Analisa dan perbandingan algoritma run length encoding dan algoritma lzw ( lempel ziv wech ) dalam pemampatan teks 68
ANALISA DAN PERBANDINGAN ALGORITMA RUN LENGTH
ENCODING DAN ALGORITMA LZW ( LEMPEL ZIV WECH )
DALAM PEMAMPATAN TEKS
Indra Sahputra Harahap (12110809)
Mahasiswa Program Studi Teknik Informatika, Stmik Budidarma Medan Jl. Sisimangaraja No.338 Simpang Limun Medan
http://stmik-budidarma.ac.id// E-Mail : [email protected] ABSTRAK
Kompresi data, dalam konteks ilmu komputer merupakan ilmu dan seni yang menampilkan informasi dalam bentuk yang pendek .Kompresi data bertujuan untuk mengurangi jumlah bit yang digunakan untuk menyimpan atau mengirim informasi. Berbagai jenis kompresi data secara umum digunakan pada komputer pribadi, termasuk kompresi pada program biner, data, suara, dan gambar. Teknik data kompresi dibagi menjadi dua bagian utama yaitu kompresi lossy dan loseless. Kompresi data lossy tidak dapat membangun lagi data asli dari data yang telah dikompresi. Ada beberapa detail penting yang mungkin hilang selama proses kompresi. Kompresi data lossy akan menjadi efektif apabila diaplikasikan pada gambar, film dan suara digital. Kompresi data loseless menggunakan teknik-teknik yang menjamin sebuah duplikat yang sama persis dengan data yang diinput, setelah data tersebut dikompresi .Dalam proses dekompresi tidak ada informasi yang hilang. Kompresi data loseless disebut juga kompresi reversibel karena data asli mungkin dapat dikembalikan dengan sempurna dengan dekompresi. Teknik kompresi data loseless digunakan ketika sumber data asli sangat penting sehingga tidak dapat kehilangan detail apapun. Jenis kompresi ini digunakan untuk menyimpan database,spreadsheet, atau untuk memproses file teks.Diimplementasikan kompresi dengan algoritma LZW dan Run Length Encoding yang mewakili sebuah kategori teknik pengkodean, dalam bentuk perangkat lunak. Metode ini diujikan untuk mengkompresi dan mendekompresi file.
Kata Kunci: Kompresi Data, Kompresi Data Lossy Dan Kompresi Data Loseless, Algoritma LZW Dan Run Length Encoding.
I. PENDAHULUAN
1.1. Latar Belakang Masalah
Berkembangnya teknologi komputer di masa sekarang ini dapat dimanfaatkan untuk berbagai hal, salah satunya adalah menyimpan data. Data tersebut tidak hanya berupa teks saja, tetapi juga berupa gambar, suara dan video. Dalam penyimpanan data, arsip atau file yang berukuran besar memakan ruang penyimpanan yang besar. Semakin besar tempat penyimpanan yang dibutuhkan maka semakin besar juga biaya yang akan dikeluarkan. Begitu juga dalam komunikasi data, pesan yang dikirim seringkali ukurannya sangat besar sehingga waktu pengirimannya lama. Kedua masalah tersebut dapat diatasi dengan mengkodekan pesan atau isi arsip sesingkat mungkin, sehingga waktu pengiriman pesan juga relatif cepat, dan ruang penyimpanan yang dibutuhkan juga sedikit. Cara pengkodean seperti ini disebut pemampatan atau kompresi data.
Kompresi data, dalam konteks ilmu komputer merupakan ilmu dan seni yang menampilkan informasi dalam bentuk yang pendek. (Ida Mengyi, 2006) Kompresi data bertujuan untuk mengurangi jumlah bit yang digunakan untuk menyimpan atau mengirim informasi. Berbagai jenis kompresi data secara umum digunakan pada komputer pribadi, termasuk kompresi pada program biner, data, suara,
dan gambar. (Nelson, 1996).Teknik data kompresi dibagi menjadi dua bagian utama yaitu kompresi lossy dan loseless. Kompresi data lossy tidak dapat membangun lagi data asli dari data yang telah dikompresi. Ada beberapa detail penting yang mungkin hilang selama proses kompresi. Kompresi data lossy akan menjadi efektif apabila diaplikasikan pada gambar, film dan suara digital. Kompresi data loseless menggunakan teknik-teknik yang menjamin sebuah duplikat yang sama persis dengan data yang diinput, setelah data tersebut dikompresi. (Nelson, 1996 ) Dalam proses dekompresi tidak ada informasi yang hilang. Kompresi data loseless disebut juga kompresi reversibel karena data asli mungkin dapat dikembalikan dengan sempurna dengan dekompresi. Teknik kompresi data loseless digunakan ketika sumber data asli sangat penting sehingga tidak dapat kehilangan detail apapun. Jenis kompresi ini digunakan untuk menyimpan database, spreadsheet, atau untuk memproses file teks (Ida Mengyi, 2006).
Ada beberapa faktor yang sering menjadi pertimbangan dalam memilih suatu metode kompresi yang tepat, yaitu kecepatan kompresi, sumber daya yang dibutuhkan (memori, kecepatan PC), ukuran file hasil kompresi, dan kompleksitas algoritma. Kecepatan dan hasil kompresi dari program tidak dapat ditentukan secara pasti karena algoritma
Analisa dan perbandingan algoritma run length encoding dan algoritma lzw ( lempel ziv wech ) dalam pemampatan teks 69
memiliki tingkat kesesuaian kompresi dengan setiap tipe file yang berbeda-beda. Hal ini menyebabkan hasil kompresi dan kecepatan kompresi akan bervariasi tergantung dari tipe file.
1.2 Perumusan Masalah
Dari uraian lat ar belakang d i at a s maka dapat dirumuskan masalah yait u :
1. Bagaimana menerapkan algoritma Run Length Encoding dan LZW dalam proses kompresi(pemampatan) dan dekompresi (penirmampatan) file dokumen?
2. Bagaimana merancang suatu aplikasi kompresi(pemampatan) dan dekompresi (penirmampatan) file dokumen?
1.3 Batasan Masalah
Adapun batasan-batasan masalah dalam penelitian ini adalah:
1. Jenis data yang diproses dalam perancangan aplikasi ini adalah teks ( .txt )
2. Studi perbandingan ini akan membandingkan dua metode kompresi data loseless yaitu algoritma Run Length Encoding dan LZW.
3. Dalam studi perbandingan ini parameter pembanding yang digunakan adalah rasio
4. kompresi, redudancy dan waktu. Bahasa pemrograman yang digunakan adalah Visual Basic.Net 2008
1.4 Tujuan
Penulisan skripsi ini memiliki tujuan dan manfaat, adapun tujuan penelitian sebagai berikut:
1. Untuk membandingkan dua metode kompresi file teks yaitu algoritma Run Length Encoding dan LZW
2. Untuk merancang aplikasi kompresi file teks dengan menggunakan algoritma Run Length Encoding dan LZW
1.5 Manfaat
Manfaat dari penelitian ini, sebagai berikut :
1. Dapat mengetahui perbedaan kedua metode kompresi file teks yaitu algoritma Run Length Encoding dan LZW
2. Dapat menghasil suatu aplikasi kompresi file teks dengan menggunakan algoritma Run Length Encoding dan LZW
2. LANDASAN TEORI 2.1 Kompresi Data
Kompresi data di dalam konteks ilmu komputer adalah merupakan ilmu atau seni dalam merepresentasikan informasi yang terdapat pada data ke dalam suatu bentuk yang lebih padat (kecil) (Ida Mengyi, 2006). Perkembangan komputer dan multimedia mengakibatkan kompresi data menjadi hal yang sangat penting dan berguna dalam teknologi pada saat sekarang ini. Solomon (2010) mengemukakan definisi kompresi data adalah proses yang mengkonversi sebuah masukan berupa aliran data (the source atau data asli mentah) menjadi suatu aliran data lain (the Output, aliran bit, atau aliran sudah dikompres) yang memiliki ukuran lebih kecil.
Aliran data (stream) dapat berupa sebuah file atau buffer pada memori. Data dalam konteks kompresi data melingkupi segala bentuk digital dari informasi, yang dapat diproses oleh sebuah program komputer. Bentuk dari informasi tersebut secara luas dapat diklasifikasikan sebagai teks, suara, gambar dan video.
2.2 LZW (Lempel Ziv Welch)
Algoritma Lempel-Ziv-Welch (LZW) menggunakan teknik adaptif dan berbasiskan “kamus” Pendahulu LZW adalah LZ77 dan LZ78 yang dikembangkan oleh Jacob Ziv dan Abraham Lempel pada tahun 1977 dan 1978 (Abdullah, 2009). Terry Welch mengembangkan teknik tersebut pada tahun 1984. LZW banyak dipergunakan pada UNIX, GIF, V.42 untuk modem (Abdullah, 2009). Algoritma ini melakukan kompresi dengan menggunakan dictionary, di mana fragmen-fragmen teks digantikan dengan indeks yang diperoleh dari sebuah “kamus”. Prinsip sejenis juga digunakan dalam kode Braille, di mana kode-kode khusus digunakan untuk merepresentasikan kata-kata yang ada. Pendekatan ini bersifat adaptif dan efektif karena banyak karakter dapat dikodekan dengan mengacu pada string yang telah muncul sebelumnya dalam teks. Prinsip kompresi tercapai jika referensi dalam bentuk pointer dapat disimpan dalam jumlah bit yang lebih sedikit dibandingkan string aslinya (Abdullah, 2009).
2.3 Algoritma Run-Length Encoding (RLE)
Algoritma RLE adalah algoritma yang memanfaatkan karakter-karakter yang berulangsecara berurutan pada data yaitu dengan mengkodekannya dengan sebuah string yang terdiri dari jumlah perulangan karakter yang terjadi, diikuti dengan sebuah karakteryang berulang tersebut(Said, 2004). Sehingga banyak tidaknya deretan karakter yang berulang pada data merupakan penentu keberhasilan kompresi algoritma RLE. Namun, pada prakteknya setiap kode perlu ditambahkan sebuah penanda (marker byte) yang berfungsi untuk menghindari keambiguan pada saat decoding. Jadi, secara umum format kode yang dihasilkan oleh algoritma RLE dapat dituliskan sebagai berikut(Telaumbanua, 2011) 3. ANALIS DAN PERANCANGAN
Analisis sistem merupakan tahap awal dari sebuah penelitian yang bertujuan untuk mengetahui masalah yang terkait dalam pembuatan sistem dengan mempelajari dan memahami masalah yang akan diselesaikan dengan menggunakan sistem ini. Setelah mengetahui permasalahan yang ingin diselesaikan maka dilanjutkan dengan proses perancangan model yang nantinya akan memenuhi kebutuhan dan permintaan pengguna. Analisis selanjutnya yang merupakan analisis terakhir yaitu analisis proses yang diimplementasikan dalam sebuah sistem. Adapun yang akan dianalisa adalah bagaimana cara mengkompres data text dengan menggunakan algoritma Run Length Code dan LZW.
Analisa dan perbandingan algoritma run length encoding dan algoritma lzw ( lempel ziv wech ) dalam pemampatan teks 70
3.1.1 Proses Kompresi
Berikut ini merupakan contoh kompresi menggunakan Algoritma Run Length Code Ada sebuah text fileyang berisi string: INDRA SAHPUTRA HARAHAP
Penyelesaian: Hitung frequency dan bit dari string sebelum dikompresi.
Setelah menghitung data sebelum dikompresi, dari tabel tadi dilakukan kompresi menggunakan RLE, dengan mengkodekan karakter yang muncul berdasarkan urutan kemunculannya.
I diurutan pertama kemudian dikodekan dengan 0000 N diurutan kedua kemudian dikodekan dengan 0001
Ddiurutan ketiga kemudian dikodekan dengan 0010 R diurutan keempat kemudian dikodekan dengan 0011 A diurutan kelima kemudian dikodekan dengan 0100 S diurutan keenam kemudian dikodekan dengan 0101 A diurutan ketujuh kemudian dikodekan dengan 0110 H diurutan kedelapan kemudian dikodekan dengan
0111
P diurutan kesembilan kemudian dikodekan dengan 1000
U diurutan kesepuluh kemudian dikodekan dengan 0000
T diurutan kesebelas kemudian dikodekan dengan 0010
R diurutan keduabelas kemudian dikodekan dengan 0101
A diurutan ketigabelas kemudian dikodekan dengan 0110
H diurutan keempatbelas kemudian dikodekan dengan 0111
A diurutan kelimabelas kemudian dikodekan dengan 0110
R diurutan keenambelas kemudian dikodekan dengan 0011
A diurutan ketujuhbelas kemudian dikodekan dengan 0111
H diurutan kedelapanbelas kemudian dikodekan dengan 0110
A diurutan kesembilanbelas kemudian dikodekan dengan 0011
P diurutan keduapuluh kemudian dikodekan dengan 1000
Kemudian jumlah bit dari karakter yang dikodekan dikalikan dengan frequency kemunculan darikarakter tersebut.
I yng dikodekan dengan 0000 mempunyai 4 bit dan frequency kemunculan sebanyak 1 kali, maka bit x fequency = 4
N yang dikodekan dengan 0001 mempunyai 4 bit dan frequency kemunculan sebanyak 1 kali, maka bit x frequency = 4
D yang dikodekan dengan 0010 mempunyai 4 bit dan frequency kemunculan sebanyak 1 kali, maka bit x frequency = 4
R yang dikodekan dengan 0011 mempunyai 4 bit dan frequency kemunculan sebanyak 1 kali, maka bit x frequency = 4
A yang dikodekan dengan 0100 mempunyai 4 bit dan frequency kemunculan sebanyak 1 kali, maka bit x frequency = 4
S yang dikodekan dengan 0101 mempunyai 4 bit dan frequency kemunculan sebanyak 1 kali, maka bit x frequency = 4
A yang dikodekan dengan 0110 mempunyai 4 bit dan frequency kemunculan sebanyak 1 kali, maka bit x frequency = 4
H yang dikodekan dengan 0111 mempunyai 4 bit dan frequency kemunculan sebanyak 1 kali, maka bit x frequency = 4
P yang dikodekan dengan 1000 mempunyai 4 bit dan frequency kemunculan sebanyak 1 kali, maka bit x frequency = 4
U yang dikodekan dengan 0000 mempunyai 4 bit dan frequency kemunculan sebanyak 1 kali, maka bit x frequency = 4
T yang dikodekan dengan 0010 mempunyai 4 bit dan frequency kemunculan sebanyak 1 kali, maka bit x frequency = 4
R yang dikodekan dengan 0101 mempunyai 4 bit dan frequency kemunculan sebanyak 1 kali, maka bit x frequency = 4
A yang dikodekan dengan 0110 mempunyai 4 bit dan frequency kemunculan sebanyak 1 kali, maka bit x frequency = 4
H yang dikodekan dengan 0111 mempunyai 4 bit dan frequency kemunculan sebanyak 1 kali, maka bit x frequency = 4
A yang dikodekan dengan 0110 mempunyai 4 bit dan frequency kemunculan sebanyak 1 kali, maka bit x frequency = 4
R yang dikodekan dengan 0011 mempunyai 4 bit dan frequency kemunculan sebanyak 1 kali, maka bit x frequency = 4
A yang dikodekan dengan 0110 mempunyai 4 bit dan frequency kemunculan sebanyak 1 kali, maka bit x frequency = 4
H yang dikodekan dengan 0111 mempunyai 4 bit dan frequency kemunculan sebanyak 1 kali, maka bit x frequency = 4
Analisa dan perbandingan algoritma run length encoding dan algoritma lzw ( lempel ziv wech ) dalam pemampatan teks 71
A yang dikodekan dengan 0110 mempunyai 4 bit dan frequency kemunculan sebanyak 1 kali, maka bit x frequency = 4
P yang dikodekan dengan 1000 mempunyai 4 bit dan frequency kemunculan sebanyak 1 kali, maka bit x frequency = 4
Kemudian setiap hasil perkalian dari bit dan frequency dijumlahkan, I + N + D + R + A + S + A + H+ P + U + T + R + A + H + A + R + A + H + A + P = 8 + 8 + 8 + 24 + 48 + 24 + 16 + 8 + 8 + 16= 168 Bit
Jadi 168 Bit adalah hasil kompresi dengan menggunakan algoritma RLE
3.2 Algoritma LZW
3.2.1 Proses Kompresi
contoh, string “INDRA SAHPUTRA HARAHAP” akan dikompresi dengan LZW. Isi dictionary pada awal proses diset dengan lia karakter dasar yang ada: “I”, “N”, “D”, “R”, “A”, “S”, “A”, “H”, “P”, “U”, “T”, “R”, “A”, “H”, “A”, “R”, “A”, “H”, “A”, “P”, Bit dictionary yang dipakai adalah 8 bit. Tahapan proses kompresi ditunjukkan pada Tabel 3.1.
Input String: “I”, “N”, “D”, “R”, “A”, “S”, “A”, “H”, “P”, “U”, “T”, “R”, “A”, “H”, “A”, “R”, “A”, “H”, “A”, “P”, bit dictionary: 8 bit
Output String: “I”, “N”, “D”, “R”, “A”, “S”, “A”, “H”, “P”, “U”, “T”, “R”, “A”, “H”, “A”, “R”, “A”, “H”, “A”, “P”,
Tabel Proses Kompresi LZW
Total Input sebelum kompresi = Total Input * bit dictionary
= 20 * 8 bit
= 168 bit
Total Output sesudah kompresi = Total Output * bit dictionary = 12 * 8 bit = 96 bit 3.2.2 Proses Dekompresi ‘I’,‘N’,‘D’,R’,‘A’‘S’,‘A’,‘H’,P’,‘U’‘T’,‘R’,‘A’, H’,‘A’‘R’,‘A’,‘H’,A’,‘P’ didekompresi dengan algoritma LZW. Bit dictionary yang dipakai adalah 8
bit. Tahapan proses dekompresi ditunjukkan pada Tabel 3.2.
InputString:‘I’,‘N’,‘D’,R’,‘A’‘S’,‘A’,‘H’,P’,‘U’‘T’,‘ ’,‘A’,H’,‘A’‘R’,‘A’,‘H’,A’,‘P’
bit dictionary: 8 bit
4.IMPLEMENTASI
Implementasi merupakan langkah yang digunakan untuk mengoperasikan sistem yang dibangun. Dalam bab ini dijelaskan bagaimana menjalankan sistem tersebut. Sistem pengolahan program merupakan suatu kesatuan pengolahan yang terdiri dari prosedur dan pelaksanaan data. Komputer sebagai sarana pengolahan program haruslah menyediakan fasilitas-fasilitas pendukung dalam pengolahan nantinya Berikut ini hasil dari implementasi program keseluruhan yang telah dirancang adalah:
1. Form Menu Utama
Pada tampilan menu utama adalah bentuk atau gambar perancangan halaman depan yang berisi beberapa menu diantaranya adalah: Menu, RLE, LZW dan Keluar, dapat dilihat pada gambar dibawah ini.
Gambar 1: Form Menu Utama 2. Form RLE
Form ini digunakan untuk menampilkan form dan button guntuk melakukan proses retinex. Adapun form tersebut dapat dilihat pada gambar dibawah ini:
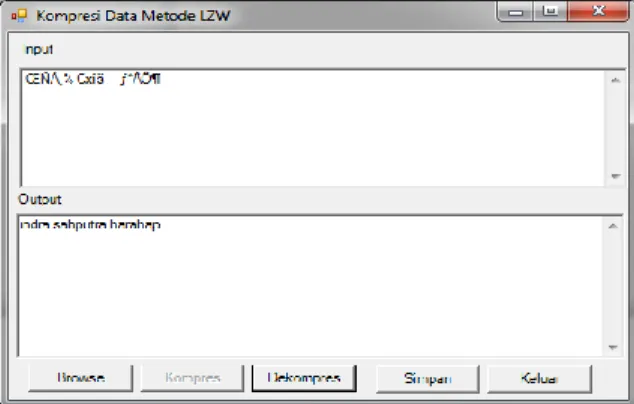
Gambar 2 Form RLE 3. Form LZW
Pada Form ini akan dilakukan proses pengkompresan data dengan menggunakan metode
Analisa dan perbandingan algoritma run length encoding dan algoritma lzw ( lempel ziv wech ) dalam pemampatan teks 72
LZW . Adapun proses yang dilakukan adalah dengan mengklik tombol load yang berfungsi untuk menampilkan file yang akan di kompres kemudian klik tombol compress untuk melakukan proses kompresi. Setelah tahap kompresi maka selanjutnya klik tombol simpan untuk untuk menyimpan hasil dari pengkompresan. Adapun proses dapat dilihat pada gambar dibawah ini.
1. Proses Kompresi
Gambar 3 Form Proses Kompresi 2. Proses Dekompresi
Pada Form ini akan dilakukan proses dekompresan data dengan menggunakan metode LZW . Adapun proses yang dilakukan adalah dengan mengklik tombol load yang berfungsi untuk menampilkan file yang akan di dekompresi kemudian klik tombol dekompress untuk melakukan proses dekompresi. Setelah tahap dekompresi maka selanjutnya klik tombol simpan untuk untuk menyimpan hasil dari dekompres. Adapun proses dapat dilihat pada gambar dibawah ini.
Gambar 4 Form Proses Dekompresi 5.KESIMPULAN DAN SARAN
5.1 Kesimpulan
Dari hasil penulisan dan analisa dari bab-bab sebelumnya, maka dapat diambil kesimpulan-kesimpulan, dimana kesimpulan-kesimpulan tersebut kiranya dapat berguna bagi para pembaca, sehingga penulisan skripsi ini dapat lebih bermanfaat. Adapun kesimpulan-kesimpulan tersebut adalah sebagai berikut :
1. Algoritma Kompresi data dapat digunakan untuk mengurangi penggunaan memory yang terlalu besar pada saat menyimpan data, juga untuk mempercepat proses pengiriman data.
2. Untuk Kompresi dalam bentuk Teks, Algoritma RLE lebih tepat digunakan daripada algoritma LZW.
3. Algoritma RLE dan LZW dapat digunakan dengan menyesuaikan type data yang akan dikompresi.
4. Dalam perbandingan algoritma LZW (Lempel Ziv Welch) dan Run Length Encoding mewakili sebuah tehnik pengkodean dalam bentuk perangkat lunak yaitu tehnik kompresi data yang dimana kompresi data terbagi dua bagian yaitu kompresi data lossy dan loseless.
5.2 Saran
Adapun saran-saran yang dapat diberikan pada penulisan sekripsi ini adalah sebagai berikut: 1. Sebaiknya dilakukan perbaikan pada sistem dari
segi tampilan, dan file agar user tidak merasa jenuh jika Program ini dapat diujikan kembali untuk membandingkan kompresi file yang telah dikompres, dengan menggabungkan kedua algoritma yang ada, serta menambahkan algoritma yang lain untuk digabungkan.
2. Program ini dapat dikembangkan kembali agar dapat melakukan kompresi data pada beberapa type file yang tadinya tidak dapat dilakukan oleh aplikasi ini,
3. Dengan adanya perbandingan algoritma LZW (Lempel Ziv Welch) dan Run Length Encoding mempermudah kita mengetahui bagaimana untuk penempatan file teks setelah adanya pengkompresian
DAFTAR PUSTAKA
1. Abdullah, Muhammad Maulana. 2009. Kompresi String Menggunakan Algoritma LZW dan HUFFMAN. Bandung, Indonesia : Institut Teknologi Bandung.
2. Amir, Said. 2004.Comparative Analysis of Arithmetic Coding Computational Complexity.HP Laboratories Palo Alto California USA:Imaging Systems Laboratory 3. Adi Nugroho. 2010. Rekayasa Perangkat Lunak
Berbasis Objek dengan Metode USDP. Andi. Yogyakarta
4. Indrajani. (2011). Perancangan Basis Data dalam All in 1, PT. Elex Media Komputindo, Jakarta 5. Ida, Mengyi. 2006. Fundamental Data
Compression. Jordan Hill, Oxford
6. Priyanto, Rahmat. (2009), Langsung Bisa Visual Basic.Net 2008, Penerbit Andi, Yogyakarta 7. Salomon, D. Motta, G. 2010. Handbook of Data
Compression.Fifth Edition
8. Sudewa, I. B. A. 2003. Mengenal Character Set. IlmuKomputer.com
9. Telaumbanua, P. 2011. Analisis Perbandingan Algoritma Kompresi Lempel Ziv Welch,
Analisa dan perbandingan algoritma run length encoding dan algoritma lzw ( lempel ziv wech ) dalam pemampatan teks 73
Arithmetic Coding, Dan Run-Length Encoding Pada File Teks. Skripsi. Fakultas Ilmu Komputer dan Teknologi Informasi, Program Studi Ilmu Komputer. Universitas Sumatera Utara