KAJIAN PUS TAKA
2.1 Visi Komputer
Visi komputer (Computer Vision) merupakan bidang ilmu yang melakukan studi tentang bagaimana sistem komputer mengenali pola atau objek yang diamati melalui sistem sensor (kamera, dll). Bidang ilmu ini mengembangkan berbagai pendekatannya dengan cara mengkombinasikan teknik-teknik Pengolahan Citra dan Pengenalan Pola atau Objek. Bersama bidang Intelijensia Semu (Artificial Intelligence), bidang Visi Komputer akan mampu menghasilkan sebuah Sistem Cerdas (Intelligent System). Visi Komputer oleh beberapa ahli didefinisikan sebagai berikut:
• Menurut Ballard dan Brown, pembangunan fisik, yang berarti deskripsi sebuah fisik objek dari gambar.
• Menurut Forsyth dan Ponce, mengekstrak deskripsi dunia atau informasi dari gambar atau urutan gambar.
• Menurut Adrian Low (1991), visi dengan perolehan gambar, pemrosesan, klarifikasi, pengenalan, dan menjadi penggabungan, pengurutan pembuatan keputusan menuju pengenalan komputer berhubungan.
• Menurut Saphiro dan Stochman (2001), visi komputer adalah suatu bidang yang bertujuan untuk membuat suatu keputusan yang berguna mengenali objek fisik
kombinasi antar pengolahan citra dan pengolahan pola. Hasil keluaran dari proses visi komputer adalah pengertian tentang citra.
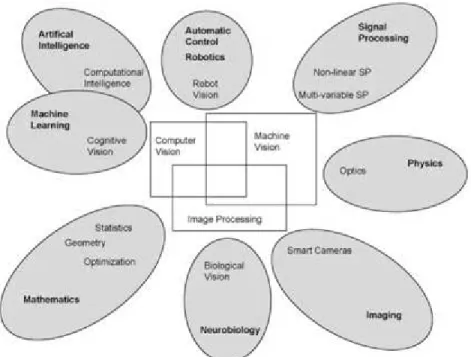
Gambar 2.1 S kema hubungan visi komputer dengan bidang lain.
2.2 Citra dan Pemrosesan Citra
2.2.1 Definisi Citra dan Citra Dijital
Citra dalam penelitian ini mengacu kepada citra dijital. Sebuah citra didefinisikan sebagai matriks berukuran N baris dan M kolom yang terdiri dari sekumpulan nilai dijital yang disebut piksel. Piksel merupakan elemen terkecil dari suatu gambar. Nilai pada matriks merepresentasikan intensitas atau tingkat
kecerahan dari suatu piksel. Dengan kata lain, intensitas suatu warna pada citra merupakan fungsi posisi f(x,y) dari suatu citra (Aguado dan Nixon, 2002, p32).
Gambar 2.2 Representasi pixel dalam sebuah potongan citra dijital
Citra sebagai keluaran dari suatu sistem perekaman data dapat bersifat:
1. Optik berupa foto,
2. Analog berupa sinyal video seperti gambar pada monitor televisi, 3. Dijital yang dapat langsung disimpan pada suatu pita magnetik.
Sebuah citra dijital dapat diciptakan secara langsung dari sebuah pemandangan fisik oleh sebuah kamera atau alat yang serupa. Citra dijital juga
dapat dihasilkan dari medium analog atau sinyal, seperti dari lukisan, foto, atau kertas yang telah dicetak, dengan bantuan scanner.
2.2.2 Pengolahan Citra
Pengolahan citra/image processing mengacu kepada pengolahan citra dengan menggunakan komputer. Contoh operasi pemrosesan citra : mengubah ukuran citra, menghitung histogram dari suatu citra, mengubah tingkat kecerahan, komposisi (menggabungkan dua citra atau lebih), dan lain-lain.
Seperti yang dijelaskan oleh Gonzales dan Woods, 2008, p2, visi merupakan indra yang paling berkembang. Namun tidak seperti manusia, komputer mampu mengolah hampir semua jenis spektrum elektromagnetik. Komputer dapat melakukan bermacam-macam pengolahan citra yang tidak biasa dilakukan oleh manusia. Karenanya pengolahan citra mempunyai ruang dan variasi yang sangat luas dalam aplikasinya.
Operasi-operasi yang dilakukan di dalam pengolahan citra banyak ragamnya. Namun, secara umum, operasi pengolahan citra dapat diklasifikasikan dalam beberapa jenis sebagai berikut: (ITTELKOM , 2008, pp7-11)
1. Perbaikan kualitas citra (image enhancement)
Jenis operasi ini bertujuan untuk memperbaiki kualitas citra dengan cara memanipulasi parameter-parameter citra. Dengan operasi ini, ciri-ciri khusus yang terdapat di dalam citra lebih ditonjolkan. Contoh-contoh operasi perbaikan citra:
a) Perbaikan kontras gelap atau terang
c) Penajaman (sharpening)
d) Pemberian warna semu (pseudocoloring) e) Penapisan derau (noise filtering)
2. Pemugaran Citra (image restoration)
Operasi ini bertujuan menghilangkan atau meminimumkan cacat pada citra. Tujuan pemugaran citra hampir sama dengan operasi perbaikan citra. Bedanya, pada pemugaran citra penyebab degradasi gambar diketahui. Contoh-contoh operasi pemugaran citra:
a) Penghilangan kesamaran (deblurring) b) Penghilangan derau (noise removal) 3. Pemampatan citra (Image Compression)
Jenis operasi ini dilakukan agar citra dapat direpresentasikan dalam bentuk yang lebih kompak sehingga memerlukan memori yang lebih sedikit. Hal penting yang harus diperhatikan dalam pemampatan adalah citra yang telah dimampatkan harus tetap mempunyai kualitas gambar yang bagus. Contoh metode pemampatan citra adalah metode JPEG.
4. Segmentasi Citra (Image Segmentation)
Jenis operasi ini bertujuan memecah suatu citra ke dalam beberapa segmen dengan kriteria tertentu. Jenis operasi ini berkaitan erat dengan pengenalan pola.
5. Analisis Citra (Image Analysis)
Jenis operasi ini bertujuan menghitung besaran kuantitatif dari suatu citra untuk menghasilkan deskripsinya. Teknik analisis citra mengekstraksi ciri-ciri tertentu dari suatu citra yang membantu dalam proses identifikasi objek. Proses segmentasi kadang kala diperlukan untuk lokalisasi objek yang diinginkan dari sekelilingnya. Contoh-contoh operasi analisis citra adalah:
a) Pendeteksian tepi objek (edge detection) b) Ekstraksi batas (boundary extraction) c) Representasi daerah (region representation) 6. Rekonstruksi Citra (Image Reconstruction)
Jenis operasi ini bertujuan untuk membentuk ulang objek dari beberapa citra hasil proyeksi. Operasi rekonstruksi citra banyak digunakan dalam bidang medis. M isalnya beberapa foto rontgen dengan sinar X digunakan untuk membentuk ulang gambar organ tubuh.
2.3 Fitur dan Ekstraksi Fitur
Ketika suatu input data berukuran terlalu besar untuk diproses dan diperkirakan memiliki banyak data tetapi sedikit informasi, maka terhadap input tersebut perlu transformasi menjadi sekumpulan fitur yang direpresentasikan dengan vektor, yang disebut vektor fitur (feature vector). Proses transformasi diatas disebut ekstraksi fitur (feature extraction). Suatu fitur merupakan ciri yang
diamati dari suatu objek dalam hal ini merupakan citra dan juga merupakan suatu deskriptor numerik yang dapat menangkap karakteristik visual tertentu. Ekstraksi fitur memiliki dua tujuan, yaitu membuang aspek yang tidak relevan dari suatu objek sehingga representasi informasi hanya mengandung data yang perlu, penting, dan mentransformasi data menjadi sebuah representasi yang membawa informasi lebih eksplisit atau secara jelas dan tidak membingungkan. (dikutip dari http://en.wikipedia.org/wiki/Feature_extraction)
Fitur dapat diekstrak dari suatu citra secara keseluruhan yang mendeskripsikan karakteristik visual secara global, ataupun dari bagian tertentu suatu citra yang mendeskripsikan karakteristik secara lokal. Secara umum, representasi suatu citra dalam fitur membutuhkan ruang penyimpanan yang jauh lebih kecil daripada meyimpan citra itu sendiri.
2.4 Retrival Berbasis Konten (Content Based Retrival)
Citra memiliki informasi yang tidak terstruktur yang membuat proses pencarian menjadi sangat sulit dilakukan. Sebuah kueri yang umum dilakukan dalam basis data pada umumnya akan meminta menampilkan semua kolom-kolom (field-field) yang berada di dalam basis data. Sedangkan, sebuah kueri yang umum pada basis data dari citra akan meminta semua citra yang di dalamnya terdapat bus berwarna merah. Kueri pertama ambil saja contoh dalam basis data di bidang transaksi keuangan. Dengan mudahnya, kueri yang akan di cari akan langsung didapat karena semua transaksi pada record basis data mengandung semua informasi yang dibutuhkan (tanggal, tipe, jumlah, dan
lain-lain) dan sistem manajemen basis data dibuat untuk mengeksekusinya dengan efisien. Kueri kedua yang berupa pencarian citra merupakan suatu hal yang sangat sulit, kecuali semua citra dalam basis data telah diberi kata kunci. Dan sering kali dalam hal ini sering terjadi kesalahan pengertian dari komputer untuk mengartikan kueri yang telah diinputkan. Hal ini sering sekali disebut dengan permasalahan semantik (semantic problem) atau sama pengertian namun berbeda makna.
Informasi tidak terstruktur yang terkandung dari suatu citra sulit untuk ditangkap secara otomatis. Oleh sebab itu, teknik yang mencari cara untuk mengindeks informasi visual tidak terstruktur ini disebut retrival berbasis konten.
2.5 RCBK (Retrival Citra Berbasis Konten) / CBIR (Content Based Image Retrival)
RCBK (Retrival Citra Berbasis Konten) / Content based image retrieval (CBIR), adalah suatu aplikasi computer vision yang digunakan untuk melakukan pencarian gambar-gambar dijital pada suatu basis data. Yang dimaksud dengan "Content-based" di sini adalah bahwa yang dianalisa dalam proses pencarian itu adalah actual contents (kandungan-kandungan aktual) sebuah gambar. Istilah content pada konteks ini merujuk pada warna, bentuk, tekstur, atau informasi lain yang didapatkan dari gambar tersebut. Istilah ini diduga diperkenalkan oleh T.Kato pada tahun 1992 untuk mendeskripsikan percobaan dalam retrival citra
secara otomatis dari basis data berdasarkan warna dan bentuk. (dikutip dari
http://en.wikipedia.org/wiki/Content-based_image_retrieval).
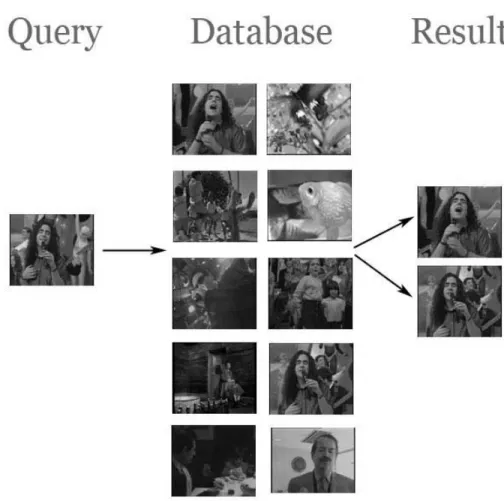
Proses umum dari RCBK adalah pada gambar yang menjadi kueri dilakukan proses ekstraksi fitur (feature extraction), begitu halnya dengan gambar yang ada pada sekumpulan gambar juga dilakukan proses seperti pada gambar kueri. Parameter fitur gambar yang dapat digunakan untuk retrival pada sistem ini dapat berupa histogram, susunan warna, tekstur, dan bentuk, tipe spesifik dari obyek, tipe event tertentu, nama individu, lokasi, emosi.
Pada tahun 1990an dilakukan pengembangan terhadap image retrieval dengan menggunakan pendekatan gambar yaitu teknik untuk mencari gambar yang mempunyai kemiripan dengan kriteria gambar dari sekumpulan gambar. Proses secara umum dari image retrieval adalah gambar yang menjadi kueri dilakukan proses ekstraksi, begitu halnya dengan gambar yang berada pada sekumpulan gambar juga dilakukan proses seperti gambar kueri.
Beberapa gambar basis data dibuat untuk menunjukkan bagaimana sistem retrival bekerja. IBM dengan Query by Image Content (QBIC) adalah contoh dari sistem RCBK ini. Parameter ciri gambar yang dapat digunakan untuk retrival pada sistem ini antara lain seperti histogram, susunan warna, tekstur dan bentuk, tipe spesifik dari objek, tipe event tertentu, nama individu, lokasi, emosi. M enurut Eakins klasifikasi jenis kueri dibagi menjadi tiga tingkat, yaitu :
1. Level 1 terdiri dari pengambilan fitur primitif seperti warna, tekstur, bentuk atau lokasi spasial dari elemen gambar. Contoh pertanyaan tersebut mungkin termasuk "mencari gambar dengan panjang benda gelap tipis di sudut kiri atas", "menemukan gambar-gambar berisi bintang kuning diatur dalam cincin" atau paling sering "menemukan saya lebih banyak gambar yang terlihat seperti ini". Tingkat pengambilan menggunakan fitur (seperti warna tertentu kuning) yang keduanya objektif, dan langsung diturunkan dari foto diri, tanpa perlu untuk mengacu pada setiap basis pengetahuan eksternal. Penggunaannya sangat terbatas untuk aplikasi khusus seperti pendaftaran merek dagang, identifikasi gambar dalam arsip desain, atau warna pencocokan fashion accessories.
2. Level 2 terdiri dari pengambilan fitur logis, yang melibatkan beberapa derajat kesimpulan logis tentang identitas objek digambarkan dalam gambar. Hal ini dapat dibagi lebih lanjut menjadi:
a. pengambilan objek dari suatu jenis tertentu (misalnya "menemukan gambar bus double-decker");
b. pengambilan objek individu atau orang-orang ("menemukan gambar menara Eiffel").
Untuk menjawab pertanyaan pada tingkat ini, mengacu pada beberapa toko di luar pengetahuan biasanya diperlukan - terutama untuk pertanyaan yang lebih spesifik pada level 2 (b). Pada contoh pertama di atas, beberapa pemahaman sebelum diperlukan untuk mengidentifikasi objek sebagai bus daripada truk, dalam contoh kedua, orang perlu pengetahuan yang struktur individu tertentu telah diberi nama "menara Eiffel". Kriteria Pencarian pada tingkat ini, terutama pada tingkat 2 (b), biasanya masih cukup objektif. Tingkat kueri lebih umum dijumpai dari level 1 - misalnya, pertanyaan paling diterima oleh perpustakaan gambar koran tampaknya jatuh ke kategori ini keseluruhan [Enser, 1995].
3. Level 3 terdiri dari pengambilan oleh atribut abstrak, yang melibatkan sejumlah besar penalaran tingkat tinggi tentang arti dan tujuan benda atau adegan digambarkan. tingkat pengambilan berguna dapat dibagi menjadi:
a. Pengambilan peristiwa bernama atau jenis aktivitas (misalnya "menemukan gambar tarian rakyat Skotlandia");
b. Pengambilan gambar dengan makna emosional atau keagamaan ("menemukan gambar yang menggambarkan penderitaan").
Sukses dalam menjawab pertanyaan pada tingkat ini dapat memerlukan beberapa kecanggihan di pihak pencari. Kompleks penalaran, dan sering penilaian subjektif, bisa diminta untuk membuat hubungan antara isi gambar dan konsep-konsep abstrak diperlukan untuk mengilustrasikan. Pertanyaan pada tingkat ini, meskipun mungkin kurang umum dari tingkat 2, yang sering dijumpai dalam kedua perpustakaan surat kabar dan seni.
Seperti yang akan dilihat nanti, klasifikasi jenis kueri ini dapat bermanfaat dalam menggambarkan kekuatan dan keterbatasan teknik pengambilan gambar yang berbeda. Kesenjangan yang paling signifikan pada saat ini terletak antara tingkat 1 dan 2. Banyak penulis [mis Gudivada dan Raghavan, 1995] mengacu pada tingkat 2 dan 3 bersama sebagai pencarian citra semantik, sehingga kesenjangan antara tingkat 1 dan 2 sebagai kesenjangan semantik. Perhatikan bahwa klasifikasi ini mengabaikan jenis lebih lanjut kueri gambar - pengambilan oleh metadata yang terkait seperti yang menciptakan gambar, di mana, dan kapan. Hal ini bukan karena pengambilan tersebut tidak penting. Hal ini dikarenakan (setidaknya saat ini) metadata tersebut secara eksklusif, tekstual, dan manajemen yang merupakan masalah utama dalam pengambilan teks.
2.5.1 Tahap-tahap dalam RCBK
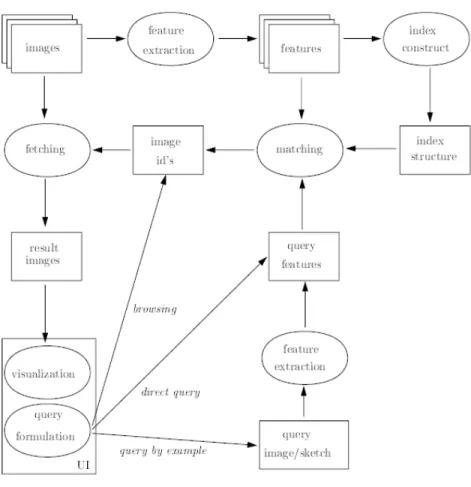
Gambar 2.4 Arsitektur Sistem RCBK
M ayoritas tahap inti dari sebuah sistem retrival (retrieval) citra, terdiri dari pendekatan dua tahapan, yaitu:
1. Pengindeksan (indexing)
Untuk setiap citra dalam basis data, dilakukan pengekstrakan fitur (feature extraction). Setiap citra direpresentasikan oleh vektor berdimensi n yang disebut vektor fitur (feature vektor). Selanjutnya setiap vektor fitur disimpan ke dalam basis data fitur.
2. Pencarian (searching)
Untuk setiap kueri citra yang diberikan, dilakukan pengekstrakan ciri dan direpresentasikan dalam vektor fitur, selanjutnya vektor fitur dari kueri akan dibandingkan ke dalam basis data fitur untuk mencari citra atau sekumpulan citra yang paling mirip dengan kueri citra. Selanjutnya, citra-citra yang paling mirip tersebut ditampilkan kepada pengguna. Dan ditampilkan berdasarkan prioritas dari tingkat kemiripan antara kueri dengan basis data.
2.5.1.1 Pengindeksan
Jika membicarakan pengindeksan pada citra, maka harus dilakukan pemikiran apakah yang akan mengacu pada sebuah deskripsi formil dari citra atau pada objektifitas dan retrival. Deskripsi formil dari citra adalah sebuah penjelasan formil seperti pada buku.
Pendeskripsian citra menemukan banyak halangan. Salah satu kesulitannya adalah bagaimana akan mendeskripsikan fotografi, yang hampir semua hasilnya tidak memiliki judul, pembuat, tanggal pembuatan, atau informasi teks lainnya. Tidak seperti buku, citra tidak menjelaskan apa yang mereka kandung, dan citra digunakan untuk berbagai macam kegunaan melewati antisipasi dari pembuatnya (Besser, Visual access to visual images: the UC Berkeley Image Database Project, 1990). Besser juga memberikan komentar:
“Sebuah set foto dari sebuah jalanan yang sibuk pada satu abad yang lalu mungkin akan berguna bagi sejarawan yang
menginginkan sebuah pemandangan pada waktu itu, bagi arsitek yang melihat bangunan-bangunan, bagi sejarawan adat yang melihat perubahan pada pakaian, bagi peneliti kesehatan yang melihat kebiasaan wanita merokok, bagi sosiolog yang melihat perbedaan kelas, atau bagi pelajar yang melihat penggunaan dari sebuah proses fotografi dan tekniknya.”
Saat ini teknik-teknik pengideksan citra telah mempunyai banyak kekuatan. Indeks berdasarkan kata kunci (keyword) memiliki daya deskripsi yang hebat, yang melahirkan banyak konsep baru lainnya, dan dapat mendeskripsikan citra dengan berbagai macam kompleksitasnya. Namun teknik manual ini mempunyai masalah-masalah seperti besarnya sumber daya manusia untuk melakukan klasifikasi dan deskripsi. M asalah-masalah lainnya adalah tidak dapat diandalkannya kemampuan konsistensi dari pelaku pengindeksan, M arkey (Access to iconographical research collections, 1988) menemukan banyak variasi deskripsi yang diberikan pada satu buah citra oleh beberapa pelaku pengindeksan, dalam satu buah dekade kosa kata yang digunakan juga akan berubah, dan masalah besar lainnya adalah betapa subjektifitas dari pendeskripsian citra sangat berperan.
Rangkuman yang tidak dapat dihindarkan adalah basis teks tidak cukup atau tidak layak untuk retrival citra. Bukti yang ada mengatakan bahwa efektifitas dari sistem tersebut mengkhawatirkan.
Berbeda dengan pendekatan yang berbasis teks, pengindeksan berbasis konten memiliki prinsip yaitu meretriv citra yang telah disimpan di dalam koleksi dengan membandingkan fitur-fitur yang dimiliki dari citra itu sendiri.
Fitur-fitur yang paling umum digunakan untuk ini adalah warna, tekstur dan bentuk. Sistem-sistem RCBK yang ada pada saat ini dapat dikatakan bekerja dengan menggunakan fitur tersebut. Biasanya sistem tersebut memberikan pengguna untuk melakukan kueri dengan memasukan tipe citra yang diinginkan. Ada juga beberapa sistem yang memberikan alternatif dengan membiarkan pengguna memilih dari koleksi citra sistem tersebut. Sistem tersebut kemudian akan membandingkan kueri dengan koleksi citra, dan memberikan hasil yang paling sebanding. Berikut adalah fitur-fitur yang paling banyak digunakan.
2.5.1.1.1 Warna
M odel warna hardware-oriented banyak digunakan untuk warna alat-alat. M isalnya model warna RGB (red, green, blue), biasa digunakan untuk warna monitor dan kamera. M odel warna CM Y (cyan, magenta, yellow), digunakan untuk warna printer; dan warna YIQ digunakan untuk penyiaran tv warna. Sedangkan model warna yang user-oriented termasuk HLS, HCV, HSV, MTM , dan CIE-LUV, didasarkan pada tiga persepsi manusia
tentang warna, yaitu hue (keragaman warna), saturation (kejenuhan), dan brightness (kecerahan). Berikut penjelasan ringkas tentang berbagai macam model atau format warna (Yanu Widodo, 2003, p1-2):
a) Format warna RGB
Format ini digunakan untuk menghasilkan warna di monitor dan televisi tabung yang menggunankan gelombang elektromagnetik. Sebuah titik ditembak dengan spektrum R, G dan B.
b) Format warna HS V atau HS I atau HS L
Format ini merupakan format warna alamiah dengan mempertimbangkan bahwa spektrum warna adalah sebuah koordinat polar seperti warna pantulan yang jatuh di mata manusia. Format ini sangat baik untuk membedakan warna-warna yang terlihat.
c) Format warna CIE
Format warna ini adalah varian dari RGB dengan normalisasi spektrum, sehingga sifat orthogonalitas dari masing-masing komponen warna lebih dijamin. Format ini merupakan standar dalam QBIC.
d) Format warna YCrCb
Format warna ini disebut juga dengan warna chrominant. Format ini banyak digunakan dalam skin-detection.
e) Format warna CMYK
Format warna ini adalah penghasil warna pada cat atau tinta. Format warna ini yang digunakan oleh mesin cetak.
Warna dari sebuah citra menyampaikan banyak informasi. Beberapa metode retrival citra yang berbasiskan warna memiliki beberapa ide dasar yang sama. Setiap citra yang dimasukan kedalam koleksi data akan dikomputasi histogram warnanya, yaitu kuantisasi dari warna setiap piksel yang terkandung di dalam citra. Nilai histogram warna dari setiap citra kemudian disimpan di dalam basis data. Pada saat melakukan pencarian citra, pengguna dapat memasukan besarnya proporsi warna yang diinginkan, atau mereka dapat memberikan sebuah kueri citra yang akan dikomputasikan histogram warnanya. Sistem akan membandingkan kesamaan nilai histogram antara citra kueri dengan koleksi citra dan meretriv nilai yang terdekat.
2.5.1.1.2 Tekstur
Tekstur merupakan salah satu fitur citra yang penting, akan tetapi sulit untuk dideskripsikan dan persepsi tentang tekstur subjektif dalam tingkat tertentu (Lu, p155). Tekstur memiliki kemampuan untuk membedakan antara daerah citra dengan warna yang mirip seperti langit dengan laut atau daun dengan rumput (Dunckley, p363).
Ada 6 fitur yang dapat digunakan untuk mendeskripsikan tekstur (Lu, p155) yaitu:
1. Kekasaran / coarseness
Kekasaran merupakan fitur tekstur yang paling fundamental dan bagi beberapa orang, tekstur berarti kekasaran. Semakin besar jarak dari elemen sebuah citra maka citra tersebut semakin kasar.
2. Kontras / contrast
Kontras diukur menggunakan 4 parameter, yaitu: jarak dinamis tingkat keabuan citra, polarisasi distribusi hitam dan putih pada histogram tingkat keabuan / grey level histogram, ketajaman tepi, dan periode pola terulang. 3. Directionality
M erupakan properti global terhadap daerah yang diberikan. Directionality mengukur bentuk elemen dan penempatannya.
4. Kemiripan garis / line likeness
Parameter ini bersangkutan dengan bentuk dari elemen tekstur. Dua bentuk umum dari tekstur adalah bentuk garis atau bentuk gumpalan.
5. Keteraturan / regularity
Fitur ini mengukur variasi dari aturan penempatan elemen. Hal ini bersangkutan dengan apakah tekstur tersebut
teratur atau tidak teratur. Perbedaan bentuk elemen mengurangi keteraturan. Tekstur yang baik cenderung teratur.
6. Kekesatan / roughness
Kekesatan mengukur apakah tekstur kesat atau halus. Kekesatan berhubungan dengan kekasaran dan kontras.
Representasi tekstur lain yang biasa dilakukan adalah :
1. Dimensi fraktal / fractal dimension
Dimensi fraktal mencirikan kompleksitas geometri dari himpunan. Sebuah citra dapat dilihat sebagai himpunan 3 dimensi dimana 2 dimensi pertama adalah posisi piksel dan dimensi ketiga merupakan intensitas piksel. Semakin kesat / rough sebuah citra maka dimensi fraktalnya semakin besar.
2. Koefisien fourier / fourier coefficients
Koefisien fourier pada sebuah citra mendeskripsikan seberapa cepat perubahan dari intensitas piksel. Koefisien tersebut kemudian digunakan untuk menunjukkan kekesatan sebuah citra.
3. Statistik distribusi warna / color distribution statistic Statistik distribusi warna seperti momen pertama, kedua, dan ketiga dari distribusi warna dapat menunjukkan tekstur sebuah citra.
M etode alternatif lain dalam merepresentasikan tekstur adalah menggunakan filter gabor dan fraktal. Filter gabor merupakan salah satu dari teknik yang sangat baik / powerfull dalam analisa citra. (Dunckley, p364).
2.5.1.1.3 Bentuk
Kemampuan untuk meretriv berdasarkan bentuk melibatkan memberikan bentuk dari benda deskripsi kuantitatif yang dapat digunakan untuk mencocokkan citra lain. Bentuk dari citra terdefinisikan dengan baik dan ada banyak bukti bahwa di dalam otak, objek alami pada dasarnya dikenali dengan bentuknya. Proses ini melibatkan perhitungan dari jumlah karakteristik fitur dari bentuk objek yang independen terhadap ukuran atau orientasi. Fitur ini kemudian dihitung untuk setiap objek yang teridentifikasi didalam setiap citra yang disimpan. Kemudian hasil dari kueri diperoleh dengan menghitung kumpulan fitur yang sama untuk citra kueri, kemudian meretriv citra yang disimpan tersebut yang fiturnya paling mirip dengan citra kueri. Dua jenis fitur bentuk yang biasa digunakan adalah:
1. Fitur global / global features seperti aspek rasio, circularity dan moments invariants.
2. Fitur lokal / local features seperti himpunan segmen batas berurutan / consecutive boundary segments.
Batas 2 dimensi dari objek 3 dimensi memungkinkan pengenalan objek. Representasi dari bentuk sangatlah sulit. Bentuk didefinisikan dengan koordinat x dan y dari titik batasnya. Transformasi kemiripan dapat mencakup translasi, pembesaran seragam/uniform scaling dan perubahan orientasi. Jika sudut pandang kamera berubah dengan tetap fokus ke objek, bentuk dari objek akan berubah, sebagai contoh sebuah lingkaran akan berubah menjadi elips.
2.5.1.2 Pencarian
Dalam melakukan pencarian, untuk basis data citra dalam jumlah yang kecil dapat dilakukan pencarian linier, yaitu kueri dicocokkan dengan semua citra dalam basis data satu per satu. Jumlah data yang besar akan mengakibatkan proses pencocokkan yang lambat, maka dari itu dibutuhkan metode lain untuk mempercepat proses retrival. Terdapat beberapa metode yang dapat digunakan untuk mempercepat proses retrival, seperti:
1. Reduksi dimensi dengan menggunakan Principal Components Analysis / PCA, Latent Semantic Indexing.
2. Pengindeksan, antara lain dengan hashing, R-tree, dan Kd-tree. 3. Pengelompokan / Clustering
2.6 Histogram Warna
Pendekatan histogram pertama kali dilakukan oleh Swain dan Ballard pada 1991. Variasi dari teknik ini banyak dilakukan oleh sistem RCBK saat ini. M etode seperti Cumulative Colour Histogram (Stricker dan Orengo, 1995) adalah salah satu contohnya.
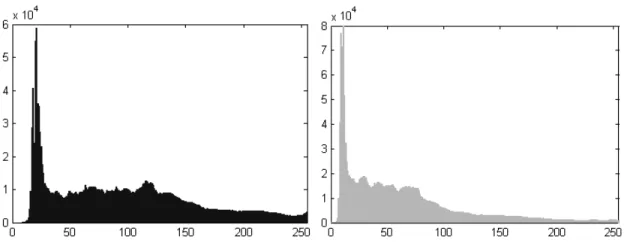
Histogram warna dibuat dari menghitung berapa jumlah piksel untuk setiap saluran warna (merah, hijau, biru, untuk RGB). Setiap pikselnya dikalkulasikan berapa banyak intensitas setiap saluran warna.
) , , ( ) , , ( , , ab c Nprob A a B b C c
h
ABC = = = =Gambar 2.5 Histogram Warna
M etode berdasarkan histogram warna ini mengukur kesamaan dari dua citra dapat diukur dari jarak kedua histogram warna citra yang bersangkutan. Ada beberapa macam teknik pengukuran jarak pada histogram warna, salah satunya adalah Histogram Euclidean distance. Jika d adalah jarak dari histogram, h dan g adalah dua citra yang bersangkutan, a, b, dan c adalah saluran warna yang ada (contoh: RGB) maka jarak kedua histogram dengan menggunakan Euclidean adalah:
( )
=∑∑∑
(
(
) (
−)
)
A B C c b a g c b a h g hd
2 , , , , , 2Dengan pengukuran jarak ini perbandingan dilakukan hanya dengan bins yang sama nilainya, tidak ada perbandingan silang dengan bins yang mungkin mempunyai warna sama namun dengan nilai bins yang berbeda.
2.7 Momen Warna
Stricker dan Orengo juga memperkenalkan pendekatan lain pada retrival citra dengan fitur warna yaitu color moment, dimana pengindeksan dari distribusi warna sebagai fitur.
Untuk sebuah RCBK dengan fitur warna, color moment mengalahkan histogram kumulatif dalam hal efektifitas dan ketepatan (Stricker dan Orengo, 1995). Salah satu penyebabnya adalah pendekatan ini menghapus masalah semantik dari histogram warna yang dapat tergeser pengenalan warnanya dikarenakan perbedaan pencahayaan.
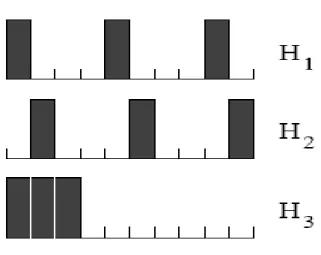
Gambar 2.6 Tiga buah Histogram Warna
Dengan d sebagai jarak dan Hi sebagai histogram warna bersangkutan, Citra diatas menghasilkan jarak histogram warna sebagai berikut:
(
H1,H2) (
d H1,H3) (
d H2,H3)
Citra H1 dan H2 yang hanya berbeda pada intensitas cahaya menghasilkan jarak yang lebih besar dibandingkan dengan jarak dengan H3 memperlihatkan salah satu masalah semantik yang ditemukan pada pendekatan histogram warna. (disadur dari Similarity of Color Image, Markus Stricker and M arkus Orengo, Communications Technology Laboratory, Swiss Federal Institure of Techno1ogy, ETH, CH-8092 Zurich, Switzerland, 1995)
Dasar dari color moment adalah asumsi bahwa distribusi warna dari sebuah citra dapat di anggap sebagai distribusi probabilitas, karenanya distribusi warna dapat dikarakterisasikan dari momennya. M omen-momen tersebut adalah rata-rata(average), deviasi standar (standard deviation), dan kelengkungan (skewness). Ketiganya dimaksudkan untuk pengindeksan.
Jika nilai dari i adalah saluran warna (color channel) di j piksel adalah Pij maka, nilai untuk rata-rata warna adalah:
p
E
ij j N i N 1 1∑
= =Nilai untuk deviasi standar adalah:
) ) ( 1 (
∑
1 2 = − = j N i ij ip
E
Nσ
Nilai untuk kelengkungan adalah:
(
)
3 3 1 1 ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − =∑
=p
E
s
ij i j N i NJika A dan B adalah distribusi warna dari dua buah citra, dan r adalah saluran warna (cth: HSV), dan indeks dari dua citra tersebut adalah Ei dan Fi untuk warna rata-rata, σi dan ςi untuk deviasi standar, si dan ti untuk
kelengkungan, maka kita dapat mendefinisikan kesamaan kedua citra dengan:
(
)
w
E
F
w
s
w
s
t
d
i i i i i i i i i r i mom H I =∑
− + − + − =1 1 2 3 ,σ
Dimana w adalah berat (weight) yang ditentukan oleh pengguna. Stricker dan Orengo melakukan beberapa percobaan pemberatan;
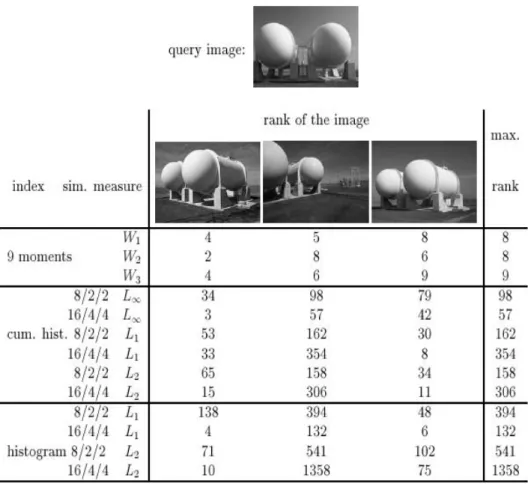
Hasil yang mereka miliki adalah pemberatan W1 yang paling berhasil dalam penggunaan color moment pada retrival citra.
Gambar 2.7 Hasil dari percobaan S tricker dan Orengo
M enurut Stricker dan Orengo, color moment melebihi kekuatan dari metode-metode lainnya yang ada pada saat ini, bahkan pada hasil yang terburuk. Color moment juga menyelesaikan masalah-masalah semantik seperti perbedaan pencahayaan pada citra seperti yang dijelaskan sebelumnya di atas. M etode ini juga menyelesaikan masalah perbedaan ukuran dari citra. Dimana histogram warna dapat menghasilkan false negative, sedangkan color moment dapat menjadi lebih akurat dikarenakan ketidak-tergantungan pada jumlah warna dari piksel, namun penyebaran dan rata-rata warna pada piksel citra.
2.8 Pohon Berdimesi K (KD Tree)
Pencarian dalam ruang berdimensi tinggi merupakan proses yang diperlukan dalam RCBK. Fitur dari suatu citra seperti warna, tekstur maupun bentuk direpresentasikan dalam vektor fitur yang dapat dianggap sebagai titik pada ruang multidimensi.
Proses pencarian dapat dilakukan secara lebih efisien dengan menggunakan pengindeksan multidimensi. Terdapat beberapa metode pengindeksan multidimensi, perbedaan dari beberapa metode yang ada terletak pada jenis kueri yang dapat dilakukan dan juga banyaknya dimensi dimana suatu metode memiliki keunggulan dibandingkan metode yang lain.
Sebagian besar sistem manajemen basis data yang ada saat ini tidak mendukung pengindeksan multidimensi dan sistem manajemen basis data yang mendukung memberikan sedikit sekali pilihan untuk metode pengindeksan multidimensi. Penelitian aktif dilakukan untuk menyediakan mekanisme pada sistem manajemen basis data yang memungkinkan pengguna untuk menyertakan pengindeksan multidimensi yang dipilih ke dalam mesin pencari.
Salah satu metode pengindeksan multidimensi yang mudah diimplementasikan dan berguna untuk berbagai macam masalah pencarian adalah pohon berdimensi k.
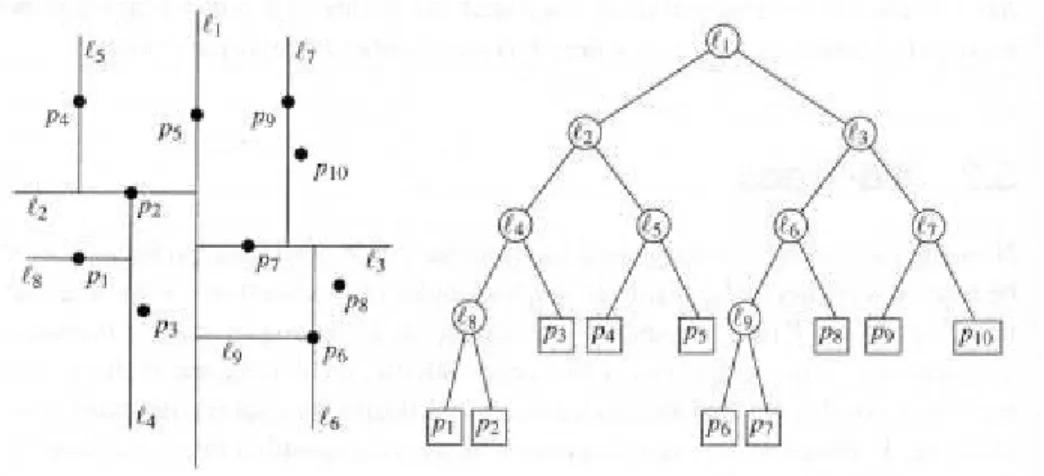
2.8.1 Definisi dan konstruksi
Pohon berdimesi k adalah struktur data yang berbentuk pohon biner dimana setiap daun (leaf) menyimpan satu titik berdimensi d. Dalam dua dimensi, setiap titik mempunyai koordinat x dan y, dengan demikian
untuk membentuk pohon berdimesi dua, pertama kali titik dibagi menurut koordinat x, lalu koordinat y, dan kembali ke koordinat x, demikian seterusnya.
Gambar 2.8 Contoh Pohon Berdimensi K
Algorithm BUILDKDTREE(P,depth)
Input. A set of point P and the current depth depth
Output. The root of a kd-tree storing P.
1. if P contains only one point
2. then return a leaf storing this point
4. then split P into two subsets with a vertical line l through the median x-coordinate of the points in P. Let P1 be the set of
points to the left of l or on l, and let P2 be the set of points
to the right of l.
5. else split P into two subsets with a horizontal line l through the median y-coordinate of the points in P. Let P1 be the set of
points below l or on l, and let P2 be the set of points above
l.
6. vleft ← BUILDKDTREE(P1,depth + 1)
7. vright ← BUILDKDTREE(P2,depth + 1)
8. Create a node v storing l , make vleft the left child of v, and make vright
the right child of v.
9. return v
Gambar 2.9 Algoritma pembentukan Pohon Berdimensi K
2.8.2 Algoritma kueri
Pada saat diberikan sebuah rentang (range) dalam d dimensional, algoritma kueri pada pohon berdimensi k akan melaporkan titik mana saja yang berada dalam rentang. Simpul dalam pohon berdimensi k menyatakan suatu daerah berbentuk bidang (dalam 2 dimensi) atau
hyperlane dalam d dimensi. Untuk sebuah simpul v, daerah yang direpresentasikan oleh v dinyatakan oleh region(v).
Region yang dinyatakan oleh simpul dalam pohon berdimensi k dapat memiliki batas ataupun tidak. Sebuah titik berada dalam subtree dengan root u, jika dan hanya jika titik tersebut berada dalam region(u). Dalam algoritma kueri, dilakukan dengan menelusuri pohon dengan DFS(Depth First Search), suatu simpul dikunjungi hanya jika region dari simpul tersebut berpotongan dengan rentang kueri, R.
Algorithm SEARCHKDTREE(v,R)
Input. The root of (a subtree of) a kd-tree, and a range R.
Output. All points at leaves below v that lie in the range.
1. if v is a leaf
2. then Report the point stored at v if it lies in R.
3. else if region (lc(v)) is fully contained in R
4. then REPORTSUBTREE((lc(v))
5. else if region (lc(v)) intersects R
7. if region (lc(v)) is fully contained in R
8. then REPORTSUBTREE((rc(v))
9. else if region (rc(v)) intersects R
10. then SEARCHKDTREE(rc(v),R)
Gambar 2.10 Algoritma Kueri
2.9 Evaluasi Kinerja Retrival
M etode retrival dapat dikatakan baik jika memiliki error yang sedikit mungkin. Ada dua jenis error yang terjadi dalam sistem retrival :
1. False Positive (FP)
Dapat di retriv, tetapi bukan citra yang relevan dengan kueri. 2. False Negative (FN)
Tidak dapat di retriv padahal citra relevan.
M etode retrival yang baik harus dapat meminimalkan kedua error diatas. Untuk melakukan evaluasi terhadap metode retrival, dapat dilakukan dengan menghitung nilai recall dan precision.
recall = b a precision = c a
Dimana :
• a = banyaknya citra yang dapat di retriv dan relevan
• b = banyaknya citra yang relevan terhadap kueri dalam basis data • c = banyaknya citra yang dapat di retriv
Nilai precision yang tinggi berarti sedikit terjadi false positif dan nilai recall yang tinggi berarti sedikit terjadi false negative.
Harmonic Mean / F-Measure / F-score / F1-score adalah suatu pengukuran yang menggabungkan nilai precision dan recall.
p r rp p r F + = + = 2 1 1 2
r : nilai recall ; p: nilai precision
Nilai F berada dalam rentang [0,1], nilai F semakin tinggi jika nilai precison dan recall tinggi. Semakin tinggi nilai F dari suatu metode retrival, berarti semakin baik pula performa RCBK.
Nilai recall dan precision akan divisualisasikan dalam bentuk grafik. Untuk itu, dari semua citra dalam basis data yang terurut menaik berdasarkan jarak, dihitung nilai recall dan precision untuk setiap kemunculan citra yang relevan dengan kueri.
Tabel 2.1 Contoh Urutan Hasil Retrival Kueri 1 Kueri 2 Kueri 3
T R R T R R T R R T R T T R T R T R R T R R T T R T T R T T
M isalkan terdapat 3 urutan seperti table diatas, maka jika hanya diambil 5 teratas
Tabel 2.2 Nilai Recall dan Precision
Recall Precision Urutan 1 0 0 Urutan 2 1 1 Urutan 3 0,6 0,6 R : Citra yang relevan T : Citra yang tidak relevan
Jika diambil 10 teratas maka ketiga urutan diatas akan menghasilkan nilai recall dan precision yang sama, yaitu recall 1 dan precision 0,5. Untuk mendapatkan grafik visual, dilakukan pengukuran nilai precision dan recall yang sama, untuk setiap kueri. Umumnya nilai precision dihitung pada nilai recall yang standar yaitu 11 titik (biasanya 100%, 90% .... 0%) dan 3 titik (biasanya 75%, 50%, 25%) (Universitas Indonesia, 2008, pp37).
Selanjutnya dari titik-titik yang didapat, dilakukan interpolasi untuk membuat kurva precision dan recall. Precision interpolasi pada suatu titik recall r didefinisikan sebagai nilai precision terbesar pada semua titik recall r’≥ r. Selanjutnya dari nilai precision interpolasi, digambar kurva recall dan precision.
( )
( )
( )
'int r max P r
P
erpolasi = untuk semua r ≥r'
Tabel 2.3 Precision Interpolasi
Recall Precision Precision Interpolasi
0 1 1
0.1 0.66 0.66
0.2 0.62 0.62
0.3 0.56 0.56
0.5 0.42 0.42 0.6 0.28 0.30 0.7 0.30 0.30 0.8 0.14 0.14 0.9 0.11 0.11 1 0.09 0.09
Precision Interpolasi
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Precision Interpolasi Recall Pre cisi onDari interpolasi pada tabel 2.3 akan menghasilkan kurva pada gambar 2.11, dimana nilai precision dengan recall 0% adalah 1.
Untuk menghitung nilai rata-rata precision terhadap semua kueri, maka dihitung rata-rata precision untuk tiap tingkatan recall untuk semua kueri. (Universitas Indonesia, 2008, pp38)
( )
( )
N r r PP
i N i∑
= = 1P (r) = rata-rata precision untuk nilai recall r
Pi(r) = rata-rata precision untuk nilai recall r pada kueri ke-i