BAB II
LANDASAN TEORI
Pada landasan teori berikut akan dibahas tentang variabel, skala data, varians kovarians, analisis multivariat, analisis kovarians (ANCOVA), dan gizi untuk menunjang pembahasan MANCOVA satu arah dengan dua kovariat dengan uji Wilk’s Lambda dan penerapannya pada bidang gizi.
A. Variabel
Variabel adalah sesuatu yang nilainya berubah-ubah. Suatu variabel disebut juga dengan karakteristik (Bluman, 2003: 3). Variabel merupakan obyek yang diukur dalam penelitian, sehingga nilai yang diperoleh adalah nilai karakteristik dari suatu elemen. Variabel yang melekat pada suatu elemen disebut dengan atribut, sedangkan variabel yang dimanipulasi atau ditambahkan disebut dengan variabel aktif (Sudjana & Ibrahim, 2001: 11-12).
Terdapat dua variabel yang biasa digunakan dalam penelitian, yaitu variabel bebas (independent variable) dan variabel terikat (dependent variable). Variabel bebas merupakan variabel yang dianggap memberikan suatu pengaruh, dinotasikan dengan 𝑋. Variabel terikat merupakan variabel yang terkena pengaruh dari variabel bebas, disebut juga dengan variabel respon (respon variable), dinotasikan dengan 𝑌.
Dalam pengukuran variabel, variabel dikelompokkan menjadi dua, yaitu variabel kuantitatif dan variabel kualitatif. Variabel kuantitatif menunjukkan suatu nilai yang dapat diukur atau diurutkan. Variabel kualitatif menghasilkan sebuah
data kategori (Bluman, 2003: 7). Jenis data atau skala data akan dibahas pada sub bab selanjutnya.
B. Skala Data
Data merupakan informasi yang sangat berguna yang diperoleh dari variabel penelitian. Data yang berasal dari variabel kuantitatif disebut data kuantitatif, sedangkan yang berasal dari variabel kualitatif disebut data kualitatif.
Dalam pengelompokan skala data (kemudian disebut data), terdapat empat skala yaitu nominal, ordinal, interval, dan rasio (Bluman, 2003: 8-9).
1. Nominal
Data nominal adalah data yang berfungsi untuk membedakan. Data nominal tidak menunjukkan sebuah ukuran maupun urutan, operasi matematis tidak berlaku, dan hanya menunjukkan kategori. Contoh data nominal adalah jenis kelamin, 1 untuk laki-laki, 2 untuk perempuan.
2. Ordinal
Data ordinal merupakan data nominal sekaligus menunjukkan urutan. Biasa digunakan untuk menunjukkan peringkat (ranking), akan tetapi jarak tidak sama. Contoh data ordinal adalah status pendidikan terakhir, 1 untuk sekolah dasar (SD), 2 untuk sekolah menengah pertama (SMP), 3 untuk sekolah menegah atas (SMA), dan 4 untuk perguruan tinggi (PT).
3. Interval
Data interval memiliki ciri data nominal dan ordinal serta memiliki jarak yang sama. Akan tetapi tidak memiliki titik awal (original point) dan tidak
menunjukkan perbandingan mutlak. Contoh data interval adalah IQ, nilai IQ digunakan untuk mengukur kecerdasan intelektual. Namun tidak dapat diartikan orang yang memiliki IQ 120 tingkat kecerdasannya 1,2 kali dari orang yang memiliki IQ 100.
4. Rasio
Data Rasio memiliki ciri data nominal, ordinal, interval, sekaligus memiliki perbandingan mutlak. Nilai data rasio menunjukan nilai satuan yang sesungguhnya. Contoh data rasio adalah berat badan. Misalnya Orang yang memiliki berat badan 50 kg beratnya dua kali lipat dari orang yang memiliki berat 25 kg.
Data nominal dan ordinal disebut juga dengan data non metrik atau data kualitatif atau data kategoris. Data interval dan rasio disebut juga dengan data metrik atau data kuantitatif.
C. Varians dan Kovarians
Varians (variance) disebut juga dengan ragam merupakan ukuran yang menunjukkan persebaran data pada suatu kelompok. Semakin besar varians maka semakin besar persebaran data (Bluman, 2003: 119). Varians untuk populasi disimbolkan dengan 𝜎2 dan untuk sampel disimbolkan dengan 𝑠2. Notasi lain dari varians untuk variabel acak 𝑋 adalah 𝑉𝑎𝑟(𝑋) atau 𝜎𝑋2. Dalam Walpole (1988: 33)
varians populasi terhingga 𝑥1, 𝑥2, ⋯, 𝑥𝑁 didefinisikan sebagai:
𝜎2 = ∑𝑁𝑖=1(𝑥𝑖−𝜇)2
𝑁 , (2. 1)
𝜇 : rata-rata populasi, 𝑁 : banyak data populasi.
Varians sampel dari sampel acak 𝑥1, 𝑥2, ⋯, 𝑥𝑛 didefinisikan sebagai
(Walpole, 1988: 35):
𝑠2 =∑𝑛𝑖=1(𝑥𝑖−𝑥̅)2
𝑛−1 , (2. 2)
dengan
𝑥̅ : rata-rata sampel, 𝑛 : banyak data sampel.
Varians dari variabel acak 𝑋 dinotasikan sebagai 𝑉𝑎𝑟(𝑋) dan didefinisikan sebagai (Bain & Engelhardt, 1992: 73):
𝑉𝑎𝑟(𝑋) = 𝐸[(𝑋 − 𝜇)2], (2. 3) 𝑉𝑎𝑟(𝑋) = 𝐸(𝑋2) − 𝜇2, (2. 4)
dengan
𝐸(𝑋) = ∫ 𝑥𝑓(𝑥)𝑑𝑥, jika x variabel acak kontinu, 𝐸(𝑋) = ∑ 𝑥𝑓(𝑥)𝑑𝑥, jika x variabel acak diskret.
Kovarians (Keppel & Wickens, 2004: 314) sama dengan varians tetapi secara umum menunjukkan variasi bersama dari dua variabel atau persebaran dua variabel secara bersama. Misal dua variabel 𝑋 dan 𝑌, kovarians dinotasikan 𝐶𝑜𝑣(𝑋, 𝑌) atau 𝜎𝑋𝑌. Kovarians dari variabel acak 𝑋 dan 𝑌 didefinisikan sebagai (Bain & Engelhardt, 1992: 174):
𝐶𝑜𝑣(𝑋, 𝑌) = 𝐸[(𝑋 − 𝜇𝑋)(𝑌 − 𝜇𝑌)], (2. 5)
D. Analisis Multivariat
Analisis Multivariat adalah metode-metode statistik yang mengolah beberapa pengukuran menyangkut obyek atau individu sekaligus. Tujuan dari analisis multivariat adalah mengukur, menerangkan, dan memprediksi tingkat relasi antar variat (Simamora, 2005 : 2-3). Sedangkan menurut Suryanto (1988: 1-2), analisis multivariat adalah teknik-teknik analisis statistika yang memperlakukan sekelompok variabel terikat yang saling berkolerasi sebagai satu sistem, dengan memperhitungkan korelasi antar variabel-variabel tersebut.
Analisis Multivariat dikelompokkan menjadi dua metode, yaitu metode dependensi dan metode interdependensi. Metode dependensi digunakan pada suatu penelitian untuk mengetahui pengaruh variabel bebas terhadap variabel terikat. Metode interdependensi digunakan untuk menganalisis semua variabel secara simultan, dimana penggunaan metode ini tidak terdapat pengelompokkan variabel bebas dan variabel terikat. (Hair dkk, 2006: 13).
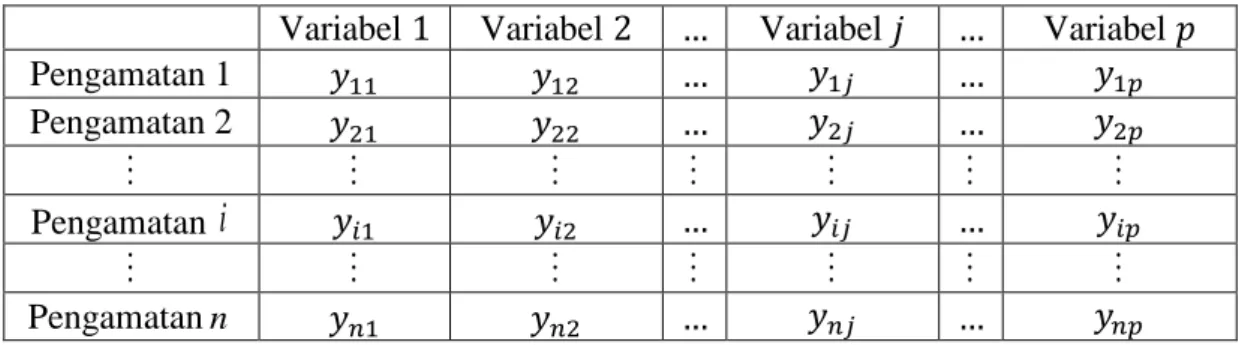
1. Matriks Data Multivariat
Misalkan sebuah pengukuran data diperoleh dari 𝑛 pengamatan dan sebanyak 𝑝 variabel, 𝑦𝑖𝑗 menunjukkan pengamatan variabel ke- 𝑗 pada
pengamatan ke- 𝑖. Penyajian data multivariat disajikan dalam tabel 1 berikut. Tabel 1. Penulisan Data Multivariat
Variabel 1 Variabel 2 … Variabel 𝑗 … Variabel 𝑝
Pengamatan 1 𝑦11 𝑦12 … 𝑦1𝑗 … 𝑦1𝑝 Pengamatan 2 𝑦21 𝑦22 … 𝑦2𝑗 … 𝑦2𝑝 Pengamatan
i
𝑦𝑖1 𝑦𝑖2 … 𝑦𝑖𝑗 … 𝑦𝑖𝑝 Pengamatann 𝑦𝑛1 𝑦𝑛2 … 𝑦𝑛𝑗 … 𝑦𝑛𝑝Data multivariat pada tabel 1 di atas dituliskan dalam bentuk matriks 𝒀, dengan 𝑛 baris dan 𝑝 kolom sebagai:
𝒀 = [ 𝑦11 𝑦12 … 𝑦21 𝑦22 ⋯ ⋮ ⋮ ⋯ 𝑦1𝑗 ⋯ 𝑦1𝑝 𝑦2𝑗 ⋯ 𝑦2𝑝 ⋮ ⋯ ⋮ 𝑦𝑖1 𝑦𝑖2 ⋯ ⋮ ⋮ ⋯ 𝑦𝑛1 𝑦𝑛2 ⋯ 𝑦𝑖𝑗 ⋯ 𝑦𝑖𝑝 ⋮ ⋯ ⋮ 𝑦𝑛𝑗 ⋯ 𝑦𝑛𝑝] , (2. 7) dengan
𝑦𝑖𝑗 : data pengamatan ke-𝑖 pada variabel ke-𝑗,
𝑛 : banyak pengamatan, 𝑝 : banyak variabel. 2. Vektor Rata-rata
Misalkan 𝒀 merupakan matriks pengukuran 𝑛 pengamatan dan 𝑝 variabel, vektor rata-rata untuk setiap variabel dari 𝒀 didefinisikan sebagai:
𝒀̅ = 1 𝑛𝒚𝒊 = [ 1 𝑛∑ 𝑦𝑖1 𝑛 𝑖=1 1 𝑛∑ 𝑦𝑖2 𝑛 𝑖=1 ⋮ 1 𝑛∑ 𝑦𝑖𝑝 𝑛 𝑖=1 ] = [ 𝑌̅1 𝑌̅2 ⋮ 𝑌̅𝑝] . (2. 8) Dengan, 𝒚𝒊= [ ∑𝑛𝑖=1𝑦𝑖1 ∑𝑛𝑖=1𝑦𝑖2 ⋮ ∑𝑛𝑖=1𝑦𝑖p] . (2. 9)
Misalkan 𝒀̅ merupakan vektor 𝑝×1, nilai harapan dari 𝒀̅ didefinisikan sebagai vektor nilai-nilai harapan dari 𝑝 variabel,
𝐸(𝒀̅) = 𝐸 [ 𝑌̅1 𝑌̅2 ⋮ 𝑌̅𝑝] = [ 𝐸(𝑌̅1) 𝐸(𝑌̅2) ⋮ 𝐸(𝑌̅𝑝)] = [ 𝜇1 𝜇2 ⋮ 𝜇𝑝 ] = 𝝁. (2. 10)
3. Matriks Varians Kovarians
Matriks varians kovarians populasi didefinisikan sebagai:
𝐸(𝒀 − 𝝁)(𝒀 − 𝝁)′= 𝐸 ([ 𝑌1− 𝜇1 𝑌2− 𝜇2 ⋮ 𝑌𝑝− 𝜇𝑝 ] [𝑌1− 𝜇1 𝑌2− 𝜇2 ⋯ 𝑌𝑝− 𝜇𝑝]) = 𝐸 [ (𝑌1− 𝜇1)2 (𝑌2− 𝜇2)(𝑌1− 𝜇1) ⋮ (𝑌𝑝− 𝜇𝑝)(𝑌1− 𝜇1) (𝑌1− 𝜇1)(𝑌2− 𝜇2) (𝑌2− 𝜇2)2 ⋮ (𝑌𝑝− 𝜇𝑝)(𝑌2− 𝜇2) ⋯ ⋯ ⋮ ⋯ (𝑌1− 𝜇1)(𝑌𝑝− 𝜇𝑝) (𝑌2− 𝜇2)(𝑌𝑝− 𝜇𝑝) ⋮ (𝑌𝑝− 𝜇𝑝)2 ] = [ 𝐸(𝑌1− 𝜇1)2 𝐸(𝑌2− 𝜇2)(𝑌1− 𝜇1) ⋮ 𝐸(𝑌𝑝− 𝜇𝑝)(𝑌1− 𝜇1) 𝐸(𝑌1− 𝜇1)(𝑌2− 𝜇2) 𝐸(𝑌2− 𝜇2)2 ⋮ 𝐸(𝑌𝑝− 𝜇𝑝)(𝑌2− 𝜇2) ⋯ ⋯ ⋮ ⋯ 𝐸(𝑌1− 𝜇1)(𝑌𝑝− 𝜇𝑝) 𝐸(𝑌2− 𝜇2)(𝑌𝑝− 𝜇𝑝) ⋮ 𝐸(𝑌𝑝− 𝜇𝑝) 2 ] .
Dari persamaan (2. 3) dan (2. 5) maka matriks varians kovarians populasi dapat dituliskan sabagai berikut.
𝐸(𝒀 − 𝝁)(𝒀 − 𝝁)′= [ 𝜎11 𝜎21 ⋮ 𝜎𝑝1 𝜎12 𝜎22 ⋮ 𝜎𝑝2 ⋯ ⋯ ⋮ ⋯ 𝜎1𝑝 𝜎2𝑝 ⋮ 𝜎𝑝𝑝 ] = 𝚺. (2. 11) Dengan,
𝜎𝑖𝑖 = 𝜎𝑖2 = 𝑉𝑎𝑟(𝑌𝑖) menyatakan varians populasi untuk 𝑖 = 1,2, ⋯ , 𝑝
𝜎𝑖𝑗 = 𝐶𝑜𝑣(𝑌𝑖, 𝑌𝑗) menyatakan kovarians antara 𝑌𝑖dan 𝑌𝑗untuk 𝑖, 𝑗 = 1,2, ⋯ , 𝑝.
Matriks varians kovarians sampel dapat didefinisikan sebagai berikut. 𝑺 = 1
𝑛−1∑ (𝒚𝒊− 𝒚̅)(𝒚𝒊− 𝒚̅) ′ 𝑛
𝑺 = 1 𝑛 − 1∑ ([ 𝑦𝑖1− 𝑦̅1 𝑦𝑖2− 𝑦̅2 ⋮ 𝑦𝑖𝑝− 𝑦̅𝑝 ] [𝑦𝑖1− 𝑦̅1 𝑦𝑖2− 𝑦̅2 ⋯ 𝑦𝑖𝑝− 𝑦̅𝑝]) 𝑛 𝑖=1 𝑆= [ 1 𝑛−1∑ (𝑦𝑖1− 𝑦̅1) 2 𝑛 =1 1 𝑛−1(𝑦𝑖2− 𝑦̅2)(𝑦𝑖1− 𝑦̅1) ⋮ 1 𝑛−1(𝑦𝑖𝑝− 𝑦̅𝑝)(𝑦𝑖1− 𝑦̅1) 1 𝑛−1(𝑦𝑖1− 𝑦̅1)(𝑦𝑖1− 𝑦̅1) 1 𝑛−1∑ (𝑦𝑖2− 𝑦̅2) 2 𝑛 =1 ⋮ 1 𝑛−1(𝑦𝑖𝑝− 𝑦̅𝑝)(𝑦𝑖2− 𝑦̅2) ⋯ ⋯ ⋮ ⋯ 1 𝑛−1(𝑦𝑖1− 𝑦̅1)(𝑦𝑖𝑝− 𝑦̅𝑝) 1 𝑛−1(𝑌2− 𝜇2)(𝑦𝑖𝑝− 𝑦̅𝑝) ⋮ 1 𝑛−1∑ (𝑦𝑖𝑝− 𝑦̅𝑝) 2 𝑛 =1 ] , sehingga 𝑺 = [𝑠𝑗𝑙] = [ 𝑠11 𝑠21 ⋮ 𝑠𝑝1 𝑠12 𝑠22 ⋮ 𝑠𝑝2 ⋯ ⋯ ⋮ ⋯ 𝑠1𝑝 𝑠2𝑝 ⋮ 𝑠𝑝𝑝 ]. (2. 13) Dengan 𝑠𝑗𝑗 = 𝑠𝑗2 = 1 𝑛−1∑ (𝑦𝑖𝑗− 𝑦̅𝑗) 2 𝑛
𝑖=1 adalah varians sampel dari variabel ke-𝑗,
𝑠𝑗𝑙 = 1
𝑛−1∑ (𝑦𝑖𝑗− 𝑦̅𝑗)(𝑦𝑖𝑙− 𝑦̅𝑙) 𝑛
𝑖=1 adalah kovarians sampel dari variabel ke-𝑗 dan
variabel ke-𝑙.
4. Partisi Matriks Varians Kovarians
Diberikan vektor 𝒀 berorder 𝑝×1 dipartisi menjadi dua bagian 𝑞 dan 𝑝 − 𝑞 dituliskan (Johnson & Wichern, 2007: 73):
𝒀 = [ 𝑌1 ⋮ 𝑌𝑞 𝑌𝑞+1 ⋮ 𝑌𝑝 ] = [𝒀(𝟏) 𝒀(𝟐)] dan 𝝁 = 𝐸(𝒀) = [ 𝜇1 ⋮ 𝜇𝑞 𝜇𝑞+1 ⋮ 𝜇𝑝 ] = [𝝁 (𝟏) 𝝁(𝟐)]. (2. 14)
Berdasarkan transpose dan perkalian matriks,
(𝒀(𝟏)− 𝝁(𝟏))(𝒀(𝟐)− 𝝁(𝟐))′= [ 𝑌1− 𝜇1 𝑌2− 𝜇2 ⋮ 𝑌𝑞− 𝜇𝑞 ] [𝑌𝑞+1− 𝜇𝑞+1 𝑌𝑞+2− 𝜇𝑞+2 ⋯ 𝑌𝑝− 𝜇𝑝]
= [ (𝑌1− 𝜇1)(𝑌𝑞+1− 𝜇𝑞+1) (𝑌2− 𝜇2)(𝑌𝑞+1− 𝜇𝑞+1) ⋮ (𝑌𝑞− 𝜇𝑞)(𝑌𝑞+1− 𝜇𝑞+1) (𝑌1− 𝜇1)(𝑌𝑞+2− 𝜇𝑞+2) (𝑌2− 𝜇2)(𝑌𝑞+2− 𝜇𝑞+2) ⋮ (𝑌𝑞− 𝜇𝑞)(𝑌𝑞+2− 𝜇𝑞+2) ⋯ ⋯ ⋮ ⋯ (𝑌1− 𝜇1)(𝑌𝑝− 𝜇𝑝) (𝑌2− 𝜇2)(𝑌𝑝− 𝜇𝑝) ⋮ (𝑌𝑞− 𝜇𝑞)(𝑌𝑝− 𝜇𝑝)] .
Dengan ekspektasi pada (𝒀(𝟏)− 𝝁(𝟏))(𝒀(𝟐) − 𝝁(𝟐))′ diperoleh 𝐸(𝒀(𝟏)− 𝝁(𝟏))(𝒀(𝟐)− 𝝁(𝟐))′ = 𝐸 [ (𝑌1− 𝜇1)(𝑌𝑞+1− 𝜇𝑞+1) (𝑌2− 𝜇2)(𝑌𝑞+1− 𝜇𝑞+1) ⋮ (𝑌𝑞− 𝜇𝑞)(𝑌𝑞+1− 𝜇𝑞+1) (𝑌1− 𝜇1)(𝑌𝑞+2− 𝜇𝑞+2) (𝑌2− 𝜇2)(𝑌𝑞+2− 𝜇𝑞+2) ⋮ (𝑌𝑞− 𝜇𝑞)(𝑌𝑞+2− 𝜇𝑞+2) ⋯ ⋯ ⋮ ⋯ (𝑌1− 𝜇1)(𝑌𝑝− 𝜇𝑝) (𝑌2− 𝜇2)(𝑌𝑝− 𝜇𝑝) ⋮ (𝑌𝑞− 𝜇𝑞)(𝑌𝑝− 𝜇𝑝)] = [ 𝐸(𝑌1− 𝜇1)(𝑌𝑞+1− 𝜇𝑞+1) 𝐸(𝑌2− 𝜇2)(𝑌𝑞+1− 𝜇𝑞+1) ⋮ 𝐸(𝑌𝑞− 𝜇𝑞)(𝑌𝑞+1− 𝜇𝑞+1) 𝐸(𝑌1− 𝜇1)(𝑌𝑞+2− 𝜇𝑞+2) 𝐸(𝑌2− 𝜇2)(𝑌𝑞+2− 𝜇𝑞+2) ⋮ 𝐸(𝑌𝑞− 𝜇𝑞)(𝑌𝑞+2− 𝜇𝑞+2) ⋯ ⋯ ⋮ ⋯ 𝐸(𝑌1− 𝜇1)(𝑌𝑝− 𝜇𝑝) 𝐸(𝑌2− 𝜇2)(𝑌𝑝− 𝜇𝑝) ⋮ 𝐸(𝑌𝑞− 𝜇𝑞)(𝑌𝑝− 𝜇𝑝)] . 𝐸(𝒀(𝟏)− 𝝁(𝟏))(𝒀(𝟐)− 𝝁(𝟐))′= [ 𝜎1,q+1 𝜎2,q+1 ⋮ 𝜎𝑞,𝑞+1 𝜎1,q+2 𝜎2,q+2 ⋮ 𝜎𝑞,𝑞+2 ⋯ ⋯ ⋮ ⋯ 𝜎1𝑝 𝜎2𝑝 ⋮ 𝜎𝑞𝑝 ] = 𝚺𝟏𝟐. (2. 15)
Dengan kovarians 𝜎ij, 𝑖 = 1,2, … , 𝑞 dan 𝑗 = 𝑞 + 1, 𝑞 + 2, … , 𝑝 merupakan
komponen dari 𝒀(𝟏) dan 𝒀(𝟐).
Dengan persamaan partisi pada (2. 13) (𝒀 − 𝝁)(𝒀 − 𝝁)′ dituliskan sebagai
(𝒀 − 𝝁)(𝒀 − 𝝁)′= [(𝒀
(𝟏)− 𝝁(𝟏))(𝒀(𝟏)− 𝝁(𝟏))′ (𝒀(𝟏)− 𝝁(𝟏))(𝒀(𝟐)− 𝝁(𝟐))′
(𝒀(𝟐)− 𝝁(𝟐))(𝒀(𝟏)− 𝝁(𝟏))′ (𝒀(𝟐)− 𝝁(𝟐))(𝒀(𝟐)− 𝝁(𝟐))′]. (2. 16) Dari persamaan (2. 10) dan (2. 15) matriks varians kovarians dituliskan 𝚺 = 𝐸(𝒀 − 𝝁)(𝒀 − 𝝁)′
= [𝐸(𝒀
(𝟏)− 𝝁(𝟏))(𝒀(𝟏)− 𝝁(𝟏))′ 𝐸(𝒀(𝟏)− 𝝁(𝟏))(𝒀(𝟐)− 𝝁(𝟐))′ 𝐸(𝒀(𝟐)− 𝝁(𝟐))(𝒀(𝟏)− 𝝁(𝟏))′ 𝐸(𝒀(𝟐)− 𝝁(𝟐))(𝒀(𝟐)− 𝝁(𝟐))′]
𝚺 = [𝚺𝟏𝟏 𝚺𝟏𝟐 𝚺𝟐𝟏 𝚺𝟐𝟐] = [ σ11 … σ1q ⋮ ⋮ ⋮ σq1 … σqq σ1,q+1 … σ1p ⋮ ⋮ ⋮ σq,q+1 … σqp σq+1,1 … σq+1,q ⋮ ⋮ ⋮ σp1 … σpq σq+1,q+1 … σ1q ⋮ ⋮ ⋮ σp,q+1 … σpp] . (2. 17)
Dengan 𝚺𝟏𝟏 adalah matriks varians kovarians dari elemen 𝒀(𝟏), 𝚺𝟐𝟐 adalah matriks varians kovarians dari elemen 𝒀(𝟐), dan 𝚺𝟏𝟐 = 𝚺𝟐𝟏 adalah matriks varians kovarians dari elemen 𝒀(𝟏) dan 𝒀(𝟐).
Dengan langkah yang sama di atas dan persamaan (2. 12), partisi vektor rata-rata dan matriks varians kovarians sampel dituliskan
𝒚 ̅ = [ 𝑦̅1 ⋮ 𝑦̅𝑞 𝑦̅𝑞+1 ⋮ 𝑦̅𝑝 ] = [𝒚̅ (𝟏) 𝒚̅(𝟐)] dan 𝑺 = [ 𝑠11 … 𝑠1q ⋮ ⋮ ⋮ 𝑠q1 … 𝑠qq 𝑠1,q+1 … 𝑠1p ⋮ ⋮ ⋮ 𝑠q,q+1 … 𝑠qp 𝑠q+1,1 … 𝑠q+1,q ⋮ ⋮ ⋮ 𝑠p1 … 𝑠pq 𝑠q+1,q+1 … 𝑠1q ⋮ ⋮ ⋮ 𝑠p,q+1 … 𝑠pp] . (2. 18) 𝐒 = [𝐒𝟏𝟏 𝐒𝟏𝟐 𝐒𝟐𝟏 𝐒𝟐𝟐]. (2. 19) 𝒚
̅(𝟏) dan 𝒚̅(𝟐) adalah vektor rata-rata, 𝐒𝟏𝟏 adalah matriks varians kovarians sampel dari elemen 𝒚̅(𝟏), 𝐒𝟐𝟐 adalah matriks varians kovarians sampel dari elemen 𝒚̅(𝟐), dan 𝐒𝟏𝟐 = 𝐒𝟐𝟏 adalah matriks varians kovarians sampel dari elemen 𝒚̅(𝟏) dan 𝒚̅(𝟐).
E. Analisis Kovarians (ANCOVA)
Analisis Kovarians atau disebut juga dengan ANCOVA merupakan kombinasi prosedur uji hipotesis untuk general linear model (GLM) dan notion
linear regression (Keppel & Wickens, 2004: 312). Menurut Rencher (1998: 178),
regresi. Dalam ANCOVA terdapat variabel konkomitan, disebut juga dengan kovariat, yaitu variabel yang dianggap mempengaruhi variabel terikat atau variabel respon tetapi tidak dapat dikendalikan. Variabel konkomitan berasal dari karakteristik obyek penelitian (variabel bebas) yang mana variabel tersebut berskala metrik (kuantitatif). Dengan demikian ANCOVA berfungsi untuk memurnikan pengaruh galat varians yang berupa variabel konkomitan terhadap variabel respon.
Dalam ANCOVA perlakuan disebut juga dengan faktor. Banyaknya faktor membedakan analisis pada ANCOVA, yaitu satu arah (satu faktor), dua arah (dua faktor), dan seterusnya. Data ANCOVA satu faktor disajikan dalam tabel 2 sebagai berikut.
Tabel 2. Pengamatan ANCOVA Satu Arah Perlakuan Rata-rata Skor 1 2 … ℎ 𝑌 𝑋 𝑌 𝑋 … 𝑌 𝑋 𝑌 𝑋 𝑦11 𝑦12 ⋮ 𝑦1𝑛 𝑥11 𝑥12 ⋮ 𝑥1𝑛 𝑦21 𝑦22 ⋮ 𝑦2𝑛 𝑥21 𝑥22 ⋮ 𝑥2𝑛 𝑦ℎ1 𝑦ℎ2 ⋮ 𝑦ℎ𝑛 𝑥ℎ1 𝑥ℎ2 ⋮ 𝑥ℎ𝑛 𝑦̅.1 𝑦̅.2 ⋮ 𝑦̅.𝑛 𝑥̅.1 𝑥̅.2 ⋮ 𝑥̅.𝑛 Rata-rata total 𝑦̅1. 𝑥̅1. 𝑦̅2. 𝑥̅2. … 𝑦̅ℎ. 𝑥̅ℎ. 𝑦̅.. 𝑥̅..
Tabel 2 menunjukkan ANCOVA satu arah sebanyak ℎ level faktor dengan satu kovariat 𝑋 dan ulangan sebanyak 𝑛.
Model ANCOVA dengan satu kovariat (Rencher, 1998: 179) dituliskan sebagai:
𝑦𝑘𝑖 = 𝜇 + 𝜏𝑘+ 𝛽𝑥𝑘𝑖+ 𝜀𝑘𝑖 , 𝑘 = 1,2, … , ℎ, 𝑖 = 1,2, … , 𝑛; (2. 20) dengan
𝑦𝑘𝑖 : nilai respon ke-𝑖 pada perlakuan ke-𝑘, 𝜇 : rata-rata keseluruhan,
𝜏𝑘 : pengaruh perlakuan ke-𝑘,
𝛽 : koefisien regresi 𝑦𝑘𝑖 terhadap 𝑥𝑘𝑖,
𝑥𝑘𝑖 : nilai kovariat pengamatan ke-𝑖 pada perlakuan ke-𝑘,
𝜀𝑘𝑖 : nilai galat pada pengamatan ke-𝑖 pada perlakuan ke-𝑘.
Persamaan (2. 20) mempunyai bentuk model regresi linear (Rencher, 1998: 181): 𝑦𝑘𝑖 = 𝛽0+ 𝛽1𝑥𝑘𝑖+ 𝜀𝑘𝑖. (2. 21)
Pada ANCOVA diperlukan perhitungan jumlah kuadrat dan jumlah hasil kali sebagai berikut.
1. Jumlah kuadrat total (JKT) dan jumlah hasil kali total (JHKT) untuk variabel 𝑌 dan 𝑋. 𝐽𝐾𝑇𝑦 = ∑ℎ𝑘=1∑𝑛𝑖=1(𝑦𝑘𝑖 − 𝑦̅..)2. (2. 22) 𝐽𝐾𝑇𝑥= ∑ ∑𝑛 (𝑥𝑘𝑖− 𝑥̅..)2 𝑖=1 ℎ 𝑘=1 . (2. 23) 𝐽𝐻𝐾𝑇 = ∑𝑘=1ℎ ∑𝑖=1𝑛 (𝑦𝑘𝑖− 𝑦̅..)(𝑥𝑘𝑖− 𝑥̅..). (2. 24)
Dengan derajat total bebas ℎ𝑛 − 1.
2. Jumlah kuadrat perlakuan (JKP) dan jumlah hasil kali perlakuan (JHKP) untuk variabel 𝑌 dan 𝑋.
𝐽𝐾𝑃𝑦 = 𝑛 ∑ℎ (𝑦̅𝑘.− 𝑦̅..)2
𝑘=1 . (2. 25)
𝐽𝐾𝑃𝑥 = 𝑛 ∑ℎ (𝑥̅𝑘.− 𝑥̅..)2
Dengan derajat bebas perlakuan ℎ − 1.
3. Jumlah kuadrat galat (JKG) dan jumlah hasil kali galat (JHKG) untuk variabel 𝑌 dan 𝑋. 𝐽𝐾𝐺𝑦 = 𝐽𝐾𝑇𝑦− 𝐽𝐾𝑃𝑦. (2. 28) 𝐽𝐾𝐺𝑦 = ∑ℎ𝑘=1∑𝑛𝑖=1(𝑦𝑘𝑖 − 𝑦̅𝑘.)2. (2. 29) 𝐽𝐾𝐺𝑥= 𝐽𝐾𝑇𝑥− 𝐽𝐾𝑃𝑥, (2. 30) 𝐽𝐾𝐺𝑥= ∑ℎ𝑘=1∑𝑛𝑖=1(𝑥𝑘𝑖− 𝑥̅𝑘.)2. (2. 31) 𝐽𝐻𝐾𝐺 = 𝐽𝐻𝐾𝑇 − 𝐽𝐻𝐾𝑃, (2. 32) 𝐽𝐻𝐾𝐺 = ∑𝑘=1ℎ ∑𝑖=1𝑛 (𝑦𝑘𝑖− 𝑦̅𝑘.)(𝑥𝑘𝑖 − 𝑥̅𝑘.). (2. 33)
Dengan derajat bebas galat ℎ(𝑛 − 1).
Untuk memperoleh jumlah kuadrat (JK) terkoreksi akibat dari pengaruh kovariat yaitu dengan mengestimasi nilai 𝛽, persamaan (2. 20) diubah ke dalam bentuk
𝑦𝑘𝑖− 𝛽𝑥𝑘𝑖 = 𝜇 + 𝜏𝑘+ 𝜀𝑘𝑖. (2. 34) Dengan menggunakan pendekatan ANOVA dari 𝑦𝑘𝑖 − 𝛽𝑥𝑘𝑖, varians populasi dari 𝑦𝑘𝑖− 𝛽𝑥𝑘𝑖,
𝜎𝑦−𝛽𝑥2 = 𝜎𝑦2− 2𝛽𝜎𝑥𝑦+ 𝛽2𝜎𝑥2 . (2. 35)
Untuk varians sampel, 𝑧 = 𝑦𝑖 − 𝛽𝑥𝑖 dituliskan 𝑠𝑧2 = 1 𝑛−1∑ (𝑧𝑖 − 𝑧̅) 2 𝑛 𝑖=1 , 𝑠𝑦2𝑖−𝛽𝑥𝑖 = 1 𝑛−1∑ [(𝑦𝑖 − 𝛽𝑥𝑖) − (𝑦̅ − 𝛽𝑥̅)] 2 𝑛 𝑖=1 , 𝑠𝑦 𝑖−𝛽𝑥𝑖 2 = 1 𝑛−1∑ [(𝑦𝑖 − 𝑦̅) − (𝛽𝑥𝑖− 𝛽𝑥̅)] 2 𝑛 𝑖=1 , 𝑠𝑦2𝑖−𝛽𝑥𝑖 = 1 𝑛−1∑ [(𝑦𝑖 − 𝑦̅) 2− 2𝛽(𝑦 𝑖− 𝑦̅)(𝑥𝑖− 𝑥̅) + 𝛽2(𝑥𝑖− 𝑥̅)2] 𝑛 𝑖=1 ,
𝑠𝑦2𝑖−𝛽𝑥𝑖 = 1 𝑛−1[∑ (𝑦𝑖− 𝑦̅) 2 𝑛 𝑖=1 ] − 2𝛽 1 𝑛−1[∑ (𝑦𝑖− 𝑦̅)(𝑥𝑖− 𝑥̅) 𝑛 𝑖=1 ] + 𝛽2 1𝑛−1[∑𝑛𝑖=1(𝑥𝑖− 𝑥̅)2], 𝑠𝑦 𝑖−𝛽𝑥𝑖 2 = 𝑠 𝑦2− 2𝛽𝑠𝑥𝑦+ 𝛽2𝑠𝑥2. (2. 36) 𝐽𝐾𝐺𝑦−𝛽𝑥 ℎ(𝑛−1) = 𝐽𝐾𝐺𝑦 ℎ(𝑛−1)− 2𝛽 𝐽𝐻𝐾𝐺 ℎ(𝑛−1)+ 𝛽 2 𝐽𝐾𝐺𝑥 ℎ(𝑛−1). (2. 37)
Untuk mengestimasi 𝛽 persamaan (2. 37) ditulis 𝐽𝐾𝐺𝑦−𝛽𝑥 = 𝐽𝐾𝐺𝑦− (2𝛽)𝐽𝐻𝐾𝐺 + (𝛽2)𝐽𝐾𝐺
𝑥 . (2. 38)
Persamaan (2. 38) diubah menjadi bentuk kuadrat sempurna pada 𝛽 𝐽𝐾𝐺𝑦−𝛽𝑥 = (𝛽 − 𝐽𝐻𝐾𝐺 𝐽𝐾𝐺𝑥) 2 𝐽𝐾𝐺𝑥+ 𝐽𝐾𝐺𝑦− (𝐽𝐻𝐾𝐺)2 𝐽𝐾𝐺𝑥 , (2. 39) sehingga diperoleh nilai 𝛽̂ =𝐽𝐻𝐾𝐺
𝐽𝐾𝐺𝑥, merupakan estimasi dari 𝛽. 𝐽𝐾𝐺𝑦−𝛽𝑥 selanjutnya ditulis 𝐽𝐾𝐺𝑦.𝑥 merupakan jumlah kuadrat galat penyesuaian akibat adanya kovariat. Dengan mensubstitusikan 𝛽̂ pada persamaan (2. 39) diperoleh nilai minimum
𝐽𝐾𝐺𝑦.𝑥 = 𝐽𝐾𝐺𝑦−
(𝐽𝐻𝐾𝐺)2
𝐽𝐾𝐺𝑥 , (2. 40)
dengan derajat bebas 𝑛ℎ − ℎ − 1, yaitu ℎ(𝑛 − 1) derajat bebas dari 𝐽𝐾𝐺𝑦 dan 1
derajat bebas dari (𝐽𝐻𝐾𝐺) 2
𝐽𝐾𝐺𝑥 .
Dengan analogi pada persamaan (2. 40) jumlah kuadrat total (JKT) untuk 𝑦 − 𝛽𝑥 dituliskan
𝐽𝐾𝑇𝑦.𝑥 = 𝐽𝐾𝑇𝑦−
(𝐽𝐻𝐾𝑇)2
𝐽𝐾𝑇𝑥 , (2. 41)
dengan derajat bebas 𝑛ℎ − 2, yaitu 𝑛ℎ − 1 merupakan derajat bebas 𝐽𝐾𝑇𝑦 dan 1
merupakan derajat bebas (𝐽𝐻𝐾𝑇) 2
Untuk memperoleh jumlah kuadrat perlakuan (JKP) untuk 𝑦 − 𝛽𝑥, yaitu dengan mengurangkan JKG terhadap JKT dituliskan
𝐽𝐾𝑃𝑦.𝑥 = 𝐽𝐾𝑇𝑦.𝑥− 𝐽𝐾𝐺𝑦.𝑥, (2. 42) dengan derajat bebas ℎ − 1.
Kuadrat tengah terkoreksi diperoleh dengan membagi jumlah kuadrat terkoreksi dengan derajat bebasnya.
Tabel ANCOVA satu arah sebelum dan sesudah mendapat penyesuaian dari kovariat ditampilkan pada tabel 3 berikut.
Tabel 3. ANCOVA Satu Arah
Variabel
Sebelum dikoreksi Setelah dikoreksi
Db 𝐽𝐾𝑋 𝐽𝐾𝑌 𝐽𝐻𝐾 Db JK
Perlakuan ℎ − 1 𝐽𝐾𝑃𝑋 𝐽𝐾𝑃𝑌 𝐽𝐻𝐾𝑃 ℎ − 1 𝐽𝐾𝑃𝑌.𝑋
Galat ℎ(𝑛 − 1) 𝐽𝐾𝐺𝑋 𝐽𝐾𝐺𝑌 𝐽𝐻𝐾𝐺 𝑛ℎ − ℎ − 1 𝐽𝐾𝐺𝑌.𝑋
Total 𝑛ℎ − 1 𝐽𝐾𝑇𝑋 𝐽𝐾𝑇𝑌 𝐽𝐻𝐾𝑇 𝑛ℎ − 2 𝐽𝐾𝑇𝑌.𝑋
1. Asumsi pada ANCOVA
Asumsi-asumsi yang harus dipenuhi dalam ANCOVA adalah tiga asumsi ANOVA dan dua asumsi berkaitan dengan kovariat, yaitu:
a. Variabel terikat berhubungan linear dengan kovariat
Asumsi ini mempengaruhi nilai galat. Jika asumsi ini terpenuhi maka nilai galat akan menjadi lebih kecil. Asumsi ini diuji dengan hipotesis 𝐻0: 𝛽 = 0 dan 𝐻1: 𝛽 ≠ 0 dengan 𝛽 pada persamaan (2. 20) merupakan
koefisien regresi variabel terikat pada kovariat. Statistik uji yang digunakan adalah uji F (Rencher, 1998: 182) yaitu
𝐹 = 𝐽𝐻𝐾𝐺2⁄𝐽𝐾𝐺𝑥
𝐽𝐾𝐺𝑦.𝑥⁄(𝑛ℎ−ℎ−1). (2. 43) Dengan kriteria keputusan 𝐻0 ditolak jika nilai 𝐹ℎ𝑖𝑡𝑢𝑛𝑔 > 𝐹𝛼(1,𝑛ℎ−ℎ−1). Jika 𝐻0 ditolak artinya variabel terikat berhubungan linear dengan
kovariat.
b. Koefisien regresi homogen antar perlakuan
Asumsi ini menunjukkan bahwa gradien pada setiap perlakuan sama. Untuk dua kovariat asumsinya adalah kesamaan bidang regresi pada setiap perlakuan. Untuk lebih dari dua kovariat asumsinya adalah kesamaan bidang banyak regresi antar perlakuan. Jika asumsi ini tidak terpenuhi, maka antara kovariat dan perlakuan dianggap terjadi interaksi. Sebagaimana dalam persamaan (2. 20), 𝛽 merupakan koefisien regresi, sehingga hipotesis ujinya 𝐻0: 𝛽1 = 𝛽2 = ⋯ = 𝛽ℎ dan 𝐻1: paling sedikit dua 𝛽𝑘 tidak sama (𝑘 = 1,2, … , ℎ), dengan 𝛽𝑘 merupakan gradien pada grup ke-𝑘.
Untuk menguji asumsi ini adalah dengan membandingkan model lengkap (2. 20), estimasi gradien yang berbeda tiap grup 𝛽𝑘, terhadap model regresi linear (2. 21), gradien 𝛽 (Rencher, 1998: 181). Diberikan
𝐽𝐾𝐺𝑥𝑘 = ∑𝑛𝑖=1(𝑥𝑘𝑖− 𝑥̅𝑘.)2, (2. 44)
𝐽𝐻𝐾𝐺𝑘= ∑𝑛𝑖=1(𝑥𝑘𝑖− 𝑥̅𝑘.)(𝑦𝑘𝑖− 𝑦̅𝑘.). (2. 45)
Estimasi gradien untuk 𝑋 pada grup ke-𝑘 adalah 𝛽̂ =𝐽𝐻𝐾𝐺𝑘
𝐽𝐾𝐺𝑥𝑘, (2. 46)
dengan jumlah kuadrat 𝛽𝑘= (𝐽𝐻𝐾𝐺𝑘)2 𝐽𝐾𝐺 𝑥𝑘
⁄ . Jumlah kuadrat dari model lengkap (2. 20) dengan gradien 𝛽𝑘 setiap grup
𝐽𝐾𝐹 = ∑ (𝐽𝐻𝐾𝐺𝑘 )2 𝐽𝐾𝐺𝑥𝑘
ℎ
𝑘=1 , (2. 47)
dan jumlah kuadrat dari model regresi linear (2. 21) dengan gradien 𝛽 𝐽𝐾𝑅 =(𝐽𝐻𝐾𝐺)2
𝐽𝐾𝐺𝑥 . (2. 48)
Jumlah kuadrat untuk menguji hipotesis 𝐻0: 𝛽1= 𝛽2 = ⋯ = 𝛽ℎ dan 𝐻1: paling sedikit dua 𝛽𝑘 tidak sama (𝑘 = 1,2, … , ℎ) merupakan selisisih jumlah kuadrat model lengkap (2. 47) dan jumlah kuadrat model regresi linear (2. 48) 𝐽𝐾𝐹− 𝐽𝐾𝑅 = ∑ (𝐽𝐻𝐾𝐺𝑘)2 𝐽𝐾𝐺𝑥𝑘 ℎ 𝑘=1 − (𝐽𝐻𝐾𝐺)2 𝐽𝐾𝐺𝑥 , (2. 49)
dengan derajat bebas ℎ − 1. Jumlah kuadrat galat berdasarkan model lengkap (2. 20)
𝐽𝐾𝐺(𝐹)𝑦.𝑥 = 𝐽𝐾𝐺𝑦− ∑ (𝐽𝐻𝐾𝐺𝑘)2
𝐽𝐾𝐺𝑥𝑘
ℎ
𝑘=1 , (2. 50)
dengan derajat bebas ℎ(𝑛 − 2) = 𝑛ℎ − 2ℎ = 𝑁 − 2ℎ. Statistik uji 𝐹 𝐹 =(𝐽𝐾𝐹−𝐽𝐾𝑅)/(ℎ−1) 𝐽𝐾𝐺(𝐹)𝑦.𝑥/(𝑁−2ℎ), (2. 51) 𝐹 = [∑ (𝐽𝐻𝐾𝐺𝑘) 2 𝐽𝐾𝐺𝑥𝑘 ℎ 𝑘=1 − (𝐽𝐻𝐾𝐺)2 𝐽𝐾𝐺𝑥 ]/(ℎ−1) [𝐽𝐾𝐺𝑦−∑ (𝐽𝐻𝐾𝐺𝑘) 2 𝐽𝐾𝐺𝑥𝑘 ℎ 𝑘=1 ]/(𝑁−2ℎ) . (2. 52)
Jika nilai 𝐹ℎ𝑖𝑡𝑢𝑛𝑔 ≤ 𝐹𝛼(ℎ−1,𝑁−2ℎ) maka 𝐻0 diterima, yang artinya koefisien regresi homogen antar perlakuan.
c. Independensi obyek pengamatan
Terpenuhinya asumsi ini menunjukkan bahwa sebuah sampel diambil secara acak dari suatu populasi.
d. Variabel terikat berdistribusi normal
Dalam ANOVA variabel terikat berdistribusi normal univariat. Pengujian asumsi ini dapat menggunakan dua metode, yaitu dengan dengan grafik dan secara analitik (tanpa grafik). Metode grafik dengan
Quantile-vs-Quantile plot (Q-Q Plot) dan metode analitik menggunakan uji
Kolmogorov-Smirov (Stevens, 2009: 224). e. Kesamaan varians (Homoskedastisitas)
Untuk pengujian asumsi ini menggunakan uji Bartlett dengan hipotesis 𝐻0: σ12 = σ22 = ⋯ = σℎ2 dan 𝐻1: paling sedikit dua σ𝑘2 tidak sama, (𝑘 =
1,2, … , ℎ). Terdapat hubungan yang simultan antara homoskedastisitas dengan normalitas. Data homoskedastisitas akan menyebar secara normal, sehingga perlu diuji normalitas terlebih dahulu sebelum melakukan uji ini.
Statistik uji Bartlett (Milliken & Johnson, 2009: 24) adalah 𝑈 = 1 𝐶[𝑣 log(𝑠 2) − ∑ 𝑣 𝑗log(𝑠𝑗2) ℎ 𝑗=1 ]. (2. 53) Dengan, 𝑣𝑗 = 𝑛𝑗 − 1, 𝑣 = ∑ℎ𝑗=1𝑣𝑗, 𝑠𝑗2 = ∑ (𝑦𝑖𝑗−𝑦̅.𝑗) 2 ℎ 𝑗=1 𝑣𝑗 , 𝜎 2 =∑ℎ𝑗=1𝑣𝑗𝜎𝑗2 𝑣 , dan 𝐶 = 1 + 1 3(ℎ−1)[∑ 1 𝑣𝑗− 1 𝑣 ℎ 𝑗=1 ].
2. Pengujian Hipotesis pada ANCOVA
Uji hipotesis ANCOVA mengikuti langkah-lagkah berikut. a. Hipotesis,
menyatakan hipotesis nol dan hipotesis alternatifnya. Untuk ANCOVA satu arah hipotesisnya adalah:
𝐻0: 𝜏1 = 𝜏2 = ⋯ = 𝜏ℎ = 0,
(tidak terdapat pengaruh perlakuan terhadap variabel respon yang diamati setelah disesuaikan dengan variabel konkomitan).
𝐻1: ∃𝜏𝑘 ≠ 0,
(terdapat pengaruh perlakuan terhadap variabel respon yang diamati setelah disesuaikan dengan variabel konkomitan).
b. Menentukan Taraf Signifikansi, 𝛼. c. Memilih statistik uji (Rencher, 1978: 181)
𝐹 = 𝐽𝐾𝑃𝑦.𝑥⁄(ℎ−1)
𝐽𝐾𝐺𝑦.𝑥⁄(𝑛ℎ−ℎ−1). (2. 54) d. Menentukan wilayah kritik,
𝐻0 ditolak jika 𝐹 > 𝐹(𝛼;ℎ−1,𝑛ℎ−ℎ−1).
e. Melakukan perhitungan dengan statistik uji. f. Keputusan,
jika 𝐹 > 𝐹(𝛼;ℎ−1,𝑛ℎ−ℎ−1) maka 𝐻0 ditolak. Artinya terdapat pengaruh
perlakuan terhadap variabel respon yang diamati setelah disesuaikan dengan variabel konkomitan.
3. Uji Post Hoc pada ANCOVA
Jika hasil uji hipotesis ANCOVA menunjukkan 𝐻0 diterima yang artinya
pengaruh perlakuan terhadap variabel terikat setelah disesuaikan dengan kovariat tidak signifikan maka pengujian hipotesis selesai. Jika 𝐻0 ditolak yang artinya pengaruh perlakuan signifikan terhadap variabel terikat setelah disesuaikan dengan kovariat maka dilakukan uji Post Hoc atau disebut juga dengan uji lanjut. Uji Post Hoc yang digunakan adalah prosedur Bryant-Paulson (BP).
Prosedur BP merupakan generalisasi dari metode uji Tukey’s HSD (Kirk, 1995: 726). Prosedur BP digunakan untuk menentukan apakah rata-rata populasi berpasangan setelah disesuaikan dengan kovariat berbeda secara signifikan, yang didasarkan pada desain acak atau tidak acak dan banyaknya kovariat yang digunakan. Hipotesis ujinya dituliskan:
𝐻0: 𝜇𝑘∗ = 𝜇𝑙∗ (rata-rata populasi setelah disesuaikan dengan kovariat pada perlakuan ke-𝑗 dan ke-𝑙 tidak berbeda secara signifikan).
𝐻1: 𝜇𝑘∗ ≠ 𝜇𝑙∗ (rata-rata populasi setelah disesuaikan dengan kovariat pada
perlakuan ke-𝑗 dan ke-𝑙 berbeda secara signifikan).
Untuk statistik uji prosedur BP untuk satu kovariat (Stevens, 2009: 309): 𝐵𝑃 = 𝑦̅𝑘∗−𝑦̅𝑙∗ √𝐾𝑇𝐻𝐾𝐺(2 𝑛+ [(𝑥̅𝑘−𝑥̅𝑙)2/𝐽𝐾𝐺𝑥] 2 ) . (2. 55)
Untuk lebih dari satu kovariat:
𝐵𝑃 = 𝑦̅𝑘∗−𝑦̅𝑙∗
√𝐾𝑇𝐻𝐾𝐺[(2 𝑛⁄ )+𝒅𝒌𝒍′𝑬𝒙𝒙−𝟏𝒅𝒌𝒍] 2
. (2. 56)
𝑦̅𝑘∗ = 𝑦̅𝑘− 𝛽1(𝑥̅𝑘1− 𝑥̅1) − 𝛽2(𝑥̅𝑘2− 𝑥̅2) − ⋯ − 𝛽𝑞(𝑥̅𝑘q− 𝑥̅k), (2. 57) 𝒅𝒌𝒍 = [ 𝑋̅𝑗𝑘1− 𝑋̅𝑗𝑙1 𝑋̅𝑗𝑘2− 𝑋̅𝑗𝑙2 ⋮ 𝑋̅𝑗𝑘q− 𝑋̅𝑗𝑙q] . (2. 58) Dengan,
𝑦̅𝑘∗ : rata-rata variabel terikat setelah disesuaikan dengan kovariat pada perlakuan ke-𝑘,
𝑦̅𝑙∗ : rata-rata variabel terikat setelah disesuaikan dengan kovariat pada perlakuan ke-𝑙,
𝐾𝑇𝐻𝐾𝐺 : kuadrat tengah galat dari kovarians, 𝐽𝐾𝐺𝑥 : Jumlah kuadrat galat pada kovariat, 𝑥̅𝑘 : rata-rata kovariat pada perlakuan ke-𝑘,
𝑥̅𝑙 : rata-rata kovariat pada perlakuan ke-𝑙,
𝑬𝒙𝒙 : matriks jumlah kuadrat dan hasil kali silang galat pada kovariat, 𝒅𝒌𝒍 : matriks kolom selisih antara kovariat pada perlakuan ke-𝑘 dan ke-𝑙, 𝑛 : ukuran sampel dalam perlakuan,
𝑞 : banyak kovariat,
𝑦̅𝑘 : rata-rata variabel terikat pada perlakuan ke-𝑘, 𝑥̅𝑘q : rata-rata kovariat ke-𝑞 pada perlakuan ke-𝑘, 𝛽𝑞 : koefisien regresi 𝑥̅𝑘q.
𝐻0 ditolak jika 𝐵𝑃 > 𝐵𝑃𝛼;ℎ𝑛−ℎ−𝑞 yang artinya rata-rata populasi pada perlakuan
F. Gizi
Ilmu yang mempelajari tentang gizi disebut dengan ilmu gizi. Menurut Moehji (1979: 1) ilmu gizi adalah ilmu yang mempelajari hubungan antara makanan yang dimakan dengan kesehatan tubuh. Terdapat faktor internal maupun eksternal yang mempengaruhi status gizi. Faktor internal diantaranya umur, kondisi fisik, asupan makanan, dan riwayat penyakit. Faktor eksternal berupa pendidikan, pendapatan, pekerjaan, dan budaya.
Dalam ilmu gizi terdapat istilah antropometri. Antropometri merupakan metode yang sering dilakukan dalam penentuan status gizi. Menurut Supariasa dkk. (2002) antropometri gizi berhubungan dengan berbagai macam pengukuran dimensi tubuh dan komposisi tubuh dari berbagai tingkat umur dan tingkat gizi. Ukuran tubuh yang biasa digunakan antara lain berat badan, tinggi badan, lingkar lengan atas, dan tebal lemak dibawah kulit. Status gizi sangat mempengaruhi aktivitas seseorang. Seseorang yang bergizi cukup dapat dilihat dari keaktifan, giat bekerja, ekspresi kegembiraan, dan jarang sakit (Sutarto & Mu'rifah, 1980: 51). Pada masa pertumbuhan pemenuhan asupan gizi berupa asupan energi dan asupan protein penting untuk menunjang aktivitas. Menurut Hardinsyah dkk. (2012: 5) faktor yang mempengaruhi kecukupan energi adalah berat badan, tinggi badan, usia, jenis kelamin, energi cadangan bagi anak dan remaja, serta thermic
effect of food (TEF). Kecukupan protein seseorang dipengaruhi oleh berat badan,
usia, dan mutu protein dalam pola konsumsi pangannya (Hardinsyah dkk., 2012: 9).
Dari uraian di atas, asupan energi dan asupan protein dapat menjadi bahan penelitian pada bidang gizi. Dengan faktor usia dan berat badan menjadi variabel konkomitan, dapat menjadi penerapan MANCOVA satu arah dengan dua kovariat pada bidang gizi.