Analisis Variansi dan Statistik Matematika Yang Terkait
http://oc.its.ac.id/jurusan.php?fid=1&jid=3Wiwiek Setya Winahju wiwiek@statistika.its.ac.id Analisis Variansi merupakan alat yang digunakan
untuk mengevaluasi kebaikan model regresi. Model regresi yang baik, salah satunya ditandai oleh ting-ginya koefisien determinasi, dinotasikan R2 atau
2 adj
R , yang dapat dihasilkan oleh Tabel Analisis Va-riansi.
Apabila terdapat himpunan data random yang saling independen, dan tidak ada faktor yang mempenga-ruhi, maka data tersebut akan bervariasi terhadap meannya. Pada data random yang dipengaruhi oleh suatu faktor, variasi terhadap pengaruh faktor ikut berkontribusi.
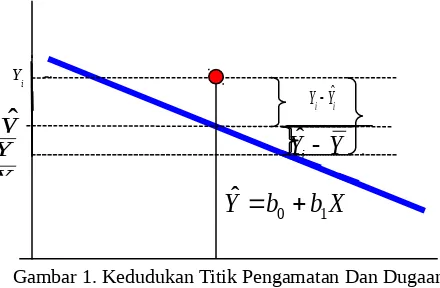
Secara geometri kedudukan titik pengamatan ke i , yaitu Yi (digambarkan oleh titik bulatan hitam),
du-gaan model regresi (digambarkan oleh garis biru), sumbu X dan sumbu Y dinyatakan pada Gambar 1.
Gambar 1. Kedudukan Titik Pengamatan Dan Dugaan Model Regresi
Berdasarkan kedudukan titik pengamatan dan duga-an model regresi dapat disusun persamaduga-an berikut :
(
: Jumlah Kuadrat Sekitar Rataan,Sum of Square Total, SST
(
: Jumlah Kuadrat Karena RegresiSum of Square Regressionl, SSR
(
: Jumlah Kuadrat Sekitar Regresi,atau Error, Sum of Square Error, SSE
SST = SSR + SSE
Tiga suku di atas akan menjadi komponen Tabel A-nalisis Variansi (ANOVA) sebagai berikut :
Tabel ANOVA
Sumber
(
KTRegresiError atau
Koefisien Determinasi,
R
2Koefisien ini dinyatakan dalam %, yang menyata-kan kontribusi regresi, secara fisik adalah akibat prediktor, terhadap variasi total variabel respon, yai-tu Y. Makin besar nilai R2, makin besar pula
kontri-busi atau peranan prediktor terhadap variasi respon. Biasanya model regresi dengan nilai R2 sebesar 70%
atau lebih dianggap cukup baik, meskipun tidak se-lalu. Rumus koefisien determinasi adalah sebagai berikut :
Hubungan antara prediktor X dengan respon Y, sela-in dapat dsela-inyatakan oleh koefisien regresi, yaitu b1,
dapat pula dinyatakan dengan koefisien korelasi, yang dinotasikan
r
X,Y.
Bedanya, koefisien regresidapat digunakan untuk memprediksi nilai respon, sedang pada koefisien korelasi tidak dapat. Persa-maan yang menyatakan hubungan ini adalah :
b
1=
n XYBuktikanlah !
Rumus R2 ini juga menyatakan kuadrat koefisien
korelasi antara Yˆ dengan Y, sehingga bila dikaitkan dengan
r
X,Y terdapat hubungan sebagai berikut :=
n XYi i n
i i n
i
i i
r
Y
Y
Y
X
b
Y
Y
Y
X
b
,
1
2 1
2 1
1 1
)
(
)
(
)
)(
(
2 2
, 2
ˆ , ,
ˆ
, r , maka r r R
rYY XY YY XY
Lack of Fit
Lack of fit artinya penyimpangan atau ketidak tepat-an terhadap model linier order pertama. Pengujian
lack of fit artinya pengujian untuk mendeteksi apa-kah model linier order pertama tepat. Bila lack of fit tidak bermakna maka model linier order pertama te-pat, sedang bila lack of fit bermakna maka model li-nier order pertama tidak tepat, perlu dikembangkan menjadi model linier kuadratik atau model nonlini-er. Pengujian lack of fit ini diperlukan bila terdapat pengamatan berulang, yaitu satu nilai prediktor a-tau satu kombinasi nilai prediktor (bila digunakan beberapa prediktor) yang berpasangan dengan bebe-rapa nilai respon.
Berikut ini akan ditampilkan organisasi data hasil pengamatan berulang pada eksperimen dengan satu dan dua prediktor.
Organisasi Data Untuk Perhitungan Jumlah Kuadrat Error Murni
Nilai Prediktor
Xj
Nilai-nilai Respon Yju
Mean Respon
j
Y
Pengulangan ni
Jumlah Kuadrat Penyimpangan Terhadap Mean Respon,
2
1
)
(
j
n
u
j
ju
Y
Y
=
j
n
u
j j
ju
n
Y
Y
1
2 2
Derajat Bebas
db
X1 Y11 , Y12 , . . . , Y1n1
1
Y
n1
2
1
1
1
)
(
1
nu
u
Y
Y
=
1
1
2 1 1 2 1
n
u
u
n
Y
Y
n1 – 1
X2 Y21 , Y22 , . . . , Y2n2
2
Y
n2
2
1
2
2
)
(
2
nu
u
Y
Y
=
2
1
2 2 2 2 2
n
u
u
n
Y
Y
n2 – 1
Xm Y11 , Y12 , . . . , Ynnm
m
Y
nn
2
1
)
(
m
n
u
m
mu
Y
Y
=
m
n
u
m m
mu
n
Y
Y
1
2 2
nm – 1
Total Jumlah Kuadrat Penyimpang-an Terhadap MePenyimpang-an Respon, disebut:
Error Murni, Galat Murni, Pure Error
Contoh
1
:Berikut ini data hasil eksperimen :
Eksperimen
ke Y X
Eksperimen
ke Y X
Eksperimen
ke Y X
1 2 3
2,3 1,8 2,8
1,3 1,3 2,0
9 10 11
1,7 2,8 2,8
3,7 4 4
17 18 19
3,5 2,8 2,1
4 5 6 7 8
1,5 2,2 3,8 1,8 3,7
2,0 2,7 3,3 3,3 3,7
12 13 14 15 16
2,2 5,4 3,2 1,9 1,8
4 4,7 4,7 4,7 5
20 21 22 23 24
3,4 3,2 3 3 5,9
5,7 6 6 6,3 6,3 Sumber : Applied Regression Analysis, Second Edition, Norman Draper dan Harry Smith, halaman 38.
Untuk mempermudah, data disusun ke bentuk berikut :
Nilai Pre-diktor yg
diulang, Xj
Nilai-nilai Respon, Yju
Mean Respon,
j
Y
Pengulangan, nj
Jumlah Kuadrat Penyimpangan Terhadap Mean Respon
Derajat Bebas
db
1,3 2,3 1,8 2,05 2 0,125 1
2 2,8 1,5 2,07 2 0,845 1
3,3 3,8 1,8 ... 2 2,000 1
3,7 3,7 1,7 ... 2 2,000 1
4 2,8 2,8 2,2 ... 3 0,240 2
4,7 5,4 3,2 1,9 ... 3 6,260 2
5,3 3,5 2,8 2,1 ... 3 0,980 2
6 3,2 3,0 ... 2 0,020 1
12,470 11
Pengujian kemaknaan lack of fit dilakukan dengan cara memecah Jumlah Kuadrat Error menjadi dua, yaitu Jumlah Kuadrat Error Murni dan Jumlah Kua-drat Lack of Fit. Perhitungan jumlah kuaKua-drat error murni dilakukan seperti yang ditampilan pada tabel di atas, sedang Jumlah Kuadrat Lack of Fit merupa-kan selisih antara Jumlah Kuadrat Error dengan Jumlah Kuadrat Error Murni. Tabel ANOVA men-jadi seperti berikut :
Tabel ANOVA 1
Sumber Variasi
(Source)
Derajat Bebas
(db) (df)
Jumlah Kuadrat
(JK) (SS)
Kuadrat tengah
(KT) = JK/db
(MS)
F
KT Reg / KT Error
Regresi Error atau Residual
1 22
6,326 21,192
6,326 963 , 0 2 s
6,569
Total,
terkoreksi 23 27,518
Pada tabel di bawah ini ditambahkan baris ke tiga yang berisikan Kuadrat Tengah Error atau MSE yang dipecah menjadi dua, yaitu Kuadrat Tengah Lack of Fit dan Kuadrat Tengah Error Murni.
Tabel ANOVA 2
Sumber Variasi
(Source)
Derajat Bebas
(db) (df)
Jumlah Kuadrat (JK) (SS)
Kuadrat tengah
(KT) = JK/db
(MS)
F
Regresi
Error atau Residual
1 22
6,326 21,192
6,326 963 , 0 2 s
6,569
(KTRegresi
dibagi
KTerror)
Lack of
Fit 11 8,722 0,793 0,699
Error
Murni 11 12,470 1,134
(KTL of F dibagi
KTerror murni)
Total,
terkoreksi 23 27,518 Keterangan : L of F = Lack of Fit
Penggunaan Tabel Anova ada dua, pertama untuk menguji kemaknaan pengaruh variabel bebas (Tabel ANOVA 1), dan ke dua untuk menguji kemaknaan Lack of Fit (Tabel ANOVA 2). Statistik uji yang digunakan adalah F.
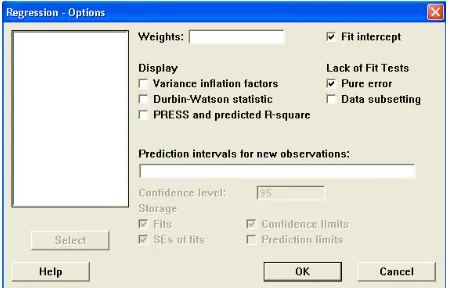
Pengujian secara cepat, yaitu dengan memanfaatkan hasil atau keluaran MINITAB. Tabel ANOVA yang memuat Lack of Fit ditampilkan dengan cara meng-klik Pure Error pada Window Option.
Data pada contoh 1 bila diolah menggunakan MINI-TAB tanpa memperhatikan lack of fit menghasilkan Tabel ANOVA 1 berikut :
Analysis of Variance 1
Source DF SS MS F P Regression 1 6,3247 6,3247 6,57 0,018 Residual Error 22 21,1937 0,9633
Total 23 27,5183
Analysis of Variance 2
Source DF SS MS F P Regression 1 6,3247 6,3247 6,57 0,018 Residual Error 22 21,1937 0,9633
Lack of Fit 11 8,7237 0,7931 0,70 0,718 Pure Error 11 12,4700 1,1336
Total 23 27,5183
Cara cepat menyimpulkan hasil pengujian, yaitu dengan memanfaatkan hasil MINITAB dapat dila-kukan dengan melihat nilai P. Nilai P sebesar 0,018, yang kurang dari 0,05 pada Analysis Vari-ansi 1, menandakan prediktor berpengaruh pada res-pon. Pada Analysis Variansi 2, didapatkan nilai P Lack of Fit sebesar 0,718 yang lebih dari 0,05, sehingga disimpulkan Lack of Fit tidak bermakna; ini berarti model linier order pertama sudah sesuai.
Cara lain mendeteksi lack of fit dengan mengguna-kan statistik uji F = (MS Lack of Fit)/(MS Pure Error). Bila F < 1, maka Lack of Fit tidak bermakna, sementara kalau F>1 belum tentu Lack of Fit ber-makna.
Kalau diterapkan pada soal contoh 1 di atas, nilai F sebesar 0,7931/1,1336; nilai ini kurang dari satu. Jadi Lack of Fit tidak bermakna. Hasil melalui F ini tidak bertentangan dengan hasil melalui P. Kedua tolok ukur ini menghasilkan kesimpulan yang sama, yaitu Lack of fit tidak bermakna.
Contoh
2
,Soal K
Y X RESI1 FITS1
0,971 3 -0,02239 0,99339 0,979 4,7 -0,00945 0,988454 0,982 8,3 0,003999 0,978001 0,971 9,3 -0,0041 0,975098 0,957 9,9 -0,01636 0,973356 0,961 11 -0,00916 0,970162 0,956 12,3 -0,01039 0,966387 0,972 12,5 0,006193 0,965807 0,889 12,6 -0,07652 0,965516 0,961 15,9 0,005065 0,955935 0,982 16,7 0,028388 0,953612 0,975 18,8 0,027485 0,947515 0,942 18,8 -0,00551 0,947515 0,932 18,9 -0,01522 0,947224 0,908 21,7 -0,03109 0,939094 0,97 21,9 0,031486 0,938514 0,985 22,8 0,0491 0,935901 0,933 24,2 0,001164 0,931836 0,858 25,8 -0,06919 0,92719 0,987 30,6 0,073747 0,913253 0,958 36,2 0,061007 0,896993 0,909 39,8 0,022459 0,886541 0,859 44,3 -0,01448 0,873475 0,863 46,8 -0,00322 0,866216 0,811 46,8 -0,05522 0,866216 0,877 58,1 0,043593 0,833407 0,798 62,3 -0,02321 0,821212 0,855 70,6 0,057887 0,797113 0,788 71,1 -0,00766 0,795661 0,821 71,3 0,02592 0,79508
0,83 83,2 0,069472 0,760528 0,718 83,6 -0,04137 0,759367 0,642 99,5 -0,0712 0,713201 0,658 111,2 -0,02123 0,67923
Sebagai langkah awal adalah memplot Y terhadap X. Dihasilkan plot berikut :
X
Y
120 100 80 60 40 20 0 1,0
0,9
0,8
0,7
0,6
Scatterplot of Y vs X
Hasil plot Y terhadap X di atas menunjukkan bahwa model regresi cukup baik, ditandai dengan titik-titik pengamatan yang merata disekitar garis regresi. Be-berapa hasil perhitungan ditampilkan sebagai beri-kut :
MTB > let k1=sum(X) MTB > let k2=sum(Y) MTB > let k3=sum(X**2) MTB > let k4=sum(Y**2) MTB > let k5=sum(X*Y) MTB > print k1-k5
Data Display
n
i i
X
1
= K1 = 1244,50
n
i i
Y
1
2 = K4 =
27,5736
n
i i
Y
1
= K2 = 30,4580
n
i
XY
1
= K5 =
1032,49
n
i i
X
1
2 = K3 = 73920,1
Dengan menggunakan command regresi didapatkan model regresi berikut :
MTB > Name c3 "RESI1" c4 "FITS1" MTB > Regress 'Y' 1 'X';
SUBC> Residuals 'RESI1'; SUBC> Fits 'FITS1'; SUBC> Constant; SUBC> Brief 1.
Regression Analysis: Y versus X
The regression equation is Y = 1,00 - 0,00290 X
Predictor Coef SE Coef T P Constant 1,00210 0,01089 92,04 0,000 X -0,0029035 0,0002335 -12,43 0,000
S = 0,0393282 R-Sq = 82,9% R-Sq(adj) = 82,3%
Analysis of Variance
Source DF SS MS F P Regression 1 0,23915 0,23915 154,62 0,000 Residual Error 32 0,04949 0,00155
Kesimpulannya model cukup baik, berdasarkan pada :
- Plot Y terhadap X menunjukkan model linier order pertama yang baik.
- Variabel bebas berbeda dengan nol se-cara bermakana, ditandai dengan nilai P yang kurang dari 0,05, jadi X berpenga-ruh pada Y.
- Nilai R2 = 82%, menunjukan variasi Y
karena pengaruh X tinggi.
- Empat plot residual tampak baik, seper-ti yang ditampilkan pada gambar di ba-wah ini.
Standardized Residual
P
e
rc
e
n
t
2 1 0 -1 -2 99 90 50 10 1
Fitted Value
S
ta
n
d
a
rd
iz
e
d
R
e
si
d
u
a
l
1,0 0,9 0,8 0,7 2 1 0 -1 -2
Standardized Residual
F
re
q
u
e
n
cy
2 1 0 -1 -2 10,0
7,5 5,0 2,5 0,0
Observation Order
S
ta
n
d
a
rd
iz
e
d
R
e
si
d
u
a
l
30 25 20 15 10 5 1 2 1 0 -1 -2
Normal Probability Plot of the Residuals Residuals Versus the Fitted Values
Histogram of the Residuals Residuals Versus the Order of the Data Residual Plots for Y
C1
P
e
rc
e
n
t
0,10 0,05 0,00 -0,05 -0,10
99 95 90 80 70 60 50 40 30 20 10 5 1
Mean 0,364 -1,47059E-07 StDev 0,03873
N 34
AD 0,390
P-Value
Probability Plot of C1 Normal - 95% CI
Contoh
3, Soal L
Pada soal K di atas, tampak terdapat nilai-nilai pre-diktor yang sangat dekat, sehingga pantas dianggap ulangan, dinamai ulangan hampiran.
Data ulangan hampiran berdasarkan data soal K: X = 9,3 9,9
X = 12,3 12,5 12,6 X = 18,8 18,8 18,9 X = 21,7 21,9 X = 46,8 46,8 X = 70,6 71,1 71,3 X = 83,2 83,6
Dengan dihimpunnya data ulangan hampiran ini maka dapat dideteksi kemaknaan lack of fit. Namun demikian, perhitungan tidak dapat dilakukan meng-gunakan program paket, harus secara manual. Untuk mempermudah, data disusun ke bentuk berikut :
Nilai Prediktor yg diulang, atau
ulangan hampiran
(Xj )
Nilai-nilai Respon, (Yju)
Mean Respon, (Yj )
Pengulangan, (nj)
Jumlah Kuadrat Penyimpangan Terhadap
Mean Respon
Derajat Bebas
(db)
9,3 9,9 0,971 0,957 9,6 2 ... 1
12,3 12,5 12,6 0,956 0,972 0,889 12,5 3 ... 2
18,8 18,8 18,9 0,975 0,942 0,932 18,83 3 ... 2
21,7 21,9 0,908 0,970 21,8 2 ... 1
46,8 46,8 0,863 0,811 46,8 2 ... 1
70,6 71,1 71,3 0,855 0,788 0,821 71 3 ... 2
83,2 83,6 0,830 0,718 ... 2 ... 1
0,01678 10
Lengkapilah perhitungan dan isikan pada tabel di atas. Selanjutnya, lengkapilah pula tabel ANOVA berikut :
Analysis of Variance
Source DF SS MS F P Regression 1 0,23915 0,23915 154,62 0,000 Residual Error 32 0,04949 0,00155
Lack of Fit ... ... ... ... ... Pure Error 10 0,01678 ...
Total 33 0,28864
Lakukanlah evaluasi, apakah lack of fit bermakna ? Lakukan analisis kebaikan model.
Statistik Matematika Pada ANOVA
Yang akan diuraikan pada topik Statistik Matema-tika pada ANOVA ini adalah :
- Distribusi setiap komponen Tabel Ana-lisis Variansi
- Hubungan antara komponen - Ekspektasi setiap komponen
Untuk mengingat kembali, akan ditampilkan lagi Tabel ANOVA berikut ini.
Error atau Residual
KTRegresi
2
Distribusi Komponen Tabel ANOVA
Yang akan dibahas adalah distribusi : Jumlah Kua-drat Regresi, Jumlah KuaKua-drat Residual, dan Jumlah Kuadrat Total.
Review ANOVA searah :
Organisasi Data :
i
Variasi total respon merupakan jumlahan dari variasi respon ter-hadap mean setiap perlakuan dengan
variansi mean setiap perlakuan ter-hadap mean keseluruhan.
Bila dinyatakan dengan persamaan:
Penalaran suku 1,
Diasumsikan : Yij~N(,2)
Didapatkan hasil :
2 2Penalaran suku 2,
Diasumsikan : Yij~N(i,2)
Didapatkan hasil :
2 1 12
1
~
ki i i
k n k
i n
j
i ij
Y
Y
2Penalaran suku 3,
2 1
1 2
2 . 2
1 2
2 .
2
1 2
2 . 2
1 2
2 .
2 / 1 2 . 2
.
~ ) (
~ ) (
~ ) (
~ ) (
) 1 , 0 ( ~ ),
, ( ~
k k
i i i k
k i
i i
k k
i
i i
i i
i i i
i
Y Y n Y
n
n Y
n Y
N
n Y n
N Y
Hasil Keseluruhan :
2 21 1 1
2
1
~
ki i i
n k
i n
j
ij
Y
Y
21 1
2
1
~
ki i i
k n k
i n
j
i ij
Y
Y
2 2
1 1
2 .
1 1
2
.
)
(
)
~
(
kk
i i i k
i n
j
i
Y
n
Y
Y
Y
iPerlu diingat :
) 1 , 0 ( ~ ))
(var( ) (
) var( ),
( ),
, ( ~
2 / 1
2 2
N Y
Y Y E Y
Y Y
E N
Y
Kembali ke
Regresi
Penalaran distribusi
ni
i
Y
Y
1
2