17
ALGORITMA KLASIFIKASI SUPPORT VECTORE MACHINE
BERBASIS PARTICLE SWARM OPTIMIZATION UNTUK
PENENTUAN KELAYAKAN PEMBERIAN KREDIT
KOPERASI
Andi Wijaya
Jurusan Teknik Informatika, STT Nurul Jadid Probolinggo
Email : [email protected]
ABSTRACT
Credit analysis done by analysts sometimes inaccurate, so some credit given the debtor has no ability to pay that cause bad credit. Of this problem we need a model that is able to classify as well as predict which troubled borrowers and not problematic. By applying Decision Tree algorithm based on support vector machine (PSO) based particle swarm optimization (PSO) is expected to improve the accuracy of credit analysis. Of the existing problems as well use a classification method to predict creditworthiness that is the model of support vectore machine algorithm based particle swarm optimization. From the research, the determination of credit worthiness using lagoritma support vector machine based on particle swarm optimization is able to analyze Non-performing loans and are not troubled as much as 94.17 %. Credit analysis is performed using support vector machine algorithm based particle swarm optimization is more accurate than on the analysis done by an analysis that is sometimes inaccurate.To see better accuracy using support vector machine algorithm based particle swarm optimization than using credit analysis is done manually .
Keyword : Credit analysis, Algorithm support vectore mahine, PSO
1. PENDAHULUAN 1.1 Latar Belakang
Lembaga pembiayaan kredit merupakan lembaga yang memberikan jasa pemberian kredit dalam bentuk barang berupa kendaraan atau yang lainnya. Dalam lembaga pembiayaan kredit ini jasa yang ditawarkan adalah kredit pembiayaan. Perusahaan pembiayaan kredit memperoleh keuntungan dari tingkat suku bunga. Di dalam memberikan kredit, pihak pembiayaan kredit harus memiliki prosedur-prosedur kredit yang akan menjadi pedoman didalam memberikan suatu kredit. Proses pemberian kredit membutuhkan pertimbangan dan analisis dari pihak manajemen kredit berdasarkan peraturan dan kebijakan lembaga pembiayaan kredit.
Berdasarkan Undang-undang Nomor 25 tahun 1992 tentang pengkoprasian, koperasi merupakan suatu wadah atau perkumpulan kerja sama dinamakan koperasi apabila memenuhi persayaratan tertentu seperti : memiliki landasan, asas, tujuan, prinsip organisasi, jumlah anggota minimal, struktur organisasi, job discription (pembagian kerja), wewenang dan tanggung jawab yang jelas dan khas.
Kredit macet atau problem loan adalah kredit yang mengalami kesulitan pelunasan akibat adanya faktor-faktor atau unsur kesengajaan atau kondisi di luar kemampuan debitur. Kredit macet yaitu kredit yang pengembalian pokok pinjaman
18 dan pembayaran bunganya terdapat tunggakan telah melampaui 270 hari. Kredit macet merupakan kondisi dimana pihak pemberi pinjaman merasa dirugikan.
Ada beberapa tahap yang harus dilalui sebelum pinjaman dicairkan, mulai dari calon debitur mengisi data dan mengajukan aplikasi, setelah aplikasi diterima oleh koperasi, maka koperasi akan melakukan survey untuk memastikan apakah data yang diisi oleh calon debitur benar adanya. Apabila tidak ada masalah dalam proses
survey, koperasi akan melakukan analisa berdasarkan aplikasi calon debitur,
termasuk latar belakang, kemampuan debitur dan lain-lain. Jika tahap ini sudah disetujui maka dana yang diajukan oleh debitur akan dicairkan.
Kredit yang diajukan oleh debitur memiliki resiko, karena dari sekian banyak debitur yang mengajukan ada kemungkinan beberapa debitur yang bermasalah dalam pembayarannya sehingga menyebabkan kredit macet. Sebelum koperasi menyetujui kredit yang diajukan oleh debitur, koperasi melakukan analisis kredit terhadap debitur apakah pengajuan kredit disetujui atau tidak disetujui. Analisa kredit adalah penyelidikan faktor-faktor yang berpengaruh pada lancarnya atau kurang lancarnya pengembalian kredit (Basuki, 2007).
Analisis kredit merupakan hal yang penting dalam lingkup resiko keuangan oleh karena itu perlunya dilakukan analisa. Namun, melakukan proses analisa kredit membutuhkan waktu lama (Kotsiantis, Kanellopoulos, Karioti, & Tampakas, 2009) dan mengidentifikasi data debitur yang bermasalah merupakan hal yang sulit (Odeh, Featherstone, & Das, 2010). Data yang besar dan banyaknya parameter tentunya membutuhkan alat yang efektif dan efisien untuk melakukan analisa kredit dan menilai debitur yang mempunyai resiko bermasalah dan tidak bermasalah dalam pembayaran kredit.
Di samping peningkatan sistem pembinaan nasabah, rencana kredit disusun lebih matang, analisis atas permohonan kredit lebih terarah dan pengamanan kredit juga lebih digalakkan. Semua ini adalah bertujuan untuk meningkatkan pelayanan terhadap kebutuhan pembiayaan masyarakat. Aktivitas koperasi yang terbanyak akan berkaitan erat secara langsung ataupun tidak langsung dengan kegiatan perkreditan. Berkaitan dengan kredit macet di atas Koperasi simpan pinjam koperasi Arta Jaya Kecamatan Maesan Kabupaten Bondowoso ini sudah jelas bahwa usaha yang dilakukannya bergerak dalam bidang perkreditan.
Sebagai tolak ukur bahwa debitur disetujui atau ditolak, dapat digunakan data histori debitur yang diperoleh dari tesis sebelumnya sebagai acuan telah disetujui oleh koperasi. Namun, perlu diperhatikan juga bahwa debitur yang telah disetujui juga tidak semuanya pembayar kredit yang baik, artinya ada beberapa debitur yang telah disetujui tapi beberapa bulan kemudian pembayarannya menunggak.
Untuk mengatasi permasalahan di atas, maka penulis menggunakan model algoritma Support Vector Machine berbasis Particle Swarm Optimization. Model ini akan digunakan untuk memprediksi apakah debitur nantinya akan bermasalah dalam pembayaran kredit atau tidak.
1.2 Perumusan Masalah
Berdasarkan latar belakang permasalahan yang ada bahwa pemberian kredit yang diberikan selama ini masih kurang akurat. Sedangkan pertanyaan penelitian ini adalah bagaimanakah akurasi algoritma klasifikasi Support Vectore Machine 18
19 berbasis Particle Swarm Optimization untuk penentuan kelayakan pemberian kredit koperasi?.
1.3 Tujuan Penelitian
Berdasarkan latar belakang dan rumusan masalah diatas, Dengan menerapkan Pohon Keputusan berbasis algoritma support vector machine berbasis
particle swarm optimization diharapkan dapat meningkatkan keakuratan analisis
kredit.
1.4 Manfaat Penelitian
1. Manfaat praktis dari penelitian ini adalah untuk memudahkan analis kredit dalam memberikan keputusan.
2. Manfaat penelitian ini yaitu untuk memberikan sumbangan penerapan model algoritma klasifikasi support vector machine berbasis particle
swarm optimization dalam memberikan keputusan kelayakan kredit.
3. Manfaat kebijakan, hasil penelitian ini diharapkan dapat digunakan sebagai bahan pertimbangan bagi lembaga pembiayaan untuk digunakan sebagai penunjang alat bantu untuk meningkatkan akurasi dalam penentuan kelayakan pemberian kredit.
2. TINJAUAN PUSTAKA 2.1 Penelitian Terkait
Berikut ini beberapa penelitian terkait pemberian kredit dengan beberapa metode yang digunakan dalam State of the Art sebagaimana dalam tabel 2.1. berikut :
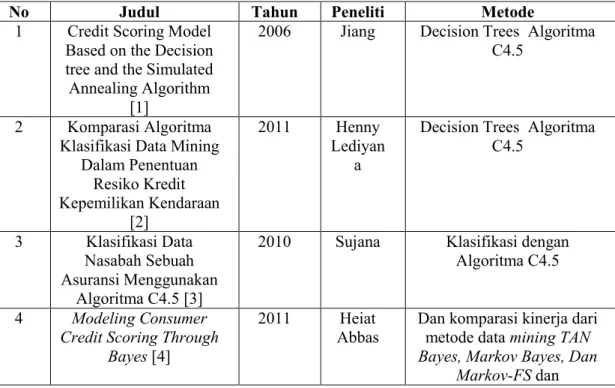
Tabel 2.1 State of the Art
No Judul Tahun Peneliti Metode
1 Credit Scoring Model Based on the Decision tree and the Simulated Annealing Algorithm
[1]
2006 Jiang Decision Trees Algoritma C4.5
2 Komparasi Algoritma Klasifikasi Data Mining
Dalam Penentuan Resiko Kredit Kepemilikan Kendaraan [2] 2011 Henny Lediyan a
Decision Trees Algoritma C4.5
3 Klasifikasi Data Nasabah Sebuah Asuransi Menggunakan
Algoritma C4.5 [3]
2010 Sujana Klasifikasi dengan Algoritma C4.5
4 Modeling Consumer
Credit Scoring Through Bayes [4]
2011 Heiat Abbas
Dan komparasi kinerja dari metode data mining TAN
Bayes, Markov Bayes, Dan Markov-FS dan
20 mengidentifikasi prediktor
untuk menentukan mana yang kredit 2.2 Landasan Teori
2.2.1 Kredit
Pada pasal 1 angka 11 Undang-undang no. 10 tahun 1998 tentang perubahan undang-undang no 7 tahun 1992 tentang perbankan yang dimaksud dengan kredit adalah penyediaan uang atau tagihan yang dapat dipersamakan dengan itu, berdasarkan persetujuan pinjam meminjam antara bank dengan pihak lain yang mewajibkan pihak peminjam melunasi hutangnya setelah jangka waktu tertentu dengan pemberian bunga.
2.2.2 Support Vectore Machine (SVM)
Support Vector Machine (SVM) dikembangkan oleh Boser, Guyon, Vapnik,
dan pertama kali dipresentasikan pada tahun 1992 di Annual Workshop on
Computational Learning Theory. Konsep dasar SVM sebenarnya merupakan
kombinasi harmonis dari teori-teori komputasi yang telah ada puluhan tahun sebelumnya, seperti margin hyperplane (Duda & Hart tahun 1973, Cover tahun 1965, Vapnik 1964, dan lain-lainnya), kernel diperkenalkan oleh Aronszajn tahun 1950, dan demikian juga dengan kosep-konsep pendukung yang lain. Akan tetapi hingga tahun 1992, belum pernah ada upaya merangkaikan komponen-komponen tersebut.[5]
2.2.3 Particle Swarm Optimization
Particle Swarm Optimimization (PSO) adalah algoritma pencarian berbasis
populasi dan diinisialisasi dengan populasi solusi acak yang disebut partikel (Abraham, 2006). PSO merupakan metode pencarian penduduk yang berasal dari penelitian untuk gerakan sekelompok burung atau ikan. Serupa dengan algoritma genetik (GA), PSO melakukan pencarian menggunakan populasi (swarm) dari individu (partikel) yang akan duperbaharui dari iterasi ke iterasi.[6]
Untuk PSO dapat diasumsikan sebagai kelompok burung secara acak mencari makanan disuatu daerah. Burung tersebut tidak tahu dimana makanan tersebut berada, tapi mereka tahu sebarapa jauh makanan itu berada, jadi strategi terbaik untuk menemukan makanan tersebut adalah dengan mengikuti burung yang terdekat dari makanan tersebut (Abraham, 2006). PSO digunakan untuk memecahkan masalah optimasi.
2.2.3 Evaluasi dan Validasi Hasil
Dalam melakukan evaluasi pada algoritma support vectore dengan teknik
particle swarm optimization dilakukan dengan menggunakan model counfusion matrix, dan ROC curve (Receiver Operating Characteristic).
1. Confusion Martix
Confusion matrix merupakan tabel matrix yang terdiri dari dua kelas, yaitu
kelas yang dianggap sebagai positif dan kelas yang dianggap sebagai negatif (Vercellis, 2009). Confusion matrix berisi informasi aktual (actual) dan prediksi (predicted) pada system klasifikasi.
21 Tabel 2.1 Model Confusion Matrix (Gorunescu, 2011)
Classification Predicted Class
Observed Class
Class = Yes Class = No Class = Yes A (true positive
– tp)
B (false
negative – fn)
Class = No C (false positive – fp)
D
true negative
tn) Keterangan:
True Positive (tp) = proporsi positif dalam data set yang
diklasifikasikan positif
True Negative (tn) = proporsi negative dalam data set yang diklasifikasikan negative
False Positive (fp) = proporsi negatif dalam data set yang diklasifikasikan potitif
FalseNegative (fn) = proporsi negative dalam data set yang diklasifikasikan negatif
Berikut adalah persamaan model confusion matrix:
a. Nilai akurasi (acc) adalah proporsi jumlah prediksi yang benar. Dapat dihitung dengan menggunakan persamaan:
tp + tn
acc =
tp + tn + fp + fn
b. Sensitivity digunakan untuk membandingkan proporsi tp terhadap tupel yang positif, yang dihitung dengan menggunakan persamaan:
tp
sensitivity =
tp + fn
c. Specificity digunakan untuk membandingan proporsi tn terhadap tupel yang negatif, yang dihitung dengan menggunakan persamaan:
tn specificity =
tp + fp
d. PPV (positive predictive value) adalah proporsi kasus dengan hasil diagnosa positif, yang dihitung dengan menggunakan persamaan: tp
ppv = tp + fp
e. NPV (negative predictive value) adalah proporsi kasus dengan hasil diagnosa negatif, yang dihitung dengan menggunakan persamaan: tn
npv =
tn + fn
22 2. ROC Curve
Kurva ROC (Receiver Operating Characteristic) adalah cara lain untuk mengevaluasi akurasi dari klasifikasi secara visual (Vercellis, 2009). Sebuah grafik ROC adalah plot dua dimensi dengan proporsi positif salah (fp) pada sumbu X dan proporsi positif benar (tp) pada sumbu Y. Titik (0,1) merupakan klasifikasi yang sempurna terhadap semua kasus positif dan kasus negatif. Nilai positif salah adalah tidak ada (fp = 0) dan nilai positif benar adalah tinggi (tp = 1). Titik (0,0) adalah klasifikasi yang memprediksi setiap kasus menjadi negatif {-1}, dan titik (1,1) adalah klasifikasi yang memprediksi setiap kasus menjadi positif {1}. Grafik ROC menggambarkan
trade-off antara manfaat („true positives‟) dan biaya („false positives‟).
Berikut tampilan dua jenis kurva ROC (discrete dan continous).
Gambar 2.1 Grafik ROC (discrete dan continous) (Gorunescu, 2011) Pada Gambar 1.1garis diagonal membagi ruang ROC, yaitu:
1. (a) poin diatas garis diagonal merupakan hasil klasifikasi yang baik. 2. (b) point dibawah garis diagonal merupakan hasil klasifikasi yang
buruk.
Dapat disimpulkan bahwa, satu point pada kurva ROC adalah lebih baik dari pada yang lainnya jika arah garis melintang dari kiri bawah ke kanan atas didalam grafik. Tingkat akurasi dapat di diagnosa sebagai berikut (Gournescu, 2011):
Akurasi 0.90 – 1.00 = Excellent classification Akurasi 0.80 – 0.90 = Good classification Akurasi 0.70 – 0.80 = Fair classification Akurasi 0.60 – 0.70 = Poor classification Akurasi 0.50 – 0.60 = Failure
2.3 Kerangka Pemikran
Dalam penyelesaian penelitian ini, dimulai dari problem (permasalahan) analisa kredit yang tidak akurat kemudian dibuat approach (model) yaitu algoritma
support vectore machine (SVM) berbasis particle swarm optimization untuk
memecahkan permasalahan. Untuk mengembangkan aplikasi (development) berdasarkan model yang dibuat, digunakan Rapid Miner. Tahap berikutnya yaitu
implementation (implementasi), pada tahap ini objek implementasi dilakukan di
koperasi simpan pinjam, tehnik sampling menggunakan random sample, dan desain ekperimennya digunakan CRISP-DM. Kerangka pemikiran dalam penulisan thesis ini yaitu:
23 Gambar 2.2 Kerangka Pemikiran
3. METODE PENELITIAN 1. Pengumpulan Data
Ada dua tipe dalam pengumpulan data, yaitu pengumpulan data primer dan pengumpulan data sekunder. Data primer adalah data yang dikumpulkan pertama kali dan untuk melihat apa yang sesungguhnya terjadi. Data sekunder adalah data yang sebelumnya pernah dibuat oleh seseorang baik di terbitkan atau tidak (C.R.Kothari, 2004).[1] Dalam pengumpulan data primer, penulis menggunakan metode observasi dan interview, dengan menggunakan data-data yang berhubungan pengajuan kredit dan bertanya secara langsung kepada pihak yang terlibat secara langsung di dalam sistem. Sedangkan dalam pengumpulan data sekunder menggunakan buku, jurnal, publikasi dan lain-lain.
2. Eksperiment
Ada beberapa tahap yang dilakukan dalam melakukan eksperimen ini, penulis menggunakan model Cross-Standard Industry for Data Mining (CRISPDM) (Larose, 2005) [1] yang terdiri dari 6 tahap, yaitu :
1. Tahap business understanding.
Berdasarkan laporan kredit tahun 2008 ditemukan kredit macet sebanyak 25 orang, sehingga ini menjadi permasalahan koperasi dan merupakan imbas dari analisa analis yang kurang akurat.
24 2. Tahap data understanding.
Data kredit diambil dari koperasi Arta Jaya Maesan Bondowoso pada tahun 2008 hingga 2009, dimana dari 265 debitur, 38 diantaranya bermasalah dalam pembayaran atau dengan istilah lain macet dalam pembayaran kreditnya.
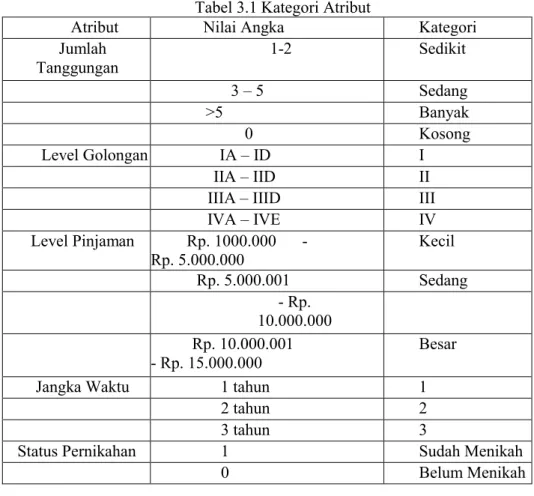
Nilai dari semua atribut yang ada di tabel, merupakan nilai kategorikal dan bukan nilai angka, misalnya seperti atribut Jumlah Tanggungan yang mempunyai nilai sedikit merupakan kategori jika debitur mempunyai jumlah anak 1 sampai 2. Gambar 3.1 di bawah ini ditampilkan nama atribut, kategori, dan nilai angka (rangenya). Berikut rule nilainya :
Tabel 3.1 Kategori Atribut
Atribut Nilai Angka Kategori
Jumlah Tanggungan 1-2 Sedikit 3 – 5 Sedang >5 Banyak 0 Kosong Level Golongan IA – ID I IIA – IID II
IIIA – IIID III
IVA – IVE IV Level Pinjaman Rp. 1000.000 - Rp. 5.000.000 Kecil Rp. 5.000.001 Sedang - Rp. 10.000.000 Rp. 10.000.001 - Rp. 15.000.000 Besar
Jangka Waktu 1 tahun 1
2 tahun 2
3 tahun 3
Status Pernikahan 1 Sudah Menikah
0 Belum Menikah
3. Tahap Data Reparation
a. Data cleaning bekerja untuk membersihkan nilai yang kosong ,tidak konsisten atau mungkin tupel yang kosong (missing values dan noisy). b. Data integration berfungsi menyatukan tempat penyimpanan (arsip)
yang berbeda ke dalam satu data. Dalam hal ini, ada dua arsip yang diambil sebagai data warehouse yaitu data anggota dan data kredit.
25 c. Data reduction. Jumlah atribut dan tupel yang digunakan untuk data
training mungkin terlalu besar, hanya beberapa atribut yang diperlukan sehingga atribut yang tidak diperlukan akan dihapus.
4. Tahap modelling (modeling).
Tahap ini juga dapat disebut tahap learning karena pada tahap ini data training diklasifikasikan oleh model dan kemudian menghasilkan sejumlah aturan.Model yang digunakan dalam tahap ini menggunakan algoritma support vector machine seperti yang telah dijelaskan sebelumnya.
a. Penerapan dengan Rapidminer
Ada beberapa tahap dalam menggunakan Rapid Miner yaitu:
1. Untuk menganalisa, dibutuhkan data training. Data training yang akan dimasukkan ke dalam Rapid Miner bisa dalam format .csv, .xls, .mdb dan lain-lain. Data yang penulis gunakan adalah dalam format .csv.
2. Buka program Rapid Miner, kemudian akan muncul tampilan awal. Untuk memasukkan data training yang telah dibuat sebelumnya, pilih menu File – Import Data – Import CSV File. 3. Tampil jendela Data import wizard dengan total 5 langkah.
ada langkah ke-1 ini tentukan nama file yang berisi data training dalam direktori kemudian pilih Next seperti terlihat pada gambar 3.1.
Gambar 3. 1 Tampilan langkah 1 : memilih data training. Data yang digunakan bisa dalam format .xls, .csv, atau .xml. Pada langkah ke-2 pastikan Skip Comment, Semicolon, dan Use Quote sudah ditandai kemudian pilih Next. Langkah ke-3 menentukan anotasi dari setiap tupel, abaikan kemudian pilih Next. Pada langkah ke-4 yaitu menentukan nama atribut. Walaupun nama atribut sudah tertulis seperti att1 dan lain-lain, namun untuk memudahkan maka harus dibuat nama artribut sesuai dengan data training. Setelah semua telah terisi, klik Reload data untuk menyimpan. Pilih next untuk berlanjut ke tahap berikutnya. Lihat gambar 3.2. di bawah ini :
26 Gambar 3. 2 Tampilan langkah 4 : menentukan atribut dan label Pada langkah terakhir, tentukan nama data dan disimpan dalam New local repository kemudian pilih Finish.
4. Data training yang sebelumnya disimpan, akan tersimpan otomatis ke dalam Repositories. Pilih tab Repositories – NewLocalRepository – modelsvm1. Geser DataTraining ke area Main Process. Untuk menambahkan model, pilih tab Operators – Modelling – Classification and Regression – Support Vectore Modeling – Support Vectore Machine. Geser Decision Tree ke area Main Process dan hubungkan seperti gambar 3.3 di bawah ini :
Gambar 3. 3 Relasi antara data dan optimize selection.
Gambar 3. 4 Proses validation dalam optimation
Gambar 3. 5 Proses dalam validasi.
27 5. Untuk melihat hasilnya, pilih menu Process – Run maka akan tampil
hasil seperti gambar 3.5 di bawah:
Gambar 3. 6 Hasil Ketika Dijalankan 6. Tahap Evaluation (Evaluasi).
Tahap ini dapat disebut tahap klasifikasi karena pada tahap ini menguji akrurasi dengan memasukkan data uji pada tahun. Tahap ini dijelaskan secara lebih rinci pada bab IV.
7. Tahap Deployment (Penyebaran).
Pada tahap ini yaitu menerapkan model algoritma support vectore
machine berbasis particle swarm optimization ke koperasi untuk
penentuan kelayakan pemberian kredit. 4. HASIL PENELITIAN DAN PEMBAHASAN 1. Hasil Penelitian
Analisa kredit yang dilakukan menggunakan algoritma support vector
machine berbasis particle swarm optimization lebih akurat dari pada analisa yang
dilakukan oleh seorang analisis yang terkadang tidak akurat. 2. Pengujian Model
Nilai accuracy, precision, dan recall dari data training dapat dihitung dengan menggunakan Rapid Miner. Setelah diuji coba dengan metode
cross- validation, didapatkan hasil pengukuran terhadap data training yaitu accuracy =94.17%, precision = 0.00% dan recall = positiv class : bermasalah.
Model yang telah dikembangkan akan diuji keakuratannya dengan memasukkan sejumlah data uji (test set) ke dalam model. Data uji diambil dari laporan kredit koperasi tahun 2009. Ada 35 sampel yang diambil dari data keseluruhan, jumlah data sebanyak 265 tidak diambil karena jumlah ini sama dengan data tahun 2008 dan tidak ada perubahan, hanya 35 sampel yang bertambah sehingga totalnya menjadi 265.
Terlihat pada tabel 4.1, pengujian akan dilakukan dari populasi data training. Karena jumlah data training hanya 35 maka berdasarkan tabel yang dibuat diambil keseluruhan yaitu 20 sampel dengan tingkat kesalahan 5% baik data debitur bermasalah dan data debitur tidak bermasalah (baik) secara acak (simple random sampling).[2]
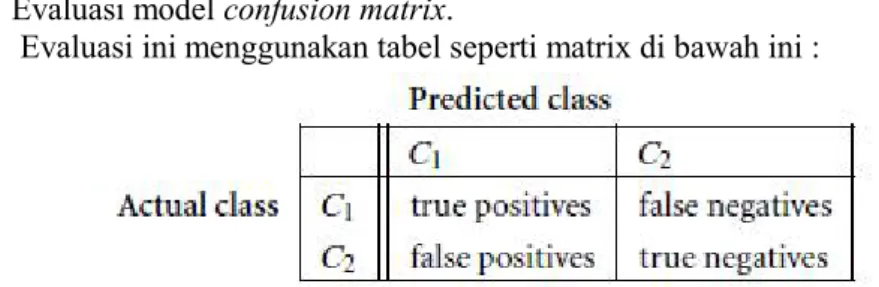
28 1. Evaluasi model confusion matrix.
Evaluasi ini menggunakan tabel seperti matrix di bawah ini :
Gambar 4. 1 Model confusion matrix : nilai true positives, false negatives, false positives,dan true negatives didapat dari data uji (Han & Kamber,
2006)
Kemudian masukkan data uji yang ada di gambar 4.1 ke dalam model
confusion matrix maka akan didapatkan hasil pada tabel 4.3.
Tabel 4. 2 Konversi ke confusion matrix
Baik Bermasalah
Baik 33 2
Bermasalah 0 0
Setelah data uji dimasukkan ke dalam confusion matrix, hitung nilai-nilai yang telah dimasukkan tersebut untuk dihitung jumlah sensitivity,
specificity, precision dan accuracy. Sensitivity digunakan untuk
membandingkan jumlah true positives terhadap jumlah tupel yang positives sedangkan specificity adalah perbandingan jumlah true negatives terhadap jumlah tupel yang negatives. Untuk menghitung digunakan persamaan di bawah ini : t_pos sensitifity = pos t_neg specificity = neg t_pos precision = ( t_ pos + f_ps) Pos neg
accuracy = sensituvity + specyfity
(pos+neg) (pos+neg)
Dimana :
t_pos = jumlah true positives
t_neg = jumlah true negatives
pos = jumlah tupel positif
neg = jumlah tupel negatif f_pos = jumlah false positives 28
29 Kemudian masukkan nilai yang ada di dalam confusion matrix ke dalam persamaan di atas, sehingga akan menghasilkan nilai seperti di bawah ini :
Tabel 4. 3 Nilai sensitivity, specificity, precision, dan accuracy dalam persentase. Terlihat bahwa nilai akurasi mencapai 94,17%.
Nilai (%) Sensitivity 100 Specificity 0 Precision 0 Accuracy 94,17 Recall 0
Terlihat pada gambar 4.4, nilai accuracy, recall dan precision yang dihasilkan oleh Rapid Miner menggunakan model confusion matrix.
Gambar 4. 1 Confusion matrix menggunakan Rapid Miner. 2. Kurva ROC (Receiver Operating Characteristic)
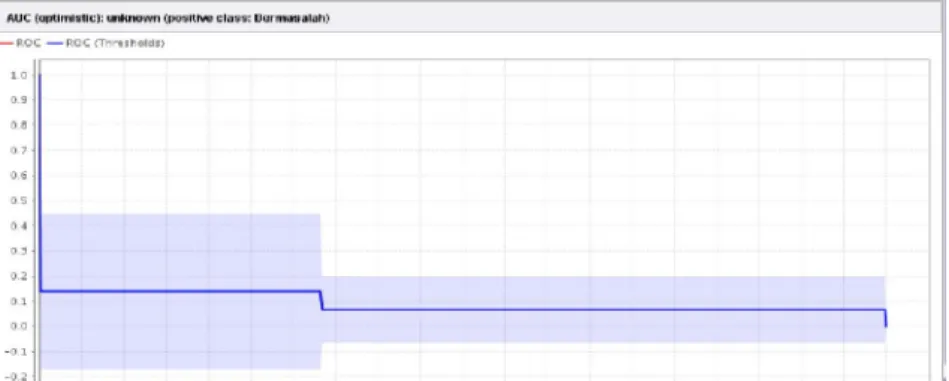
Gambar 4.3 menunjukkan grafik ROC dengan nilai AUC (Area Under Curve) dengan metode information gain sebesar 0.500, metode gain ratio juga menunjukkan hasil yang sama. Sedangkan nilai AUC yang menggunakan metode gini index mencapai angka 0.703 seperti terlihat pada gambar 4.4. Akurasi AUC dikatakan sempurna apabila nilai AUC mencapai 1.000 dan akurasinya buruk jika nilai AUC dibawah 0.500.
Gambar 4. 2 Nilai AUC dalam grafik ROC dengan memasukkan data uji.
30 5. KESIMPULAN DANSARAN
5.1. Kesimpulan
Dari hasil penelitian terbukti bahwa algoritma support vectore machine berbasi particle swarm optimization lebih akurat dibandingkan analisa yang dilakukan oleh analis kredit. Hal ini dibuktikan dengan hasil evaluasi penelitian bahwa algoritma Support Vectore Machine (SVM) berbasis Particle Swarm
Optimization (PSO) mampu menganalisa kredit yang bermasalah dan yang debitur
yang tidak bermasalah sebanyak 94.17%. 5.2. Saran
Walaupun model algoritma support vectore machine berbasis particle
swarm optimization sudah diterapkan dan berjalan dengan baik di dalam sistem,
namun ada beberapa hal yang harus ditambahkan untuk menambah akurasi algoritma support vectore machine, yaitu :
a) Untuk melihat tingkat akurasi dari algoritma, akan lebih baik algoritma
support vectore machine berbasis particle swarm optimization dibandingkan
atau dikomparasi dengan model algoritma lain.
b) Pada riset selanjutnya dapat digunakan metode seleksi atribut yang lain seperti Chi-Square untuk ketepatan penyeleksian atribut.
c) Menerapkan algoritma support vectore machine berbasis particle swarm
optimization ke dalam data yang lebih besar untuk menguji akurasi dari
algoritma.
d) Menambahkan atribut tambahan seperti jaminan.
31 DAFTAR PUSTAKA
1. Firmansyah. (2011). Penerapan Algoritma Klasifikasi C4.5 Untuk Penentuan Kelayakan Pemberian Kredit Koperasi.
2. Henny Lediyana. (2011). Komparasi Algoritma Klasifikasi Data Mining Dalam Penentuan Resiko Kredit Kepemilikan Kendaraan Bermotor.
3. Sunjana. (2010). Klasifikasi Data Sebuah Nasabah Asuransi Menggunakan Algoritma C4.5. Seminar Nasional Aplikasi Teknologi Informasi 2010, D-31.
4. Heiat, Abbas. (2011). Modeling Consumer Credit Scoring Through Bayes
Network. World Journal of Social Sciences, Volume 1, Number 3,
pp.132-141, July 2011
5. Sayed Fachurrazi. (2011), Penggunaan Metode Support Vector Machine (SVM) Untuk Mengklasifikasikan dan Memprediksi Angkutan Udara Jenis Penerbangan Domestik dan Penerbangan Internasional di Banda Aceh. 6. Eviciena. (2011), Penerapan Algoritma C4.5 Berbasis Particle Swarm
Optimization Untuk Prediksi Hasil Pemilihan Legeslatif DPRD DKI Jakarta. 7. Hu, X., Shi, Y., & Eberhart, R. (2004). Recent Advances in Particle Swarm.
IEEE, 90-97.
8. Han, J., & Kamber, M. (2006). Data Mining Concepts and technique. San Francisco: Diane Cerra.
9. Vercellis, C. (2009). Business Intelligence: Data Mining and Optimization
for Decision Making. Southern Gate, Chichester, West Sussex: John Wiley
& Sons, Ltd.
10. Dunham, Margaret,H. (2003), Data Mining Introuctory and Advanced
Topics, New Jersey, Prentice Hall.
11. Kotsiantis, S., Kanellopoulos, D., Karioti, V., & Tampakas, V. (2009). An ontology-based portal for credit risk analysis. 2009 2nd IEEE International
Conference on Computer Science and Information Technology, (hal.
165-169). Beijing.
12. Odeh, O. O., Featherstone, A. M., & Das, S. (2010). Predicting Credit Default: Comparative Results from an Artificial Neural Network, Logistic Regression and Adaptive Neuro-Fuzzy Inference System. EuroJournals
Publishing, Inc. 2010 , 7-17.
13. Prof. Dr. H.M. Syafi’ie Idrus, M.Ec., P.hD. 2008. Islam dan Manajemen Koperasi Prinsip san Strategi Pengembangan Koperasi di Indonesia. UIN – MALANG PRESS.
14. Undang-Undang Nomor 25 tahun 1992
15. Abraham, A., Grosan, C., & Ramos, V. (2006). Swarm Intelligence in Data
Mining. USA: Spinger.
16. Nugroho, Anto Satrio., 2003, Support Vector Machine Teori dan
Aplikasinya dalam Bioinformatika.
17. Abraham, A., Grosan, C., & Ramos, V. (2006). Swarm Intelligence in Data
Mining. USA: Spinger.
18. Gorunescu, F. (2011). Data Mining Concepts, Model and Techniques. Berlin: Springer.