(
)
()2 2 2 2 2 1 s m ps x x e x f = --(
)
(
)
÷ ÷ ø ö ç ç è æ = -2 2 2 / 1 exp 2 2 1 s s p mx x +¥ < < ¥ -x ú û ù ê ë é = ú û ù ê ë é = S 22 21 12 11 2 1 2 2 1 1 Var( ) ) , ( K ) , ( Kov ) ( Var s s s s X X X ov X X XAN
ALISA D
A
T
A PEMODELAN UNTUK ILMU SOSIAL & SAINS
Dr. H.A. Parhusip
Dr. Sri Yulianto Joko Prasetyo
Sri Winarso Martyas Edi, S.Kom, M.Cs
Dr
. H.A. Parhusip
Dr
. Sri
Y
ulianto Joko Prasetyo
Sri W
inarso Martyas Edi, S.Kom, M.Cs
G R A F I K A Dr. Hanna Arini Parhusip, l
Sarjana bidang Matematika diperoleh pada tahun 1992 dari UGM, S2 bidang Matematika Industri diperoleh tahun 1997 dari Univ. Kaiserslautern Jerman, dan S3 Matematika Terapan diperoleh tahun 2003 dari ITB dan Sandwich program dengan Univ. Kaiserslautern, Jerman.
Bergabung sebagai pengajar di UKSW tahun 1994. Mengajar matematika di UKSW untuk berbagai mata kuliah S1 seperti analisa real, aljabar linear, optimasi nonlinear, persamaan diferensial, metode numerik, komputasi matematika, pemodelan dan analisa data multivariat, English mathematics, filosofi untuk sains, dan juga menjadi konsultan pengajar di SMP dan SMA Kalam Kudus Solo dan Kumon di Salatiga. Kegiatan ini juga mendorong untuk memperhatikan matematika pada dunia pendidikan dengan berbagai kurikulum internasional yang digunakan di Indonesia. Selain itu, juga menjadi dosen tamu untuk beberapa universitas di luar Jawa dan beberapa sekolah.
Penelitian yang sering dilakukan adalah menganalisa data industri di Salatiga dan sekitarnya sehingga banyak terkait dengan pemodelan dan optimasi. Dari Laboratorium Kimia di UKSW dengan beberapa kajian: optimasi protein, optimasi steviosida, optimasi untuk bidang pertanian dan pemodelan matematika dengan diferensial juga menjadi kegemarannya. Sekalipun demikian, penelitian bidang pendidikan matematika juga dilakukan (pengajaran Kalkulus dengan MATLAB, visualisasi fungsi kompleks).
Terdorong untuk mempromosikan matematika melalui budaya, cabang kalkulus diolah dan dimanfaatkannya untuk membuat motif-motif cantik untuk batik. Kegiatan ini akan dikembangkan agar menjadi aktivitas kreatif dari mahasiswa bersama secara
ber-ahir di kota Salatiga, 27 Februari 1968.
Dr. Sri Yulianto Joko Prasetyo, lahir di Klaten 25 Juli 1971, Pendidikan S1 bidang Biologi dari UKDW Yogyakarta pada tahun 1996, S2 bidang Ilmu Komputer dari UGM pada tahun 2003, dan S3 bidang Ilmu Komputer dari UGM pada tahun 2013. Saat ini aktif mengajar di Universitas Kristen Satya Wacana Salatiga pada Program Strata 1 Fakultas Teknologi Informasi pada Mata Kuliah Rekayasa Perangkat Lunak, Sistem Terdistribusi dan Basisdata, Strata 2 Program Magister Agroteknologi pada Mata Kuliah Analisis Spasial dan Analisis Statistik dan Strata 2 Program Magister Manajemen Pendidikan pada Mata Kuliah Literasi Komputer dan Sistem Informasi Manajemen Pendidikan. Penelitian yang telah dikerjakan atas pembiayaan Dikti sejak tahun 2008 hingga sekarang meliputi Hibah Bersaing 3 tahun, Hibah Stranas 2 tahun, dan Hibah Unggulan PT 2 tahun. Penelitian atas pembiayaan Asean Development Bank (ADB) diperoleh pada tahun 2014. Sejak tahun 2008 telah mempublikasikan 11 jurnal internasional.
Sri Winarso Martyas Edi, S.Kom,M.Cs. Lahir di Kab. Semarang, 29 Maret 1980. Pendidikan terakhir di Magister Sistem Informasi Fakultas Teknologi Informasi UKSW. Riwayat pekerjaan: bergabung dengan program studi Diploma 3 Teknik Informatika Fakultas Teknologi Informasi tahun 2006 - sekarang, resmi bergabung dengan pusat studi SIMITRO tahun 2014, bidang minat penelitian rekayasa sistem web dan multimedia, GIS, simulasi dan modeling.
ú û ù ê ë é -=178.686 80547.231 686 . 178 314 . 323 S () (i) i N i Y F N i N i Y F D -=££ , 1 ( max 1 ()()' 1 2() a c m m p x x £ -S - -ú û ù ê ë é = S- 22 21 12 11 1 B B B B
G R A F I K A
Penerbit Tisara Grafika
ANALISA DATA DENGAN PEMODELAN
UNTUK ILMU SAINS dan SOSIAL
menggunakan MATLAB, SCILABMenggunakan SPSS 16 menggunakan R
Untuk peneliti dan pengajar : mahasiswa S1, S2 , S3, saintis, ekonom dan pengguna matematika pada umumnya.
Untuk kalangan pemula membuat karya tulis ilmiah,
Aplikasi di bidang sains dan ilmu sosial untuk staff perencana program pembangunan
Dr. H.A. Parhusip
Sri Winarso Martyas Edi, S.Kom,M.Cs. Dr. Sri Yulianto Joko Prasetyo
Cetakan pertama : Juni 2014
ISBN :
Hak Cipta : Pada Penulis Editor : Dr. Sri Yulianto Desain Sampul : Tisara Grafika Tata letak : Harrie Siswanto Percetakan : Tisara Grafika Penerbit : Tisara Grafika
978-602-9493-16-0
Diterbitkan oleh:
JL. DIPONEGORO 98 D - SALATIGA 50714 - JAWA TENGAH Telp.: 0298-321798 | Fax : 0298-321798
Mobile: 081 228 598 985 | 0819 0488 340| 0298-6138702 email: [email protected], [email protected] Bank: BNI Cabang Salatiga No. Rek. 369 57809
G R A F I K A G R A F I K A
Hak Cipta dilindungi oleh Undang-undang
Dilarang mengutip atau memperbanyak sebagian atau seluruh buku ini tanpa seijin penulis
Katalog Dalam Terbitan
001.422
PAR Parhusip, H. A.
a Analisa data pemodelan untuk ilmu sosial dan sains / H. A. Parhusip. – (et al).--
Salatiga : Tisara Grafika, 2014. xvii, 398 hlm. ; 25 cm. ISBN 978-602-9493-16-0
1. Statistics. I. Title.
Data dan program pada buku ini dapat didownload dari: mathica2014.wix.com
Kata Pengantar
Buku ini ditulis untuk memberikan contoh-contoh menganalisa data dengan statistika maupun dengan matematika yang diintegrasikan dengan cara melakukan pemodelan dan cara pemrograman dengan MATLAB dan R. Hal ini sebagai materi untuk menterjemahkan data yang ada di dalam sehari-hari dan dapat dipakai untuk melakukan perencanaan.
Data yang diambil untuk studi merupakan data-data dari sekitar Salatiga, Jawa Tengah sehingga dapat dimanfaatkan untuk contoh membuat penelitian dan karya ilmiah.
Masalah yang sering muncul bukanlah cara menggunakan metode tetapi lebih pada cara memformulasi suatu masalah dari data atau lebih dikenal dengan melakukan pemodelan yang selanjutnya dapat merujuk teori yang terkait dengan model tersebut.
Buku ini ditulis sebagai media bagi para peneliti untuk berbagai strata. Untuk para matematikawan dan statistikawan, buku ini sangat membantu dalam memberikan contoh mengintegrasikan matematika dan statistik. Bagi para pengguna matematika dan statistika, maka buku ini membantu untuk lebih menajamkan cara mengemukakan karya ilmiah dengan lebih saintifik terutama yang bermula dengan adanya data.
Salatiga, Juni 2014
Daftar Isi
Kata Pengantar iii
Daftar Isi v
Daftar Tabel viii
Daftar Gambar xiii
1 STATISTIKA DISKRIPTIF 1
1.1.Variansi dan matriks kovariansi 1
1.2. Cara Bekerja dengan SPSS 8
1.3.Variansi-Kovariansi dan korelasi formula dalam SPSS 13
1.4. Studi Korelasi (Linear) 15
1.5. Distribusi Frekuensi 34
2 DISTRIBUSI NORMAL 67
2.1 Fungsi kepadatan distribusi normal 67
2.1.1. Untuk Satu variabel random 67
2.1.2. Untuk Satu variabel random 67
2.1.3. Untuk 3 variabel random 69
2.2. Uji Data 72
2.2.1. Uji chi-kuadrat 72
2.2.2. Uji Kolmogorov Smirnov (K-S test) 73
2.2.3. Uji normal multivariat 75
2.2.4. Uji normal multivariat dengan plot chi-kuadrat 81 2.2.5. Transformasi data menjadi berdistribusi
normal
88
3 MULTI VARIAT REGRESI 96
3.1. Regresi linear sederhana 96
3.2. Regresi fungsi 1 peubah untuk polinomial derajat k (k >1)
98 3.3. Regresi linear Multivariat (klasik) 107
3.4. Residu dan Hasil Regresi 111
3.5. Hasil analisis variansi 111
3.6. Regresi dengan SPSS 113
3.8 Linear regresi dengan variabel prediktor banyak 146 3.9 Regresi GSTAR (Generalized Space Time Auto
Regressive)
165
3.9.1 Model GSTAR 167
4 PCA (PRINCIPAL COMPONENT ANALYSIS) 188
4.1 Pendahuluan 188
4.2 Dasar-Dasar PCA 189
4.3 PCA dengan standarisasi Variabel 193
4.4. Kegiatan Penelitian 4.1 198
4.5. Bagaimana Memulai Analisa Data dengan Pemodelan 210
4.6 Kegiatan Penelitian 217
4.6.1 Kasus Kependudukan 217
5 ANOVA DAN MANOVA 224
5.1 Latar Belakang 224
5.2 Repeated Measures (Pengukuran Berulang) ANOVA 225
5.3 One way-ANOVA 230
5.3.1 Bagaimana ANOVA dengan SPSS 232
5.3.2 Two Way-ANOVA 233
5.4 Two –Way ANOVA dengan SPSS 238
5.5 Perbandingan Berpasangan (Paired Comparisons) 244
6 METODE DISKRIMINAN 269
6.1 Pendahuluan 269
6.2. Dasar-Dasar Metode Diskriminan 269
6.2.1 Metode Fisher untuk Mendiskriminasi Beberapa Populasi
271
6.3. Kegiatan penelitian 272
7 LEBIH LANJUT DENGAN GSTAR dan HASIL PENELITIAN TERKAIT
291
7.1 Pendahuluan 291
7.2 Modifikasi GSTAR 292
7.3 Masalah optimasi padi dan modifikasi GSTAR 298 7.3.1 Modifikasi GSTAR untuk produksi padi 299
8 BERBAGAI KEGIATAN PENELITIAN TEORI DENGAN PEMROGRAMAN
331
8.1 Jarak Statistik 331
8.2. Dekomposisi Spektral untuk matriks Kovariansi 342 8.3. Uji statistik untuk hasil parameter dari model modifikasi
GSTAR
346
DAFTAR PUSTAKA 350
9 PENELITIAN BERBASIS KONSEP DAN PENDEKATAN SPASIAL
351
9.1. Pendahuluan 351
9.2. Sains Informasi Geografis 355
9.3. Analisis Data Spasial 363
9.4. Metode Eksplorasi dan Analisis Data Spasial 365
9.5. Visualisasi Data Spasial 369
9.6. Teknologi Informasi dalam Analisis Spasial 372
DAFTAR PUSTAKA 374
10 KONSEP ANALISIS SPASIAL STATISTIKA 378
10.1 Klasifikasi metode analisis dan tujuan analisis Spasial Statistik
378
10.2 Konsep Spatial Autocorrelation 382
Daftar Tabel
1.1 Notasi statistik dan maknanya 2
1.2 Istilah statistik dan maknanya 2
1.3 Cara mendapatkan variansi satu variabel random 3 1.4 Program scilab untuk menghitung variansi 4 1.5 Cara mendapatkan variansi dua variabel random 5 1.6 Mencari nilai variansi X dan Y dengan program scilab 6 1.7 Cara mendapatkan variansi tiga variabel random 7
1.8 Pola data yang akan diolah 18
1.9 Bentuk data berdasarkan angket yang diberikan (diperoleh dari informasi informal oleh observer)
19 1.10 Nilai rata-rata tiap subvariabel dalam variabelX1 untuk
tiap responden
20
1.11 Rata-rata tiap 3 pertanyaan berturutan untuk tiap responden pada variabel
21 1.12 Rata-rata 3 pertanyaan untuk tiap responden dalam
variabel Y
23 1.13. Hasil korelasi (hanya yang lebih besar 0.5) antara
subvariabel dalam Y
26
1.14 Korelasi antara subvariabel dalam X1 dan X2
(hanya yang lebih besar 0.5)
29
1.15 Korelasi antara sub variabel dalam X1 dan X2
(hanya yang lebih besar 0.5)
31
1.16 Korelasi X2 dan Y 32
1.17 Data untuk 4 macam perlakuan pada 19 anjing 34 1.18 Program Scilab untuk menyusun matriks kovariansi
data pada Tabel 1.18, 1.3
39
1.19 Data Tabel 1.3 yang distandarisasi 39
1.20 Daftar program yang merupakan kelanjutan program pada Tabel 1.15
41 2.1 Data diambil dari (Johnson, and Wichern, 2007) 71
2.3 Data tekanan udara Boyolali bulan Juli-November 2009
82 2.4 Daftar pertanyaan untuk mengevaluasi dosen
(Parhusip dan Setiawan, 2011)
85 2.5 Hasil evaluasi terhadap 6 dosen untuk berbagai mata
kuliah yang disajikan
85 2.6 Daftar nilai hasil 3 matakuliah (Johnson andWichern,
hal.195)
86 3.1 Data indeks saham LQ45 dari 5 perusahaan pada
periode 1 Agustus 2011 - 9 September 2011
104 3.2 Pola data indeks LQ45 (variabel tak bebas) (sumbu
vertikal) dan indeks saham AALI (sumbu horizontal) pada 1 Agustus 2011-9 September 2011
105
3.3 Hasil regresi linear (k =1) 106
3.4 Hasil regresi univariat untuk polinomial derajat k=1,2,3, dan 4
107 3.5 Data 2 variabel prediktor dan 1 variabel respon (Y)
dalam Excel
114 3.6 Indeks Harga Saham per Sektor di Bursa Efek Jakarta 116 3.7 Indeks LQ45 (kolom ke-3) dengan nilai saham pada
saat penutupan (kolom ke-4 hingga 8)
139
3.8 Rata-rata suhu udara tahun 2000-2009 150
3.9 Rata-rata kelembaban udara tahun 2000-2009 151 3.10 Rata-rata curah hujan tahun 2000-2009 151 3.11 Rata-rata suhu udara, curah hujan, dan kelembaban
udara tiap bulan di tahun 2000-2009
156 3.12 Rata-rata curah hujan dan kelembaban udara 157
3.13 Data curah hujan dan kelembaban udara 157
3.14 Hasil keluaran regresi program R 160
3.15 Hasil keluaran dengan program SPSS 160
3.16 Sifat dari yang diperoleh 162
3.17 Sifat-sifat dari 163
3.18 Rata-rata Suhu Udara tahun 2000-2009 164
3.19 Rata-rata Kelembaban Udara tahun 2000-2009 164 3.20 Rata-rata Curah hujan tahun 2000-2009 165
3.21 Hasil uji korelasi Pearson untuk Kecamatan Selo, Ampel, dan Boyolali
183 3.22 Hasil penaksiran parameter dengan bobot lokasi
seragam
185 3.23 Hasil penaksiran parameter dengan bobot lokasi
normalisasi korelasi silang
185 4.1 Data pengukuran variabel untuk 4 sektor saham 195 4.2 Data pengukuran variabel untuk 4 sektor saham
(tak berdimensi)
196 4.3 Daftar 15 kota dengan nilai korelasi terbesar 199 4.4 Nilai Korelasi Indeks Harga Konsumen dan Inflasi
dengan Metode Regresi
202 4.5 Principal Component Analysis Inflasi di 66 Kota di
Indonesia
204 4.6 Principal Component Analysis Indeks Harga Konsumen
di 66 Kota di Indonesia
206 4.7 Contohdata lingkar dada, berat pupuk urea dan berat untuk
sapi dari Peternakan Rakyat Dukuh Belon, Kel. Kumpul-rejo, Kec. Argomulyo, Kota Salatiga dari tanggal 15 Juli 2008 s/d 30 Agustus 2008 (Parhusip dan Ayunani, 2009)
208
4.8 Data pupuk urea yang diberikan sesuai dengan berat untuk sapi dari Peternakan Rakyat Dukuh Belon, Kel. Kumpulrejo, Kec. Argomulyo, Kota Salatiga dari tanggal 15 Juli 2008 s/d 30 Agustus 2008 (Parhusip dan Ayunani, 2009)
209
4.9 Data berbagai variabel yang diukur pada sapi dari Peternakan Rakyat Dukuh Belon, Kel. Kumpulrejo, Kecamatan Argomulyo, Kota Salatiga dari tanggal 15 Juli 2008 sampai dengan 30 Agustus 2008 (Parhusip dan Ayunani, 2009)
210
4.10 Data berbagai variabel yang diukur pada sapi (lanjutan Tabel 4.9)
210 4.11 Data pengguna kontrasepsi pada tiap desa di Kecamatan
Sidorejo
211 4.12 Data Kepadatan Penduduk Kota Salatiga pada tahun 212
4.13 Daftar data banyaknya tenaga kerja tahu dan tempe berdasarkan wilayah di Salatiga
216 4.14 Daftar pengguna kontrasepsi pada penduduk pada tiap
Kecamatan di Salatiga pada tahun 2008
220 4.15 Kepadatan Penduduk kota Salatiga tahun 2008 untuk
tiap kecamatan dan kelurahan
221
5.1a Perbedaan ANOVA dan MANOVA 224
5.1b Keluaran ANOVA 232
5.2 Between-Subjects Factors 239
5.3 Daerah konfidensi 95% untuk 𝛿 240
5.4 Hasil analisa paired comparisons kelas B 251
5.5 Daerah konfidensi 95% untuk 𝛿 252
5.5a Rata-rata dan standar deviasi Kelas A 256 5.5b Hasil dari tes multivariat untuk Kelas A minggu
pertama, kedua, dan ketiga
256 5.5c Hasil analisa perbandingan berpasangan Kelas A 258 5.5d Rata-rata dan standar deviasi Kelas B 259 5.5e Hasil analisa perbandingan berpasangan Kelas B 259
5.5f Hasil tes multivariat Kelas A dan B untuk variabel Kelas
260 5.5g Perbedaan rata-rata respon Kelas A dan B untuk
variabel Kelas
260 5.5h Hasil tes multivariat rata-rata respon mahasiswa 261
5.5i Rata-rata respon mahasiswa 261
5.5j Hasil tes multivariat dari interaksi Kelas dengan Rata-rata respon mahasiswa
261 5.5k Hasil analisa perbandingan berpasangan minggu
pertama sampai minggu ketiga
264 6.1 Data jumlah penduduk miskin dan garis kemiskinan di
kota dan desa di seluruh provinsi di Indonesia pada bulan Maret 2013
274
6.2 Data Pengamatan Tingkat Kemiskinan di Kota 278 6.3 Data Pengamatan Tingkat Kemiskinan di Desa 280 6.4 Tabel substitusi nilai 𝑥0 masing-masing Kab/Kota pada
persamaan (6.4)
6.5 Pengelompokkan Kab/Kota penghasil ternak besar atau ternak kecil
289
7.1 Parameter pada model modifikasi GSTAR (persamaan 7.2) untuk data luas lahan kritis pada Selo, Ampel, dan Cepogo
294
7.2 Model modifikasi GSTAR untuk banyaknya produksi padi
296 7.3 Parameter untuk model modifikasi GSTAR untuk
produksi padi yang tergantung pada area lahan kritis
296 7.4 Parameter dari produksi panen padi (tak berdimensi)
yang dimodelkan dengan persamaan (7.7)
297 7.5 Nilai tiap parameter pada model (P.4)-(P.6) 306 7.6 Hasil optimasi produksi panen padi dari tiap daerah 312
8.1 Data kegiatan penelitian 8.1 335
10.1 Klasifikasi metode analisis dan tujuan analisis Spasial Statistik
380 10.2 Metode atau fungsi yang digunakan setiap jenis 381 10.3 Metode analisis menurut Legendre dan Marie (1989) 396
Daftar Gambar
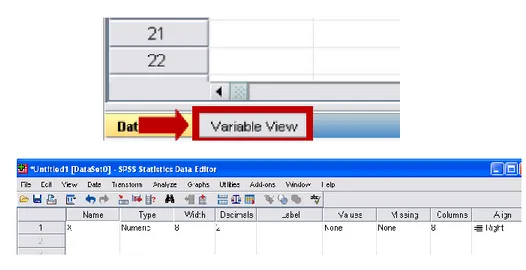
1.1 Jendela untuk menulis data 8
1.2 Jendela nama variabel 9
1.3 Jendela tipe variabel 9
1.4 Jendela analisa 10
1.5 Jendela keluaran SPSS 10
1.6 Input variabel 11
1.7 Jendela SPSS untuk variabel 11
1.8 Hasil keluaran SPSS 11
1.9 Pilihan pada jendela descriptive 12
1.10 Menu korelasi dari SPSS 13
1.11 Kovariansi data X dan Y dari contoh 2 13
1.12 Keluaran SPPS dengan fungsi Correlate 19
2.1 Daerah hipotesis, penerimaan dan penolakan H0 73
2.2 Keluaran SPSS 75
2.3 Keluaran SPSS untuk histogram 75
2.4 Data polusi Tabel 1 yang diuji kenormalannya 80 2.5 Plot chi-square data tekanan udara Boyolali
Juli-November tahun 2009
84 2.6 Horizontal merupakan nilai dan vertikal menyatakan
nilai kritis batas normal
91 2.7 Uji normal data tekanan udara bulan Juli-November 2009 93 2.8 Histogram untuk normalitas data tiap bulan dari Juli-
November 2009
94 2.9 QQ-Plot dari data bulan Juli-November tahun 2009 95
3.1 Data yang diolah 99
3.2 Pola data indeks LQ45 (variabel tak bebas)(sumbu vertikal) dan indeks saham AALI (sumbu horizontal) pada 1 Agustus 2011-9 September 2011
105
3.3 Hasil regresi linear (k =1) 106
3.4 Hasil regresi univariat untuk polinomial derajat k=1,2,3, dan 4
107 3.5 Data 2 variabel prediktor dan 1 variabel respon (Y) dalam 115
3.6 Tampilan SPPS17 untuk layar tampilan Variabel View 117 3.7 Data Tabel 3.2 yang ditampilkan sebagian 118
3.8 Jendela Analyze 118
3.9 Isi Jendela Analyze 118
3.10 Pilihan kajian statistik untuk variabel Pertanian saja 119 3.11 Hasil keluaran analisis untuk Pertanian 120 3.12 Hasil keluaran analisis untuk Pertanian 121 3.13 Uji normalitas untuk variabel pertanian dengan Q-Q plot 122 3.14 Hubungan linear volume saham pada AAL Sep 2010-Sep
2011 terhadap nilai saham pada pembukaan, tinggi dan rendah
125
3.15 Profil data Perusahaan AAL dan BPKP pada 1 Sep 2010- 9 Sep 2011 dengan data nilai saham pada saat pembukaan, tinggi, rendah, penutupan dan volume saham tiap waktu
128
3.16 Hubungan nilai volume data (horizontal ) dan yang hasil regresi (vertical dari perusahaan AAL Sep 2010-Sep 2011)
133 3.17 Hubungan nilai volume data (horizontal) dan yang hasil
regresi (vertikal dari perusahaan BBKP Sep 2010-Sep 2011)
133
3.18 Ilustrasi setiap variabel X (perusahaan) terhadap nilai indeks LQ45
141 3.19 Perbandingan data dan hasil estimasi regresi multivariate;
data disimbolkan (*) dan pendekatan disimbolkan o
141 3.20 Ilustrasi hubungan linear antar variabel tak bebas dan
tak bebas untuk tiap variabel untuk data Tabel 3.4.
145
3.21 Uji normalitas data 158
3.22 Gambar Hasil analisis regresi dari Tabel 3.10 dengan program R
159 3.23. Gambar hasil analisis regresi pada tabel 3 dengan program
R
161 3.24 Jendela Minitab untuk memulai analisa diskriptif 173 3.25 Jendela Minitab untuk menyimpan matriks kovariansi 174 3.26 Jendela Minitab untuk membangkitkan data normal xiv
multivariate
174
3.27 Jendela minitab tampilan akhir 175
3.29 Jendela minitab untuk transformasi Box -Cox 176 3.30 Jendela minitab untuk transformasi Box -Cox 177 3.31 Jendela minitab untuk transformasi Box -Cox 177
3.32 Jendela minitab untuk trend analysis 178
3.33 Jendela minitab untuk trend analysis 178
3.34 Jendela minitab untuk trend analysis dengan differencing 179 3.35 Grafik Transformasi Box-Cox untuk Kecamatan Selo,
Ampel, dan Cepogo
184 3.36 Hasil perbandingan data asli dengan data model dengan
bobot lokasi seragam
184 3.37 Hasil perbandingan data asli dengan data model dengan
bobot lokasi seragam
185 3.38 Hasil perbandingan data asli dengan data model dengan
bobot lokasi normalisasi korelasi silang
186 4.1 Grafik korelasi indeks harga konsumen dan inflasi 66 kota
dalam diagram batang dan scatter plot
198 4.2 Histogram indeks harga konsumen 66 kota dengan principal
component analysis
200 4.3 Principal Component Analysis Inflasi di 66 Kota di
Indonesia
204 4.4 Contoh daftar penerima subsidi kedelai perkecamatan kota
Salatiga Oktober 2008 (Hanya ditunjukkan sebagian)
215 4.5 Kepadatan penduduk Sidorejo sebagai fungsi jenis
kontra-sepsi yang digunakan. Tanda (*) untuk data dan tanda ‘o’ hasil pendekatan fungsi linear
219
5.1 Jendela SPSS untuk anova 235
5.2 Lokasi dan distribusi curah hujan (Sumber: web) 239 5.3 Pola hujan daerah Aceh, Ambon, Ampenan, Bandung,
Banjarmasin
240 5.4 Pola hujan daerah Bengkulu, Denpasar, Gorontalo,
Jakarta, Jambi
240 5.5 Pola hujan daerah Kendari, Kupang, Manado, Medan,
Padang
241 5.6 Pola hujan daerah Palangkara, Palembang, Palu, Pangkal
pinang, Pekan baru.
5.7 Pola hujan daerah Pontianak, Samarinda, Semarang, Sentani, Serang
241 5.8 Pola hujan daerah Surabaya, Tanjung karang, Ternate,
Ujung pandang, Yogyakarta
241 5.9 Distribusi normal multivariate curah hujan di Indonesia 241 5.10 Skema pola data respon mahasiswa sebagai hasil survei
oleh Rahandika A (Pritasari, dkk,2013)
246 5.11 Grafik rata-rata respon mahasiswa pada Kelas A dan Kelas B 263
6.1 Sumbu horisontal menunjukkan indeks data (provinsi), sumbu vertikal menunjukkan quantile distribusi chi-square dengan signifikansi 5%
275
6.2 Hasil plot x0 menurut pertidaksamaan (6.4): sumbu vertikal menunjukkan nilai ruas kiri dari pertidaksamaan (6.4), sumbu horisontal menunjuk-kan indeks x0
276
6.3 Hasil plot data kemiskinan di kota dengan perhitungan
Fisher’s Discriminant: sumbu horisontal menunjukkan nilai y1, sumbu vertikal menunjukkan nilai y2
279
6.4 Hasil plot data kemiskinan di desa dengan perhitungan
Fisher’s Discriminant: sumbu horisontal menunjukkan nilai y1, sumbu vertikal menunjukkan nilai y2
2.80
6.5 plot data asli dan data simulasi (“si Kaya”) di kota 281 6.6 plot data asli dan data simulasi (“si Kaya”) di desa 282 6.7 Grafik Cek Normal untuk data peternakan tiap kabupaten
di Jawa Tengah
284 6.8 Grafik Karakteristik Peternakan Kab/Kota di Jawa Tengah 288 7.1 Pendekatan curah hujan dengan persamaan (7.2) pada Selo
Horizontal: indeks, Vertikal: banyaknya curah (tak ber-dimensi, karena data sudah distasionerisasi)
293
7.2 Regresi GSTAR untuk curah hujan di Selo. Data (*,o,dan model (*) ditunjukkan dengan garis
293 7.3 Pendekatan dan data hasil produksi padi di Selo sebagai
model produksi padi yang tergantung produksi padi di Selo pada waktu sebelumnya, dan produksi padi dari Ampel dan Cepogo
7.4 Model GSTAR (disimbolkan ‘-o’ ) dan data (disimbolkan ‘*’) untuk produksi panen padi sebagai fungsi lahan kritis dan curah hujan pada waktu yang sama
298
7.5 Luas lahan kritis di Selo sebagai fungsi luas lahan kritis di Ampel dan Cepogo pada waktu yang sama
304 7.6 Banyaknya curah hujan di Selo sebagai fungsi curah hujan
di Ampel dan Cepogo pada waktu yang sama dimana data tak berdimensi
304
7.7 Banyaknya panen padi di Selo sebagai fungsi lahan kritis dan curah hujan menurut model (P.4)-(P.6)
305 7.8 Gambar peta Boyolali berdasarkan zona arkeologi dengan
pembobotan
318 7.9 Hasil pemrograman untuk peta Boyolali dengan
pem-bobotan dengan data simulasi
319
8.1 Scatter plot data Tabel 8.1 336
8.2 Data dalam ellips untuk c = 2. 338
8.3 Data dalam ellips untuk c = 4 (tanda ‘. ‘) dan untuk c=2 (tanda ‘-‘)
339
8.4 Grafik ellips yang dirotasikan 341
8.5 Hasil rotasi ellips dengan c = 4 341
9.1 Citra satelit dalam sistem pranatamangsa baru versi 1 Kabupaten Boyolali
357
9.2 Peta analog Kabupaten Boyolali 358
9.3 Foto udara erupsi Gunung Merapi 358
9.4 LIDAR DSM (Digital Surface Model) Sumatera Selatan 359
9.5 Data raster 360
9.6 Data dalam bentuk titik 361
9.7 Data dalam bentuk gari 362
9.8 Data dalam bentuk area 363
9.9 Representasi serangan wereng batang coklat di wilayah Lab. PHP V Surakarta bulan Januari - Desember 2010
371 10.1 Contoh Moran Scatterplot Kepadatan Penduduk
di Kabupaten Semarang
385 10.2 Proses pembangunan GIS menurut Anselin dan Ord 393
1
STATISTIKA DISKRIPTIF
Statistik diskriptif merupakan statistik untuk menjelaskan data misalkan dengan grafik, perhitungan rata-rata dan menentukan ekstrim data. Statistik Inferensial umumnya mengijinkan kita untuk menjelaskan parameter dari populasi berdasarkan sampel tes dengan tes statistik, misalkan Chi-Square, T-Tests, Korelasi, ANOVA. Untuk melakukan keduanya maka kita perlu beberapa definisi standar dalam statistik.1.1 Variansi dan matriks kovariansi
Sebelum matriks kovariansi dibahas, maka perlu dibahas definisi variansi dan matriks kovariansi. Variansi untuk variabel acak X dengan data sebanyak n adalah
( )
( )
( )
, ( )) (
Var X 2 E X 2 E X2 E X 2 E X (1.1)
NotasiE(X)dibaca sebagai nilai harapan X dan secara komputasi
berdasarkan sampel hal ini ditunjukkan dengan nilai rata-rata-rata sampel (disimbolkan x). Secara sama kita dapat menuliskan untuk populasi dan sampel besaran-besaran statistik yang banyak kita jumpai dengan notasi menurut Tabel 1.1.
Tabel 1.1 Notasi statistik dan maknanya
Notasi populasi Notasi/formula
untuk sampel Makna notasi
) (X E n x x n i i
1 Rata-rata ) (X2 E n x n i i
1 2 Setiap data dikuadratkan kemudian dirata-rata Var(X)=2 2 s
n x n i i 1 2
2 x Variansi
2 s s Deviasi standard S Matriks kovariansi
X Y XY XY Ε Y Ε X Ε XY Ε y x n y x s n i i i XY
1 Variansi antara X dan YCatatan: beberapa istilah dasar yang sering digunakan tidak banyak dibahas di sini, diantaranya ditunjukkan pada Tabel 1.2.
Tabel 1.2. Istilah statistik dan maknanya
Istilah statistik Arti
Mean Jenis rata-rata data yang diperoleh dari jumlah data dibagi banyaknya.
Median Jenis rata-rata data yang merupakan nilai tengah data setelah data diurutkan
Mode Data yang paling sering muncul (frekuensi terbesar)
Quantil Membagi data dalam 4 bagian Central tendency Pengukuran pusat data Dispersion Penyebaran data
Skewness Ukuran kecondongan (kurva yang tidak simetris) Kurtosis Ukuran keruncingan/ketinggian kurva
Contoh 1.1 Misalkan X = [1 2 3 4 5 6 ]T
2 2 2 ) ( ) ( ) ( Var X E X X = 15,1667-125 = 2,9167. Nilai tersebut secara rinci ditunjukkan pada Tabel 1.3.Tabel 1.3. Cara mendapatkan variansi satu variabel random
X 2 X 1 1 2 4 3 9 4 16 5 25 6 36 Jumlah
n i i x 1 21
n i i x 1 2 =91 Rata-rata x 3.5 15.1667Mencari variansi untuk variabel acak X data sebanyak n dengan Program Scilab ditujukan pada Tabel 1.4.
Tabel 1.4. Program scilab untuk menghitung variansi
Program scilab Keterangan
X=[1:6]' X2=X.^2 JX=sum(X) JX2=sum(X2) Jbar=mean(X) X2bar=mean(X2) X=[1:6]' EX=mean(X) X2=X.^2 EX2=mean(X2) arX=EX2-EX^2 Data vector x x2 Menjumplahkan komponen-komponen x Menjumplahkan x2 Menghitung x yaitu Menghitung n xi
2 Menghitung var (x)Variansi menunjukkan perbedaan data terhadap rata-rata. Jika variabel acak lebih dari 1 (sebutlah X dan Y), maka variansi dapat bervariasi yaitu: variansi antar data dalam variabel acak X, variansi antar data dalam variabel acak Y dan variansi antara data dalam X dan data dalam Y. keseluruhan variansi disimbolkan dengan kovariansi. Variansi antar data dalam variabel acak X disimbolkan Var(X) = Kov(X,X). Variansi antar data dalam variabel acak Y ditulis Var(Y)=Kov(Y,Y). Variansi antara data dalam X dan data dalam Y disimbolkan Kov(X,Y)=Kov(Y,X). Jika banyaknya variabel acak banyak maka penulisan variansi antar variabel acak perlu disusun secara praktis sehingga ditampilkan dalam bentuk matriks. Untuk kovariansi antara 2 variabel acak X dan Y disimbolkan
) , ( K ) , ( Kov ) , ( K ) , ( Kov Y Y ov X Y Y X ov X X Y YX XY X Y X Y ov Y X X ) ( Var ) , ( K ) , ( Kov ) ( Var . (1.2)
dengan Kov(X,Y) diformulasikan sebagai
X
Y
XY X Y X Y Kov ,
X Y XY XY X Y XY (1.3)Untuk data yang diberikan, maka notasi Xdinyatakan dalam x dan notasiY dinyatakan dalam y. Demikian pula notasi
XY menyatakan rata-rata dari perkalian data antara X dan Y.Contoh 1.2 Diberikan 2 variabel acak X dan Yyaitu
Secara detail maka nilai variansi X dan Y dinyatakan pada Tabel 1.5. Diperoleh XY Ε
XY Ε X ΕY Ε
XY XY=0.833333-(3.5)(1.166667)=-3.25. Untuk Var(X)=Kov(X,X) yaitu
( ) 15.1667 12.25 2.9167. ) ( ) ( Var X 2 E X2 X 2 Sedangkan Var(Y)=Kov(Y,Y) diperoleh
2 2 2 ) 5 . 0 ( 1667 . 15 ) ( ) ( ) ( Var Y E Y E Y = 15,1667-0.25 = 14.9167.Secara keseluruhan kovariansi antar variabel dapat diperoleh dengan menggunakan persamaan (1.2) diperoleh
9167 . 14 25 . 3 25 . 3 9167 . 2 ) ( Var ) , ( Kov ) , ( Kov ) ( Var Y X Y Y X X .
Tabel 1.5. Cara mendapatkan variansi dua variabel random
X 2 X Y Y2 XY 1 1 1 1 1 2 3 4 5 6 4 9 16 25 36 2 -3 -4 -5 6 4 9 16 25 36 4 -9 -16 -25 36 Jumlah
n i i x 1 21
n i i x 1 2 =91 1 3 n i i y
n i i y 1 2 =91
n i i iy x 1 = -9 Rata-rata x 3.5 15.1667 y -0.5 15.1667 -1.5Mencari nilai variansi X dan Y dengan program scilab ditunjukan pada Tabel 1.6.
Tabel 1.6. Mencari nilai variansi X dan Y dengan program scilab
Program scilab Keterangan
X=[1 2 3 4 5 6]' X2=X^2 Y=[1 2 -3 -4 -5 6]' Y2=Y^2 XY=X.*Y JX=sum(X) JX2=sum(X2) JY=sum(Y) JY2=sum(Y2) JXY=sum(XY) kovXY=JXY-JX*JY EXY=mean(XY);EX=mean(X);EY=mean(Y) EXY EX kovXY=EXY-EX*EY EX2=mean(X2) varX=EX2-EX2^2 varX=EX2-EX^2 EY2=mean(Y2);varY=EY2-EY^2 Data X, Y, X2 dan Y2 Hasil XY Menjumlahkan X, X2, Y, Y2, XY Menghitung kovariansi antar variabel
Secara sama maka matriks kovariansi untuk 3 variabel acak X, Y, Z adalah
Z,Z Z,Y Z,X Y,Z Y,Y Y,X X,Z X,Y X,X Cov Cov Cov Cov Cov Cov Cov Cov Cov . (1.4)Contoh 1.3 . Diberikan 3 variabel acak X ,Y,Z
X = [1 2 3 4 5 6 ]T ; Y = [1 2 -3 4 -5 6 ]T; Z= [2 3 4 6 -7 9]T. Secara sama, matriks kovariansi dapat diperoleh dari data Tabel 1.7.
Tabel 1.7. Cara mendapatkan variansi tiga variabel random X Y Z Z2 XY XZ YZ XYZ 1 1 2 4 1 2 2 2 2 2 3 9 4 6 6 12 3 -3 4 16 -9 12 -12 -36 4 -4 6 36 -16 24 -24 -96 5 -5 -7 49 -25 -35 35 175 6 6 9 81 36 54 54 324 Jm l 21 1 n i i x 3 1 n i i y 17 1 n i i z 195 1 n i i z 9 1 n i i iy x 63 1 n i i i iz x 61 1 n i i iz y 381 1 i n i i iyz x Ra -ta Ra -ta x 3.5 y -0.5 8 . 2 z 2 32.5 z -1.5 10.5 10.2 63.5
Diketahui bahwa Kov(X,Z)Kov(Z,X)Xz. Demikian pula
Yz Y Z Z Y, )Kov( , ) ( Kov .
Sehingga dapat diperoleh
) , ( Kov X Z Ε
XZ Ε X ΕZ Ε
XZ XZ 10.59.80.7. ) , ( KovY Z Ε
YZ ΕY Ε Z Ε
YZ YZ 10.21.411.6Untuk Var(X) = Kov(X,X) diperoleh
( )
15.1667 12.25 2.9167. ) ( ) ( Var X 2 E X2 E X 2 Sedangkan Var(Y)=Kov(Y,Y) diperoleh
2 2 2 ) 5 . 0 ( 1667 . 15 ) ( ) ( ) ( Var Y E Y E Y = 15,1667-0.25 = 14.9167.Demikian pula secara sama pada Var(Z)=Kov(Z,Z)
( )
32.5
2.8 32.5 7.84 24.66 ) ( ) ( Var Z E Z2 E Z 2 2 . Akhirnya matriks kovariansi untuk 3 variabel random X,Y dan Z dengan data di atas adalah
. 66 . 24 1 . 15 7 . 0 1 . 15 9167 . 14 25 . 0 7 . 0 25 . 0 9167 . 2 Var Cov Cov Cov Var Cov Cov Cov Var Cov Cov Cov Cov Cov Cov Cov Cov Cov Z Z,Y Z,X Y,Z Y Y,X X,Z X,Y X Z,Z Z,Y Z,X Y,Z Y,Y Y,X X,Z X,Y X,XInvers matriks kovariansi muncul pada fungsi densitas distribusi normal multivariat. Hal ini dibahas pada fungsi densitas distribusi normal yang dimulai dari 1 variabel, kemudian dilanjutkan untuk 2 dan 3 variabel. Akhirnya akan diperumum untuk p variabel random. Selanjutnya kita akan belajar cara bekerja dengan SPSS.
1.2 Cara Bekerja dengan SPSS
Untuk pengguna SPSS maka data yang kita olah akan kita kerjakan dengan SPSS. Berikut ini kita perlu memperkenalkan terlebih dahulu SPSS. Kasus 1. Untuk 1 variabel
Perhatikan bahwa standard deviasi adalah akar dari variansi.
Tahap 1. Jendela SPSS untuk data, kita input dengan memilih menu Data View sebagaimana yang ditunjukkan pada Gambar 1.1 (kiri)
Tahap 2. Untuk menamakan variabel maka kita perlu memilih jendela variabel View.
Gambar 1.2. Jendela nama variabel
Untuk tipe data maka dapat dipilih sebagai berikut
Gambar 1.3. Jendela tipe variabel
Tahap 3. Jendela untuk menganalisa
Dalam hal ini kita menghendaki keluaran standar deviasi. Kita memilih menu berturut-turut adalah Analyze, Descriptive Statistics, Descriptives dan contreng pada options untuk standar deviasi dan yang lain yang diperlukan.
Gambar 1.4. Jendela analisa
Tahap 4. Hasil keluaran ditunjukkan pada Gambar 1.5.
Tahap 5. Analisa data
Jadi variansi data Tabel 2 adalah 3.5 sehingga s1.87083. Perhatikan bahwa dari formula yang digunakan diperoleh nilai eksak adalah s = 1.707825. Jadi hasil yang diperoleh dapat dianggap sama. Dari hasil kita dapat belajar memahami bagaimana angka-angka yang muncul pada SPSS diperoleh dengan mengerti formula yang terkait terlebih dahulu.
Kasus 2. Variansi untuk 2 variabel random Contoh 1.3
Diberikan 2 variabel acak X dan Yyaitu
X = [1 2 3 4 5 6 ]T ; Y = [1 2 -3 -4 5 6 ]T. Tahap 1. Input data pada SPSS ditunjukkan pada Gambar 6.
Gambar 1.6. Input variabel
Tahap 2. Penamaan Variabel
Tahap 3. Kita akan mencari variansi ataupun standard deviasi, maka kita dapat memilih menu yang sama:
Analyze Descriptive StatisticsDescriptives
Kita dapat memilih jenis analisis yang dikehendaki dengan memilih Options, maka akan muncul jendela options dan kita memilih tiap tipe analisis yang kita kehendaki dengan menggunakan tanda V (mencontreng) pada kotak yang disediakan.
Gambar 1.8 Hasil keluaran SPSS
Gambar 1.9. Pilihan pada jendela descriptive
Bandingkan dengan matriks kovariansi yang muncul (lihat subbab 1.1) yaitu 9167 . 14 25 . 3 25 . 3 9167 . 2 ) ( Var ) , ( Kov ) , ( Kov ) ( Var Y X Y Y X X .
Dari hasil ini kita tetap menganggap hasil yang diperoleh dari SPPS benar (sekalipun ada error) karena standar yang kita gunakan dalam pembahasan adalah analisa data dengan SPSS. Pada bagian ini variansi antar 2 variabel
tidak muncul di SPSS. Padahal hal itulah yang diamati. Hal ini dapat diperoleh dengan menggunakan fungsi correlation dari SPSS.
Dengan memilih Correlate -> Bivariate->Options , kemudian contreng yang diperlukan sebagaimana ditunjukkan pada Gambar 1.9.
Gambar 1.10.Menu korelasi dari SPSS
Gambar 1.11. Kovariansi data X dan Y dari contoh 1.3
1.3 Variansi-Kovariansi dan korelasi formula dalam SPSS
Catatan: Dari formula diperoleh bahwa Cov(X,Y)=-3.25. Sedangkan SPSS memberikan 3.300. Hal ini membingungkan bagi pengguna. Demikian pula dengan menggunakan formula yang juga muncul dari literatur lain (Web1) yaitu
n i i i x y y x n Y X Cov 1 ) )( ( 1 ) , ( .Dari formula ini diperoleh Cov(X,Y)=2.75. Ada pula, yang menggunakan formula
n i i i x y y x n Y X Cov 1 ) )( ( 1 1 ) , ( (1.5)Dari formula ini diperoleh
3 . 3 ) )( ( 1 1 ) , ( 1
n i i i x y y x n Y X Cov .Hasil ini menggembirakan karena sesuai dengan keluaran SPSS. Jadi formula yang kita gunakan untuk menjelaskan keluaran kovariansi adalah persamaan (1.5). Kita dapat memperluas pengetahuan ini untuk menye-lidiki nilai-nilai hasil SPSS yang berbeda dengan formula baku yang digunakan pada umumnya.
Demikian pula untuk variansi, setelah dicermati, maka Var(X) didefinisikan pada SPSS sebagai
n i i x x n X Var X X Cov 1 2 ) ( 1 1 ) ( ) , ( (1.6) Contoh 1.4Untuk data X=[1,2,3,4,5,6] maka Cov(X,X)=Var(X) = 3.5 yang sama dengan hasil keluaran SPSS. Sedangkan data Y=[1,2,-3,-4,5,6] maka Cov(Y,Y)=Var(Y) = 16.56667 yang sesuai dengan hasil keluaran SPSS. Oleh karena itu korelasi formula SPSS dapat diselidiki lebih lanjut. Yaitu
) ( ) ( ) )( ( 1 1 ) , ( 1 Y Var X Var y y x x n r Y X Corr n i i i XY
(1.7)Contoh 1.5
Untuk data yang diberikan di atas diperoleh hasil yang sama dengan keluaran SPSS yaitu: 433 . 0 ) ( ) ( ) )( ( 1 1 ) , ( 1
Y Var X Var y y x x n r Y X Corr n i i i XY . Daftar Pustaka Web1. http://www.lse.ac.uk/Depts/economics/pdf/chapter1.PDF 1.4 Studi Korelasi (Linear)Hubungan antara 2 variabel dinyatakan dalam bentuk koefisien korelasi. Formula yang umum digunakan adalah korelasi menurut Pearson. Korelasi antara 2 variabelX dan Y memenuhi (Web1)
] ) ( ][ ) ( [ ) )( ( 2 2 y y x x y y x x r i i i i XY . (1.8)Ada pula yang memformulasikan dalam bentuk
) ( ) ( ) )( ( Y Var X Var y y x x rXY
i i (1.9)Nilai korelasi ini berkisar diantara -1 dan 1, atau 1rXY 1. Korelasi bernilai negatif dikatakan korelasi antara 2 variabel negatif (meningkatnya salah satu variabel menyebabkan nilai variabel yang lain menurun). Demikian pula secara analog dapat didefinisikan korelasi positif. Nilai korelasi 1 berarti korelasi terhadap dirinya sendiri.
Contoh 1.6 Carilah korelasi antara variabel X dan Y pada Contoh 1.2. Jawab: kita dapat menggunakan SPSS dengan keluaran yang ditunjukkan pada Gambar 1.12.
Gambar 1.12. Keluaran SPPS dengan fungsi Correlate
Nilai yang diperoleh sesuai dengan formula (1.5). Nilai 1 pada kolom 1 dan 2 menunjukkan korelasi antara dirinya sendiri. Kita dapat menulis hasil ini dengan menuliskan dalam bentuk matriks korelasi yaitu
1 433 . 0 433 . 0 1 R .
Sebagaimana diketahui dari teori bahwa korelasi dikatakan ada jika koefisien korelasi lebih besar dari |0.5|. Jadi dapat kita tulis
433 . 0 YX XY
Korelasi antara variabel X dan Y sama artinya dengan korelasi antara Y dan
X. Dari hasil ini maka korelasi antara kedua variabel dikatakan tidak kuat. Jika ada 3 variabel maka kita akan mempunyai matriks korelasi 3 x 3.
Seringkali ada banyak variabel yang harus diamati korelasi antar variabel secara bersama-sama. Sehingga kita mempunyai matriks korelasi. Perhatikan bahwa rjjmenyatakan korelasi antar variabel yang sama sehinggarjj=1. Korelasi antar 2 variabel yang berbeda dikatakan kuat jika
5 . 0
ij
r dan semakin kuat rij jika mendekati 1. Perhatikan bahwa rjj
Jika kita mempunyai 3 variabel, maka kita akan mempunyai matriks korelasi berukuran 3 x 3 sebutlah
33 31 31 23 22 21 13 12 11 r r r r r r r r r R .
Contoh 1.7. Diberikan 3 variabel X1, X2, dan Y
Sebagai contoh hasil analisa , maka matriks berikut merupakan matriks korelasi yang diperoleh dengan bantuan program (Excel) dengan fungsi correl (menggunakan persamaan 1), yaitu
1.0000 0.3780 0.1172 0.3780 1.0000 0.0316 0.1172 0.0316 1.0000 R .
Dari matriks ini berarti antara variabel X1 danX2 tidak berkorelasi karena
0316 . 0
21
12 r
r .Demikian pula korelasi X1 dan Y adalah
1172 . 0
31
13 r
r menunjukkan tidak berkorelasi. Secara sama, diperoleh kesimpulan yang sama korelasi antara X2dan Y karenar32 r23 0.3780.
Contoh 1.8
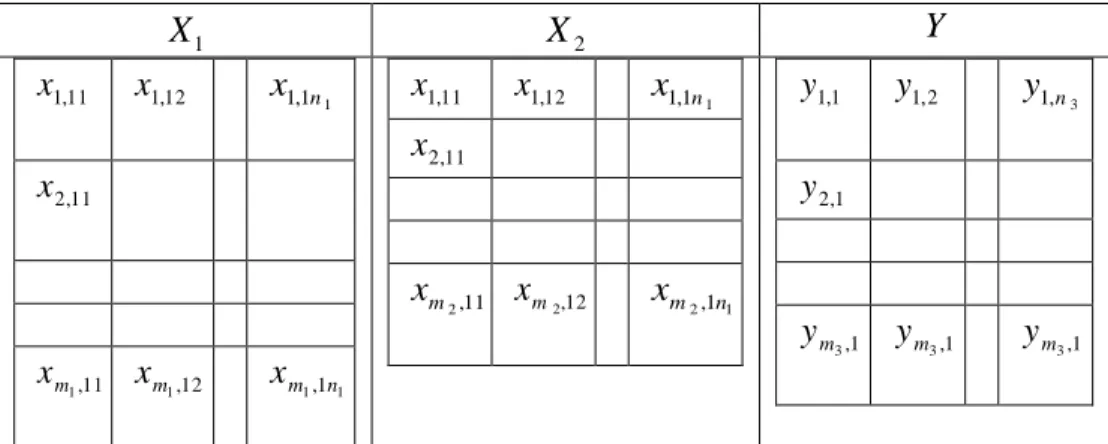
Dalam aplikasi seringkali dijumpai data dimana kita perlu mende-finisikan sendiri variabel yang dibahas. Dari observasi, diperoleh data dengan 2 variabel bebas (independent) (sebutlah X1 dan X2) dan 1 variabel dependent (sebutlah Y). Pada analis data multivariat variabel bebas disebut juga variabel prediktor, dan variabel tak bebas dikenal juga sebagai variabel respon.
Setiap variabel X1 ,X2, dan Y mempunyai banyaknya variabel berturut-turutn1, n2 dan n3. Jadi X1 [x11,x12,...,x1n ]
] ,..., , [ 2 2 22 21 2 x x x n X , [ , ,..., ] 3 2 1 y yn y
Y . Selain itu setiap x1mempunyai
1
m pengamatan (yang menyatakan banyaknya sampel). Demikian pula setiap x2 mempunyai m2 pengamatan dan y mempunyai m3 sampel. Pola data yang diamati mempunyai bentuk sebagaimana ditunjukkan pada Tabel 1.8 .
Tabel 1.8. Pola data yang akan diolah
1 X X2 Y 11 , 1 x x1,12 1 1 , 1 n x 11 , 2 x 11 , 1 m x xm1,12 xm1,1n1 11 , 1 x x1,12 1 1 , 1 n x 11 , 2 x 11 , 2 m x ,12 2 m x 1 2,1n m x 1 , 1 y y1,2 3 , 1n y 1 , 2 y 1 , 3 m y ,1 3 m y ,1 3 m y
Contoh 1.9. Misalkan diberikan bentuk data berdasarkan angket yang diberikan menurut Tabel 1.9. Bahan ini sebenarnya materi tesis S2, tapi karena belum dipublikasikan maka saya tuliskan disini sebagai contoh analisa yang datang dari riset S2.
Perhatikan bahwa setiap kolom menunjukkan 1 jenis pertanyaan yang diajukan pada m1sampel. Kita akan menyelidiki korelasi antara variabel respon dengan variabel prediktor. Karena masing-masing variabel mempunyai subvariabel yang lain maka kita dapat melakukan analisa dengan beberapa tahap.
Tabel 1.9. Bentuk data berdasarkan angket yang diberikan (diperoleh dari informasi informal oleh observer)
VARIABEL PENELITIAN INDIKATOR NO Item Jumlah Item Manajamen pada tempat A (X1) 1. Fungsi manajemen 2. Planning 3. Organizing 4. Actuating 5. Controlling 1 - 3 4 - 6 7 - 9 10 - 12 13 - 15 3 3 3 3 3 Kepemimpinan tempat A (X2)
1. Pemimpin yang Visioner 2. Pemimpin yang Handal 3. Pemimpin Pekerja Keras 4. Pemimpin Yang Melayani 5. Pemimpin Yang Bertanggung Jawab 16-18 19- 21 22 – 24 25 – 27 28 - 30 3 3 3 3 3 Manajemen dan Kepemimpinan tempat B (Y ) 1. Visi 2. Planning 3. Organizing 4. Actuating 5. Controlling
6. Pemimpin yang Visioner 7. Pemimpin yang Handal 8. Pemimpin Pekerja Keras 9. Pemimpin Yang Melayani
31 - 33 34 – 36 37 – 39 40 - 42 43 – 45 46 - 48 49 – 51 52 - 54 55 – 56 3 3 3 3 3 3 3 3 2
Kita perhatikan bahwa setiap 3 pertanyaan dalam observasi menyatakan 1 variabel kualitas. Oleh karena itu kita dapat menyederhanakan variabel data dengan melakukan rata-rata tiap 3 item pertanyaan.
Contoh 1.10 Berdasarkan hasil angket, maka nilai rata-rata fungsi mana-jemen adalah 5=(5 + 5 + 5)/3. Secara sama kita dapat melakukan perataan terhadap pertanyaan yang lain. Artinya kita dapat menyusun nilai variabel
1
X untuk tiap sampel sebagaimana ditunjukkan pada Tabel 1.10. Demikian pula untuk variabel X2dan Y, nilai rata-rata masing-masing subvariabel tiap variabel ditunjukkan berturut-turut pada Tabel 1.10 dan Tabel 1.11.
Tabel 1.10. Nilai rata-rata tiap subvariabel dalam variabelX1 untuk tiap responden
No
responden No1-3 No.4-6 No.7-9 N0.10-12 No.13-15
1 5.000 5.000 5.000 5.000 5.000 2 5.000 4.667 4.333 4.333 4.333 3 5.000 4.333 4.333 4.667 4.333 4 4.000 4.000 5.000 4.333 4.333 5 4.000 5.000 4.333 4.333 5.000 6 5.000 4.000 4.333 4.667 4.667 7 4.667 5.000 4.333 5.000 4.333 8 4.333 4.000 4.000 4.000 4.000 9 5.000 5.000 5.000 5.000 5.000 10 3.667 4.000 4.333 4.000 4.667 11 4.667 4.333 4.667 4.333 4.000 12 4.667 4.667 4.333 4.667 4.667 13 4.333 4.333 4.333 4.667 5.000 14 2.667 3.667 4.667 4.000 3.667 15 4.000 3.333 4.333 3.667 4.667 16 2.667 3.000 4.667 4.333 4.333 17 4.000 3.333 3.667 3.667 3.667 18 5.000 5.000 5.000 5.000 5.000 19 4.333 3.667 4.000 5.000 5.000 20 4.333 4.667 4.667 4.667 4.000 21 4.667 4.667 5.000 4.667 4.000 22 5.000 5.000 5.000 5.000 5.000 23 4.667 5.000 4.333 4.333 4.333 24 4.667 4.000 4.333 4.000 4.000 25 4.000 4.000 4.333 4.333 4.000 26 5.000 5.000 4.667 5.000 4.333 27 4.000 4.000 4.000 4.000 4.000 28 5.000 5.000 4.333 4.667 4.667 29 5.000 5.000 4.667 4.333 4.000 30 5.000 4.333 4.333 4.333 3.667 31 5.000 4.667 4.333 4.667 4.000 32 4.333 4.000 4.333 4.333 4.000 33 4.000 4.333 4.000 4.333 4.000 34 4.000 4.333 4.000 4.333 4.000 35 4.667 4.333 4.000 4.000 4.333 36 4.333 4.000 4.333 4.000 4.000 37 4.333 4.333 4.333 4.333 4.333 38 4.333 4.000 4.333 4.333 4.000 39 4.333 4.000 4.000 4.000 4.000
No
responden No1-3 No.4-6 No.7-9 N0.10-12 No.13-15
41 4.000 4.333 4.333 4.333 4.000 42 4.667 4.333 3.667 3.667 3.667 43 5.000 5.000 4.667 4.667 5.000 44 4.000 4.333 4.333 5.000 5.000 45 4.667 4.333 3.667 3.667 3.667 46 4.667 4.333 3.667 3.667 3.667 47 4.333 4.333 4.667 4.000 4.333 48 5.000 4.000 4.333 4.333 4.000 49 4.333 4.333 4.333 4.667 4.000 50 4.000 4.000 4.333 4.000 4.000 51 4.000 5.000 4.333 5.000 5.000 52 4.000 4.333 4.667 4.333 4.000 53 4.000 4.333 4.333 4.333 4.000 54 4.000 4.000 4.000 4.000 4.000 55 4.333 4.000 4.000 4.333 4.000 56 5.000 4.000 4.000 4.667 4.000
Tabel 1.11. Rata-rata tiap 3 pertanyaan berturutan untuk tiap responden pada
variabel X2 No responden No No No No No 1 4.500 4.000 4.000 4.000 4.000 2 4.500 4.667 5.000 4.333 4.333 3 4.000 4.000 4.667 5.000 4.000 4 5.000 4.333 4.667 4.333 4.333 5 4.000 4.000 4.333 5.000 4.333 6 5.000 4.667 4.667 5.000 5.000 7 5.000 4.667 4.333 5.000 4.333 8 4.000 4.000 4.000 4.000 4.000 9 5.000 5.000 5.000 5.000 5.000 10 4.500 4.667 5.000 4.667 4.667 11 5.000 4.667 4.333 4.667 4.000 12 4.500 5.000 4.333 4.333 4.667 13 4.500 4.667 5.000 4.000 4.667 14 4.500 3.333 4.000 4.667 3.667 15 4.500 4.000 3.667 4.333 4.667 16 5.000 4.000 4.000 4.333 3.333 17 4.500 2.667 3.667 4.000 4.333 18 5.000 5.000 5.000 5.000 5.000 19 5.000 4.000 4.000 5.000 4.333 20 5.000 5.000 4.667 5.000 4.667
No responden No No No No No 22 5.000 5.000 5.000 5.000 5.000 23 5.000 4.000 4.333 5.000 5.000 24 4.500 4.667 4.667 5.000 4.667 25 4.000 4.333 4.667 4.333 4.333 26 4.500 5.000 5.000 5.000 5.000 27 4.500 4.000 4.000 4.000 4.000 28 4.500 5.000 5.000 4.667 4.667 29 4.000 4.000 4.000 5.000 5.000 30 5.000 4.333 4.667 5.000 4.667 31 5.000 4.667 4.667 4.667 5.000 32 4.000 4.667 4.667 4.000 4.667 33 4.000 4.000 4.000 4.333 4.000 34 4.500 4.667 4.000 5.000 4.333 35 4.000 4.667 4.333 4.000 4.333 36 4.000 4.333 4.000 4.000 4.333 37 4.000 4.000 4.333 4.333 4.000 38 4.000 4.333 4.000 4.333 4.667 39 4.500 4.333 4.000 4.333 4.000 40 4.000 4.000 4.333 4.000 4.000 41 4.000 4.000 4.000 4.000 4.000 42 4.500 4.000 3.667 5.000 4.667 43 5.000 5.000 5.000 5.000 5.000 44 4.500 4.333 4.000 5.000 5.000 45 5.000 4.000 3.667 5.000 4.667 46 4.500 4.000 3.667 5.000 4.667 47 4.500 4.333 4.333 5.000 4.333 48 4.000 4.000 4.000 5.000 4.333 49 4.500 4.333 4.667 5.000 5.000 50 4.000 4.333 4.000 4.333 4.333 51 4.500 4.333 4.333 5.000 5.000 52 4.000 4.333 4.667 5.000 4.333 53 4.000 4.333 4.000 4.000 4.000 54 4.500 4.333 4.000 4.000 4.000 55 4.000 4.000 4.667 4.000 4.000 56 4.000 4.667 4.333 4.000 4.000
Tabel 1.12. Rata-rata 3 pertanyaan untuk tiap responden dalam variabel Y No responden No. 31-33 No. 34-36 No. 37-39 No. 40-42 No. 43-45 No. 46-48 No. 49-51 No. 52-54 No. 55-56 1 5.000 5.000 4.333 4.000 4.000 4.000 5.000 4.000 4.500 2 4.000 4.000 4.333 4.000 4.000 4.333 4.000 4.000 4.000 3 5.000 4.333 4.333 4.333 4.667 4.667 4.333 4.667 5.000 4 4.333 4.667 4.333 4.667 4.667 4.667 4.333 4.000 5.000 5 4.333 4.667 4.667 4.333 4.333 4.333 4.667 4.667 4.000 6 4.667 5.000 5.000 4.333 5.000 5.000 5.000 5.000 5.000 7 4.333 4.333 4.667 5.000 4.667 4.333 4.667 5.000 5.000 8 4.000 4.000 4.000 4.000 4.000 4.000 4.000 4.000 4.000 9 5.000 5.000 4.333 5.000 4.667 4.333 4.000 5.000 5.000 10 4.333 4.667 5.000 4.000 4.333 4.667 5.000 4.667 5.000 11 4.333 4.000 4.000 4.333 4.333 4.667 4.000 4.667 4.000 12 4.000 4.667 4.667 4.000 4.667 4.333 4.333 4.667 4.500 13 4.000 4.000 4.000 4.333 4.333 3.667 4.000 4.000 4.000 14 3.667 3.667 3.667 4.000 3.333 3.333 3.333 4.000 3.500 15 3.333 3.667 4.000 4.333 4.000 3.667 3.333 4.000 3.500 16 4.333 3.667 4.333 4.333 3.000 3.667 3.333 3.667 4.500 17 4.333 3.333 3.333 4.000 3.667 3.667 3.667 4.000 4.000 18 4.667 5.000 5.000 5.000 5.000 5.000 4.667 5.000 5.000 19 3.667 4.333 3.333 3.667 3.333 3.333 3.333 3.667 3.500 20 4.000 4.333 4.000 4.333 4.667 4.333 4.333 4.667 4.000 21 4.000 4.333 4.000 4.000 4.000 4.000 4.000 4.000 4.000 22 4.333 5.000 5.000 4.667 5.000 5.000 5.000 5.000 5.000 23 4.667 5.000 4.333 4.667 4.667 4.333 4.000 4.667 5.000 24 4.000 4.333 4.000 4.000 4.000 4.000 4.000 4.333 4.000 25 4.000 4.000 4.333 4.000 4.000 4.000 4.000 4.000 4.500 26 5.000 4.667 4.667 5.000 5.000 5.000 5.000 5.000 5.000 27 4.000 4.000 4.000 4.000 4.000 4.000 4.000 4.000 4.000 28 4.333 4.333 4.000 4.000 5.000 5.000 4.667 5.000 5.000 29 4.000 3.333 3.667 4.000 4.000 4.000 4.000 4.667 5.000 30 4.000 3.667 4.000 4.333 4.000 4.333 4.000 5.000 4.500 31 4.667 4.000 4.333 5.000 5.000 5.000 4.667 5.000 5.000 32 4.000 4.333 5.000 4.333 4.000 4.333 4.333 4.333 4.000 33 4.000 4.667 4.667 4.000 4.000 4.333 4.333 5.000 5.000 34 4.667 4.000 4.000 4.333 4.333 4.333 4.333 4.000 4.000 35 4.000 4.333 4.667 4.000 4.667 4.333 4.333 4.667 4.000 36 5.000 4.667 4.333 4.333 4.333 4.667 4.667 5.000 5.000 37 4.000 4.667 5.000 4.333 4.333 4.667 4.333 4.667 4.000 38 4.333 5.000 4.000 4.333 4.667 4.000 5.000 5.000 5.000 39 4.333 4.333 4.667 4.000 4.333 4.667 4.000 4.667 4.000 40 4.000 4.000 4.000 4.333 4.000 4.333 4.333 4.333 4.000
No responden No. 31-33 No. 34-36 No. 37-39 No. 40-42 No. 43-45 No. 46-48 No. 49-51 No. 52-54 No. 55-56 41 4.333 4.667 4.000 4.000 4.000 4.000 4.333 4.667 4.000 42 4.333 4.333 4.667 4.000 4.333 5.000 5.000 5.000 5.000 43 5.000 5.000 5.000 5.000 5.000 5.000 5.000 5.000 5.000 44 5.000 5.000 5.000 5.000 5.000 5.000 5.000 5.000 5.000 45 4.333 4.333 4.667 4.000 4.333 5.000 5.000 5.000 5.000 46 4.333 4.333 4.667 4.000 4.333 5.000 5.000 5.000 5.000 47 4.000 4.333 4.333 4.333 4.333 4.000 4.667 4.000 4.000 48 4.000 4.333 4.333 4.000 4.000 4.000 4.000 4.000 4.000 49 5.000 4.333 4.000 5.000 5.000 5.000 5.000 5.000 5.000 50 4.000 4.000 4.000 4.000 4.000 4.000 4.000 4.000 4.000 51 5.000 5.000 4.667 5.000 5.000 5.000 4.667 5.000 5.000 52 4.000 4.667 4.000 4.000 4.000 4.333 4.333 4.667 4.000 53 4.000 4.000 4.000 4.333 4.000 4.000 4.000 4.667 4.000 54 4.000 4.333 4.000 4.000 4.000 4.333 4.000 4.667 4.000 55 4.000 4.333 4.333 4.000 4.000 4.333 4.000 4.333 4.000 56 4.000 4.667 4.000 4.333 4.333 4.333 4.667 4.333 4.500
Jadi kita dapat menyederhanakan data variabel X1 menjadi 5 subvariabel dan variabel X2 dengan 5 subvariabel dan variabel Y adalah 10 variabel. Analisa selanjutnya dapat dilakukan korelasi antara subvariabel dalam X1
dan X2 dengan setiap subvariabel Y.
Kita akan menyelidiki korelasi X1,X2 dan Y. Matriks korelasi berukuran 19 x 19. Untuk menyederhanakan penyusunan matriks korelasi kita akan menampilkan bagian demi bagian. Perhitungan korelasi mengikuti formula korelasi yang standar dan kita dapat menggunakan correl pada Excell untuk menghitung korelasi.
Korelasi antar subvariabel dalam X1
1.0000 0.6408 0.4447 0.3950 0.1611 0.6408 1.0000 0.5584 0.5647 0.3516 0.4447 0.5584 1.0000 0.3844 0.0920 0.3950 0.5647 0.3844 1.0000 0.6033 0.1611 0.3516 0.0920 0.6033 1.0000 1 X R .
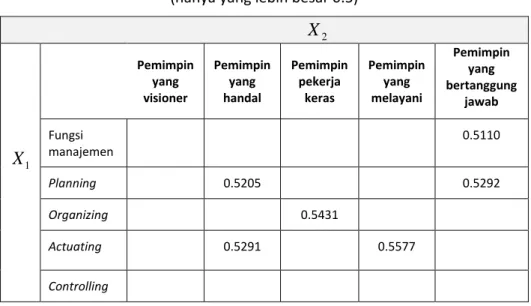
Dari hasil ini menunjukkan bahwa subvariabel kedua dan subvariabel ke-1 (Planning dan Fungsi manajemen) serta subvariabel ke-4 dan ke-5) yaitu (Actuating dan Controlling) yang saling berkorelasi. Sedangkan sub-variabel ke-3 dengan subsub-variabel yang lain tidak berkorelasi. Oleh karena itu subvariabel ketiga dapat kita abaikan.
Pembahasan Contoh 1.9
Korelasi antar subvariabel dalam X2
Secara sama dapat diperoleh matriks korelasi antara subvariabel dalam
2 X yaitu 1.0000 0.5795 0.4070 0.4857 0.3632 0.5795 1.0000 0.2343 0.2592 0.4734 0.4070 0.2343 1.0000 0.6929 0.2443 0.4857 0.2592 0.6929 1.0000 0.2953 0.3632 0.4734 0.2443 0.2953 1.0000 2 X R . (1.10)
Dari hasil ini maka dapat disimpulkan bahwa hanya subvariabel ke-2 dan ke-3 dan subvariabel ke-4 dan ke-5 yang saling berkorelasi (sekalipun tidak kuat). Jadi subvariabel ke-1 tidak berkorelasi dengan yang lain yaitu pemimpin yang Visioner. Hal ini nampaknya tidak seperti dengan anggapan pada umumnya.
Korelasi antar subvariabel dalam Y
Demikian pula matriks korelasi antar subvariabel dalam Y adalah
1.0000 0.6957 0.6866 0.6957 1.0000 0.6697 0.6866 0.6697 1.0000 0.6997 0.7698 0.7713 0.6551 0.7090 0.7312 0.5315 0.4746 0.3990 0.4957 0.5033 0.6140 0.4802 0.4913 0.6387 0.7001 0.5162 0.6030 0.6997 0.6551 0.5315 0.4957 0.4802 0.7001 0.7698 0.7090 0.4746 0.5033 0.4913 0.5162 0.7713 0.7312 0.3990 0.6140 0.6387 0.6030 1.0000 0.7946 0.5063 0.6752 0.5122 0.6268 0.7946 1.0000 0.6800 0.5423 0.6074 0.6194 0.5063 0.6800 1.0000 0.3965 0.3950 0.6389 0.6752 0.5423 0.3965 1.0000 0.6119 0.3959 0.5122 0.6074 0.3950 0.6119 1.0000 0.5336 0.6268 0.6194 0.6389 0.3959 0.5336 1.0000 Y R
Kita dapat memahami subvariabel ke 1 dan 3. ke 2 dan ke-9. ke 3 dan 9. ke 4 dan ke-9. ke 3 dan ke-4. ke 4 dan ke-8. ke 6 dan ke-4. ke-6 dan ke-5 tidak berkorelasi secara signifikan. Agar lebih jelas. kita dapat menuliskan nilai korelasi yang lebih besar dari 0.5 dengan makna kualitatif dari masing-masing subvariabel dalam Tabel 1.13. Sebagian korelasi ditunjukkan pada Tabel untuk menjelaskan hubungan korelasi terhadap nama masing-masing subvariabel.
Tabel 1.13. Hasil korelasi (hanya yang lebih besar 0.5) antara subvariabel dalam Y
Y
Visi Plan-ning Organiz-ing Actuat-ing Controll-ing
Pemimpin yang Visioner Pemimpin yang Handal Pemimpin Pekerja Keras Pemimpin Yang Melayani Y Visi 0.5336 0.6389 0.6194 0.6268 0.6030 0.5162 0.7001 Planning 0.5336 0.6119 Organiz-ing 0.6119 Actuating Controlling 0.7946 Pemimpin yang Visioner Pemimpin yang Handal Pemimpin Pekerja Keras Pemimpin Yang Melayani
Pada matriks korelasi ataupun Tabel 1.13, subvariabel controlling
dan pemimpin yang visioner berkorelasi paling besar. Hal ini sesuai dengan harapan umum adanya pemimpin yang visioner dapat menjadi pengontrol alannya program.
Secara sama dapat dipelajari pula korelasi antara X1 dan X2. Kita juga dapat menggunakan semua variabel yang sudah mendapat respon dari
responden dan kita asumsikan berdasarkan linearitas bahwa setiap subvariabel Y (yaitu yjmempunyai hubungan linear terhadap variabel X1
dan X2). Korelasi X1 danX2 1.0000 0.5795 0.4070 0.4857 0.5795 1.0000 0.2343 0.2592 0.4070 0.2343 1.0000 0.6929 0.4857 0.2592 0.6929 1.0000 0.3632 0.4734 0.2443 0.2953 0.3325 0.1898 0.4222 0.3920 0.3362 0.2990 0.5577 0.5291 0.2111 0.2433 0.5431 0.4390 0.5292 0.4280 0.4588 0.5205 0.5110 0.2731 0.3696 0.4540 0.3632 0.3325 0.3362 0.2111 0.5292 0.5110 0.4734 0.1898 0.2990 0.2433 0.4280 0.2731 0.2443 0.4222 0.5577 0.5431 0.4588 0.3696 0.2953 0.3920 0.5291 0.4390 0.5205 0.4540 1.0000 0.2908 0.2865 0.2744 0.1788 0.1475 0.2908 1.0000 0.6408 0.4447 0.3950 0.1611 0.2865 0.6408 1.0000 0.5584 0.5647 0.3516 0.2744 0.4447 0.5584 1.0000 0.3844 0.0920 0.1788 0.3950 0.5647 0.3844 1.0000 0.6033 0.1475 0.1611 0.3516 0.0920 0.6033 1.0000 2 1,X X R (1.11) Perhatikan bahwa komponen matriks dari baris ke-1.kolom ke-1 hingga baris ke-5. kolom ke-5 merupakan merupakan matriks korelasi antar subvariabel X1 saja yaitu matriks
1
X
R (sebagaimana ditunjukkan pada persamaan (1.1)). Demikian pula komponen-komponen matriks baris ke-6. kolom ke-6 hingga baris ke-10.kolom ke-10 merupakan matriks korelasi antar subvariabel dalam X2saja yaitu
2
X
R . Blok matriks yang lain menjelaskan korelasi antar subvariabel pada X1dan X2. Contohnya komponen pada baris ke 1. kolom ke-6 atau baris ke-6 . kolom ke-1 menyatakan besar korelasi antara Fungsi manajemen (subvariabel pertama dalam X1) dan Pemimpin yang Visioner (subvariabel pertama dalam X2). Besar korelasi sebesar 0.1475 yang menunjukkan korelasi yang kecil atau dikatakan tidak berkorelasi secara signifikan. Kita dapat mengamati antar subvariabel pada kedua variabel tersebut. Matriks korelasi menunjukkan bahwa besar korelasi tidak signifikan. Hal ini nampaknya berbeda dengan