C-253
SEGMENTASI PELANGGANPLN MENGGUNAKAN FUZZY KLUSTERING SHORT TIME SERIES
Maria Titah Jatipaningrum1 1
Jurusan Matematika, Fakultas Sains Terapan, IST AKPRIND Yogyakarta e-mail :[email protected]
ABSTRACT
Clustering is a descriptive statistical technique that helps in determining the central points, is the most fundamental concepts to determine the pattern of the data in the segmentation data. The advantages of fuzzy clustering gives a fuzzy clustering partition data, stronger, broader, and more realistic than crisp partition. In this research, conducted an empirical analysis with fuzzy clustering method with short time seriesdistance. The reason behind it,because of capturing time interval information from sample data. Analysis of empirical data is used time series data, customers loads sample Yogyakarta’s State Electricity Enterprise..e
Keywords: short time series distance, fuzzy clustering, fuzzy clustering short time series, customers segmentation, loads sample Yogyakarta’s State Electricity Enterprise
PENDAHULUAN
Tenaga listrik tidak dapat disimpan dalam skala besar, karenanya tenaga ini harus disediakan pada saat dibutuhkan. Akibatnya timbul persoalan dalam menghadapi kebutuhan daya listrik yang tidak tetap dari waktu ke waktu, bagaimana mengoperasikan suatu sistem tenaga listrik yang selalu dapat memenuhi permintaan daya pada setiap saat, dengan kualitas baik dan harga yang murah. Apabila daya yang dikirim dari bus-bus pembangkit jauh lebih besar daripada permintaan daya pada bus-bus beban, maka akan timbul persoalan pemborosan energi pada perusahaan listrik, terutama untuk pembangkit termal. Sedangkan apabila daya yang dibangkitkan dan dikirimkan lebih rendah atau tidak memenuhi kebutuhan beban konsumen maka akan terjadi pemadaman lokal pada bus-bus beban, yang akibatnya merugikan pihak konsumen. Oleh karena itu diperlukan penyesuaian antara pembangkitan dengan permintaan daya.
Masalah yang unik dalam operasi sistem adalah bahwa: “Daya yang dibangkitkan atau diproduksi harus selalu sama dengan daya yang dikonsumsi oleh para pemakai tenaga listrik yang secara teknis umumnya dikatakan sebagai beban sistem”[Marsudi,1990]. Realisasinya tidak harus selalu sama, pada kasus-kasus tertentu apabila ada permintaan khusus dari pelanggan, pihak PLN harus dapat mencukupi kebutuhan listrik tak terduga tersebut Timbul permasalahan bahwa beban masing-masing pengguna jasa listrik berbeda-beda. Beban listrik yang berbeda menyebabkan overload sehingga menimbulkan terjadinya pemadaman lokal. Pemadaman lokal menyebabkan efisiensi dan efektifitas kerja menurun. Untuk mengatur kestabilan pasokan listrik pelanggan, diperlukan klustering data berdasarkan pola beban untuk segmentasi pelanggan. Informasi yang diambil dari hasil klustering digunakan pihak PLN untuk pemeriksaan (inspection) apabila terdapat keanehan data historical sehingga tindak pencurian listrik dapat terdeteksi, mengetahui tipikal pola beban pelanggan guna menentukan tarif langganan perbulan berdasarkan pemakaian listrik dan masukan bagi tim marketing untuk menganalisis perilaku pelanggan (Customer Relationships Management). Untuk melakukan analisis time series, didefinisikan ukuran relevan dari jarak antara time series dalam kumpulan data. Ukuran yang digunakan dalam analisis time series pada kasus ini adalah ukuran jarak (distance) short time series. Kemudian digabungkan dengan prosedur FCM dan lebih dikenal dengan Fuzzy Short Time series (FSTS) yang dikembangkan oleh [Levet et al, 2003] dikenal juga sebagai modifikasi jarak euclidean yang digunakan dalam FCM.
Dari uraian latar belakang permasalahan diatas, secara umum permasalahan yang dibahas adalah bagaimana mendapatkan fuzzy klustering short time series yang optimal dengan tingkat validitas tinggi. Penelitian yang dilakukan dalam rangka menjawab pertanyaan berikut: Bagaimana langkah-langkah pengklusteran data short time series menggunakan FSTS untuk menghasilkan tingkat validitas pengklusteran yang lebih baik. Penerapan algoritma fuzzy short time series dalam berbagai aplikasi dalam soft-computing fuzzy telah banyak pula menjadi perhatian banyak peneliti, antara lain
C-254
dapat dilihat pada Moller-Levet (2003) diterapkan pada data gen (microarray). Referensi yang berkaitan dengan konsep dan bentuk dari model fuzzy klustering secara umum dapat ditemukan di Sato-Ilic (2006), Olievera (2007), Miyamoto dkk (2008).
Penentuan validitas pengklusteran menggunakan indeks Xie-Beni, ditemukan oleh Xie-Beni (1991). Program yang digunakan untuk aplikasi FC-STS adalah MATLAB.Kode matlab untuk jarak STS diperoleh dari www.sbi.uni-rostock.de/ yang diunduh tanggal 4 Oktober 2011, dimodifikasi dengan code matlab FCM kemudian dihasilkan FC-STS yang ditampilkan dalam GUI Matlab beserta nilai indeks Xie-Beni terkait kluster yang terbentuk.
METODE PENELITIAN
Adapun tahapan dalam penelitian ini adalah sebagai berikut :
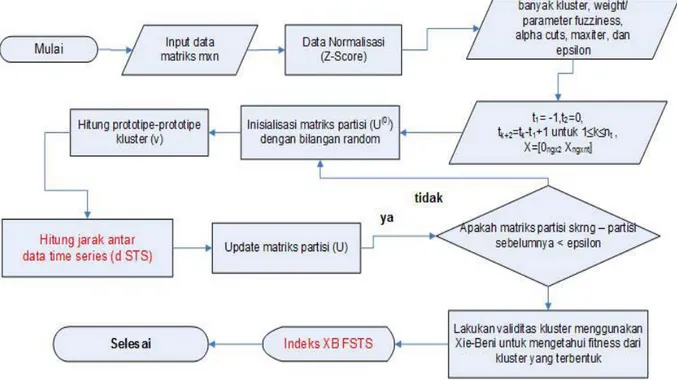
Gambar 1. Alur Tahapan Penelitian
PEMBAHASAN Prosedur Fuzzy Clustering Short Time Series
Ringkasan prosedur FC-STS seperti yang diuraikan di atas adalah sebagai berikut dan dapat dilihat pula flowchart yang ditampilkan pada Gambar 1 untuk membantu pembentukan prosedur FC- STS (Hussain, 2011):
Langkah 1: Inisialisasi g
n
= banyaknya sampel loads/ beban pelanggan = 15 tn
= banyaknya titik waktu = 50 time points X = matriks load profile⎡
⎣
n
g×
n
t⎤
⎦
=
[
15 50
×
]
c
n
= banyaknya kluster dimulai dari 2 sampai 4w
= bobot/ weight fuzziness, w=1, 6α
= alpha cuts, α =0, 3ε
= epsilon, digunakan nilai ε =0, 0001Langkah 2: Penambahan dua titik waktu tetap dan fuzzifikasi
1
1
C-255 2
0
t
=
2 11
k kt
+= − +
t
t
, untuk1
≤ ≤
k
n
t ( 2)0
2 g t g g t n n n n nX
⎡ × + ⎤ ⎡ × ⎤X
⎡ × ⎤ ⎣ ⎦ ⎣ ⎦ ⎣ ⎦⎡
⎤
= ⎢
⎣
⎥
⎦
Langkah 3: Inisialisasi matriks partisi awal
Inisialisasi matriks awal yang dibangkitkan dengan bilangan random
U
( )0⎡
⎣
n
c×
n
g⎤
⎦
Langkah 4: ulangi untuk l=1, 2,…
Perhitungan jarak short time series atau dSTS menggunakan persamaan
( )
( ) ( ) ( ) ( ) 2 1 1 1 2 0 1 1 , − + + = + + ⎛ − − ⎞ ⎜ ⎟ = − ⎜ − − ⎟ ⎝ ⎠∑
t n k k k k STS k k k k k v v x x d x v t t t t ... (1)dengan
1
≤ ≤
i
n
cdan3
≤ ≤
n
n
t. Perhitungan prototipe kluster:v i
( )
,1
( )l=
0
danv i
( )
,2
( )l=
0
untuk perhitunganv i n
( )
,
( )l digunakan persamaan( )
( ) ( )(
( ) ( ))
2 1 1 1 1 1 3 2 1 1 1 3 1 1 2 2 3 1 1 2 1 1 1 1 2 , / / − − − − − − − = = = + = + = + = − = + = − − − − − − − = = = ⎡ ⎛ ⎞ ⎤ = ⎢ ⎜ + + ⎟ ⎥+ ⎢ ⎝ ⎠ ⎥ ⎣ ⎦ ⎡ ⎤ + + ⎢ ⎥ ⎣ ⎦∑
∏ ∏
∏
∑
∏ ∏
∏
∏
∏
∏
p r n n n n n n ir q q q j j q r q q r q r p r j p j r q n n n q q q i n i n n n q q q v i n m c a c c a c m c m c a c c ... (2),dengan untuk
1
≤ ≤
i
n
cdan3
≤ ≤
n
n
tUpdate matriks partisi menggunakan persamaan
(
)
(
)
1 1 1 1 , , − = = ⎛ ⎞ ⎜ ⎟ ⎜ ⎟ ⎝ ⎠∑
c ij w n STS i j q STS i q u d x v d x v ... ... (3) jika 2 0 ij STSd > untuk
1
≤ ≤
i
n
cdan3
≤ ≤
n
n
t , sebaliknya uij( )l = jika 0 2 0ij STS d > dan uij( )l ∈
[ ]
0,1 dengan ( ) 11
c n l ij iu
==
∑
sampaiU
( )l−
U
( )l−1<
ε
Langkah 5: Perhitungan indeks Xie-Beni untuk mengetahui performansi hasil klustering terbaik, dengan menggunakan persamaan
( )
(
)
, 2 1 1 2 , min = = = −∑∑
( ) x i j c N w ik ik k i i k i j u d v XB c N v v (4)dan dipilih indeks yang paling minimum dan terbaik, diantara kluster yang terbentuk. Pada pembahasan ini akan diujikan data Fuzzy Short Time Series yang terdiri dari:
1. Pengujian pada data STS dengan ukuran 15x50 dengan alpha cuts yang berbeda-beda yakni: 0,1, 0,2, 0.3, 0.4, 0.5, dan 0.6 untuk mengetahui jumlah pusat kluster yang optimal dengan melihat nilai indeks XB yang terkecil.
2. Pengujian pada jumlah kluster yang optimal untuk mengidentifikasi pola (pattern) data yang terdistribusi untuk setiap kluster.
Hasil pengujian pada data STS dengan ukuran 15x50 dengan alpha cuts yang berbeda-beda yakni: 0,1, 0,2, 0.3, 0.4, 0.5, dan 0.6. Jumlah kluster yang diujikan secara iteratif pada 2, 3, 4, sedangkan variabel fuzzy 1.6 dan kriteria stopping dengan epsilon 0.0001 dan maksimum iterasi 50 sebagai berikut :
C-256
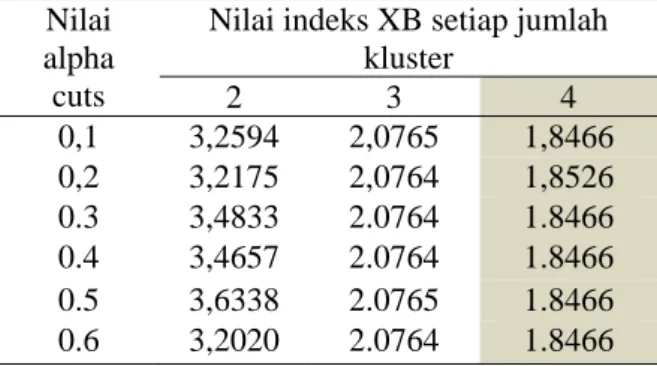
Tabel 1. Hasil FSTS pada setiap alpha cut yang berbeda Nilai
alpha cuts
Nilai indeks XB setiap jumlah kluster 2 3 4 0,1 3,2594 2,0765 1,8466 0,2 3,2175 2,0764 1,8526 0.3 3,4833 2.0764 1.8466 0.4 3,4657 2.0764 1.8466 0.5 3,6338 2.0765 1.8466 0.6 3,2020 2.0764 1.8466
Berdasarkan Tabel1 terlihat bahwa nilai indeks XB cenderung menurun dengan bertambahnya jumlah kluster yang didefinisikan. Nilai indeks XB yang terbaik adalah pada jumlah kluster 4. Grafik nilai XB pada setiap nilai alpha cuts ditunjukkan pada Gambar 2. Selanjutnya ditinjau berdasarkan nilai alpha cuts yang berbeda-beda, pada setiap jumlah klustering cenderung tidak berubah atau konstan.
Gambar 2.Grafik nilai indeks XB
Hasil pengujian selanjutnya adalah menggunakan data STS yang sama dengan ukuran 15x50. Berdasarkan nilai alpha cuts yang berbeda-beda yakni: 0,1, 0,2, 0.3, 0.4, 0.5, dan 0.6. Jumlah kluster yang diujikan diambil dari kluster dengan nilai indeks XB terbaik dalam hal ini terkecil. Variabel lainnya adalah variabel fuzzy 1,6 dan kriteria stopping dengan epsilon 0.0001 dan maksimum iterasi 50, sebagai berikut:
Berdasarkan Tabel 2 pada setiap nilai alpha cuts yang berbeda, menghasilkan nilai indeks XB terbaik pada jumlah kluster yang sama. Setelah diuji jumlah kluster terbaik menghasilkan pola data yang bervariasi. Jumlah data yang semula 15 loads time series setelah dilakukan fuzzy klustering menghasilkan pola data yang berbeda dari data awal.
C-257
Tabel 2. Hasil FSTS pada indeks XB terbaik
Data yang hilang disebabkan oleh pembangkitan bilangan random untuk menghasilkan derajat keanggotaan fuzzy setiap data dan pemilihan alpha cuts. Derajat bilangan fuzzy (degree of membership) dengan jangkauan antara 0 sampai 1 akan dipotong dengan menggunakan alpha cuts. Pola-pola data yang derajat keanggotaan yang lebih kecil alpha cuts dipotong sebagai data yang hilang. Sedangkan pola data yang muncul, lebih dari satu kluster (overlapping), karena nilai derajat keanggotaan lebih besar dari alpha cuts.
Pada Tabel 3 ditunjukkan pola data pada setiap kluster. Data yang digunakan sama dengan data pada Tabel 4.2 dengan nilai potongan alpha 0.3 dihasilkan pola data sebagai berikut :
1. Pada kluster 1 berisi data 2, 8, 9, 10, 12 (rsud panembahan, pasar niten, pengadilan tinggi Yogyakarta, RRI Yogyakarta, Sindunegaran)
2. Pada kluster 2 berisi data 1,4,5,7,11, 12,13,15 (BNI 1946, arcade, id gar, palace, sahid, Sindunegaran, teknik UNY, duta wacana)
3. Pada kluster 3 berisi data 6 (inter)
4. Pada kluster 4 berisi data 3, 14 (Aquila, ternas)
Tidak ada data yang hilang pada proses FSTS pembentukan 4 kluster pada data sampel PLN.Data yang mengalami overlapping adalah data 12 (sindunegaran) pada kluster 1 dan 2, dapat diartikan bahwa data 12 bisa masuk kategori pelanggan kluster 1 atau kluster 2.
Tabel 3.Pola Sebaran Data Hasil Bentukan 4 Kluster DataClust = Columns 1 through 8 2 8 9 10 12 0 0 0 1 4 5 7 11 12 13 15 6 0 0 0 0 0 0 0 3 14 0 0 0 0 0 0 KESIMPULAN
Dari hasil penulisan yang telah dikemukakan sebelumnya, dapat disimpulkan beberapa hal sebagai berikut:
1. Pengklusteran data 15 ID loads pelanggan PLN menggunakan FC-STS dihasilkan 4 kluster, pada kluster 1 berisi data 2, 8, 9, 10, 12 (rsud panembahan, pasar niten, pengadilan tinggi Yogyakarta, RRI Yogyakarta, Sindunegaran); pada kluster 2 berisi data 1,4,5,7,11, 12,13,15 (BNI 1946, arcade, id gar, palace, sahid, Sindunegaran, teknik UNY, duta wacana); pada kluster 3 berisi data 6 (inter) ; pada kluster 4 berisi data 3, 14 (Aquila, ternas).
2. Tidak ada data yang hilang pada proses FC-STS pembentukan 4 kluster pada data sampel PLN. Data yang mengalami overlapping adalah data 12 (sindunegaran) pada kluster 1 dan 2, dapat diartikan bahwa data 12 bisa masuk kategori pelanggan kluster 1 atau kluster 2.
3. Nilai validitas indeks Xie-Beni untuk data di atas dengan terbentuknya 4 kluster, yaitu: 1.8466. Nilai ini dipilih dari hasil masing-masing pembentukan kluster dari 2 sampai dengan 4 yang paling minimum dan yang terbaik.
4. Pemilihan alpha cuts 0,3 yang digunakan dalam penelitian ini, dengan pertimbangan diperoleh kluster yang paling optimal (tidak ada data yang hilang dan data yang overlapping hanya satu).
C-258 DAFTAR PUSTAKA
Hussain, Sadiq (2011), A Fuzzy Approach for Clustering Gene Expression Time Series Data, International Journal Computer Science and Information Technology (IJCSIT) Vol 3, No 4, Dibrugarh University.
Levet, Moller, Carla., Klawonn, Frank., (2003), Clustering of Unevenly Sampled Gene Expression Time-Series Data, UMIST, Manchester, U.K, code matlab (diunduh tanggal 04 Oktober 2011) Marsudi, Djiteng (1990). Operasi Sistem Tenaga Listrik. Jakarta: Balai Penerbit dan HUMAS ISTN.
Miyamoto, Sadaaki., Ichihashi, Hidetomo., Honda, Katsuhiro (2008) Algorithms for Fuzzy Clustering
Methods in c-Means Clustering with Applications, Studies in Fuzziness and Soft Computing,
Volume 229 Springer.
Oliveira, Jose Valente de., Pedrycz, Witold.,(2007). Advances in Fuzzy Clustering and Its Applications. John Wiley & Sons Ltd, The Atrium, Southern Gate, Chichester, West Sussex PO19 8SQ, England.
Sato-Ilic,Mika., Jain, Lakhmi C. (2006) Innovations in Fuzzy ClusteringTheory and ApplicationsStudies in Fuzziness and Soft ComputingVol. 205. Springer ISBN 3-540-34356-3.
Xie, Xuanli Lisa., Beni, Gerardo., (1991), A Validity Measure for Fuzzy Clustering, IEEE Transactions on Pattern Analysis and Machine Intelligence, 13(8): 841-847, University of California, Santa Barbara.