KNSI2014-25
WEB USAGE MINING UNTUK PENENTUAN POLA AKSES USER
MENGGUNAKAN ALGORITMA HIERARCHICAL
AGGLOMERATIVE CLUSTERING
Arham Maulana1, Angelina Prima Kurniati, ST., MT2, Yanuar Firdaus A. W., ST., MT3 Fakultas Teknik Telkom Engineering School
Telkom University, Bandung
1[email protected], 2[email protected], 3[email protected]
Abstrak
Perkembangan teknologi Internet yang sangat pesat berdampak pada semakin tingginya aktivitas user dalam pemanfaatannya. E-commerce, e-news, dan e-learning adalah beberapa contoh dari pemanfaatan teknologi internet ini. Aktivitas user dalam mengakses halaman-halaman pada suatu website dapat menjadi informasi yang dapat digunakan guna menjaga kualitas website tersebut. Dengan menerapkan ilmu web usage mining, makalah ini menyajikan hasil penelitian tentang kemiripan-kemiripan aktivitas user dalam mengakses website e-learning kampus, dengan melihat jarak antar-user yang ada atau Euclidean Distance. Aktivitas-aktivitas user yang disimpan didalam sebuah log file akan diolah dengan teknik clustering menggunakan algoritma Hierarchical Agglomerative Clustering sebagai salah satu teknik web usage mining. Data log ini akan diolah dengan mengambil beberapa bagian data yang diperlukan seperti Ip address, userId, pageId dan waktu akses user. Clusters yang terbentuk akan dianalisis untuk mendapatkan pola dan segmentasi user saat mengakses e-learning. Kata Kunci : aktivitas user, web usage mining, clustering, data log, pola akses, segmentasi user.
1. Pendahuluan
Perkembangan era internet saat ini meningkat dengan sangat pesat. Pemanfaatan teknologi internet (World Wide Web) telah mencakup semua aspek kehidupan. Seiring perkembangan ini, aktivitas user dalam penggunaannya ikut meningkat. Untuk menjamin kepuasan user dalam menggunakan website, perlu diperhatikan performansi dan kualitasnya. Salah satu tolok ukurnya adalah kecenderungan user dalam mengakses website.
Web usage mining merupakan proses analisis terhadap pola akses user dan segala aktivitasnya pada suatu website. Web server menyimpan semua data tentang interaksi user dengan website pada sebuah log file. Log file ini kemudian akan diolah melalui beberapa tahap, yaitu preprocessing, pattern discovery, dan pattern analysis. Dalam kaitannya dengan web usage mining, teknik clustering [8,15] sering digunakan untuk menentukan segmentasi pengunjung suatu situs e-commerce berdasarkan kesamaan pola akses maupun demografinya [1,4].
Metode hierarchical agglomerative clustering adalah salah satu teknik clustering yang dapat diterapkan untuk mencari kesamaan pola akses suatu website. Metode ini adalah teknik clustering yang membentuk kontruksi hirarki berdasarkan tingkatan tertentu seperti struktur pohon. Algoritma ini bekerja
dengan menggabungkan N clusters menjadi satu cluster berdasarkan jarak antar cluster secara bertahap dengan melihat jarak antar clusters.
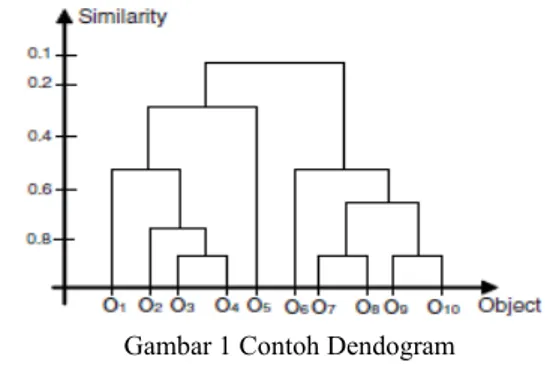
Dengan metode seperti ini, HAC cocok dengan kebutuhan untuk pengolahan dan pengelompokan data log file. Hasil pengelompokan ini disajikan dalam bentuk dendogram seperti pada Gambar 1.
Gambar 1 Contoh Dendogram 2. LANDASAN TEORI
2.1 Web Mining
Web mining adalah salah satu cabang ilmu dari data mining. Web mining menggunakan teknik data mining untuk menemukan dan mengekstrak informasi dari dokumen dan layanan web. Menurut Liu [11], web mining bertujuan untuk menemukan informasi atau pengetahuan yang bermanfaat dari struktur web hyperlinks, halaman web, dan data
penggunaan web. Berdasarkan jenis data primer dalam proses penggalian informasi, web mining dapat dikategorikan menjadi 3, yaitu Web Structure Mining [7], Web Content Mining, Web Usage Mining.
2.2 Web Usage Mining
Web usage mining merupakan proses untuk menangkap dan memodelkan pola perilaku dan profil dari pengunjung web [12]. Pola-pola tersebut dapat digunakan untuk meningkatkan pemahaman mengenai perilaku pengunjung web yang berbeda, untuk memaksimalkan tata letak dan struktur dari situs web, dan untuk memberikan informasi sesuai dengan profil pengunjung. Berbeda dengan dua jenis web mining lainnya, sumber data primer dari web usage mining adalah log akses web server [10], bukan halaman web. Tujuan dari web usage mining adalah menemukan dan memprediksi tingkah laku user, membantu developer mengembangkan website, menarik pengunjung atau untuk mengelompokkan user berdasarkan kebiasaan aksesnya [11].
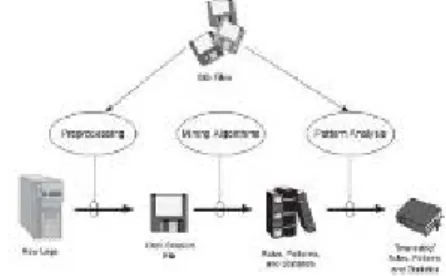
Secara umum, proses web usage mining terbagi menjadi 3 (tiga) fase, yaitu preprocessing, pattern discovery dan pattern analysis [9]. Proses-proses tersebutseperti pada Gambar 2.1 [1,2,3].
Gambar 2.2 Proses Web usage mining
2.3 Hierarchical Agglomerative Clustering Teknik hirarki (hierarchical methods) adalah teknik clustering yang membentuk kontruksi hirarki berdasarkan tingkatan tertentu seperti struktur pohon, secara bertingkat atau bertahap. Hasilnya dapat disajikan dalam bentuk dendogram. Ada dua pendekatan dalam hierarchical clustering yaitu agglomerative dan divisive. Gambar 2.2 adalah gambaran mengenai Agglomerative dan Divisive.
Gambar 2.3 Agglomerative dan Divisive 2.4 Cophenetic Correlation Coefficient (CP)
Cophenetic Correlation adalah salah satu metode evaluasi cluster dengan menghitung indeks yaitu Cophenetic Correlation Coefficient. Metode ini biasa digunakan pada Hierarchical Clustering. Untuk menghitung Cophenetic Correlation Coefficient pada Hierarchical Clustering, metode ini membutuhkan dua informasi, yaitu [14] :
1. Distance Matrix
Gambar 2.3 Distance matrix 2. Cophenetic Matrix
Gambar 2.4 Cophenetic Matrix Untuk mendapatkan nilai cophenetic correlation coefficient, maka digunakan formula sebagai berikut:
3. MODEL DAN PERANCANGAN SISTEM 3.1 Gambaran Umum Sistem
Secara umum, sistem akan melakukan analisa terhadap pola akses user pada halaman web dengan metode Hierarchical Agglomerative Clustering. Tahapan-tahapan prosesnya sesuai Gambar 3.1.
Gambar 3.4 Alur Proses pada Sistem Preprocessing
Proses ini bertujuan untuk mendapatkan bagian-bagian data yang diinginkan. - Cleaning Data
Setelah data selesai pada tahap parsing, data yang terkelompok tersebut dibersihkan dari bagian-bagian yang tidak perlu seperti data berekstensi .jpg, .gif, ukuran byte, dan status. Hasil dari cleaned data ini adalah informasi yang dibutuhkan untuk penelitian ini. Tabel 3.1 Contoh data sebelum cleaning
Tabel 3.2 Contoh data setelah cleaning
- User Identification
Proses ini bertujuan untuk mengidentifikasi user yang melakukan akses terhadap website. Proses ini dilakukan setiap sistem menemukan baris data “userId=”.
39.210.211.63 - - [03/Apr/2013:03:43:45 +0700] "GET
/login/index.php?key=d6ef1166cb2adc2412b199fde28 11cd9&userId=2841 HTTP/1.1" 303 406
- Page Access Identification
Proses ini sama seperti proses sebelumnya. Disini yang diidentifikasi adalah pageId yang diakses user. Sistem mengidentifikasi pages tersebut jika menemukan"view.php?id=", "index.php?id=", "courseId=",
"category.php?id=" pada baris data.
182.12.5.228 - - [08/Apr/2013:05:36:16 +0700] "GET /course/view.php?id=1310 HTTP/1.1" 200 8644
Pattern Discovery
Pada tahap pattern discovery akan dilakukan proses pencarian user cluster berdasarkan kemiripan akses oleh users yang login. Pencarian cluster tersebut menggunakan disiplin ilmu Clustering dengan algoritma Hierarchical Agglomerative Clustering. Metode yang digunakan pada algoritma ini adalah Unweighted Average Linkage, dimana
metode ini akan menghitung kemiripan antara dua cluster dengan menghitung rata-rata jarak semua kombinasi pasangan yang mungkin
.
S(AB),C = (SAC + SBC)/2
S(AB),(CD) = (SAC + SAD + SBC + SBD)/4 SE,(C,(AB)) = (SAE + SBE + SCE)/3 Pattern Analysis
Tahap berikutnya dari proses ini adalah pattern analysis dari user cluster yang didapatkan. Dari cluster ini dapat dicari pola kemiripan akses user dengan melihat page-page yang diakses sebelumnya. 4. ANALISIS DAN PENGUJIAN SISTEM 4.1 Pengujian Pattern Discovery Dataset
Februari
Hasil preprocessing data berdasarkan parameter yang di set sebelumnya.
Tabel 4.1 Potongan hasil parsing dan cleaning
Selanjutnya akan dicari pages yang diakses oleh masing-masing user. Setiap page yang diakses akan diberi nilail dan yang lainnya 0 [13].
Tabel 4.2 Potongan list page yang diakses user
UserId PageId Jumlah UserId PageId Jumlah
7667 255 1 7667 259 0 7667 258 1 7667 264 0 7667 114 0 7667 263 0 7667 852 0 7667 257 0 7667 226 0 7667 245 0 7667 228 0 7667 242 0 7667 214 0 …. …. …. 7667 267 0 7702 447 0 7667 260 0
Dari data tersebut, nilai Euclidean dihitung berdasarkan kemiripan aktivitas antar-user. Tabel 4.3 Euclidean Distance dataset Februari
User User ED User User ED 7667 7667 0.00 7667 9397 2.00 7667 7713 2.65 7667 9098 2.00 7667 52239 2.45 7667 8934 3.32 7667 51733 2.24 7667 9343 2.24 7667 50559 2.00 7667 51172 2.00 7667 50823 3.00 …. …. …. 7667 219 3.16 7702 7702 0.00 7667 50511 2.65
User yang memiliki nilai 0 berarti pola aksesnya tepat sama sama lain. Setelah nilai Euclidean didapat, maka nilai ini akan divisualisasikan menggunakan multidendogram 3.1.0. Hasilnya adalah seperti pada Gambar 4.1. Ip address Rfc931 Userna
me Time Request Status Size
118.96.202. 212 - - [24/Feb/2013 :11:29:28 +0700] "GET /course/view.ph p?id=279 HTTP/1.1" 200 22572 1 ip : 222.124.204.252 4 ip : 222.124.204.252 time: 13/Feb/2013:18:52:30 time: 14/Feb/2013:11:46:33 user id : 7667 user id : 7713 page id : page id : 2 ip : 222.124.204.252 5 ip : 222.124.204.252 time: 13/Feb/2013:18:53:12 time: 14/Feb/2013:11:46:49 user id : 7667 user id : 7713 page id : 255 page id : 1114 3 ip : 222.124.204.252 6 ip : 222.124.204.252 time: 13/Feb/2013:18:55:11 time: 14/Feb/2013:11:46:51 user id : 7667 user id : 7713
page id : 258 page id : 852
Ip address User Id Time Page Id
Gambar 4.1 User cluster untuk bulan Februari
Gambar 4.1 menunjukkan user clusters. Dengan mengacu pada nilai jarak, dua atau lebih user digabungkan mulai dari user dengan jarak terkecil, nilai 0, sampai dengan user dengan jarak terjauh, nilai 3.46. Penggabungan user tersebut dilakukan dengan melihat nilai minimum rata-rata jarak antar semua user/cluster.
Pola penggabungan user/cluster ini memiliki perbedaan satu sama lain. Ada beberapa user/cluster yang digabungkan dengan pola membentuk tangga (naik ke kanan). Ini menandakan user/cluster yang digabungkan memiliki kemiripan pola cukup jauh dengan cluster-cluster yang terbentuk sebelumnya.
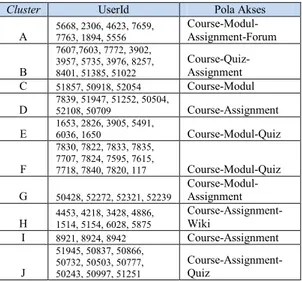
Setelah menganalisis cluster yang ditemukan, didapatlah pola akses user pada beberapa cluster, seperti ditunjukkan pada Tabel 4.4.
Tabel 4.4 Pola akses cluster Februari
Cluster UserId Pola Akses
A 7667, 51410 Course-Modul-Assignment B 9397, 9098, 4886, 7872, 3817, 2455, 3342, 2199, 7618, 51783, 51506, 7622 Course-Modul-Assignment-Forum C 9343, 5894, 7657, 7626, 5958, 7702, 7639, 7663 Course-Quiz-Grade report D 4336, 5962, 5394 Course-Modul-Assignment E 51733, 50559, 50565, 52364, 50408 Course-Modul F 7715, 7810, 7820, 7595, 7604, 7839, 7684 Assignment-Grade Course-Modul-report G 50511, 51172, 8486, 8413 Course-Modul-Assignment-Forum H 52239, 50594, 52297 Course-Modul I 8950, 8953, 8955, 8929, 8951, 8952, 8923, 8935, 8924 Course-Assignment
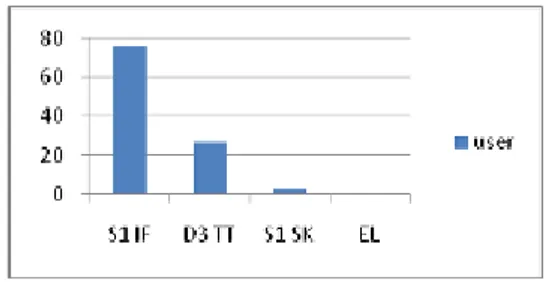
Dari data tersebut, dapat dilihat bahwa pola akses user paling banyak adalah mengakses mata kuliah, modul atau materi kuliah lalu latihan atau assignment. Untuk beberapa cluster lainnya ada user yang mengakses page yang lainnya seperti forum, quiz dan laporan hasil (grade report). Segmentasi pengguna bulan ini ditunjukkan Gambar 4.2.
0 20 40 S1 IF D3 IF D3 TT S1 SI S1 SK User
Gambar 4.2 Segmentasi User dataset Februari 4.2. Pengujian Pattern Discovery Dataset Maret
User Cluster yang terbentuk pada Gambar 4.3.
Gambar 4.3 User Cluster untuk bulan Maret Untuk user cluster ini, simpangan terjauh nilai jaraknya adalah 5 yang berarti jarak user yang paling maksimum adalah 5 dan akan digabungkan pada tahap terakhir setelah cluster yang lain terbentuk. Pola yang dapat terbentuk dari user cluster ini ditunjukkan pada Tabel 4.5.
Tabel 4.5 Pola akses dataset bulan Maret
Cluster UserId Pola Akses
A 5668, 2306, 4623, 7659, 7763, 1894, 5556 Course-Modul-Assignment-Forum B 7607,7603, 7772, 3902, 3957, 5735, 3976, 8257, 8401, 51385, 51022 Course-Quiz-Assignment C 51857, 50918, 52054 Course-Modul D 7839, 51947, 51252, 50504, 52108, 50709 Course-Assignment E 1653, 2826, 3905, 5491, 6036, 1650 Course-Modul-Quiz F 7830, 7822, 7833, 7835, 7707, 7824, 7595, 7615, 7718, 7840, 7820, 117 Course-Modul-Quiz G 50428, 52272, 52321, 52239 Course-Modul-Assignment H 4453, 4218, 3428, 4886, 1514, 5154, 6028, 5875 Course-Assignment-Wiki I 8921, 8924, 8942 Course-Assignment J 51945, 50837, 50866, 50732, 50503, 50777, 50243, 50997, 51251 Course-Assignment-Quiz
Untuk segmentasi user pada bulan Maret dapat dilihat dari grafik pada Gambar 4.4.
Gambar 4.4 Grafik segmentasi user Maret 4.3 Pengujian Pattern Discovery Bulan April Untuk dataset bulan April, user cluster yang terbentuk seperti ditunjukkan pada Gambar 4.5.
Gambar 4.5 User cluster dataset bulan April Cluster yang yang terbentuk dengan nilai jarak antar user 0 semakin meningkat. Hal ini disebabkan pola yang sama persis. Pola akses yang dihasilkan dari cluster ini ditunjukkan pada Tabel 4.6.
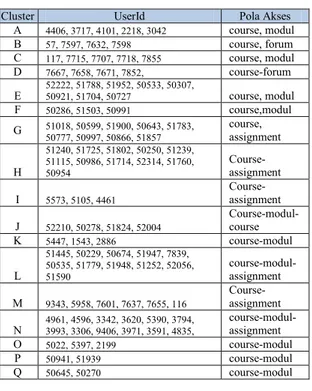
Tabel 4.6 Pola akses user April
Cluste
r UserId Pola Akses
A 8292, 8379 course, modul, assignment, grade report, B 2841, 2746 course, forum C 51903, 51439, 59785, course, modul D 3844, 125, 6349, 2813, 448, 4961 course E 7684, 7813, 117, 7834, 7715, 7595, 7827, 7811, 7819, 7683, 7838, 7825 course-modul F 50349,51010,50559, 50665, 50643, 52364, 50254, 50565,51875, 51733, 50777, 51246, 51425, 52381, 50404, 51251, 51018, 50732, 51974, 52223, 50782 course-assignment G 50241, 50986 course-modul H 51827, 50459, 7641, 51653, 51869, 52056, 51953 course-modul-assignment I 7637, 7643, 7601, 5377, 7655, 7664, 7670, 9343, 7665, 7654 course-modul-page J 3596, 4101, 4000, 2218 course-modul K 7772, 7594, 7620, 7596, 7611, 7610, 7632, 7635, 5979, 1825 course-modul-page L 4241, 2067, 5652 course-assignment M 52049, 52177, 50905, 50394, 51171, 50465, 51272, 52093, 50494, 50227, 51258, 51443, 51871, 51170, 52122, 50461, 51506 course-modul-assignment-quiz O 73, 8958, 8954, 8921, 8926 course-modul-assignment P 7817, 7815, 7628, 7729, 7615, 7691, 7710 course-modul-quiz Q 7795, 7781, 7788 course-modul
Kecenderungan user melakukan akses lebih banyak untuk melihat materi saja. Sedangkan untuk assignment dan quiz hanya untuk beberapa cluster tetentu saja. Segmentasi user untuk bulan ini ditunjukkan pada Gambar 4.6.
Gambar 4.6 Segmentasi user dataset April 4.4 Pengujian Pattern Discovery Dataset Mei User cluster yang terbentuk untuk bulan Mei, ditunjukkan pada Gambar 4.7.
Gambar 4.7 User cluster dataset Mei
Dari Gambar 4.7, simpangan terjauh pada nilai 4. Dapat dilihat juga bahwa pola penggabungan semakin menyerupai anak tangga ke kanan. Namun berbeda dengan data sebelumnya, pola itu terbentuk setelah penggabungan dari beberapa user/cluster yang memliki nilai kemiripan yang dekat. Pola akses yang dihasilkan ditunjukkan pada Tabel 4.7.
Tabel 4.7 Pola Akses user Mei
Untuk segmentasi user pada bulan Mei adalah sebagaimana ditunjukkan pada Gambar
4.8.
Gambar 4.8 Segmentasi user Mei 4.5 Pengujian Cophenetic Correlation Coeffient
Pengujian dilakukan terhadap keempat dataset dengan menghitung distance dan cophenetic. Nilai cophenetic didapat dari perhitungan nilai distance minimum dari hasil penggabungan dua atau lebih user. Empat nilai CP didapat dari multidendogram untuk membentuk cluster sebelumnya. Hasil perbandingan CP ditunjukkan pada Gambar 4.10.
Gambar 4.5 Perbandingan CP keempat cluster Keempat data memiliki nilai diatas 0.8 yang berarti kualitas cluster yang dihasilkan sudah baik.
4.6 Kesimpulan Pengujian dan Rekomendasi Dari pengujian, dapat ditarik kesimpulan bahwa pola akses user untuk keempat dataset tersebut tidak jauh berbeda. Pola akses tersebut masih hanya pada beberapa fungsi saja seperti course, modul, quiz dan assignment. Dapat disimpulkan bahwa beberapa page atau fungsionalitas yang lain seperti forum, media chat, pesan belum sepenuhnya digunakan secara baik. Padahal media-media tersebut merupakan penunjang e-learning. Sehingga disarankan agar lebih mengaktifkan pages yang jarang terpakai.
Dari kesimpulan diatas, beberapa rekomendasi pengembangan e-learning adalah sebagai berikut : 1. Page Course-Modul-Assignment dipertahankan
dengan setiap assignment diikuti dengan modul sebagai sumber pencarian bahan latihan. 2. Page Forum ditempatkan pada setiap
Course-Modul sehingga pemanfaatan forum ini lebih baik lagi sebagai tempat berdiskusi mahasiswa mengenai mata kuliah dan informasi lainnya. 3. Page Quiz ditempatkan terpisah dengan Modul
karena quiz sifatnya tertutup dan disetiap quiz harus disertakan waktu per soal dan di akhir quiz juga disediakan langsung page untuk hasil nilainya (untuk tipe soal pilihan ganda). 4. Page Grade Report ditempatkan untuk setiap
mata kuliah agar mahasiswa dapat melihat rincian nilainya. Sehiangga nantinya akan muncul pola akses Course-Grade Report. 5. Untuk keseluruhan Course, ditempatkan media
chat dimana media ini akan bermanfaat untuk interaksi yang langsung (online) antar mahasiswa pada satu kelas. Berbeda dengan forum yang sifatnya tidak selamanya online. 5. PENUTUP
5.1 Kesimpulan
1. Pola akses yang dianalisis dapat menjadi informasi untuk pengelolaan website. 2. Setiap cluster yang terbentuk tidak selalu
dapat di polakan karena aktivitas akses user yang hanya mengakses satu page saja atau memiliki kemiripan yang sangat jauh dengan cluster yang lain.
3. Pola akses user menunjukkan bahwa pemanfaatan website e-learning terbatas pada pages tertentu seperti course, modul, assignment, quiz.
4. Pada setiap cluster yang terbentuk untuk semua dataset, masih terdapat outlier dimana kemiripan user atau cluster sangat jauh dari user atau cluster yang lain. 5. Segmentasi akses user pada e-learning
masih terbatas pada beberapa prodi saja. 6. Cluster yang dihasilkan untuk setiap dataset
memiliki nilai CP diatas 0.8 sehingga
Cluster UserId Pola Akses
A 4406, 3717, 4101, 2218, 3042 course, modul B 57, 7597, 7632, 7598 course, forum C 117, 7715, 7707, 7718, 7855 course, modul D 7667, 7658, 7671, 7852, course-forum E 52222, 51788, 51952, 50533, 50307, 50921, 51704, 50727 course, modul F 50286, 51503, 50991 course,modul G 51018, 50599, 51900, 50643, 51783, 50777, 50997, 50866, 51857 course, assignment H 51240, 51725, 51802, 50250, 51239, 51115, 50986, 51714, 52314, 51760, 50954 Course-assignment I 5573, 5105, 4461 Course-assignment J 52210, 50278, 51824, 52004 Course-modul-course K 5447, 1543, 2886 course-modul L 51445, 50229, 50674, 51947, 7839, 50535, 51779, 51948, 51252, 52056, 51590 course-modul-assignment M 9343, 5958, 7601, 7637, 7655, 116 Course-assignment N 4961, 4596, 3342, 3620, 5390, 3794, 3993, 3306, 9406, 3971, 3591, 4835, course-modul-assignment O 5022, 5397, 2199 course-modul P 50941, 51939 course-modul Q 50645, 50270 course-modul
cluster dapat dikategorikan sebagai cluster yang baik.
5.2 Saran
1. Melakukan perbaikan website berdasarkan pola akses dan segmentasi user.
2. Pencarian outlier langsung dilakukan saat mencari nilai Euclidean sehingga pola cluster yang dihasilkan lebih baik lagi. 3. Mencoba metode web usage mining lain
sebagai pembanding pola yang dihasilkan. DAFTAR PUSTAKA
[1] Abdurrahman, Bambang Riyanto T., Rila
Mandala, 2006, Pemodelan Web usage mining untuk Mengelola E-Commerce, Sekolah Teknik Elektro dan Informatika, Institut Teknologi Bandung.
[2] Cooley R. Web usage mining: Discovery and Application of Interesting Patterns from Web data [Report]. - [s.l.] : PhD thesis, Dept. of Computer Science, University of Minnesota, 2000.
[3] Cooley R., Mobasher B. and Srivastava J. Data preparation for mining world wide Web browsing patterns [Conference] // Knowledge and Information Systems. - 1999.
[4] Cooley R., Tan P-N. and Srivastava J Discovery of interesting usage patterns from web data. [Conference] // WEBKDD. - 1999. - pp. 163-182. [7] Gomes, M. and Gong, Z., 2005, Web Structure
Mining: An Introduction, Proceedings of the 2005 IEEE International Conference on Information Acquisition
[8] Han Jiawei and Kamber Micheline Data Mining: Concepts and Techniques [Book]. - [s.l.] : Morgan Kaufmann Publisher, 2006.
[9] Kimpball Ralph and Merz Richard The Data Webhouse Toolkit: Building the Web-Enabled Data Warehouse [Book]. - [s.l.] : Wiley Computer Publishing, 2000.
[10] Kurniawan, Agus, Desain dan Implementasi Aplikasi untuk Visualisasi Informasi pada File Offline Log Web Server, Fakultas Ilmu Komputer, Universitas Indonesia, Depok, Indonesia.
[11] Liu, B., 2007, Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data, Springer. [12] R.Khanchana and M. Punithavalli.2011, Web
usage mining for Predicting Users’ Browsing Behaviors by using FPCM Clustering, IACSIT International Journal of Engineering and Technology.
[13] Solichin Achmad, Ferdiansyah, Wahyu
Pramusinto, 2010, Web usage mining: Proses, Aplikasi dan Penggunaannya, Universitas Budi Luhur.
[14] Teknomo, Kardi. (2009) Hierarchical Clustering Tutorial.http://people.revoledu.com/kardi/tutorial/ Clustering/Cophenetic.htm, diakses 30 Agustus 2013.
[15] Wang Yan, Web Mining and Knowledge
Discovery of Usage Patterns [Conference]. - [s.l.]: CS 748T Project, 2000.