PREDIKSI KELULUSAN MAHASISWA PADA PERGURUAN
TINGGI KABUPATEN MAJALENGKA BERBASIS
KNOWLEDGE BASED SYSTEM
Tri Ferga Prasetyo, Dony Susandi, Ida Siti WidianingrumTeknik Informatika, Teknik Industri, Teknik Informatika Fakultas Teknik - Universitas Majalengka Jl. K.H Abdul Halim No. 103 Majalengka 45418
Telp. (0233) 8187177
[email protected], [email protected], [email protected]
Abstrak
Salah satu faktor untuk menentukan kualitas pendidikan tinggi adalah kemampuan siswa untuk menyelesaikan studi tepat waktu. Perguruan tinggi perlu mendeteksi perilaku dari mahasiswa aktif sehingga dapat dilihat faktor kegagalan siswa yang lulus tidak berdasarkan waktu yang ditentukan. Teknik klasifikasi data mining yang digunakan untuk memprediksi lama studi mahasiswa yaitu menggunakan algoritma back propagation neural network dan k-nearest neighbor. Evaluasi hasil proses klasifikasi menggunakan k-fold cross validation dan confusion matrix. Pengujian dengan confusion matrix menggunakan algoritma k-nearest neighbor menghasilkan nilai akurasi tertinggi yang diperoleh dengan nilai jarak (k-100) terhadap data baru sebesar 97,90 %. Dalam memprediksi kelulusan, data mahasiswa digunakan sebagai knowledge based system dengan menentukan pola data mining. Analisis kelulusan mahasiswa yang dinyatakan lulus tepat waktu adalah 98 %. Sementara itu, 2 % mahasiswa tidak lulus tepat waktu, karena IPK rendah dan ketika mendaftar telah melebihi batas usia.
Kata Kunci: Prediksi, Klasifikasi Data Mining, K-Nearest Neighbor, Knowledge Based System, Confusion Matrix.
Abstract
One important factor to determine the quality of higher education is the ability of the students to complete studies on time. Universities need to detect the behavior of active students in order to see the failure factors of graduating students are not based
on the specified time. Classification of data mining technique are used to predict the the future of a student's study is using back propagation neural network algorithm and k-nearest neighbor. Evaluation results of the classification process are using k-fold cross validation and confusion matrix. Tests with the confusion matrix using k-nearest neighbor algorithm produces the highest accuracy values obtained with the value of the distance (k-100) to the new data by 97.90%. In predicting graduation, the student data is used as knowledge based system to determine the pattern of data mining. Analysis of students who passed the graduation on time is 98%. Meanwhile, 2% of students do not graduate on time, because the GPA is low and when the register has exceeded the age limit.
Keywords: Prediction, Classification Data Mining, K-Nearest Neighbor, Knowledge Based Systems, Confusion Matrix.
I. PENDAHULUAN
Perguruan tinggi merupakan satuan penyelenggara pendidikan akademik bagi mahasiswa. Data yang diperoleh dari Dirjen DIKTI (Direktorat Jendral Pendidikan Tinggi) Republik Indonesia menyebutkan bahwa jumlah lembaga penyelenggara perguruan tinggi sampai dengan tahun 2014 tercatat 4.256 perguruan tinggi diselenggarakan di Indonesia, yang terdiri dari akademik, sekolah tinggi, politeknik, institut dan universitas. Semakin bertambah jumlah perguruan tinggi maka semakin meningkat pula jumlah sumber daya manusia berkualitas yang dihasilkan perguruan tinggi. Salah satu faktor yang menentukan kualitas perguruan tinggi adalah
persentasi kemampuan mahasiswa untuk menyelesaikan studi tepat waktu (Khafiizh, 2012).
Data dari DIKTI (Direktorat Jendral Pendidikan Tinggi) Republik Indonesia menyebutkan bahwa jumlah mahasiswa S1 adalah sebanyak 3.647.515 mahasiswa aktif yang tercatat hingga tahun 2014. Oleh karena itu, Perguruan tinggi perlu mendeteksi perilaku mahasiswa yang memiliki status mahasiswa aktif sehingga dapat diketahui faktor-faktor penyebab kegagalan mahasiswa yang tidak lulus seuai dengan lama masa studi mahasiswa. Beberapa penyebab kegagalan mahasiswa yakni rendahnya kemampuan akademik, faktor pembiayaan, domisili saat menempuh studi dan faktor lainnya (Hastuti, K., 2012).
Database perguruan tinggi menyimpan data akademik, administrasi dan biodata mahasiswa. Data tersebut apabila dieksplorasi dengan tepat maka dapat diketahui pola atau pengetahuan untuk mengambil keputusan (El-Halees, A., 2009). Serangkaian proses mendapatkan pengetahuan atau pola dari kumpulan data disebut dengan data mining (Hall, M., Witten, I., & Frank, E., 2011).
Data mining berfungsi untuk menemukan hubungan yang berarti, pola, dan kecenderungan dengan memeriksa dalam sekumpulan besar data yang tersimpan dalam penyimpanan dengan menggunakan teknik pengenalan pola seperti teknik statistik dan matematika (Larose, D. T., 2005). Perguruan tinggi perlu melakukan prediksi perilaku mahasiswa untuk mencegah secara dini kegagalan akademik mahasiswa.
Penelitian ini dimaksudkan untuk memprediksi kelulusan mahasiswa diambil dari basis pengetahuan data mahasiswa. Basis pengetahuan tersebut adalah pola algoritma yang di hasilkan dari proses perbandingan algoritma backpropagation neural network dan algoritma k-nearest neighbor. Perbandingan akurasi dari kedua algoritma dilakukan dengan dibantu tool penunjang data mining, dan dapat memberikan rekomendasi dari penggunanaan kedua algoritma berdasarkan pendekatan kuantitatif.
II. KAJIANLITERATUR
Kajian literatur ini dijadikan sebagai bahan acuan membuat penelitian dari beberapa penelitian sebelumnya yang merupakan satu acuan tema yang sama.
1. Penelitian yang pernah dilakukan mengenai prediksi kelulusan masa studi sarjana yang dilakukan oleh Muhammad Hanief Meinanda dkk. (2009) yang melakukan penelitian pada mahasiswa Gemastik dengan menggunakan algoritma Artificial Neural Network & multiple regressions, yang tujuan menentukan kebijakan terhadap mahasiswa yang diprediksi memiliki masa studi melebihi batas;
2. Penelitian terdahulu tentang perbandingan performansi algoritma untuk prediksi kinerja akademik mahasiswa baru yang dilakukan oleh Arief Jananto (2010) dengan menggunakan data dari data akademik mahasiswa fakultas Teknologi Informasi di UNISBANK dengan membandingkan algoritma Nearest Neighbor dan SLIQ, tujuan penelitian ini adalah membangun sebuah aplikasi data mining sederhana, mengimplementasikan algoritma Nearest Neighbor dan membandingkan performansi dari aplikasi yang dibangun; 3. Khafiizh Hastusti (2012) melakukan analisis
komparasi algoritma data mining untuk memprediksi mahasiswa nonaktif. Algoritma yang dibandingkan adalah algoritma logistic regression, Decision Tree dan Neural Network sedangkan objek yang diteliti adalah mahasiswa program studi teknik informatika, sistem informasi dan komunikasi di Universitas Dian Nuswantoro Semarang dengan tujuan untuk mengetahui algoritma yang paling akurat untuk memprediksi kelulusan mahasiswa;
4. Penelitian yang dilakukan oleh Muhammad Syukri Mustafa dan I Wayan Simpen (2014) mengenai perancangan aplikasi kelulusan tepat waktu bagi mahasiswa baru di STMIK Dipanegara Makasar dengan menggunkan algoritma k-Nearest Neighbor dengan tujun untuk merancang suatu sistem yang dapat melakukan prediksi terhadap mahasiswa baru apakah berpeluang untuk menyelesaikan studi tepat waktu atau tidak.
III. METODEPENELITIAN
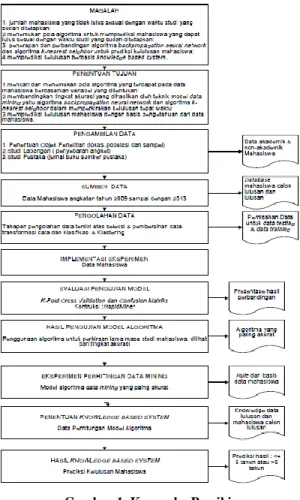
Gambar 1. Kerangka Pemikiran
III.1 Tujuan Penelitian
Tujuan pelaksanaan penelitian ini adalah:
1. Mencari dan menemukan pola algoritma yang yang terbaik dengan objek data mahasiswa berdasarkan beberapa variabel yang ditentukan dalam menentukan kelulusan tepat waktu;
2. Membandingkan hasil dari tingkat akurasi dan teknik atau model data mining yang terpilih dari dua algoritma;
3. Mendapatkan hasil prediksi kelulusan mahasiswa dengan basis pengetahuan dari data mahasiswa yang telah diolah dengan. III.2 Analisis Data Mining
Pada penelitian ini data mahasiswa dalam kondisi acak dan tidak semua data mahasiswa akan dicari hubungannya dengan data kelulusan, hanya beberapa atribut yang kira-kira berguna. Karena data yang terlalu acak akan membuat proses mining
memakan waktu lama. Data mahasiswa yang akan dicari hubungannya meliputi jenis kelamin, usia saat mendaftar, kota asal mahasiswa, jurusan asal sekolah, agama, IPK dan fakultas. Adapun yang akan diproses mining meliputi :
1. Hubungan tingkat kelulusan dengan jenis kelamin;
2. Hubungan tingkat kelulusan dengan jurusan asal sekolah;
3. Hubungan tingkat kelulusan dengan usia saat mendaftar;
4. Hubungan tingkat kelulusan dengan IPK; 5. Hubungan tingkat kelulusan dengan agama; 6. Hubungan tingkat kelulusan dengan kota asal
mahasiswa;
7. Hubungan tingkat kelulusan dengan fakultas; III.3 Data Yang Digunakan
Pada penulisan penelitian i n i mencari hubungan beberapa atribut dari data induk mahasiswa dengan tingkat kelulusan. Karena tidak semua tabel digunakan maka perlu dilakukan pembersihan data agar data yang akan diolah benar-benar relevan dengan yang dibutuhkan. Pembersihan ini penting guna meningkatkan performa dalam proses mining.
Setelah melalukan proses pembersihan data, didapatkan data lulusan dan data mahasiswa dengan tidak menampilkan data NPM (Nomor Pokok Mahasiswa) dan nama dari mahasiswa dengan alasan merupakan data pribadi
Dari jumlah sampel sebanyak 382 data yang terbagi atas data training dan data testing, dengan pembagian 75% sebagai data training dan 25% data testing. Jumlah data training sebanyak 286 data lulusan dan jumlah data testing sebanyak 96 data mahasiswa.
IV. ANALISISDANPERANCANGAN IV. 1 Pengujian Model Algoritma Data Mining
Dalam menyelesaikan penelitian tentang prediksi kelulusan mahasiswa perguruan tinggi kabupaten majalengka, model yang digunakan menggunakan k-nearest neighbor dan back propagation nueral network dengan 8 parameter yaitu 7 atribut dan 1 label yang terdiri dari jenis kelamin, kota asal, agama, IPK, Fakultas, jurusan asal sekolah dan label tepat wkatu dan tidak tepat waktu. Pengujian metode dilakukan dengan cara confusion matrix dan k-fold cross validation, untuk
menguji metode yang diuji menggunakan tools RapidMiner 5.3.
IV. 2 Pengujian Model Algoritma k-Nearest Neighbor
1. Proses Pengujian Model
Pengujian model k-nearest neighbor dengan menggunakan rapid miner akan menguji akurasi metode k-nearest neighbor, seberapa besar akurasi yang akan dihasilkan nantinya hasil pengujian akurasi akan dibandingkan dengan metode lainnya. Adapun langkah-langkah yang akan dilakukan dalam pengujian ini menggunakan performa untuk menghasilkan tingkat akurasi dan dari metode yang digunakan. Pengujian model k-nearest neighbor dengan menggunakan data training dan data testing seperti ditunjukan pada gambar 2.
Gambar 2. Proses Pengujian Algoritma K-Nearest
Neighbor 2. Hasil Running Pengujian Model
Setelah proses pengujian running, menghasilkan output accuracy dengan waktu yang ditempuh selama 2 detik.
Gambar 3. Accuracy K-Nearest Neighbor
Gambar 3 memberikan informasi bahwa hasil accuracy dari metode klasifikasi k-nearest neighbor adalah sebesar 97,90% ini menunjukan bahwa hasil akurasi yang diperoleh masuk dalam kategori sangat baik.
Ketelitian yang dihasilkan dari metode k-nearest neighbor yang diproses dengan rapidminer
menghasilkan tingkat presisi yang sangat baik dengan nilai precision sebesar 100,00% dan hasil recall k-nn yang diperoleh melalui proses validasi sebesar 25,00 % nilai ini meunjukkan bahwa hasil yang diperoleh adalah baik.
IV. 3 Pengujian Model Algoritma Backpropagation Neural Network
1. Proses Pengujian Model
Pengujian model backpropagation neural network dengan menggunakan rapid miner akan menguji akurasi metode backpropagation neural network, seberapa besar akurasi yang akan dihasilkan yang nantinya hasil pengujian akurasi akan dibandingkan dengan metode lainnya. Adapun langkah-langkah yang akan dilakukan dalam pengujian ini menggunakan k-fold cross validation untuk menghasilkan tingkat akurasi dan dari metode yang digunakan. Pengujian model backpropagation neural network dengan menggunakan data training seperti ditunjukan pada gambar 4.
Gambar 4 Proses Pengujian Algoritma Backpropagation
Neural Network 2. Hasil Running Pengujian Model
Setelah proses pengujian running, menghasilkan output accuracy dengan waktu yang ditempuh selama 2 menit 12 detik.
Gambar 5 Gambar Accuracy Backpropagation Neural
Network
Gambar 5 memberikan informasi bahwa hasil accuracy dari metode klasifikasi backpropagation neural network adalah sebesar 97,22% ini menunjukan bahwa hasil akurasi yang diperoleh masuk dalam kategori sangat baik.
Precision yang dihasilkan dari metode backpropagation neural network yang diproses dengan rapidminer menghasilkan presisi yang sangat baik dengan nilai precision sebesar 99,64% dan hasil recall k-nn yang diperoleh melalui proses validasi sebesar 12,50 % nilai ini meunjukkan bahwa hasil yang diperoleh adalah baik.
IV. 4 Hasil Pengujian Model Algoritma
Setelah melakukan proses pengujian pada masing-masing metode algoritma data mining, diketahui bahwa algoritma k-nearest neighbor lebih akurat atau lebih tinggi akurasinya dibandingkan dengan algoritma backpropagation neural network.
Secara keseluruhan nilai hasil performance menggunakan kinerja model confusion matrix dengan nilai jarak (k-2) serta menggunakan 7 variabel nilai akurasinya adalah accuracy = 97,90%, precision = 100,00%, dan recall = 25,00%, Hasil pengujian algoritma k-nearest neighbor dengan menggunakan akurasi seperti pada tabel 1
Tabel 1 Hasil Akurasi K-Nearest Neighbor
k-nearest neighbor Accuracy 97,90 %
Precision 100,00 %
Recall 25,00 %
Dengan demikian, berdasarkan evaluasi model algoritma data mining dengan bantuan rapidminer model algoritma k-nearest neighbor terpilih sebagai algoritma yang lebih akurat dibandingkan dengan backpropagation neural network didalam memprediksi kelulusan mahasiswa. Selanjutnya untuk menentukan knowledge base system data kelulusan mahasiswa adalah dengan menggunakan eksperimen perhitungan algoritma k-nearest neighbor.
IV. 5 Pola Hasil Klasifikasi Algoritma
Setelah melakukan perhitungan dari data algoritma, perlu adanya pola hasil klasifikai untuk menemulan pengetahuan dari data mahasiswa. Identifikasi pola-pola algoritma k-nearest neighbor ke dalam bentuk aturan produksi. Hal ini berguna untuk penentuan apakah mahasiswa dengan data tertentu sesuai dengan pola atau tidak, kemudian di munculkan hasil mahasiswa tersebut memiliki predikat “lulus tepat waktu” atau “tidak tepat waktu”.
Tabel 2. Contoh Tabel Aturan Produksi Kelulusan “Tidak Tepat Waktu”
IV. 6 Implementasi Program Knowledge Based System
Program mengambil keputusan berdasarkan aturan-aturan yang dibangkitkan dari setiap pertanyaan yang diajukan pada mahasiswa. Proses running tampilan antar muka komputer dan user terlihat seperti pada gambar 7 untuk prediksi “tepat waktu” dan gambar 8 untuk prediksi “tidak tepat waktu”. Setiap mahasiswa dihadapkan pada pertanyaan yang mengharuskan untuk menjawab dengan menuliskan “y” atau “t”.
Gambar 8 Running “Prediksi Tepat Waktu”
Program akan berjalan ke pertanyaan berikutnya sesuai dari algoritma pengumpulan data. Pertanyaan berikutnya akan muncul sesuai dari algoritma yang sudah dibuat dipengumpulan data, terus memproses sampai memenuhi kondisi yang ada pada algoritmanya.
Sehingga apabila data seorang mahasiswa di inputkan seperti yang terjadi pada gambar 8 menjelaskan bahwa pada saat mahasiswa berjenis kelamin perempuan, mendaftar pada usia yang kurang dari 26 tahun dan memilki jumlah IPK yang lebih dari 2,01 maka mahasiswa tersebut diprediksi lulus “TEPAT WAKTU”. Rule diatas sesuai dengan
rule-rule pada aturan produksi tepat waktu.
Gambar 8. Running Prediksi “Tidak Tepat Waktu”
Pada gambar 8 dapat dilihat program running untuk prediksi “tidak tepat waktu”. Analisa dari proses prediksi yang tergambar pada aturan produksi menjelaskan bahwa ketika program menanyakan “apakah Anda seorang laki-laki ? (y/t)” maka jenis saat mahasiswa menjawab “y”, program akan berjalan ke pertanyaan berikutnya sesuai dari algoritma pengumpulan data. Pertanyaan berikutnya akan muncul sesuai dari algoritma yang sudah dibuat dipengumpulan data, terus memproses sampai memenuhi kondisi yang ada pada algoritmanya.
Sehingga pada saat data seorang mahasiswa di inputkan sebagai mahasiswa berjenis kelamin laki-laki, mendaftar pada usia yang lebih dari 26 tahun, berasal dari kota majalengka, beragama islam, sekolah asalnya SMK dan memilki jumlah IPK yang kurang dari 2,01 maka mahasiswa tersebut diprediksi lulus “TIDAK TEPAT WAKTU”. Rule diatas sesuai dengan rule-rule yang sudah dikemukakan pada aturan produksi.
V. KESIMPULAN
Proses penentuan pola lama studi mahasiswa dapat dilakukan dengan menerapkan algoritma data mining dengan metode algoritma k-nearest neighbor. Dengan metode tersebut, ketepatan masa studi mahasiswa dapat diprediksi berdasarkan hasil klasifikasi data mining dan menghasilkan prediksi sesuai dengan data akademik dan latar belakang sekolah sebelumnya. Pengujian dengan bantuan Rapidminer dapat digunakan untuk membandingkan antara algoritma k-nearest neighbor dengan agoritma backpropagation neural network.
Dari proses pengujian dengan confusion matrix diketahui bahwa metode algoritma k-nearest neighbor menghasilkan nilai akurasi tertinggi yang diperoleh dengan nilai jarak (k-100) serta menggunakan 7 variabel terhadap data baru yaitu sebesar 97,90 %. Penerapan rule dari algoritma k-nearest neighbor yang digunakan dalam klasifikasi kelulusan mahasiswa kedalam aplikasi knowledge based system menggunakan CLIPS, dapat membantu dalam proses prediksi kelulusan mahasiswa.
REFERENSI
Dikti, 2015. Grafik Mahasiswa Berdasarkan Jenjang. Diperoleh dari Website Kemenristekdikti : http://forlap.dikti.go.id/mahasiswa/homegra phjenjang. Diakses tanggal 17 Mei 2015. Hastuti, K. (2012). Analisis komparasi algoritma
klasifikasi data mining untuk prediksi mahasiswa Non aktif. Semantik, 2(1). El-Halees, A. (2009). Mining students data to analyze
e-Learning behavior: A Case Study. Department of Computer Science, Islamic University of Gaza PO Box, 108.
Hall, M., Witten, I., & Frank, E. (2011). Data mining: Practical machine learning tools and techniques. Kaufmann, Burlington.
Larose, D. T. (2005). Discovering Knowledge in Databases. New Jersey: John Willey & Sons Inc.
Meinanda, M. H., Annisa, M., Muhandri, N., & Suryadi, K. (2009). Prediksi masa studi sarjana dengan artificial neural network. Internetworking Indonesia Journal, 1(2), 31-35.
Jananto, A. (2010). Perbandingan Performansi Algoritma Nearest Neighbor dan SLIQ untuk Prediksi Kinerja Akademik Mahasiswa Baru. Dinamik-Jurnal Teknologi Informasi, 15(2).
Mustafa, M. S., & Simpen, I. W. (2014). Perancangan Aplikasi Prediksi Kelulusan Tepat Waktu Bagi Mahasiswa Baru Dengan Teknik Data Mining (Studi Kasus: Data Akademik Mahasiswa STMIK Dipanegara Makassar). Creative Information Technology Journal, 1(4), 270-281.