8 BAB II
TINJAUAN PUSTAKA
2.1 Penelitian Terkait
Penelitian yang dilakukan oleh Dinda Setiawati Devi dengan menggunakan metode Apriori untuk analisa keranjang pasar untuk 100 data transaksi dan 55 jenis barang menghasilkan 8 asosiasi data dengan parameter confidence >- 10% dan min-support >- 5% [7].
Penelitian yang dilakukan oleh S.Moertini Veronica dan Yulita Marsela dengan algoritma hash-based pada data transaksi penjualan obat di apotik menyimpulkan kinerja hash-based ternyata bergantung kepada bilangan prima yang digunakan pada fungsi hashing. Semakin besar bilangan ini ( hingga di atas dan paling dekat dengan jumlah item ), semakin cepat waktu komputasinya [19].
Penelitian yang dilakukan oleh Afif Syaifullah Muhammad, melakukan implementasi data mining algoritma Apriori pada system penjualan menyimpulkan teknik data mining dengan algoritma Apriori dapat diimplementasikan pada system penjualan [1].
Penelitian yang dilakukan Erwin, melakukan analisis market basket dengan algoritma Apriori dan FP-Growth menyimpulkan bahwa algoritma Apriori membutuhkan waktu komputasi yang lama untuk mendapatkan frequent itemsets, karena berulang kali melakukan pemindahan data dan membutuhkan memori yang besar sedangkan FP-Growth hanya membutuhkan dua kali scanning database dalam mencari frequent itemsets sehingga waktu yang dbutuhkan menjadi relatif singkat dan efisien [8].
9
– rata nilai confidence yang lebih tinggi dibandingkan dengan Fuzzy C-Means (83%) pada nilai minimum support 20 dan 40 [20].
Penelitian yang dilakukan oleh Andreas, Gregorius Satia Budhi, Hendra Rusly , meneliti asosiasi pembelian barang di supermarket dengan metode market basket analysis menyimpulkan [11] :
x Menemukan frequent itemset dan association rule yang memenuhi syarat minimum support, berdasarkan item yang ada dalam transaksi.
x Dapat mengetahui asosiasi barang apa saja yang sering dibeli bersamaan oleh konsumen.
x Semakin kecil minimum support dan confidence yang ditentukan maka semakin banyak rules yang dapat dihasilkan.
x Pada proses pembuatan 2 – itemset candidate membutuhkan waktu yang paling lama, semakin banyak jumlah 1-itemset candidate yang memenuhi minimum support, maka semakin banyak pula jumlah 2-itemset yang harus dihasilkan.
Dalam aturan asosiasi pertambangan tinjauan terbaru dari Sotiris Kotsiantis, Dimitris Kanellopoulos , menyimpulkan algoritma konvensional aturan asosiasi penemuan berlangsung dalam dua langkah. Semua itemset sering ditemukan pada langkah pertama. The Frequent itemset adalah itemset yang disertakan dalam setidaknya transaksi minimum support. Asosiasi aturan dengan kepercayaan pada minimum confidence setidaknya dihasilkan pada langkah kedua [14].
Penelitian Christian Borgelt , menyimpulkan pada tahap preprocessing dilakukan penghapusan item transaksi yang tidak sering muncul sehingga waktu lebih efisien. Implementasi algoritma FP-pertumbuhan melebihi algoritma Apriori dan algoritma Eclat [4].
10
Penelitian Mohammad El-Hajj dan Osmar R.Zaiane , menyimpulkan pendekatan lompatan traversal secara signifikan mengurangi jumlah calon itemsets dan cocok sebagai kerangka kerja yang baik untuk pertambangan dan pemrosesan parallel, serta menunjukkan penghematan drastis dalam penggunaan memori [9].
Penelitian Xun Zhu, Hongtao Deng, Zheng Chen , menyimpulkan aturan asosiasi pertambangan pola yang sering muncul mengalami perkembangan yang cukup pesat yang telah diterapkan untuk berbagai aplikasi domain, seperti pengindeksan dan pencarian kesamaan kompleks data terstruktur, pertambangan multimedia, dan pertambangan web [2].
Tabel 2.1 . Rangkuman penelitian terkait analisis data transaksi penjualan barang No Nama Peneliti dan
Tahun
Masalah Metode Hasil
1 Dinda Setiawati Devi, 2009
Penggalian asosiasi data transaksi penjualan.
Algoritma Asosiasi Apriori, dengan 100 data transaksi penjualan.
Ada 8 Asosiasi, dengan min-support 5% dan min-confidence 10%
2 S.Moertini
Veronica dan Yulita Marsela, 2004
Penggalian asosiasi data transaksi penjualan.
Algoritma Hash-Based
Bilangan prima yang paling efektif untuk digunakan dalam fungsi
hashing adalah yang terdekat dan lebih besar dari jumlah seluruh produk.
3 Afif Syaifullah Muhammad. 2009
Penggalian asosiasi data transaksi penjualan.
Algoritma Apriori
Teknik data mining
dengan algoritma Apriori dapat
11
Tabel 2.1 Rangkuman penelitian terkait analisis data transaksi penjualan barang (lanjutan)
No Nama Peneliti dan Tahun
Masalah Metode Hasil
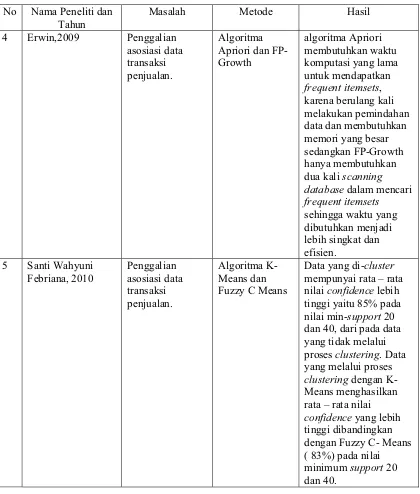
4 Erwin,2009 Penggalian
asosiasi data transaksi penjualan.
Algoritma Apriori dan FP-Growth
algoritma Apriori membutuhkan waktu komputasi yang lama untuk mendapatkan
frequent itemsets, karena berulang kali melakukan pemindahan data dan membutuhkan memori yang besar sedangkan FP-Growth hanya membutuhkan dua kali scanning database dalam mencari
frequent itemsets
sehingga waktu yang dibutuhkan menjadi lebih singkat dan efisien.
5 Santi Wahyuni
Febriana, 2010
Penggalian asosiasi data transaksi penjualan.
Algoritma K-Means dan Fuzzy C Means
Data yang di-cluster
mempunyai rata – rata nilai confidence lebih tinggi yaitu 85% pada nilai min-support 20 dan 40, dari pada data yang tidak melalui proses clustering. Data yang melalui proses
clustering dengan K-Means menghasilkan rata – rata nilai
12
Tabel 2.1 . Rangkuman penelitian terkait analisis data transaksi penjualan barang (lanjutan)
No Nama Peneliti dan Tahun
Masalah Metode Hasil
6 Andreas Handojo,
Gregorius Satia Budhi, Hendra Rusli, 2004.
Menggali asosiasi item barang
Metode Market Basket Analysis
- Menemukan
frequent itemset
dan association rule yang memenuhi syarat minimum support, berdasarkan item yang ada dalam transaksi.
- Dapat
mengetahui asosiasi barang apa saja yang sering dibeli bersamaan oleh konsumen.
- Semakin kecil
minimum support dan
confidence yang ditentukan maka semakin banyak rules
yang dapat dihasilkan. waktu yang paling lama, semakin banyak jumlah
1-itemset
candidate yang memenuhi
13
Tabel 2.1 . Rangkuman penelitian terkait analisis data transaksi penjualan barang (lanjutan)
No Nama Peneliti dan Tahun
Masalah Metode Hasil
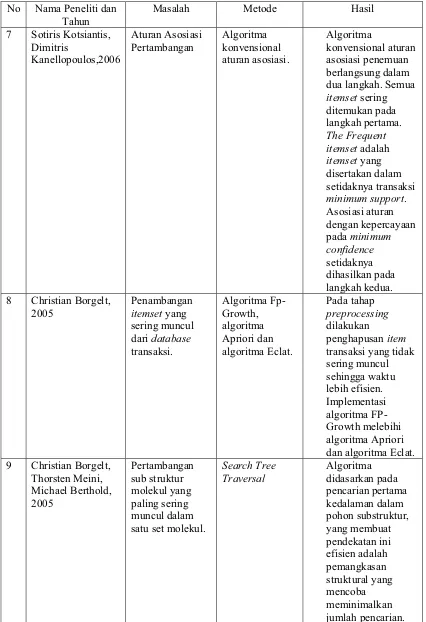
7 Sotiris Kotsiantis, Dimitris
Kanellopoulos,2006
Aturan Asosiasi Pertambangan
Algoritma konvensional aturan asosiasi.
Algoritma
konvensional aturan asosiasi penemuan berlangsung dalam dua langkah. Semua
itemset sering ditemukan pada langkah pertama.
The Frequent itemset adalah
itemset yang disertakan dalam setidaknya transaksi
minimum support. Asosiasi aturan dengan kepercayaan pada minimum confidence
setidaknya dihasilkan pada langkah kedua. 8 Christian Borgelt,
2005
Penambangan
itemset yang sering muncul dari database
transaksi.
Algoritma Fp-Growth, algoritma Apriori dan algoritma Eclat.
Pada tahap
preprocessing
dilakukan penghapusan item
transaksi yang tidak sering muncul sehingga waktu lebih efisien. Implementasi algoritma FP-Growth melebihi algoritma Apriori dan algoritma Eclat. 9 Christian Borgelt,
Thorsten Meini, Michael Berthold, 2005
Pertambangan sub struktur molekul yang paling sering muncul dalam satu set molekul.
Search Tree Traversal
14
Tabel 2.1 . Rangkuman penelitian terkait analisis data transaksi penjualan barang (lanjutan)
No Nama Peneliti dan Tahun
Masalah Metode Hasil
10 El-Hajj Mohammad
dan Osmar R.Zaiane, 2005
Menemukan maksimal pola dengan
memperkenalkan metode baru menghitung dukungan kandidat berdasarkan dukungan dari pola kandidat lainnya.
Leap Traversal
dengan dua pendekatan, pertama
mengurangi pola pohon yang tidak sering muncul , yang kedua partisi ruang transaksi menggunakan Cofi-pohon.
Pendekatan lompatan traversal secara signifikan mengurangi jumlah calon itemsets dan cocok sebagai kerangka kerja yang baik untuk
pertambangan dan pemrosesan parallel, serta menunjukkan penghematan drastis dalam penggunaan memori.
11 XunZhu, Hongtao
Deng , Zheng Chen .2011
Asosiasi aturan pertambangan pola yang sering muncul.
Algoritma Apriori, Fp-Growth, Eclat.
Aturan asosiasi pertambangan pola yang sering muncul mengalami
perkembangan yang cukup pesat yang telah diterapkan untuk berbagai aplikasi domain, seperti
pengindeksan dan pencarian kesamaan kompleks data terstruktur, pertambangan multimedia, dan pertambangan web
2.2. Landasan Teori
2.2.1. Konsep Dasar Aturan Asosiasi Algoritma.
15
adalah proses dua bagian. Pertama identifikasi set item atau itemsets dalam dataset. Kedua derivasi selanjutnya dari kesimpulan dari itemsets tersebut. Sebagian besar penelitian terkait sampai saat ini difokuskan pada penemuan efisiensi itemsets sebagai tingkat kompleksitas jauh lebih besar dibandingkan generasi inferensi.[6] Selama satu dekade terakhir berbagai algoritma telah dikembangkan melalui penyempurnaan strategi pencarian, teknik pemangkasan, struktur data dan penggunaan organisasi dataset alternatif. Sementara sebagian besar algoritma fokus pada penemuan eksplisit dari semua kesimpulan untuk dataset tertentu, pertimbangan peningkatan sedang diberikan kepada algoritma khusus yang berusaha untuk meningkatkan waktu pemrosesan. Untuk mengurangi waktu pengolahan bisa dilakukan dengan teknik pemangkasan dinamis mengurangi dataset selama pengolahan, membuang item yang tidak perlu.[6]
Kendala yang paling umum digunakan untuk mengurangi eksplorasi selama identifikasi itemsets adalah spesifikasi dari minsup ambang batas dukungan, dimana dukungan berkaitan dengan berapa kali itemsets akan muncul. Ini secara efektif mengurangi identifikasi itemsets dengan penemuan hanya itemsets yang melebihi minsup kemunculan dianggap sebagai itemsets yang valid.[6]
Meningkatkan Apriori[6] :
x Mengurangi melewati scan database transaksi. x Kecilkan jumlah calon / itemsets.
x Memfasilitasi dukungan menghitung calon.
x Menghapus transaksi yang jarang muncul dari k-itemset dari database untuk scan lebih lanjut.
16
dari item adalah 0.1%, itu berarti hanya 0,1 persen dari transaksi mengandung pembelian item ini [14].
Keyakinan atau kepercayaan adanya aturan asosiasi didefinisikan sebagai prosentasi ber transaksi yang mengandung X U Y dengan jumlah total transaksi yang mengandung X. Keyakinan adalah ukuran kekuatan aturan asosiasi, misalnya keyakinan dari aturan asosiasi X Y adalah 80%, itu berarti bahwa 80% dari transaksi yang mengandung X juga mengandung Y bersama-sama [14].
Umumnya sebuah asosiasi aturan algoritma pertambangan berisi langkah-langkah sebagai berikut [14] :
x Himpunan kandidat k-itemset yang dihasilkan oleh 1-ekstensi besar (k-1) – itemsets dihasilkan dalam iterasi sebelumnya.
x Mendukung untuk calon k-itemsets yang dihasilkan dari database.
x Itemsets yang tidak memiliki dukungan minimal dibuang dan sisanya disebut k-itemsets.
Algoritma konvensional aturan asosiasi menemukan dua langkah pertambangan asosiasi, langkah pertama menemukan semua itemset. The frequent itemset adalah itemset yang disertakan dalam setidaknya transaksi minsupport. Asosiasi aturan dengan kepercayaan pada minconfidence setidaknya dihasilkan pada langkah kedua [14].
2.2.2. Teknik Clustering
Teknik cluster termasuk teknik yang sudah cukup dikenal dan banyak dipakai dalam data mining. Usaha – usaha untuk menghitung jumlah cluster yang optimal dan peng-cluster-an yang paling baik masih terus dilakukan. Dengan demikian menggunakan metode yang sekarang, kita tidak bisa menjamin hasil peng-cluster-an sudah merupakan hasil yang optimal. Namun hasil yang dicapai biasanya sudah cukup bagus dari segi praktis. [22]
17
jaraknya dekat ) dalam satu cluster dan membuat jarak antar cluster sejauh mungkin. Ini berarti obyek dalam satu cluster sangat mirip satu sama lain dan berbeda dengan obyek dalam cluster – cluster yang lain.[22]
2.2.3. Algoritma Klasifikasi K-Means.
Algoritma klasifikasi K-Means merupakan metode clustering berbasis jarak yang mempartisi data ke sejumlah kelompok dan bekerja pada atribut numerik Algoritma ini dimulai dengan pemilihan jumlah kelompok ( k ) secara acak serta pengambilan sebagian populasi sejumlah ( k ) untuk dijadikan sebagai titik pusat awal. Salah satu metode perhitungan jarak yang bisa digunakan adalah Euclidean Distance. Perhitungan jarak menggunakan metode Euclidean dinyatakan sebagai berikut :
d ( x,y ) =
∑ (
−
)
………..(1)
Dimana : x ; obyek ke – 1 y ; obyek ke – 2
n ; banyaknya atribut obyek ke – 1, obyek ke – 2.
Prosedur dasar clustering K-Means adalah sebagai berikut : 1. Menentukan k sebagai jumlah cluster yang ingin dibentuk.
2. Membangkitkan k centroid ( titik pusat cluster ) awal secara random. 3. Menghitung jarak setiap data ke masing – masing centroids.
4. Setiap data memilih centroid yang terdekat.
5. Menentukan posisi centroid baru dengan cara menghitung nilai rata – rata dari data – data yang berada pada centroid yang sama.
18
Ada dua pendekatan dalam clustering yaitu partisioning dan hirarki. Dalam partisioning kita mengelompokkan obyek ke dalam k cluster. Ini bisa dilakukan dengan menentukan pusat cluster awal, lalu dilakukan realokasi obyek berdasarkan kriteria tertentu sampai dicapai pengelompokkan yang optimum. Dalam cluster hirarki, kita mulai dengan membuat m cluster dimana setiap cluster beranggotakan satu obyek dan berakhir dengan satu cluster dimana anggotanya adalah m obyek. Dalam clutering hirarki kita hitung jarak masing – masing obyek dengan setiap obyek yang lain. Selanjutnya kita temukan pasangan obyek yang jaraknya terdekat. Sehingga tiap obyek akan berpasangan dengan satu obyek atau kelompok obyek yang lain yang paling dekat jaraknya. Langkah – langkah yang perlu dilakukan untuk melakukan clustering hirarki adalah [ 21 ] :
1. Kelompokkan setiap obyek ke dalam kelompok / clusternya sendiri.
2. Temukan pasangan paling mirip untuk dimasukkan ke dalam cluster yang sama dengan melihat data dalam matriks kemiripan.
3. Gabungkan kedua obyek dalam satu cluster. 4. Ulangi sampai tersisa hanya satu cluster.
2.2.4. Algoritma Apriori
Analisis asosiasi atau association rule mining adalah teknik data mining untuk menemukan aturan asosiatif antara suatu kombinasi item. Biasanya digunakan untuk analisis pembelian barang di pasar swalayan dengan maksud untuk mengetahui berapa besar kemungkinan seorang konsumen membeli satu jenis barang bersamaan dengan jenis barang yang lainnya. Sehingga perusahaan dapat mengatur strategi promosi dengan penempatan barang yang saling berhubungan ditempatkan secara berdekatan dan menetapkan strategi harga promosi untuk barang – barang tertentu yang saling berhubungan.
19
Tahap ini mencari kombinasi item yang memenuhi syarat minimum dari nilai support dalam database. Nilai support sebuah item diperoleh dengan rumus berikut :
Support A =
………( 2 )
Sementara itu, nilai support dari 2 item diperoleh dari rumus 2 berikut : Support ( A,B ) = P ( A ∩ B )
Support ( A,B ) = …………...………( 3 )
2. Pembentukan Aturan Asosiasi
Setelah semua pola frekuensi tinggi dtemukan, barulah dicari aturan asosiasi yang memenuhi syarat minimum untuk confidence dengan menghitung confidence aturan asosiatif A→B.
Nilai confidence dari aturan A→B diperoleh dari rumus berikut :
Confidence = P ( B | A ) =
……….( 4 )
2.2.5. Confusion Matrix
20
Confusion Matrix Tar get
Positive Negative
Model Positive a b
Positive Predictive
Value a/(a+b)
Negative c d
Negative Predictive
Value d/(c+d)
sensitivity Specificity
a/(a+c) d/(b+d) Accuracy = (a+d)/(a+b+c+d)
Akurasi : proporsi jumlah prediksi yang benar.[12]
- Positif presisi nilai prediktif atau proporsi kasus positif yang diidentifikasi dengan benar.
- Negatif prediktif value : proporsi kasus negatif yang diidentifikasi dengan benar. - Sensitivitas : proporsi kasus positif sebenarnya yang diidentifikasi dengan benar. - Kekhususan : proporsi kasus negatif yang sebenarnya yang diidentifikasi dengan
21 2.3.Kerangka Pemikirian
Bagan 2.1. Kerangka Pemikiran RUMUSAN MASALAH
Data Transaksi Penjualan Data Transaksi Penjualan 1.Banyaknya jumlah transaksi dengan item
barang yang sangat bervariasi.
2.Daya beli masyarakat setiap transaksi sangat bervariasi.
3. Belum mengetahui adanya asosiasi barang yang dijual secara umum maupun berdasarkan kemampuan daya beli.
4. Belum mengetahui nilai support
dan confidence untuk masing –
masing asosiasi barang
TUJUAN & MANFAAT
MANFAAT TUJUAN
Perusahaan bisa menyediakan persediaan barang di gudang sesuai permintaan konsumen, melakukan penjualan barang secara paket dengan harga lebih murah.
Evaluasi cluster jenis barang, memetakan daya beli konsumen, memetakan asosiasi barang secara umum maupun sesuai cluster daya beli, mengukur nilai
support dan confidence untuk masing-masing asosiasi barang dan mengukur waktu asosiasi.
PENDEKATAN
Cluster jenis barang dan daya beli masyarakat dengan Algoritma
K-Means
Asosiasi jenis barang menggunakan Algoritma
Asosiasi
Tools
Untuk cluster jenis barang dan cluster daya beli masyarakat dengan Rapidminer sedangkan untuk Asosiasi dengan Java
EVALUASI
Mengevaluasi hasil eksperimen, untuk asosiasi dievaluasi nilai support dan