PRAKTIKUM 3 ANALISA CLUSTER
Definisi Cluster
Analisis cluster merupakan pengelompokan objek berdasarkan informasi yang diperoleh dari suatu data yang menjelaskan hubungan antar objek satu dengan objek lainnya. Tujuannya untuk mengelompokan objek yang memiliki kesamaan karakteristik dengan objek lainnya dalam satu kelompok dan memiliki perbedaan karakteristik dengan objek kelompok lain ( Steinbach et al, 2006)
Tujuan Praktikum Cluster
1. Mahasiswa mempunyai pengetahuan dan kemampuan dasar dalam melakukan dan menerapkan analisis Cluster
2. Mahasiswa dapat mengetahui dan memahami arti dan garis besar dari analisis Cluster
dalam data mining, mulai dari pengambilan data, pengolahan data sampai dengan tahap pengelompokan, serta mengaplikasikannya dalam kasus yang dihadapi.
Knowledge Discovery in Database (KDD) dan Data Mining
Data mining merupakan proses semi otomatik yang menggunakan teknik statistik, matematika, kecerdasan buatan, dan machine learning untuk mengekstraksi dan mengidentifikasi informasi pengetahuan potensial dan berguna yang bermanfaat yang tersimpan di dalam database besar. (Turban et al, 2005 ). Knowledge discovery in database (KDD) adalah keseluruhan proses non-trivial untuk mencari dan mengidentifikasi pola (pattern) dalam data, dimana pola yang ditemukan bersifat sah, baru, dapat bermanfaat dan dapat dimengerti.Istilah data mining dan
menjelaskan proses penggalian informasi tersembunyi dalam suatu basis data yang besar. Sebenarnya kedua istilah tersebut memiliki konsep yang berbeda, tetapi berkaitan satu sama lain. Dan salah satu tahapan dalam keseluruhan proses KDD adalah data mining. Proses KDD secara garis besar dapat dijelaskan sebagai berikut (Fayyad, 1996).
1. Data Selection
Pemilihan (seleksi) data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil seleksi yang akan digunakan untuk proses data mining, disimpan dalam suatu berkas, terpisah dari basis data operasional.
2. Pre-processing/Cleaning
Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses cleaning pada data yang menjadi fokus KDD. Proses cleaning mencakup antara lain membuang duplikasi data, memeriksa data yang inkonsisten, dan memperbaiki kesalahan pada data, seperti kesalahan cetak (tipografi). Juga dilakukan proses enrichment, yaitu proses “memperkaya” data yang sudah ada dengan data atau informasi lain yang relevan dan diperlukan untuk KDD, seperti data atau informasi eksternal.
3. Transformation
Coding adalah proses transformasi pada data yang telah dipilih, sehingga data tersebut sesuai untuk proses data mining. Proses coding dalam KDD merupakan proses kreatif dan sangat tergantung pada jenis atau pola informasi yang akan dicari dalam basis data.
4. Data Mining
Data mining adalah proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu. Teknik, metode, atau algoritma dalam
data mining sangat bervariasi. Pemilihan metode dan algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan. Dalam modul ini kita menggunakan salah satu teknik data mining yaitu cluster.
5. Interpretation/Evaluation
Pola informasi yang dihasilkan dari proses data mining perlu ditampilkan dalam bentuk yang mudah dimengerti oleh pihak yang berkepentingan. Tahap ini merupakan bagian dari proses KDD yang disebut interpretation. Tahap ini mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dengan fakta atau hipotesis yang ada sebelumnya.
Konsep Cluster
Dalam konteks memahami data, cluster mampu mengelompokan data dan analisis cluster merupakan ilmu yang secara teknis dapat mengelompokan data secara otomatis. Sebagai contoh, anak-anak dapat dengan cepat mengelompokan jenis gambar seperti gambar bangunan, tumbuhan, hewan, dan lainnya. (Michael et al, 2006)
Ada beberapa tahapan dalam malekukan Analisis Cluster, diantaranya yaitu: 1. Tujuan Analisis Cluster
2. Desain Penelitian dalam Analisis Cluster
3. Asumsi-asumsi dalam Analisis Cluster
4. Proses Mendapatkan Cluster dan Menilai kelayakan secara keseluruhan (overall fit) 5. Interpretasi terhadap Cluster.
Penerapan analisis Cluster di dalam pemasaran adalah sebagai berikut : 1. Identifikasi obyek (Recognition) :
Dalam bidang image Processing , Computer Vision atau robot vision 2. Decission Support System dan data mining
Membuat segmen pasar (segmenting the market).
Memahami perilaku pembeli.
Mengenali peluang produk baru
Tahap-tahap dalam Analisis Cluster
Ada beberapa tahapan dalam malekukan Analisis Cluster, diantaranya yaitu:
Tahap Pertama : Tujuan Analisis Cluster
Tujuan utama analisis Cluster adalah memisahkan suatu himpunan objek menjadi dua kelompok atau lebih berdasarkan kesamaan karakteristik khusus yang dimilikinya.
Sedangkan tujuan analisis Cluster secara khusus, antara lain:
Penyederhanaan Data
Penyederhanaan data merupakan bagian dari suatu taksonomi. Dengan struktur yang terbatas observasi/objek dapat dikelompokkan untuk analisis selanjutnya.
Identifikasi Hubungan (Relationship Identification)
Hubungan antar objek diidentifikasi secara empiris. Struktur analisis Cluster yang sederhana dapat menggambarkan adanya hubungan atau kesamaan dan perbedaan yang tidak dinyatakan sebelumnya.
Pemilihan pada Pengelompokan Variabel
Tujuan analisis Cluster tidak dapat dipisahkan dengan pemilihan variabel yang digunakan untuk menggolongkan objek ke dalam clucter-Cluster. Cluster yang terbentuk merefleksikan
struktur yang melekat pada data seperti yang didefinisikan oleh variabel-variabel. Pemilihan variabel harus sesuai dengan teori dan konsep yang umum digunakan dan harus rasional. Rasionalitas ini didasarkan pada teori-teori eksplisit atau penelitian sebelumnya. Variabel-variabel yang dipilih hanyalah Variabel-variabel yang dapat mencirikan objek yang akan dikelompokkan dan secara spesifik harus sesuai dengan tujuan analisis Cluster.
Tahap Kedua : Desain Penelitian dalam Analisis Cluster
2 hal penting dalam tahap ini adalah pendeteksian outlier dan mengukur kesamaan.
Pendeteksian Outliers
Outlier adalah suatu objek yang sangat berbeda dengan objek lainnya. Outliers dapat terjadi karena:
a. Observasi ‘menyimpang’ yang tidak mewakili populasi
b. Suatu undersampling kelompok-kelompok dalam populasi yang menyebabkan
underrepresentation kelompok-kelompok dalam sampel
Dalam kedua kasus tersebut, outliers dapat mengubah struktur sebenarnya dalam populasi sehingga kita akan memperoleh Cluster-Cluster yang tidak sesuai dengan struktur sebenarnya dari populasi tersebut dan tidak representatif.
Mengukur Kesamaan antar Objek
Konsep kesamaan adalah hal yang sangat penting dalam analisis Cluster. Kesamaan antar objek merupakan ukuran kedekatan antar objek. Kesamaan dapat diketahui dengan melakukan pengukuran jarak antar setiap individu. Ukuran jarak merupakan ukuran ketidakmiripan, dimana jarak yang besar menunjukkan sedikit kesamaan sebaliknya jarak yang pendek/kecil menunjukkan bahwa suatu objek makin mirip dengan objek lain.
Gambar 1. Ilustrasi Pengukuran jarak Metode untuk mengukur kesamaan obyek antara lain :
1). Euclidean Distance
Jarak euclidean antara dua titik i dan j merupakan sisi miring (sisi terpanjang) dari segitiga ABC.
𝐷(𝑖, 𝑗) = √𝐴2+ 𝐵2 = √∑(𝑋
𝑖 − 𝑌𝑖)2 = √(𝑋1𝑖− 𝑋1𝑗)2+(𝑋2𝑖− 𝑋2𝑗)2
2). Squared Euclidean Distance
Merupakan pengukuran kuadrat jarak euclidean antara dua titik i dan j. 𝐷(𝑖, 𝑗) = 𝐴2 + 𝐵2= ∑(𝑋𝑖 − 𝑌𝑖)2 = (𝑋1𝑖− 𝑋1𝑗)2+(𝑋2𝑖− 𝑋2𝑗)2
3). Chebychev
D(X,Y)= 𝑚𝑎𝑥𝑖|𝑋𝑖 − 𝑌𝑖|
4). City Block Distance
D(X,Y)= ∑|𝑋𝑖− 𝑌𝑖|
Tahap Ketiga : Asumsi-asumsi dalam Analisis Cluster
Seperti hal teknik analisis lain,analisis Cluster juga menetapkan adanya suatu asumsi. Ada dua asumsi dalam analisis Cluster, yaitu :
a. Kecukupan Sampel untuk merepresentasikan/mewakili Populasi
Biasanya suatu penelitian dilakukan terhadap populasi diwakili oleh sekelompok sampel. Sampel yang digunakan dalam analisis ckuster harus dapat mewakili populasi yang ingin dijelaskan, karena analisis ini baik jika sampel representatif. Jumlah sampel yang diambil tergantung penelitinya, seorang peneliti harus yakin bahwa sampel yang diambil representatif terhadap populasi.
b. Pengaruh Multikolinieritas
Ada atau tidaknya multikolinieritas antar variabel sangat diperhatikan dalam analisis
Cluster karena hal itu berpengaruh, sehingga variabel-variabel yang bersifat multikolinieritas secara eksplisit dieprtimbangkan dengan lebih seksama.
Tahap Keempat : Proses Mendapatkan Cluster dan Menilai kelayakan secara keseluruhan (overall fit)
Ada dua proses penting yaitu algoritma Cluster dalam pembentukan Clusterdan menentukan jumlah Cluster yang akan dibentuk. Keduanya mempunyai implikasi substansial tidak hanya pada hasil yang diperoleh tetapi juga pada interpretasi yang akan dilakukan terhadap hasil tersebut.
Gambar 2. Algoritma Analisa Kluster
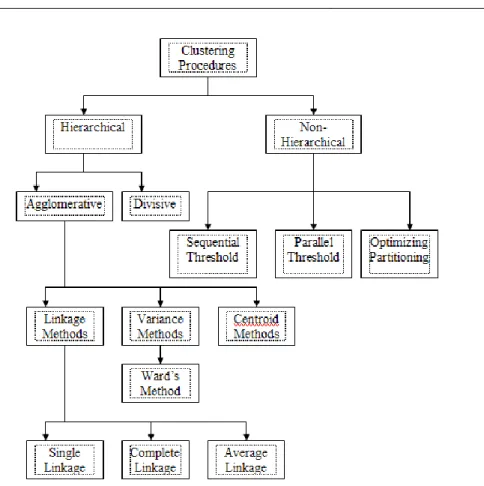
Adapun metode pengelompokan dalam analisis Cluster meliputi : 1. Metode Non-Hirarkis.
dimulai dengan menentukan terlebih dahulu jumlah Cluster yang diinginkan (dua,tiga, atau yang lain). Setelah jumlah Clusterditentukan, maka proses Cluster dilakukan dengan tanpa mengikuti proses hirarki. Metode ini biasa disebut “K-Means Cluster”.
Berbeda dengan metode hirarkikal, prosedur non hirarkikal (K-means Clustering) dimulai dengan memilih sejumlah nilai Cluster awal sesuai dengan jumlah yang diinginkan dan kemudian obyek digabungkan ke dalam Cluster-Cluster tersebut.
a. Sequential Threshold Procedure
Metode ini melakukan pengelompokan dengan terlebih dahulu memilih satu obyek dasar yang akan dijadikan nilai awal Cluster, kemudian semua obyek yang ada didalam jarak terdekat dengan Cluster ini akan bergabung lalu dipilih Cluster kedua dan semua obyek yang mempunyai kemiripan dimasukkan dalam Cluster ini. Demikian seterusnya hingga terbentuk beberapa Cluster dengan keseluruhan obyek didalamnya.
b. Parallel Threshold Prosedure
Secara prinsip sama dengan prosedur sequential threshold, hanya saja dilakukan pemilihan terhadap beberapa obyek awal Cluster sekaligus dan kemudian melakukan penggabungan obyek ke dalamnya secara bersamaan.
c. Optimizing
Merupakan pengembangan dari kedua metode diatas dengan melakukan optimasi pada penempatan obyek yang ditukar untuk Cluster lainnya dengan pertimbangan krteria optimasi.
2. Metode Hirarkis.
Memulai pengelompokan dengan dua atau lebih obyek yang mempunyai kesamaan paling dekat. Kemudian dilanjutkan pada obyek yang lain dan seterusnya hingga Cluster
akan membentuk semacam ‘pohon’ dimana terdapat tingkatan (hirarki) yangjelas antar obyek, dari yang paling mirip hingga yang paling tidak mirip. Teknik hirarki (hierarchical methods) adalah teknik Clustering membentuk kontruksi hirarki atau berdasarkan tingkatan tertentu seperti struktur pohon (struktur pertandingan). Alat yang membantu untukmemperjelas proses hirarki ini disebut “dendogram”.
Teknik hirarki (hierarchical methods) adalah teknik Clustering membentuk kontruksi hirarki atau berdasarkan tingkatan tertentu seperti struktur pohon (struktur pertandingan). Dengan demikian proses pengelompokkannya dilakukan secara bertingkat atau bertahap. Hasil dari pengelompokan ini dapat disajikan dalam bentuk dendogram. Metode-metode yang digunakan dalam teknik hirarki:
a. Agglomerative Methods
Metode ini dimulai dengan kenyatan bahwa setiap obyek membentuk Clusternya masing-masing. Kemudian dua obyek dengan jarak terdekat bergabung. Selanjutnya obyek ketiga akan bergabung dengan Cluster yang ada atau bersama obyek lain dan membentuk Cluster baru. Hal ini tetap memperhitungkan jarak kedekatan antar obyek. Proses akan berlanjut hingga akhirnya terbentuk satu Cluster yang terdiri dari keseluruhan obyek. Ada beberapa teknik dalam Agglomerative methods yaitu:
Single linkage (nearest neighbor methods)
Metode ini menggunakan prinsip jarak minimum yang diawali dengan mencari dua obyek terdekat dan keduanya membentuk Cluster yang pertama. Pada langkah selanjutnya terdapat dua kemungkinan, yaitu :
a. Obyek ketiga akan bergabung dengan Cluster yang telah terbentuk, atau b. Dua obyek lainnya akan membentu Cluster baru.
Proses ini akan berlanjut sampai akhirnya terbentuk Cluster tunggal. Pada metode ini jarak antar Cluster didefinisikan sebagai jarak terdekat antar anggotanya.
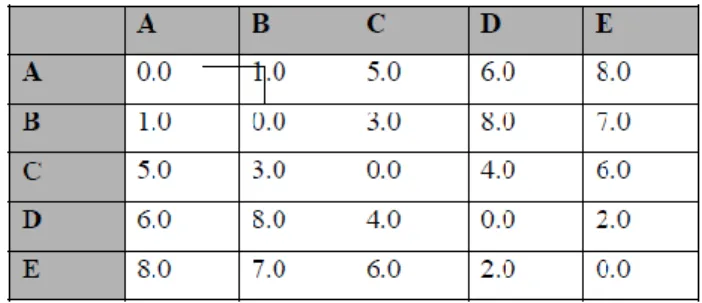
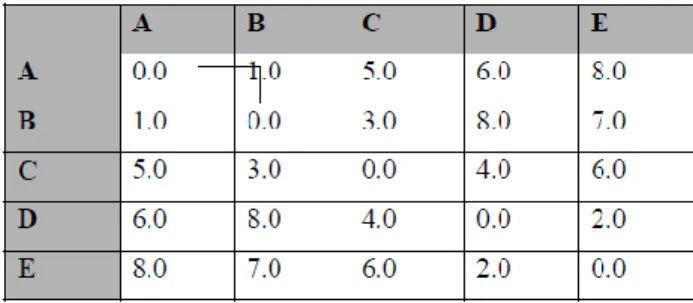
Contoh : Terdapat matriks jarak antara 5 buah obyek, yaitu :
Gambar 3. Matriks Antara 5 Buah Objek. Langkah penyelesaiannya :
a). Mencari obyek dengan jarak minimum
Menghitung jarak antara Cluster AB dengan obyek lainnya. D(AB)C = min {dAC, dBC}= dBC = 3.0
D(AB)D = min {dAD, dBD}= dAD = 6.0 D(AB)E = min {dAE, dBE}= dBE = 7.0
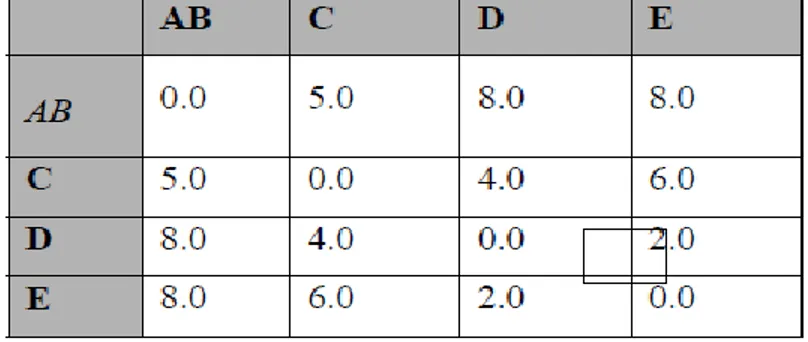
Dengan demikian terbentuk matriks jarak yang baru
Gambar 4. Matriks 5 Buah Objek Dengan Jarak Baru b). Mencari obyek dengan jarak terdekat.
D dan E mempunyai jarak terdekat, yaitu 2,0 maka obyek D dan E bergabung menjadi satu Cluster.
D(AB)C = 3.0
D(AB)(DE) = min {dAD, dAE, dBD, dBE} = dAD = 6.0 D(DE)C = min {dCD, dCE} = dCD = 4.0
d). Mencari jarak terdekat antara Cluster dengan obyek dan diperoleh obyek C bergabung dengan Cluster AB
e). Pada langkah yang terakhir, Cluster ABC bergabung dengan DE sehingga terbentuk Cluster tunggal.
Complete linkage (furthest neighbor methods)
Metode ini merupakan kebalikan dari pendekatan yang digunakan pada single linkage. Prinsip jarak yang digunakan adalah jarak terjauh antar obyek.
Contoh : Terdapat matriks jarak antara lima buah obyek yaitu :
Gambar 5. Matriks Antara 5 Buah Objek. Langkah penyelesaiannya :
a) Mencari obyek dengan jarak minimum
A dan B mempunyai jarak terdekat yaitu 1.0 maka obyek A dan B bergabung menjadi satu Cluster.
b) Menghitung jarak antara Cluster AB dengan obyek lainnya d(AB)C = max {dAC, dBC} = dAC = 5,0
d(AB)D = max {dAD, dBD} = dBD = 8,0 d(AB)E = max {dAE, dBE} = dAE = 8,0
Dengan demikian terbentuk matriks jarak yang baru :
Gambar 4. Matriks 5 Buah Objek Dengan Jarak Baru c) Mencari obyek dengan jarak terdekat.
D dan E mempunyai jarak terdekat yaitu 2.0 maka obyek D dan E bergabung menjadi satu Cluster
d) Menghitung jarak antara Cluster dengan obyek lainnya.
d(AB)C = 4,0
d(AB)(DE) = 1/2{dAD, dAE, dBD, dBE} = 7,25 d(DE)C = 1/2{dCD, dCE,} = dCE = 5,00
Maka terbentuklah matrik jarak yang baru, yaitu :
Gambar 5. Matriks Akhir
e) Mencari jarak terdekat antara Cluster dengan obyek dan diperoleh obyek C bergabung dengan Cluster AB.
f) Pada langkah yang terakhir, Cluster ABC bergabung dengan DE sehingga terbentuk Cluster tunggal
Ward’s error sum of squares methods
Ward mengajukan suatu metode pembentukan Cluster yang didasari oleh hilangnya informasi akibat penggabungan obyek menjadi Cluster. Hal ini diukur dengan jumlah total dari deviasi kuadrat pada mean Cluster untuk tiap observasi.
Error sum of squares (ESS) digunakan sebagai fungsi obyektif. Dua obyek akan digabungkan apabila mempunyai fungsi obyektif terkecil diantara kemungkinan yang ada.
ESS= ∑ ∑ 𝑋𝑖𝑗
2−1
𝑛𝑗(∑ 𝑋𝑖𝑗) 2
Dengan Xij adalah nilai untuk obyek ke-i pada Cluster ke-j.
b. Divisive Methods
Metode divisive berlawanan dengan metode agglomerative. Metode ini pertama-tama diawali dengan satu Cluster besar yang mencakup semua observasi (obyek). Selanjutnya obyek yang mempunyai ketidakmiripan yang cukup besar akan dipisahkan sehingga membentuk Cluster yang lebih kecil. Pemisahan ini dilanjutkan sehingga mencapai sejumlah Cluster yang diinginkan.
Splinter average distance methods
Metode ini didasarkan pada perhitungan jarak rata-rata masing-masing obyek dengan obyek pada grup splinter dan jarak rata-rata obyek tersebut dengan obyek lain pada grupnya. Proses tersebut dimulai dengan memisahkan obyek dengan jarak terjauh sehingga terbentuklan dua group. Kemudian dibandingkan dengan jarak rata-rata masing-masing obyek dengan group splinter dengan groupnya sendiri. Apabila suatu obyek mempunyai jarak yang lebih dekat ke group splinter daripada ke groupnya sendiri, maka obyek tersebut haruslah dikeluarkan dari groupnya dan dipisahkan ke
group splinter. Apabila komposisinya sudah stabil, yaitu jarak suatu obyek ke groupnya selalu lebih kecil daripada jarak obyek itu ke group splinter, maka proses berhenti dan dilanjutkan dengan tahap pemisahan dalam group.
Contoh : Terdapat matriks jarak antara 5 buah obyek, yaitu :
Gambar 6. Matriks Perbandingan 5 buah Objek Perhitungan :
a) Menghitung jarak rata-rata antar obyek
A = ¼ (12+9+32+31) = 21 D = ¼ (32+25+23+9) = 22.25 B = ¼ (12+9+25+27) = 18.25 E = ¼ (31+27+24+9) = 22.75 C = ¼ (9+9+23+24) = 16.25
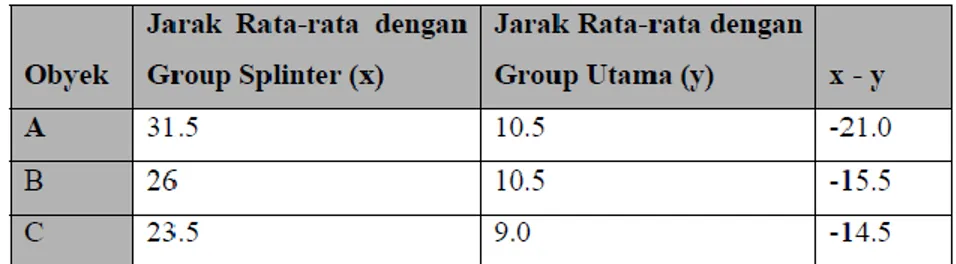
Terlihat bahwa E mempunyai nilai jarak terjauh, yaitu 22.75, maka E dipisahkan dari group utama dan membentuk group splinter.
Gambar 7. Perhitungan Rata-Rata Group Utama Dengan Group Splinter
Pada D, jarak rata-rata dengan group splinter lebih dekat daripada dengan group utama. Dengan demikian D harus dikeluarkan dari group utama dan masuk ke group splinter.
c) Perhitungan jarak rata-rata
Gambar 7. Perhitungan Rata-Rata Group Utama Dengan Group Splinter
Karena jarak semua obyek ke group utama sudah lebih besar daripada jaraknya ke group splinter, maka komposisinya sudah stabil.
Tahap Kelima : Interpretasi terhadap Cluster
Tahap interpretasi meliputi pengujian tiap Cluster dalam term untuk menamai dan menandai dengan suatu label yang secara akurat dapat menjelaskan kealamian Cluster.
Membuat profil dan interpretasi Cluster tidak hanya untuk memperoleh suatu gambaran saja melainkan pertama, menyediakan suatu rata-rata untuk menilai korespondensi pada Cluster yang terbentuk, kedua, profil Cluster memberikan araha bagi penilainan terhadap signifikansi praktis. Namun demikian yang perlu diperhatikan pada tahapan interpretasi adalah karakteristik yang membedakan masing-masing Cluster sehingga kita dapat memberikan label pada masing-masing
Tahap Keenam: Proses Validasi dan Pembuatan Profil (profiling) Cluster
1. Proses validasi solusi Cluster
Proses validasi bertujuan menjamin bahwa solusi yang dihasilkan dari analisis Cluster
dapat mewakili populasi dan dapat digeneralisasi untuk objek lain. Pendekatan ini membandingkan solusi Cluster dan menilai korespondensi hasil. Terkadang tidak dapat dipraktekkan karena adanya kendala waktu dan biaya atau ketidaktersediaan objek untuk analisis Cluster ganda.
2. Pembuatan Profil ( profiling) solusi Cluster
Tahap ini menggambarkan karakteristik tiap Cluster untuk menjelaskan Cluster-Cluster
tersebut dapat dapat berbeda pada dimensi yang relevan. Titik beratnya pada karakteristik yang secara signifikan berbeda antar cluster dan memprediksi anggota dalam suatu Cluster
Studi Kasus
Salah satu perguruan tinggi ingin memberikan beasiswa kepada beberapa kelompok mahasiswa yang dinyatakan berhak untuk menerima kategori beasiswa berdasarkan hasil seleksi yang telah dilakukan sebelumnya. Dalam pemberian beasiswa akan dikelompokan jenis pemberian beasiswa yaitu kelompok mahasiswa yang mendapatkan beasiswa sebesar Rp 1.000.000,00, kelompok mahasiswa yang mendapatkan beasiswa sebesar Rp 2.000.000,00, kelompok mahasiswa yang mendapatkan beasiswa sebesar Rp 3.000.000,00, kelompok mahasiswa yang mendapatkan beasiswa sebesar Rp 4.000.000, dan kelompok mahasiswa yang mendapatkan beasiswa sebesar Rp 5.000.000. Dalam pemberian beasiswa ini perguruan tinggi mengelompokan berdasarkan 5 kriteria yaitu pendapatan orang tua, jumlah tanggungan anak dari orang tua, pekerjaan orang tua, ipk, dan nilai wawancara.
Berikut adalah data yang telah diperoleh dari 30 mahasiswa yang mengikuti seleksi. Data Mahasiswa : No Nama Pendapatan Orang Tua (Dalam Rupiah) Jumlah Tanggungan Anak Dari Orang Tua Pekerjaan
Orang Tua IPK
Nilai Wawancara 1 Rino 5000000 2 2 3,16 65 2 Abdul 3500000 2 2 3,35 75 3 Viant 3000000 4 2 3,65 85 4 Aan 7500000 1 2 3,00 60 5 Romi 4500000 3 2 3,45 70 6 Ririn 1500000 4 1 3,85 88 7 Rahma 2000000 3 2 3,70 84 8 Okta 3000000 5 1 3,50 78 9 Andre 5000000 2 2 3,40 72 10 Niko 3000000 2 2 3,45 74 11 Ayuk 1000000 3 1 3,80 86 12 Wanti 1500000 4 2 3,60 83 13 Mey 8000000 2 2 3,30 68 14 Farah 1000000 3 1 3,90 86
No Nama Pendapatan Orang Tua (Dalam Rupiah) Jumlah Tanggungan Anak Dari Orang Tua Pekerjaan
Orang Tua IPK
Nilai Wawancara 15 Maryana 750000 4 1 3,75 90 16 Sifa 5000000 2 2 3,35 62 17 Wulan 2500000 3 2 3,68 79 18 Ulfa 2000000 3 1 3,72 86 19 Syahdan 3000000 2 2 3,58 73 20 Awan 1000000 2 1 3,74 85 21 Rafi 500000 3 1 3,73 84 22 Edgar 1500000 2 1 3,86 90 23 Ira 3000000 6 2 3,65 75 24 Nuca 4000000 3 2 3,46 68 25 Tere 10000000 2 2 3,25 70 26 Ehsan 7500000 3 2 3,15 67 27 Ghina 2000000 3 2 3,35 87 28 Affan 1000000 2 1 3,64 78 29 Dika 5000000 3 2 3,40 72 30 Aya 3000000 2 2 3,63 77 Keterangan:
Metode Hirarki
Langkah Penyelesaian : 1. Tahap Standarisasi Data
- Input Data pada Variable View
Mengisi data view seperti gambar dibawah ini
- Mengganti values dari variabel pekerjaan seperti gambar dibawah
- Pindahkan semua variabel ke kolom variable (S)
- Centang pada save standardized values as variables
- Kenudian klik OK
- Output normalisasi data
Dari hasil Output diatas merupakan tampilan pertama hasil proses nomalisasi data. Dari tabel menunjukkan hasil nilai N, Minimum, Maximum, Mean, dan Standar Deviation
dari masing-masing kriteria. Jika sudah tampil output seperti gambar diatas, maka anda memastikan tampilan Data View anda sebelumnya sudah seperti gambar dibawah ini.
Terdapat tambahan variabel “Z” hasil dari normalisasi data kuesioner dari masing-masing kriteria. Data "Z score” inilah yang kemudian akan diolah untuk tahap pengelompokkan (clustering) berikutnya.
2. Tahap Pengelompokkan (clustering)
- Memindahkan semua variabel Z Score pada kotak variable (s)
- Memindahkan variabel nama pada label cases by
- Pilih Statistics
- Pada kotak dialog statistics centang Agglomerative Schedule dan Proxy Matrix
- Pilih range of solution , kemudian isi minimum number menjadi 2, dan maximum number menjadi 5. Kemudian klik continue
- Pada kotak dialog Plots mencentang Dendogram, All Cluster, dan Vertical
- Pada kotak dialog Method gantilah cluster Method menjadi Nearest Neighboor, dan centang Interval kemudian mengganti pilihannya menjadi Squared Euqlidean Distance
- Klik continue
-- Maka akan tampillah output spss sepeti beberapa tabel dibawah ini
OUTPUT 1 Agglomeration Schedule
Agglomeration Schedule
Stage
Cluster Combined
Coefficients
Stage Cluster First Appears
Next Stage
Cluster 1 Cluster 2 Cluster 1 Cluster 2
1 5 24 ,099 0 0 2 2 5 29 ,146 1 0 17 3 11 21 ,193 0 0 4 4 11 14 ,196 3 0 7 5 2 10 ,253 0 0 8 6 19 30 ,263 0 0 8 7 11 18 ,299 4 0 18 8 2 19 ,345 5 6 12 9 6 15 ,347 0 0 20 10 7 17 ,385 0 0 21 11 3 12 ,493 0 0 22 12 2 9 ,560 8 0 17 13 20 22 ,660 0 0 16 14 1 16 ,756 0 0 23 15 13 25 ,797 0 0 19 16 20 28 ,851 13 0 18 17 2 5 ,902 12 2 21 18 11 20 ,960 7 16 20 19 13 26 1,007 15 0 24 20 6 11 1,047 9 18 27 21 2 7 1,047 17 10 22 22 2 3 1,138 21 11 23 23 1 2 1,407 14 22 24 24 1 13 1,860 23 19 25 25 1 27 2,385 24 0 26 26 1 4 2,823 25 0 27 27 1 6 4,411 26 20 28
Agglomeration Schedule
Stage
Cluster Combined
Coefficients
Stage Cluster First Appears
Next Stage
Cluster 1 Cluster 2 Cluster 1 Cluster 2
28 1 23 4,901 27 0 29
29 1 8 4,931 28 0 0
Hasil output tabel pertama memberikan penjelasan mengenai penggabungan antara setiap anggota 1 dengan anggota lainnya. Seperti contoh pembacaan tabel agglomeration schedule :
a) Pada stage 1 responden 5 bergabung dengan responden 24 pada jarak yang terdekat pertama yaitu (lihat pada kolom coefficients) 0,099. Dimana anggota 5 dan 24 belum pernah bergabung sebelumnya (nilai 0) dengan anggota manapun (lihat pada kolom stage cluster first appears. Untuk melihat penggabungan anggota yang terlibat pada stage 1 berikutnya lihat pada kolom next stage.
b) Pada stage 2 responden 5 bergabung dengan responden 29 pada jarak yang terdekat kedua yaitu (lihat pada kolom coefficients) 0,146. Dimana anggota 5 pernah bergabung sebelumnya (nilai 1) pada stage 1 dan anggota 29 belum pernah bergabung sebelumnya dengan anggota manapun ditandai dengan nilai 0 (lihat pada kolom stage cluster first appears. Untuk melihat penggabungan anggota yang terlibat pada stage 1 berikutnya lihat pada kolom next stage.
OUTPUT 2Cluster Membership
Cluster Membership
Case 5 Clusters 4 Clusters 3 Clusters 2 Clusters
1:Rino 1 1 1 1 2:Abdul 1 1 1 1 3:Viant 1 1 1 1 4:Aan 2 1 1 1 5:Romi 1 1 1 1 6:Ririn 3 2 1 1 7:Rahma 1 1 1 1 8:Okta 4 3 2 2 9:Andre 1 1 1 1 10:Niko 1 1 1 1 11:Ayuk 3 2 1 1 12:Wanti 1 1 1 1 13:Mey 1 1 1 1 14:Farah 3 2 1 1 15:Maryana 3 2 1 1 16:Sifa 1 1 1 1 17:Wulan 1 1 1 1 18:Ulfa 3 2 1 1 19:Syahdan 1 1 1 1 20:Awan 3 2 1 1 21:Rafi 3 2 1 1 22:Edgar 3 2 1 1 23:Ira 5 4 3 1 24:Nuca 1 1 1 1 25:Tere 1 1 1 1 26:Ehsan 1 1 1 1 27:Ghina 1 1 1 1 28:Affan 3 2 1 1 29:Dika 1 1 1 1
Cluster Membership
Case 5 Clusters 4 Clusters 3 Clusters 2 Clusters
30:Aya 1 1 1 1
Output diatas menunjukkan bahwa setiap terbentuknya n kelompok, maka terdaftarlah anggota-anggota setiap kelompoknya seperti yang sudah tertera pada tabel diatas. Ketika menentukan banyaknya kelompok (cluster) tidak semua anggota berada pada cluster
yang sama ketika peneliti ingin membuat kelompok menjadi 2, 3, 4, atau 5. Contohnya : Anggota ke 28 menjadi anggota cluster 3 ketika kelompok yang dibentuk sebanyak 5 kelompok, dan menjadi anggota cluster 2 ketika kelompok yang dibentuk sebanyak 4 kelompok , dan menjadi anggota cluster 1 ketika kelompok yang dibentuk sebanyak 3 kelompok. Hasil ini membantu anda dalam menentukan cluster berdasarkan metode cut off pada hasil dendogram.
OUTPUT 3 Dendogram
Hasil dendogram menunjukkan bahwa penggabungan setip anggota berdasarkan jarak yang paling dekat, sehingga membentuk satu cluster yang sangat besar. Hasil dendogram
ini akan mudah dibaca jika pembacaannya dibantu oleh hasil Agglomerative Schedule
Pembentukkan jumlah cluster dapat dibentuk dengan metode cut off pada hasil dendogram. Sebagai contoh:
a) Melakukan cut off pada angka 12
b) Akan terlihat cluster yang terbentuk sebanyak 5 cluster dengan 4 Outlier ,
c) Untuk melihat anggota masing-masing cluster dapat dilihat dari gambar berikut ini:
Cluster 5 merupakan 2 outlier dimana memiliki karakter yang sama dilihat dari hasil dendogram sebelum dilakukannya cut off
Jumlah masing-masing anggota cluster yang terbentuk adalah sebagai berikut:
Cluster 1 = 17 (60%) Orang
Cluster 2 (Outlier) = 1 (3,3%) Orang
Cluster 3 (Outlier) = 1 (3,3%) Orang
Cluster 4 = 9 (630%) Orang
Cluster 5 (Outlier) = 2 (3,3%) Orang
Cluster yang terbentuk jika menggunakan metode Cut Off, sebagai berikut:
Jarak Cut Off Cluster yang terbentuk Outlier yang terbentuk
6 5 4
10 3 4
12 2 4
16 2 2
2
Cut off pada angka 12
3 5
4 1
3. Tahap pengujian crosstab
- Pada Data View menambah variabel baru yaitu variabel Cluster. - Kemudian mengganti measur- nya menjadi nominal
- Pada Data View mengisi data untuk variabel cluster berdasarkan masing-anggota pada setiap kelompok seperti gambar dibawah.
- Memindahkan seluruh variabel Z score pada kotak dialog Row(s)
- Memindahkan variabel cluster pada kotak dialog Coloumn (s).
- Pada menu Statistics beri tanda centang pada Correlations
- Pada menu cell display beri centang pada Observed dan total
a) Output Crosstab pertama (Penghasilan Orang Tua)
Crosstab
cluster
Total cluster 1 cluster 2 cluster 3 cluster 4 cluster 5
Zscore(penghasilan_orangtua) -1,19772 Count 0 0 0 1 0 1 % of Total 0,0% 0,0% 0,0% 3,3% 0,0% 3,3% -1,09357 Count 0 0 0 1 0 1 % of Total 0,0% 0,0% 0,0% 3,3% 0,0% 3,3% -,98942 Count 0 0 0 4 0 4 % of Total 0,0% 0,0% 0,0% 13,3% 0,0% 13,3% -,78112 Count 1 0 0 2 0 3 % of Total 3,3% 0,0% 0,0% 6,7% 0,0% 10,0% -,57282 Count 1 1 0 1 0 3 % of Total 3,3% 3,3% 0,0% 3,3% 0,0% 10,0% -,36452 Count 1 0 0 0 0 1 % of Total 3,3% 0,0% 0,0% 0,0% 0,0% 3,3% -,15622 Count 4 0 0 0 2 6 % of Total 13,3% 0,0% 0,0% 0,0% 6,7% 20,0% ,05207 Count 1 0 0 0 0 1 % of Total 3,3% 0,0% 0,0% 0,0% 0,0% 3,3% ,26037 Count 1 0 0 0 0 1 % of Total 3,3% 0,0% 0,0% 0,0% 0,0% 3,3% ,46867 Count 1 0 0 0 0 1 % of Total 3,3% 0,0% 0,0% 0,0% 0,0% 3,3% ,67697 Count 4 0 0 0 0 4 % of Total 13,3% 0,0% 0,0% 0,0% 0,0% 13,3% 1,71847 Count 1 0 1 0 0 2 % of Total 3,3% 0,0% 3,3% 0,0% 0,0% 6,7% 1,92677 Count 1 0 0 0 0 1
Crosstab
cluster
Total cluster 1 cluster 2 cluster 3 cluster 4 cluster 5
% of Total 3,3% 0,0% 0,0% 0,0% 0,0% 3,3%
2,75997 Count 1 0 0 0 0 1
% of Total 3,3% 0,0% 0,0% 0,0% 0,0% 3,3%
Total Count 17 1 1 9 2 30
% of Total 56,7% 3,3% 3,3% 30,0% 6,7% 100,0%
b) Output Crosstab yang ke 2 (tanggungan anak)
Crosstab
cluster
Total cluster 1 cluster 2 cluster 3 cluster 4 cluster 5
Zscore(tanggungan_anak) -1,74075 Count 0 0 1 0 0 1 % of Total 0,0% 0,0% 3,3% 0,0% 0,0% 3,3% -,79125 Count 9 0 0 3 0 12 % of Total 30,0% 0,0% 0,0% 10,0% 0,0% 40,0% ,15825 Count 6 1 0 4 0 11 % of Total 20,0% 3,3% 0,0% 13,3% 0,0% 36,7% 1,10775 Count 2 0 0 2 0 4 % of Total 6,7% 0,0% 0,0% 6,7% 0,0% 13,3% 2,05725 Count 0 0 0 0 1 1 % of Total 0,0% 0,0% 0,0% 0,0% 3,3% 3,3% 3,00676 Count 0 0 0 0 1 1 % of Total 0,0% 0,0% 0,0% 0,0% 3,3% 3,3% Total Count 17 1 1 9 2 30 % of Total 56,7% 3,3% 3,3% 30,0% 6,7% 100,0%
c) Output Crosstab yang ke 3 (Pekerjaan)
Crosstab
cluster
Total cluster 1 cluster 2 cluster 3 cluster 4 cluster 5
Zscore(pekerjaan) -1,39044 Count 0 0 0 9 1 10 % of Total 0,0% 0,0% 0,0% 30,0% 3,3% 33,3% ,69522 Count 17 1 1 0 1 20 % of Total 56,7% 3,3% 3,3% 0,0% 3,3% 66,7% Total Count 17 1 1 9 2 30 % of Total 56,7% 3,3% 3,3% 30,0% 6,7% 100,0%
d) Output Crosstab yang ke 4 (IPK)
Crosstab
cluster
Total cluster 1 cluster 2 cluster 3 cluster 4 cluster 5
Zscore(ipk) -2,38288 Count 0 0 1 0 0 1 % of Total 0,0% 0,0% 3,3% 0,0% 0,0% 3,3% -1,67422 Count 1 0 0 0 0 1 % of Total 3,3% 0,0% 0,0% 0,0% 0,0% 3,3% -1,27560 Count 2 0 0 0 0 2 % of Total 6,7% 0,0% 0,0% 0,0% 0,0% 6,7% -1,05414 Count 1 0 0 0 0 1 % of Total 3,3% 0,0% 0,0% 0,0% 0,0% 3,3% -,87697 Count 1 0 0 0 0 1 % of Total 3,3% 0,0% 0,0% 0,0% 0,0% 3,3% -,83268 Count 1 1 0 0 0 2
Crosstab
cluster
Total cluster 1 cluster 2 cluster 3 cluster 4 cluster 5
% of Total 3,3% 3,3% 0,0% 0,0% 0,0% 6,7% -,61122 Count 2 0 0 0 0 2 % of Total 6,7% 0,0% 0,0% 0,0% 0,0% 6,7% -,38977 Count 2 0 0 0 0 2 % of Total 6,7% 0,0% 0,0% 0,0% 0,0% 6,7% -,34547 Count 1 0 0 0 0 1 % of Total 3,3% 0,0% 0,0% 0,0% 0,0% 3,3% -,16831 Count 0 0 0 0 1 1 % of Total 0,0% 0,0% 0,0% 0,0% 3,3% 3,3% ,18602 Count 1 0 0 0 0 1 % of Total 3,3% 0,0% 0,0% 0,0% 0,0% 3,3% ,27461 Count 1 0 0 0 0 1 % of Total 3,3% 0,0% 0,0% 0,0% 0,0% 3,3% ,40748 Count 1 0 0 0 0 1 % of Total 3,3% 0,0% 0,0% 0,0% 0,0% 3,3% ,45177 Count 0 0 0 1 0 1 % of Total 0,0% 0,0% 0,0% 3,3% 0,0% 3,3% ,49607 Count 1 0 0 0 1 2 % of Total 3,3% 0,0% 0,0% 0,0% 3,3% 6,7% ,62894 Count 1 0 0 0 0 1 % of Total 3,3% 0,0% 0,0% 0,0% 0,0% 3,3% ,71752 Count 1 0 0 0 0 1 % of Total 3,3% 0,0% 0,0% 0,0% 0,0% 3,3% ,80611 Count 0 0 0 1 0 1 % of Total 0,0% 0,0% 0,0% 3,3% 0,0% 3,3% ,85040 Count 0 0 0 1 0 1
Crosstab
cluster
Total cluster 1 cluster 2 cluster 3 cluster 4 cluster 5
% of Total 0,0% 0,0% 0,0% 3,3% 0,0% 3,3% ,89469 Count 0 0 0 1 0 1 % of Total 0,0% 0,0% 0,0% 3,3% 0,0% 3,3% ,93898 Count 0 0 0 1 0 1 % of Total 0,0% 0,0% 0,0% 3,3% 0,0% 3,3% 1,16044 Count 0 0 0 1 0 1 % of Total 0,0% 0,0% 0,0% 3,3% 0,0% 3,3% 1,38190 Count 0 0 0 1 0 1 % of Total 0,0% 0,0% 0,0% 3,3% 0,0% 3,3% 1,42619 Count 0 0 0 1 0 1 % of Total 0,0% 0,0% 0,0% 3,3% 0,0% 3,3% 1,60335 Count 0 0 0 1 0 1 % of Total 0,0% 0,0% 0,0% 3,3% 0,0% 3,3% Total Count 17 1 1 9 2 30 % of Total 56,7% 3,3% 3,3% 30,0% 6,7% 100,0%
e) Output Crosstab yang ke 5 (nilai wawancara)
Crosstab
cluster
Total cluster 1 cluster 2 cluster 3 cluster 4 cluster 5
Zscore(wawancara) -1,99252 Count 0 0 1 0 0 1 % of Total 0,0% 0,0% 3,3% 0,0% 0,0% 3,3% -1,76128 Count 1 0 0 0 0 1 % of Total 3,3% 0,0% 0,0% 0,0% 0,0% 3,3% -1,41442 Count 1 0 0 0 0 1 % of Total 3,3% 0,0% 0,0% 0,0% 0,0% 3,3% -1,18318 Count 1 0 0 0 0 1 % of Total 3,3% 0,0% 0,0% 0,0% 0,0% 3,3% -1,06756 Count 2 0 0 0 0 2 % of Total 6,7% 0,0% 0,0% 0,0% 0,0% 6,7% -,83632 Count 2 0 0 0 0 2 % of Total 6,7% 0,0% 0,0% 0,0% 0,0% 6,7% -,60508 Count 2 0 0 0 0 2 % of Total 6,7% 0,0% 0,0% 0,0% 0,0% 6,7% -,48946 Count 1 0 0 0 0 1 % of Total 3,3% 0,0% 0,0% 0,0% 0,0% 3,3% -,37384 Count 1 0 0 0 0 1 % of Total 3,3% 0,0% 0,0% 0,0% 0,0% 3,3% -,25822 Count 1 0 0 0 1 2 % of Total 3,3% 0,0% 0,0% 0,0% 3,3% 6,7% -,02698 Count 1 0 0 0 0 1 % of Total 3,3% 0,0% 0,0% 0,0% 0,0% 3,3%
Crosstab
cluster
Total cluster 1 cluster 2 cluster 3 cluster 4 cluster 5
,08864 Count 0 0 0 1 1 2 % of Total 0,0% 0,0% 0,0% 3,3% 3,3% 6,7% ,20426 Count 1 0 0 0 0 1 % of Total 3,3% 0,0% 0,0% 0,0% 0,0% 3,3% ,66674 Count 1 0 0 0 0 1 % of Total 3,3% 0,0% 0,0% 0,0% 0,0% 3,3% ,78236 Count 1 0 0 1 0 2 % of Total 3,3% 0,0% 0,0% 3,3% 0,0% 6,7% ,89798 Count 1 0 0 1 0 2 % of Total 3,3% 0,0% 0,0% 3,3% 0,0% 6,7% 1,01360 Count 0 0 0 3 0 3 % of Total 0,0% 0,0% 0,0% 10,0% 0,0% 10,0% 1,12922 Count 0 1 0 0 0 1 % of Total 0,0% 3,3% 0,0% 0,0% 0,0% 3,3% 1,24484 Count 0 0 0 1 0 1 % of Total 0,0% 0,0% 0,0% 3,3% 0,0% 3,3% 1,47608 Count 0 0 0 2 0 2 % of Total 0,0% 0,0% 0,0% 6,7% 0,0% 6,7% Total Count 17 1 1 9 2 30 % of Total 56,7% 3,3% 3,3% 30,0% 6,7% 100,0%
Berikut ini merupakan pedoman ketentuan untuk menafsirkan tabel hasil analisis pada hasil crosstab:
1. Jika terdapat karakter yang angkanya menunjukkan angka negatif, berarti cluster yang bersangkutan ada di bawah rata-rata total.
2. Jika terdapat karakter yang angkanya menunjukkan angka positif, berarti cluster yang bersangkutan ada di atas rata-rata total.
Dari seluruh hasil crosstab diatas, dapat diketahui karakteristik masing-masing cluster
berdasarkan karakteristik anggota anggota cluster yang dominan, dapat dilihat dari tabel berikut ini:
Cluster 1 Cluster 2 Cluster 3 Cluster 4 Cluster 5
Penghasilan orang tua 0,67697 (13,3%) - 0,1562 (13,3%) - 0,5728 (3,3%) 1,7184 (3,3%) - 0,9894 (3,3%) - 0,1562 (6,7%) Tanggungan anak -0,7912 (30%) 0,1582 (3,3%) - 1,740 (3,3%) 0,1582 (13,3%) Untuk kriteria Tanggungan anak pada cluster ini dominan diatas rata-rata total Pekerjaan 0,69522 (56,7%) 0,69522 (3,3%) 0,69522 (3,3%) -1,3904 (30%) 0,69522 (3,3%) -1,3904 (3,3%)
IPK Untuk kriteria
IPK pada cluster ini dominan diatas bawah - 0,8326 (3,3%) - 2,3828 (3,3%) Untuk kriteria IPK pada cluster ini dominan diatas rata-rata total -0,168 (3,3%) 0,496 (3,3%) Nilai Wawancara Untuk kriteria Nilai wawancara pada cluster ini dominan dibawah rata-rata total 1,12922 (3,3%) -1,9925 (3,3%) Untuk kriteria Nilai wawancara pada cluster ini dominan diatas rata-rata total - 0,258 (3,3%) 0,0886 (3,3%)
Dari tabel rekapitulasi diatas, maka dapatlah dilihat masing-masing cluster sebagai berikut:
Dalam cluster-1 terdiri dari mahasiswa dengan dominan pendapatan orang tua dibawah rata-rata total, jumlah tanggungan anak orang tua dibawah rata-rata-rata-rata total, pekerjaan orang tua diatas rata-rata total (pekerjaan tetap), IPK diatas rata-rata total, nilai wawancara dibawah rata-rata total. Sehingga, cluster-1 yang terdiri dari 17 mahasiswa mendapatkan beasiswa sebesar Rp 2.000.000,00.
Dalam cluster-2 terdiri dari mahasiswa dengan dominan pendapatan orang tua dibawah rata-rata total, jumlah tanggungan anak orang tua diatas rata-rata-rata-rata total, pekerjaan orang tua diatas rata-rata total (pekerjaan tetap), IPK dibawah rata-rata total, nilai wawancara diatas rata-rata total. Sehingga, cluster-2 yang terdiri dari 1 mahasiswa mendapatkan beasiswa sebesar Rp 3.000.000,00.
Dalam cluster-3 terdiri dari mahasiswa dengan dominan pendapatan orang tua diatas rata-rata total, jumlah tanggungan anak orang tua dibawah rata-rata-rata-rata total, pekerjaan orang tua diatas rata-rata total (pekerjaan tetap), IPK dibawah rata-rata total, nilai wawancara dibawah rata-rata total. Sehingga, cluster-3 yang terdiri dari 1 mahasiswa mendapatkan beasiswa sebesar Rp 1.000.000,00.
Dalam cluster-4 terdiri dari mahasiswa dengan dominan pendapatan orang tua dibawah rata-rata total, jumlah tanggungan anak orang tua diatas batas rata-rata-rata-rata total, pekerjaan orang tua dibawah rata-rata total (pekerjaan tidak tetap), IPK diatas rata-rata total, nilai wawancara diatas rata-rata total. Sehingga, cluster-4 yang terdiri dari 9 mahasiswa mendapatkan beasiswa sebesar Rp 5.000.000,00.
Dalam cluster-5 terdiri dari mahasiswa dengan dominan pendapatan orang tua dibawah rata-rata total, jumlah tanggungan anak orang tua diatas rata-rata-rata-rata total, pekerjaan orang tua diatas rata-rata total (pekerjaan tetap), IPK dibatas rata-rata total, nilai wawancara diatas rata-rata
total. Sehingga, cluster-1 yang terdiri dari 1 mahasiswa mendapatkan beasiswa sebesar Rp 4.000.000,00.
Metode Non Hierarki (K-Means Cluster)
Langkah Penyelesaian 1. Standarisasi Data
Karena data yang dikumpulkan berada dalam satuan yang berbeda maka terlebih dahulu dilakukan proses standarisasi (normalisasi) data. Jika data sudah berada dalam satuan yg sama atau tidak memiliki satuan maka langkah ini dapat diabaikan.
Masukkan seluruh data ke dalam spss :
b. Pindahkan variabel dikolom kiri ke kolom Variable(s)
c. Aktifkan Save Standardized as Variables
d. Klik OK e. Hasil SPSS
Descriptive Statistics
N Minimum Maximum Mean Std. Deviation
Pendapatan_Orang_Tua 30 500000,00 10000000,00 3375000,0000 2400386,1040 0 Jumlah_Tanggungan_An ak 30 1,00 6,00 2,8333 1,05318 Pekerjaan_Orang_Tua 30 1,00 2,00 1,6667 ,47946 IPK 30 3,00 3,90 3,5350 ,23057 Nilai_Wawancara 30 60,00 90,00 77,2333 8,64903 Valid N (listwise) 30
Setelah tahap tersebut dilakukan, maka akan muncul tabel Descriptive Statistics yang akan digunakan untuk membantu menganalisis pengelompokan cluster nantinya.
Pastikan tampilan pada data view telah berubah seperti gambar berikut ini:
2. Analisis Cluster Metode K-Means Cluster
a. Pada Analyze Classify K-Means Cluster
c. Tentukan jumlah Cluster dengan mengisikan angka 5 pada Number of Cluster
d. Pilih Save dan aktifkan Cluster Membership dan Distance from Cluster center, kemudian
e. Pilih Option, aktifkan Initial Cluster center dan Anova Table
f. Klik OK
Langkah tersebut akan menghasilkan tabel Initial Cluster seperti pada gambar di bawah ini. Tabel Initial Cluster Centers menunjukkan hasil proses sementara pengelompokan data yang di lakukan.
Initial Cluster Centers
Cluster 1 2 3 4 5 Zscore(Pendapatan_Orang_ Tua) ,67697 -,15622 -,15622 1,71847 -,78112 Zscore(Jumlah_Tanggunga n_Anak) -,79125 2,05725 1,10775 -1,74075 -,79125 Zscore(Pekerjaan_Orang_T ua) ,69522 -1,39044 ,69522 ,69522 -1,39044 Zscore(IPK) -,58550 -,15180 ,49876 -2,32031 1,40953 Zscore(Nilai_Wawancara) -,60508 ,08864 ,89798 -1,99252 1,47608
Tabel diatas merupakan tampilan pertama proses clustering data sebelum dilakukan iterasi. Untuk mendeteksi berapa kali proses iterasi dilakukan dalam proses clustering menggunakan 30 data objek dapat dilihat tampilan output berikut:
Iteration Historya
Iteration
Change in Cluster Centers
1 2 3 4 5
1 ,397 ,000 ,498 1,061 1,045
2 ,300 ,000 ,000 ,580 ,000
3 ,156 ,000 ,000 ,273 ,000
4 ,000 ,000 ,000 ,000 ,000
a. Convergence achieved due to no or small change in cluster centers. The maximum absolute coordinate change for any center is ,000. The current iteration is 4. The minimum distance between initial centers is 2,516.
Ternyata proses clustering dilakukan melalui 4 iterasi untuk menentukan cluster yang tepat. Dari tabel diatas disebutkan bahwa jarak minimum antar pusat cluster yang terjadi dari hasil iterasi adalah 2,516.
Cluster Membership Nama QCL_1 QCL_2 Rino 4 1,09055 Abdul 1 0,71352 Viant 3 0,49758 Aan 4 1,3932 Romi 1 0,68707 Ririn 5 1,13859 Rahma 3 0,92739 Okta 2 0 Andre 1 0,57372 Niko 1 0,60094 Ayuk 5 0,15775 Wanti 3 0,39411 Mey 4 0,62404 Farah 5 0,54842
Nama QCL_1 QCL_2 Maryana 5 1,17413 Sifa 1 1,28944 Wulan 3 0,93314 Ulfa 5 0,44765 Syahdan 1 0,78306 Awan 5 0,86691 Rafi 5 0,41308 Edgar 5 1,04476 Ira 3 2,24368 Nuca 1 0,74862 Tere 4 1,15239 Ehsan 4 0,96217 Ghina 3 1,47674 Affan 5 1,37803 Dika 1 0,79352 Aya 1 1,13173
Terlihat dari gambar diatas menunjukkan tiap responden masuk kedalam masing-masing cluster
yang dibentuk. Seperti responden 1 bernama Rino masuk dalam cluster 4, nilai distance sebesar 1,09055.
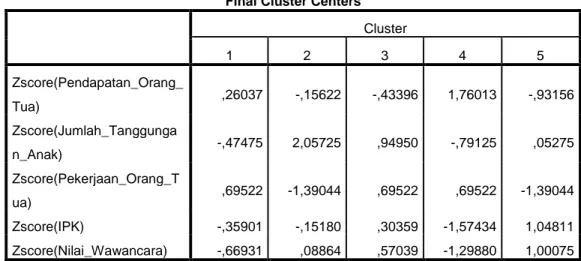
Final Cluster Centers Cluster 1 2 3 4 5 Zscore(Pendapatan_Orang_ Tua) ,26037 -,15622 -,43396 1,76013 -,93156 Zscore(Jumlah_Tanggunga n_Anak) -,47475 2,05725 ,94950 -,79125 ,05275 Zscore(Pekerjaan_Orang_T ua) ,69522 -1,39044 ,69522 ,69522 -1,39044 Zscore(IPK) -,35901 -,15180 ,30359 -1,57434 1,04811 Zscore(Nilai_Wawancara) -,66931 ,08864 ,57039 -1,29880 1,00075
Tabel Final Cluster Centers menunjukkan hasil analisisnya untuk masing-masing krieria dan cluster yang dibentuk.
Berikut ini merupakan pedoman ketentuan untuk menafsirkan tabel hasil analisis pada
Final Cluster Centers:
1. Jika hasil perhitungan ditemukan negatif, berarti cluster yang bersangkutan ada di bawah rata-rata total.
2. Jika hasil perhitungan ditemukan positif, berarti cluster yang bersangkutan ada di atas rata-rata total.
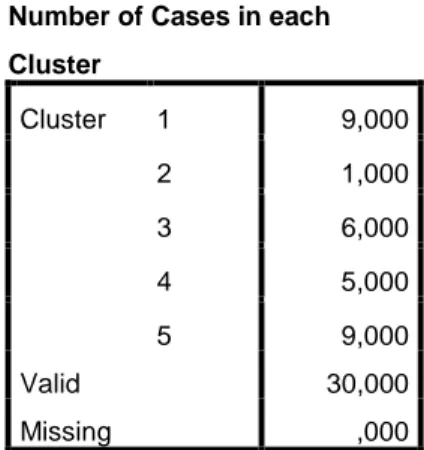
Number of Cases in each Cluster Cluster 1 9,000 2 1,000 3 6,000 4 5,000 5 9,000 Valid 30,000 Missing ,000
Tabel Number of cases in each cluster menunjukkan jumlah mahasiswa yang masuk ke dalam tiap cluster. Cluster 1 (9 mahasiswa), cluster 2 (1 mahasiswa) dan cluster 3 (6 mahasiswa), cluster 4 (5 mahasiswa), cluster 5 (9 mahasiswa).
Dari tabel output Final Cluster Centers, dengan ketentuan yang telah dijabarkan diatas pula, dapat didefinisikan sebagai berikut :
1. Cluster 1
Dalam cluster-1 terdiri dari mahasiswa dengan dominan pendapatan orang tua diatas rata-rata total, jumlah tanggungan anak orang tua dibawah rata-rata total, pekerjaan orang tua diatas rata-rata total (pekerjaan tetap), IPK dibawah rata-rata total, nilai wawancara dibawah rata-rata total.
Sehingga, cluster-1 yang terdiri dari 9 mahasiswa mendapatkan beasiswa sebesar Rp 1.000.000,00.
2. Cluster 2
Dalam cluster-2 terdiri dari mahasiswa dengan dominan pendapatan orang tua dibawah rata-rata total, jumlah tanggungan anak orang tua diatas rata-rata total, pekerjaan orang tua dibawah rata-rata total (pekerjaan tidak tetap), IPK dibawah rata-rata total, nilai
wawancara diatas rata-rata total.
Sehingga, cluster-2 yang terdiri dari 1 mahasiswa mendapatkan beasiswa sebesar Rp 3.000.000,00.
3. Cluster 3
Dalam cluster-3 terdiri dari mahasiswa dengan dominan pendapatan orang tua dibawah rata-rata total, jumlah tanggungan anak orang tua atas rata-rata total, pekerjaan orang tua diatas rata-rata total (pekerjaan tetap), IPK diatas rata-rata total, nilai wawancara diatas rata-rata total.
Sehingga, cluster-3 yang terdiri dari 6 mahasiswa mendapatkan beasiswa sebesar Rp 4.000.000,00
4. Cluster 4
Dalam cluster-4 terdiri dari mahasiswa dengan dominan pendapatan orang tua diatas rata-rata total, jumlah tanggungan anak dibawah rata-rata total, pekerjaan orang tua diatas rata-rata total (pekerjaan tetap), IPK dibawah rata-rata total, nilai wawancara dibawah rata-rata total.
Sehingga, cluster-4 yang terdiri dari 5 mahasiswa mendapatkan beasiswa sebesar Rp 2.000.000,00.
Walaupun karakteristik anggota cluster 4 mirip dengan cluster 1, namun melihat angka dalam hasil SPSS, maka cluster 4 diberi nominal beasiswa lebih besar karena pendapatan orang tua lebih kecil dan nilai IPK serta wawancara lebih besar daripada cluster 1.
5. Cluster 5
Dalam cluster-5 terdiri dari mahasiswa dengan dominan pendapatan orang tua dibawah rata-rata total, jumlah tanggungan anak diatas rata-rata total, pekerjaan orang tua dibawah rata-rata total (pekerjaan tidak tetap), IPK diatas rata-rata total, nilai
wawancara diatas rata-rata total.
Sehingga, cluster-5 yang terdiri dari 9 mahasiswa mendapatkan beasiswa sebesar Rp 5.000.000,00
DAF
TAR PUSTAKA Bertalya. 2009. Konsep Data Mining. Universitas Gunadarma.
Fayyad, Usama. 1996. Advances in Knowledge Discovery and Data Mining. MIT Press.
Susanto, Hery Tri. 2009. Cluster Analysis. Seminar Nasional Matematika dan Pendidikan Matematika. Yogyakarta: Universitas Negeri Yogyakarta.
Turban, Efraim et al. 2005. Decision Support Systems and Intelligent Systems. Yogyakarta: Andi Offset
Walpole, Ronald E. dan Myers, Raymond H. 1986. Ilmu Peluang dan Statistik Untuk Insinyur Dan Ilmuwan. Bandung: ITB Press.