2.1. Rekomendasi Berita
Portal berita online saat ini menjadi popular yang bisa menyediakan berita yang dapat diakses melalui internet, tantagannya adalah membantu user menemukan berita yang disukai secara personal (Liu, et al. 2010). Rekomendasi berita menjadi solusi dari tatangan tersebut, karena bisa memberikan bantuan kepada user untuk menemukan lebih banyak berita yang mereka inginkan.
Salah satu rekomendasi berita telah dilakukan oleh peneliti Google untuk diterapkan pada google news yang memberikan rekomendasi berita secara personal kepada user yang sudah login ke dalam sistem google news. Sehingga google news bisa mengambil jejak penjelajahan yang lebih banyak untuk bisa memberikan rekomendasi yang lebih tepat kepada user.
2.2. Pengguna Anonim
Pengguna anonim merupakan pengakses suatu situs atau service yang tidak membutuhkan untuk mengisi username dan password dalam mengakses dan tidak tervalidasi (Janssen, 2014). Tipe user ini belum menetap untuk akses disuatu situs. Karena pengguna anonim tidak memiliki identitas yang spesifik dan bersifat unik yang bisa dicatat secara permanen, sehingga mengalami kesulitas dari sistem untuk mencatat setiap jejak penjelajahan berita dari pengguna anonim. Yang bisa dicatat nantinya hanya selama cookie pada browsernya tidak terhapus dan belum expired. Dalam penelitian ini, penulis mengasumsikan pengguna anonim sebagai pembaca
2.3. Content Based Recommendation
Content based recommendation merupakan sistem rekomendasi yang diberikan
kepada user dengan cara menganalisa sekumpulan dokumen dan dibandingkan dengan apa yang telah diakses sebelumnya atau user profile dari masing – masing user. Salah satu metode yang bisa digunakan untuk content based recommendation adalah model relevansi yang menggunakan vector space model dengan basis nilai TF-IDF (Lops, 2011). Metode vector space model yang penulis gunakan adalah sparse matrix vector
multiplication yang akan penulis bahas pada bagian 2.7.
2.4. Sparse Matrix
Sparse matrix adalah sebuah matriks yang didalamnya didominasi oleh nilai 0. Secara
lebih jelas, jika jumlah nilai non-zero lebih sedikit dari jumlah nilai 0, maka itu disebut sparse matrix, akan tetapi jika nilai 0 lebih sedikit dari jumlah nilai non-zero, maka itu disebut dense martix (Stoer, et al. 2002).
Menurut Bank (2001) penyimpanan data pada sparse matrix sama seperti penyimpanan data matriks pada umumnya. Setiap item di dalam sparse matrix akan diakses melalui Ai,j, I = menyatakan baris dan j = menyatakan kolom. Unutk efisiensi
dalam penyimpanan, ada 5 jenis format kompresi dalam sparse matrix yaitu COO (coordinate storage), CSR (Compressed Sparse Row), CCS (Compressed Column
Storage ), JDS (Jagged Diagonal Storage) dan TJDS (Transposed Jagged Diagonal Storage) (Shahnaz, et al. 2006).
Dalam penelitian ini, penulis menggunakan format kompresi CSR yang akan menempatkan nilai non-zero dalam 1 baris vector. Pada CSR terdapat 3 vektor yaitu
val, col_ind, row_ptr. Val merupakan vektor untuk menyimpan nilai non-zero dari sparse matrix dengan proses pengambilannya dimulai dari kiri atas lalu kekanan
sampai ke baris paling bawah dan akan disimpan dalam 1 baris. Col_ind merupakah vektor yang menyimpan kolom pada sparse matrix dari setiap item val dan disimpan dalam 1 baris. Row_ptr merupakan vektor yang menyimpan indeks baris dengan cara menambahkan jumlah item non-zero pada suatu baris dari sparse matrix (Goharian, et
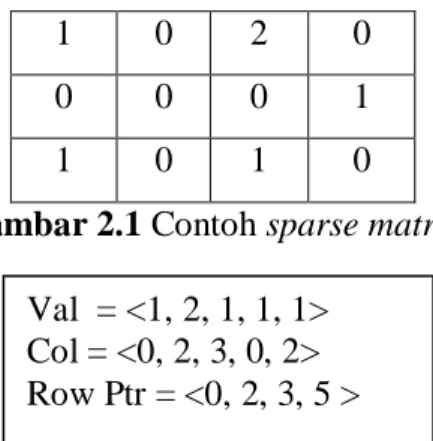
al. 2001). Diberikan contoh matriks pada gambar 2.1 yang selanjutnya akan dibentuk dalam format CSR yang ditunjukkan pada gambar 2.2.
1 0 2 0
0 0 0 1
1 0 1 0
Gambar 2.1 Contoh sparse matrix
Gambar 2.2 Contoh hasil format kompresi CSR dari sparse matrix gambar 2.1
2.5. Information Filtering
Information filtering (IF) adalah penyaringan informasi berdasarkan user profile yang
dibentuk dengan menanyakan kepada user atau dengan memonitor perilaku user terhapat sistem (Smirnov, et al. 2008). Dalam penelitian penulis metode untuk
Information filtering yang akan digunakan adalah bayesian framework for user interest prediction dan lebih spesifik pada rekomendas berita personal yang
merupakan pengembangan dari rumus Naïve Bayes yang akan penulis bahas pada bagian 2.9.
2.6. Information Retrieval
Information retrieval dalam arti sederhana mencari informasi, sedangkan dalam
pengertian teknis adalah mendapatkan informasi yang relevan dengan informasi yang dibutuhkan dari sekumpulan dokumen dengan menggunakan algoritma yang mampu mengetahui ukuran kesamaan antara query dan dokumen (Goker, 2009).
Saat ini, user menginginkan hasil relevansi dalam bentuk ranking, maka dari itu penggunaan information retrieval dengan model vektor dan probabilitas menjadi pilihan utama (Kneepkens, 2009). Algoritma information retrieval yang akan penulis gunakan dalam penelitian ini adalah CSR SpMV (Sparse Matrix Vector
Val = <1, 2, 1, 1, 1> Col = <0, 2, 3, 0, 2> Row Ptr = <0, 2, 3, 5 >
Multiplication) dan proximity processing. CSR SpMV penulis jelaskan pada bagian
2.7 dan proximity processing penulis jelaskan pada 2.8.
2.7. CSR SpMV (Sparse Matrix Vector Multiplication)
CSR SpMV merupakan perkalian antara sparse matrix dengan vector pengali dengan melakukan perhitungan y = y + A * x, dimana A menyatakan sparse matrix, y menyatakan baris dan x vector pengali yang sudah banyak diaplikasikan pada bidang ilmu science dan engineering untuk melakukan efisiensi pemrosesan (Liu, et al. 2013). Salah satu penerapan sparse matrix untuk information retrieval, dengan membentuk format kompresi CSR lalu melakukan perkalian dengan query yang dibentuk dalam vector, sehingga untuk setiap baris memiliki nilai penjumlahan dari setiap perkalian (Goharian, et al. 2001).
Gambar 2.3 Algoritma CSR SpMV (Goharian, et al. 2001).
Sebelum dilakukan proses CSR SpMV ada beberapa tahapan proses yang akan dilakukan (Goharian, et al. 2001) yaitu :
1. Mengubah dokumen yang berisi term menjadi term frequency (tf)
2. Mengindefikasi setiap jumlah term yang unik pada masing – masing dokumen untuk mendapatkan document frequency (df)
3. Menghitung nilai inverse document frequency (idf) untuk setiap term dengan rumus log(d/df), d menyatakan jumlah dokumen.
4. Membuat dokumen vektor dan query dengan panjang kolom n, dengan n menyatakan jumlah term yang unik yang tersedia secara kesuluruhan.
for(count = 0; count < D; count++) temp = 0;
for(row_ind=row_vector[count]; row_ind <= (row_vector[count+1] - 1); row_ind++) col_ind = col_vector[row_ind];
temp = temp + non_zero_vector[row_ind] * Q[col_ind]; end for
CSR_output[count] = temp endfor
5. Membentuk sparse matrix dengan cara memasukkan term sesuai kolom setiap baris matrix dengan masing – masing dokumen
6. Membuat vector untuk query dengan mengikuti kolom dari 7. Lakukan kompresi sparse matrix ke dalam format CSR.
8. Lakukan algoritma CSR SpMV sesuai algoritma pada gambar 2.3.
2.8. Proximity Processing
Proximity processing yang merupakan pengembangan dari CSR SpMV. Metode proximity processing dikembangkan oleh Goharian dkk pada tahun 2001 dalam
jurnalnya “On the Enhancements of a Sparse Matrix Information Retrieval
Approach”. Tujuan utama dari proximity processing dalam penelitian ini untuk
memberikan hasil rekomendasi yang akurat dan term yang sesuai urutan antara query dan dokumen (Goharian, et al. 2001).
Gambar 2.4 Algoritma untuk proximity processing
Untuk melakukan proximity processing yang merupakan lanjutan setelah melakukan CSR SpMV yang telah penulis jelaskan pada bagian 2.7 diharuskan untuk memodifikasi format CSR dengan menambahkan vektor yang kelima dan keenam, yaitu offset_vector dan offset_marker. Tujuan dari penambahan tersebut adalah untuk mencatat posisi setiap dari setiap term pada masing – masing dokumen (Goharian, et
FOR each document ranked with the highest similary score in the query processing using sparse matrix vector multiplication DO
Find from row_vector the element (term id) and the number of elements in col_vector belonging to that document and the start position in col_vector IF the element (term id) mathes to any query term id Then DO
FOR each found position in col_vector DO
Find the corresponding element in offset_marker Find the corresponding elements in offset_vector END
Build pairs (in the order of query terms) between the elements found in offset_vector across each col_vector
FOR each pair DO
Compute the difference between the elements of the pair IF the difference >= 1 and <= query window size
Then mark the pair for selection END
END END
2.9. Rekomendasi Berita Personal
Rekomendasi berita personal merupakan bagian dari sistem rekomendasi yang memberikan rekomendasi berita yang berbeda untuk setiap pembaca berita, sesuai dengan kesukaan berita yang pernah dibaca (Liu, et al. 2010).
Rekomendasi berita personal dikembangkan dari Naïve Bayes untuk memprediksi
news interest dari setiap pembaca berita. Dalam penelitian ini penulis menggunakan bayesian framework for user interest yang telah dikembangkan dalam penelitian Liu
dkk pada tahun 2010. 𝑝 𝑐𝑎𝑡𝑒𝑔𝑜𝑟𝑦 = 𝑐𝑖 𝑐𝑙𝑖𝑐𝑘) = 𝑝0 𝑐𝑎𝑡𝑒𝑔𝑜𝑟𝑦 =𝑐𝑖 𝑥 𝑁𝑡𝑥𝑝 𝑡 𝑐𝑎𝑡𝑒𝑔𝑜𝑟𝑦 =𝑐𝑖 𝑐𝑙𝑖𝑐𝑘 ) 𝑝 𝑡 (𝑐𝑎𝑡𝑒𝑔𝑜𝑟𝑦 = 𝑐𝑖) 𝑡 𝑁𝑡 𝑡 (2.1) Keterangan
𝑝0 𝑐𝑎𝑡𝑒𝑔𝑜𝑟𝑦 = 𝑐𝑖 = probabilitas akses kategori pada waktu terakhir terhadap total click di semua kategori
𝑝𝑡 𝑐𝑎𝑡𝑒𝑔𝑜𝑟𝑦 = 𝑐
𝑖 𝑐𝑙𝑖𝑐𝑘) = probabilitas akses kategori i dalam pada waktu t.
sebelum dihitung akan dijabarkan lebih dahulu, maka = 𝑝
𝑡 𝑐𝑙𝑖𝑐𝑘 𝑐𝑎𝑡𝑒𝑔𝑜𝑟𝑦 =𝑐
𝑖) 𝑝𝑡(𝑐𝑎𝑡𝑒𝑔𝑜𝑟𝑦 =𝑡𝑖)
𝑝𝑡(𝑐𝑙𝑖𝑐𝑘 )
𝑝𝑡 𝑐𝑎𝑡𝑒𝑔𝑜𝑟𝑦 = 𝑐
𝑖 = probabilitas akses kategori padat waktu t terhadap
total click disemua kategori pada waktu t 𝑁𝑡 = total click pada waktu t
2.10. Stopword Removal
Stopword adalah kata – kata yang tidak memberikan pengertian yang signifikan
terhadap kalimat atau pernyataan yang disampaikan (Dragut, et al 2009). Kata – kata
stopword dikenali sistem melalui daftar stopword, sehingga kata – kata yang tersedia
dalam suatu dokumen yang akan diproses untuk rekomendasi memiliki kata tersebut maka akan dihapus.
2.11. Stemming
Stemming merupakan proses transformasi dari kata ke kata dasarnya (root word)
menggunakan aturan – aturan tertentu. Contohnya seperti kata bersama, kebersamaan, menyamai memiliki satu kata dasar (root word) yaitu “sama”. Proses stemming dalam Bahasa Indonesia memiliki perbedaan dengan stemming yang ada dalam Bahasa Inggris. Dalam Bahasa Inggris, proses stemming yang diperlukan hanya proses menghilangkan sufiks, sedangkan untuk Bahasa Indonesia selain sufiks, prefiks dan konfiks juga dihilangkan (Agusta, 2009). Dalam penelitian penulis menggunakan algoritma porter. Langkah – langkah algoritma porter (Agusta, 2009) adalah sebagai berikut :
1. Hapus Particle,
2. Hapus prosessive Pronoun
3. Hapus awalan pertama. Jika tidak ditemukan lanjutkan ke langkah 4a, jika ada cari maka lanjutkan ke langkah 4b
4. a. Hapus awalan kedua, lanjutkan ke langkah 5a.
b. Hapus akhiran, jika tidak ditemukan amaka kata tersebut diasumsikan sebagai
root word. Jika ditemukan maka lanjutkan ke langkah 5b
5. a. Hapus akhiran. Kemudian akata akhir diasumsikan sebagai root word b. Hapus awalan kedua. Kemudian kata akhir diasumsikan sebagai root word
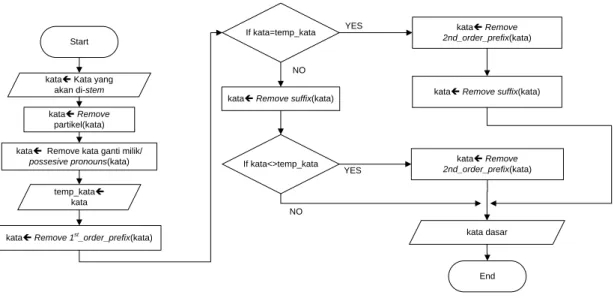
kataç Kata yang akan di-stem
kataç Remove partikel(kata)
kataç Remove kata ganti milik/
possesive pronouns(kata) temp_kataç kata kataç Remove 1st _order_prefix(kata) Start
If kata=temp_kata kataç Remove
2nd_order_prefix(kata)
kataç Remove suffix(kata) kataç Remove suffix(kata)
If kata<>temp_kata kataç Remove
2nd_order_prefix(kata) YES NO YES NO kata dasar End
Ada 5 aturan yang akan penulis jabarkan dalam bentuk tabel, dimulai dari tabel 2.13 sampai tabel 2.17 (Agusta, 2009).
Tabel 2.1 Aturan untuk inflectional particle Akhiran Replacement Measure
Condition
Additional Condition
Contoh
-kah NULL 2 NULL bukukah
-lah NULL 2 NULL pergilah
-pun NULL 2 NULL bukupun
Tabel 2.2 Aturan untuk inflectional possesive pronoun Akhiran Replacement Measure
Condition
Additional Condition
Contoh
-ku NULL 2 NULL bukuku
-mu NULL 2 NULL bukumu
-nya NULL 2 NULL bukunya
Tabel 2.3 Aturan untuk first order derivational prefix Awalan Replacement Measure
Condition
Additional Condition
Contoh
meng- NULL 2 NULL mengukur -> ukur
meny S 2 V…* menyapu -> sapu
men- NULL 2 NULL menduga -> duga
mem- P 2 V… memaksa -> paksa
mem- NULL 2 NULL membaca -> baca
me- NULL 2 NULL merusak -> rusak
peng- NULL 2 NULL pengukur -> ukur
peny- S 2 V… penyapu -> sapu
pen- NULL 2 NULL penduga -> duga
pem- P 2 V.. pemaksa -> paksa
pem- NULL 2 NULL pembaca -> baca
di- NULL 2 NULL diukur -> ukur
ter- NULL 2 NULL tersapu -> sapu
ke- NULL 2 NULL kekasih -> kasih
Tabel 2.4 Aturan untuk second order derivational prefix Awalan Replacement Measure
Condition
Additional Condition
Contoh
ber- NULL 2 NULL berlari -> lari
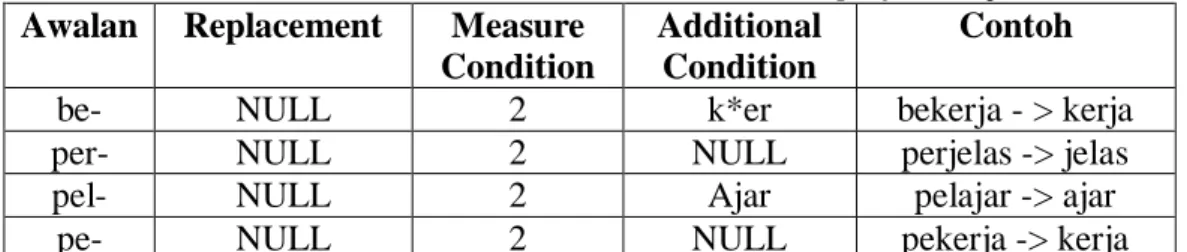
Tabel 2.5 Aturan untuk second order derivational prefix (lanjutan) Awalan Replacement Measure
Condition
Additional Condition
Contoh
be- NULL 2 k*er bekerja - > kerja
per- NULL 2 NULL perjelas -> jelas
pel- NULL 2 Ajar pelajar -> ajar
pe- NULL 2 NULL pekerja -> kerja
Tabel 2.6 Aturan untuk derivational suffix Akhi-ran Replace-ment Measure Condition Additional Condition Contoh
-kan NULL 2 Prefix bukan anggota {ke, peng}
tarikkan -> tarik, mengambilkan -> ambil
-an NULL 2 prefix bukan anggota {di, meng, ter}
makanan -> makan, perjanjian -> janji -i NULL 2 prefix bukan anggota
{ber, ke, peng}
Tandai -> tanda, mendapati -> dapat
2.12. Penelitian Sebelumnya
Penelitian yang pernah dilakukan terkait dengan sistem rekomendasi personal adalah dengan memanfaat collaborative filtering (Das, et al. 2007) merekomendasikan secara personal dengan parameter lokasi sebagai panduan utama, berita akan direkomendasikan kepada user berdasarkan berita yang disukai oleh user lain dilokasi yang sama. Selain penelitian tersebut, ada juga menggunakan News Interest dari Click
Behavior (Liu, et al. 2010) memberikan rekomendasi berita berdasarkan kategori yang
pernah dikunjungi oleh user.
Tabel 2.7Penelitian sebelumnya
Penulis Judul Penelitian Teknik Kelemahan
Das et al. 2007 Google News Personalization : Scalabel Online Collborative Filtering Menggunakan metode collaborative filtering yang memberikan rekomendasi dengan menggabungkan kesukaan user lain
terhadap 1 berita
Memberikan rekomendasi berdasarkan kesukaan orang
lain yang pasti belum tentu
menjadi kesukaan user
Tabel 2.7 Penelitian sebelumnya (lanjutan)
Penulis Judul Penelitian Teknik Kelemahan
Liu et al. 2010 Personalized News Recommendation Based On Click Behavior Menggunakan bayesian
framework for user interest untuk memberikan prediksi rekomendasi berita berdasarkan riwayat penjelajahan dalam 1 kategori Membutuhkan banyak riwayat penjelajahan berita, karena memberikan rekomendasi berdasarkan kategori, yang belum tentu berita dikategori yang sama akan disukai semua.