CHURN PREDICTION PADA TELEKOMUNIKASI SELULER DENGAN METODE BAGGING DAN BOOSTING
Teks penuh
Gambar
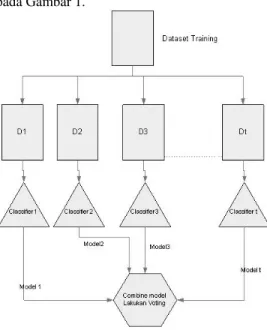
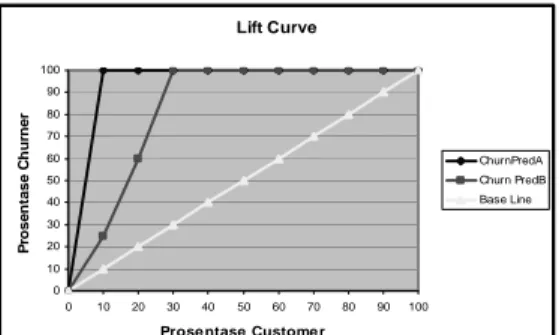
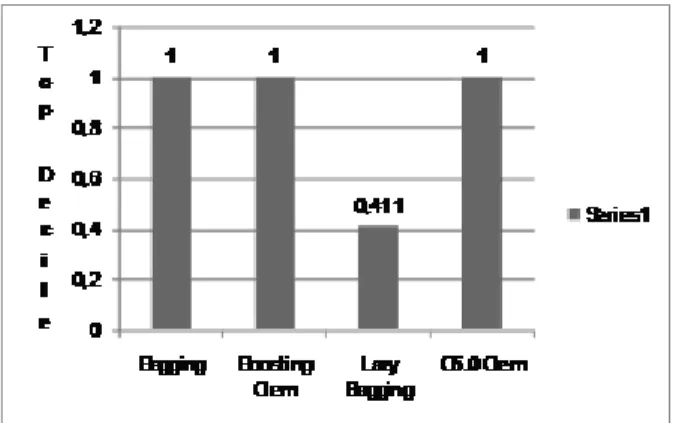
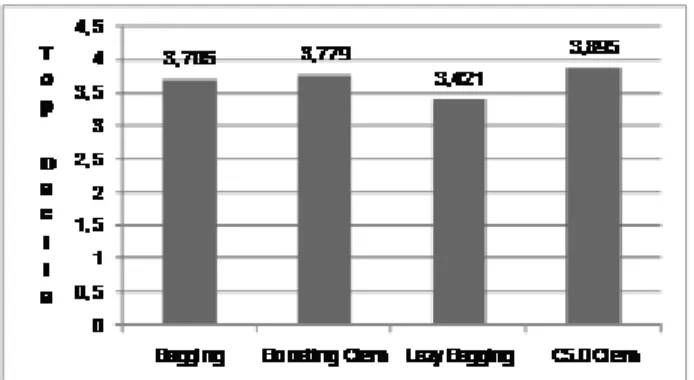

Dokumen terkait
Sampharindo Perdana Semarang dapat meminimalkan biaya total persediaan apabila dibandingkan dengan metode Lot Sizing Part Period Balancing dan Algoritma Wagner Within
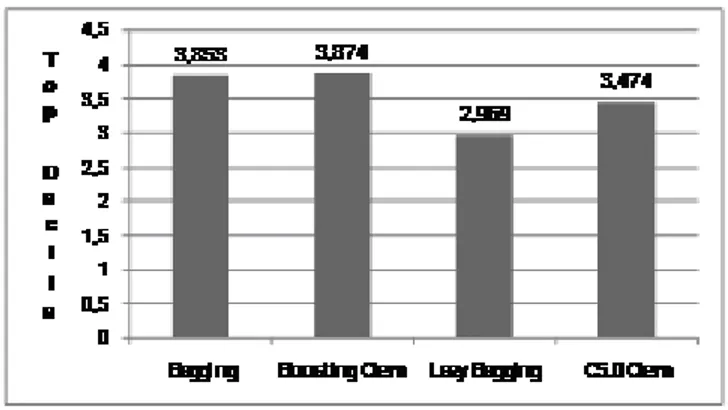
Dataset diambil dari salah satu perusahaan telekomunikasi di Amerika bernama Orange yang tersedia di situs Kaggle yang kemudian diolah untuk menganalisis performa
Nilai dari Silhouette Coefficient dan Purity metode single linkage selalu lebih tinggi jika dibandingkan dengan metode K-means. Kurang optimalnya metode K-means ini
cenderung memiliki akurasi yang lebih tinggi dibandingkan dengan SMOTE XGboost akan tetapi SMOTE XGboost memiliki nilai recall yang lebih tinggi dibandingkan SMOTE Random
Melalui penelitian ini diketahui metode spektrofotometri sinar tampak memberikan akurasi yang lebih tinggi dibandingkan metode titrasi asam basa dalam menetapkan kadar
Perbandingan penelitian yang akan digunakan menggunakan load balancing menggunakan 4 line internet, membandingkan performa 3 metode load balancing dengan metode pengujian menggunakan
Dari hasil pengujian tersebut menunjukkan bahwa bagging mampu mengurangi tingginya noise yang ditunjukkan dari varians yang tinggi pada dataset airfoil, sehingga menghasilkan kinerja
Cara melakukan load balancing dengan metode PCC dan fail over pada
