analisis, dilanjutkan dengan perancangan dan implementasi, diakhiri dengan pengujian.
Metode pengujian yang digunakan adalah black box testing. Metode pengujian ini hanya terbatas menguji fungsionalitas dari sistem. Pengujian dilakukan dengan mengikuti langkah-langkah yang didefinisikan dalam dokumen test case yang telah disediakan sebelumnya.
Gambar 3 Alur pengembangan sistem (System Development Life Cycle) dengan metode
waterfall menurut Pressman (2001). Analisis Kebutuhan
Tahap analisis kebutuhan mendefinisikan kebutuhan ap a saja yang harus dipenuhi oleh sistem. Kebutuhan yang harus didefinisikan mencakup kebutuhan fungsional dan kebutuhan non fungsional. Kebutuhan fungsional mendefinisikan fungsi-fungsi dasar yang harus diimplementasikan, kebutuhan fungsional ini yang nantinya akan membedakan modul evaluasi yang dibuat dan modul evaluasi yang ada dalam JITS.
Perancangan
Tahap perancangan mendefinisikan bentuk abstrak dari modul evaluasi. Arsitektur modul evaluasi disusun untuk memenuhi kebutuhan fungsional yang telah didefinisikan dalam tahap sebelumnya. Setiap bagian penting dari modul evaluasi dirancang lebih mendetail menggunakan notasi dan diagram.
Algoritma yang digunakan dalam modul evaluasi didefinisikan menggunakan notasi ilmiah beserta abstraksi berupa flowchart.
Implementasi
Modul evaluasi dibuat dalam Tahap Implementasi. Proses pembuatan modul evaluasi diawali dengan menyusun parser dan lexer, dilanjutkan dengan menyusun sistem penjelas dan diakhiri dengan sistem Perbaikan Terotomasi.
Implementasi modul evaluasi berupa kode program dan tampilan aplikasi didokumentasikan secara lengkap. Kendala dan issue yang muncul dalam tahap implementasi dicatat sebagai bahan masukan untuk penelitian selanjutnya.
Pengujian
Tahap pengujian dimaksudkan untuk mengetahui sejauh mana kinerja Sistem Evaluasi dalam memenuhi tujuan penelitian ini. Pengujian juga dimaksudkan mengurangi kesalahan (bug) sistem.
Proses pengujian dilaksanakan dengan beberapa tahap, antara lain: pengujian kinerja sistem, pengujian dengan metode black box testing dan pengujian dengan metode analisis algoritma.
HASIL DAN PEMBAHASAN Analisis
1 Kebutuhan Fungsional
Kebutuhan fungsional mendefinisikan tiga aspek penting dalam modul evaluasi, yaitu: strategi penilaian jawaban siswa, strategi pengenalan kesalahan dan strategi perbaikan terotomasi. Ketiga aspek di atas merupakan fungsionalitas utama dari modul evaluasi.
Ketiga aspek kebutuhan fungsional dapat dipecah-pecah menjadi poin-poin penting sebagai berikut:
a Memahami variasi sintaks. Siswa harus diperbolehkan untuk menggunakan variabel yang berbeda, struktur kondisi dan struktur iterasi yang berbeda.
b Memahami variasi implementasi. Algoritma yang berbeda untuk konsep yang sama harus bisa dikenali.
c Mengenali kesalahan. Jika terdapat kesalahan harus ada penjelasan yang lengkap. Analisis Kebutuhan Desain Sistem Implementasi Sistem Integrasi dan Pengujian Sistem Penggunaan dan Pemeliharaan
d Membantu siswa memperbaiki kesalahan. Selain penjelasan yang lengkap atas kesalahan, siswa juga dibantu dalam memperbaiki kesalahan dengan memberikan petunjuk solusi yang benar.
e Mengenali batasan-batasan. Jika terdapat kesalahan yang tidak diketahui oleh sistem, harus diberikan keterangan yang jelas, hal ini berkaitan dengan faktor reliabilitas.
f Memberikan penilaian atas jawaban siswa. Penilaian yang diberikan didasarkan beberapa parameter dan kondisi, tidak hanya dari kebenaran jawaban.
2 S trategi Penilaian
Proses penilaian jawaban siswa menggunakan metode grading. Metode grading memerlukan kumpulan pasangan data input/output untuk setiap soal. Data input/output disimpan dalam struktur penyimpanan data. Ketika proses penilaian akan berlangsung, sistem akan membaca data input/output dari sumber data dan menyimpannya dalam memori.
Langkah berikutnya dalam strategi penilaian adalah mengkompilasi kode sumber hasil jawaban siswa menjadi file executable. Data input akan dimasukkan ke dalam file executable. Agar proses pemasukan data ini berhasil, kode sumber hasil jawaban siswa harus menyertakan kode untuk menerima input berupa data input. File executable juga harus mengeluarkan output sesuai dengan format data output.
Penilaian akan didasarkan pada perbandingan output dari file executable dengan data output. Agar penilaian akurat, kumpulan pasangan data input/output disediakan sebanyak mungkin, semakin banyak data input/output maka semakin akurat nilai yang dihasilkan. 3 Strategi Pengenalan Kesalahan
Kode sumber hasil jawaban siswa tidak selalu bebas dari kesalahan. modul evaluasi harus mampu mengenali kesalahan dalam kode sumber. Cara yang paling efektif untuk mengenali kesalahan dalam kode sumber adalah mengembangkan aplikasi yang bisa ”mengenali” kode sumber bahasa C. Aplikasi demikian disebut language recognizer. Language recognizer adalah aplikasi yang dapat
menentukan apakah sebuah kalimat mematuhi aturan dalam tata bahasa atau tidak (Parr 2007).
Kesalahan yang ditemukan oleh language recognizer dikategorikan dalam beberapa kategori. Pengkategorian kesalahan memudahkan modul evaluasi menyusun penjelasan kesalahan. Kesalahan dengan kategori yang sama dapat dijelaskan dengan pola yang sama. Penjelasan kesalahan secara kasus per kasus sangat tidak efisien, pengguna tidak memerlukan penjelasan panjang lebar bertele-tele, tetapi penjelasan yang singkat dan padat tentang kesalahan yang dibuatnya.
4 Strategi Perbaikan Terotomasi
Kecerdasan modul evaluasi diwujudkan dalam kemampuannya memperbaiki kesalahan tertentu pada kode sumber secara terotomasi. Siswa cukup memberikan persetujuan “y a” atau “tidak” terhadap langkah perbaikan terotomasi, tanpa perlu secara manual memperbaiki kesalahan.
Siswa dapat menyetujui atau menolak proses perbaikan terotomasi, dan siswa dapat membatalkan semua langkah perbaikan terotomasi yang diajukan oleh sistem.
5 Kebutuhan Non Fungsional a Kebutuhan Perangkat Keras
1 Prosesor : Intel Pentium 800 MHz 2 Memori : 256 M B DDR RAM 3 Hardisk : 40 GB
4 VGA : 32 MB 5 Keyboard dan Mouse b Kebutuhan Perangkat Lunak
1 Sistem Operasi Microsoft Windows XP Professional
2 Java 6 Runtime Environment
Perancangan
1 Arsitektur Sistem
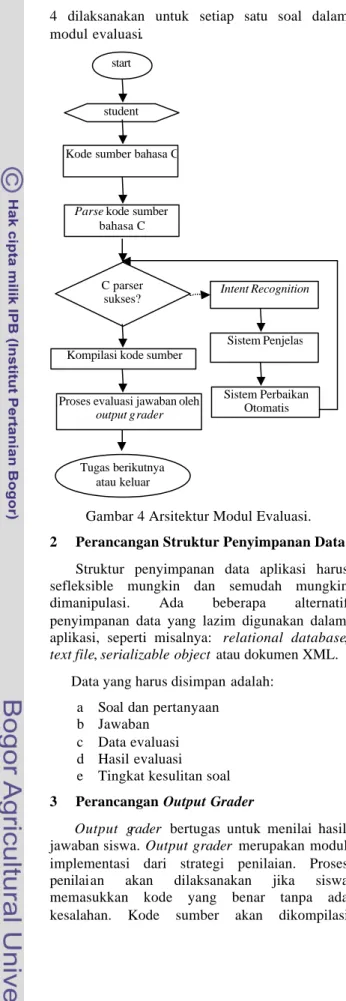
Berdasarkan analisis kebutuhan sistem, disusunlah arsitektur modul evaluasi sep erti yang terlihat pada Gambar 4. Proses penilaian jawaban siswa ditunjukkan oleh diagram lurus dari atas hingga bawah. Jika terdapat kesalahan dalam kode sumber jawaban siswa, maka Intent Recognition akan mengambil alih dan mulai melakukan serangkaian langkah membantu siswa menemukan, mengerti dan memperbaiki kesalahan. Alur eksekusi program pada Gambar
4 dilaksanakan untuk setiap satu soal dalam modul evaluasi.
Gambar 4 Arsitektur Modul Evaluasi. 2 Perancangan Struktur Penyimpanan Data
Struktur penyimpanan data aplikasi harus sefleksible mungkin dan semudah mungkin dimanipulasi. Ada beberapa alternatif penyimpanan data yang lazim digunakan dalam aplikasi, seperti misalnya: relational database, text file, serializable object atau dokumen XML.
Data yang harus disimpan adalah: a Soal dan pertanyaan
b Jawaban c Data evaluasi d Hasil evaluasi e Tingkat kesulitan soal 3 Perancangan Output Grader
Output grader bertugas untuk menilai hasil jawaban siswa. Output grader merupakan modul implementasi dari strategi penilaian. Proses penilaian akan dilaksanakan jika siswa memasukkan kode yang benar tanpa ada kesalahan. Kode sumber akan dikompilasi
menggunakan C compiler dan menghasilkan file executable. Kemudian file executable tersebut dijalankan dengan memasukkan data input. Output yang dihasilkan file executable akan dicocokan menggunakan output data yang diambil dari struktur data yang telah disediakan sebelumnya.
Berikut ini langkah-langkah yang akan diambil oleh modul output grader.
1 Kode sumber bahasa C hasil pekerjaan siswa melalui proses kompilasi menggunakan Digital Mars C Compiler yang menghasilkan file executable (exe).
2 File yang XML berisi input output data dibaca dan disimpan dalam memori, data ini lah yang digunakan sebagai patokan benar atau tidaknya hasil pekerjaan yang dilakukan oleh siswa
3 File eksekusi hasil kompilasi dari kode sumber bahasa C dijalankan dan data input dimasukkan dalam standard input (stdin). Operasi ini akan menghasilkan output dari program.
4 hasil output dari program akan dibandingkan dengan data output yang diperoleh dari data input/output.
5 dari hasil perbandingan ini dapat ditentukan apakah pekerjaan siswa benar atau salah. Langkah-langkah di atas dapat digambarkan dalam sebuah bagan seperti pada Gambar 5.
Compiler yang digunakan adalah DMC dari Digital Mars. Sedangkan metode untuk menjalankan Sistem output grader dilakukan dengan memasukkan data ke standard input (stdin) dan mengambil output dari standard output (stdout) dari program hasil kompilasi.
Set elah output grader selesai dilaksanakan, akan dihitung persentase keberhasilan tes ini. Semakin banyak item dalam output grader diharapkan semakin akurat hasil penilaian terhadap pekerjaan siswa.
Penilaian terhadap pekerjaan siswa diperoleh dari rasio antara tes yang benar dan jumlah tes.
Nilai = (Jawaban benar / Jumlah tes) * 100 Kompilasi kode sumber
Proses evaluasi jawaban oleh output grader C parser sukses? start Intent Recognition Sistem Penjelas Parse kode sumber
bahasa C
Tugas berikutnya atau keluar Kode sumber bahasa C
student
Sistem Perbaikan Otomatis
Gambar 5 Langkah-langkah dalam modul Output Grader .
4 Perancangan Intent Recognition
Beberapa jenis sistem pembelajaran cerdas, memerlukan solusi yang spesifik terhadap persoalan yang diberikan kepada siswa, kemudian jawaban siswa akan dicocokan karakter demi karakter dengan solusi tersebut. Bentuk sistem pembelajaran cerdas tersebut sangat kaku dan tidak dapat mengakomodasi jawaban siswa yang sangat bervariasi.
Intent Recognition menyempurnakan kelemahan ini dengan berusaha mengerti jawaban siswa tanpa harus membandingkanya huruf demi huruf dengan solusi yang telah ditentukan terlebih dahulu.
Intent Recognition praktis merupakan language recognition tools untuk mengenali bahasa C. Kata Intent berarti bahwa proses pemeriksaan bahasa C oleh Intent Recognition disertai dengan ”tujuan” tertentu selain hanya memeriksa saja.
Intent Recognition akan memeriksa kode sumber jawaban siswa dengan tujuan:
a Mencari kesalahan dalam kode sumber. b Menjelaskan kesalahan.
c Mencatat kesalahan yang bisa diperbaiki secara terotomasi.
d Mencatat semua token dalam tabel token. Bagian utama dari Intent Recognition adalah lexer dan parser untuk memeriksa kode sumber siswa. Lexer akan membaca karakter per karakter kode sumber siswa. Kemudian mengubah aliran karakter menjadi aliran token. Parser akan mengambil setiap token yang dihasilkan oleh
lexer dan mencocokkannya dengan kumpulan aturan-aturan yang mendefinisikan tata bahasa C.
Kumpulan aturan yang mendefinisikan tata bahasa C disebut C Language Grammar Specification. Seperti sudah dibahas di bagian sebelumnya, terdapat dua jenis rule: lexer rule dan parser rule. Setiap rule pada dasarnya merupakan satu mesin DFA (Deterministic Finite Automata). Lexer rule adalah DFA yang memuat rangkaian langkah dan state untuk mengubah karakter menjadi token. Sedangkan parser rule adalah DFA yang memuat rangkaian langkah dan state untuk memvalidasi urutan token, apakah sudah memenuhi grammar atau tidak.
Perbedaan utama lexer rule DFA dan parser rule DFA adalah set input yang diterima lexer rule adalah karakter dengan hasil string yang diterima DFA adalah token. Parser rule mempunyai set input berupa token dengan hasilnya berupa statement (kalimat) yang valid.
DFA dapat divisualisasikan menggunakan notasi graph. Gambar 6 menggambarkan DFA yang menerima string Identifier dalam bahasa C sebagai valid input. String Identifier dalam bahasa C harus diawali dengan huruf atau karakter $ atau _, kemudian boleh diikuti dengan huruf, angka, $ dan _.
Definisi DFA: 1 Q = {q0, q1} 2 ? = {$, _, 0..9, a..z, A..Z} 3 d = { d(q0,$) = q1, d(q0,_) = q1, d(q0,a..z) = q1, d(q0,A...Z) = q1, d(q1,$) = q1, d(q1,_) = q1, d(q1,a..z) = q1, d(q1,A...Z) = q1, d(q1,0..9) = q1 } 4 q0 5 F = {q0,q1}
Gambar 6 DFA untuk menerima string Identifier dalam bahasa C.
DFA pada Gambar 6 di atas termasuk ke dalam kategori DFA yang merepresentasikan Memasukkan data input
ke dalam program hasil proses kompilasi
Baca data input dari penyimpanan data
Membandingkan data output dengan output dari
program hasil kompilasi Program hasil kompilasi
kode sumber
Hasil evaluasi output grader
Baca data output dari penyimpanan data
lexer rule, hal ini terlihat jelas dari simbol input, ?, yang terdiri dari karakter.
Definisi DFA:
1 Q = {q0, q1, q2, q3, q4, q5}
2 ? = {’if’, ’)’, ’(’, expression, statement, ’else’} 3 d = { d(q0, ’if’)=q1, d(q1, ’(’)=q2, d(q2, expression)=q3, d(q3, ’)’)=q4, d(q4, statement)=q5 , d(q5, ’else’)=q6, d(q6, statement)=q7 } 4 q0 5 F = {q5, q7}
Gambar 7 DFA untuk memvalidasi sintaks if dalam bahas a C.
Gambar 7 menerangkan DFA yang berasal dari parser rule untuk memvaliadasi sintaks if dalam bahasa C. Token ’if’ berada di depan kemudian harus diikuti dengan token ’(’ setelah itu diikuti oleh rule lain yang disebut expression. Token berikutnya adalah ’)’ diikuti dengan statement. Statement ini bisa merupakan apa saja, bisa saja statement tersebut adalah if, hal ini mengijinkan bahasa C untuk mempunyai nested if. Setelah statement, ada token ’else’. Token setelah ’else’ adalah rule lain yaitu statement. Seperti yang telah disinggung sebelumnya, statement bisa apa saja, bisa juga if lain, pola ini yang mengijikan adanya bentuk else if dalam bahasa C.
Tujuan pertama dari Intent Recognition adalah mencari kesalahan dalam kode sumber. Proses pencarian kesalahan terjadi dalam parser rule. Ketika DFA berusaha mencocokkan aturan dalam fungsi transisi (d) dengan token yang berhasil dikenali oleh lexer rule, DFA akan melaporkan kesalahan jika fungsi transisi tidak dipenuhi. Setiap kesalahan akan mempunyai kategori, hal ini untuk memudahkan penjelasan kesalahan oleh Intent Recognition dan memudahkan sistem perbaikan terotomasi dalam memperbaiki kesalahan.
Intent Recognition mempunyai tabel simbol yang mencatat semua simbol Identifier yang valid dalam kode sumber. Ketika DFA menemukan sebuah Identifier, Intent Recognizer akan tahu apakah Identifier itu sedang didefinisikan atau sedang digunakan.
Jika Identifier sedang didefinisikan, maka Intent Recognition akan menambahkan simbol tersebut dalam tabel simbol. Jika Identifier sedang digunakan, maka Intent Recognition akan mencari Identifier dalam simbol tabel. Jika Identifier belum ada pada tabel simbol, maka telah terjadi kesalahan dalam kode program.
Algoritma transformasi token akan dipanggil untuk mencari kemungkinan apakah token Identifer bisa ditransformasikan menjadi token lain yang ada dalam tabel simbol. Jika Identifier berhasil ditransformasi menjadi Identifier yang cocok dengan tabel simbol, Identifier tersebut dicatat sebagai kesalahan yang bisa diperbaiki. Jika Identifier tidak berhasil ditransformasi menjadi Identifier yang cocok, maka Intent Recognition hanya akan memberikan penjelasan kesalahan dan mengkategorikannya sebagai kesalahan yang tidak dapat diperbaiki secara terotomasi. Cara ini memenuhi tujuan ketiga Intent Recognition, y aitu mencatat kesalahan yang dapat diperbaiki secara terotomasi.
Intent Recognition mempunyai kemampuan untuk menambahkan, menghapus satu token untuk membuat kode sumber menjadi valid. Jenis kesalahan seperti ini juga dicatat oleh Intent Recognition sebagai kesalahan yang dapat diperbaiki secara terotomasi.
Sistem penjelas juga termasuk dalam Intent Recognition. Sistem penjelas bertugas untuk menjelaskan bagaimana kesalahan akan dijelaskan kepada siswa. Setiap kategori kesalahan akan mempunyai template penjelasan Start
yang sama. Menjelaskan setiap kesalahan dengan penjelasan yang berbeda merupakan pekerjaan yang sangat kompleks. Sistem penjelas menjalankan tujuan ketiga Intent Recognition: menjelaskan kesalahan dalam kode sumber.
Aturan utama yang harus dipenuhi oleh Intent Recognition adalah menghindari propagasi kesalahan. Propagasi kesalahan adalah kesalahan yang diakibatkan oleh kesalahan sebelumnya. Propagasi kesalahan akan membuat Intent Recognition menemukan terlalu banyak kesalahan dan sistem penjelas menampilkan terlalu banyak kesalahan daripada seharusnya.
Intent Recognition mencatat semua token baik yang valid atau tidak dalam tabel token. Tabel token diperlukan oleh sistem perbaikan terotomasi. Setiap token akan diberi nomor indeks yang unik. Misalnya untuk penghapusan satu token dan token tersebut banyak terdapat dalam kode sumber, diperlukan suatu identifier unik untuk setiap token.
Algoritma Transformasi Token
Misalkan L adalah himpunan tidak kosong yang terdiri dari simbol-simbol yang digunakan dalam bahasa C. Asumsikan bahwa sebuah string yang tidak terdapat dalam L dapat diturunkan dari string dalam L dengan melakukan serangkaian transformasi kesalahan. Modul Intent Recognition mengenal empat buah buah tipe kesalahan sintaks:
a Penggantian sebuah simbol dengan simbol yang lainnya (TR).
b Penyisipan simbol (TI). c Penghapusan simbol (TD).
d Letak yang terbalik antara dua simbol (TS). Keempat kesalahan di atas dapat direpresentasikan dalam empat transformasi TR,
TI, TD, dan TS. Transformasi-transformasi tersebut
dirumuskan sebagai berikut.
Misalkan x dan y adalah karakter yang ada dalam token, sedangkan a dan b adalah karakter yang akan ditambahkan atau dihapus dari token. a xby ditransformasikan dengan penggantian
satu huruf menjadi TR(xay) untuk a <> b b xay ditransformasikan dengan penyisipan
satu huruf menjadi TI(xy) untuk semua a c xy ditransformasikan dengan penghapusan
satu huruf menjadi TD(xay) untuk semua a
d xy ditransformasikan dengan pemindahan posisi menjadi TS(yx)
Misalnya, L={while }, dan terdapat string “Wihle”, ‘h’ dan ‘i’ adalah kesalahan letak yang terbalik (TS), sedangkan ‘W’ adalah kesalahan penggantian simbol dengan simbol yang lainnya (TR).
Wihle –TRà wihle –TSà while Algoritma Pemeriksaan dan Pencatatan Kesalahan
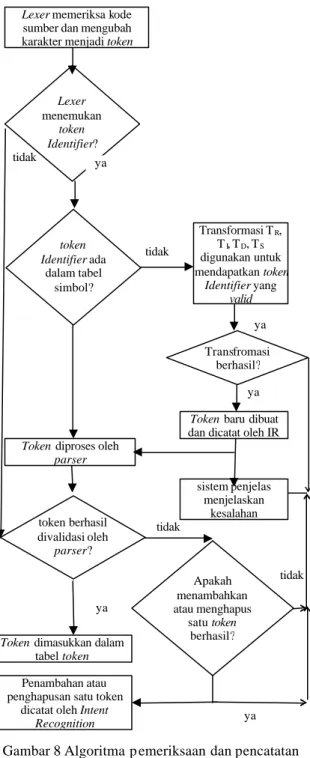
Untuk melakukan perbaikan kesalahan Intent Recognition mengambil langkah-langkah algoritmik sebagai berikut, sebagian langkah diilhami oleh konsep Intent Recognition yang digagas oleh Franek (2003):
1. Lexer memeriksa kode sumber yang ditulis siswa dan berusaha mengubahnya menjadi token. Misalkan S adalah aliran karakter yang akan dirubah menjadi token T.
2. Jika T adalah Identifier,
a Parser akan memeriksa apakah parser sedang dideklarasikan atau sedang digunakan.
b Jika sedang dideklarasikan, maka T akan dimasukkan dalam tabel simbol.
c Jika sedang digunakan T akan dicocokkan dengan Identifier dalam tabel simbol.
d Jika parser tidak menemukan T dalam tabel simbol, maka transformasi TR, TI,
TD dan TS akan dijalankan untuk
mendapatkan token yang valid.
e Jika transformasi berhasil, Intent Recognition akan mencatat kesalahan sebagai kesalahan yang dapat diperbaiki secara terotomasi. Kemudian panggil sistem penjelas untuk menampilkan kesalahan.
f Jika transformasi gagal cukup panggil sistem penjelas untuk menampilkan kesalahan, dan beri keterangan sebagai kesalahan yang bisa diperbaiki secara terotomasi.
3. Parser akan memvalidasi token menggunakan parser rule.
a Jika valid maka token akan disimpan oleh parser sebagai valid token.
b Jika tidak valid, lakukan percobaan untuk menghapus atau menambahkan satu token. Jika berhasil catat sebagai
tidak tidak ya ya tidak tidak token Identifier ada dalam tabel simbol? token berhasil divalidasi oleh parser? Lexer memeriksa kode sumber dan mengubah karakter menjadi token
ya
Token diproses oleh parser Lexer menemukan token Identifier? ya Penambahan atau penghapusan satu token
dicatat oleh Intent Recognition Apakah menambahkan atau menghapus satu token berhasil? Token dimasukkan dalam
tabel token sistem penjelas menjelaskan kesalahan Transformasi TR, TI, TD, TS digunakan untuk mendapatkan token Identifier yang valid tidak Transfromasi berhasil? ya Token baru dibuat dan dicatat oleh IR kesalahan yang dapat diperbaiki secara
terotomasi.
Proses pemeriksaan dan pencatatan kesalahan oleh Intent Recognition digambarkan pada Gambar 8.
5 Perancangan Sistem Perbaikan
Terotomasi
Sistem perbaikan terotomasi bekerja sangat erat dengan Intent Recognition. Ketika Intent Recognition memeriksa kode sumber dan terjadi kesalahan dalam kode sumber, Intent Recognition akan memeriksa apakah kesalahan bisa diperbaiki secara terotomasi. Proses perbaikan terotomasi dilaksanakan setelah Intent Recognition selesai memeriksa semua kode sumber.
Kesalahan yang bisa diperbaiki secara terotomasi dicatat oleh Intent Recognition. Kesalahan penulisan token Identifier, yang dap at diperbaiki menggunakan algoritma transformasi token dicatat dalam satu tabel. Sedangkan kesalahan karena penambahan atau pengurangan satu token dicatat dalam tabel yang lain. Pemisahan ini untuk mempermudah proses perbaikan terotomasi.
Perbaikan kesalahan penulisan Identifier dilakukan terlebih dahulu. Proses perbaikan sangat sederhana, menemukan nomor urut token dalam tabel token, kemudian mengganti token tersebut dengan token yang benar. Tidak ada perubahan nomor urut token.
Proses perbaikan kesalahan karena penambahan atau pengurangan satu token lebih rumit dibanding perbaikan kesalahan penulisan Identifier. Jika kesalahannya karena penambahan satu token, proses perbaikan harus menemukan nomor urut token yang berlebih tersebut, kemudian menghapusnya. Proses pengapusan ini dicatat dalam tabel perubahan token, karena akan mempengaruhi nomor urut token. Sebaliknya jika kesalahannya karena ada satu token yang tidak lengkap, proses perbaikan terotomasi harus menemukan token terakhir sebelum token yang hilang. Kemudian menyisipkan satu token pada posisi yang telah ditentukan. Proses penyisipan juga dicatat dalam tabel perubahan token.
Gambar 8 Algoritma p emeriksaan dan pencatatan kesalahan oleh Intent Recognition. Proses perbaikan terotomasi berjalan secara interaktif. Siswa dapat memutuskan untuk menjalankan proses perbaikan kesalahan terotomasi atau tidak. Pilihan yang bisa diambil oleh siswa ada tiga:
a Yes: siswa menerima proses perbaikan terotomasi.
Jendela Project Jendela Soal Jendela Kode Jendela Output Menu bar, Tool bar
b No: siswa menolak perbaikan terotomasi yang sedang dilaksanakan.
c Cancel: siswa membatalkan semua perbaikan terotomasi yang akan dilaksanakan.
6 Perancangan Antarmuka
Antarmuka modul evaluasi digambarkan dalam Gambar 9:
Gambar 9 Perancangan Antarmuka Modul Evaluasi.
Gambar 9 memperlihatkan empat buah jendela utama:
a Jendala kode: menampilkan kode sumber jawaban siswa. Jendela kode merupakan text editor yang mempunyai fasilitas seperti: copy, paste, cut, find, undo, redo, save dan nomor baris.
b Jendela project: menampilkan struktur data dari modul evaluasi, setiap soal ditampilkan dalam bentuk tree. Jendela project juga menampilkan file .c hasil jawaban siswa atas setiap pertanyaan. c Jendela soal: menampilkan pertanyaan
secara lengkap, termasuk data input/output yang digunakan oleh output grader .
d Jendela output: menampilkan penjelasan kesalahan kode sumber dan keterangan tentang event yang sedang terjadi dalam modul evaluasi.
Implementasi
1 Implementasi Struktur Penyimpanan Data
Struktur penyimpanan data yang dipilih adalah XML. Format XML yang fleksibel menjadi kelebihan utama XML dibanding format penyimpanan data lain, seperti basis data relasional.
Berikut ini adalah struktur dokumen XML yang digunakan dalam modul evaluasi untuk merepresentasikan satu buah soal:
1<ITS nama="Module pelatihan level 1"> 2 <soal id="1">
3 <nama>faktorial</nama>
4 <pertanyaan>buat sebuah aplikasi yang menghitung bilangan faktorial 5 </pertanyaan> 6 <sintaks-khusus> 7 <elemen>for</elemen> 8 <elemen>if</elemen> 9 </sintaks-khusus> 10 <jawaban-jawaban>
11 <jawaban id="1" asupan="0" keluaran="1"/> 12 <jawaban id="2" asupan="1"
keluaran="1"/> 13 <jawaban id="3" asupan="2"
keluaran="2"/> 14 <jawaban id="4" asupan="3"
keluaran="6"/> 15 </jawaban-jawaban> 16 <tingkat-kesulitan>mudah </tingkat-kesulitan> 17 <waktu-mengerjakan>3 </waktu-mengerjakan> 18 <terjawab>tidak</terjawab> 19 <hasil-jawaban></hasil-jawaban> 20 <template-atas> <![CDATA[ #include <stdio.h>; int main(){ int a, b; ]]> 21 </template-atas> 22 <template-bawah> <![CDATA[ printf("%d",b); return 0; } ]]> 23 </template-bawah> 24</soal> 25</ITS>
Tag ITS adalah tag root dalam dokumen XML ini. Setiap dokumen ITS ini bisa diibaratkan satu modul latihan soal untuk setiap satuan pengajaran, misalny a per bab.
Dalam setiap modul latihan soal, terdapat beberapa soal yang harus diselesaikan oleh siswa. Dalam setiap definisi soal akan disertakan data, antara lain:
a Id soal. b Nama soal. c Pertanyaan.
d Sintaks khusus yang harus terdapat dalam jawaban siswa.
e Data untuk output grader. f Tingkat kesulitan soal.
g Waktu normal yang dibutuhkan siswa untuk mengerjakan soal (dalam satuan menit) h Status soal, apakah sudah terjawab atau
belum.
i Hasil jawaban siswa berupa kode sumber. j Template atas dan template bawah yang
ditujukan untuk output grader .
Pengajar mendefinisikan dokumen soal sebagai bahan evaluasi sekaligus pembelajaran bagi siswa. Dokumen yang berbentuk XML ini idealnya harus divalidasi menggunakan XML Schema atau DTD (Data Transformation Diagram), namun untuk saat ini masih belum dicakup dalam penelitian ini.
2 Implementasi Output Grader
Output grader diimplementasikan menjadi class Grader. Di dalam class Grader terdapat dua buah method compile dan grade. Method compile bertugas mengkompilasi kode sumber bahasa C menjadi file executable, method compile mempunyai tipe kembalian boolean. Jika proses kompilasi berhasil, method compile akan mengembalikan true, dan nilai false dikembalikan jika proses kompilasi gagal.
Modul evaluasi memanggil method compile untuk menget ahui apakah terdapat kesalahan atau tidak dalam kode sumber. Jika method compile mengembalikan nilai false, berarti terdapat kesalahan dalam kode sumber. Modul evaluasi selanjutnya akan memanggil Intent Recognition untuk menganalisa kode sumber.
Method grade digunakan untuk menjalankan proses grading. Salah satu parameter input dari method grader adalah object dari class Soal yang didalamnya terdapat data pasangan input dan output. Parameter lainnya tentu saja adalah file executable yang dihasilkan jika method compile mengembalikan nilai true. Method grade akan mengeksekusi executable file dengan memasukkan data input, kemudian mengambil hasil output dari hasil eksekusi tersebut. Hasil output akan dibandingkan dengan data output. Jika sama, maka kode sumber yang ditulis siswa benar, jika berbeda artinya terdapat kesalahan logika dalam penulisan kode sumber.
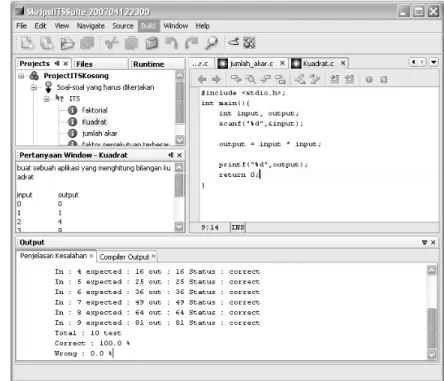
Berikut ini ditampilkan contoh hasil keluaran dari output grader :
Start to test… *************
In: 2 Out: 4 Status: Correct In: 3 Out: 8 Status: Correct In: 4 Out: 16 Status: Correct In: 5 Out: 32 Status: Correct ************
Total: 4 test Correct: 100% Wrong: 0%
3 Implementasi Intent Recognition
ANTLR (ANother Tool for Language Recognition) adalah sebuah pustaka Java yang menyediakan alat untuk membuat language recognition, language generator dan translator. ANTLR menyediakan bahasa mark-up tingkat tinggi untuk mendefinisikan grammar dari sebuah bahasa, kemudian membuat lexer dan parser untuk mengenali grammar dari bahasa tersebut. Bahasa mark-up tersebut adalah grammar specification.
Grammar specification merupakan sekumpulan rule-rule yang mirip regular expression. Seperti yang telah dibahas dalam perancangan, terdapat dua jenis rule, yaitu lexer rule dan parser rule.
Lexer rule digunakan untuk mendefinisikan bagaimana memotong-motong karakter menjadi token, berikut ini contoh implementasi dari lexer rule untuk mengenali Identifier seperti diterangkan DFA dalam Gambar 6:
IDENTIFIER : Letter (Letter|'0'..'9')* ; fragment Letter : 'a'..'z' | 'A'..'Z' | '$' | '_' ;
Dua buah lexer rule di atas digunakan untuk mendefinisikan token dengan tipe Identifier. Identifier adalah token yang terdiri dari kombinasi huruf a-z, A–Z, $ dan _. Dalam konsep bahasa, lexer rule digunakan untuk mengubah huruf menjadi kata.
Parser rule digunakan untuk memeriksa apakah urutan dari token sudah sesuai dengan grammar (tata bahasa) atau belum. Setiap bahasa, termasuk C, mempunyai tata bahasa yang harus dipatuhi, kesalahan urutan token membuat
program tersebut melanggar tata bahasa yang sudah ditentukan.
Dalam konteks bahasa indonesia, mirip dengan pengertian: apakah suatu urutan kata (token) sudah sesuai dengan kaidah Subjek Predikat Objek Keterangan (grammar) .
Sebagai contoh, di bawah ini adalah parser rule untuk mengecek tata bahasa C untuk kondisi if-else seperti diterangkan DFA dalam Gambar 7.
conditional_statement
: 'if' '(' expression ')' statement ('else' statement)?
;
Grammar specification akan diterjemahkan menjadi Java class menggunakan ANTLR tool generator. Hasil terjemahannya adalah dua buah class: CLexer.java dan CParser.java. Setiap parser rule akan diterjemahkan menjadi sebuah public method dalam CParser.java dan setiap lexer rule akan diterjemahkan menjadi public method dalam CLexer.java.
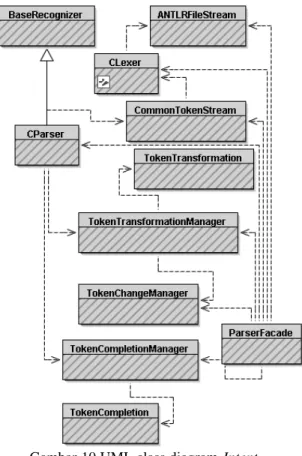
Gambar 10 adalah UML class diagram yang menggambarkan struktur class implementasi Intent Recognition dan sistem perbaikan terotomasi.
Class ParserFacade memegang kendali proses pemeriksaan kode sumber. Method parse dari class ParserFacade akan memanggil class CLexer dan CParser, kemudian memerintahkan keduanya untuk mulai memeriksa kode sumber. Kode untuk memanggil lexer dan parser dalam class ParserFacade: 1 CharStream inputStream =
new ANTLRFileStream(file.getPath()); 2 CLexer lexer = new CLexer(inputStream);
3 CommonTokenStream stream = new CommonTokenStream(lexer); 4 CParser parser = new CParser(stream); 5 parser.translation_unit();
Method translation_unit pada class CParser di atas memerintahkan parser untuk mulai memeriksa kode sumber. Setiap kali parser memeriksa kode sumber, method nextToken dari CLexer dipanggil untuk mengambil token berikutnya. Ketika parser rule gagal mengenali kode sumber, CParser akan membuat salah satu dari delapan subclass RecognitionException yang ada dalam Tabel 1.
Gambar 10 UML class diagram Intent Recognition dan Sistem Perbaikan Terotomasi.
Class BaseRecognizer adalah superclass dari CParser yang mempunyai method emitErrorMessage yang bertugas untuk menjelaskan kesalahan yang ada dalam kode sumber.
Tabel 1 Daftar Jenis Kesalahan yang Dikenali oleh Lexer dan Parser.
Jenis Kesalahan
Keterangan
Recognition Semua jenis kesalahan
merupakan subclass dari Recognition.
Mismatched Token
Mengindikasikan bahwa token yang dicari oleh parser tidak ada.
Mismatched
Tree Node M engindikasikan bahwa token yang dicari untuk membentuk
Abstract Syntax Tree tidak ditemukan.
Failed
Predicate Hasil evaluasi semantic predicate gagal token oleh Mismatched
Set
Lexer berusaha mencocokkan sekumpulan simbol, tetapi gagal
Jenis Kesalahan
Keterangan
No Viable Alternatives
Kesalahan karena lookahead yang didefinisikan tidak cukup panjang untuk menentukan antara dua alternatif. Dengan kata lain grammar yang didefinisikan bersifat ambigu.
Early Exit Parser sampai pada rule yang menyaratkan kecocokan dengan satu alternatif atau lebih ( (..)+ ), tetapi rule tidak dapat mencocokkan dengan apapun.
Mismatched Range
Lexer berusaha mencocokkan karakter yang sedang aktif dengan range karakter, dan ternyata gagal.
Mismatched Not Set
Lexer berusaha mencocokkan kebalikan dari kumpulan simbol (~), tetapi gagal
Penjelasan terhadap kesalahan sangat sederhana, di mana setiap jenis kesalahan dijelaskan dengan minimal satu cara, sehingga minimal ada tujuh macam penjelasan kesalahan dalam kode sumber. D i bawah ini adalah cuplikan implementasi method emitErrorMessage y ang menerangkan kesalahan dengan jenis Mismatched Token . 1 if (e instanceof MismatchedTokenException ) 2 { 3 MismatchedTokenException mte = MismatchedTokenException) e; 4 String tokenName="<unknown>"; 5 if ( mte.expecting == Token.EOF ) { tokenName = "EOF"; 6 } else { 7 tokenName = tokenNames[mte.expecting]; 8 } 9 msg = "input " + getTokenErrorDisplay(e.token) + " tidak cocok" + " seharusnya "+tokenName; 10 }
Class CParser juga memeriksa apakah kesalahan bisa diperbaiki secara terotomasi. Seperti yang telah dibahas di bagian perancangan, terdapat dua jenis kesalahan yang dapat diperbaiki secara terotomasi.
Kesalahan pertama adalah kesalahan penulisan Identifier. Kesalahan ini termasuk dalam jenis kesalahan Failed Predicate. Jika
kesalahan Failed Predicate ditemukan, CParser akan memanggil method getClosestToken dari class TokenTransformationManager untuk mendapatkan token Identifier yang paling mirip dengan token yang sedang diperiksa.
Method getClosestToken
mengimplementasikan algoritma transformasi token. Empat proses transformasi token TR, TI,
TD, TS dilaksanakan terhadap token yang
diperiksa, kemudian dicocokkan dengan simbol tabel. Jika proses transformasi berhasil mencocokkan token yang sedang diperiksa dengan token-token yang berada dalam tabel simbol, maka kesalahan Failed Predicate dapat diperbaiki secara terotomasi. Informasi kesalahan tersebut dicatat dengan membuat object dari class TokenTransformation. Setelah informasinya dicatat, informasi tersebut disimpan dalam class TokenTransformationManager.
Kesalahan kedua adalah kesalahan Mismatched Token. Kesalahan Mismatched Token terjadi karena CParser berharap untuk menemukan suatu token tertentu ternyata yang ditemukan adalah jenis token yang lain. Misalnya setelah token ’(’ ditemukan, maka CParser akan mengharapkan token ’)’ akan ditemukan pada titik tertentu dalam kode sumber. Jika ternyata yang ditemukan adalah token dengan jenis lainnya, maka kesalahan ini dikategorikan sebagai Mismatched Token. Tidak semua jenis kesalahan Mismatched Token dapat diperbaiki secara terotomasi. Kesalahan Mismatched Token yang dapat diperbaiki dengan cara menambahkan atau menghapus satu token adalah kesalahan yang dapat diperbaiki secara terotomasi. Kesalahan Mismatched Token yang dapat diperbaiki dalam dua langkah penambahan atau penghapusan token, tidak dapat diperbaiki secara terotomasi. Class TokenCompletion mencatat informasi kesalahan dan class TokenCompletionManager menyimpan semua informasi tersebut.
4 Implementasi Sistem Perbaikan
Terotomasi
Sistem perbaikan terotomasi berjalan setelah Intent Recognition selesai memeriksa semua kode sumber. Sistem perbaikan t erotomasi menggunakan informasi kesalahan dari class TokenCompletionManage r dan class TokenTransformationManager sebagai basis untuk melakukan perbaikan secara terotomasi.
Proses perbaikan terotomasi dilaksanakan dalam dua tahap. Tahap pertama adalah memperbaiki kesalahan yang ada dalam class TokenTransformationManager. Informasi kesalahan tersebut akan dikirim ke class TokenChangeManager, kemudian class TokenChangeManager akan merubah token yang ada dalam text editor. Proses perbaikan kesalahan Mismatched Token dalam TokenTransformationManager sangat sederhana. Token yang salah akan digantikan oleh token yang benar, tidak ada perubahan nomor indeks token, hanya pergantian teks biasa. Tahap kedua adalah proses perbaikan kesalahan yang ada dalam TokenCompletionManager. Informasi kesalahan akan dikirimkan ke class TokenChangeManager, kemudian akan diputuskan apakah perubahan yang terjadi merupakan penyisipan satu token atau penghapusan satu token, berdasarkan pada informasi yang terkandung dalam object TokenCompletion. Proses penyisipan atau penghapusan kesalahan direkam oleh TokenChangeManager, hal ini dikarenakan terjadi perubahan nomor indeks dari tabel token. Penyisipan satu token akan menyebabkan indeks token setelah penyisipan bertambah satu, dan penghapusan satu token akan menyebabkan indeks token setelah penghapusan berkurang satu. Jika perubahan indeks token ini tidak dihitung secara cermat, TokenChangeManager akan menyisipkan atau menghapus token di tempat yang salah.
Sistem perbaikan terotomasi mempunyai hubungan langsung dengan kode sumber yang ada dalam text editor. Setiap kali sistem perbaikan terotomasi merubah kode sumber, perubahan tersebut langsung terlihat pada text editor. Class javax.swing.text.Document menyimpan semua text yang ditampilkan oleh text editor. Jika isi dari class Document dirubah, maka tampilan dari text editor juga berubah.
Di bawah ini kode yang digunakan oleh sistem perbaikan terotomasi untuk mengganti token yang salah dengan token yang benar pada class Document:
1 public static void transformToken( Document doc, int index,
String newToken){ 2 int listIndex =
getListIndex(doc, index);
3 int position =
getPosition(doc, index);
4 List tokens = getTokenList(doc); 5 String oldToken = (String)tokens.get(listIndex); 6 doc.remove(position, oldToken.length()); 7 doc.insertString(position, newToken, null); 8 tokens.set(listIndex, newToken); 9 } 5 Proses Tutorial
Proses perbaikan kesalahan oleh Intent Recognition, tidak dilakukan secara otomatis untuk semua kesalahan, namun melibatkan siswa untuk melakukan klarifikasi atas perbaikan kesalahan yang dilakukan oleh Intent Recognition. Hal ini akan menyebabkan hanya perubahan yang disetujui oleh siswa yang akan benar-benar dilakukan.
Dengan demikian siswa diajak untuk berfikir bagaimana memperbaiki kesalahan dengan sesedikit mungkin bergantung pada Intent Recognition. Berikut ini dialog yang akan terjadi antara siswa dengan IR:
inr I,val=1
For ( I = 0 ; I <= 4 ; I++{ Val *= 2;
}
IR: “apakah maksud anda adalah keyword “int”?”
Siswa: Ya
Intent Recognition akan melakukan perubahan terhadap string “inr” menjadi “int” dan parser akan memvalidasi perubahan ini karena user telah mengklarifikasi perubahan. Hasil perbaikan:
int I,val=1
For ( I = 0 ; I <= 4 ; I++{ Val *= 2;
}
IR: “apakah maksud anda menambahkan “;” setelah “val=1” “? Siswa: Ya Hasil perbaikan: int I,val=1; For ( I = 0 ; I <= 4 ; I++{ Val *= 2; }
IR: “apakah maksud anda adalah keyword “for” ?“
Siswa: Ya Hasil perbaikan: int I,val=1;
Val *= 2; }
IR: “apakah maksud anda menambahkan “)” diantara “I++” dan “{“ “?
Siswa: Ya Hasil perbaikan: int I,val=1; for ( I = 0 ; I <= 4 ; I++){ Val *= 2; }
IR: “apakah maksud anda adalah variabel “val” “? Siswa: Ya Hasil perbaikan: int I,val=1; for ( I = 0 ; I <= 4 ; I++){ val *= 2; }
Proses tut orial ini bersifat dinamik, siswa tidak harus mengikuti proses tutorial hingga semua kesalahan berhasil diperbaiki. Siswa bisa dengan mudah kembali ke text editor untuk memperbaiki kesalahannya secara langsung tanpa menunggu Intent Recognition melakukannya, kemudian memproses jawaban yang baru tersebut dari awal. 6 Implementasi Antarmuka Sistem
Antarmuka sistem disusun menurut kaidah usability yang baik. Dengan menggunakan komponen-komponen yang dimiliki oleh NetBeans Platform, sehingga tampilan aplikasi menjadi sangat menarik dan intuitif.
Gambar 11 Tampilan A ntarmuka Modul Evaluasi Tampilan aplikasi dibagi menjadi empat
jendela utama seperti terlihat dalam Gambar 11. Jendela navigasi disebelah kiri digunakan untuk menampilkan soal-soal dan hasil pengerjaan siswa dalam bentuk Tree. Jendela utama disebelah kanan digunakan untuk menampilkan soal dan text editor untuk menuliskan jawabannya. Text editor dilengkapi dengan kemampuan editing standard: copy, cut, paste, undo dan redo.
Jendela bagian bawah menampilkan output aplikasi. Output berupa penjelas an dari sistem penjelas tentang kesalahan yang dibuat oleh
siswa atau keterangan aktifitas yang terjadi dalam modul evaluasi. Jendela output juga digunakan sebagai kontrol untuk memperoleh interaksi dari user apakah memerlukan bantuan sistem perbaikan otomatis atau tidak.
Output grader juga akan memanfaatkan jendela output untuk mencetak proses pengujian program siswa menggunakan data input/output yang telah didefinisikan untuk setiap soal. Secara umum, semua yang terjadi dalam sistem akan ditampilkan dalam jendela output.
7 Issue dalam Implementasi Sistem
ANTLR menyediakan banyak fitur yang bisa memotong waktu penulisan grammar hingga separuh lebih. Namun lingkungan pengembangan aplikasi ANTLR tidak cukup produktif.
Pertama kita harus mendefinisikan grammar dengan menggunakan Grammar Specification Language, kemudian membangkitkan lexer dan parser menjadi file Java. Langkah berikutnya adalah melakukan kompilasi file Java menjadi class. Setelah itu lexer dan parser baru bisa dites menggunakan contoh bahasa yang akan dikenali.
Semua langkah tersebut dilaksanakan dalam aplikasi berbasis console, sehingga terasa sangat menyulitkan. Namun, beberapa waktu lalu direlease sebuah IDE dengan nama AntlrWorks. IDE ini digunakan untuk mengembangkan aplikasi ANTLR yang telah dilengkapi dengan tampilan yang intuitif, text editor dengan code completion, fasilitas debugging dan visualisasi ANTLR rule dalam bentung NFA ataupun DFA. Gambar 12 memperlihatkan tampilan dari AntlrWorks.
Gambar 12 AntlrWorks membantu mengembangkan aplikasi ANTLR. Text editor yang digunakan dapat telah
dilengkapi dengan operasi dasar text editor, sehingga memudahkan user untuk menuliskan jawabannya.
NetBeans Platform adalah framework dan pustaka pengembangan aplikasi desktop di Java yang masih sangat muda. Berbeda dengan pustaka swing yang telah mapan, NetBeans Platform tergolong masih muda. Oleh karena itu mencari sumber pembelajaran dan teman yang dapat ditanyai mengenai NetBeans platform sangat sulit.
Konsep MVC (Model, View, Controller) yang diterapkan dalam NetBeans Platform pada
awalnya sangat membingungkan dan membutuhkan waktu cukup lama untuk memahami alur pengembangan aplikasi. Namun setelah dikuasai, produktifitas menjadi meningkat sangat tajam. Dengan usaha yang tidak terlalu besar, aplikasi yang dihasilkan sangat memuaskan. Librari yang disediakan NetBeans platform sangat banyak, walaupun dokumentasinya minimalis.
8 Kelebihan Sistem
Dengan desain antarmuka yang intuitif, sistem terlihat profesional dan mudah digunakan oleh user. Menu, toolbar dan icon yang digunakan disesuaikan dengan kebutuhan user,
untuk mempermudah pekerjaan user dan tidak membingungkan.
Jendela output sangat informatif memberikan informasi lengkap tentang apa yang sedang terjadi dalam sistem, sehingga user dengan dapat dengan mudah memantau kegiatan yang telah dilaksanakannya.
Format penyimpanan data berbasis XML sangat fleksibel dan mudah dimengerti oleh pengajar. Hanya dengan berbekal text editor, pengajar bisa dengan mudah mendefinisikan modul soal untuk user. Penambahan dan pengurangan modul soal sangat gampang, hanya dengan menambahkan file XML yang telah dibuat, maka modul tersebut secara otomatis akan dikenali oleh sistem.
NetBeans Platform telah dilengkapi dengan sistem docking yang superior. Jendela aplikasi dapat dipindahkan ke sana kemari sesuai selera user, sehingga user dapat mengkustomisasi tampilan sistem sesuai dengan preference masing-masing.
9 Kekurangan Sistem
Sistem yang dikembangkan dengan Java dan NetBeans platform memerlukan PC yang mempunyai sumber daya memadai. PC lama yang mempunyai sumber daya terbatas membuat kinerja sistem terasa lambat dan tidak responsif.
Format penyimpanan data yang berupa XML memungkinkan siswa untuk berbuat curang dengan secara langsung merubah isi dari modul soal.
Pengujian Kinerja Sistem Evaluasi
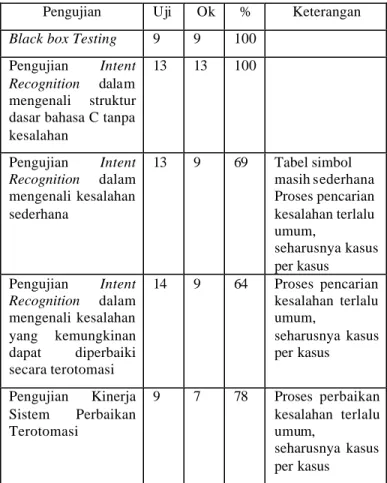
Pengujian kinerja sistem evaluasi dibagi menjadi tiga bagian, bagian pertama adalah pengujian fungsionalitas antarmuka sistem dengan metode black box testing, hasil pengujian dapat dilihat di lampiran 3. Bagian kedua adalah pengujian kinerja Intent Recognition dengan melakukan serangkaian test untuk mengukur keberhasilan Intent Recognition dalam memeriksa kode sumber, hasil tes kinerja Intent Recognition dapat dilihat pada Lampiran 1. Bagian terakhir adalah pengujian kinerja sistem perbaikan terotomasi, hasilnya dapat dilihat pada Lampiran 2. Hasil pengujian modul evaluasi dapat dilihat pada Tabel 2:
Tabel 2 Hasil Pengujian Modul Evaluasi
Pengujian Uji Ok % Keterangan Black box Testing 9 9 100
Pengujian Intent Recognition dalam mengenali struktur dasar bahasa C tanpa kesalahan 13 13 100 Pengujian Intent Recognition dalam mengenali kesalahan sederhana 13 9 69 Tabel simbol masih sederhana Proses pencarian kesalahan terlalu umum, seharusnya kasus per kasus Pengujian Intent Recognition dalam mengenali kesalahan yang kemungkinan dapat diperbaiki secara terotomasi 14 9 64 Proses pencarian kesalahan terlalu umum, seharusnya kasus per kasus Pengujian Kinerja Sistem Perbaikan Terotomasi 9 7 78 Proses perbaikan kesalahan terlalu umum, seharusnya kasus per kasus
Hasil pengujian menunjukkan bahwa Intent Recognition dapat mengenali 100% kode yang benar. Tetapi proses pendeteksian kesalahan dan perbaikan kesalahan masih harus ditingkatkan lagi untuk memperoleh persentase 100%. Kekurangan Intent Recognition terletak pada ”konteks”, Intent Recognition memeriksa kode program dengan aturan umum, tidak kasus per kasus.
Pengujian Kompleksitas Algoritma Pada Modul Evaluasi
Analisis kompleksitas algoritma dalam modul evaluasi pada sistem pembelajaran cerdas: 1 LL(*) parser
Parser dengan metode ini mempunyai efisiensi terburuk O(n2), tanpa adanya ambiguitas, efisiensinya adalah O(n). 2 Memoization
Memoization digunakan untuk menghindari non deterministik dalam LL(*)
parser, mempunyai efisiensi O(n) dalam best case dan O(n2) dalam worse case.
3 Backtracking
Backtracking adalah pilihan yang membutuhkan komputasi intensif karena dapat menyebabkan LL(*) parser mempunyai efisiensi exponensial, namun backtracking digunakan secara terbatas dalam kasus-kasus t ertentu saja, sehingga tidak semua kasus menggunakan backtracking. Efisiensi terburuk dari backtracking adalah O(n2).
4 Algoritma perbaikan otomatis
a Perbaikan kesalahan penulisan identifier Algoritma perbaikan kesalahan sintaks sangat sederhana dengan hanya mengetes apakah suatu pola tertentu dapat didekati dengan salah satu dari emp at metode pergantian: TR, TI, TD, TS. Efisiensi algoritmanya adalah linier O(n).
b Perbaikan kesalahan penghapusan atau penambahan satu token
Algoritma untuk melakukan kesalahan semantik terbatas pada penghapusan satu token dan penambahan satu token. Algoritma ini akan mencari posisi dari token yang akan dihapus atau ditambahkan. Efisiensinya adalah linier O(n).
KESIMPULAN DAN SARAN Kesimpulan
Sistem pembelajaran cerdas menjanjikan solusi optimal untuk mengajarkan bahasa pemrograman kepada siswa. Metode pembelajaran private dapat dilaksanakan secara intensif menggunakan sistem pembelajaran cerdas.
Modul evaluasi mengajarkan bahasa pemrograman kepada siswa dengan metode learning by doing. Metode learning by doing adalah metode paling tepat untuk mengajarkan bahasa pemrograman kepada siswa.
Intent Recognition mengenali kode sumber yang dibuat oleh siswa, jika dalam proses pengenalan kode sumber ditemukan kesalahan,
sistem penjelas akan memberikan penjelasan yang memadai. Sistem perbaikan terotomasi membantu siswa memperbaiki kesalahan dalam kode sumber siswa, proses perbaikan kesalahan dilaksanakan secara interaktif.
Kinerja Intent Recognition dalam mengenali kode sumber sudah 100% benar, tetapi kinerja Intent Recognition untuk mengenali kesalahan dan memperbaiki kode sumber secara terotomasi masih dibawah 100%. Hasil ini dikarenakan implementasi tabel simbol yang hanya menyimpan simbol saja, sedangkan metadata dari simbol tidak disimpan. Penyebab lainnya adalah proses pencarian kesalahan dilaksanakan dengan analisis umum untuk semua kasus, seharusnya ada analisis untuk kasus per kasus.
Saran
Penelitian ini dapat dilanjutkan dengan usaha untuk menyatukan semua modul sistem pembelajaran cerdas menjadi satu aplikasi yang lengkap dan dapat digunakan.
Kinerja Intent Recognition yang berhasil disusun dalam penelitian ini masih dibawah 100%. Diperlukan usaha lebih lanjut untuk meningkatkan kinerja Intent Recognition dalam memeriksa kesalahan dan memperbaiki kesalahan secara terotomasi. Perbaikan tersebut dapat dilaksanakan dengan menambahkan unsur “konteks” pada proses pemeriksaan kesalahan. Perwujudan dari unsur “konteks” adalah tabel simbol yang menyimpan metadata dari setiap simbol dengan lebih lengkap. Tabel simbol tidak hanya menyimpan simbol saja, tetapi juga menyimpan informasi metadata dari simbol tersebut, misalnya tipe data, scope dan range data.
Pengembangan Intent Recognition untuk bisa mengenali kesalahan logika. Salah satu cara untuk mengenali kesalahan logika adalah menggunakan metode static analysis . Metode static analysis lazim digunakan untuk mencari pola-pola kesalahan logika yang sering muncul dalam kode sumber.
Pengembangan lebih lanjut sistem pembelajaran cerdas tidak hanya terbatas pada pengajaran bahasa C, tetapi juga bahasa pemrograman lain. Misalnya: bahasa pemrograman Java untuk mata kuliah Sistem Berorientasi Object dan SQL untuk mata kuliah Basis Data.