iii
PERNYATAAN KEASLIAN PENELITIAN
Saya yang bertandatangan dibawah ini menyatakan bahwa, skripsi ini merupakan karya saya sendiri (ASLI), dan isi dalam skripsi ini tidak terdapat karya yang pernah diajukan oleh orang lain untuk memperoleh gelar akademis di suatu institusi pendidikan tinggi manapun, dan sepanjang pengetahuan saya juga tidak terdapat karya atau pendapat yang pernah ditulis dan/atau diterbitkan oleh orang lain, kecuali yang secara tertulis diacu dalam naskah ini dan disebutkan dalam daftar pustaka.
Segala sesuatu yang terkait dengan naskah dan karya yang telah dibuat adalah menjadi tanggungjawab saya pribadi.
Bekasi, 3 November 2018
Materai 6.000
Harnoto NIM: 311410296
iv
ABSTRAK
Melalui era perdagangan bebas, persaingan bisnis antara perusahaan yang berlangsung ketat, termasuk pula pada perdangangan di bidang industri. Perusahaan tetap mempertahankan produk yang berkualitas dan layak dikonsumsi oleh konsumennya. Metode yang akan digunakan untuk menyelesaikan penelitian ini adalah jenis penelitian eksperimen yaitu melakukan pengujian tingkat akurasi algoritma naïve bayes dalam penentuan penyebab keluhan pelanggan. Hasil evaluasi tahap akhir pendekatan training dan testing supplied test lebih baik dibandingkan pendekatan cross validation 8 dan 10 fold, juga lebih baik dari pada pendekatan percentage splite 50 dan 60. Maka dengan hasil pendekatan training dan testing supplied test bisa di simpulkan selama ini pelanggan puas dengan pelayanan perusahaan walaupun ada sedikit pelanggan yang merasa tidak puas.
v
ABSTRACT
Through the era of free trade, business competition between companies is taking place tightly, including in trade in the industrial sector. The company retains quality and consumable products for its consumers. The method that will be used to complete this research is the type of experimental research that is testing the accuracy of the naïve Bayes algorithm in determining the cause of customer complaints. The evaluation results of the final training and testing supplied test are better than the cross validation 8 and 10 fold approaches, also better than the percentage splite approach 50 and 60. So the results of training and testing supplied test approaches can be concluded that customers are satisfied with the service company even though there are few customers who feel dissatisfied.
vi
KATA PENGANTAR
Puji syukur penulis panjatkan ke hadiran Allah SWT. yang telah melimpahkan segala rahmat dan hidayah-Nya, sehingga tersusunlah Skripsi yang berjudul “ANALISIS DATA MINING UNTUK MENGETAHUI KELUHAN PELANGGAN MENGGUNAKAN METODE NAIVE BAYES”.
Skripsi tersusun dalam rangka melengkapi salah satu persyaratan dalam rangka menempuh ujian akhir untuk memperoleh gelar Sarjana Komputer (S.Kom.) pada Program Studi Teknik Informatika di Sekolah Tinggi Teknologi Pelita Bangsa.
Penulis sungguh sangat menyadari, bahwa penulisan Skripsi ini tidak akan terwujud tanpa adanya dukungan dan bantuan dari berbagai pihak. Sudah selayaknya, dalam kesempatan ini penulis menghaturkan penghargaan dan ucapan terima kasih yang sebesar-besarnya kepada:
a. Bapak Dr. Ir. Suprianto, M.P selaku Ketua STT Pelita Bangsa
b. Bapak Aswan Supriyadi Sunge, SE.,M.Kom selaku Ketua Program Studi Teknik Informatika STT Pelita Bangsa.
c. Bapak Donny Maulana, S.Kom.,M.MSi selaku Pembimbing Utama yang telah banyak memberikan arahan dan bimbingan kepada penulis dalam penyusunan Skripsi ini.
d. Seluruh Dosen STT Pelita Bangsa yang telah membekali penulis dengan wawasan dan ilmu di bidang teknik informatika.
e. Seluruh staf STT Pelita Bangsa yang telah memberikan pelayanan terbaiknya kepada penulis selama perjalanan studi jenjang Strata 1.
f. Rekan-rekan mahasiswa STT Pelita Bangsa, khususnya angkatan 2014, yang telah banyak memberikan inspirasi dan semangat kepada penulis untuk dapat menyelesaikan studi jenjang Strata 1.
g. Ibu dan Ayah tercinta yang senantiasa mendo’akan dan memberikan semangat dalam perjalanan studi Strata 1 maupun dalam kehidupan penulis.
vii
Akhir kata, penulis mohon maaf atas kekeliruan dan kesalahan yang terdapat dalam Skripsi ini dan berharap semoga Skripsi ini dapat memberikan manfaat bagi khasanah pengetahuan Teknologi Informasi di lingkungan STT Pelita Bangsa khususnya dan Indonesia pada umumnya.
Bekasi, 3 November 2018
viii DAFTAR ISI
PERSETUJUAN ... i
PENGESAHAN ... ii
PERNYATAAN KEASLIAN DAN PENELITIAN ... iii
ABSTRAKSI ... iv
ABSTRACT ... v
KATA PENGANTAR ... vi
DAFTAR ISI ... viii
DAFTAR TABEL ... xii
DAFTAR GAMBAR ... xv
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Identifikasi Masalah dan Batasan Masalah ... 3
1.2.1 Identifikasi Masalah... 3
1.2.2 Batasan Masalah ... 3
1.3 Rumusan Masalah ... 4
1.4 Tujuan dan Manfaat ... 4
1.4.1 Tujuan ... 4
1.4.2 Manfaat ... 4
ix
BAB II TINJAUAN PUSTAKA ... 7
2.1 Keluhan Pelanggan ... 7
2.2 Data Mining ... 9
2.2.1 Pengelompokan Data Mining ... 10
2.2.2 Tahap – Tahap Data Mining... 12
2.2.3 Metode Data Mining ... 13
2.3 Naïve Bayes Classification ... 15
2.4 Weka ... 20
2.5 Kerangka Berfikir ... 21
BAB III METODE PENELITIAN... 23
3.1 Objek Penelitian ... 23
3.1.1 Profil Perusahaan... 23
3.1.2 Deskripsi Bisnis Perusahaan ... 24
3.2 Metode Penelitian ... 25
3.3 Metode Pengumpulan Data ... 25
3.4 Perangkat Lunak ... 25
3.5 Sumber Data ... 26
3.6 Tahapan Penelitian ... 27
BAB IV HASIL PENELITIAN DAN PEMBAHASAN ... 29
4.1 Dataset ... 29
4.2 Koleksi Dokumen ... 29
x
4.3.1 Hasil Evaluasi Algoritma Naive Bayes ... 30 4.3.2 Hasil Evaluasi Algoritma Naive Bayes dengan cross
validation 10 fold ... 33 4.3.3 Hasil Evaluasi Algoritma Naive Bayes dengan cross
validation 8 fold ... 37 4.3.4 Hasil Evaluasi Algoritma Naive Bayes dengan
percentage split 50 ... 40 4.3.5 Hasil Evaluasi Algoritma Naive Bayes dengan
percentage split 66 ... 43
4.4 Hasil Analisis Algoritma Naive Bayes ... 47 4.4.1 Hasil analisis pendekatan training set dan testing set
Algoritma Naive Bayes... 47
4.4.2 Hasil analisis pendekatan training set dan testing
cross validation 10 fold Algoritma Naive Bayes ... 48
4.4.3 Hasil analisis pendekatan training set dan testing
cross validation 8 fold Algoritma Naive Bayes ... 50
4.4.4 Hasil analisis pendekatan training set dan testing
percentage split 50 Algoritma Naive Bayes ... 51 4.4.5 Hasil analisis pendekatan training set dan testing percentage
split 66 Algoritma Naive Bayes ... 52
xi BAB V PENUTUP ... 57 5.1 Kesimpulan ... 57 5.2 Saran ... 57 DAFTAR PUSTAKA ... 58 LAMPIRAN ... 60
xii
DAFTAR TABEL
Tabel 3.1 Sampel Data Primer ... 26
Tabel 4.1 Atribut Dataset Penelitian ... 29
Tabel 4.2 Koleksi dokumen training dan testing claim pelanggan sari roti 30 Tabel 4.3 Hasil Training Set Naive Bayes ... 30
Tabel 4.4 Hasil akurasi data training kelayakan konsumsi ... 31
Tabel 4.5 Hasil data training matrik kelas ... 31
Tabel 4.6 Hasil Evaluasi Supplied Test Set Naive Bayes ... 32
Tabel 4.7 Hasil akurasi data testing kelayakan konsumsi ... 32
Tabel 4.8 Hasil data testing matrik kelas ... 33
Tabel 4.9 Hasil Training Set cross validation 10 fold Naive Bayes ... 33
Tabel 4.10 Hasil akurasi data training kelayakan konsumsi ... 34
Tabel 4.11 Hasil data training matrik kelas ... 34
Tabel 4.12 Hasil Evaluasi cross validation 10 fold Naive Bayes ... 35
Tabel 4.13 Hasil akurasi data testing cross validation 10 fold kelayakan konsumsi ... 36
Tabel 4.14 Hasil data testing cross validation 10 fold matrik kelas... 36
Tabel 4.15 Hasil Training Set cross validation 8 fold Naive Bayes ... 37
Tabel 4.16 Hasil akurasi data training kelayakan konsumsi ... 37
Tabel 4.17 Hasil data training matrik kelas ... 38
Tabel 4.18 Hasil Evaluasi cross validation 8 fold Naive Bayes ... 38
Tabel 4.19 Hasil akurasi data testing cross validation 8 fold kelayakan konsumsi ... 39
xiii
Tabel 4.20 Hasil dan testing cross validation 8 fold matrik kelas ... 39
Tabel 4.21 Hasil Training Set percentage split 50 Naive Bayes ... 39
Tabel 4.22 Hasil akurasi data training kelayakan konsumsi ... 41
Tabel 4.23 Hasil data training matrik kelas ... 41
Tabel 4.24 Hasil Evaluasi percentage split 50 Naive Bayes ... 42
Tabel 4.25 Hasil akurasi data testing percentage split 50 kelayakan konsumsi ... 42
Tabel 4.26 Hasil data testing percentage split 50 matrik kelas... 43
Tabel 4.27 Hasil Training Set percentage split 66 Naive Bayes ... 43
Tabel 4.28 Hasil akurasi data training kelayakan konsumsi ... 44
Tabel 4.29 Hasil data training matrik kelas ... 45
Tabel 4.30 Hasil Evaluasi percentage split 66 Naive Bayes ... 45
Tabel 4.31 Hasil akurasi data testing percentage split 66 kelayakan konsumsi ... 46
Tabel 4.32 Hasil data testing percentage split 66 matrik kelas... 46
Tabel 4.33 Hasil data training test dan testing test naïve bayes ... 47
Tabel 4.34 Hasil data training test dan testing cross validation 10 fold naïve bayes ... 49
Tabel 4.35 Hasil data training test dan testing cross validation 8 fold naïve bayes ... 50
Tabel 4.36 Hasil data data training test dan testing percentage split 50 naïve bayes ... 51
Tabel 4.37 Hasil data training test dan testing percentage split 66 naïve bayes ... 53
xiv
Tabel 4.38 Hasil akurasi dan mean error data macam – macam
1
BAB I
PENDAHULUAN
1.1 Latar Belakang
Melalui era perdagangan bebas, persaingan bisnis antara perusahaan yang berlangsung ketat, termasuk pula pada perdangangan di bidang industri. Perusahaan perlu mengembangkan strategi yang tepat untuk menghadapi perubahan di dunia bisnis. Perusahaan tetap mempertahankan produk yang berkualitas dan layak dikonsumsi oleh konsumennya. Maka dengan ini perusahaan harus mempertahankan eksistensisnya dan memperbaiki kinerja didalam pembuatan produk dengan hasil yang dapat diterima oleh pelanggan.
Dengan kemajuan teknologi informasi diharapkan dapat menjadi media yang lebih efektif untuk meninjau kemajuan kualitas produk pada perusahaan. Kualitas produk bisa diartikan sebagai kesesuaian atau kepuasan konsumen terhadap produk yang dikonsumsi oleh pelanggan. Maka produk yang diproduksi harus menghasilkan produk yang sesuai dengan standar dan ditetapkan oleh perusahaan tersebut. Kepuasan pelanggan mencakup kualitas produk (quality of product), biaya (quality of cost), keselamatan (quality of safety) dan penyampaian (quality of delivery).
Aspirasi pelanggan yang terjadi karena adanya ketidakpuasan suatu barang yang diperjual belikan kepada konsumen. Ketidakpuasan yang dirasakan oleh konsumen ketika membeli dan mengkonsumsi barang maka akan menjadi suatu keluhan pelanggan yang tidak bisa diabaikan begitu saja, karena hal tersebut akan
2
membuat pelanggan merasa tidak dihargai dan tidak diperhatikan sama sekali. Banyak hal yang mempengaruhi keluhan pelanggan diantaranya produk yang di produksi tidak berkualitas tinggi dan mutu pangannya tidak terjaga.
PT. Nippon Indosari Corpindo Tbk, bergerak di bidang bakery/roti akan selalu memberikan kualitas yang lebih baik bagi para pelanggan dan konsumennya. Khususnya dalam kualitas produk yang dihasilkan PT. Nippon Indosari Corpindo Tbk, memiliki beberapa departement yang harus menjamin kualitas produk tersebut seperti departemen PPIC, Produksi, Quality Control, Finish Good dan Where house. Survei pelanggan diantaranya untuk menjaring keluhan pelanggan dengan data keluhan pelanggan yang cukup banyak dan data yang sangat besar maka perlu dilakukan analisis data mining. Pelanggan perusahaan mana dan siapa saja diperlukan untuk meningkatkan kualitas produk sesuai dengan selera pelanggan maka perlu dilakukn survei pelanggan karena pelanggan cukup banyak sehingga menghasilkan data cukup besar maka perlu analisis data mining. Kemajuan teknologi informasi yang mencakup di sebuah perusahaan tentunya memiliki data yang sangat besar. Pemanfaatan data dalam sistem informasi untuk menunjang kegiatan pengambilan kesimpulan, tidak hanya mengandalkan data operasional yang tersedia saja, diperlukan analisa data untuk menggali potensi suatu produk yang ada di sistem informasi.
Dari masalah yang dijabarkan diatas maka penulis tertarik untuk meneliti mengenai data keluhan pelanggan terhadap kualitas produk perusahaan ini. Oleh karena itu peneliti tertarik untuk melakukan penelitian yang berkaitan dengan keluhan pelanggan dengan judul penelitian “ANALISIS DATA MINING UNTUK
3
MENGETAHUI KELUHAN PELANGGAN MENGGUNAKAN METODE NAIVE BAYES”
1.2 Identifikasi Masalah dan Pembatasan Masalah
1.2.1 Identifikasi Masalah
Berdasarkan latar belakang yang telah disampaikan, maka penulis akan memberikan identifikasi masalah yang akan dijadikan bahan penelitian sebagai berikut:
1. Menurunnya kepuasaan pelanggan terhadap produk yang di hasilkan oleh perusahaan.
2. Meningkatnya data keluhan pelanggan sehingga perusahaan harus memperbaiki kualitas produk.
3. Menganalisa data keluhan pelanggan untuk mengukur seberapa puaskah pelanggan dengan produk yang dihasilkan.
1.2.2 Batasan Masalah
Agar penulisan penelitian ini tidak menyimpang dan tetap fokus terhadap tujuan yang semula direncanakan sehingga mempermudah mendapatkan data informasi yang diperlukan, maka penulis menetapkan batasan masalah sebagai berikut:
Pada penelitian ini penulis hanya membahas yang berhubungan dengan 1. keluhan pelanggan dan Kepuasan pelanggan
2. Analisa Data Mining 3. Naïve Bayes
4 1.3 Rumusan Masalah
Berdasarkan latar belakang dan identifikasi masalah yang telah disampaikan, maka perlu dirumuskan suatu masalah yang akan dipecahkan/diselesaikan pada penelitian ini.
1. Bagaimana cara menganalisa menggunakan pendekatan supplied test naïve bayes?
2. Bagaimana cara menganalisa data keluhan pelanggan menggunakan metode Naïve Bayes ?
3. Bagaimana cara membandingkan antara pendekatan cross validation 8 fold dan 10 fold serta percentage splite 50 dan 66 splite?
1.4 Tujuan dan Manfaat
1.4.1 Tujuan
1. Untuk meningkatkan efektifitas dan efesiensi kinerja karyawan agar produk yang diproduksi dapat memuaskan pelanggan.
2. Dapat mengetahui keluhan pelanggan apakah pelanggan tersebut puas atau tidak puas dengan produk yang kita produksi.
3. Untuk mengetahui perbandingan antara cross validation 8 fold , 10 fold, percentage splite 50 dan 66 splite serta supplied test naïve bayes. 1.4.2 Manfaat
Besar harapan penulis dalam menyusun skripsi ini agar dapat memberikan kontribusi berbagai pihak antara lain:
5 1. Manfaat bagi penulis
Penulis berharap agar skripsi ini merupakan implementasi dari teori semasa perkuliahan yang telah didapatkan di STT Pelita Bangsa terutama pada data mining naive bayes.
2. Manfaat bagi perusahaan
Semoga dengan adanya penelitian di perusahaan, dapat membantu untuk mengetahui seberapa puaskah pelanggan dengan produk yang dihasilkan oleh perusahaan.
1.5 Sistematika Penulisan
Sistematika penulisan merupakan uraian tentang penyusunan dari penulis itu sendiri yang dibuat secara teratur dan terperinci, sehingga dapat memberikan gambaran secara menyeluruh.
BAB I : PENDAHULUAN
Pada bab ini penulis mengemukaan tentang Latar Belakang, Identifikasi Masalah, Rumusan Masalah, Batasan Masalah, Tujuan dan Manfaat, Sistematika Penulisan. BAB II : TINJAUAN PUSTAKA
Pada bab ini terdapat Kajian Pustaka, Dasar Teori dan Kerangka Berfikir. BAB III : METODE PENELITIAN
6
BAB IV : HASIL PENELITIAN DAN PEMBAHASAN
Pada bab ini menguraikan tentang Hasil penelitian dan Pembahasan dari data yang telah diperoleh.
BAB V : PENUTUP
Pada bab ini berisikan Kesimpulan dari apa yang telah dibahas dari bab I sampa dengan bab IV serta berisikan Saran yang bersifat membangun untuk kepentingan perusahaan itu sendiri atau untuk kepentingan umum.
7
BAB II
TINJAUAN PUSTAKA
2.1 Keluhan Pelanggan
Keluhan adalah satu pernyataan atau ungkapan rasa kurang puas terhadap satu produk atau layanan, baik secara lisan maupun tertulis, dari pelanggan internal maupun eksternal. Adanya keluhan dalam satu sisi sebetulnya menjadi alat kontrol atau evaluasi terhadap pemberian kualitas pelayanan yang selama ini diberikan kepada pelanggan/masyarakat. Dalam Modul Public Services STIA LAN (2004) menjelaskan dalam menyelesaikan keluhan ada faktor penting yang diperhatikan, yakni: kecepatan penanganan komplain dan penyelesain komplain. Lembaga yang tidak care/perhatian terhadap keluhan pelanggan akan cenderung menanganinya dengan lamban dan penyelesaianya pun relatif lambat. Hal ini yang kadang tidak menjadi perhatian lembaga, padahal semakin terjadi keterlambatan maka keluhan semakin bermasalah dan mempunyai dampak yang luas.
Menurut Kotler (2013 : 59) ada beberapa macam keluhan, yakni :
1. Keluhan yang disampaikan secara lisan melalui telepon dan komunikasi secara langsung.
2. Keluhan yang disampaikan secara tertulis melalui guest complain form.
8
Menurut Sugiarto (2014), keluhan pelanggan dapat dikategorikan atau dikelompokkan menjadi empat, yaitu:
1. Mechanical Complaint (Keluhan mekanikal)
Mechanical Complaint adalah suatu keluhan yang disampaikan oleh pelanggan sehubungan dengan tidak berfungsinya peralatan yang dibeli atau disampaikan kepada pelanggan tersebut. Atau dengan kata lain, produk atau output dari pelayanan yang diberikan tidak sesuai dengan yang diharapkan. Hal ini dapat terjadi karena kerusakan atau kualitas tidak maksimal.
2. Attitudinal Complaint (Keluhan akibat sikap petugas pelayanan) Attitudinal complaint adalah keluhan pelanggan yang timbul karena sikap negatif petugas pelayanan pada saat melayani pelanggan. Hal ini dapat dirasakan oleh pelanggan melalui sikap tidak peduli dari petugas pelayanan terhadap pelanggan.
3. Service Related Complaint (Keluhan yang berhubungan dengan pelayanan) Service Related Complaint adalah suatu keluhan pelanggan karena hal-hal yang berhubungan dengan pelayanan itu sendiri. Misalnya seseorang mendaftar untuk ikut serta suatu pertandingan, ternyata formulir pendaftaran belum siap dan oleh petugas diminta untuk menunggu.
4. Unusual Complaint (Keluhan yang aneh)
Unusual Complaint adalah keluhan pelanggan yang bagi petugas merupakan keanehan (tidak wajar). Pelanggan yang mengeluh seperti
9
ini biasanya secara psikologis adalah orang-orang yang hidupnya tidak bahagia atau kesepian.
Keluhan pelanggan merupakan umpan balik dari pelanggan yang bersifat negatif agar produk yang dikeluhkan bisa diterima kembali maka pihak perusahaan akan segera memperbaiki kualitas produk yang diproduksi.
2.2 Data Mining
Data mining adalah serangkaian proses untuk menggali nilai tambah berupa informasi yang selama ini tidak diketahui secara manual dari suatu basis data. Informasi yang dihasilkan diperoleh dengan cara mengekstraksi dan menggali pola yang penting atau menarik dari data yang terdapat pada basis data. Data mining terutama digunakan untuk mencari pengetahuan yang terdapat dalam basis data yang besar sehingga sering disebut Knowledge Discovery Databases (KDD) ( Retno, 2017 : 1 ).
Data mining adalah proses yang menggunakan teknik statistik, matematika, kecerdasan buatan, dan machine learning untuk mengekstrasi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dari berbagai database besar (Yuda, 2013 : 2-3).
Ada beberapa penelitian yang membahas tentang keluhan pelanggan menggunakan metode data mining Naïve Bayes yang pernah dilakukan oleh peneliti sebelumnya antara lain dilakukan oleh :
Sabtono Ristu, Wiranto & Suryono Daga Wachid (2016), “Sistem Klasifikasi Keluhan Pelanggan di UPT TIK UNS Menggunakan Algoritma Naïve
10
Bayesian Classifier” ketidakpuasan terhadap perusahaan yang membahas tentang pembangunan sebuah sistem untuk mengklasifikasikan keluhan. Sistem di bangun menggunakan algoritma Naïve Bayes Classifier berdasarkan supervise learning.
Mahardhika Alfiani Aisha, Sabtono Ristu & Anggrainingsih Rini (2015), “Sistem Klasifikasi Feedback Pelanggan dan Rekomedasi Solusi atas Keluhan di UPT PUSKOM UNS dengan Algoritma Naïve Bayes Classifier dan Cosine Similarity”. Algoritma cosine similarity digunakan untuk mengelompokan mentions keluhan yang memiliki term yang sama. Dari kelompok mentions tersebut, administrator akan memberikan solusi yang relevan terhadap keluhan.
Meysandes Jojo, Haidar Mirza A & Muzakir Ari (2016), “ Model Data Mining untuk Prediksi Data Konsumen FINANSIA MULTI FINANCE (FMF) Prabumulih dengan Metode Naïve Bayes Classifier “ Tujuan dilakukan penelitian ialah untuk membuat model data mining untuk prediksi data konsumen dengan metode naïve bayes Classifier dan untuk pemanfaatan data riwayat performance konsumen untuk proses pengambilan keputusan pemberian kredit dengan memanfaatkan komputer yang dimiliki perusahaan.
2.2.1 Pengelompokan Data Mining
Menurut Larose, data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang dapat di lakukan, yaitu :
1. Deskripsi
Terkadang peneliti dan analisis secara sederhana ingin mencoba mencari cara untuk menggambarkan pola dan kecendrungan yang terdapat dalam data.
11 2. Estimasi
Estimasi hampir sama dengan klasifikasi, kecuali variabel target estimasi lebih ke arah numerik dari pada ke arah kategori.
3. Prediksi
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam prediksi nilai dari hasil akan ada di masa mendatang.
4. Klasifikasi
Dalam klasifikasi, terdapat target variabel kategori.
5.
PengklusteranClustering merupakan suatu metode untuk mencari dan mengelompokkan data yang memiliki kemiripan karakteriktik (similarity) antara satu data dengan data yang lain. Clustering merupakan salah satu metode data mining yang bersifat tanpa arahan (unsupervised).
6.
AsosiasiTugas asosiasi dalam data mining adalah menemukan atribut yang muncul dalam suatu waktu. Dalam dunia bisnis lebih umum disebut analisis keranjang belanja.
12 2.2.2 Tahap – Tahap Data Mining
Tahap – tahap data mining ada 6 yaitu : 1. Pembersihan data (Data Cleaning)
Pembersihan data merupakan proses menghilangkan noise dan data yang tidak konsisten atau data tidak relevan.
2. Intergrasi data (data integration).
Integrasi data merupakan penggabungan data dari berbagai database ke dalam satu database baru.
3. Seleksi data (data selection)
Data yang ada pada database sering kali tidak semuanya dipakai, oleh karena itu hanya data yang sesuai untuk di analisis untuk diambil dari database.
4. Transformasi data (Transformation data)
Data diubah atau digabung kedalam format yang sesuai untuk diproses kedalam data mining.
5. Proses Mining
Merupakan suatu proses utama saat metode diterapkan untuk menemukan pengetahuan berharga dan tersembunyi dari data.
6. Evalusai pola (pattern evaluation)
Untuk mengidentifikasi pola – pola menarik kedalam knowledge based yang ditemukan.
13
7. Presentasi pengetahuan (knowledge presentation)
Merupakan visualisasi dan penyajian pengetahuan mengenai metode yang digunakan untuk memperoleh pengetahuan yang diperoleh pengguna.
2.2.3 Metode Data Mining
Menurut Larose, data mining memiliki enam fase CRISP-DM (Cross Industry Standard Process for Data Mining).
1. Fase Pemahaman Bisnis (Business Understanding Phase)
Pemahaman tentang substansi dari kegiatan data mining yang akan dilakukan, kebutuhan dari perspektif bisnis. Kegiatannya antara lain : menentukan sasaran atau tujuan bisnis, memahami situasi bisnis, menentukan tujuan data mining dan membuat perencanaan strategi serta jadwal penelitian. 2. Fase Pemahaman Data (Data Understanding Phase)
Fase mengumpulkan data awal, mempelajari data untuk bias mengenal data yang akan dipakai, mengindentifikasikan masalah yang berkaitan dengan kualitas data, mendeteksi subset yang menarik dari data untuk membuat hipotesa awal.
3. Fase Pengolahan Data (Data Preparation Phase)
Sering disebut sebagai fase padat karya. Aktifitas yang dilakukan antara lain memilih table dan field yang akan ditransformasikan ke dalama database baru untuk bahan data mining.
14 4. Fase Pemodelan (Modeling Phase)
Fase menentukan teknik data mining yang digunakan, menentukan tools data mining, teknik data mining, algoritma data mining, menentukan
parameter dengan nilai optimal. 5. Fase Evaluasi (Evaluation Phase)
Fase interpretasi terhadap hasil data mining yang ditunjukkan dalam proses pemodelan pada fase sebelumnya.
6. Fase Penyebaran (Deployment Phase)
Fase penyusunan laporan atau presentasi dari pengetahuan yang didapat dari evaluasi pada proses data mining.
Gambar 2.1 Model CRISP-DM (Sumber : academia.edu) 2.2.4 Metode Klasifikasi
Klasifikasi adalah proses untuk menemukan model atau fungsi untuk menjelaskan atau membedakan konsep atau kelas data, dengan tujuan untuk dapat memperkirakan kelas daru suatu objek yang labelnya tidak diketahui. Dalam mencapai tujuan tersebut, proses klasifikasi
15
membentuk suatu model yang mampu membedakan data kedalam kelas-kelas yang berbeda berdasarkan auran atau fungsi tertentu. Model itu sendiri bias berupa auran “jika-maka”m berupa pohon keputusan atau formula matematis.
Gambar 2.2 Blok Diagram Model Klasifikasi (Sumber : academia.edu)
1.6 2.3 Naïve Bayes Classification
Menurut Kusrini dan Lutfhi (2010:199) “Bayesian Classification merupakan pengklasifikasian statistic yang dapat digunakan untuk memprediksi probabilitas keanggotaan suatu class. Bayesian classification didasarkan pada teorema bayes yang mempunyai kemampuan klasifikasi serupa dengan decision tree dan neural network. Bayesian classification terbuksi memiliki akurasi dan kecepatan yang tinggi saat diaplikasikan kedalam database dengan data yang besar.”
Pendekatan naïve bayes membuat asumsi sederhana bahwa semua atribut bersifat independen. Hal ini menyebabkan penggolongan yang jauh lebih sederhana, ini membuat efektif dalam praktiknya. Berikut persamaan dari teorema
bayes:
( | )
( | ) ( )16 Keterangan :
X : Data dengan kelas yang belum diketahui Y : Hipotesis dan X adalah suatu kelas spesifik P(Y|X) : Probabilitas hipotesis Y berdasar kondisi X P(Y) : Probabilitas Hipotesis Y
P(X|Y) : Probabititas X berdasarkan kondisi pada saat hipotesis Y P(X) : Pribabilitas X
Untuk menjelaskan metode Naive Bayes, perlu diketahui bahwa proses Klasifikasi memerlukan sejumlah petunjuk untuk menentukan kelas apa yang cocok bagi sampel yang dianalisis tersebut. Karena itu, metode Naive Bayes diatas disesuaikan sebagai berikut :
( | ) ( ) ( | ) ( )
Dimana variabel C merepresentasikan kelas, sementara variabel F1 ... Fn merepresentasikan karakteristik petunjuk yang dibutuhkan untuk melakukan klasifikasi. Maka rumus tersebut menjelaskan bahwa peluang masuknya sampel karakteristik tertentu dalam kelas C (Posterior) adalah munculnya peluang kelas C (sebelum masuknya sampel tersebut, sering kali disebut Prior), dikali dengan peluang kemunculan karakteristik - karakteristik sampel pada kelas C (disebut juga likelihood), dibagi dengan peluang kemunculan karakteristik - karakteristik sampel secara global (disebut juga evidence). Karena itu, rumus di atas dapat pula ditulis secara sederhana sebagai berikut :
17
Nilai Evidence selalu tetap untuk setiap kelas pada satu sampel. Nilai dari posterior tersebut nantinya akan dibandingkan dengan nilai-nilai posterior kelas lainnya untuk menentukan ke kelas apa suatu sampel akan diklasifikasikan. Penjabaran lebih lanjut rumus Bayes tersebut dilakukan dengan menjabarkan ( | 1... ) menggunakan aturan perkalian sebagai berikut:
( | 1,…,= ( ) ( 1,…, | ) =( ) ( 1| ) ( 2,…, | , 1)
= ( ) ( 1| ) ( 2| , 1 ) ( 3,…, | , 1, 2
=( ) ( 1| ) ( 2| , 1 ) ( 3| , 1, 2) ( 4,…, | , 1, 2, 3) = ( ) ( 1| ) ( 2| , 1 ) ( 3| , 1, 2)… ( | , 1, 2, 3,…, −1)
Dapat dilihat bahwa hasil penjabaran tersebut menyebabkan semakin banyak dan semakin kompleksnya faktor - faktor syarat yang mempengaruhi nilai probabilitas, yang hampir mustahil untuk dianalisa satu persatu. Akibatnya, perhitungan tersebut menjadi sulit untuk dilakukan. Di sinilah digunakan asumsi independensi yang sangat tinggi (naif), bahwa masing-masing petunjuk (F1,F2...Fn) saling bebas (independen) satu sama lain. Dengan asumsi tersebut, maka berlaku suatu kesamaan sebagai berikut:
( | ) ( ) ( )
( ) ( )
( ) ( ) Untuk i≠j, sehingga
18
( ) ( )
Dari persamaan diatas dapat disimpulkan bahwa asumsi independensi naif tersebut membuat syarat peluang menjadi sederhana, sehingga perhitungan menjadi mungkin untuk dilakukan. Selanjutnya, penjabaran P(C|F1, …, Fn) dapat
disederhanakan menjadi :
Persamaan diatas merupakan model dari teorema Naive Bayes yang selanjutnya akan digunakan dalam proses klasifikasi.
Umumnya, Bayes mudah dihitung untuk fitur bertipe kategoris seperti pada kasus fitur “jenis kelamin” dengan nilai {pria,wanita} namun untuk fitur numerik ada perlakuan khusus sebelum dimasukkan dalam Naïve Bayes. Caranya adalah :
1. Melakukan diskretisasi pada setiap fitur kontinyu dan mengganti niai fitur kontinyu tersebut dengan nilai interval diskret. Pendekatan ini dilakukan dengan mentransformasikan fitur kontinyu ke dalam fitur ordinal.
2. Mengasumsikan bentuk tertentu dari distribusi probabilitas untuk fitur kontinyu dan memperkirakan parameter distribusi dengan data pelatihan. Distribusi Gaussian sering dipilih untuk merepresentasikan peluang kelas bersyarat untuk atribut kontinyu. Distribusi dikarakterisasi dengan dua parameter yaitu mean, μ ,dan varian, σ2. Untuk tiap kelas yj , peluang
19 ( | ) √ ( ) Di mana : P : Peluang Xi : Atribut ke i Xi : Nilai atribut ke i Y : Kelas yang dicari Yi : Sub kelas Y yang dicari
μ : mean, menyatakan rata – rata dari seluruh atribut σ :Deviasi standar, menyatakan varian dari seluruh atribut. Adapun alur dari metode Naïve Bayes adalah sebagai berikut :
1. Baca data training
2. Hitung Jumlah dan probabilitas, namun apabila data numerik maka:
a. Cari nilai mean dan standar deviasi dari masing masing parameter yang merupakan data numeric.
b. Cari nilai probabilistik dengan cara menghitung jumlah data yang sesuai dari kategori yang sama dibagi dengan jumlah data pada kategori tersebut.
20
3. Mendapatkan nilai dalam tabel mean, standart deviasi dan probabilitas.
Gambar 2.3 Skema Naïve Bayes
1.7 2.4 Weka
WEKA adalah sebuah machine learning tool yang ditulis dengan bahasa pemrograman Java. WEKA ini memuat banyak machine learning algoritma di dalam nya. Dengan WEKA kita bisa melakukan pre-processing data, classification, regression, clustering, association rules, dan juga visualization. WEKA merupakan singkatan dari Waikato Environment for Knowledge Analysis, yang dikembangkan oleh Waikato University di New Zealand. WEKA juga merupakan sebuah nama dari burung yang cuma berhabitat di New Zealand.
21
Gambar 2.4 Tolls Weka 1.8 2.5 Kerangka Berfikir
Adapun kerangka berfikir dari penelitian yang dilakukan adalah sebagai berikut:
22
Kerangka berfikir diatas menjelaskan tentang rumusan masalah untuk mengetahui keluhan pelanggan. Untuk membantu menyelesaikan masalah tersebut maka penulis menggunakan aplikasi perangkat lunak WEKA dan menggunakan metode naïve bayes. Dengan mereferensi dari buku dan jurnal maka akan diimplementasikan dengan hasil apakah produk yang kita produksi layak konsumsi atau tidak layak konsumsi.
23
BAB III
METODE PENELITIAN
3.1 ObjekPenelitian
Objek penelitian dilaksanakan pada PT Nippon Indosari Corp Tbk Cibitung, yang menjadi objek penelitian adalah data keluhan dari pelanggan PT Nippon Indosari Corp Tbk.
3.1.1 Profil Perusahaan
Roti umumnya dikonsumsi untuk sarapan pagi. Namun, saat ini roti juga dikonsumsi lebih dari sekedar untuk sarapan, dengan sifatnya yang praktis, padat dan bergizi, roti dapat memenuhi kebutuhan gaya hidup masyarakat yang semakin mobile kapan saja dan dimana saja.
Nippon Indosari Corpindo Tbk (Sari Roti) didirikan 08 Maret 1995 dengan nama PT Nippon Indosari Corporation dan mulai beroperasi komersial pada tahun 1996. Kantor pusat dan salah satu pabrik sari roti ini berkedudukan di Kawasan Industri MM 2100 Jl. Selayar blok A9, Desa Mekarwangi, Cikarang Barat, Bekasi 17530 – Jawa Barat, dan pabrik lainnya berlokasi di Kawasan Industri Jababeka Cikarang blok U dan W – Bekasi, Pasuruan, Semarang, Makassar, Purwakarta, Palembang, Cikande dan Medan.
24
3.1.2 Deskripsi Bisnis Perusahaan
Dalam proses pembuatan roti, dikenal beberapa metode proses pembuatannya. Mulai dari proses yang hanya memerlukan satu kali pencampuran seperti straight dough mixing dan no time dough mixing, hingga proses pembuatan roti yang memerlukan dua kali proses pencampuran seperti sponge and dough mixing. Masing-masing metode memiliki kelebihan dan kekurangan. Dalam proses pembuatan roti, Sari roti menggunakan metode sponge and dough mixing.
Pada proses pencampuran pertama atau sponge mixing, sebagian bahan baku dicampurkan terlebih dahulu untuk menghasilkan adonan biang. Bahan baku yang telah tercampur selanjutnya disimpan pada tempat khusus untuk kemudian disimpan pada ruang fermentasi. Proses fermentasi ini berlangsung antara 3 hingga 4 jam pada ruangan khusus yang dijaga suhu dan kelembabannya agar proses fermentasi dapat berlangsung secara sempurna.
Setelah proses fermentasi selesai, adonan akan kembali dimasukkan ke dalam mixer untuk dilakukan proses pencampuran bahan kedua atau dikenal sebagai dough mixing. Proses fermentasi akhir (final proofing) ini memiliki prinsip yang sama dengan proses fermentasi pertama, namun dilakukan dengan waktu yang lebih singkat. Setelah adonan mengembang dan diperoleh volume adonan yang sesuai dengan standar yang diharapkan, adonan selanjutnya dikeluarkan dan siap untuk dipanggang.
25
1.9 3.2 Metode Penelitian
Metode yang akan digunakan untuk menyelesaikan penelitian ini adalah jenis penelitian eksperimen yaitu melakukan pengujian tingkat akurasi algoritma naïve bayes dalam penentuan penyebab keluhan pelanggan. Data eksperimen diambil dari data customer claim.
1.10 3.3 Metode Pengumpulan Data
Dalam penelitian ini metode pengumpulan data yang digunakan yaitu : 1. Metode Observasi
Melakukan pengamatan langsung ke PT Nippon Indosari Corp Tbk untuk memperoleh data yang dibutuhkan.
2. Metode Wawancara
Mengadakan wawancara dengan pihak-pihak yang berkaitan langsung dengan permasalahan yang sedang dibahas pada penelitian ini untuk memperoleh gambaran dan penjelasan secara mendasar.
3. Metode Studi Pustaka
Metode ini dengan mengumpulkan referensi dari literature-literatur yang bisa mendukung penelitian sebagai landasan teori dan dasar pedoman dalam pembuatan laporan.
3.4 Perangkat Lunak
Setelah menentukan dataset untuk penelitian, kemudian mencari perangkat lunak yang digunakan untuk alat bantu penelitian. Dari sejumlah perangkat lunak dan dataset yang ada, peneliti memilih menggunakan perangkat lunak WEKA dan dataset customer claim .
26
Weka adalah perangkat lunak yang beorientasi objek, open source berbasis java yang bisa digunakan untuk klasifikasi dalam penentuan kerusakan radiator dengan menganalisis dan membandingkan tingkat akurasi kedua algoritma dalam penelitian ini.
1.11 3.5 Sumber Data
Data yang diperoleh dalam penelitian ini merupakan data primer yaitu data yang didapatkan langsung dari sumber data selain itu dalam membantu penyusunan skripsi ini digunakan beberapa studi pustaka yang merupakan data sekunder.
1. Data Primer
Tabel 3.1 Sampel Data Primer
Jenis Kelamin Jenis Produk Agen Status Keluhan
Perempuan WB JKT Tidak Berjamur
Laki-laki WB BKS Berjamur
Perempuan SB JKT Tidak Berjamur
Perempuan SB JKT Berjamur
Laki-laki WB CKR Tidak Berjamur
Keterangan: WB : White Bread SB : Sweet Bread JKT : Jakarta BKS : Bekasi CKR : Cikarang
27
2. Data Sekunder
a. Buku yang membahas data mining khususnya algoritma naïve bayes b. E-book mengenai data mining dan algoritmanya
c. Jurnal mengenai kasus klasifikasi keluhan pelanggan 1.12 3.6 Tahapan Penelitian
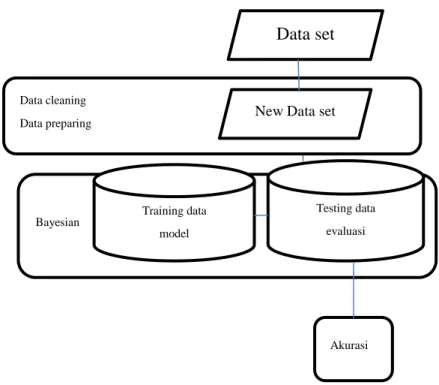
Metode yang akan digunakan dalam penelitian ini adalah algoritma naïve bayes untuk melakukan pengukuran akurasi dalam penelitian ini akan menggunakan tools WEKA.
Gambar 3.1 Model Penelitian yang diusulkan
Data cleaning
Data preparing New Data set
Bayesian Data set Akurasi Training data model Testing data evaluasi
28
Data Set.
Data set diambil dari data real disuatu perusahaan manufacture yaitu data customer claim
New Data Set.
Data set dari data real disuatu perusahaan manufacture kemudian dilakukan pembersihan data untuk menentukan atribut.
Training Data.
New data set kemudian dibagi menjadi 2 yaitu ; sebagai training data dan testing data. Data training digunakan untuk data preprocess
Testing Data evaluasi.
Testing data untuk proses klasifikasi dengan algoritma yang digunakan dalam penelitian ini
Accuracy.
Proses klasifikasi akan menghasilkan tingat akurasi suatu algoritma yang digunakan
29
BAB IV
HASIL PENELITIAN DAN PEMBAHASAN
Bab ini membahas tentang hasil penelitian yang dilakukan mulai dari dataset yang digunakan dan hasil yang diperoleh. Dalam penelitian ini dilakukan percobaan terhadap dataset customer claim pelanggan sari roti dengan algoritma naïve bayes.
4.1 Dataset`
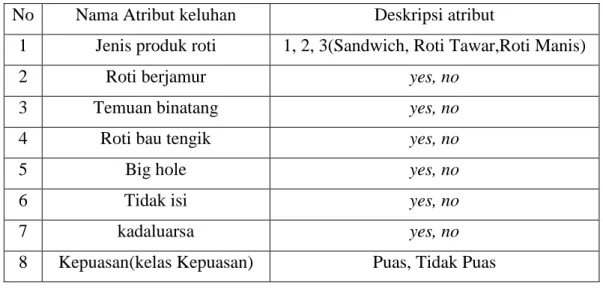
Penelitian ini menggunakan dataset yaitu dataset customer claim sari roti yang terdiri dari 7 atribut dataset yang digunakan :
Tabel 4.1 Atribut Dataset Penelitian
No Nama Atribut keluhan Deskripsi atribut
1 Jenis produk roti 1, 2, 3(Sandwich, Roti Tawar,Roti Manis)
2 Roti berjamur yes, no
3 Temuan binatang yes, no
4 Roti bau tengik yes, no
5 Big hole yes, no
6 Tidak isi yes, no
7 kadaluarsa yes, no
8 Kepuasan(kelas Kepuasan) Puas, Tidak Puas
4.2 Koleksi Dokumen
Koleksi dokumen yang digunakan untuk pengujian adalah dokumen training sebanyak 91 dokumen claim pelanggan sari roti dan 60 dokumen claim pelanggan sari roti testing dan akan dilakukan evaluasi pada tahapan training dan testing dokumen.
30
Tabel 4.2 koleksi dokumen training dan testing claim pelanggan sari roti
No Kelas Kepuasan Sample Training Testing
1 Puas 81 46 35
2 Tidak Puas 70 45 25
Total dokumen claim pelanggan 151 91 60
4.3 Hasil Evaluasi
4.3.1 Hasil Evaluasi Algoritma Naive Bayes
Hasil evaluasi dataset customer claim pelanggan sari roti dengan menggunakan algoritma naive bayes:
1) Training data
Evaluasi klasifikasi data customer claim pelanggan sari roti dengan pilihan use training set dengan menggunakan training data yang berjumlah 91 menghasilkan data pada Tabel 4.3
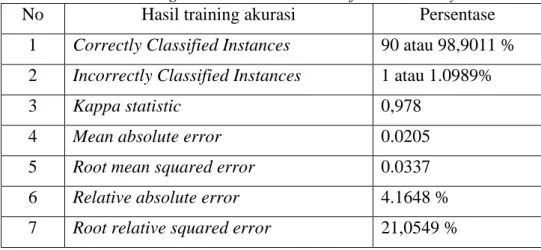
Tabel 4.3 Hasil Training Set Naive Bayes
No Hasil training akurasi Persentase
1 Correctly Classified Instances 90 atau 98,9011 % 2 Incorrectly Classified Instances 1 atau 1.0989% 3 Kappa statistic 0,978
4 Mean absolute error 0.0205 5 Root mean squared error 0.0337 6 Relative absolute error 4.1648 % 7 Root relative squared error 21,0549 % 8 Total Number of Instances 91
Tabel 4.3 menunjukkan akurasi yang diperoleh adalah 98,9011 % dengan hasil klasifikasi benar sebanyak 90, jumlah data training tidak terklasifikasi sebanyak 1 atau 1.0989%.
31
Tabel 4.4 hasil akurasi data training Kepuasan Pelanggan
No Klasifikasi Training naïve bayes Akurasi Terklasifikasi Tidak terklasifikasi
1 Puas 46 0 50.54945
2 Tidak Puas 44 1 48.35164
Persentase 90 1 98,9011%
Tabel 4.4 menunjukkan klasifikasi Puas sebanyak 46 dokumen dan tidak Puas sebanyak 44 dokumen dan 1 kelas prediksi tidak puas keluar dari kelas asal ke kelas puas .
Tabel 4.5 hasil data training matrik kelas
Tabel 4.5 menunjukkan bahwa data yang terklasifikasi puas sebanyak 46 data, dan data tidak puas sebanyak 44 data.
Confusion Matrix
a b akurasi Kelas kepuasan 44 1 48.35164 Tidak puas
0 46 50.54945 puas Persentase 98,9011%
32
2) Testing data / evaluasi
Klasifikasi yang telah terbentuk pada tahap training selanjutnya diuji dengan menggunakan data testing evaluasi dengan data testing sebanyak 60 data testing menghasilkan data pada Tabel 4.6
Tabel 4.6 Hasil Evaluasi Supplied Test Set Naive Bayes
No Hasil testing akurasi Persentase
1 Correctly Classified Instances 59 atau 98,3333 % 2 Incorrectly Classified Instances 1 atau 1,6667 % 3 Kappa statistic 0.9659
4 Mean absolute error 0.013 5 Root mean squared error 0.0667 6 Relative absolute error 12,6132% 7 Root relative squared error 28,5918% 8 Total Number of Instances 60
Tabel 4.6 menunjukkan akurasi yang diperoleh adalah 98,3333% dengan test record yang diklasifikasi secara benar sebanyak 59, jumlah test record yang diklasifikasi secara tidak benar sebanyak 1 atau 1,6667%, dengan hasil mean squared error adalah 0,013%.
Tabel 4.7 Hasil akurasi data testing kepuasan pelanggan
No Klasifikasi Testing naïve bayes Akurasi
Terklasifikasi Tidak terklasifikasi
1 Puas 34 0 56.6666
2 Tidak Puas 25 1 41.6666
33
Tabel 4.7 menunjukkan klasifikasi Puas sebanyak 34 dokumen dan tidak Puas sebanyak 25 dokumen 1 kelas prediksi tidak Puas keluar dari kelas asal ke kelas Puas.
Tabel 4.8 hasil data testing matrik kelas
Tabel 4.8 menunjukkan bahwa data yang terklasifikasi Puas sebanyak 34 data, dan data Tidak Puas sebanyak 25 data.
4.3.2 Hasil Evaluasi Algoritma Naive Bayes dengan cross validation 10 fold 1) Training data
Evaluasi klasifikasi data customer claim pelanggan sari roti dengan pilihan cross validation 10 fold dengan menggunakan training data yang berjumlah 91 menghasilkan data pada Tabel 4.9
Tabel 4.9 Hasil Training Set cross validation 10 fold Naive Bayes
No Hasil training akurasi Persentase
1 Correctly Classified Instances 90 atau 98,9011 % 2 Incorrectly Classified Instances 1 atau 1.0989%
3 Kappa statistic 0,978
4 Mean absolute error 0.0205
5 Root mean squared error 0.0337 6 Relative absolute error 4.1648 % 7 Root relative squared error 21,0549 %
Confusion Matrix
a b akurasi Kelas kepuasan 25 1 41.6666 Tidak Puas
0 34 56.6666 Puas
34
8 Total Number of Instances 91
Tabel 4.9 menunjukkan akurasi yang diperoleh adalah 98,9011 % dengan hasil klasifikasi benar sebanyak 90, jumlah data training tidak terklasifikasi sebanyak 1 atau 1.0989%.
Tabel 4.10 hasil akurasi data training kelayakan konsumsi No Klasifikasi
Training naïve bayes cross
validation 10 fold Akurasi Terklasifikasi Tidak terklasifikasi
1 Puas 46 0 50.54945
2 Tidak Puas 44 1 48.35164
Persentase 90 1 98,9011%
Tabel 4.10 menunjukkan klasifikasi Puas sebanyak 46 dokumen dan tidak Puas sebanyak 44 dokumen dan 1 kelas prediksi tidak puas keluar dari kelas asal ke kelas layak konsumsi .
Tabel 4.11 hasil data training matrik
Tabel 4.11 menunjukkan bahwa data yang terklasifikasi Puas sebanyak 46 data, dan data tidak puas sebanyak 44 data.
Confusion Matrix
a b akurasi Kelas Kepuasan
44 1 48.35164 Tidak Puas
0 46 50.54945 Puas
35
2) Testing data / evaluasi
Klasifikasi yang telah terbentuk pada tahap training selanjutnya diuji dengan menggunakan data testing evaluasi naïve bayes cross validation 10 fold dengan data testing sebanyak 60 dokumen menghasilkan data pada Tabel 4.12
Tabel 4.12 Hasil Evaluasi cross validation 10 fold Naive Bayes
No Hasil testing akurasi Persentase
1 Correctly Classified Instances 59 atau 98.3333 % 2 Incorrectly Classified Instances 1 atau 1.6667 % 3 Kappa statistic 0.9659
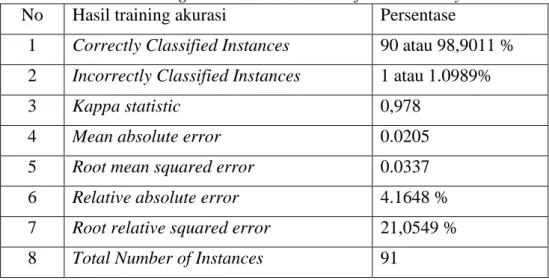
4 Mean absolute error 0.0837 5 Root mean squared error 0.1622 6 Relative absolute error 17.0152% 7 Root relative squared error 32.6834% 8 Total Number of Instances 60
Tabel 4.12 menunjukkan akurasi yang diperoleh adalah 98.3333% dengan test record cross validation 10 fold yang diklasifikasi secara benar sebanyak 59, jumlah test record cross validation 10 fold yang diklasifikasi secara tidak benar sebanyak 1 atau 1.6667%, dengan hasil mean squared error adalah 0.1622%.
36
Tabel 4.13 hasil akurasi data testing cross validation 10 fold Kepuasan pelanggan
No Klasifikasi
Testing cross validation 10 fold
naïve bayes Akurasi
Terklasifikasi Tidak terklasifikasi
1 Puas 34 0 56.66667
2 Tidak Puas 25 1 41.66667
Persentase 59 1 98.3333%
Tabel 4.13 menunjukkan klasifikasi Puas sebanyak 34 dokumen 1 kelas prediksi Puas keluar dari kelas asal ke kelas tidak puas dan tidak puas sebanyak 25 dokumen 1 kelas prediksi tidak puas keluar dari kelas asal ke kelas puas.
Tabel 4.14 hasil data testing cross validation 10 fold matrik kelas
Tabel 4.14 menunjukkan bahwa data yang terklasifikasi Puas 34 data, dan data tidak puas sebanyak 25 data.
Confusion Matrix
a b akurasi Kelas kepuasan
25 1 41.66667 Tidak puas
0 34 56.66667 puas
37
4.3.3 Hasil Evaluasi Algoritma Naive Bayes dengan cross validation 8 fold 1) Training data
Evaluasi klasifikasi data customer claim pelanggan sari roti dengan pilihan cross validation 8 fold dengan menggunakan training data yang berjumlah 91 menghasilkan data pada Tabel 4.15
Tabel 4.15 Hasil Training Set cross validation 8 fold Naive Bayes
No Hasil training akurasi Persentase
1 Correctly Classified Instances 90 atau 98,9011 % 2 Incorrectly Classified Instances 1 atau 1.0989% 3 Kappa statistic 0,978
4 Mean absolute error 0.0205 5 Root mean squared error 0.0337 6 Relative absolute error 4.1648 % 7 Root relative squared error 21,0549 % 8 Total Number of Instances 91
Tabel 4.15 menunjukkan akurasi yang diperoleh adalah 98,9011 % dengan hasil klasifikasi benar sebanyak 90, jumlah data training tidak terklasifikasi sebanyak 1 atau 1.0989%.
Tabel 4.16 hasil akurasi data training kepuasan pelanggan No Klasifikasi
Training cross validation 8 fold
naïve bayes Akurasi
Terklasifikasi Tidak terklasifikasi
1 Puas 46 0 50.54945
2 Tidak Puas 44 1 48.35164
38
Tabel 4.16 menunjukkan klasifikasi Puas sebanyak 46 dokumen dan tidak Puas sebanyak 44 dokumen dan 1 kelas prediksi tidak puas keluar dari kelas asal ke kelas puas.
Tabel 4.17 hasil data training matrik kelas
Tabel 4.17 menunjukkan bahwa data yang terklasifikasi Puas sebanyak 46 data, dan data tidak puas sebanyak 44 data.
2) Testing data / evaluasi
Klasifikasi yang telah terbentuk pada tahap training selanjutnya diuji dengan menggunakan data testing evaluasi naïve bayes cross validation 8 fold dengan data testing sebanyak 60 dokumen menghasilkan data pada Tabel 4.18
Tabel 4.18 Hasil Evaluasi cross validation 8 fold Naive Bayes
No Hasil testing akurasi Persentase
1 Correctly Classified Instances 59 atau 98.3333 % 2 Incorrectly Classified Instances 1 atau 1.6667 % 3 Kappa statistic 0.9659
4 Mean absolute error 0.0837 5 Root mean squared error 0.1622 6 Relative absolute error 17.0152% 7 Root relative squared error 32.6834%
Confusion Matrix
a b akurasi Kelas kepuasan
44 1 48.35164 Tidak puas
0 46 50.54945 Puas
Persentase 98,9011% %
39
8 Total Number of Instances 60
Tabel 4.18 menunjukkan akurasi yang diperoleh adalah 98.3333% dengan test record cross validation 8 fold yang diklasifikasi secara benar sebanyak 59, jumlah test record cross validation 8 fold yang diklasifikasi secara tidak benar sebanyak 1 atau 1.6667%, dengan hasil mean squared error adalah 0.0837%.
Tabel 4.19 hasil akurasi data testing cross validation 8 fold kepuasan pelanggan
No Klasifikasi
Testing cross validation 8 fold naïve
bayes Akurasi
Terklasifikasi Tidak terklasifikasi
1 Puas 34 0 56.66667
2 Tidak puas 25 1 41.66667
Persentase 59 1 98.3333%
Tabel 4.19 menunjukkan klasifikasi Puas sebanyak 34 dokumen terklasifkasi dengan benar kelas Puas dan tidak puas sebanyak 25 dokumen 1 kelas prediksi tidak puas keluar dari kelas asal ke kelas puas. Tabel 4.20 hasil data testing cross validation 8 fold matrik kelas
Tabel 4.20 menunjukkan bahwa data yang terklasifikasi Puas sebanyak 34 data, dan data tidak puas sebanyak 25 data.
Confusion Matrix
a b akurasi Kelas kepuasan
25 1 41.66667 Tidak puas
0 34 56.66667 Puas
40
4.3.4 Hasil Evaluasi Algoritma Naive Bayes dengan percentage split 50 1) Training data
Evaluasi klasifikasi data customer claim pelanggan sari roti dengan pilihan percentage split 50 dengan menggunakan training data yang berjumlah 91 dengan splite sebanyak 46 dokumen menghasilkan data pada Tabel 4.21
Tabel 4.21 Hasil Training Set percentage split 50 Naive Bayes
No Hasil training akurasi Persentase
1 Correctly Classified Instances 22 atau 48.8889 % 2 Incorrectly Classified Instances 23 atau 51.1111% 3 Kappa statistic 0
4 Mean absolute error 0.5005 5 Root mean squared error 0.5009 6 Relative absolute error 100 % 7 Root relative squared error 100 % 8 Total Number of Instances 45
Tabel 4.21 menunjukkan akurasi yang diperoleh adalah 48.8889 % dengan hasil klasifikasi benar sebanyak setelah splite 22 dokumen, jumlah data training tidak terklasifikasi sebanyak 23 dokumen setelah splite dengan akurasi 5.1111 %
41
Tabel 4.22 hasil akurasi data training Kepuasan Pelanggan No Klasifikasi
Training percentage split 50 naïve
bayes Akurasi
Terklasifikasi Tidak terklasifikasi
1 Puas 22 0 48.8889
2 Tidak Puas 0 23 0
Persentase 22 23 48.8889%
Tabel 4.22 menunjukkan klasifikasi Puas sebanyak 22 dokumen dan tidak Puas sebanyak 0 dokumen dan 23 kelas prediksi tidak puas keluar dari kelas asal ke kelas puas.
Tabel 4.23 hasil data training matrik kelas
Tabel 4.23 menunjukkan bahwa data yang terklasifikasi Puas sebanyak 22 data, dan data tidak puas sebanyak 0 data dan 23 data keluar dari kelas asalnya.
2) Testing data / evaluasi
Klasifikasi yang telah terbentuk pada tahap training selanjutnya diuji dengan menggunakan data testing evaluasi naïve bayes percentage split 50 dengan data testing sebanyak 60 dokumen dan splite 50 menjadi 30 dokumen menghasilkan data pada Tabel 4.24
Confusion Matrix
a b akurasi Kelas kepuasan
0 23 0 Tidak Puas
0 22 48.8889 Puas
Persentase 48.8889% %
42
Tabel 4.24 Hasil Evaluasi percentage split 50 Naive Bayes
No Hasil testing akurasi Persentase
1 Correctly Classified Instances 18 atau 60 % 2 Incorrectly Classified Instances 12 atau 40% 3 Kappa statistic 0
4 Mean absolute error 0.4938 5 Root mean squared error 0.4947 6 Relative absolute error 100% 7 Root relative squared error 100% 8 Total Number of Instances 30
Tabel 4.24 menunjukkan akurasi yang diperoleh adalah 60% dengan test record percentage split 50 yang diklasifikasi secara benar sebanyak 18 dokumen, jumlah test record percentage split 50 yang diklasifikasi secara tidak benar sebanyak 12 atau 40%, dengan hasil mean squared error adalah 0.4938%.
Tabel 4.25 hasil akurasi data testing percentage split 50 kepuasan pelanggan
No Klasifikasi
Testing percentage split 50 naïve
bayes Akurasi
Terklasifikasi Tidak terklasifikasi
1 Puas 18 0 60
2 Tidak Puas 0 12 0
Persentase 18 12 60%
Tabel 4.25 menunjukkan klasifikasi Puas sebanyak 18 dokumen terklasifkasi dengan benar kelas Puas dan tidak puas sebanyak 0 dokumen dan 12 dokumen kelas prediksi tidak puas keluar dari kelas asal ke kelas puas.
43
Tabel 4.26 hasil data testing percentage split 50 matrik kelas
Tabel 4.26 menunjukkan bahwa data yang terklasifikasi Puas sebanyak 18 data, dan data tidak puas sebanyak 0 data dengan hasil keluar dari kelas sebanyak 12 dokumen.
4.3.5 Hasil Evaluasi Algoritma Naive Bayes dengan percentage split 66 1) Training data
Evaluasi klasifikasi data customer claim pelanggan sari roti dengan pilihan percentage split 66 dengan menggunakan training data yang berjumlah 91 dengan splite sebanyak 60 dokumen menghasilkan data pada Tabel 4.27
Tabel 4.27 Hasil Training Set percentage split 66 Naive Bayes
No Hasil training akurasi Persentase
1 Correctly Classified Instances 15 atau 48.3871 % 2 Incorrectly Classified Instances 16 atau 51.6129% 3 Kappa statistic 0
4 Mean absolute error 0.5 5 Root mean squared error 0.5 6 Relative absolute error 100 % 7 Root relative squared error 100 % 8 Total Number of Instances 31
Confusion Matrix
a b akurasi Kepuasan Pelanggan
0 12 0 Tidak Puas
0 18 60 Puas
44
Tabel 4.27menunjukkan akurasi yang diperoleh adalah 48.3871 % dengan hasil klasifikasi benar sebanyak setelah splite 15 dokumen, jumlah data training tidak terklasifikasi sebanyak 16 dokumen setelah splite dengan akurasi 51.6129%.
Tabel 4.28 hasil akurasi data training kepuasan pelanggan No Klasifikasi
Training percentage split 66 naïve
bayes Akurasi
Terklasifikasi Tidak terklasifikasi
1 Puas 0 16 0
2 Tidak Puas 15 0 48.3870
Persentase 15 16 48.3870%
Tabel 4.28 menunjukkan klasifikasi Puas sebanyak 0 dan 16 dokumen kelas prediksi Puas keluar dari kelas asal ke kelas tidak puas dan tidak puas sebanyak 31 dokumen.
45
Tabel 4.29 hasil data training matrik kelas
Tabel 4.29 menunjukkan bahwa data yang terklasifikasi Puas sebanyak 0 data, dan data tidak puas sebanyak 15 data.
2) Testing data / evaluasi
Klasifikasi yang telah terbentuk pada tahap training selanjutnya diuji dengan menggunakan data testing evaluasi naïve bayes percentage split 66 dengan data testing sebanyak 60 dokumen dan splite 66 menjadi 20 dokumen menghasilkan data pada Tabel 4.30
Tabel 4.30 Hasil Evaluasi percentage split 66 Naive Bayes
No Hasil testing akurasi Persentase
1 Correctly Classified Instances 13 atau 65 % 2 Incorrectly Classified Instances 7 atau 35% 3 Kappa statistic 0
4 Mean absolute error 0.4929 5 Root mean squared error 0.4934 6 Relative absolute error 100% 7 Root relative squared error 100% 8 Total Number of Instances 20
Tabel 4.30 menunjukkan akurasi yang diperoleh adalah 65% dengan test record percentage split 66 yang diklasifikasi secara benar sebanyak 13
Confusion Matrix
a b akurasi Kepuasan pelanggan
15 0 0 Tidak Puas
16 0 48.3870 Puas
Persentase 48.3870% %
46
dokumen, jumlah test record percentage split 66 yang diklasifikasi secara tidak benar sebanyak 7 atau 35%, dengan hasil mean squared error adalah 0.4929%.
Tabel 4.31 hasil akurasi data testing percentage split 66 kepuasan pelanggan
No Klasifikasi
Testing percentage split 66 naïve
bayes Akurasi
Terklasifikasi Tidak terklasifikasi
1 Puas 13 0 65
2 Tidak Puas 0 7 0
Persentase 13 7 65%
Tabel 4.31 menunjukkan klasifikasi Puas sebanyak 13 dokumen terklasifkasi dengan benar kelas Puas dan tidak puas sebanyak 0 dokumen dan 7 dokumen kelas prediksi tidak puas keluar dari kelas asal ke kelas puas.
Tabel 4.32 hasil data testing percentage split 66 matrik kelas
Tabel 4.32 menunjukkan bahwa data yang terklasifikasi puas sebanyak 13 data, dan data tidak puas sebanyak 0 data dengan hasil keluar dari kelas sebanyak 7 dokumen.
Confusion Matrix
a b akurasi Kepuasan pelanggan
7 0 0 Tidak puas
0 13 65 Puas
47
4.4 Hasil Analisis Algoritma Naive Bayes
setelah proses training dan testing oleh beberapa pendekatan naiave bayes, cross validation 10 fold, cross validation 8 fold serta percentage splite 50 dan 66. Kemudian data dianalisa dilakukan evaluasi dari analisa manakah pendekatan yang mempunyai akurasi terbaik dan mean error nya kecil sehingga bisa dipastikan pelanggan merasa Puas atau Tidak Puas dengan produk tersebut.
4.4.1 Hasil analisis pendekatan training set dan testing set Algoritma
Naive Bayes
Berikut hasil tabel beserta grafik analisis dari hasil pendekatan training set dan testing set algoritma naïve bayes yang ditunjukan dengan tabel dan garifk berikut ini:
Tabel 4.33 hasil data training test dan testing test naïve bayes
No Hasil analisa Training Testing
1 Correctly Classified Instances 90 59 2 Incorrectly Classified Instances 1 1
3 Kappa statistic 0,978 0.9659
4 Mean absolute error 0.0205 0.013 5 Root mean squared error 0.0337 0.0667 6 Relative absolute error 4.1648 % 12,6132% 7 Root relative squared error 21,0549 % 28,5918% 8 Total Number of Instances 91 60
9 Accuracy 98,9011 % 98,3333 %
Dari tabel 4.33 hasil dari data training dari 91 data training dengan akurasi 98,9011 %, dan data testing sebanyak 60 data dengan akurasi 98,3333 % .
48
Grafik 4.1 hasil data training test dan testing test naïve bayes
4.4.2 Hasil analisis pendekatan training set dan testing cross
validation 10 fold Algoritma Naive Bayes
Berikut hasil tabel beserta grafik analisis dari hasil pendekatan training set dan testing cross validation 10 fold algoritma naïve bayes yang ditunjukan dengan tabel dan garifk berikut ini:
98.9 98.3 90 91 92 93 94 95 96 97 98 99 100 Training Testing
Grafik training set dan testing set
49
Tabel 4.34 hasil data training test dan testing cross validation 10 fold
naïve bayes
No Hasil analisa Training Testing
1 Correctly Classified Instances 90 59 2 Incorrectly Classified Instances 1 1
3 Kappa statistic 0,978 0.9659
4 Mean absolute error 0.0205 0.0837 5 Root mean squared error 0.0337 0.1622 6 Relative absolute error 4.1648 % 17.0152% 7 Root relative squared error 21,0549 % 32.6834% 8 Total Number of Instances 91 60
9 Accuracy 98,9011 % 98.3333 %
Dari tabel 4.34 hasil dari data training dari 91 data training dengan akurasi 98,9011 %, dan data testing sebanyak 60 data dengan akurasi 98.3333 % .
Grafik 4.2 hasil data training test dan testing cross validation 10 fold naïve bayes 98.9 98.3 90 91 92 93 94 95 96 97 98 99 100 Training Testing
Grafik training set dan testing cross validation 10
fold
50
4.4.3 Hasil analisis pendekatan training set dan testing cross
validation 8 fold Algoritma Naive Bayes
Berikut hasil tabel beserta grafik analisis dari hasil pendekatan training set dan testing cross validation 8 fold algoritma naïve bayes yang ditunjukan dengan tabel dan garifk berikut ini:
Tabel 4.35 hasil data training test dan testing cross validation 8 fold naïve bayes
No Hasil analisa Training Testing
1 Correctly Classified Instances 90 59 2 Incorrectly Classified Instances 1 1 3 Kappa statistic 0,978 0.9659 4 Mean absolute error 0.0205 0.0837 5 Root mean squared error 0.0337 0.1622 6 Relative absolute error 4.1648 % 17.0152% 7 Root relative squared error 21,0549 % 32.6834% 8 Total Number of Instances 91 60
9 Accuracy 98,9011 % 98.3333 %
Dari tabel 4.35 hasil dari data training dari 91 data training dengan akurasi 98,9011 %, dan data testing sebanyak 60 data dengan akurasi 98.3333 % .
51
Grafik 4.3 hasil data training test dan testing cross validation 8 fold naïve bayes 4.4.4 Hasil analisis pendekatan training set dan testing percentage
split 50 Algoritma Naive Bayes
Berikut hasil tabel beserta grafik analisis dari hasil pendekatan training set dan testing testing percentage split 50 algoritma naïve bayes yang ditunjukan dengan tabel dan grafik berikut ini:
Tabel 4.36 hasil data training test dan testing percentage split 50 naïve bayes
No Hasil analisa Training Testing
1 Correctly Classified Instances 22 18 2 Incorrectly Classified Instances 23 12 3 Kappa statistic 0 0 4 Mean absolute error 0.5005 0.4938 5 Root mean squared error 0.5009 0.4947 6 Relative absolute error 100 % 100% 7 Root relative squared error 100 % 100% 8 Total Number of Instances 45 30
9 Accuracy 48.8889 % 60 % 98.9 98,3 90 91 92 93 94 95 96 97 98 99 100 Training Testing