C-1
Pemodelan Sistem Informasi Perencanaan Pembangunan Kelurahan
Amiq Fahmi, M.Kom
Manajemen Informatika Fakultas Ilmu Komputer Universitas Dian Nuswantoro
Jl. Nakula I No. 5-11 Semarang
Telepon (024) 3517261
E-mail : amiq_fahmi@dosen.dinus.ac.id
Abstrak
Sistem perencanaan pembangunan merupakan suatu kesatuan tata cara perencanaan
pembangunan daerah untuk menghasilkan rencana-rencana pembangunan jangka panjang,
jangka menengah, dan tahunan. Musyawarah perencanaan pembangunan (Musrenbang)
kelurahan adalah forum perencanaan tahunan kelurahan untuk membahas dan menyepakati
usulan kegiatan pembangunan hasil musrenbang tingkat RT dan RW sebagai identifikasi
permasalahan secara nyata bagi penyiapan usulan kebutuhan kegiatan pembangunan di tingkat
kelurahan dengan menggunakan prinsip partisipative, sustainable dan holistic. Penelitian
dilakukan di Pemerintahan Kota Semarang, object penelitian adalah Kelurahan, pemodelan
dan pengembangan sistem informasi menggunakan metode development dengan pendekatan
model sekuensial linear (system development life cycle – SDLC) mencakup sejumlah fase (1).
Analisis sistem (2). Desain sistem dan (3). Implementasi sistem. Hasil dari pemodelan dan
pengembangan sistem adalah sistem informasi perencanaan pembangunan yang digunakan
untuk menghimpun, menyimpan, memproses, mengendalikan keputusan, dan menghasilkan
informasi baik berupa laporan, dokumen dan keluaran lainnya yang relevan. Pada tahap
implementasi diharapkan perencanaan dan pelaksanaan pembangunan dapat berjalan secara
optimal dan memenuhi sasaran pembangunan sesuai skala prioritas pencapaian serta
memenuhi aspek akuntabilitas/transparansi dalam mewujudkan pemerintahan yang dapat
dipercaya atau good governance.
Kata Kunci : Sistem Informasi, Musrenbang, RT, RW, Kelurahan.
Pendahuluan
Ditetapkannya Undang-Undang No. 25 Tahun 2004 tentang Sistem Perencanaan Pembangunan Nasional (SPPN) mengamanatkan bahwa setiap daerah harus menyusun rencana pembangunan daerah secara sistematis, terarah, terpadu dan tanggap terhadap perubahan, maka setiap daerah (propinsi/kabupaten /kota) harus menetapkan perencanaan Jangka Panjang, Jangka Menengah maupun Jangka Pendek atau disebut Rencana Pembangunan Daerah Tahunan (RKPD). Hal tersebut mendorong ditetapkannya Peraturan Daerah Kota Semarang Nomor 9 Tahun 2007 Tentang Tata Cara Penyusunan Rencana Pembangunan Daerah Kota Semarang.
Rencana Pembangunan Tahunan Daerah Kota Semarang (RKPD) disusun berdasarkan hasil Musyawarah Perencanaan Pembangunan (Musrenbang) Tingkat Kota. Musrenbang Tingkat Kota didahului dengan kegiatan Musrenbang RT, Musrenbang RW, Musrenbang Kelurahan, Musrenbang Kecamatan dan Forum Satuan Kerja Perangkat Daerah (SKPD). Musrenbang Kelurahan adalah forum musyawarah tahunan pemangku kepentingan pembangunan di kelurahan untuk menyepakati rencana kegiatan tahun
anggaran berikutnya yang didahului dengan kegiatan Pra Musrenbang Kelurahan atau selanjutnya disebut dengan Musrenbang RT dan RW yang merupakan kegiatan non formal berupa forum musyawarah tingkat RT/RW tahunan untuk mengidentifikasi kebutuhan kegiatan pembangunan tingkat RT/RW tahun berikutnya.
Di dalam Undang-Undang No. 25 tersebut mendasarkan bahwa Perencanaan Pembangunan Nasional yang semula bersifat Top Down Planning menjadi Bottom Up Planning yang menekankan pada penjaringan aspirasi masyarakat secara patisipatif, demokrasi, terarah, dan menyeluruh. Sedangkan dalam pelaksanaannya diharapkan memenuhi tiga prinsip utama, yaitu:
C-2 2. Prinsip kesinambungan (sustainable), prinsip ini
menunjukkan bahwa perencanaan pembangunan tidak hanya berhenti pada satu tahap, tetapi harus berkelanjutan sehingga menjamin adanya kemajuan terus-menerus dalam kesejahteraan, dan jangan sampai terjadi kemunduran. Juga diartikan perlunya evaluasi dan pengawasan dalam pelaksanaanya sehingga secara terus menerus dapat diadakan koreksi dan perbaikan selama perencanaan dijalankan
3. Prinsip keseluruhan (holistic), prinsip ini menunjukkan bahwa masalah dalam perencanaan dan pelaksanaannya tidak dapat hanya dilihat dari satu sisi atau unsur tetapi harus dilihat dari berbagai aspek, dan dalam keutuhan konsep secara keseluruhan.
Berdasarkan pendekatan perencanaan yang dilakukan, maka perencanaan daerah perlu dituangkan dalam suatu sistem perencanaan pembangunan daerah sebagai pedoman dan acuan dalam proses penyusunan perencanaan pembangunan daerah yang di dalamnya mengatur tata cara penyelenggaraan Musrenbang tingkat RT, RW dan Kelurahan sebagai sarana dalam penjaringan aspirasi masyarakat (sarana prasarana, keluarga miskin, usulan pelatihan, dan usulan kelompok masyarakat) dalam proses perencanaan pembangunan di Kota Semarang.
Seiring dengan kemajuan teknologi informasi, guna mencapai proses perencanaan serta pelaksanaan pembangunan yang dapat dipercaya, maka perlu didukung dengan sistem informasi perencanaan pembangunan yang berbasis pada teknologi informasi. Dengan pemodelan sistem informasi perencanaan pembangunan diharapkan pengelolaan data dan informasi menjadi lebih mudah (user friendly), efisien, fleksibel mulai dari menghimpun, mencatat, menyimpan, memproses, mengendalikan keputusan, dan menghasilkan informasi (laporan, dokumen dan keluaran lainnya) yang akurat, relevan serta tepat waktu. Dengan diimplementasikannya sistem informasi berbasis komputer diharapkan perencanaan dan pelaksanaan pembangunan dapat memenuhi sasaran pembangunan sesuai prioritas pencapaian dengan memenuhi aspek akuntabilitas dalam mewujudkan pemerintahan yang dapat dipercaya atau good governance.
Metodologi Penelitian
Penelitian dilakukan di Kelurahan Kota Semarang dengan variabel-variabel penelitian yang dibutuhkan dalam penelitian ini mengacu pada komponen-komponen program dan kegiatan pembangunan, daftar usulan sarana prasarana, keluarga miskin, usulan pelatihan, usulan kelompok masyarakat, penilaian prioritas, dan sebagainya ditingkat RT, RW maupun Kelurahan. Data-data yang didapatkan berdasarkan variabel kemudian dimodelkan dengan cara mendesain aktivitas atau proses-proses untuk merekayasa perangkat lunak berdasarkan sifat aplikasi, metode beserta alat-alat bantu yang dipakai, kontrol dan
penyampaian yang dibutuhkan. Metodologi penelitian yang digunakan dalam pemodelan sistem informasi perencanaan pembangunan ini adalah development dengan menggunakan pendekatan siklus hidup pengembangan sistem (system development life cycle – SDLC). Metode ini mencakup sejumlah fase atau tahapan, yaitu:
a. Tahap Analisis, Tahapan ini meliputi kegiatan analisis permasalahan, analisis kebutuhan dan analisis kelayakan pengembangan perangkat lunak sistem informasi perencanaan pembangunan. Secara garis besar pada tahap ini merupakan penguraian dari suatu sistem yang utuh ke dalam bagian-bagian komponennya dengan maksud untuk mengidentifikasi dan mengevaluasi permasalahan, kesempatan-kesempatan, hambatan yang terjadi dan kebutuhan yang diharapkan. b. Tahap Desain, dilaksanakan setelah analisis
dilakukan. Tahapan ini merupakan kegiatan mendesain konseptual perangkat lunak yang meliputi perancangan database, dan interface berupa input, proses, output dan kendali keputusan berbasis kebutuhan user (user oriented). Disain perangkat lunak difokuskan pada spesifikasi detil dari solusi berbasis komputer dengan menggunakan alat bantu data flow diagram (DFD).
c. Tahap Testing / Implementasi
Tahapan ini merupakan tahapan kegiatan programming untuk menerjemahkan desain lojik rinci menjadi konstruksi aktual dari program. Program komputer yang digunakan dalam pengembangan perangkat lunak sistem informasi perencanaan pembangunan adalah bahasa pemrograman visual foxpro 9.0 dengan dukungan database MySql. Implementasi sistem merupakan tahap meletakkan sistem (instalasi perangkat keras dan lunak) supaya siap untuk dioperasikan termasuk pelatihan kepada pemakai sekaligus uji coba teknis program.
Hasil dan Perancangan
1.
Analisis Sistem
a.
Musrenbang RT
Musrenbang RT merupakan rembug warga di tingkat RT untuk melakukan identifikasi permasalahan secara nyata bagi penyiapan usulan kebutuhan kegiatan pembangunan di tingkat RT. Tujuan dari Musrenang RT ini adalah melakukan identifikasi permasalahan serta menetapkan prioritas kebutuhan yang akan menjadi bahan masukan lebih lanjut pada musrenbang RW. Outcome dari Musrenbang RT ini adalah berupa: 1. Form-form Usulan bantuan pembangunan sarana
C-3 2. Hasil dari musrenbang RT, setelah pelaksanaan
diserahkan ke RW
b.
Musrenbang RW
Musrenbang RW merupakan rembug warga di tingkat RW untuk melakukan seleksi kegiatan prioritas dari usulan RT dan identifikasi permasalahan secara nyata bagi penyiapan usulan kebutuhan kegiatan pembangunan di tingkat RW. Musrenbang RW merupakan kelanjutan dari musrenbang RT. Tujuan dari Musrenang RW ini adalah menghimpun dan melakukan identifikasi permasalahan serta menetapkan prioritas kebutuhan, baik dari usulan Musrenbang RT maupun yang muncul dari Musrenbang RW yang akan menjadi bahan masukan lebih lanjut pada musrenbang Kelurahan. Outcome dari Musrenbang RT ini adalah berupa :
1. Form-form Usulan bantuan pembangunan sarana prasarana, Keluarga Miskin, Bantuan Kelompok Masyarakat, Bantuan pelatihan yang telah ditetapkan dalam musrenbang RT dan dibuat proposalnya oleh RW sesuai dengan petunjuk pembuatan proposal
2. Hasil dari musrenbang RW, setelah pelaksanaan diserahkan ke Kelurahan
c.
Musrenbang Kelurahan
Musrenbang Kelurahan dimaksudkan sebagai forummusyawarah bagi pemangku kepentingan pembangunan Kelurahan untuk membahas dan menyepakati usulan kegiatan hasil Musrenbang RT dan RW serta untuk mengidentifikasi permasalahan secara nyata bagi penyiapan usulan kebutuhan kegiatan pembangunan di tingkat Kelurahan, yang akan diajukan pada Musrenbang Kecamatan. Adapun tujuannya adalah:
1. Mendorong partisipasi masyarakat Kelurahan dalam menyusun perencanaan pembangunan tahunan di tingkat Kelurahan, untuk melakukan klasiflkasi atas prioritas kegiatan pembangunan Kelurahan berdasarkan fungsi.
2. Menampung dan membahas kebutuhan masyarakat yang diperoleh dari Musrenbang RT dan RW. 3. Mengidentifikasi kebutuhan kegiatan pembangunan
Kelurahan yang belum terakomodir di Tingkat RT dan RW.
4. Memadukan perencanaan pembangunan di tingkat Kelurahan.
5. Menyusun dan menetapkan prioritas usulan kegiatan pembangunan prioritas tahunan Kelurahan sebagai bahan pengajuan yang akan dibahas pada Musrenbang Kecamatan.
6. Mendapatkan prioritas usulan dan Rencana Kerja dan Anggaran (RKA) Kelurahan.
Flow of Document Musrenbang Kelurahan
RT RW Kelurahan Kecamatan
Gambar 1. Diagram alir dokumen Musrenbang Kelurahan C Daftar Sarpras Prioritas RW
Daftar Keluarga Miskin RT Daftar Prioritas Usulan Pelatihan Daftar Usulan Kelompok Masyarakat
RW
Sarpras Daftar Keluarga Miskin Usulan Daftart Usulan
Pelatihan Daftar Usulan Kelompok Masyarakat
Skala Prioritas Usulan RT dan Penambahan Usulan RW
A
Proposal
Daftar Sarpras Prioritas RW Daftar Keluarga Miskin RT Daftar Prioritas Usulan Pelatihan Daftar Usulan Kelompok Masyarakat
RW
Daftar Sarpras Prioritas Kelurahan Daftar Keluarga Miskin RT Daftar Prioritas Usulan Pelatihan Kel. Daftar Usulan Kelompok Masyarakat
Kelurahan Rencana Kerja dan Anggaran
Kelurahan
Daftar Sarpras Prioritas Kelurahan Daftar Keluarga Miskin RT Daftar Prioritas Usulan Pelatihan Kel. Daftar Usulan Kelompok Masyarakat
Kelurahan Rencana Kerja dan Anggaran
Kelurahan Proposal
Proposal
C-4 Dari flow of document diatas, diketahui bahwa permasalahan yang dihadapi kelurahan adalah: a. Belum adanya database usulan kegiatan berdasarkan
program dan kegiatan berdasarkan proposal yang masuk dan usulan masyarakat tingkat RT dan RW terutama yang belum terakomodir pada tahun anggaran.
b. Tingkat perumusan peserta tentang kriteria prioritas untuk menyeleksi usulan kegiatan, masih mempergunakan pendekatan yang sederhana melalui musyawarah dan bersifat subjektif.
c. Belum adanya sistem informasi perencanaan pembangunan yang digunakan untuk menghimpun, menyimpan, memproses, mengendalikan keputusan, dan mampu mengasilkan informasi berdasarkan usulan masyarakat yang bersifat berkelanjutan di tingkat RT, RW dan Kelurahan.
2.
Desain Sistem
Berdasarkan hasil deteksi permasalahan sistem tersebut maka dapat diusulkan pemecahan masalah dalam mengembangkan sebuah sistem berbasis komputer berupa sistem informasi perencanaan pembangunan yang dapat membantu pihak kelurahan dalam menentukan daftar skala prioritas usulan pra-pengajuan ke Musrenbang Kecamatan. Dengan sistem ini diharapkan memberikan kemudahan bagi pihak kelurahan untuk menentukan skala prioritas berdasarkan kriteria yang diformulasikan menggunkan model Analitycal Hierarchy Proses (AHP). Pada pemodelan ini kriteria yang dipertimbangkan adalah: 1. Tingkat kebutuhan Mendesak (kebutuhan tersebut
tak dapat ditunda dan apabila tidak segera ditangani
akan mengganggu aktivitas warga masyarakat). 2. Kebermanfaatannya tinggi (kebutuhan tersebut
menyangkut hajat hidup orang banyak, jika tak dipenuhi akan mengakibatkan munculnya masalah lain);
3. Dukungan sumber daya yang cukup (kemampuan sumberdaya yang tersedia dalam jumlah yang cukup);
4. Berdampak pada Lingkungan (kalau tidak segera diatasi akan mengakibatkan dampak yang mempengaruhi lingkungan sekitarnya).
Kriteria dipertimbangkan beserta penilaiannya, yaitu (1). Tinggi, (2). Cukup, dan (3). Kurang.
Setelah pemodelan ditentukan, untuk perancangan sistem dibutuhkan alat bantu perancangan data flow diagram (DFD). DFD adalah suatu model logika data atau proses yang dibuat untuk menggambarkan asal dan tujuan data yang keluar dari sistem, tempat penyimpanan data, proses apa yang menghasilkan data tersebut, serta interaksi antara data yang tersimpan dan proses yang dikenakan pada data tersebut. Perancangan sistem perencanaan pembangunan kelurahan seperti tampak pada gambar 2. dalam bentuk context diagram dan gambar 3 data flow diagram (DFD) level 0.
a.
Context Diagram
Diagram konteks dibawah ini menerangkan alir data usulan kegiatan yang masuk dari entitas ke sistem serta informasi yang keluar dari sistem ke entitas. Dalam diagram konteks terdiri dari 4 (empat) entitas, yaitu: (1). RT (2). RW (3). Kecamatan (4). Bappeda.
Gambar 2. Context diagram 0
Lap. Usulan Kegiatan Prioritas RT
Data Program Data Kegiatan Data Jebis Bantuan
Daftar Usulan Kegiatan Sarpras Prioritas Kelurahan
Daftar Usulan Sarana Prasana
Daftar Usulan Kegiatan Prioritas RW Daftar Usulan Keluarga Miskin
Daftar Usulan Kelompok Masyarakat Daftar Usulan Pelatihan
Daftar Usulan Sarana Prasana Prioritas RW Daftar Usulan Keluarga Miskin RT
Daftar Usulan Kelompok Masyarakat Prioritas RW Daftar Usulan Pelatihan Prioritas RW
Daftar Usulan Keluarga Miskin Daftar Usulan Kelompok Masyarakat
Prioritas Kelurahan Daftar Usulan Pelatihan Prioritas Kelurahan
RKA Data RW
C-5
b.
Data Flow Diagram Level 0
Gambar 3. Data flow diagram level 0
c.
Perancangan Database
Model Data menunjukkan suatu cara/mekanisme yang digunakan untuk mengelola/mengorganisasikan data secara fisik dalam memori sekunder yang akan berdampak pada pengelompokan dan membentuk keseluruhan data pada sistem informasi perencanaan pembangunan. Pada sistem informasi perencanaan pembangunan ini, model data yang digunakan adalah
Model Relational, yaitu dimana Basis data akan disebar ke dalam berbagai tabel 2 dimensi. Setiap tabel akan selalu terdiri atas lajur mendatar (row/record) dan lajur vertikal (column/field). Disetiap pertemuan baris dan kolom inilah item-item data ditempatkan. Tabel merupakan bentuk natural (alamiah) dalam menyatakan fakta/data yang digunakan. Perancanag Tabel Sistem Informasi Perencanaan Pembangunan Kelurahan seperti tampak pada gambar 4. dibawah ini
RT
Daftar Kelompok Masyarakat prioritas Daftar Keluarga Miskin
Daftar Usulan Sarana Prasarana Prioritas Kelurahan Daftar Usulan Keluarga Miskin
Daftar Usulan Kelompok Masyarakat Prioritas Kelurahan
Daftar Usulan Pelatihan Prioritas Kelurahan Data RW
Data Kelompok Masyarakat RT
RW
Data Kegiatan Data Kegiatan
Daftar Usulan Sarana Prasana Prioritas RW Daftar Usulan Keluarga Miskin RT
Daftar Usulan Pelatihan Prioritas RW Daftar Usulan Kelompok Masyarakat Prioritas RW
Sarpras
DataUsulan Pelatihan Data Usulan Sarana Prasarana Data RW
Data Kelompok Masyarakat DataUsulan Pelatihan
Data Keluarga Miskin RT
Data Usulan Kelompok Masyarakat
Data Usulan Sarana Prasarana Data Keluarga Miskin RT
Kegiatan Program
Kecamatan Daftar Usulan Sarana Prasarana Prioritas Kelurahan
Daftar Usulan Keluarga Miskin
Daftar Usulan Kelompok Masyarakat Prioritas Kelurahan RKA
C-6
Gamabr 4. Rancangan tabel sistem informasi perencanaan pembangunan
3.
Implementasi Sistem
Berdasarkan context diagram dan data flow diagram pada tahap desain sistem, maka tahap selanjutnya yang dilakukan adalah konversi fungsi-fungsi dari sistem tersebut ke dalam pemrograman. Bahasa pemrograman yang digunakan untuk menuliskan kode program adalah Microsoft Visual FoxPro Professional 9.0. Dan sebagai tahap akhir dalam pembangunan perangkat lunak ini adalah tahap pengujian dan
evaluasi sistem berdasarkan data-data transaksi berupa usulan-usulan perencanaan pembangunan tingkat RT, RW dan Kelurahan.
Pada tahap pengujian ini, akan ditampilkan semua proses mulai dari pemasukan data, pemrosesan transaksi, proses pengambilan keputusan sampai dengan menghasilkan keluaran yang berupa informasi, laporan, dokumen dan keluaran yang lain yang relevan berupa daftar skala prioritas usulan pada program dan kegiatan tingkat kelurahan pra-musrenbang kecamatan.
C-7
Gambar 6. Pencatatan usulan sarana dan prasarana RT
Gambar 7. Pemodelan keputusan skala prioritas usulan sarana dan prasarana
Gambar 8. Laporan daftar usulan berdasarkan skala prioritas
Kesimpulan
Musyawarah Perencanaan Pembangunan (Musrenbang) Kelurahan adalah forum musyawarah tahunan pemangku kepentingan pembangunan di kelurahan untuk menyepakati rencana kegiatan tahun anggaran berikutnya. Mengingat betapa pentingnya murenbang yang merupakan sarana dalam penjaringan aspirasi masyarakat dengan memenuhi prinsip partisipatif, berkesinambungan, dan menyeluruh dalam proses perencanaan pembangunan di Kota Semarang dan agar pelaksanaan musrenbang dapat berjalan dengan baik dan terarah, maka diperlukan pengembangan sistem informasi perencanaan pembangunan yang dapat digunakan untuk menghimpun, menyimpan, dan memproses data transaksi dan mengendalikan keputusan yang merupakan bagian dari transaksi serta
mampu menghasilkan informasi berupa laporan, dokumen dan keluaran lainnya yang akurat, relevan dan tepat waktu.
Dengan diimplementasikannya pemodelan sistem informasi perencanaan pembangunan di kelurahan diharapkan perencanaan dan pelaksanaan pembangunan dapat memenuhi sasaran pembangunan sesuai prioritas pencapaian program dan kegiatan dengan memenuhi aspek akuntabilitas/transparansi dalam mewujudkan pemerintahan yang dapat dipercaya atau good governance.
Daftar Pustaka
C-8 [2] Keputusan Menteri Bersama Nomor :
00008/M.PPA/01/2007/050/264A/S tanggal 12 Januari 2007 perihal Petunjuk Teknis Penyelenggaraan Musyawarah Perencanaan Pembangunan Tahun 2007.
[3] Kusrini, M. Kom., (2007), Konsep dan Aplikasi Sistem Pendukung Keputusan, Penerbit Andi, Yogyakarta
[4] Peraturan Daerah Kota Semarang Nomor 9 Tahun 2007 tentang Tata Cara Penyusunan Rencana Pembangunan Kota Semarang.
[5] Petunjuk Pelaksanaan dan Petunjuk Teknis Musyawarah Perencanaan Pembangunan (Juklak Juknis Musrenbang) Tingkat RT, RW dan Kelurahan, Badan Perencanaan Pembangunan Daerah Kota Semarang, 2008
[6] Powell, G., (2006), Beginning Database Design. Wiley Publishing, Inc.
[7] Prof. Dr. Sugiyono., (2009). Metode Penelitian Kuantitatif Kualitatif dan R&D, Cetakan ke 7, Alfabeta, Bandung
[8] Undang-undang Nomor 25 Tahun 2004 tentang Sistem Perencanaan Pembangunan Nasional (SPPN).
C-9
Aplikasi N-Gram Untuk Deteksi Plagiat Pada Dokumen Teks
Amir Hamzah
Jurusan Teknik Informatika Fakultas Teknologi Industri IST AKPRIND Yogyakarta
Jl. Kalisahak No 28 Yogyakarta
Telepon (0274) 563029 ekst 239
E-mail : miramzah@yahoo.co.id
Abstrak
Semakin intensifnya penggunaan komputer dan melimpahnya dokumen teks dalam jaringan
internet telah menyebabkan ketersediaan dokumen yang hampir tanpa batas. Salah satu
dampak negatif dari fenomena ini adalah semakin mudahnya orang memproduksi atau
menggandakan teks dari sumber yang melimpah tersebut. Pada gilirannya ketika ini dilakukan
oleh orang-orang yang tidak bertanggung jawab maka akan menyuburkan praktek plagiarisme.
Orang yang malas akan dengan mudah melakukan “copy-paste” karya orang tanpa harus
bersusah-susah menyusun sendiri karya tulisnya. Untuk mengatasi persoalan itu upaya
menyusun program komputer yang dapat melakukan deteksi plagiat kiranya penting untuk
dilakukan. Penggunaan N-gram untuk aplikasi deteksi plagiat telah dicoba dalam penelitian ini.
N-gram adalah susunan N-karakter yang diambil dari suatu teks. Distribusi frekuensi
kemunculan N-gram dalam suatu teks dengan demikian dapat dijadikan sebagai identifikasi
dari suatu teks yang dapat berupa kata, kalimat atau paragraf. Dengan identifikasi ini
selanjutnya dapat digunakan sebagai alat pembanding apakah suatu teks memiliki tingkat
kemiripan tertentu dengan teks yang lain. Penelitian ini mengelaborasi kemampuan N-gram
sebagai identifikasi teks dalam upaya deteksi plagiat dokumen teks. Kinerja penggunaan
N-gram untuk deteksi plagiat dibandingkan dengan metode similaritas dokumen dalam system
information retrieval (IR). Percobaan dilakukan dengan menggunakan 80 abstrak dan 200 teks
artikel panjang. Hasil percobaan menunjukkan bahwa tingkat kesamaan yang dapat dideteksi
oleh N-gram mampu mendeteksi sampai tingkat kemiripan 97% untuk abstrak dan 90% untuk
artikel teks panjang
.
Kata Kunci :
N-gram, deteksi plagiat, dokumen teks
Pendahuluan
Perkembangan teknologi digital dan jaringan komputer, utamanya internet telah memudahkan orang mengakses informasi. Volume informasi yang sangat besar juga memudahkan orang mendapatkan informasi apapun dalam berbagai bentuk dengan cepat dan mudah. Namun pada sisi lain kenyataan ini juga dapat memancing tindakan yang kurang terpuji, yaitu plagiarisme (penjiplakan). Plagiarisme didefinisikan sebagai tindakan penyalahgunaan, pencurian/ perampasan, penerbitan, pernyataan, atau menyatakan sebagai milik sendiri sebuah pikiran, ide, tulisan, atau ciptaan yang sebenarnya milik orang lain [11]. Mudahnya fasilitas menyalin dan mengkopi informasi ini telah mendorong orang untuk melakukan hal tersebut.
Untuk mengatasi hal tersebut diperlukan upaya untuk melakukan deteksi apakah suatu tulisan adalah murni hasil tulisan sendiri atau hasil copy paste dari pihak lain. Upaya ini tidak dapat atau sangat sulit jika dilakukan secara manual, sehingga diperlukan upaya
menyusun suatu program komputer yang dapat melakukan deteksi plagiat. Menurut [5,9] ada beberapa tipe plagiarisme, yaitu:
1. Word-word plagiarism, yaitu menyalin setiap kata secara langsung tanpa diubah sedikitpun. 2. Plagiarism of authorship, yaitu mengakui
hasil karya orang lain sebagai hasil karya sendiri dengan cara mencantumkan nama sendiri menggantikan nama pengarang yang sebenarnya.
3. Plagiarism of sources, jika seorang penulis menggunakan kutipan dari penulis lain tanpa mencantumkan sumbernya.
Pada prakeknya dengan perkembangan internet yang intensif, plagiarism tipe 1, yaitu word-word plagiarism sangat mudah dilakukan. Pada plagiarisme tipe ini pengkopian teks bisa sebagian teks dan bisa keseluruhan teks. Pada tipe inilah pengolahan teks dan manipulasi teks seperti pemanfaatan N-gram dapat dielaborasi untuk membuat system yang dapat mendeteksi terjadinya plagiarisme.
C-10 adalah plagiat pada informasi teks. Hal ini wajar karena informasi teks merupakan informasi terbanyak yang dapat kita temukan dalam bentuk digital [16]. Untuk itu pencarian dan penelitian algoritma untuk mendeteksi plagiat dari informasi teks sangat penting dilakukan. Penelitian ini bertujuan melihat sejauh mana penggunaan N-gram dapat diterapkan untuk melakukan deteksi plagiarisme jika dibandingkan dengan teknik melihat kesamaan dokumen dalam aplikasi sistem IR (Information Retrieval).
Berbagai analisis untuk deteksi plagiat telah banyak dilakukan. Menurut [15] berbagai teknik itu bertumpu pada tiga pendekatan, yaitu substring matching, keyword similarity dan fingerprint analysis. Pada pendekatan susbtring matching banyaknya match dari dua pasangan substring yang masing-masingnya diambil dari dua dokumen yang akan diperiksa dijadikan sebagai indikator terjadinya plagiarisme. Pada pendekatan keyword similarity sejumlah keyword yang dapat mewakili isi topik diekstrak dari masing-masing dokumen yang akan diperiksa kemiripannya. Suatu dokumen dikatakan sebagai plagiat dari dokumen lain apa bila vector dokumen yang diwakili oleh keyword yang terekstrak memiliki tingkat kesamaan melebihi suatu nilai threshold tertentu. Pendekatan fingerprinting merupakan pendekatan yang paling sering digunakan. Pada pendekatan ini ada tidaknya plagiarism dideteksi berdasarkan adanya overlap dari urutan teks dari dua dokumen yang diperbandingkan [3, 13]. Peralatan yang digunakan untuk mewakili urutan teks tersebut adalah fingerprint dari masing-masing dokumen. Fingerprint dari suatu dokumen adalah urutan posisi potongan-potongan teks dari dokumen tersebut, yang merupakan informasi unik dari dokumen tersebut. Infomasi unik ini umumnya diwakili oleh n-gram, yaitu deretan n-karakter dari suatu kata atau teks [8].
Contoh n-gram jika dimiliki suatu teks
“YOGYAKARTA”, adalah sebagai berikut :
N=1 : UNIGRAM, yaitu :Y,O,G,Y,A,K,A,R,T dan A N=2 : BIGRAM, yaitu :YO, OG, GY, YA, AK, AR,
RT, TA dan A_
N=3 :TRIGRAM, yaitu: YOG, OGY, GYA, YAK, AKA, KAR, ART, RTA
N=4, yaitu :YOGY, OGYA, GYAK, YAKA, AKAR, KART dan ARTA
dan seterusnya
Analisis terhadap N-gram dari suatu teks dapat diterapkan pada berbagai aplikasi yang terkait dengan text mining. Hamzah [4] meneliti aplikasi n-gram untuk deteksi bahasa dari suatu teks berdasarkan pola sebaran dari n-gram, khususnya bigram dan trigram. Analisis dilakukan dengan menganalisis distribusi bigram dan trigram dari dokumen berbahasa inggris, selanjutnya dokumen baru yang akan dideteksi bahasanya dilakukan analisis frekuensi bigram dan trigramnya. Perbedaan distribusi frekuensi bigram dan trigram pada dokumen baru dengan dokumen yang ada
pada koleksi dijadikan indikator bahwa dokumen baru tersebut dokumen dengan bahasa yang berbeda dengan dokumen yang ada pada koleksi.
Aplikasi lain dari N-gram adalah pada information retrieval (IR), yaitu untuk meningkatkan recall dan precision dalam pemrosesan query [7]. Kinerja system IR akan meningkat manakala query dikembangkan dengan menggunakan dua kata yang berbeda yang memiliki kemiripan makna. Teknik N-gram menggantikan representasi kata yang akan digabungkan dengan menggunakan informasi N-gram. Similaritas dua kata sebagai dasar penggabungan diukur berdasarkan banyaknya N-gram yang dimiliki secara bersama oleh dua kata tersebut.
Aplikasi lain yang banyak sekali diteliti adalah pada penerapan N-gram dalam upaya deteksi plagiat dari suatu dokumen teks [8,10,12,14]. Seperti telah diutarakan sebelumnya definisi plagiat adalah mengambil tulisan orang lain dan dianggap sebagai karya sendiri tanpa menyebutkan sumbernya. Jika dokumen teks sumber dianggap sebagai suatu string dan dokumen teks yang diuji adalah suatu substring, maka permasalahan deteksi plagiat dapat direduksi menjadi mengecek apakah suatu substring ada dalam string lain. Permasalahan ini dalam teknik operasi string masuk dalam wilayah string matching. Telah banyak algoritma string matching yang diajukan, antara lain : Rabin-Karp [6], Knuth-Morris-Pratt, dan Boyer Moore[1]. Di antara 3 algoritma tersebut yang paling banyak diterapkan untuk deteksi plagiat dokumen adalah Rabin-Karp [2,9,10,12].
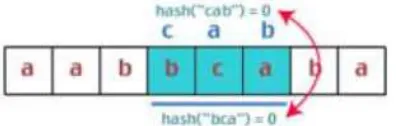
Algoritma Rabin-Karp memiliki cara kerja berdasarkan fungsi hash dari suatu sub-string. Fungsi hash adalah fungsi yang memetakan suatu substring pada nilai bilangan tertentu dengan aturan tertentu sedemikian sehingga setiap substring yang unik diwakili oleh bilangan yang unik. Nilai fungsi hash dapat dianggap sebagai fingerprint dari string masukan tersebut. Misalnya akan dicari substring “cab” dalam string “aabbcaba” [2,12]. Diberikan masukan input string s=”cab” dalam teks=”aabbcaba”. Algoritma pencarian dimulai dari posisi karakter paling kiri. Gambaran fungsi hash, misalnya nilai bilangan yang mewakili masing-masing karakter adalah a=1, b=2 dan c=3. Pencarian awal ditunjukkan oleh Gambar 1:
Gambar 1.Fingerprint awal
Diasumsikan nilai hash ditetapkan dengan cara :
C-11 Dimana c1, c2 dan c3 adalah nilai bilangan dari setiap karakter pembentuk string. Dengan demikian nilai hash dari “cab”, hash(“cab”)=(3+1+2) mod3 = 0
Perbandingan nilai hash dari string “cab”=0, dan nilai hash dari 3 karakter pertama, hash(“aab”)=1. Hasilnya tidak sama, sehingga karakter digeser kekanan 1 posisi, seperti gambar 2.
Gambar 2. Menggeser fingerprint 1 karakter
Setelah digeser, didapat string “abb” yang memilki nilai hash hash(“abb”)=2. Nilai hash ini tidak dihitung dari awal tetapi dihitung dengan cara rolling hash, yaitu mengurangi dengan nilai karakter yang keluar (di sebelah ujung kiri) dan menambah nilai karakter yang masuk (di sebelah ujung kanan). Hash(“abb”)=hash(“aab”)-a+b)=1-1+2=2 (Gambar 3).
Gambar 3. Nilai hash tidak sama
Hasil perbandingan juga tidak sama, maka dilakukan pergeseran. Begitu pula dengan perbandingan ketiga. Pada perbandingan keempat, didapatkan nilai hash yang sama. Karena nilai hash sama, maka dilakukan perbandingan string karakter per karakter antara”bca” dan ”cab”. Didapatkan hasil bahwa kedua string tidak sama (Gambar 4). Maka, kembali substring bergeser ke kanan.
Gambar 4.Nilai hash sama string berbeda
Pada perbandingan yang kelima, kedua nilai hash dan karakter pembentuk string sesuai, sehingga solusi ditemukan (Gambar 5).
Gambar 5. Pencarian berhasil
Algoritma tersebut dapat dituliskan sebagai mana pseudocode dalam Gambar 5 berikut dengan masukan fungsi teks dengan panjang n, dan string s dengan panjang m.
Gambar 6. Algoritma Rabin-Karp [2,6,12]
Algoritma tersebut menurut beberapa penlitian [2,6,12] memilki kinerja yang kurang baik dibandingkan dengan Knuth-Morris-Pratt, dan Boyer Moore. Akan tetapi algoritma Rabin-Karp memiliki keunggulan jika digunakan untuk membandingkan multiple string. Untuk itu pada perkembangannya algoritma Rabin-Karp modifikasi (untuk mencari multiple string dalam suatu string) lebih sering digunakan.
Penerapan algoritma Rabin-Karp dalam deteksi plagiat dilakukan dengan melakukan proses awal pada dokumen referensi dan dokumen yang diuji. Proses awal ini adalah (1) menghilangkan white space, dan tanda baca yang tidak diperlukan, (2) menggabungkan seluruh kata yang ada sehingga menjadi satu string saja, (3) membangkitkan N-gram yang mungkin. Dari proses awal tersebut algoritma Rabin-Karp diterapkan dengan mula-mula mencari nilai hash bagi seluruh N-gram. Dari seluruh nilai hash yang terbentuk dari seluruh N-gram tersebut dipilih sejumlah nilai hash tertentu. Nilai-nilai hash tertentu yang terpilih itulah yang akan menjadi fingerprint dari document yang akan diuji kesamaannya. Salah satu cara terpopuler untuk memilih nilai hash sebagai fingerprint adalah nilai hash yang memenuhi kriteria O mod p, atau nilai hash yang jiga dioperasikan dengan mod p , dengan p dipilih oleh pengguna, menghasilkan nilai 0 [14]. Berikut ini gambaran menentukan fingerprint dari dokumen, misalkan dimiliki dokumen : ”A do run run, a do run run [14]. Langkah-langkah penentuan fingerprint dokumen.
A do run run run, a do run run function RabinKarp (input s:
string[1..m], teks: string[1..n]) ->boolean
{ Melakukan pencarian string s pada string teks dengan algoritma Rabin-K} Deklarasi
i : integer ketemu = boolean Algoritma:
ketemu false hs hash(s*1..m+) for i 0 to n-m do
hsub hash(teks*1..i+m-1]) if hsub = hs then
if teks[i..i+m-1] = s then ketemu true
else
hsub hash(teks*i+1..i+m+) endfor
C-12 (a) teks semula
Adorunrunrunadorunrun (b) menghilangkan white space
adoru dorun orunr runru unrun nrunr runru unrun nruna runad unado nador adoru dorun
orunr runru unrun ( c) Hasil 5-gram dari teks
77 72 42 17 98 50 17 98 8 88 67 39 77 72 42 17 98
(d) Nilai-nilai hash yang mungkin
72 8 88 72 (e) Fingerprint dokumen
Gambar 7. Langkah penentuan fingerprint dokumen
Selanjutnya untuk mengukur similaritas atau kesamaan dokumen menggunakan N-gram digunakan coefisien Dice, yaitu rasio antara banyaknay N-gram yang sama antara dokumen pertama dengan dokumen kedua dibagi dengan total banyaknya N-gram dari kedua dokumen [8]. Misalnya dokumen tersebut adalah X dan Y, maka similaritas dokumen tersebut adalah :
Sim=
Pendekatan lain untuk mengukur kesamaan dokumen adalah menggunakan teknik yang biasa dipakai dalam IR untuk mengukur kesamaan query dengan dokumen. Metode yang sering digunakan adalah kesamaan dengan Cosine similarity, yaitu dalam model ruang vector untuk dokumen dan query. Dalam model ini query Q dan dokumen D dimodelkan dalam ruang vector berdimensi t,dengan t adalah cacah term terindeks dalam koleksi dokumen, maka similaritas cosine adalah :
Formula ini kemudian dapat dijadikan sebagai teknik untuk mencari kesamaan antara dokumen referensi dengan dokumen yang akan diuji apakah terjadi plagiarisme atau tidak.
Metodologi Penelitian
Dalam penelitian ini digunakan dokumen teks berupa dokumen abstrak sebanyak 80 buah dan artikel panjang sebanyak 200 dokumen normal yang lengkap.
Pembuatan program dilakukan dengan menggunakan komputer PC Intel Atom 1.5GHz, RAM 2GB, Hard Disk 250 GB, dan sistem operasi Windows 7. Bahasa
pemrograman yang dipergunakan adalah java jdk1.6.4, NetBean 6.01.
Dalam pengujian ini dokumen uji dan dokumen referensi berasal dari dokumen yang sama. Dokumen uji berasal dari dokumen referensi yang telah dirubah isinya dengan berbagai tingkatan perubahan. Dokumen referensi yang dirubah dengan 0% (atau tanpa perubahan) diharapkan jika dijadikan dokumen uji maka akan menghasilkan kesamaan 100%, yaitu terjadinya plagiat. Selanjutnya perubahan dokumen referensi yang dijadikan dokumen uji dirubah sebanyak 10%, 20%, 30% dan 50% isi. Tabel
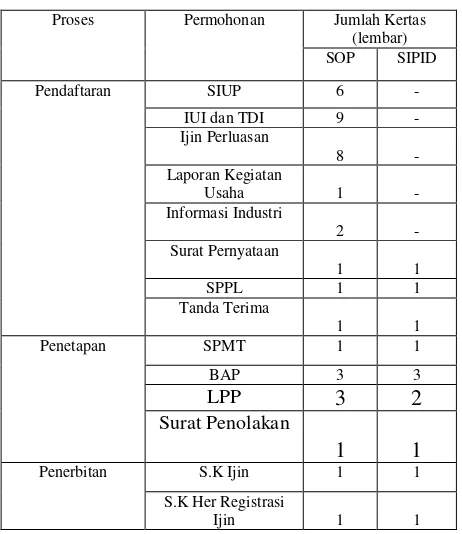
Tabel 1. Kelompok Dokumen referensi dan Dokumen Uji Untuk abstrak
Doc. Referensi Doc. Uji CchDok Keterangan
DocRef1.txt DocUji1.txt 20
0% perubahan
DocRef2.txt DocUji2.txt 15
10% perubahan
DocRef3.txt DocUji3.txt 15
20% perubahan
DocRef4.txt DocUji4.txt 15
30% perubahan
DocRef5.txt DocUji5.txt 15
50% perubahan
Tabel 2. Kelompok Dokumen referensi dan Dokumen Uji Untuk Dokumen Panjang
Doc. Referensi Doc. Uji CchDok Keterangan
DocRef6.txt DocUji1.txt 40
0% perubahan
DocRef7.txt DocUji2.txt 40
10% perubahan
DocRef8.txt DocUji3.txt 40
20% perubahan
DocRef9.txt DocUji4.txt 40
30% perubahan
DocRef10.txt DocUji5.txt 40
50% perubahan
Tahapan penelitian dilakukan dengan melakukan preprocessing dokumen, baik dokumen referensi maupun dokumen uji antara lain:
Untuk pendekatan similaritas dengan teknik IR.
1. Melakukan filtering dokumen dengan membuang karakter yang tidak berguna, seperti koma, titik koma.
2. Membuang kata yang masuk dalam kategori STOP WORD seperti ini, itu, di, dari dan seterusnya.
3. Menyusun vector bobot dokumen referensi dan dokumen uji.
Untuk pendekatan similaritas dengan teknik IR.
C-13 2. Membuang kata yang masuk dalam kategori
STOP WORD seperti ini, itu, di, dari dan seterusnya.
3. Menggabungkan setiap kata dalam dokumen sedemikian sehingga suatu dokumen dipandang sebagai suatu string saja. Ini dilakukan pada dokumen referensi dan dokumen uji.
4. Membangkitkan N-gram yang mungkin dari dokumen refernsi dan dokumen uji
5. Mencari fingerprint dari dokumen refernsi dan dokumen uji
Algoritma yang digunakan untuk mencari fingerprint adalah modifikasi dari algoritma Rabin-Karp (Gambar 6), yaitu algoritma yang dapat digunakan untuk mencari multiple pattern dalam suatu teks (Gambar 8). Masukan algoritma adalah suatu string teks (yaitu dokumen refernsi) dan sejumlah substring dengan panjang m (dalam hal ini substring adalah N-gram yang diambilkan dari dokumen uji).
Gambar 8. Algoritma Rabin-Karp modifikasi
Gambar 8. Algoritma Rabin-Karp modifikasi [2,6,12]
Langkah berikutnya adalah mencari similaritas antara dokumen referensi dan membandingkan kinerja deteksi plagiat menggunakan dua metode. Yang pertama adalah dengan menggunakan metode IR dengan mencari similaritas dokumen menggunakan similaritas COSINE antara vector dokumen referensi dan dokumen (persamaan (2)). Pengujian yang kedua adalah menggunakan metode similaritas DICE seperti pada persamaan (3), setelah sebelumnya analisis
N-gram telah dilakukan. Selanjutnya kinerja proN-gram akan dibandingkan antara teknik IR dengan teknik N-gram. Dilakukan juga analisis tentang N-gram, yaitu nilai N berapa yang memberikan kinerja yang optimal dalam melakukan deteksi plagiat. Dilakukan juga analisis untuk perbedaan objek yang dideteksi, yaitu kemampuan mendeteksi terhadap penjiplakan 100%, 50%,30%,20% dan 10%.
Hasil dan Perancangan
Antar muka program deteksi telah berhasil dirancang. Salah tampilan hasil deteksi adalah seperti pada Gambar 9. Pada tampilan tersebut dokumen referensi dan dokumen uji adalah dokumen yang sama, sehingga similaritas menghasilkan nilai 100%. Tabel 3 berikut ini adalah kinerja program deteksi plagiat jika digunakan N-gram dengan n=3 untuk dokumen abstrak untuk berbagai level plagiat. Terlihat dari table tersebut nilai similaritas dengan metode N-gram lebih tinggi (rata-rata kemampuan deteksi 98%) dibandingkan dengan method IR.(rata-rata kemampuan deteksi 90%). Kemampaun deteksi diukur berdasarkan rasio antara similaritas yang dihitung oleh program dengan nilai similaritas yang seharusnya. Misalnya untuk kelompok dokuji2.txt (dokumen dengan perubahan sebesar 10%), maka kesamaan seharusnya adalah sebesar 0.9. Sehingga jika nilai similaritas adalah 0.878 berarti kemempuan deteksinya adalah 97%. Terlihat bahwa kemampuan deteksi pada dokumen abstrak relatif tinggi karena dokumen yang diperiksa rata-rata cukup kecil yaitu antara 200 sampai 300 kata.
Tabel 3. Kinerja Deteksi untuk dokumen abstrak
Dok Uji N-Gram IR-base
Untuk dokumen yang lebih panjang didapatkan hasil seperti dalam Tabel 4. Dari tabel tersebut apabila dibandingkan dengan Tabel 3 terlihat bahwa nilai Function RabinkarpMultiplePattern
(input teks: string [1..n], s: set of string, m:integer) -> integer
Masukkan hash (s[1..m]) kedalam hs
For i 0 to n-m
Hsub hash (teks[i..i+m-1]) if hsub = hs then
if teks [i..i+m-1] = sebuah
substring dengan hash hsub then
cch_ketemu cch_ketemu+1 Else hsub <- hash
(teks[i+1..i+m]) endfor
C-14
Gambar 9. Antar Muka Program Deteksi Plagiat
Tabel 4. Kinerja Deteksi untuk dokumen panjang
Dok Uji N-Gram IR-base Sim Detect% Sim Detect%
dokuji6.txt 0.980 98% 0.990 99%
dokuji7.txt 0.812 90% 0.805 89%
dokuji8.txt 0.721 90% 0.654 82%
dokuji9.txt 0.623 89% 0.575 82%
dokuji10.txt 0.423 85% 0.356 71%
Rata2 90% Rata2 85%
similaritas baik dengan metode N-gram maupun metode IR memberikan nilai yang jauh lebih kecil, sehingga kemampuan deteksinya rata-rata hanya sebesar 90% untuk metode N-gram dan 85% untuk metode IR. Hal ini dapat dimaklumi karena untuk dokumen yang panjang akan lebih mungkin terjadi kesamaan N-gram yang berasal dari kata yang sama sekali berbeda secara makna namun memiliki kemiripan dalam susunan karakter.
Analisis terhadap variasi N-gram untuk hasil deteksi memberikan kinerja seperti dalam gambar 10.
Gambar 10. Pengaruh N-gram pada Kemampuan deteksi Antar
C-15
Kesimpulan
Beberapa kesimpulan yang dapat ditarik dari penelitian ini adalah sebagai berikut :
1. Aplikasi N-gram mampu melakukan deteksi apakah sudah terjadi plagiat dalam suatu dokumen teks. Kemampuan deteksi ini lebih baik dibandingkan dengan aplikasi metode IR.
2. Kemampuan deteksi dokumen dapat menurun keakuratannya jika ukuran dokumen meningkat jumlah katanya. Pada dokumen abstrak rata-rata kemampuan deteksi sampai 97% sedangkan pada dokumen panjang hanya meencapai 90%.
3. Pemilihan ukuran N-gram akan mempengaruhi kinerja baik dalam akurasi dalam deteksi atau dalam kecepatan proses dari program deteksi. Pada kedua jenis dokumen kemampuan optimal didapatkan pada ukuran N-gram 3.
Daftar Pustaka
[1] Atmopawiro, A., (2006). Pengkajian Dan Analisis Tiga Algoritma Efisien Rabin-Karp, Knuth-Morris-Pratt, Dan Boyer-Moore Dalam Pencarian Pola Dalam Suatu Teks, Program Studi Teknik Informatika, Institut TeknologiBandung.
[2] Firdaus, H.,B., (2008). Deteksi Plagiat Dokumen Menggunakan Algoritma Rabin-Karp. Program Studi Teknik Informatika Sekolah Teknik Elektro dan Informatika, Institut Teknologi Bandung (ITB). Bandung.
[3] Frantzeskou,G., Stamatatos, E.,Gritzalis,S.,(2007) Identifying Authorship by Byte-level n-grams:The Source Code Author Profile (scap) Method, Int‘l. Journal of Digital Evidence, 6(1).
[4] Hamzah, A.,(2010). Deteksi Bahasa Untuk Dokumen Teks Berbahasa Indonesia, Prosiding Seminar Nasional Teknik Informatika SEMNASIF 2010, UPN Veteran Yogyakarta, 22 Mei 2010
[5] Iyer P. dan Singh, A.,(2005). Document Similarity Analysis for a Plagiarism Detection System, 2nd Indian International Conference on Artificial Intteligence (IICAI-05),pp 2534-2544, 2005.
[6] Karp, Richard M.; Rabin, Michael O. (1987). Efficient randomized pattern-matching algorithms [7] Kasinov, S.,(2002). Evaluation of N-Grams Conflation Approachin Text-Based Information Retrieval. University of Alberta.Canada
[8] Kodrak, G.,(2005). N-gram Similarity and Distance, SPIRE2005, LNCS 3772,pp.115-126. [9] Kurniawati, A., dan Wicaksana, I.W.S.,(2008).
Perbandingan Pendekatan Deteksi Plagiarisme Dokumen dalam Bahasa Inggris, Prosiding Seminar Ilmiah Nasional Komputer dan
Sistem Intelijen, KOMMIT2008, Universitas Gunadarma, Depok,20-21 Agustus 2008.
[10] Mutiara, B. dan Agustina, S.,. (2008). Anti Plagiarsm Applicationwith Algorithm Karp-Rabin, Thesis, GunadarmaUniversity, Depok, Indonesia [11] Ridhatillah, A. . (2003). Dealing with Plagiarism
in the Information System Research Community: A Look at Factors that Drive Plagiarism and Ways to Address Them, MIS Quarterly; Vol. 27, No. 4, p. 511-532/December 2003
[12] Nugroho, E.,(2011), Perancangan Sistem Deteksi Plagiarisme Dokumen Teks dengn Menggunakan Algoritma Rabin Karp, Program STudi Ilmu Komputer, Jurusan Matematika, Universitas Brawijaya, Malang.
[13] Si, A., Leong H.V., Lau, R.W.H.,(1997), Check:a document plagiarism detection system, Proc.of the 1997 ACM Symposium on Applied Computing, San Jose California, USA:70-77
[14] Schleimer, Saul; Wilkerson, Daniel, Aiken Alex. (2003). Winnowing: Local Algorithms for Document Fingerprinting. SIGMOD.San Diego, CA. 2003, June 9-12, 2003
[15] Stein, B., and Eissen, S.M.,(2006). Near Similarity Search and Plagiarism Analysis, 29th Annual Conference of the German Classification Society(GfKl), Magdeburg, ISDN 1431-
8814,pp.
430 – 437
C-16
Pemilihan Perilaku Tarung
Non Player Character
Pada
Game
Perang
Menggunakan
Fuzzy Coordinator
Ika Widiastuti
1.2), Supeno Mardi S.N
1),
Mochamad Hariadi
1),
Mauridhi Hery P
1)Jurusan Teknik Elektro, Institut Teknologi Sepuluh Nopember
1)Gedung Teknik Elektro, Jl. Raya ITS, Kampus ITS, Sukolilo, Surabaya, 60111
Jurusan Teknologi Informasi, Politeknik Negeri Jember
2)Gedung Teknologi Informasi, Jl. Mastrip PO BOX 164, Jember, 68121
E-Mail:
ika10@mhs.ee.its.ac.id
Abstrak
Penggunaan teknik kecerdasan buatan (Artificial intelligent) untuk meningkatkan perilaku Non
Player Character (NPC) semakin populer. Agen NPC diharapkan dapat berperilaku otonom
seperti manusia sehingga dapat menanggapi dan mengambil keputusan sesuai dengan kondisi
yang sedang dihadapi. Paper ini mengusulkan metode Fuzzy Coordinator pada sekelompok NPC
prajurit dalam game pertarungan jarak dekat dengan satu Leader yang memiliki kemampuan
mengkoordinasi anggota tim NPC prajurit. Leader sebagai koordinator menentukan perilaku
NPC mana yang harus menyerang, bertahan atau melarikan diri berdasarkan kekuatan (health)
masing-masing NPC. Dengan adanya Leader sebagai koordinator diharapkan perilaku tim
menjadi lebih terarah dan lebih cepat mencapai kemenangan.
Kata Kunci : Artificial Intelligent, Non Player Character, Leader, Fuzzy Coordinator, Otonom
Pendahuluan
Perkembangan teknologi game yang mempunyai agen berperilaku seperti manusia semakin populer. Khususnya pada game perang, dalam pertarungan dibutuhkan pemilihan perilaku yang lebih bervariasi agar game lebih menyenangkan, tidak membosankan dan lebih natural menyerupai perilaku seperti manusia[1]. Pemilihan perilaku gerakan diharapkan sealami mungkin berdasarkan kondisi yang dihadapi oleh agen dan respon yang diberikan oleh lawan. Beberapa penelitian telah dilakukan untuk mempelajari perilaku pemilihan gerakan oleh agen baik secara manual maupun secara adaptif. Pada penelitian [1], pemilihan gerakan tidak adaptif dan tidak terkontrol karena parameter mean untuk distribusi Gaussian dimasukkan secara manual. Agen Non player character (NPC) tidak berkelompok dan belum ada koordinasi diantara agen tersebut. Selanjutnya pada penelitian [2] mengembangkan game bertipe pertarungan jarak jauh dengan pola perilaku NPC menggunakan HFSM. Sudah terdapat strategi berkelompok, akan tetapi belum ada koordinasi antar NPC. Sudah cukup optimal tetapi belum ada pemilihan target musuh yang lemah karena parameter health belum diperhitungkan.
Penggunaan fuzzy coordinator pada aplikasi game telah banyak digunakan untuk kontrol robot berbasis perilaku [3], untuk sistem kontrol peralatan dalam ruangan [5] dan sebagainya.
Penelitian ini mengembangkan perilaku NPC secara berkelompok dengan satu pemimpin (leader) yang menggunakan fuzzy coordinator untuk mendapatkan perilaku kelompok maupun individu yang adaptif. Leader sebagai koordinator dapat menentukan perilaku NPC mana yang harus menyerang, bertahan atau melarikan diri berdasarkan kekuatan (health) masing-masing NPC. Penggunaan fuzzy disini karena fuzzy control dapat diaplikasikan untuk mengkoordinasi perilaku sistem tertentu pada respon terhadap lingkungan [3].
C-17 Penelitian ini melakukan pemodelan sekelompok NPC yang selanjutnya disebut sebagai NPC prajurit dengan satu Leader pada game pertarungan jarak dekat. NPC Leader akan melakukan koordinasi dengan NPC anggota tim mengenai aksi yang akan dilakukan dalam menghadapi tim lawan menggunakan fuzzy coordinator. Fuzzy coordinator yang dimaksud disini adalah logika fuzzy yang terdapat pada NPC Leader sebagai coordinator.
Gambar 1 menunjukkan tahapan-tahapan dalam penelitian yang meliputi perancangan gerak NPC yaitu tiga kategori gerakan untuk leader dan empat gerakan untuk NPC prajurit dan Perancangan Fuzzy coordinator.
Perancangan Perilaku NPC
Pada simulasi pertarungan jarak dekat ini, perilaku gerakan NPC leader dibagi menjadi tiga kategori gerakan yaitu Menyerang (Offense), Bertahan (Defense) dan Melarikan diri (Run Away). Gerakan menyerang (Offense) terbagi menjadi beberapa aksi yaitu Pukulan ringan, Pukulan sedang, Pukulan kuat, Tendangan sedang dan Tendangan kuat. Gerakan bertahan (Defense) terbagi menjadi Menangkis serangan dan Menghindari serangan. Perilaku gerakan NPC prajurit dibagi menjadi empat kategori gerakan yaitu Menyerang (Offense), Bertahan (Defense), Melarikan diri (Run Away) dan Mengikuti Leader (Follow Leader). Seperti yang terlihat pada gambar 2.
Pada penelitian ini, parameter yang digunakan untuk menentukan perilaku tarung hanya parameter health, baik health NPC tim maupun health musuh.
Gambar 2. Diagram Perilaku NPC
Skenario Koordinasi Antara NPC Prajurit
dengan NPC Leader
Skema koordinasi disini berdasarkan mekanisme fuzzy behavior coordination [4] yang menggabungkan beberapa output fuzzy menggunakan operator tertentu, kemudian dengan proses defuzzifikasi dilakukan pemilihan aksi tertentu. Masing-masing NPC dikontrol oleh sebuah fuzzy baik NPC Leader maupun NPC prajurit seperti pada gambar 3.
NPC Leader mempunyai individual command selection dan team command selection. Individual
command selection merupakan pemilihan aksi untuk dirinya sendiri sedangkan Team command selection merupakan pemilihan aksi baik untuk diri sendiri (Leader) maupun NPC anggota tim. NPC prajurit anggota tim hanya mempunyai Individual command selection yang terdiri dari perilaku Menyerang (Offense), Bertahan (Defense) dan Melarikan Diri (Runaway).
Kondisi team command selection untuk NPC prajurit terjadi pada saat status perilakunya adalah Follow Leader dengan parameter health bernilai Enough (cukup). Kondisi individual command selection untuk Leader terjadi pada saat parameter health yang dimiliki sangat lemah.
Jika perilaku NPC Leader berstatus melarikan diri (runaway) atau mati, maka posisi Leader akan digantikan oleh NPC prajurit anggota tim yang mempunyai nilai health paling besar.
Gambar 3. Blok diagram Koordinasi NPC
Pada penelitian ini dibuat skenario koordinasi pada game pertarungan jarak dekat yaitu pada saat pertarungan, tim NPC prajurit bergerak mengikuti Leader dan harus tetap dalam formasi, sambil diberi perintah. Perintah ini berupa perilaku NPC untuk menghadapi lawan yang telah dikalkulasi oleh Leader berdasarkan health NPC tersebut dan health lawan. Sebelum memberikan perintah, Leader melakukan pengamatan terhadap kondisi lingkungan baik posisi lawan maupun kekuatan lawan. NPC prajurit hanya melaksanakan perintah dari Leader saja. Karena yang melakukan pengamatan dan kalkulasi hanya Leader maka diharapkan proses komputasi akan lebih cepat dan pertarungan menjadi lebih terarah (proses pemilihan perilaku tidak acak karena berdasarkan pada kondisi lingkungan) Dalam penelitian ini, formasi belum dibahas dan akan menjadi target penelitian berikutnya.
Perancangan Fuzzy
C-18 Gambar 4. Logika Fuzzy perilaku tarung untuk NPC
Logika fuzzy untuk menghasilkan perilaku NPC Leader dapat dilihat pada Gambar 4.
Gambar 5. Rancangan Fuzzy untuk menghasilkan perilaku NPC
Untuk menghasilkan perilaku NPC seperti pada gambar 5 terdapat dua variabel yang digunakan, yaitu NPC Health dan Enemy Health (very weak,weak, enough, strong, very strong). Pada gambar 6, derajat keanggotaan masukan variabel NPC Health mempunyai interval antara 0 sampai 100 dalam satuan persen (%). Variabel NPC Health mempunyai variabel linguistik: vw (very weak), w (weak), E (Enough), S (Strong) dan vs (very strong). Variabel vw (very weak) mempunyai interval antara 0% sampai 20%. Variabel w (weak) mempunyai interval antara 10% sampai 50%. Variabel E (Enough) mempunyai interval antara 30% sampai 70%. Variabel S (Strong) mempunyai interval antara 50% sampai 90%. Variabel vs (very strong) mempunyai interval antara 80% sampai 100%.
Gambar 6. Derajat keanggotaan masukan variabel NPC Health
Gambar 7. Derajat keanggotaan masukan variabel Enemy Health
Pada gambar 7, derajat keanggotaan masukan variabel Enemy Health mempunyai interval antara 0 sampai 100 dalam satuan persen (%). Variabel Enemy Health mempunyai variabel linguistik: vw (very weak), w (weak), E (Enough), S (Strong) dan vs (very strong). Variabel vw (very weak) mempunyai interval antara 0% sampai 20%. Variabel w (weak) mempunyai interval antara 10% sampai 50%. Variabel E (Enough) mempunyai interval antara 30% sampai 70%. Variabel S (Strong) mempunyai interval antara 50% sampai 90%. Variabel vs (very strong) mempunyai interval antara 80% sampai 100%.
Tabel 1. Aturan Fuzzy untuk menghasilkan perilaku NPC
Input
Enemy Health
N
P
C
H
e
a
lt
h
Level
VW
W
E
S
VS
VW
Esc
Esc
Esc
Esc
Esc
W
D1
D2
Esc
Esc
Esc
E
AK1 AP2 AP3
D1
D2
S
AP1 AP2 AP3 AK1
D1
VS
AP1 AP2 AP3 AK1 AK2
C-19
Tabel 2.Hasil Percobaan Pemilihan Perilaku pada NPC Leader berdasarkan NPC Health dan Enemy Health
Hasil dan Perancangan
Pada penelitian ini bertujuan untuk menguji suatu hipotesa bahwa sekumpulan NPC prajurit pada game pertarungan jarak dekat, jika tanpa coordinator, bergerak secara acak dan mengambil keputusan sendiri-sendiri maka akan lambat untuk mencapai kemenangan. Akan tetapi jika terdapat proses koordinasi oleh Leader yang melakukan pengamatan terhadap anggota tim mana yang masih memiliki kekuatan (health) penuh, anggota tim mana yang sudah berkurang kekuatannya atau bahkan yang sudah habis kekuatannya, dan memberikan perintah yang sesuai dengan kondisi kekuatan masing-masing NPC anggota tim maka untuk mencapai kemenangan akan lebih cepat karena proses komputasi hanya terdapat pada Leader saja.
Percobaan yang dilakukan disini masih sampai pada tahap pengujian fuzzy untuk NPC Leader. Pemilihan perilaku masih dilakukan dengan hanya memperhatikan satu health NPC anggota tim dan satu health lawan. NPC Leader belum melakukan pengamatan terhadap keseluruhan tim. Hasil pemilihan perilaku tersebut ditunjukkan pada Tabel 2.
Pada penelitian selanjutnya NPC Leader diharapkan telah memperhitungkan kondisi keseluruhan tim dan kondisi lawan sehingga dapat mengambil keputusan yang tepat sesuai dengan kondisi lingkungan.
Kesimpulan
Dari percobaan yang dilakukan dapat disimpulkan bahwa aturan fuzzy dapat diimplementasikan untuk menghasilkan perilaku NPC
yang bervariasi sesuai dengan variabel masukan yang dimiliki.
Ucapan Terima Kasih
[1] Direktorat Jenderal Pendidikan Tinggi (Dikti), yang telah memberikan beasiswa selama masa studi
[2] Politeknik Negeri Jember, yang telah memberikan dukungan selama masa studi
Daftar Pustaka
[1] Nur Kholis M, Supeno Mardi S.N, Moch Hariadi, Mauridhi Hery P (2010). Variasi Perilaku Tarung Non Player Character Prajurit Berbasis Distribusi Gaussian pada Real Time Strategy. Jurusan Teknik Elektro, Institut Teknologi Sepuluh Nopember, Surabaya
[2] Supeno Mardi S.N, Yunifa Miftachul Arif, Mochamad Hariadi, Mauridhi H.P (2011). Perilaku Taktis untuk Non Player Character di Game Peperangan Meniru Strategi Manusia menggunakan Fuzzy logic dan Hierarchical Finite State Machine. Jurnal Ilmiah Kursor vol 6. No 1 [3] Prahlad Vadakkepat, Ooi Chia Miin, Xiao Peng,
Tong Heng Lee (2004). Fuzzy Behavior-Based Control of Mobile Robot, IEEE Transaction on Fuzzy System vol. 12 no 4
[4] Paolo Pirjanian (1999). Behavior Coordination Mechanism, State of the art, University of Southern California, Los Angeles
[5] Anastasios I. Dounis, Christos Caraiscos (2007) Intelligent Coordinator of Fuzzy Controller Agents for Indoor Environment Control in Buildings using 3-D Fuzzy Comfort Set, IEEE
C-20 [6] Hani Hagras, Rabie A.Ramadan, Mina Zaher, Hala
Gabr, Hussein Fahmy. A Fuzzy Based Hierarchical Coordination and Control System for a Robotic Agent Team in the Robot Hockey Competition. University of Cairo, Cairo city [7] Memmert Daniel, Bischof Jurgen, Endler Stefan,
Grunz Andreas, Schmid Markus, Schmidt Andrea and Perl Jurgen (2010). World-Level Analysis in Top Level Football Analysis and Simulation of Football Specific Group Tactics by Means of Adaptive Neural Networks. Institute of Sport and
Sport Science, University of Heidelberg,
C-21
Pengembangan Sistem Informasi Perijinan Usaha Industri dan Perdagangan :
Studi Kasus Kota Batu
Karina Auliasari, ST.
Jurusan Teknik Informatika Fakultas Teknologi Industri Institut Teknologi Nasional Malang
Jl. Raya Karanglo km. 2 Malang
Telepon (0341) 417636
E-mail : karina.auliasari86@gmail.com
Abstrak
Pesatnya kemajuan teknologi dan tingginya harapan konsumen terhadap suatu produk dan jasa
merupakan dua faktor utama yang mendorong peningkatan pelayanan oleh suatu organisasi,
termasuk organisasi pemerintahan. Pada organisasi pemerintahan salah satu fokus
pemanfaatan teknologi informasi adalah untuk meningkatkan mutu pelayanan pada
masyarakat. Pelayan perijinan industri dan perdagangan yang mengacu pada standar prosedur
operasional di Kota Batu merupakan salah satu upaya pemerintah dalam menerapkan
peraturan di bidang perindustrian dan perdagangan. Proses-proses yang berkaitan dengan
berkas perijinan belum ditangani secara komputerisasi. Dalam penelitian ini dibahas
perancangan dan pembuatan sistem informasi perijinan usaha industri dan perdagangan yang
memungkinkan semua proses dapat ditangani secara komputerisasi dan sesuai dengan standar
prosedur operasional. Sistem informasi tersebut dikembangkan untuk meningkatkan efektiftas
dan efisiensi dalam proses perijinan di Kota Batu. Hasil pengujian menunjukkan bahwa dengan
menggunakan sistem informasi, penggunaan waktu dan kertas dalam tiap proses perijinan
menjadi lebih efektif dan efisien.
Kata kunci:
sistem, informasi, perijinan, perindustrian, perdagangan, pelayanan.
Pendahuluan
Kemajuan teknologi yang pesat serta meningkatnya harapan konsumen terhadap produk dan jasa merupakan dua diantara banyak faktor yang menciptakan tekanan pada organisasi, termasuk organisasi pemerintahan. Sebagai respon atas tekanan tersebut, organisasi kemudian melakukan usaha peningkatan mutu dan daya saing yang didukung oleh teknologi informasi. Pelayanan perijinan industri dan perdagangan di Kota Batu merupakan salah satu upaya pemerintah dalam menerapkan peraturan di bidang perindustrian dan perdagangan. Pelayanan tersebut mengacu pada standar prosedur operasional perijinan usaha industri dan perdagangan di Kota Batu, namun tidak semua prosedur dilakukan secara komputerisasi. Data pendaftaran semua permohonan masih dicatat dengan menggunakan formulir, data penetapan tiap permohonan disimpan dalam bentuk berkas, data penerbitan ijin dicatat di dalam buku induk dan pembuatan laporan pendirian perusahaan, konsep S.K ijin, surat pemberitahuan, surat penolakan, dan surat perintah membayar keseluruhan diketik dengan menggunakan aplikasi Microsoft Word.
Sistem pelayanan perijinan tersebut kurang efisien karena besarnya jumlah anggaran untuk penyediaan formulir-formulir dan pengarsipan berkas-berkas perijinan serta kurang efektif dalam penelusuran data-data perijinan. Sehingga dibutuhkan suatu sistem
informasi yang dapat mengelola, menyimpan dan menyajikan data perijinan yang sesuai dengan standar prosedur operasional industri dan perdagangan Kota Batu.
C-22 Supriyono (2009) mengembangkan sistem informasi prosedur ijin mendirikan bangunan (IMB) di Kabupaten Kudus. Sistem dikembangkan dengan maksud untuk membantu pemerintahan daerah dalam melakukan pengolahan perijinan mendirikan bangunan. Proses pengolahan perijinan yang dimaksud adalah proses pendataan IMB, proses transaksi pembayaran IMB dan proses penyajian laporan rekapitulasi IMB yang telah dikeluarkan. Sistem yang dihasilkan dalam penelitian ini belum terlihat dengan jelas, karena desain sistem berfokus pada perancangan sistem informasi untuk pengolahan sumber daya air tanah.
Dalam penelitian yang dilakukan oleh Cahyono dan Sarwosari (2010) aplikasi pelayanan informasi perijinan dirancang untuk memberikan pelayanan perijinan kepada pemohon perijinan industri di Kota Surabaya. Sistem yang dikembangkan berbasis web untuk memberikan kemudahan bagi pemohon perijinan industri dalam proses pendaftaran dan keemudahan mengakses informasi status permohonan ijin yang diajukan. Penanganan perijinan industri oleh sistem yang dikembangkan masih terbatas pada ijin tanda daftar industri saja. Selain itu belum terlihat pemanfaatan sistem untuk menangani proses-proses perijinan secara menyeluruh.
Pada penelitian ini dikembangkan sistem informasi perijinan yang menangani Ijin Usaha Perdagangan (IUP), Tanda Daftar Industri (TDI), Ijin Usaha Industri (IUI), dan Ijin Perluasan (IP). Sistem informasi perijinan juga akan menangani keseluruhan proses perijinan yaitu mulai dari proses pendaftaran, penerimaan, penetapan, penerbitan dan pembayaran.
Metodologi Penelitian
Metode penelitian yang digunakan adalah deskriptif dengan pendekatan kualitatif. Wawancara mendalam (in-dept interview) dan pengamatan dilakukan untuk mengidentifikasi permasalah-permasalahan pada proses perijinan dan mengkaji lebih lanjut proses-proses perijinan usaha industri dan perdagangan di Kota Batu.
Dalam penelitian ini, tahapan penelitian yang digunakan diantaranya adalah :
• Proses studi literatur untuk mengumpulkan dan mempelajari dasar pengetahuan tentang hal-hal yang berkaitan dengan proses perijinan usaha industri dan perdagangan,
• Pengumpulan data berupa peraturan-peraturan pemerintahan Kota Batu terkait dengan perijinan usaha industri dan perdagangan,
• Pengumpulan data-data standard operating proocedure (SOP) proses perijinan usaha industri dan perdagangan Kota Batu,
• Wawancara pada pihak Dinas Perindustrian dan Perdagangan Kota Batu,
• Kuisoner dalam bentuk daftar pertanyaan pada pihak Dinas Perindustrian dan Perdagangan Kota Batu,
• Analisis dokumen-dokumen yang telah dikumpulkan,
• Identifikasi fungsi dan prosedur dalam organisasi, • Analisis kebutuhan sistem dengan menggunakan
pemodelan,
• Perancangan sistem, untuk menerjemahkan model sesuai kebutuhan calon pengguna,
• Implementasi model yang telah dirancang ke dalam bahasa pemrograman,
• Menguji coba sistem secara keseluruhan.
Hasil dan Perancangan Sistem
Data Flow Diagram (DFD)
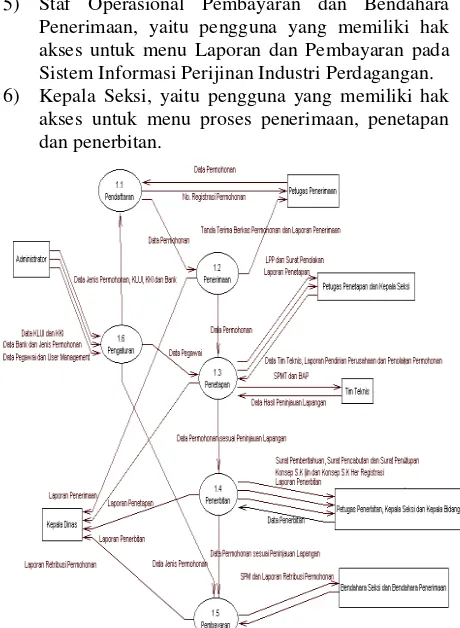
Hasil dari proses analisis kebutuhan sistem maka diperoleh diagram konteks sistem perijinan usaha industri dan perdagangan Kota Batu yang digambarkan pada gambar 1.
Gambar 1. Diagram konteks sistem informasi perijinan usaha induustri dan perdagangan Kota Batu
Berdasarkan gambar 1 diagram konteks ditunjukkan pengguna yang terlibat dalam sistem informasi perijinan ada tujuh pengguna dengan hak akses yang berbeda. Komponen proses bisnis inti pada sistem informasi perijinan usaha industri dan perdagangan diitunjukkan pada DFD level 1 pada gambar 2.
Perancangan Basis Data (Database)
Perancangan basis data untuk sistem perijinan usaha industri dan perdagangan menggunakan beberapa tabel, relasi antar tabel-tabel tersebut diperlihatkan pada gambar 3.
Akses Kontrol
Pembagian kontrol atas hak akses pada sistem informasi perijinan usaha industri dan perdagangan, dibagi menjadi enam hak akses, diantaranya :
1) Administrator Dinas Perindustrian dan Perdagangan, yaitu pengguna yang memiliki hak akses penuh terhadap semua menu pada Sistem Informasi Perijinan Industri Perdagangan.