SISTEM PENDUKUNG KEPUTUSAN SERVICE LEVEL AGREEMENT (SLA)
KLAIN ASURANSI KESEHATAN DENGAN METODE REGRESI LINEAR
DAN METODE K-MEANS
Fahrul Nurzaman1), Agus Herwanto2)
1,2)Jurusan Teknik Informatika Fakultas Teknik UPI YAI E-mail:fnurzaman@gmail.com,aerwanto@gmail.com
Abstrak
Service Level Agreement (SLA) atau Perjanjian Tingkat Layanan merupakan hal yang sangat penting untuk diperhatikan dalam meningkatkan kualitas pelayanan pada Asuransi Kesehatan. Salah satu kualitas pelayanan adalah penyelesaian klaim yang sesuai dengan Service Level Agreement (SLA). Penyelesaian klaim yang sesuai dengan Service Level Agreement (SLA) memberikan jaminan terhadap kepuasan Pelanggan, sehingga mempengaruhi tingkat kepercayaan Pelanggan terhadap Perusahaan. Untuk meningkatkan daya saing bisnis perlu dilakukan peningkatan pelayanan dengan cara memperbaiki Service Level (SLA), sehingga diperlukan penggalian data agar perbaikan Service Level Agreement (SLA) menghasilkan keputusan yang tepat. Penggalian data terdiri dari menganalisa hubungan Service Level Agreement (SLA) klaim dengan faktor pengaruh penyelesaikan klaim dan membuat gambaran pengelompokan data berdasarkan kategori tingkat performansi Service Level Agreement (SLA). Hal ini bertujuan membantu dan memudahkan para pengambil keputusan dalam menentukan Service Level Agreement (SLA) yang tepat. Penelitian ini bertujuan memberikan solusi kepada Perusahaan Asuransi Kesehatan dengan membangun Sistem Pendukung Keputusan berbasis Web dimana Sistem akan menyajikan informasi berupa data dan grafik keterhubungan faktor-faktor yang mempengaruhi kinerja dan performansi penyelesaian terhadap Service Level Agreement (SLA) klaim serta gambaran pengelompokan data berdasarkan kategori tingkat performansi Service Level Agreement (SLA). Metode yang digunakan adalah Metode Regresi Linear untuk melihat keterhubungan faktor-faktor yang mempengaruhi kinerja dan performansi penyelesaian klaim terhadap Service Level Agreement (SLA) klaim, dan Metode K-Means untuk membuat gambaran pengelompokan data.
Kata kunci: Service Level Agreement (SLA), Sistem Pendukung Keputusan, Metode Regresi Linear, Metode K-Means
Pendahuluan
klaim dengan pembayaran Cashless dan dengan pembayaran Reimburse. Jenis Pembayaran Cashless adalah Pembayaran ditanggung terlebih dahulu oleh penyedia pelayanan kesehatan, sedangkan Jenis pembayaran Reimburse ditanggung terlebih dahulu oleh Pasien atau Peserta Asuransi Kesehatan. Service Level Agreement (SLA) terbagi menjadi dua yaitu penyelesaian Klaim Cashless dengan 14 hari kerja, dan penyelesaian klaim Reimburse dengan 7 hari kerja. Agar mendapatkan keputusan yang tepat dalam menentukan berapa hari kah Service Level Agreement (SLA), diperlukan penggalian data yang terdiri dari menganalisa hubungan Service Level Agreement (SLA) klaim dengan faktor pengaruh penyelesaikan klaim dan membuat gambaran pengelompokan data berdasarkan kategori tingkat performansi Service Level Agreement (SLA). Faktor-faktor tersebut di atas dapat terdiri dari jumlah petugas verifikator, jenis layanan dan kompleksitas klaim yang terdiri dari jumlah item benefit, jumlah berkas dokumen, besaran nilai klaim, serta faktor luar seperti pengembalian atau penyerahan kelengkapan dokumen dari Rumah Sakit atau Pasien yang berobat. Pengelompokan data dapat dibuat berdasarkan kategori tingkat performansi Service Level Agreement (SLA) dibandingkan dengan jenis pembayaran klaim atau jenis layanan. Hal ini bertujuan membantu dan memudahkan para pengambil keputusan dalam menentukan Service Level Agreement (SLA) yang tepat. Penelitian ini bertujuan memberikan solusi kepada Perusahaan Asuransi Kesehatan dengan membangun Sistem Pendukung Keputusan berbasis Web dimana Sistem akan menyajikan informasi berupa data dan grafik keterhubungan faktor-faktor yang mempengaruhi kinerja dan performansi penyelesaian terhadap Service Level Agreement (SLA) klaim serta gambaran pengelompokan data berdasarkan kategori tingkat performansi Service Level Agreement (SLA). Metode yang digunakan adalah Metode Regresi Linear untuk melihat keterhubungan faktor-faktor yang mempengaruhi kinerja dan performansi penyelesaian klaim terhadap Service Level Agreement (SLA) klaim, dan Metode K-Means untuk membuat gambaran pengelompokan data.
Studi Pustaka
Menurut Turban (2004), definisi awal Decision Support System menunjukan bahwa Decision Support System sebagai sebuah sistem yang dimaksudkan untuk mendukung para pengambil keputusan manajerial dalam situasi keputusan semiterstruktur. Decision Support System adalah sistem informasi yang membantu untuk mengidentifikasikan kesempatan pengambilan keputusan atau penyediaan informasi untuk mambantu pengambilan keputusan. Menurut Santosa (2007) Data mining atau juga disebut sebagai Knowledge Discovery In Database (KDD adalah kegiatan yang meliputi pengumpulan, pemakaian data, histori untuk menemukan keteraturan, pola atau hubungan dalam set data berukuran besar. Menurut Ritonga dan Setiawan (Ferdiansyah, 2011) , analisis regresi merupakan teknik statistik untuk mengivestigasi dan menyusun model mengenai hubungan antar variabel. Algoritma Regresi Linear Sederhana Dalam Regresi Linear, data dimodelkan dalam bentuk grafik berbentuk garis continues dua dimensi. Oleh karena penggambaran data menggunakan dua dimensi, maka dibutuhkan variabel X dan Y. Dalam regresi linear, variabel Y disebut sebagai response variable sedangkan variabel X disebut sebagai predictor variable. Kedua variabel diformulasikan secara statistik dengan rumus sebagai berikut :
X
Y
……….. (1)Diberikan nilai sampel data S dengan titik-titik (Xt , Yt), (X2, Y2), ... (X3, Y3), maka regression coefficient dapat dicari menggunakan rumus sebagai berikut:
Dimana adalah rata-rata dari x1, x2, .... xsdan adalah rata-rata dari y1, y2, .... ys. Salah satu kemampuan yang dimiliki oleh data mining adalah kemampuannya untuk melakukan proses pengklusteran pada suatu data. Analisis cluster merupakan salah satu teknik data mining yang bertujuan untuk mengidentifikasi sekelompok obyek yang mempunyai kemiripan karakteristik tertentu yang dapat dipisahkan dengan kelompok obyek lainnya, sehingga obyek yang berada dalam kelompok yang sama relatif lebih homogen daripada obyek yang berada pada kelompok yang berbeda.. Salah satu metode clustering yang paling dasar, yaitu K-means Clustering. Means berarti nilai rata-rata dari suatu grup data (cluster). K-Means adalah suatu metode penganalisaan data. Metode k-means berusaha mengelompokkan data yang ada ke dalam beberapa kelompok, dimana data dalam satu kelompok mempunyai karakteristik yang sama satu sama lainnya dan mempunyai karakteristik yang berbeda dengan data yang ada di dalam kelompok yang lain. Dengan kata lain, metode ini berusaha untuk meminimalkan variasi antar data yang ada di dalam suatu cluster dan memaksimalkan variasi dengan data yang ada di cluster lainnya. Algoritma K-Means merupakan algoritma pengelompokan iteratif yang melakukan partisi set data ke dalam sejumlah K cluster yang sudah ditetapkan di awal. K-Means dapat diterapkan pada data yang direpresentasikan dalam r-dimensi ruang tempat. Kmeans mengelompokan set data r-dimensi, X= {xi|i=1,...,N}. Secara umum algoritma K-Means memiliki langkah-langkah dalam pengelompokan, diantaranya Langkah pertama menentukan nilai K centroid yang diinginkan dan metrik ketidakmiripan (jarak) yang diinginkan,. Langkah kedua memilih K data dari set X sebagai centroid. Untuk menentukan centroid dapat menggunakan persamaan :
(Jumlah data)/(Jumlah Class+1) ………. (4)
Langkah ketiga mengalokasikan semua data ke centroid terdekat dengan metrik jarak yang telah ditetapkan. Langkah keempat menghitung kembali centroid C berdasarkan data yang mengikuti cluster masing – masing. Langkah kelima m`engulangi langkah ke-3 dan ke-4 hingga kondisi konvergen tercapai. Berikut ini adalah rumus untuk menentukan jumlah cluster:
……….. (5) dimana : K = klaster , N = jumlah data
Menghitung jarak pada ruang jarak Euclidean menggunakan formula: ……… (6)
Dimana : D = euclidean distance , x = banyaknya objekƩp = jumlah data record
Metodologi Penelitian
sedangkan tahap pengembangan dan implementasi berfokus merancang sistem pendukung keputusan dalam bentuk model diagram, pembuatan proses penggalian data dengan mendapatkan pola informasi dan pengetahuan dengan menggunakan metode Regresi dan Metode K-Means, dan membuat kode pemrograman untuk mengimplementasikan perancangan yang telah dibuat. Sedangkan tahapan pengumpulan data pasca pengembangan adalah untuk pembenahan Sistem Pendukung Keputusan yang dibuat, penarikan kesimpulan, dan saran untuk topik penelitian selanjutnya. Tahapan Penelitian meliputi Identifikasi Masalah mengenai bagaimana memberikan kemudahan dalam mengambil keputusan berkenaan dengan SLA penyelesaian klaim, Pengumpulan Data berkenaan dengan SLA penyelesaian klaim, Membuat kode SQL untuk mengambil data dari sistem sumber data, Menganalisa Permasalahan, Penggalian Data dan Pembentukan Pola penyajian informasi dan knowledge, Implementasi dan Pengembangan Sistem Pengambil Keputusan , Ujicoba dan Evaluasi Sistem, Pengambilan Kesimpulan dan Saran dari Hasil Penelitian.
Hasil dan Pembahasan Analisis Kebutuhan Data
Data yang dibutuhkan sebagai masukkan dalan proses perhitungan adalah tahun dan bulan pengerjaan klaim, petugas verifikasi klaim, jenis manfaat klaim, jenis layanan, nomor klam , jumlah item tindakan, besar nilai klaim dan jumlah SLA berdasarkan hari kerja. Sumber data berasal dari Basis Data Transaksional atau Basis Data Operasional yang akan dimasukkan ke dalam Sistem Datawarehouse atau Basis Data Staging.
Analisis Sistem Arsitektur Basis Data
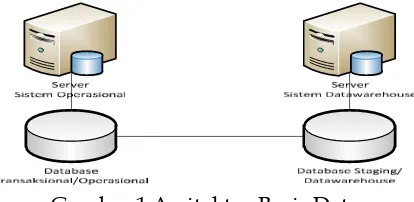
Sumber Data yang digunakan untuk proses data mining dan proses perhitungan data adalah Sistem Datawarehouse atau Basis Data Staging. Data di Basis data transaksional atau Basis Data operasional secara otomatis diambil sesuai dengan data yang dibutuhkan menggunakan implementasi kode query dimasukkan ke dalam Sistem Datawarehouse atau Basis Data Staging.
Gambar 1 Arsitektur Basis Data Analisis Skema Basis Data Transaksional
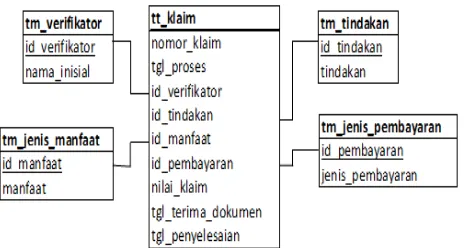
Gambar 2 Skema Basis Data Transaksional Hasil Perhitungan Metode Regresi Linear
Proses Perhitungan data dimulai dari pengambilan data dari tabel klaim yang terdapat pada Sistem Datawarehouse atau Basis Data Staging. Data tabel klaim didapat dari proses insert data klaim dari Basis data transaksional ke dalam Sistem Datawarehouse atau Basis Data Staging. Dari Tabel data klaim di Basis Data staging, dilakukan proses perhitungan jumlah petugas verifikator, jumlah kasus berdasarkan nilai klaim dengan melihat nilai klaim sampai dengan 25.000.000 , jumlah kasus berdasarkan kompleksitas klaim dengan melihat jumlah item benefit sampai dengan 3 item serta jumlah kasus yang SLA nya terpenuhi sampai dengan 7 Hari Kerja. Variabel yang terbentuk adalah Variabel Predictor Terdiri dari tiga variabel diantara nya adalah Jumlah Verifikator (X1) , jumlah kasus klaim berdasarkan kategori (X2 ), jumlah kasus klaim berdasarkan kompleksitas (X3 ) . Sedangkan Variabel Response adalah jumlah kasus klaim yang terpenuhi SLA nya (Y1 ).
Dari hasil prorses perhitungan Persamaan Regresi Linear yang dihasilkan adalah Y = 158.20 + 14.23 X1 - 3.54 X2 + 3.81 X3 . Sedangkan Hasil Pengujian Hipotesis Untuk probabilitas menggunakan nilai 0.05. Nilai F tabel didapat dari Tabel Distribusi F dimana Dk pembilang = k dan Dk penyebut = n – k -1 , untuk k adalah jumlah variable predictor dan n adalah jumlah data yang diteliti. Maka nilai yang didapat adalah : F tabel = F tabel (0.05, 3 , 3.2 ) = 2.9 . Dalam Menentukan formulasi hipotesis Berdasarkan hasil perhitungan maka didapat nilai sebagai berikut : H1: B1 : 14.23 B2 : - 3.54 B3 : 3.81 ≠ 0 F hitung (6.12) > F tabel (2.9) = H0 ditolak, H1 diterima.
Hasil Perhitungan Metode K-Means
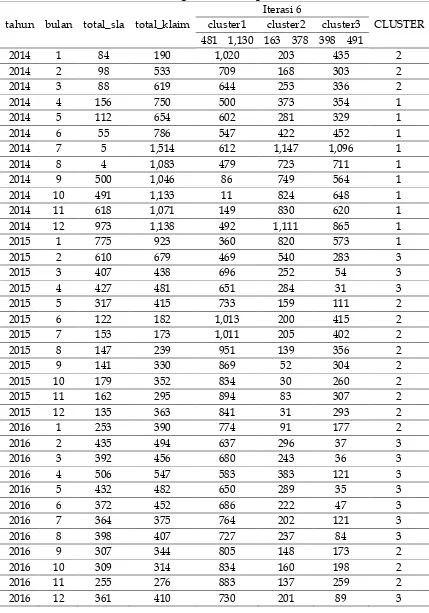
Tabel 1. Perhitungan Distance Space Iterasi ke-6
tahun bulan total_sla total_klaim
Iterasi 6
CLUSTER cluster1 cluster2 cluster3
481 1,130 163 378 398 491
2014 1 84 190 1,020 203 435 2
2014 2 98 533 709 168 303 2
2014 3 88 619 644 253 336 2
2014 4 156 750 500 373 354 1
2014 5 112 654 602 281 329 1
2014 6 55 786 547 422 452 1
2014 7 5 1,514 612 1,147 1,096 1
2014 8 4 1,083 479 723 711 1
2014 9 500 1,046 86 749 564 1
2014 10 491 1,133 11 824 648 1
2014 11 618 1,071 149 830 620 1
2014 12 973 1,138 492 1,111 865 1
2015 1 775 923 360 820 573 1
2015 2 610 679 469 540 283 3
2015 3 407 438 696 252 54 3
2015 4 427 481 651 284 31 3
2015 5 317 415 733 159 111 2
2015 6 122 182 1,013 200 415 2
2015 7 153 173 1,011 205 402 2
2015 8 147 239 951 139 356 2
2015 9 141 330 869 52 304 2
2015 10 179 352 834 30 260 2
2015 11 162 295 894 83 307 2
2015 12 135 363 841 31 293 2
2016 1 253 390 774 91 177 2
2016 2 435 494 637 296 37 3
2016 3 392 456 680 243 36 3
2016 4 506 547 583 383 121 3
2016 5 432 482 650 289 35 3
2016 6 372 452 686 222 47 3
2016 7 364 375 764 202 121 3
2016 8 398 407 727 237 84 3
2016 9 307 344 805 148 173 2
2016 10 309 314 834 160 198 2
2016 11 255 276 883 137 259 2
Tabel 2 Titik Pusat Cluster Hasil Iterasi ke-6
cluster centorid (x1) centroid(x2) keterangan
1 481 1,130 rata-rata data Cluster 1 Iterasi Ke-6
2 163 378 rata-rata data Cluster 2 Iterasi Ke-6
3 398 491 rata-rata data Cluster 3 Iterasi Ke-6
Hasil Implementasi Aplikasi Sistem
Hasil implementasi Aplikasi sistem yang dibangun dapat ditampilkan seperti di bawah ini :
Gambar 3 Tampilan Hasil Aplikasi Kesimpulan
Dari hasil dan pembahasan penelitian dapat disimpulkan sebagai berikut :
a) Penyelesaian klaim yang sesuai dengan Service Level Agreement (SLA) dipengaruhi oleh ke-3 faktor yaitu diantaranya jumlah verifikator, jumlah item benefit , besar nilai klaim dimana ke-3 faktor tersebut menjadi variabel prediktor dan variable response nya adalah jumlah kasus yang diselesaikan sesuai dengan Service Level Agreement (SLA) nya.
b) Persamaan Regresi Linear nya adalah Y = 158.20 + 14.23 X1 - 3.54 X2 + 3.81 X3 , sehingga faktor yang paling besar mempengaruhi adalah jumlah petugas verifikator. c) Nilai F hitung (6.12) > F tabel (2.9) = H0 ditolak, H1 Diterima dapat disimpulkan
d) Cluster dibagi menjadi tiga kelompok berdasarkan jumlah penyelesaian klaim berdasarkan SLA Terpenuhi dan Total Jumlah Klaim yang diselesaikan.
e) Iterasi clustering pada data kinerja penyelesaian klaim sebanyak 6 kali iterasi, sampai ditemukannya konvergensi pada titik pusat cluster.
f) Hasil dari pengelompokan dengan Metode K-Means memberikan informasi kinerjav erifikator dalam menyelesaikan klaim berdasarkan SLA yang terpenuhi.
g) Hasil dari Aplikasi dapat menyajikan informasi dalam bentuk tabel dan grafik sehingga dapat membantu dalam menganalisa dan membantu memberi keputusan yang berkenaan dengan penyelesaian klaim.
Ucapan Terima kasih
Penelitian ini dibiayai oleh Kemenristek DIKTI Direktur Riset dan Pengabdian Masyarakat.
Daftar pustaka
Andayani, Sri., 2007, Pembentukan Cluster dalam Knowledge Discovery in database dengan Algoritma K-Means, Semnas Matematika dan Pendidikan Matematika.
Andry Syafrianto., 2012, Perancangan aAplikasi K-Means Untuk Pengelompokan Mahasiswa Stmik Elrahma Yogyakarta Berdasarkan Frekuensi Kunjungan Ke Perpustakaan dan IPK, Yogyakarta
Efraim, T., dkk, 2005, Decision Support Systems and Intelligent Systems, Edisi ke-7, Dwi Prabantini, Andi, Yogyakarta.
Kusrini, 2007, Konsep dan Aplikasi Sistem Pendukung Keputusan Keputusan, Andi Offset, Yogyakarta
Larose, Daniel T., 2005, Discovering Knowledge in Data: An Introduction to Data Mining, John Willey & Sons, Inc
Mc Leoad, Raymond. ,1995,SIstem Informasi Manajemen, PT. Tema Baru, Klaten
Turban, Efraim., Aronso, Jay., Liang Peng Ting., 2005, Decision Support System and Intelligence System (Versi Bahasa Indonesia), Edisi Ke-7. Yogyakarta : ANDI Offset Santosa, Budi. 2007. Data Mining Teknik Pemanfaatan Data untuk Keperluan Bisnis. Yogyakarta : Graha Ilmu