Vol. 5, No. 3, Januari 2010 ISSN 0216-0544
DAFTAR ISI
ALGORITMA PEMUTUSAN SIKLUS ITERATIF PADA 137-146 ESTIMASI ROTASI CITRA DENGAN MENGGUNAKAN
PSEUDO-POLAR FOURIER TRANSFORM
Arya Yudhi Wijaya, Agus Zainal Arifin, dan Diana Purwitasari
PENGENALAN CITRA WAJAH MENGGUNAKAN 147-156 METODE TWO-DIMENSIONAL LINEAR DISCRIMINANT
ANALYSIS DAN SUPPORT VECTOR MACHINE
Fitri Damayanti, Agus Zainal Arifin, dan Rully Soelaiman
ESTIMASI BENTUK STRUCTURING ELEMENT 157-165 BERDASAR REPRESENTASI OBYEK
Sri Huning Anwariningsih, Agus Zainal Arifin, dan Anny Yuniarti
OPTIMASI METODE DISCRIMINATIVELY 166-174
REGULARIZED LEAST SQUARE CLASSIFICATION
DENGAN ALGORITMA GENETIKA
Ariadi Retno Tri Hayati Ririd, Agus Zainal Arifin, dan Anny Yuniarti
PERBAIKAN STRUKTUR WEIGHTED TREE DENGAN 175-185 METODE PARTISI FUZZY DALAM PEMBANGKITAN
FREQUENT ITEMSET
Budi Dwi Satoto, Daniel O Siahaan, dan Akhmad Saikhu
SIMULASI PERGERAKAN PENGUNJUNG MALL 186-196 MENGGUNAKAN POTENTIAL FIELD
Arik Kurniawati, Supeno MS Nugroho, dan Moch Hariadi
DETEKSI OUTLIER BERBASIS KLASTER PADA SET DATA 197-204 DENGAN ATRIBUT CAMPURAN NUMERIK DAN KATEGORIKAL
Vol. 5, No. 3, Januari 2010 ISSN 0216 - 0544
137
ALGORITMA PEMUTUSAN SIKLUS ITERATIF PADA
ESTIMASI ROTASI CITRA DENGAN MENGGUNAKAN
PSEUDO-POLAR FOURIER TRANSFORM
*Arya Yudhi Wijaya, **Agus Zainal Arifin, ***Diana Purwitasari Program Pasca Sarjana, Jurusan Teknik Informatika, ITS
Jl. Raya ITS, Kampus ITS, Sukolilo, Surabaya, 60111 E-Mail: *[email protected], **[email protected], ***[email protected]
Abstrak
Registrasi citra adalah proses sistematik untuk menempatkan citra yang terpisah dalam sebuah kerangka acuan yang sama, sehingga informasi yang dikandung oleh citra tersebut dapat diintregasikan atau dibandingkan secara optimal. Estimasi sudut rotasi dan translasi untuk registrasi citra dilakukan menggunakan Pseudo-polar Fourier Transform (PPFT). Akurasi akan dicapai secara optimal apabila dilakukan iterasi pada estimasi dengan batasan tingkat kesalahan sesuai nilai threshold yang ditentukan sebelumnya. Proses iterasi membuat kompleksitas registrasi menjadi kurang efisien. Penelitian ini bertujuan mengoptimasi registrasi citra dengan mengusulkan estimasi rotasi citra non-iteratif dengan PPFT. Optimasi dilakukan dengan menghapus sejumlah iterasi pada estimasi rotasi citra iteratif dengan PPFT menjadi satu kali proses estimasi, yaitu dengan menjadikan nilai-nilai sekitar estimasi sudut rotasi sebagai kandidat yang baru. Selanjutnya, I1 dirotasi dengan kandidat
sudut estimasi. Sudut estimasi yang paling akurat adalah sudut estimasi yang menghasilkan penghitungan nilai phase correlation tertinggi antara I2 dan citra-citra
hasil rotasi I1 oleh kandidat sudut estimasi. Uji coba menunjukkan bahwa nilai iterasi
yang dapat dihapus pada registrasi citra iteratif menggunakan PPFT adalah sebesar 3-11. Metode yang diusulkan juga memiliki kekuatan estimasi pada citra ber-noise jenis gaussian noise yang memiliki mean µ = 0 hingga varian σ sebesar 0,13.
Kata kunci: registrasi citra, Pseudo-polar Fourier Transform, phase-correlation. Abstract
Image registration is a systematic process to put the separated image in a frame, so the information of the image can be integrated or compared optimally. The estimation of rotation and translation to register image is done by using Pseduo-polar Fourier Transform (PPFT). The accuracy will be reached optimally if iteration on estimation by the limitation in the level of mistake according to treshold which is determined. The iteration process creates the complexity of registration less efficient. This research purposes to optimize the image registration by giving suggestion estimation of non interactive of image rotation by using PPFT. The optimum which is done by deleting a number of estimation of iterative image rotation with the PPFT becomes once of estimation process. The deletion of iteration value which is done by uniting the surround of estimation of rotation side as a new candidate. Furthermore, I1 is
rotated with estimation of estimation side. The most accurate side is the side resulting in the calculation of the highest phase correlation value between I2 and rotation
image I1, candidate estimation side. The try out shows that the iteration value which
is deleted on registration of iterative image using PPTF is 3–11. The method pruposed has estimation on image of noise of gaussian noise having mean u=0 till variant 0 for 0,13.
PENDAHULUAN
Registrasi citra adalah proses menemukan kembali titik-titik yang bersesuaian antara citra I1 dengan citra I2. Citra I2 adalah citra I1 yang mengalami transformasi geometri antara lain translasi (translation), rotasi, perbesaran (scaling), pembalikan (fliping), dan penarikan (stretching). Registrasi citra memainkan peran utama dalam banyak aplikasi misalnya kompresi video [1], perbaikan kualitas video [2], scene representation [3], dan analisa citra medis [4].
Beberapa metode telah diusulkan untuk registrasi citra. Registrasi citra pada domain spasial dilakukan dengan cara mencari nilai rata-rata, median, atau ukuran statistika lainnya pada setiap nilai derajat keabuan (grayscale) atau RGB citra [5]. Registrasi citra pada domain frekuensi spasial bekerja dengan baik ketika diaplikasikan terhadap citra yang memiliki tingkat ketidakteraturan kecil.
Registrasi citra pada domain frekuensi dilakukan dengan menggunakan Transformasi Fourier. Metode berbasis Transformasi Fourier mampu memperkirakan skala perbesaran, rotasi, dan translasi lebih akurat dibandingkan dengan metode pada domain spasial. Sebagian besar pendekatan yang dilakukan berdasarkan Transformasi Fourier memanfaatkan nilai translasi pada domain yang dapat diestimasi dengan akurat oleh phase correlation [6]. Phase correlation adalah metode dalam registrasi citra untuk mengestimasi translasi dua citra yang mirip dengan memanfaatkan nilai puncak fase pada domain frekuensi.
Metode mutahir yang diusulkan dalam registrasi citra pada domain frekuensi adalah estimasi skala rotasi dan translasi menggunakan Pseudo-polar Fourier Transform (PPFT) [7,8]. Perbedaan mendasar pada penelitian yang dilakukan Reddy dkk [7] dan Guo dkk [8] adalah penggunaan metode penghitungan translasi PPFT pada koordinat polar. Penghitungan translasi PPFT dapat dilakukan dengan menggunakan Analytical Fourier-Mellin Transform [7] maupun phase correlation [8].
Langkah pertama yang dilakukan untuk estimasi rotasi dengan PPFT adalah dengan melakukan mapping citra dari domain spasial
ke domain frekuensi di atas pseudopolar-grid. Rotasi diestimasi dengan mengubah basis koordinat kartesian (x,y) ke basis koodinat polar (r,θ). Sudut rotasi adalah translasi I2 terhadap I1 pada sumbu θ. Estimasi rotasi dan translasi dengan PPFT memiliki akurasi yang tinggi. Akan tetapi, akurasi akan dicapai secara optimum apabila dilakukan iterasi dengan batasan tingkat kesalahan sesuai nilai threshold yang ditentukan sebelumnya. Proses iterasi ini menjadikan registrasi menjadi boros dalam hal komputasi.
Penelitian ini mengusulkan suatu metode untuk meningkatkan efisiensi komputasi dengan cara mengubah cara iteratif menjadi non-iteratif tanpa mengurangi akurasi dari hasil estimasi rotasi dan translasi. Cara non-iteratif dilakukan dengan dua tahap utama yaitu tahap representasi PPFT dan tahap estimasi dengan memanfaatkan phase correlation. Tahap representasi melakukan perbaikan representasi PPFT, sehingga phase correlation akan dapat mengestimasi translasi dengan lebih akurat. Sedangkan tahap estimasi dilakukan tanpa iterasi karena menggunakan kandidat lain sebagai sudut rotasi yang merupakan tetangga dari sudut yang ditemukan.
KONSEP REGISTRASI CITRA PADA DOMAIN SPASIAL DAN FREKUENSI
Estimasi Pergeseran
I2 adalah citra I1 yang mengalami translasi pada sumbu x dan sumbu y sebesar (∆x,∆y) sehingga didapatkan Persamaan (1).
∆y)
+
y
∆x,
+
(x
I
=
y)
(x,
I
1 2 (1)maka besar translasi I2 terhadap I1 sebesar (∆x,∆y) dapat ditemukan secara akurat dengan phase correlation [9]. Metode estimasi translasi dengan phase correlation dapat dilakukan dengan Transformasi Fourier 2D pada I1 dan I2 sehingga secara berturut-turut menghasilkan ˆI1 dan ˆI2. ˆI1 dan ˆI2 berturut- turut adalah citra I1 dan I2 dalam domain Fourier Transform yang dinotasikan dengan Persamaan (2).
{ }
1 1ˆ = I
I ℑ ; Iˆ2=ℑ
{ }
I2 (2)Selanjutnya dilakukan penghitungan phase correlation dengan Persamaan (3).
Wijaya dkk, Algoritma Pemutusan Siklus Iteratif… 139 | I I | I I = ∗ ∗ ℜ 2 1 2 1 ˆ ˆ ˆ ˆ (3) dimana ℜ adalah phase correlation dari ˆI1 dan ˆI2. Sedangkan I2* adalah complex conjugate dari I2. Selanjutnya dicari phase correlation R pada domain spasial dimana R adalah seperti yang ditunjukkan oleh Persamaan (4).
{ }
ℜ ℑ−1 =R (4) Translasi citra I2 terhadap I1 dapat ditemukan dengan mencari letak puncak dari R yaitu degan menggunakan Persamaan (5).
{ }
R = ∆y) (∆∆x y) (x, x am g r a (5) ∆x adalah besar translasi I2 terhadap I1 pada arah sumbu x, sedangkan ∆y adalah besar translasi I2 terhadap I1 pada arah sumbu y. Estimasi RotasiApabila I2 adalah citra I1 yang mengalami rotasi sebesar ∆θ, maka cara untuk menemukan sudut rotasi relatif I2 terhadap I1 sebesar ∆θ adalah dengan mengubah sistem koordinat kartesian pada citra I1 dan I2 menjadi sistem koordinat polar sehingga didapatkan Persamaan (6). ∆θ) + θ (r, I = θ) (r, I1 2 (6)
)
,
(
1r
θ
I
adalah citra I1 pada koordinat polardan
I
2(
r
,
θ
+
∆
θ
)
adalah citra I2 padakoordinat polar dimana I2 memiliki sudut rotasi
relatif sebesar ∆θ terhadap I1. r adalah jarak
suatu titik dengan pusat koordinat dan θ adalah rotasi relatif terhadap sumbu x positif dengan pusat rotasi pangkal koordinat.
Gambar 1(a) dan (b) adalah I1 dan I2 pada koordinat kartesian. Dilakukan transformasi I1 dan I2 menuju sistem koordinat polar sehingga secara berurutan I1 dan I2 berubah menjadi seperti pada Gambar 1(c) dan (d). Sumbu horisontal pada Gambar 1(c) dan (d) merupakan sumbu r. Sedangkan sumbu vertikal pada Gambar 1(c) dan (d) merupakan sumbu θ.
Dapat diamati bahwa
I
2(r,
θ
+
∆θ)
yang ditunjukkan oleh Gambar 1(d) merupakan versi translasi sepanjang sumbu θ dariI
1(r,
θ)
yang ditunjukkan Gambar 1(c). Besar translasi sepanjang sumbu θI
2(r,
θ
+
∆θ)
terhadapθ)
(r,
I
1 dapat ditemukan secara akurat dengan phase correlation. Sehingga, sudut rotasi relatif I2 terhadap I1 sebesar ∆θ dapat dicari dengan mereduksi peristiwa rotasi menjadi peristiwa translasi pada koordinat polar.(a) (b) (c) (d)
Gambar 1. Estimasi rotasi. (a) Citra I1, (b) Citra I2 yang merupakan versi rotasi sebesar ∆θ
terhadap I1, (c) I1 pada sistem koordinat polar, dan (d) I2 pada sistem koordinat polar.
(a) (b) (c)
Kendala Estimasi Rotasi pada Domain Spasial
Konsep estimasi translasi dan rotasi dengan phase correlation yang dipaparkan pada bagian sebelumnya akan menghasilkan estimasi yang akurat apabila I1 dan I2 memiliki pusat rotasi yang sama, dimana pusat tersebut telah didefinisikan terlebih dahulu (secara default pusat perbesaran berada di titik tengah citra). Akan tetapi, hasil estimasi rotasi I2 terhadap I1 tidak akurat apabila diterapkan pada citra yang memiliki pusat rotasi yang tidak sama. Kendala ini terjadi akibat adanya translasi citra I2 terhadap I1, sehingga pusat rotasi dan perbesaran yang seharusnya sama menjadi bergeser. Peristiwa ini seharusnya tidak akan menjadi kendala apabila pengerjaannya dilakukan pada domain frekuensi. Domain frekuensi menjadi solusi karena adanya sifat shift invariant pada domain frekuensi, yang berarti bahwa domain frekuensi tidak dipengaruhi oleh translasi.
Berdasarkan konsep ini, maka diusulkan metode yang mengadopsi prinsip yang dilakukan pada sub bagian sebelumnya, akan tetapi dilakukan pada domain frekuensi [8]. Domain frekuensi yang diusulkan adalah Pseudo-polar Fourier Transform (PPFT) seperti yang diperlihatkan dalam Persamaan (7). 2 1 P P P≡ ∪ (7) dimana − ≤ ≤ − ≤ ≤ − ≡ k,k | N l N, N k N N P 2 2 2l 1 dan (8) − ≤ ≤ − ≤ ≤ − ≡ k | N l N, N k N N k, P 2 2 2l 2 (9)
P adalah pseudopolar-grid yang tersusun dari gabungan P1 dan P2. P1 adalah komponen P pada arah vertikal dan P2 adalah komponen P pada arah horisontal. k disebut sebagai pseudoradius dan l disebut sebagai pseudoangle. Resolusi dari pseudopolar-grid untuk citra ukuran N x N adalah 2N +1 pada bagian angular dan N + 1 pada bagian radial.
Ilustrasi himpunan P1 dan P2 dapat dilihat pada Gambar 2(a) dan (b). Pseudopolar-grid P diilustrasikan pada Gambar 2(c). Dengan representasi pada koordinat polar (r,θ), pseudopolar-grid didefinisikan dengan Persamaan (10). ) θ , (r = l) (k, P1 k1 l1 dan ) θ , (r = l) (k, P2 k2 l2 (10) Dimana 1 4 2 1 + N l k = rk , 2 4 2 1 + N l k = rk (11) − N π = θl 2l arctan 2 / 1 dan N = θl 2l arctan 2 (12) Nilai k = –N, …, N dan l = – N/2, …, N/2. Nilai PPFT didefinisikan sebagai sampel dari Transformasi Fourier di atas pseudopolar-grid P yang diberikan pada Persamaan (8) dan (9). Secara detil, PPFT Ij (j= )
pp 1,2
ˆ adalah sebuah transformasi linear, dimana terdefinisi untuk k = –N,…,N dan l = – N/2,…,N/2, sebagai Persamaan (13) dan (14).
∑
− − − − − ≡ 1 2 / 2 / 1 1 2i 2π exp ˆ 2l ˆ ˆ N N = v u, pp pp kv + ku N M v) I(u, = I k k, N I I (13) . 2i 2π exp ˆ 2l ˆ ˆ 1 2 / 2 / 2 2∑
− − − − − ≡ N N = v u, pp pp kv N ku M v) I(u, = I k N k, I I (14)Iˆ adalah I pada domain frekuensi. Iˆ1pp adalah
nilai PPFT yang akan diberikan di atas P1 dan 2
ˆ
pp
I adalah nilai PPFT yang akan diberikan di atas P2.
Sebagaimana dapat dilihat pada Gambar 2(c), untuk setiap sudut yang telah ditentukan sebesar l, sampel dari pseudopolar-grid memiliki space yang sama pada bagian radial. Akan tetapi, space ini berbeda untuk sudut yang berbeda. Demikian pula, grid memiliki space yang tidak sama dalam bagian angular, tetapi memiliki space kemiringan yang sama (lihat Persamaan (15) dan (16)).
N = θ θ (l) θ
∆tan pp cot l1+1 cot l1 2
1 ≡ − (15) N = θ θ (l) θ ∆ pp l+ l 2 cot cot tan 2 2 1 2 ≡ − (16) dimana θpp 1 dan θpp 2 diberikan pada Persamaan (12).
Properti penting PPFT adalah bahwa transformasi ini memiliki kemampuan invert.
Wijaya dkk, Algoritma Pemutusan Siklus Iteratif… 141
Selain itu, PPFT forward dan invert dapat diaplikasikan dengan sebuah komputasi yang cepat dengan bantuan FrFT. Dan yang lebih penting lagi, algoritma ini tidak membutuhkan regriding atau interpolasi sehingga memiliki keakuratan yang tinggi.
Fractional Fourier Fourier (FrFT)
Kompleksitas penghitungan PPFT dapat ditekan dengan bantuan FrFT. FrFT adalah algoritma cepat dengan komputasi O(N logN) yang dapat memetakan Transformasi Fourier Diskrit (DFT) di atas beberapa himpunan dari N titik pada sebuah keliling lingkaran [8]. Sehingga FrFT menjadikan kompleksitas komputasi keseluruhan PPFT pada Persamaan (13) dan (14) yang semula adalah O(N3) kemudian dapat direduksi menjadi O(N2 logN).
Lebih spesifik, diberikan sebuah vektor C dengan panjang N+1, C=C(u), ) 2 / ,..., 2 / ( N N u= − , α ∈R. FrFT
didefinisikan sebagai Persamaan (17).
∑
− − 2 / 2 / 1 exp 2ππi / 1 N N = u α + N C)(k)= C(u) [ ku(N+ )] (F N/2 , N2,... k =− (17)Algoritma Estimasi Rotasi Iteratif dengan
PPFT
Algoritma estimasi rotasi iteratif dengan menggunakan PPFT [8] dapat dilihat pada Gambar 3. Penjelasan algoritma pada Gambar 3 adalah sebagai berikut:
1. Magnitude PPFT dihitung setelah dilakukan zero-padding pada citra masukan sehingga memiliki ukuran yang sama.
2. θ ditemukan dengan melakukan 1D phase correlation sepanjang sumbu θ pada domain pseudo-polar.
3. Salah satu dari citra masukan diputar dengan sudut akumulasi θn.
4. Dilakukan iterasi langkah 1-3 hingga ∆θ lebih kecil dari threshold yang ditentukan yaitu sebesar εθ.
5. Ambiguitas θ diselesaikan dengan menggunakan 2D phase correlation, yaitu dengan memutar salah satu citra sebesar θ dan θ+π. Ambiguitas ini disebabkan oleh ambiguitas nilai arctan p yang dapat bernilai θ atau θ + π.
6. Pergeseran ditemukan dengan menggunakan 2D phase correlation.
Gambar 4. Estimasi Rotasi Non-iteratif dengan PPFT.
(a) (b) (c) (d)
Gambar 5. (a) Citra I1, (b) Citra I2, (c) GIˆp1(r,θ), dan (d) GIˆp2(r,θ).
Wijaya dkk, Algoritma Pemutusan Siklus Iteratif… 143
(a) (b) (c) (d)
Gambar 7. Salah Satu Contoh Uji Coba. (a) Citra I1, (b) Citra I2 Memiliki Rotasi Relatif 66°
terhadap I1, (c) PPFT I1 dan I2 dalam Representasi Grayscale, dan (d) Citra I1
Ditambah Hasil Estimasi Rotasi.
(a) (b) (c) (d)
Gambar 8. Salah Satu Contoh Hasil Uji Coba. (a) Citra I1, (b) Citra I2 Memiliki Rotasi Relatif
33,7° terhadap I1, gaussian noise µ = 0 dan Varian σ = 0,09, (c) PPFT I1 dan I2 dalam
Representasi Grayscale, dan (d) Citra I1 Ditambah Hasil Estimasi Rotasi Citra I2.
ALGORITMA PEMUTUSAN SIKLUS ITERATIF ESTIMASI ROTASI DENGAN PPFT
Algoritma yang diusulkan yaitu estimasi rotasi non-iteratif dengan PPFT akan memperbaiki algoritma estimasi rotasi iteratif dengan PPFT yang terdapat pada Gambar 3. Perbaikan dilakukan dengan membuang iterasi untuk menemukan sudut rotasi optimum. Secara keseluruhan algoritma yang diusulkan dapat dilihat pada Gambar 4.
Algoritma memiliki dua tahap utama, yaitu tahap representasi dan tahap estimasi. Tahap representasi bertujuan melakukan pemrosesan PPFT sehingga siap untuk dilakukan pencarian nilai translasinya pada koordinat polar. Sedangkan tahap estimasi bertujuan mengestimasi translasi maupun mengukur tingkat kesamaan dua buah citra dengan memanfaatkan kemampuan phase correlation. Tahap Representasi
Masukan dari tahap representasi adalah dua buah citra grayscale I1 dan I2. Dilakukan penghitungan magnitude PPFT pada masing-masing citra I1 dan I2 sehingga menghasilkan
1
ˆ
pp
I
M untuk I1 dan menghasilkan MIˆpp2 untuk
I2. Representasi PPFT dalam pseudopolar-grid
ditransformasikan pada koordinat polar sehingga ˆ 1
pp
I
M dan MIˆpp2 masing-masing
diubah menjadi MIˆp1(r,θ) dan MIˆp2(r,θ)pada
koordinat polar.
Dikarenakan jangkauan nilai yang sangat besar pada MI (r,θ)
p1
ˆ dan MI (r,θ)
p2
ˆ , maka dilakukan operasi logaritma pada MIˆp1(r,θ) dan
θ) (r, I
Mˆp2 sehingga menghasilkan LIˆp1(r,θ) dan θ) (r, I Lˆp2 sebagaimana Persamaan (18). θ)) (r, I (M ln + = θ) (r, I Lˆp 1 ˆp (18) θ) (r, I
Lˆp1 dan LIˆp2(r,θ) masih terlalu kasar untuk dilakukan pemrosesan berikutnya karena nilai kontras yang kecil. Oleh karena itu,
θ) (r, I
Lˆp1 dan LIˆp2(r,θ) perlu diinterpolasikan
nilainya dalam interval grayscale sesuai Persamaan (19).
{ {
= θ) (r, I G θ) (r, I L : jika , > I L : jika ; x θ) (r, I L < θ) (r, I L : jika ; p p p p p ˆ 14 ˆ 4 14 ˆ 255 255 4 14 4 ˆ 4 ˆ 0 ≤ ≤ − − (19)) , (rθ I G p ∧
adalah representasi PPFT dalam grayscale yang telah dinormalisasi. GIp1(r,θ)
∧
dan GIp2(r,θ)
∧
adalah PPFT milik citra masukan I1 dan I2 yang siap diestimasi
translasinya dengan phase correlation. Ilustrasi mengenai representasi GIp(r,θ)
∧
dapat dilihat di Gambar 5. Gambar 5(a) dan (b) masing masing adalah citra masukan I1 dan I2. Gambar 5(c)
dan (d) adalah representasi PPFT pada grayscale yang telah dinormalisasi dengan Persamaan 19. Terlihat dengan jelas bahwa Gambar 5(d) adalah versi translasi dari Gambar 5(c) pada sumbu θ (vertikal).
Tahap Estimasi
Tahap estimasi diawali dengan melakukan estimasi translasi relatif G ˆIp1 terhadap G ˆ Ip2 sepanjang sumbu θ dengan phase correlation sebagaimana Persamaan (3). Sudut rotasi relatif I2 terhadap I1 sebesar α ditemukan dengan mencari besar translasi sepanjang sumbu θ. G ˆ memiliki periode 180º, yang Ip berarti bahwa selain sudut rotasi α masih terdapat kandidat sudut rotasi yang lain yaitu sebesar α + 180º. Sehingga terdapat dua kadidat sudut rotasi sebesar α1 dan α2 yang nilainya ditunjukkan pada Persamaan (20) dan (21). α = α1 (20) ° + α = α2 180 (21)
Sudut rotasi sebenarnya sebesar αT dapat
dihitung dengan memanfaatkan phase correlation 2D. I1 masing-masing diputar sebesar α1 dan α2. Sudut rotasi sebenarnya sebesar αT adalah sudut yang menghasilkan puncak phase correlation terbesar.
Penghalusan sudut rotasi dengan pembandingan sudut tetangga bertujuan untuk meningkatkan akurasi estimasi rotasi sebesar αT. Ide langkah ini adalah adanya
ketidakpercayaan bahwa sudut rotasi yang sebenarnya adalah αT. Mungkin saja sudut
rotasi yang sebenarnya adalah sudut di sekitar αT. Langkah ini akan menghemat biaya
komputasi dibandingkan dengan iterasi yang dilakukan oleh registrasi citra iteratif dengan PPFT. Penghematan terjadi karena iterasi yang dilakukan akan digantikan dengan pembandingan sudut tetangga sehingga tidak
diperlukan lagi iterasi. Gambaran mengenai pembandingan sudut tetangga disajikan pada Gambar 6. Jika banyaknya tetangga di atas sudut αT adalah p dan banyaknya tetangga di
bawah sudut αT juga berjumlah p, maka
terdapat himpunan kandidat sudut rotasi yang baru yaitu αK. Sudut rotasi akhir hasil
penghalusan adalah αR yang merupakan elemen αK yang memiliki puncak phase correlation
tertinggi.
HASIL DAN PEMBAHASAN
Hasil Uji Coba untuk Menentukan Banyak Iterasi yang Dihilangkan dan Akurasi Estimasi
Uji coba pertama bertujuan untuk menentukan banyak iterasi metode estimasi rotasi iteratif dengan PPFT yang dapat dihapus oleh metode yang diusulkan. Selain itu, uji coba juga bertujuan untuk menentukan akurasi estimasi rotasi algoritma iteratif maupun non-iteratif.
Uji coba dilakukan dengan melakukan registrasi terhadap empat pasang citra berbeda dimana masing-masing pasang memiliki sudut rotasi relatif sesamanya. Sudut rotasi sebenarnya pada masing-masing pasang citra telah diketahui sebelumnya yaitu: 66°; 33,7°; 0,8°; dan 177°. Sudut 66° diharapkan mewakili rotasi pada kondisi umum dengan sudut rotasi berupa bilangan bulat di kuadran I. Selanjutnya sudut 33,7° diharapkan mewakili rotasi pada kondisi umum dengan sudut rotasi berupa bilangan desimal di kuadran I. Kemudian sudut rotasi 0,8° diharapkan dapat mewakili pada kondisi sudut rotasi yang kecil yaitu ±1° dimana pada umumnya sudutnya merupakan bilangan desimal. Terakhir, sudut 177° diharapkan mewakili rotasi pada kondisi umum dengan sudut rotasi > 90°.
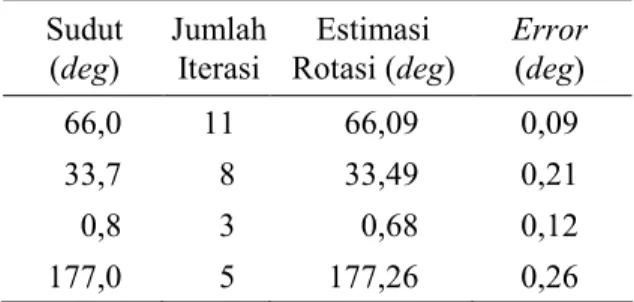
Tabel 1. Jumlah Iterasi dan Akurasi Estimasi Rotasi Iteratif dengan PPFT. Sudut (deg) Jumlah Iterasi Estimasi Rotasi (deg) Error (deg) 066,0 11 066,09 0,09 033,7 08 033,49 0,21 000,8 03 000,68 0,12 177,0 05 177,26 0,26
Wijaya dkk, Algoritma Pemutusan Siklus Iteratif… 145
Tabel 2. Akurasi Estimasi Rotasi Non-Iteratif dengan PPFT. Sudut (deg) Jumlah Iterasi Estimasi Rotasi (deg) Error (deg) 066,0 1 066,09 0,09 033,7 1 033,75 0,05 000,8 1 000,70 0,10 177,0 1 177,19 0,19
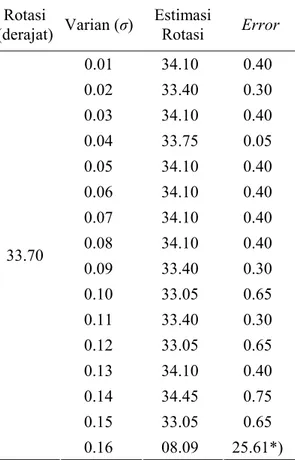
Tabel 3. Akurasi Estimasi Rotasi pada Citra ber-noise (Gaussian noise, mean µ = 0). Rotasi (derajat) Varian (σ) Estimasi Rotasi Error 0.01 34.10 0.40 0.02 33.40 0.30 0.03 34.10 0.40 0.04 33.75 0.05 0.05 34.10 0.40 0.06 34.10 0.40 0.07 34.10 0.40 0.08 34.10 0.40 0.09 33.40 0.30 0.10 33.05 0.65 0.11 33.40 0.30 0.12 33.05 0.65 0.13 34.10 0.40 0.14 34.45 0.75 0.15 33.05 0.65 33.70 0.16 08.09 25.61*) *)nilai error estimasi rotasi terlalu besar sehingga tidak
dilanjutkan untuk nilai varian berikutnya.
Salah satu contoh uji coba dengan metode yang diusulkan dapat dilihat pada Gambar 7. Gambar 7(a) dan (b) adalah citra masukan I1 dan I2. I2 memiliki rotasi relatif 66° terhadap I1. Gambar 7(c) adalah PPFT I1 dan I2 dalam representasi grayscale. Gambar 7(d) adalah Citra I1 ditambah hasil estimasi rotasi citra I2.
Hasil uji coba dengan metode iteratif dapat dilihat pada Tabel 1. Iterasi yang dilakukan untuk mencapi tingkat kesalahan terkecil adalah sebesar 3-11 kali. Tingkat kesalahan
terbesar adalah 0,26°. Sedangkan hasil uji coba dengan metode yang diusulkan yaitu estimasi rotasi non-iteratif dengan PPFT yang hanya memerlukan satu kali iterasi dapat diamati pada Tabel 2. Tingkat kesalahan maksimum estimasi rotasi yang diusulkan adalah sebesar 0,19°.
Hasil uji coba pada Tabel 1 dan 2 menunjukkan bahwa metode yang diusulkan mampu memutus siklus iteratif pada estimasi rotasi iteratif dengan PPFT. Tingkat akurasi metode yang disulkan juga menunjukkan tingkat kesalahan yang lebih kecil dibandingkan metode iteratif.
Hasil Uji Coba Ketahanan Terhadap Noise Uji coba kedua bertujuan untuk menentukan akurasi estimasi rotasi oleh metode yang diusulkan pada citra yang memiliki noise. Noise yang dipilih adalah Gaussian Noise dengan mean µ = 0 dan varian σ = 0,01; 0,02; hingga metode yang diusulkan tidak mampu lagi mengestimasi rotasi secara akurat. Gaussian Noise dipilih karena lebih umum terjadi pada dunia nyata. Sudut rotasi yang dipilih adalah 33,7°.
Salah satu contoh uji coba kedua dapat dilihat pada Gambar 8. Gambar 8(a) dan (b) masing-masing adalah citra masukan I1 dan I2. I2 adalah versi rotasi 33,7° terhadap I1 dan I2 diberi Gaussian Noise dengan mean µ = 0 dan varian σ = 0,09. Gambar 8(c) adalah PPFT milik I1 dan I2 pada representasi grayscale. Sedangkan Gambar 8(d) adalah hasil estimasi rotasi I2 terhadap I1 yang merupakan penjumlahan I1 dan I2 hasil rekonstruksi dari rotasi dan translasi yang ditemukan.
Hasil uji coba kedua dapat diamati pada Tabel 3. Tingkat kesalahan tetap bernilai kecil (di bawah 1°) hingga gaussian noise memiliki varian 0,15. Uji coba ini membuktikan bahwa metode yang diusulkan memiliki ketahanan terhadap noise. Hal ini dikarenakan bahwa dengan pengamatan visual citra yang memiliki Gausian noise dengan mean µ = 0 dan varian σ = 0,10 sudah tidak nampak lagi bentuk aslinya.
SIMPULAN
Berdasarkan hasil uji dan pembahasan yang dilakukan, maka dapat ditarik simpulan:
1. Algoritma yang diusulkan mampu memutus siklus iterasi berkisar 3-11 dibanding
algoritma registrasi citra untuk estimasi rotasi dengan menggunakan PPFT.
2. Algoritma registrasi citra dengan PPFT yang sebelumnya memiliki kompleksitas komputasi O(MN2 logN), dimana M menunjukkan banyak iterasi dan N menyatakan ukuran citra masukan ukuran NxN, dapat direduksi menjadi O(N2 logN) dikarenakan iterasi sebanyak M bernilai 1. 3. Ditinjau dari segi akurasi, hasil registrasi
citra dengan metode yang diusulkan memiliki tingkat akurasi yang signifikan yang didapatkan secara otonom tanpa
pendefinisian nilai threshold sebelumnya. Berbeda dengan metode registrasi PPFT yang menggunakan iterasi, akurasi didefinisikan sebagai nilai threshold dan iterasi akan berhenti ketika nilai estimasi rotasi mencapai nilai threshold yang ditentukan.
4. Metode yang diusulkan juga memiliki ketahanan terhadap gaussian noise yang memiliki mean µ = 0 hingga varian σ sebesar 0,13.
DAFTAR PUSTAKA
[1] Dufaux F and Konrad J. Efficient, Robust, and Fast Global Motion Estimation for Video Coding. IEEE Transaction on Image Processing. 9: 497-501. 2000. [2] Kuglin CD and Hines DC. The Phase
Correlation Image Alignment Method. Proc. IEEE Conf. Cybernetics and Society. 163-165. 1975.
[3] Irani M and Peleg S. Motion Analysis for Image Enhancement: Resolution, Occlusion, and Transparency. J Visual Comm and Image Representation. 4: 324-335. 1993.
[4] Mann S and Picard R. Virtual Bellows: Constructing High Quality Stills from Video. Proc IEEE Int’l Conf Image Processing. 363-367. 1994.
[5] Wan R and Li M. An Overview of Medical Image Registration. Fifth International Conference on Computational Intelligence and Multimedia Applications (ICCIMA'03). 385. 2003.
[6] Wolberg G and Zokai S. Robust Image Registration using Log-Polar Transform. Proc. IEEE Int. Conf. Image Processing. 493-496. 2000.
[7] Reddy S and Chatterji BN. An FFT-Based Technique for Translation, Rotation, and Scale-Invariant Image Registration. IEEE Trans. Image Processing. 3: 1266-1270. 1996.
[8] Guo X, Xu Z, Lu Y, Liu Z, and Pang Y. Image Registration Based on Pseudo-Polar FFT and Analytical Fourier-Mellin Transform. Lecture Notes in Computer Science. Berlin: Springer Berlin. 2005. [9] Keller Y, Averbuch A, and Israeli M.
Pseudopolar-Based Estimation of Large Translations, Rotation, and Scalings in Images. IEEE Transactions on Image Processing. 14: 12-22. 2005.
Vol. 5, No. 3, Januari 2010 ISSN 0216 - 0544
147
PENGENALAN CITRA WAJAH MENGGUNAKAN
METODE TWO-DIMENSIONAL LINEAR DISCRIMINANT
ANALYSIS DAN SUPPORT VECTOR MACHINE
*Fitri Damayanti, Agus Zainal Arifin, Rully Soelaiman
Program Magister Teknik Informatika,ITS Jl. Raya ITS, Kampus ITS, Sukolilo, Surabaya, 60111
E-Mail: *[email protected] Abstrak
Linear Discriminant Analysis telah digunakan secara luas dalam pola linier pengenalan terhadap fitur ekstraksi dan pengurangan dimensi. Hal ini dimaksudkan untuk membuat seperangkat vektor proyeksi yang sangat berbeda untuk dipadatkan sepadat mungkin pada jenis yang sama. Projection vector bekerja dalam hitungan jenis Sw dan antara jenis Sh matrix scatter. Umumnya pada aplikasi pengenalan wajah jumlah dimensi data lebih besar dibandingkan jumlah sampelnya, hal ini menyebabkan tunggalnya isi jenis scatter matrix Sw, sehingga fitur wajah tidak diekstraksi dengan baik. Dalam penelitian ini digunakan metode Two Dimensional Linier Discrimination Analysis (TDLDA) untuk ekstraksi fitur, yang menilai secara langsung isi jenis scatter matrix tanpa pencitraan terhadap transformasi vektor, sehingga mengurangi masalah tunggal dalam isi jenis scatter matrix. Penelitian ini akan mengembangkan aplikasi pengenalan wajah yang dintegrasikan dengan metode TDLDA dan SVM untuk pengenalan wajah. Dengan kombinasi kedua metode tersebut terbukti dapat memberikan hasil yang optimal dengan tingkat akurasi pengenalan antara 84,18% sampai 100% dengan uji coba menggunakan basis data ORL, YALE, dan BERN.
Kata kunci: Linear Discriminant Analysis, Two Dimensional Linear Discriminant Analysis, Support Vector Machine.
Abstract
Linear Discriminant Analysis (LDA) has been widely used in linear pattern recognition for feature extraction and dimension reduction. It aims to find a set of projection vector that separate the different as far as possible while compressing the same class as compact as possible. It works by calculated the within class Sw and between class Sb scatter matrices. In face recognition application, generally the dimension of data larger than the number of samples, this causes the within class scatter matrix Sw is singular, that can make the face features’s not well extracted. Two Dimensional Linear Discriminant Analysis (TDLDA) is used on this research for feature extraction, that evalutes directly the within class scatter matrix from the image matrix without image to vector transformation, and hence dilutes the singular problem of within class scatter matrix. This research will develop a face recognition application that combined Two Dimensional Linear Discriminant Analysis and Support Vector Machine. The combination of two methods give optimal results that have high accuracy of recognition between 84.18% until 100% with the ORL, YALE, and BERN database.
Key words: Linear Discriminant Analysis, Two Dimensional Linear Discriminant Analysis, Support Vector Machine.
PENDAHULUAN
Pengenalan wajah dewasa ini telah menjadi salah satu bidang yang banyak diteliti dan juga dikembangkan oleh para pakar pengenalan pola. Hal ini disebabkan karena semakin luasnya penggunaan teknik identifikasi wajah dalam aplikasi yang digunakan oleh masyarakat. Para peneliti telah melakukan penelitian terhadap teknik yang sudah ada dan mengajukan teknik baru yang lebih baik dari yang lama, meskipun banyak teknik baru telah diajukan, akan tetapi teknik-teknik tersebut masih belum dapat memberikan akurasi yang optimal. Dua hal yang menjadi masalah utama pada identifikasi wajah adalah proses ekstraksi fitur dari sampel wajah yang ada dan juga teknik klasifikasi yang digunakan untuk mengklasifikasikan wajah yang ingin dikenali berdasarkan fitur-fitur yang telah dipilih.
Ekstraksi fitur adalah proses untuk mendapatkan ciri-ciri pembeda yang membedakan suatu sampel wajah dari sampel wajah yang lain. Bagi sebagian besar aplikasi pengenalan pola, teknik ekstraksi fitur yang handal merupakan kunci utama dalam penyelesaian masalah pengenalan pola. Metode Analisa Komponen Utama (PCA) untuk pengenalan wajah dikenalkan oleh Turk dan Pentland pada tahun 1991. Metode tersebut bertujuan untuk memproyeksikan data pada arah yang memiliki variasi terbesar (ditunjukkan oleh vektor eigen) yang bersesuaian dengan nilai eigen terbesar dari matrik kovarian. Kelemahan dari metode PCA adalah kurang optimal dalam pemisahan antar kelas. Pada tahun 1991, Cheng dkk memperkenalkan metode Analisa Diskriminan Linier (LDA) untuk pengenalan wajah. Metode ini mencoba menemukan sub ruang linier yang memaksimalkan perpisahan dua kelas pola menurut Fisher Criterion JF. Hal ini dapat
diperoleh dengan meminimalkan jarak matrik sebaran dalam kelas yang sama (within-class) Sw dan memaksimalkan jarak matrik sebaran
antar kelas (between-class) Sb secara simultan
sehingga menghasilkan Fisher Criterion JF
yang maksimal. Diskriminan Fisher Linier akan menemukan sub ruang dimana kelas-kelas saling terpisah linier dengan memaksimalkan Fisher Criterion JF. Jika dimensi data jauh
lebih tinggi daripada jumlah sample training,
maka Sw menjadi singular. Hal tersebut
merupakan kelemahan dari metode LDA [1]. Telah banyak metode yang ditawarkan untuk mengatasi kovarian kelas yang sama (within class) yang selalu singular karena small sample size problem. Pada tahun 1997, Belheumeur memperkenalkan metode fisherface untuk pengenalan wajah. Metode ini merupakan penggabungan antara metode PCA dan LDA. Proses reduksi dimensi dilakukan oleh PCA sebelum melakukan proses LDA. Hal ini dapat mengatasi singular problem. Tetapi kelemahan dari metode ini adalah pada saat proses reduksi dimensi PCA akan menyebabkan kehilangan beberapa informasi diskriminan yang berguna dalam proses LDA [1]. Metode-metode lainnya yang dapat mengatasi singular problem adalah Direct-LDA, Null-space based Direct-LDA, Pseudo-inverse LDA, Two-stage LDA, dan Regularized LDA [2]. Semua teknik LDA tersebut memakai model representasi data berdasarkan vektor yang menghasilkan vektor-vektor yang biasanya memiliki dimensi tinggi. Metode Two Dimensional Linear Discriminant Analysis (TDLDA) menilai secara langsung matrik within-class scatter dari matrik citra tanpa transformasi citra ke vektor, dan hal itu mengatasi singular problem dalam matrik within-class scatter [3]. TDLDA memakai fisher criterion untuk menemukan proyeksi diskriminatif yang optimal.
Dalam pengenalan wajah, proses klasifikasi sama pentingnya dengan proses ekstraksi fitur. Setelah fitur-fitur penting data atau citra wajah dihasilkan pada proses ekstraksi fitur, fitur-fitur tersebut nantinya akan digunakan untuk proses klasifikasi. Metode klasifikasi yang digunakan adalah pengklasifikasi Support Vector Machine (SVM). Pengklasifikasi SVM menggunakan sebuah fungsi atau hyperplane untuk memisahkan dua buah kelas pola. SVM akan berusaha mencari hyperplane yang optimal dimana dua kelas pola dapat dipisahkan dengan maksimal.
Penelitian ini mengintegrasikan TDLDA dan SVM untuk pengenalan wajah. TDLDA sebagai metode ekstraksi fitur yang dapat mengatasi singular problem dan SVM sebagai metode klasifikasi yang mempunyai kemampuan generalisasi yang tinggi dibanding metode klasifikasi KNN.
Damayanti dkk, Pengenalan Citra Wajah… 149
Two-Dimensional Linear Discriminant Analysis (TDLDA)
TDLDA adalah pengembangan dari metode LDA. Di dalam LDA, matrik 2D terlebih dahulu ditransformasikan ke dalam bentuk citra vektor satu dimensi. Sedangkan pada TDLDA atau disebut teknik proyeksi citra secara langsung, matrik citra wajah 2D tidak perlu ditransformasikan ke dalam bentuk citra vektor. Matrix scatter citra dapat dibentuk langsung dengan menggunakan matrik citra aslinya.
{A1,….,An} adalah n matrik citra, dimana Ai
(i=1,…,k) adalah r x c matrik. Mi (i=1,…,k)
adalah rata-rata citra pelatihan dari kelas ke i, M adalah rata-rata citra dari semua data pelatihan dan X adalah matrik masukan. Menganggap
l
1 xl
2 ruang dimensi (dimensional space) L⊗R, dimana ⊗ menunjukkan tensor product, L menjangkau {u1,…,ul
1} dan R menjangkau {v1,..,vl
2}.Sehingga didefinisikan dua matrik L = [u1,…,u
l
1] dan R = [v1,..,vl
2].Metode ekstraksi fitur adalah untuk menemukan L dan R sehingga ruang citra asli (original image space) Ai diubah ke dalam
ruang citra dimensi rendah (low-dimensional image) menjadi Bi=L
T
AiR. Ruang dimensi
rendah (low-dimensional space) diperoleh dengan transformasi linier L dan R, sedangkan jarak between-class Db dan jarak within-class
Dw didefinisikan dalam Persamaan (1) dan (2).
Db = n L M M R k i i T i ( ) 1 −
∑
= 2 F (1) Dw = 2 1 ) ( F i k i x T X M R L i −∑ ∑
= ∈Π (2) Dimana F merupakan Frobenius norm.Meninjau bahwa 2
F
A = Ptrace(ATA) = trace(AAT) untuk matrik A. Sedemikian hingga Persamaan (1) dan (2) dapat direpresentasikan lebih lanjut sebagai Persamaan (3) dan (4).
) ) ( ) ( ( 1 L M M RR M M L n trace D T i T k i i T i b =
∑
− − = (3) ) ) ( ) ( ( L X M RR X M L trace D i T T i k 1 i x Π T w i − − =∑ ∑
= ∈ (4)Sama halnya dengan LDA, metode TDLDA digunakan untuk menemukan matrik L dan R,
sedemikian hingga struktur kelas dari ruang orisinil tetap di dalam ruang proyeksi. Sehingga patokan (criterion) dapat didefinisikan sebagai Persamaan (5).
J1(L,R) = max W b D D (5) Hal tersebut jelas bahwa Persamaan (9) terdiri dari matrik transformasi L dan R. Matrik transformasi optimal L dan R dapat diperoleh dengan memaksimalkan Db dan
meminimumkan Dw. Namun, sangatlah sulit
untuk menghitung L dan R yang optimal secara simultan. Dua fungsi optimasi dapat didefinisikan untuk memperoleh L dan R. Untuk sebuah R yang pasti, L dapat diperoleh dengan menyelesaikan fungsi optimasi pada Persamaan (6). J2(L) = maxtrace((L T SWR L)-1(LTSRb L)) (6) dimana T i T k i i i R b
n
M
M
RR
M
M
S
(
)
(
)
1−
−
=
∑
= (7) T i T i k i x R W X M RR X M S i ) ( ) ( 1 − − =∑∑
= ∈Π (8)Dengan catatan bahwa ukuran matrik
R W S dan R b
S adalah r x r yang lebih kecil daripada ukuran matrik Sw dan Sb pada LDA klasik.
Untuk sebuah L yang pasti, R dapat diperoleh dengan menyelesaikan fungsi optimasi pada Persamaan (9).
J3(R) = maxtrace((RTS L WR)-1(RTS L bR)) (9) Dimana ) ( ) ( 1 M M LL M M n S T T i k i i i L b =
∑
− − = (10) ) ( ) ( 1 i T T i k i x L W X M LL X M S i − − =∑ ∑
= ∈Π (11) Ukuran matrik SLwdan SLbadalah c x c yang lebih kecil daripada ukuran matrik Sw dan Sbpada LDA klasik.
Secara khusus, untuk sebuah R yang pasti, L yang optimal dapat diperoleh dengan menyelesaikan generalized eigenvalue problem dari Persamaan (6). Demikian pula, R dapat diperoleh dengan menyelesaikan generalized eigenvalue problem dari Persamaan (9) pada L yang pasti.
Gambar 1. Hard Margin Hyperplane.
Support Vector Machine (SVM)
SVM berusaha menemukan hyperplane yang terbaik pada input space. Prinsip dasar SVM adalah linear classifier yang selanjutnya dikembangkan agar dapat bekerja pada problem non-linear dengan memasukkan konsep kernel trick pada ruang kerja berdimensi tinggi [4].
SVM dapat melakukan klasifikasi data yang terpisah secara linier (linearly separable) dan non-linier (nonlinear separable) [5]. Linearly separable data merupakan data yang dapat dipisahkan secara linier. Misalkan {x1,..., xn} adalah dataset danxi∈ℜd, serta yi∈{+1,−1} adalah label kelas dari data xi.. Anggap ada
beberapa hyperplane yang memisahkan sampel positif dan negatif, maka x yang berada pada hyperplane akan memenuhi persamaan
0 .x+ b=
w . Untuk permasalahan data linier, algoritma support vector hanya mencari hyperplane dengan margin yang terbesar (jarak antara dua kelas pola). Hard margin hyperplane ditunjukkan pada Gambar 1. Hyperplane terbaik tidak hanya dapat memisahkan data dengan baik tetapi juga yang memiliki margin paling besar. Data yang berada pada bidang pembatas ini disebut support vector.
Untuk menyelesaikan permasalahan data non-linier dalam SVM adalah dengan cara memetakan data ke ruang dimensi lebih tinggi (ruang fitur atau feature space) [5], dimana data pada ruang tersebut dapat dipisahkan secara linier, dengan menggunakan transformasi Ф pada Persamaan (12).
Η
Φ:ℜd a (12) Dengan demikian algoritma pelatihan tergantung dari data melalui dot product dalam H. Sebagai contoh Ф(xi). Ф(xj). Jika terdapat
fungsi kernel K, sedemikian hingga K(xi,xj) =
Ф(xi). Ф(xj), maka algoritma pelatihan hanya
memerlukan fungsi kernel K, tanpa harus mengetahui transformasi Ф secara pasti.
SVM pertama kali dikembangkan oleh Vapniks untuk klasifikasi biner, namun selanjutnya dikembangkan untuk klasifikasi multiclass (banyak kelas). Pendekatannya adalah dengan membangun multiclass classifier, yaitu dengan cara menggabungkan beberapa SVM biner. Pendekatan ini terdiri dari metode satu lawan semua (One Against All) dan metode satu lawan satu (One Against One) [6].
PERANCANGAN SISTEM
Secara garis besar sistem terdiri dari dua bagian, yaitu proses pelatihan citra dan proses pengujian. Gambar 2 merupakan gambaran garis besar sistem pengenalan wajah. Pada proses pelatihan terdapat proses TDLDA yang digunakan untuk mengekstraksi fitur. Fitur-fitur yang terpilih pada saat proses pelatihan digunakan dalam proses klasifikasi dan juga digunakan untuk mendapatkan fitur-fitur yang terpilih pada data uji coba. Masing-masing basisdata wajah yang digunakan dibagi menjadi dua, yaitu satu bagian digunakan untuk proses pelatihan (training) dan sisanya digunakan untuk proses pengujian (testing). Ekstraksi Fitur
Ekstraksi fitur pada proses pelatihan dilakukan dengan menggunakan metode TDLDA. Tahap ini bertujuan untuk mendapatkan fitur-fitur yang terpilih dari masukan data-data pelatihan. Fitur-fitur yang terpilih nantinya digunakan untuk proses klasifikasi pelatihan dan digunakan untuk ekstraksi fitur data pengujian.
Ekstraksi fitur pada proses pengujian dilakukan dengan cara mengambil hasil ekstraksi fitur pada proses pelatihan untuk diterapkan pada data pengujian. Hasil ekstraksi fitur pada data pengujian ini nantinya digunakan sebagai masukan pada proses klasifikasi pengujian. Support vector Kelas 2 Kelas 1 xi.w+b = -1 xi.w+b = +1 -b/w m
Damayanti dkk, Pengenalan Citra Wajah… 151
Proses Pelatihan Proses Pengujian
Gambar 2. Sistem Pengenalan Wajah.
Klasifikasi
Proses klasifikasi pelatihan dilakukan setelah data-data pelatihan diambil fitur-fitur khusus. Fitur-fitur khusus ini berupa vektor fitur yang dimensinya lebih kecil. Penelitian ini menggunakan SVM metode satu lawan semua dengan kernel gaussian. Pada proses klasifikasi, pelatihan variabel hyperplane untuk setiap pengklasifikasi (classifier) yang didapat akan disimpan dan nantinya akan digunakan sebagai data tiap pengklasifikasi dalam proses pengujian. Dengan kata lain proses klasifikasi pelatihan adalah untuk mencari support vector dari data masukan (dalam hal ini digunakan quadratic programming).
Pada proses klasifikasi pengujian menggunakan hasil ekstraksi fitur data pengujian dan hasil proses klasifikasi pelatihan. Hasil dari proses ini berupa nilai indeks dari fungsi keputusan yang terbesar yang menyatakan kelas dari data pengujian. Jika kelas yang dihasilkan dari proses klasifikasi pengujian sama dengan kelas data pengujian, maka pengenalan dinyatakan benar.
Hasil akhirnya berupa citra wajah yang sesuai dengan nilai indeks dari fungsi keputusan yang terbesar hasil dari proses klasifikasi pengujian. Algoritma TDLDA
Berikut ini adalah langkah-langkah dalam proses TDLDA terhadap suatu basisdata citra pelatihan:
1. Jika dalam suatu basisdata citra wajah terdapat himpunan sebanyak n citra pelatihan Ai = [A1,A2,…,An] (i = 1,2,…,n)
dengan dimensi citra (r x c), maka himpunan total matrik dari semua citra tersebut adalah: An =
rc n r n r n c n n n c n n nA
A
A
A
A
A
A
A
A
) ( 2 ) ( 1 ) ( 2 ) ( 22 ) ( 21 ) ( 1 ) ( 12 ) ( 11 ) (...
...
...
...
...
...
...
2. Menentukan nilai
l
1 (dimensi proyeksi baris) danl
2(dimensi proyeksi kolom). Nilail
1≤ r danl
2 ≤ c.Memasukkan basis data pelatihan Ekstraksi fitur TDLDA
Pengklasifikasi SVM
Memasukkan data pengujian
Ekstraksi fitur data pengujian
Pengklasifikasi SVM
3. Tahapan berikutnya adalah perhitungan rata-rata citra pelatihan dari kelas ke-I dengan menggunakan Persamaan (13).
∑
∈Π = i X i i X n M 1 (13) 4. Menghitung rata-rata semua citra pelatihandengan menggunakan Persamaan (14).
∑ ∑
= ∈Π = k i X i X n M 1 1 (14)5. Menetapkan matrik transformasi R ukuran (c,
l
2) yang diperoleh dari gabungan antara matrik identitas ukuran (l
2,l
2) dengan matrik nol ukuran (c-l
2,l
2).6. Menghitung matrik between class scatter R sesuai dengan Persamaan (7).
T i T k i i i R b n M M RR M M S ( ) ( ) 1 − − =
∑
= , ukuran matriknya (r x r).7. Menghitung matrik within class scatter R sesuai dengan Persamaan (8).
, ) ( ) ( 1 T i T i k i x R b X M RR X M S i − − =
∑ ∑
= ∈Π ukuran matriknya (r x r).8. Hitung generalized eigenvalue (
λ
i) dari SRb dan SWR menggunakan SVD sesuai denganPersamaan (6). )) ( ) ) ( 1 4 L maxtrace((L S L L S L J bR T R W T − = , ukuran matriknya (r x r).
9. Ambil sebanyak
l
1 eigenvector dari langkah 8 sebagai matrik transformasi baris] ,..., [ ). ( 1L L1 L L = φ φl , ukuran matriknya
)
(
r
×
l
1 .10. Menghitung matrik between class scatter L sesuai dengan Persamaan (10).
) ( ) ( 1 M M LL M M n S k T T i i i i L b =
∑
− − = , ukuran matriknya (c x c).11. Menghitung matrik within class scatter L sesuai dengan Persamaan (11).
), ( ) ( 1 i T T i k i x L W X M LL X M S i − − =
∑ ∑
= ∈Π ukuran matriknya (c x c).12. Hitung generalized eigenvalue (
λ
i) dari SLb dan SWL menggunakan SVD sesuai dengan Persamaan (9). )) ( ) (( ) ( 1 5 R maxtrace R S R R S R J L b T L W T − = , ukuran matriknya (c x c).13. Ambil sebanyak
l
2 eigenvector dari langkah 12 sebagai matrik transformasi kolom (R). R = [φ
1R, ..., R2
l
φ
], ukuran matriknya (c xl
2).14. Hitung matrik fitur ekstraksi adalah R A L B i T i = , ukuran matriknya (
l
1 xl
2). 15. Keluaran: matrik fitur ektraksi Bi, matriktransformasi baris L, dan matrik transformasi kolom R.
Tabel 1. Hasil Uji Coba Menggunakan TDLDA-KNN.
Prosentase Pengenalan Basisdata
Uji 3 Uji 4 Uji 5 ORL 92,14 % 94,58 % 97,00 % Yale 91,67 % 97,14 % 98,89 % Bern 82,65 % 92,26 % 95,71 %
Tabel 2. Hasil Uji Coba Menggunakan TDLDA-SVM.
Prosentase Pengenalan Basisdata
Uji 3 Uji 4 Uji 5 ORL 92,86 % 96,67 % 97,50 % Yale 95,00 % 99,05 % 100 % Bern 84,18 % 94,05 % 97,14 %
Tabel 3. Perbandingan Hasil Uji Coba dengan Basis Data ORL.
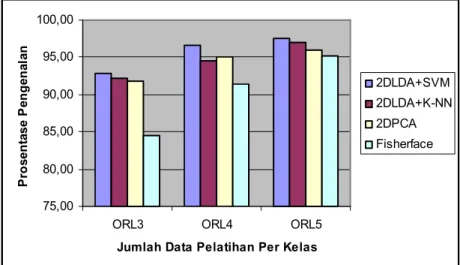
Prosentase Pengenalan Variasi Pengujian TDLDA-SVM TDLDA-KNN 2DPCA* Fisherface** Uji ORL 3 92,86 % 92,14 % 91,80 % 84,50 % Uji ORL 4 96,67 % 94,58 % 95,00 % 91,46 % Uji ORL 5 97,50 % 97,00 % 96,00 % 95,15 %
Ket: *) diperoleh dari sumber [7]
Damayanti dkk, Pengenalan Citra Wajah… 153
Gambar 3. Blok Diagram Proses Pelatihan dan Klasifikasi Menggunakan SVM.
Rancangan Algoritma SVM
Blok diagram proses pelatihan dan pengujian SVM dapat ditunjukkan pada Gambar 3. Pengklasifikasian dengan SVM dibagi menjadi dua proses, yaitu proses pelatihan dan proses pengujian. Pada proses pelatihan SVM menggunakan matrik fitur yang dihasilkan pada proses ekstraksi fitur sebagai masukan. Sedangkan pada pengujian SVM memanfaatkan
matrik proyeksi yang dihasilkan pada proses ekstraksi fitur yang kemudian dikalikan dengan data uji (sampel pengujian) sebagai masukan.
Pengklasifikasian SVM untuk multiclass One Against All akan membangun sejumlah k SVM biner (k adalah jumlah kelas). Fungsi keputusan yang mempunyai nilai maksimal menunjukkan bahwa data xd merupakan
angggota dari kelas fungsi keputusan tersebut.
Proses pengujian pada setiap SVM biner
Memetakan input space ke feature space menggunakan kernel Gaussian
K(x,y) = exp ) ) 2 ( | | ( 2 2 σ y x − −
Menghitung fungsi keputusan :
i i d i i K x x w b f = ( , ) +
Dimana : i = 1 sampai k; xi = support vector; xd = data pengujian
Membangun sejumlah k SVM biner (k adalah jumlah kelas)
Menentukan nilai fi yang paling maksimal. Kelas i dengan fi terbesar adalah kelas dari data
pengujian
Memetakan input space ke feature space menggunakan kernel Gaussian
K(x,y) = exp ) ) 2 ( | | ( 2 2 σ y x − −
Menentukan sejumlah support vector dengan cara menghitung nilai alpha α1, ..., αN (
N = sejumlah data pelatihan) menggunakan quadratic programming
∑
∑
= = − = l i i j i j i j i l i i y y xx Q 1 , 1 2 1 ) (α α αα rr Subject to: 0( 1,2,..., ) 0 1 = = ≥∑
= i l i i i i l α y αData xri yang berkorelasi dengan αi > 0 inilah yang disebut sebagai support vector
Solusi bidang pemisah didapatkan dengan rumus w =Σαiyixi ; b = yk- wTxk untuk
setiap xk , dengan αk≠ 0.
75,00 80,00 85,00 90,00 95,00 100,00
ORL3 ORL4 ORL5
Jumlah Data Pelatihan Per Kelas
P ro s e n ta s e P e n g e n a la n 2DLDA+SVM 2DLDA+K-NN 2DPCA Fisherface
Gambar 4. Grafik Tingkat Keberhasilan Pengenalan untuk Tiap Variasi Pengujian pada Basisdata ORL Menggunakan Metode TDLDA-SVM dan Metode Lainnya.
Data pelatihan yang sudah diproyeksikan oleh TDLDA selanjutnya menjadi data pelatihan SVM. Jika sebaran data yang dihasilkan pada proses TDLDA mempunyai distribusi yang tidak linier, maka salah satu metode yang digunakan SVM untuk mengklasifikasikan data tersebut adalah dengan mentransformasikan data ke dalam dimensi ruang fitur (feature space), sehingga dapat dipisahkan secara linier pada feature space. Feature space biasanya memiliki dimensi yang lebih tinggi dari vektor masukan (input space). Hal ini mengakibatkan komputasi pada feature space mungkin sangat besar, karena ada kemungkinan feature space dapat memiliki jumlah feature yang tidak terhingga.
Metode SVM menggunakan ”kernel trick”. Fungsi kernel yang digunakan pada penelitian ini adalah Gaussian (Persamaan (15)).
) ) 2 ( | | ( ) , ( 2 2
σ
y x exp y x K = − − (15)Sejumlah support vector pada setiap data pelatihan harus dicari untuk mendapatkan solusi bidang pemisah terbaik. Persoalan solusi bidang pemisah terbaik dapat dirumuskan dalam Persamaan (16).
∑
∑
= =−
=
l i i j i j i j i l i iy
y
x
x
Q
1 , 12
1
)
(
α
α
α
α
r
r
(16) dimana: 0( 1,2,..., ) 0 1 = = ≥∑
= i l i i i i lα
yα
Data xri yang berkorelasi dengan αi > 0
inilah yang disebut sebagai support vector.
Dengan demikian, dapat diperoleh nilai yang nantinya digunakan untuk menemukan w. Solusi bidang pemisah didapatkan dengan rumus w=∑aiyixi ; b= yk −wTxk untuk setiap xk, dengan αk≠ 0.
Proses pengujian atau klasifikasi dilakukan juga pada setiap SVM biner menggunakan nilai w, b, dan xi yang dihasilkan pada proses
pelatihan di setiap SVM biner. Fungsi yang dihasilkan untuk proses pengujian didefinisikan dalam Persamaan (17).
i i d i i
K
x
x
w
b
f
=
(
,
)
+
(17) Dimana: i = 1 sampai k xi = support vector xd = data pengujian.Keluarannya adalah berupa indeks i dengan fi
terbesar yang merupakan kelas dari data pengujian.
HASIL DAN PEMBAHASAN
Uji coba terhadap sistem pengenalan wajah pada penelitian ini dilakukan pada tiga jenis basisdata wajah baku, yaitu Olivetti Research Laboratorium atau Basis Data ORL, dan The Yale Face Database atau Basisdata Yale, dan The University of Bern atau Basisdata Bern. Untuk masing-masing basisdata wajah, pelatihan menggunakan tiga wajah (uji 3), empat wajah (uji 4), lima wajah (uji 5). Sisa

![Gambar 4. Taksonomi Teknik Representasi Shape Menggunakan Region-Based [6].](https://thumb-ap.123doks.com/thumbv2/123dok/4518520.3274489/27.892.154.749.135.400/gambar-taksonomi-teknik-representasi-shape-menggunakan-region-based.webp)