PENGELOMPOKAN TINGKAT KELULUSAN MAHASISWA
MENGGUNAKAN ALGORITMA K-MEANS
Yulius Palumpun1), Sitti Nur Alam2)
1) Program Studi Sistem Informasi
Fakultas Ilmu Komputer dan Manajemen (FIKOM) - Universitas Sains dan Teknologi Jayapura (USTJ) 2) Program Studi Teknik Informatika STIMIK SEPNOP Jayapura
Email : [email protected]
Abstrak
Masa studi mahasiswa program sarjana biasanya bervariasi antara 3.5 – 7 tahun, demikian juga Indeks Prestasi Komulatif (IPK) lulusan biasanya berada pada range 2.50 – 3.75. Melalui penelitian ini, ingin diketahui apakah ada hubungan antara masa studi dengan IPK kelulusan yang diperolehnya. Ujicoba dilakukan terhadap 171 lulusan dari dua program sarjana di lingkungan Fakultas Ilmu Komputer dan Manajemen (FIKOM) Universitas Sains dan Teknologi Jayapura (USTJ) , yaitu Program Studi (prodi) Teknik Informatika (137 orang) dan Prodi Sistem Informasi (34 orang). Pengelompokan/klaster dilakukan menggunakan Algoritma k-means dengan pengukuran jarak antar data menggunakan Euclidean Distance. Jumlah klaster yang akan dibentuk sebanyak tiga klaster.
Dari hasil klaster diperoleh kesimpulan bahwa lulusan yang memiliki Lama Studi Kurang Tepat Waktu (5 – 6 tahun), memiliki IPK dalam kelompok Baik (3.01 – 3.50). Lulusan yang memiliki Lama Studi Tidak Tepat Waktu (6 – 7 tahun), memiliki IPK dalam kelompok Cukup (2.00 – 2.75) sampai dengan Cukup Baik (2.76 – 3.00). Sedangkan lulusan yang memiliki Lama Studi Tepat Waktu (3 – 4.5 tahun), memiliki IPK dalam kelompok Baik (3.01 – 3.50) dan Sangat Baik (> 3.50).
Kata kunci: IPK, Lama Studi, klaster, k-means, Euclidean Distance
1. Pendahuluan 1.1. Latar Belakang
Lulusan dari dua program sarjana di lingkungan Fakultas Ilmu Komputer dan Manajemen (FIKOM) Universitas Sains dan Teknologi Jayapura (USTJ), yaitu Prodi Teknik Informatika dan Sistem Informasi memiliki lama studi dan IPK kelulusan yang sangat bervariasi. Data dari 171 orang lulusan yang berhasil dikumpulkan menunjukkan masa studi lulusan mulai dari 7 semester (3.5 tahun) sampai dengan 14 semester (7 tahun) yang merupakan batas akhir masa studi untuk program sarjana. Demikian halnya dengan IPK lulusan bervariasi antara 2.40 sampai dengan 3.89.
Dari data tersebut, yaitu data IPK, Lama Studi dan Program Studi dapat dilakukan pengelompokan (klaster) untuk mengetahui kelompok tingkat kelulusan mahasiswa di kedua program studi tersebut di atas.
Analisa klaster adalah metode pengelompokan data/obyek ke dalam klaster sehingga dalam setiap kluster akan berisi data yang semirip mungkin. Artinya dalam suatu proses klasterisasi, suatu obyek yang mirip akan berada dalam klaster yang sama (sedekat mungkin), sedangkan obyek yang tidak mirip akan berada dalam klaster yang berbeda.
Kemiripan suatu obyek dapat dihitung berdasarkan jarak tiap data yang akan diklaster.
Algoritma k-means merupakan salah satu metode pengelompokan data non hirarki yang berusaha mempartisi data ke dalam satu atau lebih kelompok/ kluster. Data yang sama akan dipartisi ke dalam kelompok/klaster sehingga data yang memiliki karakteristik sama dikelompokkan ke dalam satu klaster yang sama [1].
1.2. Rumusan Masalah
Rumusan masalah dari penelitian ini adalah bagaimana melakukan pengelompokan data lulusan berdasarkan IPK, Lama Studi dan Program Studi?
1.3. Tujuan
Tujuan dari penelitian ini adalah melakukan klaster (pengelompokan) data lulusan program sarjana pada Program Studi Teknik Informatika dan Sistem Informasi Fakultas Ilmu Komputer dan Manajemen (FIKOM) Universitas Sains dan Teknologi Jayapura (USTJ). Pengelompokan dilakukan berdasarkan IPK, Lama Studi dan Program Studi.
1.4. Metodologi
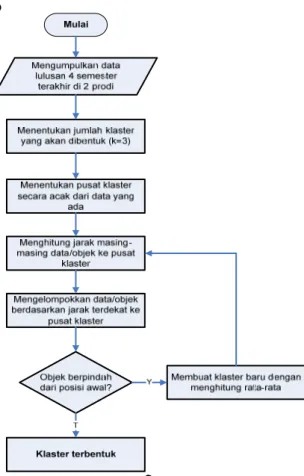
Adapun metodologi penelitian yang digunakan dalam menyelesaikan penelitian ini adalah sebagai berikut:
a. mengumpulkan data yang akan diteliti dari kedua program studi, yaitu Program Studi Teknik Informatika dan Sistem Informasi di lingkungan FIKOM-USTJ, data yang dikumpulkan adalah data mahasiswa lulusan yang berasal dari 4 (empat) semester, mulai dari Semester Ganjil Tahun Akademik 2015/2016 sampai dengan Semester Genap Tahun Akademik 2016/2017; b. melakukan tinjauan pustaka terhadap penelitian
terdahulu yang berkaitan dengan metode klaster menggunakan k-means dan pengukuran jarak menggunakan Euclidean Distance;
c. melakukan kluster terhadap data menggunakan metode k-means, dengan tahapan:
1) menentukan jumlah klaster yang akan dibentuk 2) menginisialisasi pusat (centroid) dari setiap
klaster
3) menghitung jarak objek ke centroid tiap klaster menggunakan Euclidean Distance
4) menghitung mean (rata-rata) tiap klaster untuk membentuk klaster yang baru. Proses pembentukan klaster akan dihentikan jika nilai centroid (pusat kluster) tidak berubah lagi. Jika nilai centroid masih berubah maka iterasi dilakukan kembali pada langkah ke-3
5) untuk melakukan klaster digunakan Software Matlab sebagai tools.
Metodologi penelitian di atas dapat digambarkan dalam bentuk diagram seperti Gambar 1 berikut:
Gambar 1. Metodologi penelitian
1.5. Tinjauan Pustaka dan Landasan Teori
a. Tinjauan Pustaka
Dengan menggunakan metode k-means dan Euclidean Distance dapat dilakukan pengelompokan terhadap mahasiswa berdasarkan nilai Body Mass Index (BMI) dan ukuran rangka. Terhadap 20 data mahasiswa yang dikelompokkan, dibutuhkan sembilan iterasi sampai didapatkan posisi data pada kluster tidak berubah. [2]
Metode k-means juga dapat digunakan pada pengelompokan mahasiswa berdasarkan nilai ujian nasional dan IPK [3]. Berdasarkan penelitian yang dilakukan tersebut 40 sampel, diperoleh kesimpulan bahwa nilai UN tidak menjamin seseorang akan mempunyai IPK yang relatif tinggi.
Metode k-means dapat digunakan pada klasterisasi mahasiswa berdasarkan nilai akademik [4]. Berdasarkan penelitian yang dilakukan dapat diketahui kluster mahasiswa berdasarkan IPK untuk rekomendasi mengikuti lomba.
Metode k-means juga dapat digunakan pada clustering angka melek huruf dan jumlah sekolah dasar [5]. Berdasarkan penelitian tersebut, dilakukan kluster angka melek huruf dan jumlah sekolah dasar di 29 kabupaten/kota di Provinsi Papua.
Metode k-means juga dapat digunakan pada klasifikasi data mahasiswa untuk menunjang pemilihan strategi pemasaran [6]. Pada penelitian ini data yang digunakan sebanyak 402 data (66 mahasiswa D3 dan 336 mahasiswa S1). Hasil penelitian tersebut dapat diketahui kelompok IPK mahasiswa pada tiga wilayah yang diteliti, yaitu: Wilayah DIY-Jateng, Wilayah Jatim-Jabar, dan wilayah luar Jawa.
b. Landasan Teori 1) Algoritma k-means
Algoritma k-means merupakan model centroid. Centroid adalah “titik tengah” suatu cluster. Centroid berupa nilai. Centroid digunakan untuk menghitung jarak suatu objek data terhadap centroid. Suatu objek data termasuk dalam suatu klaster jika memiliki jarak terpendek terhadap centroid cluster tersebut.
Secara umum Algoritma K-Means adalah [1]: a) Tentukan jumlah klaster
b) Alokasikan data ke dalam klaster secara random c) Hitung centroid/rata-rata dari data yang ada di
setiap klaster
d) Alokasikan masing-masing data ke centroid/ rata-rata data terdekat
e) Kembali ke langkah c, apabila masih ada data yang berpindah klaster atau apabila perubahan nilai centroid, ada yang di atas nilai threshold yang ditentukan atau apabila perubahan nilai pada objective function yang digunakan di atas nilai threshold yang ditentukan
2) Pengukuran Jarak
Terdapat beberapa teknik yang dapat digunakan untuk mengukur jarak antar obyek, salah satunya 99
adalah Euclidean Distance seperti ditunjukkan pada Persamaan 1 berikut [3]:
……… (1) Dimana: d = jarak j = banyaknya data c = centroid x = data 2. Pembahasan 2.1. Data Pengujian
Data yang akan digunakan untuk melakukan klasterisasi sebanyak 171 orang lulusan program sarjana yang berasal dari dua program studi. Beberapa karakteristrik dari data yang digunakan adalah sebagai berikut:
a. Dari 171 data lulusan yang digunakan, 137 orang berasal dari Prodi Teknik Informatika dan 34 orang berasal dari Prodi Sistem Informasi.
b. Data yang digunakan merupakan lulusan dari Semester Ganjil Tahun Akademik 2015/2016 sampai dengan Semester Genap Tahun Akademik 2016/2017.
c. Data tahun angkatan (tahun masuk kuliah) lulusan yang digunakan berasal dari tahun 2009 sampai dengan tahun 2013.
d. Data mahasiswa yang digunakan adalah mahasiswa regular (bukan transfer atau pindahan)
e. Data yang digunakan adalah data IPK Lulusan, Lama Studi (tahun) dan Prodi. Data IPK Lulusan ditentukan dalam 4 kelompok, seperti terlihat pada Tabel 1, sedangkan Lama Studi ditentukan dalam 3 kelompok seperti terlihat pada Tabel 2.
Tabel 1. Klasifikasi IPK
IPK Klasifikasi 2.00 – 2.75 Cukup 2.76 – 3.00 Cukup Baik 3.01 – 3.50 Baik > 3.50 Sangat Baik
Tabel 2. Klasifikasi Lama Studi
Lama Studi
(tahun) Klasifikasi
3.0 – 4.5 Tepat Waktu 5.0 – 6.0 Kurang Tepat Waktu 6.5 – 7.0 Tidak Tepat Waktu
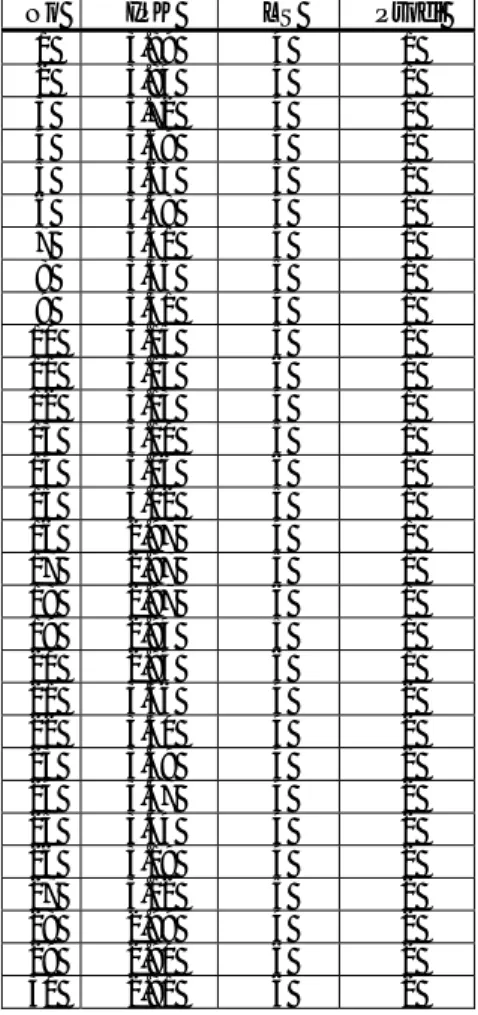
Tabel 3 berikut menampilkan 30 data dari 171 data yang digunakan:
Tabel 3. Sebagiandata lulusan yang digunakan
No IPK LS Prodi 1 3.89 4 1 2 3.84 4 1 3 3.72 4 1 4 3.69 4 1 5 3.63 5 1 6 3.48 4 1 7 3.41 4 1 8 3.35 5 1 9 3.31 4 1 10 3.15 5 1 11 3.15 6 1 12 3.13 4 1 13 3.10 5 1 14 3.06 6 1 15 3.02 5 1 16 2.97 4 1 17 2.97 5 1 18 2.97 6 1 19 2.94 5 1 20 2.94 6 1 21 3.56 4 2 22 3.50 4 2 23 3.49 4 2 24 3.47 4 2 25 3.44 4 2 26 3.19 4 2 27 3.12 5 2 28 2.99 4 2 29 2.90 6 2 30 2.81 6 2
Sumber: Tata Usaha FIKOM-USTJ
Keterangan:
IPK = Indeks Prestasi Komulatif
LS = Lama Studi (tahun)
Prodi = Program Studi (1 = Teknik Informatika, 2 =
Sistem
Informasi)
2.2. Proses Klasterisasi
Proses pembentukan kelompok/klaster dilakukan menggunakan algoritma k-means. Dalam penelitian ini, data akan dikelompokkan menjadi 3 (tiga) kelompok. Adapun langkah-langkah pengelompokan data adalah sebagai berikut:
a. menentukan pusat klaster secara acak dari kumpulan data yang digunakan. Pusat klaster yang digunakan adalah K1 = (3.12, 5, 2); K2 = (2.90, 7, 1); K3 = (3.30, 3.5, 1)
b. menghitung jarak setiap data yang ada (menggunakan Persamaan 1) terhadap setiap pusat klaster. Tabel 4 berikut menampilkan hasil perhitungan jarak (ditampilkan 30 buah data dari 171 data yang digunakan):
Tabel 4. Hasil Perhitungan Jarak
No IPK LS Prodi K1 K2 K3
1 3.89 4 1 1.2621 3.1591 0.7734
2 3.84 4 1 1.2322 3.1438 0.7359
3 3.72 4 1 1.1662 3.1100 0.6530
4 3.69 4 1 1.1510 3.1023 0.6341 5 3.63 5 1 0.5100 2.1291 1.5359 6 3.48 4 1 1.0628 3.0556 0.5314 7 3.41 4 1 1.0412 3.0430 0.5120 8 3.35 5 1 0.2300 2.0500 1.5008 9 3.31 4 1 1.0179 3.0279 0.5001 10 3.15 5 1 0.0300 2.0156 1.5075 11 3.15 6 1 1.0004 1.0308 2.5045 12 3.13 4 1 1.0000 3.0088 0.5281 13 3.10 5 1 0.0200 2.0100 1.5133 14 3.06 6 1 1.0018 1.0127 2.5115 15 3.02 5 1 0.1000 2.0036 1.5259 16 2.97 4 1 1.0112 3.0008 0.5991 17 2.97 5 1 0.1500 2.0012 1.5359 18 2.97 6 1 1.0112 1.0024 2.5217 19 2.94 5 1 0.1800 2.0004 1.5426 20 2.94 6 1 1.0161 1.0008 2.5258 21 3.56 4 2 2.0121 0 3.5228 22 3.50 4 2 1.0239 1.0000 2.5318 23 3.49 4 2 2.0181 0.0500 3.5288 24 3.47 4 2 0.3000 2.0016 1.5749 25 3.44 4 2 2.0321 0.1400 3.5414 26 3.19 4 2 2.0377 0.1700 3.5461 27 3.12 5 2 2.0640 0.2900 3.5674 28 2.99 4 2 2.0665 0.3000 3.5693 29 2.90 6 2 2.0716 0.3200 3.5733 30 2.81 6 2 2.0716 0.3200 3.5733 Keterangan:
K1: klaster 1; K2 : klaster 2; K3 : klaster 3 c. Suatu data akan menjadi anggota dari suatu
klaster/ kelompok yang memiliki jarak terdekat dari pusat klasternya. Posisi klaster yang diperoleh berdasarkan Tabel 5 adalah:
Tabel 5. Letak kluster berdasarkan iterasi pertama
No. IPK LS Prodi K1 K2 K3
1 1.2621 3.1591 0.7734 * 2 1.2322 3.1438 0.7359 * 3 1.1662 3.1100 0.6530 * 4 1.1510 3.1023 0.6341 * 5 0.5100 2.1291 1.5359 * 6 1.0628 3.0556 0.5314 * 7 1.0412 3.0430 0.5120 * 8 0.2300 2.0500 1.5008 * 9 1.0179 3.0279 0.5001 * 10 0.0300 2.0156 1.5075 * 11 1.0004 1.0308 2.5045 * 12 1.0000 3.0088 0.5281 * 13 0.0200 2.0100 1.5133 * 14 1.0018 1.0127 2.5115 * 15 0.1000 2.0036 1.5259 * 16 1.0112 3.0008 0.5991 * 17 0.1500 2.0012 1.5359 * 18 1.0112 1.0024 2.5217 * 19 0.1800 2.0004 1.5426 * 20 1.0161 1.0008 2.5258 * 21 2.0121 0 3.5228 * 22 1.0239 1.0000 2.5318 * 23 2.0181 0.0500 3.5288 * 24 0.3000 2.0016 1.5749 * 25 2.0321 0.1400 3.5414 * 26 2.0377 0.1700 3.5461 * 27 2.0640 0.2900 3.5674 * 28 2.0665 0.3000 3.5693 * 29 2.0716 0.3200 3.5733 * 30 2.0716 0.3200 3.5733 *
d. Berdasarkan hasil klaster iterasi pertama seperti ditunjukkan pada Tabel 5, diketahui klaster baru yaitu K1(3.0634, 4.9375, 1.1429), K2(2.7092, 6.6224, 1.2449), K3(3.3359, 3.8864, 1.2121).
Klaster baru dibentuk dari rata-rata objek pada masing-masing klaster.
e. Proses pengelompokan data dilakukan sampai dengan posisi klaster data tidak mengulangi perubahan.
Berikut ditunjukkan perubahan letak klaster pada beberapa iterasi:
Tabel 6. Letak klaster berdasarkan iterasi kedua
No. IPK LS Prodi K1 K2 K3
1 3.89 4 1 * 2 3.84 4 1 * 3 3.72 4 1 * 4 3.69 4 1 * 5 3.63 5 1 * 6 3.48 4 1 * 7 3.41 4 1 * 8 3.35 5 1 * 9 3.31 4 1 * 10 3.15 5 1 * 11 3.15 6 1 * 12 3.13 4 1 * 13 3.10 5 1 * 14 3.06 6 1 * 15 3.02 5 1 * 16 2.97 4 1 * 17 2.97 5 1 * 18 2.97 6 1 * 19 2.94 5 1 * 20 2.94 6 1 * 21 3.56 4 2 * 22 3.50 4 2 * 23 3.49 4 2 * 24 3.47 4 2 * 25 3.44 4 2 * 26 3.19 4 2 * 27 3.12 5 2 * 28 2.99 4 2 * 29 2.90 6 2 * 30 2.81 6 2 *
Tabel 7. Letak klaster berdasarkan iterasi ketiga
No. IPK LS Prodi K1 K2 K3
1 3.89 4 1 * 2 3.84 4 1 * 3 3.72 4 1 * 4 3.69 4 1 * 5 3.63 5 1 * 6 3.48 4 1 * 101
7 3.41 4 1 * 8 3.35 5 1 * 9 3.31 4 1 * 10 3.15 5 1 * 11 3.15 6 1 * 12 3.13 4 1 * 13 3.10 5 1 * 14 3.06 6 1 * 15 3.02 5 1 * 16 2.97 4 1 * 17 2.97 5 1 * 18 2.97 6 1 * 19 2.94 5 1 * 20 2.94 6 1 * 21 3.56 4 2 * 22 3.50 4 2 * 23 3.49 4 2 * 24 3.47 4 2 * 25 3.44 4 2 * 26 3.19 4 2 * 27 3.12 5 2 * 28 2.99 4 2 * 29 2.90 6 2 * 30 2.81 6 2 *
Tabel 8. Letak klaster berdasarkan iterasi keempat
No. IPK LS Prodi K1 K2 K3
1 3.89 4 1 * 2 3.84 4 1 * 3 3.72 4 1 * 4 3.69 4 1 * 5 3.63 5 1 * 6 3.48 4 1 * 7 3.41 4 1 * 8 3.35 5 1 * 9 3.31 4 1 * 10 3.15 5 1 * 11 3.15 6 1 * 12 3.13 4 1 * 13 3.10 5 1 * 14 3.06 6 1 * 15 3.02 5 1 * 16 2.97 4 1 * 17 2.97 5 1 * 18 2.97 6 1 * 19 2.94 5 1 * 20 2.94 6 1 * 21 3.56 4 2 * 22 3.50 4 2 * 23 3.49 4 2 * 24 3.47 4 2 * 25 3.44 4 2 * 26 3.19 4 2 * 27 3.12 5 2 * 28 2.99 4 2 * 29 2.90 6 2 * 30 2.81 6 2 * 2.3. Hasil Pengujian
Sampai dengan iterasi ke-4, posisi kluster untuk 171 data yang diuji tidak mengalami perubahan posisi. Jumlah data pada masing-masing kluster terlihat pada Tabel 9 berikut:
Tabel 9. Jumlah data pada masing-masing kluster
Kluster Jumlah Data
Kluster Pertama (K1) 53 data Kluster Kedua (K2) 52 data Kluster Ketiga (K3) 66 data
3. Kesimpulan
Dari hasil klasterisasi yang diperoleh, yaitu K1=53 data, K2=52 data dan K3=66 data, dapat diambil beberapa kesimpulan sebagai berikut:
a. Pada klaster pertama (K1), lulusan memiliki Lama Studi Kurang Tepat Waktu (5 – 6 tahun), dengan IPK dalam kelompok Baik (3.01 – 3.50). Hal ini dapat diartikan bahwa mereka yang memiliki Lama Studi Kurang Tepat Waktu (berdasarkan pengelompokan Tabel 2), memiliki IPK dalam kelompok Baik (berdasarkan pengelompokan pada Tabel 1).
b. Pada klaster kedua (K2), rata-rata lulusan memiliki Lama Studi Tidak Tepat Waktu (6 – 7 tahun), dengan IPK dalam kelompok Cukup (2.00 – 2.75) sampai dengan Cukup Baik (2.76 – 3.00). Hal ini dapat diartikan bahwa mereka yang memiliki Lama Studi Tidak Tepat Waktu, cenderung memiliki IPK yang hanya berada pada kelompok Cukup sampai dengan Cukup Baik.
c. Pada klaster ketiga (K3), lulusan memiliki Lama Studi Tepat Waktu (3 – 4.5 tahun), dengan IPK dalam kelompok Baik (3.01 – 3.50) dan Sangat Baik (> 3.50). Hal ini dapat diartikan bahwa mereka yang memiliki Lama Studi Tepat Waktu, cenderung memiliki IPK yang Baik dan Sangat Baik.
Daftar Pustaka
[1] Agusta Yudi, 2007, “K-Means-Penerapan, Permasalahan, dan Metode Terkait” Jurnal Sistem dan Informatika Vol. 3, Hal. 47-60
[2] Rismawan Tedy, Kusumadewi Sri, 2008, “Aplikasi K-Means Untuk Pengelompokan Mahasiswa Berdasarkan Nilai Body Mass (BMI) dan Ukuran Kerangka”, Seminar Nasional Aplikasi Teknologi Informasi (SNATI 2008), ISSN: 1907-5022, Yogyakrta
[3] Hartatik, 2014, “Pengelompokan Mahasiswa Berdasarkan Nilai Ujian Nasional dan IPK Menggunakan Metode K-Means, Seminar Nasional Informatika
[4] Asroni, Ronald Adrian, 2015, “Penerapan Metode K-Means Untuk Clustering Mahasiswa Berdasarkan Nilai Akademik Dengan Weka Interface Studi Kasus Pada Jurusan Teknik Informatika UMM Magelang”, Jurnal Ilmiah Semesta Teknika, Vol. 18, No. 1, Hal. 76-82
[5] Alam Sitti Nur, Palumpun Yulius, 2014, “Penerapan Algoritma K-Means Untuk Pengelompokan Angka Melek Huruf dan Jumlah Sekolah Dasar di Provinsi Papua”, Konferensi Nasional Ilmu Komputer (KONIK)
[6] Suprawoto Totok, 2016, “Klasifikasi Data Mahasiswa Menggunakan Metode K-Means Untuk Menunjang Pemilihan Strategi Pemasaran, Jurnal Informatika dan Komputer (JIKO), Vol. 1, No. 1