PERINGKASAN TEKS MODEL GRAF PADA SINGLE DOKUMEN
DENGAN METODE SPARSE NON NEGATIVE MATRIX
FACTORIZATION
Irwan Darmawan*1, Reddy Alexandro Harianto2, Hendrawan Armanto3
1,2,3Sekolah Tinggi Teknik Surabaya pasca sarjana teknologi informasi,
Kontak Person :
Irwan Darmawan, Reddy Alexandro Harianto, Hendrawan Armanto e-mail: [email protected], [email protected], [email protected]
Abstrak
Isi dari sebuah dokumen yang memiliki pembahasan panjang akan menyulitkan bagi pembaca untuk menentukan ide pokok dari pembahasan dokumen tersebut. Pendekatan yang digunakan dalam mengaplikasikan sistem peringkasan ini adalah pendekatan ekstraktif yaitu menghasilkan ringkasan dengan cara memotong bagian penting dari teks asli dan menyusunnya untuk membentuk ringkasan yang koheren Dengan menggunakan sistem peringkasan teks model graf ini diharapkan akan mempermudah bagi pembaca untuk mengetahui secara tepat dan cepat topik atau ide pokok yang dibicarakan pada dokumen yang dibaca. Salah satu metode untuk menemukan hubungan antar kalimat yang satu dengan kalimat yang lain adalah menggunakan model graf. Kemudian diperlukan metode SNMF (sparse non negative matrix factorization) untuk mengelompokkan / mengcluster kalimat didalam sebuah dokumen. Kumpulan cluster dengan metode SNMF tersebut dapat diambil beberapa bagian yang penting untuk dijadikan sebagai penentu dari topik yang ada didalam single dokumen tersebut.
Kata Kunci: Cluster, Kalimat, SNMF
1. Pendahuluan
Peringkasan teks secara otomatis dapat digunakan untuk mengelola sejumlah besar informasi di
web atau dokumen. Ringkasan dapat membantu pembaca untuk mendapatkan gambaran singkat keseluruhan dokumen atau kumpulan dokumen dan dengan demikian mengurangi waktu untuk membaca. Proses dokumen summarizationdapat berguna untuk berbagai aplikasi seperti (document indexing) pengindekan dokumen, (question-answering system) sistem tanya jawab, sistem pencarian, dan klasifikasi dokumen. peringkasan teks otomatis dapat dikategorikan sebagai peringkasan dokumen tunggal dan peringkasan multi dokumen. Bila inputannya hanya satu dokumen, maka disebut
summarization teks dokumen tunggal dan bila inputannya adalah satu set dokumen teks yang saling berhubungan maka disebut multi-dokumen (kamal sakar 2013). Dalam penelitian ini yang akan dibahas adalah kalimat didalamsingledokumen yang akan di buat ringkasannya secaraautomatic.
Ada tiga pendekatan utama dalam meringkas sebuah dokumen. Yang pertama adalah mengurangi inputan panjang teks dengan menghapus kata-kata dalam text asli namun tetap memperhatikan susunan katanya ini dikenal dengan namacompressive summarization. Model kedua adalah ekstraktif menghasilkan ringkasan dengan cara memotong bagian penting dari teks asli dan menyusunnya untuk membentuk ringkasan yang koheren yang ketiga adalah model abstraktif menghasilkan ringkasan dari tulisan yang sudah ada tanpa dibatasi untuk menggunakan kembali ungkapan ungkapan Dari teks aslinya (Alex Alifimoff 2015). Jadi intinya abstraktif memanfaatkan metode linguistik dalam menafsirkan teks asli sehingga kalimat yang tersusun tidak ada dalam kalimat aslinya.
Rangking kalimat bertujuan untuk menentukan kalimat mana yang paling banyak dirujuk oleh kalimat yang lain sehingga menghasilkan kalimat yang paling penting berdasarkan rumus pembobotan rangking kalimat. Hal ini tujuannya sama dalam menentukan peringkat halaman pada sebuah situs di internet (Larry Page, S. Brian, R.Motwani dan T.Winograd 1998)
yang diekstrak dari sejumlah objek yang berukuran besar. Cara kerja metode ini adalah memecah dokumen teks ke dalam kalimat-kalimat dan menghitung frekuensi masing-masingtermdalam kalimat yang direpresentasikan dengan matrik tidak negativeA berukuran m x n, m jumlahtermdan n jumlah kalimat dalam dokumen. Matrik A didekomposisi ke dalam suatu perkalian matrik fitur semantik berukuran m x r W dan matrik variabel semantik tidak negativeberukuran r x n H. Nilai r dipilih lebih kecil dari m atau n sehingga total ukuran W dan H lebih kecil dari matrik A (Patrik O. Hoyer 2004)
Cluster-clusteryang sudah terbentuk selanjutnya akan diurutkan berdasarkan bobot kalimat yang paling penting dan dilakukan pemilihan kalimat representatif pada setiap cluster berdasarkan bobot kalimat pada hasil cluster tersebut.
2. Metode Penelitian
Dalam peringkasan sebuah dokumen, algoritma yang umum digunakan adalah algoritma yang merangkum sebuah dokumen tanpa menambahkan informasi apapun. Jenis algoritma yang lain adalah melakukan perangkuman dari dokumen berdasarkan topik atauquery yang diberikan. Proses ektraksi sebuah kalimat yang penting dari sebuah dokumen dapat dihasilkan dari kalkulasi semua kalimat, dan memilih kalimat dengan skor yang tinggi. Membuat sebuah graph model untuk sebuah dokumen dan mengimplementasikan graph ranking algorithm seperti algoritmaPageRankuntuk menghitung skor dari sebuah kalimat adalah metode yang sangat efisien.
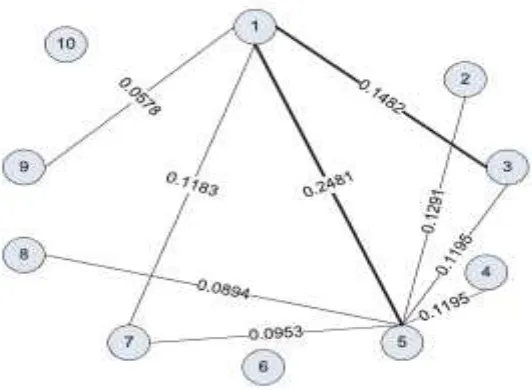
Gambar 1IlustrasiGraph Model
Pada gambar diatas graph G={V,E} dibagun untuk pemodelan dokumen dimana V adalah himpunan simpul atauvertexdan E adalah himpunanEdgedarigraph.Setiap kalimat dimodelkanvertex
darigraph, jika kemiripan antar dokumen melebihi 0 (nol) maka duavertextersebut akan dihubungkan dengan sebuah bobot antar keduanya yaitu antar kalimat Si dan kalimat Sj Rumus persamaannya adalah :
wij=λwsim(si, sj) + (1− λ)wdis(si, sj) (1)
Dimanawsim (si, sj)adalah kesamaancosinusantara vektor dari dua kalimat dan wdis(si, sj)
adalah bobot kalimat itu danλ∈[0,1] adalah parameter yang menyeimbangkan bobot kesamaan, dan jika sebuah kalimat menghubungkan ke dirinya sendiri Wii maka nilainya 0 (nol). Sedangkan rumus
Wdisadalah :
1 0
( , )
{
Wdis sj si
(2)Berikut penanda discourse konektor berdasarkan jenis hubungan
Tabel 1 Bagian dari discourse connectors Hubungan penanda wacana
Cause - effect Karena jadi, karena alasan itulah, karenanya
Temporal Sebelum, setelah, baru – baru ini, sekarang nanti, masa lalu Comparison Meskipun, tapi, meskipun, sementara, bagaimanapun sebaliknya Expansion selain itu, misalnya
Metode Cosine Similarity merupakan metode yang digunakan untuk menghitung similarity
(tingkat kesamaan) antar dua buah objek. Secara umum penghitungan metode ini didasarkan pada
vector space similarity measure. Metode cosine similarity ini menghitung similarity antara dua buah objek (misalkan D1 dan D2) yang dinyatakan dalam dua buahvectordengan menggunakankeywords
(kata kunci) dari sebuah dokumen sebagai ukuran.
1 ,
2 2
1 1
(q .d )
.
(d , q )
| q || d |
( ) .
(
)
t
ij ij j
i i
i i t t
i i ij ij j j
q d
CosSim
q
d
(3) Keterangan := bobot istilahjpada dokumeni=
= bobot istilahjpada dokumeni=
Untuk mencari peringkat dari sebuah kalimat kita dapat menggunakan algoritma pagerank
dengan cara semua kalimat di peringkat dalam sebuah dokumen. Berdasarkan model graph diatas maka peringkat masing-masingvertexdapat dihitung sebagai berikut :
Untuk mencari peringkat dari sebuah kalimat kita dapat menggunakan algoritma pagerank
dengan cara semua kalimat di peringkat dalam sebuah dokumen. Berdasarkan model graph diatas maka peringkat masing-masingvertexdapat dihitung sebagai berikut :
1
(u )
(u ) w
(1 d)
n
i j ji
j
r
d
r
(4)Dimana
r
(u )
i danu
j dua vertex pada graph dan d adalah parameter antara 0 dan 1.Mapping dari dokumen dibentuk dalam bentuk matrix dan algoritma faktorisasi matrix seperti
Singular Value Decomposition(SVD),Non-Negative Matrix Factorization(NMF) danSymmetric Matrix Factorization juga digunakan untuk proses perangkuman dokumen. Dari berbagai kalimat dibagi menjadi beberapagroupdan setiapgroupakan dilakukan ektraksi kalimat pentingnya. Dari pandangan terkait dengan artinya, metodecluster kalimat akan menemukan sematiknya dengan cara menelusuri kumpulan sub topic yang tersebunyi (latent) dari dokumen yang secara tidak langsung memberikan informasi tambahan untukclustertersebut.
Dalam paper ini, diusulkan sebuah metode untuk melakukan perangkuman dokumen yang tidak menambahkan informasi tambahan, metode yang diusulkan adalah memanfaatkan informasi dari efek saling kalimat(sentence mutual effects) danclusterkalimat. Penelitian dibentuk pemodelangraphdari dokumen yang ada, yang dilakukan perangkingan menggunakan graph-rangking algorithm. Sebuah matriks tambahan juga dibentuk dari kalimat yang diklasifikasikan berdasarkan perbedaan group menggunakan algoritma yang didasarkan pada Sparse Non-negative Matrix Factorization (SNMF). Kalimat yang berkaitan dalam satu cluster dan cluster tersebut memiliki rangking yang tinggi akan dipilih sebagai kalimat dalam menyusun rangkuman. Kontribusi pada penelitian ini adalah:
3. Sebuah model graph berbobot (weighted graph) yang mempertimbangkan hubungan antar kalimat pada cluster dan pengurutan kalimat dalam suatu dokumen.
Pada permasalahan ini tidak perlu dilakukan perangkuman isi dari dokumen lain (multi dokumen ) karena yang akan dibandingkan hanya antar kalimat pada satu dokumen. Cara mendapatkan hasil evaluasi pada paper ini memanfaatkan perhitungan ROUGE dan diterapkan pada dataset yang berasal dari 103 tugas akhir mahasiswa yang terdiri dari bagian abstrak dan isi tugas akhir.
3. Hasil Penelitian dan Pembahasan
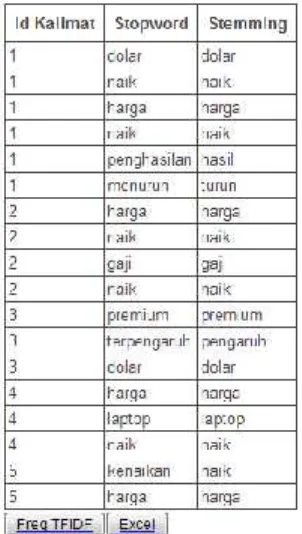
Pada proses tahap awal isi darisingledokumen yang yang terformat Pdf dipecah terlebih dahulu menjadi kata perkata dengan tujuan untuk mengambil kata pokok atau kata dasar didalam dokumen. Dalam mengambil kata dasar ini melalui proses preprocessing yaitu tokenizing atau membaca isi perkata didalam dokumen Pdf kemudian menjadikan casefoldingatau merubah format huruf menjadi kecil semua setiap kata, tahap berikutnya melewati cekstopwordjika kata dalam dokumen merupakan kata yang ada dilistkata yang termasukstopwordmaka dilewati atau dibuang.
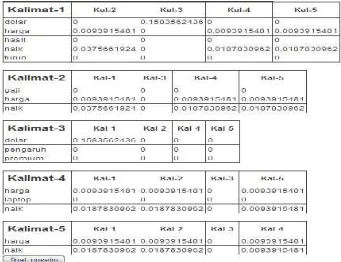
Tahapan selanjutnya adalahstemmingatau pemotongan kata untuk mengambil kata dasar dari setiap kata. Kemudian setelah didapatkan kata dasar tersebut dihitung bobot perkata dengan metode tf-idf. Dalam kasus ini tf-idf diasumsikan bahwa satu kalimat dianggap satu dokumen. Setelah mendapatkan bobot perkata langkah selanjutnya adalah menghitung tingkat kemiripan kalimat yang satu dengan kalimat yang lain menggunakan perhitungan panjang vektor dan metodecosinus similarity
untuk mengukur tingkat kemiripan kalimat yang satu dengan kalimat yang lainnya.
Perhitungan tingkat kemiripan ini dimaksudkan untuk menemukan keterhubungan kalimat yang satu dengan kalimat yang lain jika memiliki nilai tidak nol (0) maka kalimat tersebut dapat dikatakan memiliki hubungan similaritas. Pada tahap selanjutnya nilai cosinus similarity antar kalimat tersebut dihubungkan satu sama lain dengan menggunakan simpul (kalimat) dan vertex (bobot antar kalimat yang satu dengan kalimat yang lain) pada graph tidak ber-arah (undirected graph) dengan tujuan mencari bobot kalimat pada simpul-simpul graph tersebut. Setelah didapatkan masing-masing bobot antar kalimat tahap berikutnya adalah melakukan rangking pada kalimat dengan tujuan kalimat mana yang memiliki paling banyak hubungannya dengan kalimat yang lain.
Tahap berikutnya adalah kalimat tersebut diclustermenggunakan metode snmf dari metode snmf inilah nanti didapatkan kalimat inti dari masing-masing cluster sebagaisummarizationkemudian hasil
summarization tersebut disorting. dan berikutnya hasil dari peringkasan tersebut (ekstraktif) dibandingkan dengan hasil peringkasan abstraktif yg dilakukan oleh para ahli menggunakan metode rouge dan kesesuaian antar hasil keduanya diberikan dalam bentuk prosentase nilai prosentase ini dimaksudkan untuk memberikan nilai ambang batas kesesuaian abstrak dan isi yang dianggap baik menurut para pakar dansystemyang dibuat. Hasil dari system dan hasil dari para ahli inilah yang dibuat sebagai data latih dan sebagai data uji adalah dari tugas akhir mahasiswa Universitas Madura.
Apabila abstrak tersebut tidak menggambarkan isi dari laporan tugas akhir maka mahasiswa yang bersangkutan direkomendasikan untuk menulis ulang abtrak tugas akhirnya. Apabila mencapai dalam nilai prosentase yang telah ditentukan maka secara otomatis abstrak dan isi laporan tugas akhir mahasiswa tersebut diterima oleh system. Ruang lingkup yang akan digunakan dalam penelitian ini akan dijabarkan sebagai berikut:
Pada bab hasil dan penelitian dijelaskan hasil dari penelitian dan pembahasan yang lengkap. Hasil dapat direpresentasikan dalam gambar, grafik, tabel dan lainnya yang dapat mempermudah pembaca dalam memahami makalah [5]. Penjelasan dapat dibuat dalam bentuk sub bab.
3.1. Rancangan dan Metode
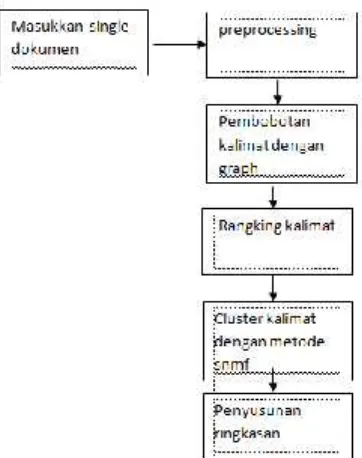
Rancangan Metode yang digunakan pada proses sistem untuk meringkas dokumen memiliki langkah-langkah sebagai berikut:
Preprocessing Pembobotan kalimat
Rangking kalimat
ClusterKalimat
Pemilihan Kalimat Representatif
Gambar 2Blok Diagram proses sistem peringkasan dokumen
Blok diagram proses dari penelitian yang digunakan dalam penelitian ini dapat dilihat pada
Gambar 2. Penjelasan mengenai tahapan-tahapan dari blok diagram di atas:
3.2.Preprocessing
Gambar 3Blok Diagram prosesPreprocessing
Pada tahapan preprocessing meliputi Tahapantokenizingadalah tahap pemotongan string input bersadarkan tiap kata yang menyusunnya, pada permasalahan ini satu dokumen dibaca secara keseluruhan isinya yang berupa teks serta hanya mengambil isi dari teksnya saja dan file tersebut bertipe PDF, penanganan seluruh subbab akan dianggap satu dokumen. Selanjutnya tahapan case folding adalah tahapan merubah huruf kapital menjadi lowercase, kemudian tahapan stop word dan menghilangkan tanda baca kecuali tanda titik (sebagai pembatas akhir kalimat) dan tidak dihilangkan.
3.3. Bobot Kalimat dengan graf model
Setelah tahapan preprocessing dilalui maka tahap berikutnya adalah menentukan bobot perkalimat. Untuk memperoleh bobot perkalimat pertama kali yang harus dilakukan adalah menghitung bobot perkata dengan menggunakan metode tf-idf. Setelah ditemukan masing-masing bobot perkata didalam satu dokumen langkah selanjutnya adalah menentukan panjang vektor masing-masing kalimat kemudian menghitung cosinus similarity atau tingkat kemiripan antar kalimat yang satu dengan kalimat yang lain. Apabila nilai cosinus similarity memiliki nilai 0 (nol) berarti kalimat tersebut tidak memiliki hubungan. Dari hasilcosinus similaritykemudian dimasukkan ke pembobotan modelgraph. Pada model
graphini berdasarkan jurnal rujukan utama dikatakan satu kalimat apabila dipisahkan oleh titik (.) atau koma (,)
3.3. Rangking kalimat
Pada tahap ini kalimat yang sudah memiliki bobot berdasarkan model graph di rangking menggunakan algoritmapagerankdengan tujuan untuk menemukan kalimat mana yang paling banyak memiliki hubungan atau keterkaitan dengan kalimat yang lain.
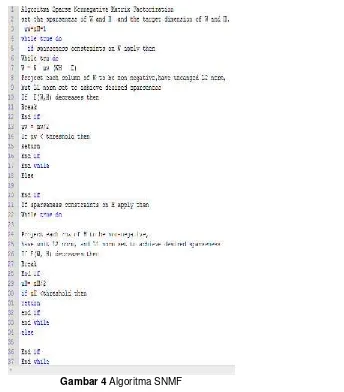
3.4.Clusterkalimat menggunakan SNMF
Cluster kalimat merupakan suatu komponen penting yang berbasis pada sistem perangkuman karena sub topik atau beberapa tema pada single dokumen harus dapat diidentifikasi menemukan persamaan dan perbedaan di dalamsingledokumen, dalam hal ini kita menggunakan metode SNMF untuk mengclusterkalimat .
Berikut adalah algoritma SNMF
3.5. Ekstraksi Kalimat
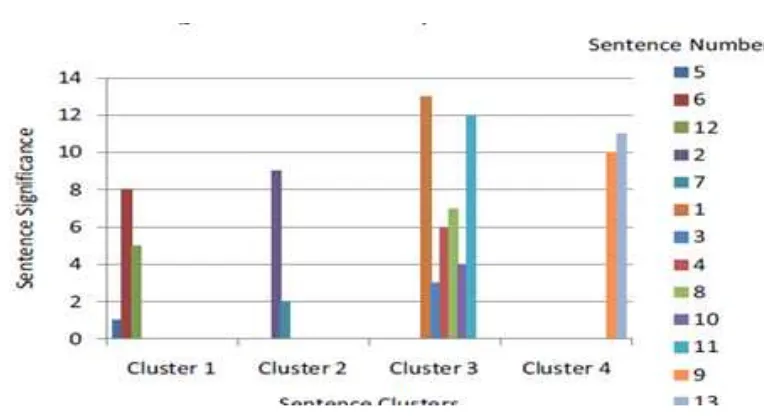
Gambar 5Ilustrasi hasil ekstraksi daricluster
Gambar diatas mengilustrasikan algoritma ekstraksi kalimat setelah merangking kalimat dan meng-cluster kalimat. Hal itu bisa dilihat dari gambar, dokumen tersebut memiliki 13 kalimat dan mereka dibagi menjadi 4 kelompok. Sumbu Y dari gambar menunjukkan signifikansi sebuah kalimat yang diperoleh oleh algoritma peringkat kalimat. Indeks dari setiap kalimat di dokumen ditampilkan di sisi kanan gambar. Untuk setiapcluster, kalimat yang didapat berpangkat tertinggi dipilih sebagai komponen
summarization. Dalam dokumen ini, kalimat ke 6, 2, 1 dan 13 dipilih sebagai rangkuman. kalimat tersebut ditambahkan ke ringkasan mengikuti perintah dari kalimat dalam dokumen Jika panjang ringkasan yang diinginkan masih belum tercapai bila kalimat teratas dari setiap clusterdipilih, kalimat yang tidak terpakai dengan skor tertinggi di setiap cluster dipilih sebagai bagian dari summarization. Kalimat itu kemudian ditandai seperti yang digunakan. Prosesnya berulang sampai panjang yang diinginkan darisummarizationtercapai.
3.6. Penyusunan Ringkasan
Setelah mengelompokkan kalimat, cluster diperintahkan menggunakan algoritma pengurutan
cluster. Satu kalimat representatif dari setiap cluster dipilih dengan memanfaatkan algoritma representatif pemilihan. Dipilih satu kalimat yang sudah tercluster pada posisi paling atas dan kemudian memilih memilih kalimat dari subsequence clusterberada pada daftarcluster urutan sampai panjang dari ringkasan ditemukan.
3.7 Hasil Penelitian
Gambar 7Proses stopworddanstemming
Gambar 8Proses Tf-Idf
Gambar 10Proses menghitungcosinus similarity
Gambar 11ProsesFinal cosinus similarity
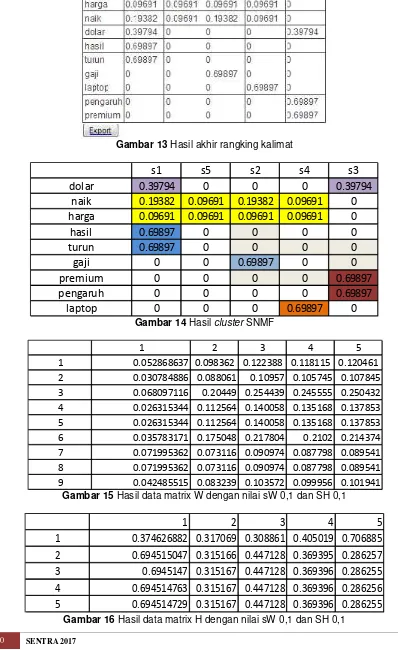
Gambar 13Hasil akhir rangking kalimat
Gambar 14HasilclusterSNMF
Gambar 15Hasil data matrix W dengan nilai sW 0,1 dan SH 0,1
Gambar 16Hasil data matrix H dengan nilai sW 0,1 dan SH 0,1
s1
s5
s2
s4
s3
dolar
0.39794
0
0
0
0.39794
naik
0.19382
0.09691
0.19382
0.09691
0
harga
0.09691
0.09691
0.09691
0.09691
0
hasil
0.69897
0
0
0
0
turun
0.69897
0
0
0
0
gaji
0
0
0.69897
0
0
premium
0
0
0
0
0.69897
pengaruh
0
0
0
0
0.69897
laptop
0
0
0
0.69897
0
1
2
3
4
5
1
0.052868637 0.098362 0.122388 0.118115 0.120461
2
0.030784886 0.088061
0.10957 0.105745 0.107845
3
0.068097116
0.20449 0.254439 0.245555 0.250432
4
0.026315344 0.112564 0.140058 0.135168 0.137853
5
0.026315344 0.112564 0.140058 0.135168 0.137853
6
0.035783171 0.175048 0.217804
0.2102 0.214374
7
0.071995362 0.073116 0.090974 0.087798 0.089541
8
0.071995362 0.073116 0.090974 0.087798 0.089541
9
0.042485515 0.083239 0.103572 0.099956 0.101941
1
2
3
4
5
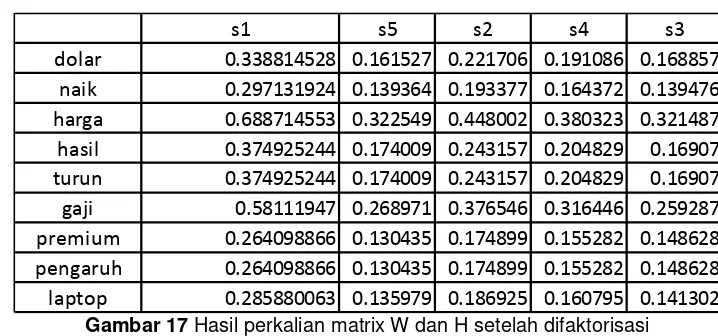
Gambar 17Hasil perkalian matrix W dan H setelah difaktorisasi
Gambar 18Hasil ringkasan
4. Kesimpulan
Dengan menggunakan metode SNMF untuk cluster setiap kalimat dapat meringkas teks yang panjang menjadi lebih singkat sehingga dapat ditemukan topik yang dibahas pada sebuah dokumen. Untuk pengembangan kedepannya diharapkan misalnya dapat menentukan sebuah abstrak daripaper
yang dibahas pada masing-masingpaper
5. Daftar Notasi
Daftar notasi dapat diuraikan dengan keterangan sebagai berikut:
wsim (si, sj) : kesamaan cosinus antara vektor dari dua kalimat
wdis(si, sj) : adalah bobot kalimat itu danλ∈[0,1] adalah parameter yang menyeimbangkan bobot kesamaan
: bobot istilahjpada dokumeni=
: bobot istilahjpada dokumeni=
(u )
ir
danu
j dua vertex pada graph dan d adalah parameter antara 0 dan 1 sW, sH : adalah nilai konvergensi dari 2 matrix W dan HReferensi
[1] Shuzhi Sam Ge, Zhengchen Zhang, Hongsheng He (2013), “Weighted graph Model based sentence clustering and Rangking for Document Summarization”,Journal of IEEE,2013
[2] Anyman El-Kilany, Iman Saleh (2012), “Unsupervised Document Summarization Using Clusters of Dependency Graph Nodes”, Journal ofInternational Conference on Intelligent Systems Design and Applications (ISDA),IEEE (2012),hal 557-561.
[3] Ailin Li, Tao Jiang, Qingshuai Wang, Hongzhi Yu (2016), “The Mixture of TextRank and LexRank Techniques of Single Document Automatic Summarization Research in Tiben”, Journal of International Conference on Intelligent Human-Machine Systems and Cybernetics, IEEE (2016) hal. 514-519.
[4] Patrik O. Hoyer, (2004), “Non-Negative Matrix Factorization with Sparseness Constrains”,
International Journal of Machine Learning Research, 5,(2004), hal. 1457-1459.
[5] L. Page, S. Brin, R. Motwani, and T. Winograd, “The pagerank citation ranking: Bringing order to the web,” Technical report, Stanford Digital Library Technologies Project, Tech. Rep., 1998. [6] Sarkar, Kamal, (2013), “Automatic single document Text Summarization Using Key Consepts in
Document,”The Journal of J Inf Process Syst, vol. 9,no.4, pp. 602–620, 2013.
[7] Alex Alifimoff, “ Abstraktive sentence Summarization with Attentive Deep RecurrentNeural Networks,”Journal of https://cs224d.stanford.edu/report/aja2015.pdf, (2015)
s1
s5
s2
s4
s3
dolar
0.338814528 0.161527 0.221706 0.191086 0.168857
naik
0.297131924 0.139364 0.193377 0.164372 0.139476
harga
0.688714553 0.322549 0.448002 0.380323 0.321487
hasil
0.374925244 0.174009 0.243157 0.204829
0.16907
turun
0.374925244 0.174009 0.243157 0.204829
0.16907
gaji
0.58111947 0.268971 0.376546 0.316446 0.259287
premium
0.264098866 0.130435 0.174899 0.155282 0.148628
pengaruh
0.264098866 0.130435 0.174899 0.155282 0.148628