BAB 2
LANDASAN TEORI
2.1 Kerangka Teori
2.1.1 Algoritma Lingo
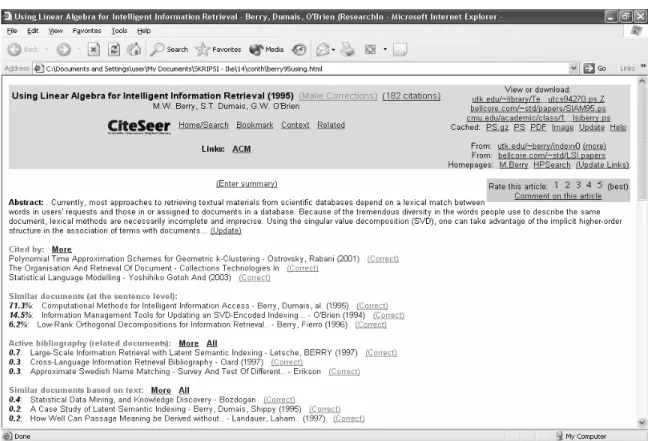
Sebelum masuk dalam pembahasan teori lebih dalam tentang algoritma Lingo, analisis akan dilakukan terhadap website yang menyediakan fasilitas search engine pada gambar berikut yang menjadikannya lebih baik jika dibandingkan dengan search engine lain yang umumnya ada saat ini seperti Google, Yahoo, dan sebagainya..
Search engine di atas memiliki suatu keunikan dibanding dengan yang ada pada umumnya saat ini, yaitu adanya nilai persentase pada sebelah kiri dari masing-masing link dokumen.
Persentase yang terlihat menggambarkan kedekatan hubungan antara suatu dokumen dengan setiap dokumen lainnya. Dokumen yang ditampilkan pada hasil pencarian hanya merupakan sejumlah dokumen yang memiliki kekerabatan yang erat dengan dokumen yang ditampilkan. Hasil pencarian oleh search engine di atas ditampilkan secara berurut mulai dari tingkat persentase tertinggi hingga terendah. Dengan demikian user dapat merasakan kemudahan dalam melakukan pencarian dokumen dengan adanya urutan relevansi yang jelas yang direpresentasikan dalam nilai yang ditampilkan.
Sementara search engine yang ada saat ini hanya mampu mengembalikan hasil pencarian dokumen berupa sejumlah besar dokumen yang mengandung kata yang dicari tanpa mengetahui urutan yang jelas, dokumen mana yang paling relevan dengan query yang diinput oleh user. Hal ini yang membuat hasil pencarian dengan search engine pada Gambar 2.1 memberikan kemudahan yang lebih baik bagi user jika dibandingkan dengan search engine yang ada saat ini.
Berikut istilah-istilah akan dijumpai dalam pembahasan mengenai algoritma Lingo pada skripsi ini, diambil dari situs http://www.searchenginedictionary.com/terms-term-frequency.shtml [1].
Query merupakan satu atau sekumpulan kata kunci yang terdiri atas sekumpulan frase yang dimasukkan oleh user ke dalam kotak pencarian. Digunakan oleh mesin pencari untuk dibandingkan dengan dokumen–dokumen yang tersedia untuk mendapatkan hasil pencarian yang relevan.
Stop words merupakan kata–kata seperti kata sambung, awalan, dll, memiliki pengaruh yang sangat kecil bahkan tidak sama sekali terhadap relevansi. Mesin pencari pada umumnya mengabaikan stop words yang berada dalam suatu query.
Vektor dokumen merupakan vektor yang merepresentasikan sebuah dokumen. Term document matrix merupakan matriks di mana setiap kolomnya merupakan sebuah vektor dokumen, jadi matriks ini mengandung informasi dari sekumpulan dokumen. Term document matrix terdiri atas baris yang mewakili sejumlah kata dan kolom yang mewakili sejumlah dokumen.
Term Frequency (TF) merupakan pengukuran frekuensi munculnya kata dalam suatu dokumen. TF dikombinasikan dengan Inverse Document Frequency (IDF) untuk mencari sejumlah dokumen yang paling relevan dengan query.
Inverse Document Frequency (IDF) merupakan pengukuran frekuensi kemunculan suatu kata dalam sekumpulan dokumen. Perhitungan dilakukan dengan mengkalkulasi total dokumen dalam koleksi dibagi dengan jumlah dokumen yang mengandung kata tertentu.
Dalam algoritma Lingo, yang pertama kali dilakukan adalah menciptakan label kelompok yang mudah dimengerti oleh manusia, kemudian menandai keseluruhan dokumen yang ada ke dalam label–label kelompok yang telah terbentuk. Secara spesifik, dilakukan pengekstrakan frequent phrase dari dokumen yang diinput dengan harapan dapat menjadi sumber yang paling informatif yang menggambarkan deskripsi dari suatu topik. Kemudian dilakukan pengurangan term document matrix menggunakan SVD untuk menemukan konsep abstrak dari bermacam–macam topik, dengan tujuan untuk mendapatkan hasil pencarian. Pada akhirnya, dilakukan pencocokkan deskripsi grup dengan topik yang diekstrak dan menandai dokumen yang relevan masuk dalam
deskripsi grup yang tepat. Langkah spesifik dari algoritma Lingo disajikan sebagai berikut:
a) Preprocessing
Tujuan dari fase Preprocessing adalah untuk melakukan pembuangan karakter-karakter dan kata–kata yang tidak perlu dari suatu dokumen, yang dapat mempengaruhi kualitas pengelompokan.
Ada 2 tahap dalam melakukan Preprocessing, yaitu Stop Words Removal dan Stemming. Keduanya merupakan operasi yang umum dalam pengumpulan informasi. Berikut algoritma Preprocessing:
D ← Masukkan semua dokumen;
Untuk setiap d∈D lakukan langkah–langkah berikut {
Jika kata d dikenali maka {
Lakukan proses Stop Words Removal dan Stemming; }
}
1. Metode Stop Words Removal
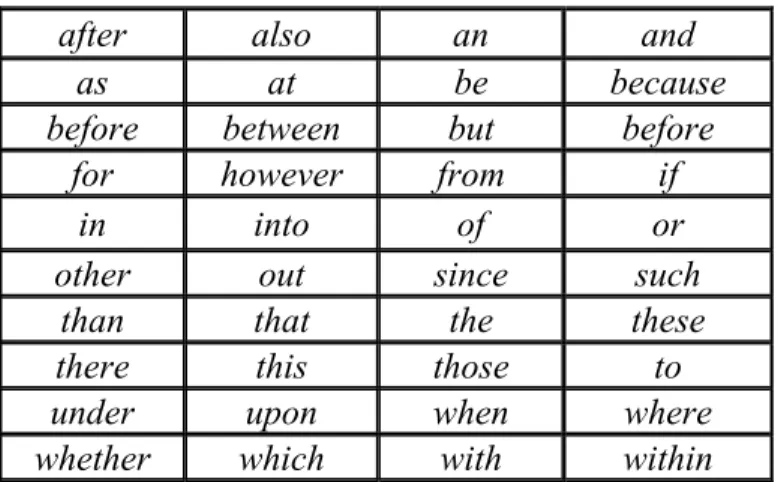
Stop Words merupakan sekumpulan kata yang dianggap sebagai kata yang terlalu umum dipakai dalam sistem online, sehingga nilai informasi yang terkandung di dalam kata tersebut sangat sedikit. Dengan demikian pencarian kata yang termasuk dalam daftar stop words akan diabaikan, contohnya dalam frase “to be or not to be”.
Tabel 2.1 Daftar kata yang termasuk Stop Words Removal
2. Metode Stemming
Metode Stemming merupakan proses penggunaan salah satu algoritma Stemmer untuk mendapatkan bentuk dasar dari sebuah kata. Stemmer pertama dipublikasikan oleh Julie Beth Lovins: Lovins JB (1968) Development of Stemming Algorithm, Mechanical Translation and Computational Linguistics, 11:22-31. Stemmer yang kemudian yang terkenal dengan algoritma Porter ditulis oleh Martin Porter, dan dipublikasikan pada Program, Vol 14 no. 3 pp 130-137, Juli 1980. Stemmer ini menjadi sangat luas dalam penggunaannya, dan menjadi standar algoritma yang biasa digunakan dalam melakukan proses Stemming pada dokumen berbahasa Inggris. Sebagai contoh, penggunaan Stemmer untuk bahasa Inggris dapat mengidentifikasikan kata “stemmer”, “stemming”, “stemmed” menjadi kata dasarnya, yaitu “stem”.
Stemmer merupakan salah satu elemen yang cukup umum dalam tahap awal pengolahan query. Mungkin saja seseorang yang menuliskan kata “stemmer” dalam pencarian suatu dokumen, juga menginginkan dokumen yang di dalamnya terdapat kata “stem” (tanpa “er”).
after also an and
as at be because
before between but before
for however from if
in into of or other out since such than that the these there this those to under upon when where whether which with within
Sebelum masuk dalam pembahasan mengenai algoritma Porter yang akan digunakan dalam melakukan proses Stemming, berikut beberapa kemungkinan kondisi kondisi persyaratan dari algoritma Porter.
*S Kata diakhiri dengan “S”, atau lainnya disesuaikan huruf setelah tanda “*”. *v* Kata mengandung huruf vokal..
*d Kata diakhiri dengan 2 buah huruf konsonan yang sama (contoh: -TT, -SS).
*o
Kata diakhiri dengan cvc (konsonan-vokal-konsonan), di mana c yang kedua selain huruf W, X or Y (contoh:. -WIL, -HOP).
m>0
m merupakan jumlah perulangan VC (vokal-konsonan), sebagai contoh: m=0 TR, EE, TREE, Y, BY.
m=1 TROUBLE, OATS, TREES, IVY.
m=2 TROUBLES, PRIVATE, OATEN, ORRERY.
Berikut contoh penulisan aturan untuk membuang akhiran kata dalam algoritma Stemmer:
(kondisi) S1 → S2
yang memiliki arti, jika sebuah kata memiliki akhiran S1, dan susunan huruf-huruf sebelumnya memenuhi persyaratan kondisi yang diberikan, maka dilakukan penggantian
1
S dengan S2.
Berikut algoritma Porter beserta contoh kata dalam aplikasinya, sumber http://www.snowball.tartarus.org/algorithms/porter/stemmer.html [2].
Langkah 1a
SSES -> SS caresses -> caress IES -> I ponies -> poni
ties -> ti SS -> SS caress -> caress S -> cats -> cat Langkah 1b
(m>0) EED -> EE feed -> feed agreed -> agree (*v*) ED -> plastered -> plaster
bled -> Bled (*v*) ING -> motoring -> motor
sing -> sing
Jika langkah 1b yang kedua atau ketiga sukses, lanjutkan dengan langkah berikut: AT -> ATE conflat(ed) -> conflate BL -> BLE troubl(ed) -> trouble IZ -> IZE siz(ed) -> size (*d and not (*L or *S or *Z)) -> single letter hopp(ing) -> hop Tann(ed) -> tan fall(ing) -> fall hiss(ing) -> hiss fizz(ed) -> fizz (m=1 and *o) -> E fail(ing) -> fail fil(ing) -> file
Dalam tahap ini terdapat langkah pembuangan pasangan huruf yang sama pada akhiran menjadi 1 buah huruf tunggal. Akhiran -E akan ditambahkan kembali pada -AT, -BL and -IZ, dengan demikian akhiran -ATE, -BLE and -IZE dapat diberikan, namun E
mungkin saja dihilangkan pada langkah 4. Langkah 1c
(*v*) Y -> I happy -> Happi sky -> sky Langkah 2
(m>0) ATIONAL -> ATE relational -> relate (m>0) TIONAL -> TION conditional -> condition
rational -> rational (m>0) ENCI -> ENCE valenci -> valence (m>0) ANCI -> ANCE hesitanci -> hesitance (m>0) IZER -> IZE Digitizer -> digitize
(m>0) ABLI -> ABLE conformabli -> conformable (m>0) ALLI -> AL Radicalli -> radical (m>0) ENTLI -> ENT differentli -> different (m>0) ELI -> E vileli -> vile (m>0) OUSLI -> OUS analogousli -> analogous (m>0) IZATION -> IZE vietnamization -> vietnamize (m>0) ATION -> ATE Predication -> predicate (m>0) ATOR -> ATE operator -> operate (m>0) ALISM -> AL feudalism -> feudal (m>0) IVENESS -> IVE decisiveness -> decisive (m>0) FULNESS -> FUL hopefulness -> hopeful (m>0) OUSNESS -> OUS Callousness -> callous (m>0) ALITI -> AL Formaliti -> formal (m>0) IVITI -> IVE sensitiviti -> sensitive (m>0) BILITI -> BLE sensibiliti -> sensible Langkah 3
(m>0) ICATE -> IC triplicate -> triplic (m>0) ATIVE -> formative -> Form (m>0) ALIZE -> AL formalize -> formal (m>0) ICITI -> IC electriciti -> electric (m>0) ICAL -> IC electrical -> electric (m>0) FUL -> hopeful -> hope (m>0) NESS -> goodness -> good Langkah 4
(m>1) AL -> revival -> reviv (m>1) ANCE -> allowance -> allow (m>1) ENCE -> Inference -> infer (m>1) ER -> airliner -> airlin (m>1) IC -> gyroscopic -> gyroscop (m>1) ABLE -> adjustable -> adjust (m>1) IBLE -> defensible -> defens (m>1) ANT -> irritant -> irrit (m>1) EMENT -> replacement -> replac (m>1) MENT -> adjustment -> adjust (m>1) ENT -> dependent -> depend (m>1 and (*S or *T)) ION -> adoption -> adopt (m>1) OU -> homologou -> homolog (m>1) ISM -> communism -> commun (m>1) ATE -> activate -> activ (m>1) ITI -> angulariti -> angular
(m>1) OUS -> homologous -> homolog (m>1) IVE -> effective -> effect (m>1) IZE -> bowdlerize -> bowdler Dalam langkah di atas dilakukan pembuangan akhiran. Langkah 5a
(m>1) E -> probate -> Probat Rate -> rate (m=1 and not *o) E -> Cease -> ceas Langkah 5b
(m > 1 and *d and *L) -> single letter controll -> control roll -> roll
b) Metode Frequent Phrase Extraction
Secara intuisi, ketika menulis tentang suatu topik, seorang penulis terbiasa melakukan pengulangan subjek yang memiliki keterkaitan dengan kata kunci untuk mendapatkan perhatian pembaca. Frequent Phrase Extraction merupakan proses penemuan sejumlah kata yang disebutkan berulang–ulang dalam suatu dokumen. Untuk menjadi suatu kandidat label, sebuah frequent phrase harus muncul minimal sejumlah ambang batas (threshold) dari term frequency. Berikut algoritma Frequent Phrase Extraction:
Lakukan penggabungan seluruh dokumen; c
P ← daftar seluruh kata yang terdapat pada seluruh dokumen yang diinput; f
P ← p : { p∈ P c ∧ frekuensi ( p ) > batas ambang term frequency };
Dalam melakukan Frequent Phrase Extraction, yang perlu dilakukan adalah membangun suatu term document matrix yang mewakili atas seluruh dokumen yang ada,
kemudian lakukan pembobotan, dan terakhir lakukan pemilihan kata yang termasuk dalam kandidat label di mana memiliki bobot di atas batas ambang term frequency.
Langkah pertama dalam Frequent Phrase Extraction adalah dengan membangun suatu term document matrix yang terdiri atas kumpulan vektor dokumen. Vektor dokumen adalah vektor yang merepresentasikan sebuah dokumen. Term document matrix merupakan matriks di mana setiap kolomnya merupakan sebuah vektor dokumen, jadi matriks ini mengandung informasi dari sekumpulan dokumen. Term document matrix terdiri atas baris yang mewakili sejumlah kata dan kolom yang mewakili sejumlah dokumen.
Langkah kedua dalam Frequent Phrase Extraction adalah dengan melakukan pembobotan setiap kolom dari term document matrix. Perhitungan bobot bertujuan untuk melakukan penyaringan kata yang sering muncul. Pembobotan dapat mengevaluasi seberapa penting suatu kata bagi sebuah dokumen Pembobotan seringkali digunakan oleh mesin pencari (search engine) untuk menemukan dokumen yang paling relevan dengan kata kunci yang dicari.
TFIDF (Term Frequency Inverse Document Frequency) merupakan teknik pembobotan yang sering digunakan dalam pengumpulan informasi. Perhitungan bobot bertujuan untuk melakukan penyaringan kata yang sering muncul. TFIDF dapat digunakan untuk mengevaluasi seberapa penting suatu kata bagi sebuah dokumen. TFIDF seringkali digunakan dalam search engine untuk menemukan dokumen yang paling relevan dengan query.
Term frequency menggambarkan ukuran seberapa penting suatu kata dalam suatu dokumen.
∑
= k k i n n TF in = frekuensi munculnya suatu kata dalam suatu dokumen.
∑
k k
n = banyaknya kata dalam suatu dokumen.
Document frequency merupakan pengukuran secara umum tingkat kepentingan dari suatu kata (log dari hasil perhitungan jumlah dokumen dibagi dengan banyaknya dokumen yang mengandung kata tertentu).
| ( | | | log j j t d D TF TFIDF ⊃ × = Contoh kasus:
5 buah kata yang terdapat dalam keseluruhan dokumen: 1 T : Information 2 T : Singular 3 T : Value 4 T : Computations 5 T : Retrieval
2 buah frase yang ingin dicari: 1
P: Singular Value 2
P : Information Retrieval 7 buah dokumen yang tersedia:
1
D : Large Scale Singular Value Computations 2
D : Software for the Sparse Singular Value Decomposition 3
D : Introduction to Modern Information Retrieval 4
D : Linear Algebra for Intelligent Information Retrieval 5
6
D : Singular Value Analysis of Cryptograms 7
D : Automatic Information Organization
Vektor dokumen untuk D4 sebagai berikut:
Vektor Dokumen untuk D4: (setelah dilakukan normalisasi):
1 0 0 0 1 83 . 0 0 0 0 56 . 0 NB:
Proses normalisasi vektor dokumen D4 untuk kata Information:
5 1 =
TF (dari 5 buah kata, kata Information mucul sebanyak 1 kali)
3 7 =
IDF (dari 7 buah dokumen, kata Information terdapat pada 3 buah dokumen)
TFIDF = 0.0736 3 7 log 5 1 log = × = × IDF TF
Proses normalisasi vektor dokumen D4 untuk kata Retrieval:
5 1 =
TF (dari 5 buah kata, kata Retrieval mucul sebanyak 1 kali)
2 7 =
IDF (dari 7 buah dokumen, kata Retrieval terdapat pada 2 buah dokumen)
1088 . 0 2 7 log 5 1 log = × = =TF x IDF TFIDF
Normalisasi dilakukan untuk mendapatkan panjang vektor dokumen = 1.
(
0.0736) (
2 + 0.1088)
2 =1a a
0.0173a2 =1 a=7.6124
bobot dalam D4 untuk kata Information = 0.0736×a=0.0736×7.6124 = 0.56 bobot dalam D4 untuk kata Retrieval = 0.1088×a=0.1088×7.6124 = 0.83
Term Document Matrix:
= 0 0 0 8300 . 0 8300 . 0 0 0 0 0 0000 . 1 0 0 0 7200 . 0 0 7100 . 0 0 0 0 7100 . 0 4900 . 0 0 7100 . 0 0 0 0 7100 . 0 4900 . 0 0000 . 1 0 0 5600 . 0 5600 . 0 0 0 A
Dalam D4, terdapat satu buah kata Information dan satu buah kata Retrieval, hal ini yang membentuk vektor dokumen V4. Setelah vektor dokumen terbentuk, lakukan normalisasi hingga didapatkan panjang masing–masing vektor dokumen yang merupakan kolom pada term document matrix = 1, hal ini dilakukan untuk menjaga relevansi di mana sebelumnya setiap vektor dokumen memiliki panjang berbeda-beda.
Dengan memasukkan vektor dokumen milik D1 ke dalam kolom I, vektor dokumen milik D2 ke dalam kolom II, vektor dokumen milik D3 ke dalam kolom III dan seterusnya, didapatkan sebuah term document matrix.
c) Metode Cluster Label Induction
Dari satu tahap sebelum Cluster Label Induction, didapatkan daftar dari frequent phrase yang memiliki frekuensi di atas batas ambang term frequency yang telah ditentukan. Seluruh kata yang tercakup dalam daftar frequent phrase kemudian akan
diproses lebih lanjut dalam fase Cluster Label Induction untuk mendapatkan label yang sebenarnya.
Ada beberapa tahap dalam melakukan Cluster Label Induction: - penemuan konsep abstrak.
- pencocokan frase dan pelabelan.
Penemuan konsep abstrak dilakukan dengan metode Singular Value Decomposition (SVD). SVD dari term document matrix A dituliskan sebagai
T V U
A= ∑ ,
di mana U merupakan t ×t matriks ortogonal di mana kolom–kolomnya berperan sebagai vektor singular kiri dari A, V merupakan d ×d matriks ortogonal di mana kolom–kolomnya berperan sebagai vektor singular kanan dari A dan ∑ merupakan
d
t × matriks diagonal yang memiliki nilai singular σ1 ≥σ2 ≥ ...≥σmin(t,d). Matriks U yang merupakan salah satu hasil dari SVD merepresentasikan konsep abstrak yang terdapat pada suatu dokumen. Peringkat dari matriks A (rA) sama dengan jumlah dari nilai singular yang bukan nol.
Hanya sejumlah k pertama dari vektor pada matriks U digunakan dalam fase lebih lanjut. Nilai dari k ditentukan dari estimasi, dengan bantuan Frobenius norms dari matriks A. q merupakan batas ambang kandidat label. Semakin besar nilai q, semakin banyak jumlah kandidat label yang akan terbentuk. Setelah tahap perhitungan SVD matriks A, kemudian lakukan perhitungan nilai k minimum yang memenuhi kondisi
berikut q A A F F k
≥ , di mana X F merupakan simbol dari Frobenius norm dari
∑
= = A r j j A 1 2 F σBerikut algoritma Cluster Label Induction:
Contoh kasus lanjutan:
Dari tahap Preprocessing didapatkan term document matrix sebagai berikut:
= 0 0 0 8300 . 0 8300 . 0 0 0 0 0 0000 . 1 0 0 0 7200 . 0 0 7100 . 0 0 0 0 7100 . 0 4900 . 0 0 7100 . 0 0 0 0 7100 . 0 4900 . 0 0000 . 1 0 0 5600 . 0 5600 . 0 0 0 A
Menggunakan software matematika, MATLAB 6.1, didapatkan SVD dari matrix A sebagai berikut:
A ← term document matrix yang sudah melewati tahap Stop Words Removal dan memiliki frekuensi lebih tinggi daripada batas ambang term frequency;
V U, ,
∑ ← SVD (A ); { Produk SVD dari A } k ← 0; { Mulai dengan 0 jumlah kelompok } n← Peringkat ( A ); repeat k ← k + 1;
∑
∑
= = ∑ ∑ = n i ii k i ii q 1 1 ; − − − − − − = 0 7526 . 0 0 6584 . 0 0 0 0 9220 . 0 0 3873 . 0 7071 . 0 0 2738 . 0 0 6519 . 0 7071 . 0 0 2738 . 0 0 6519 . 0 0 6584 . 0 0 7526 . 0 0 U = ∑ 0 0 0 0 0 0 0 0 0 0 7514 . 0 0 0 0 0 0 0 0 1440 . 1 0 0 0 0 0 0 0 5622 . 1 0 0 0 0 0 0 0 6450 . 1
Dari diagonal matriks ∑ di atas didapatkan: 1 σ = 1.6450, σ2= 1.5622, σ3= 1.1440, σ4= 0.7514
∑
= = A r j j A 1 2 F σ = 1.64502 +1.56222 +1.14402+ 0.75142 = 2.6495Misalkan kita tetapkan q = 0.9, maka ..
Jika k = 0 → q = 0.6209 6495 . 2 6450 . 1 2 = Jika k = 1 → q = 0.8562 6495 . 2 5622 . 1 6450 . 1 2 2 = + Jika k = 2 → q = 0.9589 6495 . 2 1440 . 1 5622 . 1 6450 . 1 2 2 2 = + +
Perulangan berhenti pada k = 2, karena kondisi berhenti yaitu q > batas ambang kandidat label, di mana batas ambang kandidat label dalam hal ini ditetapkan sama dengan 0.9. Maka jumlah dari kelompok = k = 2.
Tahap terakhir pada Cluster Label Induction adalah pencocokan frase dan pelabelan. Pada tahap ini, konsep abstrak dan frequent phrase diekspresikan dalam satu buah ruang vektor di mana deskripsi kelompok dapat diketahui. Untuk selanjutnya dapat dilakukan perhitungan jarak klasik dengan menggunakkan kosinus untuk mengkalkulasi seberapa dekat jarak/kekerabatan antara frase dan konsep abstrak.
Misalkan ada sebuah matriks P dan sejumlah i kolom dari matriks U hasil dari perhitungan SVD. Vektor mi adalah kosinus sudut antara konsep abstrak yang ke–i dan frequent phrase dapat dikalkulasikan dengan rumus m UT P
i
i = . Frase yang sesuai dengan komponen maksimum dari vektor mi, dipilih sebagai kandidat label kelompok. Sedangkan nilai kosinusnya menjadi skor bagi kandidat label kelompok. Berikut algoritmanya:
P → matriks frase P ; f
Untuk setiap kolom hasil dari UT P k
{
cari satu yang maksimum untuk setiap kolom m ; i
tambahkan frase yang bernilai maksimum tersebut ke dalam kandidat label;
skorLabel = m ; i }
Contoh kasus lanjutan: Dari tahap sebelumnya didapatkan:
− − − − − − = 0 7526 . 0 0 6584 . 0 0 0 0 9220 . 0 0 3873 . 0 7071 . 0 0 2738 . 0 0 6519 . 0 7071 . 0 0 2738 . 0 0 6519 . 0 0 6584 . 0 0 7526 . 0 0 U
k = 2 (k di sini menandakan jumlah kelompok yang akan dibentuk. Dengan demikian hanya sejumlah k kolom dari U yang merupakan konsep abstrak yang dihasilkan oleh SVD yang akan dipergunakan dalam proses berikut).
maka: − − − = 6584 . 0 0 0 3873 . 0 0 6519 . 0 0 6519 . 0 7526 . 0 0 k U − − − = 6584 . 0 0 0 0 7526 . 0 0 3873 . 0 6519 . 0 6519 . 0 0 T k U = 0000 . 1 0 0 0 0 8300 . 0 0 0 0000 . 1 0 0 0 0 0 0 0 0000 . 1 0 0 0 7100 . 0 0 0 0 0000 . 1 0 0 7100 . 0 0 0 0 0 0000 . 1 5600 . 0 0 P P U M T k ⋅ = = 6600 . 0 0 0 0 7500 . 0 9700 . 0 0 0 3900 . 0 6500 . 0 6500 . 0 0 0 9200 . 0 M Perhitungan M UT P k ⋅
= dilakukan untuk menemukan deskripsi dari kelompok – kelompok yang ada, di mana dari hasil perhitungan didapatkan jumlah kelompok = 2 (diperoleh dari nilai k = 2). P merupakan term document matrix berukuran t×(p +t),
di mana t merupakan jumlah dari frequent terms dan pmerupakan jumlah dari frequent phrases. P dibentuk dari frequent phrase dan seluruh kata yang terdapat pada dokumen, di mana telah dilakukan pembobotan dan normalisasi terhadap P.
Di satu sisi, kita ingin mendapatkan informasi yang sifatnya umum dari sejumlah dokumen, di sisi lain kita ingin membaginya ke dalam deskripsi label yang paling cocok. Baris pada matriks M merepresentasikan kelompok, sedangkan kolom pada matriks M merepresentasikan deskripsi dari kelompok. Untuk setiap baris, dipilih sebuah kolom yang nilainya paling maksimum, dengan demikian 2 buah kelompok yang didapat: Singular Value (skor: 0.92) dan Information Retrieval (skor: 0.97). Berikut algoritma Frequent Phrase Extraction:
d) Metode Cluster Content Discovery
Dalam fase ini, kita menggunakan model ruang vektor klasik untuk menandai setiap dokumen yang diinput kedalam label–label kelompok yang telah terbentuk dari fase Cluster Label Induction. Rumus perhitungan yang dipakai dalam fase ini yaitu
A Q
C= T⋅ , di mana Q adalah matriks yang terdiri atas kelompok–kelompok label, A adalah term document matrix asli dari dokumen–dokumen yang tersedia. Dengan
Hitung kosinus antara setiap pasang kandidat label;
Identifikasi label yang memenuhi batas ambang kesamaan label ke dalam kelompok-kelompok;
Untuk setiap kelompok yang dibentuk dari label yang serupa {
Pilih satu label dengan skor tertinggi; }
demikian, elemen Cij dari matriks C mengindikasikan kekuatan hubungan antara dokumen ke– j dan kelompok ke-i. Dokumen ditambahkan ke dalam kelompok jika
j i
C termasuk dalam batas ambang yang ditetapkan. Dokumen yang tidak ditandai kepada kelompok tertentu, akan dimasukkan ke dalam kelompok yang dinamakan “Others”. Berikut algoritma Cluster Content Discovery:
Untuk setiap L ∈ kandidat label kelompok lakukan langkah – langkah berikut {
Buat kelompok C dengan L sebagai deskripsi;
Tambahkan ke dalam C semua dokumen yang skor kemiripannya dengan C masuk dalam batas ambang;
}
Masukkan ke dalam kelompok “Others” setiap dokumen yang belum menjadi anggota dari kelompok manapun kelompok manapun;
Contoh kasus lanjutan:
Pada akhirnya, dokumen ditandai pada kelompok dengan mengaplikasikan matriks Q dengan ATFIDF.
Dari tahap sebelumnya diketahui:
= 0000 . 1 0 0 0 0 8300 . 0 0 0 0000 . 1 0 0 0 0 0 0 0 0000 . 1 0 0 0 7100 . 0 0 0 0 0000 . 1 0 0 7100 . 0 0 0 0 0 0000 . 1 5600 . 0 0 P
= 8300 . 0 0 0 0 0 7100 . 0 0 7100 . 0 5600 . 0 0 Q = 8300 . 0 0 0 0 5600 . 0 0 0 7100 . 0 7100 . 0 0 T Q
Lakukan perhitungan C=QT A, didapatkan matriks C sebagai berikut:
= 5600 . 0 0 0 0000 . 1 0000 . 1 0 0 0 0000 . 1 0 0 0 0000 . 1 6900 . 0 C
Terakhir, lakukan proses penandaan dokumen pada kelompok–kelompok yang ada:
Information Retrieval [skor: 0.97] 3
D : Introduction to Modern Information Retrieval 4
D : Linear Algebra for Intelligent Information Retrieval 7
D : Automatic Information Organization Singular Value [skor: 0.92]
2
D : Software for the Sparse Singular Value Decomposition 6
D : Singular Value Analysis of Cryptograms 1
D : Large Scale Singular Value Computations
Others: [yang tidak ditandai kedalam kelompok manapun] 5
2.1.2 Matriks Ortogonal
Matriks ortogonal adalah matriks persegi di mana inversnya dapat diperoleh dengan melakukan transpos matriks (A−1=AT). Matriks ortogonal juga dapat didefinisikan sebagai berikut:
“Jika 1AAT = atau ATA=1, maka matriks A disebut matriks ortogonal.” Berikut rumus untuk memperoleh vektor basis ortogonal urk sebagai kolom dari matriks ortogonal: ) , ... , , peroleh di sudah (misalkan : k ke Langkah > , < > , v < , -> , v < -= : 3 Langkah > , v < -v > , v < -v = : 2 Langkah v v = : 1 Langkah 1 -k 1 2 1 2 2 3 2 2 3 1 1 3 3 1 1 3 3 3 1 1 2 2 1 1 2 2 2 1 1 1
µ
µ
µ
µ
µ
µ
µ
µ
µ
µ
µ
µ
µ
µ
µ
µ
µ
µ
µ
> <v v vVektor vrk merupakan vektor eigen dari matriks A . Matriks ortogonal U merupakan penggabungan vektor basis ortogonal dalam tiap kolomnya U=
[
ur1 ur2 ...urk]
2.2 Kerangka Pikir
Proses pencarian dokumen yang diinginkan pada search engine dilakukan dengan menginput data yang disebut query pada kotak pencarian, setelah itu mesin pencari akan melakukan pencarian pada seluruh dokumen yang sesuai dengan query yang diinput. Pada umumnya hasil pencarian ditampilkan tanpa adanya urutan relevansi yang jelas.
Dalam skripsi ini digunakan algoritma Lingo, di mana dihasilkan pengurutan dokumen hasil pencarian sesuai dengan urutan kekerabatan antara frase yang diinput dengan dokumen, mulai dari kekerabatan tertinggi hingga terendah. Hal ini tentu saja sangat menguntungkan bagi user, di mana user mendapatkan hasil pencarian yang paling relevan berada pada posisi teratas.
Proses yang dilakukan Lingo sehingga algoritma ini dapat mengetahui kekerabatan antara dokumen dengan frase yaitu dengan menyatukan seluruh dokumen yang dimiliki menjadi sebuah matriks yang disebut dengan term document matrix yang terdiri atas kolom mendeskripsikan dokumen, dan baris mendeskripsikan kata
Proses awal pengolahan dokumen, dilakukan Preprocessing, di mana dalam tahap ini dilakukan pemrosesan terhadap sejumlah kata yang telah dikumpulkan dari seluruh dokumen. Pemrosesan terhadap sejumlah kata mencakup pemotongan kata menjadi kata dasarnya (Stemming) dan pembuangan kata yang umum dipakai seperti “and, or” (Stop Words Removal).
Tahap selanjutnya dalam pemrosesan awal dokumen, dilakukan tahap Frequent Phrase Extraction yang akan menyaring sejumlah kata yang merupakan penggabungan kata pada seluruh dokumen, di mana ditetapkan minimal kata yang akan menjadi kandidat pembentukan term document matrix harus muncul sejumlah n kali
Sejumlah kata terpilih yang telah melalui berbagai proses penyaringan yang mewakili seluruh kata pada seluruh dokumen kemudian dipakai dalam pembentukan term document matrix yang merupakan matriks yang mewakili seluruh dokumen. Jadi deskripsi dari seluruh dokumen disajikan dalam bentuk matriks.
Setelah melakukan pembentukan term document matrix, dilakukan proses pengolahan query yang sama dengan proses terbentuknya term document matrix,
hasilnya berupa phrase matrix yang terdiri atas baris sebagai deskripsi kata dan kolom sebagai deskripsi frase.
Dalam tahap pembentukan matriks, akan diperoleh dua buah matriks, yaitu term document matrix yang mendeskripsikan seluruh dokumen yang dimiliki, dan phrase matrix yang mendeskripsikan frase yang diinput pada kotak pencarian.
Jika matriks yang mewakili seluruh dokumen dan seluruh frase telah terbentuk, maka selanjutnya akan dilakukan proses yang secara garis besar dapat digambarkan dengan mengalikan term document matrix dengan phrase matrix, di mana akan dihasilkan sebuah matriks yang menggambarkan kekerabatan antara sejumlah frase dan dokumen. Dari matriks ini dapat terlihat, ke dalam kelompok frase mana dokumen X terkategori (terjadi pengelompokan dokumen ke dalam kelompok frase yang paling sesuai). Terlihat pula skor yang didapat untuk tiap dokumen, sebagai contoh:
- skor dokumen D1 untuk kelompok K1 yaitu 0.12, - skor dokumen D1 untuk kelompok K2 yaitu 0.5,
maka dokumen D1 akan menjadi bagian dalam kelompok K2 karena memiliki skor kekerabatan dengan kelompok K2 lebih tinggi daripada dengan kelompok K1 (skor kekerabatan dokumen D1 dengan kelompok K2 adalah 0.5).
Skor suatu dokumen akan diperbandingkan dengan skor dokumen lain pada kelompok yang sama, misalkan dokumen–dokumen yang tergabung dalam kelompok
2
K terdiri atas:
- dokumen D1 dengan skor 0.4, - dokumen D2 dengan skor 0.3, - dokumen D3 dengan skor 0.2,
maka dapat disimpulkan bahwa dokumen D1 memiliki kekerabatan paling tinggi dengan kelompok K2 jika dibandingkan dengan dokumen D2 dan D3.
Contoh di atas merupakan gambaran dari hasil yang akan diperoleh dalam skripsi “Perancangan Program Aplikasi Klasifikasi dan Visualisasi Teks Menggunakan Algoritma Lingo”, yang menjadikan hasil proses pencarian lebih relevan dari hasil proses pencarian yang umum ada saat ini.
Hasil yang diperoleh dengan algoritma Lingo lebih baik dibandingkan dengan hasil yang dikembalikan oleh search engine yang umum ada saat ini di mana jumlahnya sangat banyak, di sisi lain tidak adanya urutan kekerabatan (urutan kerelevanan) yang jelas dengan frase yang diinput, sehingga hasil pencarian memakan cukup banyak waktu bagi user untuk mencari sejumlah di antara sekian banyak hasil pencarian yang benar-benar relevan.