BRUTE FORCE & GREEDY
Diajukan untuk memenuhi salah satu tugas mata kuliah Analisis Algoritma
Penyusun
Nama /NIM : Huril In Afqiha Taubatin - 10115704
Kelas : Analgo-1
JURUSAN TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
UNIVERSITAS KOMPUTER INDONESIA
2016
KATA PENGANTAR
Puji syukur kita panjatkan kehadirat Allah SWT atas limpahan rahmat, taufik dan inayah-Nya serta nikmat sehat sehingga penyusunan makalah guna memenuhi tugas mata kuliah Analisis Algoritma ini dapat selesai sesuai dengan yang diharapkan. Shalawat serta salam selalu tercurahkan kepada baginda Nabi Muhammad SAW dan semoga kita selalu berpegang teguh pada sunnahnya Amiin.
Dalam penyusunan makalah ini tentunya hambatan yang selalu mengiringi. Namun atas bantuan, dorongan dan bimbingan dari orang tua, dosen pembimbing dan teman-teman yang tidak bisa saya sebutkan satu per satu akhirnya semua hambatan dalam penyusunan makalah ini dapat teratasi.
Semoga makalah ini dapat memberikan manfaat dan sebagai sumbangsih pemikiran khususnya untuk para pembaca. Tidak lupa kami mohon maaf apabila dalam penyusunan makalah ini terdapat kesalahan baik dalam kosa kata ataupun isi dari keseluruhan makalah ini. Kami sebagai penulis sadar bahwa makalah ini masih jauh dari kata sempurna dan untuk itu kritik dan saran sangat kami harapkan demi kebaikan kami untuk kedepannya.
DAFTAR ISI
KATA PENGANTAR...I DAFTAR ISI...ii DAFTAR TABEL...iii DAFTAR GAMBAR...iv BAB IPENDAHULUAN...1 1.1Pendahuluan...1 1.2Tujuan...1 BAB IIPEMBAHASAN...2 2.1 Egyptian Fractions...2 2.2 Penjadwalan...6 2.3 Knapsack...72.4 Job Scheduling dengan Deadline...8
2.5 Minimum Spanning Tree (Kruskal & Prim)...13
2.6 Shortest Path...15
2.7 Algoritma Huffman...16
2.8 Map Coloring...19
DAFTAR TABEL
Tabel 1 Pekerjaan pada Penjadwalan Produksi Industri Konveksi...9 Tabel 2 Langkah ke-1: Hasil Himpunan Solusi Sementara ...10 Tabel 3 Langkah ke-2: Hasil Himpunan Solusi Sementara
Tabel 4 Langkah ke-3: Hasil Himpunan Solusi Sementara Tabel 5 Langkah ke-4: Hasil Himpunan Solusi Sementara Tabel 6 Langkah ke-5: Hasil Himpunan Solusi Sementara Tabel 7 Langkah ke-6: Hasil Himpunan Solusi Sementara Tabel 8 Langkah ke-7: Hasil Himpunan Solusi Sementara Tabel 9 Langkah ke-8: Hasil Himpunan Solusi Sementara Tabel 10 Langkah ke-n: Hasil Himpunan Solusi Akhir (n=14) Tabel 11 Solusi Algoritma Greedy
DAFTAR GAMBAR
Gambar 2.1 Ilustrasi Pembagian Karung Beras...2
Gambar 2.2 Urutan Yang Mungkin ...6
Gambar 2.3 Algortima Penjadwalan...6
Gambar 2.4 Penjadwalan Produksi...8
Gambar 2.5 Ilustrasi Penjadwalan Single-Stage Pada Mesin Parallel...9
Gambar 2.6 Implementasi Penjadwalan Produksi Dengan Pemrograman Java...12
Gambar 2.7 Pseudo Code Minimum Spanning Tree Prim...14
Gambar 2.8 Pseudo Code Algoritma Kruskal...15
Gambar 2.9 Contoh Graph Coloring...20
BAB I
PENDAHULUAN
1.1 Pendahuluan
Algoritma Brute force adalah pendekatan langsung (straight forward) untuk memecahkan suatu masalah. Algoritma brute force memecahkan masalah dengan sangat sederhana, langsung dan dengan cara yang jelas (obvious way). Algoritma ini memiliki karakteristik yaitu :
a. Algoritma brute force umumnya tidak “Cerdas” dan tidak efisien b. Membantu menemukan algorima yang lebih cerdas
c. Mudah diimplementasikan
d. Lebih relevan untuk input yang berukuran kecil
Algoritma Greedy merupakan jenis algoritma yang menggunakan pendekatan penyelesaian masalah dengan mencari nilai maksimum sementara (local optimum) pada setiap langkahnya. Prinsip algoritma greedy yaitu “ Take what you can get now”. Karakteristik algoritma greedy yaitu :
a. Mengambil pilihan terbaik tanpa memikirkan konsekuensi kedepan
b. Berharap bahwa dengan memilih optimum lokal pada setiap langkah, akan berakhir pada optimum global.
1.2 Tujuan
Makalah ini dibuat bertujuan untuk :
a. Memahami algortima brute force dan penerapannya b. Memahami algorima greedy dan penerapannya
BAB II
PEMBAHASAN
2.1 Egyptian Fractions
Egyptian Fraction (pecahan Mesir) adalah representasi dari pecahan sebagai penjumlahan dari unit - unit pecahan. Representasi ini digunakan pada peradaban mesir kuno dan masih berdiri. Permasalahan yang ada adalah cara efisien menuemukan unit – unit pecahan pembentuk pecahan tersebut. Dimana, pemecahan permasalahan ini telah dicoba oleh matematikawan dari seluruh dunia. Walaupun, metode untuk menemukan unit – unit pecahan tersebut telah banyak ditemukan, namun belum ada di antaranya yang paling efisien untuk memecahkan permasalahan ini. Sedangkan, sebelum metode – metode tersebut bermunculan, metode sitametik permasalahan ini dipublikasikan pertama kali oleh Fibonacci pada tahun 1202. Metode tersebut disebut Algoritma Greedy karena setiap langkah dari algotima tersebut secara greed (rakus) memilih unit pecahan terbesar yang dapat digunakan sebagai representasi dari pecahan tersebut dan secara rekursif melakukan hal yang sama dengan pecahan yang tersisa.
Untuk penggunaan Egyptian Fraction salah satunya adalah dengan menyelesaikan permasalahan pembagian beras. Pertama, kita lihat bahwa masing-masing timbunan paling tidak mendapat setengah karung sehingga tiap timbunan dapat dituang dengan setengah karung, dan
tinggal 1 karung yang belum dibagi. Sekarang, menjadi lebih mudah untuk membagi satu karung menjadi 8 timbunan. Maka dari satu karung tersebut, dapat dibagi menjadi 8 timbunan, dan masing – masing karung terbagi secara merata ke menjadi 8 timbunan.
Gambar2.1 Ilustrasi pembagian karung beras
Penggunaan lain Egyptian Fraction adalah untuk membandingkan pecahan. Contohnya adalah, manakah yang lebih besar antara 3
4 dengan 4
5 ? Kita dapat menggunakan
besar dari 34 . Bagaimana caranya, menentukan pecahan yang lebih besar dengan Egyptian Fraction? Dengan Egyptian Fraction, kita dapat menulis masing-masing pecahan sebagai penjumlahan dari unit pecahan.
3 4= 1 2+ 1 4 4 5= 1 2+ 3 10 Dimana, 3 10= 1 4+ 1 20
Sehingga kita dapati,
4 5= 1 2+ 1 4+ 1 20
Sekarang kita dapat menentukan bahwa 45 lebih besar dengan perbedaan 201 . A. Dari Pecahan Ke Egyptian Fraction
Egyptian Fraction untuk pecahan TB merupakan penjumlahan dari unit-unit pecahan, dengan masing – masing unit berbeda sehingga jika dijumlahkan menjadi sebesar
T
B . Matematikawan telah membuktikan bahwa setiap pecahan T
B dapat dituliskan sebagai penjumlahan dari unit-unit pecahan dan masing-masing unit pecahan dapat dituliskan dengan berbagai unit pecahan yang tak terbatas. Contohnya adalah pecahan ¾, dimana dapat dituliskan sebagai, 3 4= 1 2+ 1 4 3 4= 1 2+ 1 8+ 1 12+ 1 24, atau 3 4= 1 2+ 1 8+ 1 12+ 1 48+ 1 72+ 1 144
Hal ini menunjukkan bahwa bila kita menuliskan TB dalam suatu cara, maka kita dapat memperoleh hasil yang lain sebanyak mungkin.
B. Metode Fibonacci
Metode ini dituliskan Fibonacci dalam bukunya yang berjudul Liber Abaci yang diprodulsi pada tahun 1202. Pertama, harus kita pastikan terlebih dahulu bahwa,
T
B<1 dan Jika T=1, permasalahan telah terselesaikan (sebagaimana kita ketahui T B sudah termasuk unit pecahan). Jadi kini kita akan mendalami pecahan dimana nilai T lebih besar dari 1. Metode ini digunakan untuk menemukan unit pecahan terbesar dari TB dan merupakan algoritma Greedy. Setelah unit pecahan terbesar dari pecahan tersebut ditemukan, maka proses tersebut diulang kembali untuk menemukan unit pecahan dari sisa pecahan. Dapat diketahui bahwa rentetan unit pecahan ini akan selalu mengecil dan mengecil nilainya, tidak pernah mengulang unit pecahan yang telah ada, dan tidak berakhir. Proses ini disebut algoritma dan algoritma ini adalah salah satu contoh algoritma greedy, karena kita (secara greed) mengambil unit pecahan terbesar dan mengulangnya untuk sisa pecahan. Dalam algoritma ini, untuk menemukan unit-unit pecahan dari pecahan TB , dan untuk mengambil unit pecahan terbesar, dapat dilakukan dengan melakukan langkah-langkah berikut:
Langkah 1.
Lakukan peng-assign-an T = x dan B= y Langkah 2.
Jika x= 1, xy maka menjadi bagian perluasan, dan perluasan berhenti disini. Jika tidak, lakukan perluasan melalui persamaan berikut :
x y= 1 [y x] +−y mod x y[ y x]
Langkah 3. Kembali ke Langkah 2. Contohnya : 7 15= 1 3+ 2 15= 1 3+ 1 8+ 1 120
Dari hasil perluasan di atas, 3, penyebut dari unit pecahan pertama merupakan hasil dari pembulatan 157 ke integer yang lebih besar, dan pecahan sisanya 152 adalah hasil dari
penyederhanaan (−15mod7)
15 ×3 =
6 45 .
Penyebut dari unit pecahan kedua, 8, adalah hasil dari membulatkan 152 ke integer
yang lebih besar, dan sisa pecahan 1
120 adalah sisa dari 7
15 setelah dikurangi dengan 1
3 dan 1
8 . Masing-masing langkah perluasan menurunkan penyebut dari sisa pecahan
yang akan diperluas. Langkah-langkah dalam algortima Greedy tersebut dapat diterjemahkan menjadi pseudo-code, sebagai berikut:
Akan tetapi, bagaimanapun juga, Egyptian Fraction yang dihasilkan oleh metode ini tidak kesemuanya merupakan hasil yang terbaik. Contohnya, dengan metode greedy, 174 tereduksi menjadi : 4 17= 1 5+ 1 29+ 1 1233+ 1 3039345
Dimana dapat kita cek bahwa :
4 17= 1 5+ 1 30+ 1 510
Sehingga, dapat disimpulkan bahwa hasil perluasan dari pecahan ini, tidak selalu yang terbaik.
function GreedyEgypt(int T, int B)->List {fungsi untuk mencari unit-unit pecahan dari Egyptian Fraction}
deklarasi: L:List; x’:integer y’:integer algoritma: begin x:=T y:=B if (x=1) begin
ListL, berisi satu elemen x/y end
else begin
ListL, berisi unit pecahan 1/[y div x]
x’:= (-y) mod x y’:= y*[y div x] GreedyEgypt(x’,y’) end
return L end;
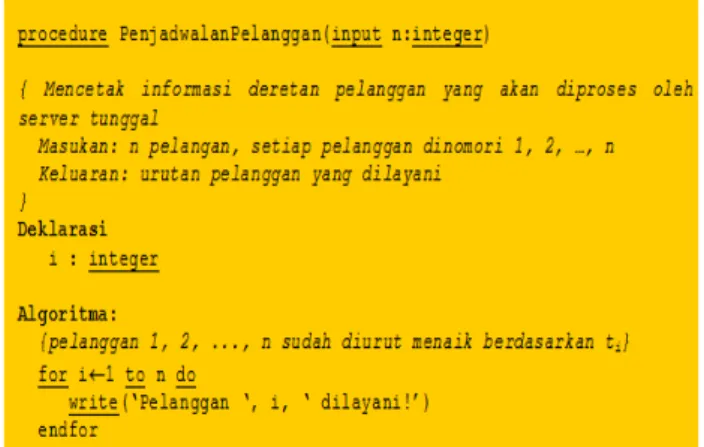
2.2 Penjadwalan
Persoalan: Sebuah server (dapat berupa processor, pompa, kasir di bank, dll) mempunai n pelanggan (customer, client) yang harus dilayani. Waktu pelayanan untuk setiap pelanggan i adalah ti. Minimumkan total waktu di dalam sistem :
T=
∑
i=1 n(Waktu DalamSistem)
Ekivalen dengan meminimumkan waktu rata-rata pelanggan di dalam sistem. Tiga pelanggan dengan :
t1=5,t2=10, t3=3
Enam urutan pelayanan yang mungkin :
Gambar 2.2 Urutan yang mungkin
Agar proses pemilihan pelanggan berikutnya optimal, urutkan pelanggan berdasarkan waktu pelayanan dalam urutan yang menaik. Jika pelanggan sudah terurut, kompleksitas algoritma :
Greedy=O(n)
2.3Knapsack
Dalam kehidupan sehari-hari, kita sering dipusingkan dengan media penyimpanan yang terbatas padahal kita diharuskan menyimpan beberapa objek kedalam media tersebut. Bagaimana kita mengatur objek apa saja yang dipilih dan seberapa besar objek tersebut disimpan?
Dari permasalahan tersebut, munculah suatu permasalahan yang dikenal dengan “Permasalahan Knapsack” atau lebih dikenal dengan “Knapsack Problem”. Masalah Knapsack merupakan suatu permasalahan bagaimana memilih objek dari sekian banyak dan berapa besar objek tersebut akan disimpan sehingga diperoleh suatu penyimpanan yang optimal dengan memperhatikan objek yang terdiri dari n objek (1,2,3,…) dimana setiap objek memiliki bobot (Wi) dan profit (Pi) dengan memperhatikan juga kapasitas dari media penyimpanan sebesar M dan nilai probabilitas dari setiap objek (Xi). Metode Greedy merupakan salah satu cara untuk mendapatkan solusi optimal dalam proses penyimpanan. Pada metode ini untuk mendapatkan solusi optimal dari permasalahan yang mempunyai dua kriteria yaitu Fungsi Tujuan/Utama dan Nilai Pembatas (Constrain). Fungsi Tujuan hanya terdiri atas satu fungsi sedangkan Fungsi Pembatas dapat terdiri atas lebih dari satu fungsi. Menyelesaikan suatu masalah dengan beberapa fungsi pembatas untuk mencapai satu fungsi tujuan. Jadi dalam penyelesaiannya harus ditentukan mana sebagai fungsi pembatas dan mana sebagai fungsi tujuan. Cara menyelesaikan masalah Knapsack adalah :
1. Tentukan Fungsi Tujuan, yaitu mencari nilai maximum dari jumlah hasil perkalian antara nilai profit (Pi) dengan nilai probabilitas (Xi) Maximum ∑ Pi.Xi
2. Tentukan Fungsi Pembatas, yang merupakan hasil penjumlahan dari perkalian antara bobot (Wi) dengan nilai probabilitas (Xi) yang tidak boleh melebihi dari kapasitas media penyimpanan (M) ∑Wi.Xi≤M, dimana 0≤Xi≤1, Pi>0, Wi>0
Dari ke-2 cara di atas berarti kita harus mengetahui : 1. Jumlah objek (n)
2. Bobot setiap objek (Wi) 3. Profit setiap objek (Pi)
4. Probabilitas setiap objek (Xi), dan 5. Kapasitas media penyimpanan (M)
Algoritma greedy untuk penyelesaian knapsack yaitu :
2.4 Job Sceduling Dengan Deadline
Gambar 2.4 Penjadwalan produksi
Penjadwalan produksi adalah pengalokasian sumber daya yang terbatas untuk mengerjakan sejumlah pekerjaan. Penjadwalan produksi terbagi atas beberapa kelompok seperti ditunjukkan pada Gambar 2.4. Penjadwalan single-stage adalah penjadwalan setiap pekerjaan (job) hanya melewati satu stasiun kerja saja untuk menghasilkan produk. Jika
PROCEDURE GREEDY KNAPSACK (P, W, X, n) REAL P(1:n), W(1:n), X(1:n), M, isi
INTEGER i, n X(1:n) = 0 isi = M
FOR i = 1 TO n DO
IF W(i) > isi THEN EXIT ENDIF X(i) = 1
isi = isi – W(i) REPEAT
IF i ≤ n THEN X(i) = isi/W(i) ENDIF END GREEDY KNAPSACK
pekerjaan dilayani oleh lebih dari satu stasiun kerja maka disebut single-stage in parallel machines, contoh: antrian pelayanan di teller bank. Penjadwalan multi-stage adalah penjadwalan setiap job yang harus melewati beberapa stasiun kerja untuk sebelum menghasilkan produk jadi.
Penjadwalan flow shop adalah proses penjadwalan job-job yang memiliki urutan pengerjaan yang sama saat melewati beberapa stasiun kerja. Sedangkan penjadwalan job shop adalah proses penjadwalan job-job yang memiliki urutan pengerjaan yang tidak sama. Penjadwalan job shop biasanya digunakan untuk menjadwalkan pekerjaan yang beragam dengan menggunakan fasilitas yang sama.
Penjadwalan job adalah penjadwalan untuk memecahkan masalah urutan saja, karena ukuran job telah diketahui sedangkan penjadwalan batch adalah penjadwalan untuk memecahkan masalah penentuan ukuran batch dan masalah urutan secara simultan. Dengan contoh kasus sebagai berikut :
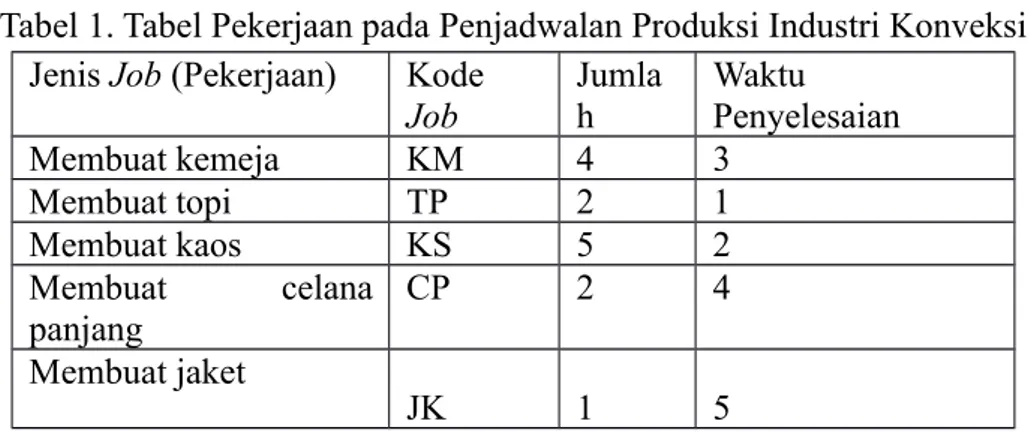
Berikut ini ilustrasi permasalahan pada penjadwalan produksi single-stage pada mesin parallel. Misalkan terdapat 5 (lima) jenis pekerjaan untuk membuat pakaian, jumlahnya serta waktu penyelesaian untuk setiap job seperti ditunjukkan oleh Tabel 1.
Tabel 1. Tabel Pekerjaan pada Penjadwalan Produksi Industri Konveksi Jenis Job (Pekerjaan) Kode
Job Jumla h Waktu Penyelesaian Membuat kemeja KM 4 3 Membuat topi TP 2 1 Membuat kaos KS 5 2 Membuat celana panjang CP 2 4 Membuat jaket JK 1 5
Pekerjaan dijadwalkan pada 3 (tiga) stasiun kerja (mesin jahit dan operator) seperti ditunjukkan pada Gambar 2.5. Penelitian ini mengasumsikan bahwa setiap operator penjahit memiliki skill yang sama sehingga setiap jenis pekerjaan akan diselesaikan dengan waktu yang sama.
Berikut ini adalah penyelesaian permasalahan penjadwalan produksi dengan algoritma greedy:
Kondisi saat inisialisasi
C = {JK, CP, CP, KM, KM, KM, KM, KS, KS, KS, KS, KS, TP, TP} // Himpunan kandidat S = { } // Himpunan solusi
Tabel 2 Langkah ke -1 : Hasil himpunan solusi sementara
Stasiun Kerja 1 Stasiun Kerja 2 Stasiun Kerja 3
JK -
-Kumulatif beban stasiun kerja 1,2,3 = 5,0,0 C = { CP, CP, KM, KM, KM, KM, KS, KS, KS, KS, KS, TP, TP}
Tabel 3 Langkah ke -2 : Hasil himpunan solusi sementara
Stasiun Kerja 1 Stasiun Kerja 2 Stasiun Kerja 3
JK CP
-Kumulatif beban stasiun kerja 1,2,3 = 5,4,0 C = { CP, KM, KM, KM, KM, KS, KS, KS, KS, KS, TP, TP}
Tabel 4 Langkah ke -3 : Hasil himpunan solusi sementara
Stasiun Kerja 1 Stasiun Kerja 2 Stasiun Kerja 3
JK CP CP
Kumulatif beban stasiun kerja 1,2,3 = 5,4,4 C = { KM, KM, KM, KM, KS, KS, KS, KS, KS, TP, TP}
Tabel 5 Langkah ke -4 : Hasil himpunan solusi sementara
Stasiun Kerja 1 Stasiun Kerja 2 Stasiun Kerja 3
JK CP CP
- KM
-Kumulatif beban stasiun kerja 1,2,3 = 5,7,4 C = { KM, KM, KM, KS, KS, KS, KS, KS, TP, TP}
Tabel 6 Langkah ke -5 : Hasil himpunan solusi sementara
Stasiun Kerja 1 Stasiun Kerja 2 Stasiun Kerja 3
JK CP CP
- KM KM
Kumulatif beban stasiun kerja 1,2,3 = 5,7,7 C = { KM, KM, KS, KS, KS, KS, KS, TP, TP}
Tabel 7 Langkah ke -6 : Hasil himpunan solusi sementara
Stasiun Kerja 1 Stasiun Kerja 2 Stasiun Kerja 3
JK CP CP
KM KM KM
Kumulatif beban stasiun kerja 1,2,3 = 8,7,7 C = { KM, KS, KS, KS, KS, KS, TP, TP}
Tabel 8 Langkah ke -7 : Hasil himpunan solusi sementara
Stasiun Kerja 1 Stasiun Kerja 2 Stasiun Kerja 3
JK CP CP
KM KM KM
- KM
-Kumulatif beban stasiun kerja 1,2,3 = 8,10,7 C = { KS, KS, KS, KS, KS, TP, TP}
Tabel 9 Langkah ke -8 : Hasil himpunan solusi sementara
Stasiun Kerja 1 Stasiun Kerja 2 Stasiun Kerja 3
JK CP CP
KM KM KM
- KM KS
Kumulatif beban stasiun kerja 1,2,3 = 8,10,9 C = { KS, KS, KS, KS, TP, TP}
Tabel 10 Langkah ke -n : Hasil himpunan solusi akhir (n=14)
Stasiun Kerja 1 Stasiun Kerja 2 Stasiun Kerja 3
JK CP CP
KM KM KM
KS KM KS
KS KS KS
TP - TP
Kumulatif beban stasiun kerja 1,2,3 = 13,12,12 C = { } // Himpunan kandidat telah kosong, iterasi berakhir
Dengan algoritma greedy maka hasil penjadwalan produksi dihasilkan dengan total waktu penyelesaian pekerjaan = max(13, 12, 12) = 13 jam. Algoritma greedy untuk kasus ini mempunyai kompleksitas waktu O(n). Berdasarkan pengujian dengan metode exhaustive search, algoritma greedy selalu menghasilkan solusi optimal minimum dan waktu penyelesaiaan yang lebih cepat dibanding metode exhaustive search. Hasil akhir algoritma greedy ditunjukkan oleh Table 11.
Tabel 11 . Solusi algoritma greedy
Job Stasiun Kerja 1 Stasiun Kerja 2 Stasiun Kerja 3
Membuat Kemeja 1 buah 2 buah 1 buah
Membuat topi 1 buah - 1 buah
Membuat kaos 2 buah 1 buah 2 buah
Membuat celana panjang - 2 buah 1 buah
Membuat jaket 1 buah -
-Total 13 jam 12 jam 12 jam
Pseudo Code :
2.5 Minimum Spanning Tree (Kruskal & Prim)
Pada Tahun 1926, Seorang Czech scientist, Otakar Boruvka, menemukan sebuah algoritma yang dikenal dengan Boruvka’s Algorithm. Seiring berjalannya waktu, ada 2 algoritma lain yang lebih umum untuk dipakai yaitu Algoritma Prim dan Algoritma Kruskal. Walau ada lebih dari 1 algoritma yang berbeda, namun jalan yang didapat akan sama panjangnya. Metode yang dipakai oleh ketiga Algoritma ini adalah metode Minimum Spanning Tree.
a. Algoritma Prim adalah suatu algoritma di dalam teori graf yang bertujuan menemukan Minimum Spanning Tree untuk menghubungkan graf berbobot. Ini berarti algoritma ini menemukan subset dari sebuah tepi yang membentuk sebuah Tree yang meliputi setiap titik nya. Dimana total beban dari setiap tepi di Tree diminimalkan. Jika Graf tidak terhubung, maka ini hanya akan menemukan sebuah Minimum Spanning Tree menjadi satu jalur untuk komponen yang terhubung. Algoritma ini ditemukan pada tahun 1930 oleh seorang ahli matematika Vojtech Jarnik, dan kemudian dipublikasikan oleh seorang computer scientist Robert C. Prim pada tahun 1957 dan ditemukan kembali oleh Dijkstra pada tahun 1959. Oleh karena itu terkadang Algoritma ini juga disebut DJP algorithm atau algoritma Jarnik. Cara Kerja Algoritma Prim yaitu :
Buat sebuah Tree yang mengandung vertex tunggal, pilih yang berbobot minimum
Buat sebuah set ( yang belum tercakup ) yang mengandung semua vertices yang lain di dalam graf
Buat sebuah set (fringe vertices) yang di inisialiasai kosong
Loop(jumlah vertices - 1) :
a. Pindahkan tiap vertives yang belum tercakup dan secara langsung terhubung kepada node terakhir, tambahkan ke fringe set
b. Untuk tiap titik di set sisi, tentukan, jika sebuah sisi menghubungkan vertices dengan node terakhir yang ditambahkan, jika iya, maka jika sisi tersebut memiliki bobot lebih kecil dari sisi sebelumnya yang menghubungkan vertex ke Tree yang telah terbuat, masukkan sisi baru ini melalui node terakhir yang ditambahkan sebagai rute terbaik di Tree yang telah terbuat.
c. Pilih sisi dengan bobot minimum yang menghubungkan vertex dalam fringe set ke vertex pada Tree yang sudah terbuat
d. Tambahkan sisi tersebut ke Tree dan pindahkan fringe vertex dalam fringe set ke sebuah vertex dalam Tree yang sudah terbuat.
e. Update node terakhir yang ditambahkan untuk menjadi fringe vertex yang baru ditambahkan
Hanya | V | -1, dimana | V | adalah jumlah dari vertices dalam graf, pengulangan diperlukan. Sebuah Tree menghubungkan | V | vertices hanya membutuhkan | V |-1 sisi dan tiap pengulangan dari algoritma yang dideskripsikan diatas tertarik dalam tepat 1 sisi. Implementasi yang simpel menggunakan representasi adjacency matrix graph dan mencari sebuah barisan bobot untuk mencari sisi dengan bobot minimum. Dengan pseudo code seperti berikut :
Gambar 2.7 pseudo code minimum spanning tree prim
b. Algoritma Kruskal pertama kali dipopulaerkan oleh Joseph Kruskal pada tahun 1956. Algoritma Kruskal adalah sebuah algoritma dalam teori graf yang mencari sebuah Minimum Sanning Tree untuk sebuah graf berbobot yang terhubung. Ini berarti mencari subset dari sisi yang membentuk sebuah Tree yang menampung setiap vertex, dimana total bobot dari semua sisidalam Tree adalah minimum. Jika graf tidak terhubung, kemudian ini mencari sebuah Minimum Spanning Forest (sebuah Minimum Spanning Tree untuk tiap komponen yang terhubung ). Algoritma Kruskal adalah suatu contoh dari algoritma greedy. Cara kerja algoritma kruskal yaitu :
a. Buat sebuah Forest F (set dari Tree), yang tiap vertex dalam graf adalah Tree pemisah
b. Buat sebuah set S yang mengandung semua sisi didalam graf c. While S tidak kosong :
Jika sebuah sisi menghubungkan dua pohon yang berbeda, kemudian tambahkan ini kedalam Forest, kombinasikan 2 Tree kedalam1 Tree.
Dilain pihak, buang sisi tersebut
Dalam terminasi dari algoritma ini, Forest hanya memiliki satu komponen dan membentuk sebuah Minimum Spanning Tree dari graf. Dengan pseudo code sebagai berikut :
Gambar 2.8 pseudo code algoritma kruskal 2.6 Shortest Path
Lintasan terperndek adalah lintasan minimum yang diperlukan untuk mencapai suatu tempat dari tempat tertentu. Lintasan minimum yang dimaksud dapat dicari dengan menggunakan graf. Graf yang digunakan adalah graf yang berbobot, yaitu graf yang setiap sisinya diberikan suatu nilai atau bobot. Dalam kasus ini, bobot yang dimaksud berupa jarak dan waktu kemacetan terjadi. Ada beberapa macam persoalan lintasan terpendek, antara lain:
Lintasan terpendek antara dua buah simpul tertentu (a pair shortets path).
Lintasan terpendek antara semua pasangan simpul (all pairs shortest path).
Lintasan terpendek dari simpul tertentu ke semua simpul yang lain (single-source shoertest path).
Lintasan terpendek antara dua buah simpul yang melalui beberapa simpul tertentu (intermediate shortest path).
Dalam makalah ini, persoalan yang digunakan adalah single-source shortest path. Diberikan sebuah persoalan :
“Diberikan sebuah graf berbobot G (V, E). Tentukan lintasan terpendek dari simpul awal, a, ke setiap simpul lainnya di G. Asumsi bahwa bobot semua sisi bernilai positif.”
Algoritma greedy untuk mencari lintasan terpendek dapat dirumuskan sebagai berikut: 1. Perikasa semua sisi yang langsung bersisian dengan simpul a. Pilih sisi yang
bobotnya terkecil. Sisi ini menjadi lintasan terpendek pertama, sebut saja L(1). 2. Tentukan lintasan terpendek kedua dengan cara berikut :
(i) hitung: d(i) = panjang L(1) + bobot sisi dari simpul akhir L(1) ke simpul i yang lain
(ii) pilih d(i) yang terkecil Bandingkan d(i) dengan bobot sisi (a, i).
(iii) Jika bobot sisi (a, i) lebih kecil dari pada d(i), maka L(2) = L(1) U (sisi dari simpul akhir L(i) ke simpul (i).
3. Dengan cara yang sama, ulangi langkah 2 untuk menentukan lintasan terpendek berikutnya.
2.7 Kompresi Data dengan Algoritma Huffman
Prinsip kode Huffman adalah mengganti karakter yang paling sering muncul di dalam data dengan kode yang lebih pendek, sedangkan karakter yang lebih jarang muncul dikodekan dengan kode yang lebih panjang. Algoritma memiliki kompleksitas sebesar O(n log n) untuk himpunan dengan n karakter. Huffman menerapkan metode statik yaitu menggunakan peta kode yang selalu sama. Metode ini membutuhkan dua fase, sebagai berikut:
1. fase pertama untuk menghitung kemungkinan kemunculan tiap karakter dan menentukan peta kodenya
2. fase kedua untuk mengubah pesan menjadi kumpulan kode yang akan ditransmisikan. Algoritma greedy membentuk kode prefiks yang optimal pada kode Huffman. Langkah-langkah pembentukan pohon Huffman adalah sebagai berikut :
1. Baca semua karakter di dalam data untuk menghitung frekuensi kemunculan setiap karakter. Setiap karakter penyusun data dinyatakan sebagai pohon bersimpul tunggal. Dan setiap simpul ini di-assign dengan frekuensi kemunculan karakter tersebut.
2. Terapkan strategi greedy dengan menggabungkan dua buah pohon yang mempunyai frekuensi terkecil pada sebuah akar. Akar mempunyai frekuensi yang merupakan jumlah dari frekuensi dua buah pohon penyusunnya
3. Ulangi langkah dua sampai hanya tersisa satu buah pohon Huffman. Agar pemilihan dua pohon yang akan digabungkan berlangsung dengan cepat, maka semua pohon yang ada selalu terurut menaik berdasarka frekuensi.
4. Baca kembali karakter-karakter di dalam data, kodekan setiap karakter dengan kode Huffman yang bersesuaian.
Algoritma greedy digunakan untuk meminimumkan jumlah cost yang dibutuhkan untuk menggabungkan dua buah pohon pada akar yang telah disebut diatas. Penggabungan dua buah pohon dilakukan setiap langkah dan algoritma Huffman selalu memilih dua buah pohon yang memiliki frekuensi terkecil untuk meminimumkan total cost. Inilah alasan mengapa strategi greedy diterapkan dalam strategi penggabungan dua buah pohon. Misalnya, data dengan panjang 100 karakter dan disusun oleh huruf-huruf a,b,c,d,e dengan frekuensi kemunculan setiap huruf sebagai berikut :
Karakter Frekuens i A 45% B 13% C 12% D 16% E 9% F 5%
Langkah – langkah membuat pohon Huffman : 1. Langkah pertama :
3. Langkah ketiga :
4. Langkah keempat :
6. Langkah terakhir :
Pada langkah (2) diambil akar yang memiliki jumlah kemunculan terkecil. Dalam hal ini karakter yang memiliki nilai frekuensi terkecil adalah f dan e. Karakter e dan f kemudian dibentuk menjadi akar dari pohon yang baru. Pada langkah (3) diambil lagi 2 akar dari pohon yang memiliki jumlah kemunculan terkecil. Dalam hal ini adalah akar c dan b. Akar c dan b tadi digabung sehingga membentuk akar dari pohon yang baru dengan jumlah frekuensi sama dengan hasil penjumlahan frekuensi akar c dan b. Selanjutnya 2 akar terkecil pada langkah (3) digabungkan kembali untuk membentuk pohon dengan akar yang baru dengan frekuensi yang merupakan penjumlahan dari frekuensi akar pembentuknya. Akar terkecil yang diambil pada langkah (3) adalah fe dan d. Pada langkah (5) akar fed dan cb digabungkan untuk membentuk pohon yang baru. Langkah-langkah tadi terus dilakukan hingga semua akar yang ada telah digabung sehingga membentuk satu pohon yang baru dengan akar yang memiliki frekuensi sama dengan jumlah frekuensi seluruh akar pertama kali. Dalam hal ini seluruh akar pada langkah (1).
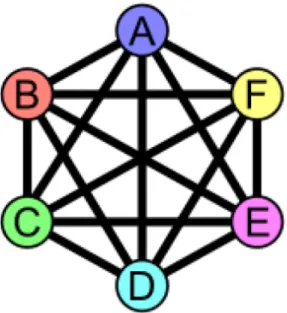
2.8 Map Coloring
Sejarah pewarnaaan graf berhubungan dengan pewarnaan peta. Ketika itu, muncul sebuah postulat yang menyatakan bahwa empat warna berbeda cukup untuk mewarnai seluruh daerah di Inggris sedemikian sehingga tidak ada daerah yang
sebagai permasalahan algoritmik sejak tahun 1970. Permasalahan bilangan kromatik pada pewarnaan graf merupakan salah satu masalah NP komplit.
Pewarnaan graf (graph coloring) merupakan permasalahan pewarnaan graf M-warna yang fokus pada pencarian seluruh jalan untuk meM-warnai graf tidak berarah menggunakan paling banyak M warna sedemikian hingga tidak ada simpul tetangga yang memiliki warna yang sama (pewarnaan titik) atau tidak ada garis yang saling bertetangga yang memiliki warna yang sama (pewarnaan garis). Dalam teori graf, pewarnaan graf merupakan kasus khusus pada pelabelan graf. Pelabelan tersebut dikaitkan dengan “warna‟ yang menunjuk pada elemen pada graf yang memiliki konstrain tersendiri.
Gambar 2.9 contoh graph coloring
Pewarnaan graf biasanya dikaitkan dengan pewarnaan pada simpul-simpulnya. Pewarnaan menggunakan paling banyak k warna disebut k-coloring. Jumlah paling sedikit warna yang dibutuhkan untuk mewarnai sebuah graf G disebut bilangan kromatik.
Algoritma greedy mengatur simpul-simpul yang ada dengan pengaturan tertentu v1, ..., vn dan mengisi vi dengan warna terkecil yang tersedia yang tidak digunakan oleh seluruh tetangga vi, diantara v1, ..., vi-1. Jika diperlukan, dapat ditambahkan warna baru pada simpul yang sedang diproses. Pewarnaan greedy tidak selalu menghasilkan jumlah warna minimal. Kualitas dari warna-warna yang dipilih tergantung pada pengurutan yang dipilih. Terdapat pengurutan yang menghasilkan pewarnaan greedy dengan jumlah warna yang optimal. Di samping itu, algoritma pewarnaan greedy juga dapat memberikan hasil yang cukup buruk, contohnya pada crown graph. Pada makalah ini, strategi pengurutan simpul pada graf didasarkan pada jumlah derajat pada masing-masing simpul. Algoritma greedy yang
mempertimbangkan jumlah derajat tiap simpul dalam pemilihan solusinya mempunyai warna paling banyak sebesar derajat terbesar simpul + 1.
X ¿ d¿ ¿ ¿ Maximin¿
Perhitungan heuristik ini sering disebut sebagai Welch Powell algorithm. Algoritma greedy untuk pewarnaan graf :
1. Pada graf G, cari derajat setiap simpul pada G
2. Inisialisasi himpunan simpul takberwarna dengan semua simpul pada graf G dengan urutan derajat tak menaik. Elemen pertama pada himpunan adalah simpul dengan derajat tertinggi.
3. Inisialisasi sebuah himpunan solusi dengan himpunan kosong.
4. Melakukan pemilihan simpul yang akan diisi warnanya dengan fungsi seleksi simpul pada himpunan simpul tak berwarna.
5. Menghapus simpul yang terpilih dari daftar simpul tak berwarna dan mengeset warna simpul terpilih dengan warna yang sekarang aktif.
6. Masukkan simpul dalam himpunan solusi
7. Memeriksa seluruh simpul yang ada di himpunan simpul yang tak berwarna:
a. Simpul yang layak akan dimasukkan dalam himpunan solusi (tidak bertetangga dengan simpul yang telah ada di himpunan solusi)
b. Simpul yang telah dinyatakan layak dihapuskan dari himpunan simpul tak berwarna
c. Simpul yang telah dinyatakan layak diberi warna dengan warna yang sedang aktif.
8. Naikkan indeks warna aktif
9. Jika seluruh simpul sudah diwarnai, proses berakhir. Jika belum semua simpul terwarnai, kembali ke langkah 3. Dengan pseudo code sebagai berikut :
DAFTAR PUSTAKA
1. Fitrhia Naila, 2008, Penerapan Algoritma Greedy Dalam Egyptian Franction, Bandung, ITB
2. http://slideplayer.info/slide/2789226/ diakses pada tanggal 8 desember 2016
3. Junair Ahmad, 2015, Penerapan Algoritma Greedy Pada Penjadwalan Produksi Single-Stage Dengan Parallel Machine Di Industri Konveksi, Jakarta, STMI
4. Ghaziani Fadli Hadyan, 2007, Studi Minimum Spanning Tree Dengan Algoritma Prim Dan Kruskal, Bandung, ITB
5. Defindal Prama Irvan, dkk, 2007, Algoritma Greedy Untuk Menentukan Lintasan Terpendek, Bandung, ITB
6. Callista Nessya, 2007, Aplikasi Greedy Pada Algoritma Huffman Untuk Kompresi Teks, Bandung, ITB
7. Passa Fitriana, 2010, Aplikasi Algoritma Greedy Pada Persoalan Pewarnaan Graf, Bandung, ITB