BAB II
DASAR TEORI & STUDI LITERATUR
Pada Bab ini, akan dibahas hasil studi literatur maupun eksplorasi yang akan dipakai untuk merancang sebuah sistem penilaian source code otomatis. Studi literatur mencakup penjelasan mengenai Computer Aided Assessment, dan metodologi penilaian source code. Teori yang digunakan dalam Tugas Akhir ini adalah mengenai pemrosesan source code.
2.1 Computer Aided Assessment (CAA)
Pada Subbab ini akan dibahas mengenai Computer Aided Assessment (CAA) secara umum, sistem penilaian yang terotomasi dan berbagai format penerapannya dalam lingkungan ilmu komputer, khususnya pada mata kuliah yang berhubungan dengan pemrograman.
2.1.1 Ikhtisar CAA
Perkembangan Teknologi Informasi dan Komunikasi (TIK) telah membuka peluang-peluang aktivitas pembelajaran baru, salah satunya ialah Computer Aided Assessment. Computer Aided Assessment (CAA), atau yang sering disebut juga e-assessment, secara umum didefinisikan sebagai proses-proses penilaian elektronik yang didukung oleh TIK [JIS06]. Perangkat lunak CAA telah digunakan untuk melakukan otomasi terhadap aspek-aspek tertentu dari penilaian, yang dikategorikan secara luas sebagai perangkat penyampaian, pemberian nilai, dan analisis hasil penilaian [RAW02]. Walaupun demikian, definisi CAA di dalam Tugas Akhir ini akan dibatasi secara lebih spesifik untuk sistem komputer berperan dalam melakukan pemberian nilai, baik secara utuh maupun parsial [CAR03].
Sistem penilaian manual yang bersifat subjektif, di mana nilai yang diberikan relatif terhadap individu penilai. Pengujian CAA tetap dapat digunakan dalam berbagai konteks, termasuk tes diagnostik, ujian untuk menentukan tingkat pengetahuan mahasiswa pada sebuah subjek khusus; uji mandiri (self-assessment); ujian formatif, yaitu ujian yang berguna sebagai umpan balik konstruktif sehingga mahasiswa dapat merencanakan studinya dengan lebih baik; ujian sumatif, yaitu ujian untuk mengukur proses belajar siswa secara keseluruhan [JIS06]; serta ujian adaptif, yaitu ujian dengan persoalan yang diberikan bergantung pada jawaban dari pertanyaan sebelumnya [RAW02].
Penggunaan CAA dapat secara dramatis menampakkan peningkatan jumlah, kualitas dan variasi umpan balik, di samping menjadi alat bantu uji baru. Umpan balik merupakan komponen penting dalam proses pembelajaran baik bagi mahasiswa (dalam bentuk nilai, petunjuk, pujian, bimbingan) maupun bagi instruktur (dalam bentuk statistik nilai dan soal, laporan). Keuntungan lain yang didapatkan antara lain yaitu perbaikan kecepatan umpan balik, meningkatkan konsistensi dengan meminimalisasi subjektivitas dan human error, serta ketersediaan selama 24 jam sehari. Alat bantu yang fleksibel seperti ini dapat mendukung kebutuhan dan kebiasaan belajar mahasiswa yang amat beragam. Tools CAA yang diimplementasikan dengan baik akan membuat pengajar terbebas dari penilaian manual yang sangat memakan waktu, sehingga ia memiliki lebih banyak waktu untuk kegiatan perancangan pendidikan dan pengujian yang lebih baik. Penilaian dalam format digital juga memungkinkan para instruktur untuk menggunakan ulang dan berbagi resource, misalnya dengan menggunakan bank soal.
CAA juga memiliki keterbatasan dan kekurangan tersendiri. Proses pembangunan sistem penilaian otomatis membutuhkan waktu lebih lama daripada pengembangan sistem evaluasi tradisional. Proses perancangan sistem juga harus dilakukan dengan hati-hati, karena kesalahan pada desain atau masalah teknis dapat membuat sistem penilaian otomatis tidak bekerja sebagaimana mestinya. Permasalahan pada sistem penilaian otomatis dapat menyebabkan hambatan belajar dan demotivasi pada siswa, khususnya jika ketergantungan pada sistem berbasis komputer amat tinggi. Keterkaitan erat antara penilaian dan proses belajar ini juga menyebabkan sistem penilaian otomatis harus memiliki reliabilitas dan keamanan yang baik.
2.1.2 Penggunaan CAA untuk Pengajaran Pemrograman
CAA telah digunakan untuk melakukan penilaian dalam bidang pemrograman sejak tahun 1961 [FOR65]. Selama empat dekade berikutnya, telah terjadi banyak perkembangan dalam penggunaan sistem komputer untuk penilaian, bukan hanya dalam bidang pemrograman saja. Banyak format CAA telah dikembangkan untuk melakukan penilaian pada subjek apapun, seperti pilihan ganda atau esai. Sistem-sistem penilaian otomatis juga telah banyak dikembangkan untuk disiplin ilmu yang lain [BON02, CAR03]. Pada Tabel II-1 dapat dilihat beberapa format CAA yang telah digunakan pada topik-topik informatika, beserta dengan proses penilaian dan tingkatan kognitif dalam Taksonomi Bloom yang dapat diujinya.
Tabel II-1 Format Ujian dengan Bantuan Sistem Komputer [CAR03]
Format Ujian Format Jawaban Metode Penilaian Tingkatan Kognitif Pilihan Ganda /
Multiple Choice Question (MCQ)
Pilihan tunggal (choice) dari beberapa opsi (option) yang tersedia
Pencocokan pilihan terhadap solusi yang disediakan perancang soal.
Pengetahuan Pemahaman
(Dengan rancangan soal khusus dapat digunakan untuk level yang lebih tinggi)
Jawaban Tekstual / Textual Answer
Teks pendek atau esai pendek sesuai dengan permintaan soal. Pencocokan string menggunakan regular expression, penilaian menggunakan Natural Language Processing [MAS02, ALF05] Pengetahuan Pemahaman
(Dengan rancangan soal khusus dapat digunakan untuk level yang lebih tinggi)
Tugas Pemrograman / Programming Assignment
Source code utuh (seluruh program) atau sebagian (fungsi atau prosedur tertentu saja)
Pengujian program menggunakan data uji tertentu (pengujian dinamis), analisis source code Aplikasi Analisis Sintesis Jawaban Visual / Visual Answer
Berbagai jenis diagram : diagram alir, diagram rancangan PL [SYM01]
Perbandingan diagram jawaban siswa dengan diagram solusi yang disediakan perancang soal [SYM01] Pemahaman Aplikasi Penilaian Rekan / Peer Assessment Penilaian/komentar terhadap hasil kerja rekan setingkat Perbandingan penilaian instruktur terhadap penilaian yang dilakukan siswa Analisis Evaluasi
Pada Tugas Akhir ini, secara khusus akan dibahas tentang CAA untuk menilai keterampilan pemrograman siswa melalui tugas berupa source code. Evaluasi tugas berupa kode program menggunakan komputer bersifat unik, karena tidak seperti esai, kode program memiliki struktur dan semantik yang jelas. Proses penilaian terhadap source code akan dibahas lebih lanjut pada bab 2.2. Beberapa sistem CAA untuk penilaian tugas source code yang sudah ada telah dieksplorasi dan akan dibahas pada Subbab 2.1.3.
2.1.3 Implementasi CAA dalam Bentuk Source Code Autograder
Perangkat lunak CAA menilai source code telah banyak dikembangkan. Pada Subbab ini akan dibahas deskripsi umum sistem dan kekuatan serta kelemahan dari beberapa autograder yang memiliki keunggulan atau karakteristik tertentu. ASSYST merupakan autograder pertama dengan skema penilaian intensif. CourseMaster merupakan sistem pengumpulan tugas ekstensif yang telah dikembangkan dan diuji selama lebih dari 15 tahun. GAME merupakan program penilai otomatis yang dirancang dengan karakteristik utama generik. Mooshak merupakan sistem khusus yang dikembangkan untuk menangani kompetisi pemrograman. Hasil eksplorasi aplikasi autograder yang sudah ada ini digunakan sebagai dasar analisis dan perancangan autograder dalam Tugas Akhir ini.
2.1.3.1 ASSYST
ASSYST (Assessment System) merupakan alat bantu penilai otomatis yang dikembangkan oleh Jackson dan Usher [JAC97] di Universitas Liverpool pada akhir 1990-an. ASSYST berjalan pada sistem operasi Unix, dan digunakan untuk menilai program dalam bahasa Ada. Sistem ASSYST juga mampu menangani pengumpulan tugas, membangkitkan laporan, dan memungkinkan pembobotan variabel pada berbagai aspek penilaian. Kontribusi terbesar ASSYST yaitu sistem ini memperkenalkan konsep bahwa pengujian program yang diotomatisasi dapat juga digunakan sebagai perangkat pembantu penilaian secara penuh. ASSYST merupakan sistem autograder pertama yang menggunakan skema penilaian yang lebih rumit dari sekadar pengujian dinamis.
Penilaian yang dilakukan dalam ASSYST mencakup berbagai aspek sebagaimana dapat dilihat pada Gambar II-2, yaitu kebenaran program, efisiensi, gaya, kompleksitas, dan kelengkapan data uji. Efisiensi diukur dari jumlah siklus CPU yang digunakan dan melalui analisis statik program untuk menghitung jumlah statement yang dieksekusi. Kompleksitas diukur menggunakan besaran kompleksitas McCabe, yang dijelaskan lebih lanjut pada bagian LAMPIRAN A. Gaya penulisan kode diukur menggunakan besaran gaya penulisan kode C oleh Berry dan Meeking [JAC97] yang diadaptasi ke dalam bahasa Ada, yang antara lain mencakup indentasi, jumlah komentar, dan panjang modul. Kelengkapan data tes diukur dengan menggunakan besaran Test Effectiveness Ratio1 (TER1) yang membandingkan jumlah pernyataan yang dieksekusi paling tidak satu kali dengan jumlah seluruh pernyataan dalam program.
ASSYST merupakan sebuah sistem yang bersifat mainframe-centric [BLU04] serta hanya menangani bahasa pemrograman Ada dan C [JAC97]. Mengingat bahwa terdapat kebutuhan akan penanganan terhadap berbagai bahasa pemrograman sekaligus dan implementasi yang memanfaatkan arsitektur terdistribusi dari jaringan komputer dan internet, terbuka kemungkinan untuk mengembangkan sistem baru dengan memperhatikan kebutuhan-kebutuhan ini.
2.1.3.2 CourseMaster
CourseMaster adalah sebuah sistem yang dibangun menggunakan Java dengan arsitektur client-server untuk memfasilitasi mata kuliah yang berbasis pada latihan-latihan pemrograman atau pembuatan diagram [SYM01, ZIN91]. CourseMaster dikembangkan oleh peneliti dan instruktur pada Departemen Ilmu Komputer Universitas Nottingham, Inggris, dirilis pertama kali pada tahun 1998. Perangkat lunak ini dibuat untuk memberikan spesifikasi program, memberi siswa kesempatan untuk membuat program dan mengirimkannya, serta melakukan penilaian otomatis dan memonitor respon dari siswa.
CourseMaster merupakan pengembangan dari sistem penyerahan tugas sebelumnya, Ceilidh, yang telah diujicobakan dan beroperasi sejak tahun 1988. Sistem ini tangguh dan mudah digunakan, khususnya untuk para siswa. Instruktur dapat melihat berbagai statistik tugas yang dikumpulkan oleh siswa. Proses penilaian yang dapat dilakukan CourseMaster amat fleksibel. CourseMaster dapat digunakan dalam berbagai mode konfigurasi, dan menyediakan berbagai antarmuka untuk akses. Semua aspek implementasinya telah dipikirkan secara menyeluruh, dan secara khusus, keamanannya sangat baik [RAW02].
CourseMaster merupakan sebuah paket perangkat lunak yang lengkap, yang dapat di-deploy dengan berbagai konfigurasi. Arsitektur umum CourseMaster dapat dilihat pada Gambar II-1. Dengan menggunakan platform Java, subsistem Client Layer berinteraksi dengan modul-modul lainnya memanfaatkan fitur RMI (Remote Method Invocation). Penilaian program dilakukan oleh subsistem Marking, yang hanya berhubungan dengan subsistem Submission.
CourseMaster dapat digunakan untuk menilai program dalam bahasa C++ dan Java, serta diagram alir dan diagram desain OO. Ketika pendahulunya, Ceilidh, dikembangkan untuk menangani mata kuliah pemrograman dalam bahasa C dan C++, sistem ini banyak dikembangkan oleh universitas lain untuk menangani berbagai bahasa pemrograman, seperti Pascal, Ada, Fortran, SQL, dan Prolog [SYM01].
Gambar II-2 Arsitektur Umum CourseMaster [SYM01]
CourseMaster bukan merupakan perangkat lunak open source – untuk menggunakannya dikenakan biaya, dan biaya tambahan dibebankan apabila pengguna ingin memperoleh kode program dan memodifikasinya Mengingat adanya kebutuhan untuk melakukan penilaian secara generik terhadap bahasa-bahasa di luar C, C++ atau Java dan implementasi autograder yang terdistribusi dan bersifat open source, maka terbuka peluang untuk mengembangkan sistem baru yang memperhatikan kebutuhan-kebutuhan ini.
2.1.3.3 GAME
GAME (Generic Automated Marking Environment) adalah perangkat lunak CAA yang diimplementasikan dalam bahasa Java untuk menilai tugas kode dalam berbagai bahasa pemrograman [BLU04]. GAME dikembangkan oleh Sekolah Teknologi Informasi Universitas Griffith, Australia, sejak tahun 2002. GAME dikembangkan pada JDK 1.4.1, dan dibangun atas dasar sistem yang sebelumnya digunakan untuk menilai tugas-tugas pemrograman dalam bahasa C (C-Marker). Perangkat lunak ini dirancang untuk mengatasi kekurangan-kekurangan yang ada pada sistem C-Marker dan sistem lain yang sudah ada. Modul deteksi plagiarisme yang diadaptasi dari sistem terdahulu masih belum aktif, namun direncanakan sebagai bagian integral di masa depan. Tujuan jangka panjang dari GAME adalah untuk membuat sistem ini dapat diakses oleh mahasiswa agar dapat menilai/memverifikasi tugas mereka sendiri. Sistem GAME dikembangkan untuk menangani tugas dalam berbagai bahasa pemrograman yang berbeda dengan beragam
tipe/jenis dan strategi penilaian. Sistem GAME juga mampu menangani source code yang terbagi dalam beberapa file, dan meninjau struktur source code secara akurat.
GAME, sebagaimana dapat dilihat pada Gambar II-3, terdiri dari beberapa subsistem: Analisis Struktural (menilai aspek tipografis dari program, yaitu komentar, indentasi, dan gaya pemrograman), Eksekusi Program, Analisis Keluaran, serta Deteksi Plagiarisme – yang masih belum dioperasikan. Sistem dibangun sebagai sebuah aplikasi web CGI (Common Gateway Interface), dengan antarmuka pengguna berupa web browser. Secara umum, GAME merupakan sistem yang mengintegrasikan penanganan berbagai bahasa pemrograman dengan jenis tugas dan skema penilaian yang dapat dikonfigurasi, karena sistem ini memang dikembangkan sebagai sebuah sistem penilaian generik. Namun, GAME masih terbatas pada bahasa C, C++ dan Java. Selain itu, sistem GAME juga relatif muda dan belum menganalisis mengenai permasalahan keamanan, skalabilitas dan reliabilitas.
Gambar II-3 Arsitektur Umum GAME [BLU04]
Meskipun GAME telah beroperasi dan teruji pada lingkungan Universitas Griffith dan dipresentasikan di dalam beberapa makalah, perangkat lunak ini tidak dipublikasikan pada umum. Sejauh ini penggunaan GAME masih terbatas pada perguruan tinggi pengembangnya saja. Kebutuhan untuk melakukan penilaian secara generik terhadap bahasa-bahasa di luar C, C++ atau Java dan implementasi autograder yang terdistribusi serta bersifat open source juga belum dipenuhi oleh GAME maka terbuka kemungkinan untuk mengembangkan sistem baru dengan memperhatikan kebutuhan-kebutuhan ini.
2.1.3.4 Mooshak
Mooshak adalah sebuah sistem berbasis web yang dikembangkan oleh Universitas Porto untuk menangani kegiatan kompetisi pemrograman bertaraf internasional [LEA03]. Fitur utama Mooshak adalah penjurian otomatis untuk menunjang proses penilaian program oleh juri manusia. Penyelenggaraan kompetisi juga ditunjang oleh fitur manajemen persoalan dan pengguna, dengan antarmuka dan tingkatan akses khusus untuk administrator, juri, peserta dan publik. Selain pengamanan untuk mencegah peserta menimbulkan gangguan pada sistem, Mooshak juga memiliki sistem manajemen dan recovery data yang tangguh menggunakan objek persisten. Arsitektur sistem yang bersifat skalabel memungkinkan Mooshak menangani mulai dari kontes sederhana dengan server tunggal hingga kontes multiserver kompleks.
Sistem ini dikembangkan secara open source di atas sistem operasi Linux dengan menggunakan server HTTP Apache dan bahasa pemrograman Tcl. Mooshak mampu menangani source code dalam berbagai bahasa pemrograman, khususnya yang sering digunakan dalam kompetisi pemrograman: C, C++, Java dan Pascal. Bahasa pemrograman jamak ditangani dengan menggunakan kompilator-kompilator eksternal yang telah terdefinisi pada sistem.
Hasil yang dikeluarkan oleh juri otomatis hanya berupa kategori-kategori seperti pada Tabel II-2, sehingga laporan yang dapat diberikan oleh sistem kepada peserta sangat terbatas. Siswa yang baru belajar membuat program membutuhkan umpan balik yang jauh lebih mendetil terutama saat terjadi kesalahan. Mooshak memang tidak dikembangkan untuk digunakan dalam kelas pemrograman, namun aspek reliabilitas dan keamanan yang amat baik membuatnya menarik untuk dibahas dalam Tugas Akhir ini.
Tabel II-2 Kategori Hasil Evaluasi pada Mooshak [MOO08]
Hasil Penjurian Arti
Accepted Program telah berhasil lulus semua kasus uji dan diterima
Presentation error Keluaran program tampak hampir benar namun tidak diformat sesuai spesifikasi yang diminta dalam persoalan
Wrong answer Program menghasilkan keluaran yang tidak sesuai dengan hasil yang diminta pada satu kasus uji atau lebih.
Time limit exceeded Program tidak selesai dieksekusi dalam batas waktu yang diminta Runtime error Program mengalami crash pada saat eksekusi
Compile time error Kompilator gagal menghasilkan program dari source code yang diberikan peserta
Invalid submission Submisi source code tidak lengkap atau tidak memenuhi kriteria yang diminta
Output too long Keluaran yang dihasilkan program melebihi batas yang ditetapkan Program too long Ukuran source code melebihi batas yang ditetapkan
Requires re-evaluation Program harus dievaluasi ulang karena alasan tertentu
Contest rule evaluation Program melanggar aturan kompetisi, misalnya karena menggunakan library nonstandar.
2.2 Metodologi Penilaian Program
Pada Subbab ini akan dibahas mengenai pendekatan penilaian otomatis terhadap source code program dalam konteks akademik. Proses penilaian yang dibahas akan didasarkan pada proses penilaian secara manual pada program Sarjana Teknik Informatika Institut Teknologi Bandung (S1-IF-ITB) dan proses proses penilaian otomatis sebagaimana telah dilakukan oleh aplikasi-aplikasi yang telah dibahas pada Subbab 2.1.3.
Sebuah program dapat dinilai menggunakan dua pendekatan : pendekatan blackbox dan pendekatan whitebox. Pada pendekatan blackbox, sebuah program dianggap sebagai “kotak hitam” yang dinilai hanya menggunakan masukan dan keluaran program tersebut. Pada pendekatan whitebox, sebuah program dinilai berdasarkan kualitas intrinsik dari program tersebut. Penilaian program dapat dilakukan menggunakan salah satu pendekatan atau kombinasi dari keduanya. Pendekatan blackbox akan dibahas secara lebih jauh pada Subbab 2.2.1, sementara pendekatan whitebox akan dibahas lebih jauh pada Subbab 2.2.2.
2.2.1 Pendekatan Blackbox
Sebuah program adalah sebuah spesifikasi untuk proses komputasi [AAB04]. Dengan kata lain, program komputer dibuat supaya komputer dapat melakukan komputasi untuk memenuhi tujuan tertentu. Oleh karena itu, sebuah program dikatakan tepat (correct) apabila komputasi yang dilakukan program tersebut sesuai dengan tujuan pembuatannya. Penilaian terhadap sebuah program pertama-tama dilakukan terhadap ketepatannya, karena program yang tidak tepat dapat dikatakan gagal memenuhi tujuannya. Ketepatan program, baik secara sintaks maupun semantik, akan dibahas dalam Subbab 2.2.1.1.
Penilaian terhadap ketepatan program dapat dilakukan oleh penilai manusia dengan langsung menginterpretasikan source code sebagai program secara abstrak. Seorang penilai manusia dapat menentukan benar tidaknya suatu program dengan membaca source code program dan mengeksekusi program tersebut dalam pikirannya. Keterbatasan penilaian langsung ini adalah bahwa penilai manusia hanya mampu menangani program dengan kompleksitas dan ukuran source code hingga tingkat tertentu. Keterbatasan dalam proses pembuktian ketepatan program ini kemudian melatarbelakangi pendekatan penilaian blackbox.
Dalam pendekatan penilaian blackbox, sebuah program akan dianggap sebagai “kotak hitam” dan benar tidaknya program ditentukan dari hasil eksekusinya saja. Penilai akan memroses source code menggunakan kompilator atau interpreter, memberikan masukan tertentu dan kemudian mengamati hasil keluaran program tersebut. Jika keluaran yang dihasilkan oleh program sesuai dengan keluaran yang diharapkan oleh penilai, maka program dinyatakan benar. Pendekatan blackbox merupakan cara yang paling sederhana untuk menilai ketepatan program dan dapat diotomasikan dengan mudah. Pendekatan ini diterapkan sejak proses penilaian otomatis pertama diimplementasikan [FOR65]. Sistem penilai program otomatis hingga saat ini juga menggunakan pendekatan ini [JAC97,SYM01,BLU04,MOR07] sebagaimana halnya sistem penjurian untuk kompetisi pemrograman [IOI06, MOO08].
Dalam pendekatan blackbox, proses penilaian dilakukan dalam dua tahap, tahap analisis statik dan tahap analisis dinamik. Dalam tahap analisis statik, source code program diubah ke dalam format siap eksekusi menggunakan kompilator atau interpreter. Dalam tahap analisis dinamik, program dieksekusi, diberi masukan dan kemudian keluaran yang dihasilkannya diperiksa. Proses analisis statik akan dibahas dalam Subbab 2.2.1.2 dan proses analisis dinamik akan dibahas dalam Subbab 2.2.1.3. Proses analisis statik dan pengujian dinamik yang dijelaskan pada bagian ini merupakan pengujian yang dilakukan oleh subsistem penilai otomatis analyze pada aplikasi CourseMaster [ZIN91] dan Mooshak [MOO08].
2.2.1.1 Ketepatan Sintaks & Semantik
Setiap kode program pada dasarnya terikat pada aturan sintaks dan semantik bahasa pemrograman yang digunakan untuk menulisnya [WAT90]. Source code yang memiliki kesalahan semantik tidak akan menghasilkan eksekusi program yang benar, sementara source code yang memiliki kesalahan sintaks tidak akan dapat menghasilkan program yang dapat dieksekusi sama sekali.
Sintaks sebuah bahasa pemrograman mendefinisikan hubungan formal antara komponen-komponennya, menyediakan deskripsi struktural tentang kalimat-kalimat yang legal bahasa tersebut [SLO95]. Aturan-aturan sintaks / tata bahasa (grammar) dalam sebuah bahasa pemrograman menyediakan cara agar source code dapat ditranslasikan dan kemudian dieksekusi oleh sistem komputer. Kesalahan sintaks pada source code akan menyebabkan kegagalan proses translasi, dan dengan demikian tidak akan dihasilkan program yang dapat dieksekusi. Proses analisis sintaks akan dibahas secara lebih mendalam pada Subbab 2.3.3.2.
Semantik bahasa pemrograman menggambarkan hubungan antara bentuk sintaks tertentu dengan model komputasinya, sedangkan semantik sebuah program merupakan cara untuk memahami atau menginterpretasikan program tersebut dan memprediksi hasil eksekusinya [AAB04]. Beberapa teknik penjabaran semantik program yang lazim digunakan tercantum pada Tabel II-3.
Tabel II-3 Teknik Penjabaran Semantik Program [AAB04] Teknik Penjabaran Semantik Deskripsi Semantik
Semantik Aljabar / Algebraic Semantics
Menggunakan persamaan-persamaan aljabar untuk menggambarkan hubungan antar elemen sintaksis dalam sebuah bahasa
Semantik Aksiomatis / Axiomatic Semantics
Menggunakan aksioma dan aturan-aturan inferensi untuk menggambarkan sifat-sifat program. Tidak menggambarkan bagaimana eksekusi program, melainkan hanya mendefinisikan arti program melalui asersi prakondisi dan pascakondisi.
Semantik Denotasional / Denotational Semantics
Menggunakan objek matematis (biasanya berupa fungsi) untuk menentukan perhitungan yang dilakukan oleh program. Semantik Operasional /
Operational Semantics
Menggunakan transformasi sintaksis atau fungsi rekursif untuk menirukan proses eksekusi program pada mesin abstrak.
Teknik penjabaran semantik yang paling sering digunakan oleh pemrogram dan perancang perangkat lunak adalah semantik aksiomatis, karena dengan teknik ini dapat diturunkan pembuktian kebenaran program. Semantik aksiomatis juga dapat digunakan untuk mengembangkan algoritma yang bebas cacat (bug free) dan membangkitkan kode program secara otomatis berdasarkan spesifikasi yang diberikan [SLO95]. Topik semantik aksiomatis dirintis oleh C.A.R. Hoare pada tahun 1969 [HOA69], di mana semantik program digambarkan menggunakan notasi sebagai berikut:
{P} c {R}
dengan
PÆ asersi prakondisi; asumsi dan kondisi awal yang ada saat perintah akan dieksekusi cÆ perintah yang dieksekusi
RÆ asersi pascakondisi; mencerminkan hasil komputasi yang diharapkan
Notasi di atas diartikan “jika perintah c dieksekusi dengan memenuhi kondisi yang menyebabkan
P bernilai benar (true) dan perintah c dapat mencapai terminasi, maka pada saat terminasi, asersi
R juga bernilai benar”.
Gambar II-4 mengilustrasikan penggunaan semantik aksiomatis untuk melakukan verifikasi terhadap program. Program sederhana tersebut menjumlahkan nilai-nilai yang tersimpan dalam sebuah array A yang tidak kosong dengan jumlah elemen n ke dalam variabel S. Definisi program sederhana ini dituangkan ke dalam prakondisi pada baris pertama dan pascakondisi pada baris ke-11. Setiap baris program – dalam contoh ini, pengisian variabel (assignment) dan perulangan, didahului dan diakhiri oleh pra dan pascakondisi yang bersesuaian.
Gambar II-4 Contoh Penerapan Semantik Aksiomatik [AAB04]
Sebuah program dapat dijabarkan makna semantik dan kebenarannya dengan menggunakan konsep yang sama untuk mencakup bukan hanya satu perintah namun keseluruhan program, jika diberikan prakondisi dan pascakondisi yang tepat [SLO95]. Dalam konteks pendekatan blackbox, program dibuktikan ketepatannya dengan mengevaluasi masukan program sebagai asersi prakondisi dan keluaran program sebagai asersi pascakondisi. Himpunan masukan program dengan keluaran program untuk setiap masukan tersebut disebut sebagai data uji.
Evaluasi terhadap masukan dan keluaran program idealnya melibatkan seluruh elemen yang mungkin dari domain masukan, namun dalam kondisi nyata hal ini jelas tidak mungkin [ZIN91]. Dalam prakteknya, penilaian hanya mungkin dilakukan menggunakan subset kecil dari domain masukan yang mungkin. Data uji yang digunakan perlu dipilih dengan hati-hati, agar dapat dideteksi sebanyak mungkin kesalahan potensial, dan menghindari kecurangan di mana siswa mengenumerasi keluaran yang mungkin atau menulis program secara spesifik untuk menangani data uji tertentu saja.
Penilaian sebuah program berdasarkan semantik aksiomatisnya hanya memperhitungkan kondisi awal dan akhir dari program, tidak memperhitungkan mengenai bagaimana sebuah program dieksekusi. Dalam konteks pedagogis, program sebagai cerminan keterampilan pemecahan masalah oleh siswa semestinya juga ditelaah menurut bagaimana masalah itu dipecahkan (menurut semantik operasionalnya). Semantik operasional program unik terhadap setiap source code yang berbeda, dan konstruksi teks program yang mungkin diberikan dalam suatu bahasa tidak terbatas jumlahnya [GRU98]. Penilaian terhadap semantik operasional program mengharuskan autograder untuk mengenali dan menilai implementasi algoritma untuk masing-masing solusi. Oleh karena itu, penilaian terhadap semantik operasional berada di luar cakupan dari Tugas Akhir ini sehingga tidak akan dibahas lebih lanjut.
2.2.1.2 Analisis Statik
Analisis statik dapat didefinisikan sebagai proses pemeriksaan kebenaran source code tanpa melalui eksekusi. Pada proses ini, source code akan diubah menjadi pohon sintaks abstrak menurut aturan sintaksis bahasa pemrograman sebagaimana akan dibahas dalam Subbab 2.3. Pohon sintaks abstrak yang telah dibangun kemudian dapat diubah menjadi kode biner (dalam proses kompilasi), dieksekusi (dalam proses interpretasi) atau dianalisis (oleh pemeriksa pola/pattern checker). Jika terdapat kesalahan sintaks pada source code, penyusunan pohon sintaks abstrak akan gagal dan dengan demikian program tidak akan dapat dieksekusi sama sekali. Nilai yang didapat oleh program, sebagaimana yang diberikan penilai manusia untuk source code yang gagal dikompilasi adalah 0.
Pada tahap analisis statik, informasi statistik tentang program yang diolah dapat diukur. Statistik program inilah yang kemudian digunakan dalam penilaian whitebox, sebagaimana dibahas dalam Subbab 2.2.2. Pada tahap ini kesalahan-kesalahan non-sintaksis atau kondisi-kondisi yang potensial menimbulkan kesalahan juga dapat dideteksi [ZIN91]. Kondisi-kondisi ini antara lain adalah infinite loop, rekursi tanpa basis, konflik antar kondisi, loop nesting yang tidak benar, variabel yang tidak digunakan, nilai kembalian fungsi yang tidak digunakan, statement yang tidak mungkin dieksekusi (unreachable code), atau penggunaan variabel yang belum diinisialisasi. Sebuah studi menyatakan bahwa sebagian besar kesalahan yang dapat dikenali pada saat inspeksi kode manual dapat dideteksi pada tahap analisis statik [HOV04].
Pada sistem operasi Linux terdapat sistem deteksi kesalahan pada source code dalam bahasa C/C++ menggunakan analisis statik yaitu lint, atau varian open sourcenya, splint [ZIN91]. Pemeriksa pola program, seperti FindBugs [HOV04] atau CheckStyle [CHE07] bekerja dengan melakukan analisis statik terhadap source code dalam bahasa Java.
2.2.1.3 Analisis Dinamik
Analisis dinamik dapat didefinisikan sebagai proses pemeriksaan kebenaran source code melalui eksekusi. Mekanisme pemeriksaan melalui eksekusi ini disebut juga sebagai oracle [ZIN91]. Oracle memberikan masukan tertentu kepada program yang sedang diuji, dan memeriksa keluaran program tersebut terhadap prediksi keluaran yang diharapkan. Jika keluaran program sesuai dengan keluaran yang diharapkan, maka diasumsikan bahwa eksekusi program telah memenuhi asersi pra dan pascakondisi. Data uji yang digunakan oleh oracle dapat berasal dari pembuat soal, dari siswa lain [JAC97, CAR03] atau dibangkitkan secara otomatis. Oracle memeriksa keluaran program dengan menggunakan regular expression tertentu untuk
mendefinisikan struktur-struktur teks keluaran. Sebagai contoh, pada sebuah program latihan kecil untuk mengkonversikan sentimeter ke dalam feet dan inch, jika jawaban yang tepat adalah 3 feet 4,69 inch, maka pada keluaran program, dicari string dengan aturan regular expression sebagai berikut :
“3” diikuti dengan “feet” atau “ft”, dan
“4,69” atau “4,7” atau “5” yang diikuti dengan “inch” atau “in”.
Jawaban untuk oracle jauh lebih mudah ditentukan apabila program yang dinilai melakukan perhitungan angka, tidak berorientasi pada hasil keluaran tekstual [ZIN91].
Penggunaan sebuah oracle untuk melakukan analisis hasil eksekusi program membutuhkan definisi data uji berupa set data masukan dan prediksi keluaran, yang umumnya melibatkan beberapa regular expression. Secara implisit, hal inilah yang menyebabkan program yang dinilai tidak dapat bersifat interaktif. Mekanisme Oracle telah diimplementasikan dalam setiap sistem penilai otomatis yang ada saat ini [ZIN91, CAR03].
Dalam sistem penjurian kompetisi pemrograman seperti Mooshak [MOO08] program harus menghasilkan keluaran yang diharapkan untuk seluruh masukan yang diberikan. Jika terdapat satu keluaran yang salah maka program dinyatakan gagal. Di lain pihak, oracle untuk pengajaran pemrograman dapat melakukan penilaian secara proporsional terhadap jumlah kasus uji yang ditangani dengan benar. Semakin banyak kasus uji yang berhasil ditangani, maka semakin baik pula nilai yang didapat oleh program.
2.2.1.4 Efisiensi
Efisiensi program didefinisikan sebagai pendayagunaan sumber daya komputasi yang digunakan untuk proses eksekusi program tersebut, antara lain penggunaan siklus CPU dan memori dinamis. Program yang efisien akan memiliki performansi yang tinggi.
Penilaian efisiensi secara manual dapat dilakukan oleh penilai manusia dengan cara membaca algoritma secara langsung dari source code dan mendeteksi inefisiensi yang mungkin terdapat dalam program, seperti misalnya konstruksi redundan atau loop yang tidak berguna. Penilai otomatis tidak dapat mendeteksi kode yang tidak efisien sebagaimana yang dilakukan oleh manusia.
Penilaian efisiensi secara otomatis dapat dilakukan dengan mengukur waktu yang dibutuhkan untuk eksekusi program dan jumlah instruksi dalam program yang dijalankan [JAC97]. Karena penilaian efisiensi secara otomatis membutuhkan eksekusi program, pada pembahasan selanjutnya, penilaian efisiensi akan digolongkan ke dalam penilaian blackbox. Penilaian waktu eksekusi tidak mempertimbangkan memori yang digunakan ke dalam proses penilaian. Semakin rendah waktu eksekusi, maka semakin baik pula efisiensi program tersebut, dan semakin baik pula nilai yang diperoleh oleh program tersebut.
Dalam pengajaran pemrograman, efisiensi marjinal untuk ukuran atau kecepatan eksekusi program yang dihasilkan umumnya tidak menjadi perhatian [ZIN91]. Meskipun demikian, terdapat dua alasan yang menyebabkan efisiensi perlu dipertimbangkan dalam faktor-faktor penilaian. Pada realisasi nyata, penilaian hanya perlu mempertimbangkan perbedaan besar dalam orde komputasi; misalnya, sebuah algoritma pengurutan (sorting) diharapkan untuk memiliki orde komputasi yang lebih baik dari O(n2). Perbedaan besar dalam performansi program mencerminkan penggunaan algoritma yang berbeda. Jika performansi sebuah program jauh lebih rendah daripada seharusnya, maka algoritma program tersebut kurang efisien. Selain itu, pada latihan-latihan khusus di mana performansi program bersifat kritis, instruktur harus memberikan perhatian khusus pada efisiensi dari program.
Selain penilaian berdasarkan waktu eksekusi, penilaian efisiensi dapat dilakukan secara lebih akurat menggunakan perangkat lunak khusus analisis performansi yang disebut profiler. Profiler melakukan pengukuran terhadap frekuensi dan durasi dari eksekusi prosedur atau fungsi, menghasilkan catatan dari setiap proses dalam eksekusi program dan melakukan analisis statistik terhadap catatan tersebut (yang disebut profil). Berdasarkan profil yang dibuatnya, profiler dapat dikategorikan ke dalam beberapa jenis : time profiler mengukur banyaknya instruksi program yang dieksekusi sampai pada tingkat metode; space profiler menggambarkan perkembangan memori heap, sehingga penggunaan memori oleh masing-masing metode dapat diukur; dan thread profiler digunakan untuk melacak masalah-masalah dalam sinkronisasi antar thread. Karena profiling terkait erat dengan proses eksekusi, profiler bersifat spesifik terhadap bahasa pemrograman. Aplikasi profiler telah banyak tersedia, antara lain gprof [GRA82] dan Atom [SRI94] untuk program dalam bahasa C, dan JProfiler [EJT07] untuk Java.
2.2.2 Pendekatan Whitebox
Dalam pendekatan whitebox, penilaian program dilakukan terhadap kualitas program menurut bagaimana dan seberapa baik program memecahkan sebuah masalah. Seorang penilai manusia dapat dengan mudah menilai pemecahan masalah yang diberikan dalam bentuk program, namun sebuah penilai otomatis tidak dapat melakukan hal ini secara penuh. Sebuah penilai otomatis dapat menilai kualitas program secara parsial dengan menggunakan besaran-besaran perangkat lunak (software metrics). Penggunaan besaran perangkat lunak sebagai bagian dalam proses penilaian ini dipelopori oleh ASSYST [BLU04].
Untuk sebuah proyek perangkat lunak kecil seperti tugas praktikum atau ujian, Burgess [ZIN91] menyatakan bahwa hanya empat faktor kualitas yang perlu dipertimbangkan: ketepatan (correctness), kemudahan perawatan (maintainability), kemudahan penggunaan (usability) dan efisiensi. Kemudahan penggunaan merupakan aspek yang spesifik berkaitan dengan pengguna manusia, sehingga tidak akan dipertimbangkan dalam penilai otomatis pada Tugas Akhir ini. Faktor kemudahan perawatan/maintainability umumnya diwakili oleh kompleksitas dan tipografi kode. Ketepatan, kompleksitas, keterbacaan atau tipografi source code, dan efisiensi telah digunakan oleh berbagai aplikasi penilai otomatis sebagai komponen-komponen penilaian [CAR03]. Aspek ketepatan dan efisiensi telah dibahas sebelumnya dalam Subbab 2.2.1.
Hasil pengukuran besaran-besaran kualitatif ini kemudian dapat dikonversi menjadi nilai dengan menggunakan beberapa cara bergantung pada besaran yang diukur. Beberapa besaran dapat dikonversi menjadi nilai berdasarkan apakah hasil pengukuran memenuhi batasan (constraint) tertentu. Sebagai contoh, jika rata-rata panjang nama identifier berada pada rentang tertentu (5-10 karakter) maka program akan mendapat nilai penuh. Pada beberapa besaran lain, nilai didapatkan dari perbandingan hasil pengukuran pada satu program secara relatif terhadap program lainnya. Sebagai contoh, untuk besaran kompleksitas, satu source code dapat menyelesaikan masalah dengan 100 baris kode sementara rata-rata SLOC masalah tersebut adalah 150 baris, maka program itu akan mendapat nilai yang lebih baik.
2.2.2.1 Kompleksitas
Kompleksitas program didefinisikan sebagai tingkat kerumitan program yang dibuat sebagai solusi untuk memecahkan suatu masalah. Implementasi program yang sederhana lebih baik, karena implementasi yang sederhana lebih mudah dipahami, diuji dan dibuktikan kebenarannya, serta dirawat (di-maintain) [ZIN91]. Oleh karena itu, semakin rendah kompleksitas suatu program, semakin tinggi kualitasnya. Kompleksitas suatu program bersifat relatif terhadap
masalah yang hendak dipecahkan. Penilaian kualitas suatu program berdasarkan kompleksitasnya dapat dilakukan dengan membandingkan nilai besaran kompleksitas program yang satu terhadap nilai kompleksitas program-program yang sejenis. Semakin tinggi hasil pengukuran kompleksitas suatu program, semakin rendah nilai yang diperolehnya. Terdapat beberapa cara penilaian yang dapat digunakan untuk mengukur kompleksitas kode program [SWA06]:
1) Jumlah baris kode, dikenal dengan akronim SLoC (Source Lines of Code), melambangkan jumlah baris kode tanpa komentar atau direktif untuk kompilator. Komentar dan direktif kompilator diabaikan, karena pada dasarnya ia tidak menerangkan mengenai alur program. Penilaian berdasarkan SLoC dilandasi asumsi bahwa semakin besar jumlah baris kode, komputasi atau pemrosesan yang dilakukan semakin banyak, dan dengan demikian semakin kompleks pulalah kode itu. Meskipun asumsi ini tidak berlaku untuk semua kasus dan dengan demikian dapat mengakibatkan ketidakakuratan [SWA06], besaran ini sering digunakan karena bersifat sederhana dan mudah diimplementasikan.
2) Jumlah operator dan operan, yang menandakan banyaknya komputasi yang harus dilakukan oleh program. Halstead mengusulkan sebuah besaran kompleksitas berdasarkan jumlah operator dan operan – besaran Kompleksitas Halstead [SEN98]. Semakin besar jumlah operator dan operan, semakin banyak proses komputasi yang harus dilakukan dan semakin kompleks pula program itu.
3) Keterkaitan (Coupling) adalah tingkatan keterhubungan antara satu modul (contohnya: kelas) pada modul lain – besaran ini dapat digunakan pada perangkat lunak yang terdiri dari banyak modul. Semakin rendah tingkat keterkaitan, semakin rendah kompleksitasnya, dan semakin baik pula kualitas perangkat lunak itu. Besaran yang digunakan untuk mengukur keterhubungan ini antara lain besaran Henry dan Kafura [SEN98], di mana kompleksitas modul diukur melalui perhitungan-perhitungan terhadap arus data masuk dan arus data keluar dari sebuah modul.
4) Alur (Flow) adalah bagian yang amat penting untuk memperhitungkan kompleksitas total dari sebuah metode. Metode penilaian umum yang berdasarkan pada alur program yaitu kompleksitas siklomatik McCabe [CAB76]. Penilaian ini dapat digunakan untuk mengukur kerumitan alur dan struktur dari program.
Nilai besaran-besaran kompleksitas dari suatu source code dapat diperoleh dari analisis statik terhadap kode. Hal ini disebabkan kompleksitas bersifat inheren dalam struktur program, baik secara fisik (SLoC) maupun logika (kompleksitas Halstead, Henry & Kafura, McCabe). Detil metode penilaian formal untuk kompleksitas source code, yaitu kompleksitas siklomatik, Halstead serta kompleksitas Henry dan Kafura dibahas lebih lanjut pada LAMPIRAN A.
2.2.2.2 Tipografi Kode
Source code dapat dieksekusi menggunakan interpreter atau melalui proses kompilasi, dibaca untuk memahami apa yang dilakukan oleh sebuah program dan bagaimana cara kerjanya, serta dapat dimodifikasi untuk mengubah fungsinya. Instruksi dalam bentuk source code ini amat penting, maka perlu ditetapkan konvensi penulisan kode tertentu untuk memudahkan pembacaan dan pemahaman program. Aspek keterbacaan (readability) ini pada akhirnya akan mempermudah upaya pengembangan dan perawatan perangkat lunak. Oleh karena itulah, keterbacaan source code menjadi aspek penting dalam penilaian.
Sebagai contoh, pada Kode II-1 terdapat dua potongan kode fungsi fibonacci dalam bahasa C. Kompilasi kedua source code tersebut akan menghasilkan kode mesin yang hampir sama. Fungsi pada potongan (1) akan lebih sulit dipahami karena, antara lain, nama fungsi yang tidak menggambarkan dengan apa yang dilakukannya, tidak ada keterangan tentang apa yang dilakukan oleh baris-baris kode, dan penulisan kode yang terlalu rapat. Fungsi pada potongan (2) dapat dipahami dengan mudah, karena memiliki nama yang deskriptif, penjelasan yang cukup baik dalam komentar program, dan tertata dengan jarak dan indentasi yang tepat.
1
int abracadabra(int x) {
return((!x||(x==1))?1:abracadabra(x-2)+abracadabra(x-1); }
2
/* fungsi fibonacci rekursif dalam bahasa C */ int fibonacci(int x) {
if (x==0 || x==1) {
/* kasus basis : fibonacci 0 & 1 menghasilkan 1 */
return 1;
} else {
/* rekurensi : jumlahkan nilai fibonacci dari dari dua bilangan sebelumnya */
return fibonacci(x-2) + fibonacci(x-1); }
}
Kode II-1 Perbandingan Penulisan Fungsi Fibonacci
Keterbacaan merupakan sebuah besaran yang abstrak. Pada prinsipnya, keterbacaan mengukur seberapa mudah source code akan dapat dipahami oleh pemrogram manusia di masa yang akan datang – baik itu kode miliknya sendiri maupun kode orang lain yang harus dipahami atau diubah. Penilaian keterbacaan secara total mengharuskan program penilai untuk dapat memahami identifier (dalam contoh Kode II-1 berarti program harus memahami makna kata fibonacci dan abracadabra), dan isi komentar. Pemrosesan semacam ini akan membutuhkan komputasi yang ekstensif, yang saat ini dinilai masih belum relevan. Oleh karena hal inilah, pengukuran keterbacaan didekati menggunakan besaran-besaran tipografis.
Aspek tipografi, atau kadang juga disebut sebagai gaya penulisan kode, didasarkan pada konsistensi sebuah kode mematuhi konvensi-konvensi tipografis terhadap source code. Konvensi tipografis untuk program pun bervariasi dari satu proyek ke proyek lainnya. Konvensi gaya penulisan kode pada umumnya mencakup mencakup identitas file, indentasi, keberadaan komentar, serta penamaan variabel, fungsi serta kelas. Konvensi ini biasanya dituangkan dalam bentuk sebuah panduan gaya penulisan kode (coding style guide). Aspek tipografi yang dinilai pun disesuaikan dengan konvensi penulisan kode yang telah ditentukan.
Konvensi gaya penulisan kode ini juga bergantung pada bahasa pemrograman yang digunakan untuk menulis source code. Sebagai contoh, bahasa Phyton menggunakan konvensi indentasi sebagai representasi struktur blok, sehingga secara efektif seluruh aturan tipografis mengenai indentasi akan dipenuhi. Penilaian ketaatan terhadap konvensi gaya secara generik hanya dapat dilakukan terhadap besaran-besaran tipografis tertentu, yaitu persentase baris dan rata-rata panjang komentar, serta rata-rata panjang nama identifier atau simbol. Penilaian ketaatan pada konvensi gaya penulisan secara spesifik untuk tiap bahasa pemrograman dapat dilakukan apabila dibangun penganalisa pola tipografi untuk masing-masing bahasa pemrograman.
Nilai besaran-besaran tipografi kode dapat diperoleh dari proses analisis statik terhadap kode, karena tipografi berkaitan langsung dengan rupa source code sebagaimana dibaca oleh manusia. Penilaian terhadap aspek tipografi source code dalam bahasa C/C++ telah diimplementasikan oleh beberapa sistem autograder seperti ASSYST dan CourseMaster [JAC97, ZIN91]. Besaran-besaran dalam penilaian tipografis oleh Ceilidh/CourseMaster dijabarkan secara mendetil pada LAMPIRAN B. Pemeriksaan aspek tipografi source code juga menjadi bagian dari perangkat lunak pemeriksa gaya penulisan program seperti checkstyle [CHE07].
2.3 Bahasa Pemrograman dan Source Code
Program komputer merupakan serangkaian instruksi untuk dieksekusi oleh komputer. Untuk melakukan penilaian terhadap program, baik dalam pendekatan blackbox maupun whitebox, source code harus diproses terlebih dahulu. Penilaian whitebox membutuhkan statistik dari proses analisis leksikal dan analisis sintaks, sementara penilaian blackbox membutuhkan format siap eksekusi. Subbab ini akan membahas mengenai bahasa pemrograman dan source code secara umum beserta pemrosesan terhadap source code agar dapat dieksekusi. Ikhtisar bahasa pemrograman dan paradigma-paradigmanya akan dibahas pada Subbab 2.3.1. Teknik implementasi kompilasi dan interpretasi akan dibahas pada Subbab 2.3.2. Pemrosesan bahasa pemrograman yang dijalankan pada saat kompilasi dan interpretasi dibahas pada Subbab 2.3.3.
2.3.1 Ikhtisar Bahasa Pemrograman
Pemrograman adalah sebuah kegiatan kompleks yang melibatkan banyak detil pada saat yang sama [MAC83]. Semakin rendah level abstraksi yang digunakan pada penulisan program, semakin sulit pula untuk ditulis, dibaca dan dikoreksi oleh manusia. Bahasa pemrograman diciptakan untuk menyederhanakan proses pembuatan program. Instruksi yang harus dijalankan ditulis dalam notasi khusus yang lebih mudah dipahami oleh manusia, kemudian diproses oleh program lain agar dapat dieksekusi oleh mesin. Program yang ditulis dalam notasi khusus ini disebut source code.
Bahasa pemrograman didefinisikan sebagai notasi yang digunakan untuk menulis program [AAB04]. Sebuah bahasa pemrograman dideskripsikan menggunakan model komputasional, sintaks, semantik dan pertimbangan-pertimbangan pragmatik tertentu. Berdasarkan deskripsi inilah bahasa pemrograman kemudian dapat diimplementasikan. Tujuan dari sebuah bahasa pemrograman adalah sebagai media untuk mengkomunikasikan algoritma kepada komputer dan juga pemrogram lain. Bahasa pemrograman membutuhkan ketepatan dan kelengkapan yang lebih tinggi dibandingkan bahasa alami manusia yang mengandung banyak ambiguitas dan karakteristik implisit (subtleties) [WAT95].
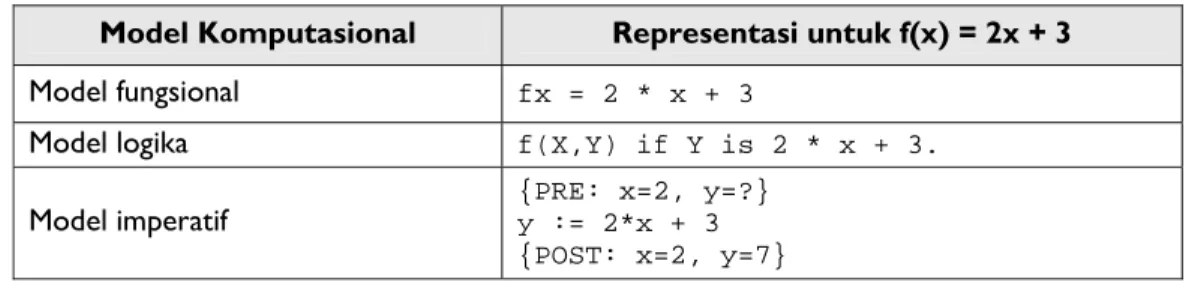
Model komputasional, atau juga disebut sebagai paradigma pemrograman, adalah sekumpulan nilai dan operasi yang digunakan untuk menggambarkan proses komputasi. Paradigma pemrograman dasar yaitu paradigma fungsional, paradigma logis dan paradigma imperatif. Contoh dari masing-masing model dapat dilihat pada Tabel II-4.
Tabel II-4 Representasi fungsi dalam berbagai model komputasional Model Komputasional Representasi untuk f(x) = 2x + 3
Model fungsional fx = 2 * x + 3
Model logika f(X,Y) if Y is 2 * x + 3.
Model imperatif {PRE: x=2, y=?} y := 2*x + 3
{POST: x=2, y=7}
Dalam paradigma fungsional, program merupakan serangkaian definisi fungsi, dan proses komputasi direpresentasikan sebagai eksekusi fungsi dengan masukan nilai tertentu. Paradigma logis didasarkan pada relasi dan inferensi logika; program merupakan definisi fungsi-fungsi dan komputasi dinyatakan sebagai serangkaian inferensi. Paradigma imperatif didasarkan pada state dan operasi-operasi pengubahan state. Program dalam model imperatif merupakan serangkaian
perintah, dan komputasi merupakan perubahan terhadap state. Karena paradigma imperatif merupakan paradigma yang paling serupa dengan perangkat keras di mana komputasi sesungguhnya dijalankan, paradigma imperatif merupakan paradigma yang paling efisien dalam banyak kasus.
Seperti yang telah disinggung sebelumnya dalam bab 2.2.1.1, sintaks merupakan struktur, atau bentuk dari program. Semantik merupakan hubungan antara sintaks bahasa dengan model komputasi, atau dengan kata lain semantik mendefinisikan arti dari kode program. Sebuah bahasa pemrograman dapat mempunyai sintaks yang sama persis dengan bahasa yang lain, namun semantik dari masing-masing simbol bisa jadi berbeda sama sekali. Pragmatik adalah aspek-aspek dalam bahasa pemrograman yang berkaitan dengan pengguna sistem, seperti kemudahan implementasi dan penggunaan sistem, metodologi pemrograman, dan efisiensi pada aplikasi bahasa, serta keberhasilan program dalam mencapai tujuan rancangannya (design goals).
Postulat Benjamin Whorf menyatakan bahwa bahasa yang digunakan mempengaruhi pola pikir seseorang, karena bahasa membatasi apa yang dapat dipikirkan oleh orang tersebut. Oleh karena itu, bahasa pemrograman yang digunakan perlu mencapai tingkatan di mana manusia menalar, mencerminkan pendekatan-pendekatan pemecahan masalah yang digunakan oleh manusia, dan memberikan jalan untuk menstrukturkan program agar memahami, merawat dan men-debug program menjadi lebih mudah [WAT95].
Salah satu alternatif implementasi kurikulum pendidikan ilmu komputer ACM ialah programming-first. Dalam pendekatan yang sudah cukup lama digunakan ini, pemrograman merupakan bagian sentral dalam pengantar menuju ilmu-ilmu komputer [ACM01]. Bahasa-bahasa pemrograman beserta paradigma-paradigmanya juga merupakan bagian penting dari kurikulum komputasi ACM secara keseluruhan. Seorang siswa ilmu komputer diharapkan untuk dapat memahami peran dari bahasa pemrograman, proses translasi antar bahasa, serta keberadaan dari berbagai paradigma itu sendiri. Pada LAMPIRAN C akan dibahas secara singkat berbagai bahasa pemrograman yang digunakan untuk mata kuliah pemrograman dasar pada S1-IF-ITB.
2.3.2 Implementasi Bahasa Pemrograman
Proses yang dilakukan agar instruksi di dalam source code dapat dieksekusi disebut sebagai implementasi bahasa pemrograman. Teknik implementasi bahasa pemrograman pada umumnya ada 2, yaitu kompilasi dan interpretasi. Langkah-langkah proses kompilasi dan interpretasi secara umum dapat dilihat pada Gambar II-5.
Gambar II-5 Perbandingan Proses Kompilasi dan Interpretasi [COO03]
Dalam proses kompilasi, kompilator mengubah source code menjadi instruksi dalam bahasa mesin dan menggabungkannya dengan kode instruksi yang sudah tersedia dalam library sistem menjadi program siap eksekusi (executable). Dalam proses interpretasi, interpreter menerima source code dan bertindak sesuai dengan instruksi yang tertulis di dalamnya. Interpreter awal bertindak sebagai komputer virtual, yang menyediakan operasi-operasi ini seolah-olah operasi tersebut tersedia pada komputer nyata [MAC83].
Eksekusi program dengan menggunakan interpreter lebih lambat dibandingkan dengan eksekusi program hasil kompilasi. Meskipun demikian, proses interpretasi memiliki kelebihan tersendiri. Interpretasi bersifat lebih fleksibel. Dalam interpretasi umumnya tidak diperlukan deklarasi variabel dan pemeriksaan tipe. Dalam interpretasi bahkan dapat dilakukan modifikasi program secara dinamis pada saat runtime. Selain itu, source code yang diinterpretasikan relatif lebih platform independent. Hal ini disebabkan karena interpreter membentuk abstraction layer terhadap platform sehingga ketergantungan pada platform dasarnya menjadi lebih sedikit. Interpretasi juga dapat menghasilkan laporan kesalahan yang lebih baik, karena kode dievaluasi per baris pada saat runtime.
Bahasa pemrograman yang secara tradisional menggunakan proses interpretasi antara lain BASIC dan PHP, sementara bahasa pemrograman yang secara tradisional menggunakan proses kompilasi antara lain FORTRAN, Pascal, dan C. Dalam teori, bahasa pemrograman yang dapat diimplementasikan dengan cara kompilasi juga dapat diimplementasikan dengan cara interpretasi dan begitu pula sebaliknya. Pilihan primer untuk pendekatan implementasi bahasa pemrograman bergantung pada rancangan kegunaan atau fungsionalitasnya sendiri.
Selain kompilasi dan interpretasi, terdapat teknik implementasi lainnya, seperti bytecode interpreter pada bahasa Java. Dalam proses ini, source code Java dikompilasi menjadi bentuk antara yang disebut bytecode. Bytecode inilah yang kemudian diinterpretasi menggunakan Java Virtual Machine. Selain itu, teknik Just-In-Time compilation yang awalnya digunakan oleh platform .NET kini menjadi populer, di mana kode antara hasil kompilasi awal diubah menjadi kode mesin persis saat sebelum dieksekusi [COO03].
2.3.3 Teknik Pemrosesan Source Code
Pemrosesan source code, baik kompilasi maupun interpretasi, merupakan proses yang kompleks. Sebuah bagan sederhana mengenai tahapan proses kompilasi dapat dilihat pada Gambar II-6. Proses kompilasi umumnya dibagi menjadi dua tahap: front-end (tahapan depan) yang bertugas menerjemahkan kode masukan ke dalam suatu bentuk antara dan back-end (tahapan belakang) yang bertugas memetakan fungsionalitas dari program kepada mesin target dalam bentuk biner.
Proses front-end mencakup translasi dari kode program ke dalam representasi antara berupa pohon sintaks abstrak (abstract syntax tree). Proses front-end sendiri, pada dasarnya terdiri dari dua proses utama : analisis leksikal – yang mengubah kode program menjadi serangkaian token (penanda), di mana token adalah potongan teks tunggal dengan arti tertentu; dan analisis sintaks, yang menyusun token-token menjadi sebuah pohon sintaks abstrak. Bagian yang bertugas melakukan analisis leksikal sering disebut lexer atau scanner, sementara bagian yang bertugas melakukan analisis sintaks disebut parser. Berdasarkan pohon sintaks abstrak inilah nantinya parser menghasilkan representasi antara. Proses analisis leksikal akan dibahas pada Subbab 2.3.3.1, sementara proses analisis sintaks akan dijabarkan lebih lanjut pada Subbab 2.3.3.2.
Proses back-end mencakup optimasi dan translasi dari representasi antara ke dalam bentuk lain, umumnya kode biner. Proses optimasi melakukan modifikasi terhadap representasi antara agar kode yang dihasilkan lebih efisien. Proses pembangkitan kode / code generation, dilakukan untuk mengubah representasi antara ke dalam bentuk lain yaitu kode objek, executable, kode assembly, bytecode, atau kode dalam bahasa lainnya. Proses optimasi dan pembangkitan kode tidak akan dilakukan dalam Tugas Akhir ini, sehingga tidak akan dibahas lebih lanjut.
Proses interpretasi hampir sama dengan proses kompilasi, hanya saja dalam proses interpretasi proses back-end tidak dilaksanakan. Tahap front-end (analisis leksikal dan analisis sintaks) pada proses interpretasi sama dengan tahap front-end pada proses kompilasi. Interpreter kemudian langsung menggunakan pohon sintaks abstrak untuk mengeksekusi instruksi yang terkandung dalam source code.
2.3.3.1 Analisis Leksikal
Analisis leksikal padalah proses pengubahan teks kode program ke dalam serangkaian simbol yang valid menurut grammar (tata bahasa) yang bersangkutan. Program yang melakukan analisis leksikal disebut sebagai lexer, sementara simbol-simbol yang dihasilkan oleh lexer ini sering disebut sebagai token. Token-token ini akan dijadikan masukan untuk proses selanjutnya, yaitu proses analisis sintaks. Token-token yang umum misalnya kata kunci/keyword, tanda baca, atau identifier (nama variabel, konstanta, fungsi dan prosedur).
Lexer pada umumnya bekerja menggunakan prinsip otomata nondeterministik. Pola leksikal dari token-token umumnya didefinisikan menggunakan regular expression (regex), karena format regex dapat menggambarkan pola leksikal secara kompak. Berikut ini adalah contoh pola regex untuk mengenali identifier (identifier didefinisikan sebagai string yang diawali oleh alfabet dan diikuti oleh sembarang alfabet atau angka) :
alfabet Æ (a|b|c|d|e|f|g|h|i|jk|l|m|n|o|p|q|r|s|t|u|v|w|x|y|z) angka Æ (0|1|2|3|4|5|6|7|8|9)
identifierÆ alfabet(alfabet|angka)*
Dengan menggunakan definisi regex untuk setiap konstruksi token yang mungkin, maka dapat dibentuk sebuah mesin nondeterministic finite automata (NFA) yang akan mengenali token-token pada source code. Pada Gambar II-7 digambarkan sebuah diagram NFA yang akan mengenali regular expressiona(b|c)*.
Gambar II-7 Diagram NFA untuk pola regular expression a(b|c)* [COO03]
Alat bantu untuk pembuatan lexer sudah banyak tersedia, di antaranya Lex (generator lexer yang umum digunakan, menghasilkan lexer dalam bahasa C) / Flex (versi open source dari Lex) / JFlex (generator lexer untuk bahasa Java), atau re2c.
2.3.3.2 Analisis Sintaks
Analisis sintaks, yang juga dikenal sebagai parsing, adalah proses verifikasi terhadap source code untuk menguji apakah program yang dihasilkan merupakan kalimat yang legal menurut aturan sintaks / grammar pada bahasa yang bersangkutan. Aturan sintaks atau aturan tata bahasa yang berlaku untuk bahasa alami maupun bahasa pemrograman secara formal didefinisikan oleh Noam Chomsky [GRU98]. Menurut Chomsky, sebuah tata bahasa / grammar <Σ, N, P, S> terdiri dari empat bagian :
1) Sebuah himpunan terhingga Σ yang terdiri dari simbol terminal, komponen penyusun terkecil dalam bahasa tersebut.
2) Sebuah himpunan terhingga N yang terdiri dari simbol nonterminal atau kategori sintaks, yang masing-masing merupakan koleksi subfrase dari kalimat.
3) Sebuah himpunan terhingga P yang terdiri dari aturan atau produksi yang menggambarkan bagaimana tiap simbol nonterminal didefinisikan menggunakan simbol terminal dan/atau simbol nonterminal.
4) Sebuah simbol nonterminal istimewa S, simbol awal, yang menspesifikasikan entitas utama yang didefinisikan – misalnya kalimat atau program.
Dalam konteks bahasa pemrograman, simbol terminal adalah token-token yang dikenali dalam bahasa tertentu. Simbol nonterminal bersama dengan aturan-aturan produksi digunakan untuk mendefinisikan bagaimana menyusun simbol-simbol terminal menjadi kalimat-kalimat yang valid agar dapat dipahami. Simbol awal merepresentasikan entitas yang hendak dibangun – misalnya, simbol awal dalam bahasa Pascal adalah <program>.
Berdasarkan aturan produksi yang dimilikinya, tata bahasa memiliki klasifikasi yang tersusun sebagai hirarki Chomsky. Hirarki Chomsky dapat dilihat secara lebih mendetil pada Tabel II-5. Unrestricted grammar (tipe 0) dan context-sensitive grammar (tipe 1) amat jarang digunakan karena membuat grammar tipe 0 dan tipe 1 yang jelas dan dapat dipahami merupakan hal yang amat sulit, dan semua parser yang diketahui untuk grammar tersebut mempunyai kompleksitas waktu eksponensial [GRU98]. Parsing bahasa pemrograman hanya menggunakan context-free grammar (tipe 2) untuk aturan sintaksis dan regular grammar (tipe 3) untuk aturan leksikal.
Tabel II-5 Hirarki Chomsky untuk Tata Bahasa [SLO95]
Tipe Grammar Aturan Produksi Keterangan
Tipe 0
Unrestricted Grammar α Æ β String atau kombinasinya) yang mengandung minimal α (himpunan simbol terminal, nonterminal, sebuah simbol nonterminal dapat didefinisikan sebagai string lain β
Tipe 1
Context-Sensitive Grammar
α <A> γ Æ α β γ Sebuah simbol nonterminal <A> dapat
didefinisikan sebagai string tidak kosong β pada konteks kombinasi string α dan γ
Tipe 2
Context-Free Grammar <A> Æα
Sebuah simbol nonterminal <A> dapat didefinisikan sebagai string α
Tipe 3
Regular Grammar
<A> Æ a | a <A> Sebuah simbol nonterminal <A> dapat disubstitusi dengan sebuah simbol terminal a atau sebuah simbol terminal dan sebuah simbol terminal a<A>.
Aturan produksi dalam sebuah grammar bahasa pemrograman umumnya dinotasikan menggunakan Backus Naur Form (BNF) atau Extended Backus Naur Form (EBNF) [FIN95]. Berikut ini adalah sebuah contoh aturan produksi:
di mana var, : dan ; merupakan simbol terminal, dan simbol nonterminal ditulis menggunakan kurung siku <>. Simbol::= pada BNF atau Æ pada EBNF dapat diartikan sebagai “didefinisikan sebagai” atau “mungkin tersusun dari”. BNF/EBNF adalah sebuah metalanguage – bahasa untuk mendefinisikan bahasa lain. Pada Gambar II-8 digambarkan contoh aturan produksi untuk Wren, sebuah bahasa pemrograman kecil hipotetis dengan sintaks yang mirip dengan bahasa Pascal. Contoh ini dipilih untuk memberikan gambaran suatu bahasa pemrograman yang utuh namun aturan sintaksnya cukup sederhana untuk dibaca dan dipahami dengan cepat.
Gambar II-8 Grammar abstrak untuk bahasa pemrograman Wren [SLO95]
Aturan-aturan sintaks digunakan untuk menentukan apakah suatu kalimat dapat dikategorikan sebagai kalimat yang valid. Pengujian validitas suatu kalimat dilakukan dengan cara menyusun komponen-komponennya ke dalam suatu pohon sintaks abstrak – aturan pembangunan pohon sintaks abstrak didefinisikan dalam aturan produksi. Pada Gambar II-9 digambarkan sebuah pohon sintaks abstrak yang dihasilkan dari kode perulangan sederhana, di mana setiap komponen loop menjadi subpohon sederhana.
Kalimat loop
while n > 0 do write n; n := n-1; end while.
pohon sintaks abstrak
Gambar II-9 Pembangkitan pohon sintaks abstrak dari sebuah kalimat loop [SLO95]
Ada banyak teknik yang dapat digunakan untuk membangkitkan pohon sintaks abstrak dari kode program, namun pada dasarnya hanya terdapat dua teknik utama : top-down dan bottom-up. Metode pertama menirukan proses produksi alami dengan cara menurunkan kalimat-kalimat dari simbol awal. Metode ini disebut top-down karena dibangun dari akar pohon turun ke arah daun,
dan karena berasal dari rule yang kemudian diturunkan menjadi simbol seringkali disebut juga metode produksi atau metode prediksi-cocokkan. Metode bottom-up membangun pohon sintaks dari daun pohon, dan mencoba menggeneralisasinya ke arah simbol awal. Metode ini disebut juga metode geser-reduksi, karena berasal dari kalimat yang direduksi menjadi rule. Sebuah ilustrasi mengenai proses parsing untuk sebuah kalimat bahasa Inggris dapat dilihat pada Gambar II-10.
Gambar II-10 Ilustrasi Teknik Parsing Top-Down dan Bottom-Up [SLO95]
Selain berdasarkan proses pembangunan pohon sintaksnya, teknik parsing juga dibedakan berdasarkan arah pemrosesan, yaitu tak terarah dan terarah / linier. Teknik tak terarah membangun pohon parse sementara mengakses masukan dalam urutan apapun yang dibutuhkannya. Teknik tak terarah digunakan antara lain dalam parser Unger dan parser Tomita. Dalam teknik terarah simbol masukan diproses satu per satu, dari kiri ke ke kanan atau dari kanan ke kiri. Teknik parsing terarah biasa dikenal dengan inisial dan jumlah simbol look-aheadnya, seperti LL(1), LALR(1), LR(k). Sebuah ikhtisar mengenai teknik-teknik parsing dapat dilihat pada Tabel II-6.
Sebuah parser ideal diharapkan mampu menangani seluruh grammar tipe 2 yang mungkin dan memiliki kompleksitas linier. Sayangnya, teknik-teknik parsing yang ada tidak mampu mencapai kedua tujuan ini. Parser general yang terbaik memiliki kompleksitas kubik O(n3), sementara parser linier yang ada hanya bisa menangani subset tertentu dari grammar CF [GRU98]. Parser linier lebih sering digunakan oleh karena eksekusinya yang cepat, meskipun grammar untuk parser linier tertentu harus dimodifikasi terlebih dahulu.
Tabel II-6 Ikhtisar Teknik Parsing [GRU98]
Top-Down Bottom-Up
Metode tak berarah Parser Unger Parser CYK
Metode berarah
Automaton Prediksi/Cocokkan :
Depth-First Search (backtrack)
Breadth-First Search (Greibach) Penurunan Rekursif / Recursive Descent Definite Clause Grammar
Automaton Geser/Reduksi :
Depth First Search (backtrack)
Breadth-First Search
Breadth-First Search, terbatas (Earley)
Metode berarah linier : breadth-first dengan breadth
terbatas pada 1 Hanya ada satu metode top-down : LL(k)
Ada berbagai metode : - Precedence
- Bounded Context - LR(k)
- LALR(1) - SLR(1)
Metode berarah general efisien : Breadth-First Search terbatas secara maksimal
- Parser Tomita
Metode linier top-down yang umum digunakan hanya ada 1, yaitu LL – huruf L yang pertama berarti bahwa simbol diproses berurutan dari kiri ke kanan, dan yang kedua berarti bahwa identifikasi produksi dimulai dari produksi terkiri. Parser LL(k) dapat dibuat secara otomatis menggunakan generator atau secara manual. Meskipun populer karena mudah dimengerti dan dibuat, metode ini memiliki kelemahan karena parser LL(k) hanya dapat menerima grammar yang memenuhi syarat tertentu. Modifikasi yang harus dilakukan untuk menghasilkan grammar LL(k) cukup ekstensif. Generator parser dengan metode LL(1) yang umum digunakan yaitu Antlr, generator parser recursive descent dalam bahasa Java [PAR94].
Dalam metode bottom-up, terdapat teknik linier LR beserta varian-variannya – huruf L berarti simbol diproses dari kiri ke kanan, sementara R berarti identifikasi produksi dimulai dari kanan ke kiri. Varian populer dari LR(k) antara lain LALR(1) / Look Ahead LR(1) dan SLR(1) atau Simple LR(1). Teknik-teknik ini populer karena subset grammar CF yang dapat ditangani amat luas. Metode ini sulit dipahami dan diimplementasikan, namun umum digunakan karena parser LR dapat dibangun secara otomatis menggunakan generator parser. Alat bantu untuk pembuatan parser untuk metode LL(1) dan LR(1) telah banyak tersedia. Generator parser yang banyak digunakan antara lain Bison yang merupakan generator parser dengan metode LR(1) yang ditulis dalam bahasa C, YACC (versi open source dari Bison).
2.4 Ringkasan
Autograder merupakan salah satu bentuk Computer Aided Assessment yang secara spesifik menangani source code. Beberapa aplikasi autograder yang telah digunakan antara lain ASSYST, CourseMaster dan GAME. Aplikasi ini telah memiliki fitur penilaian yang cukup lengkap, namun masing-masing masih memiliki keterbatasannya sendiri. Berdasarkan aplikasi autograder yang telah ada, dalam Tugas Akhir ini akan dibangun sebuah sistem penilaian source code otomatis untuk memenuhi kebutuhan pengajaran pemrograman pada S1-IF-ITB.
Penilaian source code dapat dilakukan menggunakan dua pendekatan, yaitu pendekatan blackbox dan pendekatan whitebox. Pada pendekatan blackbox, ketepatan program secara sintaks dan semantik dinilai menggunakan data uji yang terdiri dari set data masukan dan keluaran. Program yang melakukan penilaian secara blackbox ini umum dinamai sesuai dengan mekanisme pengujiannya, yaitu oracle. Pada pendekatan whitebox, program dinilai menurut hasil pengukuran besaran perangkat lunak (software metrics). Aspek-aspek kualitas perangkat lunak yang sering digunakan untuk melakukan penilaian menggunakan autograder adalah aspek kompleksitas, tipografi, dan efisiensi. Ringkasan setiap jenis penilaian dan metodologi pemberian nilai untuk masing-masing penilaian yang telah dikaji pada Tugas Akhir ini dapat dilihat pada Tabel II-7.
Source code harus diolah terlebih dahulu agar dapat dinilai. Pada pendekatan blackbox, terdapat dua tahap, yaitu analisis statik dan analisis dinamik. Pada tahap analisis statik, source code diproses ke dalam format program siap eksekusi. Program kemudian dieksekusi menggunakan masukan dari data uji, dan keluaran yang dihasilkannya akan dibandingkan terhadap keluaran yang seharusnya dalam tahap analisis dinamik. Untuk pendekatan whitebox, penilaian dilakukan terhadap pohon sintaks abstrak yang dihasilkan dalam proses analisis statik.
Tabel II-7 Ikhtisar jenis penilaian program, korelasi metode pengukurannya
Aspek Penilaian Besaran Penilaian Metode Pengukuran Penilaian Kebenaran sintaksis
program
Proses kompilasi menggunakan kompilator
Lulus/tidak Keberadaan struktur
kode yang berpotensi menimbulkan bug.
Analisis statik dengan Lint,
Splint, atau CheckStyle
Ada/Tidak Ketepatan sintaks
& semantik program
Jumlah kasus uji yang sukses dieksekusi
Oracle (perbandingan keluaran yang diharapkan dengan keluaran aktual untuk data tertentu)
Semakin banyak kasus uji lulus nilai makin tinggi Waktu eksekusi Menghitung waktu yang
digunakan saat eksekusi program
Semakin lama waktu eksekusi nilai semakin rendah
Pen d e k atan Bl ac k b o x Efisiensi Jumlah instruksi / memori program.
Melakukan time profiling / memory profiling dengan profilerseperti atom, gprof atau
JProfiler
Semakin besar memori & waktu yang digunakan nilai
makin rendah. SLOC Menghitung jumlah baris kode
non-komentar / spasi
Semakin panjang kode, program makin kompleks –
nilai makin rendah K. Halstead Menghitung jumlah operator dan
operan yang muncul dalam kode
Semakin banyak operasi yang dilakukan program makin kompleks – nilai makin rendah K. Henry & Kafura Menghitung jumlah aliran data
masuk, keluar dan panjang modul
Semakin besar dan banyak jumlah aliran data, program makin kompleks – nilai makin
rendah Kompleksitas
K. Siklomatik Menghitung jumlah titik percabangan dalam kode
Semakin banyak percabangan program, program makin kompleks – nilai makin rendah Keberadaan keterangan
pada kode
Mengukur persentase baris komentar, persentase jumlah karakter dalam komentar, persentase penutup blok tanpa komentar
Semakin banyak komentar dalam program, program makin mudah dibaca – nilai
makin tinggi Proporsi Whitespace Mengukur jumlah baris kosong,
rata-rata panjang baris, rata-rata jumlah spasi dalam tiap baris
Semakin banyak spasi dalam program, program makin mudah dibaca – nilai makin
tinggi Perimbangan Delimiter Mengukur jumlah delimiter
berimbang
Delimiter Berimbang / tidak Identifier yang
bermakna
Mengukur rata-rata panjang nama identifier, persentase identifier dengan nama memenuhi syarat
Semakin baik penamaan variabel dan fungsi, program
makin mudah dibaca – nilai makin tinggi Ketepatan Indentasi Mengukur persentase indentasi
struktur blok tepat
Semakin baik indentasi, program makin mudah dibaca
– nilai makin tinggi
Pen d e k atan W h it ebox Tipografi Konvensi Gaya Spesifik Bahasa Pemrograman Menghitung kesalahan
berdasarkan konvensi penulisan kode pemrograman
Semakin sedikit kesalahan, nilai semakin tinggi
![Tabel II-1 Format Ujian dengan Bantuan Sistem Komputer [CAR03]](https://thumb-ap.123doks.com/thumbv2/123dok/2436629.2756298/3.918.158.765.131.588/tabel-ii-format-ujian-bantuan-sistem-komputer-car.webp)
![Gambar II-1 Proses penilaian pada ASSYST [JAC97]](https://thumb-ap.123doks.com/thumbv2/123dok/2436629.2756298/4.918.344.599.672.988/gambar-ii-proses-penilaian-pada-assyst-jac.webp)
![Gambar II-2 Arsitektur Umum CourseMaster [SYM01]](https://thumb-ap.123doks.com/thumbv2/123dok/2436629.2756298/6.918.239.703.99.443/gambar-ii-arsitektur-umum-coursemaster-sym.webp)
![Gambar II-3 Arsitektur Umum GAME [BLU04]](https://thumb-ap.123doks.com/thumbv2/123dok/2436629.2756298/7.918.279.662.455.797/gambar-ii-arsitektur-umum-game-blu.webp)
![Tabel II-2 Kategori Hasil Evaluasi pada Mooshak [MOO08]](https://thumb-ap.123doks.com/thumbv2/123dok/2436629.2756298/8.918.157.766.753.1046/tabel-ii-kategori-hasil-evaluasi-pada-mooshak-moo.webp)
![Tabel II-3 Teknik Penjabaran Semantik Program [AAB04]](https://thumb-ap.123doks.com/thumbv2/123dok/2436629.2756298/11.918.157.788.238.434/tabel-ii-teknik-penjabaran-semantik-program-aab.webp)
![Gambar II-4 Contoh Penerapan Semantik Aksiomatik [AAB04]](https://thumb-ap.123doks.com/thumbv2/123dok/2436629.2756298/12.918.222.722.104.340/gambar-ii-contoh-penerapan-semantik-aksiomatik-aab.webp)
![Gambar II-5 Perbandingan Proses Kompilasi dan Interpretasi [COO03]](https://thumb-ap.123doks.com/thumbv2/123dok/2436629.2756298/22.918.234.713.104.412/gambar-ii-perbandingan-proses-kompilasi-dan-interpretasi-coo.webp)
![Gambar II-6 Bagan Proses Kompilasi yang Disederhanakan [COO03]](https://thumb-ap.123doks.com/thumbv2/123dok/2436629.2756298/23.918.201.748.802.963/gambar-ii-bagan-proses-kompilasi-disederhanakan-coo.webp)
