11 2.1 Data Mining
Data mining adalah kegiatan untuk menemukan pola yang menarik dalam
jumlah data yang cukup besar. Secara sederhana data mining adalah penambangan atau penemuan informasi baru dengan mencari pola atau aturan tertentu dari sejumlah data yang sangat besar, Data mining juga disebut sebagai serangkaian proses untuk menggali nilai tambah berupa pengetahuan yang selama ini tidak diketahui secara manual dari suatu kumpulan data.
Knowledge Discovery in Database (KDD) pada data mining tidak dapat
dipisahkan, karena pada dasarnya data mining sering juga disebut KDD yang merupakan kegiatan yang meliputi pengumpulan, pemakaian data, historis untuk menemukan keteraturan atau keterkaitan, pola atau hubungan dalam set data berukuran besar. Dengan diperolehnya informasi-informasi yang berguna dari data-data yang ada, hubungan antara item dalam transaksi maupun informasi-informasi yang potensial, selanjutnya dapat diekstrak dan dianalisa lalu diteliti lebih lanjut.
2.1.1 Karakteristik Data Mining
Karakteristik data mining dibagi menjadi beberapa hal yaitu, sebagai berikut:
a. Data mining berhubungan dengan penemuan sesuatu yang tersembunyi dan pola data tertentu yang tidak diketahui sebelumnya.
b. Data mining biasa menggunakan data yang sangat besar. Biasanya data yang besar digunakan untuk membuat hasil yang lebih dapat dipercaya. c. Data mining berguna untuk membuat keputusan yang kritis, terutama
dalam strategi .
Dari beberapa pengertian karakteristik di atas dapat diketahui pengertian dari data mining yang lebih kompleks. Data mining adalah suatu teknik menggali informasi berharga yang terpendam atau tersembunyi pada suatu koleksi data (database) yang sangat besar sehingga ditemukan suatu pola yang unik dan menarik yang sebelumnya tidak diketahui polanya seperti apa. Kata mining sendiri berarti usaha untuk mendapatkan sedikit barang berharga dari sejumlah besar material dasar. Oleh karena itu data mining sebenarnya mempunyai akar yang panjang dari bidang ilmu seperti artificial intelligent (kecerdasan buatan),
machine learning (mesin pembelajaran), statistik dan database. Beberapa metode
yang sering disebut dalam literatur data mining antara lain clustering,
classification, association rules mining, neural network, genetic algorithm, dan
lainnya.
2.1.2 Data Mining Task
Secara umum, tugas data mining dibagi menjadi dua kategori yang penting, yaitu:
a. Predictive Task
Tujuan dari task ini adalah untuk memprediksi nilai dari sebuah atribut yang penting berdasarkan nilai dari atribut yang lainnya. Atribut yang
diprediksi biasanya dikenal sebagai target atau dependent variable, sedangkan atribut yang digunakan untuk melakukan prediksi dikenal dengan explanatory atau independent variable.
b. Descriptive Task
Tujuan dari task ini adalah untuk menghasilkan pola (correlations,
trends, clusters, trajectories dan anomalies) yang merangkum keterkaitan
dalam interaksi data.
Pada data mining terdapat pekerjaan penting yang dibagi ke dalam empat kelompok, yaitu:
1. Predictive Modelling
Predictive Modelling digunakan untuk membangun sebuah model
untuk target variable sebagai fungsi dari explanatory variable. Explanatory variable dalam hal ini merupakan seluruh atribut yang
digunakan untuk melakukan prediksi, sedangkan target variable merupakan atribut yang akan diprediksi nilainya. Predictive modelling task dibagi menjadi dua tipe, yaitu:
a. Classification: Digunakan untuk memprediksi nilai dari target
variable yang discrete (diskret).
b. Regression: digunakan untuk memprediksi nilai dari target
2. Association Analysis
Association analysis digunakan untuk menemukan aturan association
yang memperlihatkan kondisi-kondisi nilai atribut yang sering muncul secara bersamaan dalam sebuah himpunan data.
3. Cluster Analysis
Tidak seperti klasifikasi yang menganalisa kelas data objek yang mengandung label. Clustering menganalisa objek data tanpa memeriksa kelas label yang diketahui. Label-label kelas dilihatkan di dalam data
training. Karena belum diketahui sebelumnya. Clustering merupakan
proses pengelompokkan sekumpulan objek yang sangat mirip.
4. Anomaly Detection
Anomaly detection merupakan metode pendeteksian suatu data dimana
tujuannya adalah menemukan objek yang berbeda dari sebagian besar objek lain. Anomaly dapat di deteksi dengan menggunakan uji statistik yang menerapkan model distribusi atau probabilitas untuk data.
2.1.3 Data Mining Model
Dalam perkembangan teknologi data mining, terdapat model yang digunakan untuk melakukan proses penggalian informasi terhadap data-data yang ada. Menurut IBM model data mining dapat dibagi menjadi dua bagian, yaitu:
1. Verification Model
Model ini menggunakan perkiraan (hypothesis) dari pengguna, dan melakukan test terhadap perkiraan yang diambil sebelumnya dengan menggunakan data-data yang ada. Penekanan terhadap model ini adalah terletak pada user yang bertanggung jawab terhadap penyusunan perkiraan dan permasalahan pada data untuk meniadakan atau menegaskan hasil perkiraan yang diambil.
Sebagai contoh misalnya dalam bidang pemasaran, sebelum sebuah perusahaan mengeluarkan suatu produk baru ke pasaran, perusahaan tersebut harus memiliki informasi tentang kecenderungan pelanggan untuk membeli produk yang akan dikeluarkan. Perkiraan dapat disusun untuk mengidentifikasikan pelanggan yang potensial dan karakteristik dari pelanggan yang ada. Permasalahan utama dengan model ini adalah tidak adanya informasi baru yang dapat dibuat, melainkan hanya pembuktian atau melemahkan perkiraan dengan data-data yang sudah ada sebelumnya. Data-data yang ada pada model ini hanya digunakan untuk membuktikan dalam mendukung perkiraan yang telah diambil sebelumnya. Jadi model ini sepenuhnya tergantung pada kemampuan user untuk melakukan analisa terhadap permasalahan yang ingin digali dan diperoleh informasinya.
2. Discovery Model
Model ini berbeda dengan verification model, dimana pada model ini system secara langsung menemukan informasi-informasi penting yang tersembunyi dalam suatu data yang besar. Data-data yang ada kemudian
dipilih untuk menemukan suatu pola, trend yang ada, dan keadaan umum pada saat itu tanpa adanya campur tangan dan tuntunan dari pengguna. Hasil temuan ini menyatakan fakta-fakta yang ada dalam data-data yang ditemukan dalam waktu yang sesingkat mungkin. Sebagai contoh, misalkan sebuah bank ingin menemukan kelompok-kelompok pelanggan yang dapat dijadikan target suatu produk yang akan dikeluarkan.
Pada data-data yang ada selanjutnya diadakan proses pencarian tanpa adanya proses perkiraan sebelumnya. Sampai akhirnya seluruh pelanggan dikelompokkan berdasarkan karakteristik yang sama.
2.1.4 Tahap-Tahap Data Mining
Data mining dapat dibagi menjadi beberapa tahap yang dapat dilihat pada
Gambar 2.1. Tahap-tahap tersebut bersifat interaktif, user terlibat langsung dalam proses pencarian KDD (Knowladge Discovery in Database).
Gambar 2.1 Data mining sebagai suatu kegiatan mengekstrasi atau menambah
Secara umum proses atau langkah-langkah KDD untuk melakukan data
mining adalah sebagai berikut:
1. Pembersihan Data (Data Cleaning)
Pada umumnya data yang diperoleh, baik dari database suatu perusahaan maupun hasil eksperimen, memiliki isian-isian yang tidak sempurna seperti data yang hilang, data yang tidak valid atau juga hanya sekedar salah ketik. Selain itu, ada juga atribut-atribut data yang tidak relevan dengan hipotesa data mining yang kita miliki. Data-data yang tidak relevan itu juga lebih baik dibuang karena keberadaannya dapat mengurangi tingkat mutu atau akurasi dari hasil data mining nantinya.
Garbage in garbage out (hanya sampah yang akan dihasilkan bila yang
dimasukkan juga sampah), merupkan istilah yang sering dipakai untuk menggambarkan tahap ini. Pembersihan data juga akan mempengaruhi performasi dari sistem data mining karena data yang ditangani akan berkurang jumlah dan kompleksitasnya.
2. Integrasi Data (Data Integration)
Tidak jarang data yang diperlukan untuk data mining tidak hanya berasal dari satu database tetapi juga berasal dari beberapa database atau
file teks. Integrasi data dilakukan pada atribut-atribut yang mengidentifikasi entitas-entitas yang unik seperti atribut nama, jenis produk, nomor pelanggan, dsb. Integrasi data perlu dilakukan secara cermat karena kesalahan pada integrasi data dapat menghasilkan hasil yang menyimpang dan bahkan menyesatkan pengambilan aksi nantinya.
Sebagai contoh bila integrasi data berdasarkan jenis produk ternyata menggabungkan produk dari kategori yang berbeda maka akan didapatkan korelasi antar produk yang sebenarnya tidak ada. Dalam integrasi data ini juga perlu dilakukan transformasi dan pembersihan data karena seringkali data dari dua database berbeda tidak sama cara penulisannya atau bahkan data yang ada di satu database ternyata tidak ada di database lainnya.
3. Transformasi Data (Data Transformation)
Beberapa teknik data mining membutuhkan format data yang khusus sebelum bisa diaplikasikan. Sebagai contoh beberapa teknik standar seperti analisis asosiasi dan klastering hanya bisa menerima input data kategorikal. Karenanya data berupa angka numerik yang berlanjut perlu dibagi-bagi menjadi beberapa interval. Proses ini sering disebut binning. Disini juga dilakukan pemilihan data yang diperlukan oleh teknik data
mining yang dipakai. Transformasi dan pemilihan data ini juga
menentukan kualitas dari hasil data mining nantinya karena ada beberapa karakteristik dari teknik-teknik data mining tertentu yang tergantung pada tahapan ini.
4. Aplikasi Teknik Data Mining
Aplikasi teknik data mining sendiri hanya merupakan salah satu bagian dari proses data mining. Ada beberapa teknik data mining yang sudah umum dipakai. Kita akan membahas lebih jauh mengenai teknik-teknik yang ada di seksi berikutnya. Perlu diperhatikan bahwa ada kalanya
teknik-teknik data mining umum yang tersedia di pasar tidak mencukupi untuk melaksanakan data mining di bidang tertentu atau untuk data tertentu. Sebagai contoh akhir-akhir ini dikembangkan berbagai teknik
data mining baru untuk penerapan di bidang bioinformatika seperti analisa
hasil micro array untuk mengidentifikasi DNA dan fungsi- fungsinya.
5. Evaluasi Pola yang Ditemukan
Dalam tahap ini hasil dari teknik data mining berupa pola-pola yang khas maupun model prediksi dievaluasi untuk menilai apakah hipotesa yang ada memang tercapai. Bila ternyata hasil yang diperoleh tidak sesuai hipotesa ada beberapa alternatif yang dapat diambil seperti menjadikannya umpan balik untuk memperbaiki proses data mining, mencoba teknik data
mining lain yang lebih sesuai, atau menerima hasil ini sebagai suatu hasil
yang di luar dugaan yang mungkin bermanfaat. Terdapat beberapa teknik
data mining yang menghasilkan hasil analisa berjumlah besar seperti
analisis asosiasi. Visualisasi hasil analisa akan sangat membantu untuk memudahkan pemahaman dari hasil data mining.
6. Presentasi Pola yang Ditemukan Untuk Menghasilkan Aksi
Tahap terakhir dari proses data mining adalah bagaimana memformulasikan keputusan atau aksi dari hasil analisa yang didapat. Ada kalanya hal ini harus melibatkan orang-orang yang tidak memahami data mining. Karenanya presentasi hasil data mining dalam bentuk pengetahuan yang bisa dipahami semua orang adalah satu tahapan yang
diperlukan dalam proses data mining. Dalam presentasi ini, visualisasi juga bisa membantu mengkomunikasikan hasil data mining.
Pada dasarnya penggalian data dibedakan menjadi dua fungsionalitas, yaitu deskripsi dan prediksi. Berikut ini beberapa fungsionalitas penggalian data yang sering digunakan:
1. Karakterisasi dan Diskriminasi, yaitu menggeneralisasi, merangkum, dan mengkontraskan karakteristik data.
2. Penggalian pola berulang, yaitu pencarian pola asosiasi (association
rule) atau pola intra-transaksi, atau pola pembelian yang terjadi dalam
satu kali transaksi.
3. Klasifikasi, yaitu membangun suatu model yang bisa mengklasifikasikan suatu objek berdasar atribut-atributnya. Kelas target sudah tersedia dalam data sebelumnya, sehingga fokusnya adalah bagaimana mempelajari data yang ada agar klasifikator bisa mengklasifikasikan sendiri.
4. Prediksi, yaitu memprediksi nilai yang tidak diketahui atau nilai yang hilang, menggunakan model dari klasifikasi.
5. Penggugusan (Cluster Analysis), yaitu mengelompokkan sekumpulan objek data berdasarkan kemiripannya. Kelas target tidak tersedia dalam data sebelumnya, sehingga fokusnya adalah memaksimalkan kemiripan intrakelas dan meminimalkan kemiripan antarkelas.
6. Analisis Outlier, yaitu proses pengenalan data yang tidak sesuai dengan perilaku umum dari data lainnya. Contoh: mengenali noise dan pengecualian dalam data.
7. Analisis trend dan evolusi: meliputi analisis regresi, penggalian pola sekuensial, analisis periodisitas, dan analisis berbasis kemiripan.
2.2 Disiplin Ilmu Dalam Menentukan Posisi Data Mining
Data mining mulai diteliti lebih jauh oleh parah ahli untuk menentukan
posisi bidang data mining diantara bidang-bidang yang lainnya. Kesamaan data
mining dengan bidang yang lainnya bisa saja terjadi karena adanya kesamaan
karakteristik pada setiap bidang yang dikaji. Diantaranya seperti perbandingan bidang data mining dengan bidang statistik terdapat kesamaan seperti penyampelan, estimasi, serta pengujian hipotesis. Terdapat kesamaan-kesamaan yang lainnya yang berhubungan dengan kecerdasan buatan (artificial
intelligence), pengenalan pola (pattern recognition), dan pembelajaran mesin
(machine learning), yaitu termasuk ke dalam algoritma pencarian, teknik pemodelan dan teori pembelajaran. Karakteristik-karakteristik tersebut memiliki kesamaan yang dapat di lihat pada Gambar 2.2.
2.3 Perbedaan Data Mining Dengan Data Warehouse
Data mining adalah bidang yang sepenuhnya menggunakan apa yang
dihasilkan oleh data warehouse, bersama dengan bidang yang menangani masalah pelaporan dan manajemen data. Sementara, data warehouse sendiri bertugas untuk menarik atau melakukan proses query data dari basis data mentah untuk memberikan hasil data yang nantinya dapat digunakan oleh bidang yang menangani manajemen, pelaporan, dan data mining.
Maka dari itu data mining sangat berguna untuk melakukan penggalian informasi baru yang dapat dilakukan dengan bekal data mentah yang diberikan oleh data warehouse. Hasil yang diberikan oleh bidang manajemen, pelaporan, dan data mining berguna untuk mendukung aktivitas bisnis cerdas (business
intelligence). Lebih jelasnya dapat dilihat pada Gambar 2.3.
BUSINESS INTELLIGENCE
PERFORMANCE MANAGEMENT
ENTERPRISE
REPORTING DATA MINING
DATA WAREHOUSE
EXTRACT, TRANSFORM, LOAD
TRANSACTIONAL DATABASE
2.4 Association Rule
Association Rule adalah salah satu teknik utama atau prosedur
dalam Market Basket Analysis untuk mencari hubungan antat item dalam suatu data set dan menampilkan dalam bentuk association rule (Budhi dkk, 2007). Association rule (aturan asosiatif) akan menemukan pola tertentu yang mengasosiasikan data yang satu dengan data yang lain. Untuk mencari association
rule dari suatu kumpulan data, tahap pertama yang harus dilakukan adalah
mencari frequent itemset terlebih dahulu. Frequent itemset adalah sekumpulan item yang sering muncul secara bersamaan. Setelah semua pola frequent
itemset ditemukan, barulah mencari aturan asosiatif atau aturan keterkaitan yang
memenuhi syarat yang telah ditentukan.
Jika diasumsikan bahwa barang yang dijual di swalayan adalah semesta, maka setiap barang akan memiliki bolean variabel yang akan menunjukkan keberadaannya atau tidak barang tersebut dalam satu transaksi atau satu keranjang belanja. Pola bolean yang didapat dugunakan untuk menganalisa barang yang sering dibeli secara bersamaan. Pola tersebut dapat dirumuskan dalam sebuah association rule. Sebagai contoh konsumen biasanya akan membeli kopi dan susu yang ditunjukkan sebagai berikut:
Kopi Susu [support =2%, confidence=60%]
Association rule diperlukan suatu variable ukuran yang ditentukan sendiri
oleh user untuk menentukan batasan sejauh mana atau sebanyak apa output yang diinginkan user.
Support dan confidence adalah sebuah ukuran kepercayaan dan kegunaan
suatu pola yang telah ditemukan. Nilai support 2% menunjukkan bahwa keseluruhan dari total transaksi konsumen membeli kopi dan susu secara bersamaan yaitu sebanyak 2%, Sedangkan confidence 60%, yaitu menunjukkan bila konsumen membeli kopi dan pasti membeli susu sebesar 60%.
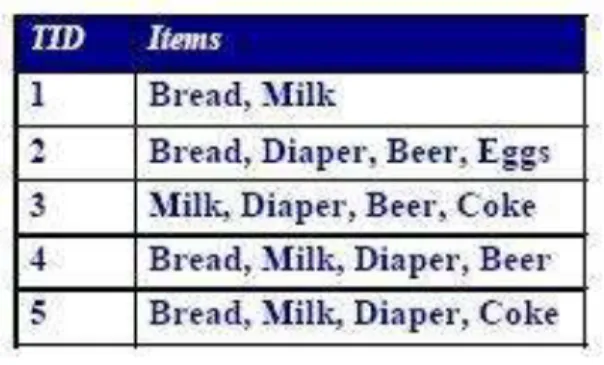
Contoh klasik lain yang sering digunakan untuk menjelaskan Association Rule Mining adalah market basket analysis. Pada market basket analysis, kita menganalisa kebiasaan customer dalam membeli barang. Misalkan terdapat data transaksi seperti Gambar 2.4.
Gambar 2.4 Transaksi data mining.
Contoh pengetahuan yang dapat diperoleh dari data di atas adalah {Beer} {Diaper}, artinya orang yang beli beer biasanya beli diaper juga. Lebih jauh,
association rule menjelaskan hubungan korelasi antar item dengan lebih jelas,
tidak hanya korelasi atau korelasi lemah saja. Hal ini karena adanya beberapa metric yang digunakan untuk evaluasi rule.
a. Frequent Itemset Generation
Tujuannya untuk mencari seluruh itemset yang memenuhi ambang batas atau minimum support. Itemset ini disebut frequent itemset (itemset yang sering muncul). Nilai support ini dapat diperoleh dengan Rumus 2.1.
( ) …….. (2.1) (Rumus mencari nilai support [2]).
b. Rule Generation
Tujuannya adalah untuk mencari pola atau aturan dengan confidence tinggi dari frequent itemset yang ditemukan dalam langkah itemset
generation. Aturan ini kemudian disebut dengan aturan yang kuat (strong rule). Nilai confidence ini dapat diperoleh dengan Rumus 2.2.
( )
( )
(Rumus mencari nilai confidence [2])
Rumus 2.2 menjelaskan bahwa untuk mencari nilai confidence itemset A, B yaitu dengan membagi jumlah transaksi yang mengandung item A dan B dengan seluruh transaksi yang mengandung item A.
Ketersediaan database mengenai catatan tranksaksi pembelian para pelanggan suatu supermarket atau tempat lain, telah mendorong pengembangan teknik-teknik yang secara otomatis menemukan asosiasi produk atau item-item yang tersimpan dalam database tersebut. Sebagai contoh adalah data mengenai transaksi yang terkumpul dari scanner
barcode dalam supermarket. Database transaksi ini seperti ini mengandung
record dalam jumlah sangat besar. Setiap record mendaftar semua item yang dibeli oleh seorang pelanggan dalam suatu transaksi pembelian.
Para manajer ingin tahu apakah suatu kelompok item selalu dibeli secara bersama-sama. Para manajer bisa menggunakan informasi tersebut untuk membuat layout supermarket sehingga penyusunan item-item tersebut bisa optimal satu sama lain. Aturan asosiasi ingin memberikan informasi tersebut dalam bentuk hubungan ‘if-then’, ‘jika-maka’, atau ‘If
antecendent, then consequent’.
Aturan ini dihitung dari data yang sifatnya probabilistik. Dalam sistem rekomendasi seperti yang diterapkan oleh toko buku online Amazon.com, ketika seseorang melihat suatu item, akan direkomendasikan untuk membeli item yang lain yang biasanya dibeli oleh pelanggan lain secara bersama-sama. Misalnya seseorang sedang memeriksa atau melihat CD tentang lagu Deep Purple pada websitenya Amazon.com, maka akan ditunjukan juga CD musik lain yang biasanya secara bersama dibeli, misalnya CD musik Rainbow, Led Zeppelin, Genesis dan lain-lain [5].
2.5 Frequent Pattern Tree (FP-Tree)
FP-Tree adalah struktur penyimpanan data yang dipadatkan. FP-Tree
dibangun dengan memetakan setiap data transaksi ke dalam setiap lintasan tertentu dalam FP-Tree. Karena dalam setiap transaksi yang dipetakan mungkin ada yang memiliki item yang sama, maka lintasannya memungkinkan untuk
saling menimpa, semakin banyak data transaksi yang mempunyai item yang sama, maka proses pemadatan dengan FP-Tree akan semakin efektif.
FP-Tree hanya memerlukan dua kali proses scanning atau penelusuran database untuk menemukan frequent itemsets (Bharat dalam Suprasetyo, 2012).
Penelusuran pertama untuk menghitung nilai support masing-masing item dan menyeleksi item yang memenuhi minimum support. Sedangkan penelusuran kedua untuk membentuk frequent itemsets dengan membaca FP-Tree yang diawali dengan membaca lintasan yang memiliki item dengan nilai frequensi paling kecil.
Gambar 2.5 FP-Tree [6].
2.6 Algoritma Frequent Pattern Growth
Algoritma FP-Growth (Frequent Pattern Growth). Algoritma ini merupakan perluasan dari algoritma apriori yang telah ada sebelumnya, oleh karena setiap melakukan kombinasi item apriori akan menscan database berulang kali menyebabkan banyaknya waktu yang dibutuhkan untuk melakukan scanning
dibutuhkan generate candidate yang besar untuk mendapatkan kombinasi item dari database. FP-Growth hadir untuk menyelesaikan masalah tersebut, karena algoritma ini hanya melakukan dua kali proses scanning database untuk menentukan frequent itemset dan juga tidak membutuhkan generate
candidate seperti yang ada di apriori.
Algoritma FP-Growth dapat menentukan frequent itemset tanpa perlu melakukan candidate generation. Growth menggunakan struktur data
FP-Tree. Dengan menggunakan cara ini scan database hanya dilakukan sebanyak dua
kali, tidak perlu berulang-ulang. Data akan direpresentasikan dalam bentuk
FP-Tree.
Setelah FP-Tree terbentuk, digunakan pendekatan divide and conquer untuk memperoleh frequent itemset. FP-Tree merupakan struktur data yang baik sekali untuk frequent pattern mining. Struktur ini memberikan informasi yang lengkap untuk membentuk frequent pattern. Item-item yang tidak frequent (tidak sering muncul) sudah tidak ada lagi dalam FP-Tree.
Sebagai gantinya FP-Growth menggunakan konsep
pembangunan tree disebut dengan FP-Tree dalam pencarian frequent itemset, sehingga pemrosesan pun lebih cepat karena frequent itemset dapat langsung diekstrak dari hasil tree tadi [7].
2.7 Divide and Conquer
Divide and Conquer memiliki peranan penting untuk memecahkan suatu
masalah yang besar menjadi beberapa bagian kecil sehingga dapat lebih mudah untuk dipecahkan. Terdapat metode pada divide and conquer yang akan dijelaskan di bawah ini:
a. Divide
Membagi masalah menjadi beberapa sub-masalah yang memiliki kemiripan dengan masalah semula namun berukuran lebih kecil.
b. Conquer
Memecahkan atau menyelesaikan masing-masing sub-masalah secara rekursif.
c. Combine
Menggabungkan solusi masing-masing sub-masalah sehingga membentuk solusi masalah semula.
Proses Divide and Conquer dapat dilihat pada Gambar 2.6.
2.8 State Of The Art
Dalam penelitian teknik penggalian data atau sering dikenal dengan data
mining ini telah dilakukan sebelumnya namun dengan pembahasan yang berbeda,
diantaranya yaitu pada jurnal Widodo [9], di dalam jurnal tersebut dijelaskan bahwa mencari informasi dalam data akademik berupa data mahasiswa yang telah mengambil mata kuliah pilihan pada angkatan sebelumnya untuk mencari pola yang terdapat di dalamnya dengan menerapkan metode aturan asosiasi, dan aplikasi tersebut dibangun menggunakan teknologi Java. Support dan Confidence menjadi hasil akhir dari keputusan dalam pengambilan mata kuliah pilihan yang akan disajikan.
Lalu dengan referensi artikel ataupun jurnal yang lainnya seperti jurnal yang dibuat oleh Ridwan [10], di dalam jurnal tersebut dijelaskan bahwa aplikasi yang dapat menampilkan informasi yang dapat digunakan untuk mengklasifikasikan kinerja akademik mahasiswa. Data yang diambil pada penelitian peneliti tersebut menggunakan data training, data target, dan data riwayat mata kuliah (data akademik) menggunakan metode Naïve Bayes Classifier dan didukung dengan teknologi PHP dan MySQL dalam pembangunan aplikasi
data mining tersebut. Proses import data training akan menjadi keputusan dalam
perhitungan nilai dari precision, recall, dan accuracy dengan confusion matrix lalu dapat memilih algoritma yang diinginkan seperti (NBC) dan (C4.5).
Lalu terdapat jurnal lainnya yang dibuat oleh Mardiani [11], pada jurnal tersebut dijelaskan bahwa hasil yang diperoleh berupa perancangan skema bintang dari data warehouse dan memberikan informasi tentang nilai-nilai mahasiswa dari
yang tertinggi sampai yang terendah. Penerapan metode pada aplikasi mining menggunakan metode asosiasi dan clustering data mining dan didukung dengan teknologi SQL Server 2008 Integration Service dan bahasa pemrograman Java. Aplikasi tersebut menyediakan layanan berupa Mining Model Viewer Cluster, yaitu untuk memberikan informasi berupa gambaran kategori berupa pengelompokan, dimana setiap kelompok memiliki perbedaan dengan anggota kelompok lainnya yang berfungsi dalam proses Itemsets Association, seperti mencari support, size, dan itemset untuk diasosiasikan.
Pada penelitian ini terdapat penelitian yang saling berkaitan dengan judul yang diangkat dan dapat dilihat pada Tabel 2.1.
Tabel 2.1 Tabel state of the art.
No Peneliti Metode Data Teknologi
1. Ridwan (2013) Algoritma Naïve Bayes Classifier. Data Akademik: 1. Data target
2. Data training dan data
testing
3. Data riwayat mata kuliah PHP dan MySQL. 2. Mardiani (2013) Asosiasi dan Clustering Data Mining. Data Akademik:
1. Data mahasiswa baru 2. Data nilai mahasiswa
SQL Server 2008 Integration Service dan Java. 3. Widodo (2008) Association Rule. Data Akademik:
1.9 Data mahasiswa yang sudah lulus selama beberapa tahun ke belakang
SQL Manager dan Java.
2.9 Unified Modelling Language (UML)
UML (Unified Model Language) adalah sebuah bahasa untuk menentukan visualisasi, kontruksi, dan mendokumentasikan artifact (bagian dari informasi yang digunakan atau dihasilkan dalam suatu proses pembuatan perangkat lunak. Artifact dapat berupa model, deskripsi atau perangkat lunak) dari sistem perangkat lunak, seperti pada pemodelan bisnis dan sistem non perangkat lunak (software) lainnya. UML merupakan suatu kumpulan teknik terbaik yang telah terbukti sukses dalam memodelkan system yang besar dan kompleks. UML tidak hanya digunakan dalam proses pemodelan perangkat lunak, namun hampir dalam semua bidang yang membutuhkan pemodelan dan UML merupakan standar dasar dalam bidang analisis dan desain berorientasi, dapat dilihat pada Gambar 2.7.
Gambar 2.7 Unifikasi berbagai metode UML [12].
2.9.1 Bagian-Bagian UML (Unified Model Language) a. View
View digunakan untuk melihat sistem yang dimodelkan dari beberapa
aspek yang berbeda. View bukan melihat grafik, tapi merupakan suatu abstraksi yang berisi sejumlah diagram. Beberapa jenis view dalam UML antara lain: use case view, logical view, component view, concurrency
view, dan deployment view.
b. Use Case View
Mendeskripsikan fungsionalitas sistem yang seharusnya dilakukan sesuai yang diinginkan external actors. Actor yang berinteraksi dengan sistem dapat berupa user atau sistem lainnya. View ini digambarkan dalam use-case diagram dan kadang-kadang dengan activity
diagram. View ini digunakan terutama untuk pelanggan, perancang
(designer), pengembang (developer), dan penguji sistem (tester). c. Logical View
Mendeskripsikan bagaimana fungsionalitas dari sistem, struktur statis (class, object, dan relationship) serta kolaborasi dinamis yang terjadi ketika object mengirim pesan ke object lain dalam suatu fungsi tertentu.
View ini digambarkan dalam class diagrams untuk struktur statis dan
dalam state, sequence, collaboration, dan activity diagram untuk model dinamisnya. View ini digunakan untuk perancang (designer) dan pengembang (developer).
d. Component View
Mendeskripsikan implementasi dan ketergantungan modul. Komponen yang merupakan tipe lainnya dari code module diperlihatkan dengan struktur dan ketergantungannya juga alokasi sumber daya komponen dan informasi administrative lainnya. View ini digambarkan dalam component
view dan digunakan untuk pengembang (developer).
e. Concurrency View
Membagi sistem ke dalam proses dan prosesor. View ini digambarkan dalam diagram dinamis (state, sequence, collaboration, dan activity
diagrams) dan diagram implementasi (component dan deployment diagrams) serta digunakan untuk pengembang (developer), pengintegrasi
(integrator), dan penguji (tester). f. Deployment View
Mendeskripsikan fisik dari sistem seperti komputer dan perangkat (nodes) dan bagaimana hubungannya dengan lainnya. View ini
digambarkan dalam deployment diagramsdan digunakan untuk pengembang (developer), pengintegrasi (integrator), dan penguji (tester). g. Diagram
Diagram berbentuk grafik yang menunjukkan simbol elemen model
yang disusun untuk mengilustrasikan bagian atau aspek tertentu dari sistem. Sebuah diagram merupakan bagian dari suatu view tertentu dan ketika digambarkan biasanya dialokasikan untuk view tertentu. Adapun jenis diagram dalam UML antara lain:
1. Use Case Diagram (Statis)
Use case adalah abstraksi dari interaksi antara sistem dan actor. Use-case bekerja dengan cara mendeskripsikan tipe interaksi antara user sebuah sistem dengan sistemnya sendiri melalui sebuah cerita
bagaimana sebuah system dipakai. Use-case merupakan konstruksi untuk mendeskripsikan bagaimana system akan terlihat di mata user. Sedangkan use case diagram memfasilitasi komunikasi diantara analis dan pengguna serta antara analis dan client.
2. Class Diagram (Statis)
Class adalah dekripsi kelompok obyek-obyek dengan property,
perilaku (operasi) dan relasi yang sama. Sehingga dengan adanya class diagram dapat memberikan pandangan global atas sebuah system. Hal tersebut tercermin dari class-class yang ada dan relasinya satu dengan yang lainnya. Sebuah sistem biasanya mempunyai beberapa class
diagram. Class diagram sangat membantu dalam visualisasi struktur
kelas dari suatu sistem.
3. Component Diagram (Statis)
Component software merupakan bagian fisik dari sebuah sistem,
karena menetap di komputer tidak berada di benak para analis. Komponent merupakan implementasi software dari sebuah atau lebih
class. Komponen dapat berupa source code, komponent biner,
atau executable component. Sebuah komponen berisi informasi tentang
pemetaan dari logical view ke component view. Sehingga component
diagram merepresentasikan dunia nyata, yaitu component software
yang mengandung component, interface dan relationship. 4. Deployment Diagram (Statis)
Menggambarkan tata letak sebuah system secara fisik, menampakkan bagian software yang berjalan pada bagian-bagian hardware, menunjukkan hubungan komputer dengan perangkat (nodes) satu sama lain dan jenis hubungannya. Di dalam nodes,
executeable component dan objek yang dialokasikan untuk memperlihatkan unit perangkat lunak yang dieksekusi oleh node tertentu dan ketergantungan komponen.
5. State Diagram (Dinamis)
Menggambarkan semua state (kondisi) yang dimiliki oleh
suatu objek dari suatu class dan keadaan yang
menyebabkan state berubah. Kejadian dapat berupa object lain yang mengirim pesan. State class tidak digambarkan untuk semua class, hanya yang mempunyai sejumlah state yang terdefinisi dengan baik dan kondisi class berubah oleh state yang berbeda.
6. Sequence Diagram (Dinamis)
Sequence Diagram digunakan untuk menggambarkan perilaku
pada sebuah skenario. Kegunaannya untuk menunjukkan rangkaian pesan yang dikirim antara objek juga interaksi antara objek, sesuatu yang terjadi pada titik tertentu dalam eksekusi sistem.
7. Collaboration Diagram (Dinamis)
Menggambarkan kolaborasi dinamis seperti sequence diagram. Dalam menunjukkan pertukaran pesan, collaboration
diagrams menggambarkan objek dan hubungannya (mengacu ke konteks). Jika penekannya pada waktu atau urutan gunakan sequence
diagrams, tapi jika penekanannya pada konteks gunakan collaboration
diagram.
8. Object Diagram (Statis)
Diagram ini meperlihatkan objek-objek serta relasi-relasi antar objek. Diagram objek memperlihatkan instansi statis dari segala sesuatu yang ditemui dari pada diagram kelas.
9. Activity Diagram (Dinamis)
Menggambarkan rangkaian aliran dari aktivitas, digunakan untuk mendeskripsikan aktifitas yang dibentuk dalam suatu operasi sehingga dapat juga digunakan untuk aktifitas lainnya seperti use caseatau interaksi.
2.9.2 Notasi Dalam UML
Di dalam UML terdapat macam-macam notasi UML yang berfungsi untuk memberikan gambaran mengenai proses dalam pembangunan sistem yang terdiri dari beberapa komponen, yaitu:
a. Use Case Diagram
Berikut di bawah ini merupakan simbol-simbol yang digunakan pada notasi UML (Use Case Diagram):
1. Actor
Actor adalah perwakilan dari orang luar, proses atau hal yang
berinteraksi dengan sistem, subsistem ataupun class. Tiap actor berpartisipasi dengan satu atau lebih use-case. Actor berpartisipas
use-case dengan pertukaran pesan. Actor dapat digambarkan
seperti Gambar 2.8.
Gambar 2.8 Notasi Actor.
2. Use Case
Use Case merupakan lingkupan sistem yang mengidentifikasikan
hal-hal yang seharusnya dilakukan oleh sistem. Use-case berguna untuk menggambarkan suatu kelakuan dari sistem tanpa mengungkapkan struktur internal dari sistem tersebut. Use-case merupakan sebuah pekerjaan tertentu, misalnya login ke sistem, membuat sebuah daftar belanja, dan yang lainnya.
Gambar 2.9 Notasi Use Case. 3. Relationship
Relatioship berguna untuk menggambarkan hubungan antar aktor dan use case dalam sistem. Di dalam diagram use case ada beberapa bentuk relationship, yaitu:
a) Association
Association, berfungsi sebagai jalur komunikasi antar actor
dengan use case yang saling berpartisipasi. Association dapat dinotasikan dengan gambar garis lurus, seperti gambar berikut:
Gambar 2.10 Notasi Associaton.
b) External
External, berfungsi untuk menambahkan kelakuan tambahan ke
dalam use case dasar yang tidak tahu menahu tentang hal tersebut.
Relationship dapat digambarkan dengan notasi berikut:
c) Use Case Generalization
Use case Generalization, menggambarkan hubungan antara use case umum dengan use case yang lebih spesifik yang mewarisi dan
menambah fitur terhadapnya. Relationship jenis akan digambarkan dalam bentuk notasi seperti berikut ini:
Gambar 2.12 Notasi Generalization.
d) Include
Include merupakan penambahan kelakuan tambahan ke dalam
use case dasar yang secara eksplisit menjelaskan penambahannya.
Gambar 2.13 Notasi Extend.
b. Activity Diagram
Berikut di bawah ini adalah notasi-notasi yang terdapat dan digunakan pada pembuatan activity diagram.
1. Swimlanes
Menunjukkan siapa yang bertanggung jawab melakukan aktivitas dalam suatu diagram.
Gambar 2.14 Notasi Swimlane.
2. Activity
Merupakan kegiatan dalam aliran kerja dan menggambarkan suatu kegiatan atau pekerjaan dalam workflow.
Gambar 2.15 Notasi Activity.
3. Start State
Menunjukkan dimana aliran kerja itu akan dimulai, hanya ada satu
start state dalam sebuah workflow.
Gambar 2.16 Notasi Start State.
4. End State
Menunjukkan dimana aliran kerja itu berakhir. Dapat lebih dari satu end state pada suatu activity diagram.
5. Decision Point
Menunjukkan dimana sebuah keputusan perlu dibuat dalam aliran kerja yang memungkinkan adanya perbedaan transisi pada activity
diagram.
Gambar 2.18 Notasi Decision Point.
6. State Transition
Menunjukkan kegiatan selanjutnya setelah melakukan kegiatan sebelumnya.
Gambar 2.19 Notasi State Transition.
c. Sequence Diagram
Berikut di bawah ini adalah notasi-notasi yang digunakan dalam pembuatan sequence diagram.
1. Object
Menunjukkan objek yang terdapat dalam sequence diagram.
2. Object Message
Menunjukkan pesan yang disampaikan untuk objek lainnya dalam
sequence diagram.
Gambar 2.21 Notasi Object Message.
d. Class Diagram
Berikut di bawah ini merupakan notasi yang digunakan pada saat membuat class diagram.
1. Package
Package berfungsi sebagai sebuah container atau kemasan yang
dapat digunakan untuk mengelompokkan kelas-kelas sehingga memungkinkan beberapa kelas yang bernama sama disimpan dalam
package yang berbeda.
Gambar 2.22 Notasi Package.
2. Class
Class berfungsi sebagai sesuatu yang membungkus informasi dan
perilaku. Secara tradisional, sistem dibangun dengan ide dasar bahwa akan menyimpan informasi pada sisi baris data dan data perilaku pengolahnya pada sisi aplikasi.
Gambar 2.23 Notasi Class.
3. Interface
Interface berfungsi sebagai suatu sistem yang dirancang untuk
mengolah input dan output dari data.
Gambar 2.24 Notasi Interface.
2.10 Business Modelling
UML dapat digunakan untuk memodelkan berbagai jenis sistem, seperti sistem software, sistem hardware dan organisasi. Namun secara umum UML sekarang ini digunakan untuk dua kepentingan, yaitu:
a. Untuk membuat model dalam proses software development. b. Untuk memodelkan bisnis (business modelling).
2.10.1 Konsep Dasar Dalam Business Modelling
Dalam dunia bisnis dan industri terdapat banyak sistem manual dan otomatis yang muncul secara regular. Setiap sistem memiliki satu atau banyak
workflow. Business modelling menggambarkan seluruh workflow yang terjadi
suatu nilai objek yang dapat dilihat bagi satu pihak atau entitas tertentu. Business
modelling adalah sarana sebagai suatu teknik pemodelan yang digunakan untuk
menggambarkan model dalam suatu bisnis.
2.10.2 Elemen Dalam Business Modelling
a. Business Actor
Menggambarkan peran yang dimainkan oleh seseorang atau sesuatu yang dengannya bisnis berinteraksi.
b. Business Use-Case
Menggambarkan urutan tindakan yang dilakukan oleh suatu bisnis yang menghasilkan sebuah nilai yang dapat dilihat dan ditunjukkan untuk suatu business actor tertentu.
c. Business Worker
Menggambarkan sebuah peran atau himpunan dari beberapa peran dalam bisnis.
d. Business Entity
Menggambarkan benda yang ditangani atau digunakan oleh business
worker selama melakukan suatu business use-case.
e. Use-Case Realization
Menggambarkan bagaimana sebuah use-casei direlasikan dalam
2.11 Model Analisis
Model analisis merupakan suatu model yang menggambarkan realisasi dari use case-use case dalam use case model dan bertindak sebagai abstraksi dari model desain. Model analisis merupakan transisi ke dalam model desain dan kelas-kelas analisis secara langsung berkembang menjadi elemen-elemen model desain.
2.11.1 Kelas Dalam Model Analisis
1. Boundary
Kelas boundary merupakan kelas yang memodelkan interaksi antara satu atau lebih actor dengan sistem. Kelas ini dapat berupa:
a. User Interface
User interface merupakan sarana komunikasi antara sistem dengan user, misalnya jendela (windows).
b. System Interface
System interface merupakan sarana komunikasi antara sistem
dengan sistem informasi yang lainnya, misalnya communication
protocol.
c. Device Interface
Device interface merupakan sarana komunikasi antara sistem
dengan device (alat), misalnya printer.
2. Control
Digunakan untuk memodelkan “Perilaku Mengatur” khusus untuk satu atau beberapa use-case saja. Control Object mengkoordinasikan perilaku
sistem dan menggambarkan dinamika dari suatu sistem, menangani tugas utama, dan mengontrol alur kerja suatu sistem. Control object
menjalankan realisasi dari use-case tersebut. Tidak semua use
case memerlukan control object.
3. Entitiy
Kelas entity memodelkan informasi yang harus disimpan oleh sistem. Kelas ini memperlhatkan struktur data dari sebuah sistem. Entity
object biasanya bersifat pasif dan tetap. Tanggung jawab utama objek ini
adalah untuk menyimpan dan mengatur informasi dalam sistem.
2.12 Basis Data (Database)
Basis data atau database adalah kumpulan data yang disimpan secara sistematis di dalam komputer dan dapat diolah atau dimanipulasi menggunakan perangkat lunak (program aplikasi) untuk menghasilkan informasi. Pendefinisian basis data meliputi spesifikasi berupa tipe data, struktur, dan juga batasan-batasan data yang akan disimpan. Basis data merupakan aspek yang sangat penting dalam sistem informasi dimana basis data merupakan gudang penyimpanan data yang akan diolah lebih lanjut. Basis data menjadi penting karena dapat menghidari duplikasi data, hubungan antar data yang tidak jelas, organisasi data, dan juga
update yang rumit.
Proses memasukkan dan mengambil data ke dan dari media penyimpanan data memerlukan perangkat lunak yang disebut dengan sistem manajemen basis data (database management system | DBMS). DBMS merupakan sistem perangkat
lunak yang memungkinkan user untuk memelihara, mengontrol, dan mengakses data secara praktis dan efisien. Dengan kata lain semua akses ke basis data akan ditangani oleh DBMS. Ada beberapa fungsi yang harus ditangani DBMS yaitu mengolah pendefinisian data, dapat menangani permintaan pemakai untuk mengakses data, memeriksa sekuriti dan integriti data yang didefinisikan oleh DBA (Database Administrator), menangani kegagalan dalam pengaksesan data yang disebabkan oleh kerusakan sistem maupun disk, dan menangani unjuk kerja semua fungsi secara efisien.
Tujuan utama dari DBMS adalah untuk memberikan tinjauan abstrak data kepada user (pengguna). Jadi sistem menyembunyikan informasi tentang bagaimana data disimpan, dipelihara, dan tetap dapat diambil (akses) secara efisien. Pertimbangan efisien di sini adalah bagaimana merancang struktur data yang kompleks tetapi masih tetap bisa digunakan oleh pengguna awam tanpa mengetahui kompleksitas strukturnya.
2.12.1 Lingkungan Basis Data
Lingkungan basis data adalah sebuah habibtat dimana terdapat bisnis basis data untuk dijadikan suatu bisnis. Dalam lingkungan basis data, pengguna mempunya alat untuk mengakses data. Pengguna (user) melakukan semua tipe pekerjaan dan keperluan mereka yang bervariasi seperti menggali data (data
mining), memodifikasi data, atau berusaha membuat data baru. Masih dalam
lingkungan basis data, pengguna tertentu tidak diperbolehkan mengakses data, baik secara fisik maupun logis [13].
2.12.2 Jenis Basis Data
a. Basis Data Flat-File
Basis data flat-file ideal untuk data berukuran kecil dan dapat dirubah dengan mudah. Pada dasarnya, mereka tersusun dari sekumpulan string dalam satu atau lebih file yang dapat diurai untuk mendapatkan informasi yang disimpan. Basis data flat-file baik digunakan untuk menyimpan daftar atau data yang sederhana dan dalam jumlah kecil. Basis data flat-file akan menjadi sangat rumit apabila digunakan untuk menyimpan data dengan struktur kompleks walaupun dimungkinkan pula untuk menyimpan data semacam itu. Salah satu masalah menggunakan basis data jenis ini adalah rentan pada korupsi data karena tidak adanya penguncian yang melekat ketika data digunakan atau dimodifikasi.
d. Basis Data Relasional
Basis data ini mempunyai struktur yang lebih logis terkait cara penyimpanan. Kata "relasional" berasal dari kenyataan bahwa tabel-tabel yang berada di basis data dapat dihubungkan satu dengan lainnya. Basis data relasional menggunakan sekumpulan tabel dua dimensi yang masing-masing tabel tersusun atas baris (tupel) dan kolom (atribute). Untuk membuat hubungan antara dua atau lebih tabel, digunakan key (atribut kunci) yaitu primary key di salah satu tabel dan foreign key di tabel yang lain. Saat ini, basis data relasional menjadi pilihan karena keunggulannya. Beberapa kelemahan yang mungkin dirasakan untuk basis data jenis ini adalah implementasi yang lebih sulit untuk data dalam jumlah besar
dengan tingkat kompleksitasnya yang tinggi dan proses pencarian informasi yang lebih lambat karena perlu menghubungkan tabel-tabel terlebih dahulu apabila datanya tersebar di beberapa tabel.
2.13 ERD (Entity Relationship Diagram)
ERD merupakan salah satu model yang digunakan untuk mendesain
database dengan tujuan menggambarkan data yang berelasi pada sebuah database. Umumnya setelah perancangan ERD selesai berikutnya adalah
mendesain database secara fisik yaitu pembuatan tabel, index dengan tetap mempertimbangkan performa. Kemudian setelah database selesai dilanjutkan dengan merancang aplikasi yang melibatkan database. Komponen penyusun ERD adalah sebagai berikut:
Tabel 2.2 Tabel diagram entity.
Entitas adalah objek dalam dunia nyata yang dapat dibedakan dengan objek lain, sebagai contoh mahasiswa, dosen, departemen. Entitias terdiri atas
beberapa atribut sebagai contoh atribut dari entitas mahasiswa adalah nim, nama, alamat, email, dan lainnya. Atribut nim merupakan unik untuk mengidentifikasikan atau membedakan mahasiswa yang satu dengan yang lainnya. Pada setiap entitas harus memiliki satu atribut unik atau yang disebut dengan primary key. Relasi adalah hubungan antara beberapa entitas. sebagai contoh relasi antar mahaiswa dengan mata kuliah dimana setiap mahasiswa bisa mengambil beberapa mata kuliah dan setiap mata kuliah bisa diambil oleh lebih dari satu mahasiswa. relasi tersebut memiliki hubungan banyak ke banyak.
2.14 Kamus Data (Data Dictionary)
Kamus data (data dictionary) adalah suatu penjelasan tertulis tentang suatu data yang berada di dalam database. Kamus data pertama berbasis kamus dokumen tersimpan dalam suatu bentuk hard copy dengan mencatat semua penjelasan data dalam bentuk yang dicetak. Walau sejumlah kamus berbasis dokumen masih ada, praktik yang umum saat ini ialah mempergunakan kamus data yang berbasis komputer. Pada kamus data berbasis computer, penjelasan data dimasukkan ke dalam komputer dengan menggunakan Data Description
Language (DDL) dari sistem manajemen database, sistem kamus atau peralatan CASE. Kamus data tidak perlu dihubungkan dengan diagram arus data dan
2.14.1 Konsep Dasar Kamus Data
a. Pendefinisian Data Elemen dalam Kamus Data Kamus data mendefinisikan data elemen dengan cara:
1. Menguraikan arti dari alur data dan data store dalam DFD.
2. Menguraikan komposisi paket data pada alur data ke dalam alur yang lebih kecil.
Contoh:
Alamat langganan yang terdiri dari nama jalan, kota dan kode pos. 1. Menguraikan komposisi paket data dalam data store.
2. Menspesifikasikan nilai dan unit informasi dalam alur data dan
data store.
3. Menguraikan hubungan yang terinci antara data store dalam suatu ERD.
2.15 Struktur Tabel
Struktur tabel merupakan kolom-kolom yang terdapat pada tabel atau biasa disebut juga dengan atribut atau field. Untuk melihat struktur tabel dapat digunakan perintah sebagai berikut:
Perhatikan contoh berikut ini:
Gambar 2.26 Hasil dari perintah pada struktur tabel.
2.16 Microsoft Visual Studio 2010
Microsoft Visual Studio 2010 merupakan sebuah perangkat lunak lengkap
(suite) yang dapat digunakan untuk melakukan pengembangan aplikasi, baik itu aplikasi bisnis, aplikasi personal, ataupun komponen aplikasinya, dalam bentuk aplikasi console, aplikasi windows, ataupun aplikasi web. Visual studio mencakup
Compiler, SDK, Integrated Development Environment (IDE), dan dokumentasi
(umumnya berupa MSDN Library).
Microsoft Visual Studio 2010 dapat digunakan untuk mengembangkan
aplikasi dalam native code (dalam bentuk bahasa mesin yang berjalan di atas Windows) ataupun managed code (dalam bentuk Microsoft Intermediate
digunakan untuk mengembangkan aplikasi Silverlight, aplikasi Windows Mobile (yang berjalan di atas .NET Compact Framework).
2.16.1 Microsoft Visual Basic (.NET)
Microsoft Visual Basic.NET adalah sebuah alat untuk mengembangkan
dan membangun aplikasi yang bergerak di atas sistem .NET Framework, dengan menggunakan bahasa BASIC (Beginner’s All-purpose Symbolic Instruction Code) yang merupakan sebuah kelompok bahasa pemrograman tingkat tinggi. Secara harfiah, BASIC mempunya arti kode instruksi simbolis semua tujuan yang dapat digunakan oleh para pemula. Dengan menggunakan alat ini, para programmer data membangun aplikasi Windows Forms, Aplikasi web berbasis ASP.NET, dan juga aplikasi command-line. Alat ini dapat diperoleh secara terpisah dari beberapa produk lainnya (seperti Microsoft Visual C++, Visual C#, atau Visual J#), atau juga dapat diperoleh secara terpadu dalam Microsoft Visual Studio.NET.
Bahasa Visual Basic.NET sendiri menganut paradigma bahasa pemrograman berorientasi objek yang dapat dilihat sebagai evolusi dari Microsoft
Visual Basic versi sebelumnya yang diimplementasikan di atas .NET Framework.
Peluncurannya mengundang kontrversi, mengingat banyak sekali perubahan yang dilakukan oleh Microsoft, dan versi baru ini tidak kompatibel dengan versi terdahulu.
2.17 Dotnetbar
Dotnetbar merupakan sekumpulan toolbox (Add-on Visual Studio) yang
professional dengan mudah. Dotnetbar telah banyak membantu pengembang
aplikasi dalam membuat tampilan user interface, selama 9 tahun lebih telah membawa banyak perubahan terhadap software developer dalam mengembangkan
software nya.
2.18 Pengujian Black-Box
Pengujian Black-Box adalah cara pengujian dilaukan dengan hanya menjalankan atau mengeksekusi unit atau modul kemudian diamati apakah hasil dari unit tersebut sesuai dengan proses bisnis yang diinginkan. Dengan kata lain,
black-box merupakan user testing, biasanya pengujian perangkat lunak dengan
metode black-box melibatkan client atau pelanggan yang memesan perangkat lunak tersebut, dari sini dapat diketahui keiinginan client terhadap perangkat lunak tersebut, missal client ingin tampilannya diubah atau proses perjalanan perangkat lunak tersebut agar lebih dimengerti.
Kesalahan-kesalahan dalam pengujian black-box dapat dilihat pada kategori di bawah ini:
b. Fungsi-fungsi yang tidak benar atau hilang. c. Kesalahan interface.
d. Kesalahan dalam struktur data atau akses database eksternal. e. Kesalahan kinerja.
![Gambar 2.1 Data mining sebagai suatu kegiatan mengekstrasi atau menambah pengetahuan dari data yang berukuran besar [2]](https://thumb-ap.123doks.com/thumbv2/123dok/4076117.3040417/6.893.275.710.744.1068/gambar-data-mining-kegiatan-mengekstrasi-menambah-pengetahuan-berukuran.webp)
![Gambar 2.2 Posisi data mining diantara bidang ilmu lainnya [3].](https://thumb-ap.123doks.com/thumbv2/123dok/4076117.3040417/11.893.243.695.932.1063/gambar-posisi-data-mining-diantara-bidang-ilmu-lainnya.webp)
![Gambar 2.3 Perbedaan data mining dengan data warehouse [4].](https://thumb-ap.123doks.com/thumbv2/123dok/4076117.3040417/12.893.262.672.685.1061/gambar-perbedaan-data-mining-data-warehouse.webp)
![Gambar 2.5 FP-Tree [6].](https://thumb-ap.123doks.com/thumbv2/123dok/4076117.3040417/17.893.293.662.568.781/gambar-fp-tree.webp)
![Gambar 2.6 Proses divde and conquer [8].](https://thumb-ap.123doks.com/thumbv2/123dok/4076117.3040417/19.893.212.756.831.1088/gambar-proses-divde-and-conquer.webp)

![Gambar 2.7 Unifikasi berbagai metode UML [12].](https://thumb-ap.123doks.com/thumbv2/123dok/4076117.3040417/22.893.305.635.662.880/gambar-unifikasi-berbagai-metode-uml.webp)