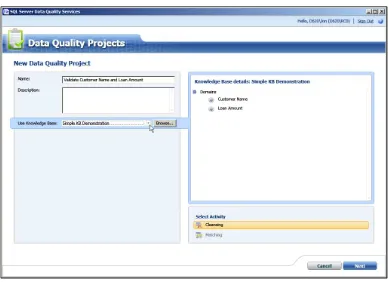
What's New in SQL Server 2012
Teks penuh
Gambar
Garis besar
Dokumen terkait
This reasearch used quasi experimental method in which the population of the research was the students of the eighth grade in SMP Negeri 1 Jatilawang. Chain story game
Seluruh Dosen serta Staf di Program Studi Teknik Mesin Fakultas Teknik Universitas Sebelas Maret Surakarta yang telah turut mendidik dan membantu penulis
Westwood (2008: 75) informs that applying writing strategies give some advantages. Firstly, writing strategies help students think productively before writing,
Hasil uji statistik menunjukkan tidak terdapat hubungan yang signifikan antara aktivitas fisik dan status obesitas dengan kadar kolesterol (p = 0,630 dan 0,988), tidak
Hasil penelitian menunjukkan ada perbedaan yang signifikan kemampuan menulis pantun antara peserta didik kelas VII SMP Negeri 1 Mojotengah Kabupaten Wonosobo
Alasan praktikan memilih Primer Koperasi Produsen Tempe Tahu Indonesia (PRIMKOPTI) Jakarta Timur, karena telah diizinkan oleh pihak koperasi tersebut serta ingin menambah
membimbing dan mengarahkan dalam penyusunan skripsi ini. 3) Ari Saptono, SE., M.Pd selaku dosen pembimbing dua yang senantiasa sabar membimbing dan mengajarkan saya dalam
angket mengenai motivasi belajar siswa pada mata pelajaran ekonomi. Bentuk. angket adalah angket tertutup dengan menggunakan skala likert
