Syukur Alhamdulillah, puji dan syukur kami panjatkan kehadirat Allah
SWT, karena dengan limpah dan rahmat dan karunia-nya penulis dapat
menyelesaikan penyusunan laporan tugas akhir “APLIKASI KLASIFIKASI
ARTIKEL TEKNOLOGI INFORMASI PADA MAJALAH CHIP
MENGGUNAKAN NAÏVE BAYES”.
Maksud dan tujuan penyusunan laporan tugas akhir adalah untuk
memenuhi salah satu syarat dalam perkuliahan guna pembelajran mahasiswa di
dunia kerja yang akan di implementasikan sepenuhnya berdasarkan dengan
keahlian mahasiswa tersebut. Dan untuk mencapai gelar sarjana pada Fakultas
Teknologi Industri, Jurusan Sistem Informasi Pembangunan Nasional “Veteran”
Jawa Timur.
Dengan keterbatasan ilmu dan pengalaman, penulis dengan rendah hati
menyadari sepenuhnya, bahwa penyusunan laporan ini masih jauh dari sempurna,
oleh karena itu penulis bersedia dan ikhlas lahir bathin untuk menerima segala
saran dan kritik dari berbagai pihak demi perbaikan laporan ini.
Akhir kata, semoga laporan ini dapat memberikan manfaat bagi diri
pribadi, almamater dan pembaca. Amin.
Surabaya, 31 Mei 2012
ABSTRAKSI ... i
KATA PENGANTAR ... ii
DAFTAR ISI ... iii
DAFTAR TABEL ... vi
DAFTAR GAMBAR ... vii
BAB I PENDAHULUAN 1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 1
1.3 Batasan Masalah ... 2
1.4 Tujuan ... 2
1.5 Manfaat ... 3
1.6 Sistematika Penulisan ... 3
BAB II TINJAUAN PUSTAKA 2.1 Pembelajaran Mesin…………... 5
2.1.1 Komponen Sistem Cerdas ... 7
2.1.2 Rekayasa Pengetahuan ... 10
2.2. Proses Pengklasifikasian ... 11
2.3. Metode Klasifikasi Teks ... 11
2.4 Representasi Dokumen ... 12
2.5 Mprfologi Bahasa Indonesia ... 12
2.6 Pembobotan Kata …………... 14
2.10 Tahapan Pra Proses ... 22
2.11 Text Mining ... 25
2.12 Diagram Proses Klasifikasi ... 27
2.13 Delphi ... 28
2.14 Majalah Chips …... 38
BAB III ANALISIS DAN PERANCANGAN 3.1 Desain Penelitian ... 41
3.2 Bahan Penelitian ... 42
3.3 Structured Chart Sistem Klasifikasi Artikel ... 43
3.4 Diagram Work Flow ... 44
3.5 Diagram Alir Sistem ... 45
3.6 Perancangan Antar Muka ... 46
BAB IV HASIL DAN PEMBAHASAN 4.1 Perangkat Keras Yang Dipergunakan ... 49
4.2 Perangkat Lunak Yang Dipergunakan ... 49
4.3 Implementasi Prosedur Proses Klasifikasi ... 50
4.4 Implementasi Prosedur Proses Parsing ... 51
4.5 Implementasi Prosedur Proses Filtering ... 52
4.6 Implementasi Prosedur Proses Stemming ... 53
4.7 Implementasi Prosedur Bayes Classifier ... 54
4.8 Data Pelatihan ... 57
5.1 Kesimpulan ... 65
5.2 Saran ... 65
Tabel 2.1 Contoh Frekuensi Kata dalam Suatu Dokumen ... 14
Tabel 2.2 Bobot Kata Dalam Vektor Dokumen ... 15
Tabel 2.3 Bobot Kata Setelah Proses Normalisasi ... 16
Tabel 2.4 Data Training ... 17
Tabel 4.1 Spesifikasi Perangkat Komputer ... 49
Tabel 4.2 Spesifikasi Perangkat Lunak ... 49
Tabel 4.3 Hasil Pengujian Probabilistic Model ... 59
Tabel 4.4 Hasil Perhitungan Bayes Pada File Uji_1.txt ... 63
Tabel 4.5 Hasil Perhitungan Bayes Pada File Uji_2.txt ... 64
Gambar 2.1 Skema Sistem Pakar ... 7
Gambar 2.2 Proses Rekayasa Pengetahuan ... 10
Gambar 2.3 Tahapan Pra Proses ... 24
Gambar 2.4 Tahapan Umum Text Mining ... 12
Gambar 2.5 Contoh Tokenisasi ... 26
Gambar 2.6 Contoh Filtering ... 26
Gambar 2.7 Contoh Stemmisasi ... 27
Gambar 2.8 Diagram Proses Klasifikasi ... 27
Gambar 3.1 Skema Desain Penelitian ... 41
Gambar 3.2 Structured Chart Klasifikasi Artikel ... 43
Gambar 3.3 Diagram Workflow Sistem Klasifikasi Artikel ... 44
Gambar 3.4 Diagram Alir Sistem ... 45
Gambar 3.5 Rancangan Form Utama ... 46
Gambar 3.6 Rancangan Form Training ... 47
Gambar 3.7 Rancangan Form Stemming ... 48
Gambar 3.8 Rancangan Form Stoplist ... 48
Gambar 4.1 Hasil Pengujian artikel uji_1.txt ... 63
Dosen 1
: Nur Cahyo Wibowo, S.Kom, M.Kom
Dosen 2
: Doddy Ridwandono, S.Kom
Penulis
: Rigtianto Setiawan
____________________________________________________________________
Abstrak
Pengklasifikasian teks sangat dibutuhkan dalam berbagai macam aplikasi, terutama
aplikasi yang jumlah dokumennya bertambah dengan cepat seiring dengan
bertambahnya waktu. Contohnya adalah aplikasi
spam email
, indek otomatis pada
artikel ilmiah, dan lain sebagainya.Ada dua varian utama dalam penggolongan teks,
yaitu
clustering text
dan klasifikasi teks
Permasalahan yang dihadapi adalah bagaimana membuat aplikasi rekomendasi
pengklasifikasian suatu artikel teks pada CHIP menggunakan algoritma Naïve Bayes
dan seberapa akuratkah proses klasifikasi dalam mengklasifikasikan artikel teks
majalah CHIP menggunakan algoritma Naïve Bayes.
Pembuatan aplikasi ini dikembangkan menggunakan bahasa pemrograman Delphi
dan diintegrasikan dengan database Microsoft Access. Aplikasi yang dihasilkan dapat
mengklasifikasikan artikel teks pada majalah komputer Chip dengan baik.
1.1. Latar Belakang
Pengklasifikasian teks sangat dibutuhkan dalam berbagai macam
aplikasi, terutama aplikasi yang jumlah dokumennya bertambah dengan cepat
seiring dengan bertambahnya waktu. Contohnya adalah aplikasi spam email,
indek otomatis pada artikel ilmiah, dan lain sebagainya.Ada dua varian utama
dalam penggolongan teks, yaitu clustering text dan klasifikasi teks. Clustering
teks berhubungan dengan menemukan sebuah struktur kelompok yang belum
kelihatan (tak terpandu atau unsupervised) dari sekumpulan dokumen. Sedangkan
pengklasifikasian teks dapat dianggap sebagai proses untuk membentuk
golongan-golongan (kelas-kelas) dari dokumen berdasarkan pada kelas kelompok yang
sudah diketahui sebelumnya (terpandu atau supervised). Naive Bayesmerupakan
salah satu metode yang digunakan dalam pengklasifikasian teks. Metode lainnya
adalah k-Nearest Neighbor, Support Vector, Rochio Classifier dan lain-lain.
1.2. Perumusan Masalah
Rumusan masalah yang digunakan dalam tugas akhir ini adalah :
a) Bagaimana membuat aplikasi rekomendasi pengklasifikasian suatu artikel
teks pada majalah CHIP menggunakan algoritma naive bayes
b) Seberapa akuratkah proses klasifikasi dalam mengklasifikasikan artikel
1.3. Batasan Masalah
Dalam pembuatan aplikasi teks untuk tugas akhir ini, menggunakan batasan
masalah sebagai berikut :
a) Artikel teks yang dipergunakan tidak lebih dari 150 kata
b) Artikel teks yang dimaksud berupa file dengan ekstensi *.txt
c) Artikel yang dipergunakan sebagai pengujian diambil dari majalah komputer
Chips
d) Pengklasifikasian artikel berdasarkan kategori yang telah ada di majalah Chips
dan ditambah satu yaitu tidak terkategori.
e) Kategori setiap artikel yang akan diklasifikasikan telah ditentukan sebelumnya
secara manual, hal ini diperlukan untuk pembuatan data pelatihan dan untuk
proses klasifikasi. Pengklasifikasian secara manual ini dapat dilakukan oleh
peneliti. Nantinya, sistem akan mengecek hasil klasifikasi secara manual dengan
hasil klasifikasi secara otomatis menggunakan sistem untuk mendapatkan angka
akurasi pengklasifikasian
1.4. Tujuan
Tujuan yang ingin dicapai pada pengerjaan tugas akhir ini adalah:
a) Dapat membuat aplikasi rekomendasi pengklasifikasian artikel teks pada
majalah komputer chips.
1.5. Manfaat
Adapun manfaat dan tujuan yang ingin diperoleh dari pengerjaan tugas
akhir ini adalah :
a) Mendapat kemampuan pemahaman dan analisa tentang algoritma naive bayes.
b) Dapat mengimplementasikan algorithma naive bayes untuk membuat aplikasi
klasifikasi data dokumen teks.
1.6. Sistematika Penulisan
Sistematika penulisan tugas akhir ini disusun untuk memberikan gambaran
umum tentang penelitian yang dijalankan. Sistematika penulisan tugas akhir ini
BAB I PENDAHULUAN
Bab ini berisi latar belakang masalah, identifikasi masalah, maksud
dan tujuan yang ingin dicapai, batasan masalah, metodologi
penelitian yang diterapkan dalam memperoleh dan mengumpulkan
data, waktu dan tempat penelitian, serta sistematika penulisan.
BAB II TINJ AUAN PUSTAKA
Membahas berbagai konsep dasar dan teori-teori yang berkaitan
dengan topik masalah yang diambil dan hal-hal yang berguna
dalam proses analisis permasalahan.
BAB III ANALISIS DAN PERANCANGAN
Menganalisis masalah dari model penelitian untuk memperlihatkan
keterkaitan antar variabel yang diteliti serta model matematis untuk
analisisnya.
BAB IV HASIL DAN PEMBAHASAN
Membahas mengenai pengimplementasian aplikasi yang telah
dibuat ke perangkat yang akan digunakan serta melakukan
pengujian terhadap aplikasi yang telah diimplementasikan tersebut.
BAB V PENUTUP
Berisi kesimpulan dan saran yang sudah diperoleh dari hasil
2.1. Pembelajaran Mesin
Pada masa-masa awal berkembangnya teknologi komputer, sudah terdapat
visi agar di masa mendatang komputer dapat “belajar dan menjadi cerdas”. Hal ini
ditandai dengan lahirnya sistem pakar sekitar tahun 70’an.
Sistem pakar merupakan sistem yang berbasis pengetahuan, yaitu sistem
yang meniru penalaran dari seorang pakar dalam bidang tertentu untuk
memecahkan suatu masalah atau untuk memberikan saran. Sistem ini
menggunakan pengetahuan manusia untuk menyelesaikan masalah yang
memerlukan kepakaran seorang ahli. Jadi sistem pakar berbeda dengan sistem
lainnya yang hanya bisa menyimpan data, sistem pakar harus mempunyai
kemampuan penalaran untuk mencari jawaban permasalahan yang diajukan.
Ada berbagai ciri dan karakteristik yang membedakan sistem pakar
dengan sistem yang lain. Ciri dan karakteristik ini menjadi pedoman utama dalam
pengembangan sistem pakar. Ciri dan karakteristik yang dimaksud adalah sebagai
berikut:
1. Pengetahuan sistem pakar merupakan suatu konsep, bukan berbentuk numerik.
Hal ini dikarenakan komputer melakukan proses pengolahan data secara
numerik sedangkan keahlian dari seorang pakar adalah fakta dan
aturan-aturan, bukan numerik.
2. Informasi dalam sistem pakar tidak selalu lengkap, subjektif, tidak konsisten,
keputusan yang diambil bersifat tidak pasti dan tidak mutlak "ya" atau "tidak"
akan tetapi menurut ukuran kebenaran tertentu. Oleh karena itu dibutuhkan
kemampuan sistem untuk belajar secara mandiri dalam menyelesaikan
masalah-masalah dengan pertimbangan-pertimbangan khusus.
3. Kemungkinan solusi sistem pakar terhadap suatu permasalahan adalah
bervariasi dan mempunyai banyak pilihan jawaban yang dapat diterima,
semua faktor yang ditelusuri memiliki ruang masalah yang luas dan tidak
pasti. Oleh karena itu diperlukan fleksibilitas sistem dalam menangani
kemungkinan solusi dari berbagai permasalahan.
4. Perubahan atau pengembangan pengetahuan dalam sistem pakar dapat terjadi
setiap saat bahkan sepanjang waktu sehingga diperlukan kemudahan dalam
modifikasi sistem untuk menampung jumlah pengetahuan yang semakin besar
dan semakin bervariasi.
5. Pandangan dan pendapat setiap pakar tidaklah selalu sama, yang oleh karena
itu tidak ada jaminan bahwa solusi sistem pakar merupakan jawaban yang
pasti benar. Setiap pakar akan memberikan pertimbangan-pertimbangan
berdasarkan faktor subjektif.
6. Keputusan merupakan bagian terpenting dari sistem pakar. Sistem pakar harus
memberikan solusi yang akurat berdasarkan masukan pengetahuan meskipun
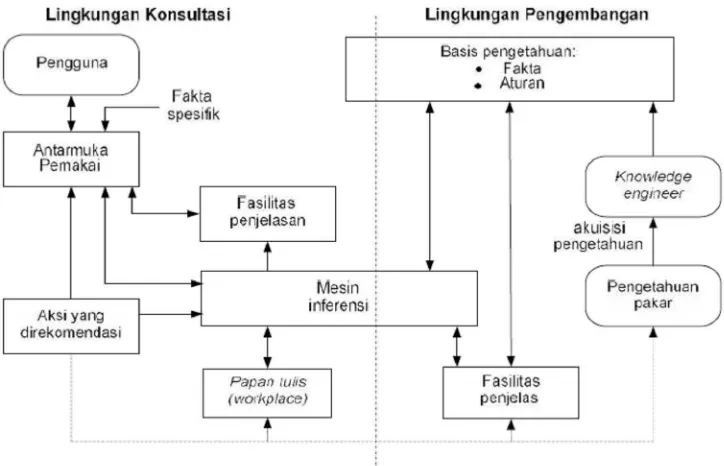
Gambar 2.1 Skema Sistem Pakar
Inti dari pengembangan sistem pakar adalah agar orang awam sekalipun dapat
menggunakan pengetahuan seorang pakar untuk menyelesaikan masalah.
Pengembangan sistem pakar terdiri dari beberapa tahap yang terus berulang. Ini
terjadi karena adanya perubahan atau tambahan pengetahuan baru. Ketika sebuah
pengetahuan baru ditambahkan ke basis pengetahuan sistem pakar, sistem
mengujinya untuk mengevaluasi apakah sistem mengerti atau tidak pengetahuan
baru tersebut, sehingga sistem dapat belajar secara mandiri untuk menyelesaikan
masalah.
2.1.1. Komponen Sistem Cer das
Secara umum, sistem pakar terdiri dari beberapa komponen yang saling berhubungan,
yaitu :
1. Basis Pengetahuan
Basis data dalam sistem pakar disebut basis pengetahuan. Basis pengetahuan
memecahkan masalah. Basis pengetahuan menggunakan aturan-aturan untuk
mengekspresikan logika masalah yang pemecahannya dibantu oleh sistem pakar.
Basis pengetahuan terdiri dari dua elemen, yaitu:
Fakta: situasi, kondisi, dan kenyataan dari permasalahan yang ada, berisi
juga teori dari bidang permasalahan tersebut
Aturan: mengarahkan pengguna pengetahuan untuk memecahkan masalah
dari bidang tersebut
2. Mesin Inferensi
Mesin Inferensi merupakan otak dari sistem pakar. Dikenal juga sebagai
penerjemah aturan (rule interpreter). Komponen ini berupa program komputer
yang menyediakan suatu metodologi untuk memikirkan (reasoning) dan
memformulasi kesimpulan. Mesin inferensi menggunalan penalaran yang serupa
dengan manusia dalam mengolah isi dari basis pengetahuan. Mesin inferensi
terdiri dari tiga bagian, yaitu:
a. Interpreter: digunakan untuk menerjemahkan aturan ke dalam bahasa
mesin agar dapat menjalankan program
b. Scheduler: digunakan untuk pencarian dan penalaran pada basis
pengetahuan dalam penyelesaian masalah
c. Consistency Enforcer: untuk menampilkan solusi permasalahan
Kerja mesin inferensi meliputi:
a. Menentukan aturan mana yang akan dipakai
b. Menyajikan pertanyaan kepada pengguna ketika diperlukan
c. Menambahkan jawaban ke dalam memori sistem pakar
3. Papan Tulis (Workplace)
Papan Tulis (Workplace) merupakan memori atau lokasi penyimpanan
untuk sistem pakar bekerja dan menyimpan hasil sementara, yang berupa basis
data. Memori ini berisi semua informasi tentang masalah tertentu, baik yang di
input oleh pengguna atau yang berada dalam basis pengetahuan.
4. Antarmuka Pengguna
Interaksi antara sistem pakar dan pengguna berupa bahasa alami, biasanya
dalam bentuk tanya jawab atau ditampilkan dalam bentuk gambar. Sistem pakar
menyediakan antarmuka agar pengguna dapat berinteraksi dengan sistem pakar.
Antarmuka pengguna memegang peranan penting dalam sistem pakar, untuk
memperoleh informasi yang akurat dari pengguna, perekayasa pengetahuan
diharapkan membuat desain antarmuka pertanyaan yang baik.
5. Fasilitas Penjelasan
Fasilitas ini merupakan fasilitas tambahan yang menyediakan penjelasan
kepada pengguna tentang mengapa sistem pakar mempertanyakan sebuah
pertanyaan tertentu kepada pengguna dan bagaimana sistem pakar membuat suatu
keputusan. Fasilitas penjelasan memberikan keuntungan kepada kedua belah
pihak, perekayasa pengetahuan dapat memeperbaiki kekurangan dari basis
pengetahuan dan pengguna mendapatkan penjelasan tentang bagaimana pemikiran
sistem pakar tersebut.
6. Knowledge Refining System
Seorang pakar mempunyai knowledge refining system artinya mereka
dapat menganalisis sendiri performa mereka, belajar dari pengalaman, serta
evaluasi ini penting sehingga dapat menganalisis alasan keberhasilan atau
kegagalan pengambilan keputusan, serta memperbaiki basis pengetahuan.
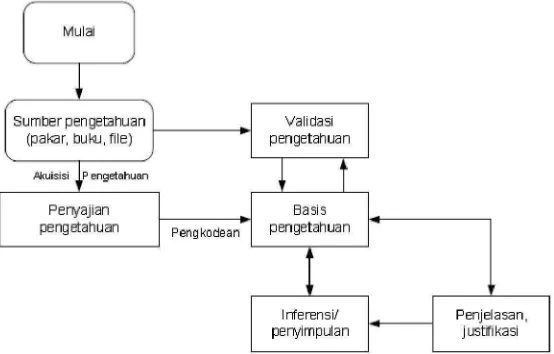
2.1.2. Rekayasa Pengetahuan
Rekayasa pengetahuan adalah proses membangun suatu sistem pakar. Tidak
seperti mengembangkan sistem biasa, pengembangan sistem pakar adalah proses
yang senantiasa berulang. Perekayasa pengetahuan membangun sistem pakar,
mengujinya, lalu merekayasa pengetahuan sistem. Proses seperti itu terus berulang.
Proses dalam rekayasa pengetahuan meliputi:
Akuisisi pengetahuan, yaitu bagaimana memperoleh pengetahuan dari pakar (dokter,
buku, jurnal atau sumber ilmiah lain)
Validasi pengetahuan, untuk menjaga kualitasnya misalnya dengan uji kasus
Representasi pengetahuan, yaitu bagaimana mengorganisir pengetahuan yang
diperoleh, mengkodekan, dan menyimpannya dalam suatu basis pengetahuan
Penyimpulan pengetahuan, menggunakan mesin inferensi yang mengakses basis
pengetahuan lalu melakukan penyimpulan
Transfer pengetahuan. Hasil inferensi berupa kesimpulan kemudian dijelaskan kepada
pengguna oleh fasilitas penjelasan
2.2. Pr oses Pengk lasifikasian
Classification adalah proses untuk menemukan model atau kelas data,
dengan tujuan untuk dapat memperkirakan kelas dari suatu objek yang labelnya
tidak diketahui. Model itu sendiri bisa berupa aturan jika-maka berbentuk pohon
pengambilan keputusan (Decision Tree), formula matematis seperti Bayesian dan
Support Vector Machine atau bisa juga berupa jaringan seperti neural network.
Ada lima ukuran yang dapat digunakan untuk mengevaluasi setiap metode:
1. Predictive accuracy yang mengukur tingkat akurasi dalam mengklasifikasikan
data baru. Ukuran ini paling sering digunakan sebagai pembanding.
2. Kecepatan. Biaya komputasi untuk menghasilkan classifier dan saat
menggunakan classifier pada proses klasifikasi.
3. Robustness. Kemampuan menangani noise dan nilai hilang.
4. Scalability. Kemampuan menangani data dalam jumlah besar.
5. Interpretability. Mengukur sejauh mana model dapat diinterpretasi.
Pada skripsi kali ini, hanya predictive accuracy yang akan digunakan untuk
pengklasifikasian artikel teks berdasarkan isinya.
2.3. Metode Klasifikasi Teks
Metode yang dapat digunakan untuk pengklasifikasian teks terpandu banyak
macamnya, antara lain adalah Na¨ıve Bayes, k-nearest neighbor, Support Vector
Machines (SVM), boosting, algoritma pembelajaran aturan (rule learning
algorithms) dan Maximum Entropy (MaxEnt). Dalam laporan ini metode yang
2.4. Representasi Dokumen
Dalam pengklasifikasian teks, dokumen direpresentasikan sebagai vektor
(W1,W2,W3, ..., Wn). Jenis representasi vektor dapat dibagi menjadi :
Binary, nilai w=1 apabila kata ditemukan dalam dokumen, jika tidak maka W = 0,
Misalnya :
V1 = contoh vektor binary dua nilai
0 0 1 0 1
Term Frequency (TF), nilai w= tf, frekuensi kehadiran kata dalam
dokumen, misalnya :
V1 = contoh vektor binary dua nilai
5 10 3 9 15
TfId (Inverse Document), nilai W = Tf*Id
V1 = contoh vektor binary dua nilai
0,365 0,261 0,946 0,128 0,299
2.5. Mor fologi Bahasa Indonesia
Sebuah kata memiliki morfologi yang dapat membuat kata tersebut berperan
sebagai kata benda, kata keterangan atau kata kerja (COVNd). Kata-kata dibawah
ini berasal dari kata dasar yang sama :
agar lebih memudahkan pengklasifikasian kata digunakan metode stemming yang
dibuat oleh Nazief dan Adriani yang berbasiskan pada morfologi bahasa Indonesia
dengan definisi sebagai berikut :
kata = stem | kata berimbuhan infleksional | kata berimbuhan derivasional | tidak
dikenal kata berimbuhan infleksional = stem Sinf | kata berimbuhan derivasional
| tidak dikenal
kata berimbuhan derivasional = stem-Sdr | Pder-stem | Pder- kata berimbuhan
derivasional | tidak dikenal
dimana :
Sder = Suffix atau akhiran derivasional
Sinf = Suffix atau akhiran infleksional
Pder = Prefix atau awalan derivasional
Setiap Sder, Sinf, Pder memiliki aturan sendiri. Metode ini menggunakan kamus
untuk menentukan hasil stem. Kata yang hendak di-stem awalnya dicari dalam
kamus, apabila tidak ditemukan maka selanjutnya kata tersebut diduga memiliki
imbuhan infleksional. Untuk mendapatkan imbuhan infleksional digunakan
struktur morfologi kedua. Dalam prosesnya struktur morfologi ketiga akan
digunakan karena kata ini diduga terdiri dari imbuhan derivasional dan Sinf.
Apabila kata dasar masih juga belum ditemukan maka kata ini selanjutnya diduga
memiliki imbuhan derivasional. Untuk mencari kata dasar dari kata dengan
imbuhan derivasional digunakan struktur aturan morfologi ketiga. Apabila kata
dasar belum juga ditemukan, maka kata yang hendak di-stem yang akan
2.6. Pembobotan Kata
Setiap kata dalam vektor dapat diberikan bobot. Bobot dari sebuah kata
menandakan tingkat kepentingan kata tersebut dalam dokumen. Pemberian bobot
kata dapat dinyatakan dengan nilai tfidf (term frquency inverse document).
Berikut ini adalah formula perhitungan tfidf :
Keterangan
• Wij adalah bobot kata i pada dokumen j
• N adalah koleksi dokumen
• tfif adalah jumlah kehadiran kata i yang akan dihitung bobotnya dalam
dokumen j
• dfj adalah dokumen j yang mengandung kata yang akan dihitung
bobotnya
• Rumusan Log disebut juga inverse document
Sebagai contoh :
Berikut ini adalah kata-kata yang ada dalam dokumen beserta frekuensinya :
Tabel 2.1. Contoh Frekuensi Kata dalam Suatu Dokumen
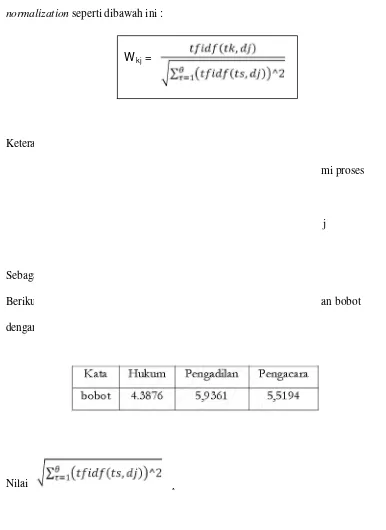
Kata yang hendak dihitung bobotnya adalah hukum. Misalkan jumlah keseluruhan
mengandung kata hukum, maka bobot kata hukum adalah w(hukum) =
4.Log(500/40)=4.3876
Agar penentuan bobot kata juga memperhitungkan panjang dokumen maka
dilakukan tahapan normalisasi. Proses normalisasi akan membuat setiap vektor
dokumen bernilai (0,1). Normalisasi dilakukan dengan rumusan cosine
normalization seperti dibawah ini :
Keterangan :
• Wkj adalah bobot kata k di dokumen j setelah mengalami proses
normalisasi
• tfidf (tk,dj) adalah nilai tfidf dari kata k pada dokumen j
• r adalah jumlah kata dalam dokumen j
Sebagai contoh :
Berikut ini adalah vektor dokumen, dimana kata-katanya telah diberikan bobot
dengan nilai tfidf.
Tabel 2.2. Bobot Kata Dalam Vektor Dokumen
Nilai pada vektor diatas adalah
= 9,2169. Sedangkan hasil vektor diatas setelah
mengalami proses normalisasi dengan cara membagi bobot kata pada vektor
dengan 9.2169 ditunjukkan pada tabel dibawah ini:
Tabel 2.3. Bobot Kata Setelah Proses Normalisasi
2.7. Training Set Dan Testing Set
Trainig set (Tr atau dokumen training) = (d1,d2,d3,...dn) adalah sekumpulan
dokumen yang digunakan oleh clasifier untuk mengobservasi karakteristik dan
kategori. Sedangkan testing set (Te atau dokumen testing) = (dn+1,...ds) adalah
sekumpulan dokumen yang ditujukan untuk menguji efektifitas dari classifier.
Setiap dokumen di Te akan diberikan kepada classifier lalu hasil dari classifier
akan dibandingkan dengan hasil dari seorang ahli. Efektifitas dari pengukuran
classifier didasarkan pada seberapa sering hasil dari classifier sama dengan hasil
dari para ahli.
2.8. Metode Naive Bayes
The Naive Bayes classifiers juga biasa dikenal dengan algoritma klasifikasi
simple Bayesian. Algoritma ini banyak digunakan karena terbukti efektif untuk
kategorisasi teks, sederhana, cepat dan akurasi tinggi.
Metode ini menghitung probabilitas P(Ci | Dj), yaitu dokumen yang
direpresentasikan oleh vektor yang telah dibahas sebelumnya (bagian 2,
representasi dokumen). Perhitungan probabilitas menggunakan teorema bayes,
P(Dj) merepresentasikan probabilitas sebuah dokumen yang diambil secara acak
memiliki vektor Dj sebagai representasinya dan P(Ci) adalah probabilitas bahwa
dokumen yang dipilih secara acak akan mempunyai kategori Ci. P(Dj | Ci)
memiliki jumlah kemungkinan vektor dj terlalu banyak. Untuk menghilangkan
kemungkinan tersebut dibuat asumsi bahwa dua koordinat dari vektor dokumen,
apabila dipandang sebagai random variable secara statistik independen satu
dengan lainnya, asumsi ini dituliskan dalam formula sebagai berikut :
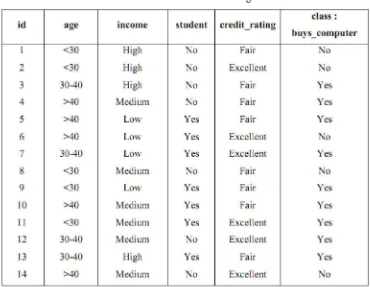
Dalam menggunakan naive bayes diperlukan data training. Misalkan
diketahui data training sebagai berikut :
Tabel 2.3. Data Training
Dari data di atas terdapat 4 atribut yaitu, age, income, student, dan credit_rating.
Class-nya adalah buys_computer yang memiliki 2 values, yaitu yes dan no.
Kemudian ada data X, dimana X = (age = “<30”, income = medium, student =
yes, credit_rating = fair). Untuk menentukan class data tersebut perlu dihitung
nilai kemungkinannya yang dapat diketahui dari data training.
Hitung nilai P(Ci) untuk i = yes dan no
P(buys_computer = yes) = 9/14 = 0.643 dan P(buys_computer = no) =
5/14 = 0.357
Hitung P(X|Ci) untuk i = 1,2
P(age <=30|buys_computer=yes) = 2/9 = 0.222
P(age <=30|buys_computer=no) = 3/5 = 0.600
P(income medium|buys_computer=yes) = 4/9 = 0.4444
P(income medium|buys_computer=no) = 2/5 = 0.400
P(student yes|buys_computer=yes) = 6/9 = 0.667
P(student yes|buys_computer=no) = 1/5 = 0.200
P(credit_rating fair|buys_computer=yes) = 6/9 = 0.667
P(credit_rating fair|buys_computer=no) = 2/5 = 0.400
Berdasarkan hasil peluang di atas, dapat dihitung berdasarkan rumus :
P(X|buys_computer=yes) = 0.222 * 0.444 * 0.667 * 0.667 = 0.044
P(X|buys_computer=no) = 0.600 * 0.400 * 0.200 * 0.400 = 0.019
P(X|buys_computer=yes)P(buys_computer=yes) = 0.044 * 0.643 = 0.028
P(X|buys_computer=no)P(buys_computer=no) = 0.019 * 0.357 = 0.007
Berdasarkan penghitungan di atas maka, sample X akan masuk kategori
2.9. Karakter istik Naive Bayes Classifier
Naive Bayes Classifier umumnya memiliki karakteristik sebagai berikut.
• Kokoh untuh titik noise yang diisolasi seperti titik yang dirata-ratakan ketika
mengestimasi peluang bersyarat data. Naive bayes classifier dapat menangani
missing value dengan mengabaikan contoh selama pembuatan model dan
klasifikasi.
• Kokoh untuk atribut tidak relevan, jika Xi adalah atribut yang tidak relevan,
maka P
( )
XiY menjadi hampir didistribusikan seragam. Peluang kelasbersyarat untuk Xi tidak berdampak pada keseluruhan perhitungan peluang
posterior.
• Atribut yang dihubungkan dapat menurunkan performance Naive bayes
classifier karena asumsi independen bersyarat tidak lagi menangani atribut
tersebut. Sebagai contoh, perhatikan peluang berikut.
P(A = 0|Y = 0) = 0.4, P(A = 1|Y = 0) = 0.6,
P(A = 0|Y = 1) = 0.6, P(A = 1|Y = 1) = 0.4,
dengan A adalah atribut biner dan Y adalah variabel kelas biner. Jika ada atribut
biner lain yaitu B yang secara tepat dihubungkan dengan A ketika Y = 0, tetapi
independen dengan A ketika Y = 1. Sederhanaya, diasumsikan bahwa peluang
kelas bersyarat untuk B sama seperti A. diberikan record dengan atribut A = 0,
B = 0, dapat dihitung peluang posterior sebagai berikut.
(
) (
(
) (
)
)
(
)
0 , 0 0 0 0 0 0 0 , 0 0 = = = = = = = = = = = B A P Y P Y B P Y A P B A Y P(
)
(
16 0)
.
0 =
(
) (
(
) (
)
)
(
)
0 , 0 1 1 0 1 0 0 , 0 1 = = = = = = = = = = = B A P Y P Y B P Y A P B A Y P(
)
(
0, 0)
1 36 . 0 = = = = B A P Y xP
Jika P
(
Y =0) (
=P Y =1)
, maka naive bayes classifier akan menugaskan record ke kelas 1. Bagaimanapun, yang benar adalah :(
A=0,B−0Y =0) (
=P A=0Y =0)
=0.4P
karena A dan B dihubungkan secara tepat ketika Y = 0. Sebagai hasil, peluang
posterior untuk Y = 0 adalah :
(
) (
(
) (
)
)
(
)
0 , 0 0 0 0 0 0 0 , 0 0 = = = = = = = = = = = B A P Y P Y B P Y A P B A Y P(
)
(
0, 0)
0 4 . 0 = = = = B A P Y xP .
yang lebih besar dibanding untuk Y = 1. Record diklasifikasikan sebagai kelas 0.
Error Rate (Tingkat Kesalahan) Bayes
Jika diketahui distribusi peluang yang benar yang mengatur P
( )
X Y . Metoda klasifikasi Bayesian menyediakan penentuan batas keputusan ideal untuk tugasklasifikasi, sebagimana diilustrasikan contoh berikut.
Perhatikan tugas mengidentifikasikan alligator dan crocodiles berdasarkan
panjang masing-masing. Panjang rata-rata crocodile dewasa sekitar 15 kaki
sedangkan panjang rata-rata alligator dewasa sekitar 12 kaki. Diasumsikan bahwa
panjang x mengikuti distribusi Gaussian dengan standar deviasi sama dengan 2
(
)
− − Π = 2 2 15 2 1 exp 2 . 2 1 X Crocodile X P ... (9)(
)
− − Π = 2 2 12 2 1 exp 2 . 2 1 X Alligator X P ... (10)Pada persamaan (9) dan (10) diatas menunjukkan perbandingan antara peluang
kelas bersyarat untuk crocodile dan alligator. Diasumsikan bahwa peluang prior
adalah sama, batas keputusan ideal diletakkan pada panjang xˆ yaitu :
(
X xCrocodile) (
P X xAlligator)
P = ˆ = = ˆ
Menggunakan persamaan 9 didapat,
2 2 2 12 ˆ 2 15 ˆ − =
−x x
yang dapat dipecahkan dengan hasil xˆ = 13.5. Batas keputusan untuk contoh ini
diletakkan di tengah antara dua mean.
Ketika peluang prior berbeda, batas keputusan menggeser kelas dengan peluang
prior lebih rendah. Selanjutnya, minimum error rate dapat dicapai dengan setiap
classifier yang diberikan data juga dapat dihitung. Batas keputusan ideal pada
contoh terdahulu mengklasifikasikan seluruh mahluk dengan panjang kurang dari
x sebagai alligator dan yang kurang dari xˆ sebagai crocodile. Error rate
classifier diberikan dengan menjumlahkan luas di bawah kurva peluang posterior
untuk crocodile (dari panjang 0 hingga xˆ ) dan luas di bawah kurva peluang
posterior untuk alligator (dari xˆ hingga ∞)
2.10. Tahapan Pra Pr oses
Data preprocessing adalah proses “pembersihan” data dari data-data yang
“kotor”, yaitu data-data yang tidak lengkap, error, atau mengandung kode atau nama
yang bertentangan.
Data preprocessing berfungsi sebagai penyaring data dari
karakteristik-karakteristik data yang tidak diinginkan. Data hasil dari data preprocessing itulah
yang nantinya akan digunakan dalam data mining. Sehingga data yang dipakai adalah
data dengan kualitas yang tinggi yang nantinya akan meningkatkan akurasi, efisiensi,
dan kualitas dari data tersebut.
Pekerjaan tahap preprocessing adalah membangun representasi (perwujudan) artikel
berita yang siap diproses sebagai input bagi algoritma mining (summarization,
classification, clustering dan contrast).
Sebelum data diklasifikasi adanya perprocesing agar data yang di mining lebih
berkualitas dan akurat. Berikut langkah-langkah preprocessing data:
1) Pember sihan data (untuk membuang data yang tidak konsisten dan noise)
Pada umumnya data yang diperoleh, baik dari database suatu perusahaan maupun
hasil eksperimen, memiliki isian-isian yang tidak sempurna seperti data yang hilang,
data yang tidak valid atau juga hanya sekedar salah ketik. Selain itu, ada juga
atribut-atribut data yang tidak relevan. Data-data yang tidak relevan itu juga lebih baik
dibuang karena keberadaannya bisa mengurangi mutu atau akurasi dari hasil data
mining. “Garbage in garbage out” (hanya sampah yang akan dihasilkan bila yang
dimasukkan juga sampah) merupakan istilah yang sering dipakai untuk
menggambarkan tahap ini. Pembersihan data juga akan mempengaruhi performasi
dari sistem data mining karena data yang ditangani akan berkurang jumlah dan
Mengapa data perlu dibersihkan sebelum diproses? Hal ini terjadi karena biasanya
data yang akan digunakan belum baik, penyebabnya antara lain :
• Incomplete: kekurangan nilai-nilai atribut atau atribut tertentu lainnya.
• Noisy: berisi kesalahan atau nilai-nilai outlier yang menyimpang dari yang
diharapkan.
• Inconsisten: ketidakcocokan dalam penggunaan kode atau nama. Disini kualitas
data yang baik didasarkan oleh keputusan yang baik dan data warehouse
memerlukan integrasi kualitas data yang konsisten.
2) Integr asi data (penggabungan data dar i beber apa sumber )
Tidak jarang data yang diperlukan untuk data mining tidak hanya berasal dari satu
database tetapi juga berasal dari beberapa database atau file teks. Integrasi data
dilakukan pada atribut-aribut yang mengidentifikasikan entitas-entitas yang unik
seperti atribut nama, jenis tabungan, nomor pelanggan dan sebagainya. Integrasi data
perlu dilakukan secara cermat karena kesalahan pada integrasi data bisa menghasilkan
hasil yang menyimpang dan bahkan menyesatkan pengambilan aksi nantinya. Dalam
integrasi data ini juga perlu dilakukan transformasi dan pembersihan data karena
seringkali data dari dua database berbeda tidak sama cara penulisannya atau bahkan
data yang ada di satu database ternyata tidak ada di database lainnya.
3) Transfor masi data (data diubah menjadi bentuk yang sesuai untuk di-mining)
Merupakan proses transformasi pada data yang telah dipilih, seperti data transaksi
pelanggan, aset pelanggan, pendapatan pelanggan, dan seterusnya. sehingga data
tersebut sesuai untuk proses data mining. Proses ini merupakan proses kreatif dan
sangat tergantung pada jenis atau pola informasi yang akan dicari dalam basis data.
nantinya karena ada beberapa karakteristik dari teknik-teknik data mining tertentu
yang tergantung pada tahapan ini.
Berikut adalah deskripsi singkat mengenai tahapan yang dilakukan dalam
preprocessing sebuah data.
Gambar 2.3. Tahapan Pra Proses
Setelah preprocessing data baru kemudian masuk ke proses klasifikasi. Proses
klasifikasi biasanya dibagi menjadi dua fase: learning (pelatihan) dan testing
(pengujian). Pada fase learning, sebagian data yang telah diketahui kelas datanya
diumpankan untuk membentuk model prediksi. Karena menggunakan data yang telah
maka klasifikasi sering juga disebut sebagai metoda diawasi (supervised method).
Kemudian pada fase test-nya model yang sudah terbentuk diuji dengan sebagian data
lainnya untuk mengetahui akurasi dari model tersebut. Bila akurasinya mencukupi
model ini dapat dipakai untuk prediksi kelas data yang belum diketahui.
2.11. Text Mining
Text Mining adalah penggalian yang dilakukan oleh komputer untuk
mendapatkan sesuatu yang baru, sesuatu yang tidak diketahui sebelumnya atau
menemukan kembali informasi yang tersirat secara implisit, yang berasal dari
informasi yang diekstrak secara otomatis dari sumber-sumber data text yang
berbeda-beda. Text Mining berbeda dari pencarian di web. Pada pencarian, pengguna biasanya
mencari sesuatu yang sudah diketahui oleh mereka atau sudah pernah ditulis oleh
orang lain.
Permasalahannya adalah bagaimana menyatukan semua data-data yang tidak
diberhubungan dengan kebutuhan pengguna tersebut agar dapat digunakan untuk
mencari informasi yang sesuai dengan yang dicari. Text Mining tidak jauh berbeda
dengan Data Mining. Yang membedakannya adalah pada sumber datanya, dimana
Text Mining bersumber dari kumpulan dokumen atau text. Pada Text Mining,
informasi yang akan digali biasanya berisi informasi-informasi yang tidak terstruktur.
Text Mining memiliki definisi menambang data yang berupa text dimana sumber data
biasanya didapat dari dokumen, dan tujuannya adalah mencari kata-kata yang dapat
mewakili isi dari dokumen sehingga dapat dilakukan analisa keterhubungan
antardokumen. Tahapan yang dilakukan secara umum dalam Text Mining adalah:
tokenizing, filtering, stemming, tagging dan analyzing.
Gambar 2.4. Tahapan Umum Text Mining
Tahap tokenizing adalah tahap pemotongan string input berdasarkan tiap kata yang
menyusunnya. Contoh dari tahap ini adalah sebagai berikut :
Gambar 2.5. Contoh Tokenisasi
Tahap filtering adalah tahap mengambil kata-kata penting dari hasil token. Bisa
menggunakan algoritma stop list (membuang kata-kata yang kurang penting) atau
word list. Contoh dari tahap ini adalah sebagai berikut:
Gambar 2.6. Contoh Filtering
Tahap Stemming adalah tahap mencari root kata dari tiap kata hasil filtering. Tahap
ini kebanyakkan dipakai untuk text berbahasa inggris. Hal ini dikarenakan karena
bahasa Indonesia tidak memiliki rumus bentuk baku yang permanen. Penggunaannya
dalam text bahasa Indonesia adalah ketika menghilangkan imbuhan pada suatu
kalimat. seperti kata “melihat” di stemming sehingga menghasilkan kata „lihat
karena dihilangkan imbuhan me-. Contoh lain dari tahap stemming adalah sebagai
berikut:
Sist em Informasi Akademik Universit as Berbasis Deskt op
• Sist em • Informasi • Akademik • Universit as • Berbasis • Deskt op Tokenisasi
input
Hasil
• Sist em • Inf ormasi • Akademik • Universit as • Berbasis • Deskt op
• Sist em • Informasi • Akademik Penyaringan (filt ering)
Hasil t okenisasi
Gambar 2.7. Contoh Stemmisasi
Dalam pengklasifikasian artikel tugas akhir ini, tahapan text mining dilakukan hanya
sampai tahap filtering. Hal ini disebabkan karena pengklasifikasian berdasarkan isi
artikel tidak menangani kalimat maupun paragraf yang berbahasa inggris.
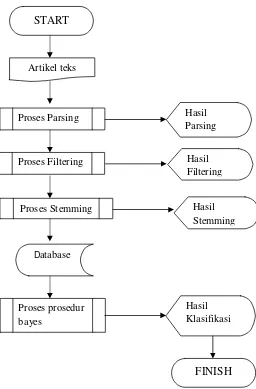
2.12. Diagram Proses Klasifikasi
Gambar 2.8. Diagram Proses Klasifikasi
berbasis st emmisasi Basis
START
Artikel teks
Proses Parsing
Proses prosedur bayes
Proses Filtering
Proses Stemming
Database
Hasil Parsing
Hasil Filtering
Hasil Stemming
Hasil Klasifikasi
Pada diagram di atas menjelaskan alur proses pengklasifikasian dari sebuah artikel
teks. Awalnya file tekx mengalami proses Parsingng yang kemudian di lanjutkan
proses Filtering dan kemudian akan di lakukan proses Stemming yang nanti di
stiap proses akan di tampilkan di layar form. Selain itu hasil dari proses tersebut
di masukan ke dalam Database pada table testdata. Yang kemudian di lanjutkan
prosedur BayesClassifier setelah semua selesai maka hasil klasifikasi akan di
tampilkan di form awal.
2.13. Delphi
Delphi adalah Suatu bahasa pemrograman yang menggunakan visualisasi sama
seperti bahasa pemrograman Visual Basic ( VB ) . Namun Delphi menggunakan
bahasa yang hampir sama dengan pascal (sering disebut objeck pascal ) . Sehingga
lebih mudah untuk digunakan . Bahasa pemrograman Delphi dikembangkan oleh
CodeGear sebagai divisi pengembangan perangkat lunak milik embarcadero .
Divisi tersebut awalnya milik borland , sehingga bahasa ini memiliki versi Borland
Delphi
Delphi juga menggunakan konsep yang berorientasi objek ( OOP ) ,
maksudnya pemrograman dengan membantu sebuah aplikasi yang mendekati
keadaan dunia yang sesungguhnya . Hal itu bisa dilakukan dengan cara mendesign
objek untuk menyelesaikan masalah . OOP ini memiliki beberapa unsur yaitu ;
Encapsulation ( pemodelan ) , Inheritance ( Penurunan ) , Polymorphism (
Awalnya bahasa pemrograman delphi hanya dapat digunakan di Microsoft
Windows, namun saat ini telah dikembangkan sehingga dapat digunakan juga di
Linux dan di Microsoft .NET . Dengan menggunakan free pascal yang merupakan
proyek OpenSource, bahasa pemrograman ini dapat membuat program di sistem
operasi Mac OS X dan Windows CE.
Umumnya delphi hanya digunakan untuk pengembangan aplikasi dekstop,
enterprise berbasis database dan program - program kecil . Namun karena
pengembangan delphi yang semakin pesat dan bersifat general purpose bahasa
pemrograman ini mampu digunakan untuk berbagai jenis pengembangan software
. Dan Delphi juga disebut sebagai pelopor perkembangan RadTool ( Rapid
Apllication Development ) tahun 1995 . Sehinnga banyak orang yang mulai
mengenal dan menyukai bahasa pemrograman yang bersifat VCL ( Visual
Component Library ) ini .
Contoh Source Code dasar Delphi
Dalam bahasa pemrograman apapun pasti dikenal suatu mekanisme looping
atau perulangan. Looping disini sangat berguna sekali untuk mengontrol jalannya
program, terutama jika ada aktivitas yang berulang-ulang dan bahkan ada suatu
kondisi tertentu di dalam looping tersebut. Nah, kali ini kita akan bahas mengenai
mekanisme looping apa saja yang terdapat dalam Borland Delphi.
Dalam penulisan program Delphi ada kalanya tidak membutuhkan program
yang terlalu panjang ketika hanya terdiri dari pengulangan dari program yang
ditulis secara singkat dengan menggunakan looping. Jenis-jenis dari looping dapat
dibagi sebagai berikut:
1. for…to..do dan for…downto…do
2. repeat…until
3. while…do
Untuk lebih jelasnya akan dibahas masing – masing dari proses looping tersebut
beserta contoh sederhana yang akan memudahkan dalam pengaplikasiannya.
1. for…to…do dan for…down…to.
Perulangan for dibagi lagi menjadi 2 jenis yaitu:
a. for…to…do
b. for…downto…do
Keduanya mempunyai fungsi yang sama dengan sintaks program seperti berikut
ini.
for variable := nilai_awal to nilai_akhir do pernyataan
for variable := nilai_awal downto nilai_akhir do pernyataan
Looping for bisa digunakan untuk beberapa jenis proses pengulangan yaitu jenis
pengulangan integer, pengulangan character dan pengulangan enumeration.
Contoh program:
– Pengulangan pada jenis variabel integer
var
i : integer;
begin
for i:= 1 to 5 do
end;
ketika di-run:
nilai i = 1
nilai i = 2
nilai i = 3
nilai i = 4
nilai i = 5
– Pengulangan pada jenis variable character
var
i : char;
begin
for i:= ‘a’ to ‘e’ do
showmessage(‘nilai i =’ + i);
end;
ketika di-run:
nilai i = a
nilai i = b
nilai i = c
nilai i = d
nilai i = e
– Pengulangan pada jenis variable enumeration
var
begin
for kota:= bandung to sidoarjo do
showmessage(‘kota i =’ + inttostr(ord(kota)));
end;
ketika di-run:
kota i = 2
kota i = 3
kota i = 4
Pada enumeration akan diberikan nomor urut (ordinal type) pada masing – masing
isi dari kota saat pendeklarasiannya pada bagian var. Nomor urut dimulai dari 0
sampai 4. Nomor urut surabaya adalah 0,nomor urut dari jakarta adalah 1 dan
seterusnya. Karena looping dimulai dari bandung yang bernomor urut 2 maka
ketika dirun yang pertama kali muncul adalah kota i = 2.
Untuk jenis looping for… downto…do hampir sama hanya saja pengulangan
dilakukan secara hitungan turun.
Contoh program:
var
i : char;
begin
for i:= ‘f’ downto ‘c’ do
showmessage(‘nilai i =’ + i);
end;
ketika di-run:
nilai i = e
nilai i = d
nilai i = c
2. repeat…until
Jenis looping ini digunakan untuk looping dengan sampai dengan batas yang
ditentukan setelah pernyataan until. Sintaks dari jenis looping ini dapat dilihat
seperti dibawah ini:
repeat pernyataan until syarat
Contoh program:
var
i,a : integer;
begin
i:=1;
repeat
a:=i*5;
showmessage(‘nilai ‘+ inttostr(i)+’ * 5 = ‘+inttostr(a));
inc(i); // inc(i)===> i=i+1
until i > 5;
end;
ketika di-run:
nilai 1 * 5 =5
nilai 2 * 5 =10
nilai 3 * 5 =15
nilai 5 * 5 =25
Pada jenis looping repeat, nilai i diberi nilai awal dahulu sebelum masuk ke
looping. Untuk menaikkan nilai i diperlukan pernyataan tambahan inc(i) atau i = i
+ 1, tidak seperti dalam looping jenis for yang tidak membutuhkan pernyataan
untuk menaikkan nilai i.
3. while…do
Jenis looping ini hampir sama dengan jenis looping repeat…until. Beda dari
kedua jenis looping ini adalah jika pada looping repeat…until dilakukan proses
dahulu baru dilihat syarat mengakhiri looping masih memenuhi atau tidak. Jika
memenuhi maka proses looping akan berhenti tapi kalau tidak maka looping akan
terus berjalan sedangkan pada jenis looping while…do syarat melakukan looping
diajukan terlebih dahulu jika memenuhi maka proses akan dilakukan tapi jika
tidak maka looping tidak dilakukan.
Sintaks dari jenis looping ini adalah sebagai berikut:
while syarat do pernyataan
Contoh program:
var
i,a : integer;
begin
i:=1;
while i i=i+1
end;
end;
nilai kuadrat dari 1 adalah 1
nilai kuadrat dari 2 adalah 4
nilai kuadrat dari 3 adalah 9
nilai kuadrat dari 4 adalah 16
nilai kuadrat dari 5 adalah 25
Menghentikan proses looping
Ketika proses looping masih dilakukan kadang kala kita perlu untuk keluar dari
looping berdasarkan suatu kondisi tertentu, untuk itu ada 3 cara untuk
menghentikan proses looping tersebut yaitu dengan menggunakan:
1. Goto
Biasanya penghentian looping dengan menggunakan sintak ini jarang digunakan.
Penghentian looping dilakukan dengan pernyataan if. Jika syarat if terpenuhi
maka looping berhenti dengan melompat ke label yang dibuat secara terpisah
dengan program proses looping.
Contoh program:
var
i,a : integer;
label
berhenti;
begin
i:=1;
begin
a:=i*i;
showmessage (‘nilai kuadrat dari ‘+ inttostr(i)+’ adalah ‘ + inttostr(a));
if a>15 then goto berhenti;
end;
berhenti:
showmessage(‘loop berhenti saat i = ‘+inttostr(i)+’ dan kuadratnya adalah
‘+inttostr(a));
end;
ketika di-run:
nilai kuadrat dari 1 adalah 1
nilai kuadrat dari 2 adalah 4
nilai kuadrat dari 3 adalah 9
nilai kuadrat dari 4 adalah 16
loop berhenti saat i = 4 dan kuadratnya adalah 16
Pada proses tersebut looping tidak dilakukan sampai i ke-17 seperti perintah
looping for…to…do, tetapi hanya hingga nilai a lebih dari 15 untuk pertama
kalinya. Looping berhenti dan program melompat pada pernyataan dalam label.
2. Continue
Penghentian loop ini digunakan dengan menggunakan pernyataan if . Jika
pernyataan if dipenuhi maka looping tidak akan mengambil nilai tersebut tetapi
meneruskan loop berikutnya.
var
i : integer;
a : string;
begin
for i:=5 to 10 do
begin
if (i=6) or (i=9) then continue;
a:=a+’ ‘ +inttostr(i);
showmessage(‘a =’ + a);
end;
end;
ketika di-run:
a = 5
a = 5 7
a = 5 7 8
a = 5 7 8 10
Pada saat i = 6 maka looping tidak dilakukan, looping dilakukan kembali untuk
nilai i = 7. Begitu pula pada saat i = 9.
3. Break
Pernyataan ini digunakan untuk keluar dari proses looping, tanpa masuk ke
pernyataan lain seperti pada goto dan juga tanpa meneruskan looping dengan
menggunakan nilai selanjutnya seperti pada continue.
var
i : integer;
begin
for i:=1 to 12 do
begin
if i=6 then
break;
showmessage(‘nilai i =’ + inttostr(i));
end;
end;
ketika di-run:
nilai i = 1
nilai i = 2
nilai i = 3
nilai i = 4
nilai i = 5
Looping dilakukan hanya sampai nilai i = 5. Ketika nilai i = 6 perintah break
menghentikan looping.
2.14. Majalah Chips
Malajah Chips adalah satu majalah yang mengkhususkan diri memilih
segmen bahasan dalam terbitan mereka. Majalah ini menasbihkan sebagai majalah
yang mengkhususkan diri untuk mengulas tentang berbagai hal yang terkait
computer tersebut. Majalah Chips muncul sejak awal tahun 2000an. Majalah ini
tergolong salah satu majalah yang sudah dikenal oleh para pecinta dunia teknologi
komputer, karena merupakan salah satu media pelopor yang khusus mengulas
masalah komputer tersebut.
Meski tergolong mahal, Majalah Chips termasuk jenis majalah yang
digemari. Hal ini karena selain memang informasi yang di tampilkan dalam
majalah tersebut selalu mengikuti perkembangan teknologi, juga selalu di sisipkan
bonus software dalam terbitannya. Tettu ini menjadi salah satu daya tarik para
pembeli untuk memiliki majalah Chips ini.
Mendapatkan majalah Chips ini sangat mudah. Dengan waktu terbit
sebulan sekali, majalah ini bisa di dapatkan di semua tempat yang menjual surat
kabar atau majalah. Pembeli tidak perlu khawatir tentang keamanan bonus
softwarenya, jika tujuan pembeli majalah ini untuk mendapatkan bonus tersebut.
Itu karena majalah ini selalu di kemas dengan plastic yang rapat saat di jual.
Sehingga, seseorang tidak bisa membuka bagian dalam majalah tersebut sebelum
membelinya atau sekedar berniat mengambil kepingan cakram yang berisi bonus
software tersebut.
Manfaat Membaca Majalah Chips
Dengan membeli atau sekedar membaca majalah Chips tersebut, anda
akan mendapat nilai tambah terutama bagi anda yang memang memiliki hobi atau
memiliki pekerjaan yang terkait dengan perkembangan teknologi komputer.
a) Selalu mendapatkan informasi terkini tentang perkembangan teknologi
dunia. Hal ini akan di ikuti dengan ulasan yang lengkap di sertai dengan
penjelasan ilmiah yang akurat serta lengkap.
b) Bahasa yang di gunakan mudah di pahami, termasuk bagi mereka yang
masih baru belajar untuk berhubungan dengan dunia teknologi komputer.
c) Terdapat bonus software yang original. Pada setiap edisi selalu ada
perbedaan pada isi bonus tersebut.
d) Memberi kesempatan konsultasi bagi para pembacanya dengan cara
mengirimkan pertanyaan melalui email ke redaksi yang akan di jawab oleh
pengasuh rubric tersebut.
e) Penampilan majalah yang di buat menarik sehingga tidak membosankan
3.1. Desain Penelitian
Berikut adalah skema desain penelitian pengklasifikasian artikel tugas akhir:
Gambar 3.1. Skema Desain Penelitian
Studi Literatur 1. Mempelajari data berupa macam-macam artikel 2. Mempelajari kategori-kategori yang memungkinkan
untuk sebuah artikel
3. Menentukan kategori untuk setiap artikel untuk membuat data pelatihan
4. Mempelajari konsep classification dalam data mining 5. Mempelajari algoritma Naïve Bayes Classifier (NBC)
Data Penelitian Pencarian Data Penelitian
Mekanisme Pengklasifikasian
Komputerisasi
Manual
Artikel yang telah terklasifikasi, lengkap
3.2. Bahan Penelitian
Dalam melakukan pengklasifikasian artikel teks tugas akhir ini,
dibutuhkan bahan penelitian yang berupa artikel dalam bentuk file text (.txt). File
ini adalah uraian artikel yang diambil dari majalah CHIPS. Setiap baris di dalam
file tersebut dapat mengandung kata-kata yang termasuk stopword atau bukan.
Kata-kata yang terdapat pada file tersebut dipisahkan dengan tanda spasi,
sehingga digunakan sebagai mekanisme dalam mengenali klasifikasi artikel.
Kumpulan berbagai artikel tersebut akan dibagi menjadi data pelatihan dan data
pengujian.
Kumpulan kata-kata tersebut kemudian akan disaring dalam beberapa
tahap. Penyaringan dalam hasil token ini merupakan kata-kata hasil dari artikel
teks dalam penelitian. Kemudian di lanjut dalamproses filtering yang akan
menghilangkan semua kata sambung yang terdapat di dalam artikel teks tersebut.
Hingga ke proses stemming yang telah mengalami proses penyaringan kata-kata
yang berimbuhan.
Kata-kata yang telah di saring dalam beberapa tahap tersebut akan di
hitung banyaknya satu kata yang terdapat dalam artikel teks, yang akan di
perhitungkan ke dalam rumus naïve bayes, yang akhirnya dapat menyimpulkan
St ru ct u re d C h a rt Sist em K la sifi k a si Ar tik el Gamb ar 3. 2. S truc tu re d Ch art Kl as if ikasi Ar tik el S is te m K la si fik a si A rt ik e l ip u la si D a ta K la si fik a si S e b u a h A rt ik e l P e n c a ria n D a ta A rt ik e l P e la tih a n D a ta P e n g u jia n D a ta L ih a t D a ta H a si l P e n g u jia n U p d a te D a ta H a si l K la si fik a si H a si l P e n c a ria n P e la tih a n D a ta P e n g u jia n D a ta L ih a t D a ta H a sil P e n g u jia n D e le te D a ta
Kat egori_art ikel art ikel_hasil_proses
hasil_pencarian keyw ord
Kum pulan_kat a_pent ing_ dat a_pelat ihan. M odel probalit as
Kum pulan_nama_art ikel ,kat egori_artikel
Kum pulan_kat a_pent ing_ha sil_pengujian
Nama_jurnal_pengujian, lat egori_art ikel,akurasi_pen gklasifikasian
akurasi_pengklasifikasian
Diagram_akurasi_pengklasif ikasian
Id_ar tikel,nama_ar t ikel, kat egori_jurnal
Nama_art ikel
Keyw ord
Kumpulan_art ikel_pelat ih an. Kat egori_artikel
Kumpulan_kat a_pent ing_ dat a_pelat ihan. M odel probalit as
Kumpulan_nama_art ikel_pe nguj ian
Nama_art ikel_pengujian, lat egori_art ikel,akurasi_pen gklasifikasian
Nama_art ikel_pengujian, lat egori_art ikel,akurasi_pen gklasifikasian
Hak Cipta © milik UPN "Veteran" Jatim :
3.4. Diagram Work Flow
Gambar 3.3. Diagram Workflow Sistem Klasifikasi Artikel
Pada gambar diatas dapat terlihat tumpukan artikel yang belum dikategorikan.
Tumpukan artikel tersebut ada dalam suatu database induk. Dengan proses
pengklasifikasian, artikel - artikel majalah tersebut akan mengalami beberapa
proses sehingga akhirnya dapat diketegorikan ke dalam kategori-kategori tertentu. Kumpulan art ikel
Input art ikel ke dalam sist em
Klasifikasi artikel secara manual untuk menciptakan data pelatihan
Pengklasifikasian artikel secara otomatis
Aplikasi berbasis desktop
Database artikel yang telah terklasifikasi
Informasi Tingkat Akurasi
3.5. Diagr am Alir Sistem
T
T
Y Y
START
Pilihan :
1. Klasifikasi Artikel
2. Proses Training
Pilihan : Klasifikasi?
Pilihan : Training ?
Preprocessing
Tampilkan Frekuensi kata
Hitung Nilai Probabilitas
Artikel teks
FINISH Hasil
Klasifikasi
Artikel teks 2 Artikel teks 1
Artikel teks 3
Preprocessing
Hitung Nilai Probabilitas
3.6. Per ancangan Antar Muka
Perancangan antarmuka dibutuhkan untuk mewakili keadaan sebenarnya
dari aplikasi yang akan dibangun. Dan seperti developer visual lainnya,
Embarcadero RAD Studio sudah menyediakan berbagai macam komponen untuk
menghemat waktu pengembangan sesuai dengan kebutuhan developer. Berikut
akan disajikan perancangan antarmuka dari aplikasi yang akan dibangun :
Gambar 3.5. Rancangan Form Utama
Form di atas menampilkan artikel teks yang di tempatkan pada data artikel, yang
kemudian melalui proses token. Kata-kata tersebut kemudian melewati proses
Data artikel Hasil Token Hasil filt ering Hasil
St eming
Data TES Tingkat
Akurasi
filtering dan di teruskan proses stemming yang memisahkan awalan dan imbuhan
pada kata-kata di artikel teks tersebut.
Gambar 3.6. Ranca
Gambar 3.6. Rancangan Form Training
Pada form di atas menjelask tentang proses training, dengan mengunduh artikel
teks pada direktori dokumen. Proses ini sebagai acuan dalam memproses
klasifikasi teks tersebut.
Kategori Hardware Kategori Software Kategori Gadget
Hasil Akurasi kategori hardware
Hasil akurasi kategori Gadget
Probabilitas model Hasil akurasi
Gambar 3.7. Rancangan Form Stemming
Pada form stemming menjelaskan bahwa proses tersebut menyimpan imbuhan
awalan dan akiran.
Gambar 3.8 Rancangan Form Stoplist
Form di atas berisi kata-kata Stoplist yaitu kata-yang tidak tersaring oleh proses
Stoplist.
Awalan Akhiran simpan
Tutup
Stop list Simpan
4.1. Perangkat Keras Yang Dipergunakan
Dalam melakukan perancangan, pengembangan dan pengujian, penulis
menggunakan perangkat keras sebagai berikut :
Tabel 4.1. Spesifikasi Perangkat Komputer
No Spesifikasi Perangkat Keterangan
1 Processor Intel Multi Core 2,4 Ghz
2 Memory 1024 Mbyte
3 Kapasitas Hard Drive Kosong 250 GB
4 Display Adapter Intel (R) HD Graphics Family
5 Display Monitor LCD 14 inch, 1366 x 768 32 Bit
Auto Refresh 60 Hz
6 Perangkat Input Standar Keyboard dan Mouse
4.2. Perangkat Lunak Yang Dipergunakan
Sedangkan perangkat lunak yang dipergunakan dalam penelitian
pembuatan aplikasi tugas akhir ini adalah :
Tabel 4.2. Spesifikasi Perangkat Lunak
No Spesifikasi Perangkat Keterangan
1 Sistem Operasi Microsoft Windows 7 Profesional
2 Dokumentasi Microsoft Office Profesional 2010
4.3. Implementasi Prosedur Proses Klasifikasi
Penjelasan source code diatas adalah :
Pertama kali sistem akan melakukan parsing dari file teks yang telah
diunggah ke memo1 dan menyimpan hasilnya pada variabel slResult. Hasil
parsing pada variabel slResult ini kemudian akan dilakukan proses filtering dan
hasilnya akan disimpan pada variabel slResult itu sendiri. Setelah proses filtering
selesai, dilakukan proses stemming dan hasilnya ditampilkan pada layar. Selain itu
hasil dari proses stemming akan ditambahkan ke dalam tupple database pada tabel
tesdata. Untuk melakukukan refresh tabel tesdata dalam database, maka
dilakukan proses buka dan tutup. Proses terakhir yang dijalankan adalah
menjalankan prosedur bayes classifier.
if mmo1.Text='' then exit;
slResult.Clear;
dtsDatates.Close;
grd.Cells[1,1]:= '';
grd.Cells[0,2]:= 'D2-Software';
grd.Cells[1,2]:= '';
grd.Cells[0,3]:= 'D3-Gadget';
grd.Cells[1,3]:= '';
Parsing(mmo1,slResult);
mmo2.Text:=slResult.Text;
Filtering(slResult);
mmo3.Text:=slResult.Text;
Stemming(slResult);
mmo4.Text:=slResult.Text;
AddTuppleData('','tesdata',slResult);
dtsDatates.Close;
dtsDatates.Open;
4.4. Implementasi Prosedur Proses Par sing
ListOut:=TStringList.Create
isNotLetter:=false
aText:= LowerCase(mIn.Text)
aText:= StringReplace(aText,tab,' ',[])
aText:= StringReplace(aText,' ',' ',[])
while (Pos(' ', aText) > 0) do
begin
wrd := Copy(aText, 1, Pos(' ', aText) - 1)
n := Length(wrd)
index := 1
while index<=n do begin
if (wrd[index] in akhirkalimat) then
wrd[index]:=#8
if not (wrd[index] in huruf) then begin
wrd[index]:=#32
isNotLetter:=true
end
inc(index)
end
if isNotLetter then begin
while (Pos(' ', wrd) > 0) do begin
s:= Copy(wrd, 1, Pos(' ', wrd) - 1)
s:=Trim(s)
if Length(s)>0 then ListOut.Add(s)
Delete(wrd,1, Pos(' ', wrd))
End
end
ListOut.Add(wrd)
end
Penjelasan source code diatas adalah :
Pertama kali sistem akan melakukan alokasi memori untuk menyimpan
data, kemudian sistem akan membaca data secara per kata dan hasilnya disimpan
ke dalam variabel wrd. Setelah keseluruhan kata berhasil dibaca ke variabel wrd,
maka sistem akan memindahkan hasilnya ke slResult dan juga menampilkan
hasilnya ke layar.
4.5. Implementasi Prosedur Proses Filter ing
Stoplist := TStringList.Create;
slFiltered := TStringList.Create;
stoplist.LoadFromFile(stoplistfile);
stoplist.Text:=LowerCase(stoplist.Text);
slFiltered.text:=slFilter.text;
nStop:=stoplist.Count;
nWords:=slFilter.Count;
nDel:=0;
for i:=0 to nWords-1 do begin
for j:=0 to nStop-1 do begin
if slFilter.Strings[i] = stoplist.Strings[j]
then begin
slFiltered.Delete(i-nDel);
inc(nDel);
Break;
end;
end;
end;
slFilter.Text:=slFiltered.Text;
stoplist.Free;
Penjelasan dari source code diatas adalah :
Sebelum memulai proses filtering, sistem akan memulai proses alokasi
memori terlebih dahulu, kemudian sistem akan membaca file stoplist kemudian
sistem akan melakukan pemeriksaan dengan membandingkan kata-kata yang
terdapat dalam stoplist dengan kata-kata di file yang sudah diunggah. Jika
menemukan kesamaan, maka kata di file tersebut dihapus.
Setelah semua kata sudah dibandingkan dan mencapai akhir file, maka
sistem akan menyimpan hasilnya dalam variabel slFilter, kemudian sistem akan
membebaskan semua alokasi memori setiap variabel penyimpan string yang tadi
dipergunakan.
4.6. Implementasi Prosedur Proses Stemming
stemlist.LoadFromFile(stemlistakhiranfile);
stemlist.Text:=LowerCase(stemlist.Text);
slStemed.text:=slFilter.text;
nStem:=stemlist.Count;
nWords:=slStemed.Count;
stemlist.Sort;
for i:=0 to nWords-1 do begin
for j:=0 to nStem-1 do begin
if AnsiEndsText(
stemlist.Strings[j],slFilter.Strings[i]) then begin
stemed:=
Copy(slFilter.Strings[i],1,Length(slFilter.Strings[i])-Length(stemlist.Strings[j]));
if length(stemed)>0 then slStemed.Strings[i]:=
stemed;
Break;
Penjelasan dari source code diatas adalah :
Sistem akan membaca daftar kata yang termasuk dalam akhiran kata,
kemudian sistem akan memeriksa akhiran dari suatu kata, jika sesuai maka kata
tersebut di-stem (dibuang) akhiran katanya. Selanjutnya sistem akan memeriksa
sekali lagi apakah kata tersebut masih mengandung akhiran yang kedua, jika ya
proses penghapusan akan dilakukan lagi.
Proses stem ini dilakukan secara iteratif mulai dari kata pertama sampai
dengan kata terakhir. Jika proses stem sudah selesai, semua kata yang di-stem
akan disimpan pada variabel slFilter.
4.7. Implementasi Prosedur Bayes Classifier
for i:=0 to slResult.Count-1 do begin
for j:=1 to dtsModel.RecordCount do begin
dtsModel.RecNo:=j;
if dtsModel.FieldValues['keywords']=
slResult.Strings[i] then begin
P[i]:=dtsModel.FieldValues['P'];
Break;
end
else P[i]:=1/Vj1;
end; pb1.Position:=i;
end;
Pv:=1;
for i:=0 to slResult.Count-1 do
begin
Pv:=Pv*P[i];
Memo1.Lines.Add(inttostr(i)+' - '+FloatToStr(P[i])+' –
'+floattostr(PV));
end;
for i:=0 to slResult.Count-1 do begin
for j:=1 to dtsModel.RecordCount do begin
dtsModel.RecNo:=j;
if dtsModel.FieldValues['keywords']=
slResult.Strings[i] then begin
P[i]:=dtsModel.FieldValues['P'];
Break;
end
else P[i]:=1/Vj2; end;
pb1.Position:=slResult.Count+i;
end;
Pv:=1;
for i:=0 to slResult.Count-1 do begin
Pv:=Pv*P[i];
Memo1.Lines.Add(inttostr(i)+' - '+FloatToStr(P[i])+' -