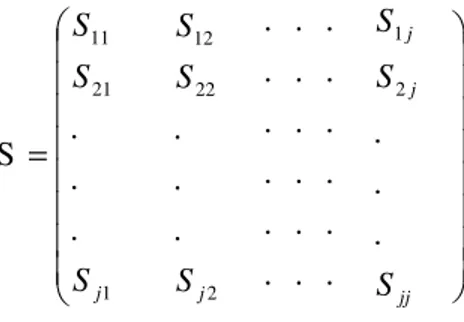BAB 2
LANDASAN TEORI
Dalam bab 2 ini akan dijelaskan teori-teori yang berhubungan dengan penelitian ini yang dapat dijadikan sebagai landasan teori atau teori pendukung dalam penelitian ini.Landasan teori ini akan mempermudah pembahasan hasil penelitian pada bab 3. Adapun teori – teori tersebut adalah sebagai berikut.
2.1 Analisis Diskiminan
Menurut Johnson dan Wichern (2007), tujuan dari Analisis Diskriminan adalah untuk menggambarkan ciri-ciri suatu pengamatan dari bermacam-macam populasi atau kelompok yang diketahui. Dengan kata lain Analisis Diskriminan digunakan untuk mengklasifikasikan individu ke dalam salah satu dari dua kelompok atau lebih.
Suatu fungsi diskriminan layak untuk dibentuk bila terdapat perbedaan nilai rataan di antara kelompok-kelompok yang ada. Oleh karena itu sebelum fungsi diskriminan dibentuk perlu dilakukan pengujian terhadap perbedaan nilai rataan dari kelompok-kelompok tersebut.
Dalam pengujian nilai rataan antar kelompok, asumsi yang harus dipenuhi adalah:
5. Variabel independen seharusnya berdistribusi normal multivariat (Multivariate Normality), jika data tidak berdistribusi normal,akan menyebabkan masalah pada ketepatan fungsi (model) diskriminan.
7. Tidak ada data yang sangat ekstrim (outlier) pada variabel independen, jika ada data ekstrim yang tetap diproses, hal ini bisa berakibat berkurangnya ketepatan klasifikasi dari fungsi diskriminan.
8. Tidak ada korelasi yang kuat antar-variabel independen , jika dua variabel independen mempunyai korelasi yang kuat,dikatakan terjadi multikolinieritas, untuk mengetahui adanya multikolinieritas dapat dilakukan dengan melihat korelasi antar variabel independen (r) yaitu jika nilai r > 0.6 menunjukkan adanya multikolinieritas.
2.2 Uji Kenormalan Peubah Ganda
Menurut Johnson dan Wichern (2007), untuk menguji kenormalan peubah ganda (Multivariate Normality) adalah dengan mencari nilai jarak kuadrat untuk setiap pengamatan yaitu: ) ( )' ( 1 2 X X S X X di = i− − i − dimana : 2 i
d adalah nilai jarak kuadrat untuk setiap pengamatan ke- i
i
X adalah pengamatan yang ke-i, dengan i = 1, 2, ..., n −
X adalah rata-rata variabel bebas X
S-1 adalah kebalikan (inverse) matriks varians-kovarians gabungan S .
Kemudian di2 diurutkan dari yang paling kecil ke yang paling besar, selanjutnya dibuat plot 2
i
d dimana: i = urutan = 1, 2, ..., n . Bila hasil plot dapat didekati dengan garis lurus, maka dapat disimpulkan bahwa peubah ganda menyebar normal.
Pada artikel Analisis_Faktor & Diskriminan, dikatakan bahwa seringkali kenormalan ganda sulit diperoleh terutama bila sampel yang diambil relatif kecil. Bila hal ini terjadi, uji vektor nilai rataan (uji kesamaan rata-rata kelompok) tetap bisa
dilakukan selama asumsi kesamaan matriks varians kovarians grup dari semua variabel independen dipenuhi.
2.3 Uji Kesamaan Matriks Varians Kovarians
Untuk menguji kesamaan matriks varians kovarians kelompok I (S1) dan kelompok II
(S2) digunakan hipotesa :
H0 : S1 = S2 ,matriks varians kovarians kelompok adalah relatif sama
H1 : matriks varians kovarians kelompok adalah berbeda secara nyata.
Terima H0 , yang berarti matriks varians kovarians sama jika :
2 ) 1 ( ) 1 ( 2 1 ; 2 + − ≤ p p k hit α χ χ Dengan : − − − =
∑
∑
= = k i k i i i i hitung C V S S V 1 1 1 2 ln 2 1 ln 2 1 ) 1 ( 2 χk = banyaknya kelompok ( grup )
P = jumlah peubah pembeda (Y) dalam fungsi diskriminan = 1
S = matriks varians kovarians dalam kelompok gabungan.
Si = matriks varians kovarians kelompok ke-i.
i = 1,2, ... , k
ni = jumlah responden pada kelompok ke- i
dengan 1 − = i i n V
∑
∑
= = = k i i i k i i V S V S 1 1 − + − + − =
∑
∑
= = 6( 1)( 1) 1 3 2 1 1 2 1 1 1 k p p p V V C k i i k i i2.4 Uji Vektor Nilai Rataan (Uji Kesamaan Rata-Rata Kelompok )
Menguji apakah semua variabel independen (variabel bebas) berbeda secara nyata berdasarkan variabel dependen.Variabel bebas diuji dengan dua cara :
1. Dengan Uji F
Statistik uji yang digunakan untuk menguji kesamaan rata-rata antar kelompok adalah statistik F dengan hipotesa :
H0 : µ1 =µ2 =...=µk ,berarti rata-rata antar kelompok sama ( tidak ada perbedaan ) H1 : µ1 ≠µ2 ≠...≠µk ( sedikitnya ada dua rataan yang berbeda )
berarti ada perbedaan rata-rata antar kelompok.
α = Taraf nyata
Daerah kritis : tolak H0 , jika Fhit > Ftabel
Ftabel = Fα (db1; db2 )
db1 = k-1
db2 = (n-k ) = (n1-1)+(n2-1)
Apabila Fhit > F tabel ,maka tolak H0 , ini berarti bahwa terdapat perbedaan
vektor nilai rataan antar kelompok. Bila dari hasil pengujian ada perbedaan vektor nilai rataan, maka fungsi diskriminan layak disusun untuk mengelompokkan suatu objek .
Keputusan atas dasar Signifikansi uji F pada output SPSS dilihat angka Sig.
a. Jika Sig. > 0.05 maka H0 diterima berarti tidak ada perbedaan yang signifikan
antar grup ( rata - rata antar kelompok sama ).
b. Jika Sig. ≤ 0.05 maka H1 diterima , berarti ada perbedaan yang signifikan antar
grup .
2. Dengan angka Wilks’ Lambda
Angka Wilks’ Lambda berkisar 0 sampai 1 , yaitu :
a. Jika angka Wilks’ Lambda mendekati 0 , maka data tiap kelompok cenderung berbeda.
b. Jika angka Wilks’ Lambda mendekati 1 , maka data tiap kelompok cenderung sama (tidak berbeda ).
Wilk’s Lambda B W W + = Dimana :
W = Jumlah Kuadrat Galat ( JK dalam kelompok ) B = Jumlah Kuadrat Antar kelompok
Analisis varians ( uji F ) dan angka Wilk’s Lambda adalah untuk menguji rata-rata dari setiap variabel.
2.5 Fungsi Analisis Diskriminan
Fungsi diskriminan menentukan kedalam kelompok mana suatu objek (melalui karakteristiknya berupa data pengamatan) seharusnya dimasukkan atau dikategorikan, maka setidak-tidaknya ada dua kelompok (grup), oleh karena itu dapat ditinjau bagaimana fungsi diskriminan ini diperoleh apabila berhadapan dengan dua grup . Sebelumnya akan dijelaskan terlebih dahulu pengertian matriks varians kovarians.
Pada data pengamatan ke-i yang berukuran n ( i=1,2,... n ) yang terdiri atas j buah variat (variabel) yaitu X1, X2, ... , Xj . Data pengamatan tersebut dapat disajikan
dalam bentuk matriks berikut.
Tabel 2.5.1 Matriks Data Pengamatan
Variabel X1 X2 . . . Xj Data Pengamatan X11 X12 . . . X1j X21 X22 . . . X2j . . . . . . . . . Xn1 Xn2 . . . Xnj
Untuk variabel Xj yang dihitung adalah variansnya, diberi lambang Sjj , dengan
rumus : ) 1 ( ) ( 1 1 2 2 − − =
∑
∑
= = n n X X n S n n n n nj nj jjSemuanya ada j buah varians, yaitu S11 ,S22 , ... , Sjj yang masing-masing merupakan
varians untuk variabel X1, X2, ... , Xj . Untuk variabel Xi dan Xj dimana i ≠ j terdapat
kovarians, diberi lambang Sij yang dapat dihitung dengan rumus berikut.
) 1 ( ) )( ( . 1 1 1 − − =
∑
∑
∑
= = = n n X X X X n S n n n n nj ni n n nj ni ijSemuanya ada ( j2 - j ) buah kovarians. Perlu dijelaskan bahwa untuk i = j maka Sij = Sji diberi lambang menjadi Sjj .
Varians dan kovarians ini disusun dalam sebuah matriks ,disebut dengan nama matriks varians-kovarians dengan lambang S , bentuknya sebagai berikut.
S = 1 21 11 . . . j S S S 2 22 12 . . . j S S S . . . . . . . . . . . . . . . . . . jj j j S S S . . . 2 1
Misalkan ada dua grup yang banyak variabelnya masing-masing j buah ,yaitu X11, X12, ... , X1j dalam grup I dan X21,X22, ... ,X2j dalam grup II . Perhatikan bahwa
Xij menyatakan variabel ke j dalam grup ke i , dengan i = grup I dan grup II. Variabel
dalam setiap grup dapat pula dituliskan dalam bentuk vektor kolom sebagai berikut.
= j X X X X 1 12 11 1 . . . dan = j X X X X 2 22 21 2 . . . j
X1 menyatakan variabel X ke j dalam grup ke 1
j
X2 menyatakan variabel X ke j dalam grupke 2
Dari setiap grup berukuran n1 dari grup ke-1 dan berukuran n2 dari grup ke-2 . Data
pengamatan akan berbentuk matriks yang bentuknya seperti berikut.
Tabel 2.5.2 Matriks Data Pengamatan dari Grup I
Variabel X11 X12 . . . X1j Data Pengamatan X111 X121 . . . X1j1 X112 X122 . . . X1j2 . . . . . . . . . X11n1 X12n1 . . . X1jn1 Rata-rata − X 11 − X 12 . . . − X 1j
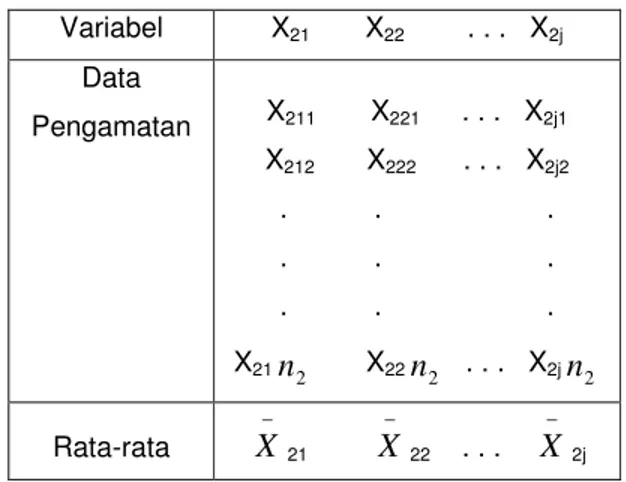
Tabel 2.5.3 Matriks Data Pengamatan dari Grup II Variabel X21 X22 . . . X2j Data Pengamatan X211 X221 . . . X2j1 X212 X222 . . . X2j2 . . . . . . . . . X21n2 X22n2 . . . X2jn2 Rata-rata − X 21 − X 22 . . . − X 2j
Hasil pengamatan ini akan menghasilkan rata-rata untuk tiap variabel yang dalam bentuk vektor bisa ditulis :
= − − − − j X X X X 1 12 11 1 . . . dan = − − − − j X X X X 2 22 21 2 . . . dimana :
X1jn menyatakan variabel X ke j dalam grup ke 1 yang berukuran n1 1
X2jn2 menyatakan variabel X ke j dalam grup ke 2 yang berukuran n2
j X1
−
menyatakan rata-rata variabel ke j dalam grup ke 1
j X1
−
menyatakan rata-rata variabel ke j dalam grup ke 2
Dari masing-masing rata-rata dari grup I dan rata-rata dari grup II , selanjutnya akan dihitung varians dan kovariansnya. Varians kovarians tersebut disusun dalam matriks S1 dan S2 ,masing-masing dari grup ke-1 dan dari grup ke-2 , yaitu :
S1 = 1 21 11 . . . j S S S 2 22 12 . . . j S S S . . . . . . . . . . . . . . . . . . jj j j S S S . . . 2 1 dan S2 = 1 21 11 . . . j S S S 2 22 12 . . . j S S S . . . . . . . . . . . . . . . . . . jj j j S S S . . . 2 1
dimana : S1 = matriks varians kovarians dari grup ke-1
S2 = matriks varians kovarians dari grup ke-2
Meskipun dalam S1 dan S2 digunakan Sij yang sama namun jelas besarnya
berlainan antara Sij dalam S1 dan Sij dalam S2 , kedua datanya juga berlainan , yaitu S1
diambil dari grup I dan S2 dari grup II .
Kedua buah matriks kovarians ini bisa dihitung matriks varians-kovarians gabungan , diberi lambang S dengan rumus :
2 ) 1 ( ) 1 ( 2 1 2 2 1 1 − + − + − = n n S n S n S
Matriks varians-kovarians gabungan ini mempunyai invers, yaitu S-1 .
Dengan adanya vektor rata-rata 1
−
X dan 2
−
X dan juga matriks varians-kovarians gabungan S bersama dengan persyaratan bahwa data variabel independen seharusnya berdistribusi normal multivariat ( bervariabel banyak ) disingkat multinormal, dan matriks varians-kovarians kedua grup relatif sama , maka rumus fungsi diskriminan untuk ini adalah :
Y = ' 2 1 ) ( − − − X X S-1 X
X adalah vektor pengamatan, yaitu X =
X X X . . . 2 1
Fungsi diskriminan ini dapat digunakan untuk membuat aturan klasifikasi yang kita cari berdasarkan salah satu dari kedua aturan dibawah ini :
ATURAN I : Jika Y > 2 1 ' 2 1 ) ( − − − X X S-1 ( 1 2) − − + X
X klasifikasi objek dengan data pengamatan X
dimasukkan ke dalam grup I .
Jika Y < 2 1 ' 2 1 ) ( − − − X X S-1 ( 1 2) − − + X
X suatu objek diklasifikasikan kedalam grup II .
ATURAN II :
Dengan menggunakan statistik W (Wald – Anderson) yaitu :
W = X' S-1 ( 1 2) − − − X X - 2 1 ' 2 1 ) ( − − − X X S-1 ( 1 2) − − + X X
Untuk memperoleh klasifikasi ini , jika W > 0 maka objek dengan pengamatan X dimasukkan kedalam grup I sedangkan dalam hal lainnya objek itu dimasukkan kedalam grup II .
2.6 Ketepatan Pengelompokan Fungsi Diskriminan
Tingkat akurasi pengelompokkan sangat menentukan baik atau tidaknya suatu pengelompokkan. Persentase ketepatan pengelompokan dapat dihitung dari matriks klasifikasi yang menunjukkan nilai sebenarnya (actual members) dan nilai prediksi (prediction members) dari setiap kelompok.
Hasil pengelompokan menurut fungsi diskriminan tidak selalu sama dengan pengelompokan awal. Besarnya kesalahan pengelompokan, dengan menganggap pengelompokan awal adalah benar, merupakan indikator tingkat akurasi dari fungsi diskriminan yang dihasilkan. Tabel berikut menunjukkan evaluasi tingkat akurasi
terhadap fungsi diskriminan dengan memperhatikan persentase ketepatan
Tabel 2.6.1 Evaluasi Terhadap Fungsi Diskriminan Pengelompokan Menurut
Fungsi Diskriminan Pengelompokan
Awal Kelompok I Kelompok II
Jumlah Kelompok I 11 n n12 n1. Kelompok II 21 n n22 n 2. Jumlah 1 . n n.2 n
Rumus persentase ketepatan pengelompokan = n
n
n )
( 11+ 22