.19 0.0317 4.23 0.0299 177.64 49.23 -1.30 0.0343 4.26 0.0359 µ Mean 163.26 2,620.97 -1.23 0 3.62 0 𝜎 Deviasi 1,763,389.59 40.95 13,111.77 0.32 43,749.91 0.23
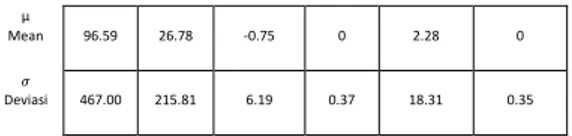
Tabel 4.5 Nilai RWP 4 mean μ dan standar deviasi σ setiap atribut berdasarkan class
Mean Deviasi Skewness Energi Entropi Smoothes Label 187.14 186.51 45.77 45.14 -1.38 -2.01 0.048 174.77 174.14 50.76 50.13 -1.30 -1.93 0.0345 174.85 174.22 50.31 49.69 -1.43 -2.06 0.0355 173.84 173.21 51.39 50.76 -1.41 -2.04 0.0376 182.01 181.38 50.65 50.02 -1.55 -2.18 0.0401 173.41 172.78 47.54 46.92 -1.56 -2.19 0.0367 177.09 176.46 42.48 41.86 -0.9545 -1.58 0.0344
10 174.85 174.22 50.31 49.69 -1.43 -2.06 0.0355 177.09 176.46 42.48 41.86 -0.9545 -1.58 0.0344 187.14 186.51 45.77 45.14 -1.38 -2.01 0.048 174.77 174.14 50.76 50.13 -1.30 -1.93 0.0345 182.01 181.38 50.65 50.02 -1.55 -2.18 0.0401 174.85 174.22 50.31 49.69 -1.43 -2.06 0.0355 170.26 169.63 48.15 47.52 -1.28 -1.91 0.0371 169.12 168.49 47.38 46.76 -1.51 -2.14 0.0342 169.00 168.37 51.02 50.39 -1.51 -2.13 0.0334 187.14 186.51 45.77 45.14 -1.38 -2.01 0.048 174.77 174.14 50.76 50.13 -1.30 -1.93 0.0345 174.85 174.22 50.31 49.69 -1.43 -2.06 0.0355 170.26 169.63 48.15 47.52 -1.28 -1.91 0.0371 174.85 174.22 50.31 49.69 -1.43 -2.06 0.0355 182.01 181.38 50.65 50.02 -1.55 -2.18 0.0401 177.09 176.46 42.48 41.86 -0.95 -1.58 0.0344 187.14 186.51 45.77 45.14 -1.38 -2.01 0.048 174.77 174.14 50.76 50.13 -1.30 -1.93 0.0345 182.01 181.38 50.65 50.02 -1.55 -2.18 0.0401 170.26 169.63 48.15 47.52 -1.28 -1.91 0.0371 173.84 173.21 51.39 50.76 -1.41 -2.04 0.0376 174.77 174.14 50.76 50.13 -1.30 -1.93 0.0345 174.85 174.22 50.31 49.69 -1.43 -2.06 0.0355 170.26 169.63 48.15 47.52 -1.28 -1.91 0.0371 169.00 168.37 51.02 50.39 -1.51 -2.13 0.0334 187.14 186.51 45.77 45.14 -1.38 -2.01 0.048 174.77 174.14 50.76 50.13 -1.30 -1.93 0.0345 174.85 174.22 50.31 49.69 -1.43 -2.06 0.0355 173.84 173.21 51.39 50.76 -1.41 -2.04 0.0376 182.01 181.38 50.65 50.02 -1.55 -2.18 0.0401 173.41 172.78 47.54 46.92 -1.56 -2.19 0.0367 177.09 176.46 42.48 41.86 -0.95 -1.58 0.0344 174.85 174.22 50.31 49.69 -1.43 -2.06 0.0355 177.09 176.46 42.48 41.86 -0.95 -1.58 0.0344 187.14 186.51 45.77 45.14 -1.38 -2.01 0.048 174.77 174.14 50.76 50.13 -1.30 -1.93 0.0345 182.01 181.38 50.65 50.02 -1.55 -2.18 0.0401 174.85 174.22 50.31 49.69 -1.43 -2.06 0.0355 170.26 169.63 48.15 47.52 -1.28 -1.91 0.0371 169.12 168.49 47.38 46.76 -1.51 -2.14 0.0342 169.00 168.37 51.02 50.39 -1.51 -2.13 0.0334 187.14 186.51 45.77 45.14 -1.38 -2.01 0.048 174.77 174.14 50.76 50.13 -1.30 -1.93 0.0345 174.85 174.22 50.31 49.69 -1.43 -2.06 0.0355 170.26 169.63 48.15 47.52 -1.28 -1.91 0.0371 174.85 174.22 50.31 49.69 -1.43 -2.06 0.0355 182.01 181.38 50.65 50.02 -1.55 -2.18 0.0401 177.09 176.46 42.48 41.86 -0.95 -1.58 0.0344 187.14 186.51 45.77 45.14 -1.38 -2.01 0.048 174.77 174.14 50.76 50.13 -1.30 -1.93 0.0345 182.01 181.38 50.65 50.02 -1.55 -2.18 0.0401 170.26 169.63 48.15 47.52 -1.28 -1.91 0.0371 173.84 173.21 51.39 50.76 -1.41 -2.04 0.0376 174.77 174.14 50.76 50.13 -1.30 -1.93 0.0345 174.85 174.22 50.31 49.69 -1.43 -2.06 0.0355 170.26 169.63 48.15 47.52 -1.28 -1.91 0.0371 169.00 168.37 51.02 50.39 -1.51 -2.13 0.0334 187.14 186.51 45.77 45.14 -1.38 -2.01 0.048 174.77 174.14 50.76 50.13 -1.30 -1.93 0.0345 174.85 174.22 50.31 49.69 -1.43 -2.06 0.0355 170.26 169.63 48.15 47.52 -1.28 -1.91 0.0371 174.85 174.22 50.31 49.69 -1.43 -2.06 0.0355 182.01 181.38 50.65 50.02 -1.55 -2.18 0.0401 177.09 176.46 42.48 41.86 -0.95 -1.58 0.0344 187.14 186.51 45.77 45.14 -1.38 -2.01 0.048 174.77 174.14 50.76 50.13 -1.30 -1.93 0.0345 182.01 181.38 50.65 50.02 -1.55 -2.18 0.0401 170.26 169.63 48.15 47.52 -1.28 -1.91 0.0371 173.84 173.21 51.39 50.76 -1.41 -2.04 0.0376 174.77 174.14 50.76 50.13 -1.30 -1.93 0.0345 174.85 174.22 50.31 49.69 -1.43 -2.06 0.0355 170.26 169.63 48.15 47.52 -1.28 -1.91 0.0371 169.00 168.37 51.02 50.39 -1.51 -2.13 0.0334 187.14 186.51 45.77 45.14 -1.38 -2.01 0.048 187.14 186.51 45.77 45.14 -1.38 -2.01 0.048 174.77 174.14 50.76 50.13 -1.30 -1.93 0.0345 182.01 181.38 50.65 50.02 -1.55 -2.18 0.0401 174.85 174.22 50.31 49.69 -1.43 -2.06 0.0355 170.26 169.63 48.15 47.52 -1.28 -1.91 0.0371 169.12 168.49 47.38 46.76 -1.51 -2.14 0.0342 169.00 168.37 51.02 50.39 -1.51 -2.13 0.0334 187.14 186.51 45.77 45.14 -1.38 -2.01 0.048 174.77 174.14 50.76 50.13 -1.30 -1.93 0.0345 174.85 174.22 50.31 49.69 -1.43 -2.06 0.0355 173.84 173.21 51.39 50.76 -1.41 -2.04 0.0376 182.01 181.38 50.65 50.02 -1.55 -2.18 0.0401 173.41 172.78 47.54 46.92 -1.56 -2.19 0.0367 177.09 176.46 42.48 41.86 -0.95 -1.58 0.0344 174.85 174.22 50.31 49.69 -1.43 -2.06 0.0355 177.09 176.46 42.48 41.86 -0.95 -1.58 0.0344
11
µ
Mean 96.59 26.78 -0.75 0 2.28 0
𝜎
Deviasi 467.00 215.81 6.19 0.37 18.31 0.35
4.5 Evaluasi Dan Validasi
Dari hasil eksperimen menggunakan metode naive bayes tersebut didapatkan hasil kecocokan data testing antara hasil dari metode yang diusulkan dengan menggunakan 15 citra uji dan kondisi biji kopi yang sebenarnya. Adapun hasil selengkapnya dapat dilihat pada tabel 4.4 dengan keterangan record berwarna merah menunjukan adanya perbedaan klasifikasi biji kopi antara hasil metode yang diusulkan dengan kondisi biji kopi yang sebenarnya.
Tabel 4.7 Pencocokan Hasil Klasifikasi 15 Data Citra Uji. No Kode Citra Prediksi Sistem Mutu Sebenarnya Hasil 1 RWP1a RWP4 RWP1 FALSE 2 RWP1b RWP1 RWP1 TRUE 3 RWP1c RWP1 RWP1 TRUE 4 RWP1d RWP1 RWP1 TRUE 5 RWP1e RWP1 RWP1 TRUE 6 RWP1f RWP4 RWP1 FALSE 7 RWP4a RWP4 RWP4 TRUE 8 RWP4b RWP1 RWP4 FALSE 9 RWP4c RWP4 RWP4 TRUE 10 RWP4d RWP4 RWP4 TRUE 11 RWP4e RWP4 RWP4 TRUE 12 RWP4f RWP4 RWP4 TRUE 13 RWP4g RWP4 RWP4 TRUE 14 RWP1g RWP1 RWP1 TRUE 15 RWP1h RWP4 RWP1 FALSE
Akurasi menyatakan rasio jumlah data citra biji kopi yang diklasifikasikan secara benar sebagai
grade tertentu (true positive) dan
jumlah data yang terklasifikasi di kelas sebaliknya (true negative) dengan jumlah seluruh data citra biji kopi yang diklasifikasikan. Nilai akurasi dihitung dengan menggunakan persamaan sebagai berikut :
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 =11
15= 0,7333 x 100% =
= 73,33%
Dari percobaan 15 data uji menggunakan metode naive bayes diperoleh akurasi sebesar 73,33% . Hal tersebut menunjukan bahwa penggunaan metode naive bayes dalam menentukan biji kopi berdasarkan tekstur pada citra menggunakan metode
statistical histogram dapat digunakan
sebagai sistem klasifikasi biji kopi. Namun hasil akurasi yang diberikan kurang maksimal jika dibandingkan dengan penelitian. Hal tersebut dapat terjadi karena faktor kurangnya data penelitiah sehingga berpengaruh terhadap hasil klasifikasi. Perbedaan jarak dalam pengambilan gambar serta pencahayaan yang tidak sama juga dapat menjadi factor teknis yang mempengaruhi hasil akurasi
5. Kesimpulan Dan Saran
5.1 Kesimpulan
Berdasarkan hasil dari eksperimen penelitian penentuan mutu biji kopi secara visual dengan menggunakan metode naive bayes berdasarkan tekstur pada citra yang telah dilakukan, maka dapat disimpulkan beberapa hal sebagai berikut:
1 Hasil penelitian menunjukan bahwa klasifikasi mutu biji kopi dengan menggunakan metode
naive bayes berdasarkan tekstur
pada citra memperoleh nilai akurasi sebesar 73,33%.
2 Berdasarkan hasil penelitian ditunjukan bahwa, klasifikasi mutu biji kopi (RWP1 dan RWP4) menggunakan metode naive bayes berdasarkan tekstur pada citra dapat digunakan sebagai penentu biji kopi secara visual.
5.2 Saran
Berdasarkan hasil analisis dan pembahasan pada penelitian tersebut, maka untuk penelitian selanjutnya peneliti memberikan saran yang mungkin bisa dijadikan dasar untuk pengembangan penelitian ini yaitu:
1 Memperbanyak dataset citra biji kopi agar hasil yang diperoleh lebih akurat.
2 Diperlukan adanya penelitian tahap selanjutnya, yaitu dengan
12 menggunakan metode lain atau
gabungan dari beberapa metode sehingga diharapkan bisa meningkatkan akurasinya dengan menutup kekurangan–kekurangan metode yang telah digunakan ini.
DAFTAR PUSTAKA
[1] Rahardjo, Pudji. 2012. Panduan Budidaya
dan Pengolahan Kopi Arabika dan Robusta. Penebar Swadaya. Jakarta
[2] http://www.berbagaihal.com/2011/04/as al-usul-dan-sejarah-di-balik.html
[3] Sutoyo T., S.Si., M.Kom., dan dkk (2009).
Teori Pengolahan Citra Digital. Semarang:
Andi Yogyakarta.
[4] Prasetyo E. (2009). Data Mining Mengolah
Data Menjadi Informasi Menggunakan Matlab. Gresik: Andi Yogyakarta.
[5] T. Sutojo, E. Mulyanto, V. Suhartono, O. D. Nurhayati, and Wijanarto, Teori Pengolahan Citra Digital. Yogyakarta,
Indonesia: ANDI, 2009.
[6] E. R. Anandita, "Klasifikasi Tebu dengan
Menggunakan Algoritma Naive Bayes Classification pada Dinas Kehutanan Dan Perkebunan Pati," 2014.
[7] R. Munir, Pengolahan Citra Digital dengan
Pendekatan Algoritmik. Jakarta, Indonesia:
Informatika, 2004.
[8] D. Kulkarni, Artificial Neural Networks for
Image Understanding. Newyork, Unites
States of America: Van Nostrand Reinhold, 1994.
[9] E. Prasetyo, DATA MINING - Mengolah
Data Menjadi Informasi Menggunakan Matlab, A. Sahala, Ed. Yogyakarta,
Indonesia: ANDI, 2014.
[10] A. D. Kulkarni, Artificial Neural Networks for Image Understanding.
Newyork, Unites States of America: Van
Nostrand Reinhold, 1994.
[11] T. Archary and A. K. Ray, Image
Processing Principles and Applications.
New Jersey, United States of America: John Wiley & Sons, Inc., 2005.
[12] E. Prasetyo, DATA MINING - Mengolah
Data Menjadi Informasi Menggunakan Matlab, A. Sahala, Ed. Yogyakarta,
Indonesia: ANDI, 2014.
[13] I. H. Witten, E. Frank, and M. A. Hall,
Data Mining Practical Machine Learning Tools and Techniques, 3rd ed. Burlington,
United States of America: Morgan Kaufmann, 2011.
[14] J. Han, M. Kamber, and J. Pei, Data
Mining Concepts and Techniques, 3rd ed.
Waltham, United States of America: Morgan Kaufmann, 2012.