(STUDY KASUS SMA SWASTA SE-J OMBANG)
SKRIPSI
Oleh :
ALUX PERMANA
0834010112
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNOLOGI INDUSTRI
UNIVERSITAS PEMBANGUNAN NASIONAL
(STUDY KASUS SMA SWASTA SE-J OMBANG)
SKRIPSI
Diajukan Untuk Memenuhi Sebagai Persyaratan Dalam Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh :
ALUX PERMANA
0834010112
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNOLOGI INDUSTRI
UNIVERSITAS PEMBANGUNAN NASIONAL
APLIKASI KLASTERISASI KUALITAS SMA SWASTA DENGAN ALGORITMA K-MEANS
(STUDY KASUS SMA SWASTA SE-J OMBANG)
Disusun Oleh :
ALUX PERMANA NPM : 0834010112
Telah diper tahankan dihadapan dan diter ima oleh Tim Penguji Skr ipsi Pr ogr am Studi Tek nik Infor matika, Fakultas Tek nologi Industr i
Univer sita s Pembangunan Nasional “Veter an” J awa Timur Pada tanggal 15 J uni 2012
PEMBIMBING : 1.
Rinci Kembang Hapsar i, S.Si, M.Kom NPT. 377120801681
2.
Syur fa h Ayu Ithr iah, S.Kom NPT. 385011002941
TIM PENGUJ I : 1.
Basuki Rahmat, S.Si, M.Kom NPT. 369070602091
2.
Dr . Ir . Ni Ketut Sar i, MT. NIP. 19650731 199203 2 001 3.
Dian Puspita Hapsar i, S.Kom, M.Kom NPT. 37805 08 01671
Mengetahui
Dekan Fakultas Tek nologi Industr i
Univer sita s Pembangunan Nasional “Veter an” J awa Timur
APLIKASI KLASTERISASI KUALITAS SMA SWASTA DENGAN ALGORITMA K-MEANS
(STUDY KASUS SMA SWASTA SE-J OMBANG)
Disusun Oleh :
ALUX PERMANA NPM : 0834010112
Telah disetujui mengikuti Ujian Negar a Lisan Gelombang VI Tahun Akademik 2011/2012
Menyetujui,
Pembimbing Utama
Rinci Kembang Hapsar i, S.Si, M.Kom NPT. 377120801681
Pembimbing Pendamping
Syur fah Ayu Ithr iah, S.Kom NPT. 385011002941
Mengetahui,
Kepala Pr ogr am Studi Teknik Infor matika Fakultas Teknologi Industr i
Univer sitas Pembangunan Nasional “Veteran” J awa Timur
FAKULTAS TEKNOLOGI INDUSTRI
Jl. Rungkut Madya Gunung Anyar Surabaya 60294 Tlp. (031) 8706369, 8783189 Fax (031) 8706372 Website: www.upnjatim.ac.id
KETERANGAN REVISI
Mahasiswa di bawah ini :
Nama : ALUX PERMANA
NPM : 0834010112 Program Studi : Teknik Informatika Telah mengerjakan revisi skripsi dengan judul :
“ APLIKASI KLASTERISASI KUALITAS SMA SWASTA DENGAN
ALGORITMA K-MEANS (STUDY KASUS SMA SWASTA
SE-J OMBANG)”.
Oleh karenanya mahasiswa tersebut diatas dinyatakan bebas revisi skripsi dan diijinkan untuk membukukan skripsi dengan judul tersebut.
Surabaya, 18 Juni 2012 Dosen Penguji yang memerintahkan revisi:
1.) Basuki Rahmat, S.Si, M.Kom
{
}
NPT. 3690706020912.) Dr . Ir . Ni Ketut Sar i, MT.
{
}
NIP. 19650731 199203 2 001
3.) Dian Puspita Hapsar i, S.Kom, M.Kom
{
}
NPT. 37805 08 01671
Mengetahui, Dosen Pembimbing Dosen Pembimbing Utama
Rinci Kembang Hapsar i, S.Si, M.Kom NPT. 377120801681
Dosen Pembimbing Pendamping
DOSEN PEMBIMBING II : SYURFAH AYU ITHRIAH, S. Kom.
PENYUSUN : ALUX PERMANA
ABSTRAK
Pendidikan merupakan hal yang sangat penting dalam kehidupan manusia. Oleh sebab itu kita harus lebih memperhatikan kualitas sekolah yang ada. Terutama sekolah menengah atas swasta, kalau kita tidak pandai pandai memilih sekolah yang ada tanpa mempertimbangkan dari berbagai aspek tentu nantinya akan bisa merugikan kita karena selain jumlah sekolah yang banyak, juga tiap sekolah kini memberi beragam tawaran dan pilihan kepada para calon siswanya. Mulai dari yang menginginkan harga uang pangkal yang murah, biaya SPP yang murah, dekat dengan rumah, fasilitas dan sarana pra sarana yang lengkap.
Aplikasi Klasterisasi Kualitas SMA Swasta Dengan Algoritma K-Means (Study Kasus SMA Swasta Se-Jombang) diimplementasikan agar dapat mengklasterisasi sekolah menengah atas swasta berdasarkan kriteria yang telah ditentukan di Kabupaten Jombang ke dalam web untuk memudahkan pengaksesan sehingga dapat dijadikan acuan orang tua untuk memilih sekolah menengah atas swasta yang akan dituju anaknya.
Proses pengimplementasian aplikasi klasterisasi dengan metode k-means diperlukan beberapa syarat atau kriteria yang akan menjadi acuan dalam melakukan pengelompokan, dalam tugas akhir ini antara lain menggunakan kriteria biaya, lokasi, lingkungan, bangunan, jam sekolah, prestasi dan pengajar. Nilai data dari kriteria diperoleh dari penyebaran kuisioner ke sekolah yang bersangkutan. Hasil dari aplikasi ini adalah pengelompokan data pada tabel dan diagram batang.
Puji syukur ke hadirat Allah SWT yang telah memberikan rahmat dan karunia-Nya, sehingga dapat terselesaikannya Tugas Akhir ini.
Dengan selesainya tugas akhir ini tidak terlepas dari bantuan banyak pihak yang telah memberikan masukan-masukan. Untuk itu penyusun mengucapkan terima kasih sebagai perwujudan rasa syukur atas terselesaikannya tugas akhir ini dengan lancar. Ucapan terima kasih ini saya tujukan kepada :
1. Bapak Prof. Dr. Ir. Teguh Soedarto, MP selaku Rektor Universitas Pembangunan Nasional “Veteran” Jawa Timur.
2. Bapak Sutiyono, MT selaku Dekan Fakultas Teknologi Industri UPN “Veteran” Jawa Timur.
3. Dr. Ir. Ni Ketut Sari, MT. selaku Ketua Jurusan Teknik Informatika UPN “Veteran” Jawa Timur.
4. Ibu Rinci Kembang Hapsari, S.Si, M.Kom selaku dosen pembimbing I pada Tugas Akhir ini, yang telah banyak memberikan petunjuk, masukan, bimbingan, dorongan serta kritik yang bermanfaat sejak awal hingga terselesainya Tugas Akhir ini.
5. Ibu Syurfah Ayu Ithriah, S.Kom selaku dosen pembimbing II yang telah banyak memberikan petunjuk, masukan serta kritik yang bermanfaat hingga terselesainya Skripsi ini.
6. Terimakasih buat Bapak Ibuku tercinta yang telah memberi semangat, dorongan dan do’a yang tiada henti-hentinya. Terimakasih buat adik ku
7. Terimakasih teman seperjuanganku Warrior Community, Mbah Candra Ady Wahyono, Gory (Adi Wijaya), Muhamad Yusuf Ali, Bintan Ardian, Arlian Pramadani, Yunus Ronaldo Samana, Yaiyo Hamzah Alif, Dio Dedi Utama, Anjaya Parlika, Rasuko Vidya P. Ganny Andi P. Yucu (Yusuf Feriyanto), Agus Dwi Fiantoro, Mas Fahmi, Bayu Deby, Mershakti Rizky Oktariani, Alfiah Nurul Sartika, Syamsul Arif, Min Umami, Marry dan buat seseorang yang ada disana, yang telah memberi semangat dan banyak membantu selama ini dan selalu memberikan semangat…All Izz Well… suit.. suit .. suit.
8. Serta orang-orang yang tidak dapat saya sebutkan satu persatu namanya. Terimakasih atas bantuannya semoga Allah SWT yang membalas semua kebaikan dan bantuan tersebut
Surabaya, 05 Juni 2012
Syukur Alhamdulillaahi rabbil ‘alamin terucap ke hadirat Allah SWT atas segala limpahan Rahmat-Nya sehingga dengan segala keterbatasan waktu, tenaga, pikiran dan keberuntungan yang dimiliki, akhirnya penulis dapat menyelesaikan Tugas Akhir yang berjudul “Aplikasi Klaster isasi Kualitas SMA Swasta Dengan Algor itma K-Means (Study Ka sus SMA Se-Kabupaten J ombang)” tepat waktu.
Tugas Akhir ini disusun guna diajukan sebagai salah satu syarat untuk menyelesaikan program Strata Satu (S1) pada jurusan Teknik Informatika, Fakultas Teknologi Industri, UPN ”VETERAN” Jawa Timur.
Dalam penyusunan Tugas akhir ini, Penulis berusaha untuk menerapkan ilmu yang telah didapat selama menjalani perkuliahan dengan tidak terlepas dari petunjuk, bimbingan, bantuan, dan dukungan berbagai pihak.
Dengan tidak lupa akan kodratnya sebagai manusia, Penulis menyadari bahwa dalam karya tugas akhir ini masih mengandung kekurangan sehingga dengan segala kerendahan hati, Penulis masih akan tetap terus mengharapkan saran serta kritik yang membangun dari rekan-rekan pembaca.
Surabaya, 4 Juni 2012
Penulis
ABSTRAK
KATA PENGANTAR ... i
UCAPAN TERIMA KASIH ... ii
DAFTAR ISI ... iv
DAFTAR GAMBAR ... viii
DAFTAR TABEL ... xi
DAFTAR LAMPIRAN ... xiii
BAB I. PENDAHULUAN ... 1
1.1. Latar Belakang ... 1
1.2. Rumusan Masalah ... 2
1.3. Batasan Masalah ... 2
1.4. Tujuan ... 3
1.5. Manfaat ... 3
1.6. Metodelogi Tugas Akhir ... 3
1.7. Sistematika Penulisan... 5
BAB II. TUJ UAN PUSTAKA ... 7
2.1. Sistem Pendukung Keputusan ... 7
2.1.1. Konsep Dasar Sistem Pendukung Keputusan ... 7
2.1.2. Karakteristis Sistem Pendukung Keputusan ... 9
2.3. K-Means ... 12
2.3.1. Penerapan K-Means ... 14
2.3.2. Permasalahan Terkait Dengan K-Means ... 18
2.4. Teknik Membuat Skala ... 20
2.4.1. Skala Guttman ... 21
2.5. Mengenal DBMS ... 23
2.6. Mengenal MySql ... 25
2.6.1. Keistimewaan MySql ... 26
2.6.2. Koneksi Database Mysql Dengan PHP ... 27
BAB III. ANALISIS DAN PERANCANGAN SISTEM ... 29
3.1. Pengumpulan Data Dan Analisa Data ... 29
3.1.1. Pengumpulan Data ... 29
3.1.2. Analisa Data ... 29
3.2. Analisa Sistem ... 43
3.3. Desain Alur Proses Klasterisasi ... 44
3.3.1. Admin ... 44
3.3.2. User (Pemakai Informasi) ... 45
3.3.3. Proses Klasterisasi ... 46
3.4. Perancangan Sistem ... 48
3.4.1. Diagram Berjenjang ... 48
3.4.2. Data Flow Diagram (DFD) ... 49
3.5. Struktur Database (DBMS) ... 57
3.6. Desain Antarmuka ... 65
3.6.1. Desain Antar Muka Admin ... 65
3.6.2. Desain Antarmuka Pengunjung ... 69
BAB IV. IMPLEMENTASI SISTEM ... 73
4.1. Kebutuhan Sistem ... 73
4.2. Implementasi Sistem ... 74
4.3. Tampilan Pengguna (User Interface) ... 74
4.3.1. Halaman Utama (Home) ... 75
4.3.2. Halaman Berita ... 76
4.3.3. Halaman Daftar Sekolah ... 76
4.3.4. Halaman Klasterisasi ... 77
4.4. Tampilan Pengguna (Admin Interface) ... 79
4.4.1. Halaman Login Admin ... 79
4.4.2. Halaman Utama Admin ... 79
BAB V. UJ I COBA DAN PEMBAHASAN... 86
5.1. Uji Coba ... 86
5.1.1. Uji Coba Manual ... 86
5.1.2. Uji Coba Sistem ... 92
BAB VI. KESIMPULAN DAN SARAN ... 104
6.1. Kesimpulan ... 104
6.2. Saran ... 105
DAFTAR PUSTAKA ... 106
1.1. Latar Belaka ng.
1.2. Rumusan Masalah.
Berdasarkan latar belakang yang telah diuraikan sebelumnya, terdapat beberapa permasalahan yang akan diangkat dalam tugas akhir ini, antara lain : a. Bagaimana cara merancang aplikasi yang dapat mengklasterisasi kualitas
SMA swasta berdasarkan kriteria yang sudah ada di Kabupaten Jombang. b. Bagaimana mengklasterisasi SMA swasta yang berkualitas di Kabupaten
Jombang dengan Algoritma K-Means ke dalam web sehingga dapat dijadikan acuan untuk memilih SMA swasta yang berdasarkan kriteria yang ada.
1.3. Batasan Masalah.
Dalam perancangan dan pembuatan Aplikasi Klasterisasi Kualitas SMA Swasta (Studi Kasus SMA Swasta Se-Kabupaten Jombang) ini mencakup banyak hal. Agar permasalahan tidak meluas maka perlu adanya batasan masalah yang akan dibahas yaitu sebagai berikut :
a. Aplikasi ini bersifat fasilitator antara masyarakat khususnya orang tua yang ingin memilih SMA yang berdasarkan kriteria yang ada untuk anaknya yang akan melanjutkan ke jenjang SMA swasta dengan Depdiknas Kabupaten Jombang.
b. Aplikasi Klasterisasi Kualitas SMA Swasta (Studi Kasus SMA Swasta di Kabupaten Jombang) menggunakan algoritma K-Means dan menggunakan php.
d. Aplikasi Klasterisasi Kualitas SMA Swasta (Studi Kasus SMA Swasta di Kabupaten Jombang) menggunakan empat pilihan jumlah klaster bagi user yaitu pilihan tiga, empat, lima dan enam..
1.4. Tujuan.
Tujuan yang ingin dicapai pada pengerjaan tugas akhir ini adalah merancang dan membangun aplikasi klasterisasi kualitas SMA swasta yang dapat digunakan untuk membantu orang tua dalam menentukan SMA swasta yang berdasarkan kriteria yang telah ada, bagi anak-anaknya dengan menggunakan Algoritma K-Means.
1.5. Manfaat.
Manfaat yang ingin dicapai pada pengerjaan tugas akhir ini adalah dapat menjadi salah satu referensi sumber ilmu bagi mahasiswa yang ingin menambah pengetahuannya dalam bidang pengembangan sistem pendukung keputusan. Membantu dalam merekomendasi orang tua siswa untuk memilih SMA swasta yang berdasarkan kriteria yang ada bagi anak-anaknya di Kabupaten Jombang.
1.6 Metodelogi Tugas akhir
a. Survei
b. Dilakukan dengan mengumpulkan segala macam informasi secara riset kepustakaan dan melakukan wawancara terhadap Dinas Pendidikan Jombang serta SMA swasta terkait
c. Studi Literatur
Dilakukan dengan cara mencari segala macam informasi secara riset keperpustakaan dan mempelajari buku-buku yang berhubungan dengan masalah yang dihadapi.
d. Analisis
Pada tahap ini dilakukan identifikasi dan evaluasi permasalahan yang terjadi, serta mencari solusi dari permasalahan tersebut. Setelah tahap analisa selesai dilakukan, dibuat perancangan desain sistem secara keseluruhan.
e. Perancangan Sistem
Menjelaskan tahap-tahap yang dilakukan mulai dari identifikasi permasalahan sampai menghasilkan desain input ataupun output dari sistem yang akan dibuat.
e. Pembuatan Program
Pada tahap ini dilikukan implementasi terhadap sistem berdasarkan hasil dari perancangan sistem yang sesuai dengan kebutuhan.
f. Uji Coba Program
g. Penyusunan Laporan
Dalam bagian akhir tugas akhir ini adalah dibuatnya laporan dari awal sampai akhir pengerjaan dengan tujuan agar lebih mudah dipelajari oleh orang lain sistem yang telah kita buat.
1.7. Sistematika Penulisan.
Dalam laporan tugas akhir ini, pembahasan disajikan dalam enam bab dengan sistematika pembahasan sebagai berikut :
BAB I PENDAHULUAN
Bab ini berisikan tentang latar belakang, perumusan masalah, batasan masalah, tujuan, dan manfaat, metodelogi serta sistematika penulisan dalam pembuatan tugas akhir ini.
BAB II TINJ AUAN PUSTAKA
Pada bab ini menjelaskan tentang teori-teori pemecahan masalah yang berhubungan dan digunakan untuk mendukung dalam pembuatan tugas akhir ini.
BAB III ANALISIS DAN PERANCANGAN SISTEM
Pada bab ini membahas tentang perancangan sistem, diagram alir, database, serta perancangan antar muka.
BAB IV IMPLEMENTASI SISTEM
BAB V UJ I COBA DAN PEMBAHASAN
Pada bab ini menjelaskan tentang pelaksanaan uji coba dan pembahasan dari pelaksanaan uji coba dari program yang dibuat agar bisa diketahui sistem tersebut terdapat troble atau tidak.
BAB VI KESIMPULAN DAN SARAN
Pada bab ini dibahas mengenai uraian kesimpulan tentang sistem yang telah dibuat beserta saran yang dapat digunakan untuk penyempurnaan dan pengembangan sistem.
DAFTAR PUSTAKA
Pada bagian ini akan dipaparkan tentang sumber-sumber literatur yang digunakan dalam pembutan laporan ini.
LAMPIRAN
2.1. Sistem Pendukung Keputusan.
Sistem Pendukung Keputusan (SPK) adalah sistem berbasis komputer interaktif, yang membantu para pengambil keputusan untuk menggunakan data dan berbagai model untuk memecahkan masalah-masalah tidak terstruktur (Turban dkk, 2005). Sistem pendukung keputusan memadukan sumber daya intelektual dari individu dengan kapabilitas komputer untuk meningkatkan kualitas keputusan. SPK adalah sistem pendukung berbasis komputer bagi para pengambil keputusan manajemen yang menangani masalah-masalah tidak terstruktur (Turban dkk, 2005), (Keen dkk, 1978).
2.1.1. Konsep Dasar Sistem Pendukung Keputusan
Sistem Pendukung Keputusan (SPK) mulai dikembangkan pada tahun 1960-an, tetapi istilah sistem pendukung keputusan itu sendiri baru muncul pada tahun 1971, yang diciptakan oleh G. Anthony Gorry dan Micheal S.Scott Morton, keduanya adalah profesor di MIT. Hal itu mereka lakukan dengan tujuan untuk menciptakan kerangka kerja guna mengarahkan aplikasi komputer kepada pengambilan keputusan manajemen.
a. Sistem harus dapat membantu manajer dalam membuat keputusan guna memecahkan masalah semi terstruktur.
b. Sistem harus dapat mendukung manajer,bukan mencoba menggantikannya. c. Sistem harus dapat meningkatkan efektivitas pengambilan keputusan
manajer.
Tujuan-tujuan tersebut mengacu pada tiga prinsip dasar sistem pendukung keputusan (Suryadi dan Ramdhani, 1998), yaitu:
a. Struktur masalah : untuk masalah yang terstruktur, penyelesaian dapat dilakukan dengan menggunakan rumus-rumus yang sesuai, sedangkan untuk masalah terstruktur tidak dapat dikomputerisasi. Sementara itu, sistem pendukung keputusan dikembangkan khususnya untuk menyelesaikan masalah yang semi-terstruktur.
b. Dukungan keputusan : sistem pendukung keputusan tidak dimaksudkan untuk menggantikan manajer, karena komputer berada di bagian terstruktur, sementara manajer berada dibagian tak terstruktur untuk memberikan penilaian dan melakukan analisis. Manajer dan komputer bekerja sama sebagai sebuah tim pemecah masalah semi terstruktur.
c. Efektivitas keputusan : tujuan utama dari sistem pendukung keputusan bukanlah mempersingkat waktu pengambilan keputusan, tetapi agar keputusan yang dihasilakn dapat lebih baik.
2.1.2. Kar akter istik Sistem Pendukung Keputusan.
Keputusan Sistem pendukung keputusan dirancang secara khusus untuk mendukung seseorang yang harus mengambil keputusan-keputusan tertentu. Ada beberapa karakteristik sistem pendukung keputusan (Oetomo, 2002), yaitu: a. Interaktif.
SPK memiliki user interface yang komunikatif sehingga pemakai dapat melakukan akses secara cepat ke data dan memperoleh informasi yang dibutuhkan.
b. Fleksibel.
SPK memiliki sebanyak mungkin variabel masukkan, kemampuan untuk mengolah dan memberikan keluaran yang menyajikan alternatif-alternatif keputusan kepada pemakai.
c. Data kualitas.
SPK memiliki kemampuan menerima data kualitas yang dikuantitaskan yang sifatnya subyektif dari pemakainya, sebagai data masukkan untuk pengolahan data. Misalnya: penilaian terhadap kecantikan yang bersifat kualitas, dapat dikuantitaskan dengan pemberian bobot nilai seperti 75 atau 90.
d. Prosedur Pakar.
SPK mengandung suatu prosedur yang dirancang berdasarkan rumusan formal atau juga beberapa prosedur kepakaran seseorang atau kelompok dalam menyelesaikan suatu bidang masalah dengan fenomena tertentu.
2.1.3. Komponen Sistem Pendukung Keputusan.
Komponen Sistem Pendukung Keputusan (Surbakti, 2002), komponen-komponen dari SPK adalah sebagai berikut:
a. Data Management.
Termasuk database, yang mengandung data yang relevan untuk berbagai situasi dan diatur oleh software yang disebut Database Management System (DBMS).
b. Model Management.
Melibatkan model finansial, statistikal, management science, atau berbagai model kualitatif lainnya, sehingga dapat memberikan ke sistem suatu kemampuan analitis, dan manajemen software yang dibutuhkan.
c. Communication.
User dapat berkomunikasi dan memberikan perintah pada DSS melalui subsistem ini. Ini berarti menyediakan antarmuka.
d. Knowledge Management.
Subsistem optional ini dapat mendukung subsistem lain atau bertindak atau bertindak sebagai komponen yang berdiri sendiri.
2.2. Teknik Klaster isasi.
dalam satu klaster dan membuat jarak antar klaster sejauh mungkin. Ini berarti obyek dalam satu klaster sangat mirip satu sama lain dan berbeda dengan obyek dalam klaster-klaster yang lain.
Klasterisasi adalah salah satu teknik unsupervised learning dimana kita tidak perlu melatih metode tersebut atau dengan kata lain, tidak ada fase learning. Masuk dalam pendekatan unsupervised learning adalah metode-metode yang tidak membutuhkan label atau pun keluaran dari setiap data yang kita investigasi. Sebaliknya supervised learning adalah metode yang memerlukan training (melatih) dan testing (menguji).
Ada dua pendekatan dalam klasterisasi antara lain partisioning dan hirarki. Dalam partisioning kita mengelompokkan obyek x1, x2, …,xn ke dalam k klaster. Hal ini bisa dilakukan dengan menentukan pusat klaster awal, lalu dilakukan realokasi obyek berdasarkan criteria tertentu sampai dicapai pengelompokkan yang optimum. Dalam klaster hirarki, dimulai dengan membuat m klaster dimana setiap klaster beranggotakan satu obyek dan berakhir dengan
satu klaster dimana anggotanya adalah m obyek. Pada setiap tahap dalam prosedurnya, satu klaster digabung dengan satu klaster yang lain.
2.2.1. Kar akter istik klaster isasi.
(M. Helmy dan Hariadi, 2011), Karakteristik klasterisasi dibagi menjadi 4, yaitu :
a. Partitioning clustering.
Partitioning clustering disebut juga exclusive clustering, dimana setiap data
memungkinkan bagi setiap data yang termasuk cluster tertentu pada suatu tahapan proses, pada tahapan berikutnya berpindah ke cluster yang lain. Contoh : K-Means, residual analysis.
b. Hierarchical clustering.
Pada hierarchical clustering, Setiap data harus termasuk ke cluster tertentu. Dan suatu data yang termasuk ke cluster tertentu pada suatu tahapan proses, tidak dapat berpindah ke cluster lain pada tahapan berikutnya. Contoh: Single Linkage, Centroid Linkage, Complete Linkage, Average Linkage.
c. Overlapping clustering.
Dalam overlapping clustering, setiap data memungkinkan termasuk ke beberapa cluster. Data mempunyai nilai keanggotaan (membership) pada beberapa cluster. Contoh: Fuzzy C-means, Gaussian Mixture.
d. Hybrid.
Karakteristik hybrid adalah mengawinkan karakteristik dari partitioning, overlapping dan hierarchical.
2.3. K-Means.
Dalam teknik ini jika ingin mengelompokkan obyek ke dalam k kelompok atau klaster. Untuk melakukan klasterisasi, nilai k harus ditentukan terlebih dahulu. Biasanya user sudah mempunyai informasi awal tentang obyek yang sedang dipelajari termasuk beberapa jumlah klaster yang paling tepat. Secara detail bisa menggunakan ukuran ketidakmiripan untuk mengelompokkan obyek yang ada.ketidakmiripan bisa diterjemahkan dalam konsep jarak. Jika jarak dua obyek atau data titik cukup dekat, maka dua obyek mirip. Semakin dekat berarti semakin tinggi kemiripannya. Semakin tinggi nilai jarak, semakin tinggi ketidak miripannya (Santosa, 2007).
Algoritma K-Means (M. Helmy dan Hariadi, 2011):
a. Menentukan k sebagai jumlah cluster yang ingin dibentuk
b. Membangkitkan k centroid (titik pusat cluster) awal secara random c. Menghitung jarak setiap data ke masing-masing centroid
d. Setiap data memilih centroid yang terdekat
e. Menentukan posisi centroid baru dengan cara menghitung nilai rata-rata dari data data yang memilih pada centroid yang sama.
Karakteristik K-Means (M. Helmy dan Hariadi, 2011): a. K-means sangat cepat dalam proses clustering
b. K-means sangat sensitif pada pembangkitan centroids awal secara random c. Memungkinkan suatu cluster tidak mempunyai anggota
d. Hasil clustering dengan K-means bersifat tidak unik (selalu berubah-ubah)-terkadang baik, berubah-ubah)-terkadang jelek.
e. K-means sangat sulit untuk mencapai global optimum.
Gambar 2.3 Ilustrasi kelemahan K-means
2.3.1. Pener apan K-Means.
(Agusta, 2007), Beberapa alternatif penerapan K-Means dengan beberapa pengembangan teori teori penghitungan terkait telah diusulkan. Hal ini termasuk pemilihan:
a. Distance space untuk menghitung jarak di antara suatu data dan centroid b. Metode pengalokasian data kembali ke dalam setiap cluster
c. Objective function yang digunakan.
(Minkowski) distance space. Jarak antara dua titik x1 dan x2 pada Manhattan/City
Block distance space dihitung dengan menggunakan rumus sebagai berikut :
∑
=−
=
−
=
p j j jL
x
x
x
x
x
x
D
1 1 2 1 1 2 1 21
(
,
)
……… (2.1)
dimana :
p : Dimensi data
| . | : Nilai absolute
Sedangkan untuk L2 (Euclidean) distance space, jarak antara dua titik dihitung menggunakan rumus sebagai berikut :
∑
= − = p j j j yx x y
d
1
2 )
,
( ( )
...(2.2)
Dengan d adalah jarak antara titik pada data x dan titik data y, dimana x = x1 , x2
,...xi dan y = y1 , y 2 ,... yi dan j merepresentasikan nilai atribut serta p merupakan dimensi
atribut.
Lp (Minkowski) distance space yang merupakan generalisasi dari beberapa distance space yang ada seperti L1 (Manhattan/City Block) dan L2 (Euclidean), juga telah diimplementasikan. Tetapi secara umum distance space yang sering digunakan adalah Manhattan dan Euclidean.
Menghitung nilai centroid
i N k kj ij N X v i
∑
== 1 ………..……… (2.3)
dimana:
v_ij : centroid/rata-rata cluster ke-i untuk variabel ke-j
x_kj : nilai data ke-k yang ada di dalam cluster tersebut untuk variabel ke-j N_i : Jumlah data yang menjadi anggota cluster ke-i
B. Metode Pengalokasian Ulang Data ke Dalam Masing-Masing Cluster. Ada dua cara pengalokasian data kembali ke dalam masing-masing cluster pada saat proses iterasi clustering (Agusta, 2007), yaitu :
B.1. Hard K-Means
Pengalokasian kembali data ke dalam masing-masing cluster dalam metode Hard K-Means didasarkan pada perbandingan jarak antara data dengan centroid setiap cluster yang ada. Data dialokasikan ulang secara tegas ke cluster yang mempunyai centroid terdekat dengan data tersebut. Pengalokasian ini dapat dirumuskan sebagai berikut:
{
}
=
=
lainnya
v x D d
a ik min ( k i )
0
1 ,
……….. (2.4)
dimana:
aik: Keanggotaan data ke-k ke cluster ke-i
vi : Nilai centroid cluster ke-i
B.2. Fuzzy K-Means.
Metode Fuzzy K-Means (atau lebih sering disebut sebagai Fuzzy C-Means) mengalokasikan kembali data ke dalam masing-masing cluster dengan
yang merujuk pada seberapa besar kemungkinan suatu data bisa menjadi anggota ke dalam suatu cluster. Pada Fuzzy K-Means, diperkenalkan juga suatu variabel m yang merupakan weighting exponent dari membership function. Variabel ini dapat mengubah besaran pengaruh dari membership function, uik, dalam proses clustering menggunakan metode Fuzzy K-Means. m mempunyai wilayah nilai m>1. Sampai sekarang ini tidak ada ketentuan yang jelas berapa besar nilai m yang optimal dalam melakukan proses optimasi suatu permasalahan clustering. Nilai m yang umumnya digunakan adalah 2. Membership function untuk suatu data ke suatu cluster tertentu dihitung menggunakan rumus
sebagai berikut :
∑
= − = c j m j k i k ik v x D v x D u 1 1 2 ) , ( ) , (……… (2.5)
dimana:u ik : Membership function data ke-k ke cluster ke-i
v i : Nilai centroid cluster ke-i
m : Weighting Exponent
C. Objective Function.
Objective function yang digunakan khususnya untuk Hard K Means
dan Fuzzy K-Means ditentukan berdasarkan pada pendekatan yang digunakan
dalam poin 2.1. dan poin 2.2. Untuk metode Hard K-Means, objective function yang digunakan adalah sebagai berikut:
∑ ∑
= ==
N k c i i kik
D
x
v
a
V
U
J
1 1 2)
,
(
)
,
dimana:
N : Jumlah data
c : Jumlah cluster
a ik : Keanggotaan data ke-k ke cluster ke-i
v i : Nilai centroid cluster ke-i
a ik mempunyai nilai 0 atau 1. Apabila suatu data merupakan anggota
suatu kelompok maka nilai a ik =1 dan sebaliknya.
Untuk metode Fuzzy K-Means, objective function yang digunakan adalah sebagai berikut :
∑ ∑
= =
=
Nk c
i
i k m
ik
D
x
v
u
V
U
J
1 1
2
)
,
(
.
)
(
)
,
(
……… (2.7)
dimana:
N : Jumlah data
c : Jumlah cluster
m : Weighting exponent
u ik : Membership function data ke-k ke cluster ke-i
v i : Nilai centroid cluster ke-i
Di sini u ik bisa mengambil nilai mulai dari 0 sampai 1.
2.3.2. Per masalahan Terkait Dengan K-Means.
b. Pemilihan jumlah cluster yang paling tepat c. Kegagalan untuk converge
d. Pendeteksian outliers
e. Bentuk masing-masing cluster f. Masalah overlapping.
Permasalahan pertama umumnya disebabkan oleh perbedaan proses inisialisasi anggota masing-masing cluster.
Permasalahan kedua merupakan masalah laten dalam metode K-Means. Beberapa pendekatan telah digunakan dalam menentukan jumlah cluster yang paling tepat untuk suatu dataset yang dianalisa termasuk di antaranya Partition Entropy (PE) dan GAP Statistics. Satu hal yang patut diperhatikan mengenai
metode-metode ini adalah pendekatan yang digunakan dalam mengembangkan metode-metode tersebut tidak sama dengan pendekatan yang digunakan oleh K-Means dalam mempartisi data items ke masing-masing cluster.
Permasalahan ketiga, kegagalan untuk converge, kemungkinan besar akan terjadi untukmetode Hard K-Means, karena setiap data di dalam dataset dialokasikan secara tegas (hard) untuk menjadi bagian dari suatu cluster tertentu. Perpindahan suatu data ke suatu cluster tertentu dapat mengubah karakteristik model clustering yang dapat menyebabkan data yang telah dipindahkan tersebut lebih sesuai untuk berada di cluster semula sebelum data tersebut dipindahkan.
cluster tertentu dan apakah data dalam jumlah kecil yang membentuk suatu cluster tersendiri dapat dianggap sebagai outliers.
Permasalahan kelima, K-Means umumnya tidak mengindahkan bentuk dari masing-masing cluster yang mendasari model yang terbentuk, walaupun secara natural masing-masing cluster umumnya berbentuk bundar. Untuk dataset yang diperkirakan mempunyai bentuk yang tidak biasa, beberapa pendekatan perlu untuk diterapkan.
Masalah overlapping sebagai permasalahan terakhir sering sekali diabaikan karena umumnya masalah ini sulit terdeteksi. Hal ini terjadi untuk metode Hard K-Means dan Fuzzy K-Means, karena secara teori, metode ini tidak diperlengkapi feature untuk mendeteksi apakah di dalam suatu cluster ada cluster lain yang kemungkinan tersembunyi.
2.4. Tek nik Membuat Skala.
(Nasir, 1998), Teknik membuat skala tidak lain dari teknik mengurutkan sesuatu dalam suatu kontinum. Teknik membuat skala ini penting dalam penelitian ilmu-ilmu sosial, karena banyak data dalam ilmu-ilmu sosial mempunyai sifat kualitatif. Sehingga ada pendapat teknik membuat skala adalah cara mengubah fakta-fakta kualitatif (atribut) menjadi suatu urutan kuantitatif (variabel).
untuk populasi tertentu. Penggunaan skala untuk populasi lain dengan sampel yang ada harus dipertimbangkan. Karena kecurigaan tentang baik tidaknya sebuah sampel untuk mewakili populasi, telah banyak mengajak peneliti untuk menilai validasi dari skala yang dibuat. Di samping validasi, skala juga harus mempunyai reliabilitas yang cukup tinggi.
Banyak jenis skala yang dikembangkan dalam ilmu-ilmu social, antara lain :
a. Skala jarak social (skala Bogardus dan Sosiogram). b. Skala penilaian (rating scales).
c. Skala membuat ranking.
d. Skala konsistensi internal (skala Thurstone). e. Skala likert.
f. Skala komulatif Guttman. g. Semantic differential.
2.4.1. Skala Guttman.
(Nasir, 1998), Skala Guttman dikembangkan oleh Louis Guttman. Skala ini mempunyai ciri penting, yaitu merupakan skala kumulatif dan mengukur satu dimensi saja dari satu variabel yang multi dimensi, sehingga skala ini termasuk mempunyai sifat undimensional.
suatu atribut universal mempunyaidimensi satu jika menghasilkan suatu skala kumulatif yang sempurna,yaitu semua responsi diatur sebagai berikut:
Tabel 2.1. Tabel Responsi Skala Guttman.
Setuju dengan tidak setuju dengan
Skor 4 3 2 1 1 2 3 4
4 x x x x
3 x x x x
2 x x x x
1 x x x x
0 x x x x
Pada pertanyaan yang lebih banyak pola ini tidak ditemukan secara utuh. Adanya beberapa kelainan dapat dianggap sebagai error yang akan diperhitungkan dalam analisa nantinya.
Koefisien Reprodusibilitas, yang mengukur derajat ketepatan alat ukur yang telah dibuat, dihitung dengan menggunakan rumus berikut:
n
e
K
r=
1
−
……….…….… (2.8)
Dimana :
n = total kemungkinan jawaban, yaitu jumlah pertanyaan x jumlah responden e = jumlah error
Kr = Koefisien reprodusibilitas
Kr dianggap baik jika nilai Kr > 0,90, maka skala Guttman dianggap cukup baik untuk digunakan.
Langkah selanjutnya adalah mencari nilai Ks (Koefisien Skalabilitas) Koefisien ini dicari dengan rumus :
p
e
Dimana :
e = Jumlah error
p = Jumlah kesalahan yang diharapkan Ks = Koefisien skalabilitas
Untuk menghitung nilai P = 0,5 x m Dimana :
M = total kesalahan
Ks dianggap baik jika nilai Ks > 0,6, maka skala Guttman dianggap cukup baik untuk digunakan.
2.5. Mengenal DBMS.
Sistem manajemen basis data (database management system, DBMS), atau kadang disingkat SMBD, adalah suatu sistem atau perangkat lunak yang dirancang untuk mengelola suatu basis data dan menjalankan operasi terhadap data yang diminta banyak pengguna. Contoh tipikal SMBD adalah akuntansi, sumber daya manusia, dan sistem pendukung pelanggan, SMBD telah berkembang menjadi bagian standar di bagian pendukung (back office) suatu perusahaan. Contoh SMBD adalah Oracle, SQL server 2000/2003, MS Access, MySQL dan sebagainya.
yaitu file teks yang ada pada sistem operasi. Sampai sekarangpun masih ada aplikasi yang menimpan data dalam bentuk flat secara langsung. Menyimpan data dalam bentuk flat file mempunyai kelebihan dan kekurangan. Penyimpanan dalam bentuk ini akan mempunyai manfaat yang optimal jika ukuran filenya relatif kecil, seperti file password. File password pada umumnya hanya igunakan untuk menyimpan nama yang jumlahnya tidak lebih dari 1000 orang. Selain dalam bentuk flat file, penyimpanan data juga dapat dilakukan dengan menggunakan program bantu seperti spreadsheet. Penggunaan perangkat lunak ini memperbaiki beberapa kelemahan dari flat file, seperti bertambahnya kecepatan dalam pengolahan data. Namun demikian metode ini masih memiliki banyak kelemahan, diantaranya adalah masalah manajemen dan keamanan data yang masih kurang. Penyimpanan data dalam bentuk DBMS mempunyai banyak manfaat dan kelebihan dibandingkan dengan penyimpanan dalam bentuk flat file atau spreadsheet, diantaranya :
a. Performance yang idapat dengan penyimpanan dalam bentuk DBMS cukup besar, sangat jauh berbeda dengan performance data yang disimpan dalam bentuk flat file. Disamping memiliki unjuk kerja yang lebih baik, juga akan didapatkan efisiensi penggunaan media penyimpanan dan memori
c. Independensi. Perubahan struktur database dimungkinkan terjadi tanpa harus mengubah aplikasi yang mengaksesnya sehingga pembuatan antarmuka ke dalam data akan lebih mudah dengan penggunaan DBMS. d. Sentralisasi. Data yang terpusat akan mempermudah pengelolaan database.
kemudahan di dalam melakukan bagi pakai dengan DBMS dan juga kekonsistenan data yang diakses secara bersama-sama akan lebiih terjamin dari pada data disimpan dalam bentuk file atau worksheet yang tersebar. e. Sekuritas. DBMS memiliki sistem keamanan yang lebih fleksibel daripada
pengamanan pada file sistem operasi. Keamanan dalam DBMS akan memberikan keluwesan dalam pemberian hak akses kepada pengguna.
2.6. Mengenal MySQL.
Berikut ini akan dijelaskan mengenai beberapa definisi MySQL untuk memperjelas pengertian tentang software ini :
a. MySQL adalah sistem pengaturan relational database.
Suatu relational database, menyimpan data dalam bentuk tabel-tabel yang kemudian akan diletakkannya semua data dalam satu ruang penyimpanan yang besar.
b. MySQL adalah Open Source Software (perangkat lunak).
Open Source artinya bahwa software tersebut memungkinkan untuk
digunakan dan dimodifikasi oleh siapa saja.
c. MySQL menggunakan GPL (GNU General Public License)
merasa tidak nyaman dengan GPL atau ingin menggunakan MySQL untuk aplikasi bisnis, maka orang tersebut dapat membeli lisensi yang bersifat komersial.
2.6.1. Keistimewaan MySQL.
MySQL memiliki beberapa keistimewaan, antara lain :
a. Portabilitas. MySQL dapat berjalan stabil pada berbagai sistem operasi seperti Windows, Linux, FreeBSD, Mac Os X Server, Solaris, Amiga, dan masih banyak lagi.
b. Open Source. MySQL didistribusikan secara open source, dibawah lisensi GPL sehingga dapat digunakan secara cuma-cuma.
c. Multiuser. MySQL dapat digunakan oleh beberapa user dalam waktu yang bersamaan tanpa mengalami masalah atau konflik.
d. Performance tuning. MySQL memiliki kecepatan yang menakjubkan dalam menangani query sederhana, dengan kata lain dapat memproses lebih banyak SQL per satuan waktu.
e. Jenis Kolom. MySQL memiliki tipe kolom yang sangat kompleks, seperti signed / unsigned integer, float, double, char, text, date, timestamp, dan
lain-lain.
f. Perintah dan Fungsi. MySQL memiliki operator dan fungsi secara penuh yang mendukung perintah Select dan Where dalam perintah (query).
h. Skalabilitas dan Pembatasan. MySQL mampu menangani basis data dalam skala besar, dengan jumlah rekaman (records) lebih dari 50 juta dan 60 ribu tabel serta 5 milyar baris. Selain itu batas indeks yang dapat ditampung mencapai 32 indeks pada tiap tabelnya.
i. Konektivitas. MySQL dapat melakukan koneksi dengan klien menggunakan protokol TCP/IP, Unix soket (UNIX), atau Named Pipes (NT).
j. Lokalisasi. MySQL dapat mendeteksi pesan kesalahan pada klien dengan menggunakan lebih dari dua puluh bahasa. Meski pun demikian, bahasa Indonesia belum termasuk di dalamnya.
k. Antar Muka. MySQL memiliki interface (antar muka) terhadap berbagai aplikasi dan bahasa pemrograman dengan menggunakan fungsi API (Application Programming Interface).
l. Klien dan Peralatan. MySQL dilengkapi dengan berbagai peralatan (tool) yang dapat digunakan untuk administrasi basis data, dan pada setiap peralatan yang ada disertakan petunjuk online.
2.6.2. Koneksi Database MySQL dengan PHP.
Berikut penulisan fungsi script untuk koneksi ke database MySQL : a. MySQL_connect()
Perintah ini digunakan untuk melakukan koneksi ke server database MySQL, fungsi ini memiliki format penulisan sebagai berikut.
b. MySQL_select_db()
Perintah ini digunakan untuk memilih database yang ada di server MySQL, fungsi ini memiliki format penulisan sebagai berikut.
MySQL_select_db (nama_database, pengenal_koneksi).
c. MySQL_quer y()
Perintah ini digunakan untuk melakukan query atau menjalankan permintaan terhadap sebuah tabel atau sejumlah tabel database, fungsi ini memiliki format penulisan sebagai berikut.
BAB III
ANALISIS DAN PERANCANGAN SISTEM
3.1. Pengumpulan Data dan Analisa Data.
Salah satu langkah yang ditempuh untuk merancang sistem dalam aplikasi ini adalah survei dengan menggunakan dua langkah yaitu pengumpulan data dan menganalisa data yang telah didapat.
3.1.1. Pengumpulan Data.
Pengumpulan data dilakukan dengan metode: a. Metode Interview.
Metode penelitian dengan melakukian suatu tanya jawab dan penyebaran soal kuisioner untuk memperoleh data yang tidak mungkin didapat dengan cara lain.
b. Literatur.
Mempelajari buku-buku refrensi di perpustakaan yang berkaitan dengan permasalahan.
c. Telaah Dokumen.
Mempelajari dokumen, artikel dan catatan lain yang masih berkaitan dengan bidang permasalahan.
3.1.2. Analisa Data.
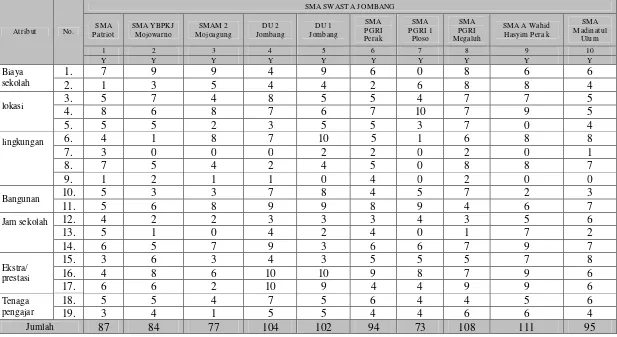
kelompok-kelompok yang mempunyai bobot nilai. Dari kelompok-kelompok-kelompok-kelompok dengan bobot nilai yang ada akan menentukan kelompok SMA swasta mana yang bisa digunakan untuk rekomendasi orang tua untuk sekolah anaknya berdasarkan kriteria. Berikut adalah beberapa kriteria yang digunakan untuk pertimbangan dalam klasterisasi sekolah swasta. Kriteria-kriteria tersebut antara lain seperti pada tabel 3.1. Tabel Kriteria Kuisioner di bawah ini.
Tabel 3.1. Tabel Kriteria Kuisioner.
No. Kriteria kuisioner Sub Kriteria kuisioner
1. Biaya sekolah Biaya sekolah, biaya sekolah identik dengan kualitas sekolah
2. Lokasi Lokasi sekolah, lokasi jauh
dari rumah, sarana transportasi
3. Lingkungan Agama, ras, social ekonomi,
tradisi
4. Bangunan sekolah Kondisi bangunan sekolah,
kelengkapan fasilitas sekolah
5. Jam sekolah Jam sekolah (masuk
pagi/siang), durasi jam sekolah, banyaknya kegiatan 6. Ekstrakulikuler dan prestasi Jenis ekstrakulikuler, prestasi
sekolah, prestasi identik dengan kemenangan lomba
7. Tenaga pengajar Latar belakang tenaga
Tabel 3.2. Tabel Tabulasi Data Kuisioner SMA Swasta Se-Jombang.
Atr ibut No.
SMA SWAST A J O MBANG
SMA Pat riot
SMA YBPKJ Mojowar no
SMAM 2 Mojoagung
DU 2 J ombang
DU 1 J ombang
SMA PGRI Perak
SMA PGRI 1
Ploso
SMA PGRI Megaluh
SMA A W ahid Hasyim Pera k
SMA Madinatul
Ulum
1 2 3 4 5 6 7 8 9 10
Y Y Y Y Y Y Y Y Y Y
Biaya sekolah
1. 7 9 9 4 9 6 0 8 6 6
2. 1 3 5 4 4 2 6 8 8 4
lokasi 3. 5 7 4 8 5 5 4 7 7 5
4. 8 6 8 7 6 7 10 7 9 5
5. 5 5 2 3 5 5 3 7 0 4
lingkungan 6. 4 1 8 7 10 5 1 6 8 8
7. 3 0 0 0 2 2 0 2 0 1
8. 7 5 4 2 4 5 0 8 8 7
9. 1 2 1 1 0 4 0 2 0 0
Bangunan 10. 5 3 3 7 8 4 5 7 2 3
11. 5 6 8 9 9 8 9 4 6 7
Jam sekolah 12. 4 2 2 3 3 3 4 3 5 6
13. 5 1 0 4 2 4 0 1 7 2
14. 6 5 7 9 3 6 6 7 9 7
Ekstra/ prestasi
15. 3 6 3 4 3 5 5 5 7 8
16. 4 8 6 10 10 9 8 7 9 6
17. 6 6 2 10 9 4 4 9 9 6
Tenaga pengajar
18. 5 5 4 7 5 6 4 4 5 6
19. 3 4 1 5 5 4 4 6 6 4
Jumlah 87 84 77 104 102 94 73 108 111 95
3
2
Tabel 3.3. Tabel Tabulasi Data Kuisioner SMA Swasta Se-Jombang.
Atr ibut No.
SMA SWAST A J OMBANG
SMA PG RI 2 J ombang SMA YPM 3 Sumobito SMA DU 3 Peterongan
SMA PG RI Peterongan
SMA Miftaqul
Ulum
SMA Budi Utomo Pera k
SMA PGRI Ngoro SMA Islam Ngor o SMA Misykat Al Anwa r
SMA Sunan Ampel
11 12 13 14 15 16 17 18 19 20
Y Y Y Y Y Y Y Y Y Y
Biaya sekolah
1. 2 5 8 5 5 5 3 5 8 9
2. 6 5 2 7 4 5 6 3 2 0
lokasi
3. 5 6 1 6 5 5 1 8 7 6
4. 9 7 9 9 7 9 9 6 9 9
5. 8 4 2 3 6 2 3 6 2 3
lingkungan
6. 2 8 8 9 6 10 3 7 10 9
7. 0 1 1 1 1 1 0 2 2 2
8. 4 5 7 6 6 5 5 4 7 4
9. 1 1 0 0 0 0 1 1 1 2
Bangunan 10. 9 4 1 7 7 6 5 6 2 4
11. 9 7 1 8 6 10 9 7 9 5
Jam sekolah
12. 4 4 0 2 1 2 6 3 2 7
13. 2 2 0 1 4 1 1 0 3 4
14. 7 9 5 9 9 6 6 4 2 4
Ekstra/pres tasi
15. 6 5 3 9 4 1 2 2 4 6
16. 9 6 5 6 6 9 6 6 8 5
17. 8 7 5 6 6 9 5 5 7 4
Tenaga pengajar
18. 8 4 5 8 4 6 4 8 9 6
19. 5 3 0 3 1 5 1 2 5 2
Jumlah 104 93 63 105 88 97 76 85 99 91
3
3
Tabel 3.4. Tabel Tabulasi Data Kuisioner SMA Swasta Se-Jombang.
Atr ib ut No.
SMA SWAST A J O MBANG
SMAM 1 J ombang
SMA Abi Huroiroh
SMA Avicena
SMA A. Wahid Hasyim Gudo
SMA A. Wahid Hasyim Tebu I reng
SMA Dar ul Ulum T apen
SMA Bahr ul
Ulum
SMA PG RI 1 J ombang
SMA Primaganda
SMA Diponegor o
21 22 23 24 25 26 27 28 29 30
Y Y Y Y Y Y Y Y Y Y
Biaya sekolah 1. 5 8 5 9 6 10 5 3 9 8
2. 3 8 1 2 6 1 3 4 4 2
Lokasi
3. 2 8 5 5 5 5 7 6 7 2
4. 7 7 10 4 8 6 10 7 10 10
5. 4 5 2 4 0 2 4 5 4 4
Lingkungan
6. 9 8 8 6 8 9 6 3 10 3
7. 1 5 2 1 1 2 2 0 4 0
8. 4 6 7 7 3 6 5 1 9 4
9. 0 1 2 1 1 1 0 0 0 1
Bangunan 10. 3 4 5 3 9 3 8 6 4 2
11. 4 8 7 5 9 6 10 10 6 9
Jam sekolah
12. 2 3 5 4 5 4 5 4 2 5
13. 1 5 1 1 4 3 2 2 5 1
14. 3 8 3 6 6 6 5 4 8 8
Ekstra/prestasi
15. 3 7 5 1 5 3 5 5 4 6
16. 9 7 6 6 7 4 7 8 6 8
17. 10 8 5 3 6 6 8 8 6 9
Tenaga pengajar
18. 9 9 3 5 5 8 8 6 5 6
19. 9 2 3 5 4 5 4 2 3 4
Jumlah 88 117 85 78 98 90 104 84 106 92
3
4
Tabel 3.5. Tabel Tabulasi Data Kuisioner SMA Swasta Se-Jombang.
Atr ibut No. SMA Pancasila SMA I slam Mojopahit SM A Kosngor o SMA PGRI K esamben
31 32 33 34
Y Y Y Y
Biaya sekolah 1. 10 8 10 5
2. 10 5 5 7
Lokasi 3. 7 3 1 6
4. 9 9 9 9
5. 3 7 4 3
Lingkungan 6. 4 3 1 9
7. 0 1 0 1
8. 5 6 9 6
9. 2 1 2 0
Bangunan 10. 7 4 0 5
11. 10 6 1 9
Jam sekolah 12. 4 0 2 2
13. 4 2 1 1
14. 6 8 10 9
Ekstra/prestasi 15. 7 8 2 9
16. 7 7 5 6
17. 5 6 2 6
Tenaga pengajar 18. 7 7 1 8
19. 6 3 5 4
Jumlah 113 94 70 105
3
5
a. Menghitung nilai Kr dan Ks dari data kuisioner.
Dari tabulasi data kuisioner akan dihitung nilai Kr dan Ks menggunakan skala Guttman, berikut ini adalah perhitungan Kr dan Ks. Nilai total error adalah 0 karena pada kuisioner tidak terjadi nilai data error.
1. SMA Patriot
Total cek = 87 Total eror = -
Jumlah pertanyaan x jumlah responden = n = 10 x19 = 190 m = 190 – 87 = 103
kemudian dihitung Koefisien reprodusibilitas dengan rumus persamaan 2.7 dan Koefisien skalabilitas dengan persamaan persamaan 2.8.
1 ) 103 .( 5 , 0 0 1 . 5 , 0 1 1 190 0 1 1 = − = − = = − = − = m e Ks n e Kr
Karena nilai Kr > 0,90, maka skala Guttman dianggap cukup baik untuk digunakan
2. SMA YBPKJ Mojowarno
Total cek = 84 Total eror = -
Jumlah pertanyaan x jumlah responden = n = 10 x19 = 190 m = 190 – 84 = 106
1 ) 106 .( 5 , 0 0 1 . 5 , 0 1 1 190 0 1 1 = − = − = = − = − = m e Ks n e Kr
Tabel 3.6. Tabel Kr dan KS Data Kuisioner SMA Swasta Se-Jombang. No. SMA Patr iot SMA YBPKJ Mojowar no SMAM 2 Mojoagung SMA DU 2 J ombang SMA DU 1 J ombang SMA PGRI Per ak SMA PGRI 1 Ploso SMA PGRI Megaluh SMA A. Wahid Hasyim Per ak SMA Madinatul Ulum
1 2 3 4 5 6 7 8 9 10
Jumlah 87 84 77 104 102 94 73 108 111 95
n 190 190 190 190 190 190 190 190 190 190
m 103 106 113 86 88 96 117 82 79 95
kr 1 1 1 1 1 1 1 1 1 1
ks 1 1 1 1 1 1 1 1 1 1
Tabel 3.7. Tabel Kr dan KS Data Kuisioner SMA Swasta Se-Jombang.
No.
SMA PGRI 2 J ombang
SMA YPM 3 Sumobito
SMA DU 3 Peter ongan SMA PGRI Peter ongan SMA Miftaqul Ulum SMA Budi Ut omo Per ak SMA PGRI Ngor o SMA Islam Ngor o SMA Misykat Al Anwar SMA Sunan Ampel
11 12 13 14 15 16 17 18 19 20
Jumlah 104 93 63 105 88 97 76 85 99 91
n 190 190 190 190 190 190 190 190 190 190
m 86 97 127 85 102 93 114 105 91 99
kr 1 1 1 1 1 1 1 1 1 1
ks 1 1 1 1 1 1 1 1 1 1
3
7
Tabel 3.8. Tabel Kr dan KS Data Kuisioner SMA Swasta Se-Jombang.
No.
SMAM 1 J ombang
SMA Abi Hur oir oh
SMA Avicena
SMA A Wahid Hasyim G udo
SMA A Wahid Hasyim Tebu
Ireng
SMA Dar ul Ulum Tapen
SMA Bahr ul
Ulum
SMA PGRI 1 J ombang
SMA Pr imaganda
SMA Diponegor o
21 22 23 24 25 26 27 28 29 30
Jumlah 88 117 85 78 98 90 104 84 106 92
n 190 190 190 190 190 190 190 190 190 190
m 102 73 105 112 92 100 86 106 84 98
kr 1 1 1 1 1 1 1 1 1 1
ks 1 1 1 1 1 1 1 1 1 1
Tabel 3.9. Tabel Kr dan KS Data Kuisioner SMA Swasta Se-Jombang.
No. SMAM 1 J ombang SMA Abi Hur oir oh SMA Avicena SMA A. Wahid Hasyim Gudo
31 32 33 34
Jumlah 113 94 70 105
n 190 190 190 190
m 77 96 120 85
kr 1 1 1 1
ks 1 1 1 1
3
8
b. Menghitung nilai rata rata kriteria.
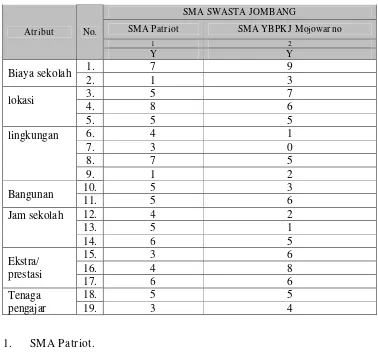
Menentukan nilai rata-rata kriteria akan dijelaskan di bawah ini, dari nilai rata-rata akan digunakan sebagai data nilai klasterisasi dengan Algoritma K-Means. Untuk melakukan perhitungan kita ambil dua contoh sekolah yaitu SMA
Patriot dan SMA YBPKJ Mojowarno.
Tabel 3.40. Tabel Tabulasi Data Kuisioner SMA Swasta Se-Jombang.
Atr ibut No.
SMA SWASTA J OMBANG
SMA Patr iot SMA YBPKJ Mojowar no
1 2
Y Y
Biaya sekolah 1. 7 9
2. 1 3
lokasi 3. 5 7
4. 8 6
5. 5 5
lingkungan 6. 4 1
7. 3 0
8. 7 5
9. 1 2
Bangunan 10. 5 3
11. 5 6
Jam sekolah 12. 4 2
13. 5 1
14. 6 5
Ekstra/ prestasi
15. 3 6
16. 4 8
17. 6 6
Tenaga pengajar
18. 5 5
19. 3 4
1. SMA Patr iot.
Rata –rata atribut biaya sekolah = 4
2 1 7
= +
Rata –rata atribut lokasi = 6
3 5 8 5
Rata –rata atribut lingkungan = 3,75
4 1 7 3
4+ + + =
Rata –rata atribut bangunan = 5
2 5 5+ =
Rata –rata atribut jam sekolah = 5
3 6 5 4 = + +
Rata –rata atribut ekstra/prestasi = 4,33 3 6 4 3 = + +
Rata –rata atribut tenaga pengajar = 4
2 3 5
= +
2. SMA YBPKJ Mojowar no.
Rata –rata atribut biaya sekolah = 6
2 3 9+ =
Rata –rata atribut lokasi = 6
3 5 6 7 = + +
Rata –rata atribut lingkungan = 2
4 2 5 0
1+ + + =
Rata –rata atribut bangunan = 4,5 2
6 3
= +
Rata –rata atribut jam sekolah = 2,67 3 5 1 2 = + +
Rata –rata atribut ekstra/prestasi = 6,67
3 6 8 6+ + =
Rata –rata atribut tenaga pengajar = 4,5
2 4 5
= +
Tabel 3.41. Tabel Nilai Rata-Rata Atribut SMA Swasta Se-Jombang.
No. Atr ibut SMA
Pat riot
SMA YBPK J Mojowar no SMAM 2 Mojoagung DU 2 J ombang DU 1 J ombang SMA PGRI Perak SMA PGRI 1 Ploso SMA PGRI Megaluh SMA A. Wahid Hasyim Pera k
SMA Madinatul
Ulum
1 Biaya sekolah 4 6 7 4 6.5 4 6 8 7 5
2 lokasi 6 6 4.67 6 5.33 5.67 5.67 7 5.33 4.67
3 lingkungan 3.75 2 3.25 2.5 4 4 0.25 4.5 4 4
4 bangunan 5 4.5 5.5 8 8.5 6 7 5.5 4 5
5 Jam sekolah 5 2.67 3 5.33 2.67 4.33 3.33 3.67 7 5
6 Ekstra/prestasi 4.33 6.67 3.67 8 7.33 6 5.67 7 8.33 6.67
7 Tenaga
pengajar 4 4.5 2.5 6 5 5 4 5 5.5 5
Tabel 3.42. Tabel Nilai Rata-Rata Atribut SMA Swasta Se-Jombang.
No. Atr ibut SMA PG RI 2 J ombang
SMA YPM 3 Sumobito
SMA DU 3 Peterongan
SMA PG RI Peterongan
SMA Miftaqul
Ulum
SM A Budi Ut omo Pera k
SMA PGRI Ngoro SMA Islam Ngor o SMA Misykat Al Anwa r
SMA Sunan Ampel
1 Biaya sekolah 4 5 5 6 4.5 5 4.5 4 5 4.5
2 lokasi 7.33 5.67 4 6 6 5.33 4.33 6.67 6 6
3 lingkungan 1.75 3.75 4 4 3.25 4 2.25 3.5 5 4.25
4 bangunan 9 5.5 1 7.5 6.5 8 7 6.5 5.5 4.5
5 Jam sekolah 4.33 5 1.67 4 4.67 3 4.33 2.33 2.33 5
6 Ekstra/prestasi 7.67 6 4.33 7 5.33 6.33 4.33 4.33 6.33 5
7 Tenaga
pengajar 6.5 3.5 2.5 5.5 2.5 5.5 2.5 5 7 4
4
1
Tabel 3.43. Tabel Nilai Rata-Rata Atribut SMA Swasta Se-Jombang.
No. Atr ibut SMAM 1
J ombang
SMA Abi Huroiroh
SMA Avicena
SMA A W ahid Hasyim Gudo
SMA A Wahid Hasyim Tebu
Ireng
SMA Dar ul Ulum
Tapen
SMA Bahr ul
Ulum
SMA PG RI 1 J ombang
SMA Primaganda
SMA Diponegor o
1 Biaya sekolah 4 8 3 5.5 6 5.5 4 3.5 6.5 5
2 lokasi 4. 33 6.67 5.67 4.33 4.33 4.33 7 6 7 5.33
3 lingkungan 3.5 5 4.75 3.75 3.25 4.5 3.25 1 5.75 2
4 bangunan 3.5 6 6 4 9 4.5 9 8 5 5.5
5 Jam sekolah 2 5.33 3 3.67 5 4.33 4 3.33 5 4.67
6 Ekstra/prestasi 7.33 7.33 5.33 3.33 6 4.33 6.67 7 5.33 7.67
7 Tenaga
pengajar 9 5.5 3 5 4.5 6.5 6 4 4 5
Tabel 3.44. Tabel Nilai Rata-Rata Atribut SMA Swasta Se-Jombang.
No. Atr ibut SMA Pancasila SMA Islam Mojopahit SMA K osngor o SMA PG RI Kesamben
1 Biaya sekolah 10 6.5 7.5 6
2 lokasi 6.33 6.33 4.67 6
3 lingkungan 2.75 2.75 3 4
4 bangunan 8.5 5 0.5 7
5 Jam sekolah 4.67 3.33 4.33 4
6 Ekstra/prestasi 6.33 7 3 7
7 Tenaga
pengajar 6.5 5 3 6
4
2
3.2. Analisa Sistem.
Sistem ini dibuat untuk pengelompokan SMA swasta berdasarkan kriterianya. Sistem yang dibuat diharapkan dapat memberikan daftar kelompok SMA swasta sesuai dengan kriteria yang ada sehingga membantu para orang tua dalam memilih sekolah swasta yang terbaik untuk anaknya. Pentingnya pengelompokan SMA swasta dikarenakan setiap sekolah mempunyai kriteria-kriteria yang berbeda-beda antara lain meliputi biaya sekolah, lokasi, lingkungan, bangunan, jam sekolah, prestasi dan tenaga pengajar. Sebelumnya hasil dari data kriteria diambil dari penyebaran kuisioner, data kuisioner akan ditabulasikan agar lebih mudah dalam pengolahan data.
Dari data kriteria yang ada akan diproses dengan algoritma k-means. Untuk melakukan proses sistem akan menghitung nilai centroid dari masing-masing cluster yang diambil dari data yang sudah ada. Kemudian setelah didapat nilai centroid semua cluster, lalu sistem akan menghitung jarak (Euclidean Distance) masing-masing obyek ke semua centroid yang ada. Lalu dilakukan
pengelompokan cluster berdasarkan pada jarak terdekat (nilai Euclidean Distance terkecil). Proses tersebut terus diulang-ulang sampai tidak ada obyek yang berpindah cluster. Dari hasil proses diatas akan terbentuk kelompok-kelompok sekolah berdasarkan kriteria yang ada dan akan berhubungan dengan sebuah link untuk melihat data profil sekolah.
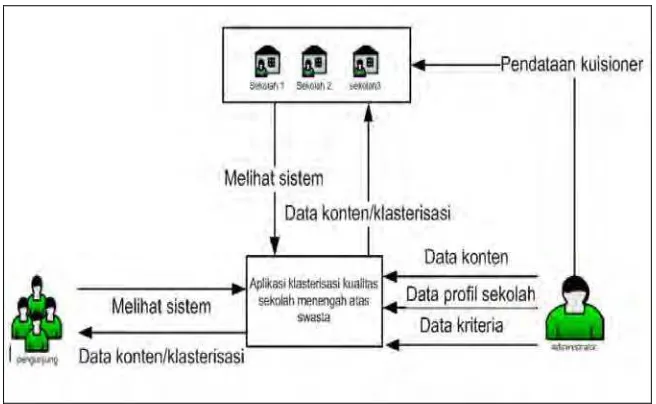
swasta. Selain menginputkan data kuisioner berupa data kriteria admin juga dapat menginputkan data profil sekolah dan data konten. Pihak user dalam hal ini masyarakat umum atau pihak sekolah dapat mengakses aplikasi dari internet dan dapat mengetahui sekolah mana yang berkualitas sesuai dengan kriteria yang ditentukan.
Gambar 3.1. Arsitektur Aplikasi Klasterisasi Kualitas SMA Swasta
3.3. Desain Alur Pr oses Klaster isasi.
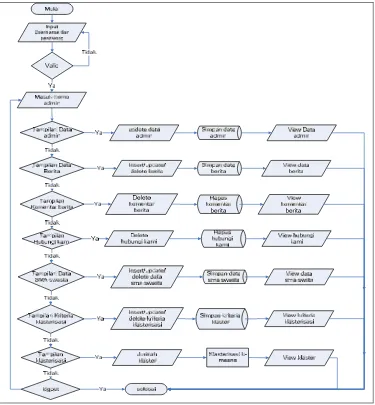
3.3.1. Admin.
Gambar 3.2. Flowchart Admin
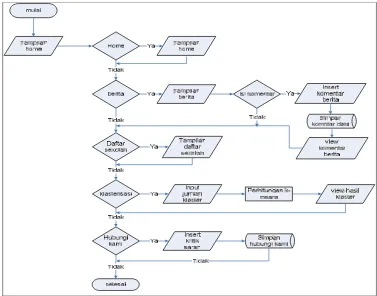
3.3.2. User (Pemakai Infor masi).
Berikut adalah alur atau flowchart dari pengguna atau user yang menjelaskan alur pada interface aplikasi. Seperti dijelaskan pada gambar gambar gambar 3.3. Flowchart User dibawah ini.
Gambar 3.3. Flowchart User.
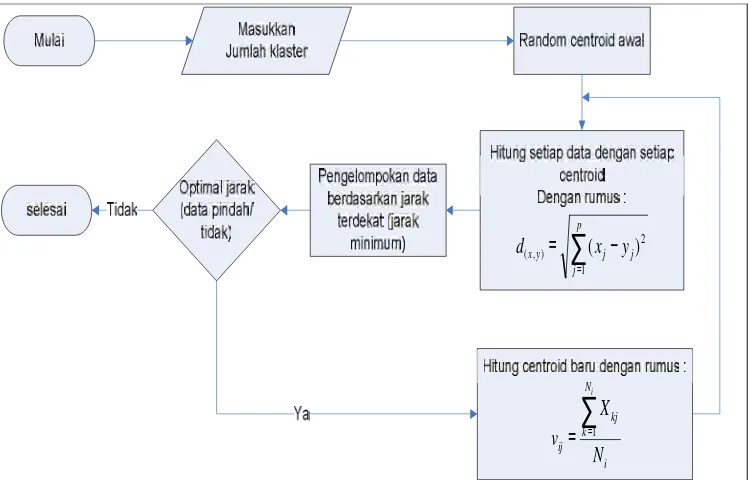
3.3.3. Pr oses Klaster .
Langkah selanjutnya melakukan pengelompokan data berdasarkan jarak terdekat kemudian melakukan optimal jarak. Jika pengelompokan data berdasarkan jarak terdekat sudah tidak ada perubahan atau tidak berpindah tempat maka proses klasterisasi selesai. Tetapi apabila pada optimal jarak masih terdapat perpindahan data berdasarkan jarak terdekat akan diulang ke proses hitung setiap data dengan centroid, untuk perhitungan centroid mengunakan rumus (2.3) pada Bab II sebelumnya.
Dilanjutkan proses pengelompokan data berdasarkan jarak terdekat dan melakukan optimal jarak. Jika data sudah optimal jaraknya tidak terjadi perpindahan maka proses selesai dan jika tidak, proses diulang kembali kehitung setiap data dengan setiap centroid proses diulang terus sampai tidak ada perpindahan lagi. Seperti dijelaskan pada gambar 3.4. Flowchart Proses Klasterisasi K-Means.
i N
k kj
ij
N X v
i
∑
== 1
∑
=
− = p
j j j y
x x y
d 1
2 )
,
( ( )
3.4. Per ancangan Sistem.
Di dalam perancangan Sistem Aplikasi Klasterisasi Kualitas Sekolah Swasta (Studi Kasus SMA Swasta Se-Kabupaten Jombang) ini, dibuat beberapa perancangan perangkat lunak yang menjelaskan penggambaran dari sistem secara konseptual sehingga akan didapat sebuah penggambaran perangkat lunak ini secara umum dan menyeluruh, sistem perancangan tersebut diantaranya adalah Diagram Berjenjang, Data Flow Diagram (DFD), Conceptual Data Model (CDM), dan Physical Data Model (PDM.).
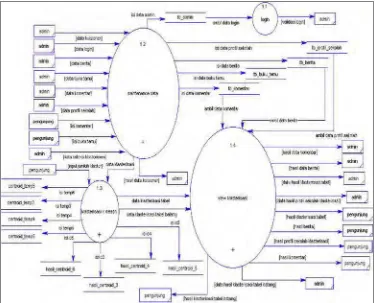
3.4.1. Diagr am Berjenjang.
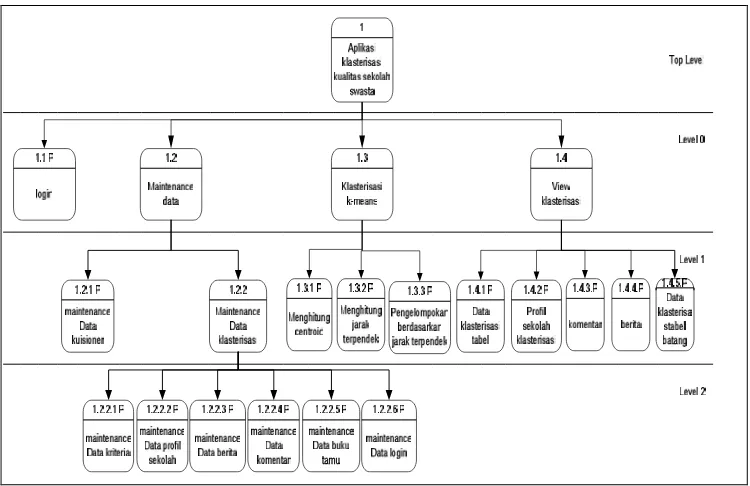
Pada diagram berjenjang ini akan dijelaskan jejang proses yang akan digunakan dalam sistem, dimana diagram tersebut akan menjabarkan tentang alur proses apa saja yang akan digunakan. Hal ini akan menjadi dasar di dalam pembentukan alur pada Data Flow Diagram (DFD). Setiap proses pada level 0 terbagi menjadi empat proses utama yaitu proses login, maintenance data, klasterisasi k-means dan view klasterisasi.
Secara detail pada gambar 3.2. Diagram Berjenjang menjabarkan setiap alur proses yang terjadi, dapat dilihat pada level 0, antara lain sebagai berikut: a. Proses 1 menjabarkan proses login admin untuk masuk kedalam halaman
administrator.
b. Proses 2 menjabarkan proses pengolahan data atau maintenance data baik insert, update, delete dan publikasi seperti pada proses data kuisioner dan
c. Proses 3 menjabarkan proses klasterisasi dengan algoritma k-means yang meliputi menghitung centroid, menghitung jarak terpendek dan mengelompokkan berdasarkan jarak terpendek.
d. Proses 4 menjabarkan proses untuk menampilkan data-data view klasterisasi yang meliputi data klasterisasi berupa tabel, profil sekolah klasterisasi, komentar, berita dan data klasterisasi berupa table batang.
Level 1 pada diagram berjenjang menjelaskan sub-sub proses dari level 0 secara detail mengenai alur datanya kemudian level 2 pada diagram berjenjang menjelaskan sub-sub proses dari level 1 secara detail, seperti terlihat pada gambar. 3.5. Diagram Berjenjang di bawah ini.
Gambar . 3.5. Diagram Berjenjang
3.4.2. Data Flow Diagram (DFD)
data yang di dalamnya memuat alur data yang terjadi. Context diagram yang akan dibentuk menjelaskan tentang gambaran umum dari alur data sehingga akan dapat diketahui data-data apa saja yang akan diakses pada Aplikasi Klasterisasi Kualitas Sekolah Swasta ini. Langkah pertama dalam pembuatan Data Flow Diagram (DFD) adalah membuat context diagram. Diagram ini dapat digambarkan
hubungan input/output antar sistem dengan dunia luar (external entity).
Dengan mengetahui data-data yang akan digunakan, maka dapat dipakai sebagai acuan dalam merancang bangun sebuah sistem basis data yang tepat dan efisien dalam penggunaannya. Pada gambar 3.6. Context Diagram dijabarkan para pengguna perangkat lunak dan sebuah alur proses pemasukan data sampai dengan pembuatan laporan akhir untuk Aplikasi Klasterisasi Kualitas Sekolah Swasta (Studi Kasus SMA Swasta Se-Kabupaten Jombang).
Gambar 3.6. Context Diagram
level ini akan dijumpai sub proses yang menggambarkan bagian proses umum yang masih belum mendetail, namun dipergunakan sebagai dasar pembuatan sub proses selanjutnya.
Pada gambar 3.7. DFD Level 0 Sub Proses Aplikasi Klasterisasi Kualitas Sekolah Swasta di bawah ini, dijabarkan sub sistem yang ada. Pada context diagram diuraikan menjadi beberapa sub proses yang terdiri proses login
untuk data login administrator, proses maintenance data untuk mengisi dan mengolah data utama yaitu proses data kuisioner dan proses data klasterisasi. Pada proses klasterisasi k-means terdapat proses menghitung centroid, menghitung jarak terpendek dan mengkelompokkan berdasarkan jarak terpendek dan view klasterisasi yang meliputi proses menampilkan data klasterisasi.
Pada gambar 3.8. DFD Level 1 Sub Proses Maintenance Data di bawah ini, menjelaskan proses data kuisioner dan data klasterisasi.
hasil data kuisioner
isi data buku tamu
ambil data kriteria klaster isi data kriteria klaster
data kriteria klasterisasi
data login
isi buku tamu
isi komentar data buku tamu
data komentar data profil sekolah data berita
data kuisioner
isi data komentar isi data admin isi data berita isi data profil sekolah admin
pengunjung
pengunjung admin
admin admin admin
tb_profil_sekolah
tb_berita
tb_admin
tb_komentar admin
admin
1 data kuisioner
2
data klasterisasi
+
tb_kriteria kalster
tb_buku_tamu admin
Ga mbar 3.8. DFD Level 1 Sub Proses Maintenance Data.
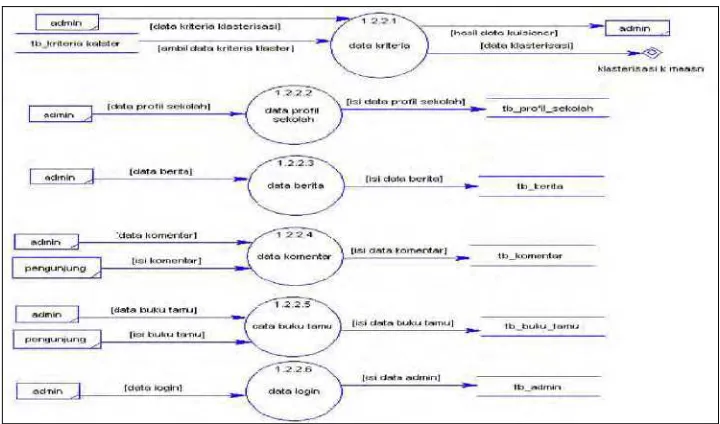
Pada gambar 3.9. DFD Level 2 Sub Proses Data Klasterisasi di bawah ini, menjelaskan proses data kriteria, data profil sekolah, data berita, data komentar, data buku tamu dan data login.
Pada gambar 3.10. DFD Level 1 Sub Proses Klasterisasi K- Means di bawah ini, menjelaskan tentang proses klasterisasi kualitas sekolah dengan algoritma k-means yang meliputi pengunjung menginputkan jumlah klaster
kemudian proses menghitung nilai centroid dari masing-masing cluster dengan data yang ada pada kriteria. Untuk menghitung nilai centroid dari data yang ada di masing-masing cluster dengan menggunakan rumus (2.3) pada bab 2 sebelumnya.
Setelah itu, didapat nilai centroid semua cluster. Langkah berikutnya sistem akan melakukan proses menghitung jarak terpendek masing-masing obyek ke semua centroid yang ada. Lalu proses pengelompokan cluster berdasarkan jarak terpendek atau terdekat. Proses tersebut terus diulang sampai tidak ada obyek yang berpindah. Untuk menghitung jarak terpendek menggunakan rumus (2.2) pada bab 2 sebelumnya. Dari proses diatas akan terbentuk kelompok sekolah yang berkualitas berdasarkan kualitasnya.
Pada gambar 3.11. DFD Level 1 Sub Proses View Klasterisasi di bawah ini, akan dijabarkan untuk menampilkan data-data yang meliputi proses data klasterisasi berupa tabel, proses profil sekolah klasterisasi, proses komentar, proses berita dan proses data klasterisasi berupa table batang.
Gambar 3.11. DFD Level 1 Sub Proses View Klasterisasi
3.4.3. Conceptual Data Model (CDM).
Perancangan tabel-tabel dalam database secara logic akan lebih memudahkan untuk dapat merancang sebuah sistem yang efektif dalam mengakses data serta efisien dalam penyimpanan data pada tabel-tabel di database. Perancamngan CDM ini didasarkan pada perancangan DFD yang telah
terbentuk sampai dengan level 1, level 2 dan hanya merupakan skema data serta belum mengarah kepada DBMS yang akan digunakan.
tabel antara lain tabel admin, profil sekolah, kriteria klaster, buku tamu, komentar, berita, centroid temp 3, centroid temp 4, centroid temp 5, centroid temp 6, hasil centroid 3, hasil centroid 4, hasil centroid 5dan hasil centroid 6. Masing-masing tabel memiliki field-field yang berbeda antara satu dengan yang lainnya, di bawah ini adalah gambar 3.12. CDM Aplikasi Klasterisasi Kualitas Sekolah Swasta.
tampilan_profi l_sekolah respon_buku_tamu input_berita komentar hasil_5 hasil_4 hasil_3 hasil_6
cen troi d_temp5 centroi d_temp6
centroi d_tem p3
centro id_temp4
input_profi l_sekolah tb_p rofi l_se kolah
id_sekolah no_nus no_rayon nama_sekola h alamat_sekol ah kecamatan no_tl pn akredi tasi <pi>VA5 VA5 VA5 VA30 VA50 VA30 VA12 VA1 <M> id_sekolah<pi>
tb_ kriteria _klaster
id_kriteria nama_sekolah_kr