BAB 2
TINJAUAN PUSTAKA
2.1. Kompresi Data
Dalam ilmu komputer, pemampatan data atau kompresi data adalah sebuah cara untuk memadatkan data sehingga hanya memerlukan ruangan penyimpanan lebih kecil sehingga lebih efisien dalam menyimpannya atau mempersingkat waktu pertukaran data tersebut. Kompresi Data adalah proses pengkodean (encoding) informasi dengan menggunakan bit yang lebih sedikit dibandingkan dengan kode yang sebelumnya dipakai dengan menggunakan skema pengkodean tertentu. Kompresi data, terutama untuk proses komunikasi, dapat bekerja jika kedua pihak antara pengirim dan
penerima data komunikasi memiliki skema pengkodean yang sama.
Gambar-gambar yang terdapat di berbagai situs internet pada umumnya merupakan hasil kompresi ke dalam format GIF atau JPEG. File video MPEG adalah hasil proses kompresi pula. Penyimpanan data berukuran besar pada server pun sering dilakukan melalui kompresi. Hal ini dilakukan agar kapasitas pada server tempat penyimpanan dapat menampung lebih banyak data.
Dalam kompresi data, tujuan utama yang perlu diperhatikan adalah rasio kompresi yang semakin baik, proses kompresi dan pengembalian yang cepat. Rasio kompresi secara matematis dapat ditulis sebagai berikut:
� � � � � = �� � � �� x %
Selain rasio kompresi, hal yang perlu diukur adalah space saving. Space saving (penghematan ruang) didefinisikan sebagai pengurangan dalam ukuran relatif terhadap ukuran uncompressed. (Ujianto dan Hartati, 2010)
��� ��� � = − �� ��� ��� x %
Atau
��� ��� � = − � � � � � x %
Teori Informasi menggunakan terminologi entropy sebagai pengukur berapa banyak informasi yang dapat diambil dari sebuah pesan. Kata “entropy” berasal dari ilmu termodinamika. Semakin tinggi entropy dari sebuah pesan semakin banyak informasi yang terdapat di dalamnya. Entropy dari sebuah simbol didefinisikan sebagai nilai logaritma negatif dari probabilitas kemunculannya. Entropy dari keseluruhan pesan adalah jumlah dari keseluruhan entropy dari seluruh symbol.
Terdapat dua jenis kompresi data yaitu Kompresi Lossy dan Kompresi Lossless.
2.1.1. Kompresi Lossy
Kompresi data yang menghasilkan file data hasil kompresi yang tidak dapat dikembalikan menjadi file data sebelum dikompresi secara utuh. Kompresi lossy menyebabkan adanya perubahan data dibandingkan sebelum dilakukan proses kompresi. Ketika data hasil kompresi di-decode kembali, data hasil decoding tersebut tidak dapat dikembalikan menjadi sama dengan data asli tetapi ada bagian data yang hilang. Dengan kata lain ada beberapa info yang hilang pada saat proses kompresi. Oleh sebab itu kompresi jenis ini tidak baik untuk kompresi data yang kritis seperti data teks. Sebagai gantinya kompresi lossy memberikan derajat kompresi lebih tinggi. (2.2) (2.1)
Kompresi jenis ini sangat baik bila digunakan pada file multi media seperti file gambar, suara dan film. File gambar, suara dan film secara alamiah masih bisa digunakan walaupun tidak berada pada kondisi yang sama sebelum dilakukan kompresi. Contoh penggunaan kompresi lossy adalah pada format file JPEG, MP3, dan MPEG.
Gambar 2.1. Skema Lossy Compression
2.1.2. Kompresi Lossless
Kompresi data yang menghasilkan file data hasil kompresi yang dapat dikembalikan menjadi file data asli sebelum dikompresi secara utuh tanpa perubahan apapun. Kompresi lossless memiliki derajat kompresi yang lebih rendah tetapi dengan akurasi data yang terjaga antara sebelum dan sesudah proses kompresi. Kompresi lossless bekerja dengan menemukan pola yang berulang di dalam pesan yang akan dikompres tersebut dan melakukan proses pengkodean pola tersebut secara efisien. Kompresi ini juga dapat berarti proses mengurangi redundancy. Kompresi jenis ini ideal untuk kompresi teks seperti basis data, dokumen atau spreadsheet. Pada kompresi jenis ini tidak diijinkan ada bit yang hilang dari data pada proses kompresi. Algoritma yang termasuk dalam kompresi lossless diantaranya adalah Elias Gamma Code, Elias Delta Code dan Levenstein Code.
Secara umum kompresi data terdiri dari dua kegiatan besar, yaitu Modeling dan Coding. Proses dasar dari kompresi data adalah menentukan serangkaian bagian dari data (stream of symbols) mengubahnya menjadi kode (stream of codes). Jika proses kompresi efektif maka hasil dari stream of codes akan lebih kecil dari segi ukuran daripada stream of symbols. Keputusan untuk mengindentikan simbol tertentu dengan kode tertentu adalah inti dari proses modeling. Secara umum dapat diartikan bahwa sebuah model adalah kumpulan data dan aturan yang menentukan pasangan antara symbol sebagai input dan code sebagai output dari proses kompresi. Sedangkan coding adalah proses untuk menerapkan modeling tersebut menjadi sebuah proses kompresi data.
Melakukan proses encoding dengan menggunakan ASCII atau EBDIC yang merupakan standar dalam proses komputasi memberikan kelemahan mendasar apabila dilihat dari paradigma kompresi data. ASCII dan EBDIC menggunakan jumlah bit yang sama untuk setiap karakter, hal ini menyebabkan banyak bit yang ”terbuang” untuk merepresentasikan karakter-karakter yang sebenarnya jarang muncul pada sebuah pesan.
Jika coding adalah roda dari sebuah mobil maka modeling adalah mesinnya. Sebaik apapun algoritma untuk melakukan coding tanpa model yang baik kompresi data tidak akan pernah terwujud. Kompresi data Lossless pada umumnya diimplementasikan menggunakan salah satu dari dua tipe modeling, yaitu statistical atau dictionary-based. Statistical-modeling melakukan prosesnya menggunakan probabilitas kemunculan dari sebuah simbol sedangkan dictionary-based menggunakan kode-kode untuk menggantikan sekumpulan simbol.
1. Statistical Modeling
Menggunakan tabel universal pada akhirnya tidak memuaskan para ahli kompresi data karena apabila terjadi perubahan pada subyek yang dikompresi dan tidak sesuai dengan tabel universal maka akan terjadi penurunan rasio kompresi secara signifikan.
Akhirnya muncul modeling dengan menggunakan tabel yang adaptif, di mana tabel tidak lagi bersifat statis tetapi bisa berubah sesuai dengan kode. Pada prinsipnya dengan model ini, sistem melakukan penghitungan atau scan pada keseluruhan data setelah itu barulah membangun tabel probabilitas kemunculan dari tiap karakter atau symbol.
Model ini kemudian dikembangkan lagi menjadi adaptive statistical modeling dimana sistem tidak perlu melakukan scan ke seluruh symbol untuk membangun tabel statistik, tetapi secara adaptif melakukan perubahan tabel pada proses scan karakter per karakter.
2. Dictionary Based Modeling
Jika statistical model pada umumnya melakukan proses encode simbol satu per satu mengikuti siklus: baca karakter hitung probabilitas buat kodenya maka dictionary-based modeling menggunakan mekanisme yang berbeda. Dictionary-based modeling membaca input data dan membandingkannya dengan isi dictionary. Jika sekumpulan string sesuai dengan isi dictionary maka indeks dari dictionary entry-lah yang dikeluarkan sebagai output dan bukan kodenya.
Sebagai perumpamaan dari dictionary-based dapat digunakan makalah ilmiah sebagai contoh. Saat kita membaca makalah ilmiah kita sering membaca nomor-nomor referensi yang bisa kita cocokkan dengan daftar pustaka di belakang. Hal ini mirip dengan proses pada dictionary-based modeling.
2.2. Sistem Pengkodean
Sistem pengkodean adalah aturan untuk mengubah informasi tertentu (seperti tulisan,
2.2.1. Fixed Length Encoding
Sistem pengkodean simbol yang menggunakan panjang bit yang sama untuk setiap simbol. Panjang bit minimal yang diperlukan oleh sistem pengkodean ini bergantung pada variasi simbol yang akan dikodekan dan sama dengan nilai entropy maksimum simbol.
2.2.2. Variable Length Encoding
Sistem pengkodean simbol yang menggunakan panjang bit yang berbeda-beda antara
simbol yang satu dengan simbol yang lainnya. Salah satu jenisnya adalah panjang simbol ditentukan berdasarkan probabilitas kemunculan dari simbol tersebut dalam suatu deretan simbol. Jenis encoding inilah yang menjadi basis pada proses kompresi data yang berbasis pada statistika.
2.2.3. Prefix Code
Berdasarkan pada pertimbangan untuk mengkodekan simbol dengan menggunakan bit string yang lebih sedikit dibandingankan dengan menggunakan kode standar yang menggunakan panjang bit tetap maka dibuatlah sistem pengkodean simbol dengan menggunakan panjang bit yang variabel. Namun masalah terjadi saat menggunakan kode yang panjangnya variabel yaitu adanya ambiguitas/kerancuan maka saat mengkodekan deretan bit string tertentu menjadi beberapa simbol yang berbeda karena tidak uniquely decodable. Oleh karena itulah digunakan kode yang memiliki properti prefix code yaitu kode dari suatu simbol tidak akan pernah menjadi prefix dari seluruh kode simbol yang selainnya.
2.3. Algoritma Elias Gamma Code
1. Tulis bilangan tersebut dalam bentuk biner.
2. Kurangi 1 dari jumlah bit yang ditulis pada langkah pertama dan tambahkan sesuai dengan banyaknya bilangan nol. Proses yang ekivalen untuk menyatakan proses yang pada point nomor dua adalah sebagai berikut:
a. Pisahkan integer menjadi pangkat 2 tertinggi (2N) yang dapat dan ditampungnya sisakan digit biner N dari integer tersebut.
b. Kodekan N dalam bentuk unary, jika N adalah nol maka diikuti oleh satu.
c. Tambahkan sisa digit biner N untuk merepresentasikan N
Sedangkan aturan untuk melakukan proses decode suatu integer dengan menggunakan Elias Gamma Code dapat dilakukan dengan cara sebagai berikut: a. Lakukan pembacaan kode sampai angka 1 ditemukan. Nyatakan jumlah angka 0 dengan N.
b. Lakukan pembacaan N berikutnya sebagai integer dari L. Hitung n = 2N + L
Tabel Elias Gamma Code yang menunjukkan 18 kode Gamma dapat dilihat pada tabel 2.1 dibawah ini.
Tabel 2.1. 18 Kode Elias Gamma
1 = 20 + 0 = 1 10 = 23 + 2 = 0001010
2 = 21 + 0 = 010 11 = 23 + 3 = 0001011
3 = 21 + 1 = 011 12 = 23 + 4 = 0001100 4 = 22 + 0 = 00100 13 = 23 + 5 = 0001101
5 = 22 + 1 = 00101 14 = 23 + 6 = 0001110
6 = 22 + 2 = 00110 15 = 23 + 7 = 0001111
7 = 22 + 3 = 00111 16 = 24 + 0 = 000010000 8 = 23 + 0 = 0001000 17 = 24 + 1 = 000010001
Pengkodean dengan Elias Gamma Code tidak melakukan pengkodean pada bilangan bulat nol ataupun negatif. Salah satu cara untuk menangani nol adalah menambahkan 1 sebelum pengkodean dan kemudian mengurangi dengan 1 setelah dilakukan proses decoding. Salah satu cara yang lain adalah dengan memberi prefix pada semua kode bukan nol dengan 1 dan kemudian kode nol sebagai suatu 0 tunggal. Salah satu cara untuk mengkodekan semua integer adalah membentuk suatu bijeksi, yaitu pemetaan bilangan bulat (0, 1, -1, 2, -2, 3, -3, ….) hingga (1, 2 , 3, 4, 5, 6, 7, ….) sebelum pengkodean dimulai.
Elias Gamma Code sangat cocok digunakan untuk mengkodekan bilangan bulat positip bahkan dalam kasus-kasus dimana bilangan bulat positip terbesar tidak diketahui sebelumnya. Selain itu, kode ini tumbuh perlahan-lahan sehingga merupakan kandidat yang baik untuk mengkompresi data integer dimana bilangan bulat kecil sering muncul dan bilangan bulat besar jarang muncul.
Sebagai contoh dari pada algoritma Elias Gamma Code dapat dilihat di bawah: String = “ADI MEMBACA BUKU DI TAMAN”
CHAR SET = ∑ = {A, D, I, M, E, B, C, SP, U, K, T, N}
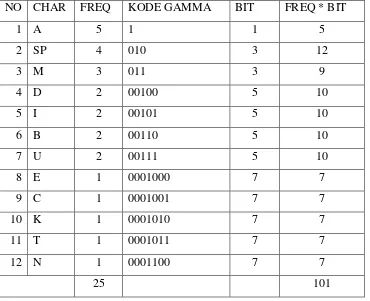
Tabel 2.2. Pemetaan Data Teks Dengan Kode Elias Gamma
NO CHAR FREQ KODE GAMMA BIT FREQ * BIT
1 A 5 1 1 5
2 SP 4 010 3 12
3 M 3 011 3 9
4 D 2 00100 5 10
5 I 2 00101 5 10
6 B 2 00110 5 10
7 U 2 00111 5 10
8 E 1 0001000 7 7
9 C 1 0001001 7 7
10 K 1 0001010 7 7
11 T 1 0001011 7 7
12 N 1 0001100 7 7
Input Stream = 25 x 8 = 200 Output Stream = 101
� � � � � = x % = . %
��� ��� � = % − . % = . %
2.4. Algoritma Elias Delta Code
Elias Delta Code merupakan satu dari tiga Elias Code yang dipelopori oleh Peter Elias. Jika pada Elias Gamma Code, Peter Elias menambahkan panjang pada unary (α) makanya pada Elias Delta Code ditambahkan pada binary (β). Elias Delta Code juga
digunakan untuk melakukan pengkodean pada bilangan bulat positip, namun sedikit lebih kompleks daripada Elias Gamma Code. Adapun aturan untuk mengkodekan sebuah bilangan dengan menggunakan Elias Delta Code adalah sebagai berikut :
1. Tuliskan n dalam bilangan biner (binary). Bit yang paling kiri (paling signifikan) akan menjadi 1.
2. Hitung jumlah bit-nya, hapus bit paling kiri dari n dan tambahkan perhitungan dalam bilangan biner (binary) pada bagian kiri dari n setelah bit paling kiri dari n dihapus.
3. Kurangi 1 dari perhitungan pada langkah ke-2 dan tambahkan jumlah nol ke
kode.
Ketika langkah-langkah ini diterapkan pada integer ke-17, hasilnya adalah : 17 = 100012 (lima bit). Hapus angka 1 yang paling kiri dan tambahkan 5 = 1012 sehingga hasilnya 101|0001. Tiga bit sudah ditambahkan, kemudian tambahkan 2 nol
untuk mendapatkan kode delta 00|101|0001.
Untuk menghitung panjang kode delta n, dapat dilihat bawah langkah 1 menghasilkan (dari Persamaan (1.1)) M = 1 + [log2 n] bits. Agar lebih sederhana, tanda [ dan ] dihilang, amati persamaan berikut:
Hitungan pada langkah ke-2 adalah M, yang panjangnya adalah C oleh karena itu C = 1 + log2, M = 1 + log2 (log2(2n)) bit. Oleh karena itu pada langkah kedua ditambahkan C bit dan menghapus bit paling kiri dari n. Pada langkah ketiga ditambahkan C – 1 = log2, M = log2(log2(2n))nol.
Selain dengan langkah-langkah pengkodean di atas, pengkodean Elias Delta juga dapat dilakukan dengan menggunakan kode Elias Gamma. Berikut adalah langkah-langkahnya:
1. Tentukan bilangan bulat N yang terbesar sehingga 2N≥ n < 2N+1 dan tuliskan
n = 2N + L. Perhatikan bahwa L merupakan bilangan bulat N yang paling besar.
2. Lakukan pengkodean N + 1 dengan Elias Gamma Code.
3. Tambahkan nilai biner dari L, sebagai integer dari N-bit pada hasil dari langkah kedua.
Ketika langkah-langkah ini diterapkan pada n = 17, hasilnya adalah : 17 = 2N + L = 24 + 1. Kode gamma dari N + 1 = 5 adalah 00101, dan tambahkan L = 0001 sehingga hasilnya adalah 00101|0001.
Tabel Elias Delta Code yang menunjukkan 18 kode delta, dimana L ditulis dengan huruf miring dapat dilihat pada tabel 2.3 di bawah ini.
Tabel 2.3. 18 Kode Elias Delta
1 = 20 + 0|L| = 0 1 10 = 23 + 2 |L| = 3 00100010
2 = 21 + 0 |L| = 10100 11 = 23 + 3 |L| = 3 00100011
3 = 21 + 1 |L| = 10101 12 = 23 + 4 |L| = 3 00100100
4 = 22 + 0 |L| = 201100 13 = 23 + 5 |L| = 3 00100101
5 = 22 + 1 |L| = 2 01101 14 = 23 + 6 |L| = 3 00100110
6 = 22 + 2 |L| = 2 01110 15 = 23 + 7 |L| = 3 00100111
7 = 22 + 3 |L| = 2 01111 16 = 24 + 0 |L| = 3 001010000
8 = 23 + 0 |L| = 3 00100000 17 = 24 + 1 |L| = 3 001010001
Untuk melakukan decode dengan Elias Delta Code, berikut adalah langkah-langkahnya:
1. Baca bit dari kode sampai proses decode dengan Elias Gamma Code dapat dilakukan. Proses ini dapat dilakukan dengan beberapa langkah berikut ini: 1.1. Hitung jumlah nol terdepan dari kode tersebut lalu gantikan
perhitungan tersebut dengan C.
1.2. Periksa bit bagian kiri 2C + 1 (C nol, diikuti dengan 1, lalu diikuti dengan bit C selebihnya). Ini merupakan decode Elias Gamma Code M
+ 1.
2. Baca bit M berikutnya. Sebut ini sebagai L.
3. Bilangan bulat yang di decode adalah 2M + L.
Pada kasus dimana n = 17, kode deltanya adalah 001010001. Lewati dua nol, sehingga C = 2. Nilai bit paling kiri dari 2C + 1 = 5 adalah 00101 = 5, jadi M + 1 = 5. Pembacaan akan dilakukan berikutnya pada M = 4 bit 0001, dan diakhirnya dengan nilai decode 2M + L = 24 + 1 = 17.
Sebagai contoh dari pada algoritma Elias Delta Code dapat dilihat di bawah: String = “ADI MEMBACA BUKU DI TAMAN”
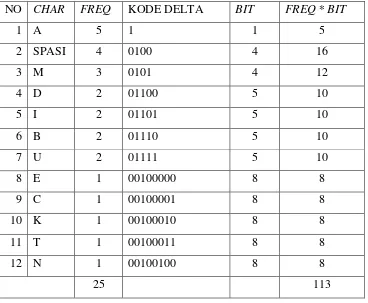
Tabel 2.4. Pemetaan Data Teks Dengan Kode Elias Delta
NO CHAR FREQ KODE DELTA BIT FREQ * BIT
1 A 5 1 1 5
2 SPASI 4 0100 4 16
3 M 3 0101 4 12
4 D 2 01100 5 10
5 I 2 01101 5 10
6 B 2 01110 5 10
7 U 2 01111 5 10
8 E 1 00100000 8 8
9 C 1 00100001 8 8
10 K 1 00100010 8 8
11 T 1 00100011 8 8
12 N 1 00100100 8 8
25 113
Input Stream = 25 x 8 = 200 Output Stream = 113
� � � � � = x % = . %
��� ��� � = % − . % = . %
2.5. Algoritma Levenstein Code
Algoritma Levenstein Code atau Levensthein Coding merupakan pengkodean universal untul bilangan bulat non-negatif yang dikembangkan oleh Vladimir Levenshein pada tahun 1968. Algoritma Levenstein Code merupakan algoritma yang prosesnya melalui tahapan-tahapan tertentu baik pada saat pengkodean maupun pembacaan sandi.
1. Atur jumlah variabel C menjadi 1.
2. Tuliskan representasi biner dari nomor tanpa awalan “1” ke kode awal. 3. Misalkan M adalah jumlah bit yang dituliskan pada langkah kedua.
4. Jika M tidak sama dengan 0, tambahkan C dengan 1. Ulangi langkah kedua dengan M dimasukkan sebagai nomor baru.
5. Jika M = 0, tambahkan C “1” bit dan 0 ke awal kode.
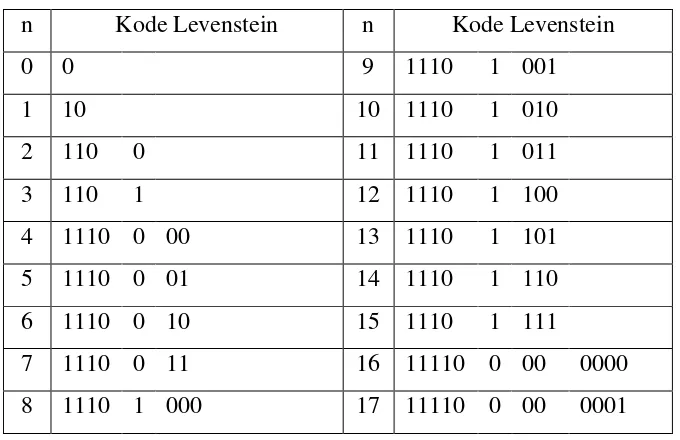
Tabel Levenstein Code yang menunjukkan 18 kode Levenstein dapat dilihat pada tabel 2.5 di bawah ini.
Tabel 2.5. 18 Kode Levenstein
n Kode Levenstein n Kode Levenstein
0 0 9 1110 1 001
1 10 10 1110 1 010
2 110 0 11 1110 1 011
3 110 1 12 1110 1 100
4 1110 0 00 13 1110 1 101
5 1110 0 01 14 1110 1 110
6 1110 0 10 15 1110 1 111
7 1110 0 11 16 11110 0 00 0000
8 1110 1 000 17 11110 0 00 0001
Tabel di atas menunjukkan beberapa kode Levenstein. Pada tabel tersebut masing-masing bagian dari kode Levenstein dipisahkan dengan tanda spasi. Hal ini dimaksud agar lebih memudahkan dalam mengindikasi bagian-bagian dari kode Levenstein. Sebagai contoh, jika dilanjutkan maka kode Levenstein untuk 18 adalah 11110 | 0 | 0010, untuk 19 adalah 11110 | 0 | 0011, dan seterusnya.
Untuk melakukan pembacaan sandi bilangan bulat pada Levenstein Code dapat dilakukan dengan langkah-langkah sebagai berikut :
1. Lakukan perhitungan pada jumlah bit C “1” sampai “0” ditemukan.
3. Aturlah nilai N = 1, lalu ulangi langkah empat (C-1) kali.
4. Lakukan pembacaan bit N, tambahkan 1, lalu berikan nilai yang dihasilkan ke N (sehingga menghapus nilai sebelumnya dari N). String yang diberikan ke N pada iterasi terakhir merupakan hasil dari pembacaan sandi.
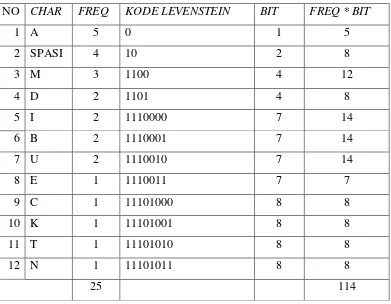
Sebagai contoh dari pada algoritma Levenstein Code dapat dilihat di bawah: String = “ADI MEMBACA BUKU DI TAMAN”
CHAR SET = ∑ = {A, D, I, M, E, B, C, SPASI, U, K, T, N}
Tabel 2.6. Pemetaan Data Teks Dengan Kode Levenstein
NO CHAR FREQ KODE LEVENSTEIN BIT FREQ * BIT
1 A 5 0 1 5
2 SPASI 4 10 2 8
3 M 3 1100 4 12
4 D 2 1101 4 8
5 I 2 1110000 7 14
6 B 2 1110001 7 14
7 U 2 1110010 7 14
8 E 1 1110011 7 7
9 C 1 11101000 8 8
10 K 1 11101001 8 8
11 T 1 11101010 8 8
12 N 1 11101011 8 8
25 114
Input Stream = 25 x 8 = 200 Output Stream = 114
� � � � � = x % = %
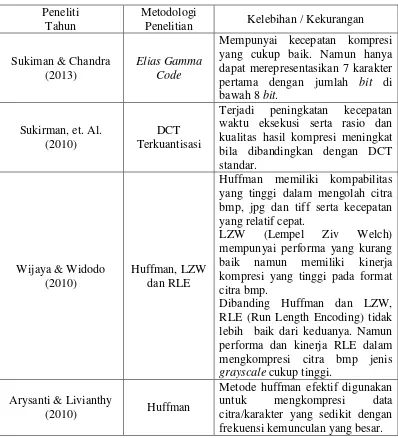
2.6. Riset Terkait
Sukiman & Chandra (2013) melakukan penelitian terhadap algoritma Elias Gamma Code dengan melakukan pemodelan data yang akan dikompresi untuk kemudian direpresentasikan dengan simbol-simbol tertentu dimana data yang disertakan memilki informasi seperti frekuensi mengenai setiap simbol. Sementara pengkodean dilakukan untuk menghasilkan representasi data terkompresi dengan mengacu pada model guna menentukan kode untuk setiap simbol. Dengan metode tersebut didapat hasil bahwa algoritma Elias Gamma Code mempunyai rentang rasio kompresi 60% – 80%.
Sukirman, et. al. (2010) melakukan penelitian dengan mengoptimalkan proses pada transformasi DCT dan Kuantisasi. Proses yang dilakukan yaitu dengan cara menggabungkan proses DCT dan Kuantisasi. Dari hasil penggabungan tersebut didapatkan bahwa formulasi matematis pada DCT terkuantisasi mengandung jumlah operasi perkalian dan penambahan yang lebih kecil dibandingkan pada formulasi matematis DCT standar. Sehingga DCT terkuantisasi dapat meningkatkan rasio dan kualitas kompresi JPEG.
Wijaya & Widodo (2010) melakukan penelitian terhadapat objek citra digital dengan menggunakan algoritma Huffman, LZW (Lempel Ziv Welch) dan RLE (Run-Length Encoding). Pengujian dilakukan terhadap waktu kompressi dan dekompressi pada objek citra dengan format bmp, jpg dan tiff. Dari pengujian tersebut algoritma Huffman memiliki kompabilitas tinggi untuk dapat mengkompresi setiap format objek citra. Sedangkan waktu kompresi dan dekompresi algoritma LZW (Lempel Ziv Welch) kurang begitu baik tetapi memiliki kinerja kompresi yang tinggi pada format citra bmp. Sementara kemampuan kompabilitas yang dimiliki algoritma RLE (Run-Length Encoding) tidak lebih baik dari algoritma Huffman dan LZW. Algoritma RLE hanya mampu mengkompresi citra dengan format bmp berjenis grayscale saja. Tetapi dalam hal ini memiliki performa kinerja yang cukup tinggi.
Hyper Text Markup Language(*.htm). Pada penelitian ini hanya dilakukan pengujian pada tingkat efektivitas metode Huffman untuk kompresi data citra dan teks.
Untuk riset-riset yang terkait dengan penelitian ini dapat dilihat pada tabel 2.7 di bawah ini.
Tabel 2.7. Riset Terkait
Peneliti Tahun
Metodologi
Penelitian Kelebihan / Kekurangan
Sukiman & Chandra (2013)
Elias Gamma Code
Mempunyai kecepatan kompresi yang cukup baik. Namun hanya dapat merepresentasikan 7 karakter pertama dengan jumlah bit di bawah 8 bit.
Sukirman, et. Al. (2010)
DCT Terkuantisasi
Terjadi peningkatan kecepatan waktu eksekusi serta rasio dan kualitas hasil kompresi meningkat bila dibandingkan dengan DCT standar.
Wijaya & Widodo (2010)
Huffman, LZW dan RLE
Huffman memiliki kompabilitas yang tinggi dalam mengolah citra bmp, jpg dan tiff serta kecepatan yang relatif cepat.
LZW (Lempel Ziv Welch) mempunyai performa yang kurang baik namun memiliki kinerja kompresi yang tinggi pada format citra bmp.
Dibanding Huffman dan LZW, RLE (Run Length Encoding) tidak lebih baik dari keduanya. Namun performa dan kinerja RLE dalam mengkompresi citra bmp jenis grayscale cukup tinggi.
Arysanti & Livianthy
(2010) Huffman
2.7. Perbedaan dengan Riset yang Lain
Dalam penelitian ini, pengkompresian data akan dilakukan pada data berupa teks (*.txt) dengan menggunakan algoritma Elias Gamma Code, Elias Delta Code dan Levenstein Code dengan mengacu pada rasio kompresi dan kecepatan kompresi.
2.8. Kontribusi Riset